Bài giảng chi tiết môn Xử lý tiếng nói | Học viện Công nghệ Bưu chính Viễn thông
Bài giảng chi tiết môn Xử lý tiếng nói của Học viện Công nghệ Bưu chính Viễn thông với những kiến thức và thông tin bổ ích giúp sinh viên tham khảo, ôn luyện và phục vụ nhu cầu học tập của mình cụ thể là có định hướng ôn tập, nắm vững kiến thức môn học và làm bài tốt trong những bài kiểm tra, bài tiểu luận, bài tập kết thúc học phần, từ đó học tập tốt và có kết quả cao cũng như có thể vận dụng tốt những kiến thức mình đã học vào thực tiễn cuộc sống. Mời bạn đọc đón xem!
Môn: Xử lý tiếng nói 2 tài liệu
Trường: Học viện Công Nghệ Bưu Chính Viễn Thông 1.8 K tài liệu
Tác giả:
















































































































Preview text:
lOMoARcPSD| 36086670
BỘ THÔNG TIN VÀ TRUYỀN THÔNG HỌC VIỆN CÔNG NGHỆ BƢU CHÍNH VIỄN THÔNG
*******************************
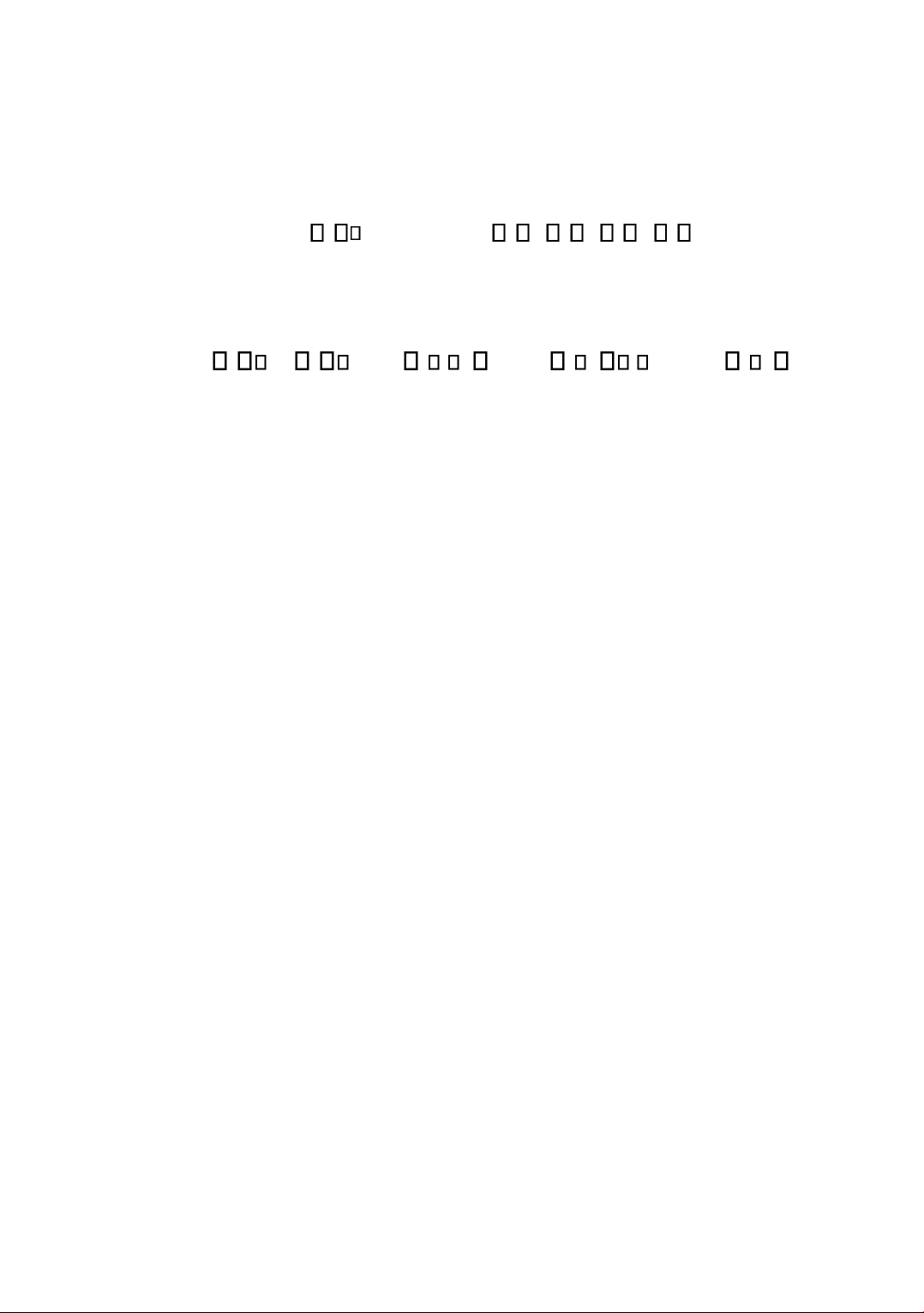
BÀI GI Ả NG XỬ Ế LÝ TI NG NÓI BIÊN SO Ạ N:
PH ẠM VĂN SỰ LÊ XUÂN THÀNH LỜI NÓI ĐẦU
Tiếng nói là một phƣơng tiện trao ổi thông tin tiện ích vốn có của con ngƣời. Ƣớc
mơ về những "máy nói", "máy hiểu tiếng nói" ã không chỉ xuất hiện từ những câu truyện
khoa học viễn tƣởng xa xƣa mà nó còn là ộng lực thôi thúc của nhiều nhà khoa học, nhóm
nghiên cứu trên thế giới. Hoạt ộng nghiên cứu và xử lý tiếng nói ã trải qua gần một thế kỷ
cùng với nhiều thành tựu to lớn trong việc xây dựng phát triển các kỹ thuật công nghệ, hệ lOMoARcPSD| 36086670
thống xử lý tiếng nói. Tuy vậy, việc có ƣợc một "máy nói" mang tính tự nhiên (về giọng
iệu, phát âm...) cũng nhƣ một "máy hiểu tiếng nói" thực thụ vẫn còn khá xa vời.
Xu thế phát triển của công nghệ hội tụ ở thế kỷ 21 càng thôi thúc hơn nữa việc hoàn
thiện công nghệ ể có thể ạt ƣợc mục tiêu của con ngƣời về lĩnh vực xử lý tiếng nói. Chính
vì thế, việc nắm bắt ƣợc các kỹ thuật cơ bản cũng nhƣ các công nghệ tiến tiến cho việc xử
lý tiếng nói trở nên thực sự cần thiết cho sinh viên chuyên ngành Xử lý Tín hiệu và Truyền
thông nói riêng, sinh viên chuyên ngành Kỹ thuật Điện - Điện tử cũng nhƣ Khoa học Máy
tính nói chung. Với mục ích ó, bài giảng môn học Xử lý tiếng nói ƣợc biên soạn nhằm
trang bị cho sinh viên các khái niệm cơ bản quan trọng và cần thiết cũng nhƣ nhằm giới
thiệu cho sinh viên một cách tổng quan về các công nghệ tiên tiến, xu thế nghiên cứu và
phát triển của lĩnh vực xử lý tiếng nói. Trong lần tái bản này, cuốn sách ƣợc phân chia lại thành 5 chƣơng:
1. Một số khái niệm cơ bản.
2. Phân tích tín hiệu tiếng nói. 3. Mã hóa tiếng nói. 4. Tổng hợp tiếng nói.
5. Nhận dạng tiếng nói.
Cuốn bài giảng này là những kinh nghiệm úc rút của các tác giả trong quá trình giảng
dạy và nghiên cứu tại Học viện Công nghệ Bƣu chính Viễn thông. Cuốn bài giảng còn là
kết quả của những nỗ lực óng góp ầy nhiệt huyết của các thầy cô giáo, những ồng nghiệp
tại Khoa Kỹ thuật Điện tử, của các em sinh viên. Mặc dù với sự cố gắng nỗ lực hết sức,
nhƣ do kinh nghiệm còn nhiều hạn chế, nhóm tác giả không tránh khỏi những sai sót và
nhầm lẫn. Nhóm tác giả chân thành mong muốn nhận ƣợc những óng góp từ ồng nghiệp
và các em sinh viên ể hoàn thiện hơn trong phiên bản sau.
Mọi góp ý xin gửi về: Bộ môn Xử lý Tín hiệu và Truyền thông, Khoa Kỹ thuật Điện
tử I, Học viện Công nghệ Bƣu chính Viễn thông, Km10 Đƣờng Nguyễn Trãi, Hà Đông,
Hà Nội hoặc gửi email về ịa chỉ supv@ptit.edu.vn.
LỜI NÓI ĐẦU
Hà Nội, tháng 12 năm 2014
DANH MỤC CÁC TỪ VIẾT TẮT lOMoARcPSD| 36086670
DANH MỤC CÁC TỪ VIẾT TẮT ADC Analog Digital Converter
Bộ chuyển ổi tƣơng tự - số ADM Adaptive Delta Modulation
Điều chế Delta thích nghi ADPCM Adaptive Differential PCM
Điều xung mã vi sai thích nghi CSR Continuous Speech Recognition
Nhận dạng tiếng nói liên tục DCT Discrete Cosine Transform
Biến ổi Cosine rời rạc DFT Discrete Fourier Transform
Biến ổi Fourier rời rạc DM Delta Modulation Điều chế Delta DTFT Discrete Time FT
Biến ổi Fourier với thời gian rời rạc DPCM Differential PCM Điều chế xung mã vi sai FFT Fast FT Biến ổi Fourier nhanh FIR Finite Impulse Response
Bộ lọc áp ứng hữu hạn FT Fourier Transform Biến ổi Fourier HMM Hidden Markov Model Mô hình Markov ẩn IDFT Inverse Discrete FT
Biến ổi Fourier rời rạc ngƣợc IDTFT Inverse DTFT
Biến ổi Fourier với thời gian rời rạc ngƣợc IFT Inverse FT Biến ổi Fourier ngƣợc LMS Least Mean Square
Bình phƣơng trung bình tối thiểu LPC Linear Predictive Coding
Mã hóa dự oán tuyến tính LTI Linear Time-Invariant
Bộ lọc tuyến tính không thay ổi theo thời gian MFCC Mel frequency cepstral
Các hệ số cepstral tần số Mel coefficient NLP Natural Language Processing
Xử lý ngôn ngữ tự nhiên PAM Pulse Amplitude Modulation
Điều chế biên ộ xung mã SNR Signal to Noise Ratio
Tỷ số tín hiệu trên nhiễu ST Short-time Transform Biến ổi ngắn hạn
DANH MỤC CÁC TỪ VIẾT TẮT STFT Short-time FT
Biến ổi Fourier ngắn hạn TDNN Time delay Neural Network
Mạng nơ-ron với thời gian trễ lOMoARcPSD| 36086670 TD-PSOLA Time-domain PSOLA
Phƣơng pháp chồng lấn ồng bộ
pitch trong miền thời gian MỤC LỤC MỤC LỤC
LỜI NÓI ĐẦU ................................................................................................................3
DANH MỤC CÁC TỪ VIẾT TẮT ................................................................................5
MỤC LỤC ......................................................................................................................7
CHƢƠNG 1. MỘT SỐ KHÁI NIỆM CƠ BẢN ...........................................................11 1.1.
MỞ ĐẦU................................................................................................11 lOMoARcPSD| 36086670 1.2.
TỔNG QUAN VỀ XỬ LÝ TIẾNG NÓI ...............................................11 1.3.
QUÁ TRÌNH TẠO VÀ CẢM NHẬN TIẾNG NÓI ..............................13
1.3.1 Bản chất của tiếng nói ........................................................................14
1.3.2 Cấu tạo của hệ thống phát âm ............................................................15
1.3.3 Phân loại tiếng nói..............................................................................16
1.3.4 Cấu tạo của hệ thống cảm nhận tiếng nói ..........................................17
1.3.5 Đặc iểm cảm nhận tiếng nói của ngƣời ............................................20 1.4.
MÔ HÌNH HÓA HỆ THỐNG CƠ QUAN PHÁT ÂM .........................25 1.5.
BIỂU DIỄN TÍN HIỆU TIẾNG NÓI ....................................................26
1.5.1 Biểu diễn dạng sóng tín hiệu trong miền thời gian ............................27
1.5.2 Biểu diễn phổ tín hiệu tiếng nói .........................................................29
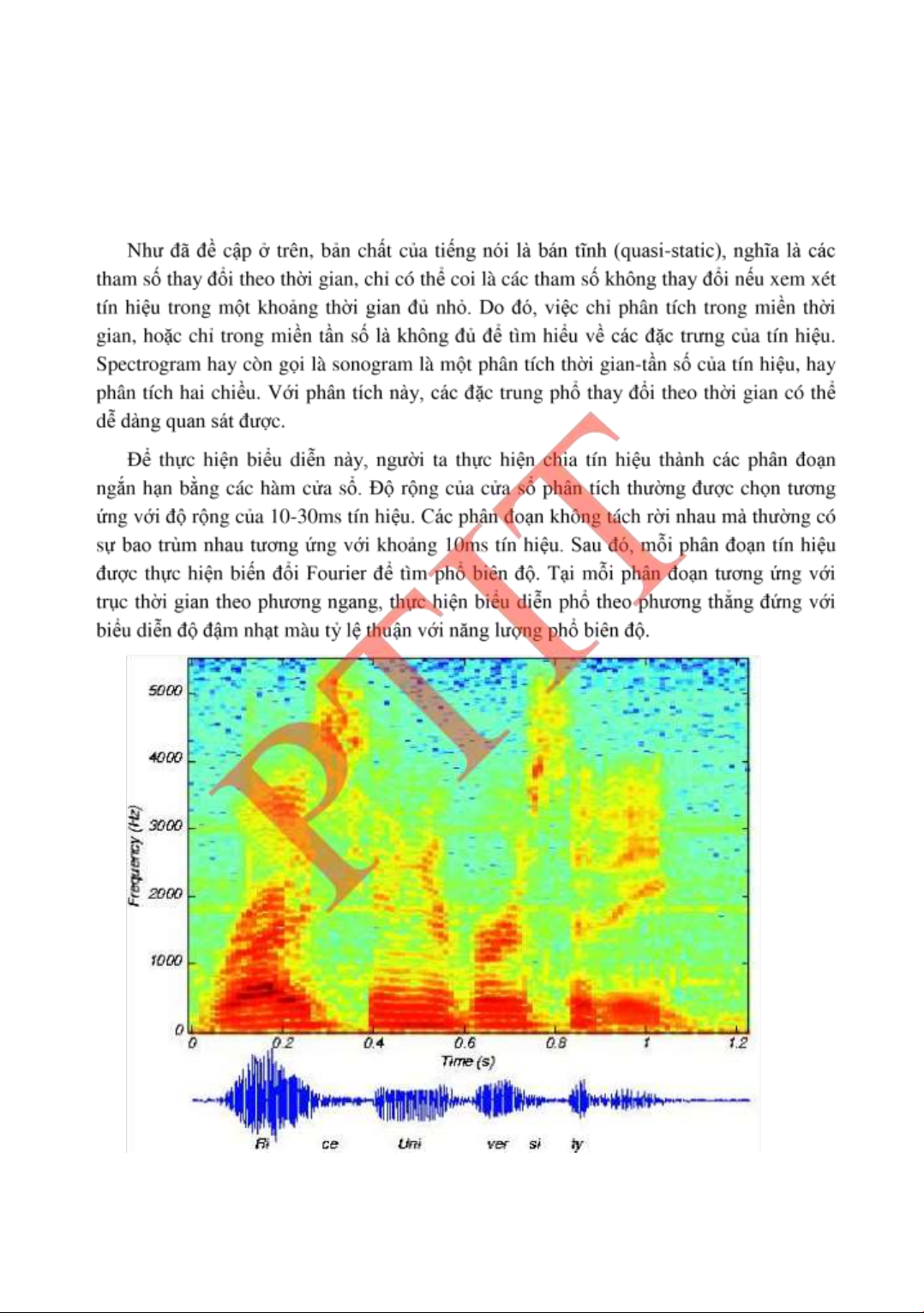
1.5.3 Biểu diễn spectrogram .......................................................................31 1.6.
CÁC THAM SỐ CƠ BẢN CỦA TÍN HIỆU TIẾNG NÓI ....................32
1.6.1 Tần số cơ bản .....................................................................................32
1.6.2 Tần số formant ...................................................................................33 1.7.
MỘT SỐ ĐẶC ĐIỂM NGỮ ÂM ...........................................................33 1.7.1
Một số ịnh nghĩa cơ bản về ơn vị ngữ âm ......................................33
1.7.2 Đặc iểm ngữ âm của tiếng Việt ........................................................34 1.8.
CÂU HỎI VÀ BÀI TẬP CUỐI CHƢƠNG ...........................................35 MỤC LỤC
CHƢƠNG 2. PHÂN TÍCH TÍN HIỆU TIẾNG NÓI ...................................................38 2.1.
MỞ ĐẦU................................................................................................38 2.2.
KHÁI NIỆM CHUNG VỀ PHÂN TÍCH TIẾNG NÓI..........................38
2.2.1 Mô hình phân tích tín hiệu tiếng nói ..................................................38
2.2.2 Phân tích ngắn hạn .............................................................................38
2.2.3 Hàm cửa sổ phân tích .........................................................................40 2.3.
CÁC PHÂN TÍCH CƠ BẢN TRONG MIỀN THỜI GIAN ..................41
2.3.1 Năng lƣợng ngắn hạn .........................................................................41 lOMoARcPSD| 36086670 2.3.2
Độ lớn biên ộ ngắn hạn ....................................................................43 2.3.3
Vi sai ộ lớn biên ộ ngắn hạn ...........................................................43 2.3.4
Tốc ộ trở về không ...........................................................................43
2.3.5 Giá trị hàm tự tƣơng quan ..................................................................44 2.4.
PHÂN TÍCH PHỔ TÍN HIỆU TIẾNG NÓI ..........................................44
2.4.1 Cấu trúc phổ của tín hiệu tiếng nói ....................................................44
2.4.2 Phân tích spectrogram ........................................................................47 2.5.
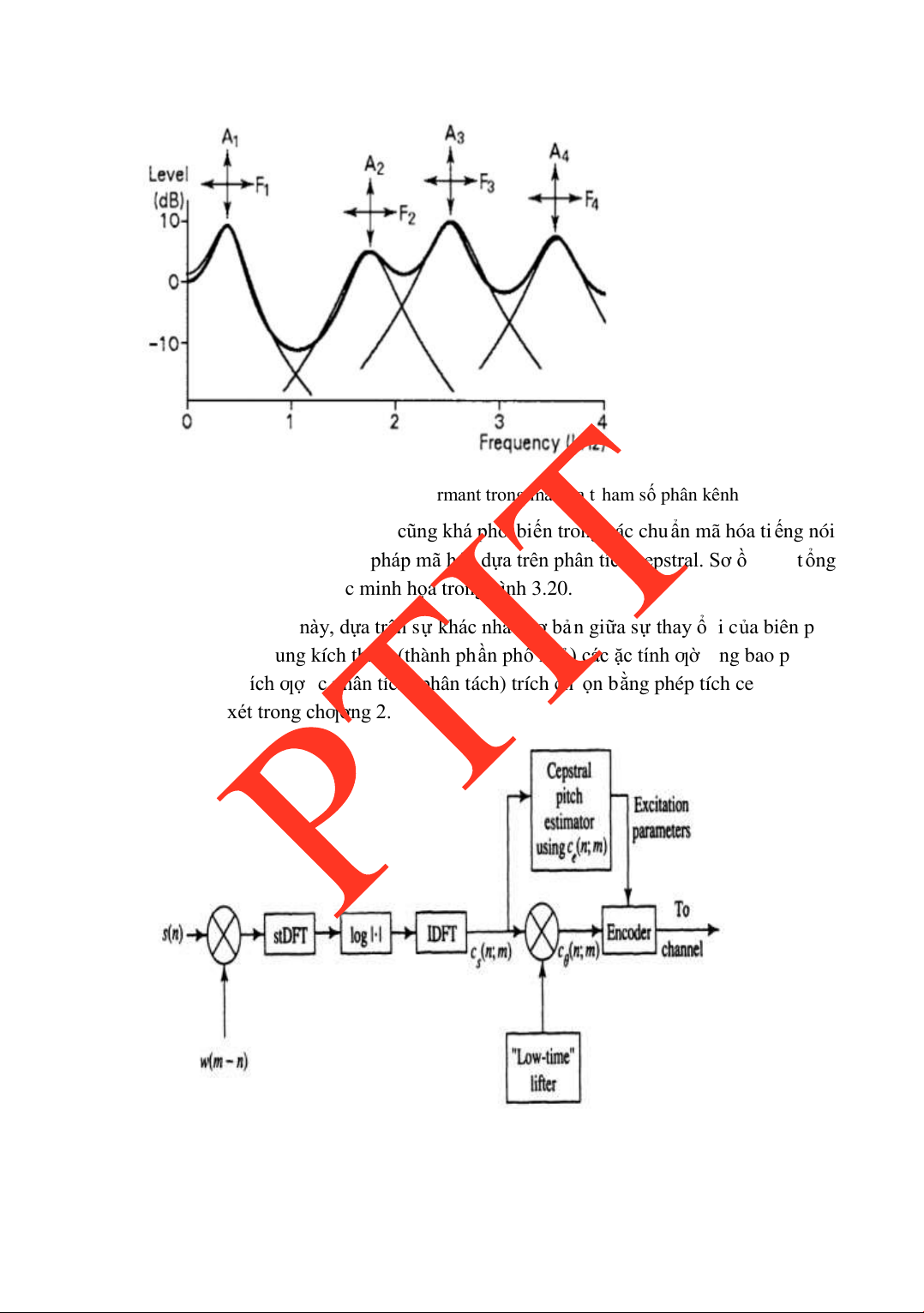
PHÂN TÍCH DỰ ĐOÁN TUYẾN TÍNH ..............................................49 2.6.
XỬ LÝ ĐỒNG HÌNH ............................................................................57 2.7.
ÁP DỤNG MỘT SỐ PHÉP PHÂN TÍCH ĐỂ XÁC ĐỊNH CÁC THAM
SỐ CƠ BẢN CỦA TÍN HIỆU TIẾNG NÓI .........................................58
2.7.1 Một số phƣơng pháp xác ịnh các tần số formant .............................58 2.7.2
Xác ịnh formant từ phân tích STFT .................................................59 2.7.3
Xác ịnh formant từ phân tích LPC ...................................................59
2.7.4 Một số phƣơng pháp xác ịnh tần số cơ bản ......................................59
2.7.5 Sử dụng hàm tự tƣơng quan ...............................................................60 2.7.6
Sử dụng Vi sai ộ lớn biên ộ ngắn hạn ............................................60 2.7.7
Sử dụng tốc ộ trở về không ..............................................................60
2.7.8 Sử dụng phân tích STFT ....................................................................60 MỤC LỤC
2.7.9 Sử dụng phân tích Cepstral ................................................................62 2.8.
CÂU HỎI VÀ BÀI TẬP CUỐI CHƢƠNG ...........................................63
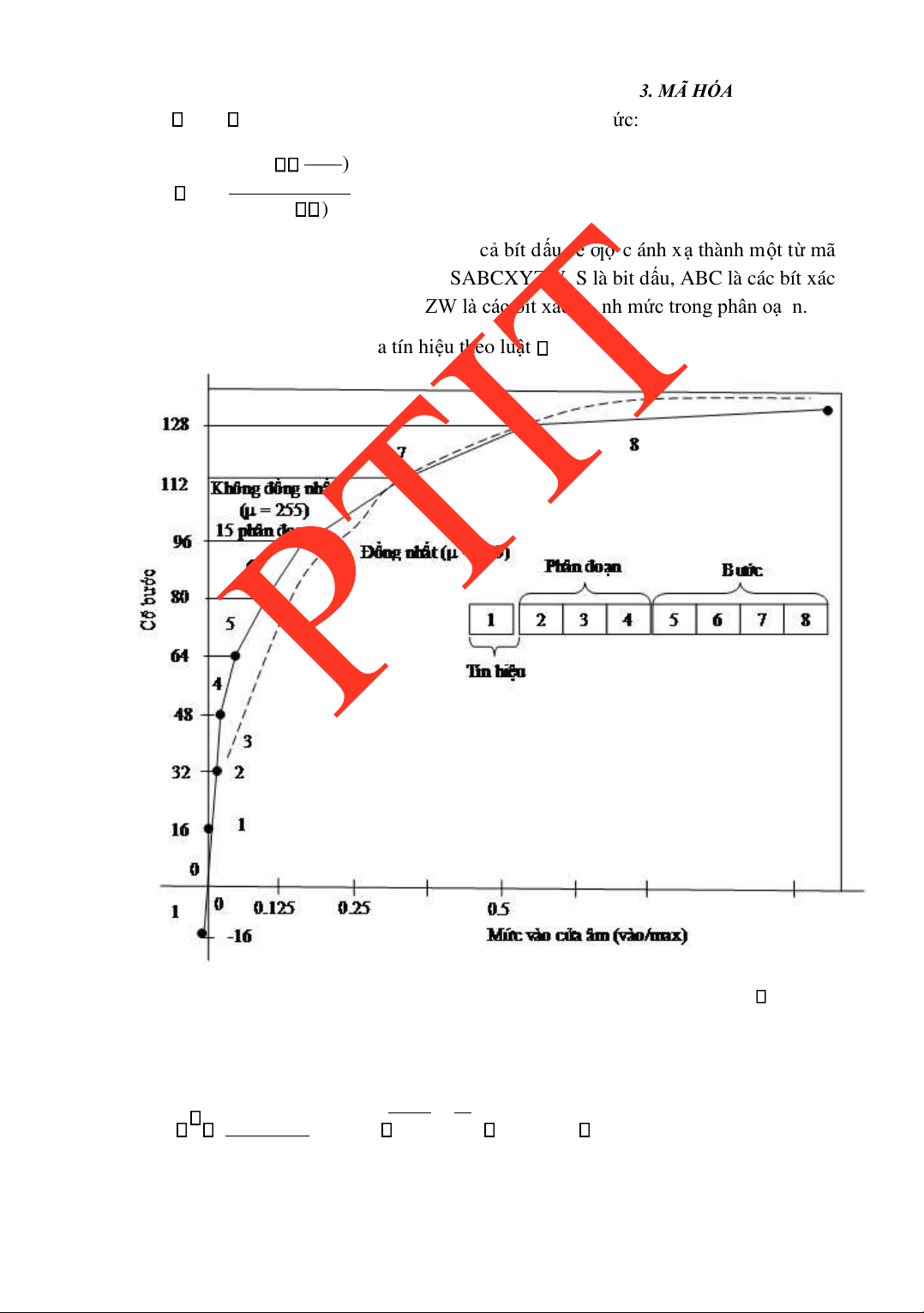
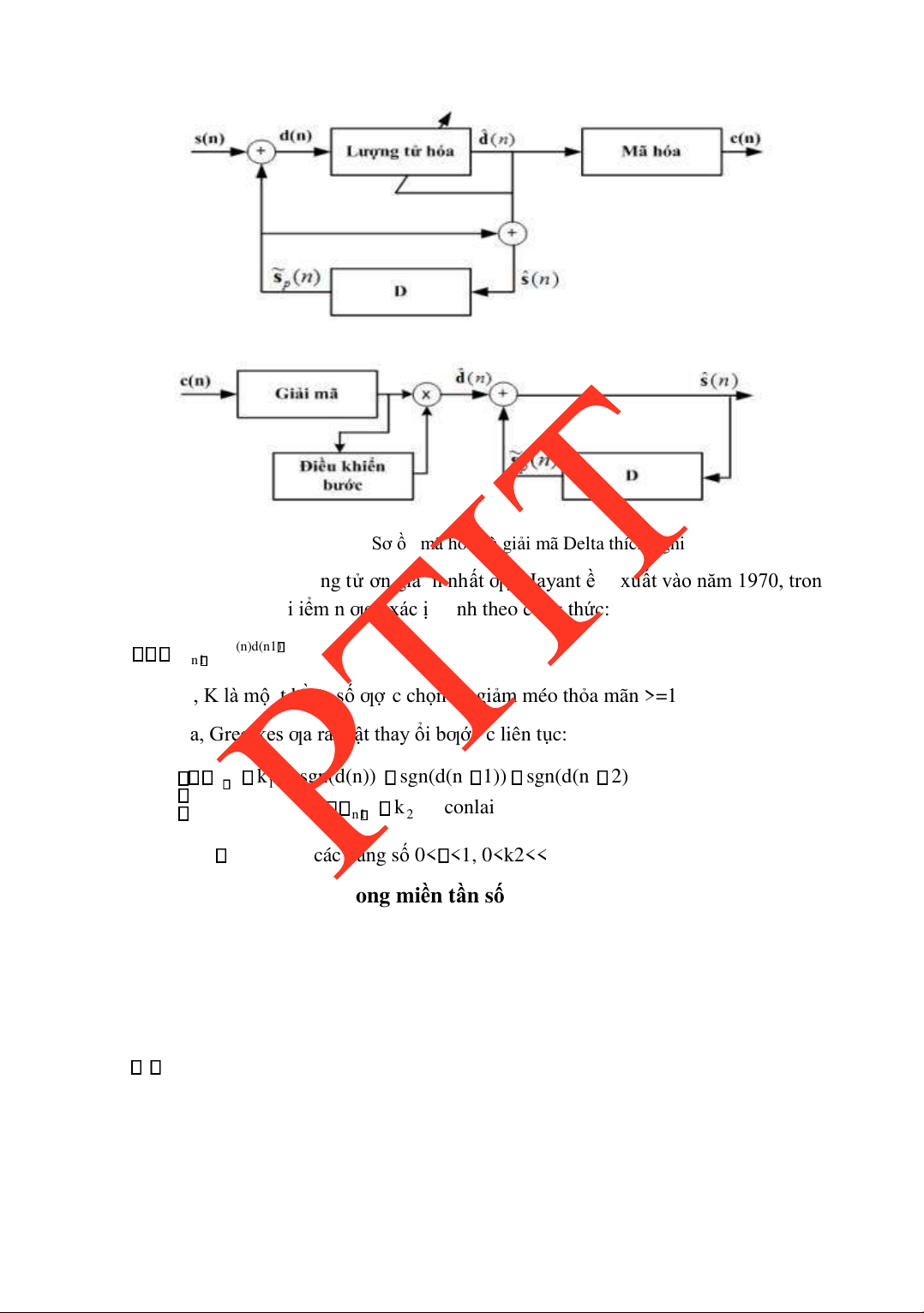
CHƢƠNG 3: MÃ HÓA TIẾNG NÓI ..........................................................................65 3.1.
KHÁI NIỆM CHUNG VỀ MÃ HÓA TIẾNG NÓI ...............................65 3.2.
MỘT SỐ PHƢƠNG PHÁP MÃ HÓA DẠNG SÓNG ..........................67
3.2.1 PCM ...................................................................................................68
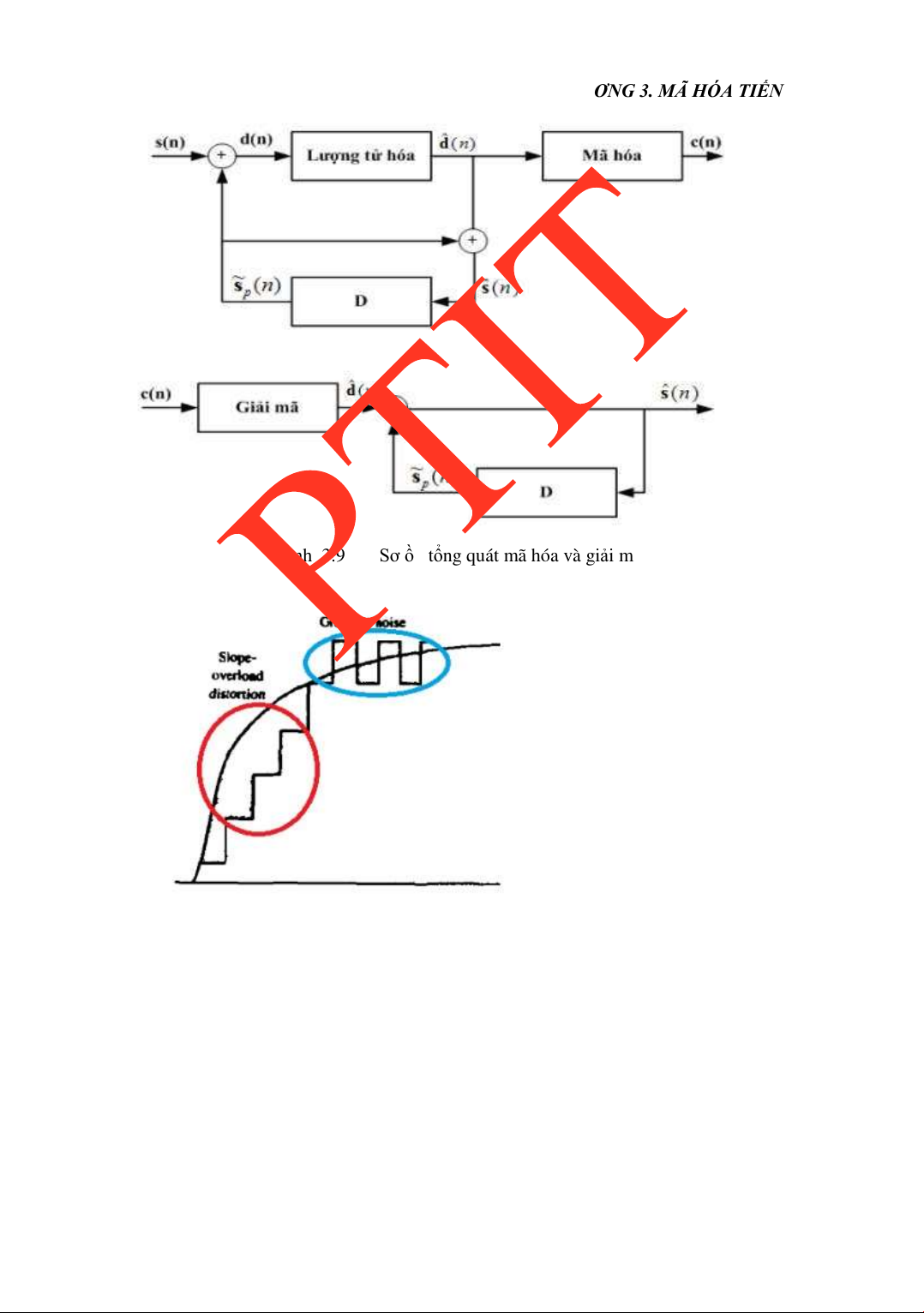
3.2.2 DPCM ................................................................................................72
3.2.3 DM .....................................................................................................74 lOMoARcPSD| 36086670
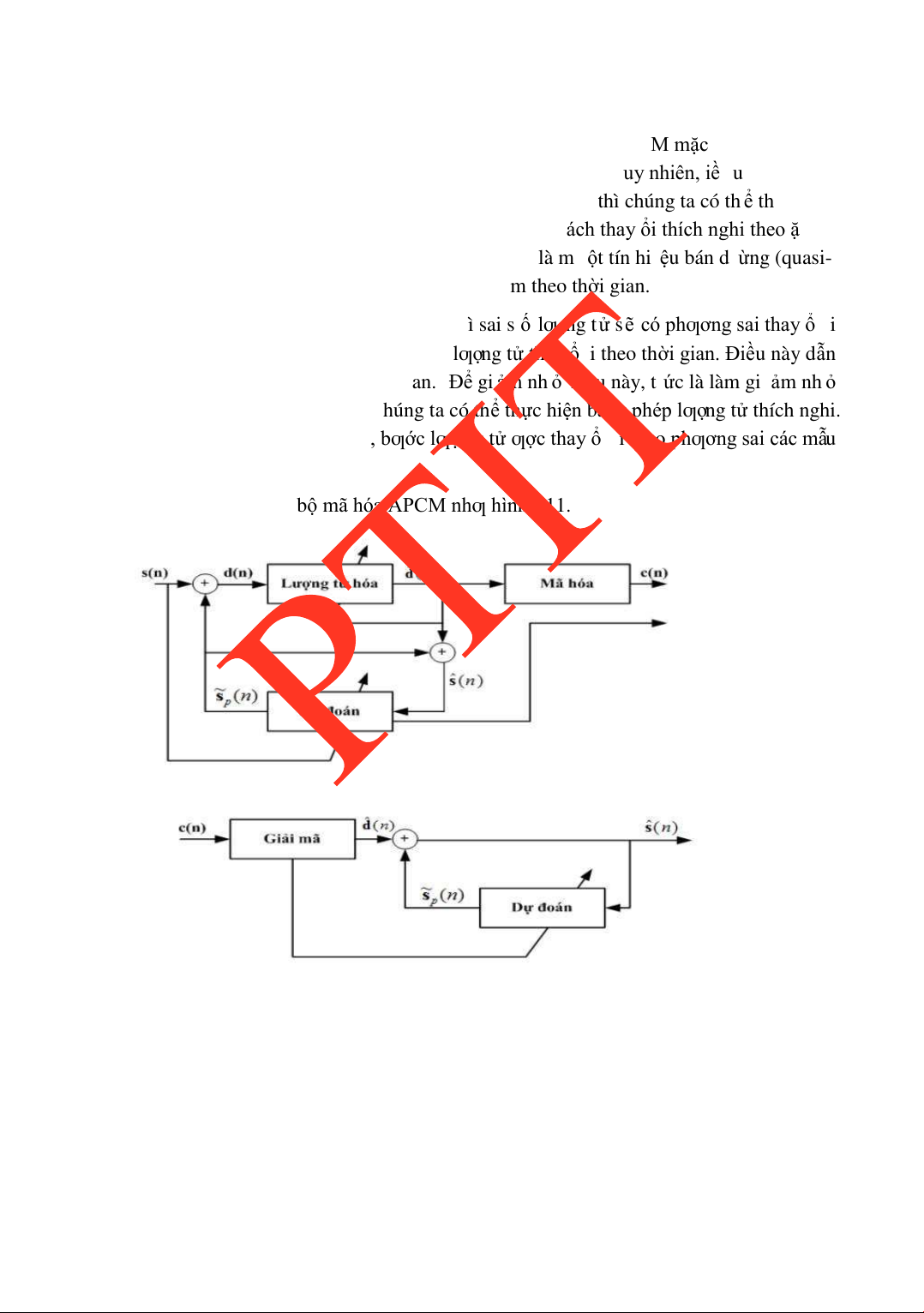
3.2.4 APCM ................................................................................................76
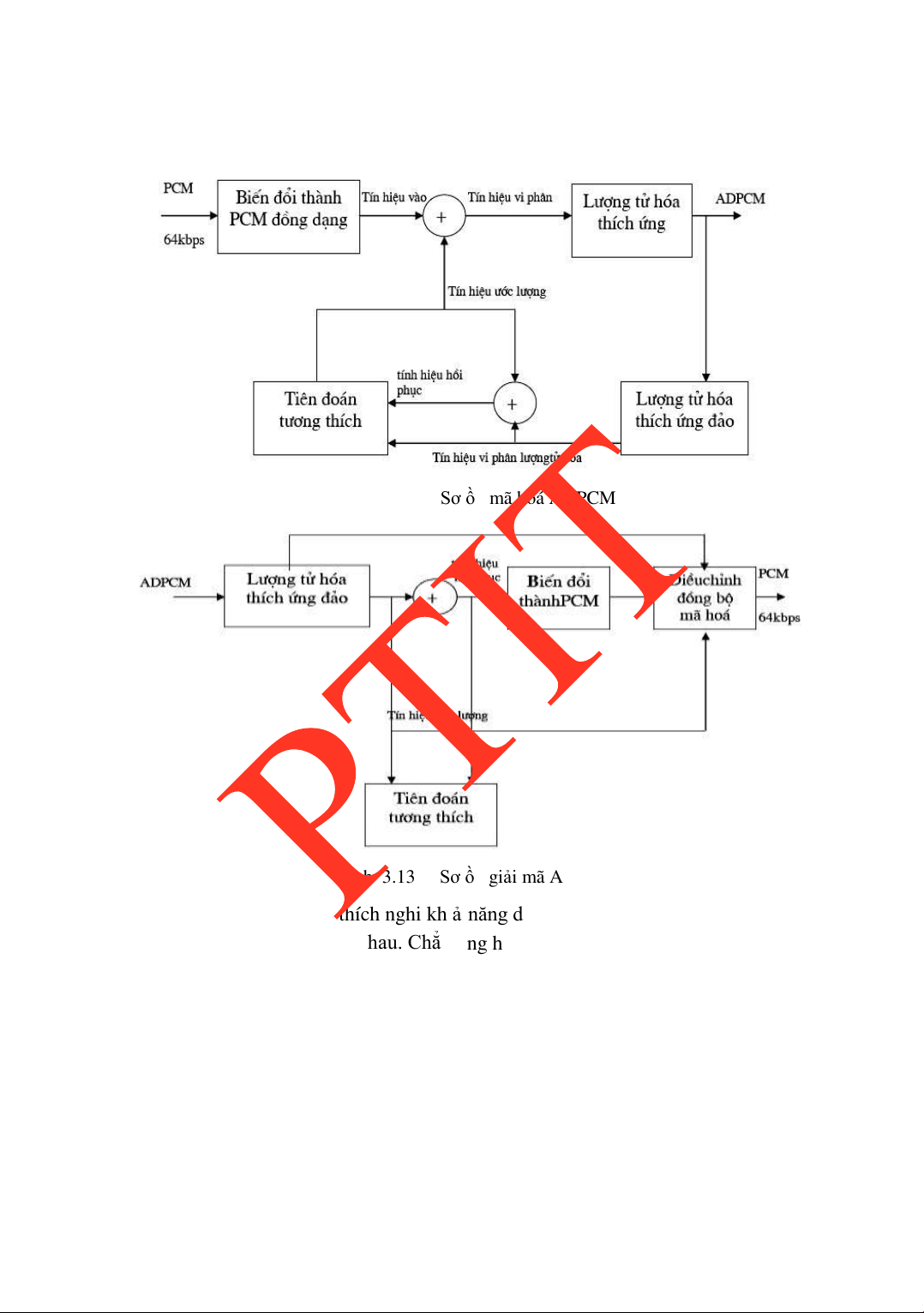
3.2.5 ADPCM .............................................................................................77
3.2.6 ADM ..................................................................................................78
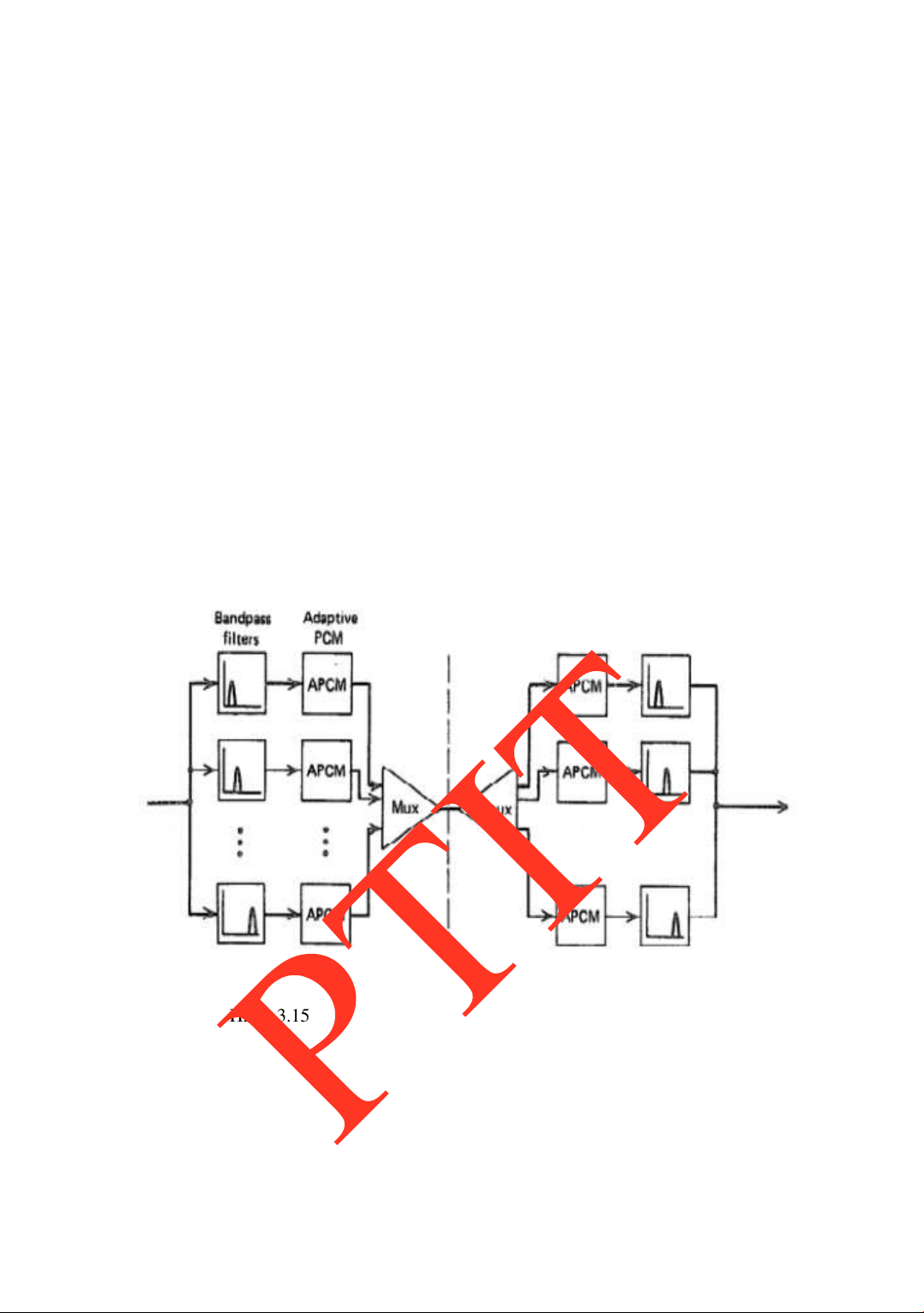
3.2.7 Mã hóa dạng sóng trong miền tần số .................................................79 3.3.
MỘT SỐ PHƢƠNG PHÁP MÃ HÓA THAM SỐ................................82 3.4.
PHƢƠNG PHÁP MÃ HÓA LAI GHÉP ...............................................85 3.5.
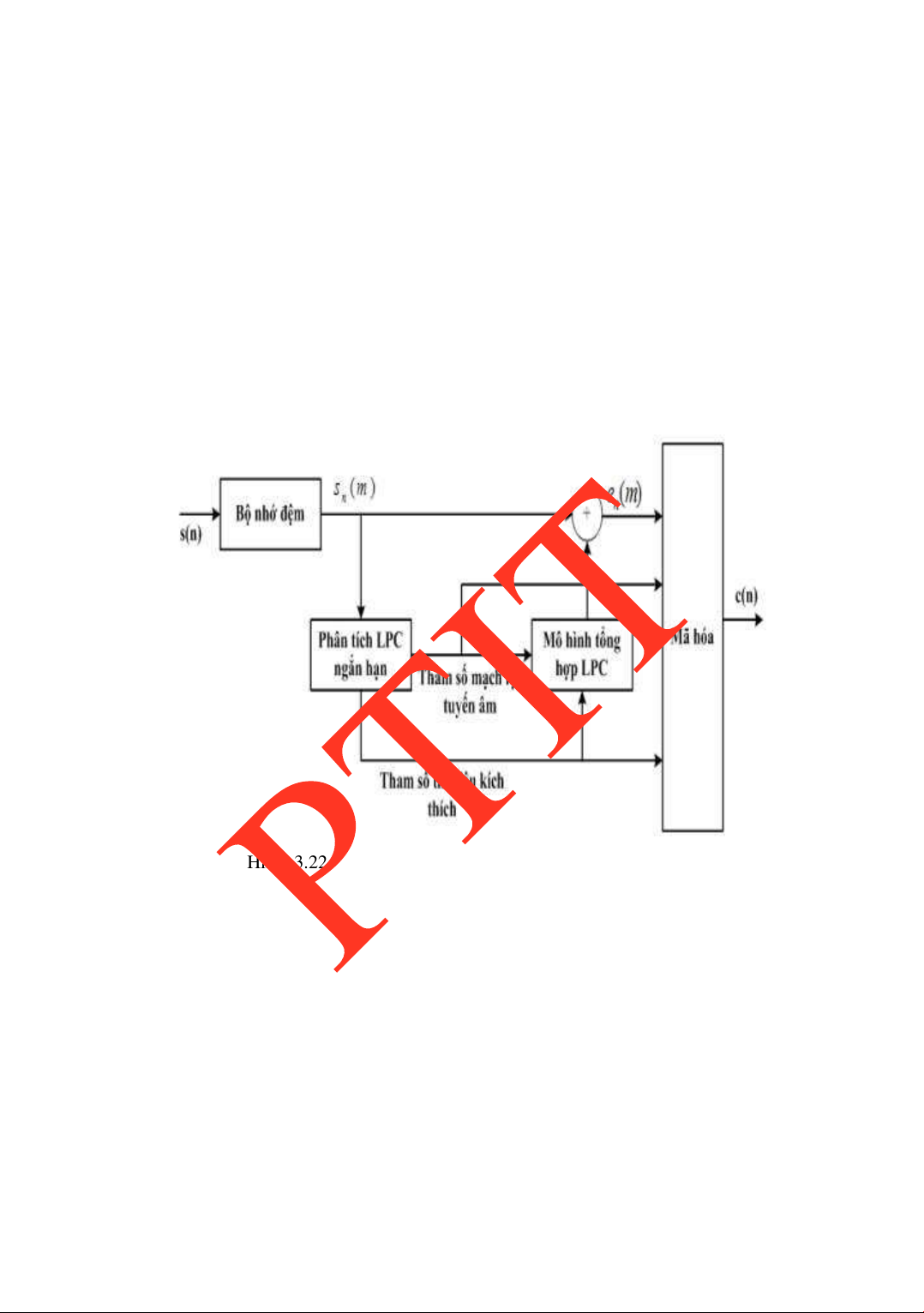
MỘT SỐ PHƢƠNG PHÁP MÃ HÓA TIẾNG NÓI TỐC ĐỘ THẤP ..87 3.6.
ĐÁNH GIÁ CHẤT LƢỢNG MÃ HÓA TIẾNG NÓI ...........................88 3.7.
CÂU HỎI VÀ BÀI TẬP CUỐI CHƢƠNG ...........................................88
CHƢƠNG 4. TỔNG HỢP TIẾNG NÓI .......................................................................91 4.1.
MỞ ĐẦU................................................................................................91 4.2.
CÁC PHƢƠNG PHÁP TỔNG HỢP TIẾNG NÓI ................................91
4.2.1 Tổng hợp trực tiếp ..............................................................................91
4.2.2 Tổng hợp tiếng nói theo Formant.......................................................94
4.2.3 Tổng hợp tiếng nói theo phƣơng pháp mô phỏng bộ máy phát âm ...99 4.3.
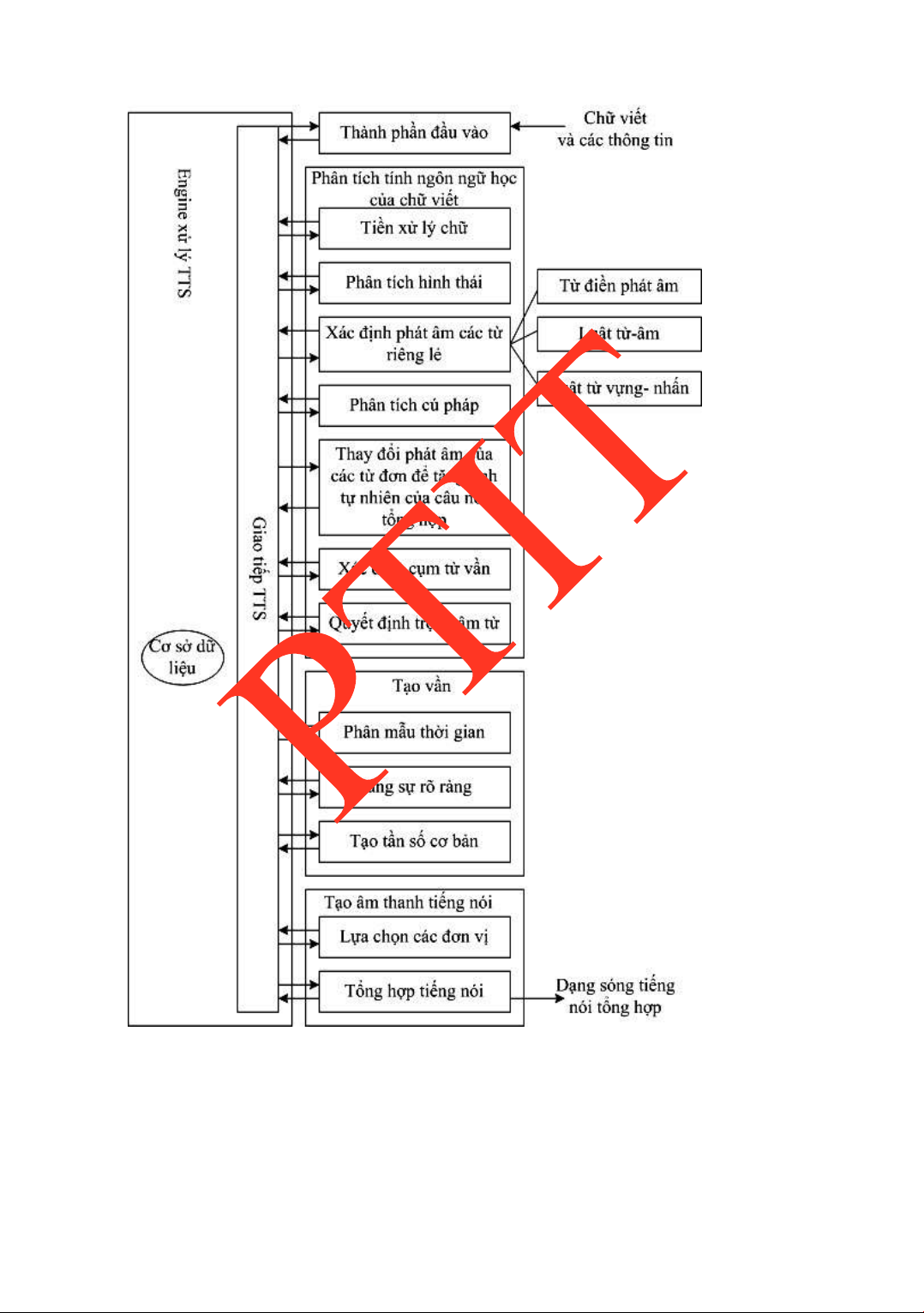
HỆ THỐNG TỔNG HỢP CHỮ VIẾT SANG TIẾNG NÓI ...............100 4.4.
MỘT SỐ ĐẶC ĐIỂM CỦA VIỆC TỔNG HỢP TIẾNG VIỆT ..........103 4.5.
CÂU HỎI VÀ BÀI TẬP CUỐI CHƢƠNG .........................................104
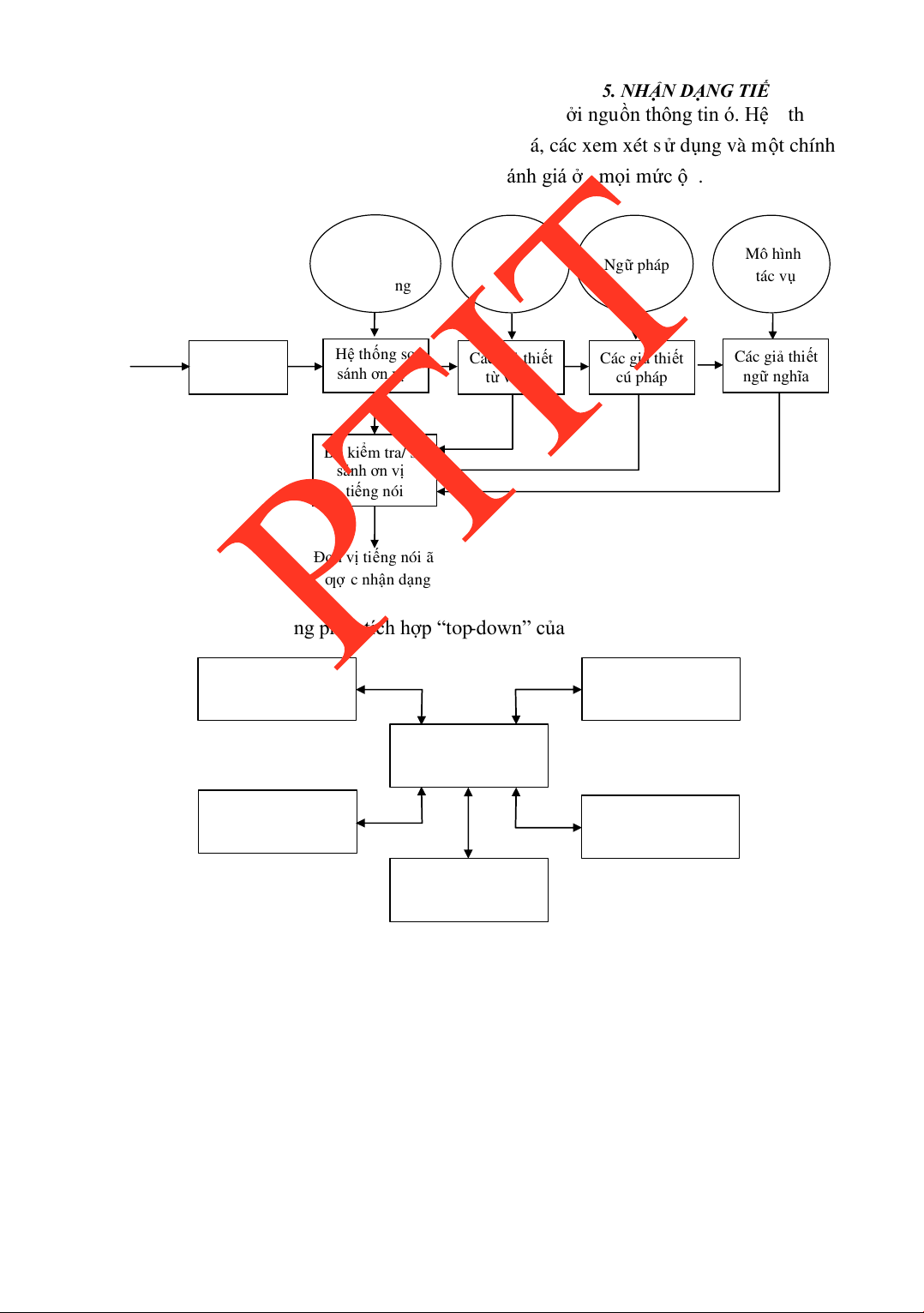
CHƢƠNG 5. NHẬN DẠNG TIẾNG NÓI .................................................................105 MỤC LỤC 5.1.
MỞ ĐẦU..............................................................................................105 5.2.
LỊCH SỬ PHÁT TRIỂN CÁC HỆ THỐNG NHẬN DẠNG TIẾNG
NÓI ......................................................................................................105 5.3.
PHÂN LOẠI CÁC HỆ THỐNG NHẬN DẠNG TIẾNG NÓI ...........106 5.4.
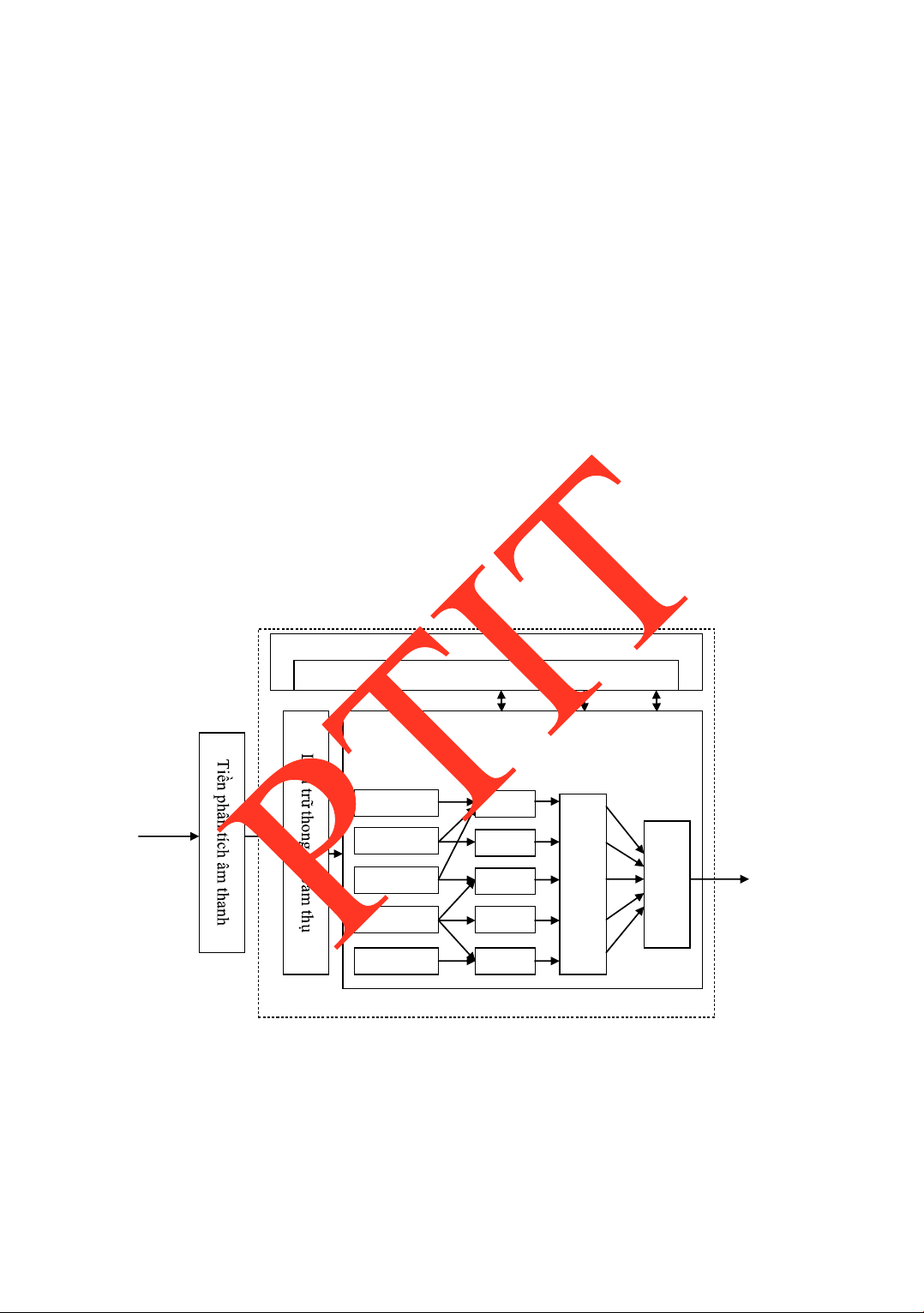
CẤU TRÚC HỆ NHẬN DẠNG TIẾNG NÓI .....................................108 5.5.
CÁC PHƢƠNG PHÁP PHÂN TÍCH CHO NHẬN DẠNG TIẾNG NÓI109
5.5.1 Lƣợng tử hóa véc-tơ .........................................................................109
5.5.2 Bộ xử lý LPC trong nhận dạng tiếng nói .........................................113 lOMoARcPSD| 36086670
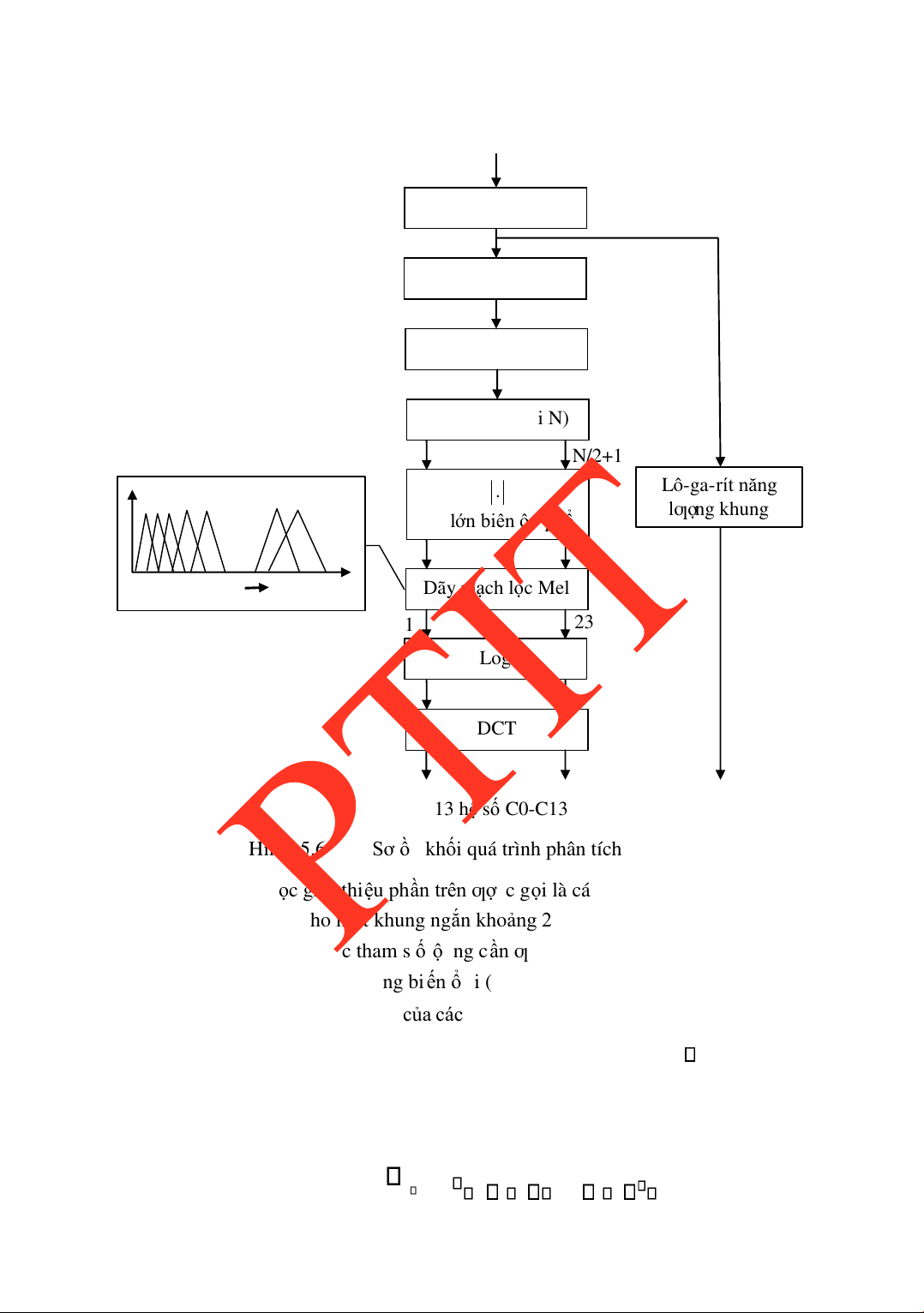
5.5.3 Phân tích MFCC trong nhận dạng tiếng nói ....................................120 5.6.
GIỚI THIỆU MỘT SỐ PHƢƠNG PHÁP NHẬN DẠNG TIẾNG NÓI123
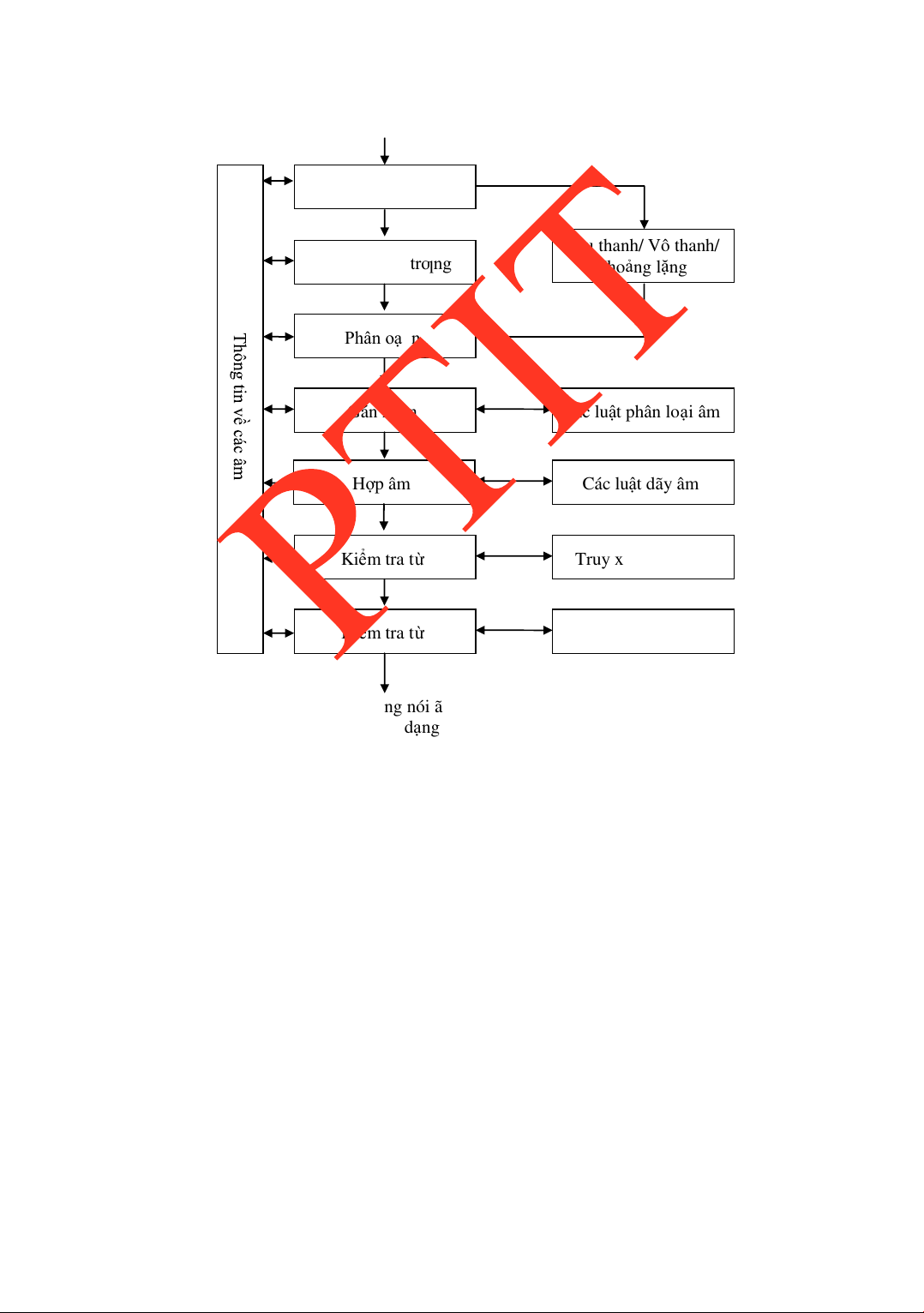
5.6.1 Phƣơng pháp acoustic-phonetic .......................................................125
5.6.2 Phƣơng pháp nhận dạng mẫu thống kê ............................................131
5.6.3 Phƣơng pháp sử dụng trí tuệ nhân tạo..............................................133
5.6.4 Ứng dụng mạng nơ-ron trong hệ thống nhận dạng tiếng nói ...........136
5.6.5 Hệ thống nhận dạng dựa trên mô hình Markov ẩn (HMM) .............139 5.7.
MỘT SỐ ĐẶC ĐIỂM CỦA VIỆC NHẬN DẠNG TIẾNG VIỆT ......142 5.8.
CÂU HỎI VÀ BÀI TẬP CUỐI CHƢƠNG .........................................142
Phụ lục 1: MẠNG NƠ-RON ......................................................................................144
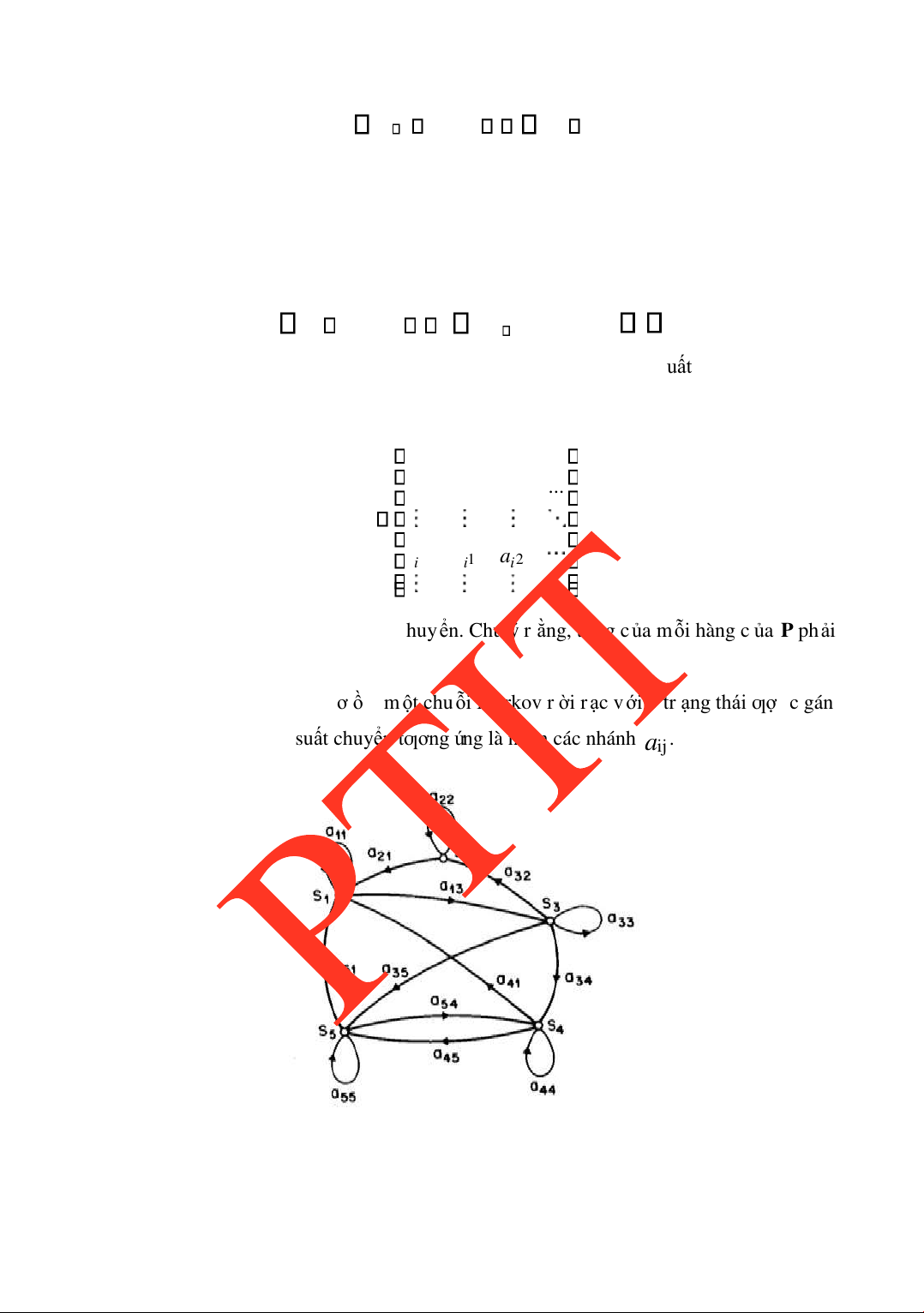
Phụ lục 2: MÔ HÌNH MARKOV ẨN ........................................................................147
TÀI LIỆU THAM KHẢO ..........................................................................................152 lOMoARcPSD| 36086670
CHƢƠNG 1. MỘT SỐ KHÁI NIỆM CƠ BẢN
CHƢƠNG 1. MỘT SỐ KHÁI NIỆM CƠ BẢN 1.1. MỞ ĐẦU
Tiếng nói là phƣơng tiện trao ổi thông tin chính yếu giữa con ngƣời và con ngƣời.
Phƣơng thức thông tin bằng tiếng nói ƣợc sử dụng một cách rộng rãi. Việc trao ổi thông
tin thông qua tín hiệu tiếng nói cho phép truyền tải thông tin một cách nhanh chóng hơn.
Một ngƣời bình thƣờng có thể nói trung bình hơn 100 từ trong một phút, trong khi ó chỉ
có thể viết ƣợc trung bình khoảng 50 từ trong vòng một phút.
Thông tin tiếng nói ơn giản mà hiệu quả. Tiếng nói là phƣơng tiện trao ổi ầy ma lực:
Bản thân ngôn từ (cách hành văn) ã vốn chứa ựng một sắc thái biểu cảm, nhƣng thông qua
ngôn ngữ nói nó còn có khả năng truyền tải cả sắc thái, thái ộ (vui, buồn,...)
Mặt khác, con ngƣời có vẻ ngày càng lƣời hơn. Nhu cầu sử dụng tiếng nói thay vì các
thao tác bằng tay ể thực hiện công việc, chẳng hạn nhƣ iều khiển, ang tăng một cách mạnh
mẽ hơn bao giờ hết. Điều này ặc biệt càng úng với sự phát triển nhanh chóng của công
nghệ khoa học hiện nay. Chúng ta không còn lạ lẫm với các ứng dụng iều khiển các thiết
bị trong nhà thông minh bằng cử chỉ và giọng nói. Thậm chí, Google còn cho phép chúng
ta có khả năng lái xe bằng cách chỉ cần ra lệnh bằng giọng nói.
Để có thể phát huy ƣợc thế mạnh, sự tiện dụng của phƣơng tiện giao tiếp này, ặc biệt
là có thể hiểu, nắm bắt và từng bƣớc có khả năng xây dựng và triển khai các hệ thống giao
tiếp bằng giọng nói thì rất cần thiết phải có ƣợc những kiến thức cơ bản về xử lý tiếng nói.
Trong chƣơng này, trƣớc hết chúng ta sẽ làm quen với một số khái niệm cơ bản của hệ
thống xử lý tiếng nói. Những khái niệm cơ bản này sẽ là nền tảng ể nghiên cứu và tìm hiểu
sâu hơn trong các chƣơng tiếp theo.
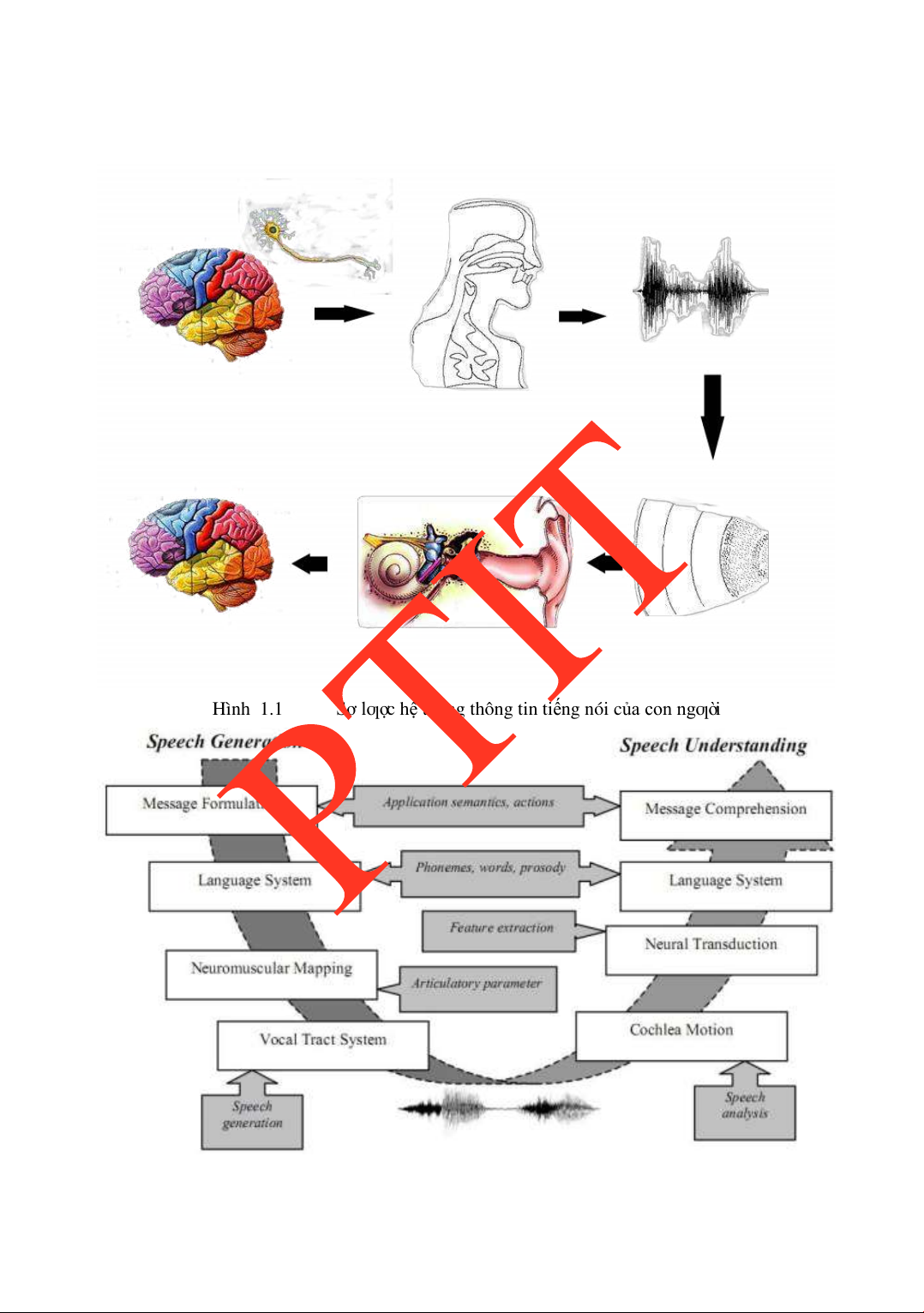
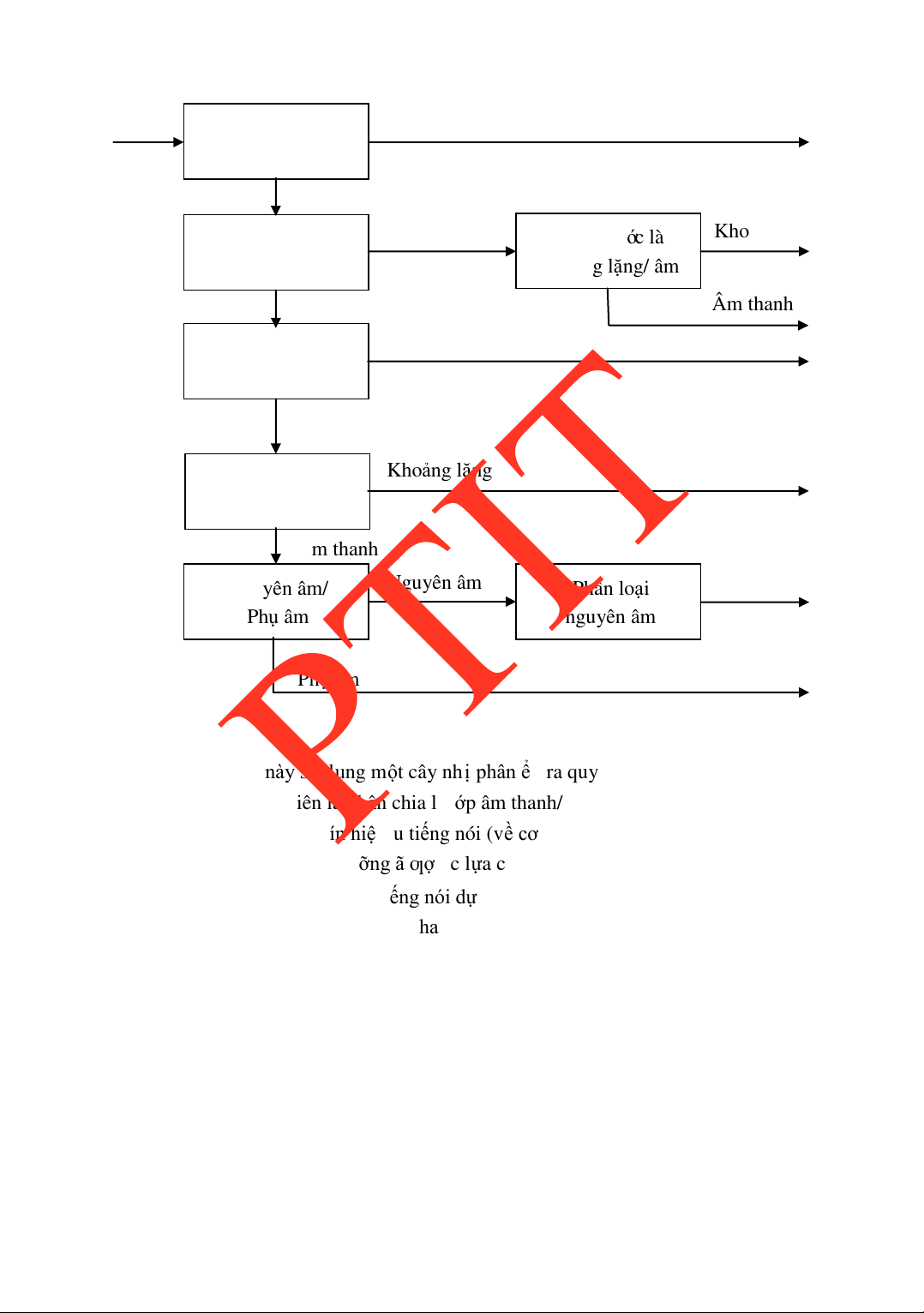
1.2. TỔNG QUAN VỀ XỬ LÝ TIẾNG NÓI
Để ơn giản có cái nhìn tổng quát về hệ thống xử lý tiếng nói và trả lời ƣợc câu hỏi
“Xử lý tiếng nói là gì?”, hãy quan sát quá trình chúng ta thực hiện giao tiếp bằng giọng
nói. Nếu chúng ta óng vai trò ngƣời nói, những thông iệp mong muốn truyền tải ƣợc ịnh
hình tại bộ não. Não sẽ thực hiện việc phân tích thông iệp này và ƣa các tín hiệu ể iều
khiển các bộ phận phát âm tƣơng ứng hoạt ộng nhằm “tổng hợp” ra âm thanh mong muốn
ể truyền tải thông iệp. Ở phía ngƣời nghe, âm thanh mang thông tin ƣợc thu nhận bởi cơ
quan cảm thụ sẽ cảm thụ, thông qua các tín hiệu thần kinh truyền ến não ể “nhận dạng” và
“suy diễn” nhằm hiểu thông tin. Một cách tổng quát, hệ thống thông tin bằng tiếng nói
của con ngƣời có thể mô tả nhƣ hình 1.1. Mặc dù cho ến nay, con ngƣời vẫn chƣa hoàn lOMoARcPSD| 36086670
CHƢƠNG 1. MỘT SỐ KHÁI NIỆM CƠ BẢN
toàn hiểu một cách toàn diện về quá trình tạo, cảm nhận tiếng nói của con ngƣời nhƣng
một số quá trình và cách thức thực hiện cơ bản có thể ƣợc tóm lƣợc nhƣ hình 1.2. Hình 1.1
Sơ lƣợ c h ệ th ố ng thông tin ti ế ng nói c ủa con ngƣờ i Hình 1.2
Tóm lƣợc một số quá trình xử lý trong hệ thống thông tin bằng tiếng nói lOMoARcPSD| 36086670
CHƢƠNG 1. MỘT SỐ KHÁI NIỆM CƠ BẢN
Nhƣ vậy, bản chất của “xử lý tiếng nói” là việc thực hiện các phép thao tác nào ó
nhằm tạo ra tiếng nói ể truyền tải tin tức, và/hoặc bóc tách thông tin từ tín hiệu tiếng nói.
Từ bản chất nói trên, chúng ta có thể dễ dàng xây dựng các hệ thống xử lý tiếng
nói trong ó có thể tái tạo một phần hoặc toàn bộ các thao tác xử lý của hệ thống thông tin tiếng nói tự nghiên.
Nói tóm lại, xử lý tiếng nói là lĩnh vực khoa học nghiên cứu về tiếng nói (cả khía
cạnh ngôn ngữ và khía cạnh tín hiệu), và các phƣơng pháp xử lý các khía cạnh của tiếng nói.
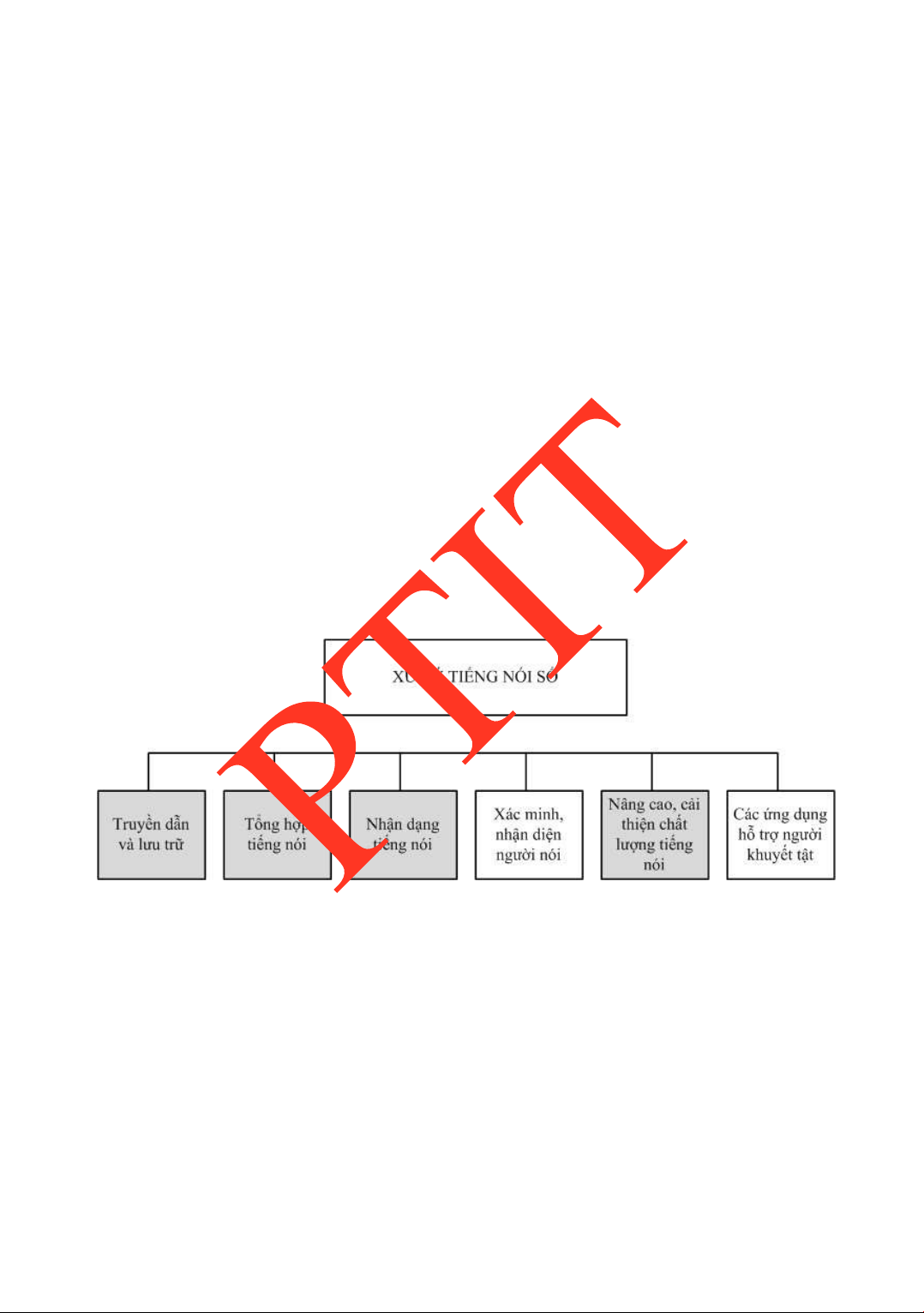
Cũng nhƣ vốn dĩ sự phức tạp của hệ thống thông tin tiếng nói (ngôn ngữ) của con
ngƣời, xử lý tiếng nói là một lĩnh vực phức tạp và bao trùm tƣơng ối rộng. Đầu tiên có thể
kể ến là xử lý tín hiệu tiếng nói về mặt vật lý nhƣ giảm/loại bỏ nhiễu, giảm méo, … trong
lĩnh vực tăng cƣờng nâng cao chất lƣợng tiếng nói nhằm cải thiện tín dễ nghe dễ hiểu của
tín hiệu tiếng nói. Hoặc có thể kể ến là việc tìm cách biểu diễn tín hiệu tiếng nói ở dạng tín
hiệu số sao cho dung lƣợng nhỏ nhất trong lĩnh vực mã hóa lƣu trữ và truyền tải tín hiệu
thoại. Không chỉ dừng lại ở ó, khi công nghệ phát triển, xử lý tiếng nói cho phép các hệ
thống có thể tái tạo tiếng nói (tổng hợp tiếng nói), hiểu ƣợc tiếng nói (nhận dạng tiếng
nói). Hình 1.3 mô tả tóm lƣợc các lĩnh vực chủ yếu của xử lý tiếng nói số. Hình 1.3
Một số lĩnh vực cơ bản của Xử lý tiếng nói số
1.3. QUÁ TRÌNH TẠO VÀ CẢM NHẬN TIẾNG NÓI
Nhƣ ã ề cập ở phần ầu của chƣơng, tiếng nói là một phƣơng tiện thông tin hiệu
quả, nhƣng quá trình xử lý cũng rất phức tạp. Để có thể hiểu và có thể áp dụng tốt những
kỹ thuật, phƣơng pháp xử lý cho tín hiệu tiếng nói, chúng ta không thể không hiểu về quá
trình tạo và cảm nhận tiếng nói của con ngƣời. Những hiểu biết về cách thức xử lý tuyệt
vời của hệ thống cảm nhận của hệ thống phát âm, hệ thống thính giác của con ngƣời sẽ là
một tham khảo áng giá. Hơn nữa, một số ặc tính cảm nhận và xử lý có thể sẽ tạo những cơ
hội xử lý thuận tiện và hiệu quả nếu ƣợc khai thác một cách hợp lý. lOMoARcPSD| 36086670
CHƢƠNG 1. MỘT SỐ KHÁI NIỆM CƠ BẢN
1.3.1 Bản chất của tiếng nói
Âm thanh tiếng nói cũng nhƣ âm thanh nói chung trong thế giới tự nhiên xung quanh
ta, về bản chất ều là những sóng âm ƣợc lan truyền trong một môi trƣờng vật lý nhất ịnh (thƣờng là không khí).
Tuy nhiên ó là những hiểu biết phía bên ngoài, phần kết quả, về hệ thống tạo tín hiệu
tiếng nói. Để ơn giản, chúng ta bỏ qua khía cạnh tâm thần (neurology) của quá trình tạo
tiếng nói. Do ó, có thể coi nguồn gốc của quá trình tạo tín hiệu tiếng nói là quá trình hoạt
ộng của hệ thống phát âm. Khi ta nói dây thanh trong hầu dao ộng. Những dao ộng này
ƣợc truyền qua hệ thống tuyến âm, một hệ thống óng vai trò nhƣ một bộ lọc cơ học, tạo
nên những sóng âm truyền tải thông tin tiếng nói. Sóng âm này, về bản chất là những dao
ộng cơ học, lan truyền trong không khí ến phía ngƣời nghe.
Nhƣ chúng ta ã ƣợc học trong chƣơng trình vật lý phổ thông, sóng âm là sóng cơ học
và thuộc loại sóng dọc. Sóng âm chỉ có thể lan truyền trong môi trƣờng có vật chất (không
khí, nƣớc, …). Về cơ bản nó cũng có các tham số nhƣ một sóng cơ học thông thƣờng nhƣ
tần số, chu kỳ, bƣớc sóng. Một số tham số cơ bản của sóng ƣợc minh họa trong hình 1.4. Hình 1.4
Một số tham số cơ bản của sóng cơ học
Cũng cần lƣu ý rằng, sóng âm thanh tiếng nói phức tạp hơn rất nhiều. Bản chất của sự
thay ổi liên tục ể truyền tải thông iệp khiến cho các tham số cơ bản ề cập ở trên luôn thay ổi
thậm chí ngay trong khoảng thời gian rất ngắn.
Sóng âm thanh mà con ngƣời có thể cảm nhận ƣợc nằm trong một dải tần số rất rộng,
khoảng từ 16Hz ến 20000Hz. Những sóng âm dao ộng có tần số nhỏ hơn 16Hz ƣợc gọi là
sóng hạ âm. Những sóng âm có tần số lớn hơn 20000Hz ƣợc gọi là sóng siêu âm. Mặc dù
hầu hết con ngƣời không cảm nhận ƣợc sóng hạ âm và không sử dụng trong thông tin,
một số ngƣời có khả năng cảm nhận sóng hạ âm sẽ có những cảm giác bồn chồn lo lắng
áp lực. Cũng tƣơng tự, con ngƣời không cảm nhận ƣợc sóng siêu âm, nhƣng sóng siêu
âm có khá nhiều ứng dụng thực tế nhƣ phát hiện chẩn oán trong ảnh y
tế, ịnh vị phát hiện kẻ thù trong hệ thống sonar trên các tàu ngầm, … lOMoARcPSD| 36086670
CHƢƠNG 1. MỘT SỐ KHÁI NIỆM CƠ BẢN
1.3.2 Cấu tạo của hệ thống phát âm
Tiếng nói là kết quả của sự phối hợp hoạt ộng giữa não, hệ dây thần kinh và các bộ
phận trong hệ thống phát âm. Hệ thống phát âm gồm hai phần chính là phổi và hệ thống tuyến âm.
Phổi có nhiệm vụ giãn/ép hơi nhằm tạo lực cần thiết cho dây thanh thực hiện dao ộng.
Nó ƣợc coi là nguồn kích thích dao ộng của dây thanh. Khi nói, lồng ngực mở rộng và thu
hẹp, không khí ƣợc ẩy từ phổi vào khí quản, luồng khí này bị ép và i qua cặp dây thanh
tạo ra dao ộng. Dao ộng này tạo ra sự xáo trộn của luồng hơi, sau khi truyền qua hệ thống
tuyến âm thì phát xạ ra ở môi.
Tuyến âm có thể ƣợc coi nhƣ một ống âm học (gồm các oạn ống với ộ dài bằng nhau
và thiết diện các mặt cắt khác nhau mắc nối tiếp, còn gọi là bộ lọc cơ học) với ầu vào là
các dây thanh (còn gọi là thanh môn) và ầu ra là môi. Hình 1.5 minh họa cấu trúc và các
bộ phận của hệ thống tuyến âm. Tuyến âm có hình dạng thay ổi và ƣợc iều khiển co thắt
ể thay ổi nhƣ một hàm theo thời gian. Các mặt cắt của tuyến âm ƣợc xác ịnh bằng vị trí
của lƣỡi, môi, hàm, vòm miệng và tiết diện của những mặt cắt này thay ổi từ 0cm2 (khi
ngậm môi) ến khoảng 20cm2 (khi hở môi). Tuyến mũi tạo thành một tuyến âm phụ trợ cho
việc truyền âm thanh, nó bắt ầu từ vòm miệng và kết thúc ở các lỗ mũi. Khi vòm miệng hạ
thấp, tuyến mũi ƣợc nối với tuyến âm về mặt âm học và tạo nên tiếng nói âm mũi.
Thanh quản là tập hợp các cơ và sụn ộng bao quanh một khoang nằm ở phần trên của
khí quản. Các dây thanh giống nhƣ là một ôi môi ối xứng nằm ngang thanh quản. Cặp môi
này có thể khép kín hoàn toàn thanh quản hoặc mở ra tạo ra ộ mở hình tam giác gọi là
thanh môn. Bình thƣờng không khí qua thanh quản một cách tự do trong quá trình thở
hoặc trong quá trình phát âm những âm câm hoặc vô thanh. Khi phát âm những âm hữu
thanh, cặp môi này óng mở liên tục một cách không tuần hoàn (còn gọi là dao ộng) ể tạo
ra âm thanh. Những rung ộng dây thanh liên tiếp ƣợc truyền qua tuyến âm. Dao ộng dây
thanh sẽ ƣợc iều biến thông qua sự thay ổi hình dạng và tiết diện của tuyến âm ể tạo ra những âm khác nhau. Hình 1.5
Hệ thống phát âm của con ngƣời
Tóm lại, tín hiệu tiếng nói ƣợc tạo ra từ hệ thống phát âm của con ngƣời có thể mô tả ơn
giản là một quá trình gồm ba khối nhƣ hình 1.6. Nguồn kích Tín hiệu Tuyến âm Tán xạ môi thích tiếng nói lOMoARcPSD| 36086670
CHƢƠNG 1. MỘT SỐ KHÁI NIỆM CƠ BẢN Hình 1.6
Quá trình cơ bản tạo tín hiệu tiếng nói
1.3.3 Phân loại tiếng nói
Tiếng nói là âm thanh mang mục ích diễn ạt thông tin, rất uyển chuyển và ặc biệt. Là
công cụ của tƣ duy và trí tuệ, tiếng nói mang tính ặc trƣng của loài ngƣời. Nó không thể
tách riêng khi nhìn vào toàn thể nhân loại, và nhờ có ngôn ngữ tiếng nói mà loài ngƣời
sống và phát triển xã hội tiến bộ, có văn hóa, văn minh nhƣ ngày nay. Trong quá trình giao
tiếp bằng tiếng nói, thông tin tiếng nói gồm có nhiều câu nói, mỗi câu gồm nhiều từ, mỗi
từ lại có thể gồm một hay nhiều ơn vị âm. Để thuận tiện trong quá trình nghiên cứu, ngƣời
ta thực hiện việc phân chia tiếng nói theo một số ặc trƣng. Tùy theo các ặc trƣng ƣợc sử
dụng ể phân loại mà chúng ta có các loại âm thanh tiếng nói khác nhau. Một cách ơn giản
nhất là dựa vào ăc trƣng phát âm, ngƣời ta chia tiếng nói thành 3 loại cơ bản nhƣ sau:
Âm hữu thanh: Là âm khi phát ra có thanh, ví dụ nhƣ ta phát âm những nguyên âm
nhƣ “i”, “a”, hay “o” chẳng hạn. Thực ra âm hữu thanh ƣợc tạo ra là do việc không
khí qua thanh môn (thanh môn tạo ra sự khép mở của dây thanh dƣới sự iều khiển
của hai sụn chóp) với một ộ căng của dây thanh sao cho chúng tạo nên dao ộng với tần số cơ bản.
Âm vô thanh: Là âm khi phát ra không có thanh, dây thanh không rung hoặc rung ôi
chút hoặc dao ộng không có tần số cơ bản. Khi phát âm các âm vô thanh, chúng ta tạo ra
giọng nhƣ giọng thở, ví dụ “h”, “p” hay “th”.
Âm bật: Để phát ra âm bật (còn gọi âm nổ), ầu tiên dây thanh óng kín, tạo nên một áp
suất không khí lớn, sau ó có sự mở khiến không khí ƣợc giải phóng một cách ột ngột tạo ra các âm thanh bật.
Cũng cần chú ý, có một số âm khác không ơn giản phân loại ƣợc vào một trong ba
nhóm âm trên bởi vì chúng là âm tổ hợp của các yếu tố của các âm ó. Chẳng hạn âm thanh
khi phát âm chữ “kh”, âm ƣợc tạo ra do sự mở hẹp của thanh môn và sự co thắt và mở hẹp của vòm miệng.
1.3.4 Cấu tạo của hệ thống cảm nhận tiếng nói
Trong hệ thống cảm nhận tiếng nói, tai là một bộ phận quan trọng và là khối ầu tiên
trong hệ thống. Không giống nhƣ các cơ quan tham gia vào quá trình tạo ra tiếng nói nhƣ
miệng, mũi, phổi, các cơ quan mà ngoài chức năng tham gia tạo tín hiệu tiếng nói còn thực
hiện các chức năng khác nhƣ ăn, ngửi, thở. Tai, một cơ quan trong hệ thống thính giác của
con ngƣời, chỉ sử dụng cho chức năng nghe. Tai ngƣời ặc biệt nhạy cảm với những tần số
tín hiệu tiếng nói nằm trong vùng nghe (trong khoảng xấp xỉ từ 200 – 5600Hz). Tai ngƣời lOMoARcPSD| 36086670
CHƢƠNG 1. MỘT SỐ KHÁI NIỆM CƠ BẢN
là một máy thu tự nhiên tuyệt hảo, nó có thể phân biệt ƣợc những sự khác biệt rất nhỏ về
thời gian và tần số của những âm thanh nằm trong vùng tần số này.
Tai gồm có ba phần: tai ngoài, tai giữa và tai trong. Tai ngoài làm nhiệm vụ dẫn hƣớng
những thay ổi áp xuất tiếng nói vào trong màng nhĩ. Nói cách khác, tai ngoài giống nhƣ
một bộ ăn-ten làm nhiệm vụ thu nhận những dao ộng âm của tiếng nói truyền ến. Dao ộng
âm, thể hiện ở áp suất hay dao ộng các phần tử không khí sẽ ƣợc biến ổi thành chuyển ộng
cơ học ở tai giữa. Những chuyển ộng cơ học ở tai giữa ƣợc chuyển ổi thành những luồng
iện trong nơron thính giác dẫn ến não ể thực hiện quá trình phân tích và bóc tách thông tin.
Tai ngoài: là phần phía bên ngoài của tai, bao gồm loa tai (pinna – vành tai) và lỗ tai
(meatus - ống tai ngoài). Loa tai hầu nhƣ không hoặc rất ít có vai trò ối với ộ thính của tai,
nhƣng có chức năng bảo vệ lối vào ống tai và dƣờng nhƣ cũng tham gia vào khả năng khu
biệt các âm, ặc biệt là ở những tần số cao hơn. Với cấu trúc vành rộng cùng các rãnh xoáy,
nó có nhiệm vụ nhƣ một ăn-ten thực hiện thu tập năng lƣợng âm và dẫn hƣớng vào tai
giữa thông qua ống tai ngoài. Ống tai ngoài ƣợc nối ở phần cuối hõm của vành tai, nó là
một ống ngắn có hình dáng thay ổi có chiều dài khoảng 2.5cm làm ƣờng dẫn cho các tín
hiệu âm thu nhận ƣợc ến tai giữa. Ống tai ngoài có hai chức năng chính. Chức năng thứ
nhất là bảo vệ các cấu trúc phức tạp và dễ bị tổn thƣơng cơ học của tai giữa. Chức năng
thứ hai là óng vai trò nhƣ một bộ lọc cơ học cộng hƣởng hình ống vốn ƣu tiên cho việc
truyền các âm có tần số cao giữa 3000 Hz và 12000Hz. Chức năng này là quan trọng ối với
việc tiếp nhận tiếng nói và ặc biệt trợ giúp cho việc tiếp nhận các âm xát, vì ặc iểm của các
âm này ƣợc tạo ra bởi nguồn kích thích không có chu kỳ và phổ năng lƣợng của chúng
nằm trong trong khu phổ này. Sự cộng hƣởng, nói cách khác là khuếch ại, ở ống tai ngoài
góp phần vào ộ thính chung của tai ở vùng tần số giữa 500Hz và 4000Hz, vốn là một dải
tần có chứa nhiều dấu hiệu chính ối với cấu trúc âm vị học. Xƣơng búa Xƣơng e Xƣơng bàn ạp Cửa sổ Thần kinh thính giác hình bầu dục Ốc tai Màng nhĩ lOMoARcPSD| 36086670
CHƢƠNG 1. MỘT SỐ KHÁI NIỆM CƠ BẢN Vòi Ot-tat Hình 1.7
Cấu trúc hệ thính giác ngoài
Tai giữa bao gồm một khoang nằm trong cấu trúc hộp sọ có chứa màng nhĩ (eardrum)
- màng ở ầu phía trong của ống tai ngoài, một bộ ba khúc xƣơng liên kết với nhau, còn ƣợc
gọi là xƣơng vồ (mallet), xƣơng e (anvil) và xƣơng bàn ạp (stirrup) (cũng có thuật ngữ là
xƣơng tai (auditory ossicle)) và cấu trúc cơ liên kết. Mục ích của tai giữa là biến ổi những
thay ổi áp suất âm (những dao ộng âm) ƣợc thu nhận từ tai ngoài dẫn vào thành những dịch
chuyển cơ khí tƣơng ứng. Quá trình biến ổi này bắt ầu ở màng nhĩ, dao ộng âm làm dịch
chuyển màng nhĩ. Sự dịch chuyển này ƣợc truyền ến các xƣơng tai, vốn óng vai trò nhƣ
một hệ thống òn bẩy cơ học khéo léo truyền những dịch chuyển này ến cửa hình bầu dục,
ô cửa ở giao tiếp giữa tai trong và chất dịch trong lỗ tai.
Với cơ chế hoạt ộng òn bẩy của các xƣơng tai, và ặc biệt là vùng diện tích bề mặt của
màng nhĩ lớn hơn nhiều so với cửa hình bầu dục, việc truyền hiệu ứng của năng lƣợng âm
học giữa 500Hz và 4000Hz ƣợc ảm bảo. Kết quả làm tăng ến mức tối a khả năng thính
của tai ở vùng tần số này. Hệ cơ gắn với các xƣơng tai cũng hoạt ộng ể bảo vệ tai chống
lại những dao ộng âm lớn nhờ hoạt ộng của cơ chế phản xạ âm học. Khi các âm có biên ộ
khoảng 90dB và lớn hơn truyền ến tai, hệ cơ kết hợp và sắp xếp lại các xƣơng tai ể làm
giảm hiệu quả truyền âm ến cửa hình bầu dục (Borden và Harris 1980, Moore 1989), kết
quả là những dao ộng âm quá mạnh bị giảm khi ến cửa hình bầu dục. Tai giữa ƣợc nối với
họng bằng một ống hẹp gọi là vòi ốc tai (eustachian tube). Việc kết nối này hình thành một
ƣờng khí và ƣờng này sẽ mở ra khi cần cân bằng những thay ổi áp suất khí nền giữa cấu
trúc tai giữa và tai ngoài.
Tai trong là một cấu trúc phức tạp ƣợc bọc trong hộp sọ, ốc tai (cochlea) có trách
nhiệm biến ổi sự chuyển dịch cơ khí thành các tín hiệu thần kinh: sự dịch chuyển cơ khí
ƣợc truyền ến cửa hình bầu dục tại các ốc tai ƣợc chuyển thành các tín hiệu thần kinh và
các tín hiệu thần kinh này ƣợc truyền ến hệ thống thần kinh trung ƣơng. Về cơ bản, ốc tai
là một cấu trúc hình xoắn cụt với một cửa sổ có một màng linh hoạt ở mỗi ầu. Ở bên trong,
ốc tai chia thành hai màng, một trong số ó là màng nền (basilar membrane). Đây là màng
cực kì quan trọng ối với hoạt ộng nghe. Khi những dịch chuyển (do các rung ộng âm gây
ra) diễn ra tại cửa sổ hình bầu dục, chúng ƣợc truyền qua chất dịch trong ốc tai và gây ra
sự dịch chuyển (displacement) của màng nền. Ở một ầu màng nền cứng hơn so với ở ầu
kia, và iều này có nghĩa là cách thức mà trong ó chất dịch ƣợc dịch chuyển phụ thuộc vào
tần số của âm tác ộng vào. Các âm có tần số cao sẽ gây ra sự dịch chuyển lớn hơn ở ầu
cứng; với tần số giảm dần, sự dịch chuyển cực ại sẽ di chuyển liên tục về phía ầu ít cứng
hơn. Gắn dọc với màng nền là cơ quan vỏ não (organ of corti), một cấu trúc phức tạp chứa lOMoARcPSD| 36086670
CHƢƠNG 1. MỘT SỐ KHÁI NIỆM CƠ BẢN
nhiều tế bào tóc. Chính sự dịch chuyển và sự kích thích của các tế bào tóc này biến sự dịch
chuyển của màng nền thành các tín hiệu thần kinh. Vì màng nền ƣợc dịch chuyển mạnh
yếu ở các vị trí khác nhau phụ thuộc vào tần số, cho nên ốc tai và các cấu trúc bên trong
của nó có thể biến tần số và cƣờng ộ của âm thành các tín hiệu thần kinh có khả năng phân
biệt. Nhƣng cần phải nhấn mạnh rằng sự tái hiện thông tin cuối cùng về tần số cảm nhận
từ tín hiệu thần kinh không chỉ ơn thuần phụ thuộc vào vị trí cũng nhƣ không chỉ phụ
thuộc riêng vào sự dịch chuyển màng nền, mà ây là một quá trình diễn giải phức tạp. Hơn
nữa, cho ến nay, hiểu biết của chúng ta về cách thức tần số ƣợc lập, mã và giải mã thông
qua hệ thống thính giác vẫn chƣa hoàn thiện. Màng tiền ịnh Cơ quan vỏ não Màng nền Hình 1.8
Mặt cắt ngang của ốc tai
Những nghiên cứu ầu tiên về cảm nhận tiếng nói quan tâm rất ít ến các thuộc tính cảm
nhận cơ bản của tai. Những nghiên cứu này ã cố gắng gắn kết các thuộc tính cảm nhận của
tín hiệu tiếng nói với kiểu tái hiện phổ thay ổi theo thời gian tuyến tính. Đến khoảng năm
1980 nhiều nhà nghiên cứu ã nhận ra rằng cần phải hiểu những hiệu ứng có tính chất phân
tích của hệ thính giác ngƣời về các tín hiệu tiếng nói và thật là sai lầm khi cho rằng ngƣời
nghe chỉ ang xử lí thông tin theo cách giống nhƣ chiếc máy ghi phổ bình thƣờng mà thôi.
1.3.5 Đặc iểm cảm nhận tiếng nói của ngƣời
Tín hiệu tiếng nói ƣợc truyền tải ến tai ngƣời nghe thông qua các dao ộng tạm thời của
các phần tử vật chất dọc theo ƣờng truyền tạo ra một áp suất âm ến tai. Tai con ngƣời có
thể cảm nhận ƣợc một dải áp suất âm rộng hợn 7 ơn vị ề-các, bắt ầu từ ngƣỡng nghe (còn
gọi là TOH – Threshold of hearing) với áp suất âm 10^-5Pa ến ngƣỡng nghe gây au với áp
suất âm 10^2Pa. Ngƣỡng nghe là ngƣỡng áp suất âm thấp nhất mà tai con ngƣời có thể
cảm nhận ƣợc. Ngƣợc lại, ngƣỡng nghe gây au (hay ơn giản gọi là ngƣỡng gây au) là mức
ngƣỡng áp suất âm mà con ngƣời bắt ầu có cảm giác au ở tai.
Để ơn giản trong ánh giá ộ lớn của âm, thay vì sử dụng áp suất âm ngƣời ta sử dụng
một ại lƣợng mức áp suất âm (ký hiệu là SPL, Lp – Sound Pressure Level). Mức áp suất
âm là một o lƣờng theo tỷ lệ lô-ga-rít của áp suất âm tƣơng ối so với một quá trị tham lOMoARcPSD| 36086670
CHƢƠNG 1. MỘT SỐ KHÁI NIỆM CƠ BẢN
chiếu. Nói một cách cụ thể, SPL là một ại lƣợng o lƣờng tƣơng ối có ơn vị là dB. Giá trị
tham chiếu thƣờng là ngƣỡng nghe. SPL ƣợc xác ịnh bởi công thức:
SPL[dB] 10log Prms22 20log PPrms0 P0
trong ó, Prmslà áp suất âm trung bình quân phƣơng, P0 là áp suất âm tham chiếu.
Một ại lƣợng o lƣờng khác là mức cƣờng ộ âm (ký hiệu là SIL, Li – Sound Intensity
Level) ƣợc xác ịnh bởi công thức: I SIL[dB] LI 10log10 I0
trong ó, I là mức cƣờng ộ âm, I0 là mức cƣờng ộ âm tham chiếu.
Mức cƣờng ộ âm tham chiếu thƣờng là mức cƣờng ộ âm ứng với ngƣỡng nghe. Giá trị
này vào khoảng 10^-12W/m2.
Khi sóng âm lan truyền trong môi trƣờng không khí tự do, giá trị của SPL và SIL bằng
nhau. Tuy nhiên, trong không hạn chế iều này không còn úng do có sự phản xạ âm.
Hầu hết các microphone, một trong nhiều loại thiết bị biến ổi áp suất âm thành tín hiệu
iện, làm việc theo nguyên lý nhạy cảm/ áp ứng với kích thích là áp suất âm. Nghĩa là những
thiết bị này sẽ o lƣờng/xác ịnh SPL chứ không phái SIL.
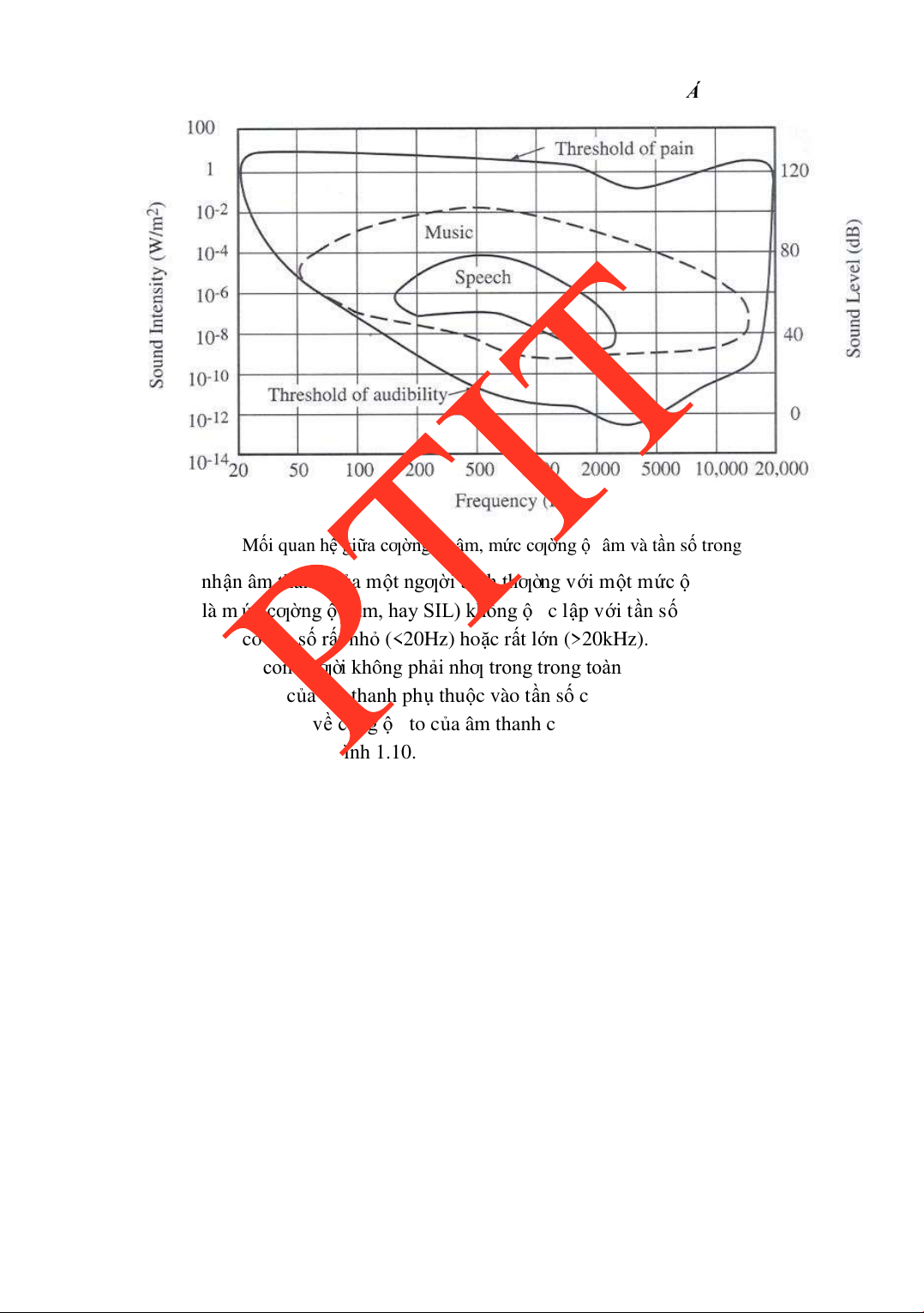
Trong nhiều tài liệu kỹ thuật, ngƣời ta thƣờng ồng nhất ộ to của âm chính là mức cƣờng
ộ âm. Mối quan hệ có thể ƣợc minh họa trong hình vẽ 1.9. lOMoARcPSD| 36086670
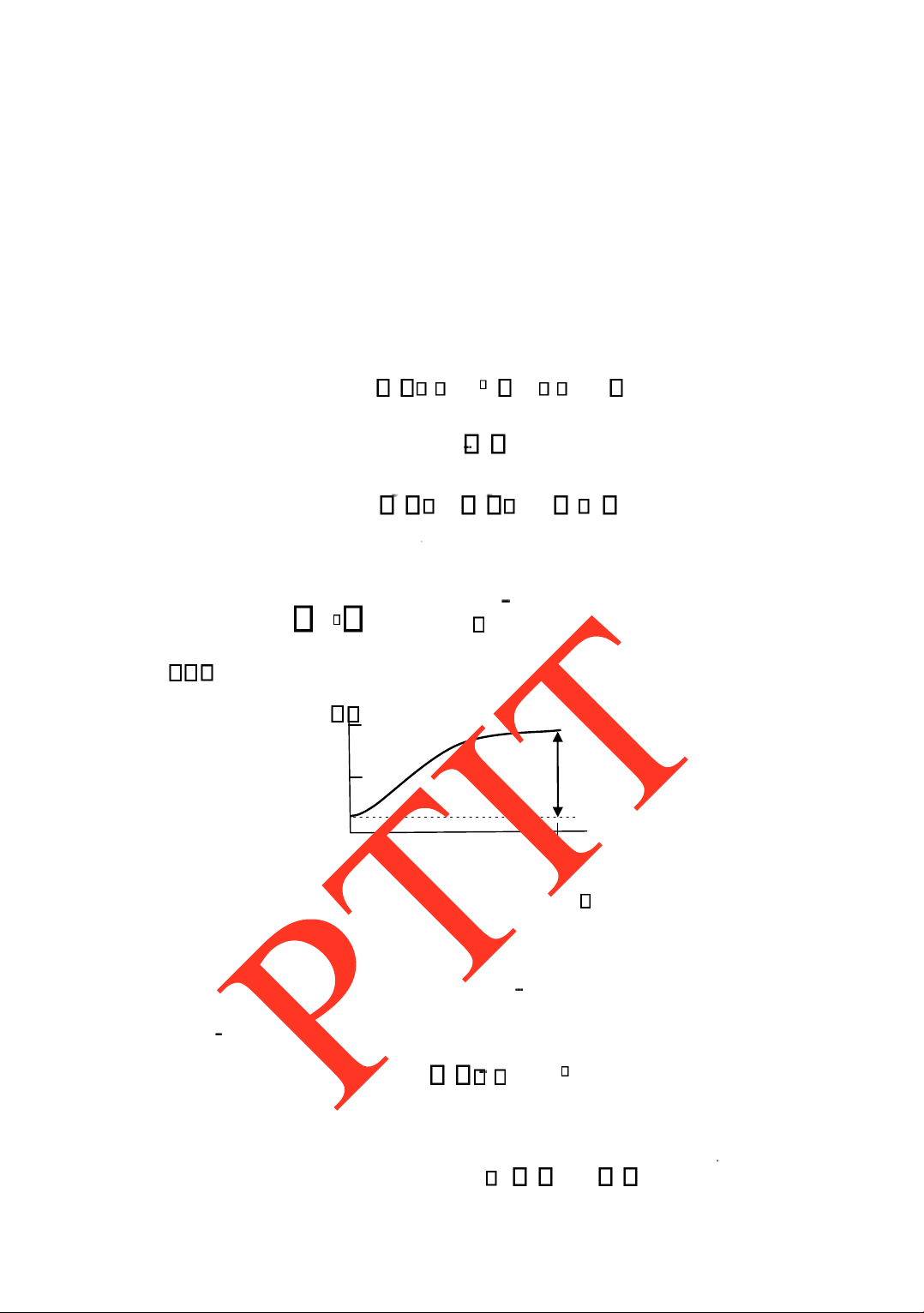
CHƢƠNG 1. MỘT SỐ KHÁI NIỆM CƠ BẢN Hình 1.9
M ố i quan h ệ gi ữa cƣờng ộ âm, m ức cƣờng ộ âm và t ầ n s ố trong vùng nghe
S ự c ả m nh ậ n âm thanh c ủ a m ột ngƣời bình thƣờ ng v ớ i m ộ t m ức ộ to âm thanh xác
ị nh (chính là m ức cƣờng ộ âm, hay SIL) không ộ c l ậ p v ớ i t ầ n s ố. Tai ngƣờ i r ấ t kém
nh ạ y v ớ i các âm có t ầ n s ố r ấ t nh ỏ (<20Hz) ho ặ c r ấ t l ớ n (>20kHz). Nói cách khác, s ự c ả m
nh ậ n âm thanh c ủa con ngƣờ i không ph ải nhƣ trong trong toàn dả i t ầ n c ủ a vùng nghe. Do
ó, rõ ràng mức ộ to c ủ a âm thanh ph ụ thu ộ c vào t ầ n s ố c ủ a âm. B ằ ng các thí nghi ệ m, ở
cùng m ộ t m ứ c c ả m nh ậ n v ề cùng ộ to c ủ a âm thanh c ủa tai ngƣờ i, s ự thay ổ i SPL theo
t ầ n s ố ƣợ c minh h ọ a trong hình 1.10. lOMoARcPSD| 36086670
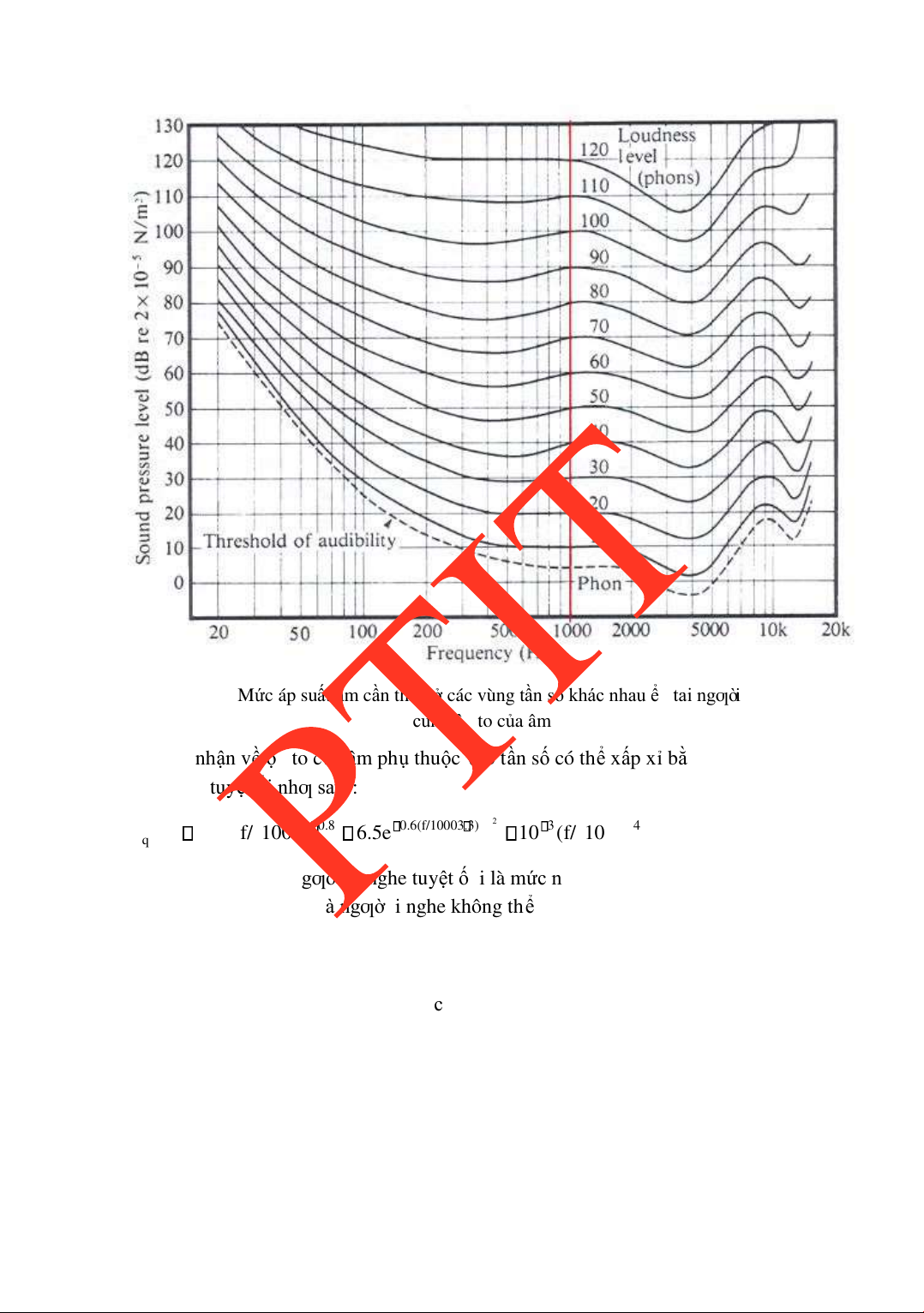
CHƢƠNG 1. MỘT SỐ KHÁI NIỆM CƠ BẢN Hình 1.10
M ứ c áp su ấ t âm c ầ n thi ế t ở các vùng t ầ n s ố khác nhau ể tai ngƣờ i c ả m nh ậ n cùng ộ to c ủ a âm
S ự c ả m nh ậ n v ề ộ to c ủ a âm ph ụ thu ộ c vào t ầ n s ố có th ể x ấ p x ỉ b ằ ng công th ứ c hàm
ngƣỡ ng nghe tuy ệt ối nhƣ sau : 0.8 0.6(f/10003.3) 2 3 4 T(f) 3.64( 1000) 6.5 e 10 ( f/ 1000) q f/
Ngƣời ta ịnh nghĩa ngƣỡ ng nghe tuy ệt ố i là m ức năng lƣợ ng t ối a củ a m ộ t tín hi ệ u
ơn âm cơ bản (pure tone) mà ngƣờ i nghe không th ể c ả m nh ận ƣợc trong môi trƣờ ng t ự do.
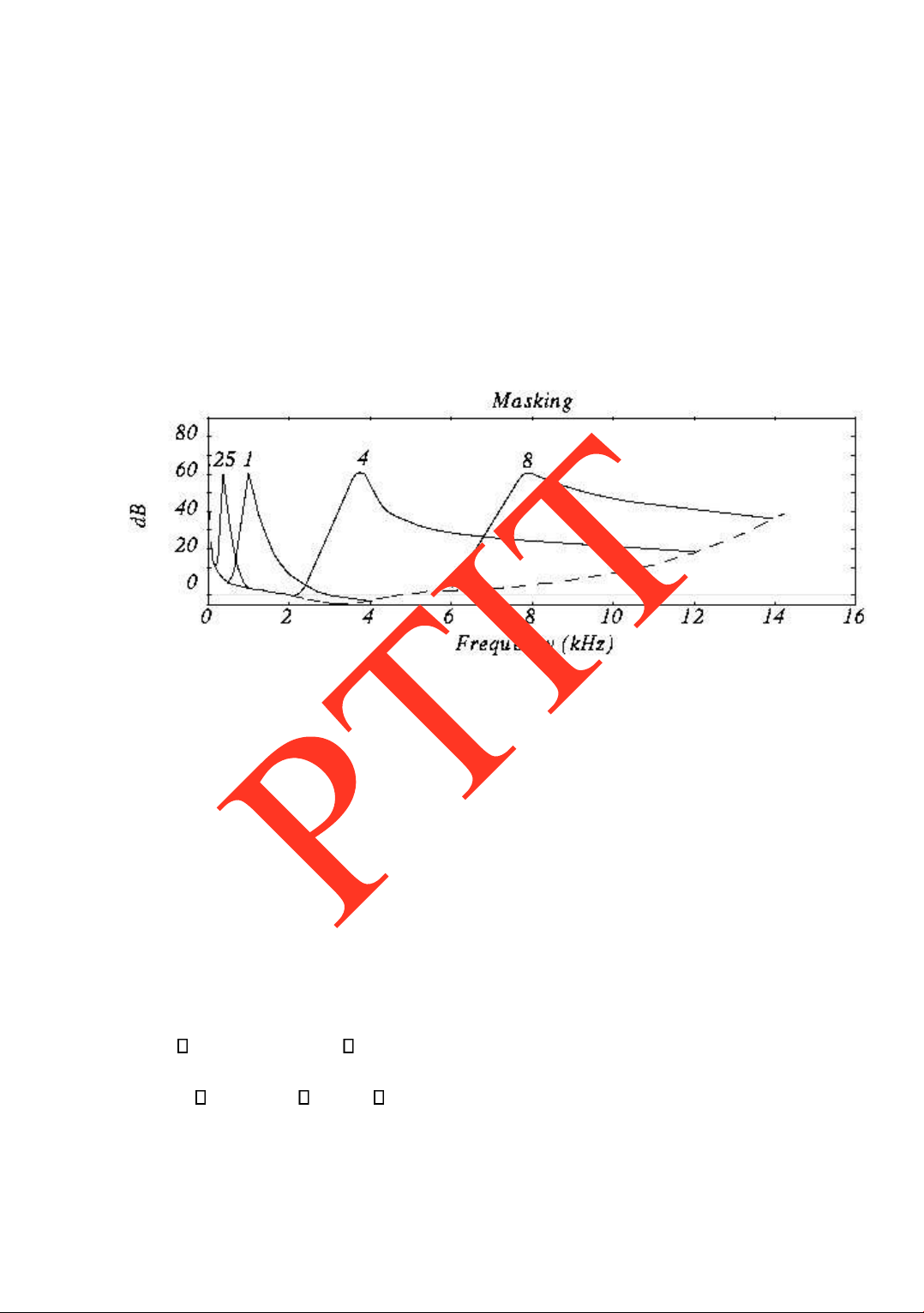
Trong quá trình cảm nhận âm thanh của tai ngƣời, có một hiện tƣợng rất quan trọng
khác ƣợc phát hiện ó là hiện tƣợng che lấp âm thanh (gọi tắt là hiện tƣợng che lấp). Hiện
tƣợng che lấp có thể quan sát trong miền tần số, còn gọi là che lấp tần số, hoặc quan sát
trong miền thời gian, còn gọi là hiện tƣợng che lấp thời gian.
Hiện tƣợng che lấp thời gian xảy ra khi chúng ta nghe một âm rất lớn, sau ó âm ó tắt
ột ngột nhƣng tai chúng ta vẫn cảm nhận về âm này trong một khoảng thời gian sau ó. Giả
sử ngay sau khi âm thanh lớn tắt ột ngột, chúng ta phát một âm thanh khác nhƣng với mức lOMoARcPSD| 36086670
CHƢƠNG 1. MỘT SỐ KHÁI NIỆM CƠ BẢN
thấp hơn. Khi ó tai chúng ta sẽ không thể cảm nhận ƣợc âm thanh khác ó. Ngƣời ta nói
âm thanh tiếp sau ó ã bị che lấp.
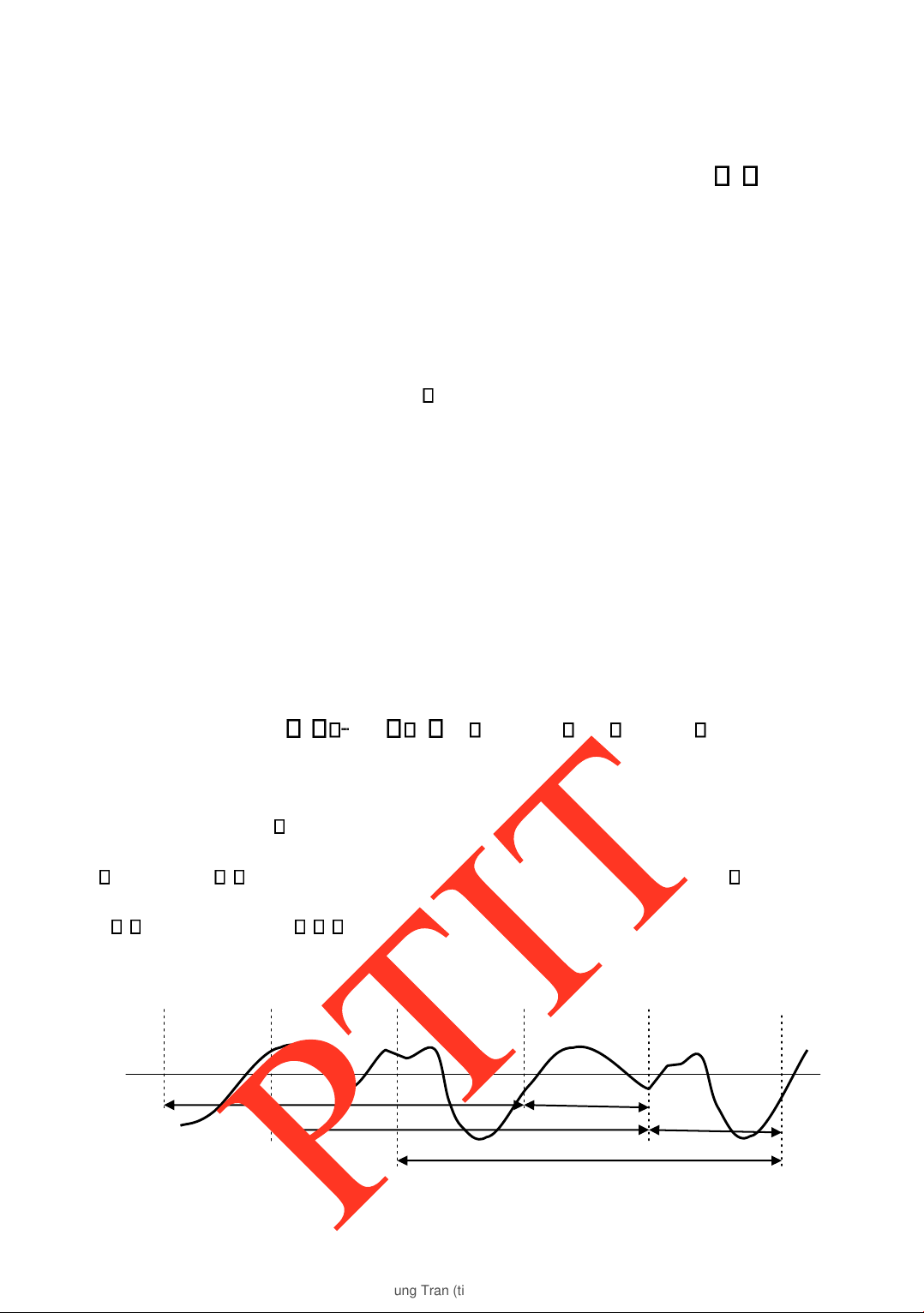
Hiện tƣợng che lấp tần số là hiện tƣợng một âm thanh bị làm mờ hoặc mất hẳn không
thể cảm nhận ƣợc khi xuất hiện một âm thanh có tần số khác. Hay nói một cách khác, sự
xuất hiện một âm thanh sẽ làm tăng mức ngƣỡng nghe của một âm thanh ở tần số khác.
Các âm tần số thấp thƣờng che lấp các âm tần số cao hơn, trong ó hiệu ứng che lấp lớn
nhất tại vùng gần các thành phần hài của âm che lấp. Các dải tín hiệu âm băng tần rộng
che lấp các dải tín hiệu âm băng tần hẹp hơn. Hình 1.11 minh họa hiện tƣợng che lấp ở
một số tần số xác ịnh. Hình 1.11
Hiện tƣợng che lấp ở các tần số khác nhau
Một iểm thú vị từ quan sát của hình 1.11 ở trên là ộ rộng vùng tần số che lấp ở các tần
số che lấp khác nhau không ồng nhất. Độ rộng vùng tần số che lấp gần nhƣ không ổi cỡ
khoảng 100Hz với các tần số che lấp <500Hz, và ộ rộng vùng này càng tăng rất nhanh theo
hàm lô-ga-rít khi tần số che lấp tăng. Độ rộng vùng tần số che lấp ƣợc gọi là băng tần cơ bản (critical band).
Với sự cảm nhận không tuyến tính vừa ề cập ở trên, Zwicker sử dụng một ơn vị o
lƣờng mới cho tần số âm: thang tần số Bark. Đơn vị này ƣợc ặt tên theo Barkhausen, một
nhà vật lý ngƣời Đức. Một cách ơn giản, 1 Bark chính là ộ rộng của một băng tần cơ bản.
Với ịnh nghĩa này, toàn dải nghe của ngƣời ƣợc chia thành 24 thang tƣơng ứng với 24
băng tần cơ bản. Mối quan hệ giữa thang tần Hz và Bark ƣợc cho bởi công thức:
Bark 13a tan(0.00076f) 3.5a tan((f /7500) )2
W[Hz] 52548/(b2 52.56b 690.39)
Ngoài thang tần Bark, trong phân tích âm thanh tiếng nói ngƣời ta còn hay sử dụng
thang tần số Mel. Khác với thang tần Bark, thang tần Mel tuyến tính trong một khoảng nhỏ
hơn 1kHz, và thay ổi theo quy luật lô-ga-rít ở vùng lớn hơn 1kHz. Thang Mel ƣợc xây lOMoARcPSD| 36086670
CHƢƠNG 1. MỘT SỐ KHÁI NIỆM CƠ BẢN
dựng từ thí nghiệm với các tân ơn (pure sine tone) trong ó ngƣời cảm nhận ƣợc yêu cầu
chia vùng tần số thành 4 vùng cảm nhận tƣơng ồng nhau. Thang tần Mel ƣợc cho là mô
phỏng gần với ặc tính ộ nhạy của tai hơn so với thang tần Bark. Thang tần Mel có mối liên
hệ với thang tần Hz theo các công thức: m[Mel] 2595log10(1 f ) 700 f[Hz] 700(10m/2595 1)
Trong một số kỹ thuật xử lý tiếng nói hiện ại, chẳng hạn nhƣ phân tích cepstral, phân
tích ặc trƣng ộng (dynamic feature), …, thƣờng sử dụng thang tần này.
Cũng cần nhấn mạnh, có một sự khác biệt cơ bản giữa các thuộc tính cảm nhận một tín
hiệu âm thanh, ặc biệt là tín hiệu tiếng nói, và các thuộc tính vật lý có thể o lƣờng của âm.
Sự tƣơng ứng giữa các thuộc tính và các ại lƣợng vật lý ƣợc cho trong bảng 1.1. Mỗi
thuộc tính dƣờng nhƣ có mối liên hệ mật thiết với một tính chất vật lý, tuy nhiên mối quan
hệ này thƣờng rất phức tạp. Điều này dễ hiểu vì các tính chất vật lý của âm thành có thể
ảnh hƣởng ến việc cảm nhận âm thanh theo một cách thức rất phức tạp. Lấy ví dụ, chúng
ta thƣởng cho rằng cƣờng ộ âm càng lớn thì âm thanh cảm nhận càng to. Tuy nhiên nhƣ
minh họa trong hình 1.10 ở trên, iều này không ơn giản nhƣ vậy. Rõ ràng là có một sự
khác biệt rõ ràng giữa cảm nhận âm to và ại lƣợng vật lý mức áp suất âm/mức cƣờng ộ
âm. Hoặc lấy một ví dụ khác, ó là cảm nhận về cao ộ của âm thanh. Rõ ràng cao ộ âm
thanh mà ta có thể cảm nhận ƣợc có một mối quan hệ mật thiết với tần số cơ bản. Dƣờng
nhƣ tần số cơ bản càng cao thì âm mà chúng ta cảm nhận ƣợc càng cao. Tuy nhiên, sự
phân biệt giữa hai cao ộ sẽ phụ thuộc vào tần số của cao ộ có tần số thấp hơn. Cao ộ mà
chúng ta cảm nhận ƣợc sẽ thay ổi khi cƣờng ộ âm tăng lên trong khi tần số giữ cố ịnh.
Hoặc một ví dụ khác nữa là hiện tƣợng che lấp ã ề cập ở trên.
Bảng 1.1: Sự liên quan giữa các ại lƣợng vật lý và thuộc tính cảm nhận Đại lƣợng vật lý Chất lƣợng cảm nhận Mức cƣờng ộ âm Độ to (loudness) Tần số cơ bản Cao ộ (pitch) Hình dạng phổ Âm sắc (timbre) lOMoARcPSD| 36086670
CHƢƠNG 1. MỘT SỐ KHÁI NIỆM CƠ BẢN Độ lệch thời gian gian Cảm giác về thời (timing) Sự lệch pha Vị trí âm (location)
1.4. MÔ HÌNH HÓA HỆ THỐNG CƠ QUAN PHÁT ÂM
Trong phần trên chúng ta ã tìm hiểu về cơ chế hoạt ộng của bộ máy phát âm. Hoạt ộng
này gồm hai quá trình: nguồn tạo dao ộng âm và cấu trúc phổ ịnh hình hay còn gọi là bộ
lọc. Cơ chế hoạt ộng có thể tóm lƣợc nhƣ minh họa hình 1.12. Hình 1.12
Minh h ọa tóm lƣợc cơ chế phát âm
Để ơn giản trong quá trình phân tích, ngƣờ i ra th ự c hi ệ n mô hình hóa quá trình làm
việc của bộ máy phát âm nhƣ sơ ồ hình 1.13. Hình 1.13
Mô hình nguồn-bộ lọc mô phỏng bộ máy phát âm lOMoARcPSD| 36086670
CHƢƠNG 1. MỘT SỐ KHÁI NIỆM CƠ BẢN
Trong mô hình này, nguồn tƣơng ứng với dao ộng dây thanh ƣợc mô tả tƣơng ứng
với hai trƣờng hợp: (1) với các âm hữu thanh, dao ộng dây thanh có tần số cơ bản xác ịnh,
khi ó nó ƣợc mô tả bởi một dãy xung tuần hoàn; (2) với các âm vô thanh, dao ộng dây
thanh không xác lập tần số, nó ƣợc mô tả tƣơng ứng nhƣ là nhiễu trắng.
Tín hiệu dao ộng dây thanh sẽ ƣcc lọc bởi bộ lọc tuyến âm ể tạo ra tín hiệu tiếng nói
mong muốn. Bản chất bộ lọc tuyến âm là một bộ lọc cơ học (bộ lọc âm), ta có thể mô tả
bởi một bộ lọc có áp ứng xung tƣơng ứng h(n).
Việc xác ịnh hàm áp ứng xung của bộ lọc tuyến âm tƣơng ối phức tạp. Mặc dù ã có rất
nhiều nghiên cứu, cùng với ó là có khá nhiều phƣơng pháp ể xấp xỉ bộ lọc này, nhƣng cho
ến nay vẫn chƣa có một mô hình hoàn toàn úng nào ƣợc ề ra. Bởi ặc tuyến của bộ lọc phụ
thuộc không những sự co thắt của tuyến âm mà còn phụ thuộc rất lớn vào hiệu quả phát xạ
âm tại môi hoặc/và mũi và những tƣơng tác giữa các bộ phận này.
Thông thƣờng, ể có thể nhấn ƣợc các ỉnh cộng hƣởng của bộ lọc tuyến âm, ngƣời ta
thƣờng xấp xỉ nó bằng bộ lọc toàn iểm cực (all-pole). Bằng cách tổng hợp mạch lọc IIR
bậc hai, chúng ta có thể mô tả một cách ầy ủ một tần số formant.
Khi có kể ến khoang mũi, hoạt ộng của khoang miệng trở nên phức tạp cũng nhƣ sự
tƣơng tác giữa khoang miệng và khoang mũi rất khó quan sát. Để ơn giản trong nghiên
cứu, ngƣời ta coi khoang mũi là khoang tĩnh, và bỏ qua sự tƣơng tác. Khi ó, khoang mũi
ƣợc xem nhƣ một bộ lọc mắc song song với khoang miệng. Quá trình thực nghiệm xác ịnh
hàm truyền ạt tổng hợp thƣờng ƣợc tiến hành bằng cách xấp xỉ hàm truyền ạt của từng bộ lọc.
1.5. BIỂU DIỄN TÍN HIỆU TIẾNG NÓI
Có 3 phƣơng pháp cơ bản thƣờng ƣợc dùng ể biểu diễn tín hiệu tiếng nói: Biểu diễn
dạng sóng tín hiệu trong miền thời gian; Biểu diễn phổ trong miền tần số; Biểu diễn spectrogram.
1.5.1 Biểu diễn dạng sóng tín hiệu trong miền thời gian
Tín hiệu tiếng nói cũng giống nhƣ các tín hiệu thông thƣờng, có thể coi là là một hàm
của thời gian s(t) (nếu xem xét tín hiệu tiếng nói liên tục, tiếng nói tự nhiên) hoặc s(n) (nếu
xem xét tin hiệu tiếng nói số, tiếng nói trong các hệ thống xử lý tín hiệu số). Trong khuôn
khổ bài giảng này, chúng ta sẽ chỉ xem xét tín hiệu tiếng nói số s(n). s(n) là kết quả lấy
mẫu và lƣợng tử hóa của s(t). lOMoARcPSD| 36086670
CHƢƠNG 1. MỘT SỐ KHÁI NIỆM CƠ BẢN
Khi thực hiện biểu diễn tín hiệu tiếng nói s(n) theo thời gian hoặc chỉ số thời gian,
ngƣời ta gọi ó là biểu diễn dạng sóng tín hiệu trong miền thời gian, hay ơn giản là biểu diễn dạng sóng. Đây là Hình 1.14
Bi ểu ồ d ạ ng sóng c ủ a c ụ m t ừ “ không m ột”
phƣơng thức biểu diễn trực quan và ơn giản nhất. Biểu diễn này có thể cho biết ƣợc sự
thay ổi về biên ộ tín hiệu, sự dao ộng nhanh hay chậm của tín hiệu theo thời gian. Hình
1.14 minh họa một biểu diễn theo thời gian của cụm từ “không một”. lOMoARcPSD| 36086670
CHƢƠNG 1. MỘT SỐ KHÁI NIỆM CƠ BẢN
Từ biểu diễn trên, chúng ta có thể thấy có sự phân biệt tƣơng ối giữa các từ. Ở trƣớc,
sau và giữa các từ có một khoảng tín hiệu ở ó biên ộ rất nhỏ gần nhƣ bằng không, chúng
ta gọi ó là các khoảng lặng (silent).
Khi quan sát ơn lẻ dạng sóng tín hiệu tiếng nói là phát âm của một từ, chẳng hạn cụm
từ “không một” nhƣ minh họa trong hình 1.14, chúng ta thấy có một oạn tín hiệu ngay sau
khoảng lặng, phần bắt ầu của âm có biên ộ khác không tuy nhiên rất nhỏ (chỉ cỡ 1/3 lần)
so với phần chính của âm. Phần này tƣơng ứng với sự phát âm của âm vô thanh. Nói một
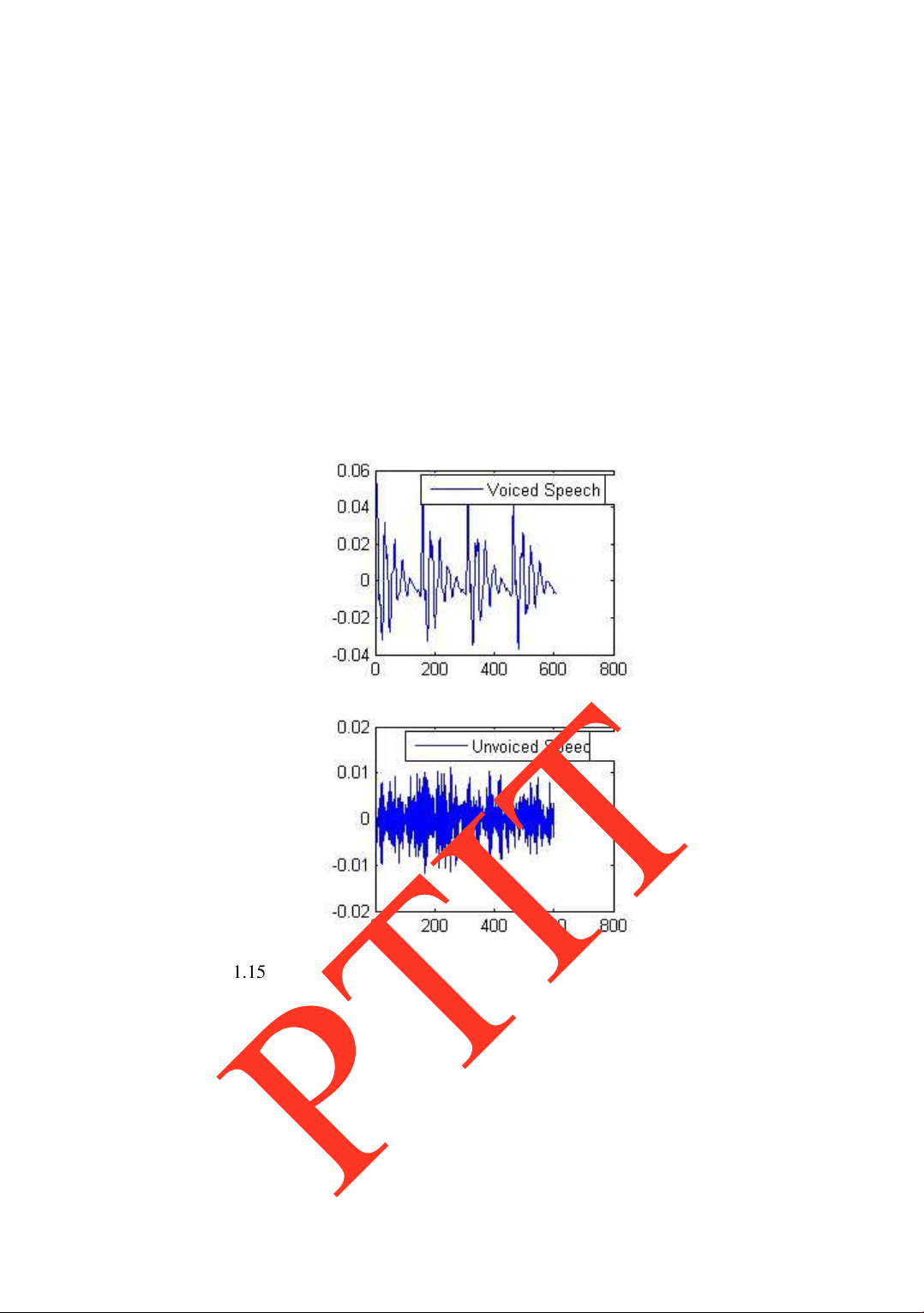
cách khác, từ biểu ồ dạng sóng chúng ta có thể phân biệt ƣợc âm vô thanh và hữu thanh.
Phần âm vô thanh tƣơng ứng với dạng tín hiệu có biên ộ thấp, không có dạng tuần hoàn
mà có dạng ngẫu nhiên. Hình 1.15 minh họa sự khác biệt dạng sóng của âm vô thanh và hữu thanh. Hình 1.15
Sự khác biệt dạng sóng tín hiệu âm hữu thanh và vô thanh
Cũng cần lƣu ý là việc phân biệt giữa khoảng lặng và âm vô thanh chỉ mang tính tƣơng
ối và chỉ có thể cho kết quả chấp nhận ƣợc khi nhiễu ủ nhỏ. Điều này là bởi vì bản chất
của nhiễu cũng có tính ngẫu nhiên, khi nhiễu có biên ộ lớn (nhiễu lớn) có thể khiến ta quan
sát nhầm giống nhƣ phần phát âm của âm vô thanh.
Chúng ta thƣờng cho rằng, giọng iệu tiếng nói của một ngƣời gần nhƣ không thay ổi:
một ngƣời nói hay hai ngƣời cùng nói từ “một” thì nó luôn có nghĩa là “một” và dạng sóng
tín hiệu của phát âm tƣơng ứng phải giống hệt nhau. Tuy nhiên, khi quan sát dạng sóng lOMoARcPSD| 36086670
CHƢƠNG 1. MỘT SỐ KHÁI NIỆM CƠ BẢN
của những lần thu âm khác nhau thì iều này không úng. Ta có thể thấy, ngay cùng với một
từ và một ngƣời phát âm, nhƣng dạng sóng ở hai thời iểm khác nhau có sự khác nhau nhất
ịnh. Quan sát tƣơng tự cũng thấy khi hai ngƣời phát âm cùng một từ, dạng sóng cũng có sự khác nhau tƣơng ối.
Ngoài ra, dạng sóng tín hiệu tiếng nói cũng có sự khác biệt áng kể khi sử dụng các thiết
bị thu âm, mã hóa có chất lƣợng khác nhau.
Chính từ những khác nhau nhất ịnh của dạng sóng này cho ta thấy ở chƣơng 5 việc
nhận dạng bằng cách sử dụng trực tiếp dạng sóng, còn gọi là sử dụng dữ liệu thô, là không khả thi.
Dữ liệu dạng sóng tín hiệu tiếng nói số thƣờng ƣợc lƣu trữ trong máy tính dƣới nhiều
ịnh dạng, phổ biến nhất là *.wav. Tín hiệu này là kết quả của việc lấy mẫu tín hiệu tiếng
nói với tần số lấy mẫu phổ biến là 8000Hz, 10000Hz, 11025Hz, 16000Hz, 22050Hz,
32000Hz, 44100Hz,…, với ộ phân giải bít phổ biến là 8bit, 16bit, 24bit, … và có thể là
một kênh (mono) hoặc hai kênh (stereo) lOMoARcPSD| 36086670
CHƢƠNG 1. MỘT SỐ KHÁI NIỆM CƠ BẢN
1.5.2 Biểu diễn phổ tín hiệu tiếng nói
Nhƣ chúng ta ã biết trong môn học Xử lý tín hiệu số, việc biểu diễn phổ, hay nói cách
khác là biểu diễn tín hiệu tiếng nói trong miền tần số có thể cho phép việc phân tích và tìm jn S(j) s(n)e n
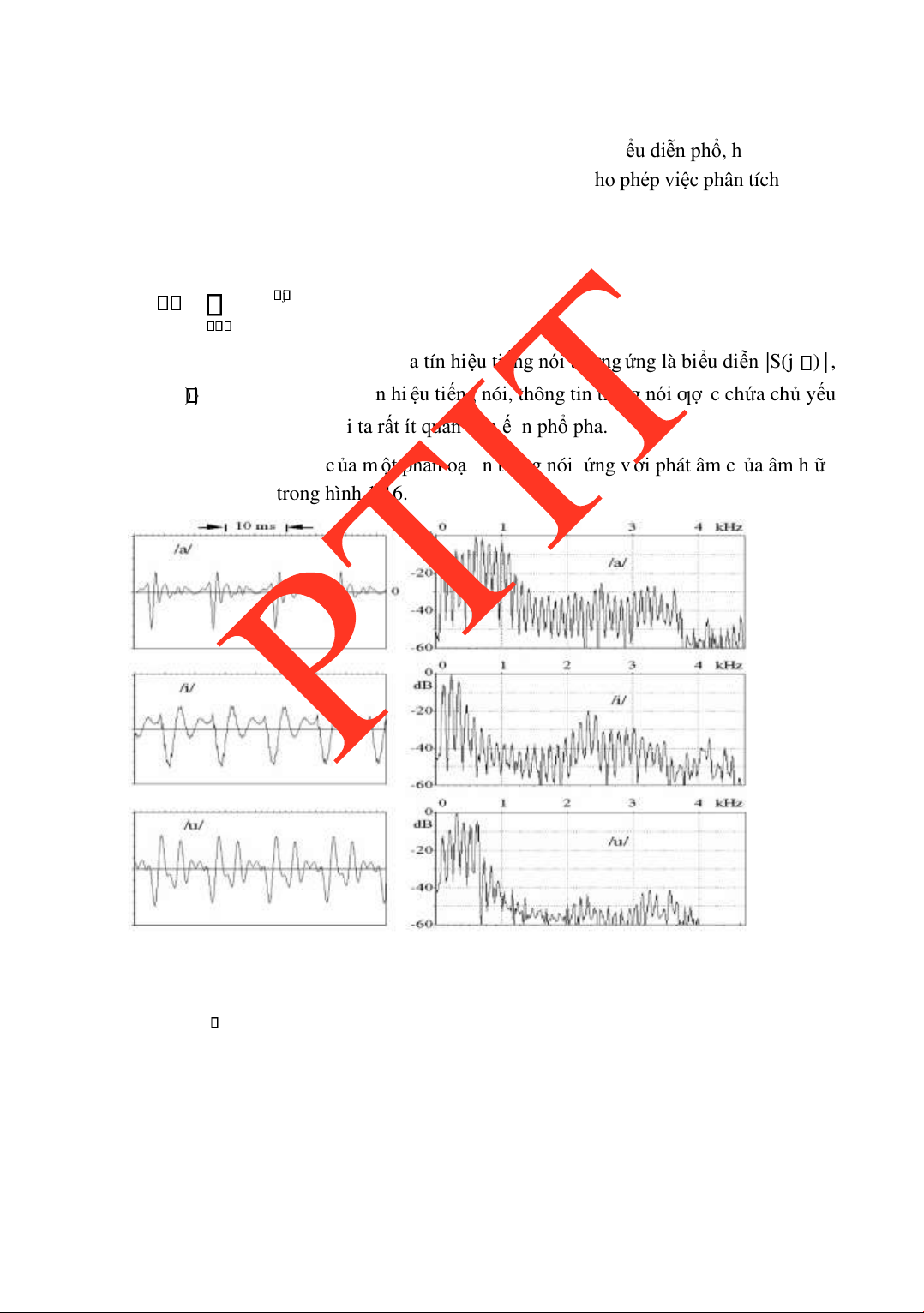
Khi ó phổ biên ộ và ph ổ pha c ủ a tín hi ệ u ti ếng nói tƣơng ứ ng là bi ể u di ễ n |S(j ) | ,
và arg{S(j)} . Trong phân tích tín hi ệ u ti ế ng nói, thông tin ti ếng nói ƣợ c ch ứ a ch ủ y ế u
trong ph ổ biên ộ, do ó ngƣờ i ta r ất ít quan tâm ế n ph ổ pha.
Bi ể u di ễ n ph ổ biên ộ c ủ a m ột phân oạ n ti ế ng nói ứ ng v ớ i phát âm c ủ a âm h ữ u
thanh ƣợ c minh h ọ a trong hình 1.16.
hiểu tín hiệu tiếng nói ƣợc thuận tiện và dễ dàng hơn.
Với tín hiệu tiếng nói số s(n), thực hiện biến ổi Fourier, ta ƣợc: lOMoARcPSD| 36086670
CHƢƠNG 1. MỘT SỐ KHÁI NIỆM CƠ BẢN Hình 1.16
Minh họa phổ tín hiệu tiếng nói
Từ quan sát biểu diễn phổ biên ộ, ta có thể thấy phổ biên ộ có thể tách thành hai thành
phần: ƣờng bao phổ và những dao ộng phổ nhỏ hay còn gọi là phổ nhỏ. Đƣờng bao phổ
tƣơng ứng là dạng phổ của một tín hiệu biến ổi chậm (tần số thấp). Nó tƣơng ứng là hàm
truyền ạt của bộ lọc tuyến âm. Phần phổ nhỏ tƣơng ứng là dạng phổ của một tín hiệu biến ổi
nhanh (tần số cao). Nó tƣơng ứng là phổ của tín hiệu tạo bởi dao ộng của dây thanh. lOMoARcPSD| 36086670
CHƢƠNG 1. MỘT SỐ KHÁI NIỆM CƠ BẢN
Cũng dễ dàng quan sát thấy rằng, mặc dù dải tần số tín hiệu tiếng nói rất rộng
(2020000Hz), nhƣng năng lƣợng phổ của tín hiệu tiếng nói chỉ tập trung trong một khoảng từ 300-3400Hz.
1.5.3 Biểu diễn spectrogram Hình 1.18
Minh họa spectrogram của phân oạn âm thanh lOMoARcPSD| 36086670
CHƢƠNG 1. MỘT SỐ KHÁI NIỆM CƠ BẢN
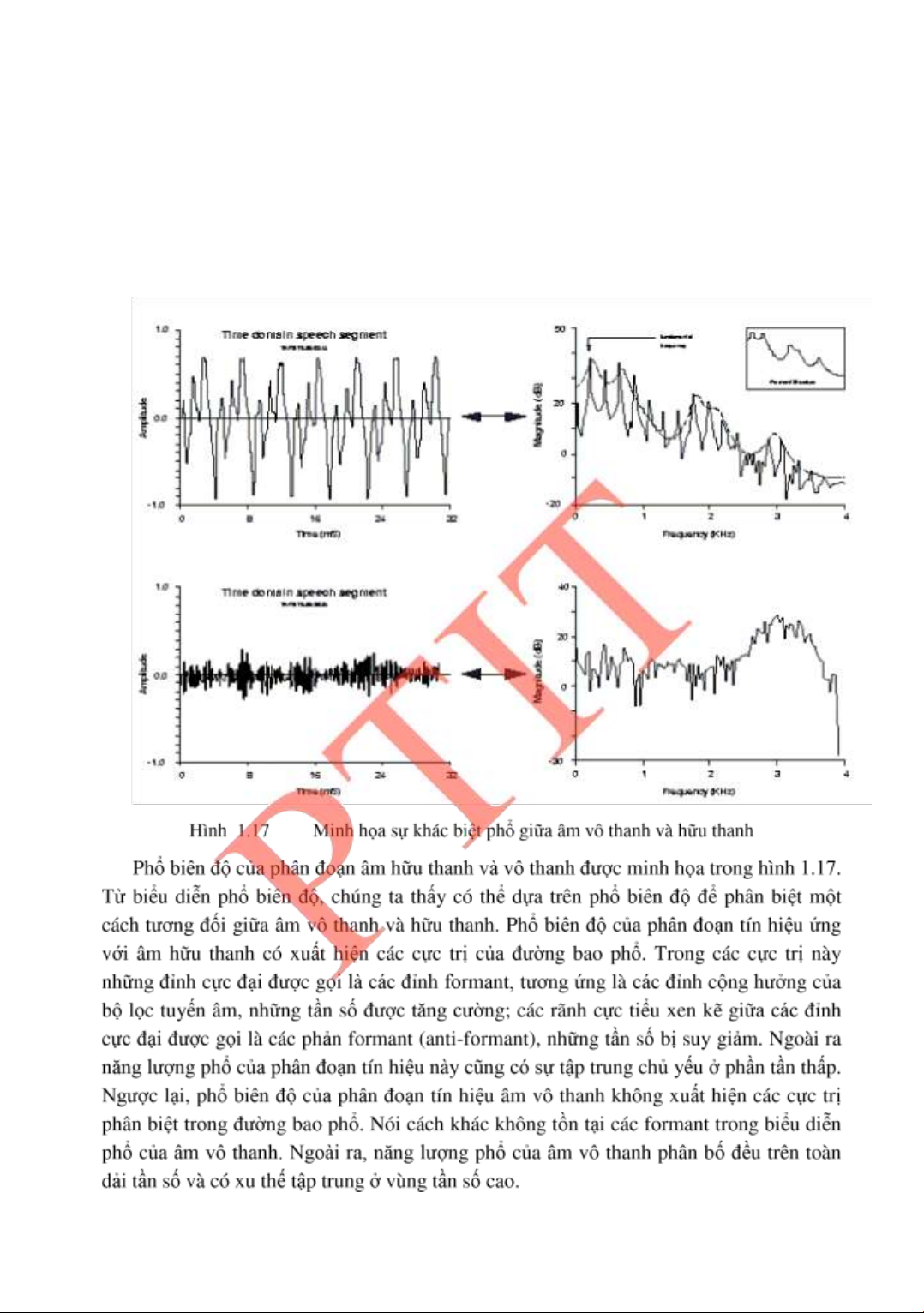
Từ biểu diễn spectrogram, chúng ta có thể thấy ây là một công cụ rất thuận tiện ể quan
sát và phân tích tín hiệu. Chẳng hạn, chúng ta có thể phân biệt một cách tƣơng ối âm vô
thanh với âm hữu thanh dựa trên biểu diễn spectrogram. Ở những phân oạn tín hiệu ứng
với âm hữu thanh thì spectrogram tƣơng ứng là những dải ậm màu có những vằn (còn gọi
là những cực trị) tƣơng ứng với tính tuần hoàn của tín hiệu. Những vạch này cho thấy có
sự phân bố không ồng ều của tần số tín hiệu nhƣ ã quan sát trong biểu diễn phổ biên ộ.
Còn ở những phân oạn tín hiệu tƣơng ứng với âm vô thanh thì spectrogram tƣơng ứng là
những dải ặc nhạt màu. Dải ặc này tƣơng ứng với sự phân bố tần số không có các cực trị
và trải ều trên toàn trục trùng với quan sát trong biểu diễn phổ biên ộ.
1.6. CÁC THAM SỐ CƠ BẢN CỦA TÍN HIỆU TIẾNG NÓI
Tín hiệu tiếng nói nhƣ ã ề cập là tín hiệu thay ổi theo thời gian. Nó có các ặc trƣng cơ
bản nhƣ nguồn kích thích (excitation), cƣờng ộ (pitch), biên ộ (amplitude), ... Các tham
số thay ổi theo thời gian của tín hiệu tiếng nói có thể kể ến là tần số cơ bản (fundamental
frequency - pitch), loại âm (âm hữu thanh - voiced, vô thanh - unvoiced, tắc - fricative hay
khoảng lặng - silence), các tần số cộng hƣởng chính (formant), hàm diện tích của tuyến âm (vocal tract area), ...
1.6.1 Tần số cơ bản
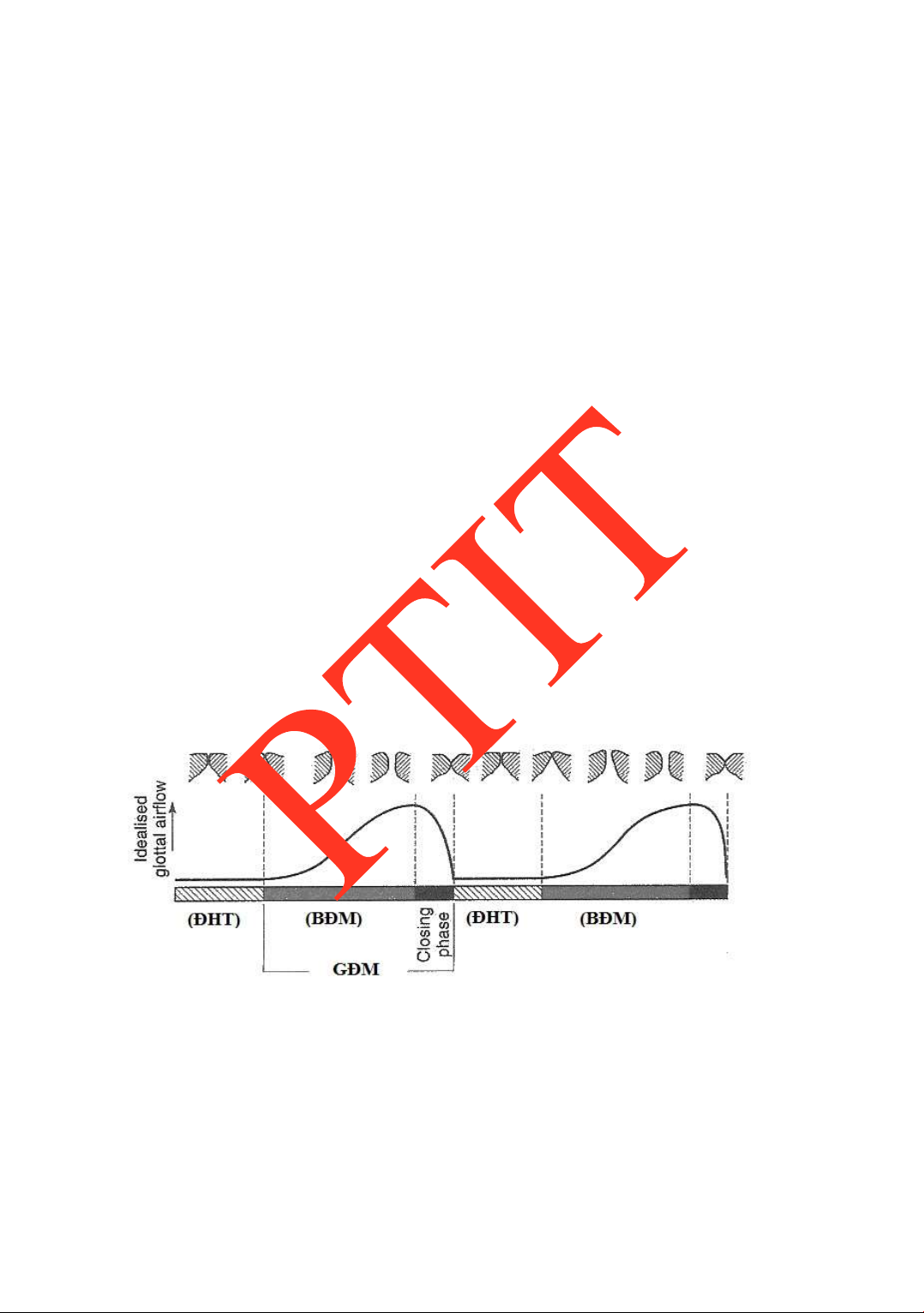
Với phần tín hiệu tiếng nói bán tuần hoàn, giá trị trung bình chu kỳ của tín hiệu ƣợc
gọi là chu kỳ cơ bản hay chu kỳ pitch (T0). Chu kỳ cho bản tƣơng ứng với chu kỳ óng mở của dây thanh. Hình 1.19
Minh họa óng mở thanh môn và chu kỳ cơ bản
Tần số cơ bản F0 ƣợc ịnh nghĩa là nghịch ảo của chu kỳ cơ bản: F0=1/T0. Tần số cơ
bản có sự khác nhau giữa các giới và ộ tuổi và ngƣời nói. Các số liệu thống kê cho thấy
tần số cơ bản của nam giới vào khoảng 85-180Hz, trong khi giá trị này là khoảng 165-
255Hz. Tần số cơ bản của tín hiệu tiếng nói trẻ em lớn cỡ gấp hai lần tần số cơ bản tiếng
nói của ngƣời lớn, cỡ 350-850Hz. Giá trị trung bình tần số cơ bản thay ổi theo ộ tuổi. Với lOMoARcPSD| 36086670
CHƢƠNG 1. MỘT SỐ KHÁI NIỆM CƠ BẢN
nam giới, tần số cơ bản có sự giảm mạnh trong thời từ tuổi kỳ dậy thì ến khoảng tầm 35
tuổi. Tuy nhiên, sau tuổi 55, tần số cơ bản của tiếng nói của nam giới lại bắt ầu có sự tăng
trở lại. Với nữ giới, tần số cơ bản giữ ổn ịnh cho ến tuổi trung niên, và sau ó bắt ầu có sự suy giảm.
Tần số cơ bản (chu kỳ cơ bản) là một trong các ặc trƣng cơ bản và ƣợc sử dụng nhiều
trong các phân tích cũng nhƣ xây dựng các ứng dụng tiếng nói.
1.6.2 Tần số formant
Nhƣ ã ề cập trong phần biểu diễn tín hiệu tiếng nói trong miền tần số, ƣờng bao phổ
tần số có những ỉnh cực ại gọi là các tần số formant. Tại các tần số này tín hiệu dao ộng
dây thanh ƣợc tăng cƣờng.
Các tần số formant ƣợc biết ến nhƣ những ặc trƣng quan trọng trong việc xác ịnh nội
dung về khía cạnh âm học của các âm. Và do ó tần số formant thƣờng ƣợc sử dụng vào nhận dạng tiếng nói.
Việc xác ịnh tần số formant thƣờng ƣợc dựa vào phân tích phổ của tín hiệu tiếng nói.
Đỉnh cộng hƣởng ầu tiên, ứng với ỉnh cộng hƣởng có tần số thấp nhất ƣợc ký hiệu là F1,
tiếp ến là tần số formant F2, F3, … Trong các phát âm của nguyên âm, ngƣời ta thấy rằng
luôn có bốn hoặc nhiều hơn bốn tần số formant phân biệt. Nhiều nghiên cứu chỉ ra rằng,
chỉ cần hai tần số formant ầu tiên là ủ ể phân biệt các nguyên âm. Hai formant ầu tiên này
cũng quyết ịnh chất lƣợng của các nguyên âm theo khía cạnh tính óng/mở và vị trí phát
âm trƣớc/sau trong vòng miệng. Tuy nhiên, những phân biệt này chỉ mang tính tƣơng ối.
1.7. MỘT SỐ ĐẶC ĐIỂM NGỮ ÂM
Trong phần này, chúng ta sẽ tìm hiểu một số khái niệm về mặt ngữ âm của ngôn ngữ.
Những khái niệm cơ bản này sẽ ƣợc sử dụng trong các chƣơng 4 và 5.
1.7.1 Một số ịnh nghĩa cơ bản về ơn vị ngữ âm
Âm vị (phoneme): chỉ một ơn vị trừu tƣợng phân biệt về mặt cảm nhận nhỏ nhất của
âm thanh tiếng nói trong một ngôn ngữ cho phép phân biệt một từ này với một từ khác.
Nói cách khác, nó là một ơn vị nhỏ nhất của tiếng nói ƣợc sử dụng ể tạo ra sự khác biệt
của một từ với một từ khác. Âm vị không phải là các phân oạn âm về mặt vật lý thông
thƣờng mà chúng ƣợc phân loại dựa trên nhận thức. Chẳng hạn nhƣ phần ơn vị âm thanh
ứng với phát âm các âm b, p, t, trong phát âm của các từ bố, phố, tố, ố
Âm tố (phone): ám chỉ một thực hiện vật lý về mặt âm học của một âm vị, tức là là
một phân oạn vật lý cụ thể biểu diễn âm vị. Ví dụ, trong tiếng Anh, âm vị /t/ có hai thực
hiện về mặt âm học (âm tố) rất khác nhau trong các phát âm của các từ sat và meter. lOMoARcPSD| 36086670
CHƢƠNG 1. MỘT SỐ KHÁI NIỆM CƠ BẢN
Cần chú ý rằng tập các âm vị sẽ có các thực hiện về mặt âm học (âm tố) khác nhau tùy
theo ngƣời nói, nhƣng chúng luôn có một chức năng mang tính hệ thống cho phép phân
biệt nghĩa của các từ.
Bán âm tố kép (diphone): là cụm kết hợp của một nửa cuối của âm tố phía trƣớc và
một nửa ầu của âm tố phía sau. Bán âm tố kép cho phép giữ ƣợc sự thay ổi về mặt phát
âm giữa các âm tố, do ó có khả năng làm tăng ộ chính xác trong việc tổng hợp tiếng nói
Âm tiết (syllable): là một ơn vị phát âm gồm có một âm của nguyên âm ứng một mình
hoặc kết hợp với các phát âm của các phụ âm ể tạo thành một từ hoặc một phần của một
từ có nghĩa. Nói cách khác, âm tiết là một phần phát âm của một từ mà có thể phân tách
một cách tự nhiên. Ví dụ, từ doctor trong tiếng Anh gồm hai âm tiết.
Từ (word): là một ơn vị ngôn ngữ nói hoặc viết mang ý nghĩa xác ịnh. Ví dụ work trong tiếng Anh là một từ.
Câu (sentence): là một tập hợp các từ với một tổ chức hoàn chỉnh ƣợc cấu thành bởi
một cấu trúc chủ ngữ - vị ngữ và mang một ý hoàn chỉnh mang tính trần thuật, hoặc mệnh
lệnh, hoặc câu hỏi, …
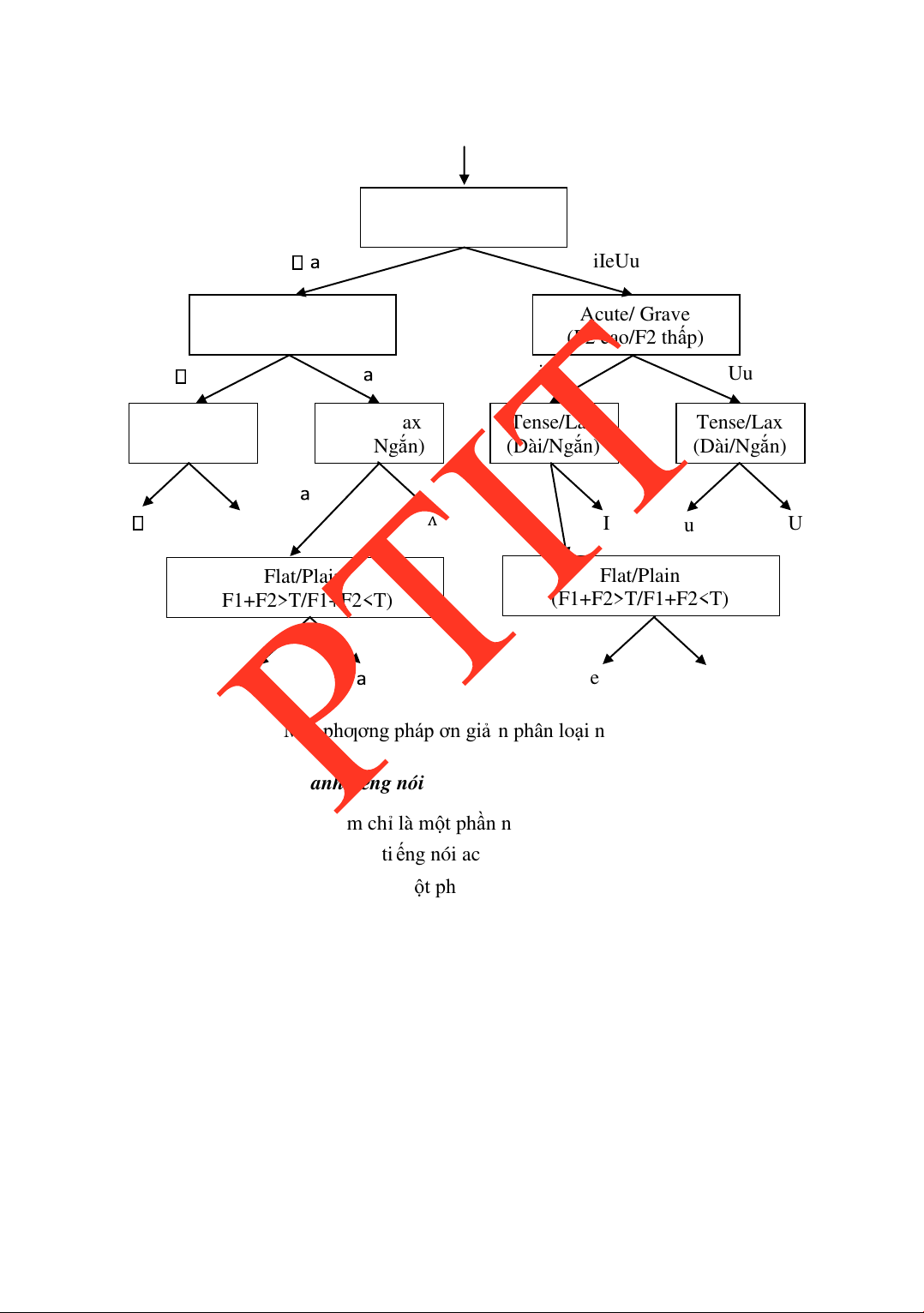
1.7.2 Đặc iểm ngữ âm của tiếng Việt
Tiếng Việt là một ngôn ngữ thuộc nhóm ngôn ngữ Nam Á (còn gọi là Mon-Khmer).
Tiếng Việt ƣợc xem là một ngôn ngữ ơn lập (mono-syllabic language) tiêu biểu mà ặc iểm
cơ bản của nó là mỗi ơn vị từ ƣợc phát âm bởi một âm tiết. Nói cách khác, mỗi âm tiết
trong tiếng Việt ều có khả năng trở thành một từ. Do ó, âm tiết giữ một vai trò cơ bản trong
hệ thống các ơn vị ngôn ngữ. Theo thống kê, tiếng Việt gồm có 2500 âm tiết. So với số
lƣợng âm tiết, số lƣợng từ thì lớn hơn rất nhiều bởi trong tiếng Việt cũng tồn tại nhiều từ
ghép. Một ặc iểm nữa là các từ tiếng Việt không có sự biến hình, một âm tiết cũng ồng
thời là một hình vị và ý nghĩa ngữ pháp ƣợc thể hiện chủ yếu bằng trật tự của từ.
Âm tiết tiếng Việt có cấu trúc ơn giản, luôn gắn liền với thanh iệu. Tiếng Việt gồm có
sáu thanh iệu: Thanh ngang, thanh bằng, thanh sắc, thanh hỏi, thanh ngã, thanh nặng. Ngữ
nghĩa của một từ thay ổi khi thanh iệu thay ổi.
Tiếng Việt là một ngôn ngữ ánh vần ƣợc, các từ ƣợc cấu thành từ các cụm phụ âm –
nguyên âm – (phụ âm). Nguyên âm trong tiếng Việt thƣờng ƣợc chia thành hai nhóm:
nguyên âm ơn, nguyên âm kép. Phụ âm thƣờng ƣợc phân loại theo cấu hình của các bộ
phân trong hệ thống phát âm và phƣơng thức phát âm: phụ âm bật (còn gọi là phụ âm nổ),
phụ âm mũi, phụ âm xát, phụ âm bật rung, phụ âm xát tắc. lOMoARcPSD| 36086670
CHƢƠNG 1. MỘT SỐ KHÁI NIỆM CƠ BẢN
1.8. CÂU H Ỏ I VÀ BÀI T Ậ P CU ỐI CHƢƠNG
1. Các b ộ ph ậ n chính và vai trò c ủ a chúng trong b ộ máy phát âm?
2. Môi, khoang mũi có vai trò gì trong quá trìn h phát âm?
3. Các b ộ ph ậ n chính và vai trò c ủa chúng trong cơ quan cả m nh ậ n ti ế ng nói?
4. Đặc iể m nghe c ủa tai ngƣờ i? M ố i quan h ệ gi ữa các ặ c tính c ả m nh ậ n âm và các
ại lƣợ ng v ậ t lý c ủ a âm?
5. Mô hình ngu ồ n-b ộ l ọ c mô ph ỏ ng b ộ máy phát âm?
6. Hi ện tƣợ ng che l ấ p là gì? Hi ện tƣợ ng này có vai trò gì?
7. Các phƣơng pháp biể u di ễn cơ bả n tín hi ệ u ti ế ng nói?
8. M ộ t s ố khái ni ệ m ng ữ âm cơ bản? Đặc iể m ng ữ âm ti ế ng Vi ệ t?
9. Các tham s ố cơ bả n c ủ a tín hi ệ u ti ế ng nói?
10. Phân bi ệ t âm vô thanh và h ữ u thanh?
11. ( Matlab) S ử d ụ ng Matlab (ho ặ c b ộ công c ụ thích h ợ p khác, ch ẳ ng h ạ n Octave),
thực hiện các công việc sau:
a. Ghi âm một oạn tiếng nói sao cho có cả âm vô thanh và hữu thanh và lƣu dƣới dạng file *.wav
b. Đọc file vừa ghi và thực hiện biểu diễn dạng sóng tín hiệu trong miền thời gian
c. Đọc file vừa ghi, tách các phân oạn tƣơng ứng với âm vô thanh, hữu thanh và
biểu diễn phổ tƣơng ứng lOMoARcPSD| 36086670
CHƢƠNG 1. MỘT SỐ KHÁI NIỆM CƠ BẢN
d. Đọc file vừa ghi, thực hiện biểu diễn spectrogram và quan sát ặc iểm của nó.
Đối chiếu với những nhận xét có ƣợc trong phần học lý thuyết ở trên. lOMoARcPSD| 36086670
CHƢƠNG 2. PHÂN TÍCH TÍN HIỆU TIẾNG NÓI 2.1. MỞ ĐẦU
Trong chƣơng này ta sẽ xem xét các phƣơng pháp phân tích tín hiệu tiếng nói. Phân
tích tiếng nói thực hiện việc giải quyết các vấn ề ể tìm ra một dạng thức tối ƣu biểu diễn
ƣợc tín hiệu tiếng nói một các hiệu quả. Mục tiêu của việc thực hiện phân tích tín hiệu
tiếng nói là nhằm trích chọn các ặc trƣng của tín hiệu tiếng nói. Nó là cơ sở cho việc phát
triển các kỹ thuật, công nghệ tổng hợp, nhận dạng và nâng cao chất lƣợng tín hiệu tiếng
nói. Phân tích tiếng nói thƣờng thực hiện việc trích chọn hoặc chuyển ổi tín hiệu tiếng nói
sang một dạng thức biểu diễn khác sao cho có thể biểu diễn thông tin tiếng nói tốt hơn theo
cách mà ta cần. Một cách tổng quát, hầu hết các phƣơng pháp phân tích tín hiệu tiếng nói
tập trung vào một trong ba vấn ề chính. Thứ nhất là tìm cách loại bỏ ảnh hƣởng của pha,
thành phần không óng vai trò quan trọng trong việc truyền tải thông tin tiếng nói. Thứ hai,
thực hiện việc chia tách nguồn âm và mạch lọc (mô hình tuyến âm) sao cho ta có thể nghiên
cứu biên phổ của tín hiệu một cách ộc lập. Cuối cùng là chuyển ổi tín hiệu hoặc biên phổ
tín hiệu sang một dạng biểu diễn khác hiệu quả hơn. lOMoARcPSD| 36086670
CHƢƠNG 2. PHÂN TÍCH TÍN HIỆU TIẾNG NÓI
2.2. KHÁI NIỆM CHUNG VỀ PHÂN TÍCH TIẾNG NÓI
2.2.1 Mô hình phân tích tín hiệu tiếng nói
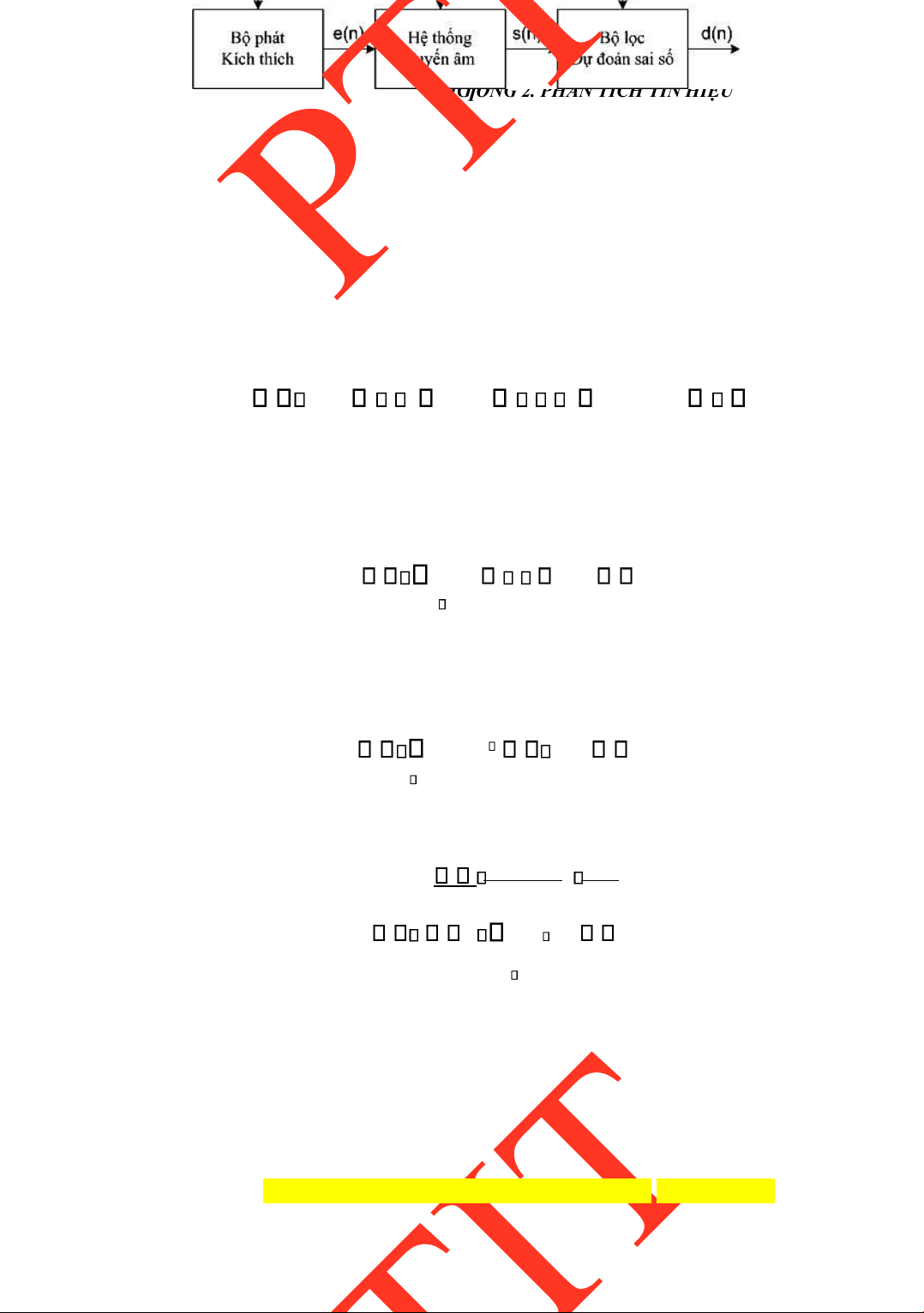
Mô hình tổng quát cho việc phân tích tiếng nói ƣợc trình bày trong hình 2.1. Các dạng tín
hiệu tại các bƣớc cũng ƣợc trình bày kèm theo trong minh họa.
Tín hiệu tiếng nói tƣơng tự (tự nhiên) ƣợc tiền xử lý bằng cách cho qua một bộ lọc
thông thấp với tần số cắt thích hợp (thƣờng khoảng 8kHz). Tín hiệu thu ƣợc sau ó ƣợc
thực hiện quá trình biến ổi sang dạng tín hiệu tiếng nói số nhờ bộ biến ổi ADC. Thông
thƣờng, tần số lấy mẫu bằng 16kHz với tốc ộ bít lƣợng tử hóa là 16bit.
Tín hiệu tiếng nói dạng số ƣợc phân khung với chiều dài khung thƣờng tƣơng ứng với
khoảng 30ms tín hiệu và khoảng lệch giữa các khung thƣờng bằng ½-1/2 khung phân tích
(khoảng 10ms tín hiệu). Khung phân tích tín hiệu sau ó ƣợc chỉnh biên bằng cách lấy cửa
sổ với các hàm cửa sổ phổ biến nhƣ Hamming, Hanning.... Tín hiệu thu ƣợc sau khi lấy
cửa sổ ƣợc ƣa vào phân tích với các phƣơng pháp phân tích thích hợp, chẳng hạn phân
tích phổ nhƣ STFT, LPC,... Hoặc sau khi thực hiện các phép phân tích cơ bản, tín hiệu
tiếp tục ƣợc ƣa ến các khối ể trích chọn các ặc trƣng.
2.2.2 Phân tích ngắn hạn
Tín hiệu tiếng nói ƣợc tạo ra từ một hệ thống tuyến âm thay ổi theo thời gian cùng với
tín hiệu kích thích cũng thay ổi theo thời gian. Trong khi ó, hầu hêt các công cụ phân tích
tín hiệu ã học khi nghiên cứu về hệ thống và xử lý tín hiệu ều giả thiết rằng chúng không
ối theo thời gian, tức là giả thiết chúng là các thể hiện của quá trình dừng. Điều này có
nghĩa là những công cụ ã học không thể ƣa váo áp dụng một cách trực tiếp cho xử lý phân
tích tín hiệu tiếng nói. Trong trƣờng hợp vẫn áp dụng một cách vô thức thì kết quả tính
toán ƣợc cũng không có hoặc có rất ít ý nghĩa cho việc phân tích tín hiệu. lOMoARcPSD| 36086670
CHƢƠNG 2. PHÂN TÍCH TÍN HIỆU TIẾNG NÓI Hình 2.1
Sơ ồ khối quá trình phân tích tín hiệu tiếng nói
Khi nói ến các phân tích tín hiệu tiếng nói, ngƣời ta thƣờng mặc ịnh các phân tích này
ƣợc tiến hành trong một phân oạn tín hiệu tƣơng ứng với thời gian rất nhỏ, cỡ khoảng 10-
30ms. Và do ó, các phân tích này ƣợc gọi là phân tích ngắn hạn. Sở dĩ nhƣ vậy là vì bản
chất của tín hiệu tiếng nói, nhƣ ã ề cập trong chƣơng trƣớc, nó là tín hiệu bán tĩnh: các
tham số chỉ có thể coi là không thay ổi nếu thời gian quan sát ủ ngắn.
Việc thực hiện phân tích ngắn hạn có thể ƣợc thực hiện trong miền thời gian hoặc miền
tần số. Việc ƣợc thực hiện phân tích trong miền nào phụ thuộc vào những thông tin/ ặc trƣng
của tín hiệu tiếng nói mà ta mong muôn trích xuất. Chẳng hạn, các tham số nhƣ năng lƣợng
ngắn hạn, tốc ộ trở về không ngắn hạn, giá trị hàm tự tƣơng quan ngắn hạn ƣợc tính toán và
xác ịnh trong miền thời gian. Trong khi ó, phổ ngắn hạn ƣợc tính toán xác ịnh bằng phân tích
ngắn hạn trong miền tần số.
Một phép phân tích ngắn hạn tổng quát có thể biểu diễn nhƣ sau: lOMoARcPSD| 36086670
CHƢƠNG 2. PHÂN TÍCH TÍN HIỆU TIẾNG NÓI X(n) T{s (m)}n m
trong ó, X(n) biểu diễn tham số phân tích (hoặc véc-tơ các tham số phân tích) tại thời
iểm phân tích n. Toán tử T{} ịnh nghĩa một hàm phân tích ngắn hạn. Tổng trên ƣợc tính
với giới hạn vô cùng ƣợc hiểu là phép lấy tổng của tất cả các thành phần khác không của
khung tín hiệu thu ƣợc sau phép lấy cửa sổ. Nói cách khác, tổng ƣợc thực hiện với mọi
giá trị của m trong vùng xác ịnh (support) của hàm cửa sổ.
2.2.3 Hàm cửa sổ phân tích
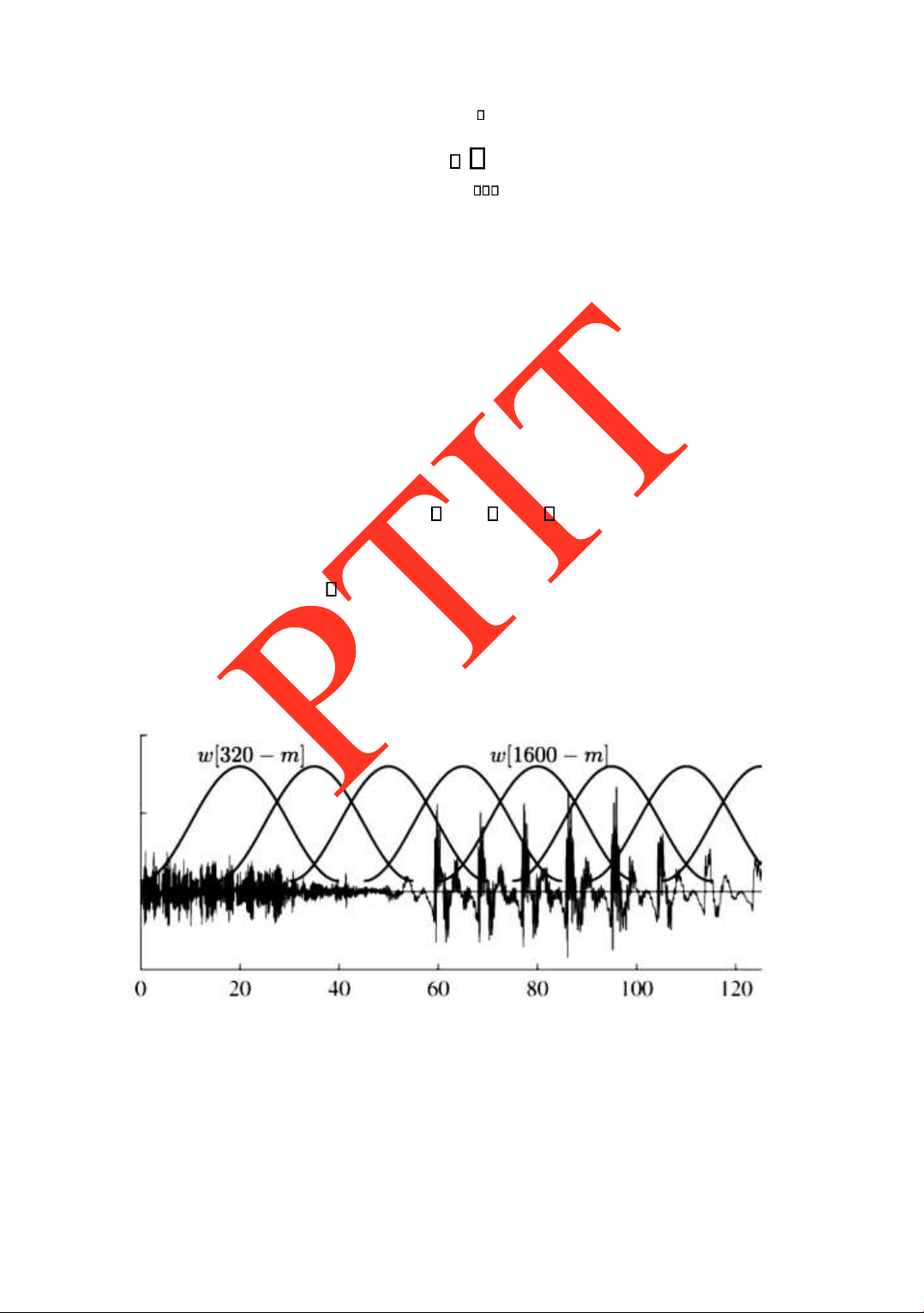
Để thực hiện các phân tích trên các phân oạn tín hiệu ngắn hạn, chúng ta phải thực hiện
việc “cắt” ra các oạn tín hiệu này. Việc “cắt” này có thể thực hiện ƣợc thông qua một phép
nhân với hàm cửa sổ. Giả sử tín hiệu tiếng nói số s(n), khi ó phân oạn tín hiệu có ộ dài N
mẫu có thể xác ịnh bởi công thức: sN(n) s(m) w(n m)
trong ó, w(n) là hàm cửa sổ, hay còn gọi là cửa sổ phân tích có ộ dài N mẫu. Để ơn
giản chúng ta ký hiệu sN(n) s (m)n ể vừa có thông số về vị trí của các mẫu s(m) trong của
sổ phân tích ở vị trí n.
Hình 2.2 minh họa việc phân chia khung với hàm cửa sổ. Hình 2.2
Minh họa của sổ phân tích tín hiệu với các oạn bao trùm nhau
Tùy theo mục ích nghiên cứu mà hàm cửa sổ phân tích có các hình dạng khác nhau.
Hình dạng ơn giản nhất là cửa sổ hình chữ nhật. Tuy nhiên, ể ạt ƣợc hiệu quả mong muốn,
ngƣời ta thƣờng hay sử dụng cửa sổ Hamming, hoặc Hanning.
Độ rộng của cửa sổ ƣợc quyết ịnh bởi việc lựa chọn phân tích ngắn hạn. lOMoARcPSD| 36086670
CHƢƠNG 2. PHÂN TÍCH TÍN HIỆU TIẾNG NÓI
2.3. CÁC PHÂN TÍCH CƠ BẢN TRONG MIỀN THỜI GIAN
Phân tích tiếng nói trong miền thời gian là phân tích trực tiếp trên dạng sóng tín hiệu
sau khi thực hiện việc lấy cửa sổ tín hiệu trong miền thời gian. Nhƣ ã ề cập trong phần
trƣớc, ta chỉ xem xét các phân tích ngắn hạn của tín hiệu. Do ó, ể ơn giản trong trình bày
ta mặc ịnh các công thức xây dựng là các phân tích ngắn hạn. Trong trƣờng hợp nếu các
phân tích không phải là ngắn hạn thì chúng sẽ ƣợc chú thích rõ ràng.
2.3.1 Năng lƣợng ngắn hạn
Tham số ầu tiên cần quan tâm trong phân tích tín hiệu tiếng nói trong miền thời gian ó
là năng lượng ngắn hạn.
Năng lƣợng gắn với tín hiệu tiếng nói cũng là một ại lƣợng thay ổi theo thời gian.
Năng lƣợng của một phân oạn tín hiệu tiếng nói gồm N mẫu ƣợc xác ịnh bởi công thức: N 1 E T s (n)2N n 0
Giá trị này còn ƣợc gọi là năng lƣợng tổng của một phân oạn tín hiệu
Mở rộng biểu thức trên, chúng ta có công thức tính năng lƣợng ngắn hạn nhƣ sau: E (n) 2 T En s (m)n (s(m)w(n m))2 m m
Trong công thức này, chỉ số n chạy/dịch trên trục các mẫu tại những vị trí mà chúng ta
quan tâm ến giá trị năng lƣợng ngắn hạn. n có thể bằng 1, ứng với mỗi lần dịch một mẫu,
hoặc có thể bằng N (bằng kích thƣớc cửa sổ phân tích), hoặc lớn hơn. Giá trị n rất nhỏ
thƣờng là không cần thiết vì các mức năng lƣợng trong khoảng thời gian nhỏ gần nhƣ
không thay ổi. Ngƣợc lại, nếu rất lớn (>=N), tức là các khung phân tích không có sự bao
trùm nhau, có thể dẫn ến sự mất thông tin. Điều này là bởi vì sự thay ổi quan sát ƣợc có
thể bắt ầu từ phần cuối của oạn trƣớc, nhƣng bị ngắt quãng sang ến ầu khung sau. Thƣờng
giá trị n ƣợc thiết lập sao cho sự bao trùm giữa các khung phân tích tín hiệu khoảng bằng ½-1/3 của khung.
Hình 2.3 minh họa năng lƣợng ngắn hạn của một oạn âm thanh.
Hình 2.3: Minh họa năng lƣợng ngắn hạn của tín hiệu tiếng nói lOMoARcPSD| 36086670
CHƢƠNG 2. PHÂN TÍCH TÍN HIỆU TIẾNG NÓI
Từ minh họa chúng ta thấy, những phân oạn tƣơng ứng với âm hữu thành (nguyên
âm), mức năng lƣợng ngắn hạn rất lớn. Ở những phân oạn tƣơng ứng với âm vô thanh,
mức năng lƣợng ngắn hạn rất nhỏ. Ở những phân oạn tƣơng ứng với khoảng lặng, mức
năng lƣợng ngắn hạn bằng không (xấp xỉ bằng không).
Nhƣ vậy, việc xác ịnh năng lƣợng ngắn hạn của tín hiệu rất hữu ích trong việc ƣớc
lƣợng các tính chất của các hàm kích thích trong mô hình mô phỏng bộ máy phát âm hay
các mô hình tổng hợp tín hiệu tiếng nói. Ngoài ra, nó là một công cụ hữu ích ể phát hiện
một tín hiệu âm là của âm hữu thanh, âm vô thanh hay một khoảng lặng.
Cần chú ý rằng ộ dài cửa sổ phân tích phải ƣợc chọn thích hợp theo nguyên tắc của
phân tích ngắn hạn ã ề cập ở trên. Nó phải ủ dài ể sự thay ổi của năng lƣợng tín hiệu trong
một khung có thể ƣợc làm mịn. Tuy nhiên cũng không ƣợc quá dài dẫn ến luật thay ổi
năng lƣợng tín hiệu từ một oạn này sang một oạn tín hiệu khác bị hiểu lầm.
Một nhƣợc iểm của việc sử dụng năng lƣợng trung bình của tín hiệu là với các mức tín
hiệu lớn, chúng có xu thế làm lệch áng kể giá trị ƣớc lƣợng năng lƣợng toàn khung.
2.3.2 Độ lớn biên ộ ngắn hạn
Từ phần trên thấy rằng năng lƣợng ngắn hạn của tín hiệu khá nhạy cảm với ộ lớn của
tín hiệu. Do ó, ngƣời ta thƣờng hay sử dụng một ại lƣợng thay thế là ộ lớn biên ộ ngắn
hạn, ƣợc xác ịnh bởi: M n | s (n) |n | s(m) |w(n m) m m
2.3.3 Vi sai ộ lớn biên ộ ngắn hạn
Hàm vi sai biên ộ trung bình ƣợc ịnh nghĩa nhƣ sau: M ( ) n | s (m)n s (mn ) | | s(m) s(m ) |w(n m) m m
Công thức trên cho thấy giá trị hàm vi sai biên ộ trung bình, với tham số về sự khác
nhau về thời gian sẽ rất nhỏ khi tiến ến chu kỳ (nếu có) của tín hiệu s(n). Do ó hàm vi
sai biên ộ trung bình là một trong các công cụ hữu ích cho việc xác ịnh tần số cơ bản của tín hiệu tiếng nói. lOMoARcPSD| 36086670
CHƢƠNG 2. PHÂN TÍCH TÍN HIỆU TIẾNG NÓI
2.3.4 Tốc ộ trở về không
Một tham số khác cũng thƣờng ƣợc quan tâm trong các phép phân tích tín hiệu tiếng nói
trong miền thời gian ó là tốc ộ trở về không (zero-crossing rate - ZCR). Sự kiện trở về
không xảy ra khi dạng sóng tín hiệu cắt trục hoành hay nói cách khác khi các mẫu liên tục
nhau có dấu khác nhau. Về mặt toán học, tốc ộ trở về không ƣợc xác ịnh nhƣ sau: Z n
0,5 sgn{s m } sgn{s m 1 } w n m m
Trong ó hàm sgn(a) là hàm dấu: bằng 1 nếu a≥0; bằng -1 nếu a<0. Dễ thấy
0,5|sgn{s(m)}-sgn{s(m-1)}| bằng 1 nếu s(m) và s(m-1) khác dấu nhau và bằng 0 nếu chúng
cùng dấu. Zn là tổng trọng số của tất cả các thay ổi dấu của các mẫu trong vùng xác ịnh
bởi cửa sổ phân tích. Tốc ộ trở về không có thể xem nhƣ là một o lƣờng của tần số. Mặc
dù tốc ộ trở về không thay ổi khá lớn theo thời gian và loại tín hiệu, nhƣng nó biểu hiện
sự khác biệt rõ rệt giữa tín hiệu âm vô thanh và hữu thanh. Các tín hiệu âm hữu thanh có
sự suy giảm lớn ở vùng tần cao do ặc tính tự nhiên thông thấp của các xung dây thanh
(glottal pulse), trong khi các tín hiệu âm vô thanh có năng lƣợng lớn ở vùng tần cao. Do
vậy, cũng nhƣ ại lƣợng năng lƣợng trung bình tín hiệu, tốc ộ trở về không cũng là các
tham số quan trọng cho phép phát hiện xem một tín hiệu là tín hiệu của âm vô thanh, hữu thanh hay khoảng lặng.
2.3.5 Giá trị hàm tự tƣơng quan
Hàm tự tƣơng quan thƣờng ƣợc sử dụng nhƣ một công cụ ể xác ịnh tính chu kỳ của
tín hiệu và nó cũng là cơ sở cho nhiều phƣơng pháp phân tích phổ khác. Hàm tự tƣơng
quan ƣợc ịnh nghĩa tƣơng tự nhƣ hàm tự tƣơng quan thông thƣờng: n k s m s m kn n m
s m w n m s m k w n k m m
s m s n m wn n m m
Công thức trên sử dụng tính chất của hàm tự tƣơng quan là một hàm chẵn, ối xứng và wk
m w m w m k . lOMoARcPSD| 36086670
CHƢƠNG 2. PHÂN TÍCH TÍN HIỆU TIẾNG NÓI
Cũng tƣơng tự nhƣ hàm tự tƣơng quan tín hiệu ã biết trong môn học Xử lý tín hiệu số,
có một mối quan hệ giữa hàm tự tƣơng quan và năng lƣợng tín hiệu: E n s m w n m 2 n 0 m
2.4. PHÂN TÍCH PHỔ TÍN HIỆU TIẾNG NÓI
2.4.1 Cấu trúc phổ của tín hiệu tiếng nói
Trong phân tích tín hiệu tiếng nói, thay vì sử dụng trực tiếp tín hiệu tiếng nói trong
miền thời gian, ngƣời ta thƣờng hay sử dụng các ặc trƣng phổ của tiếng nói. Điều này
xuất phát từ quan iểm rằng tín hiệu tiếng nói cũng giống nhƣ các tín hiệu xác ịnh khác có
thể xem nhƣ là tổng của các tín hiệu hình sin với biên ộ và pha thay ổi chậm. Hơn nữa,
một nguyên nhân quan trọng không kém ó là việc cảm nhận tiếng nói của con ngƣời liên
quan trực tiếp ến thông tin phổ của tín hiệu tiếng nói nhiều hơn trong khi các thông tin về
pha của tín hiệu tiếng nói không có vai trò quyết ịnh.
Phổ biên ộ phức của tín hiệu tiếng nói ƣợc ịnh nghĩa là biến ổi Fourier (FT) của khung tín
hiệu với khoảng thời gian phân tích n cố ịnh: Sne j s m w n m e j m m
Biểu thức trên có thể viết lại thành: S en j s n e j n *w n |n n
Biểu thức này là một cách diễn dịch phép biến ổi Fourier rời rạc theo khía cạnh mạch
lọc. Tín hiệu iều biên ~ ~
s n e( ) j n~ dịch phổ của s n( ) xuống lần và kết quả thu ƣợc sẽ
ƣợc lựa chọn bởi một bộ lọc cửa sổ thông dải với tần số trung tâm bằng không.
Mặt khác công thức biến ổi phổ cũng có thể viết là: S e n j s n * w n ej n *e j n |n n lOMoARcPSD| 36086670
CHƢƠNG 2. PHÂN TÍCH TÍN HIỆU TIẾNG NÓI
Công thức trên có thể diễn giải nhƣ sau: Tín hiệu ~
s n( ) ƣợc ƣa qua bộ lọc thông dải có tần số jn ~
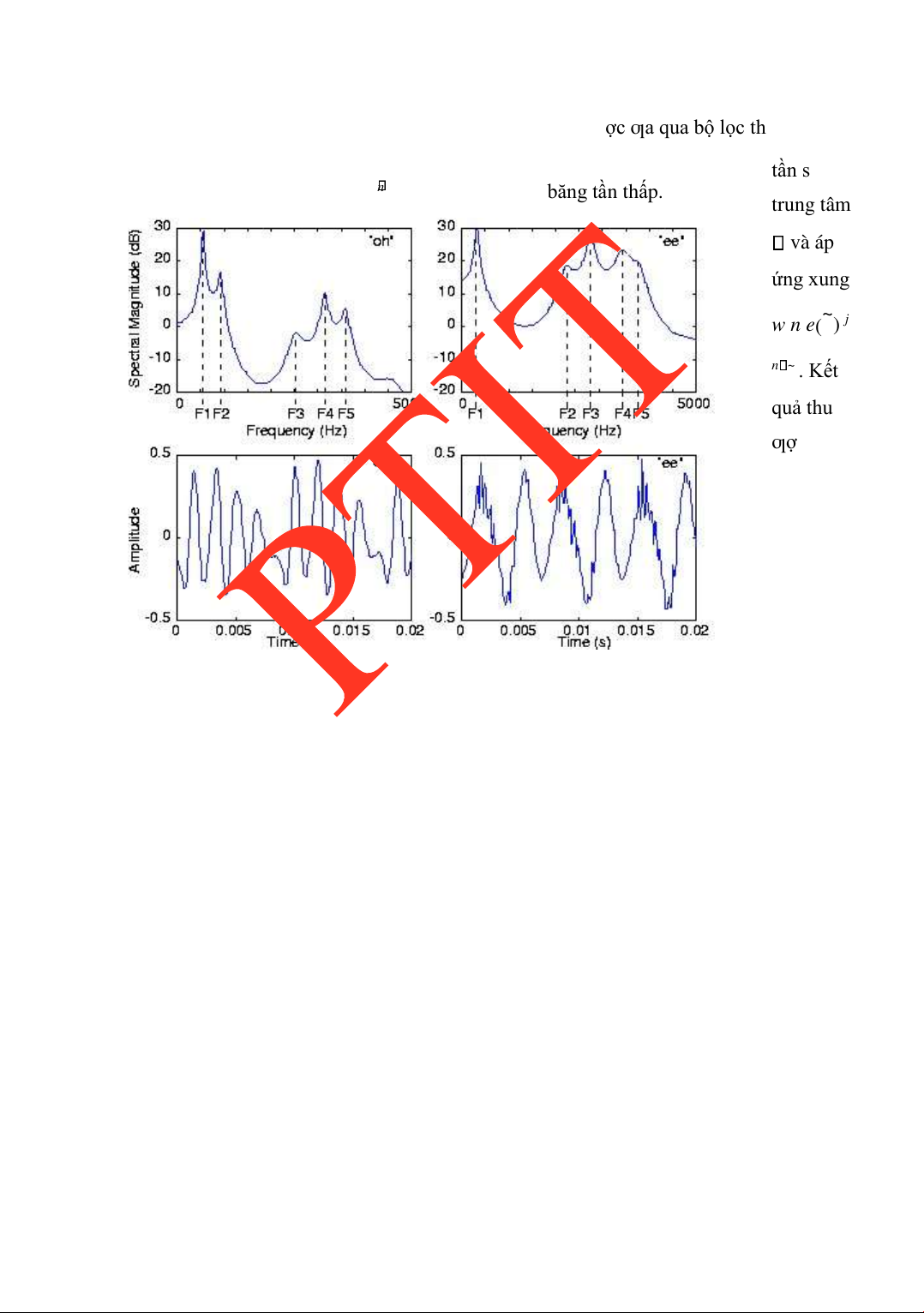
ể t ạ o ra tín hi ệu băng tầ n th ấ p. trung tâm và áp ứng xung ~ w n e( ) j n ~ . Kết quả thu ƣợc ƣợc dịch tần xuống bằng cách iều chế biên ộ với e Hình 2.3
Minh họa một khung tín hiệu và phổ tƣơng ứng. lOMoARcPSD| 36086670
CHƢƠNG 2. PHÂN TÍCH TÍN HIỆU TIẾNG NÓI
Mật ộ phổ công suất trong một khoảng thời gian ngắn, tức là phổ ngắn hạn của tín hiệu
tiếng nói, có thể ƣợc xem nhƣ là tích của hai thành phần: thành phần thứ nhất là ƣờng
biên phổ thay ổi chậm theo tần số; thành phần thứ hai là cấu trúc phổ mịn (spectral fine
structure) thay ổi rất nhanh theo tần số. Đối với các âm hữu thanh thì cấu trúc phổ mịn tạo
thành các mẫu tuần hoàn, còn ối với các âm vô thanh thì không. Biên phổ, hay cũng chính
là ặc trƣng phổ tổng quát (overall), mô tả không chỉ các ặc tính (characteristics) cộng
hƣởng và phản cộng hƣởng (anti-resonance) của các cơ quan phát âm (articulatory organs)
mà còn mô tả các ặc trƣng tổng quát của phát xạ (radiation) và phổ nguồn thanh môn
(glottal) ở môi và khoang mũi. Trong khi ó, cấu trúc phổ mịn mô tả tính tuần hoàn của nguồn âm.
Công thức ầu tiên là một hàm của tần số phân tích liên tục . Do ó ể FT trở thành một
công cụ hữu ích trong các phân tích thực tế ta cần tính toán nó với tập tần số rời rạc và
hàm cửa sổ có bề rộng hữu hạn với mỗi bƣớc dịch chuyển R>1. Khi ó ta có: rR j2 km S rR k
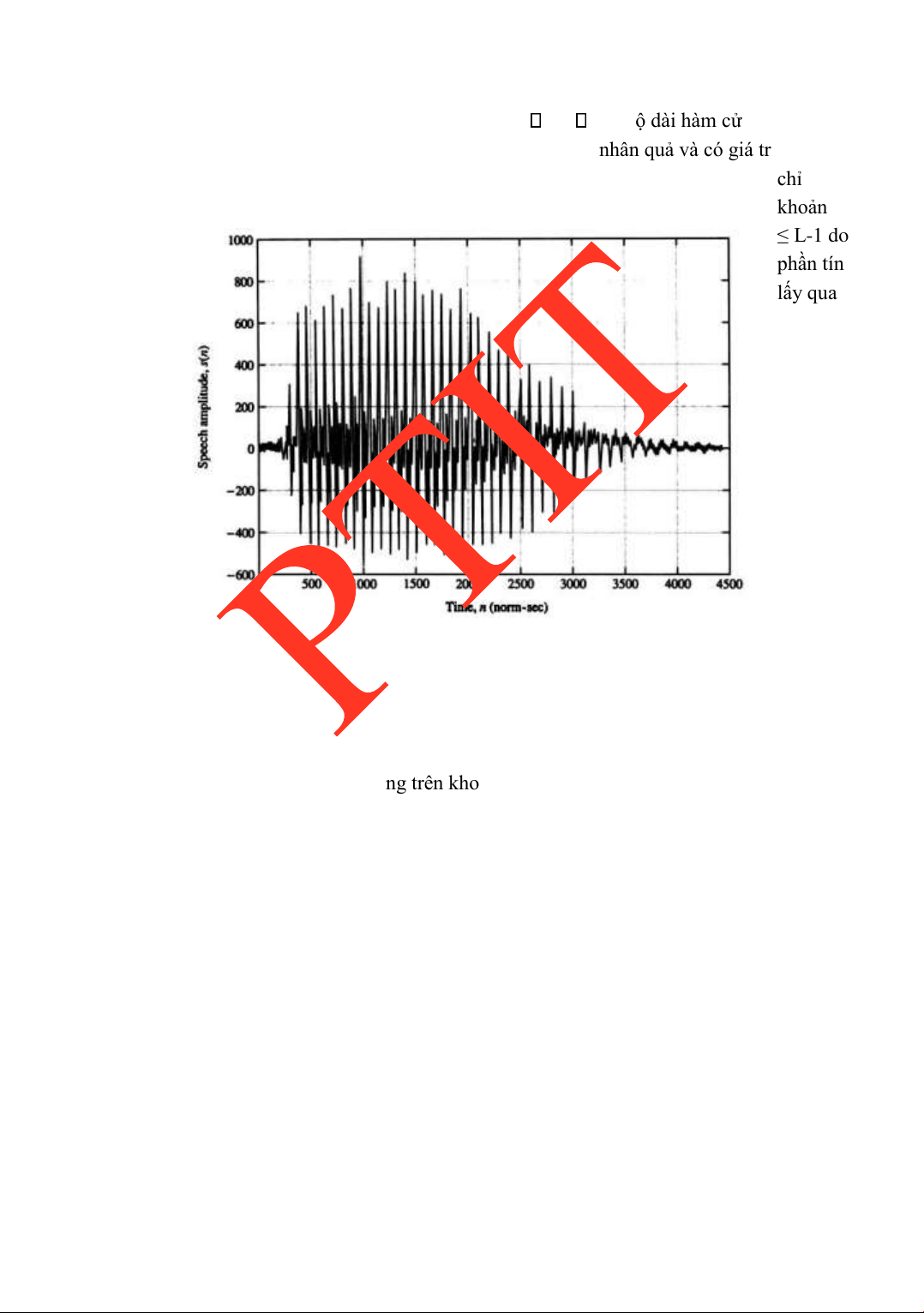
s m w rR m e N k 0,1,..., N 1 m rR L 1 lOMoARcPSD| 36086670
CHƢƠNG 2. PHÂN TÍCH TÍN HIỆU TIẾNG NÓI
N là số các tần số cách ều nhau trong khoảng 0≤ ≤ 2 , L là ộ dài hàm cửa sổ ( o lƣờng
bằng số mẫu). Vì ta giả thiết hàm cửa sổ w(n) là hàm có tính nhân quả và có giá trị khác không chỉ trong khoảng 0≤ m ≤ L-1 do ó phần tín hiệu lấy qua cửa sổ
s(m)w(rR-m) sẽ có giá trị khác không trên khoảng rR-L+1≤ m ≤ rR. lOMoARcPSD| 36086670
CHƢƠNG 2. PHÂN TÍCH TÍN HIỆU TIẾNG NÓI Hình 2.4
Khung tín hiệu và phổ tƣơng ứng
2.4.2 Phân tích spectrogram
Spectrogram là một trong những công cụ cơ bản của phân tích phổ tín hiệu tiếng nói,
trong ó nó chuyển ổi dạng sóng tín hiệu tiếng nói hai chiều thanh cấu trúc ba chiều (biên
ộ/tần số/thời gian). Trong ồ hình spectrogram, thời gian và tần số tƣơng ứng là các trục
ngang và dọc, còn biên ộ ƣợc biểu diễn bởi ộ ậm nhạt. Các ỉnh của phổ tín hiệu xuất hiện
là các dải nằm ngang màu ậm. Tần số trung tâm của các dải thƣờng ƣợc coi là các formant.
Các âm hữu thanh tạo ra các mảng dọc trong biểu ồ spectrogram vì có một sự tăng cƣờng
biên ộ tín hiệu tiếng nói mỗi khi thanh quản óng lại. Nhiễu trong các âm vô thanh tạo ra
các cấu trúc ậm hình chữ nhật và kết thúc ngẫu nhiên với nhiều ốm nhạt do sự thay ổi tức
thì của năng lƣợng tín hiệu. Lƣợc ồ spectrogram chỉ diễn tả biên ộ phổ của tín hiệu mà bỏ
qua các thông tin về pha vì các thông tin này không có vai trò quan trọng trong hầu hết các
ứng dụng liên quan ến tiếng nói.
Để xây dựng lƣợc ồ spectrogram, ngƣời ta thực hiện biểu diễn biên ộ của biến ổi
Fourier ngắn hạn (STFT) |Sn(ej )| theo thời gian trên trục nằm ngang, ồng thời theo tần
số (từ 0 ến ) trên trục thẳng ứng (tức là từ 0 ến F /2, với F s
s là tần số lấy mẫu), ồng
thời ộ lớn biên ộ bằng ộ ậm nhạt (thƣờng theo thang tỷ lệ lô-ga-rít) S t r, fk n 20log10 | SrR k |
trong ó tr=rRT và fk=k/(NT) và T là chu kỳ lấy mẫu của tín hiệu. Hình 3.4 minh họa
spectrogram của tín hiệu tiếng nói cùng với dạng sóng tín hiệu tƣơng ứng.
Lƣợc ồ spectrogram của tín hiệu tiếng nói "Should we chase" lOMoARcPSD| 36086670 CHƢƠNG H 2. P ì HÂ
nh 2.5 N TÍCH TÍN HIỆU TIẾNG NÓI
Hai lƣợc ồ spectrogram ƣợc xây dựng với các hàm cửa sổ có ộ dài khác nhau. Lƣợc
ồ spectrogram phía trên là kết quả khi sử dụng cửa sổ có chiều dài 101 mẫu tƣơng ứng với
10ms. Chiều dài của cửa sổ phân tích này xấp xỉ bằng chu kỳ của dạng sóng trong các
khoảng tín hiệu âm hữu thanh. Kết quả là trong các khoảng tín hiệu âm hữu thanh,
spectrogram biểu hiện các vằn ịnh hƣớng thẳng ứng tƣơng ứng với thực tế rằng cửa sổ
trƣợt lúc gồm hầu hết các mẫu có biên ộ lớn, lúc gồm hầu hết các mẫu có biên ộ nhỏ. Nói
một cách khác, khi cửa sổ phân tích có ộ dài ngắn, mỗi chu kỳ pitch riêng rẽ ƣợc hiển thị
rõ nét theo thời gian, trong khi ộ phân giải theo tần số thì rất kém. Cũng chính vì lý do này,
nếu chiều dài cửa sổ phân tích mà ngắn, thì lƣợc ồ spectrogram thu ƣợc gọi là lƣợc ồ
spectrogram băng rộng. Ngƣợc lại, nếu chiều dài cửa sổ phân tích lớn, thì lƣợc ồ
spectrogram thu ƣợc gọi là lƣợc ồ spectrogram băng hẹp. Lƣợc ồ spectrogram băng hẹp
có ộ phân giải theo tần số cao nhƣng theo thời gian thì nhỏ. Minh họa phía dƣới hình 2.5
là kết quả của việc sử dụng cửa sổ phân tích có ộ dài 401 mẫu, tƣơng ứng với 40ms, bằng
khoảng vài chu kỳ tín hiệu. Và nhƣ ta thấy, lƣợc ồ spectrogram tƣơng ứng không còn
nhạy với sự thay ổi về thời gian nữa.
2.5. PHÂN TÍCH DỰ ĐOÁN TUYẾN TÍNH
Phƣơng pháp phân tích dự oán tuyến tính là một trong các phƣơng pháp phân tích tín
hiệu tiếng nói mạnh nhất và ƣợc sử dụng phổ biến. Điểm quan trọng của phƣơng pháp này
là cung cấp các ƣớc lƣợng chính xác của các tham số tín hiệu tiếng nói và khả năng thực
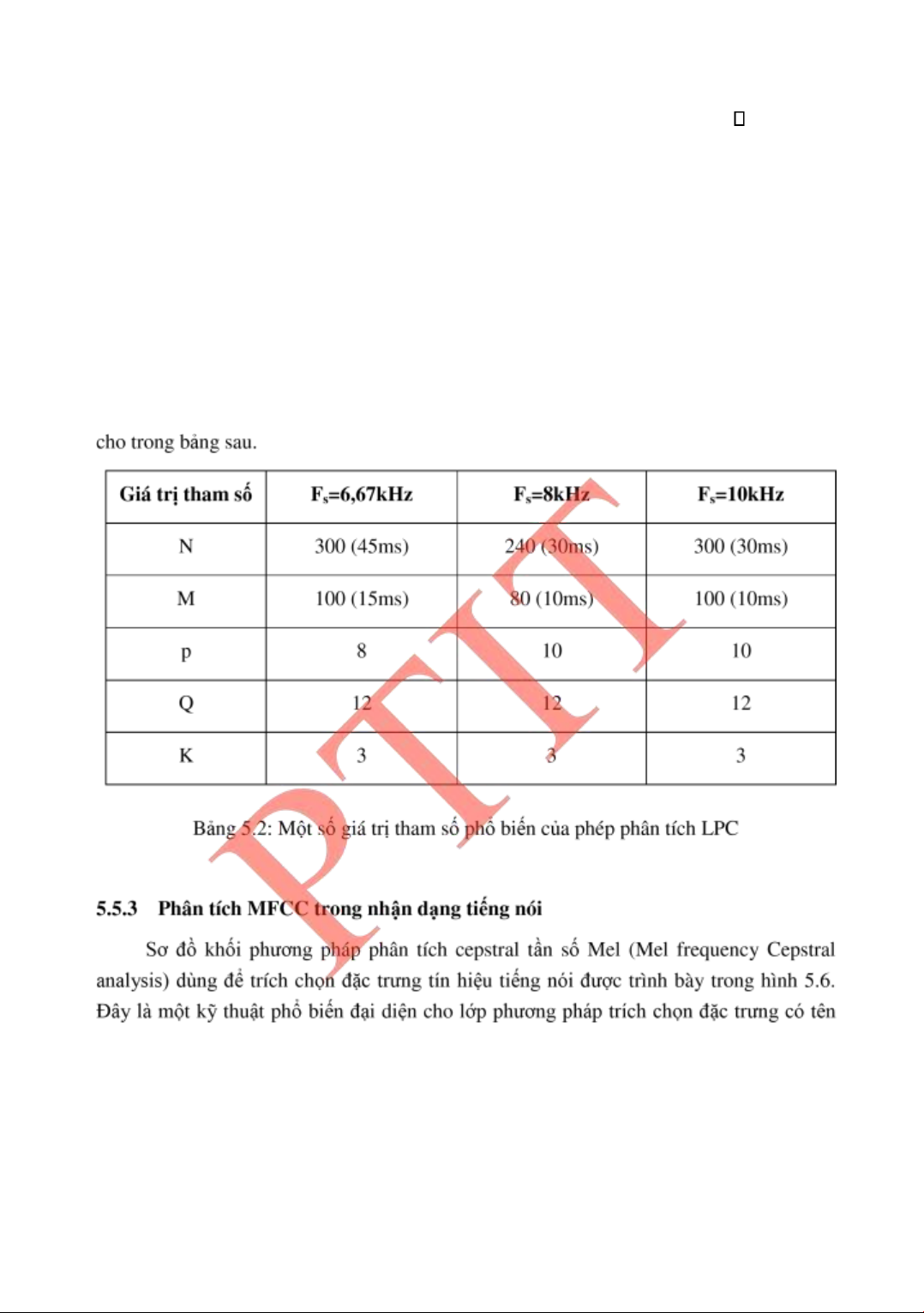
hiện tính toán tƣơng ối nhanh.
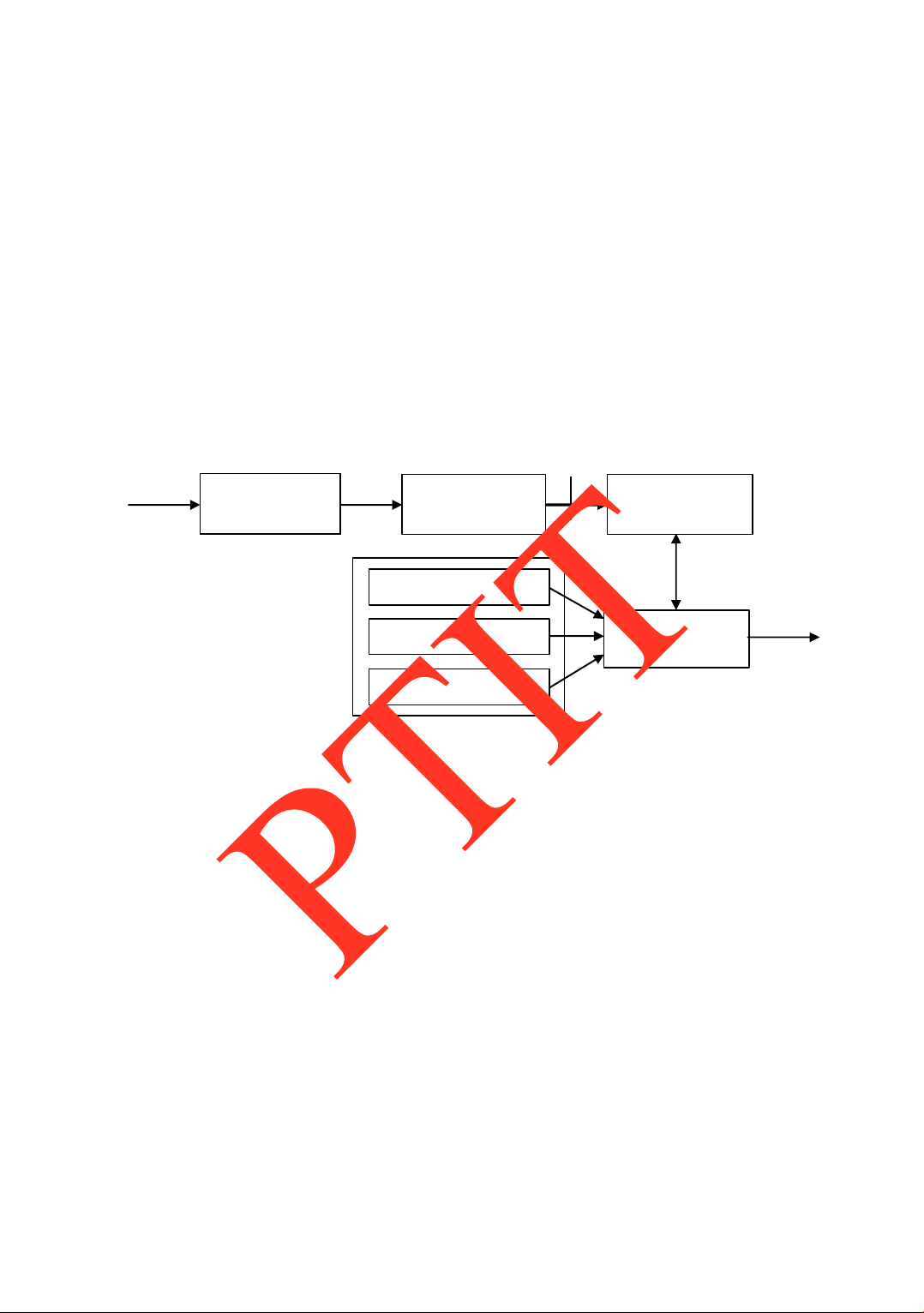
Mô hình của phƣơng pháp phân tích tín hiệu tiếng nói dựa trên mã dự oán tuyến tính
(LPC- Linear Predictive Coding) ƣợc trình bày trong hình vẽ 2.6. Phƣơng pháp phân tích
LPC thực hiện việc phân tích phổ trên các khung (khối - block) tín hiệu hay còn gọi là các
khung tín hiệu (speech frames) bằng việc sử dụng một mô hình hóa toàn iểm cực. Điều
này có nghĩa là kết quả biểu diễn phổ thu ƣợc Xn(ej ) ƣợc giới hạn trong dạng /A(ej ),
trong ó A(ej ) là một a thức bậc p tƣơng ứng khi thực hiện phép biến ổi z: A z 1 a z 1 2 p 1 a z2 ... a zp lOMoARcPSD| 36086670
CHƢƠNG 2. PHÂN TÍCH TÍN HIỆU TIẾNG NÓI Hình 2.6
Mô hình phân tích LPC cho tín hiệu tiếng nói
Bậc của a thức p còn ƣợc gọi là bậc phân tích LPC. Kết quả thu ƣợc từ khối phân tích
phổ LPC là một véc-tơ các hệ số (còn gọi là các tham số LPC) cụ thể hóa (specify) phổ
của một mô hình toàn iểm cực mà phù hợp nhất với phổ tín hiệu gốc trên toàn khoảng thời
gian xem xét các mẫu tín hiệu.
Ý tƣởng ằng sau việc sử dụng mô hình LPC là có thể xấp xỉ một mẫu tín hiệu tiếng
nói ở thời iểm n bất kỳ, s n( ) , nhƣ là một tổ hợp tuyến tính của p mẫu trƣớc ó. Nói cách khác: s n as n 1 1 a s n2 2 ... a s n pp
Giả thiết các hệ số a1, a2, …, ap không ổi trong khung phân tích tín hiệu. Biểu thức
trên có thể ƣợc viết lại thành ẳng thức nếu ta thêm vào một thành phần kích thích
(excitation term) Gu(n), ta ƣợc: s n p a s n i i Gu n i 1
Trong công thức trên, u(n) là thành phần kích thích chuẩn và G là hệ số khuếch ại của
thành phần kích thích. Nếu xem xét biểu thức trên trong miền z ta có biểu thức: p a z S z i i GU z S z i 1
Hay hàm truyền ạt tƣơng ứng là: H z S z 1 1 1 p a zi i A z GU z i 1
Hàm truyền ạt thu ƣợc biểu diễn trong sơ ồ khối trong hình 3.6. Nguyên lý hoạt ộng
của sơ ồ khối nhƣ sau: Nguồn kích thích chuẩn u(n) ƣợc nhân với hệ số khuếch ại G trở
thành ầu vào của một hệ thống toàn iểm cực H(z)=1/A(z) ể tạo ra tín hiệu tiếng nói s(n).
Ta biết rằng hàm kích thích thực của tín hiệu tiếng nói là dãy xung bán tuần hoàn ối với
tín hiệu âm hữu thanh và là nguồn nhiễu ngẫu nhiên ối với tín hiệu âm vô thanh. Từ thực
tế này, ta xây dựng ƣợc mạch tổng hợp tín hiệu tiếng nói dựa vào mô hình phân tích LPC
nhƣ trong hình 2.7. Trong sơ ồ tổng hợp tiếng nói sử dụng mô hình phân tích LPC, nguồn lOMoARcPSD| 36086670
CHƢƠNG 2. PHÂN TÍCH TÍN HIỆU TIẾNG NÓI
kích thích ƣợc chọn tƣơng ứng phù hợp với tín hiệu âm hữu thanh hay vô thanh nhờ một
chuyển mạch. Hệ số khuếch ại G của tín hiệu ƣợc ƣớc lƣợng từ tín hiệu tiếng nói. Mạch
lọc số H(z) ƣợc iều khiển bởi các tham số của bộ máy phát âm tƣơng ứng với tín hiệu
tiếng nói ƣợc tạo ra. Nói một cách cụ thể, các tham số của mô hình tổng hợp này là các
phân loại (classification) âm hữu thanh hay vô thanh, khoảng chu kỳ pitch (pitch period)
của tín hiệu, tham số ộ khuếch ại, các hệ số của bộ lọc ak. Tất cả các tham số này thay ổi chậm theo thời gian. u(n) s(n) u(n) G Hình 2.7
Mô hình dự oán mô phỏng tiếng nói
Giả sử rằng tổ hợp tuyến tính của các mẫu trƣớc thời iểm xem xét là một ƣớc lƣợng của
tín hiệu, kí hiệu là s n : p a s n k k s n k 1
Khi ó, sai số dự tính e(n) sẽ ƣợc tính là: e n s n s n s n p a s n k k k 1
Nói cách khác, hàm truyền ạt sai số tƣơng ứng là: A z E zS z 1 kp 1a zk k
Từ ó thấy rằng, nếu tín hiệu tiếng nói ƣợc tạo ra từ sơ ồ mạch 3.6 thì sai số dự oán e(n) sẽ
bằng tín hiệu kích thích Gu(n).
Vấn ề ặt ra ối với phƣơng pháp phân tích LPC là xác ịnh ƣợc tập các hệ số ak một cách
trực tiếp từ tín hiệu tiếng nói sao cho tính chất phổ của mạch lọc trong sơ ồ 2.8 tƣơng ồng
với phổ của tín hiệu tiếng nói trong khoảng cửa sổ phân tích. Vì ặc tính phổ của tín hiệu
tiếng nói luôn thay ổi theo thời gian, các hệ số dự oán ở thời iểm n xác ịnh phải là những
giá trị ƣợc ƣớc lƣợng từ các oạn ngắn hạn của tín hiệu tiếng nói xung quanh thời iểm n. lOMoARcPSD| 36086670
CHƢƠNG 2. PHÂN TÍCH TÍN HIỆU TIẾNG NÓI
Từ ây ta thấy phƣơng pháp tiếp cận cơ bản là tìm ƣợc một tập các hệ số dự oán (predictor
coefficients) sao cho chúng làm tối thiểu hóa sai số dự oán trung bình bình phƣơng trên
toàn oạn ngắn hạn của tín hiệu phân tích. Thƣờng thì phƣơng pháp phân tích phổ theo
cách này ƣợc thực hiện trên các khung tín hiệu liên tiếp mà khoảng cách giữa các khung
vào khoảng bậc của 10ms. Tần số cơ bản Chuyển mạch Bộ tạo dãy xung
Âm hữu thanh/vô thanh Các tham số tuyến âm
Bộ lọc số thay ổi s(n) u(n) theo thời gian Bộ tạo nhiễu G ngẫu nhiên Hình 2.8
Mô hình tổng hợp tiếng nói dùng LPC
Để xây dựng biểu thức và từ ó tìm ra ƣợc các hệ số dự oán thích hợp, ta ịnh nghĩa các
khung tín hiệu ngắn hạn và tƣơng ứng là các sai số ngắn hạn: s n
m s n m en n e n m
Ta cần tối thiểu hóa tín hiệu sai số trung bình bình phƣơng ở thời iểm n: n e mn2 m
Biểu thức trên ƣợc viết lại bằng cách sử dụng các ịnh nghĩa en(m) và sn(m) nhƣ sau: p 2 n s mn a s m kk n m k 1
Để tìm cực tiểu của sai số, ta lấy ạo hàm lần lƣợt theo các hệ số ak và cho chúng bằng không: lOMoARcPSD| 36086670
CHƢƠNG 2. PHÂN TÍCH TÍN HIỆU TIẾNG NÓI n
0 k 1,2,..., p ak
Ta thấy rằng, giá trị sai số trung bình bình phƣơng tối thiểu có chứa một thành phần cố
ịnh n (0,0) và các thành phần khác phụ thuộc vào các hệ số dự oán. ˆ
Để tìm các hệ số dự oán tối ƣu a k trƣớc hết ta tính n (i,k) (1≤ i≤ p và 0≤ k ≤ p)
và sau ó giải hệ ồng thời của p biểu thức. Trong thực tế, việc giải hệ và tính toán các thành
phần phụ thuộc rất nhiều vào khoảng thời gian m ƣợc sử dụng ể ịnh ra khung tín hiệu
phân tích và vùng mà trên ó sai số trung bình bình phƣơng ƣợc ƣớc lƣợng. Có hai phƣơng
pháp chuẩn ể ịnh ra khoảng thích hợp cho tín hiệu tiếng nói: phƣơng pháp sử dụng sự tự
tƣơng quan và phƣơng pháp sử dụng covariance.
Phƣơng pháp sử dụng hàm tự tƣơng quan xuất phát trực tiếp từ việc ịnh ra khoảng
giới hạn m trong tổ hợp tuyến tính sao cho oạn tín hiệu tiếng nói sn(m) bằng 0 ở ngoài
khoảng 0 ≤ m ≤ N-1. Điều này tƣơng ƣơng với việc giả thiết tín hiệu tiếng nói s(n+m)
ƣợc nhân với hàm của sổ w(m) hữu hạn có giá trị bằng 0 ở ngoài khoảng 0 ≤ m ≤ N-1. Nói lOMoARcPSD| 36086670
CHƢƠNG 2. PHÂN TÍCH TÍN HIỆU TIẾNG NÓI
một cách khác, mẫu tín hiệu tiếng nói ể làm tối thiểu hóa sai số trung bình bình phƣơng
có thể biểu diển dƣới dạng: s m n s n m w m m0 0m N,N 1 1 0
Từ công thức (3.31), khi m<0 tín hiệu sai số en(m) bằng 0 vì khi ó sn(m)=0. Mặt khác,
cũng tƣơng tự khi m>N-1+p sẽ không có sai số dự oán bởi vì khi ó ta cũng có sn(m)=0.
Tuy nhiên trong vùng m=0 (tức là từ m=0 ến m=p-1) tín hiệu thu ƣợc sau khi thực hiện
việc lấy cửa sổ có thể ƣợc dự oán từ các mẫu trƣớc ó, mà một số trong chúng có thể bằng
0. Và nhƣ vậy, khả năng sai số dự oán tƣơng ối lớn có thể tồn tại trong vùng này. Tại vùng
m=N-1 (tức là từ m=N-1 ến m=N-1+p) khả năng có thể tồn tại sai số dự oán lớn cũng có
thể tồn tại bởi vì các tín hiệu thu ƣợc từ quá trình lấy của sổ bằng 0 ƣợc dự oán từ một vài
mẫu cuối cùng khác không của tín hiêu. Với tín hiệu âm hữu thanh,các hiệu ứng tiềm năng
tồn tại sai số dự oán lớn ở ầu hoặc cuối khung tín hiệu thể hiện rõ ràng khi bắt ầu chu kỳ
của pitch hoặc rất gần với các iểm m=0 hoặc m=N-1. Đối với tín hiệu âm vô thanh thì hiện
tƣợng này gần nhƣ ƣợc loại bỏ bởi vì không có phần tín hiệu nào nhạy cảm (position
sensitive). Các hiện tƣợng này cùng với tín hiệu cửa sổ ƣợc minh họa trong các hình 2.9 - 2.11. lOMoARcPSD| 36086670
CHƢƠNG 2. PHÂN TÍCH TÍN HIỆU TIẾNG NÓI Hình 2.9
Minh h ọa trƣờ ng h ợ p sai s ố d ự oán lớ n ở ầ u khung v ớ i tín hi ệ u âm h ữ u thanh Hình 2.10 Minh họa
trƣờng hợp sai số dự oán lớn ở cuối khung với tín hiệu âm hữu thanh lOMoARcPSD| 36086670
CHƢƠNG 2. PHÂN TÍCH TÍN HIỆU TIẾNG NÓI Hình 2.11
Minh h ọa trƣờ ng h ợ p sai s ố d ự oan lớ n v ớ i tín hi ệ u âm vô thanh
M ục ích c ủ a vi ệ c l ấ y c ủ a s ổ nh ằ m ch ỉ nh (taper) tín hi ệ u ở g ần các iể m m=0 và
m=N- 1 ể làm t ố i thi ể u hóa các sai s ố ở các vùng biên này.
T ừ ịnh nghĩa khoả ng tín hi ệ u sau phép l ấ y qua c ử a s ổ , ta có th ể vi ế t bi ể u th ứ c tính
sai s ố trung bình bình phƣơng nhƣ sau: 1 N p 2 e n n n 0 m Khi ó
n (i,k) có th ể ƣợ c vi ế t l ạ i là: 1 N p n i k,
sn m i s n m k 1 ip,0 kp m 0
Bằng cách thay chỉ số biểu thức trên có thể ƣợc viết dƣới dạng: N 1 i k n i k, sn
m sn m ik 1 i p,0 k p m 0 lOMoARcPSD| 36086670
CHƢƠNG 2. PHÂN TÍCH TÍN HIỆU TIẾNG NÓI
Biểu thức cho thấy ó là một hàm chỉ phụ thuộc vào hiệu i-k chứ không phụ thuộc hai biến
số ộc lập i và k. Do ó, hàm covariance n(i,k) trở thành hàm tự tƣơng quan: n i k, n i k N 1 i k s n
m sn m i k 1 ip,0 k p m 0
Do hàm tự tƣơng quan là hàm ối xứng, tức là n k n
k , biểu thức tƣơng ứng
của LPC có thể ƣợc biểu diễn là: p n ik a ˆk n i 1 i p k 1
Nếu biểu diễn dƣới dạng ma trận ta có: n 0 n 1 n 2 n p 1 aˆ1 n 1 n 1 n 0 n 1 n p 2 aˆ2 n 2 n 2 n 1 n 0 n p 3 aˆ3 n 3 n
p 1 n p 2 n p 3 n 0 aˆp n p
Trong công thức trên, ma trận các thành phần tự tƣơng quan là một ma trận Toeplitz
(ma trận ối xứng với các thành phần ƣờng chéo chính bằng nhau), do ó việc giải hệ phƣơng
trình trên dễ dàng thực hiện ƣợc bằng việc áp dụng các thuật toán tính toán hiệu quả ã biết.
Phƣơng pháp sử dụng covariance là một phƣơng pháp khác với phƣơng pháp sử dụng
hàm tự tƣơng quan ã ề cập ở trên. Phƣơng pháp này cố ịnh khoảng mà trên ó sai số trung
bình bình phƣơng ƣợc tính trong khoảng 0≤ m ≤N-1 và sử dụng khung tín hiệu trong
khoảng ó một cách trực tiếp mà không thực hiện phép lấy của sổ.
Sai số trung bình bình phƣơng khi ó ƣợc tính là: N 1 n e mn2 m 0
Và covariance ƣợc tính bởi: lOMoARcPSD| 36086670
CHƢƠNG 2. PHÂN TÍCH TÍN HIỆU TIẾNG NÓI n i k, N
1sn m i s n m k 1 ip, 0 kp m 0
Hoặc bằng cách ổi chỉ số: n i k, N i 1sn
m sn m ik 1 i p,0 k p m 0
Để ý thấy rằng việc tính toán theo biểu thức trên liên quan ến các mẫu tín hiệu sn(m) từ
thời iểm m=-p ến m=N-1-p khi i=p, và liên quan ến các mẫu sn(m+i-k) từ thời iểm 0 ến
thời iểm N-1. Do ó, khoảng tín hiệu cần thiết ể có thể tính toán hoàn thiện là từ sn(-p) ến
sn(N-1). Nói một cách khác, việc tính toàn cần ến các mẫu bên ngoài khoảng tối thiểu sai số
gồm sn(-p), sn(-p+1), …, sn (-1).
Bằng việc sử dụng khoảng tín hiệu mở rộng ể tính toán các giá trị covariance n(i,k), biểu
thức phân tích LPC dạng ma trận ƣợc biểu diễn nhƣ sau: n 1,1 n 1,2 n 1,3 n 1, p aˆ1 n 1,0 n
2,1 n 2,2 n 2,3 n 2, p aˆ2 n 2,0 n 3,1 n 3,2 n 3,3 n 3,4 aˆ3 n 3,0 , ,0 n p,1 n p,2 n p,3 n p p aˆp n p
Ma trận các hệ số covariance là một ma trận ối xứng (vì n(i,k)= n(k,i)) tuy nhiên
không phải ma trận Toeplitz. Việc giải hệ phƣơng trình trên có thể thực hiện bằng việc sử
dụng thuật toán phân tích Cholesky. Trong thực tế, mô hình phân tích LPC biểu diễn dạng
covariance ầy ủ thƣờng không ƣợc sử dụng trong các hệ thống nhận dạng tín hiệu tiếng nói. lOMoARcPSD| 36086670
CHƢƠNG 2. PHÂN TÍCH TÍN HIỆU TIẾNG NÓI
2.6. XỬ LÝ ĐỒNG HÌNH
Khái niệm cepstrum ƣợc ƣa ra bởi Bogert, Healy và Tukey. Cepstrum ƣợc ịnh nghĩa
là biến Fourier ngƣợc (IFT) của lô-ga-rít ộ lớn biên ộ phổ của tín hiệu. Nói các khác,
cepstrum của một tín hiệu với thời gian rời rạc ƣợc cho bởi công thức: c m n 1 log S en j e dj 2
Ở ây, log|Sn(ej )| là lô-ga-rít của ộ lớn biên ộ (magnitude) của FT tín hiệu. Khái niệm trên
có thể ƣợc mở rộng thành cepstrum phức nhƣ sau: cˆ n m 21 log{Sn e j }e j m d
Trong công thức tính trên, log{Sn(ej )} là lô-ga-rít phức của Sn(ej ) và ƣợc ịnh nghĩa nhƣ sau: Sˆn e j log{Sn e j } logSn e j jarg Sn e j ˆ Giả sử s(n)=s
1(n)*s2(n), với ịnh nghĩa cepstrum dễ dàng thấy rằng c n c n c n ˆ 1 ˆ2
. Nhƣ vậy phép toán với cepstrum ã chuyển tích chập thành phép cộng.
Chính iều này ã làm cho phép phân tích cepstrum trở thành một công cụ hữu ích cho việc
phân tích tín hiệu tiếng nói.
Tuy nhiên các công thức trên là các ịnh nghĩa dựa trên các công thức toán học. Để công
thức có ý nghĩa trong các phân tích thực tế, ta phải xây dựng các công thức mà việc tính
toán có thể dễ dàng thực hiện ƣợc. Vì biến ổi Fourier rời rạc (DFT) là phiên bản lấy mẫu
của biến ổi Fourier với thời gian rời rạc (DTFT) của một dãy chiều dài cố ịnh (tức là
S(k)=S(ej2 k/N)), do ó IDFT và DFT có thể ƣợc thay thế tƣơng ứng bằng IDTFT và DTFT. N 1 S k
s n e j2 kn N/ n 0 lOMoARcPSD| 36086670
CHƢƠNG 2. PHÂN TÍCH TÍN HIỆU TIẾNG NÓI X kˆ log S k jarg S k s n 1 N 1 X k eˆ j2 kn N/ N n 0
2.7. ÁP DỤNG MỘT SỐ PHÉP PHÂN TÍCH ĐỂ XÁC ĐỊNH CÁC
THAM SỐ CƠ BẢN CỦA TÍN HIỆU TIẾNG NÓI
2.7.1 Một số phƣơng pháp xác ịnh các tần số formant
Formant của tín hiệu tiếng nói là một trong các tham số quan trọng và hữu ích có ứng
dụng rộng rãi trong nhiều lĩnh vực chẳng hạn nhƣ trong việc xử lý, tổng hợp và nhận dạng
tiếng nói. Các formant là các tần số cộng hƣởng của tuyến âm (vocal tract), nó thƣờng
ƣợc thể hiện trong các biểu diễn phổ chẳng hạn nhƣ trong biểu diễn spectrogram nhƣ là
một vùng có năng lƣợng cao, và chúng biến ổi chậm theo thời gian theo hoạt ộng của bộ
máy phát âm. Sở dĩ formant có vai trò quan trọng và là một tham số hữu ích trong các
nghiên cứu xử lý tiếng nói là vì các formant có thể miêu tả ƣợc các khía cạnh quan trọng
nhất của tiếng nói bằng việc sử dụng một tập rất hạn chế các ặc trƣng. Chẳng hạn trong
mã hóa tiếng nói, nếu sử dụng các tham số formant ể biểu diễn cấu hình của bộ máy phát
âm và một vài tham số phụ trợ biểu diễn nguồn kích thích, ta có thể ạt ƣợc tốc ộ mã hóa thấp ến 2,4kbps.
Nhiều nghiên cứu về xử lý và nhận dạng tiếng nói ã chỉ ra rằng các tham số formant là
ứng cử viên tốt nhất cho việc biểu diễn phổ của bộ máy phát âm một cách hiệu quả. Tuy
nhiên việc xác ịnh các formant không ơn giản chỉ là việc xác ịnh các ỉnh trong phổ biên ộ
bởi vì các ỉnh phổ của tín hiệu ra của bộ máy phát âm phụ thuộc một cách phức tạp vào
nhiều yếu chẳng hạn nhƣ cấu hình bộ máy phát âm, các nguồn kích thích, ...
Các phƣơng pháp xác ịnh formant liên quan ến việc tìm kiếm các ỉnh trong các biểu
diễn phổ, thƣờng là từ kết quả phân tích phổ theo phƣơng pháp STFT hoặc mã hóa dự oán tuyến tính (LPC).
2.7.2 Xác ịnh formant từ phân tích STFT
Các phân tích STFT tƣơng tự và rời rạc ã trở thành một công cụ cơ bản cho nhiều phát
triển trong phân tích và tổng hợp tín hiệu tiếng nói.
Dễ dàng thấy STFT trực tiếp chứa các thông tin về formant ngay trong biên ộ phổ.
Do ó, nó trở thành một cơ sở cho việc phân tích các tần số formant của tín hiệu tiếng nói. lOMoARcPSD| 36086670
CHƢƠNG 2. PHÂN TÍCH TÍN HIỆU TIẾNG NÓI
2.7.3 Xác ịnh formant từ phân tích LPC
Các tần số formant có thể ƣợc ƣớc lƣợng từ các tham số dự oán theo một trong hai
cách. Cách thứ nhất là xác ịnh trực tiếp bằng phân tích nhân tử a thức dự oán và dựa trên
các nghiệm thu ƣợc ể quyết ịnh xem nghiệm nào tƣơng ứng với formant. Cách thứ hai là
sử dụng phân tích phổ và chọn các formant tƣơng ứng với các ỉnh nhọn bằng một trong
các thuật toán chọn ỉnh ã biết.
Một ƣu iểm khi sử dụng phƣơng pháp phân tích LPC ể phân tích formant là tần số
trung tâm của các formant và băng tần của chúng có thể xác ịnh ƣợc một cách chính xác
thông qua việc phân tích nhân tử a thức dự oán. Một phép phân tích LPC bậc p ƣợc chọn
trƣớc, thì số khả năng lớn nhất có thể có các iểm cực liên hợp phức là p/2. Do ó, việc gán
nhãn trong quá trình xác ịnh xem iểm cực nào tƣơng ứng với các formant ơn giản hơn các
phƣơng pháp khác. Ngoài ra, với các iểm cực bên ngoài thƣờng có thể dễ dàng phân tách
trong phân tích LPC vì băng tần của chúng thƣờng rất lớn so với băng tần thông thƣờng
của các formant tín hiệu tiếng nói.
2.7.4 Một số phƣơng pháp xác ịnh tần số cơ bản
Tần số cơ bản F0 là tần số dao ộng của dây thanh. Tần số này phụ thuộc vào giới tính
và ộ tuổi. F0 của nữ thƣờng cao hơn của nam, F0 của ngƣời trẻ thƣờng cao hơn của ngƣời
già. Thƣờng với giọng của nam, F0 nằm trong khoảng từ 80-250Hz, với giọng của nữ, F0
trong khoảng 150-500Hz. Sự biến ổi của F0 có tính quyết ịnh ến thanh iệu của từ cũng nhƣ
ngữ iệu của câu. Câu hỏi ặt ra là làm thế nào ể xác ịnh tần cố cơ bản (fundamental
frequency). Một số phƣơng pháp xác ịnh tần số cơ bản có thể kể ến là: Phƣơng pháp sử
dụng hàm tự tƣơng quan, phƣơng pháp sử dụng hàm vi sai biên ộ trung bình; Phƣơng
pháp sử dụng bộ lọc ảo và hàm tự tƣơng quan; Phƣơng pháp xử lý ồng hình (homomophic).
2.7.5 Sử dụng hàm tự tƣơng quan
Hàm tự tƣơng quan n(k) sẽ ạt các giá trị cực khi tƣơng ứng tại các iểm là bội của chu
kỳ cơ bản của tín hiệu. Khi ó các tần số cơ bản là tần số xuất hiện của các ỉnh của n(t).
Bài toán trở thành bài toán xác ịnh chu kỳ hàm tự tƣơng quan.
2.7.6 Sử dụng Vi sai ộ lớn biên ộ ngắn hạn
Nhƣ ã ề cập, nếu dãy s(n) tuần hoàn với chu kỳ T thì hàm AMDF Mn sẽ triệt tiêu tại
các giá trị t là bội của số T. Do ó, ta chỉ cần xác ịnh hai iểm cực tiểu gần nhau nhất và từ ó
có thể xác ịnh ƣợc chu kỳ của dãy và từ ó suy ra tần số cơ bản. lOMoARcPSD| 36086670
CHƢƠNG 2. PHÂN TÍCH TÍN HIỆU TIẾNG NÓI
2.7.7 Sử dụng tốc ộ trở về không
Khi xem xét các tín hiệu với thời gian rời rạc, một lần qua iểm không của tín hiệu xảy
ra khi các mẫu cạnh nhau có dấu khác nhau. Do vậy, tốc ộ qua iểm không của tín hiệu là
một o lƣờng ơn giản của tần số của tín hiệu. Ví dụ, một tín hiệu hình sin có tần số F0 ƣợc
lấy mẫu với tần số Fs sẽ có Fs/F0 mẫu trong một chu kỳ. Vì mỗi chu kỳ có hai lần qua iểm
không nên tốc ộ trung bình qua iểm không là Zn=2F0/Fs. Nhƣ vậy, tốc ộ qua iểm không
trung bình cho là một cách ánh giá tƣơng ối về tần số của sóng sin.
2.7.8 Sử dụng phân tích STFT
Từ kết quả phần biểu diễn Fourier của tín hiệu tiếng nói, dễ thấy rằng nguồn kích thích
của tín hiệu âm hữu thanh ƣợc tăng cƣờng ở những ỉnh nhọn và các ỉnh này xảy ra ở các
iểm là bội số của tần số cơ bản. Đây chính là nguyên lý cơ bản của một trong các phƣơng
pháp xác ịnh tần số cơ bản.
Xét biểu thức phổ tích các hài (harmonic) nhƣ sau: P en j K Sn e j r r 1
Lấy lô-ga-rít của phổ tích các hài, thu ƣợc phổ tích các hài trong thang lô-ga-rít: P eˆn j 2 K log S en j r r 1 ˆ Hàm j P e n
trong công thức trên là một tổng của K phổ nén tần số của |Sn(ej )|.
Việc sử dụng hàm trong công thức trên xuất phát từ nhận xét rằng với tín hiệu âm hữu
thanh, việc nén tần số bởi các hệ số nguyên sẽ làm các hài của tần số cơ bản trùng với tần
số cơ bản. Ở vùng tần số giữa các hài, có một hài của các số tần số khác cũng bị nén trùng
nhau, tuy nhiên chỉ tại tần số cơ bản là ƣợc củng cố. Hình 2.12 minh họa nhận xét vừa nêu. lOMoARcPSD| 36086670
CHƢƠNG 2. PHÂN TÍCH TÍN HIỆU TIẾNG NÓI Hình 2.12
Minh họa sự nén tần số lOMoARcPSD| 36086670
CHƢƠNG 2. PHÂN TÍCH TÍN HIỆU TIẾNG NÓI
2.7.9 Sử dụng phân tích Cepstral
Trong phân tích cepstral ngƣời ta quan sát thấy rằng, với tín hiệu âm hữu thanh, có một
ỉnh nhọn tại chu kỳ cơ bản của tín hiệu. Tuy nhiên với tín hiệu âm vô thanh thì ỉnh nhọn
này không xuất hiện. Do ó, phân tích cepstral có thể ƣợc sử dụng nhƣ một công cụ cơ bản
dùng ể xác ịnh xem một oạn tín hiệu tiếng nói là tín hiệu âm vô thanh hay hữu thanh, và ể
xác ịnh chu kỳ cơ bản của tín hiệu âm hữu thanh. Phƣơng pháp sử dụng phân tích cepstral
ể ƣớc lƣợng tần số cơ bản khá ơn giản. Trƣớc hết các cepstrum ƣợc tính toán và tìm kiếm
ỉnh nhọn trong một khoảng lân cận của chu kỳ phỏng oán. Nếu ỉnh cepstrum tại ó lớn hơn
một ngƣỡng ịnh trƣớc thì tín hiệu tiếng nói ƣa vào có khả năng lớn là tín hiệu âm hữu
thanh và vị trí ỉnh ó là một ƣớc lƣợng chu kỳ tín hiệu cơ bản (cũng tức là xác ịnh ƣợc tần số cơ bản).
Hình 2.13 minh họa việc sử dụng phƣơng pháp phân tích cepstral ể xác ịnh tín hiệu
âm vô thanh và hữu thanh cùng với xác ịnh tần số cơ bản của âm hữu thanh. Phía bên trái
là dãy các lô-ga phổ ngắn hạn (các ƣờng thay ổi rất nhanh theo thời gian), phía bên phải
là các dãy cepstra tƣơng ứng ƣợc tính toán từ các lô-ga phổ phía bên tai trái. Các dãy lô-
ga phổ và cepstra tƣơng ứng là các oạn liên tiếp chiều dài 50ms thu ƣợc từ hàm cửa sổ
dịch 12,5ms mỗi bƣớc (nghĩa là dịch khoảng 100 mẫu ở tần số lấy mẫu 800mẫu/giây). Từ
hình vẽ, ta thấy các dãy 1-5, cửa sổ tín hiệu chỉ bao gồm tín hiệu âm vô thanh (không xuất
hiện ỉnh, sự thay ổi phổ rất nhanh và xảy ra ngẫu nhiên không có cấu trúc chu kỳ) trong
khi các dãy 6 và 7 bao gồm cả tín hiệu âm vô thanh và hữu thanh. Các dãy 8-15 chỉ bao
gồm tín hiệu âm hữu thanh. Dễ dàng thấy ỉnh cepstrum tại tần số ứng với 11-12ms tín hiệu
âm hữu thanh. Và nhƣ vậy, tần số của ỉnh là một ƣớc lƣợng chính xác tần số cơ bản trong
khoảng tín hiệu hữu thanh. lOMoARcPSD| 36086670
CHƢƠNG 2. PHÂN TÍCH TÍN HIỆU TIẾNG NÓI 1. Hình 2.13
Lô-ga-rít các thành ph ầ n hài trong ph ổ tín hi ệ u
2.8. CÂU H Ỏ I VÀ BÀI T Ậ P CU ỐI CHƢƠNG
M ục ích củ a vi ệ c X ử lý ti ế ng nói? Li ệ t kê m ộ t s ố phép x ử lý phân tích ti ế ng nói cơ bả n
2. Các phƣơng pháp phân tích tiếng nói trong miền thời gian? Ứng dụng của các phƣơng pháp này?
3. Phƣơng pháp phân tích phổ tín hiệu tiếng nói?
4. Tại sao với tiếng nói phải thực hiện phân tích ngắn hạn?
5. Có thể dùng những tham số nào ể xác ịnh iểm ầu cuối trong một oạn âm thanh?
6. Phân tích LPC: nguyên lý, hệ phƣơng trình, áp dụng? lOMoARcPSD| 36086670
CHƢƠNG 2. PHÂN TÍCH TÍN HIỆU TIẾNG NÓI
7. Phân tích cepstral: nguyên lý, công thức tính, áp dụng?
8. Xét một phân oạn tín hiệu tiếng nói sau {0 0.6442 0.9854 0.8632 0.3350 -
0.3508 -0.8716 -0.9825 -0.6313}. Biết ây là mẫu của một phân oạn tín hiệu tiếng
nói ƣợc lấy mẫu với tần số lấy mẫu là 8000Hz. Hãy xác ịnh các thông số cơ bản cho
phân oạn tín hiệu bằng phân tích trong miền thời gian. Giả sử cửa sổ phân tích là cửa
sổ chữ nhật có chiều rộng N=4 iểm mẫu.
9. (Matlab) Sử dụng máy tính cá nhân và phần mềm Matlab (hoặc các ngôn ngữ lập trình
khác) cùng công cụ chỉnh sửa âm thanh Audicity (hoặc công cụ khác) thực hiện các công việc sau: i.
Với cùng một nội dung thông tin, các thành viên trong nhóm lần lƣợt
phát âm ( ọc/nói) và ghi âm phát âm của các nguyên âm tiếng
Việt. Lƣu tệp ở ịnh dạng *.wav ii. Sử dụng phần mềm Matlab (hoặc
các bộ công cụ, ngôn ngữ lập trình khác) và kiến thức ã học trong chƣơng này:
1. Xác ịnh tần số cơ bản của phát âm tƣơng ứng của mỗi thành viên
2. Xác ịnh formant ầu tiên (F1) trong phát âm của mỗi thành viên.
Từ kết quả ó, lập bản ồ phân bố tần số formant của các nguyên
âm tiếng Việt của các thành viên trong nhóm
10. (Matlab) Sử dụng máy tính cá nhân và phần mềm Matlab (hoặc công cụ thích hợp): i.
Ghi một file tín hiệu tiếng nói của cụm từ “Xin chào các bạn”, ghi file dƣới dạng *.wav
ii. Sử dụng thƣ viện của Matlab (hoặc các công cụ thích hợp) thực hiện
phân tích LPC của oạn tín hiệu tiếng nói trên
iii. Sử dụng thƣ viện của Matlab (hoặc các công cụ thích hợp) thực hiện
phân tích LPC của oạn tín hiệu tiếng nói trên lOMoARcPSD| 36086670
CHƢƠNG 3. MÃ HÓA TIẾNG NÓI
CHƢƠNG 3: MÃ HÓA TIẾNG NÓI
3.1. KHÁI NIỆM CHUNG VỀ MÃ HÓA TIẾNG NÓI
Mã hoá là quá trình biến ổi các giá trị rời rạc thành các mã tƣơng ứng. Mã hóa tín hiệu
tiếng nói (gọi tắt là mã hóa tiếng nói), còn ƣợc biết ến là mã hóa tín hiệu thoại, ƣợc biết
ến từ rất sớm. Ngay từ những năm 1930, mã hóa tín hiệu tiếng nói ã ƣợc nhiều nhà nghiên
cứu và vận hành hệ thống liên lạc iện thoại quan tâm. Sự bùng nổ về các thuật toán mã hóa
tín hiệu thoại phải kể ến khi có sự phát triển mạnh của hệ thống thông tin di ộng và sau ó
là sự tích hợp dịch vụ a phƣơng tiện. Không chỉ có một vai trò quan trọng trong các mạng
thông tin dân dụng, mã hóa tiếng nói cũng ƣợc ứng dụng và có mặt ở trong hầu hết các hệ
thống thông tin số cả dân sự và quân sự.
Mục tiêu của việc mã hóa tiếng nói là nhằm giảm nhỏ lƣợng dữ liệu biểu diễn thông
tin tiếng nói cần lƣu trữ hoặc truyền tải mà không làm giảm chất lƣợng cảm thụ của tiếng
nói khôi phục ƣợc sau mã hóa. Nói một cách khác, mã hóa tiếng nói là quá trình tìm kiếm
biểu diễn số nhỏ gọn nhất có thể của tín hiệu tiếng nói mà vẫn không làm mất hoặc làm
mất i thông tin (méo) ít nhất có thể. Về cơ bản thì mã hóa tín hiệu tiếng nói cũng giống với
mã hóa dữ liệu thông thƣờng. Tuy nhiên, với ặc trƣng của tín hiệu tiếng nói, bao gồm cả
ặc trƣng của quá trình tạo và cảm nhận tiếng nói của con ngƣời, mã hóa tiếng nói sẽ có
nhiều iểm khác biệt và cũng cần những cách tiếp cận riêng biệt ể có thể khai thác tốt các ặc trƣng. Hình 3.1
Sơ ồ tổng quan hệ thống mã hóa tiếng nói
Nhìn chung, mã hóa tín hiệu tiếng nói (hay gọi tắt là mã hóa tiếng nói) liên quan ến
quá trình xử lý số tín hiệu tiếng nói trong ó có việc lấy mẫu và lƣợng tử hóa. Nói một cách
khác, quá trình mã hóa tiếng nói liên quan trƣớc hết tới quá trình biến ổi các tín hiệu tiếng
nói liên tục thành các tín hiệu tiếng nói rời rạc cả về thời gian (lấy mẫu) và chuẩn hóa về 68
Downloaded by Dung Tran (tiendungtr12802@gmail.com) lOMoARcPSD| 36086670
CHƢƠNG 3. MÃ HÓA TIẾNG NÓI
biên ộ (lƣợng tử hóa). Với tín hiệu tiếng nói, từ ặc trƣng nghe của tai con ngƣời trong ó
nhạy với vùng tín hiệu tiếng nói ở tần số 0.3-3.4kHz, do ó trong các hệ thống thông tin
thoại ngƣời ta thƣờng chỉ quan tâm ến khoảng tín hiệu này. Từ ó, theo ịnh lý lấy mẫu
Shannon/Nyquist, tần số lấy mẫu với tín hiệu tiếng nói tối thiểu là 8kHz. Sơ ồ khối tổng
quan của hệ thống mã hóa tiếng nói ƣợc minh họa trong hình 3.1.
Tín hiệu tiếng nói tƣơng tự ƣợc thực hiện tiền xử lý: lọc hạn biên (Anti-aliasing filter),
tiền nhấn, khuếch ại, … Sau ó ƣợc thực hiện việc số hóa (lấy mẫu và lƣợng tử hóa). Ở
một dạng thức ơn giản nhất, việc thực hiện số hóa này có thể coi là một quá trình mã hóa.
Tuy nhiên, ể ạt ƣợc các hiệu quả mã hóa tốt hơn, một loạt các quá trình phân tích khác sẽ
ƣợc áp dụng trên tín hiệu tiếng nói số thu ƣợc. Quá trình giải mã nhằm tái tạo tín hiệu
tiếng nói thực hiện các thao tác ngƣợc lại với quá trình mã hóa. Cũng cần chú ý rằng trong
quá trình mã hóa, có một khâu mà không thể thực hiện chính xác quá trình ngƣợc lại, ó
chính là quá trình lƣợng tử hóa.
Nhƣ ã ề cập, có rất nhiều cách tiếp cận bài toán mã hóa tiếng nói. Kết quả là có rất
nhiều phƣơng pháp mã hóa. Việc phân loại các phƣơng pháp mã hóa do ó không hề ơn
giản. Tùy vào cách nhìn nhận về vấn ể, hay tùy vào sự quan tâm trong quá trình mã hóa,
ngƣời ta có nhiều cách phân loại.
Nếu dựa trên cách tiếp cận và miền tiếp cận tín hiệu chúng ta có: (1) mã hóa trực tiếp
dạng sóng miền thời gian, (2) mã hóa dạng sóng miền tần số. Mã hóa trực tiếp dạng sóng
(waveform coding) là kỹ thuật mã hóa khai thác ặc trƣng về hình dạng sóng tín hiệu trực
tiếp trong miền thời gian. Đây là một cách tiếp cận phổ dụng và có thể áp dụng cho bất cứ
loại tín hiệu nào chứ không riêng gì cho tín hiệu tiếng nói. Các phƣơng thức mã hóa phổ
biến thuộc lớp này nhƣ PCM, DPCM, …Đây là phƣơng pháp mã hóa không hiệu quả nếu
xét về mặt nén dữ liệu. Tuy nhiên, chất lƣợng theo nghĩa ộ trung thực khi khôi phục tín
hiệu mã hóa của các phƣơng pháp này khá cao. Khác với lớp mã hóa trực tiếp dạng sóng,
mã hóa dạng sóng trong miền tần số thực hiện việc mã hóa tín hiệu dựa trên các ặc trƣng
phổ của tín hiệu. Phƣơng thức mã hóa này còn ƣợc gọi là mã hóa chuyển ổi (transform coding).
Nếu phân loại theo tốc ộ mã hóa, chúng ta có: (1) mã hóa tốc ộ cao, (2) mã hóa tốc ộ
trung bình, (3) mã hóa tốc ộ thấp, (4) mã hóa tốc ộ rất thấp. Xu hƣớng phát triển hiện nay
của các phƣơng pháp mã hóa tiếng nói là các phƣơng pháp tiếp cận mã hóa tốc ộ rất thấp,
khoảng 2.4kbps hoặc thấp hơn.
Ngoài ra, ngƣời ta cũng thƣờng phân loại các phƣơng pháp mã hóa dựa trên phƣơng
thức tiếp cận. Với cách phân loại này, chúng ta có: (1) mã hóa trực tiếp dạng sóng, (2) mã
hóa dựa trên tham số tín hiệu tiếng nói, (3) phƣơng pháp mã hóa lai ghép. Khác với mã
hóa trực tiếp dạng sóng, phƣơng thức mã hóa mà chúng ta ã biết trong phần trên, phƣơng lOMoARcPSD| 36086670
CHƢƠNG 3. MÃ HÓA TIẾNG NÓI
pháp mã hóa dựa trên tham số tín hiệu (gọi tắt là mã hóa tham số) sử dụng nguyên lý của
mô hình nguồn-bộ lọc mô tả bộ máy phát âm. Phƣơng thức mã hóa lai ghép thực hiện việc
kết hợp giữa phƣơng pháp mã hóa trực tiếp dạng sóng và phƣơng thức mã hóa tham số ể
có thể kết hợp ƣợc ƣu iểm của các phƣơng thức mã hóa thành phần nhằm ạt ƣợc hiệu quả
mã hóa tốt nhất. So sánh chất lƣợng về khía cạnh chất lƣợng tiếng nói tái tạo sau mã hóa
của ba phƣơng pháp mã hóa trên ƣợc minh họa trong hình 3.2. Hình 3.2
So sánh ch ất lƣợ ng tho ạ i và t ốc ộ mã hóa c ủa ba phƣơng pháp mã hóa
Trong các ph ầ n ti ế p theo, chúng ta s ẽ tìm hi ể u v ề các phƣơng pháp mã hóa theo cách phân lo ạ i này.
3.2. MỘT SỐ PHƢƠNG PHÁP MÃ HÓA DẠNG SÓNG
Nhƣ ã ề cập ở trên, mã hóa dạng sóng thực hiện việc khai thác trực tiếp dạng sóng tín
hiệu ( ộ lớn biên ộ, sự thay ổi ộ lớn biên ồ, ƣờng bao phổ, …) ể thực hiện phƣơng pháp
mã hóa. Lấy một ví dụ phƣơng pháp mã hóa dự oán tuyến tính: bộ mã hóa sẽ sử dụng tổ
hợp tuyến tính các mẫu tín hiệu quan sát ƣợc ở thời iểm trƣớc ó, cố gắng dự oán giá trị tín
hiệu ( ộ lớn biên ộ) ở thời iểm tiếp theo. Các phƣơng pháp mã hóa trực tiếp dạng sóng
tƣơng ối ơn giản, dễ triển khai thực hiện. Tuy nhiên các phƣơng pháp mã hóa thuộc nhóm
này không hiệu quả trong việc loại bỏ ộ dƣ thừa dữ liệu. Kết quả là, các phƣơng pháp mã
hóa này không hiệu quả khi xét về khía cạnh nén dữ liệu.
Các phƣơng pháp mã hóa trực tiếp dạng sóng thƣờng ƣợc thực hiện dựa trên tiêu chí
tối thiểu hóa sai số giữa tín hiệu mã hóa và dạng sóng tín hiệu gốc. Nói cách khác, lớp
phƣơng pháp mã hóa này cố gắng bảo toàn dạng sóng của tín hiệu gốc. Đây cũng chính là
lý do mà lớp phƣơng pháp mã hóa này cho tín hiệu tiếng nói có chất lƣợng cảm nhận cao.
Do ó, một số phƣơng pháp mã hóa thuộc lớp mã hóa này thƣờng ƣợc sử dụng cho mã hóa 70
Downloaded by Dung Tran (tiendungtr12802@gmail.com) lOMoARcPSD| 36086670
CHƢƠNG 3. MÃ HÓA TIẾNG NÓI
âm thanh, âm nhạc chất lƣợng cao. Một số phƣơng pháp mã hóa dạng sóng còn có khả
năng chịu ƣợc nhiễu lớn. Hơn nữa, các phƣơng pháp mã hóa thuộc lớp mã hóa này hoạt
ộng ộc lập với cách mà tín hiệu ƣợc tạo ra. Chúng không những ƣợc sử dụng ể mã hóa
tiếng nói, âm thanh mà còn ƣợc sử dụng ể mã hóa các tín hiệu khác nữa.
Một số phƣơng pháp mã hóa thuộc lớp mã hóa này có thể kể ến nhƣ: PCM tuyến tính
(ITU G.711, 64kbps), ADPCM (CCITT/ITU G.721, 32kbps; CCITT/ITU G.726/727, 16/24/32/40kbps). 3.2.1 PCM
Phƣơng pháp mã hóa PCM (Pulse Code Modulation), còn gọi là phƣơng pháp iều chế
xung mã (hay ơn giản là ều xung mã) là phƣơng pháp mã hóa dạng sóng ơn giản nhất.
Phƣơng pháp này còn ƣợc biết ến với chuẩn G.711 của ITU. Phƣơng pháp này chỉ ơn
thuần bao gồm việc lấy mẫu và lƣợng tử hóa ể chuyển thành mã tƣơng ứng.
Một tín hiệu tiếng nói băng hẹp (0.3-3.4kHz) ƣợc lấy mẫu với tần số thỏa mãn tiêu chuẩn
Nyquist (~8kHz). Sau ó mỗi mẫu ƣợc thực hiện việc lƣợng tử hóa.
Quá trình lƣợng tử hóa là quá trình không khả nghịch, nghĩa là không tồn tại phép toán
ngƣợc ể khôi phục một cách chính xác. Nhƣ vậy, có thể nói khâu lƣợng tử hóa là khâu
gây tổn thất thông tin trong quá trình mã hóa.
Cách ơn giản nhất là thực hiện việc lƣợng tử hóa tuyến tính, còn gọi là lƣợng tử hóa
ều. Khi ó khoảng tín hiệu quan tâm (min-max) ƣợc chia ều thành 2^b mức, với b là số bít
sử dụng ể biểu diễn một mẫu. Khi ó, ộ phân giải, hay còn gọi là bƣớc lƣợng tử hóa ƣợc xác ịnh bởi: smax2 bsmin
Mối quan hệ ầu vào-ra của hàm lƣợng tử có thể mô tả bởi hàm y i Q(s) nếu s [d ,di i 1
]. Hàm này thƣờng có dạng hình bậc thang nhƣ minh họa trong hình 3.x.
Từ hình này, dễ dàng thấy, ngoại trừ có thể hai khoảng ngoài cùng bên trái và bên phải,
tất cả các khoảng khác dọc trục tín hiệu vào có ộ dài bằng nhau. Quan sát tƣơng tự với trục tín hiệu ra.
Có hai loại ặc tuyến lƣợng tử hóa tuyến tính: (1) lƣợng tử hóa bƣớc cân (midtread
quantizer), (2) lƣợng tử hóa bƣớc lệch (midrise quantizer). Lƣợng tử hóa bƣớc cân thƣờng
ƣợc sử dụng cho trƣờng hợp số mức lƣợng tử lẻ và trong các mức lƣợng tử có mức giá trị
bằng 0. Ngƣợc lại, lƣợng tử hóa bƣớc lệnh sử dụng trong trƣờng hợp số mức lƣợng tử là lOMoARcPSD| 36086670
CHƢƠNG 3. MÃ HÓA TIẾNG NÓI
số chẵn và trong các mức lƣợng tử có mức lƣợng tử có giá trị bằng 0. Sơ ồ minh họa ặc
tuyến hàm lƣợng tử bƣớc cân và bƣớc lệch cho trong hình 3.3.
Sai số của quá trình lƣợng tử là sự khác biệt giữa mẫu thu ƣợc so với giá trị tín hiệu
thực ở cùng thời iểm. Gọi s(n)ˆ là giá trị tín hiệu lƣợng tử thu ƣợc ứng với giá trị tín hiệu
vào s(n), khi ó sai số lƣợng tử: e(n) s(n) s(n)ˆ Dễ dàng có e(n)
. Để ơn giản, giả thiết sai số lƣợng tử là một quá trình 2 2
dừng với giá trị trung bình bằng 0, không tƣơng quan với tín hiệu, có phân bố ều. Nghĩa là 1 p (e)e khi 2 e 2 0 truonghop khac e 0, e2 2 12 2
e còn gọi là công suất nhiễu lƣợng tử.
Khi ó, ể ánh giá chất lƣợng mã hóa ngƣời ta sử dụng một hệ số tỷ lệ công suất trung bình
của tín hiệu trên công suất nhiễu lƣợng tử chuẩn hóa SNR SNR NS se22 2s2 q 12
Dễ dàng có, SNR 6b 4.77 20log s max 10 s
Nhƣ vậy, nếu cứ tăng thêm một bít cho biểu diễn mẫu thì SNR sẽ tăng 6dB.
Chúng ta ã ề cập ở trên, phần tín hiệu tiếng nói có biên ộ nhỏ (phần các phụ âm vô
thanh,..) thƣờng xảy ra thƣờng xuyên hơn so với phần tín hiệu có biên ộ lớn. Hơn nữa, ặc 72
Downloaded by Dung Tran (tiendungtr12802@gmail.com) lOMoARcPSD| 36086670
CHƢƠNG 3. MÃ HÓA TIẾNG NÓI
iểm cảm nhận của hệ thống thính giác ngƣời có ặc tuyến lô-ga-rít trong ó các tín hiệu có
bên ộ lớn ƣợc xử lý với ộ phân giải khác với các tín hiệu có biên ộ nhỏ. Nói cách khác,
cùng múc nhiễu lƣợng tử, tai ngƣời nhạy cảm với nhiễu lƣợng tử của tín hiệu nhỏ hơn là
tín hiệu lớn. Khi bƣớc lƣợng tử là một hằng số, SNR thay ổi theo mức tín hiệu. Chất lƣợng
gọi trở nên xấu hơn khi mức tín hiệu thấp. Vì thế ối với các tín hiệu mức thấp, bƣớc lƣợng
tử cần ƣợc giảm và ối với các tín hiệu mức cao nó ƣợc tăng ể ít hoặc nhiều cân bằng SNR
với mức tín hiệu ầu vào. Hình 3.3 minh họa sự thay ổi SNR theo mức tín hiệu mã hóa.
Nhƣ vậy, cần phải có một phƣơng pháp lƣợng tử sao có có thể phản ánh ƣợc ặc tính
cảm nhận này. Phƣơng pháp lƣợng tử thỏa mãn iều này cần có bƣớc lƣợng tử thay ổi theo
mức tín hiệu. Do ó, phƣơng pháp này ƣợc gọi là phƣơng pháp lƣợng tử hóa phi tuyến. lOMoARcPSD| 36086670
CHƢƠNG 3. MÃ HÓA TIẾNG NÓI Hình 3.3
Minh h ọ a s ự ph ụ thay ổ i c ủ a sai s ố lƣợ ng t ử và m ứ c tín hi ệ u
V ề nguyên t ắc, phƣơng pháp lƣợ ng t ử phi tuy ế n ƣợ c ti ế n hành b ằ ng cách nén biên
ộ . M ột cách lý tƣởng, ố i v ớ i các tín hi ệ u m ứ c th ấp ƣờ ng cong nén và giãn là truy ế n
tính. Đố i v ớ i các tín hi ệ u m ức cao chúng ặc trƣng bởi ƣờng cong ạ i s ố nhƣ minh họ a trong hình 3.4. Hình 3.4
Minh họa sự nén và giãn tín hiệu trong lƣợng tử hóa phi tuyến
Với cách tiếp cận lƣợng tử hóa phi tuyến, tốc ộ mã hóa cũng ƣợc giảm xuống một
cách áng kể. Ngƣời ta thấy rằng, chỉ cần sử dụng 8 bít mã hóa cho một mẫu là ủ ảm bảo
chât lƣợng thoại và gần nhƣ rất khó phân biệt giữa tín hiệu mã hóa và tín hiệu gốc.
Có hai luật lƣợng tử hóa phi tuyến phổ biến là luật và luật A. Luật ƣợc dùng phổ
biến tài Bắc Mỹ, trong khi luật A ƣợc áp dụng ở Châu Âu. Cả hai luật lƣợng tử này ều có
ặc iểm là thực hiện ơn giản, ảm bảo ƣợc chất lƣợng thoại, có ộ trễ thấp. 74
Downloaded by Dung Tran (tiendungtr12802@gmail.com) lOMoARcPSD| 36086670
CHƢƠNG 3. MÃ HÓA TIẾNG NÓI
Luật , với =255, thực hiện nén tín hiệu vào theo công thức: s(n) log(1 ) s y(n) s max sgn(s(n)) max log(1 )
Trong ó, mỗ i m ẫ u tuy ế n tính 14 bit g ồ m c ả bít d ấ u s ẽ ƣợ c ánh x ạ thành m ộ t t ừ mã
g ồ m 8 bít bao g ồ m c ả m ộ t bit d ấ u có d ạ ng SABCXYZW. S là bit d ấ u, ABC là các bít xác
ịnh phân oạ n (g ồ m 15 phân oạn), XYZW là các bít xác ị nh m ức trong phân oạ n.
Hình 3.5 minh h ọ a vi ệ c mã hóa tín hi ệ u theo lu ậ t Hình 3.5
Minh họa việc mã hóa PCM với lƣợng tử phi tuyến theo luật
Luật A, với A=87.56 gồm 13 phân oạn, thực hiện việc nén tín hiệu theo công thức: 0 1 A | s(n) | log(A) | s(n)s max A1 lOMoARcPSD| 36086670
CHƢƠNG 3. MÃ HÓA TIẾNG NÓI y(n)
smax 1 1log(A log(A)| s(n) |smax ) A1 | s(n) |smax 1
Trong ó, mỗi mẫu tuyến tính 13 bít bao gồm cả bít dấu ƣợc ánh xạ thành một từ mã 8 bít có dạng SABCXYZW.
S ự thay ổ i SNR c ủa các phƣơng pháp lƣợ
ng t ử ƣợ c so sánh và minh h ọ a trong hình Hình 3.6 3.6. 76
Downloaded by Dung Tran (tiendungtr12802@gmail.com) lOMoARcPSD| 36086670
CHƢƠNG 3. MÃ HÓA TIẾNG NÓI
So sánh SNR của các phƣơng pháp lƣợng tử hóa khác nhau
Việc giải mã cho mã thu ƣợc bằng cách tiếp cận lƣợng tử hóa phi tuyến khá ơn giản.
Bằng cách tách ra ba cụm: cụm dấu (bít S), cụm phân oạn (cụm bít ABC), và cụm mức
trong phân oạn (cụm XYZW), sau ó thực hiện việc ánh xạ ngƣợc lại. 3.2.2 DPCM
Đây là một kỹ thuật cũng ƣợc sử dụng phổ biến trong mã hóa thoại nhằm mục tiêu giảm
nhỏ tốc ộ dữ liệu sau mã hóa.
Ý tƣởng của phƣơng pháp mã hóa iều chế xung mã vi sai là tận dụng tự tƣơng quan
giữa các mẫu tín hiệu lân cận nhau. Bằng cách sử dụng dự oán tuyến tính ơn giản về giá
trị mẫu tiếp theo từ những mẫu ã biết trƣớc ó, sau ó chỉ thực hiện mã hóa và truyền i ộ
chênh lệch giữa các mẫu cạnh nhau của tín hiệu. Rõ ràng, sự khác biệt giữa các mẫu lân
cận nhau phần lớn sẽ nhỏ hơn so với chính giá trị các mẫu. Nhƣ vậy, số bít cần thiết ể mã
hóa sự khác biệt này chắc chắn sẽ thƣờng cần ít hơn mã hóa trực tiếp thông thƣờng.
Sơ ồ của bộ mã hóa và giải mã DPCM cho tín hiệu tiếng nói ƣợc cho trong hình 3.7. lOMoARcPSD| 36086670
CHƢƠNG 3. MÃ HÓA TIẾNG NÓI Hình 3.7
Sơ ồ mã hoá và gi ả i mã DPCM
Tín hi ệ u ti ếng nói tƣơng tự vào qua b ộ l ọ c thông th ấ p, h ạ n ch ế băng tầ n c ủ a tín hi ệ u
vào (thƣờ ng là m ộ t n ử a t ầ n s ố l ấ y m ẫ u), sau ó ƣợ c l ấ y m ẫu ể t ạ o các giá tr ị m ẫ u s(n).
Đồ ng th ờ i, b ộ mã hóa th ự c hi ệ n d ự oán giá trị m ẫ u theo công th ứ c: p s(n) a s(n ˆ k) p k k1 k ~
Trong ó, a là hệ số của các bộ dự oán.
Độ chênh lệch giữa xung lấy mẫu ầu vào và tín hiệu ra lấy mẫu là: d(n) s(n) ~s (n)p
Đây chính là giá trị dùng ể lƣợng tử hoá và truyền i, ở phía thu sẽ tiến hành hồi phục
lại tín hiệu sai số này và tích phân lại công với tín hiệu ã hồi phục trƣớc ó, tuy nhiên ể
giảm lỗi cộng lại của nhiều lần ta dùng phia thu một bộ dự oán giống với phía phát. Sai số
lƣợng tử trong trƣờng hợp này ƣợc xác ịnh bởi: e(n) d(n) d(n)ˆ
Việc sử dụng vòng phản hồi giúp cho bộ lƣợng tử thỏa mãn biểu thức lỗi lƣợng tử: e(n) d(n) d(n)ˆ s(n)ˆ s(n) 78
Downloaded by Dung Tran (tiendungtr12802@gmail.com) lOMoARcPSD| 36086670
CHƢƠNG 3. MÃ HÓA TIẾNG NÓI
Nói cách khác, vòng hồi tiếp cho phép hạn chế sự khác biệt giữa sai số e(n) và sai số
về ộ chênh lệch giữa các mẫu. Nhƣ vậy, nhiễu lƣợng tử không phụ thuộc vào việc sử dụng
bộ dự oán, ngoài ra, nhiễu lƣợng tử không bị tích lũy. Rõ ràng, nếu giá trị này càng nhỏ
thì chất lƣợng tiếng nói càng tốt, theo các tính toán thì phƣơng pháp này có ộ rộng băng 2 SNR 6 n 4.77 10 log s DPCM 10 2 d max Hay có th ể vi ế t: SNR S NR 10 log G DPCM PCM 10 p
Trong ó, Gp là ộ l ợi thu ƣợ c t ừ vi ệ c s ử d ụ ng b ộ d ự oán tuyế n tính.
Điề u ch ế DM là m ộ t lo ại iề u ch ế DPCM ơn giả n trong ó mỗ i t ừ mã ch ỉ có m ộ t bít
nh ị phân . Phƣơng pháp này có ƣu iể m là vi ệ c th ự c hi ệ n m ạch iệ n r ấ t d ễ dàng ch ỉ c ầ n
m ộ t b ộ so sánh phân ngƣỡng nhƣ minh họ a trong hình 3.8. tần giảm i một nửa.
SNR của phƣơng pháp này ƣợc xác ịnh theo công thức: lOMoARcPSD| 36086670
CHƢƠNG 3. MÃ HÓA TIẾNG NÓI 3.2.3 DM Hình 3.8
Mã hóa DM và sự tƣơng ƣơng phân ngƣỡng
Ý tƣởng cơ bản của phƣơng pháp là dựa trên nhận xét: các mẫu liền kề nhau có một
sự tƣơng quan rất lớn. Khi ó việc dự oán các mẫu sẽ ơn giản hơn chỉ cần. Sơ ồ tổng quát
của bộ mã hóa DM ƣợc cho trong hình 3.9. Ở ây, sai số dự oán là sự khác biệt giữa mẫu
hiện tại và giá trị dự oán xấp xỉ sau cùng nhất từ các mẫu trƣớc ó. Dễ thấy, khi ó sai số
lƣợng tử tỷ lệ với biên ộ bƣớc lƣợng tử.
Mặc dù khá ơn giản, nhƣng phƣơng pháp mã hóa DM mắc phải hai lọa méo nghiêm
trọng. Thứ nhất là méo quá ộ dốc (slope-overload distortion). Nếu bƣớc lƣợng tử quá nhỏ
thì ƣờng xấp xỉ bậc thang, chính là ƣờng kết quả mã hóa, sẽ không bắt kịp sự thay ổi
(tăng/giảm) của tín hiệu. Điều này dẫn ến ƣờng mã hóa thu ƣợc không phản ánh trung
thực tín hiệu gốc. Dạng thứ hai là méo dạng nhiễu (granular noise). Đây là trƣờng hợp xảy
ra khi tín hiệu gốc có ộ bằng phẳng lớn, nếu bƣớc lƣợng tử lớn thì tại vùng này ƣờng mã
hóa xuất hiện các ỉnh nhấp nhô. Nghĩa là tín hiệu mã hóa bị nhiễu thay vì bằng phẳng nhƣ
tín hiệu gốc. Hình 3.10 minh họa những sai số vừa ề cập của phƣơng pháp mã hóa DM. 80
Downloaded by Dung Tran (tiendungtr12802@gmail.com) lOMoARcPSD| 36086670
CHƢƠNG 3. MÃ HÓA TIẾNG NÓI Hình 3.9
Sơ ồ t ổ ng quát mã hóa và gi ả i mã DM Hình 3.10
Minh họa nhƣợc iểm của mã hóa DM
Mặc dù vậy, tốc ộ bit của phƣơng pháp mã hóa DM có thể ạt ƣợc rất thấp, cỡ bằng tốc
ộ của tần số lấy mẫu, tức là 8 kbps. Đây là phƣơng pháp duy nhất của phƣơng pháp mã
hoá dạng sóng có thể so sánh về tốc ộ mã hóa với phƣơng pháp tham số nguồn sẽ tìm hiểu
trong phần sau của chƣơng. lOMoARcPSD| 36086670
CHƢƠNG 3. MÃ HÓA TIẾNG NÓI 3.2.4 APCM
Trong các cách ti ế p c ậ n c ủa phƣơng pháp mã hóa PCM, DPCM mặc ị nh v ớ i gi ả
thi ế t tín hi ệ u mã hóa là m ộ t th ể hi ệ n c ủ a m ộ t quá trình d ừng. Tuy nhiên, iề u này không
úng vớ i tín hi ệ u ti ếng nói. Nhƣ vậ y, n ế u k ể ế n y ế u t ố này thì chúng ta có th ể th ự c hi ệ n
vi ệc tăng hiệ u qu ả và ch ất lƣợ ng tín hi ệ u mã hóa b ằng cách thay ổi thích nghi theo ặ c
trƣng thố ng kê c ủ a tín hi ệ u. Vì tín hi ệ u ti ế ng nói là m ộ t tín hi ệ u bán d ừ ng (quasi-
stationary) nên các thông s ố th ống kê thay ổ i ch ậ m theo th ờ i gian.
N ế u th ự c hi ện phép lƣợ ng t ử hóa ề u thì sai s ố lƣợ ng t ử s ẽ có phƣơng sai thay ổ i
theo th ời gian, cũng tứ c là công su ấ t nhi ễu lƣợ ng t ử thay ổ i theo th ời gian. Điề u này d ẫ n
ế n t ỷ s ố SNR thay ổ i theo th ờ i gian. Để gi ả m nh ỏ iề u này, t ứ c là làm gi ả m nh ỏ
kho ảng ộ ng c ủ a nhi ễu lƣợ ng t ử , chúng ta có th ể th ự c hi ệ n b ằng phép lƣợ ng t ử thích nghi.
Ở ây, trong phƣơng pháp APCM, bƣớc lƣợ ng t ử ƣợc thay ổ i the o phƣơng sai các mẫ u tín hi ệ u.
Sơ ồ t ổ ng quát c ủ a b ộ mã hóa APCM nhƣ hình 3. 11 . Hình 3.11
Sơ ồ tổng quát của phƣơng pháp mã hóa và giải mã APCM
Có hai phƣơng pháp lƣợng tử thích nghi ƣợc sử dụng trong mã hóa APCM: thích nghi
forward, và thích nghi backward.
Ở phƣơng pháp thích nghi forward, một bƣớc lƣợng tử mới ƣợc xác ịnh theo công thức: N 82
Downloaded by Dung Tran (tiendungtr12802@gmail.com) lOMoARcPSD| 36086670
CHƢƠNG 3. MÃ HÓA TIẾNG NÓI ref s (k)2n k 1
Nói cách khác, bƣớc lƣợng tử ƣợc xác ịnh dựa trên các mẫu s(n) ở thời iểm sau ó.
Phƣơng pháp này sẽ cho phép thích ứng nhanh với sự thay ổi hình dạng phổ và cho phép
cải thiện SNR khoảng 5dB so với phƣơng pháp PCM luật thông thƣờng. Tuy nhiên,
phƣơng pháp này cần phải truyền tải thông tin về bƣớc lƣợng tử. Điều này sẽ làm tăng
áng kể tốc ộ bít sau mã hóa trong một số trƣờng hợp.
Ngƣợc lại với phƣơng pháp thích nghi forward, phƣơng pháp lƣợng tử thích nghi
backward ƣớc lƣợng bƣớc lƣợng tử từ các mẫu ở thời iểm trƣớc ó theo công thức: n 1 ref s (k)ˆ2n k n N
Nhƣ vậy phƣơng pháp này không cần truyền tải thông tin về bƣớc lƣợng tử. Tuy
nhiên, do bƣớc lƣợng tử ƣợc ƣớc lƣợng từ các mẫu ở thời iểm trƣớc ó nên phƣơng pháp
này thích nghi chậm hơn với sự thay ổi của hình dạng phổ. 3.2.5 ADPCM
Đây là phƣơng pháp mã hoá khá quan trọng, tập hợp ƣợc những ƣu iểm của các
phƣơng pháp trên và ã ƣợc ITU-T tiêu chuẩn hoá trong khuyến nghị G721, và ã có nhiều
ứng dụng trong thực tế nhƣ hệ thống di ộng CT2 của Hàn Quốc, DECT của Mỹ. Các tốc
ộ chuẩn của chuẩn mã hóa này là 40, 32, 24, và 16kbps.
Về cơ bản, cũng nhƣ phƣơng pháp mã hóa DPCM, phƣơng pháp mã hóa này thực
hiện việc mã hóa sự sai khác giữa tín hiệu và tín hiệu dự oán. Nhƣ vậy, chất lƣợng mã hóa
phụ thuộc khá lớn vào tính chính xác của bộ dự oán. Mặc khác, nếu sự dự oán có ộ chính
xác cao thì sự khác biệt này càng nhỏ, nghĩa là số bít cần thiết ể biểu diễn mẫu càng ít.
Nhƣ vậy, tùy thuộc vào các chỉ tiêu kỹ thuật yêu cầu, cũng nhƣ tùy thuộc vào yêu cầu chất
lƣợng tín hiệu ra chúng ta có thể thực hiện việc tùy biến (thay ổi thích nghi) dự oán hoặc/và
bƣớc lƣợng tử. Khi ó, chúng ta có phƣơng pháp mã hóa iều chế xung mã vi sai thích nghi
(ADPCM – Adaptive Differential PCM).
Cách tiếp cận thực hiện phổ biến của phƣơng pháp này dựa trên tính chất thay ổi chậm
của phƣơng sai và hàm tự tƣơng quan, với phƣơng pháp PCM ta dùng bộ lƣợng tử ều có
công suất tạp âm là 2/12, phƣơng pháp ADPCM và các phƣơng pháp dự oán tuyến tính
nói chung là thay ổi hay còn gọi là phƣơng pháp dùng bộ lƣợng tử hoá tự thích nghi.
Các thuật toán ƣợc phát triển cho hệ thống iều xung mã vi sai khi khi mã hoá tín hiệu tiếng lOMoARcPSD| 36086670
CHƢƠNG 3. MÃ HÓA TIẾNG NÓI
nói bằng cách sử dụng bộ lƣợng tử hoá và bộ dự oán thích nghi, có thông số thay ổi theo
chu kỳ ể phản ánh tính thông kê của tín hiệu tiếng nói.
Hình 3.12 Sơ ồ mã hoá ADPCM
Hình 3.13 Sơ ồ gi ả i mã ADPCM
Ngoài ra, ể c ả i thi ệ n và thích nghi kh ả năng dự oán, ngƣờ i ta cũng thƣờ ng hay s ử
ồ d ự oán khác nhau. Chẳ ng h ạn nhƣ dự oán thích nghi Forward, dụng các sơ Backward, …. 84
Downloaded by Dung Tran (tiendungtr12802@gmail.com) lOMoARcPSD| 36086670
CHƢƠNG 3. MÃ HÓA TIẾNG NÓI 3.2.6 ADM
Để cải tiến và khắc phục nhƣợc iểm của phƣơng pháp DM, ngƣời ta áp dụng phƣơng
pháp ADM ( iều chế Delta thích nghi). Phƣơng pháp này còn gọi là phƣơng pháp iều chế
delta có ộ dốc thay ổi liên tục. Phƣơng pháp này dựa trên phƣơng pháp thay ổi ộng hệ số
khuyếch ại của bộ tích phân phù hợp với mức công suất trung bình của tín hiệu vào.
Sơ ồ tổng quát của bộ mã hóa ADM cho trong hình 3.14. lOMoARcPSD| 36086670
CHƢƠNG 3. MÃ HÓA TIẾNG NÓI
Hình 3.14 Sơ ồ mã hoá và gi ả i mã Delta thích nghi
Lu ật thay ổi bƣớc lƣợ ng t ử ơn giả n nh ất ƣợc Jayant ề xu ất vào năm 1970, trong
ó bƣớc lƣợ ng t ử ở th ời iểm n ƣợc xác ị nh theo công th ứ c: d(n)d(n1) n1 K
Trong ó, K là mộ t h ằ ng s ố ƣợ c ch ọn ể gi ả m méo th ỏ a mãn >=1
Ngoài ra, Greefkes ƣa ra luật thay ổi bƣớ c liên t ụ c: k sgn(d(n)) sgn(d(n 1)) sgn(d(n n1 2)) 1 n1 k conlai 2 Trong ó,
, k1, k2 là các h ằ ng s ố 0< <1 , 03.2.7 Mã hóa d ạ ng sóng trong mi ề n t ầ n s ố n n 86
Downloaded by Dung Tran (tiendungtr12802@gmail.com) lOMoARcPSD| 36086670
CHƢƠNG 3. MÃ HÓA TIẾNG NÓI
Việc mã hóa trực tiếp dạng sóng có thể tiếp cận trong miền tần số. Khi ó, thay vì dựa
trên dạng sóng tín hiệu, các phƣơng pháp mã hóa thuộc lớp tiếp cận này dựa vào ặc trƣng
phổ của tín hiệu. Lợi iểm của phƣơng pháp mã hóa trong miền tần số là có thể khai thác
một cách triệt ể ặc iểm của tín hiệu trong miền tần số. Thứ nhất, các thành phần tín hiệu
trong miền tần số ƣợc giải tƣơng quan, tức là gần nhƣ không có sự tƣơng hỗ. Hơn nữa,
với hiện tƣợng che lấp tần số ã xem xét trong chƣơng 1, chúng ta có thể thực hiện mã hóa
với lƣợng thông tin ít nhất mà vẫn ảm bảo ƣợc chất lƣợng cảm nhận.
Có rất nhiều cách thực hiện việc mã hóa dạng sóng trong miền tần số, chẳng hạn nhƣ
phƣơng pháp mã hóa băng con (Subband coding) sử dụng dãy mạch lọc, phƣơng pháp mã hóa chuyển ổi, …
Phƣơng pháp mã hóa băng con tận dụng ặc iểm cảm nhận tiếng nói của tai ngƣời: tai
ngƣời có ộ nhạy âm ở các tần số khác nhau là khác nhau, tai ngƣời cảm nhận âm chịu tác
ộng bởi hiện trƣợng che lấ tần số. Từ ó cho phép chỉ mã hóa ở những vùng tần số mà tai
ngƣời nhạy hơn, hoặc không cần mã hóa các âm bị che lấp.
Sơ ồ tổng quát của một hệ thống mã hóa băng con cho trong hình 3.15.
Hình 3.15 Sơ ồ tổng quát của phƣơng pháp mã hóa băng con
Tín hiệu thoại ầu vào ƣợc phân chia thành một số dải băng tần nhỏ hơn gọi
là các băng con thông qua các bộ lọc số. Sau ó mỗi một băng con ƣợc mã hóa ộc
lập bằng việc sử dụng các bộ mã hóa dạng sóng nhƣ ADPCM. lOMoARcPSD| 36086670
CHƢƠNG 3. MÃ HÓA TIẾNG NÓI
Phƣơng pháp mã hóa này thực hiện việc kết hợp loại bỏ dƣ thừa dữ liệu về
mặt tần số và thời gian. Do ó, nó có thể ạt ƣợc tốc ộ mã hóa cỡ 16kbps nhƣng chất
lƣợng tín hiệu có thể so sánh với phƣơng pháp mã hóa PCM 64kbps thông thƣờng.
Ngoài phƣơng pháp mã hóa băng con ở trên, ngƣời ta có thể thực hiện cải
tiến ể có ƣợc phƣơng thức mã hóa tốt hơn. Cách ơn giản nhất là mã hóa băng con
với sự phân bố bít thay ổi thích nghi theo băng tần số tín hiệu (gọi là ASBC –
Adaptive Subband coding). Ở ây, các băng con tƣơng ứng với phổ tần số thấp chứa
hầu hết năng lƣợng của tín hiệu thoại sẽ ƣợc cấp phát với số bit mã hóa lớn, còn
các băng con tƣơng ứng với các phổ tần số cao, chứa ít năng lƣợng tín hiệu sẽ ƣợc
mã hóa với số bit nhỏ hơn. Kết quả là tổng số bit dùng cho mã hóa băng con sẽ ít
hơn so với trƣờng hợp mã hóa trên toàn dải phổ của tín hiệu. Tại phía thu, các tín
hiệu băng con ƣợc giải mã và kết hợp lại ể khôi phục lại tín hiệu thoại ban ầu (G. 722 1988).
Một ƣu iểm khác của mã hóa băng con là nhiễu trong mỗi băng con chỉ phụ
thuộc vào mã hóa sử dụng trong băng con ó. Bởi vậy chúng ta có thể cấp phát nhiều
bit hơn cho các băng con quan trọng sao cho nhiễu trong những vùng tần số này là
nhỏ, trong khi ó ở các băng con khác, chúng ta có thể cho phép có nhiễu mã hóa
cao vì nhiễu ở những tần số này có tầm quan trọng thấp hơn. Các mô hình cấp phát
bit thích ứng có thể ƣợc sử dụng ể khai thác thêm ý tƣởng này. Các bộ mã hóa băng
con cho chất lƣợng thoại tốt trong phạm vi tốc ộ từ 16 – 32 kbps.
Tuy nhiên, do phải cần ến bộ lọc, một khâu mà việc thực thi không hề ơn giản,
ể tách tín hiệu thoại trong các băng con nên mã hóa băng con phức tạp hơn bộ mã
hóa DPCM thông thƣờng và có thêm ộ trễ mã hóa. Tuy nhiên, ộ phức tạp và ộ trễ là
tƣơng ối thấp so với các bộ mã hóa lai ghép mà chúng ta sẽ tìm hiểu trong phần sau của bài giảng.
Trong thực tế, sơ ồ mã hóa băng con ƣợc biết ến khá nhiều ó là sơ ồ
MUSICAM ƣợc phát triển bởi hảng Philips. Trong sơ ồ này bộ mã hóa sử dụng một
dãy gồm 32 bộ lọc. Sơ ồ này ã trở thành tiêu chuẩn mã hóa âm thanh ISO/IEC, một
cơ sở của mã hóa MPEG-1,2 Layer I,II với ộ trễ thấp, cỡ khoảng 10.66ms. 88
Downloaded by Dung Tran (tiendungtr12802@gmail.com) lOMoARcPSD| 36086670
CHƢƠNG 3. MÃ HÓA TIẾNG NÓI Hình 3.16 Sơ ồ mã hóa MUSICAM
Khác với phƣơng pháp mã hóa băng con, phƣơng pháp mã hóa chuyển ổi và chuyển
ổi thích nghi xử lý và mã hóa trực tiếp mẫu ở miền tần số. Các mẫu tín hiệu ƣợc phân chia
thành các nhóm gồm N mẫu. Các nhóm mẫu này ƣợc chuyển ổi sang miền tần số bằng các
phép biến ổi thông thƣờng nhƣ DFT, FFT, ..Kết quả biến ổi là các hệ số sẽ ƣợc lựa chọn,
mã hóa ể truyền i. Dễ dàng thực hiện mã hóa thích nghi với phƣơng pháp mã hóa này.
Chúng ta chỉ cần thay ổi số bít cho mã hóa: những thành phần phổ quan trọng sẽ dùng
nhiều bít, những thành phần phổ ít quan trọng sẽ dùng ít bít.
Sơ ồ tổng quát của bộ mã hóa chuyển ổi thích nghi ƣợc minh họa trong hình 3.x.
Phƣơng pháp mã hóa chuyển ổi thích nghi (ATC) cho phép kết quả mã hóa với tốc ộ rất
thấp, cỡ 9.6kbps với chất lƣợng khá tốt.
3.3. MỘT SỐ PHƢƠNG PHÁP MÃ HÓA THAM SỐ
Mã hóa tham số còn gọi là mã hóa phân tích-tổng hợp. Ý tƣởng của phƣơng pháp mã
hóa này bắt nguồn từ mô hình của bộ máy phát âm.
Chúng ta ã biết, việc tạo ra tín hiệu tiếng nói có thể mô hình bằng sơ ồ nguồn-bộ lọc.
Nguồn óng vai trò tín hiệu kích thích là dao ộng của dây thanh (dao ộng bán tuần hoàn với
âm hữu thanh, không xác ịnh – giống nhiễu – với âm vô thanh). Âm của tín hiệu ƣợc quyết
ịnh bởi sự co thắt, hay một cách cụ thể là ặc iểm cộng hƣởng của bộ lọc tuyến âm. Nhƣ
vậy, nếu chúng ta biết ƣợc một âm là vô thanh hay hữu thanh và bộ tham số iều khiển sự
cộng hƣởng của tuyến âm (phân tích), chúng ta hoàn toàn có thể tái tạo lại âm ó (tổng
hợp). Và nhƣ vậy, thay vì phải truyền i toàn bộ tín hiệu hoặc ặc trƣng dạng sóng của tín
hiệu, chúng ta chỉ cần truyền i thông tin về các tham số của âm. Các bộ mã hóa tham số
còn ƣợc gọi là các bộ mã hóa Vocoder.
Ƣu iểm của loại mã hóa này là nó rất có hiệu quả ối với âm tiếng nói, dễ hiểu, trong
khi nó lại có nhƣợc iểm là phức tạp hơn nhiều so với phƣơng pháp mã hóa dạng sóng. Mã
hóa tham số có thể ạt ƣợc tốc ộ bit rất thấp (xuống ến 2.4 Kbps) trong khi vẫn ảm bảo là
tiếng nói ƣợc tái tạo lại là hoàn toàn dễ hiểu. Tuy nhiên, tính tự nhiên của tiếng nói ƣợc
tái tạo thì khác xa với tín hiệu tiếng nói con ngƣời.
Có rất nhiều cách tiếp cận thực hiện phƣơng pháp mã hóa tham số.
Sơ ồ tổng quát của một hệ thống mã hóa tham số có sử dụng dãy mạch lọc ƣợc minh
họa trong hình 3.17. Tín hiệu vào ƣợc ƣa vào ồng thời 3 phân tích ể trích chọn ặc trƣng.
Thứ nhất là phát hiện xem phân oạn tín hiệu cần mã hóa là của âm vô thanh hay hữu thanh
(S), với âm hữu thanh thì tiếp tục xác ịnh tần số cơ bản (pitch) (N0). Đồng thời tín hiệu lOMoARcPSD| 36086670
CHƢƠNG 3. MÃ HÓA TIẾNG NÓI
ƣợc phân tách thành những băng tần nhỏ. Mỗi băng tần tín hiệu ứng với một vùng tần số
quan tâm. Và mỗi tần số quan tâm chúng ta ƣợc bộ ặc trƣng g. Toàn bộ các tham số trích
chọn ƣợc sẽ ƣợc mã hóa và gửi ến phía thu ể thực hiện tái tạo tín hiệu tiếng nói.
Hình 3.17 Sơ ồ t ổ ng quát m ột phƣơng pháp mã hóa tham s ố phân kênh
Hình 3.18 minh h ọ a các tham s ố g là nh ững ặ c tuy ế n ph ổ mong mu ố n
Hình 3.18 Các ặc trƣng phổ trong mã hóa tham s ố phân kênh
Ho ặc các ặc trƣng là các tầ n s ố formant nhƣ minh họ a trong hình 3.9. 90
Downloaded by Dung Tran (tiendungtr12802@gmail.com) lOMoARcPSD| 36086670
CHƢƠNG 3. MÃ HÓA TIẾNG NÓI
Hình 3.19 Các ặc trƣng formant trong mã hóa t ham s ố phân kênh
M ột phƣơng pháp tiế p c ận khác cũng khá phổ bi ế n trong các chu ẩ n mã hóa ti ế ng nói
ƣợ c s ử d ụ ng g ần ây là phƣơng pháp mã hóa dựa trên phân tích cepstral. Sơ ồ t ổ ng
quát c ủ a h ệ th ống mã hóa ƣợ c minh h ọ a trong hình 3.20.
Trong phƣơng pháp này, dự a trên s ự khác nhau cơ bả n gi ữ a s ự thay ổ i c ủ a biên ph ổ
( ƣờ ng bao ph ổ ) và xung kích thích (thành ph ầ n ph ổ nh ỏ) các ặc tính ƣờ ng bao ph ổ và
thành phân kích thích ƣợ c phân tích (phân tách) trích ch ọ n b ằ ng phép tích cepstral mà
c húng ta ã xem xét trong chƣơng 2. Hình 3.20
Sơ ồ mã hóa phân tích cepstral lOMoARcPSD| 36086670
CHƢƠNG 3. MÃ HÓA TIẾNG NÓI
Một phƣơng pháp tiếp cận khác cũng khá phổ biến ó là mã hóa tham số dựa trên phân
tích LPC. Cũng tƣơng tự với a số các phƣơng pháp mã hóa tham số, phƣơng pháp này
cũng cố gắng mô phỏng quá trình tạo tiếng nói của hệ thống phát âm. Sơ ồ tổng quát của
phƣơng pháp mã hóa này ƣợc minh họa trong hình 3.x.
Hình 3.21 Minh h ọ a mã hóa tham s ố LPC
Các thông tin mã hóa c ủ a b ộ mã hóa tham s ố LPC là: thông tin v ề lo ạ i âm (h ữ u
thanh/vô thanh) c ủa phân oạ n tín hi ệu; ộ l ớ n c ủ a tín hi ệ u; t ậ p các h ệ s ố b ộ l ọ c LPC;
chu k ỳ pitch (t ầ n s ố cơ bả n) c ủ a tín hi ệ u.
Có r ấ t nhi ề u phiên b ả n mã hóa tham s ố d ự a trên LPC, ch ẳ ng h ạn nhƣ LPC -10 , CELP, MELP, …
V ới phƣơng pháp mã hóa tham số LPC, chúng ta có th ể ạt ƣợ c t ốc ộ mã hóa tho ạ i b ằ ng 2.4kbps.
3.4. PHƢƠNG PHÁP MÃ HÓA LAI GHÉP
Mã hóa lai cố gắng lấp khoảng cách ranh giới giữa mã hóa dạng sóng và mã hóa
nguồn: ạt ƣợc tốc ộ mã hóa thấp; tăng ƣợc chất lƣợng tín hiệu tiếng nói mã hóa. Các
phƣơng pháp mã hóa thuộc nhóm này thƣờng ƣợc áp dụng trong các hệ thống thông tin di ộng. 92
Downloaded by Dung Tran (tiendungtr12802@gmail.com) lOMoARcPSD| 36086670
CHƢƠNG 3. MÃ HÓA TIẾNG NÓI
Sự kết hợp lai ghép có thể ƣợc thực hiện trong miền tần số, hoặc miền thời gian.
Mặc dù có nhiều cách tiếp cận thực hiện mã hóa lai, nhƣng thành công và thƣờng
ƣợc sử dụng nhiều nhất là các bộ mã hóa kết hợp trong miền thời gian “thực hiện các phép
phân tích thông qua việc tổng hợp” - AbS (Analysic - by - Synthesis). Những bộ mã hóa
này sử dụng mô hình bộ lọc dự oán tuyến tính cho cơ quan phát âm nhƣ ƣợc trong các bộ
mã thoại LPC. Tuy nhiên, ể thay thế cho việc ứng dụng mô hình 2 trạng thái ơn giản - hữu
thanh/vô thanh, mô hình này cố gắng giảm tối a sai lệch giữa dạng sóng tín hiệu ầu vào và
dạng sóng tín hiệu ƣợc xây dựng lại bằng việc tìm kiếm tín hiệu kích thích lý tƣởng. Nói
cách khác, phƣơng pháp mã hóa này không sử dụng ƣớc lƣợng ơn giản là âm hữu thanh hay vô thanh.
Sơ ồ tổng quát bộ mã hóa lai ghép RELP ƣợc minh họa trong hình 3.22.
Hình 3.22 Minh họa phƣơng pháp mã hóa lai ghép RELP
Trƣớc tiên, bộ mã hóa thực hiện phân tích tín hiệu thoại ầu vào thành các khung
ngắn có ộ dài khoảng 10-30 ms. Các tham số của một khung sẽ xác ịnh một bộ lọc tổng
hợp tƣơng ứng với khung ó và tín hiệu kích thích tƣơng ứng cho mỗi bộ lọc này sẽ ƣợc
xác ịnh thông qua một vòng lặp. Tín hiệu kích thích phải ảm bảo rằng sai lệch giữa tín hiệu
ầu vào và tín hiệu ƣợc tái tạo lại là nhỏ nhất. Cuối cùng bộ mã hóa sẽ truyền i những thông
tin liên quan ến các bộ lọc bao gồm các tham số và tín hiệu kích thích tƣơng ứng với mỗi
bộ lọc gửi cho bộ giải mã. Ở bộ giải mã, tín hiệu kích thích sẽ ƣợc ƣa qua bộ lọc tổng hợp
ể xây dựng lại tín hiệu thoại ban ầu. Bộ lọc tổng hợp thƣờng là một bộ lọc tuyến tính, ngắn
hạn nhƣng nó cũng có thể bao gồm một bộ lọc ộ cao âm thanh (pitch filter) liên quan ến
mô hình tuần hoàn dài hạn của tín hiệu thoại. Phƣơng pháp này cung cấp tín hiệu thoại có
chất lƣợng cao tại tốc ộ bit thấp. Tuy nhiên ộ phức tạp của phƣơng pháp này là khá lớn lOMoARcPSD| 36086670
CHƢƠNG 3. MÃ HÓA TIẾNG NÓI
bởi vì tất cả các tín hiệu kích thích có thể có ều phải ƣợc ƣa qua bộ lọc tổng hợp ể tìm ra
tín hiệu kích thích thích hợp nhất.
3.5. MỘT SỐ PHƢƠNG PHÁP MÃ HÓA TIẾNG NÓI TỐC ĐỘ THẤP
Để thực hiện phƣơng pháp mã hóa tiếng nói tốc ộ thấp, xu hƣớng tiếp cận của các
phƣơng pháp là sự kết hợp giữa các phƣơng pháp mã hóa tham số cùng với một số phƣơng pháp khác.
Nhóm ầu tiên có thể kể ến là một số phƣơng pháp mã hóa lai sử dụng: bộ mã hóa
kích thích a xung - MPE (Multi – Pulse – Excited); bộ mã hóa kích thích xung ều – RPE
(Regular – Pulse – Excited); bộ mã hóa dự oán tuyến tính kích thích mã - CELP (Code -
Excited – Linear – Predictive).
Trong phƣơng pháp MPE tín hiệu kích thích u(n) ƣợc xác ịnh bằng một số lƣợng cố
ịnh các xung tƣơng ứng ối với mỗi khung tín hiệu. Do vậy thông tin cần truyền i sẽ bao
gồm thông tin về ộ lớn và về vị trí của các xung này. Phƣơng pháp này cung cấp chất
lƣợng thoại khá tốt tại tốc ộ bit khoảng 10 Kbits/s.
Phƣơng pháp RPE tƣơng tự nhƣ MPE tuy nhiên các xung kích thích sử dụng trong
phƣơng pháp này ƣợc sắp xếp cách ều nhau một khoảng cố ịnh do ó phía phát chỉ cần
truyền i thông tin về ộ lớn của các xung và vị trí của xung ầu tiên. Nhƣ vậy ở cùng một tốc
ộ bit cho trƣớc thì RPE sẽ có thể sử dụng nhiều xung kích thích hơn so với MPE. Điều này
cho phép mã hóa RPE cung cấp chất lƣợng thoại tốt hơn so với phƣơng pháp MPE song
nó lại có ộ phức tạp lớn hơn. Mặc dù hai phƣơng pháp MPE và RPE có thể cung cấp chất
lƣợng thoại tốt tại tốc ộ bit vào khoảng 10 Kbits/s hoặc cao hơn tuy nhiên chúng lại không
thích hợp cho việc sử dụng ở tốc ộ bit giảm thấp hơn nữa.
Phƣơng pháp CELP khác với hai phƣơng pháp MPE và RPE ở chỗ tín hiệu kích thích
ƣợc lƣợng tử hóa vector một cách hiệu quả. Các tín hiệu này ƣợc xác ịnh bởi một mã nằm
trong bộ mã lƣợng tử vector và một hệ số khuếch ại ể iều khiển công suất của tín hiệu. Bộ
mã lƣợng tử vector thƣờng ƣợc mã hóa bằng 10 bit và hệ số khuếch ại ƣợc mã hóa bởi 5
bit tín hiệu do ó sẽ làm giảm áng kể tốc ộ bit dùng ể truyền thông tin i. Tuy nhiên việc phải
ƣa tất cả các chuỗi tín hiệu kích thích (tƣơng ứng với số lƣợng tất cả các mã trong bộ mã
lƣợng tử) qua bộ lọc tổng hợp sẽ khiến cho mã hóa CELP có ộ phức tạp rất cao. Những
nghiên cứu gần ây nhằm cải tiến cấu trúc của bộ mã hóa lƣợng tử và những tiến bộ trong
việc chế tạo các chip vi xử lý ã giúp cho việc thực hiện mã hóa CELP trong thời gian thực.
Phƣơng pháp này cung cấp tín hiệu thoại chất lƣợng tốt ở tốc ộ 4,8 Kbps và 16 Kbps. Các
nghiên cứu trong thời gian gần ây nhằm cải tiến phƣơng pháp mã hóa CELP ã cho phép
cung cấp tín hiệu thoại tại tốc ộ 2,4 Kbps. 94
Downloaded by Dung Tran (tiendungtr12802@gmail.com) lOMoARcPSD| 36086670
CHƢƠNG 3. MÃ HÓA TIẾNG NÓI
Ngoài ra, dựa trên ặc trƣng của tín hiệu tiếng nói là tổng hòa của hai thành phần với
sự thay ổi chậm theo thời gian, ngƣời ta còn sử dụng phƣơng pháp mã hóa dựa trên phân
tích các sóng nhỏ (wavelets)
3.6. ĐÁNH GIÁ CHẤT LƢỢNG MÃ HÓA TIẾNG NÓI
Một ánh giá ơn giản và hay sử dụng là cách ánh giá ịnh lƣợng thông qua tỷ số SNR:
tỷ số công suất trung bình tín hiệu trên nhiễu. Nhƣ ã ề cập trong phần mã hóa PCM, SNR
ƣợc xác ịnh theo công thức tổng quát: SNR E e (n)E s (n) 22
Trong ó E{} là giá trị trung bình thống kê.
SNR là một thông số mang tính chất kỹ thuật mang tính chất khách quan mà gần nhƣ
không có một mối quan hệ chặt chẽ ến sự cảm nhận của tai ngƣời. Do ó, ngoài ánh giá
khách quan bằng tỷ số SNR, ngƣời ta còn ánh giá chất lƣợng mã hóa thông qua một thông
số mang tính chất chủ quan là thang o iểm ý kiến (còn ƣợc biết ến là thang o ộ hài lòng –
Mean Opinion Score). Đây là thang o ánh giá tính chủ quan cảm nhận của ngƣời nghe sau
khi ƣợc hỏi ý kiến về chất lƣợng tiếng nói thu ƣợc của bộ mã hóa và giải mã. Thông
thƣờng thang này gồm có 5 cấp ộ: 1- Tồi; 2-Kém; 3-Chấp nhận ƣợc; 4-Tốt; 5-Rất tốt. Mặc
dù nó phản ánh ƣợc ặc iểm nghe của con ngƣời, nhƣng ây là một tham số mang tính ịnh
tính, khó có thể có ƣợc công thức tính trực tiếp. Nhƣ vậy, nó không thể ƣợc dùng nhƣ là
một iều kiện trong bài toán thiết kế xây dựng bộ mã tối ƣu.
Một ánh giá nữa là tốc ộ mã hóa: là số bít trung bình cần phải truyền trong một ơn vị thời gian.
Trong các ứng dụng mã hóa tiếng nói của các hệ thống thông tin, một yêu cầu quan
trọng không kém ó là khả năng áp ứng thời gian thực, hay ộ trễ của phép mã hóa. Trong
mã hóa tiếng nói của hệ thống thoại tƣơng tác thời gian thực, ộ trễ >150ms là không thể chấp nhận ƣợc. lOMoARcPSD| 36086670
CHƢƠNG 3. MÃ HÓA TIẾNG NÓI
3.7. CÂU HỎI VÀ BÀI TẬP CUỐI CHƢƠNG
1. Mục ích của việc mã hóa tín hiệu tiếng nói?
2. Có những lớp mã hóa tiếng nói nào?
3. Các phƣơng pháp mã hóa dạng sóng tín hiệu tiếng nói: ý tƣởng, nguyên lý
thực hiện, ƣu/nhƣợc iểm?
4. Các phƣơng pháp mã hóa tham số: ý tƣởng, nguyên lý thực hiện, ƣu/nhƣợc iểm?
5. Các phƣơng pháp mã hóa lai ghép: ý tƣởng, nguyên lý thực hiện, ƣu/nhƣợc iểm?
6. ( Matlab) S ử d ụ ng máy tính cá nhân và ph ầ n m ề m Matlab (ho ặ c các ngôn
ng ữ l ậ p trình khác) th ự c hi ệ n các công vi ệ c sau:
i. Ghi âm m ột oạ n tín hi ệ u ti ế ng nói b ấ t k ỳ, lƣu ở ị nh d ạ ng *.wav
ii. S ử d ụ ng hàm thƣ việ n c ủ a Matlab ho ặ c công c ụ thích h ợ p:
1. Ki ể m nghi ệ m m ộ t s ố phƣơng pháp mã hóa dạng sóng cơ
b ản (PCM, DPCM, …), ánh giá SNR, chất lƣợ ng âm
thanh c ả m th ụ, dung lƣợ ng file d ữ li ệ u sau mã hóa
2. Ki ể m nghi ệ m m ộ t s ố phƣơng pháp mã hóa tham số cơ bả n
( LPC, CELP, …), ánh giá SNR, chất lƣợ ng âm thanh c ả m
th ụ, dung lƣợ ng file d ữ li ệ u sau mã hóa 96
Downloaded by Dung Tran (tiendungtr12802@gmail.com) lOMoARcPSD| 36086670
CHƢƠNG 4. TỔNG HỢP TIẾNG NÓI 4.1. MỞ ĐẦU
Trƣớc ây khái niệm "tổng hợp tiếng nói" thƣờng ƣợc dùng ể chỉ quá trình tạo âm
thanh tiếng nói một cách nhân tạo từ máy dựa theo nguyên lý mô phỏng cơ quan phát âm
của ngƣời. Tuy nhiên ngày nay, cùng với sự phát triển của khoa học công nghệ, khái niệm
này ã ƣợc mở rộng bao gồm cả quá trình cung cấp các thông tin dạng tiếng nói từ máy
trong ó các bản tin ƣợc tạo dựng một cách linh ộng ể phù hợp cho nhu cầu nào ó. Các ứng
dụng của các hệ thống tổng hợp tiếng nói ngày nay rất rộng rãi, từ việc cung cấp các thông
tin dạng tiếng nói, các máy ọc cho ngƣời mù, ến những thiết bị hỗ trợ cho ngƣời gặp khó
khăn trong việc giao tiếp,...
4.2. CÁC PHƢƠNG PHÁP TỔNG HỢP TIẾNG NÓI
4.2.1 Tổng hợp trực tiếp
Một phƣơng pháp ơn giản thực hiện việc tổng hợp các bản tin là phƣơng pháp tổng
hợp trực tiếp trong ó các phần của bản tin ƣợc chắp nối bởi các phần (fragment) ơn vị của
Downloaded by Dung Tran (tiendungtr12802@gmail.com) lOMoARcPSD| 36086670
CHƢƠNG 4. TỔNG HỢP TIẾNG NÓI
tiếng nói con ngƣời. Các ơn vị tiếng nói thƣờng là các từ hoặc các cụm từ ƣợc lƣu trữ và
bản tin tiếng nói mong muốn ƣợc tổng hợp bằng cách lựa chọn và chắp nối các ơn vị thích
hợp. Có nhiều kỹ thuật trong việc tổng hợp trực tiếp tiếng nói và các kỹ thuật này ƣợc
phân loại theo kích thƣớc của các ơn vị dùng ể chắp nối cũng nhƣ những loại biểu diễn
tín hiệu dùng ể chắp nối. Các phƣơng pháp phổ biến có thể kêt ến là: phƣơng pháp chắp
nối từ, chắp nối các ơn vị từ con (âm vị sub-word unit), chắp nối các phân oạn dạng sóng tín hiệu.
4.2.1.1 Phƣơng pháp tổng hợp trực tiếp ơn giản
Phƣơng pháp ơn giản nhất ể tạo các bản tin tiếng nói là ghi và lƣu trữ tiếng nói của
con ngƣời theo các ơn vị từ riêng lẻ khác nhau và sau ó chọn phát lại các từ theo thứ tự
mong muốn nào ó. Phƣơng pháp này ƣợc ƣa vào sử dụng trong hệ thống iện thoại của
nƣớc Anh từ những năm 36 của thế kỷ trƣớc, từ những năm 60 của thế kỷ trƣớc thƣờng
ƣợc dùng trong một số hệ thống thông báo công cộng, và ngày nay vẫn còn có mặt ở nhiều
hệ thống quản lý iện thoại trên thế giới. Hệ thống phải lƣu trữ ầy ủ các thành phần của các
bản tin cần thiết phải tái tạo và lƣu trong một bộ nhớ. Bộ tổng hợp chỉ làm nhiệm vụ kết
nối các ơn vị yêu cầu cấu thành bản tin lại với nhau theo một thứ tự nào ó mà không phải
thay ổi hay biến ổi các thành phần riêng rẽ.
Chất lƣợng của bản tin tiếng nói ƣợc tổng hợp theo phƣơng pháp này bị ảnh hƣởng
bởi chất lƣợng của tính liên tục của các ặc trƣng âm học (biên phổ, biên ộ, tần số cơ bản,
tốc ộ nói) của các ơn vị ƣợc chắp nối. Phƣơng pháp tổng hợp này tỏ ra hiệu quả khi các
bản tin có dạng một danh sách chẳng hạn nhƣ một dãy số cơ bản, hoặc các khối bản tin
thƣờng xuất hiện ở một vị trí nhất ịnh trong câu. Điều này dễ hiểu bởi vì iều ó cho phép
dễ dàng ảm bảo rằng bản tin ƣợc phát ra có tính tự nhiên về mặt thời gian và cao ộ. Khi
có yêu cầu một cấu trúc câu ặc biệt nào ó mà trong ó các từ thay thế ở những vị trí nhất ịnh
trong câu thì các từ ó phải ƣợc ghi lại úng nhƣ thứ tự của nó ở trong câu nếu không nó sẽ
không phù hợp với ngữ iệu của câu. Chẳng hạn với các dãy số cơ bản cũng cần thiết phải
ghi lại chúng ở hai dạng: một tƣơng ứng với vị trí cuối câu và một dạng không. Điều này
là vì cấu trúc pitch của mỗi ơn vị tiếng nói thay ổi tùy theo vị trí của từ trong câu. Nhƣ
vậy, quá trình biên soạn là một quá trình rất tốn thời gian và công sức. Ngoài ra việc chắp
nối trực tiếp các ơn vị tiếng nói gặp rất nhiều khó khăn trong việc diễn tả sự ảnh hƣởng tự
nhiên giữa các từ, cũng nhƣ ngữ iệu và nhịp iệu của câu. Một hạn chế nữa phải kể ến là
kích thƣớc của bộ nhớ cho các ứng dụng với số lƣợng các bản tin lớn là rất lớn.
Yêu cầu bộ nhớ lƣu trữ lớn có thể ƣợc phần nào giải quyết bằng việc sử dụng phƣơng
pháp mã hóa tốc ộ thấp cho các ơn vị tiếng nói trƣớc khi thực hiện việc lƣu trữ. Tuy nhiên
cả phƣơng pháp sử dụng lƣu trữ trực tiếp hoặc mã hóa của các ơn vị lớn (từ, cụm từ) của
tiếng nói, số lƣợng bản tin có thể tổng hợp ƣợc rất hạn chế. Để tăng số lƣợng bản tin có 98
Downloaded by Dung Tran (tiendungtr12802@gmail.com) lOMoARcPSD| 36086670
CHƢƠNG 4. TỔNG HỢP TIẾNG NÓI
thể tổng hợp ƣợc, các ơn vị từ có thể ƣợc chia nhỏ hơn thành ơn vị từ con, diphone,
demisyllable, syllable... ƣợc ghi và lƣu trữ. Tuy nhiên khi ơn vị tiếng nói càng ƣợc chia
nhỏ thì chất lƣợng bản tin tổng hợp ƣợc chất lƣợng càng bị giảm.
Hình 4.1 minh họa sự so sánh spectrogram của câu tổng hợp ƣợc theo phƣơng pháp
tổng hợp trực tiếp ơn giản và bản tin nguyên thủy. Hình 4.1
So sánh k ế t qu ả t ừ b ả n tin t ổ ng h ợ p tr ự c ti ế p và b ả n tin nguyên th ủ y
4.2.1.2 Phƣơng pháp tổng hợp trực tiếp từ các phân oạn dạng sóng
Nhƣ ã ề cập phần trên, phƣơng pháp tổng hợp trực tiếp ơn giản gặp phải hạn chế trong
việc khôi phục tốc ộ và tính tự nhiên (nhấn, nhịp, ngữ iệu) của bản tin ƣợc tổng hợp. Vấn
ề này có thể ƣợc giải quyết bằng cách sử dụng phƣơng pháp tổng hợp từ các phân oạn
dạng sóng hay còn gọi là phƣơng pháp tổng hợp chồng và thêm các oạn sóng theo ộ dài
pitch. Xét bài toán nối hai phân oạn của dạng sóng tín hiệu của nguyên âm, ta thấy rằng sự
không liên tục trong dạng sóng tổng hợp sẽ ƣợc giảm nhỏ tối thiểu nếu việc chắp nối xảy
ra ở cùng vị trí của một chu kỳ glottal (dao ộng thanh môn) của cả hai phân oạn. Vị trí này
thƣờng là vị trí tƣơng ứng với vùng có biên ộ tín hiệu nhỏ nhất khi áp ứng tuyến âm với
xung glottal hiện tại có sự suy giảm lớn và chỉ ngay trƣớc một xung tiếp theo. Nói cách
khác, hai phân oạn tín hiệu ƣợc nối theo kiểu ồng bộ pitch (pitch-synchronous manner).
Phƣơng pháp phổ biến thực hiện việc này là phƣơng pháp TD-PSOLA (Time domain
Pitch Synchronous Overlap Add).
TD-PSOLA thực hiện việc ánh dấu các vị trí tƣơng ứng với sự óng lại của dây thanh
(tức là xung pitch) trong dạng sóng tín hiệu tiếng nói. Các vị trí ánh dấu này ƣợc sử dụng
ể tạo ra các phân oạn cửa sổ của dạng sóng tín hiệu cho mỗi chu kỳ. Với mỗi chu kỳ, hàm
cửa sổ phải ƣợc chỉnh trùng với trung tâm của vùng có biên ộ tín hiệu cực ại và hình dạng
của hàm cửa sổ phải ƣợc chọn thích hợp. Ngoài ra, ộ dài hàm cửa sổ phải dài hơn một chu
kỳ nhằm tạo ra một sự chồng lấn nhỏ giữa các cửa sổ tín hiệu cạnh nhau.
Hình 4.2 minh họa nguyên lý làm việc của phƣơng pháp TD-PSOLA trong ó sử dụng hàm cửa sổ Hanning. lOMoARcPSD| 36086670
CHƢƠNG 4. TỔNG HỢP TIẾNG NÓI Hình 4.2
Nguyên lý phƣơng pháp TD -PSOLA
T ừ minh h ọ a, ta th ấ y r ằ ng, b ằ ng cách n ối dãy các phân oạ n c ử a s ổ tín hi ệ u sóng theo
các v ị trí tƣơng ối cho trƣớc theo các iể m d ấu pitch ã phân tích, ta có th ể tái t ạ o m ộ t
cách khá chính xác b ả n tin theo ý mong mu ố n. Ngoài ra, b ằng cách thay ổ i các v ị trí
tƣơng ố i và s ố lƣợng các iể m d ấ u pitch, ta có th ể làm thay ổ i pitch và th ờ i gian c ủ a
b ản tin ƣợ c t ổ ng h ợ p.
4.2.2 Tổng hợp tiếng nói theo Formant
Phƣơng pháp tổng hợp theo Formant là phƣơng pháp tổng hợp ích thực ầu tiên ƣợc
phát triển và là phƣơng pháp tổng hợp phổ biến cho ến tận những năm ầu của thập kỷ 80.
Phƣơng pháp tổng hợp theo Formant còn ƣợc gọi là phƣơng pháp tổng hợp theo luật. Nó
sử dụng các phƣơng pháp mô-un (modular), dựa trên mô hình (modelbased), mối quan hệ
âm thanh-âm tiết ể giải các bài toán tổng hợp tiếng nói. Trong phƣơng pháp này, mô hình
tuyến âm thanh ƣợc sử dụng một cách ặt biệt sao cho các thành phần iều khiển của ống dễ
dàng ƣợc liên hệ với các tính chất của mối quan hệ âm thanh-âm tiết (acoustic-phonetic)
và có thể quan sát ƣợc một cách dễ dàng.
Hình 4.3 mô tả sơ ồ tổng quát một hệ thống tổng hợp theo formant. Nguyên lý tổng
quát của hệ thống ƣợc mô tả nhƣ sau. Âm thanh ƣợc phát ra từ một nguồn. Đối với các
nguyên âm và các phụ âm hữu thanh thì nguồn âm này có thể ƣợc tạo ra hoặc ầy ủ bằng 100
Downloaded by Dung Tran (tiendungtr12802@gmail.com) lOMoARcPSD| 36086670
CHƢƠNG 4. TỔNG HỢP TIẾNG NÓI
một hàm tuần hoàn trong miền thời gian hoặc bằng một dãy áp ứng xung ƣa qua mạch lọc
tuyến tính mô phỏng khe thanh môn (glottal LTI filter). Đối với các âm vô thanh thì nguồn
âm này ƣợc tạo ra từ một bộ phát nhiễu ngẫu nhiên. Đối với các âm tắc thì nguồn cơ bản
này ƣợc tạo ra bằng cách kết hợp nguồn cho âm hữu thanh và nguồn cho âm vô thanh. Tín
hiệu âm thanh từ nguồn âm cơ bản ƣợc ƣa vào mô hình tuyến âm (vocal tract). Để tái tạo
tất cả các formant, mô phỏng khoang miệng và khoang mũi ƣợc xây dựng song song riêng
biệt. Do ó, khi tín hiệu i qua hệ thống sẽ i qua mô hình khoang miệng, nếu có yêu cầu về
các âm mũi thì cũng i qua hệ thống mô hình khoang mũi. Cuối cùng kết quả các thành
phần âm thanh tạo ra từ các mô hình khoang miệng và mũi ƣợc kết hợp lại và ƣợc ƣa qua
hệ thống phát xạ, hệ thống này mô phỏng các ặc tính lan truyền và ặc tính tải của môi và mũi. Khoang mũi Nguồn Phát xạ Tiếng nói Áp suất Khoang miệng Dạng sóng Nguồn Môi/Mũi Lƣu lƣợng Lƣu lƣợng Vận tốc Vận tốc Hình 4.3
Sơ ồ phƣơng pháp tổng hợp theo formant
Theo lý thuyết mạch lọc, một formant có thể ƣợc tạo ra bằng các sử dụng một mạch
lọc IIR bậc hai với hàm truyền: H z 1 a z 11 a z2 2 1
Trong ó hàm truyền ạt có thể phân tích thành: H z 1 p z 1 11 p z2 1 lOMoARcPSD| 36086670
CHƢƠNG 4. TỔNG HỢP TIẾNG NÓI 1
Ta biết rằng, ể xây dựng mạch lọc với các hệ số a1 và a2 là thực thì các iểm cực phải
có dạng là cặp liên hợp phức. Cần chú ý rằng một bộ lọc bậc hai nhƣ trên sẽ có ồ thị phổ
với hai formant, tuy nhiên chỉ có một trong hai nằm ở phần tần số dƣơng. Do ó, ta có thể
coi bộ lọc trên tạo ra một formant ơn lẻ có ích. Các iểm cực có thể quan sát ƣợc trên ồ thị,
trong ó ộ lớn biên ộ của các iểm cực quyết ịnh băng tần và biên ộ của cộng hƣởng. Độ lớn
biên ộ càng nhỏ thì cộng hƣởng càng phẳng, ngƣợc lại, ộ lớn biên ộ càng lớn thì cộng hƣởng càng nhọn.
Nếu biểu diễn các iểm cực trong tọa ộ cực với góc pha và bán kính r và chú ý ến
nhận xét cặp iểm cực là liên hợp phức ta có thể viết hàm truyền ạt trong công thức (4.1) nhƣ sau: 1 H z( ) 1 2rcos z 1 r z2 2
Từ ây ta có thể tạo ra một formant với bất cứ tần số mong muốn nào bằng việc sử dụng
trực tiếp giá trị thích hợp của . Tuy vậy việc iều khiển băng tần một cách trực tiếp khó
khăn hơn. Vị trí của formant sẽ thay ổi hình dạng của phổ do ó một mối quan hệ chính xác
cho mọi trƣờng hợp là không thể ạt ƣợc. Cũng cần chú ý rằng, nếu hai iểm cực gần nhau,
chúng sẽ có ảnh hƣởng ến việc kết hợp thành một ỉnh cộng hƣởng duy nhất và iều này lại
gây khó khăn cho việc tính toán băng tần. Thực nghiệm cho thấy mối liên hệ giữa băng tần
chuẩn hóa của formant và bán kính của iểm cực có thể xấp xỉ hợp lý bởi: Bˆ 2ln r ˆ
Khi ó ta có thể biểu diễn hàm truyền ạt theo hàm của tần số chuẩn hóa F và băng tần ˆ
chuẩn hóa B của formant nhƣ sau: H z
1 2e 2Bˆcos 2 1F zˆ
1 e 2Bˆz 2 ˆ ˆ
Ở ây, các tần số chuẩn hóa F và băng tần chuẩn hóa B có thể xác ịnh tƣơng ứng bằng
cách chia F và B cho tần số lấy mẫu Fs. 102
Downloaded by Dung Tran (tiendungtr12802@gmail.com) lOMoARcPSD| 36086670
CHƢƠNG 4. TỔNG HỢP TIẾNG NÓI
Để có thể tạo ra nhiều formant ta có thể thực hiện bằng một bộ lọc mà hàm truyền ạt
là tích của một số hàm truyền ạt bậc hai. Nói một cách khác, hàm truyền cho tuyến âm (vocal tract) có dạng: H z H z H z H z H z 1 2 3 4
Trong ó Hi(z) là hàm của tần số Fi và băng tần Bi của formant thứ i.
Tƣơng ứng biểu thức quan hệ ầu vào ầu ra trong miền thời gian có dạng: y n x n a y n 1 1 a y n2 2 ... a y n8 8
Một cách tƣơng tự, ta có thể xây dựng hệ thống mô phỏng khoang mũi. Các biểu thức
Error! Reference source not found. và Error! Reference source not found. biểu diễn
kỹ thuật tổng hợp formant theo sơ ồ nối tiếp hay còn gọi là sơ ồ cascade.
Một kỹ thuật khác là tổng hợp formant song song. Phƣơng pháp tổng hợp formant song
song mô phỏng mỗi formant riêng rẽ. Nói cách khác, mỗi mô hình có một hàm truyền Hi(z)
riêng rẽ. Trong quá trình tạo tín hiệu tiếng nói các nguồn tín hiệu ƣợc ƣa vào các mô hình
một cách riêng rẽ. Sau ó, các tín hiệu từ các mô hình yi(n) ƣợc tổng lOMoARcPSD| 36086670
CHƢƠNG 4. TỔNG HỢP TIẾNG NÓI h ợ p l ạ i. yn ... 1 2 ynyn
Hình 4.4 minh h ọ a c ấ u hình t ổ ng quát c ủa phƣơng pháp tổ ng h ợ p n ố i ti ế p và song song. A1 F1 A2 F2 + vào ra A3 F3 F1 F2 F3 F4 vào A4 F4 ra
( a) C ấ u hình t ổ ng quát c ủ a (b) C
ấ u hình t ổ ng quát c ủ a
phƣơng pháp tổ ng h ợ p n ố i ti ế p
phƣơng pháp tổ ng h ợ p song song Hình 4.4
Phƣơng pháp t ổ ng h ợp theo sơ ồ n ố i ti ếp có ƣu iể m là v ớ i m ộ t t ậ p các giá tr ị
formant cho trƣớ c, ta có th ể d ễ dàng xây d ự ng các hàm truy ền ạ t và bi ể u th ứ c quan h ệ ầu vào ầ
u ra (công th ứ c vi sai - difference equation). Vi
ệ c t ổ ng h ợ p riêng r ẽ các
Các cấu hình của phƣơng pháp tổng hợp nhiều formant
formant trong phƣơng pháp tổng hợp song song cho phép ta xác ịnh một cách chính xác
tần số của các formant.
Mặc dù là phƣơng pháp tổng hợp ơn giản và mang lại tín hiệu âm thanh rõ nhƣng
phƣơng pháp tổng hợp theo formant khó ạt ƣợc tính tự nhiên của tín hiệu tiếng nói.
Nguyên nhân là do mô hình nguồn và mô hình chuyển ổi bị ơn giản hóa quá mức và ã bỏ
qua nhiều yếu tố phụ trợ góp phần tạo ra ặc tính ộng của tín hiệu.
Bộ tổng hợp Klatt
Bộ tổng hợp Klatt là một trong các bộ tổng hợp tiến nói dựa trên formant phức tạp nhất
ã ƣợc phát triển. Sơ ồ của bộ tổng hợp này ƣợc trình bày trong hình 4.5 trong ó có sử dụng
cả các hệ thống cộng hƣởng song song và nối tiếp. 104
Downloaded by Dung Tran (tiendungtr12802@gmail.com) lOMoARcPSD| 36086670
CHƢƠNG 4. TỔNG HỢP TIẾNG NÓI
Trong sơ ồ các khối Ri tƣơng ứng với các bộ tạo tần số cộng hƣởng formant thứ i; các
hộp Ai iều khiển biên ộ tín hiệu tƣơng ứng. Bộ cộng hƣởng ƣợc thiết lập ể làm việc ở tần
số 10kHz với 6 formant chính ƣợc sử dụng.
Cần chú ý rằng, trong thực tế các bộ tổng hợp formant thƣờng sử sụng tần số lấy mẫu
khoảng 8kHz hoặc 10kHZ. Điều này không hẳn bởi một lý do nào ặc biệt liên quan ến
nguyên tắc về chất lƣợng tổng hợp mà bởi vì sự hạn chế về không gian lƣu trữ, tốc ộ xử lOMoARcPSD| 36086670
CHƢƠNG 4. TỔNG HỢP TIẾNG NÓI
lý và các yêu cầu ầu ra không cho phép thực hiện với tốc ộ lấy mẫu cao hơn. Một iểm khác
cũng cần chú ý là, các nghiên cứu ã chúng minh rằng chỉ cần ba formant ầu tiên là ủ ể phân
biệt tín hiệu âm thanh, do ó việc sử dụng 6 formant thì các formant bậc cao ơn giản ƣợc
sử dụng ể tăng thêm tính tự nhiên cho tín hiệu tổng hợp ƣợc.
4.2.3 Tổng hợp tiếng nói theo phƣơng pháp mô phỏng bộ máy phát âm
Một cách hiển nhiên, ể tổng hợp tiếng nói thì ta cần tìm một cách nào ó mô phỏng bộ
máy phát âm của ta. Đây cũng là nguyên lý của các "máy nói" cổ iển mà nổi tiếng trong
số có máy do Von Kempelen chế tạo. Các bộ tổng hợp tiếng nói cổ iển theo nguyên lý này
thƣờng là các thiết bị cơ học với các ống, ống thổi, ... hoạt ộng nhƣ các dụng cụ âm nhạc,
tuy nhiên với một chút huấn luyện có thể dùng ể tạo ra tín hiệu tiếng nói nhận biết ƣợc.
Việc iều khiển hoạt ộng của máy là nhờ con ngƣời theo thời gian thực, iều này mang lại
nhiều thuận lợi cho hệ thống ở khía cạnh con ngƣời có thể sử dụng các cơ chế chẳng hạn
nhƣ thông qua phản hồi ể iều khiển và bắt chƣớc quá trình tạo tiếng nói tự nhiên. Tuy
nhiên, ngày nay với nhu cầu của các bộ tổng hợp phức tạp hơn, các cỗ máy cổ iển rõ ràng
là lỗi thời không thể áp ứng ƣợc.
Cùng với sự hiểu biết của con ngƣời về bộ máy phát âm ƣợc nâng cao, các bộ tổng
hợp sử dụng nguyên lý mô phỏng bộ máy phát âm ngày càng phức tạp và hoàn thiện hơn.
Các hình dạng ống phức tạp ƣợc xấp xỉ bằng một loạt các ống ơn giản nhỏ hơn. Với mô
hình các ống ơn giản, vì ta biết ƣợc các ặc tính truyền âm của nó, ta có thể sử dụng ể xây
dựng các mô hình bộ máy phát âm tổng quát phức tạp.
Một ƣu iểm của phƣơng pháp tổng hợp mô phỏng bộ máy phát âm là cho phép tạo ra
một cách tự nhiên hơn ể tạo ra tiếng nói. Tuy nhiên, phƣơng pháp này cũng gặp phải một
số khó khăn. Thứ nhất ó là việc quyết ịnh làm thế nào ể có ƣợc các tham số iều khiển từ
các yêu cầu tín hiệu cần tổng hợp. Rõ ràng, khó khăn này cũng gặp phải trong các phƣơng
pháp tổng hợp khác. Trong hầu hết các phƣơng pháp tổng hợp khác, chẳng hạn các tham
số formant có thể tìm ƣợc một cách trực tiếp từ tín hiệu tiếng nói thực, ta chỉ ơn giản ghi
âm lại tiếng nói và tính toán rồi xác ịnh chúng. Còn trong phƣơng phƣơng pháp mô phỏng
bộ máy phát âm ta sẽ gặp khó khăn hơn vì các tham số về bộ máy phát âm úng ắn không
thể xác ịnh từ việc ghi lại tín hiệu thực mà phải thông qua các o lƣờng chẳng hạn ảnh X-
ray, MRI... Khó khăn thứ hai là việc cân bằng giữa việc xây dựng một mô hình mô phỏng
chính xác cao nhất giống với bộ máy phát âm sinh học của con ngƣời và một mô hình thực
tiễn dễ thiết kế và thực hiện. Cả hai khó khăn này cho ến nay vẫn ƣợc coi là thách thức
với các nhà nghiên cứu. Và ây cũng chính là lý do mà cho ến nay có rất ít các hệ thống
tổng hợp theo nguyên lý mô phỏng bộ máy phát âm có chất lƣợng so với các bộ tổng hợp theo nguyên lý khác. 106
Downloaded by Dung Tran (tiendungtr12802@gmail.com) lOMoARcPSD| 36086670
CHƢƠNG 4. TỔNG HỢP TIẾNG NÓI
4.3. HỆ THỐNG TỔNG HỢP CHỮ VIẾT SANG TIẾNG NÓI
Việc chuyển ổi từ chữ viết sang tiếng nói (TTS) là mục tiêu ầy tham vọng và vẫn ang
tiếp tục là tâm iểm chú ý của các nhà nghiên cứu phát triển. TTS có mặt ở nhiều ứng dụng
phục vụ cuộc sống. Chẳng hạn nhƣ việc các ứng dụng truy cập email qua thoại, các ứng
dụng cơ sở dữ liệu cho các dịch vụ hỗ trợ ngƣời khiếm thị... Một hệ thống TTS iển hình
có sơ ồ khối với các thành phần ƣợc minh họa trong hình 4.6. Hình 4.6
Sơ ồ kh ố i m ộ t h ệ th ố ng TTS
Từ minh họa, ta thấy rằng, hệ thống TTS có thể ặc trƣng nhƣ một quá trình phân tích-
tổng hợp 2 giai oạn. Giai oạn một của quá trình thực hiện việc phân tích chữ viết ể xác ịnh
cấu trúc ngôn ngữ ẩn trong ó. Chữ viết ầu vào thƣờng bao gồm các cụm từ viết tắt, các số
La Mã, ngày tháng, công thức, các dấu câu...Giai oạn phân tích chữ viết phải có khả năng
chuyển ổi dạng chữ viết ầu vào thành một dạng chuẩn chấp nhận ƣợc ể sử dụng cho giai
oạn sau. Các mô tả ngôn ngữ dạng trừu tƣợng của dữ liệu thu ƣợc ở giai oạn này có thể
bao gồm một dãy phoneme và các thông tin khác, chẳng hạn nhƣ cấu trúc nhấn, cấu trúc
cú pháp...Các mô tả này ƣợc chuyển ổi thành một bảng ghi âm tiết nhờ sự giúp ỡ của một
từ iển phát âm và các luật phát âm kèm theo. Giai oạn thứ hai thực hiện việc tổng hợp xây
dựng dạng sóng tín hiệu dựa trên các tham số thu ƣợc từ giai oạn trƣớc ó.
Cả quá trình phân tích và tổng hợp của một hệ thống TTS liên quan ến một loạt các
hoạt ộng xử lý. Hầu hết các hệ thống TTS hiện ại thực hiện các hoạt ộng xử lý ƣợc minh
họa theo kiến trúc mô-un nhƣ trong hình 4.7. lOMoARcPSD| 36086670
CHƢƠNG 4. TỔNG HỢP TIẾNG NÓI Hình 4.7
Sơ ồ khối kiến trúc mô-un của một hệ thống TTS hiện ại
Hoạt ộng của sơ ồ khối có thể mô tả sơ lƣợc nhƣ sau. Khi dạng dữ liệu chữ viết ƣợc
ƣa vào, mỗi mô-un trích các thông tin ầu vào hoặc thông tin từ các mô-un khác liên quan
ến chữ viết, và tạo ra các các thông tin ầu ra mong muốn cho việc xử lý ở các mô-un tiếp 108
Downloaded by Dung Tran (tiendungtr12802@gmail.com) lOMoARcPSD| 36086670
CHƢƠNG 4. TỔNG HỢP TIẾNG NÓI
theo. Việc trích chuyển ƣợc thực hiện cho ến khi dạng tín hiệu tổng hợp cuối cùng ƣợc
tạo ra. Quá trình xử lý và truyền thông tin từ mô-un này ến mô-un khác thông qua một "cơ
chế" (engine) xử lý riêng biệt. Engine xử lý iều khiển dẫy các hoạt ộng ƣợc thực thi, và
lƣu trữ mọi thông tin ở dạng cấu trúc dữ liệu thích hợp.
4.3.1. Phân tích chữ viết
Ta biết rằng, chữ viết bao gồm các ký tự chữ và số, các khoảng trắng, và có thể một
loạt các ký tự ặc biệt khác. Nhƣ vậy bƣớc ầu tiên trong việc phân tích chữ viết là việc tiền
xử lý chữ viết ầu vào (bao gồm thay thế chữ số, các chữ viết tắt bằng dạng viết ầy ủ của
chúng) ể chuyển chúng thành một dãy các từ. Quá trình tiền xử lý thông thƣờng còn phát
hiện và ánh dấu các vị trí ngắt quãng của câu và các thông tin về ịnh dạng văn bản thích
hợp khác chẳng hạn nhƣ ngắt oạn...Các mô-un xử lý chữ viết tiếp theo sẽ thực hiện việc
chuyển dãy từ thành các mô tả ngôn ngữ. Một trong các chức năng quan trọng của các khối
này là xác ịnh phát âm tƣơng ứng của các từ riêng lẻ. Trong các ngôn ngữ nhƣ ngôn ngữ
tiếng Anh, các quan hệ giữa các ánh vần của các từ và dạng ghi âm vị (phonemic
transcription) tƣơng ứng là một quan hệ cực kỳ phức tạp. Ngoài ra, mối quan hệ này còn
có thể khác nhau với các từ khác nhau có cùng cấu trúc, ví dụ nhƣ phát âm của cụm "ough"
trong các từ "through", "though", "bough", "rough" và "cough".
Nhƣ ã ề cập khái quát trong phần trên, phát âm của từ thƣờng ƣợc xác ịnh nhờ việc
sử dụng tổng hợp của một từ iển phát âm và các luật phát âm kèm theo. Trong các hệ thống
TTS trƣớc khia, nhấn mạnh trong các phát âm xác ịnh ƣợc tuân theo luật và bằng cách sử
dụng một từ iển các ngoại lệ nhỏ cho các từ chung với cách phát âm bất quy tắc (chẳng
hạn nhƣ "one", "two", "said", ...). Tuy nhiên ngày nay với sự sẵn có của bộ nhớ máy tính
với giá thành rẻ, thƣờng việc xác ịnh phát âm ƣợc hoàn thành bằng cách sử dụng một từ
iền phát âm rất lớn (có thể gồm hàng vài chục ngàn từ) ể ảm bảo rằng từ ã biết ƣợc phát
âm một cách chính xác. Mặc dù vậy, các luật phát âm vẫn cần thiết ể giải quyết vấn ề nảy
sinh với các từ không biết vì các từ vựng mới ƣợc liên tục thêm vào ngôn ngữ, và cũng
nhƣ không thể dựa hoàn toàn vào việc thêm vào tất cả các từ vựng các danh từ riêng trong
bộ từ iển. Việc xác ịnh phát âm của từ có thể ƣợc thực hiện một cách dễ dàng nếu cấu trúc,
hay còn gọi là hình thái học ngôn ngữ (morphology), của từ ƣợc biết trƣớc. Hầu hết các
hệ thống TTS bao gồm cả các phân tích hình thái ngôn ngữ. Phân tích này xác ịnh dạng
gốc (root form của mỗi từ), ví dụ dạng gốc của "gives" là "give", và tránh sự cần thiết phải
thêm cả dạng suy ra từ dạng gốc vào trong từ iển. Một số phân tích cú pháp của chữ viết
cũng có thể cần ƣợc thực hiện nhằm xác ịnh chính xác phát âm của các từ nhất ịnh nào ó.
Chẳng hạn, trong tiếng Anh từ "live" ƣợc phát âm khác nhau phụ thuộc vào nó óng vai
trò là một ộng từ hay một tính từ. Các phát âm của từ ta xác ịnh là các phát âm của các từ
khi chúng ƣợc nói riêng rẽ. Do ó, một số iều chỉnh cần ƣợc thực hiện ể kết hợp các hiệu lOMoARcPSD| 36086670
CHƢƠNG 4. TỔNG HỢP TIẾNG NÓI
ứng âm tiết (phonetic) xảy ra trên vùng biên giữa các từ, nhằm cải thiện tính tự nhiên của
tiếng nói tổng hợp ƣợc.
Ngoài việc xác ịnh phát âm của dãy từ, giai oạn phân tích chữ viết cũng phải thực hiện
việc xác ịnh các thông tin liên quan ến cách mà chữ viết sẽ ƣợc nói. Thông tin này, bao
gồm việc phân tiết tấu, dấu nhấn từ (mức từ), và mẫu các ngữ iệu của các từ khác nhau.
Các thông tin này sẽ ƣợc sử dụng ể tạo âm iệu cho tiếng nói ƣợc tổng hợp. Các ánh dấu
cho dấu nhấn từ có thể ƣợc thêm vào cho mỗi từ trong từ iển, nhƣng các luật cũng sẽ cần
ể gán dấu nhấn từ cho các từ bất kỳ không tìm thấy trong từ iển. Với một số từ, chẳng hạn
nhƣ từ "permit", về cơ bản có dấu nhấn trên các âm tiết khác nhau phụ thuộc vào việc
chúng ƣợc sử dụng nhƣ một danh từ hay một ộng từ. Và do ó, các thông tin về ngữ pháp
cũng cần thiết nhằm gán cấu trúc nhấn một cách chính xác. Kết quả của một phân tích cú
pháp cũng có thể ƣợc sử dụng ể nhóm các từ thành các cụm từ âm iệu, và từ ó quyết ịnh
các từ nào sẽ nhấn giọng sao cho mẫu nhấn giọng có thể ƣợc gán cho dãy từ. Trong khi
cấu trúc cú pháp cung cấp các ầu mối hữu ích cho việc nhấn giọng và phân tiết tấu (và từ
ó tạo âm iệu), trong nhiều trƣờng hợp, âm iệu biểu hiện thực có thể không ạt ƣợc nếu
không thực sự hiểu nghĩa của chữ viết. Mặc dù một số ảnh hƣởng ngữ nghĩa ã ƣợc sử
dụng, các phân tích ngữ nghĩa và tính thực dụng một cách ầy ủ là vƣợt quá các khả năng
của các hệ thống TTS hiện tại.
4.3.2. Tổng hợp tiếng nói
Các thông tin ƣợc trích từ các phân tích chữ viết ƣợc sử dụng ể tạo ra âm iệu của các
ơn vị tiếng nói, bao gồm cả cấu trúc thời gian, mức ộ nhấn mạnh toàn bộ và tần số cơ bản.
Mô-un cuối cùng của hệ thống TTS sẽ thực hiện việc tạo âm thanh của tín hiệu tiếng nói
bằng cách ầu tiên chọn các ơn vị tổng hợp thích hợp ể sử dụng, và sau ó thực hiện việc
tổng hợp các ơn vị này với nhau theo thông tin về âm iệu ã biết ƣợc cung cấp từ các mô-
un trƣớc ó. Việc tổng hợp có thể ƣợc thực hiện bằng một trong các phƣơng pháp ã ề cập ở phần trên.
4.4. MỘT SỐ ĐẶC ĐIỂM CỦA VIỆC TỔNG HỢP TIẾNG VIỆT
Một iểm ầu tiên cần chú ý trong việc thực hiện tổng hợp tiếng Việt là sự khác biệt
trong ngôn ngữ văn bản, văn phạm câu, khái niệm từ so với các ngôn ngữ tiếng Anh hoặc
một số ngôn ngữ phổ biến khác. Ngoài ra, cấu trúc âm của tiếng Việt cũng có cách cấu âm,
với các âm vị khác biệt rõ rệt. Đặc biệt là phải kể ến hiện tƣợng thanh iệu trong tiếng Việt.
Theo một số nghiên cứu thì thanh iệu trong tiếng Việt ƣợc quyết ịnh bởi sự phân
bố năng lƣợng tín hiệu và tần số cơ bản. Tuy nhiên, cho ến thời iểm này vẫn chƣa có một
phƣơng pháp tổng hợp chính xác nào có thể tạo ƣợc thanh iệu với các âm sắc tự nghiên. 110
Downloaded by Dung Tran (tiendungtr12802@gmail.com) lOMoARcPSD| 36086670
CHƢƠNG 4. TỔNG HỢP TIẾNG NÓI
4.5. CÂU HỎI VÀ BÀI TẬP CUỐI CHƢƠNG
1. Mục ích của tổng hợp tiếng nói? Nêu một số ứng dụng của tổng hợp tiếng nói?
2. Có những phƣơng pháp tổng hợp tiếng nói nào? Ý tƣởng của từng phƣơng pháp?
3. (Matlab) Sử dụng phƣơng pháp tổng hợp trực tiếp ơn giản:
i. Sử dụng máy tính cá nhân và phần mềm Matlab (hoặc các công
cụ khác) xây dựng một hệ thống dừng ỗ xe buýt công cộng:
1. Lƣu file âm thanh các cụm từ thông báo (ví dụ: Điểm
dừng tiếp theo”, …), các ịa danh
2. Viết chƣơng trình: chuẩn hóa dữ liệu tiếng Việt, phân tích
văn bản, và ghép nối âm thanh ể khi ngƣời nhập một cụm
từ, chƣơng trình sẽ thông báo về iểm dừng xe buýt.
4. (Matlab) Tƣơng tự nhƣ bài 3, nhƣng với hệ thống thông báo về số thứ
tự khách hàng, thông tin về bàn phục vụ tại một iểm giao dịch ngân hàng
5. (Matlab) Tƣơng tự nhƣ bài 3, nhƣng với hệ thống thông báo số iện thoại của khách hang lOMoARcPSD| 36086670
CHƢƠNG 5. NHẬN DẠNG TIẾNG NÓI
CHƢƠNG 5. NHẬN DẠNG TIẾNG NÓI 5.1. MỞ ĐẦU
Nhu cầu về những thiết bị (máy) có thể nhận biết và hiểu ƣợc tiếng nói ƣợc nói bởi
bất kỳ ai, trong bất kỳ môi trƣờng nào ã trở thành một ƣớc muốn tuột bậc của con ngƣời
cũng nhƣ các nhà nghiên cứu và các dự án nghiên cứu về nhận dạng tiếng nói trong suốt
gần một thế kỷ qua. Cho ến nay, mặc dù ã ạt ƣợc những bƣớc tiến dài trong việc hiểu ƣợc
quá trình tạo tín hiệu tiếng nói và ƣa ra nhiều kỹ thuật phân tích tiếng nói, thậm chí chúng
ta ã ạt ƣợc nhiều tiến bộ trong việc xây dựng và phát triển nhiều hệ thống nhận dạng tín
hiệu tiếng nói quan trọng, tuy nhiên, ta vẫn còn ang ở quá xa mục tiêu ặt ra là có thể xây
dựng ƣợc những cỗ máy có thể giao tiếp một cách tự nhiên với con ngƣời. Trong chƣơng
này, trƣớc hết ta sẽ xem xét lại lịch sử phát triển của lĩnh vực nghiên cứu nhận dạng tiếng
nói, sau ó tìm hiểu sơ bộ một hệ thống nhận dạng tín hiệu tiếng nói tổng quát và một số
phƣơng pháp hiện ã ang ƣợc sử dụng trong các hệ thống nhận dạng tín hiệu tiếng nói cùng
với ƣu nhƣợc iểm của nó.
5.2. LỊCH SỬ PHÁT TRIỂN CÁC HỆ THỐNG NHẬN DẠNG TIẾNG NÓI
Nghiên cứu về nhận dạng tiếng nói là một lĩnh vực nghiên cứu ã và ang diễn ra ƣợc
gần một thế kỷ. Trong suốt quá trình ó, ta có thể phân loại các công nghệ nhận dạng thành các thế hệ nhƣ sau:
Thế hệ 1: Thế hệ này ƣợc ánh dấu mốc bắt ầu từ những năm 30 cho ến những năm 50.
Công nghệ của thế hệ này là các phƣơng thức ad hoc ể nhận dạng các âm, hoặc các bộ từ
vựng với số lƣợng nhỏ của các từ tách biệt.
Thế hệ 2: Thế hệ thứ hai bắt ầu từ những năm 50 và kết thúc ở những năm 60. Công
nghệ của thế hệ này sử dụng các các phƣơng pháp acoustic-phonetic ể nhận dạng các
phonemes, các âm tiết hoặc các từ vựng của các số.
Thế hệ 3: Thế hệ này sử dụng các biện pháp nhận dạng mẫu ể nhận dạng tín hiệu tiếng
nói với các bộ từ vựng vừa và nhỏ của các từ tách biệt hoặc dãy từ có liên kết với nhau,
bao gồm cả việc sử dụng bộ LPC nhƣ là một phƣơng pháp phân tích cơ bản; sử dụng các
o lƣờng khoảng cách LPC ể cho iểm sự tƣơng ồng của các mẫu; sử dụng các giải pháp lập
trình ộng cho việc chỉnh thời gian; sử dụng nhận dạng mẫu cho việc phân hoạch các mẫu
thành các mẫu tham chiếu nhất quán, sử dụng phƣơng pháp mã hóa lƣợng tử hóa véc-tơ ể
giảm nhỏ dữ liệu và tính toán. Thế hệ thứ ba bắt ầu từ những năm 60 ến những năm 80. 112
Downloaded by Dung Tran (tiendungtr12802@gmail.com) lOMoARcPSD| 36086670
CHƢƠNG 5. NHẬN DẠNG TIẾNG NÓI
Thế hệ 4: Thế hệ thứ tƣ bắt ầu từ những năm 80 ến những năm 00. Công nghệ của thế
hệ này sử dụng các phƣơng pháp thống kê với mô hình Markov ẩn (HMM) cho việc mô
phổng tính chất ộng và thống kê của tín hiệu tiếng nói trong một hệ thống nhận dạng liên
tục; sử dụng các phƣơng pháp huấn luyện lan truyền xuôi-ngƣợc và phân oạn Ktrung bình
(segmental K-mean); sử dụng phƣơng pháp chỉnh thời gian Viterbi; sử dụng thuật toán ộ
tƣơng ồng tối a (ML) và nhiều tiêu chuẩn chất lƣợng cùng các giải pháp ể tối ƣu hóa các
mô hình thống kê; sử dụng mạng nơ-ron ể ƣớc lƣợng các hàm mật ộ xác suất có iều kiện;
sử dụng các thuật toán thích nghi ể thay ổi các tham số gắn với hoặc tín hiệu tiếng nói hoặc
với mô hình thống kê ể nâng cao tính tƣơng thích giữa mô hình và dữ liệu nhằm tăng tính
chính xác của phép nhận dạng.
Thế hệ 5: Ta ang chứng kiến sự phát triển của lớp công nghệ nhận dạng tiếng nói thế
hệ thứ năm. Công nghệ thế hệ này sử dụng các giải pháp xử lý song song ể tăng tính tín
cậy trong các quyết ịnh nhận dạng; kết hợp giữa HMM và các phƣơng pháp acoustic-
phonetic ể phát hiện và sửa chữa những ngoại lệ ngôn ngữ; tăng tính chắc chắn (chín chắn
- robustness) của hệ thống nhận dạng trong môi trƣờng có nhiễu; sử dụng phƣơng pháp
học máy ể xây dựng các kết hợp tối ƣu của các mô hình.
Cũng cần chú ý rằng, việc phân chia các giai oạn trên ây chỉ mang tính tƣơng ối về
mốc thời gian. Điều này dễ hiểu bởi vì các thế hệ công nghệ không phân tách rạch ròi nhau
mà hầu nhƣ các ý tƣởng cốt lỗi của mỗi giai oạn lại ƣợc thai nghén từ giai oạn trƣớc ó.
Các giai oạn ƣợc phân chia chỉ nhằm chỉ ra rằng trong giai oạn ó nhiều kết quả nghiên cứu
liên quan ến công nghệ của giai oạn ó ựoc ƣa ra và trở thành tiêu chuẩn cho hầu hết các
hệ thống nhận dạng của thời kỳ ó.
5.3. PHÂN LOẠI CÁC HỆ THỐNG NHẬN DẠNG TIẾNG NÓI
Tùy theo các cách nhìn mà ta có các cách phân loại các hệ thống nhận dạng tiếng nói
khác nhau. Xét theo khía cạnh ơn vị tiếng nói ƣợc sử dụng trong các hệ thống, thì các hệ
thống nhận dạng tiếng nói có thể ƣợc phân thành hai loại chính. Loại thứ nhất là các hệ
thống nhận dạng từ riêng lẻ, trong ó các biểu diễn từ phân tách ơn lẻ ƣợc nhận dạng. Loại
thứ hai là các hệ thống nhận dạng liên tục trong ó các câu liên tục ƣợc nhận dạng. Hệ thống
nhận dạng tiếng nói liên tục còn có thể chia thành lớp nhận dạng với mục ích ghi chép
(transcription) và lớp với mục ích hiểu tín hiệu tiếng nói. Lớp với mục ính ghi chép có mục
tiêu nhận dạng mỗi từ một cách chính xác. Lớp với mục ích hiểu, cũng còn ƣợc gọi là lớp
nhận dạng tiếng nói hội thoại, tập trung vào việc hiểu nghĩa của các câu thay vì việc nhận
dạng các từ riêng biệt. Trong các hệ thống nhận dạng tiếng nói liên tục, iều quan trọng là
phải sử dụng các kiến thức ngôn ngữ phức tạp. Chẳng hạn nhƣ việc ứng dụng các luật về
ngữ pháp, các luật quy ịnh về việc tổ chức dãy các từ trong câu, là một ví dụ. lOMoARcPSD| 36086670
CHƢƠNG 5. NHẬN DẠNG TIẾNG NÓI
Theo cách nhìn khác, các hệ thống nhận dạng tiếng nói có thể ƣợc phân chia thành các
hệ thống nhận dạng không phụ thuộc vào ngƣời nói (speaker-independent) và hệ thống
nhận dạng phụ thuộc vào ngƣời nói (speaker-dependent). Hệ thống nhận dạng ộc lập với
ngƣời nói có khả năng nhận dạng tiếng nói của bất cứ ai. Trong khi ó, ối với hệ thống nhận
dạng phụ thuộc ngƣời nói, các mẫu/mô hình tham khảo cần phải thay ổi cập nhật mỗi lần
ngƣời nói thay ổi. Mặc dù việc nhận dạng ộc lập với ngƣời nói khó hơn rất nhiều so với
việc nhận dạng phụ thuộc ngƣời nói, nhƣng việc phát triển các phƣơng nhận dạng ộc lập
là ặc biệt quan trọng nhằm mở rộng phạm vi sử dụng của các hệ thống nhận dạng.
Ngoài ra, các hệ thống tiếng nói cũng có thể phân chia làm các nhóm sau: các hệ thống
nhận dạng tiếng nói tự ộng, các hệ thống nhận dạng tiếng nói liên tục, và các hệ thống xử
lý ngôn ngữ tự nhiên (NLP - Natural Language Processing). Các hệ thống nhận dạng tiếng
nói tự ộng, nhƣ tên mô tả, là các hệ thống nhận dạng mà không cần thông tin ầu vào của
ngƣời sử dụng bổ sung vào. Các hệ thống nhận dạng tiếng nói liên tục, nhƣ ã ề cập ở phần
trên, là các hệ thống có khả năng nhận dạng các câu liên tục. Nói cách khác, về mặt lý
thuyết, các hệ thống loại này không yêu cầu ngƣời sử dụng (ngƣời nói) phải ngừng trong
khi nói. Các hệ thống xử lý ngôn ngữ tự nhiên có ứng dụng không chỉ trong các hệ thống
nhận dạng tiếng nói. Các hệ thống này sử dụng các phƣơng pháp tính toán cần thiết cho
các máy có thể hiểu ƣợc nghĩa của tiếng nói ang ƣợc nói thay vì chỉ ơn giản biết ƣợc từ nào ã ƣợc nói.
Một cách tổng quát, Victo Zue và ồng nghiệp ã ịnh nghĩa một số tham số và dùng nó ể
phân chia các hệ thống nhận dạng theo các tham số ó nhƣ trình bày trong bảng 5.1. Tham số Phân loại iển hình Đơn vị tiếng nói
Rời rạc (các từ ơn lẻ) – Liên tục (các câu liên tục) Huấn luyện
Huấn luyện trƣớc khi sử dụng - Huấn luyện liên tục Ngƣời sử dụng Phụ thuộc - Độc lập Từ vựng
Số lƣợng nhỏ - Số lƣợng lớn SNR Thấp – Cao Bộ chuyển ổi
Hạn chế - Không hạn chế
Bảng 5.1: Các tham số và phân loại hệ thống nhận dạng tƣơng ứng 114
Downloaded by Dung Tran (tiendungtr12802@gmail.com) lOMoARcPSD| 36086670
CHƢƠNG 5. NHẬN DẠNG TIẾNG NÓI
5.4. CẤU TRÚC HỆ NHẬN DẠNG TIẾNG NÓI
Hình 5.1 trình bày cấu trúc nguyên lý của một hệ thống nhận dạng tiếng nói. Tín hiệu
tiếng nói trƣớc hết ƣợc xử lý bằng cách áp dụng một trong các phƣơng pháp phân tích
phổ ngắn hạn hay còn ƣợc gọi là quá trình trích chọn ặc trƣng hoặc quá trình tiền xử lý
(front-end processing). Kết quả thu ƣợc sau quá trình trích chọn ặc trƣng là tập các ặc
trƣng âm học (acoustic features) ƣợc tạo dựng thành một véc-tơ. Thông thƣờng khoảng
100 véc-tơ ặc trƣng âm học ƣợc tạo ra tại ầu ra của quá trình phân tích trong một ơn vị thời gian một giây. Vector Tiếng nói ặc trƣng ầu vào Tiền xử lý Trích ch ƣngọn So sánh tƣơng ồng ặc tr Mô hình âm h ọc Đầu ra Mô hình ngôn ng ữ Giải mã Từ iển Hình 5.1
Cấu trúc tổng quát của một hệ thống nhận dạng tiếng nói
Việc so sánh (matching) trƣớc hết thực hiện bằng việc huấn luyện xây dựng các ặc
trƣng, sau ó sử dụng ể so sánh với các tham số ầu vào ể thực hiện việc nhận dạng. Trong
quá trình huấn luyện hệ thống chuỗi véc-tơ các ặc trƣng ƣợc ƣa vào hệ thống ể ƣớc lƣợng
các tham số của các mẫu tham khảo (reference patterns). Một mẫu tham khảo có thể mô
phỏng (model) một từ, một âm ơn (a single phoneme) hoặc một ơn vị tiếng nói nào ó (some
other speech unit). Tùy thuộc vào nhiệm vụ của hệ thống nhận dạng, quá trình huấn luyện
hệ thống sẽ bao gồm một quá trình xử lý phức tạp hoặc không. Chẳng hạn với hệ thống
nhận dạng phụ thuộc ngƣời nói (speaker dependent recognition), có thể chỉ bao gồm một
vài hoặc duy nhất một biểu diễn (utterances) cho mỗi từ cần ƣợc huấn luyện. Tuy nhiên, ối
với hệ thống nhận dạng ộc lập với ngƣời nói, có thể bao gồm hàng ngàn biểu diễn tƣơng
ứng với tín hiệu của mẫu tham khảo mong muốn. Những biểu diễn này thƣờng là bộ phận
(part) của một cơ sở dữ liệu tiếng nói ã ƣợc thu thập trƣớc ây. Cần chú ý rằng việc trích
chọn các ặc trƣng tiêu biểu (representative features) và xây dựng một mô hình tham khảo
(a reference model) là một quá trình tốn thời gian và là một công việc phức tạp. lOMoARcPSD| 36086670
CHƢƠNG 5. NHẬN DẠNG TIẾNG NÓI
Trong quá trình nhận dạng, dãy các véc-tơ ặc trƣng ƣợc em so sánh với các mẫu tham
khảo. Sau ó, hệ thống tính toán ộ tƣơng ồng (likelihood - ộ giống nhau) của dãy véc-tơ ặc
trƣng và mẫu tham khảo hoặc chuỗi mẫu tham khảo. Việc tính toán ộ giống nhau thƣờng ƣợc
tính toán bằng cách áp dụng các thuật toán hiệu quả chẳng hạn nhƣ thuật toán Viterbi. Mẫu
hoặc dãy mẫu có ộ tƣơng ồng (likelihood) cao nhất ƣợc cho là kết quả của quá trình nhận dạng.
Hiện nay, các phƣơng pháp trích chọn ặc trƣng phổ biến thƣờng là các mạch lọc Mel
(Mel filterbank) kết hợp với các biến ổi phổ Mel sang miền cepstral. Ta sẽ tìm hiểu sơ ồ
tiền xử lý ƣợc tiêu chuẩn hóa nhƣ một phƣơng pháp tiền xử lý bởi ETSI. Mô hình mẫu
tham chiếu thƣờng là các mô hình Markov ẩn (HMMs).
5.5. CÁC PHƢƠNG PHÁP PHÂN TÍCH CHO NHẬN DẠNG TIẾNG NÓI
5.5.1 Lƣợng tử hóa véc-tơ
Ta thấy rằng, kết quả của các phép phân tích trích chọn tham số là dãy các véc-tơ ặc
trƣng của ặc tính phổ thay ổi theo thời gian của tín hiệu tiếng nói. Để thuận tiện, ta kí hiệu
các véc-tơ phổ là vl, l=1,2,…, L, trong ó mỗi véc-tơ thƣờng là một véc-tơ có chiều dài p.
Nếu ta so sánh tốc ộ thông tin của các biểu diễn véc-tơ và các biểu diễn trực tiếp dạng sóng
tín hiệu (uncoded speech waveform), ta thấy rằng các phân tích phổ cho phép ta giảm nhỏ
i rất nhiều tốc ộ thông tin yêu cầu. Lấy ví dụ, với tín hiệu tiếng nói ƣợc lấy mẫu với tần số
lấy mẫu 10kHz, và sử dụng 16bít ể biểu diễn biên ộ của mỗi mẫu. Khi ó biểu diễn raw cần
160000bps ể lƣu trữ các mẫu tín hiệu. Trong khi ó, ối với phân tích phổ, giả sử ta sử dụng
các véc-tơ có ộ dài p=10 và sử dụng 100 véc-tơ phổ trong một ơn vị thời gian một giây. Và
ta cũng sử dụng ộ chính xác 16 bít ể biểu diễn mỗi thành phần phổ, khi ó ta cần
100x10x16bps hay 16000bps ể lƣu trữ. Nhƣ vậy phƣơng pháp phân tích phổ cho phép
giảm i 10 lần. Tỷ lệ giảm này là cực kỳ quan trọng trong việc lƣu trữ. Dựa trên khái niệm
cần tối thiểu chỉ một biểu diễn phổ ơn lẻ cho mỗi ơn vị tiếng nói, ta có thể làm giảm nhỏ
thêm nữa các biểu diễn phổ thô của tín hiệu thành các thành phần từ một tập nhỏ hữu hạn
các véc-tơ phổ duy nhất mà mỗi thành phần tƣơng ứng với một ơn vị cơ bản của tín hiệu
tiếng nói (tức là các phoneme). Lẽ tất nhiên, một biểu diễn lý tƣởng là khó có thể ạt ƣợc
trong thực tế bởi vì có quá nhiều các biến số trong các tính chất phổ của mỗi một ơn vị tín
hiệu tiếng nói cơ bản. Tuy nhiên, khái niệm về việc xây dựng một bộ mã (codebook) gồm
các véc-tơ phân tích phân biệt, mặc dù có số từ mã nhiều hơn tập cơ bản các phoneme, vẫn
là một ý tƣởng hấp dẫn và là ý tƣởng cơ bản nằm trong một loạt các kỹ thuật phân tích
ƣợc gọi chung là các phƣơng pháp lƣợng tử hóa véc-tơ. Dựa trên các suy luận trên, giả sử
ta cần một bộ mã với khoảng 1024 véc-tơ phổ ộc nhất (tức là khoảng 25 dạng khác nhau 116
Downloaded by Dung Tran (tiendungtr12802@gmail.com) lOMoARcPSD| 36086670
CHƢƠNG 5. NHẬN DẠNG TIẾNG NÓI
của mỗi tập 40 ơn vị tín hiệu tiếng nói cơ bản). Nhƣ thế, ể biểu diễn một véc-tơ phổ bất kỳ,
tất cả ta cần là một số 10 bít - khi ó chỉ số của véc-tơ bộ mã phù hợp nhất với véc-tơ vào.
Giả sử rằng ở tốc ộ 100 véc-tơ phổ trong một ơn vị thời gian một giây, ta cần tổng tốc ộ bít
vào khoảng 1000bps ể biểu diễn các véc-tơ phổ của tín hiệu. Ta thấy rằng, tốc ộ này chỉ
bằng khoảng 1/16 tốc ộ cần thiết của các véc-tơ phổ liên tục. Do ó, phƣơng pháp biểu diễn
lƣợng tử hóa véc-tơ là một phƣơng pháp có khả năng biểu diễn cực kỳ hiệu quả các thông
tin phổ của tín hiệu tiếng nói.
Trƣớc khi thảo luận các khái niệm liên quan ến việc thiết kế và thực hiện một hệ lƣợng
tử véc-tơ thực tế, ta iểm lại các ƣu iểm và nhƣợc iểm của phƣơng pháp này. Trƣớc hết,
các ƣu iểm chính của phƣơng pháp biểu diễn lƣợng tử véc-tơ bao gồm:
Cho phép giảm nhỏ việc lƣu trữ thông tin phân tích phổ tín hiệu. Điều này cho phép tạo
thuận lợi cho việc áp dụng trong các hệ thống nhận dạng tín hiệu tiếng nói thực tế.
Cho phép giảm nhỏ việc tính toán ể xác ịnh sự giống nhau (tƣơng ồng - similarity) của
các véc-tơ phân tích phổ. Ta biết rằng, trong phép nhận dạng tín hiệu tiếng nói, một bƣớc
quan trọng trong việc tính toán là quyết ịnh tƣơng ồng phổ của một cặp véc-tơ. Dựa trên
biểu diễn lƣợng tử hóa véc-tơ, việc tính toán tính tƣơng ồng phổ tín hiệu thƣờng ƣợc giảm
xuống thành một phép tra bảng của sự giống nhau giữa các cặp véc-tơ mã.
Cho phép biểu diễn rời rạc tín hiệu âm thanh tiếng nói. Bằng việc gắn một nhãn
phonetic (hoặc có thể là một tập các nhãn phonetic hoặc một lớp phonetic) với một véctơ
mã, quá trình chọn ra một véc-tơ mã biểu diễn một véc-tơ phổ cho trƣớc phù hợp nhất trở
thành việc gán một nhãn phonetic cho mỗi khung phổ của tín hiêu. Một loạt các hệ thống
nhân dạng tiếng nói tồn tại ã sử dụng những nhãn này ể cho phép nhận dạng một cách hiệu quả.
Tuy vậy cũng phải kể ến một số hạn chế của việc sử dụng bộ mã lƣợng tử hóa véctơ ể
biểu diễn các véc-tơ phổ tín hiệu tiếng nói. Chúng bao gồm:
Tồn tại sự méo phổ kế thừa (inherent) trong việc biểu diễn véc-tơ phân tích thực tế. Do
chỉ có số lƣợng hữu hạn véc-tơ mã, quá trình chọn véc-tơ thích hợp nhất biểu diễn một
véc-tơ phổ cho trƣớc tƣơng tự nhƣ quá trình lƣợng tử một véc-tơ và kết quả là dẫn ến
một sai số lƣợng tử nào ó. Sai số lƣợng tử giảm khi số lƣợng các véc-tơ mã tăng. Tuy
nhiên, với mỗi bộ mã có số véc-tơ mã hữu hạn thì luôn tồn tại một mức sai số lƣợng tử.
Dung lƣợng lƣu trữ cho các véc-tơ mã thƣờng là không bất thƣờng (nontrivial). Nếu
bộ mã càng lớn, nghĩa là ể càng giảm nhỏ sai số lƣợng tử, thì dung lƣợng lƣu trữ các
thành phần bộ véc-tơ mã yêu cầu càng cao. Với các bộ mã có kích thƣớc lớn hơn hoặc
bằng 1000, thì dung lƣợng lƣu trữ thƣờng là không bất thƣờng. Nhƣ vậy có một sự mâu lOMoARcPSD| 36086670
CHƢƠNG 5. NHẬN DẠNG TIẾNG NÓI
thuẫn giữa sai số lƣợng tử, quá trình lựa chọn véc-tơ mã, và dung lƣợng lƣu trữ các véctơ
mã. Trong các thiết kế ứng dụng thực tế cần phải cân bằng ba yếu tố này.
5.5.1.1. Sơ ồ thực hiện lƣợng tử hóa véc-tơ
Sơ ồ khối của cấu trúc phân loại (classification) và huấn luyện sử dụng lƣợng tử hóa
véc-tơ cơ bản ƣợc trình bày trong hình 5.2. Một tập lớn các véc-tơ phân tích phổ v1, v2,
…, vL tạo thành tập các véc-tơ dùng ể huấn luyện. Tập các véc-tơ này dùng ể tạo ra một
tập tối ƣu các véc-tơ mã ể biểu diễn các biến phổ quan sát ƣợc trong tập huấn luyện. Nếu
ta ký hiệu kích cỡ của bộ mã lƣợng tử hóa véc-tơ là M=2B (ta gọi ây là một bộ mã B-bít),
khi ó ta cần có L>> M ể có thể tìm ƣợc một tập gồm M véc-tơ phù hợp nhất. Trong thực
tế, ngƣời ta thấy rằng, ể quá trình huấn luyện bộ mã lƣợng tử véc-tơ hoạt ộng tốt, L thƣờng
phải tối thiểu bằng 10M. Tiếp ến là quá trình o lƣờng ộ giống nhau hay còn gọi là khoảng
cách giữa các cặp véc-tơ phân tích phổ nhằm ể có thể phân hoạch (cluster) tập các véc-tơ
huấn luyện cũng nhƣ gắn hoặc phân loại các véc-tơ phổ thành các thành phần của bộ mã
duy nhất. Khoảng cách phổ giữa hai véc-tơ phổ vi và vj ƣợc ký hiệu là dij=d(vi, vj). Quá
trình tiếp tục phân loại tập L véc-tơ huấn luyện thành M phân hoạch và ta chọn M véc-tơ
mã nhƣ là tập trung tâm (centroid) của mỗi một phân hoạch ó. Thủ tục phân loại các véc-
tơ phân tích phổ tín hiệu tiếng nói xác ịnh thực hiện việc chọn véc-tơ mã gần nhất với véc-
tơ nhập vào và sử dụng chỉ số mã nhƣ là kết quả biểu diễn phổ. Quá trình này thƣờng ƣợc
gọi là việc tìm kiếm lân cận gần nhất hoặc thủ tục mã hóa tối ƣu. Thủ tục phân loại về cơ
bản là một bộ lƣợng tử hóa với ầu vào là một véc-tơ phổ tín hiệu tiếng nói và ầu ra là chỉ
số mã hóa của một véc-tơ mã mà gần giống với ầu vào nhất (best match) d(…) Tập các vector huấn luyện { vi } Thuật toán phân hoạch Bộ mã (K-mean) vector d(…) Chỉ số Các vector mã hóa tiếng nói Bộ lƣợng tử hóa Hình 5.2
Mô hình sử dụng véc-tơ lƣợng tử huấn luyện và phân loại 118
Downloaded by Dung Tran (tiendungtr12802@gmail.com) lOMoARcPSD| 36086670
CHƢƠNG 5. NHẬN DẠNG TIẾNG NÓI
5.5.1.2. Tập huấn luyện bộ lƣợng tử hóa véc-tơ
Để có thể huấn luyện bộ mã lƣợng tử hóa véc-tơ một cách chính xác, các véc-tơ
thuộc tập huấn luyện phải bao phủ (span) các khía cạnh mong muốn nhƣ sau:
Ngƣời nói, bao gồm các nhóm (ranges) về tuổi tác, trọng âm (accent), giới tính, tốc ộ
nói, các mức ộ và các biến số khác.
Các iều kiện môi trƣờng chẳng hạn nhƣ phòng yên lặng hay trên ô-tô (automobile), hoặc
khu làm việc ồn ào (noisy workstation).
Các bộ chuyển ổi (transducers) và các hệ thống truyền dẫn, bao gồm cả các mi-cờ-rô
băng thông rộng, các ống nghe (handset) iện thoại (với các mi-cờ-rô các-bon và iện than),
các truyền dẫn trực tiếp, kênh tín hiệu iện thoại, kênh băng thông rộng, và các thiết bị khác.
Các ơn vị tiếng nói bao gồm các từ vựng sử dụng nhận dạng ặc biệt (chẳng hạn các chữ
số) và tiếng nói liên tục (conversational speech)
Mục tiêu huấn luyện càng hẹp càng rõ ràng (chẳng hạn với số lƣợng ngƣời nói hạn
chế, tiếng nói trong phòng yên lặng, ...) thì sai số lƣợng tử khi sử dụng việc biểu diễn phổ
tín hiệu với bộ mã kích thƣớc cố ịnh càng nhỏ. Tuy nhiên ể có thể ứng dụng giải quyết
nhiều loại bài toán thực tế, tập huấn luyện phải càng lớn càng tốt.
5.5.1.3. Đo lƣờng sự tƣơng ồng hay khoảng cách
Khoảng cách phổ giữa các véc-tơ phổ vi và vj ƣợc ịnh nghĩa nhƣ sau: v v d v v i i, j d ij 0 0 v vi j j (3.1)
5.5.1.4. Phân hoạch các véc-tơ huấn luyện
Thủ tục phân hoạch tập L véc-tơ huấn luyện thành một tập gồm M bộ véc-tơ mã có thể ƣợc mô tả nhƣ sau:
Bắt ầu: Chọn M véc-tơ bất kỳ từ tập L véc-tơ huấn luyện tạo thành một tập khởi ầu các từ mã của bộ mã.
Tìm kiếm lân cận gần nhất: Với mỗi véc-tơ huấn luyện, tìm một véc-tơ mã trong bộ
ang xét gần nhất (theo nghĩa khoảng cách phổ) và gán véc-tơ ó vào ô tƣơng ứng.
Cập nhật centroid: Cập nhật từ mã trong mỗi ô bằng cách sử dụng centroid của các véc-
tơ huấn luyện trong các ô ó. lOMoARcPSD| 36086670
CHƢƠNG 5. NHẬN DẠNG TIẾNG NÓI
Lặp: Lặp lại các bƣớc 2 và 3 cho ến khi khoảng cách trung bình nhỏ hơn một khoảng ngƣỡng ịnh sẵn.
5.5.1.5. Thủ tục phân loại véc-tơ
Việc phân loại các véc-tơ ối với các véc-tơ phổ bất kỳ về cơ bản là việc tìm hết trong
bộ mã ể tìm ra ƣợc một véc-tơ tƣơng ồng nhất. Ta ký hiệu bộ véc-tơ mã của một bộ mã
M véc-tơ là ym, (1≤ m≤ M) và véc-tơ phổ cần phân loại (và lƣợng tự hóa) là v, khi ó chỉ
số m* của từ mã phù hợp nhất ƣợc xác ịnh nhƣ sau:
m* arg min d v y , m (3.2) 1 m M
V ớ i các b ộ mã có giá tr ị M l ớ n (ch ẳ ng h ạ n M ≥ 1024) , vi ệ c tính toán theo công th ứ c
(3.2) s ẽ tr ở lên quá ph ứ c t ạ p (be excessive), và ph ụ thu ộ c vào tính toán chi ti ế t c ủ a quá
trình o lƣờ ng kho ả ng cách ph ổ . Trong th ự c t ế, ngƣời ta thƣờ ng s ử d ụ ng các thu ậ t gi ả i
c ậ n t ối ƣu (sub - optimal) ể tìm ki ế m.
5.5.2 B ộ x ử lý LPC trong nh ậ n d ạ ng ti ế ng nói
Trong ph ần trƣớ c ta th ả o lu ậ n v ề các tính ch ấ t chung nh ấ t c ủa phƣơng pháp phân tích
LPC. Trong ph ầ n này ta s ẽ mô t ả chi ti ế t vi ệ c s ử d ụ ng b ộ x ử lý LPC cho các h ệ th ố ng
nh ậ n d ạ ng tín hi ệ u ti ếng nói. Sơ ồ kh ố i c ủ a kh ố i x ử lý LPC ƣợ c trình bày trong hình
5.3 . Các bƣớc cơ bả n trong quá trình x ử lý c ủ a b ộ x ử lý nhƣ sau: Hình 5.3
Sơ ồ khối bộ xử lý LPC trong nhận dạng tiếng nói 120
Downloaded by Dung Tran (tiendungtr12802@gmail.com) lOMoARcPSD| 36086670
CHƢƠNG 5. NHẬN DẠNG TIẾNG NÓI
5.5.2.1. Tiền nhấn tín hiệu
Đầu tiên tín hiệu tiếng nói dạng số hóa s(n) ƣợc ƣa qua một hệ thống lọc số bậc thấp,
thƣờng là bộ lọc áp ứng xung hữu hạn (FIR) bậc nhất, nhằm làm phẳng phổ tín hiệu. Điều
này sẽ giúp cho tín hiệu ít bị ảnh hƣởng của các phép biến ổi xử lý tín hiệu có ộ chính xác
hữu hạn trong suốt quá trình sau ó. Bộ lọc số sử dụng cho việc tiền nhấn tín hiệu có thể là
một bộ lọc với các tham số cố ịnh hoặc có thể là một bộ lọc thích nghi có các tham số thay
ổi chậm. Trong xử lý tín hiệu tiếng nói, ngƣời ta thƣờng dùng một hệ thống mạch lọc bậc
nhất có các tham số cố ịnh có dạng: H z
1 az 1 0,9 a 1,0 (3.3)
Khi ó, tín hiệu ầu ra của bộ tiền nhấn s n có thể tính nhƣ sau: s n s n as n 1 (3.4)
Giá trị phổ biến của hệ số cố ịnh a là khoảng 0,95 (trong các ứng dụng thực thi với dấu
phẩy tĩnh giá trị của a thƣờng ƣợc chọn là 15/16=0.9375). Hình 5.4 biểu diễn biên ộ ặc tính hàm truyền ạt H e j
với giá trị a 0,95. Từ hình vẽ, ta có thể quan sát thấy rằng tại
, tức là bằng một nửa tốc ộ lấy mẫu, có sự gia tăng (boost) biên ộ khoảng
32dB so với biên ộ ở tần số 0. 2.0 1.0 32 dB 00 π Hình 5.4
Phổ biên ộ của mạch tiền nhấn tín hiệu
Trong trƣờng hợp mạch lọc thích nghi ƣợc sử dụng, hàm truyền ạt của nó thƣờng có dạng: H z 1 a z 1 n (3.5)
Trong ó an thay ổi theo thời gian n theo một tiêu chí thích nghi ƣợc thiết kế trƣớc.
Một giá trị iển hình thƣờng ƣợc sử dụng là a r n 1 / rn 0 . lOMoARcPSD| 36086670
CHƢƠNG 5. NHẬN DẠNG TIẾNG NÓI
5.5.2.2. Phân khung tín hiệu
Kết quả tín hiệu sau khối tiền nhấn tín hiệu là một khung tín hiệu s n gồm các
khung có N mẫu, trong ó các khung cạnh nhau cách biệt nhau M mẫu. Hình 5.5 mô tả các
khung tín hiệu trong trƣờng hợp M=N/3. Ta thấy, khung thứ nhất gồm N mẫu, khung thứ
hai bắt ầu sau khung thứ nhất M mẫu và có chung N-M mẫu với khung thứ nhất. Tƣơng
tự nhƣ vậy, khung thứ 3 bắt ầu sau khung thứ nhất 2M mẫu hay bắt ầu sau khung thứ hai
M mẫu và có chung với khung thứ nhất và thứ hai tƣơng ứng là N-2M và N-M mẫu. Quá
trình này ƣợc tiếp tục cho ến khi toàn bộ tín hiệu của một hoặc một số khung ƣợc phân
khung xong. Dễ dàng thấy rằng, nếu M N thì các khung cạnh nhau sẽ có sự bao trùm lẫn
nhau, và kết quả là các ƣớc lƣợng phổ của LPC sẽ có sự tƣơng quan giữa các khung; nếu
M<khác, nếu M>N, khi ó sẽ không có sự bao trùm lẫn nhau giữa các khung; trong thực tế khi
ó một phận tín hiệu sẽ bị mất hoàn toàn (tức là không xuất hiện trong bất cứ một khung
phân tích nào), và khi ó tính tƣơng hỗ giữa các ƣớc lƣợng phổ LPC thu ƣợc của các khung
cạnh nhau sẽ chứa một thành phần nhiễu mà biên ộ của nó tăng khi M tăng (tức là khi số
lƣợng mẫu tín hiệu bị bỏ qua càng nhiều). Đây là trƣờng hợp không thể chấp nhận ƣợc
(intolerable) trong bất cứ phép phân tích LPC nào sử dụng cho hệ thống nhận dạng tín hiệu
tiếng nói. Gọi khung tín hiệu thứ l là x nl ( ) và giả sử có toàn bộ L khung tín hiệu, khi ó: x n l s Ml
n n 0,1,...,N 1; l 0,1,...,L 1 (3.6)
Điều này có nghĩa là khung tín hiệu
ầu tiên x n0( ) bao gồm các mẫu ~ ~ ~ ~
s(0), s(1),, s L( 1); khung tín hiệu thứ hai x nl ( ) bao gồm các mẫu ~s M s M( ), ( ~ ~
1),, s M( N 1); và khung tín hiệu thứ L bao gồm các mẫu ~s M L( ( 1)), s M L( ~
( 1) 1),, s M L( ( 1) N 1); Đối với tín hiệu tiếng nói có tốc ộ lấy mẫu 6.67kHz
thì giá trị của N và M thƣờng ƣợc chọn tƣơng ứng là 300 và 100, nghĩa là tƣơng ứng với
các khung 45 mili-giây và khoảng cách giữa các khung là 15miligiây. N M N M N 122
Downloaded by Dung Tran (tiendungtr12802@gmail.com) lOMoARcPSD| 36086670
CHƢƠNG 5. NHẬN DẠNG TIẾNG NÓI Hình 5.5
Phân khung tín hiệu trong phân tích LPC cho nhận dạng tiếng nói
5.5.2.3. Lấy cửa sổ tín hiệu
Bƣớc tiếp theo trong quá trình xử lý phân tích LPC là việc lấy cửa sổ của các khung
tín hiệu riêng rẽ nhằm mục ích giảm nhỏ sự không liên tục của tín hiệu ở phần ầu và cuối
mỗi khung. Điều nãy cũng tƣơng tự nhƣ ã ề cập trong phần giới thiệu chung khi xem xét
trong miền tần số: việc lấy cửa sổ tín hiệu nhằm mục ích cắt bỏ tín hiệu về 0 ở phần bắt ầu
và kết thúc của mỗi khung. Giả sử hàm cửa sổ ƣợc ịnh nghĩa là w(n) (0 n N-1), khi ó kết
quả tín hiệu thu ƣợc sau khi lấy cửa sổ là: x nl x nl w n 0 n N 1 (3.7)
Hàm cửa sổ phổ biến dùng cho phƣơng pháp tự tƣơng quan trong LPC sử dụng trong
các hệ thống nhân dạng tiếng nói là hàm cửa sổ Hamming, trong ó biểu thức hàm ƣợc cho bởi:
w n 0,54 0,46 osc N2 n1 0 n N 1 (3.8)
5.5.2.4. Phân tích tính tự tƣơng quan
Kết quả tự tƣơng quan của mỗi khung tín hiệu sau phép lấy cửa sổ là: 1 l n N m x n x nl l m m 0,1,..., p (3.9) n 0
Trong ó, giá trị tự tƣơng quan cao nhất p là bậc của phân tích LPC. Thông thƣờng, p
ƣợc chọn từ 8 ến 16. Cần chú ý ến một lợi ích phụ của việc sử dụng phƣơng pháp tự tƣơng
quan là thành phần tự tƣơng quan bậc 0, tức là l (0), chính là năng lƣợng của khung thứ
l. Năng lƣợng của khung tín hiệu là một tham số quan trọng trong các hệ thống phát hiện tín hiệu tiếng nói.
5.5.2.5. Phân tích LPC
Bƣớc tiếp theo trong quá trình phân tích là phép phân tích LPC, trong ó mỗi khung
của p+1 tham số tự tƣơng quan ƣợc chuyển ổi thành một tập các tham số LPC. Tập các
tham số LPC có thể là tập các hệ số LPC, hoặc tập các hệ số phản ánh, hoặc các hệ số tỉ lệ
log, hoặc các hệ số cepstral, hoặc bất cứ biến ổi mong muốn nào ó từ các tập nêu trên. Việc lOMoARcPSD| 36086670
CHƢƠNG 5. NHẬN DẠNG TIẾNG NÓI
thực hiện biến ổi này thƣờng ƣợc thực hiện bằng cách áp dụng thuật toán Durbin ƣợc diễn
giải nhƣ sau. Để thuận tiện, ta tạm bỏ chỉ số l trong biểu thức r ml ( ) . E 0 l 0 (3.10) L 1 { l i ji 1 l i j } ki j 1 i 1 1 ip (3.11) E i i ki (3.12)
ji ji 1 ki i i j1 (3.13) E i 1 k2 E i 1 (3.14) i
Trong công thức tính tổng của công thức thứ hai ở trên, (3.11), ta bỏ qua trƣờng hợp
i=1. Hệ các phƣơng trình trên ƣợc giải theo phƣơng pháp truy hồi với i=1,2,…, p và kết
quả cuối cùng thu ƣợc là: p am m 1 m p (3.15) km Rcoef (3.16) g log 1 km (3.17) m 1 km
(3.15) là các hệ số LPC, (3.16) là các hệ số phản xạ, và (3.17) là lô-ga-rít các hệ số tỷ lệ diện tích. 124
Downloaded by Dung Tran (tiendungtr12802@gmail.com) lOMoARcPSD| 36086670
CHƢƠNG 5. NHẬN DẠNG TIẾNG NÓI
5.5.2.6. Chuyển ổi các tham số LPC sang các hệ số Cepstral
Một tập tham số quan trọng có thể xây dựng trực tiếp từ tập các tham số LPC là tập các
hệ số cepstral LPC. Công thức xác ịnh sử dụng phép ệ quy ƣợc cho nhƣ sau: c0 ln 2 (3.18) c m 1 m am kc ak m k 1 m p (3.19) k 1 m 1 cm m
k c ak m k m p (3.20) k 1 m
Ở ây, 2 là ộ lợi của việc sử dụng mô hình LPC. Các hệ số cepstral chính là các hệ
số tƣơng ứng với biến ổi Fourier của các giá trị lô-ga-rít của biên ộ phổ. Tập các hệ số
cepstral ƣợc chứng minh là một tập các ặc trƣng áng tin cậy và chắc chắn (robust) hơn tập
các hệ số LPC, hay tập các hệ số phản xạ cũng nhƣ tập các hệ số tỉ lệ log diện tích trong
việc nhận dạng tín hiệu tiếng nói. Thƣờng một biểu diễn gồm Q>p hệ số cepstral ƣợc sử
dụng, trong ó phổ biến Q 3p/2.
5.5.2.7. Lấy trọng các tham số - Parameter Weighting
Trong các hệ số cepstral, các hệ số bậc thấp rất nhạy cảm với ộ dốc (slope) của toàn
dải phổ, trong khi ó các hệ số bậc cao thì lại rất nhạy cảm với nhiễu. Chính vì lý do này,
nó dƣờng nhƣ trở thành một tiêu chuẩn của các phép xử lý là sử dụng lấy trọng số các hệ
số cepstral bằng một hàm cửa sổ nhằm giảm nhỏ các nhạy cảm nói trên. Một cách thông
thƣờng cho việc thay ổi việc sử dụng một cửa sổ cepstral là xem xét biểu diễn Fourier của
lô-ga-rít phổ biên ộ và các ạo hàm lô-ga-rít của phổ biên ộ. Nghĩa là: log S e j c em j m (3.21) m lOMoARcPSD| 36086670
CHƢƠNG 5. NHẬN DẠNG TIẾNG NÓI log S e j m jm c e m j m (3.22)
Thành phần vi phân của lô-ga-rit phổ biên ộ có một tính chất ặc biệt là bất cứ ộ dốc
phổ cố ịnh nào trong lô-ga-rít biên ộ phổ sẽ trở thành một hằng số. Hơn nữa, bất cứ thành
phần ỉnh phổ nào trong lô-ga-rít biên ộ phổ, tức là các formant, ều ƣợc bảo ảm giữ nguyên
trong vi phân của lô-ga-rít biên ộ phổ. Do ó, bằng việc nhân biểu diễn vi phân của lô-ga-
rít biên ộ phổ với -jm, ta ã thực hiện việc thay ổi trọng các tham số. Kết quả ta có: log S e j m
c eˆm j m (3.23) trong ó: ˆ c m m c jm (3.24)
Để có thể ạt ƣợc tính robustness cho các giá trị m lớn, tức là các trọng số nhỏ ở gần
m=Q, và có thể cắt bỏ ƣợc phần tính toán vô ịnh trong công thức (3.23), ta cần phải ƣa ra
một dạng tổng quát hơn ối với các hệ số trọng số:
cˆm wm mc (3.25)
Một phép lấy trọng số thích hợp chính là một bộ lọc thông dải (bộ lọc trong miền cepstral) có dạng: wm 1 Q2 sin Qm 1 m Q (3.26)
Hàm tính toán trọng số cho ở công thức (3.26) có khả năng cắt bỏ phần tính toán vô hạn
và giải nhấn (de-emphasizes) các hệ số cm xung quan m=1 và m=Q.
5.5.2.8. Các ạo hàm Cepstral
Các biểu diễn cepstral của phổ tín hiệu tiếng nói là một biểu diễn thích hợp cho phép
ặc tả ƣợc các tính chất phổ cục bộ của tín hiệu trong một khung tín hiệu phân tích xác ịnh.
Tuy nhiên có thể tăng chất lƣợng của các biểu diễn này bằng các mở rộng các phân tích 126
Downloaded by Dung Tran (tiendungtr12802@gmail.com) lOMoARcPSD| 36086670
CHƢƠNG 5. NHẬN DẠNG TIẾNG NÓI
bao gồm các thông tin về ạo hàm của cepstral theo thời gian (the temporal cepstral
derivative). Thực tế cho thấy rằng cả các ạo hàm cấp một và cấp hai ều mang lại khả năng
làm gia tăng chất lƣợng hoạt ộng của hệ thống nhận dạng tín hiệu tiếng nói. Để ƣa khái
niệm thời gian vào các biểu diễn cepstral, ta kí hiệu hệ số cepstral thứ m ở thời iểm t là cm(
)t . Trong thực tế, thời iểm lấy mẫu t gắn với khung tín hiệu phân tích chứ không phải là
một thời iểm bất kỳ. Việc tính ạo hàm các hệ số cepstral theo thời gian ƣợc thực hiện một
các xấp xỉ nhƣ sau: Đạo hàm theo thời gian của lô-ga-rít biên ộ phổ có biểu diễn chuỗi Fourier tƣơng ứng: log S e j ,t m
cm t t e j m (3.27) t
Do ó, ạo hàm cepstral theo thời gian cũng sẽ ƣợc xác ịnh một cách tƣơng tự. Vì cm(
)t là một biểu diễn thời gian rời rạc (trong ó t là chỉ số khung tín hiệu), ta không thể áp
dụng trực tiếp các vi phân cấp một và cấp hai ể xấp xỉ với các ạo hàm (vì iều này dẫn ến
kết quả nhiễu rất lớn). Do ó, một các tính toán hợp lý là xấp xỉ cm( )t / ( )t bởi một a thức
nội suy trực giao gần úng (an orthogonal polynomial fit), một ƣớc lƣợng bình phƣơng tối
thiểu của các ạo hàm (a least-squared estimate of the derivative), trên toàn khoảng cửa sổ hữu hạn. Nghĩa là: c t m cm t K kcm t k (3.28) t k K
Trong ó, là một hằng số chuẩn hóa thích hợp và (2K+1) là số khung tín hiệu mà
trên ó ta thực hiện việc tính toán. Thông thƣờng, giá trị của K thƣờng ƣợc lấy bằng 3 và
thấy rằng giá trị này thích hợp cho việc tính toán các ạo hàm cấp một. Từ thủ tục tính toán
ở trên, với mỗi khung tín hiệu t, kết quả của phép phân tích LPC là một véc-tơ gồm Q hệ
số cepstral ã ƣợc kể ến trọng và một véc-tơ mở rộng của Q thành phần ạo hàm theo thời gian ƣợc kí hiệu là: o't c tˆ1 ,cˆ2
t ,...,cˆQ t , c tˆ1 , cˆ2
t ,..., cˆQ t (3.29)
Trong công thức (3.29), o 't là một véc-tơ gồm 2Q thành phần và (.)' biểu diễn phép chuyển vị ma trận. lOMoARcPSD| 36086670
CHƢƠNG 5. NHẬN DẠNG TIẾNG NÓI
Một cách tƣơng tự, nếu ta thực hiện việc tính toán các ạo hàm cấp hai 2cm( )t và
thêm các giá trị này vào véc-tơ ot ta sẽ thu ƣợc một véc-tơ mới gồm 3Q thành phần.
5.5.2.9. Bảng các giá trị phổ biến của các tham số trong phân tích LPC
Trong các phân tích tính toán theo phƣơng pháp phân tích LPC, ta thấy rằng các tính
toán phụ thuộc vào số lƣợng các tham số biến số bao gồm: số mẫu trong khung tín hiệu
phân tích N, số mẫu phân cách iểm bắt ầu của các khung liền kề M, bậc của phân tích LPC
p, kích cỡ của véc-tơ cepstral ƣợc xây dựng Q, số lƣợng khung K mà trên ó các ạo hàm
theo thời gian của các hệ số cepstral ƣợc tính toán. Mặc dù mỗi một giá trị của các tham
số vừa kể thay ổi trên một dải rất lớn phụ thuộc vào các hệ thống cụ thể, một số giá trị phổ
biến ối với ba tần số lấy mẫu tƣơng ứng là 6,67kHz, 8kHz và 10kHz ƣợc
gọi là MFCCs (Mel frequency cepstral coefficients). Đầu tiên, tín hiệu tiếng nói ƣợc lọc
bởi một mạch lọc thông cao (high-pass filter) với tần số cắt (cut-off frequency) rất thấp
nhằm loại bỏ thành phần tín hiệu một chiều mà có thể do bộ chuyển ổi ADC tạo ra. Đặc
biệt việc lọc này là cần thiết ể tăng tính chính xác khi thực hiện tính toán năng lƣợng tín
hiệu theo khung trong các phân tích ngắn hạn. Năng lƣợng tín hiệu cũng nhƣ các tham số
cepstral ƣợc tính ối với mọi khung cửa sổ dịch với khoảng dịch dshift=10ms. Do việc cảm 128
Downloaded by Dung Tran (tiendungtr12802@gmail.com) lOMoARcPSD| 36086670
CHƢƠNG 5. NHẬN DẠNG TIẾNG NÓI
nhận âm thanh của con ngƣời theo thang không tuyến tính nên việc tính năng lƣợng tín
hiệu thƣờng là dùng thang lô-ga-rít. Năng lƣợng khung theo lô-ga-rít (logarithmic frame
energy) ƣợc sử dụng nhƣ một thành phần của véc-tơ ặc trƣng tín hiệu. Sau ó một mạch
lọc thông cao khác ƣợc sử dụng ể tiền nhấn tín hiệu nhằm mục ích tăng cƣờng các thành
phần tín hiệu ở vùng tần cao, vùng mà tín hiệu có xu thế có năng lƣợng thấp. Phổ tín hiệu
ngắn hạn ƣợc tính sau ó bằng cách nhân các mẫu của khung tín hiệu với một cửa sổ
Hamming và sử dụng phép biến ổi Fourier nhanh (FFT). Đến ây chỉ có biên ộ phổ ƣợc lấy
ra bởi vì phổ pha ngắn hạn không chứa các thông tin có ích của tín hiệu tiếng nói. Ta biết
rằng, hệ thống cảm nhận âm thanh (auditory) của con ngƣời tích lũy (accumulate) các
năng lƣợng theo những dải chính (critical bands). Dựa vào ặc iểm này, hệ mạch lọc thang
Mel (Mel-scale filterbank) ƣợc sử dụng. Hệ mạch lọc này gồm 23 băng con (subbands).
Các thành phần FFT phổ ƣợc nhân với một hàm tam giác và ƣợc tích lũy vào một vùng
tần số xác ịnh tạo thành một thành phần phổ Mel. Bề rộng của các dải tần tăng dần khi tần
số tăng theo quan hệ tuyến tính và tần số Mel. Với năng lƣợng tín hiệu ngƣời ta tính toán
lô-ga-rít của các phổ Mel. Các thành phần tần Mel cạnh nhau có tính tƣơng quan cao
(fairly correlated). Để trích chọn các thành phần ặc trƣng tƣơng ối ộc tập thống kê với
nhau, ngƣời ta áp dụng phép biến ổi Cosine rời rạc (DCT) cho các lô-ga-rít phổ Mel. Các
ặc trƣng ộc lập thống kê này sẽ tạo thuận lợi cho việc mô hình các ặc tính của tín hiệu
tiếng nói trong các mô hình tham chiếu (reference models) và việc tính toán các ộ tƣơng
ồng trong quá trình so sánh ối chiếu mẫu.
Với phƣơng pháp tiền xử lý theo tiêu chuẩn ƣa ra bởi ETSI thì có 13 hệ số cepstral
ƣợc tính toán bao gồm cả hệ số cepstral thứ 0. Chú ý rằng hệ số cepstral thứ 0 biểu diễn
giá trị trung bình (mean) của lô-ga-rít phổ Mel. Do ó, giá trị này có quan hệ mật thiết với
năng lƣợng khung. Thƣờng thì hoặc là lô-ga-rít năng lƣợng khung ƣợc tính từ tín hiệu
trong miền thời gian hoặc là hệ số cepstral thứ 0 ƣợc sử dụng nhƣ một tham số trong quá
trình nhận dạng tín hiệu tiếng nói. Các véc-tơ ặc trƣng cho việc nhận dạng tiếng nói thƣờng
bao gồm lô-ga-rít năng lƣợng khung và 12 hệ số cepstral C1 ến C12. Để áp dụng các kỹ
thuật thích ghi nhằm nâng cao chất lƣợng hệ thống nhận dạng, ta cần thiết biết tham số C0.
Và do ó C0 thƣờng ƣợc trích ra một cách ặc biệt ể sử dụng cho quá trình huấn luyện, và
C0 trở thành một tham số của HMM. Nghĩa là một tập các hệ số cepstral trong các mẫu
tham chiếu có thể ƣợc biến ổi ngƣợc lại thành phổ Mel. Tuy nhiên cần chú ý rằng thành
phần C0 không ƣợc sử dụng cho quá trình nhận dạng mẫu. lOMoARcPSD| 36086670
CHƢƠNG 5. NHẬN DẠNG TIẾNG NÓI Tín hiệu tiếng nói Bù l ệ ch DC
Ti ề n nh ấ n tín hi ệ u Hàm c ử a s ổ FFT (chi ề u dài N) 0 N/2+1 . Lô-ga- rít năng lƣợ Độ ng khung l ớn biên ộ ph ổ 0 f /kHz 4 Dãy m ạ ch l ọ c Mel 1 23 Log DCT 13 h ệ s ố C0-C13 Năng lƣợ ng Hình 5.6
Sơ ồ kh ố i quá trình phân tích MFCC
Các tham s ố âm h ọ c gi ớ i thi ệ u ph ần trên ƣợ c g ọ i là các tham s ố tĩnh vì chúng ƣợ c
tính t ừ tín hi ệ u ti ế ng nói cho m ộ t khung ng ắ n kho ảng 25ms. Do ó, ể tăng chất lƣợ ng h ệ
th ố ng nh ậ n d ạ ng, m ộ t lo ạ t các tham s ố ộ ng c ần ƣợc quan tâm. Điề u này có th ể ƣợ c
hi ệ n th ự c b ằ ng vi ệc quan sát ƣờ ng bi ến ổ i (contour) c ủ a m ỗ i tham s ố tĩnh theo thờ i
gian và tính toán vi phân (derivative) của các ƣờng dịch chuyển này. Các tham số ƣợc tính
toán theo cách này ƣợc gọi là các hệ số en-ta. Ta có vi phân bậc nhất C ki ( ) của hệ số
cepstral Ci ƣợc tính theo công thức: N j C k i j C k i j (3.30) 130
Downloaded by Dung Tran (tiendungtr12802@gmail.com) lOMoARcPSD| 36086670
CHƢƠNG 5. NHẬN DẠNG TIẾNG NÓI C k i j 1 N j2 j 1
Hệ số N trong công thức (3.30) thƣờng ƣợc chọn bằng 3. Khi ó các hệ số enta có
thể ƣợc tính từ 7 khung. Nghĩa là chúng chứa ựng thông tin về các biểu hiện ộng của tín
hiệu trong khoảng thời gian khoảng 85ms. Một cách tƣơng tự, các vi phân cấp hai cũng
có thể ƣợc tính bằng cách áp dụng (3.30) cho các ƣờng biến ổi của các vi phân cấp một.
Các hệ số thu ƣợc từ các vi phân cấp hai này ƣợc gọi là các hệ số en-ta-en-ta. Thời gian
cho việc tính toán các vi phân cấp hai thƣờng là thấp hơn cho việc tính toán vi phân cấp
một, do ó tổng khoảng thời gian cho việc xác ịnh các hệ số en-ta-en-ta của một oạn tín hiệu
khoảng 150ms. Các hệ số en-ta và en-ta-en-ta ƣợc thêm vào cùng với các tham số tĩnh ể
tạo thành các véc-tơ ặc trƣng. Thông thƣờng, véc-tơ ặc trƣng phổ biến gồm khoảng 39
thành phần bao gồm cả lô-ga-rít năng lƣợng khung và 12 hệ số cepstral từ C1 ến C12.
Để có thể tăng tính nhất quán (robust) của việc trích chọn ặc trƣng tín hiệu khi có
nhiễu nền (background noise) và các hàm truyền ạt không biết trƣớc ngƣời ta sử dụng sơ
ồ trích chọn ƣợc trình bày trong hình 5.7. Đây cũng là sơ ồ tiền xử lý tín hiệu ƣợc tiêu
chuẩn hóa bởi ETSI. Trong sơ ồ này, ngoài khối trích trọng ã ề cập ến ở phần trên, hai khối
xử lý ƣợc thêm vào. Thứ nhất ó là khối giảm nhiễu, nó bao gồm một mạch lọc Wiener hai
tầng (2-stage). Tín hiệu sau khi ƣợc giảm nhiễu ƣợc ƣa vào khối phân tích cepstral nhƣ ã
mô tả. Để giảm nhỏ ảnh hƣởng của các hàm truyền ạt không biết (unknown) ối với các
tham số trích chọn ra, một khối cân bằng mờ (blind equalization) ƣợc sử dụng. Khối này
làm việc trên nguyên lý so sánh phổ tiếng nói với một phổ phẳng và sử dụng thuật toán sai
số trung bình bình phƣơng nhỏ nhất (LMS - Least mean square) ể iều chỉnh bộ lọc cân bằng.
Tín hiệu Giảm nhiễu Phân tích Cân bằng blind Các ặc tiếng nói cepstral trƣng Hình 5.7
Sơ ồ khối cải thiện phƣơng pháp phân tích Cepstral
5.6. GIỚI THIỆU MỘT SỐ PHƢƠNG PHÁP NHẬN DẠNG TIẾNG NÓI
Trong phần này, ta sẽ tìm hiểu sơ lƣợc một số phƣơng pháp sử dụng trong các hệ
thống nhận dạng tín hiệu tiếng nói. Ngoài phần sơ lƣợc về nguyên lý ta cũng sẽ xem xét
ến các iểm mạnh và iểm yếu của mỗi phƣơng pháp. lOMoARcPSD| 36086670
CHƢƠNG 5. NHẬN DẠNG TIẾNG NÓI
Một cách khái quát, có ba hƣớng chính ƣợc sử dụng trong các hệ thống nhận dạng
tiếng nói. Đó là: phƣơng pháp âm thanh - âm vị (acoustic-phonetic); phƣơng pháp nhận
dạng mẫu (pattern recognition) và phƣơng pháp sử dụng trí tuệ nhân tạo.
Phƣơng pháp acoustic-phonetic là phƣơng pháp dựa trên cơ sở lý thuyết âm vị trong
ó giả thiết rằng ngôn ngữ tiếng nói tồn tại một số ơn vị âm vị phân biệt và hữu hạn, và rằng
các ơn vị âm tiết (phonetic) ƣợc ặc tả một cách ầy ủ bởi một tập các tính chất phù hợp với
tín hiệu tiếng nói, hoặc phổ của chúng. Mặc dù các ặc tính âm học của các ơn vị âm tiết
thay ổi rất lớn ối với cả ngƣời nói (speaker) và với các ơn vị âm tiết lân cận (còn gọi là co-
articulation of sound), ta giả thiết rằng những quy luật quản lý sự thay ổi trên có thể suy ra
một cách dễ dàng, có thể học và áp dụng vào các tính huống thực tế. Và do ó, bƣớc ầu tiên
trong việc sử dụng phƣơng pháp acousticphonetic vào việc nhận dạng tín hiệu tiếng nói là
việc phân oạn (segmentation) và gán nhãn. Quá trình này nhằm phân oạn tín hiệu tiếng nói
thành các vùng rời rạc (theo thời gian) trong ó các ặc tính âm học của tín hiệu là ại diện
của một (hoặc vài) ơn vị âm tiết (hoặc các lớp). Sau ó gắn một hoặc nhiều nhãn âm tiết với
mỗi oạn tùy theo các tính chất âm học của oạn ó. Bƣớc tiếp theo trong quá trình nhận dạng
là việc cố gắng quyết ịnh một từ hợp lệ (hoặc một chuỗi từ) từ một dãy các nhãn âm tiết
ƣợc tạo ra từ bƣớc ầu tiên.
Phƣơng pháp nhận dạng mẫu trong nhận dạng tiếng nói là phƣơng pháp trong ó các
mẫu tiếng nói ƣợc sử dụng trực tiếp mà không cần phải xác ịnh rõ ràng ặc trƣng (theo
nghĩa ặc trƣng âm học) và không cần quá trình phân oạn. Cũng giống nhƣ mọi phƣơng
pháp nhận dạng mẫu khác, phƣơng pháp này gồm hai bƣớc: huấn luyện các mẫu tín hiệu
tiếng nói; nhận dạng các mẫu thông qua việc so sánh các mẫu. Thông tin (hiểu biết -
knowledge) về tín hiệu tiếng nói ƣợc ƣa vào hệ thống trong quá trình huấn luyện hệ thống.
Nguyên lý của việc này là nếu có ủ các phiên bản của một mẫu cần nhận dạng (mẫu của
âm, của từ, hoặc của một cụm từ ...) trong tập dùng ể huấn luyện, thì quá trình huấn luyện
sẽ có thể ặc tả một cách chính xác các ặc tính âm học của mẫu (mà không cần quan sát
hoặc thông tin của bất cứ mẫu nào khác trong quá trình huấn luyện). Quá trình so sánh
mẫu thực hiện việc so sánh trực tiếp tín hiệu tiếng nói chƣa biết (tín hiệu tiếng nói cần
nhận dạng) với mỗi một mẫu học ƣợc trong quá trình huấn luyện và phân loại tín hiệu
tiếng nói chƣa biết theo ộ tƣơng hợp với mẫu. Phƣơng pháp nhận dạng mẫu có các ƣu iểm: - Sử dụng ơn giản.
- Nhất quán và không thay ổi với các bộ từ vựng, ngƣời sử dụng, tập các ặc trƣng
khác nhau. Điều này cho phép thuật toán có thể áp dụng một cách rộng rãi với các loại ơn
vị tín hiệu tiếng nói (từ các ơn vị phonemelike, từ, cụm từ hoặc câu), các bộ từ vựng, số
ông ngƣời nói, các môi trƣờng nền khác nhau... 132
Downloaded by Dung Tran (tiendungtr12802@gmail.com) lOMoARcPSD| 36086670
CHƢƠNG 5. NHẬN DẠNG TIẾNG NÓI
- Có chất lƣợng tốt. Ngƣời ta ã chỉ ra rằng việc sử dụng phƣơng pháp nhận dạng
mẫu trong nhận dạng tiếng nói luôn cho phép hệ thống hoạt ộng tốt ối với bất kỳ nhiệm vụ
nào với yêu cầu công nghệ vừa phải.
Phƣơng pháp sử dụng trí tuệ nhân tạo trong nhận dạng tín hiệu tiếng nói là phƣơng
pháp lai ghép giữa hai phƣơng pháp kể trên. Phƣơng pháp này cố gắng cơ chế hóa thủ tục
nhận dạng tƣơng tự nhƣ cách thức con ngƣời áp dụng trí tuệ vào việc quan sát
(visualizing), phân tích và cuối cùng là ra quyết ịnh trên các ặc tính âm học o lƣờng ƣợc.
Đặc biệt một trong các kỹ thuật ƣợc sử dụng cho các phƣơng pháp thuộc lớp phƣơng pháp
này là việc sử dụng hệ chuyên gia ể phân oạn và gán nhãn. Bằng cách này, bƣớc khó khăn
nhất và quan trọng nhất trong quá trình nhận dạng có thể ƣợc thực hiện không chỉ với các
thông tin âm học nhƣ trong các phƣơng acoustic-phonetic thuần túy; học và thích ứng
theo thời gian; sử dụng mạng nơ-ron cho việc học các mối quan hệ giữa các âm tiết và tất
cả các ầu vào ã biết cũng nhƣ cho việc phân biệt sự giống nhau giữa các lớp âm.
Việc sử dụng mạng nơ-ron có thể tạo ra một phƣơng pháp cấu trúc riêng rẽ cho việc
nhận dạng tín hiệu tiếng nói hoặc có thể ƣợc coi nhƣ một cấu trúc có thể thực thi ƣợc, cấu
trúc mà có thể tích hợp vào một trong các phƣơng pháp vừa kể.
5.6.1 Phƣơng pháp acoustic-phonetic
Hình 5.8 miêu tả sơ ồ khối của một hệ thống nhận dạng tín hiệu tiếng nói sử dụng
phƣơng pháp acoustic-phonetic.
Bộ phát hiện ặc trƣng 1 Tiếng nói ã
s(n) Hệ thống Phân oạ n Phƣơng pháp ƣợc nhận dạng phân tích iều khiển tiếng nói và gán nhãn Dãy mạch lọc Bộ phát hiện LPC ặc trƣng Q Các formant Lƣới âm vị Pitch Lƣới phân oạn Vô thanh/ Hữu thanh Nhãn xác suất Năng lƣợng Các cây quyết ịnh Âm mũi Các phƣơng pháp … phân tích từ loại … Hình 5.8
Sơ ồ khối một hệ thống nhận dạng tiếng nói
theo phƣơng pháp acoustic-phonetic lOMoARcPSD| 36086670
CHƢƠNG 5. NHẬN DẠNG TIẾNG NÓI
Bƣớc ầu tiên trong quá trình xử lý, cũng giống nhƣ trong tất cả các phƣơng pháp
nhận dạng tín hiệu tiếng nói khác, ó là việc phân tích tín hiệu tiếng nói. Việc phân tích tín
hiệu tiếng nói (còn ƣợc gọi là phƣơng pháp o lƣờng các ặc trƣng của tín hiệu) ƣa ra một
biểu diễn phổ phù hợp nhất ối với các ặc trƣng của tín hiệu tiếng nói thay ổi theo thời gian.
Nhƣ ã ề cập, các phƣơng pháp phổ biến nhất trong việc phân tích phổ tín hiệu tiếng nói
trong một hệ thống nhận dạng tín hiệu tiếng nói là phƣơng pháp phân tích LPC. Nói một
cách tổng quát, việc phân tích phổ tín hiệu tiếng nói có nhiệm vụ ƣa ra ƣợc các biểu diễn
phổ thích hợp của tín hiệu tiếng nói theo thời gian.
Bƣớc tiếp theo trong quá trình xử lý là giai oạn phát hiện các ặc trƣng. Ý tƣởng ở
ây là chuyển ổi các o lƣờng phổ thành một tập các ặc trƣng sao cho có thể mô tả một cách
bao trùm các tính chất âm học của các ơn vị âm tiết khác nhau. Trong các ặc trƣng sử dụng
cho việc nhận dạng tín hiệu tiếng nói phải kể ến âm mũi (nasality) tức là sự có mặt hoặc
không của cộng hƣởng khoang mũi, âm xát (frication) tức là sự có mặt hoặc không của
nguồn kích thích ngẫu nhiên trong tín hiệu, vị trí các tần số cộng hƣởng bộ máy phát thanh
(formant) tức là các tần số của ba ỉnh cộng hƣởng ầu tiên, tín hiệu hữu thanh hay vô thanh
tức là nguồn kích thích là tuần hoàn hay không tuần hoàn, và tỉ lệ giữa năng lƣợng của tần
cao và tần thấp. Một số ặc trƣng bản chất là nhị phân (binary) chẳng hạn nhƣ âm mũi, âm
tắc, âm hữu thanh-âm vô thanh, tuy nhiên một số khác là liên tục chẳng hạn nhƣ vị trí các
formant, tỷ số năng lƣợng. Tầng phát hiện các ặc trƣng thƣờng bao gồm một tập các bộ
phát hiện (detector) hoạt ộng song song và sử dụng phép xử lý thích hợp và lô-gic ể ƣa ra
quyết ịnh về sự có mặt hoặc không, hoặc giá trị, của một ặc trƣng. Các thuật toán dùng cho
việc phát biện các ặc trƣng riêng biệt thƣờng là rất phức tạp và chúng thƣờng thực hiện
rất nhiều phép biến ổi tín hiệu, trong một số trƣờng hợp chúng có thể là các thủ tục ƣớc
lƣợng thông thƣờng (trivial).
Bƣớc thứ ba trong quá trình là việc phân oạn và gán nhãn. Hệ thống cố gằng tìm ra
vùng ổn ịnh, vùng mà các ặc trƣng thay ổi rất nhỏ, sau ó gán nhãn cho các vùng vừa ƣợc
phân ra tƣơng ứng sao cho các ặc trƣng trong vùng này tƣơng ồng tốt với các ặc trƣng
tƣơng ứng của các ơn vị âm tiết riêng rẽ. Giai oạn này là giai oạn trung tâm của quá trình
nhận dạng tín hiệu tiếng nói theo phƣơng pháp acoustic-phonetic và nó cũng là một giai
oạn khó khăn nhất ể có thể triển khai một cách tin cậy. Vì lý do ó, nhiều chiến thuật
(strategy) iều khiển ã ƣợc sử dụng ể hạn chế khoảng của các iểm phân oạn cũng nhƣ các
khả năng gán nhãn. Chẳng hạn, ối với việc nhận dạng các từ riêng rẽ, các giới hạn chẳng
hạn nhƣ một từ có chứa ít nhất hai ơn vị âm tiết và không thể nhiều hơn sáu ơn vị âm tiết
cho phép chiến lƣợc iều khiển chỉ cần quan tâm ến các kết quả với khoảng giữa một và
năm khoảng iểm phân oạn. Hơn nữa, chiến thuật gán nhãn có thể tận dụng các giới hạn về
từ vựng (lexical) của các từ ể chỉ cần xem xét các từ với n ơn vị âm tiết, trong ó việc phân 134
Downloaded by Dung Tran (tiendungtr12802@gmail.com) lOMoARcPSD| 36086670
CHƢƠNG 5. NHẬN DẠNG TIẾNG NÓI
oạn cho ta n-1 iểm phân oạn. Những iều kiện hạn chế vừa nêu có vai trò quan trọng cho
phép ta giảm nhỏ không gian tìm kiếm và tăng áng kể chất lƣợng hoạt ộng của hệ thống.
Kết quả của giai oạn phân oạn và gán nhãn thƣờng là một lƣới phoneme (phoneme
lattice). Lƣới này ƣợc sử dụng ể thực hiện thủ tục truy xuất từ vựng (a lexical access
procedure) nhằm xác ịnh ƣợc một từ hoặc một dãy từ tƣơng ồng nhất. Ngoài các kiểu lƣới
phoneme, ngƣời ta còn có thể xây dựng lƣới từ hoặc syllable bằng cách kết hợp các iều
kiện giới hạn từ vựng và cú pháp vào chiến thuật iều khiển vừa ƣợc ề cập ở trên. Chất
lƣợng của việc so sánh tƣơng ồng của các ặc trƣng với các ơn vị âm tiết trong một phân
oạn có thể ƣợc sử dụng ể gán xác suất cho các nhãn và các nhãn này sau ó có thể ƣợc sử
dụng trong thủ tục truy xuất từ vựng thống kê (a probabilistic lexical access procedure).
Đầu ra của hệ thống nhận dạng là một từ hoặc một dãy từ mà tƣơng ồng nhất theo một
khía cạnh ịnh trƣớc với dãy các ơn vị âm tiết trong lƣới phoneme.
5.6.1.1. Bộ phân loại các âm vị nguyên âm
Ta cùng xem xét thủ tục gán nhãn trên một phân oạn ƣợc phân loại nhƣ một nguyên
âm. Sơ ồ hình 5.9 mô tả lƣu ồ phân loại nguyên âm theo phƣơng pháp acoustic-phonetic.
Ta giả sử rằng có ba ặc trƣng ã ƣợc phát hiện trong phân oạn là formant thứ nhất F1,
formant thứ hai F2 và chiều dài của phân oạn D. Thêm nữa ta chỉ xem xét tập các nguyên
âm ổn ịnh (steady), tức là loại bỏ các nguyên âm kép (diphthongs). Để phân loại một phân
oạn nguyên âm trong 10 nguyên âm ổn ịnh, một số phép thử cần phải thực hiện ể phân tách
các nhóm nguyên âm. Nhƣ trình bày trong hình 5.9, phép thử ầu tiên tách các nguyên âm
có tần số F1 thấp (còn gọi là các nguyên âm khuếch tán (diffuse) chẳng hạn nhƣ /i/, /i/, /u/,
...) với các nguyên âm có tần số cao (còn gọi là các nguyên âm gọn (compact) bao gồm /a/,
...). Mỗi tập con này lại ƣợc phân tách thêm dựa vào tần số F2, trong ó các nguyên âm
acute (âm sắc) có tần số F2 cao và các nguyên âm grave (âm huyền) có tần số F2 thấp. Phép
kiểm tra thứ ba dựa trên khoảng thời gian của phân oạn sẽ phân tách các nguyên âm căng
(tense vowel), tức là các nguyên âm có giá trị D lớn với các nguyên âm lax (thả lỏng), tức
là các nguyên âm có giá trị D nhỏ. Cuối cùng, một phép kiểm tra mịn hơn (finer) ối với
các giá trị formant ể phân tách các nguyên âm chƣa phân tách còn lại tạo ra lớp các nguyên
âm bằng (flat) tức là các nguyên âm có F1+F2 lớn hơn một ngƣỡng T nào ó và các nguyên âm ơn giản
(plain) ( các nguyên âm có F1+F2 nằm dƣới một ngƣỡng T nào ó)
Cần chú ý rằng, có một số mức ngƣỡng ƣợc sử dụng trong bộ phân loại nguyên âm.
Các mức ngƣỡng này thƣờng ƣợc xác ịnh bằng thực nghiệm sao cho có thể tăng tối a tính
chính xác của phép phân loại trên một tập tín hiệu tiếng nói cho trƣớc. lOMoARcPSD| 36086670
CHƢƠNG 5. NHẬN DẠNG TIẾNG NÓI
Các ặc trƣng củ a nguyên âm Compact/Diffuse F ( 1 cao/ ấ F1 th p) ʌ ɔ iIeUu Acute/ Grave Acute/ Grave (F 2 cao/F2 th ấ p) (F 2 cao/F2 th ấ p) ʌ ɔ iIe Uu Tense/Lax Tense/Lax Tense/Lax Tense/Lax ( Dài/Ng ắ n) (Dà i/Ng ắ n) (Dà i/Ng ắ n) ( Dài/Ng ắ n) ɔ ʌ ie I u U Flat/Plain Flat/Plain ( F1+F2>T/F1+F2 (F 1+F2>T/F1+F2 ɔ e i Hình 5.9
M ột phƣơng pháp ơn giả n phân lo ạ i nguyên âm ti ế ng Anh
5.6.1.2. Phân lo ạ i âm thanh ti ế ng nói
Vi ệ c phân lo ạ i nguyên âm ch ỉ là m ộ t ph ầ n nh ỏ trong quá trình gán nhãn âm ti ế t c ủ a
phƣơng pháp nhậ n d ạ ng tín hi ệ u ti ế ng nói acoustic-phonetic. V ề m ặ t lý thuy ế t, ta c ầ n
phải có một phƣơng pháp phân loại một phân oạn bất kỳ nào ó thành một hoặc nhiều hơn
một trong số hơn 40 ơn vị âm tiết ƣợc thảo luận trƣớc ây. Trong phần này ta xem xét một
bài toán phân loại ơn giản hơn nhằm phân loại một phân oạn tiếng nói thành một hoặc một
số lớp tín hiệu tiếng nói, chẳng hạn nhƣ các âm vô thanh ngắt (unvoiced stop), âm hữu
thanh ngắt (voiced stop), âm vô thanh xát (unvoiced fricative). Ta biết rằng không tồn tại
một thủ tục ơn giản hoặc tổng quát ƣợc chấp nhận rộng rãi ể thực hiện tác vụ này, tuy vậy,
hình 5.10 mô tả một phƣơng pháp ơn giản trực giác ể hoàn thành việc phân loại nhƣ vậy. 136
Downloaded by Dung Tran (tiendungtr12802@gmail.com) lOMoARcPSD| 36086670
CHƢƠNG 5. NHẬN DẠNG TIẾNG NÓI Âm thanh/ Kho ả ng l ặ ng Kho ả ng l ặ ng Âm thanh H ữ u thanh/ Vô thanh Phía trƣớ c là Kho ả ng l ặ ng Vô thanh kho ả ng l ặ ng/ âm H ữ u thanh Âm thanh Cao T ầ n s ố cao/ th ấ p Th ấ p Kho ả ng l ặ ng Phía trƣớ c là kho ả ng l ặ ng/ âm Âm thanh Nguyên âm/ Nguyên âm Phân lo ạ i Ph ụ âm nguyên âm Ph ụ âm Hình 5.10
Phƣơng pháp này sử d ụ ng m ộ t cây nh ị phân ể ra quy ết ị nh các l ớ p tín hi ệ u khác nhau. Quy ết ịnh ầ
u tiên là phân chia l ớ p âm thanh/kho ả ng l ặ ng (sound/silence). Ở
quy ết ịnh này các ặc trƣng tín hiệ u ti ế ng nói (v ề cơ bản là năng lƣợng trong trƣờ ng h ợ p
này) ƣợ c so sánh v ớ i m ột ngƣỡng ã ƣợ c l ự a ch ọ n, các tín hi ệ u kho ả ng l ặng ƣợ c tách
Phƣơng pháp phân loại âm thanh tiếng nói dựa vào cây nhị phân
ra nếu nhƣ phép thử là âm ối với âm thanh tiếng nói. Quyết ịnh thứ hai là việc phân lớp
các âm hữu thanh và vô thanh (cơ sở dựa trên việc xuất hiện tính tuần hoàn của tín hiệu
trong phân oạn ang xét). Kết quả của quyết ịnh này là các âm vô thanh ƣợc tách khỏi các
âm hữu thanh. Bƣớc tiếp theo là thực hiện một phép thử ể phân tách các phụ âm vô thanh
ngắt (unvoiced stop consonants) khỏi các phụ âm vô thanh xát (unvoiced fricatives). Bằng
phép thử tần số cao thấp/tần số thấp (năng lƣợng), ta có thể phân tách các âm hữu thanh
xát (voiced fricatives) khỏi các âm hữu thanh. Các âm hữu thanh ngắt (voiced stop) có thể
ƣợc phân tách bằng cách kiểm tra xem âm vị trƣớc ó có phải là yên lặng (hoặc gần giống
yên lặng). Cuối cùng một phép kiểm tra phổ nguyên âm/phụ âm ƣợc tiến hành (tìm kiếm
khe phổ) nhằm tách các nguyên âm khỏi các phụ âm. lOMoARcPSD| 36086670
CHƢƠNG 5. NHẬN DẠNG TIẾNG NÓI
Thủ tục phân tách nguyên âm ƣợc trình bày trong hình 5.9 có thể ƣợc sử dụng thêm
nhƣ một phép phân loại mịn các nguyên âm.
Chú ý là thủ tục phân loại ề cập trên và minh hoạ trong hình 5.10 chỉ mang tính minh
họa sơ lƣợc và có nhiều lỗi. Chẳng hạn, một số âm hữu thanh ngắt không phải bắt ầu bằng
khoảng lặng hoặc âm giống khoảng lặng. Một vấn ề nữa là thủ tục minh họa không ƣa ra
ƣợc một cách nào có thể phân biệt các âm kép (diphthongs) từ các nguyên âm.
5.6.1.3. Một số tồn tại trong phƣơng pháp nhận dạng acoustic-phonetic
Có rất nhiều vấn ề tồn tại trong phƣơng pháp nhận dạng tín hiệu tiếng nói acoustic-
phonetic. Những vấn ề này làm cho phƣơng pháp thiếu sự thành công trong các hệ thống
nhận dạng tín hiệu tiếng nói thực tế. Trong các tồn tại phải kể ến là: 1.
Phƣơng pháp này yêu cầu một khối lƣợng thông tin lớn (extensive) về các
tính chất âm học của các ơn vị âm tiết. Những thông tin này thƣờng là không ầy ủ và
không sẵn sàng ngoại trừ những trƣờng hợp ơn giản. 2.
Việc chọn các ặc trƣng ƣợc thực hiện chủ yếu dựa trên các xem xét ad hoc.
Với hầu hết các hệ thống, việc chọn các ặc trƣng dựa trên các nhận thức chứ không phải
tối ƣu theo một tiêu chí ịnh sẵn và có nghĩa (a well-defined and meaningful sense) 3.
Thiết kế các bộ phân loại âm thanh cũng không phải là các thiết kế tối ƣu.
Phƣơng pháp ad hoc thƣờng ƣợc sử dụng ể xây dựng các cây nhị phân quyết ịnh. Gần ây,
các phƣơng pháp cây hồi quy (regression) và phân loại (CART) ƣợc sử dụng thay thế ể
cho phép các cây quyết ịnh nhất quán hơn. Tuy vậy, vì việc lựa chọn các ặc trƣng chủ yếu
là cận tối ƣu, các thực thi tối ƣu của CART thƣờng ít khi ạt ƣợc. 4.
Không tồn tại một thủ tục ịnh sẵn và tự ộng nào cho việc iều chỉnh phƣơng
pháp (chẳng hạn nhƣ chỉnh các ngƣỡng quyết ịnh, ...) trên các tín hiệu ƣợc gán nhãn thực.
Thực tế, thậm chí còn không có một phƣơng pháp lý tƣởng của việc gán nhãn tín hiệu
tiếng nói huấn luyện một cách nhất quán và ƣợc sự ồng ý rộng rãi của các chuyên gia ngôn ngữ học.
Do các tồn tại nêu trên, mặc dù phƣơng pháp nhận dạng acoustic-phonetic là một ý
tƣởng khá thú vị nhƣng cần có nhiều nghiên cứu hiểu biết hơn nữa ể có thể thực hiện
thành công các hệ thống nhận dạng thực tế dựa trên phƣơng pháp này.
5.6.2 Phƣơng pháp nhận dạng mẫu thống kê
Hình 5.11 mô tả sơ ồ khối một hệ thống nhận dạng sử dụng phƣơng pháp nhận dạng mẫu. 138
Downloaded by Dung Tran (tiendungtr12802@gmail.com) lOMoARcPSD| 36086670
CHƢƠNG 5. NHẬN DẠNG TIẾNG NÓI
Hình 5.11 Sơ ồ khối của một hệ thống nhận dạng sử
dụng phƣơng pháp nhận dạng mẫu Phƣơng pháp nhận dạng mẫu bao gồm bốn bƣớc: 1.
Đo lƣờng các ặc trƣng, trong ó một dãy các phép o lƣờng ƣợc thực hiện
trên tín hiệu vào ể ịnh ra các mẫu cần thử. Đối với tín hiệu tiếng nói, các o lƣờng ặc trƣng
thƣờng là các ầu ra của một số phƣơng pháp phân tích phổ nào ó, chẳng hạn bộ phân tích
mạng (dãy) mạch lọc, một bộ phân tích LPC, hoặc là một phân tích DFT. 2.
Huấn luyện mẫu, trong ó một hoặc nhiều mẫu kiểm tra tƣơng ứng với các
âm thanh tín hiệu tiếng nói của cùng một lớp ƣợc sử dụng ể tạo ra một mẫu ại diện của
các ặc trƣng của lớp ó. Mẫu kết quả thu ƣợc, thƣờng ƣợc gọi là mẫu tham khảo (hoặc
tham chiếu), có thể trở thành một ví dụ (examplar) hoặc một mẫu (template) ƣợc suy ra
(derived) từ một số phƣơng pháp tính trung bình hoặc có thể trở thành một mô hình ặc tả
tính thống kê của các ặc trƣng của mẫu tham khảo. 3.
Phân loại mẫu, trong ó mẫu cần kiểm tra chƣa biết ƣợc so sánh với mỗi lớp
(âm) mẫu tham khảo và một o lƣờng ộ tƣơng ồng (khoảng cách) giữa mẫu kiểm tra và
mỗi mẫu tham khảo ƣợc tính toán. Để so sánh các mẫu tín hiệu tiếng nói (các mẫu bao
gồm một dãy các véc-tơ phổ), ta cần cả o lƣờng khoảng cách cục bộ, với khoảng cách cục
bộ ƣợc ịnh nghĩa là khoảng cách phổ giữa hai véc-tơ phổ ƣợc xác ịnh rõ, và một thủ tục
sắp xếp thời gian toàn cục (a global time alignment procedure) (thƣờng ƣợc gọi là một
thuật toán chỉnh (chỉnh lệch - warping) thời gian ộng) nhằm bù lại sự khác biệt tốc ộ tiếng
nói (tỷ lệ thời gian) của hai mẫu. 4.
Quyết ịnh lô-gic, trong ó iểm số về tính tƣơng ồng của mẫu tham chiếu ƣợc
sử dụng ể quyết ịnh xem mẫu tham chiếu nào (hoặc có thể một dãy mẫu tham chiếu) tƣơng
ồng nhất với mẫu kiểm tra chƣa biết.
Các yếu tố phân biệt các phƣơng pháp nhận dạng mẫu khác nhau là các kiểu o lƣờng
ặc trƣng, sự lựa chọn các mẫu (template) hoặc các mô hình cho các mẫu tham chiếu, và
phƣơng thức ƣợc sử dụng ể tạo các mẫu tham chiếu và phân loại các mẫu kiểm tra chƣa biết.
Các iểm mạnh và iểm yếu của phƣơng pháp nhận dạng mẫu có thể kể ến: 1.
Chất lƣợng của hệ thống nhận dạng theo phƣơng pháp nhận dạng mẫu nhạy
cảm (sensitive) với số lƣợng dữ liệu huấn luyện ể tạo ra lớp các mẫu tham chiếu; thông
thƣờng, càng huấn luyện, chất lƣợng của hệ thống càng cao với mọi tác vụ. lOMoARcPSD| 36086670
CHƢƠNG 5. NHẬN DẠNG TIẾNG NÓI 2.
Các mẫu tham chiếu nhạy cảm với môi trƣờng tiếng nói và các tính chất
truyền dẫn của phƣơng tiện truyền dẫn ể tạo tiếng nói; iều này là bởi vì các ặc tính phổ tín
hiệu tiếng nói thƣờng dễ bị ảnh hƣởng bởi quá trình truyền dẫn và nhiễu nền. 3.
Vì không có thông tin tiếng nói cụ thể ƣợc sử dụng một cách rõ ràng
(explicitly) trong hệ thống, phƣơng pháp này tƣơng ối trơ (insensitive) ối với việc chọn
các từ vựng, các tác vụ, cú pháp, và các tác vụ ngữ nghĩa. 4.
Khối lƣợng tính toán cho cả quá trình huấn luyện mẫu và phân loại mẫu
thƣờng tỷ lệ thuận với số mẫu cần ƣợc huấn luyện hoặc ƣợc nhận dạng; do ó việc tính
toán cho một số lƣợng lớn lớp tín hiệu âm có thể và thƣờng trở lên không thể thực hiện ƣợc (prohibitive) 5.
Bởi vì hệ thống trơ với lớp âm thanh, các kỹ thuật cơ bản có thể áp dụng
cho nhiều lớp tín hiệu tiếng nói, bao gồm các cụm từ, từ hoàn chỉnh, hoặc các ơn vị con
của từ (sub-word). Do ó, ta sẽ thấy cách một tập cơ bản các kỹ thuật ƣợc phát triển cho
một lớp âm (chẳng hạn cho các từ) có thể ƣợc áp dụng trực tiếp cho các lớp âm khác
(chẳng hạn cho các ơn bị sub-word) mà không cần thay ổi hoặc thay ổi rất ít ối với thuật toán. 6.
Có thể dễ dàng (straightforward) kết hợp các iều kiện hạn chế cú pháp (và
thậm chí cả ngữ nghĩa) một cách trực tiếp vào cấu trúc nhận dạng mẫu. Bằng cách ó có thể
tăng tính chính xác của việc nhận dạng và giảm nhỏ khối lƣợng tính toán.
5.6.3 Phƣơng pháp sử dụng trí tuệ nhân tạo
Ý tƣởng cơ bản của phƣơng pháp nhận dạng tín hiệu tiếng nói sử dụng trí tuệ nhân
tạo là biên dịch và kết hợp thông tin (hiểu biết) từ nhiều nguồn thông tin và dùng nó ể giải
bài toán. Do ó, chẳng hạn, phƣơng pháp sử dụng trí tuệ nhân tạo việc phân oạn và gán nhãn
có thể ƣợc gia tăng (augment) việc sử dụng thông tin âm học tổng quát với thông tin về
phonemic, thông tin về từ vựng, thông tin về cú pháp, thông tin về ngữ nghĩa, và thậm chí
cả các thông tin thực dụng (pragmatic knowledge). Để hiểu rõ, ta ịnh nghĩa các nguồn thông tin khác nhau nhƣ sau:
- Thông tin âm học là các dữ kiện (evidence) các âm thanh (các ơn vị âm tiết ịnh
nghĩa sẵn) ƣợc nói trên cơ sở các o lƣờng phổ và sự có mặt hoặc không của ặc trƣng.
- Thông tin từ vựng (lexical) là các thông tin về sự kết hợp giữa các dữ kiện âm học
ể tạo thành các cấu trúc từ và ƣợc cụ thể hóa bởi một bộ từ vựng ánh xạ các âm thanh vào
các từ (hoặc tƣơng ứng tách các từ thành các âm tƣơng ứng).
- Thông tin cú pháp là các thông tin về sự kết hợp của các từ ể tạo thành một dãy úng
ngữ pháp (theo một mô hình ngôn ngữ nào ó) chẳng hạn nhƣ các câu hoặc các cụm từ. 140
Downloaded by Dung Tran (tiendungtr12802@gmail.com) lOMoARcPSD| 36086670
CHƢƠNG 5. NHẬN DẠNG TIẾNG NÓI
- Thông tin ngữ nghĩa (semantic) là sự hiểu thông tin nhằm có thể ánh giá ƣợc các
câu hoặc các cụm từ mà nhất quán với tác vụ ang ƣợc thực hiện hoặc nhất quán với các
câu ã ƣợc giải mã trƣớc ó.
- Thông tin thực dụng là các thông tin cho phép có khả năng suy diễn (inference) cần
thiết nhằm giải quyết trƣờng hợp có sự mập mờ về nghĩa dựa trên hiểu biết rằng các từ
hoặc cụm từ nào thƣờng ƣợc dùng nhiều hơn.
Để hiểu úng về các khái niệm nguồn thông tin vừa ề cập cũng nhƣ hạn chế của chúng,
chúng ta xem xét các câu tiếng Anh sau:
1. Go to the refrigerator and get me a book. 2. The bears killed the rams.
3. Power plants colorless happily old.
4. Good ideas often run when least expected.
Ta thấy rằng, câu ầu tiên là một câu úng về mặt cú pháp nhƣng không nhất quán về
mặt ngữ nghĩa, sách không ƣợc mong chờ ể ở tủ lạnh. Câu thứ hai tùy thuộc vào ngữ cảnh
mà có nghĩa khác nhau. Ví dụ nếu ngữ cảnh là ở rừng thì nó miêu tả sự kiện gấu giết cừu,
tuy nhiên nếu ta ang nói ến bóng á có thể hiểu là ội có tên là những con gấu ã chiến thằng
ội có tên là những con cừu. Câu thứ ba thì hoàn toàn không úng cú pháp cũng nhƣ không
có nghĩa. Câu thứ tƣ không nhất quán về mặt ngữ nghĩa, tuy nhiên theo hiểu biết thực
dụng có thể ơn giản thay ổi "run" thành "come" thì sẽ có nghĩa mặc dù có chú khác biệt về mặt âm tiết.
Việc kết hợp các iều kiện hạn chế của các nguồn thông tin vừa kể sẽ cho phép hệ
thống nhận dạng tín hiệu tiếng nói hoạt ộng với chất lƣợng cao hơn. Có nhiều cách kết
hợp các nguồn thông tin vừa kể vào một hệ thống nhận dạng. Phƣơng pháp ầu tiên phổ
biến nhất có thể kể ến là bộ xử lý "bottom-up" ƣợc trình bày trong hình 5.12. lOMoARcPSD| 36086670
CHƢƠNG 5. NHẬN DẠNG TIẾNG NÓI Đơn vị ti ế ng nói X ử lý tín hi ệ u H ữ u thanh/ Vô thanh/ Trích ch ọn ặc trƣng Kho ả ng l ặ ng Phân oạ n Gán nhãn
Các lu ậ t phân lo ạ i âm H ợ p âm Các lu ậ t dãy âm Ki ể m tra t ừ Truy xu ấ t t ừ v ự ng Ki ể m tra t ừ Mô hình ngôn ng ữ Đơn vị ti ế ng nói ã ƣợ c nh ậ n d ạ ng Hình 5.12
Phƣơng pháp tích hợp “bottom-up” của hệ thống nhận dạng tiếng nói
Trong phƣơng pháp "bottom-up", các xử lý cấp thấp nhất (chẳng hạn nhƣ trích chọn
ặc trƣng, giải mã âm tiết, ...) ƣợc thực hiện trƣớc các phép xử lý cấp cao ( giải mã từ vụng,
mô hình ngôn ngữ, ...) theo một thứ tự nối tiếp sao cho iều kiện hạn chế của mỗi bƣớc xử
lý là nhỏ nhất có thể. Một phƣơng pháp khác là phƣơng pháp xử lý "topdown". Trong
phƣơng pháp này mô hình ngôn ngữ tạo ra các giả thuyết từ (word hypotheses) phù hợp
với tín hiệu tiếng nói, và tiếp theo là các câu với cú pháp và ngữ nghĩa có nghĩa ƣợc xây
dựng dựa trên số iểm ánh giá sự tƣơng ồng các từ. Sơ ồ phƣơng pháp xử lý "top-down"
ƣợc trình bày trong hình 5.13. Một phƣơng pháp thứ ba phải kể ến là phƣơng pháp
"blackboard", ƣợc mô tả trong hình 5.14. Ở phƣơng pháp này, tất các các nguồn kiến thức
ƣợc xem xét một các ộc lập, một lƣợc ồ giả thiêt-vàkiểm tra có nhiệm vụ thực hiện việc
thông tin giữa các nguồn thông tin. Mỗi nguồn thông tin là một nguồn iều khiển dữ liệu
dựa trên sự xuất hiện của các mẫu trên "blackboard" 142
Downloaded by Dung Tran (tiendungtr12802@gmail.com) lOMoARcPSD| 36086670
CHƢƠNG 5. NHẬN DẠNG TIẾNG NÓI
mà tƣơng ồ ng v ớ i các m ẫu (template) ƣợc quy ị nh b ở i ngu ồn thông tin ó. Hệ th ố ng
ho ạt ộ ng theo ch ế ộ c ận ồ ng b ộ, các hàm ị nh giá, các xem xét s ử d ụ ng và m ộ t chính
sách ánh giá toàn cụ c k ế t h ợ p và lan truy ề n vi ệc ánh giá ở m ọ i m ức ộ . T ạ o ra các Mô hình kh ối ơn vị Ng ữ pháp tác v ụ nh ậ n d ạ ng Ti ế ng nói Phân tích H ệ th ố ng so Các gi ả thi ế t Các gi ả thi ế t Các gi ả thi ế t ặc trƣng sánh ơn vị t ừ v ự ng cú pháp ng ữ nghĩa B ộ ki ể m tra/ so sánh ơn vị ti ế ng nói Đơn vị ti ế ng nói ã ƣợ c nh ậ n d ạ ng Hình 5.13
Phƣơng pháp tích hợp “top -down” củ a h ệ th ố ng nh ậ n d ạ ng ti ế ng nói X ử lý âm h ọ c X ử lý t ừ v ự ng B ả ng X ử lý iề u ki ệ n môi trƣờ ng X ử lý ng ữ nghĩa X ử lý cú pháp Từ iển từ lOMoARcPSD| 36086670
CHƢƠNG 5. NHẬN DẠNG TIẾNG NÓI Hình 5.14
Phƣơng pháp tích hợp “blackboard” của hệ thống nhận dạng tiếng nói
5.6.4 Ứng dụng mạng nơ-ron trong hệ thống nhận dạng tiếng nói
Ta biết rằng, có rất nhiều nguồn thông tin (kiến thức) khác nhau cần ƣợc thiết lập
trong hệ thống nhận dạng tín hiệu tiếng nói sử dụng giải pháp trí tuệ nhận tạo. Do vậy,
phƣơng pháp sử dụng trí tuệ nhân tạo có hai khái niệm chính yếu là tự ộng thu nhận nguồn
thông tin (khả năng học) và khả năng thích ứng (adaption). Một giải pháp ể thực hiện các
yêu cầu này là sử dụng mạng nơ-ron. Trong phần này ta sẽ thảo luận về ộng lực tại sao
ngƣời ta nghiên cứu về các mạng nơ-ron và cách mà con ngƣời ã áp dụng mạng nơ-ron
vào hệ thống nhận dạng tín hiệu tiếng nói.
Hình 5.15 là một mô hình một hệ thống hiểu ƣợc tiếng nói con ngƣời. Trong hệ
thống này, các phân tích âm thanh ƣợc dựa một cách không chặt chẽ vào hiểu biết của con
ngƣời vào quá trình xử lý âm trong tai. Các phân tích ặc trƣng khác nhau biểu diễn cho
các quá trình xử lý ở nhiều mức ộ trong các ƣờng dây thần kinh tới não. Các bộ nhớ ngắn
hạn và dài hạn sẽ cho phép iều khiển từ bên ngoài của các quá trình thần kinh ƣợc tiến
hành theo một cách mà cho ến nay con ngƣời chƣa hiểu biết rõ ràng. Cấu trúc tổng quát
của mô hình là một mạng kết nối lan truyền thuận hay còn gọi là mạng nơ-ron. Lƣu trữ dài hạn Bộ nh ớ tạm
Phân tích Phân tích Kết hợp các ặc các ặc Bộ ệm các ặc trƣng âm trƣng âm vị trƣng âm vị Âm thanh ầu vào Sự hiểu tiếng nói con ngƣời Hình 5.15
Sơ ồ khối ý tƣởng của một hệ thống hiểu tiếng nói con ngƣời
Các mạng nơ-ron nhân tạo truyền thống (conventional) là các cấu trúc dùng ể giải
quyết các bài toán liên quan ến các mẫu tĩnh. Do ó, ể có thể áp dụng cho tín hiệu tiếng nói,
một tín hiệu có bản chất ộng, ta cần có một số thay ổi trong các cấu trúc mạng truyền 144
Downloaded by Dung Tran (tiendungtr12802@gmail.com) lOMoARcPSD| 36086670
CHƢƠNG 5. NHẬN DẠNG TIẾNG NÓI
thống. Mặc dù cho ến nay chƣa có một cách úng ắn hoặc chính xác ể giải quyết vấn ề tính
chất ộng của tín hiệu tiếng nói ƣợc biết ến, các nhà nghiên cứu ã ƣa ra một số cấu trúc
chấp nhận ƣợc, trong ó phải kể ến là cấu trúc mạng nơ-ron với thời gian trễ (TDNN - Time
delay neural network) ƣợc mô tả trong hình 5.16. Cấu trúc này mở rộng ầu vào của mỗi
phần tử tính toán ể thêm vào N khung tín hiệu tiếng nói (tức là các véc-tơ phổ sẽ bao trùm
khoảng thời gian N giây, trong ó là khoảng thời gian phân tách giữa các thành phần
phổ cạnh nhau). Bằng việc mở rộng ầu vào tới N khung (trong ó N thƣờng cỡ 15), các loại
bộ phát hiện acoustic-phonetic khác nhau trở thành hiện thực thông qua mạng TDNN.
Một cấu trúc mạng nơ-ron khác cho ứng dụng nhận dạng tiếng nói ƣợc trình bày
trong hình 5.17. C ấ u trúc này k ế t h ợ p khái ni ệ m m ạ ch l ọc tƣơng hợ p (matched filter) v ớ i m ộ t m ạng nơ ron tr -
uy ề n th ống ể gi ả i quy ế t v ấn ề tính ch ất ộ ng c ủ a tín hi ệ u ti ế ng nói.
Các ặc trƣng âm họ c c ủ a tín hi ệ u ti ếng nói ƣợc ƣớc lƣợ ng thông qua ki ế n trúc m ạ ng nơ ron tr -
uy ề n th ố ng; b ộ phân lo ạ i m ẫ u s ử d ụ ng các véc- tơ ặc trƣng âm học ã ƣợ c phát
hi ệ n (v ới ộ tr ễ thích h ợ p) và ch ậ p chúng v ớ i các m ạ ch l ọc tƣơng hợ p v ới các ặc trƣng
âm h ọ c và c ộ ng d ồ n k ế t qu ả theo th ờ i gian. Ở th ời iể m thích h ợp (tƣơng ứ ng v ớ i th ờ i
iể m cu ố i c ủ a m ộ t s ố ơn vị ti ếng nói ƣợ c phát hi ệ n ho ặc ƣợ c nh ậ n d ạng), các ơn vị
ầ u ra di ễ n t ả tín hi ệ u ti ế ng nói. DN uj wj+N ⋮ D1 wj+1 wj ⋮ + F DN ui wi+N ⋮ D1 wi+1 wi lOMoARcPSD| 36086670
CHƢƠNG 5. NHẬN DẠNG TIẾNG NÓI Hình 5.16
Sơ ồ khối một mạng TDNN Hình 5.17
Sơ ồ kh ố i m ộ t h ệ th ố ng k ế t h ợ p m ạng nơ - ron và m ạ ch l ọc tƣơng hợ p cho
vi ệ c nh ậ n d ạ ng ti ế ng nói
Các m ạng nơ - ron ã ƣợ c xem xét và ứ ng d ụ ng r ộ ng rãi trong nhi ều lĩnh vự c b ở i m ộ t s ố lý do sau:
- Các mạng nơ-ron có thể dễ dàng thực thi với cấp ộ rất lớn các tính toán song song.
Điều này là bởi vì cấu trúc mạng nơ-ron là một cấu trúc có tính song song cao của các
thành phần tính toán tƣơng tự nhau và ơn giản.
- Các mạng nơ-ron kế thừa bản chất là một cấu trúc chịu lỗi tốt (fault tolerance). Vì
các thông tin nhúng trong mạng ƣợc trải (lan) ến mọi phần tử tính toán trong mạng, iều
này khiến cho cấu trúc khá trơ (least sensitive) với nhiễu hoặc các lỗi không hoàn hảo bên trong cấu trúc.
- Các trọng số kết nối trong mạng không bị hạn chế là phải cố ịnh, chúng có thể thay
ổi theo thời gian thực ể nâng cao chất lƣợng của hệ thống. Đây chính là khái niệm cơ bản
của việc học thích nghi có tính kế thừa từ cấu trúc của mạng nơ-ron.
- Bởi vì sự không tuyến tính bên trong mỗi phần tử tính toán, một mạng có cấu trúc
ủ lớn có thể xấp xỉ (với sự khác biệt nhỏ bất kỳ) mọi cấu trúc không tuyến tính hoặc hệ
thống ộng không tuyến tính. Nói một cách khác, các mạng nơ-ron cho phép thực hiện các
phép biến ổi không tuyến tính giữa các tập ầu ra và ầu vào bất kỳ và thƣờng trở lên hiệu
quả hơn các phƣơng pháp thực hiện vật lý các biến ổi không tuyến tính khác.
5.6.5 Hệ thống nhận dạng dựa trên mô hình Markov ẩn (HMM)
Hầu hết các hệ thống nhận dạng liên tục hiện nay dựa trên các mô hình Markov ẩn
(HMM). Mặc dù nền tảng của các hệ thống nhận dạng liên tục (CSR) dựa trên HMM có
trƣớc hàng thập kỷ, ến gần ây mới có ƣợc một số tiến bộ trong việc cải thiện công nghệ ể
giảm nhỏ sự phụ thuộc của các giả thiết cố hữu và tính thích ứng các mô hình cho các ứng
dụng và các môi trƣờng nhất ịnh. Các vector ặc trƣng Trích chọn Các từ
Bộ giải mã Tiếng nói ặc trƣng 146
Downloaded by Dung Tran (tiendungtr12802@gmail.com) lOMoARcPSD| 36086670
CHƢƠNG 5. NHẬN DẠNG TIẾNG NÓI
Mô hình Từ iền Mô hình âm thanh phát âm ngôn ngữ Hình 5.18
Sơ ồ cấu trúc một hệ thống nhận dạng tiếng nói dựa trên mô hình HMM
Các thành phần chính của một hệ thống CSR làm việc với bộ từ vựng lớn ƣợc mô
tả trong hình 5.18. Dạng sóng âm thanh ầu vào từ một mi-cờ-rô ƣợc chuyển ổi thành một
dãy có ộ dài cố ịnh các véc-tơ âm y y1,..., yT nhờ một quá trình trích chọn mẫu. Bộ giải
mã sau ó cố gắng tìm kiếm một dãy từ w w1,...,wK có khả năng cao nhất ã tạo ra y . Nói
cách khác, bộ giải mã cố gắng giải bài toán: wˆ argmax p w y| (3.31) w
Tuy nhiên, vì p(wy) rất khó xác ịnh trong thực tế, do ó bằng cách áp dụng công thức Bayes ta có: wˆ argmax
p y w| p w (3.32) w
Độ tƣơng ồng p(yw) ƣợc xác ịnh bằng một mô hình âm và xác suất tiên nghiệm p(w)
ƣợc xác ịnh bằng mô hình ngôn ngữ. Trong thực tế, mô hình âm
(acoustic model) không ƣợc chuẩn hóa và mô hình ngôn ngữ thƣờng ƣợc tỷ lệ bằng một
hằng số ƣợc xác ịnh một cách thực nghiệm và một tham số bất lợi của việc chèn từ ƣợc
thêm vào. Nói cách khác, lô-ga-rít của ộ tƣơng ồng tổng ƣợc tính bằng log( (p yw)) p(w)
p(w), trong ó là giá trị phổ biến trong khoảng 8-20 và phổ biến trong
khoảng từ 0 ến -20. Đơn vị cơ bản của âm ƣợc biểu diễn bởi mô hình âm là âm vị (phone).
Ví dụ từ bat trong tiếng Anh gồm ba âm vị là /b/, /ae/ và /t/. Đối với tiếng Anh cần có
khoảng 40 âm vị nhƣ vậy.
Với mỗi w cho trƣớc, mô hình âm tƣơng ứng ƣợc tổng hợp bằng cách chắp nối các
mô hình âm vị ể tạo ra các từ nhƣ ã ƣợc quy ịnh bằng một từ iển phát âm. Các tham số
của các mô hình âm vị này ƣợc ƣớc lƣợng từ các dữ liệu huấn luyện bao gồm các dạng
sóng tín hiệu và các bản ghi hệ thống chính tả của chúng. Mô hình ngôn ngữ thƣờng là
một mô hình N-gram trong ó xác suất của mỗi từ chỉ phụ thuộc iều kiện vào N-1 thành
phần trƣớc nó. Các tham số của mô hình N-gram ƣợc ƣớc lƣợng bằng cách ếm các tuýp
N trong một tập (corpora: corpus - a collection of recorded utterances used as a basis for lOMoARcPSD| 36086670
CHƢƠNG 5. NHẬN DẠNG TIẾNG NÓI
the descriptive analysis of a language) chữ thích hợp. Bộ giải mã hoạt ộng bằng cách tìm
kiếm qua tất cả các dãy từ có thể, nó sử dụng phƣơng pháp chặt (prune) ể loại bỏ các giả
thiết gần nhƣ không xảy ra và bằng cách ó giữ cho việc tìm kiếm có thể kiểm soát ƣợc.
Khi việc tìm kiếm ến tiến ến phần cuối cùng, dãy từ có sự tƣơng ồng nhất chính là kết quả.
Trong các bộ giải mã hiện ại, thay vì sử dụng các phƣơng pháp vừa nêu, bộ giải mã sinh
ra các lƣới chứa các biểu diễn gọn của hầu hết các giả thiết có khả năng nhất.
5.6.5.1. Trích chọn ặc trƣng
Nhƣ ã ề cập, việc trích chọn ặc trƣng tìm các tạo ra một biểu diễn (thƣờng là dạng
mã hóa) tối ƣu tín hiệu tiếng nói. Quá trình này cũng phải ảm bảo giảm thiểu sự mất mát
thông tin và tạo ra một sự phù hợp tốt nhất với các giả thiết phân tán tạo ra bởi các mô
hình âm. Các véc-tơ ặc trƣng thƣờng ƣợc tính toán trong mỗi khung có ộ dài khoảng 10ms
và sử dụng các hàm cửa sổ phân tích chồng lấn nhau. Phƣơng pháp trích trọn phổ biến
nhất trong các ứng dụng nhận dạng sử dụng mô hình HMM là phƣơng pháp MFCC nhƣ
ã trình bày trong phần trên.
5.6.5.2. Các mô hình âm học HMM
Nhƣ ã ề cập, các từ ƣợc phát ra trong w ƣợc phân tách thành một dãy các âm cơ bản
ƣợc gọi là các âm vị cơ sở. Để cho phép các thay ổi phát âm có thể, ộ tƣơng ồng p(yw) có
thể ƣợc tính trên các phƣơng án phát âm: p y w|
p y | Q p Q | w (3.33) Q
Các bộ nhận dạng thƣờng xấp xỉ công thức này bằng phép tính cực ại do ó các phƣơng
pháp phát âm khác nhau có thể ƣợc giải mã nhƣ thể chúng là các giả thiết từ thay thế. Mỗi Q
là một dãy các phát âm của từ Q1,...,QK trong ó mỗi phƣơng án phát âm là một dãy các âm vị cơ sở Q ( )k ( )k K q1 ,q1 ,.... Khi ó ta có: K p Q | w
p Q k | wk (3.34) k 1
Ở ây p Q w( Kk ) là xác suất từ wk ƣợc phát âm dựa trên dãy các âm vị cơ sở Q. 148
Downloaded by Dung Tran (tiendungtr12802@gmail.com) lOMoARcPSD| 36086670
CHƢƠNG 5. NHẬN DẠNG TIẾNG NÓI
Trong thực tế, chỉ có rất ít số khả năng có thể các phƣơng án phát âm QK cho mỗi từ wk , iều Mô hình 1 2 3 4 5 Markov Dãy vector âm ( ) ( ) ( by ( ) 2 b 3 y 2 by 4 ( ) 2 b y 2 by ) 1 2 2 Y= 1 y y2 3 y y4 Hình 5.19
Mô hình âm v ị cơ sở d ự a trên mô hình HMM
M ỗi âm cơ sở q ƣợ c bi ể u di ễ n b ở i m ộ t mô hình Markov ẩ n m ật ộ liên t ụ c (HMM)
ƣợ c minh h ọ a trong hình 5.19. Trong minh h ọ a này, các tham s ố d ị ch chuy ể n là { } a và
các phân b ố quan sát ầ u ra { ()} b
. Các phân b ố quan sát ầu ra thƣờ ng là s ự pha tr ộ n j
c ủ a các phân b ố chu ẩ n Gausse: M (3.35) by ; , j c jm y jm 1 m jm
này cho phép tổng (3.33) dễ dàng kiểm soát ƣợc. 5 y5 lOMoARcPSD| 36086670
CHƢƠNG 5. NHẬN DẠNG TIẾNG NÓI ij
biểu diễn phân bố chuẩn với giá trị trung bình jm và covariance jm . Số lƣợng
các thành phần trong công thức (3.35) thƣờng lấy trong khoảng 10 ến 20. Vì kích thƣớc
của các véc-tơ âm y thƣờng tƣơng ối lớn, các covariance thƣờng ƣợc giới hạn là các ma
trận ƣờng chéo. Các trạng thái ầu và kết thúc là các trạng thái không phát xạ (nonemitting)
và chúng ƣợc thêm vào nhằm ơn giản hóa quá trình chắp nối các mô hình âm vị ể tạo ra các từ.
Cho trƣớc một HMM tổng hợp với Q ƣợc tạo ra bằng các chắp nối tất cả các âm vị cơ
sở cấu thành, ộ tƣơng ồng âm ƣợc tính bởi: p y Q | p x y Q , | (3.36) X
Trong ó X x(0),..., x T( ) là một dãy các trạng thái trong toàn bộ mô hình tổng hợp và T p x y Q , | ax 0 ,x 1 b ax t x t x t , 1 (3.37) t 1
Các tham số mô hình âm {aij} và {bj ()} có thể ƣợc ƣớc lƣợng một cách hiệu quả từ
tập các bộ huấn luyện bằng phƣơng pháp cực ại kỳ vọng.
5.7. MỘT SỐ ĐẶC ĐIỂM CỦA VIỆC NHẬN DẠNG TIẾNG VIỆT
Việc xây dựng một hệ thống nhận dạng tiếng Việt một cách chính xác với lƣợng từ
vựng lớn và có áp ứng thời gian thực là rất khó khăn vì tính phức tạp của ngôn ngữ. Cùng
một âm vị phát ra bởi nhiều ngƣời sẽ có những ặc iểm về mặt âm học khác nhau. So với
ngôn ngữ của nhiều nƣớc, thì tiếng Việt có sự phân hóa về mặt thổ ngữ tƣơng ối lớn. Có
một sự thay ổi lớn giữa cách phát âm giữa ba miền Bắc, Trung, Nam. Ngay trong một
miền, ở các vùng ịa phƣơng khác nhau cũng có sự phát âm dẫn khác nhau. 150
Downloaded by Dung Tran (tiendungtr12802@gmail.com) lOMoARcPSD| 36086670
CHƢƠNG 5. NHẬN DẠNG TIẾNG NÓI
Thêm nữa, cũng giống nhƣ ngôn ngữ của một số nƣớc khu vực Châu Á, tiếng Việt
có thanh iệu. Sự khác biệt giữa các thanh iệu có khi rất nhỏ khi ƣợc phát âm bởi một số
vùng miền. Chẳng hạn, phía Bắc có sự phát âm s và x tƣơng ƣơng nhau; hoặc dấu “?” và
“~” ƣợc phát âm giống nhau ở vùng Bắc Trung bộ.
Sự phức tạp này khiến cho những phƣơng pháp nhận dạng của các ngôn ngữ khác không
hiệu quả khi áp dụng với tiếng Việt
5.8. CÂU HỎI VÀ BÀI TẬP CUỐI CHƢƠNG 1.
Ý tƣởng cơ bản của phƣơng pháp ối sánh mẫu trong nhận dạng tiêng nói? 2.
Ý tƣởng cơ bản của phƣơng pháp sử dụng mạng nơ-ron trong nhận dạng tiếng nói? 3.
Ý tƣởng cơ bản của việc sử dụng HMM trong nhận dạng tiếng nói? 4.
Sự khác biệt của giác hệ thống nhân dạng tiếng nói: rời rạc và liên tục; nhận
dạng tiếng nói và nhận dạng ngƣời nói? 5.
(Matlab) Sử dụng máy tính cá nhân và phần mềm Matlab (hoặc các ngôn ngữ
lập trình khác) thực hiện các công việc sau:
- Xây dựng hệ thống nhận dạng tiếng nói ơn giản (từ vựng hạn chế) dựa vào: o Mạng nơ-ron o Mô hình HMM lOMoARcPSD| 36086670
CHƢƠNG 5. NHẬN DẠNG TIẾNG NÓI 152
Downloaded by Dung Tran (tiendungtr12802@gmail.com) lOMoARcPSD| 36086670
C 1. MẠNG NƠ - RON
Phụ lục 1: MẠNG NƠ-RON MỞ ĐẦU
Hoạt ộng nghiên cứu về cơ chế hoạt ộng, cấu trúc bộ não con ngƣời ƣợc chú ý khá
sớm. Cùng với sự phát triển của khoa học, chúng ta ã ạt ƣợc một số bƣớc tiến quan trọng
trong lĩnh vực nghiên cứu này. Tuy nhiên, bộ não con ngƣời là một tổ hợp rất phức tạp và
cho ến nay hiểu biết của con ngƣời về kiến trúc và hoạt ộng của não vẫn còn chƣa ầy ủ.
Mặc dù vậy con ngƣời ta tạo ra ƣợc các máy có một số tính năng tƣơng tự não nhờ mô phỏng các ặc iểm:
- Tri thức thu nhận ƣợc nhờ quá trình học
- Tính năng có ƣợc nhờ kiến trúc mạng và tính chất kết nối
Các máy mô phỏng này có tên chung là mạng nơ-ron nhân tạo hay ơn giản là mạng
nơron. Đặc iểm chính của các mạng nơ-ron:
- Phi tuyến. Cho phép xử lý phi tuyến.
- Cơ chế ánh xạ ầu vào - ầu ra cho phép học có giám sát.
- Cơ chế thích nghi. Thay ổi tham số phù hợp với môi trƣờng.
- Đáp ứng theo mẫu huấn luyện.
- Thông tin theo ngữ cảnh.Tri thức ƣợc biểu diễn tuỳ theo trạng thái và kiến trúc của mạng.
- Cho phép có lỗi (fault tolerance). - Phỏng sinh học
CƠ SỞ VỀ MẠNG NƠ-RON
Sơ ồ một mạng nơ-ron ơn giản ƣợc minh họa trong hình A.1. Giả sử có N ầu vào ƣợc
ánh nhãn x x1, 2,..., xN với các trọng số tƣơng ứng là w w1, 2,...,wN . Khi ó quan hệ phi tuyến
ầu vào ầu ra ƣợc xác ịnh nhƣ sau: lOMoARcPSD| 36086670 PHỤ LỤ y f N wi ix i 1
PHỤ LỤC 1. MẠNG NƠ - RON
Trong ó là mức ngƣỡng nội tại hay còn gọi là offset, f (.) là một hàm phi tuyến. 154
Downloaded by Dung Tran (tiendungtr12802@gmail.com) lOMoARcPSD| 36086670 x 1 y1 x2 y2 lOMoARcPSD| 36086670 PHỤ LỤ (a) (b)
Hình A.2: Cấu trúc mạng nơ-ron một tầng (a) và hai tầng (b)
C 1. MẠNG NƠ - RON 8. Mạng hồi quy: 1 x 1 y x2 y2 ⋮ ⋮ xN yM
Hình A.3: C ấ u trúc m ạng nơ ron h - ồ i quy
9. M ạ ng t ự t ổ ch ứ c:
Hình A.4: C ấ u trúc m ạng nơ ron t - ự t ổ ch ứ c (SOM) 3x3 156
Downloaded by Dung Tran (tiendungtr12802@gmail.com) lOMoARcPSD| 36086670
PHỤ LỤC 2. MÔ HÌNH MARKOV ẨN
Phụ lục 2: MÔ HÌNH MARKOV ẨN QUÁ TRÌNH MARKOV
Một quá trình ngẫu nhiên X t( )ƣợc gọi là một quá trình Markov nếu tƣơng lai của một
quá trình với trạng thái hiện tại ã cho không phụ thuộc vào quá khứ của quá trình.
Nói một cách khác, với các thời gian xác ịnh t 1 t2 ... tk tk 1 thì: Pr X t k 1
xk 1 | X t k xk ,..., X t 1 x1 Pr X t k 1
xk 1 | X t k xk1
Các giá trị của X t( ) tại thời iểm t thƣờng ƣợc gọi là trạng thái của quá trình tại thời iểm t.
CHUỖI MARKOV VỚI THỜI GIAN RỜI RẠC
Giả sử X n là một chuỗi Markov với giá trị nguyên và thời gian rời rạc với trạng thái
bắt ầu tại n=0 có hàm phân bố xác suất rời rạc (pmf): p (0) j Pr[X0 j] (j=0,1,…)
Khi ó, hàm mật ộ phân bố xác suất rời rạc hợp của n+1 giá trị ầu tiên của quá trình ƣợc tính bằng:
Pr Xn in,..., X0 i0
Pr Xn in | Xn 1 in 1 ...Pr X1 i1 | X0 i0 Pr X0 i0
Từ công thức trên ta thấy, hàm mật ộ phân bố xác suất hợp rời rạc của một dãy xác ịnh
là tích của xác suất của trạng thái khởi ầu và các xác suất của các dãy con chuyển ổi trạng thái một bƣớc.
Giả sử các xác suất chuyển ổi trạng thái một bƣớc là cố ịnh và không thay ổi theo thời gian, nghĩa là: lOMoARcPSD| 36086670 PHỤ LỤ Pr X n 1 j X| n i aij n
C 2. MÔ HÌNH MARKOV ẨN
Khi ó X n ƣợc nói là có các xác suất chuyển ổi ồng nhất. Khi ó xác suất phân bố
hợp rời rạc cho Xn,..., X0 trở thành: Pr X n in,...,X0 i0
ain 1in ...ai i01 0pi 0
Nhƣ vậy, X n hoàn toàn ƣợc xác ịnh bởi hàm mật ộ phân bố xác suất rời rạc khởi ầu pi ... 00 a a01 02 a ... 10 a 11 a 12 a P a 0 i a 1 i a 2 i
P ƣợ c g ọ i là ma tr ậ n xác su ấ t chuy ể n. Chú ý r ằ ng, t ổ ng c ủ a m ỗ i hàng c ủ a P ph ả i
Hình B.1 minh h ọa sơ ồ m ộ t chu ỗ i Markov r ờ i r ạ c v ớ i 5 tr ạng thái ƣợ c gán
nhãn S – S 5 và các xác su ấ t chuy ển tƣơng ứ ng là nhãn các nhánh ij a .
(0) và ma trận các xác suất chuyển một bƣớc P: bằng 1. 158
Downloaded by Dung Tran (tiendungtr12802@gmail.com) lOMoARcPSD| 36086670
PHỤ LỤC 2. MÔ HÌNH MARKOV ẨN 1
Hình B.1: Minh họa một chuỗi Markov rời rạc với 5 trạng thái MÔ HÌNH MARKOV ẨN
Trong phần trên ta ví dụ về mô hình Markov mà mỗi trạng thái tƣơng ứng với một sự
kiện (vật lý) quan sát ƣợc. Tuy nhiên các mô hình nhƣ vậy có ứng dụng hạn chế trong các
bài toán thực tế. Do ó, mô hình ƣợc mở rộng bao gồm cả những trƣờng hợp việc quan sát
là một hàm xác suất của trạng thái - tức là mô hình là một quá trình thống kê chồng kép
với một quá trình thống kê bên trong mà không quan sát ƣợc (ẩn sâu bên trong), nhƣng
có thể chỉ quan sát ƣợc thông qua một tập các quá trình thống kê khác, các quá trình mà
tạo ra dãy các quan sát ƣợc. Mô hình nhƣ vậy ƣợc gọi là mô hình Markov ẩn (HMM).
Để minh họa, ta xét ví dụ các mô hình tung ồng xu nhƣ sau. Một ngƣời thực hiện việc
tung ồng xu nhƣng không nói cho ta biết anh ta ã làm chính xác những gì. Anh ta chỉ thông
báo cho ta kết quả của mỗi ồng xu lật. Nhƣ vậy, ối với ta, một loạt các thí nghiệm tung
ồng xu ƣợc ẩn dấu, mà chỉ có dãy quan sát ƣợc về nó là dãy các kết quả chẵn và lẻ. Vấn
ề ặt ra làm sao xây dựng một mô hình HMM thích hợp ể mô hình dãy chẵn và lẻ quan sát
ƣợc. Vấn ề ầu tiên là việc quyết ịnh các trạng thái nào trong mô hình tƣơng ứng với và
sau ó là quyết ịnh bao nhiêu trạng thái cần thiết trong mô hình. lOMoARcPSD| 36086670 PHỤ LỤ
Hình B.2: Minh họa ba mô hình Markov có thể ối với thí nghiệm tung ồng xu ẩn
Hình B.2 minh họa 3 trƣờng hợp ví dụ. Trƣờng hợp thứ nhất tƣơng ứng với giả thiết
chỉ một ộng xu không cân ƣợc tung. Mô hình trong trƣờng hợp này là mô hình hai trạng
thái trong ó mỗi trạng thái tƣơng ứng với một mặt của ồng xu. Dễ thấy rằng, mô C 2. MÔ
HÌNH MARKOV ẨN hình Markov trong trƣờng hợp này là quan sát ƣợc. Cũng cần chú ý
rằng, ta có thể sử dụng mô hình Markov một trạng thái trong ó trạng thái tƣơng ứng với
một ồng xu không cân ơn lẻ, và tham số chƣa biết là sự không cân của ồng xu.
Trƣờng hợp thứ hai tƣơng ứng với mô hình hai trạng thái trong ó mỗi trạng thái tƣơng
ứng với một ồng xu không cân khác nhau ƣợc tung. Mỗi trạng thái ƣợc ặc trƣng bởi một
phân bố xác suất của mặt chẵn và mặt lẻ, và các chuyển ổi giữa các trạng thái ƣợc ặc trƣng
bởi một ma trận chuyển trạng thái.
Trƣờng hợp thứ ba tƣơng ứng với thí nghiệm sử dụng ba ồng xu không cân khác nhau,
và việc chọn một trong ba ồng xu này ƣợc dựa trên một sự kiện xác suất.
Với một lựa chọn một trong ba trƣờng hợp trên ể giải thích dãy mặt chẵn và mặt lẻ
quan sát ƣợc, câu hỏi ặt ra là mô hình nào mô phỏng tƣơng ồng nhất với các quan sát thực
tế. Ta thấy rằng, mô hình trong trƣờng hợp một chỉ có một tham số chƣa biết, hay nói
cách khác, bậc tự do chỉ bằng một. Trong khi ó các mô hình trƣờng hợp hai và ba có bậc
tự do tƣơng ứng là 4 và 9. Do ó, với bậc tự do lớn hơn, mô hình HMM lớn hơn sẽ dƣờng
nhƣ có khả năng hơn trong việc mô tả một dãy các thí nghiệm tung xu so với các mô hình
nhỏ hơn. Tuy nhiên cũng cần chú ý, iều nhận xét trên là úng về mặt lý thuyết, trong thực
tế có một số hạn chế với kích thƣớc của mô hình.
Một HMM ƣợc ặc trƣng bởi:
11. Số các trạng thái trong mô hình N. Mặc dù các trạng thái là ẩn, nhƣng với một
số ứng dụng thực tế thƣờng có một số ý nghĩa vật lý gắn với các trạng thái hoặc
một tập các trạng thái của mô hình.
12. Số các ký hiệu quan sát phân biệt với mỗi trạng thái, tức là kích thƣớc bộ chữ rời rạc.
13. Phân bố xác suất chuyển trạng thái P trong ó a ij Pr[Xn 1 S Xj n Si ] , (1 i j,
N). Trong trƣờng hợp ặc biệt trong ó một trạng thái bất kỳ có thể ạt ến bất kỳ
trạng thái nào khác trong một bƣớc duy nhất, ta có a ij
0 với mọi i, j. Với các
loại HMM khác, ta có a ij
0cho một hoặc nhiều hơn một cặp (i,j). 160
Downloaded by Dung Tran (tiendungtr12802@gmail.com) lOMoARcPSD| 36086670
PHỤ LỤC 2. MÔ HÌNH MARKOV ẨN
14. Phân bố xác suất ký hiệu quan sát ở trạng thái j, B {b kj ( )} , trong ó b k j ( )
Pr[v t Xk ( )t S j ], (1 j N,1 k M).
15. Phân bố trạng thái khởi ầu { i} trong ó
i Pr[X1 Si ], (1 j N).
Với các giá trị của N, M, P, B và π cho trƣớc, HMM có thể ƣợc sử dụng nhƣ một
bộ tạo cho một dãy quan sát O O O1 2...OT (với mỗi quan sát Ot là một ký hiệu từ tập v
và T là số các quan sát trong dãy) nhƣ sau:
1. Chọn một trạng thái khởi ầu X 1
Si theo phân bố trạng thái khởi ầu π. 2. Đặt t=1. 3. Chọn O t
vk theo phân bố xác suất ký hiệu ở trạng thái Si , tức là b ki ( ) . t 1
cho tr ạ ng thái S , t ứ c là . j aij
5. Đặ t t=t+1; tr ở l ại bƣớ c 3 n ế u t4. Chuyển sang trạng thái mới X S j theo phân bố xác suất chuyển trạng thái lOMoARcPSD| 36086670 PHỤ LỤ 162
Downloaded by Dung Tran (tiendungtr12802@gmail.com) lOMoARcPSD| 36086670
TÀI LIỆU THAM KHẢO
TÀI LIỆU THAM KHẢO
[1]. John R. Deller, John H. L. Hassen, and John G. Proakis, Discrete-Time
Processing of Speech Signals, Wiley-IEEE Press, 2000.
[2]. Editors: Rainer Martin, Ulrich Heuter and Christiane Antweiler, Advances in
Digital Speech Transmission, Wiley, 2008.
[3]. Lawrence Rabiner and Biing-Hwang Juang, Fundamentals of Speech
Recognition, Prentice-Hall, 1993.
[4]. Editors Jacob Benesty, M. Mohan Sondhi and Yiteng Huang, Handbook of
Speech Processing, Springer-Verlag Berlin, 2008.
[5]. Antonio M. Peinado and Jose C. Segura, Speech Recognition over Digital
Channels: Robustness and Standards, John Wiley \& Sons, 2006.
[6]. John Holmes and Wendy Holmes, Speech Synthesis and Recognition, second
edition, Taylor and Francis, 2001.
[7]. Paul Taylor, Text-to-Speech Synthesis, Cambridge University Press, 2009.
[8]. Lawrence R. Rabiner and Ronald W. Schafer, Introduction to Digital Speech
Processing, Now Publishers Inc., 2007.
[9]. Lawrence R. Rabiner and Ronald Schafer, Digital Processing of Speech Signals, Prentice-Hall, 1978.
[10]. Sadaoki Furui, Digital Speech Processing, Synthesis, and Recognition, second
edition, Marcel Dekker Inc., 2001.
[11]. Lawrence R. Rabiner, A Tutorial on Hidden Markov Models and Selected
Applications in Speech Recognition, Proceeding of the IEEE, Vol.77, No.2, Feb. 1989, pp.257-286. 163
Downloaded by Dung Tran (tiendungtr12802@gmail.com)
