Báo cáo bài tập lớn môn An toàn bảo mật thông tin đề tài "Tìm hiểu về trình dịch ngược và IDA PRO"
Báo cáo bài tập lớn môn An toàn bảo mật thông tin đề tài "Tìm hiểu về trình dịch ngược và IDA PRO" của Đại học Xây dựng Hà Nội với những kiến thức và thông tin bổ ích giúp sinh viên tham khảo, ôn luyện và phục vụ nhu cầu học tập của mình cụ thể là có định hướng ôn tập, nắm vững kiến thức môn học và làm bài tốt trong những bài kiểm tra, bài tiểu luận, bài tập kết thúc học phần, từ đó học tập tốt và có kết quả cao cũng như có thể vận dụng tốt những kiến thức mình đã học vào thực tiễn cuộc sống. Mời bạn đọc đón xem!
Môn: An toàn bảo mật thông tin (66MHT) 10 tài liệu
Trường: Trường Đại học Xây Dựng Hà Nội 540 tài liệu
Tác giả:








































Preview text:
lOMoARcPSD| 36625228
TRƯỜNG ĐẠI HỌC XÂY DỰNG HÀ NỘI
KHOA CÔNG NGHỆ THÔNG TIN
BÁO CÁO BÀI TẬP LỚN MÔN HỌC
AN TOÀN BẢO MẬT THÔNG TIN
ĐỀ TÀI: TÌM HIỂU VỀ TRÌNH DỊCH NGƯỢC VÀ IDA PRO
Sinh viên thực hiện: 1. Hồ Sỹ Trung Kiên 2. Đỗ Minh Quân 3. Trần Văn Sáng 4. Tô Minh 5. Lớp : 66MHT1 Nhóm : 10
Hà Nội, tháng 12, năm 2023 1 lOMoARcPSD| 36625228 Mục lục
1. KHÁI NIỆM TRÌNH DỊCH NGƯỢC VÀ IDA PRO................................................3
2. NỀN TẢNG CỦA IDA PRO.......................................................................................12
2.1 Bắt đầu với IDA………………………………………………...14
2.2 Hiển thị Dữ liệu của IDA………………….…………………...17
2.3 Điều hướng Giải Mã…………………………………………...21
2.4 Kiểu và dữ liệu………………………………………………….25
2.5 Liên kết và đồ thị hóa……………………………………………
3. CÁCH SỬ DỤNG IDA PRO NÂNG CAO................................................................19
4. ỨNG DỤNG IDA TRONG THỰC TẾ......................................................................19
5. PHÂN CHIA CÔNG VIỆC.........................................................................................33
6. TÀI LIỆU THAM KHẢO………………..…………………………………………34 lOMoARcPSD| 36625228
1. KHÁI NIỆM TRÌNH DỊCH NGƯỢC VÀ IDA PRO
Phần 1 Giới thiệu về IDA
I.Giới thiệu về dịch ngược
Bạn có thể đang tự hỏi điều gì sẽ xuất hiện trong một cuốn sách dành riêng cho IDA Pro. Mặc
dù rõ ràng là tập trung vào IDA, nhưng cuốn sách này không nhằm mục đích làm sách hướng
dẫn người dùng IDA Pro. Thay vào đó, chúng tôi có ý sử dụng IDA như một công cụ hỗ trợ để
thảo luận về các kỹ thuật đảo ngược mà bạn sẽ thấy hữu ích khi phân tích đa dạng phần mềm, từ
các ứng dụng có lỗ hổng đến phần mềm độc hại. Khi cần thiết, chúng tôi sẽ cung cấp các bước
chi tiết để thực hiện các hành động cụ thể liên quan đến nhiệm vụ đang thực hiện trong IDA. Do
đó, chúng ta sẽ đi một cách khá vòng vo quanh các khả năng của IDA, bắt đầu từ các nhiệm vụ
cơ bản mà bạn muốn thực hiện khi kiểm tra một tệp và tiến lên đến những sử dụng và tùy chỉnh
nâng cao của IDA để giải quyết các vấn đề đảo ngược khó khăn hơn. Chúng tôi không cố gắng
bao quát tất cả các tính năng của IDA. Tuy nhiên, chúng tôi sẽ bao gồm những tính năng mà bạn
sẽ thấy hữu ích nhất trong việc đối mặt với thách thức đảo ngược của bạn. Cuốn sách này sẽ giúp
IDA trở thành vũ khí mạnh mẽ nhất trong bộ công cụ của bạn.
Trước khi đào sâu vào bất kỳ chi tiết cụ thể nào của IDA, việc tìm hiểu một số kiến thức cơ bản
về quá trình disassembly cũng như xem xét một số công cụ khác có sẵn để đảo ngược mã máy
biên dịch sẽ hữu ích. Mặc dù không có công cụ nào cung cấp toàn bộ phạm vi các khả năng của
IDA, mỗi công cụ đều giải quyết các phần nhỏ cụ thể của chức năng IDA và mang lại cái nhìn có
giá trị vào các tính năng cụ thể của IDA. Phần còn lại của chương này sẽ dành để hiểu rõ quá trình disassembly
Lý thuyết tháo rời
Những người đã dành thời gian để nghiên cứu ngôn ngữ lập trình có lẽ đã biết về các thế hệ khác
nhau của ngôn ngữ, nhưng tôi sẽ tóm tắt chúng ở đây cho những người có thể đã bỏ quên.
Ngôn ngữ thế hệ đầu tiên
Đây là hình thức ngôn ngữ thấp nhất, thường bao gồm các số một và số không hoặc một dạng
rút gọn như hệ thập lục phân, chỉ có thể đọc được bởi các binja nhị phân. Mọi thứ ở mức độ này
trở nên phức tạp vì thường khó phân biệt dữ liệu và hướng dẫn vì mọi thứ đều trông giống nhau.
Ngôn ngữ thế hệ đầu tiên cũng có thể được gọi là ngôn ngữ máy, và trong một số trường hợp là
mã byte, trong khi chương trình ngôn ngữ máy thường được gọi là các tập tin nhị phân.
Ngôn ngữ thế hệ thứ hai
Còn được gọi là ngôn ngữ hợp nguyên, ngôn ngữ thế hệ thứ hai chỉ cách một bảng tra cứu xa
ngôn ngữ máy và thường ánh xạ các mẫu bit cụ thể, hoặc các mã hoạt động (opcode), thành các
dãy ký tự ngắn nhưng dễ nhớ được gọi là mnemonics. Đôi khi, những mnemonics này thực sự lOMoARcPSD| 36625228
giúp nhớ những hướng dẫn mà chúng được liên kết. Một bộ biên dịch là một công cụ được sử
dụng bởi các lập trình viên để dịch chương trình ngôn ngữ hợp nguyên của họ thành ngôn ngữ
máy thích hợp để thực thi. Ngôn ngữ thế hệ thứ ba Những ngôn ngữ này tiến thêm một bước nữa
đến khả năng diễn đạt của ngôn ngữ tự nhiên bằng cách giới thiệu từ khóa và cấu trúc mà lập
trình viên sử dụng như là các khối xây dựng cho chương trình của họ.
Ngôn ngữ thế hệ thứ ba
Thường độc lập với nền tảng, mặc dù các chương trình được viết bằng chúng có thể phụ thuộc
vào nền tảng do sử dụng các tính năng đặc biệt của một hệ điều hành cụ thể. Những ví dụ
thường được trích dẫn bao gồm FORTRAN, COBOL, C và Java. Lập trình viên thường sử dụng
trình biên dịch để dịch chương trình của họ thành ngôn ngữ hợp nguyên hoặc cho đến ngôn ngữ
máy (hoặc một đối tượng tương đương như mã byte). Ngôn ngữ thế hệ thứ tư
Những ngôn ngữ này có tồn tại nhưng không liên quan đến cuốn sách này và sẽ không được thảo luận. Về Tháo Rời
Trong mô hình phát triển phần mềm truyền thống, trình biên dịch, bộ hợp nguyên và trình liên
kết được sử dụng độc lập hoặc kết hợp với nhau để tạo ra các chương trình có thể thực thi. Để đi
ngược lại (hoặc phân tích ngược) các chương trình, chúng ta sử dụng các công cụ để hoàn tác
quá trình hợp nguyên và biên dịch. Không ngạc nhiên, các công cụ như vậy được gọi là
disassemblers và decompilers, và chúng thực hiện khá chính xác những gì tên của chúng ngụ ý.
Một disassembler hoàn tác quá trình hợp nguyên, vì vậy chúng ta có thể mong đợi đầu ra là ngôn
ngữ hợp nguyên (và do đó đầu vào là mã máy). Decompilers nhằm tạo ra đầu ra bằng ngôn ngữ
cấp cao khi được đưa vào mã hợp nguyên hoặc thậm chí là mã máy.
Lời hứa về "khôi phục mã nguồn" luôn luôn hấp dẫn trong một thị trường phần mềm cạnh
tranh, và do đó, việc phát triển decompilers có thể sử dụng tiếp tục là một lĩnh vực nghiên cứu
tích cực trong ngành khoa học máy tính. Dưới đây chỉ là một số lý do mà quá trình decompilation là khó khăn:
Quá trình biên dịch là quá trình mất mát thông tin.
Ở cấp độ ngôn ngữ máy, không có tên biến hoặc hàm, và thông tin về loại biến chỉ có thể được
xác định thông qua cách dữ liệu được sử dụng thay vì các khai báo loại rõ ràng. Khi bạn quan sát
32 bit dữ liệu được truyền, bạn sẽ cần thực hiện một số công việc điều tra để xác định liệu 32 bit
đó có đại diện cho một số nguyên, một giá trị dấu chấm động 32 bit, hay một con trỏ 32 bit.
Quá trình biên dịch là một quá trình nhiều đối nhiễu.
Điều này có nghĩa là một chương trình nguồn có thể được dịch thành ngôn ngữ hợp nguyên
theo nhiều cách khác nhau, và ngôn ngữ máy có thể được dịch ngược trở lại nguồn theo nhiều lOMoARcPSD| 36625228
cách khác nhau. Kết quả là, rất phổ biến khi biên dịch một tệp và ngay lập tức giải mã nó có thể
tạo ra một tệp nguồn hoàn toàn khác với tệp đã đầu vào.
Decompilers phụ thuộc rất nhiều vào ngôn ngữ và thư viện.
Xử lý một tệp nhị phân được tạo ra bởi trình biên dịch Delphi với một decompiler được thiết
kế để tạo mã C có thể đưa ra kết quả rất kỳ lạ. Tương tự, đưa một tệp nhị phân Windows đã biên
dịch qua một decompiler không biết về API lập trình Windows có thể không mang lại bất kỳ điều gì hữu ích.
Để có khả năng giải mã chính xác một tệp nhị phân, cần có khả năng tháo rời gần như hoàn hảo.
Bất kỳ lỗi hoặc sót sót nào trong giai đoạn tháo rời đều hầu như chắc chắn sẽ lan rộng sang mã
giải mã.Hex-Rays, decompiler phức tạp nhất hiện nay trên thị trường.
Tại sao phải tháo rời
Công cụ tháo rời thường được sử dụng để hỗ trợ trong việc hiểu rõ các chương trình khi mã
nguồn không khả dụng. Các tình huống phổ biến mà tháo rời được sử dụng bao gồm: -
Phân tích phần mềm độc hại -
Phân tích phần mềm mã nguồn đóng để tìm lỗ hổng -
Phân tích phần mềm mã nguồn đóng để kiểm tra khả năng tương thích -
Phân tích mã máy được tạo ra bởi trình biên dịch để xác nhận hiệu suất/chính xác của trình biêndịch -
Hiển thị các lệnh chương trình trong quá trình gỡ lỗi
Các phần tiếp theo sẽ giải thích chi tiết hơn về mỗi tình huống.
Phân tích Phần mềm độc hại
Trừ khi bạn đang xử lý một loại ký tự worm, tác giả malware hiếm khi hỗ trợ bạn bằng cách
cung cấp mã nguồn cho tác phẩm của họ. Thiếu mã nguồn, bạn đối mặt với một bộ lựa chọn rất
hạn chế để khám phá chính xác cách malware hoạt động. Hai kỹ thuật chính cho phân tích
malware là phân tích động và phân tích tĩnh. Phân tích động liên quan đến việc cho phép
malware thực thi trong một môi trường kiểm soát cẩn thận (sandbox) trong khi ghi lại mọi khía
cạnh quan sát được của nó bằng bất kỳ số lượng tiện ích hệ thống nào. Ngược lại, phân tích tĩnh lOMoARcPSD| 36625228
cố gắng hiểu về hành vi của một chương trình chỉ bằng cách đọc mã nguồn của chương trình,
trong trường hợp của malware, thường bao gồm một danh sách tháo rời.
Phân tích Lỗ hổng
Vì sự đơn giản, hãy chia quá trình kiểm thử bảo mật thành ba bước: phát hiện lỗ hổng, phân tích
lỗ hổng và phát triển exploit. Các bước này áp dụng như nhau có mã nguồn hay không; tuy
nhiên, mức độ nỗ lực tăng đáng kể khi bạn chỉ có một file nhị phân. Bước đầu tiên trong quá
trình này là phát hiện điều kiện có thể bị tận dụng trong một chương trình. Thông thường, điều
này được thực hiện bằng các kỹ thuật động như fuzzing, nhưng nó cũng có thể được thực hiện
(thường với nhiều nỗ lực hơn) thông qua phân tích tĩnh. Khi một vấn đề đã được phát hiện,
thường cần phải phân tích thêm để xác định liệu vấn đề có thể bị tận dụng hay không và nếu có, trong điều kiện nào.
Danh sách tháo rời cung cấp mức độ chi tiết cần thiết để hiểu rõ cách trình biên dịch đã chọn
cách phân bổ biến của chương trình. Ví dụ, có thể hữu ích biết rằng một mảng ký tự 70 byte
được khai báo bởi một lập trình viên đã được làm tròn lên thành 80 byte khi được phân bổ bởi
trình biên dịch. Danh sách tháo rời cũng cung cấp phương tiện duy nhất để xác định chính xác
cách mà trình biên dịch đã chọn cách sắp xếp tất cả các biến được khai báo toàn cục hoặc trong
các hàm. Hiểu về mối quan hệ không gian giữa các biến thường là quan trọng khi cố gắng phát
triển exploit. Cuối cùng, bằng cách sử dụng một công cụ tháo rời và một bộ gỡ lỗi cùng nhau,
một exploit có thể được phát triển.
Xác thực trình biên dịch
Vì mục đích của một trình biên dịch (hoặc bộ hợp ngữ) là tạo ra ngôn ngữ máy, thường cần sử
dụng các công cụ tháo rời chất lượng để xác minh rằng trình biên dịch đang thực hiện công việc
của nó theo các đặc tả thiết kế. Người phân tích cũng có thể quan tâm đến việc tìm kiếm cơ hội
bổ sung để tối ưu hóa đầu ra của trình biên dịch và, từ góc độ an ninh, xác định xem trình biên
dịch có bị tấn công đến mức mà nó có thể chèn cửa sau vào mã máy được tạo ra hay không. Hiển thị Gỡ lỗi
Có lẽ việc sử dụng tháo rời để tạo danh sách trong các bộ gỡ lỗi là một trong những ứng dụng
phổ biến nhất. Thật không may, các công cụ tháo rời được tích hợp trong các bộ gỡ lỗi thường
khá đơn giản. Thông thường, chúng không thể thực hiện tháo rời hàng loạt và đôi khi gặp khó
khăn khi tháo rời khi không thể xác định ranh giới của một hàm. Điều này là một trong những lý
do tại sao việc sử dụng một bộ gỡ lỗi kết hợp với một công cụ tháo rời chất lượng cao là tốt nhất
để cung cấp cái nhìn toàn cảnh và ngữ cảnh tốt hơn trong quá trình gỡ lỗi.
Làm thế nào để Tháo rời
Bây giờ bạn đã thông thạo về mục đích của tháo rời, là lúc chuyển sang cách quá trình này thực
sự hoạt động. Hãy xem xét một công việc đầy thách thức thường gặp đối mặt bởi một công cụ
tháo rời: Lấy 100KB này, phân biệt mã từ dữ liệu, chuyển đổi mã thành ngôn ngữ lập trình hợp
ngữ để hiển thị cho người dùng, và xin đừng bỏ sót bất cứ điều gì trên đường đi. lOMoARcPSD| 36625228
Chúng ta có thể thêm bất kỳ yêu cầu đặc biệt nào vào cuối công việc này, như yêu cầu công cụ
tháo rời để định vị các hàm, nhận diện bảng nhảy và xác định biến cục bộ, làm cho công việc của
công cụ tháo rời trở nên khó khăn hơn.
Để đáp ứng tất cả các yêu cầu của chúng ta, bất kỳ công cụ tháo rời nào sẽ cần lựa chọn từ nhiều
thuật toán khi điều hướng qua các tệp mà chúng ta cung cấp. Chất lượng của danh sách tháo rời
được tạo ra sẽ trực tiếp liên quan đến chất lượng của các thuật toán được sử dụng và cách chúng
đã được triển khai. Trong phần này, chúng ta sẽ thảo luận về hai thuật toán cơ bản đang được sử
dụng ngày nay để tháo rời mã máy. Khi chúng tôi trình bày những thuật toán này, chúng tôi cũng
sẽ chỉ ra nhược điểm của chúng để chuẩn bị bạn cho những tình huống khi công cụ tháo rời của
bạn có vẻ không thành công. Bằng cách hiểu rõ về những hạn chế của công cụ tháo rời, bạn có
thể can thiệp thủ công để cải thiện chất lượng tổng thể của đầu ra tháo rời.
Một Thuật toán Tháo rời Cơ bản
Đầu tiên, hãy phát triển một thuật toán đơn giản để nhận mã máy làm đầu vào và tạo ra ngôn
ngữ lập trình hợp ngữ làm đầu ra. Trong quá trình này, chúng ta sẽ hiểu về những thách thức, giả
định và sự hy sinh đằng sau quá trình tháo rời tự động. Bước 1
Bước đầu tiên trong quá trình tháo rời là xác định một khu vực mã để tháo rời. Điều này không
nhất thiết đơn giản như có vẻ. Hướng dẫn thường được trộn lẫn với dữ liệu, và quan trọng là
phải phân biệt giữa chúng. Trong trường hợp phổ biến nhất, tháo rời của một tệp thực thi, tệp sẽ
tuân theo một định dạng chung cho tệp thực thi như định dạng Portable Executable (PE) sử dụng
trên Windows hoặc định dạng Executable and Linking Format (ELF) phổ biến trên nhiều hệ
thống dựa trên Unix. Những định dạng này thường chứa các cơ chế (thường dưới dạng các tiêu
đề tệp phân cấp) để xác định các phần của tệp chứa mã và điểm vào (entry points) vào mã đó. Bước 2
Được đưa vào địa chỉ ban đầu của một lệnh, bước tiếp theo là đọc giá trị chứa tại địa chỉ đó
(hoặc vị trí tệp) và thực hiện tìm kiếm trong bảng để so khớp giá trị opcode nhị phân với hình
ảnh mnemonics ngôn ngữ lập trình. Tùy thuộc vào sự phức tạp của bộ chỉ thị được tháo rời, điều
này có thể là một quá trình đơn giản hoặc có thể liên quan đến một số hoạt động bổ sung như
hiểu các tiền tố có thể sửa đổi hành vi của lệnh và xác định bất kỳ toán tử nào cần thiết bởi lệnh.
Đối với các bộ chỉ thị với lệnh có chiều dài biến, như Intel x86, có thể cần phải lấy thêm byte
lệnh để hoàn toàn tháo rời một lệnh duy nhất. Bước 3
Sau khi lệnh đã được lấy và bất kỳ toán tử cần thiết nào đã được giải mã, phiên bản ngôn ngữ lập
trình tương đương được định dạng và xuất ra như một phần của danh sách tháo rời. Có thể có
khả năng chọn từ nhiều cú pháp ngôn ngữ lập trình. Ví dụ, hai định dạng chủ yếu cho ngôn ngữ
lập trình hợp ngữ x86 là định dạng Intel và định dạng AT&T. lOMoARcPSD| 36625228
Cú pháp X86 ASSEMBLY: AT&T VS. INTEL
Có hai cú pháp chính được sử dụng cho mã nguồn lập trình hợp ngữ: AT&T và Intel. Mặc dù
chúng là ngôn ngữ thế hệ thứ hai, nhưng hai loại này khác nhau rất nhiều về cú pháp từ truy cập
biến, hằng số và thanh ghi đến ghi đè kích thước phân đoạn và lệnh, gián tiếp và offset. Cú pháp
lập trình hợp ngữ AT&T được phân biệt bởi việc sử dụng ký hiệu % để tiền tố cho tất cả tên
thanh ghi, việc sử dụng $ như một tiền tố cho hằng số chữ (còn được gọi là toán hạng ngay lập
tức), và thứ tự toán hạng của nó, trong đó toán hạng nguồn xuất hiện như toán hạng bên trái và
toán hạng đích xuất hiện bên phải. Sử dụng cú pháp AT&T, lệnh cộng bốn vào thanh ghi EAX sẽ
đọc: add $0x4,%eax. Bộ Assembler GNU (Gas) và nhiều công cụ GNU khác, bao gồm gcc và
gdb, sử dụng cú pháp AT&T.
Cú pháp Intel khác biệt so với AT&T ở chỗ nó không yêu cầu tiền tố cho thanh ghi hoặc hằng số
và thứ tự toán hạng được đảo ngược sao cho toán hạng nguồn xuất hiện bên phải và toán hạng
đích xuất hiện bên trái. Cùng một lệnh cộng bằng cách sử dụng cú pháp Intel sẽ đọc: add
eax,0x4. Assembler sử dụng cú pháp Intel bao gồm Microsoft Assembler (MASM), Turbo
Assembler của Borland (TASM) và Netwide Assembler (NASM). Bước 4
Sau khi xuất lệnh, chúng ta cần tiến tới lệnh tiếp theo và lặp lại quy trình trước đó cho đến khi
chúng ta đã tháo rời mọi lệnh trong tệp.Có nhiều thuật toán khác nhau để xác định nơi bắt đầu
quá trình tháo rời, cách chọn lệnh tiếp theo cần tháo rời, cách phân biệt giữa mã và dữ liệu, và
cách xác định khi nào lệnh cuối cùng đã được tháo rời. Hai thuật toán tháo rời quan trọng nhất là
linear sweep và recursive descent.
Phần 2 CÔNG CỤ ĐẢO NGƯỢC VÀ THÁO RỜI
Với một số kiến thức về tháo rời, và trước khi chúng ta bắt đầu khám phá cụ thể về IDA Pro,
việc hiểu biết về một số công cụ khác được sử dụng để đảo ngược mã nhị phân sẽ hữu ích. Nhiều
trong số này đã xuất hiện trước IDA và vẫn hữu ích để nhanh chóng xem qua các tệp cũng như
kiểm tra lại công việc của IDA. Như chúng ta sẽ thấy, IDA tích hợp nhiều khả năng của những
công cụ này vào giao diện người dùng của nó để cung cấp môi trường tích hợp duy nhất cho đảo
ngược mã nhị phân. Cuối cùng, IDA chứa một trình gỡ lỗi tích hợp.
Công cụ Phân loại
Khi đối mặt với một tệp không xác định lúc đầu, thường hữu ích để trả lời những câu hỏi đơn
giản như "Đây là cái gì?" Quy tắc đầu tiên khi cố gắng trả lời câu hỏi đó là không bao giờ dựa
vào phần mở rộng tên tệp để xác định điều gì thực sự là một tệp. Đó cũng là quy tắc thứ hai, thứ
ba và thứ tư. Khi bạn đã trở thành người ủng hộ cho quan điểm rằng phần mở rộng tên tệp không
có ý nghĩa, bạn có thể muốn làm quen với một hoặc nhiều trong các tiện ích sau đây. file lOMoARcPSD| 36625228
Lệnh file là một tiện ích tiêu chuẩn, được bao gồm trong hầu hết các hệ điều hành kiểu *NIX và
trong các công cụ Cygwin1 hoặc MinGW2 cho Windows. Lệnh file cố gắng xác định loại tệp
bằng cách xem xét các trường cụ thể trong tệp. Trong một số trường hợp, lệnh file nhận ra chuỗi
phổ biến như #!/bin/sh (một script shell) hoặc (một tài liệu HTML). Tệp chứa nội dung
không phải ASCII đôi khi đặt ra thách thức lớn hơn. Trong những trường hợp như vậy, lệnh file
cố gắng xác định xem nội dung có dạng theo một định dạng tệp biết đến hay không. Trong nhiều
trường hợp, nó tìm kiếm các giá trị thẻ cụ thể (thường được gọi là magic numbers3) được biết
đến là duy nhất đối với các loại tệp cụ thể. Các mã hex dưới đây thể hiện một số ví dụ về các
magic numbers được sử dụng để xác định một số loại tệp phổ biến.
Tệp có khả năng xác định một số lượng lớn định dạng tệp, bao gồm nhiều loại tệp văn bản
ASCII và các định dạng tệp thực thi và dữ liệu khác nhau. Việc kiểm tra số phép thuật (magic
number) được thực hiện bởi tệp được điều khiển bởi các quy tắc chứa trong một tệp số phép
thuật. Tệp số phép thuật mặc định thay đổi tùy thuộc vào hệ điều hành, nhưng các địa điểm phổ
biến bao gồm /usr/share/file/magic, /usr/share/misc/magic và /etc/magic.
MÔI TRƯỜNG CYWIN
Cygwin là một bộ công cụ dành cho hệ điều hành Windows, cung cấp một dòng lệnh và các
chương trình liên quan giống như trong hệ điều hành Linux. Trong quá trình cài đặt, người dùng
có thể chọn từ một số lượng lớn các gói tiêu chuẩn, bao gồm các trình biên dịch (gcc, g++),
trình thông dịch (Perl, Python, Ruby), các tiện ích mạng (nc, ssh), và nhiều gói khác. Sau khi cài
đặt Cygwin, nhiều chương trình được viết để sử dụng trên Linux có thể được biên dịch và thực
thi trên hệ thống Windows.
Trong một số trường hợp, file có thể phân biệt các biến thể trong một loại tệp nhất định. Danh
sách dưới đây thể hiện khả năng của file trong việc xác định không chỉ một số biến thể của các
tệp nhị phân ELF mà còn thông tin liên quan đến cách liên kết của tệp nhị phân (tĩnh hoặc động)
và liệu tệp nhị phân đã được loại bỏ thông tin hay không. lOMoARcPSD| 36625228
LOẠI BỎ CÁC BIỂU TƯỢNG TRONG TỆP NHỊ PHÂN THỰC HIỆN
Quá trình loại bỏ biểu tượng (stripping) là quá trình loại bỏ các biểu tượng khỏi tệp nhị phân. Các
tệp nhị phân đối tượng chứa các biểu tượng như là kết quả của quá trình biên dịch. Một số trong số các
biểu tượng này được sử dụng trong quá trình liên kết để giải quyết các tham chiếu giữa các tệp khi tạo ra
tệp thực thi hoặc thư viện cuối cùng. Trong các trường hợp khác, các biểu tượng có thể tồn tại để cung
cấp thông tin bổ sung cho việc sử dụng với các công cụ gỡ lỗi. Sau quá trình liên kết, nhiều biểu tượng
không còn cần thiết nữa. Các tùy chọn được truyền cho trình liên kết có thể khiến trình liên kết loại bỏ
các biểu tượng không cần thiết trong quá trình xây dựng. Một cách khác, một tiện ích mang tên strip có
thể được sử dụng để loại bỏ các biểu tượng từ các tệp nhị phân hiện tại. Mặc dù một tệp nhị phân đã
được loại bỏ sẽ nhỏ hơn so với phiên bản chưa được loại bỏ, nhưng hành vi của tệp nhị phân đã được
loại bỏ sẽ không thay đổi.
Các tiện ích như file và tương tự không phải là hoàn toàn đáng tin cậy. Rất có khả năng một tệp nhất
định bị nhận dạng sai chỉ vì nó có nhãn hiệu nhận dạng của một định dạng tệp nào đó. Bạn có thể tự kiểm
tra điều này bằng cách sử dụng một trình chỉnh sửa hex để sửa đổi bốn byte đầu tiên của bất kỳ tệp nào
thành chuỗi số phép thuật của Java: CA FE BA BE. Tiện ích file sẽ nhận dạng sai tệp mới được sửa đổi
này là dữ liệu lớp Java đã được biên dịch. Tương tự, một tệp văn bản chỉ chứa hai ký tự MZ sẽ được nhận
dạng là một tệp thực thi MS-DOS. Một cách tiếp cận tốt trong bất kỳ nỗ lực nghịch đảo nào là không bao
giờ tin tưởng hoàn toàn vào đầu ra của bất kỳ công cụ nào cho đến khi bạn đã đối chiếu đầu ra đó với
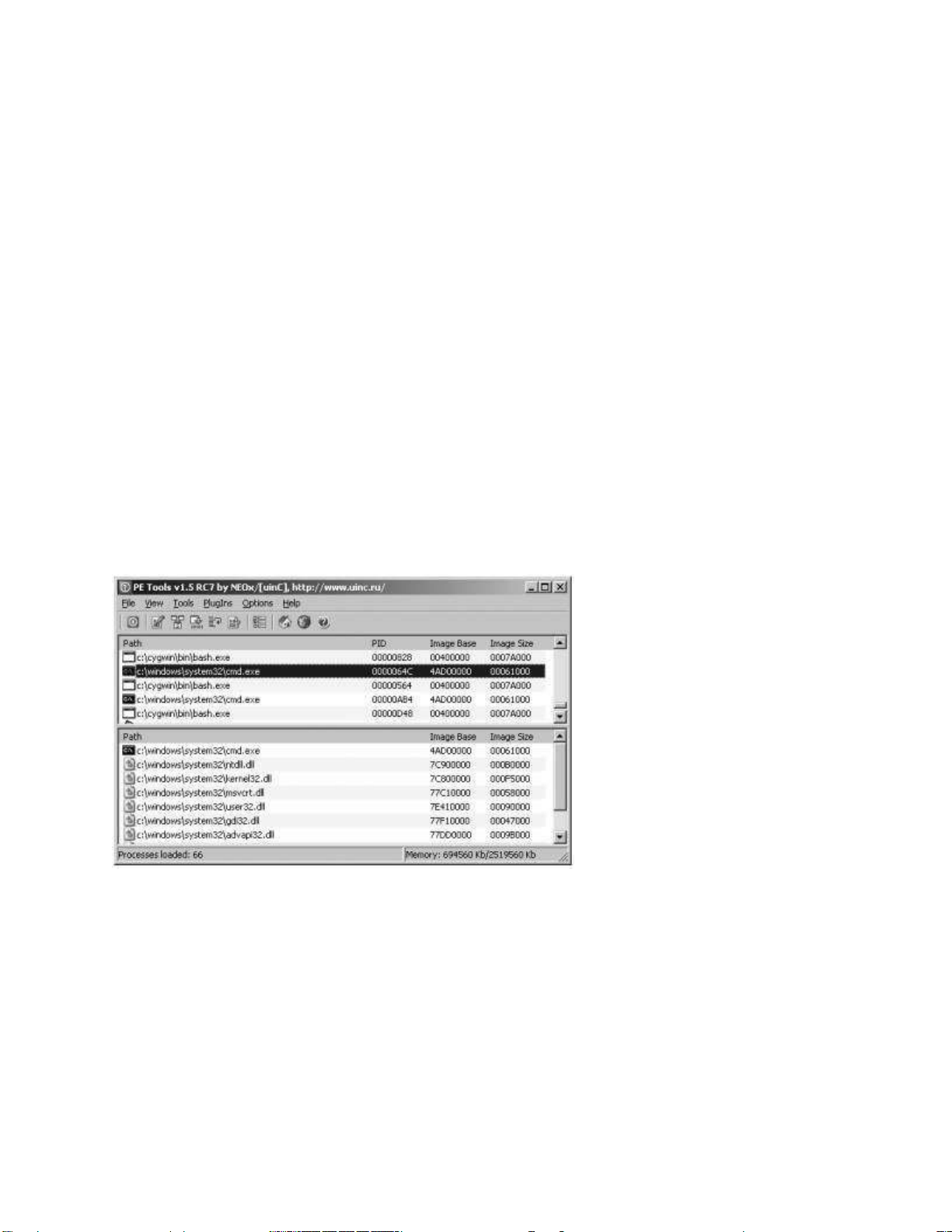
nhiều công cụ và phân tích thủ công. Công cụ PE Tools4
Là một bộ sưu tập các công cụ hữu ích để phân tích cả quy trình đang chạy và các tệp thực thi trên hệ
thống Windows. Hình 2-1 cho thấy giao diện chính của PE Tools, hiển thị một danh sách các quy trình
hoạt động và cung cấp quyền truy cập đến tất cả các tiện ích của PE Tools.
Hình 2-1: Tiện ích PE Tools
Từ danh sách quy trình, người dùng có thể ghi dữ liệu hình ảnh bộ nhớ của quy trình vào một tệp hoặc sử
dụng tiện ích PE Sniffer để xác định bộ biên dịch nào đã được sử dụng để xây dựng tệp thực thi hoặc xem
xét liệu tệp thực thi đã được xử lý bởi bất kỳ tiện ích làm rối nào đã biết. Menu Công cụ cung cấp các tùy
chọn tương tự cho phân tích các tệp trên đĩa. Người dùng có thể xem các trường tiêu đề PE của một tệp
bằng cách sử dụng tiện ích PE Editor tích hợp, cũng cho phép dễ dàng sửa đổi bất kỳ giá trị tiêu đề nào.
Việc sửa đổi tiêu đề PE thường cần thiết khi cố gắng tái tạo một PE hợp lệ từ một phiên bản bị làm rối của tệp đó.
PEiD5 là một công cụ Windows khác, với mục đích chính là xác định trình biên dịch đã được sử dụng để
xây dựng một tệp nhị phân Windows PE cụ thể và xác định bất kỳ công cụ nào đã được sử dụng để làm
rối một tệp nhị phân Windows PE. Hình 2-2 cho thấy việc sử dụng PEiD để xác định công cụ (trong
trường hợp này là ASPack) được sử dụng để làm rối một biến thể của worm Gaobot. lOMoARcPSD| 36625228
Tóm tắt về Công Cụ
Vì mục tiêu của chúng ta là nghịch đảo các tệp chương trình nhị phân, chúng ta sẽ cần những công cụ tinh
vi hơn để trích xuất thông tin chi tiết sau khi phân loại ban đầu của một tệp. Các công cụ được thảo luận
trong phần này, theo cách tự nhiên, hiểu rõ hơn về định dạng của các tệp mà chúng xử lý. Trong hầu hết
các trường hợp, những công cụ này hiểu rõ về một định dạng tệp cụ thể, và chúng được sử dụng để phân
tích các tệp đầu vào để trích xuất thông tin cụ thể rất cụ thể.
PHẦN 3 Nền tảng của IDA PRO
IDA Pro, được biết đến là một Disassembler Nghệ Thuật Chuyên Nghiệp, là sản phẩm của Hex-Rays, có
trụ sở tại Liège, Bỉ. Được sáng tạo bởi Ilfak Guilfanov, IDA Pro xuất phát từ một ứng dụng MS-DOS
console-based cách đây hơn một thập kỷ. IDA Pro không chỉ là một disassembler theo chiều sâu đệ quy
mà còn sử dụng nhiều kỹ thuật heuristics để xác định mã nguồn bổ sung và loại dữ liệu. Mục tiêu chính
của IDA là tạo ra một hình ảnh gần với mã nguồn, với chú thích chi tiết bao gồm thông tin về loại dữ liệu,
tên biến và hàm. IDA Pro đã trải qua quá trình phát triển để trở thành một công cụ mạnh mẽ trong lĩnh
vực nghịch đảo và phân tích mã nguồn.
The Interactive Disassembler Professional, được biết đến tốt hơn và cho đến nay được biết đến là IDA
Pro hoặc đơn giản là IDA, là một sản phẩm của Hex-Rays,1 nằm ở Liège, Bỉ. Thiên tài lập trình đằng sau
IDA là Ilfak Guilfanov, được biết đến tốt hơn với cái tên Ilfak. IDA bắt đầu cuộc sống của mình hơn một
thập kỷ trước dưới dạng một ứng dụng dựa trên MS-DOS, dựa trên console, điều quan trọng là nó giúp
chúng ta hiểu một số điều về bản chất của giao diện người dùng của IDA. Ngoài ra, các phiên bản không
có giao diện người dùng (non-GUI) của IDA được phát hành cho tất cả các nền tảng được hỗ trợ bởi
IDA2 và vẫn tiếp tục sử dụng giao diện kiểu console được dẫn xuất từ các phiên bản DOS ban đầu.
Ở tâm điểm của nó, IDA là một trình giải lắp đặt đệ quy; tuy nhiên, đã có một lượng lớn công sức được
bỏ vào việc phát triển logic để bổ sung quá trình giải lắp đặt đệ quy. Để vượt qua một trong những hạn
chế lớn của giải lắp đặt đệ quy, IDA sử dụng một số lượng lớn các kỹ thuật lược đồ để xác định mã nguồn
bổ sung có thể không được tìm thấy trong quá trình giải lắp đặt đệ quy. Vượt qua quá trình giải lắp đặt đệ
quy, IDA không chỉ phân biệt giữa giải lắp đặt dữ liệu và giải lắp đặt mã, mà còn xác định chính xác loại
dữ liệu đang được biểu diễn bởi những giải lắp đặt dữ liệu đó. Trong khi mã bạn xem trong IDA là ngôn
ngữ lập trình hợp ngữ, một trong những mục tiêu cơ bản của IDA là tạo ra một hình ảnh gần nhất có thể
với mã nguồn. IDA nỗ lực để chú thích các giải lắp đặt tạo ra không chỉ với thông tin kiểu dữ liệu mà còn
với tên biến và hàm tạo ra từ đó. Những chú thích này giảm thiểu lượng hex thô và tối đa hóa lượng thông
tin biểu tượng được trình bày cho người dùng.
Sự chặt chẽ của Hex-Rays
Đối với việc sao chép trái phép sản phẩm mũi nhọn của họ, IDA, là rất rõ ràng. Công ty đã quan sát
được mối liên quan trực tiếp giữa việc phát hành các phiên bản IDA bị sao chép trái phép và sự giảm giá
bán. Những người phát hành trước đó, như DataRescue, thậm chí đã công khai xấu hổ những kẻ sao chép
trái phép bằng cách liệt kê tên họ. Để chống lại việc sao chép trái phép, IDA sử dụng nhiều kỹ thuật chống sao chép.
Đầu tiên, mỗi bản IDA đều được đánh dấu nước, liên kết duy nhất với người mua. Nếu một bản IDA
xuất hiện trên các trang web không được phép, Hex-Rays có khả năng theo dõi bản sao đó về người mua lOMoARcPSD| 36625228
gốc, người sau đó có thể bị cấm mua trong tương lai. Thường xuyên có các thảo luận về bản IDA "rò rỉ"
trên diễn đàn hỗ trợ của Hex-Rays.
Một kỹ thuật khác liên quan đến việc quét các bản sao bổ sung của IDA đang chạy trên mạng cục bộ.
Khi phiên bản Windows của IDA được khởi chạy, một gói UDP được phát sóng, kiểm tra phản hồi để
xem liệu có các bản IDA khác dưới cùng một khóa cấp phép trên mạng cùng một mạng con hay không.
Nếu phát hiện quá nhiều bản sao trên mạng, IDA có thể từ chối khởi động. Lưu ý rằng việc chạy nhiều
bản IDA trên cùng một máy tính với một bản quyền là được phép.
Phương thức cuối cùng của việc thực thi giấy phép liên quan đến việc sử dụng các tệp khóa liên kết với
mỗi người mua. Khi khởi động, IDA tìm kiếm một tệp ida.key hợp lệ. Việc không tìm thấy tệp khóa hợp
lệ sẽ khiến IDA tắt ngay lập tức. Tệp khóa cũng được sử dụng để xác định quyền lợi đối với các bản IDA
được nâng cấp. Nói một cách đơn giản, ida.key đại diện cho biên nhận mua của bạn, và bạn nên bảo vệ nó
để đảm bảo được quyền lợi cho các nâng cấp IDA trong tương lai. Thu thập IDA ProO
Đầu tiên và quan trọng nhất, IDA không phải là phần mềm miễn phí. Nhóm tại Hex-Rays kiếm sống
một phần thông qua việc bán IDA. Có một phiên bản miễn phí với chức năng giới hạn, dành cho những
người muốn làm quen với các khả năng cơ bản của nó, nhưng nó không theo kịp với các phiên bản mới
nhất. Phiên bản miễn phí này, được thảo luận chi tiết hơn trong Phụ lục A, là một phiên bản giản lược của
IDA 5.0 (phiên bản hiện tại là 6.1). Bên cạnh phiên bản miễn phí, Hex-Rays cũng phân phối một bản sao
giới hạn chức năng của phiên bản hiện tại. Nếu những đánh giá tích cực xuất hiện mọi nơi khi nói về đảo
ngược kỹ thuật, không đủ để thuyết phục bạn mua một bản sao, thì thời gian dành với phiên bản miễn phí
hoặc phiên bản demo sẽ giúp bạn nhận ra rằng IDA, và hỗ trợ khách hàng đi kèm, đều đáng để sở hữu. Các phiên bản IDA
Tính đến phiên bản 6.0, IDA có sẵn ở cả phiên bản GUI và console cho Windows, Linux và OS X. IDA
sử dụng thư viện GUI đa nền tảng Qt để cung cấp một giao diện người dùng nhất quán trên ba nền tảng
này. Về mặt chức năng, IDA Pro được cung cấp ở hai phiên bản: tiêu chuẩn và nâng cao. Hai phiên bản
này khác nhau chủ yếu ở số lượng kiến trúc bộ xử lý mà chúng hỗ trợ giải lắp đặt. Một cái nhìn nhanh
vào danh sách các bộ xử lý được hỗ trợ cho thấy rằng phiên bản tiêu chuẩn (khoảng 540 USD tính đến
thời điểm viết bài) hỗ trợ hơn 30 họ gia đình xử lý, trong khi phiên bản nâng cao (với giá gần gấp đôi) hỗ
trợ hơn 50 họ gia đình. Các kiến trúc bổ sung được hỗ trợ trong phiên bản nâng cao bao gồm x64,
AMD64, MIPS, PPC và SPARC, cùng nhiều loại khác. Giấy phép IDA
Có hai tùy chọn giấy phép khi bạn mua IDA. Theo trang web của Hex-Rays: "Giấy phép có tên được liên
kết với một người dùng cụ thể và có thể được sử dụng trên bất kỳ máy tính nào mà người dùng đó sử
dụng," trong khi "Giấy phép máy tính được liên kết với một máy tính cụ thể và có thể được sử dụng bởi
các người dùng khác nhau trên máy tính đó miễn là chỉ có một người dùng hoạt động vào mọi thời điểm."
Lưu ý rằng mặc dù một giấy phép có tên cho phép bạn cài đặt phần mềm trên bất kỳ máy tính nào bạn
muốn, bạn là người duy nhất có thể chạy các bản IDA đó, và đối với một giấy phép duy nhất, IDA chỉ có
thể chạy trên một trong những máy tính đó vào bất kỳ thời điểm nào. 2.1 Bắt đầu với IDA Khởi chạy IDA
Khi bạn khởi chạy IDA, bạn sẽ được chào đón ngắn gọn bởi một màn hình splash hiển thị tóm tắt thông
tin về giấy phép của bạn. Sau khi màn hình splash biến mất, IDA hiển thị một hộp thoại khác cung cấp ba
cách để tiếp tục vào môi trường làm việc của nó, như thể hiện trong Hình 4-1. lOMoARcPSD| 36625228
Nếu bạn không muốn xem thông báo chào mừng, hãy thoải mái bỏ chọn hộp kiểm Display at startup ở
dưới cùng của hộp thoại. Nếu bạn chọn hộp kiểm, các phiên sau sẽ bắt đầu như bạn đã nhấp vào nút Go,
và bạn sẽ được chuyển trực tiếp đến không gian làm việc trống rỗng của IDA. Nếu có một lúc nào đó bạn
cảm thấy muốn có lại hộp thoại Chào mừng (cuối cùng, nó thuận tiện khi cho phép bạn quay lại các tệp
đã sử dụng gần đây), bạn sẽ cần chỉnh sửa khóa registry của IDA để đặt giá trị DisplayWelcome trở lại là
1. Hoặc, việc chọn Windows X Reset hidden messages sẽ khôi phục tất cả các thông báo đã bị ẩn trước đó. Tải tệp trong IDA
Khi chọn mở một tệp mới bằng lệnh File Open, bạn sẽ thấy hộp thoại tải trình như trong Hình 4-2. IDA
tạo ra một danh sách các loại tệp tiềm năng và hiển thị danh sách đó ở đầu của hộp thoại. Danh sách này
đại diện cho các trình tải IDA phù hợp nhất để xử lý tệp đã chọn. Danh sách này được tạo ra bằng cách
thực thi mỗi trình tải tệp trong thư mục trình tải của IDA để tìm bất kỳ trình tải nào nhận ra tệp mới. Lưu
ý rằng trong Hình 4-2, cả trình tải Windows PE (pe.ldw) và trình tải MS-DOS EXE (dos.ldw) đều khẳng
định nhận ra tệp đã chọn. Độc giả quen thuộc với định dạng tệp PE sẽ không ngạc nhiên khi thấy điều
này, vì định dạng tệp PE là một dạng mở rộng của định dạng tệp MS-DOS EXE. Mục cuối cùng trong
danh sách, Binary File, luôn có mặt vì đó là tùy chọn mặc định của IDA để tải các tệp mà nó không nhận
ra, và đây là phương thức tải tệp ở mức độ thấp nhất. Khi được đề xuất lựa chọn giữa một số trình tải,
không tệ là chấp nhận lựa chọn mặc định, trừ khi bạn có thông tin cụ thể mà phản đối quyết định của IDA. lOMoARcPSD| 36625228
Đôi khi, "Binary File" sẽ là mục duy nhất xuất hiện trong danh sách trình tải. Trong những trường hợp
như vậy, thông điệp ngụ ý là không có trình tải nào nhận diện được tệp đã chọn. Nếu bạn chọn tiếp tục
quá trình tải, đảm bảo bạn chọn loại bộ xử lý phù hợp với hiểu biết của bạn về nội dung tệp.
Trong menu thả xuống "Processor Type," bạn có thể chỉ định mô-đun bộ xử lý nào (từ thư mục procs của
IDA) sẽ được sử dụng trong quá trình giải lắp đặt. Trong hầu hết các trường hợp, IDA sẽ tự động chọn bộ
xử lý phù hợp dựa trên thông tin đọc từ các tiêu đề của tệp thực thi. Khi IDA không thể xác định đúng
loại bộ xử lý liên kết với tệp đang được mở, bạn cần chọn thủ công một loại bộ xử lý trước khi tiếp tục với thao tác tải tệp.
Các trường "Loading Segment" và "Loading Offset" chỉ hoạt động khi định dạng đầu vào "Binary File"
được chọn kèm theo một bộ xử lý họ x86. Vì trình tải nhị phân không thể trích xuất thông tin bố trí bộ
nhớ, các giá trị đoạn và độ lệch nhập vào đây được kết hợp để tạo thành địa chỉ cơ sở cho nội dung tệp
được tải. Nếu bạn quên chỉ định một địa chỉ cơ sở trong quá trình tải ban đầu, bạn có thể sửa đổi địa chỉ
cơ sở của hình IDA bất kỳ lúc nào bằng cách sử dụng lệnh "Edit Segments Rebase Program."
Các nút "Kernel Options" cung cấp quyền truy cập để cấu hình các tùy chọn phân tích giải lắp đặt cụ thể
mà IDA sẽ sử dụng để tăng cường quá trình giảm đệ quy. Trong đa số lớn các trường hợp, các tùy chọn
mặc định cung cấp giảm lắp đặt tốt nhất có thể. Các tệp trợ giúp của IDA cung cấp thông tin bổ sung về
các tùy chọn nhân hạt có sẵn.
Nút "Processor Options" cung cấp quyền truy cập để cấu hình các tùy chọn áp dụng cho mô-đun bộ xử lý
đã chọn. Tuy nhiên, tùy chọn bộ xử lý không nhất thiết có sẵn cho mọi mô-đun bộ xử lý. Hỗ trợ hạn chế
có sẵn cho các tùy chọn bộ xử lý vì những tùy chọn này phụ thuộc rất nhiều vào mô-đun bộ xử lý đã chọn
và khả năng chuyên môn lập trình của tác giả mô-đun.
Các hộp kiểm "Options" còn lại được sử dụng để có kiểm soát tốt hơn quá trình tải tệp. Mỗi tùy chọn
được mô tả thêm trong tệp trợ giúp của IDA. Các tùy chọn không áp dụng cho tất cả các loại tệp đầu vào
và trong hầu hết các trường hợp, bạn có thể tin tưởng vào các lựa chọn mặc định.
Tệp Cơ sở dữ liệu IDA
Khi bạn hài lòng với các tùy chọn tải của mình và nhấp OK để đóng hộp thoại, công việc thực sự của
việc tải tệp bắt đầu. Tại điểm này, mục tiêu của IDA là tải tệp thực thi đã chọn vào bộ nhớ và phân tích
các phần liên quan. Điều này dẫn đến việc tạo ra một cơ sở dữ liệu IDA với bốn tệp, mỗi tệp có tên cơ sở
phù hợp với tệp thực thi đã chọn và có các phần mở rộng là .id0, .id1, .nam và .til. Tệp .id0 chứa nội dung
của một cơ sở dữ liệu theo kiểu cây B, trong khi tệp .id1 chứa các cờ mô tả từng byte chương trình. Tệp
.nam chứa thông tin chỉ mục liên quan đến các vị trí chương trình có tên như hiển thị trong cửa sổ Names
của IDA (được thảo luận thêm trong Chương 5). Cuối cùng, tệp .til được sử dụng để lưu trữ thông tin về
các định nghĩa kiểu cục bộ cụ thể cho một cơ sở dữ liệu đã chọn. Các định dạng của mỗi tệp này đều
thuộc sở hữu của IDA và chúng không dễ dàng chỉnh sửa bên ngoài môi trường IDA. Vì sự thuận tiện,
bốn tệp này được lưu trữ lại, và có thể nén, thành một tệp IDB duy nhất mỗi khi bạn đóng dự án hiện tại
của mình. Khi người ta nói đến cơ sở dữ liệu IDA, họ thường đang nói về tệp IDB. Một tệp cơ sở dữ liệu
không nén thường có kích thước khoảng 10 lần kích thước của tệp nhị phân đầu vào ban đầu. Khi cơ sở
dữ liệu được đóng đúng cách, bạn không bao giờ thấy các tệp có phần mở rộng .id0, .id1, .nam hoặc .til
trong thư mục làm việc của bạn. Sự xuất hiện của chúng thường chỉ ra rằng một cơ sở dữ liệu không được
đóng đúng cách (ví dụ, khi IDA bị sự cố) và có thể bị hỏng.
Tạo Cơ sở dữ liệu IDA
Sau khi bạn đã chọn một tệp để phân tích và chỉ định các tùy chọn, IDA bắt đầu quá trình tạo cơ sở dữ
liệu. Trong quá trình này, IDA chuyển quyền kiểm soát cho mô-đun loader được chọn, nhiệm vụ của nó
là tải tệp từ đĩa, phân tích thông tin tiêu đề tệp mà nó có thể nhận biết, tạo các phần chương trình chứa mã
hoặc dữ liệu như được chỉ định trong tiêu đề của tệp, và cuối cùng, xác định các điểm nhập cụ thể vào mã
trước khi trả quyền kiểm soát lại cho IDA. Liên quan đến điều này, các mô-đun loader của IDA hoạt động
giống như cách các loader hệ điều hành hoạt động. Mô-đun loader của IDA sẽ xác định bố cục bộ nhớ ảo
dựa trên thông tin chứa trong tiêu đề của tệp chương trình và cấu hình cơ sở dữ liệu tương ứng. lOMoARcPSD| 36625228
Khi loader hoàn thành, bộ máy dịch trong IDA tiếp tục và bắt đầu truyền từng địa chỉ một đến mô-đun
xử lý được chọn. Nhiệm vụ của mô-đun xử lý là xác định loại lệnh tại địa chỉ đó, độ dài của lệnh tại địa
chỉ đó, và vị trí(s) mà việc thực hiện có thể tiếp tục từ địa chỉ đó (ví dụ, lệnh hiện tại có phải là tuần tự
hay nhảy nhánh không?). Khi IDA chắc chắn rằng nó đã tìm thấy tất cả các lệnh trong tệp, nó thực hiện
lượt điều tra thứ hai qua danh sách các địa chỉ lệnh và yêu cầu mô-đun xử lý tạo ra phiên bản ngôn ngữ
lập trình hợp ngữ của mỗi lệnh để hiển thị.
Sau quá trình dịch này, IDA tự động tiến hành phân tích thêm của tệp nhị phân để trích xuất thông tin bổ
sung có khả năng hữu ích cho nhà phân tích. Người dùng có thể mong đợi tìm thấy một số hoặc tất cả các
thông tin sau đây tích hợp vào cơ sở dữ liệu sau khi IDA hoàn thành phân tích ban đầu của nó.
Đóng Cơ sở dữ liệu IDA
Mọi khi bạn đóng một cơ sở dữ liệu, cho dù bạn đang đóng toàn bộ IDA hay chỉ đơn giản là chuyển sang
một cơ sở dữ liệu khác, bạn sẽ nhìn thấy hộp thoại Lưu Cơ sở dữ liệu.
Mở lại một Cơ sở dữ liệu
Dĩ nhiên, việc mở lại một cơ sở dữ liệu hiện có không đòi hỏi sự phức tạp như việc phát triển tên lửa,5 vì
vậy bạn có thể tự hỏi tại sao chủ đề này lại được đề cập. Dưới điều kiện bình thường, việc quay lại làm
việc trên một cơ sở dữ liệu hiện có đơn giản như việc chọn cơ sở dữ liệu bằng một trong những phương
pháp mở tệp của IDA. Các tệp cơ sở dữ liệu mở nhanh chóng hơn trong lần thứ hai (và những lần sau) vì
không có phân tích nào cần thực hiện. Như một phần thưởng thêm, IDA khôi phục lại bàn làm việc IDA
của bạn với cùng trạng thái như nó đã đóng cửa.
2.2 Hiển thị Dữ liệu của IDA
I.Các Hiển thị Chính của IDA
Mặc định, IDA tạo bảy (tính đến phiên bản 6.1) cửa sổ hiển thị trong giai đoạn tải và phân tích ban đầu
cho một tệp nhị phân mới. Mỗi cửa sổ hiển thị này có thể truy cập thông qua một bộ thẻ tiêu đề hiển thị
ngay phía dưới dải điều hướng (đã được hiển thị trước đó trong Hình 4-9). Ba cửa sổ ngay lập tức hiển thị
là cửa sổ IDA-View, cửa sổ Functions và cửa sổ Output. Cho dù chúng có được mở mặc định hay không,
tất cả các cửa sổ được thảo luận trong chương này có thể được mở qua menu View → Open Subviews.
Hãy nhớ điều này, vì khá dễ vô tình đóng các cửa sổ hiển thị.
Phím ESC là một trong những phím tắt hữu ích nhất trong IDA. Khi cửa sổ dịch mã đang hoạt động, phím
ESC hoạt động giống như nút quay lại của trình duyệt web và do đó rất hữu ích trong việc điều hướng
hiển thị mã dịch (điều hướng được đề cập chi tiết trong Chương 6). Thật không may, khi bất kỳ cửa sổ
nào khác đang hoạt động, phím ESC phục vụ để đóng cửa sổ. Đôi khi, điều này chính là điều bạn muốn.
Tuy nhiên, có những lúc bạn ngay lập tức ước rằng bạn có thể khôi phục lại cửa sổ đã đóng.
II. Hiển thị Phụ của IDA lOMoARcPSD| 36625228 Cửa sổ Hex Window
Tên Hex View có vẻ như không phù hợp trong trường hợp này, vì cửa sổ IDA Hex View có thể được cấu
hình để hiển thị nhiều định dạng và đóng vai trò như một trình soạn thảo hex. Mặc định, cửa sổ Hex View
cung cấp một bản in hex tiêu chuẩn của nội dung chương trình với 16 byte trên mỗi dòng và phiên bản
ASCII được hiển thị cùng bên. Tương tự như cửa sổ dịch mã, có thể mở nhiều cửa sổ hex cùng một lúc.
Cửa sổ Hex đầu tiên có tiêu đề là Hex View-A, Hex thứ hai là Hex View-B, Hex tiếp theo là Hex View-C
và cứ tiếp tục như vậy. Theo mặc định, cửa sổ Hex đầu tiên được đồng bộ với cửa sổ dịch mã đầu tiên.
Khi một dạng xem dịch mã được đồng bộ với một dạng xem hex, cuộn trong một cửa sổ sẽ khiến cửa sổ
khác cuộn đến cùng một vị trí (cùng địa chỉ ảo). Ngoài ra, khi một mục được chọn trong dạng xem dịch
mã, các byte tương ứng sẽ được đánh dấu nổi bật trong dạng xem hex. Trong hình dưới, con trỏ dạng xem
dịch mã đang được đặt tại địa chỉ 0040108C, một lệnh gọi, làm cho năm byte tạo thành lệnh được đánh
dấu nổi bật trong cửa sổ Hex.
Các Hiển thị Tertiary IDA
Các cửa sổ cuối cùng mà chúng ta sẽ thảo luận là những cửa sổ mà IDA không mở theo mặc định. Mỗi
cửa sổ này có thể mở qua View → Open Subviews, nhưng chúng thường cung cấp thông tin mà bạn có
thể không cần truy cập ngay lập tức và do đó ban đầu được giữ ngoài đường. lOMoARcPSD| 36625228
Tổng quan về IDA Text View
Cửa sổ dịch mã tập trung vào văn bản là hiển thị truyền thống được sử dụng để xem và thao tác các bảng
dịch mã do IDA tạo ra. Bảng hiển thị văn bản trình bày toàn bộ danh sách dịch mã của một chương trình
(so với chỉ một hàm tại một thời điểm ở chế độ đồ thị) và cung cấp phương tiện duy nhất để xem các khu
vực dữ liệu của một tệp nhị phân. Tất cả thông tin có sẵn trong bảng hiển thị đồ thị đều có sẵn trong bảng
hiển thị văn bản dưới một dạng nào đó.
Cửa sổ Chức năng
Cửa sổ Chức năng được sử dụng để liệt kê mọi hàm mà IDA đã nhận biết trong cơ sở dữ liệu. Một mục
trong cửa sổ Chức năng có thể trông như sau: Cửa sổ đầu ra
Cửa sổ Đầu ra ở phía dưới không gian làm việc của IDA hoàn tất bộ cửa sổ mặc định mà bạn thấy khi một
tệp mới được mở. Cửa sổ Đầu ra phục vụ như bảng điều khiển đầu ra của IDA và là nơi để xem thông tin
về các nhiệm vụ mà IDA đang thực hiện. Khi một tệp nhị phân được mở lần đầu, ví dụ, các thông báo
được tạo ra để chỉ ra cả pha phân tích mà IDA đang ở trong bất kỳ thời điểm nào và các hành động mà
IDA đang thực hiện để tạo ra cơ sở dữ liệu mới.
Khi bạn làm việc với một cơ sở dữ liệu, cửa sổ Đầu ra được sử dụng để xuất trạng thái của các hoạt động
khác nhau mà bạn thực hiện. Nội dung của cửa sổ Đầu ra có thể được sao chép vào clipboard hệ thống
hoặc xóa hoàn toàn bằng cách nhấp chuột phải bất kỳ nơi nào trong cửa sổ và chọn thao tác thích hợp.
Cửa sổ Đầu ra thường sẽ là phương tiện chính để hiển thị đầu ra từ các kịch bản và plug-in mà bạn phát triển cho IDA.
III. Các Hiển thị IDA Cấp Ba
Cửa sổ Strings là phiên bản tích hợp của IDA tương đương với tiện ích strings và nhiều tính năng khác.
Trong các phiên bản IDA từ 5.1 trở về trước, cửa sổ Strings được mở sẵn như một phần của giao diện
người dùng mặc định; tuy nhiên, từ phiên bản 5.2 trở đi, cửa sổ Strings không còn mở sẵn theo mặc định,
mặc dù vẫn có thể mở qua View → Open Subviews → Strings.
Mục đích của cửa sổ Strings là hiển thị danh sách các chuỗi được trích xuất từ mã nhị phân cùng với địa
chỉ mà mỗi chuỗi đó đang nằm. Tương tự như việc nhấp đúp vào tên trong cửa sổ Names, việc nhấp đúp
vào bất kỳ chuỗi nào được liệt kê trong cửa sổ Strings sẽ khiến cửa sổ tháo rời nhảy đến địa chỉ của chuỗi
được chọn. Khi sử dụng cùng với các tham chiếu chéo (Chương 9), cửa sổ Strings cung cấp cách nhanh
chóng để nhận diện một chuỗi quan trọng và theo dõi ngược lại đến bất kỳ vị trí nào trong chương trình
tham chiếu đến chuỗi đó. Ví dụ, bạn có thể thấy chuỗi SOFTWARE\Microsoft\Windows\CurrentVersion\
Run được liệt kê và muốn biết tại sao một ứng dụng đang tham chiếu đến khóa cụ thể này trong registry
của Windows. Như bạn sẽ thấy trong chương tiếp theo, việc di chuyển đến vị trí chương trình tham chiếu
đến chuỗi này chỉ mất bốn lần nhấp chuột. Hiểu cách hoạt động của cửa sổ Strings là quan trọng để sử
dụng nó một cách hiệu quả.
IDA không lưu trữ vĩnh viễn các chuỗi mà nó trích xuất từ mã nhị phân. Do đó, mỗi khi cửa sổ Strings
được mở, toàn bộ cơ sở dữ liệu phải được quét hoặc quét lại để tìm nội dung chuỗi. Việc quét chuỗi được
thực hiện theo cài đặt của cửa sổ Strings, và bạn có thể truy cập các cài đặt này bằng cách nhấp chuột phải
trong cửa sổ Strings và chọn Setup. Như được thể hiện trong Hình 5-7, cửa sổ Setup Strings được sử dụng
để chỉ định loại chuỗi mà IDA nên quét. Loại chuỗi mặc định mà IDA quét là chuỗi ASCII kiểu C, kết
thúc bằng null, 7-bit, có ít nhất năm ký tự. lOMoARcPSD| 36625228
2.3:Điều hướng Giải Mã
Trong trải nghiệm đầu tiên của bạn với IDA, bạn có thể chỉ cần sử dụng các tính năng điều
hướng mà IDA cung cấp. Ngoài việc cung cấp các tính năng tìm kiếm khá chuẩn mà bạn quen
thuộc từ việc sử dụng trình soạn thảo văn bản hoặc xử lý từ, IDA phát triển và hiển thị một
danh sách toàn diện các tham chiếu chéo hoạt động tương tự như các liên kết siêu văn bản trên
một trang web. Kết quả cuối cùng là, trong hầu hết các trường hợp, việc điều hướng đến các vị
trí quan tâm không yêu cầu gì ngoài một cú nhấp đúp. Double-Click Navigation
Khi một chương trình được giải mã, mọi vị trí trong chương trình đều được gán một địa chỉ ảo.
Do đó, chúng ta có thể điều hướng đến bất kỳ đâu trong chương trình bằng cách cung cấp địa
chỉ ảo của vị trí mà chúng ta quan tâm để truy cập. Thật không may cho chúng ta, việc duy trì
một danh mục địa chỉ trong đầu không phải là một nhiệm vụ đơn giản. Sự thực này đã thôi thúc
những lập trình viên đầu tiên gán tên biểu tượng cho các vị trí chương trình mà họ muốn tham
chiếu, làm cho mọi thứ trở nên dễ dàng hơn nhiều cho họ. Việc gán tên biểu tượng cho các địa
chỉ chương trình không khác gì việc gán tên lệnh ghi nhớ cho các mã lệ Jump to Address
Đôi khi, bạn sẽ biết chính xác địa chỉ mà bạn muốn điều hướng đến, nhưng không có tên nào
hiện có trong cửa sổ disassembly để đơn giản hóa việc nhấp đúp để điều hướng. Trong trường
hợp như vậy, bạn có một vài lựa chọn. Lựa chọn đầu tiên, và cũng là cách primitve nhất, là sử
dụng thanh cuộn cửa sổ disassembly để cuộn lên hoặc xuống cho đến khi vị trí mong muốn xuất
hiện. Thường thì điều này chỉ khả thi khi bạn biết vị trí bạn đang điều hướng đến thông qua địa lOMoARcPSD| 36625228
chỉ ảo, vì cửa sổ disassembly được tổ chức theo thứ tự tuyến tính theo địa chỉ ảo. Nếu bạn chỉ
biết về một vị trí có tên như một subroutine được đặt tên là "foobar", thì việc điều hướng bằng
thanh cuộn trở thành việc tìm kiếm giống như tìm kim trong đống cỏ khô. Tại thời điểm đó, bạn
có thể chọn sắp xếp cửa sổ Functions theo thứ tự bảng chữ cái, cuộn đến tên mong muốn và
nhấp đúp vào tên. Lựa chọn thứ ba là sử dụng một trong các tính năng tìm kiếm của IDA có sẵn
qua menu Tìm kiếm, thường thì điều này liên quan đến việc xác định một số tiêu chí tìm kiếm
trước khi yêu cầu IDA thực hiện tìm kiếm. Trong trường hợp tìm kiếm vị trí đã biết, điều này
thường là một sự lãng phí thời gian. Stack Frames
Để hiểu và sử dụng IDA Pro, người dùng cần có kiến thức cơ bản về các khái niệm thấp hơn
trong ngôn ngữ lập trình biên dịch. Cuốn sách này cung cấp một số khái niệm cơ bản, trong đó
có khung ngăn xếp (stack frame), một khối bộ nhớ được sử dụng trong chương trình để quản lý
các lời gọi hàm cụ thể.
Khi một hàm được gọi, nó cần bộ nhớ cho tham số và biến cục bộ. Trình biên dịch sử dụng
khung ngăn xếp để quản lý việc này, làm cho quá trình trở nên trong suốt đối với người lập trình.
Các bước khi gọi hàm bao gồm: •
Đặt tham số vào vị trí quy định theo quy tắc gọi hàm. •
Chuyển quyền điều khiển cho hàm được gọi và lưu địa chỉ trả về. •
Hàm được gọi cấu hình khung ngăn xếp và lưu giữ các giá trị đăng ký. •
Hàm được gọi cấp phát không gian cho biến cục bộ. •
Hàm thực hiện các hoạt động của mình, có thể trả về kết quả. •
Sau khi hoàn thành, hàm giải phóng không gian trên ngăn xếp. •
Khôi phục giá trị đăng ký và khung của người gọi. •
Trả quyền điều khiển cho người gọi và xóa tham số khỏi ngăn xếp. Người gọi có
thể cần xóa tham số khỏi ngăn xếp.
Bước 3 và 4 là phần mở đầu của hàm, còn bước 6 đến 8 là phần kết thúc của hàm. Ngoại trừ
bước 5, tất cả các bước này đại diện cho công đoạn gọi hàm.
CHAPTER 6:DISASSEMBLY MANIPULATION
Sau khi điều hướng, các tính năng quan trọng tiếp theo của IDA được thiết kế để cho phép bạn
chỉnh sửa disassembly theo nhu cầu của bạn. Trong chương này, chúng tôi sẽ chỉ ra rằng do tính lOMoARcPSD| 36625228
chất cơ sở dữ liệu cơ bản của IDA, các thay đổi bạn thực hiện trên disassembly dễ dàng được áp
dụng cho tất cả các chế độ xem con của IDA để duy trì một hình ảnh nhất quán về disassembly
của bạn. Một trong những tính năng mạnh mẽ nhất mà IDA cung cấp là khả năng dễ dàng chỉnh
sửa disassembly để thêm thông tin mới hoặc định dạng lại danh sách để phù hợp với nhu cầu
cụ thể của bạn. IDA tự động xử lý các hoạt động như tìm kiếm và thay thế toàn cục khi có ý
nghĩa và làm việc không đáng kể với việc định dạng lại hướng dẫn và dữ liệu và ngược lại, tính
năng không có trong các công cụ disassembly khác.
LƯU Ý: Hãy nhớ rằng không có chức năng "hoàn tác" trong IDA. Hãy lưu ý điều này khi bạn bắt
đầu chỉnh sửa cơ sở dữ liệu. Điều gần giống nhất mà bạn có thể là lưu cơ sở dữ liệu thường
xuyên và quay trở lại phiên bản cơ sở dữ liệu đã lưu gần đây. Names and Naming
Tại điểm này, chúng ta đã gặp hai loại tên trong disassembly của IDA: tên liên quan đến địa chỉ
ảo (vị trí có tên) và tên liên quan đến biến trong khung ngăn xếp. Trong hầu hết các trường hợp,
IDA sẽ tự động tạo tất cả các tên này theo các hướng dẫn đã được thảo luận trước đó. IDA gọi
những tên được tạo tự động như "dummy names" (tên giả).
Thật không may, những tên này hiếm khi gợi ý về mục đích dự định của một vị trí hoặc biến và
do đó thường không đóng góp nhiều vào sự hiểu biết về hành vi của chương trình. Khi bạn bắt
đầu phân tích một chương trình, một trong những cách đầu tiên và phổ biến nhất mà bạn
muốn thay đổi danh sách disassembly là thay đổi tên mặc định thành các tên có ý nghĩa hơn.
May mắn thay, IDA cho phép bạn dễ dàng thay đổi bất kỳ tên nào và xử lý tất cả chi tiết liên
quan đến việc truyền tên đã thay đổi này ra toàn bộ disassembly. Trong hầu hết các trường
hợp, việc thay đổi tên chỉ đơn giản là bấm chuột vào tên bạn muốn thay đổi (điều này sẽ làm
nổi bật tên) và sử dụng phím tắt N để mở hộp thoại thay đổi tên. Hoặc, bạn có thể nhấp chuột
phải vào tên cần thay đổi và thường sẽ xuất hiện một menu phản ứng theo ngữ cảnh chứa tùy chọn
Parameters and Local Variables
Names associated with stack variables are the simplest form of name in a disassembly listing,
primarily because they are not associated with a speci 昀椀 c virtual address and thus can
never appear in the Names window. As in most programming languages, such names are
considered to be restricted in scope based on the function to which a given stack frame
belongs. Thus, every function in a program might have its own stack variable named arg_0, but
no function may have more than one variable named arg_0. The dialog shown in Figure 7-1 is
used to rename a stack variable. Named Locations
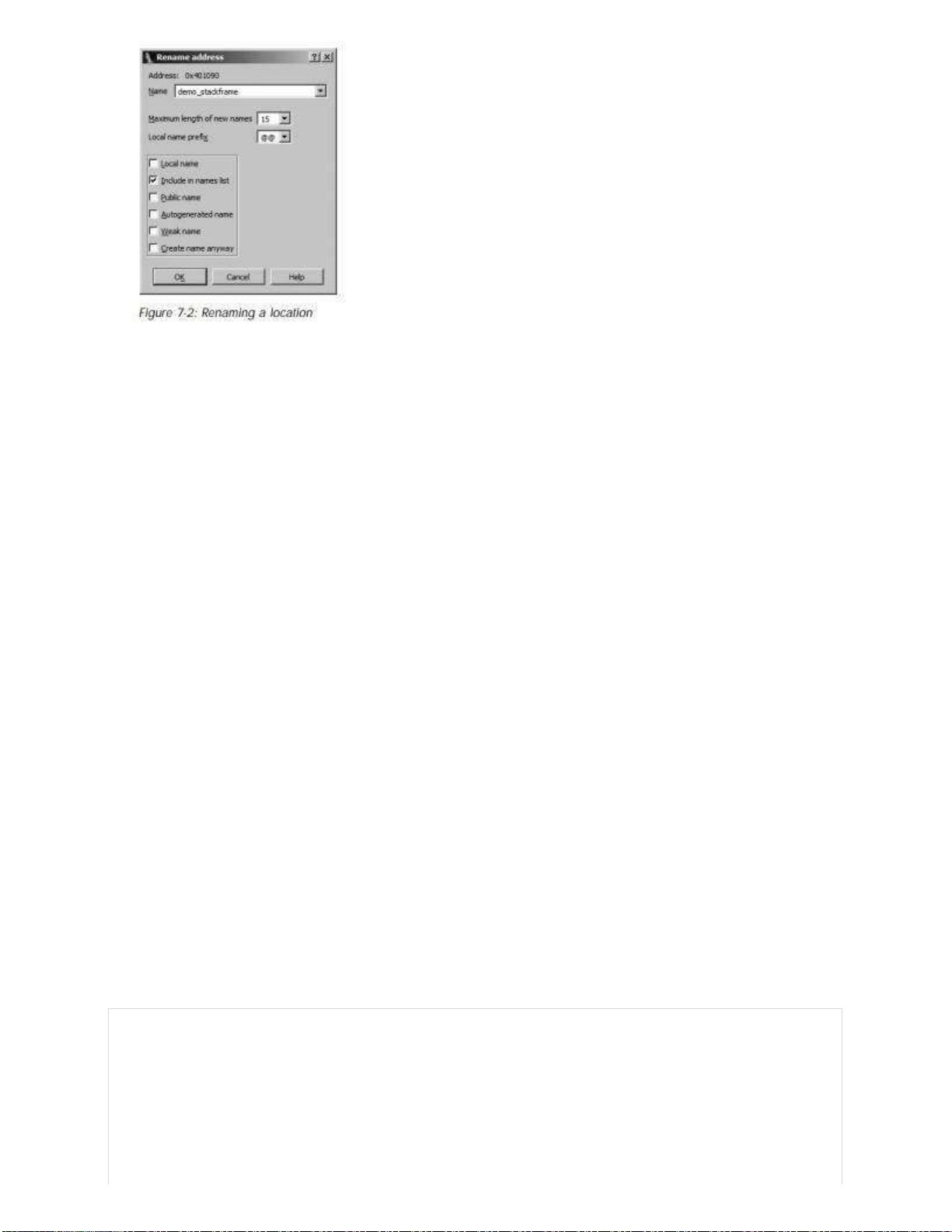
Việc đổi tên một vị trí đã được đặt tên hoặc thêm tên cho một vị trí chưa được đặt tên có chút
khác biệt so với việc thay đổi tên biến trong ngăn xếp. Quá trình truy cập hộp thoại đổi tên
tương tự (phím tắt N), nhưng có sự khác biệt nhanh chóng. Hình 7-2 hiển thị hộp thoại đổi tên
liên quan đến các vị trí đã được đặt tên.
Hộp thoại này cung cấp thông tin về địa chỉ bạn đang đặt tên cùng với danh sách các thuộc tính
có thể được gắn liền với tên. Độ dài tên tối đa chỉ là một giá trị sao chép từ một trong các tệp
cấu hình của IDA (/ cfg/ida.cfg). Bạn có thể tự do sử dụng tên dài hơn giá trị này, điều
này sẽ khiến IDA phàn nàn một cách yếu ớt bằng cách thông báo bạn đã vượt quá độ dài tên tối
đa và đề nghị tăng độ dài tối đa tên cho bạn. Nếu bạn chọn làm như vậy, giá trị độ dài tối đa tên
mới sẽ được áp dụng (một cách yếu ớt) chỉ trong cơ sở dữ liệu hiện tại. Bất kỳ cơ sở dữ liệu mới
nào bạn tạo ra sẽ tiếp tục được quản lý bằng độ dài tên tối đa được chứa trong tệp cấu hình. lOMoARcPSD| 36625228 Local name
Một tên địa phương (local name) bị giới hạn trong phạm vi của hàm hiện tại, do đó tính duy nhất
của các tên địa phương chỉ được áp dụng trong một hàm cụ thể. Tương tự như biến địa phương
(local variables), hai hàm khác nhau có thể chứa các tên địa phương giống nhau, nhưng một hàm
duy nhất không thể chứa hai tên địa phương giống nhau. Những vị trí có tên mà tồn tại bên ngoài
giới hạn của hàm không thể được xem xét là các tên địa phương. Điều này bao gồm cả các tên
đại diện cho tên hàm cũng như các biến toàn cục. Sử dụng phổ biến nhất cho các tên địa phương
là cung cấp các tên biểu tượng cho các mục tiêu của các lệnh nhảy bên trong một hàm, chẳng
hạn như các mục tiêu liên quan đến cấu trúc kiểm soát nhánh. Include in names list
Chọn tùy chọn này sẽ khiến tên được thêm vào cửa sổ "Names" (Danh sách tên), điều này có
thể làm cho việc tìm kiếm tên dễ dàng hơn khi bạn muốn quay lại nó. Tên được tạo tự động
(dummy) mặc định sẽ không bao giờ được bao gồm trong cửa sổ "Names" (Danh sách tên).
2.4 Kiểu và dữ liệu
Các trường hợp dễ nhất để hiểu về hành vi của các chương trình nhị phân nằm ở việc liệt kê các hàm thư
viện mà chương trình gọi. Một chương trình C gọi hàm connect đang tạo một kết nối mạng. Một chương
trình Windows gọi hàm RegOpenKey đang truy cập vào Registry của Windows. Tuy nhiên, cần phân tích
thêm để hiểu cách và tại sao các hàm này được gọi. Để hiểu cách một hàm được gọi, cần biết các tham
số nào được truyền vào hàm. Trong trường hợp gọi connect, ngoài việc xác định rằng hàm đang được
gọi, quan trọng biết rõ địa chỉ mạng mà chương trình đang kết nối tới. Hiểu về dữ liệu được truyền vào
các hàm là chìa khóa để phân tích ngược chữ ký của một hàm (bao gồm số lượng, kiểu và thứ tự các
tham số cần thiết cho hàm), và vì vậy, làm nổi bật tầm quan trọng của việc hiểu cách các kiểu dữ liệu và
cấu trúc dữ liệu được thao tác tại cấp độ ngôn ngữ lập trình hợp ngữ (assembly).
Recognizing Data Structure Use
Mặc dù các kiểu dữ liệu nguyên thủy thường phù hợp tự nhiên với kích thước của thanh ghi
CPU hoặc toán tử hướng dẫn, các kiểu dữ liệu phức hợp như mảng và cấu trúc thường yêu cầu
chuỗi hướng dẫn phức tạp hơn để truy cập các mục dữ liệu riêng lẻ chứa trong chúng. Trước
khi chúng ta có thể thảo luận về tính năng của IDA để cải thiện tính đọc của mã sử dụng các
kiểu dữ liệu phức hợp, chúng ta cần xem xét mã đó trông như thế nào.
Truy cập Thành viên trong Mảng Mảng là cấu trúc dữ liệu phức tạp đơn giản nhất về bố cục bộ
nhớ. Theo truyền thống, mảng là các khối liên tiếp trong bộ nhớ chứa các phần tử liên tiếp cùng lOMoARcPSD| 36625228
kiểu dữ liệu. Kích thước của một mảng dễ tính, vì nó là tích của số phần tử trong mảng và kích
thước của mỗi phần tử. Sử dụng biểu thức C, số byte tối thiểu được tiêu thụ bởi mảng
Crea 琀椀 ng a New Structure (or Union)
Khi một chương trình dường như đang sử dụng một cấu trúc mà IDA không có thông tin về bố cục, IDA
cung cấp các tính năng để chỉ định cấu trúc và cho phép cấu trúc mới được định nghĩa được tích hợp vào
phần giải mã. Việc tạo cấu trúc trong IDA diễn ra trong cửa sổ Cấu trúc (xem Hình 8-2). Không cấu trúc
nào có thể được tích hợp vào phần giải mã cho đến khi nó được liệt kê lần đầu trong cửa sổ Cấu trúc.
Bất kỳ cấu trúc nào mà IDA biết và được nhận diện là được sử dụng bởi chương trình sẽ tự động được
liệt kê trong cửa sổ Cấu trúc.
Có hai lý do khiến việc sử dụng một cấu trúc có thể không được nhận dạng trong quá trình phân
tích. Thứ nhất, mặc dù IDA có thể biết về bố cục của một cấu trúc cụ thể, có thể thiếu thông tin
đủ để IDA kết luận rằng chương trình sử dụng cấu trúc đó. Thứ hai, cấu trúc có thể là một cấu
trúc phi tiêu chuẩn mà IDA không biết gì về nó. Trong cả hai trường hợp, vấn đề có thể được
khắc phục và trong cả hai trường hợp, giải pháp bắt đầu từ cửa sổ Cấu trúc.
Bốn dòng đầu tiên trong cửa sổ Cấu trúc hoạt động như một lời nhắc liên tục về các hoạt động
có thể thực hiện trong cửa sổ. Các hoạt động chính mà chúng ta quan tâm liên quan đến việc
thêm, loại bỏ và chỉnh sửa cấu trúc. Việc thêm một cấu trúc được khởi đầu bằng cách sử dụng
phím INSERT, mở hộp thoại Tạo Cấu Trúc/Union như trong Hình 8-3.
2.5 Liên kết và đồ thị hóa
Trong quá trình reverse engineering một tệp nhị phân, các câu hỏi phổ biến thường là "Hàm
này được gọi từ đâu?" và "Các hàm nào truy cập vào dữ liệu này?" nhằm mục đích liệt kê các
tham chiếu đến và từ các tài nguyên khác nhau trong chương trình. IDA, một công cụ reverse
engineering, giúp giải quyết những câu hỏi này thông qua tính năng liên quan cắt xén của nó. Ví
dụ, nếu bạn tìm thấy một hàm có lỗ hổng trong một ứng dụng phức tạp, bạn cần xác định cách
thực thi hàm đó, và IDA giúp bạn tìm các hàm gọi hàm đó. Hoặc khi bạn gặp một chuỗi ASCII
đáng ngờ trong tệp nhị phân, IDA giúp bạn xác định nơi mà chuỗi đó được sử dụng trong mã nguồn.
IDA cung cấp các công cụ và tính năng để truy cập và hiển thị dữ liệu liên quan cắt xén, giúp bạn
hiểu rõ mối quan hệ giữa các phần của chương trình và dữ liệu. Điều này giúp cho việc phân
tích và reverse engineering trở nên dễ dàng hơn. lOMoARcPSD| 36625228 Cross-References
Chúng ta bắt đầu cuộc thảo luận của mình bằng việc lưu ý rằng các liên quan cắt xén trong IDA
thường được gọi đơn giản là "xrefs". Trong văn bản này, chúng tôi sẽ sử dụng "xref" chỉ khi nó
được sử dụng để đề cập đến nội dung của một mục menu hoặc hộp thoại của IDA. Trong tất cả
các trường hợp khác, chúng tôi sẽ sử dụng thuật ngữ "cross-reference".
Có hai loại cơ bản của liên quan cắt xén trong IDA: liên quan cắt xén mã và liên quan cắt xén dữ
liệu. Trong mỗi loại, chúng tôi sẽ chi tiết vài loại liên quan cắt xén khác nhau. Khi liên quan đến
mỗi liên quan cắt xén là khái niệm về hướng. Tất cả các liên quan cắt xén đều được thực hiện từ
một địa chỉ đến một địa chỉ khác. Các địa chỉ "from" và "to" có thể là địa chỉ mã hoặc địa chỉ dữ
liệu. Nếu bạn quen thuộc với lý thuyết đồ thị, bạn có thể tưởng tượng địa chỉ như các nút trong
một đồ thị có hướng và liên quan cắt xén như các cạnh trong đồ thị đó. Hình 9-1 cung cấp một
bản cập nhật nhanh về thuật ngữ đồ thị. Trong đồ thị đơn giản này, ba nút X được kết nối bằng hai cạnh có hướng Y.
4.ỨNG DỤNG IDA TRONG THỰC TẾ
Tại điểm này, nếu chúng ta đã làm công việc của mình một cách đúng đắn, bạn hiện tại đã sở hữu những
kỹ năng cần thiết để sử dụng IDA một cách hiệu quả và, quan trọng hơn, có khả năng kiểm soát nó theo
ý muốn của bạn. Bước 琀椀 ếp theolà học cách phản ứng trước những tệp nhị phân (khác với IDA) sẽ đưa bạn. lOMoARcPSD| 36625228
Tùy thuộc vào động cơ để bạn học ngôn ngữ lập trình assembly, bạn có thể quen thuộc với những gì bạn
đang nhìn thấy, hoặc bạn có thể không bao giờ biết bạn sẽ đối mặt với gì. Nếu bạn dành toàn bộ thời
gian của mình để xem xét mã được biên dịch trên nền tảng Linux, bạn có thể trở nên rất quen thuộc với
kiểu mã mà nó tạo ra. Ngược lại, nếu ai đó để lại một phiên bản gỡ lỗi của một chương trình được biên
dịch bằng Microso 昀琀 Visual C++ (VC++) trong tay bạn, bạn có thể hoàn toàn bối rối. Đặc biệt, những
người phân 琀 ch malware thường phải đối mặt với nhiều loại mã để xem xét. Bỏ qua đề tài làm mờ
tạm thời, những người phân 琀 ch malware có thể thấy mã được tạo ra bằng Visual Basic, Delphi, và
Visual C/C++; các đoạn mã máy nhúng trong tài liệu; và nhiều hơn nữa.
Bảng nhảy và Câu lệnh Switch
Câu lệnh switch trong ngôn ngữ lập trình C thường là một mục 琀椀 êu thường xuyên cho các tối ưu hóa
của trình biên dịch. Mục 琀椀 êu của những tối ưu hóa này là phù hợp biến switch với một nhãn case
hợp lệ một cách hiệu quả nhất có thể. Phương 琀椀 ện để đạt được điều này thường phụ thuộc vào 琀
nh chất của các nhãn case trong câu lệnh switch. Khi các nhãn case được phân tán rộng, như trong ví
dụ dưới đây, hầu hết các trình biên dịch tạo mã để thực hiện 琀 m kiếm nhị phân để phù hợp biến
switch với một trong các trường hợp.
Câu lệnh switch trong C thường là đối tượng phổ biến để trình biên dịch tối ưu hóa. Mục 琀椀 êu của
những tối ưu hóa này là phù hợp biến switch với một nhãn case hợp lệ một cách hiệu quả nhất có thể.
Phương 琀椀 ện để đạt được điều này thường phụ thuộc vào 琀 nh chất của các nhãn case trong câu
lệnh switch. Khi các nhãn case được phân tán rộng, như trong ví dụ dưới đây, hầu hết các trình biên dịch
tạo mã để thực hiện 琀 m kiếm nhị phân để phù hợp biến switch với một trong các trường hợp.
Có nhiều sự khác biệt rõ ràng khi so sánh mã nguồn này với mã nguồn được tạo ra bởi trình biên dịch
Borland. Một sự khác biệt rõ ràng là bảng nhảy đã được di chuyển đến không gian ngay sau hàm chứa
câu lệnh switch (không như mã nguồn của Borland, nơi bảng nhảy được nhúng trực 琀椀 ếp trong hàm
đó). Ngoại trừ việc cung cấp một sự tách biệt sạch sẽ giữa mã nguồn và dữ liệu, việc di chuyển bảng
nhảy theo cách này ít ảnh hưởng đến hành vi của chương trình. Mặc dù mã nguồn có bố cục khác nhau,
IDA vẫn có khả năng chú thích các đặc điểm chính của câu lệnh switch, bao gồm số lượng các trường
hợp và các khối mã nguồn liên quan đến mỗi trường hợp.
Một trong những điểm chúng tôi muốn làm rõ ở đây là không có một cách biên dịch duy nhất và chính
xác để chuyển đổi mã nguồn thành mã hợp ngữ. Sự quen thuộc với mã được tạo ra bởi một trình biên
dịch cụ thể không đảm bảo rằng bạn sẽ nhận ra các cấu trúc cấp cao được biên dịch bằng một trình biên
dịch hoàn toàn khác (hoặc thậm chí là các phiên bản khác nhau của cùng một họ trình biên dịch). Quan
trọng hơn, đừng giả định rằng một điều gì đó không phải là một câu lệnh switch chỉ vì IDA không thêm
chú thích cho điều đó. Giống như bạn, IDA quen thuộc với kết quả của một số trình biên dịch hơn là các
trình khác. Thay vì hoàn toàn phụ thuộc vào khả năng phân 琀 ch của IDA để nhận diện các cấu trúc mã
và dữ liệu phổ biến, bạn luôn nên sẵn sàng sử dụng kỹ năng của mình - sự quen thuộc với một ngôn ngữ
hợp ngữ cụ thể, kiến thức về trình biên dịch và khả năng nghiên cứu của bạn - để diễn giải một đoạn mã hợp ngữ.
Trong Chương 8, chúng ta đã thảo luận về Run 琀椀 me Type Iden 琀椀昀椀 ca 琀椀 on (RTTI) trong ngôn ngữ lập trình lOMoARcPSD| 36625228
C++ và về việc rằng không có 琀椀 êu chuẩn nào tồn tại cho cách thức mà RTTI được triển khai bởi một
trình biên dịch. Việc nhận diện tự động các cấu trúc liên quan đến RTTI trong một 昀椀 le nhị phân là một
lĩnh vực khác mà khả năng của IDA thay đổi tùy theo trình biên dịch. Không ngạc nhiên, khả năng của IDA
trong lĩnh vực này mạnh mẽ nhất với các 昀椀 le nhị phân được biên dịch bằng trình biên dịch của Borland.
Đọc giả quan tâm đến việc nhận diện tự động các cấu trúc dữ liệu RTTI của Microso 昀琀 có thể thử sử
dụng script IDC của Igor Skochinsky, có sẵn tại The IDA Palace, hoặc sử dụng plug-in Class Informer của
Sirmabus, sẽ được thảo luận chi 琀椀 ết hơn trong Chương 23.
Một chiến lược đơn giản để hiểu cách một trình biên dịch cụ thể nhúng thông 琀椀 n loại (type informa
琀椀 on) cho các lớp C++ là viết một chương trình cơ bản sử dụng các lớp chứa các hàm ảo. Sau khi biên
dịch chương trình, bạn có thể tải 昀椀 le thực thi kết quả vào IDA và 琀 m kiếm các chuỗi chứa tên của
các lớp được sử dụng trong chương trình. Bất kể trình biên dịch nào được sử dụng để xây dựng một 昀
椀 le nhị phân, điều chung của cấu trúc dữ liệu RTTI là chúng đều chứa một con trỏ đến một chuỗi chứa
tên của lớp mà chúng đại diện. Sử dụng các cross-references dữ liệu, bạn có thể định vị một con trỏ đến
một chuỗi như vậy, từ đó xác định các cấu trúc dữ liệu RTTI ứng viên. Bước cuối cùng là liên kết một cấu
trúc RTTI ứng viên với bảng chứa con trỏ hàm (vtable) của lớp tương ứng, điều này được thực hiện tốt
nhất bằng cách theo dõi các cross-references dữ liệu ngược từ một cấu trúc RTTI ứng viên cho đến khi
đạt được một bảng con trỏ hàm. Xác định hàm main
Nếu bạn đủ may mắn để có mã nguồn của một chương trình C/C++ mà bạn muốn phân 琀 ch, một nơi
tốt để bắt đầu phân 琀 ch có thể là hàm main, vì đây là nơi theo lý thuyết mà việc thực thi bắt đầu. Khi
phải phân 琀 ch một 昀椀 le nhị phân, đây không phải là một chiến lược tồi. Tuy nhiên, như chúng ta đã
biết, điều này trở nên phức tạp do trình biên dịch/linker (và việc sử dụng thư viện) thêm vào mã nguồn
bổ sung mà thực thi trước khi đến main. Do đó, thường là không chính xác khi giả định rằng điểm vào
của một 昀椀 le nhị phân tương ứng với hàm main được viết bởi tác giả chương trình.
Trên thực tế, quan điểm rằng tất cả các chương trình đều có một hàm main là một quy ước của trình
biên dịch C/C++ chứ không phải là một quy tắc cứng nhắc cho việc viết chương trình. Nếu bạn từng viết
một ứng dụng GUI Windows, thì bạn có thể quen thuộc với biến thể WinMain thay vì main. Khi bạn
chuyển sang những ngôn ngữ khác ngoài C/C++, bạn sẽ thấy rằng các ngôn ngữ khác sử dụng tên khác
nhau cho hàm điểm vào chính của chương trình. Bất kể tên gọi là gì, chúng tôi sẽ đề cập đến hàm này
một cách tổng quát như là hàm main.
Chương 12 đã đề cập đến khái niệm về các tệp chữ ký IDA, cách tạo chúng và ứng dụng của chúng. IDA
sử dụng các chữ ký khởi động đặc biệt để cố gắng xác định hàm main của một chương trình. Khi IDA có
thể so khớp chuỗi khởi động của một 昀椀 le nhị phân với một trong các chuỗi khởi động trong các tệp
chữ ký của mình, IDA có thể xác định hàm main của chương trình dựa trên hiểu biết của nó về hành vi
của chuỗi khởi động đã so khớp. Điều này hoạt động tốt cho đến khi IDA không thể so khớp chuỗi khởi lOMoARcPSD| 36625228
động trong một 昀椀 le nhị phân với bất kỳ chữ ký nào đã biết của nó. Nói chung, mã khởi động của một
chương trình chặt chẽ liên quan đến cả trình biên dịch được sử dụng để tạo mã và nền tảng mà mã đó được xây dựng.
Nhớ lại từ Chương 12 rằng các chữ ký khởi động được nhóm lại và lưu trữ trong các tệp chữ ký cụ thể
cho các loại 昀椀 le nhị phân. Ví dụ, chữ ký khởi động được sử dụng với trình nạp PE được lưu trữ trong
tệp pe.sig, trong khi chữ ký khởi động được sử dụng với trình nạp MS-DOS được lưu trữ trong tệp
exe.sig. Việc có một tệp chữ ký cho một loại 昀椀 le nhị phân cụ thể không đảm bảo rằng IDA sẽ có thể
xác định hàm main của một chương trình 100%. Có quá nhiều trình biên dịch và chuỗi khởi động thay
đổi quá nhanh để IDA đi kèm với mọi chữ ký có thể có.
Đối với nhiều loại 昀椀 le nhị phân, chẳng hạn như ELF và Mach-O, IDA không bao gồm bất kỳ chữ ký
khởi động nào. Kết quả net là IDA không thể sử dụng chữ ký để xác định hàm main trong một 昀椀 le
nhị phân ELF (tuy nhiên, nếu hàm đó được đặt tên là main, IDA vẫn có thể 琀 m thấy). Mục đích của
cuộc thảo luận này là chuẩn bị bạn cho việc, đôi khi, bạn sẽ phải tự mình xác định hàm main của một
chương trình. Trong những trường hợp như vậy, có ích khi bạn có một số chiến lược để hiểu cách chính
chương trình chuẩn bị cho cuộc gọi đến hàm main. Ví dụ, xem xét một 昀椀 le nhị phân đã được làm rối
một chút. Trong trường hợp này, IDA chắc chắn sẽ không khớp với một chữ ký khởi động vì chính chuỗi
khởi động đã được làm rối. Nếu bạn thành công giải mã 昀椀 le nhị phân này (chủ đề của Chương 21),
bạn có thể cần xác định không chỉ hàm main mà còn quy trình bắt đầu ban đầu.
Bản Debug và Bản Release
Các dự án của Microso 昀琀's Visual Studio thường có khả năng xây dựng bản thử nghiệm (debug) hoặc
bản phát hành (release) của các 昀椀 le nhị phân chương trình. Một cách để nhận biết sự khác biệt là so
sánh các tùy chọn xây dựng được chỉ định cho phiên bản debug của một dự án với các tùy chọn xây
dựng được chỉ định cho phiên bản release. Sự khác biệt đơn giản bao gồm việc phiên bản release
thường được tối ưu hóa,7 trong khi phiên bản debug thì không, và phiên bản debug được liên kết với
thông 琀椀 n biểu tượng bổ sung và phiên bản thư viện thời gian chạy được debug, trong khi phiên bản
release thì không. Việc thêm các biểu tượng liên quan đến debug cho phép trình gỡ lỗi ánh xạ lại các
lệnh ngôn ngữ hợp ngữ về các đối tác mã nguồn của chúng và xác định tên của các biến địa phương.8
Thông 琀椀 n như vậy thường bị mất trong quá trình biên dịch. Các phiên bản debug của thư viện thời
gian chạy của Microso 昀琀 cũng đã được biên dịch với các biểu tượng liên quan đến debug bao gồm,
tối ưu hóa bị vô hiệu hóa và các kiểm tra an toàn bổ sung được bật để kiểm tra rằng một số tham số hàm là hợp lệ.
Khi được disassemble bằng IDA, phiên bản debug của các dự án Visual Studio trông khác biệt đáng kể so
với các phiên bản release. Điều này là kết quả của các tùy chọn của trình biên dịch và liên kết chỉ được
chỉ định trong các phiên bản debug, chẳng hạn như các kiểm tra thời gian chạy cơ bản (/RTCx9), đưa vào
mã nhị phân kết quả thêm mã. Một hiệu ứng phụ của mã thêm này là nó làm hỏng quá trình so khớp
chữ ký khởi động của IDA, dẫn đến việc IDA thường xuyên không thể tự động định vị được main trong
các phiên bản debug của các 昀椀 le nhị phân. lOMoARcPSD| 36625228
Các Phương Thức Gọi Khác
Trong Chương 6, chúng ta đã thảo luận về các phương thức gọi phổ biến nhất được sử dụng trong mã
nguồn C và C++. Mặc dù việc tuân thủ một phương thức gọi đã được xuất bản là quan trọng khi cố gắng
kết nối một mô-đun biên dịch với một mô-đun khác, không có gì cản trở việc sử dụng các phương thức
gọi tùy chỉnh bởi các hàm trong một mô-đun duy nhất. Điều này thường thấy trong các hàm được tối ưu
hóa cao không được thiết kế để được gọi từ bên ngoài mô-đun mà chúng tồn tại. Tóm Lược
Số lượng hành vi cụ thể của từng trình biên dịch là quá nhiều để bao quát trong một chương (hoặc thậm
chí là một cuốn sách đơn). Giữa các hành vi khác nhau, trình biên dịch khác nhau trong các thuật toán
mà chúng sử dụng để triển khai các cấu trúc cấp cao khác nhau và cách mà chúng chọn tối ưu hóa mã
nguồn được tạo ra. Bởi vì hành vi của một trình biên dịch bị ảnh hưởng nặng nề bởi các tùy chọn được
cung cấp cho trình biên dịch trong quá trình xây dựng, có khả năng một trình biên dịch có thể tạo ra các
昀椀 le nhị phân hoàn toàn khác nhau khi được cung cấp cùng một nguồn, nhưng với các tùy chọn xây
dựng khác nhau. Thật không may, việc học cách xử lý tất cả những biến thể này thường là một vấn đề
của kinh nghiệm. Làm phức tạp thêm là việc rằng thường rất khó khăn để 琀 m kiếm sự giúp đỡ về các
cấu trúc ngôn ngữ hợp ngữ cụ thể, vì việc tạo các biểu thức 琀 m kiếm có thể tạo ra kết quả cụ thể cho
trường hợp cụ thể của bạn là một công việc khó khăn. Khi điều này xảy ra, nguồn tư duy nhất của bạn
thường là một diễn đàn dành riêng cho ngành ngược kỹ thuật, nơi bạn có thể đăng mã và hưởng lợi từ
kiến thức của những người đã có những trải nghiệm tương tự.
PHÂN TÍCH MÃ NGUỒN BỊ LÀM RỐI
Ngay cả trong các điều kiện lý tưởng, việc hiểu một danh sách disassembly là một công việc khó khăn
nhất. Những disassembly chất lượng cao là quan trọng đối với bất kỳ ai đang cân nhắc nghiên cứu sâu
vào bản bin, chính vì lý do đó mà chúng ta đã dành 20 chương cuối cùng để thảo luận về IDA Pro và khả
năng của nó. Có thể cho rằng IDA làm công cụ này hiệu quả đến nỗi nó đã giảm ngưỡng cửa cho việc
nghiên cứu đối với lĩnh vực phân 琀 ch bin. Mặc dù không thể chỉ đơn thuần là nhờ vào IDA, nhưng
thực tế rằng lĩnh vực đảo mã nguồn bin đã phát triển đến mức độ đáng kể trong những năm gần đây
không thoả mãn những người không muốn phần mềm của mình bị phân 琀 ch. Do đó, trong vài năm
qua, một cuộc đua vũ trang tương tự đã diễn ra giữa kỹ sư đảo mã và các lập trình viên muốn giữ bí mật
mã nguồn của họ. Trong chương này, chúng ta sẽ xem xét vai trò của IDA trong cuộc đua vũ trang này và
thảo luận về một số biện pháp đã được thực hiện để bảo vệ mã nguồn, cũng như cách để vượt qua
những biện pháp đó bằng cách sử dụng IDA.
Nhiều định nghĩa từ điển sẽ cho bạn biết rằng làm rối (obfusca 琀椀 on) là hành động làm cho một điều
gì đó trở nên mơ hồ, phức tạp, khó hiểu, hoặc làm rối để ngăn chặn người khác hiểu được mục được
làm rối. Ngược lại, chống đảo mã nguồn (an 琀椀-reverse engineering) bao gồm một loạt các kỹ thuật
rộng lớn (trong đó có làm rối) được thiết kế để làm trở ngại phân 琀 ch của một mục. Trong ngữ cảnh
của cuốn sách này và việc sử dụng IDA, các mục mà các kỹ thuật chống đảo mã nguồn này có thể được
áp dụng là các tệp thực thi nhị phân (so với các tệp nguồn hoặc vi mạch silicon, ví dụ).
Để xem xét ảnh hưởng của việc làm rối và kỹ thuật chống đảo mã nguồn nói chung đối với việc sử dụng
IDA, đầu 琀椀 ên cần phân loại một số trong số những kỹ thuật này để hiểu rõ cách mỗi kỹ thuật có thể
thể hiện. Quan trọng lưu ý rằng không có cách phân loại chính xác nào cho mỗi kỹ thuật, vì các danh mục
chung sau đây thường chồng lắp trong mô tả của chúng. Ngoài ra, các kỹ thuật chống đảo mã nguồn mới lOMoARcPSD| 36625228
đang 琀椀 ếp tục được phát triển, và không thể cung cấp một danh sách duy nhất, bao gồm tất cả mọi thứ.
Địa Chỉ Mục Tiêu Được Tính Toán Động
Đừng nhầm lẫn 琀椀 êu đề của phần này với một kỹ thuật chống phân 琀 ch động. Cụm từ
"dynamically computed" đơn giản chỉ có nghĩa là một địa chỉ mà luồng thực thi sẽ chảy tới được 琀 nh
toán tại thời điểm chạy. Trong phần này, chúng ta sẽ thảo luận về một số cách mà một địa chỉ như vậy
có thể được tạo ra. Mục đích của những kỹ thuật như vậy là ẩn (làm rối) đường đi kiểm soát thực tế mà
một 昀椀 le nhị phân sẽ theo từ sự quan sát của quá trình phân 琀 ch 琁⤀nh.
Một ví dụ về kỹ thuật này đã được thể hiện trong phần trước đó. Ví dụ sử dụng một câu lệnh gọi để đặt
một địa chỉ trả về trên ngăn xếp. Địa chỉ trả về được đưa trực 琀椀 ếp từ ngăn xếp vào một thanh ghi, và
một giá trị hằng số được thêm vào thanh ghi để tạo ra địa chỉ đích cuối cùng, cuối cùng được đạt được
bằng cách thực hiện một lệnh nhảy đến vị trí được chỉ định bởi nội dung thanh ghi.
Nhiều loại ẩn định dạng kiểm soát phức tạp hơn đã được phát triển và sử dụng trong những năm gần
đây. Trong những trường hợp phức tạp nhất, một chương trình sẽ sử dụng nhiều luồng hoặc 琀椀 ến
trình con để 琀 nh toán thông 琀椀 n kiểm soát dạng và nhận thông 琀椀 n đó thông qua một hình
thức giao 琀椀 ếp giữa các 琀椀 ến trình (đối với các 琀椀 ến trình con) hoặc các nguyên tắc đồng bộ
(đối với nhiều luồng). Trong những trường hợp như vậy, phân 琀 ch 琁⤀nh có thể trở nên rất khó khăn,
vì nó trở nên cần thiết phải hiểu không chỉ hành vi của nhiều thực thể thực thi mà còn cách chính xác mà
những thực thể đó trao đổi thông 琀椀 n. Ví dụ, một luồng có thể đợi trên một đối tượng semaphore3
chia sẻ, trong khi một luồng thứ hai 琀 nh toán giá trị hoặc chỉnh sửa mã mà luồng đầu 琀椀 ên sẽ sử
dụng sau khi luồng thứ hai báo hiệu hoàn thành thông qua semaphore.
Một kỹ thuật khác, thường được sử dụng trong malware hướng tới hệ điều hành Windows, liên quan
đến cấu hình một bộ xử lý ngoại lệ4, gây ra một ngoại lệ có chủ ý, và sau đó thao tác trạng thái của các
thanh ghi của quy trình trong khi xử lý ngoại lệ.
Làm Mã Opcode trở nên mơ hồ
Trong khi các kỹ thuật mà chúng ta đã mô tả đến đây có thể cung cấp - thực sự, được thiết kế để cung
cấp - một trở ngại cho việc hiểu luồng kiểm soát của chương trình, nhưng không có kỹ thuật nào ngăn
bạn quan sát được dạng disassembly chính xác của một chương trình bạn đang phân 琀 ch. Việc giả
mạo đạt được ảnh hưởng lớn nhất đối với disassembly, nhưng nó dễ dàng bị đánh bại bằng cách định
dạng lại disassembly để phản ánh luồng lệnh chính xác.
Một kỹ thuật hiệu quả hơn để ngăn chặn disassembly đúng đắn là mã hóa hoặc mã hóa các lệnh thực sự
khi tệp thực thi được tạo ra. Các lệnh đã bị làm mơ hồ này không có ý nghĩa với CPU và phải được giải
mã trở lại dạng ban đầu của chúng trước khi chúng được lấy để thực thi bởi CPU. Do đó, ít nhất một
phần của chương trình phải được giữ không mã hóa để phục vụ làm quy trình khởi động, và trong
trường hợp của một chương trình bị làm mơ hồ, thường có trách nhiệm giải mã một số hoặc tất cả phần
còn lại của chương trình.
Quá trình quá mức hóa này, dù đơn giản hóa, thay đổi rộng rãi dựa vào công cụ mà nó sử dụng để tạo ra
tệp nhị phân được làm mơ hồ. Ngày càng có nhiều công cụ sẵn có để xử lý quá trình làm mơ hồ. Các
công cụ như vậy cung cấp các 琀 nh năng từ nén đến các kỹ thuật chống disassembly và chống debug. lOMoARcPSD| 36625228
Các ví dụ bao gồm các chương trình như UPX7 (nén, cũng hoạt động với ELF), ASPack8 (nén), ASProtect
(chống đảo mã nguồn bởi những người làm ASPack), và tElock9 (nén và chống đảo mã nguồn) cho tệp
PE Windows, và Burneye10 (mã hóa) và Shiva11 (mã hóa và chống debug) cho các tệp ELF Linux. Khả
năng của các công cụ làm mơ hồ đã 琀椀 ến triển đến mức mà một số công cụ chống đảo mã nguồn như
WinLicense12 cung cấp 琀 ch hợp nhiều hơn trong toàn bộ quá trình xây dựng, cho phép các lập trình
viên 琀 ch hợp các 琀 nh năng chống đảo mã nguồn ở mọi bước, từ mã nguồn đến xử lý sau cùng trên
tệp nhị phân được biên dịch.
Một phát triển gần đây hơn trong thế giới của các chương trình làm mơ hồ liên quan đến việc bọc tệp
thực thi gốc bằng một bộ máy ảo thực thi. Tùy thuộc vào sự 琀椀 nh tế của công cụ làm mơ hồ ảo hóa,
mã máy gốc có thể không bao giờ được thực hiện trực 琀椀 ếp; thay vào đó, mã đó được giải thích bởi
một máy ảo hóa tập trung vào bytecode. Các máy ảo hóa phức tạp rất có khả năng tạo ra các phiên bản
máy ảo duy nhất mỗi lần chúng chạy, làm cho việc tạo ra một thuật toán giải mã hóa đa dụng để đánh
bại chúng trở nên khó khăn. VMProtect13 là một ví dụ về một công cụ làm mơ hồ ảo hóa. VMProtect đã
được sử dụng để làm mơ hồ trojan Clampi14.
Giống như bất kỳ công nghệ tấn công nào, đã có các biện pháp phòng ngự được phát triển để đối phó
với nhiều công cụ chống đảo mã nguồn. Trong hầu hết các trường hợp, mục 琀椀 êu của các công cụ
như vậy là khôi phục lại tệp thực thi gốc, không được bảo vệ (hoặc một bản sao gần đúng hợp lý), sau đó
có thể được phân 琀 ch bằng các công cụ truyền thống hơn như disassemblers và debuggers. Một công
cụ như vậy được thiết kế để giải mã tệp thực thi Windows được gọi là QuickUnpack.15 QuickUnpack,
giống như nhiều công cụ giải mã tự động khác, hoạt động như một trình gỡ lỗi và cho phép một tệp nhị
phân bị làm mơ hồ chạy qua giai đoạn giải mã của nó, sau đó chụp ảnh quy trình từ bộ nhớ. Cần lưu ý
rằng loại công cụ này thực sự chạy các chương trình có thể gây hại với hy vọng chặn thực hiện của
những chương trình sau khi chúng đã tự giải mã hoặc làm mơ hồ chúng, nhưng trước khi chúng có cơ
hội thực hiện bất kỳ hành động độc hại nào. Do đó, bạn nên luôn chạy những chương trình như vậy
trong một môi trường loại hộp cát.
Sử dụng một môi trường phân 琀 ch 琁⤀nh thuần túy để phân 琀 ch mã đã bị làm mơ hồ là một công
việc thách thức trong tốt nhất. Mà không có khả năng thực hiện giai đoạn giải mã, phải sử dụng một
phương 琀椀 ện giải mã hoặc giải mã các phần đã được làm mơ hồ của tệp nhị phân trước khi bắt đầu
phân 琀 ch mã đã bị làm mơ hồ.
Mơ Hồ Hóa Chức Năng Được Nhập
Để tránh rò rỉ thông 琀椀 n về các hành động 琀椀 ềm ẩn mà một tệp nhị phân có thể thực hiện, một kỹ
thuật chống phân 琀 ch 琁⤀nh bổ sung nhằm làm cho việc xác định xem thử các thư viện và chức năng
thư viện chia sẻ nào được sử dụng trong một tệp nhị phân đã bị làm mơ hồ trở nên khó khăn. Trong hầu
hết các trường hợp, có thể làm cho các công cụ như dumpbin, ldd và objdump trở nên không hiệu quả
để liệt kê các phụ thuộc thư viện.
Ảnh hưởng của các kỹ thuật làm mơ hồ như vậy đối với IDA là rõ nhất trong cửa sổ Nhập khẩu (Imports). lOMoARcPSD| 36625228
Chỉ có hai hàm ngoại vi được đề cập, GetModulehandleA (từ kernel32.dll) và MessageBoxA (từ
user32.dll). Thực tế, không thể suy luận được nhiều về hành vi của chương trình từ danh sách ngắn này.
Vậy thì làm thế nào một chương trình như vậy có thể thực hiện được bất cứ điều gì hữu ích? Các kỹ
thuật ở đây đa dạng, nhưng chúng chủ yếu dựa vào việc chương trình phải tự tải bất kỳ thư viện nào mà
nó phụ thuộc vào và, khi các thư viện đã được tải, chương trình phải định vị bất kỳ hàm cần thiết nào
trong những thư viện đó. Trong hầu hết các trường hợp, những nhiệm vụ này được thực hiện bởi đoạn
mã giải mã trước khi chuyển quyền kiểm soát cho chương trình đã giải mã. Mục 琀椀 êu cuối cùng là
bảng nhập của chương trình đã được khởi tạo đúng cách, giống như quá trình đã được thực hiện bởi
trình tải của hệ điều hành.
Đối với các tệp nhị phân Windows, một cách 琀椀 ếp cận đơn giản là sử dụng hàm LoadLibrary để tải các
thư viện cần thiết theo tên và sau đó thực hiện 琀 m kiếm địa chỉ hàm trong mỗi thư viện bằng cách sử
dụng hàm GetProcAddress. Để sử dụng những hàm này, một chương trình phải được liên kết một cách
rõ ràng với chúng hoặc có một phương 琀椀 ện thay thế để 琀 m kiếm chúng. Danh sách Names cho ví
dụ tElock không bao gồm cả hai hàm này, trong khi danh sách Names cho ví dụ UPX hiển thị cả hai.
Việc xây dựng lại bảng nhập của chương trình thông qua phân 琀 ch cẩn thận của mã nguồn của chương
trình trở nên dễ dàng hơn trong trường hợp của UPX và tElock bởi vì cuối cùng, cả hai đều chứa dữ liệu
ký tự ASCII mà chúng ta có thể sử dụng để xác định chính xác thư viện và các hàm đang được tham chiếu.
Bài báo của Skape mô tả một quá trình giải quyết hàm mà không có chuỗi xuất hiện trong mã nguồn. Ý
tưởng cơ bản được thảo luận trong bài báo là 琀 nh toán trước một giá trị băm duy nhất cho tên của
mỗi hàm bạn cần giải quyết. Để giải quyết mỗi hàm, một 琀 m kiếm được thực hiện qua bảng tên đã
xuất của thư viện. Mỗi tên trong bảng được băm và giá trị băm kết quả được so sánh với giá trị băm
được 琀 nh trước cho hàm mong muốn. Nếu các giá trị băm trùng khớp, hàm mong muốn đã được định
vị và bạn có thể dễ dàng 琀 m địa chỉ của nó trong bảng địa chỉ xuất của thư viện. Để phân 琀 ch 琁⤀nh
các tệp nhị phân được làm mờ theo cách này, bạn cần hiểu thuật toán băm được sử dụng cho mỗi tên
hàm và áp dụng thuật toán đó cho tất cả các tên được xuất bởi thư viện mà chương trình đang 琀 m
kiếm. Có được một bảng đầy đủ các giá trị băm, bạn sẽ có thể 琀 m kiếm đơn giản từng giá trị băm mà
bạn gặp trong chương trình để xác định hàm mà giá trị băm đó tham chiếu đến.
Việc Skape sử dụng giá trị băm để giải quyết tên hàm ban đầu được phát triển và được tài liệu hóa ban
đầu để sử dụng trong các tải động khai thác lỗ hổng Windows; tuy nhiên, giá trị băm đã được áp dụng
để sử dụng trong các chương trình đã được làm mờ cũng. Tiện ích làm mờ WinLicense là một ví dụ sử
dụng các kỹ thuật băm như vậy để che giấu hành vi của nó.
Một chú ý cuối cùng về bảng nhập là rằng, thú vị thay, IDA đôi khi có thể cung cấp gợi ý rằng có điều gì
đó không đúng với bảng nhập của một chương trình. Các tệp nhị phân Windows đã được làm mờ
thường có bảng nhập được sửa đổi đủ mạnh mẽ để IDA cảnh báo rằng có vẻ có điều gì đó không bình
thường với một tệp nhị phân như vậy. Hình ảnh 21-3 hiển thị hộp thoại cảnh báo mà IDA hiển thị trong
những trường hợp như vậy.
Kỹ Thuật Giải Quyết Tên Hàm: •
Skape đề cập đến việc sử dụng giá trị băm để giải quyết tên hàm mà không có chuỗi
xuất hiện trong mã nguồn. Ý tưởng cơ bản là 琀 nh toán trước một giá trị băm duy nhất
cho tên của mỗi hàm cần giải quyết. lOMoARcPSD| 36625228 •
Quá trình giải quyết mỗi hàm bao gồm 琀 m kiếm trong bảng tên xuất của thư viện.
Mỗi tên được băm, và giá trị băm kết quả được so sánh với giá trị băm được 琀 nh
trước cho hàm cần 琀 m. Nếu giá trị băm trùng khớp, hàm đã được xác định và địa chỉ
của nó có thể dễ dàng được 琀 m thấy trong bảng địa chỉ xuất của thư viện. •
Phân 琀 ch 琁⤀nh của các tệp nhị phân được làm mờ bằng cách này đòi hỏi hiểu thuật
toán băm được sử dụng cho mỗi tên hàm và áp dụng nó cho tất cả các tên được xuất
bởi thư viện mà chương trình đang 琀 m kiếm. IDA và Bảng Nhập: •
IDA (Interac 琀椀 ve Disassembler) đôi khi có thể cung cấp gợi ý rằng có vấn đề với bảng
nhập của chương trình. Các tệp nhị phân Windows được làm mờ thường có bảng nhập
bị sửa đổi đủ mạnh để IDA cảnh báo về sự không bình thường của chúng. Hình ảnh 21-3
hiển thị hộp thoại cảnh báo mà IDA sẽ hiển thị trong trường hợp như vậy.
Trên tất cả, đoạn văn này giải thích cách các chương trình được làm mờ có thể đạt được chức năng hữu
ích bằng cách tự tải các thư viện và giải quyết các hàm cần thiết trong những thư viện này. Sự sáng tạo
trong việc sử dụng giá trị băm để giải quyết tên hàm là một trong những kỹ thuật quan trọng được thảo
luận, và IDA cung cấp thông báo khi bảng nhập của chương trình có vấn đề, giúp người phân 琀 ch nhận
biết các trường hợp có thể đặc biệt.
3. CÁCH SỬ DỤNG IDA PRO NÂNG CAO I.CUSTOMIZING IDA
Sau khi dành một thời gian với IDA, bạn có thể đã phát triển một số cài đặt ưa thích mà bạn muốn sử
dụng làm mặc định mỗi khi mở một cơ sở dữ liệu mới. Một số tùy chọn bạn đã thay đổi có thể được lưu
giữ giữa các phiên làm việc, trong khi các tùy chọn khác dường như cần phải đặt lại mỗi khi bạn tải một
cơ sở dữ liệu mới. Trong chương này, chúng tôi xem xét các cách khác nhau mà bạn có thể điều chỉnh
hành vi của IDA thông qua các tệp cấu hình và tùy chọn truy cập từ menu. Chúng tôi cũng xem xét nơi
IDA lưu trữ các cài đặt cấu hình khác nhau và thảo luận về sự khác biệt giữa cài đặt cụ thể cho cơ sở dữ
liệu và cài đặt toàn cầu. Tệp cấu hình
Hành vi mặc định của IDA được điều chỉnh chủ yếu bởi các cài đặt trong các tệp cấu hình khác nhau. Đa
phần, các tệp cấu hình được lưu trữ trong thư mục /cfg, với một ngoại lệ đáng chú ý là tệp cấu
hình cho các plugin, nằm tại /plugins/plugins.cfg (plugins.cfg sẽ được trình bày trong Chương
17). Mặc dù bạn có thể thấy khá nhiều tệp trong thư mục cấu hình chính, hầu hết các tệp này được sử
dụng bởi các module bộ xử lý và chỉ áp dụng khi các loại CPU cụ thể đang được phân tích. Ba tệp cấu
hình chính là ida.cfg, idagui.cfg và idatui.cfg. Các tùy chọn áp dụng cho tất cả các phiên bản của IDA
thường được tìm thấy trong ida.cfg, trong khi idagui.cfg và idatui.cfg chứa các tùy chọn cụ thể cho các
phiên bản giao diện đồ hoạ và phiên bản văn bản của IDA, tương ứng.
Tệp cấu hình chính: ida.cfg
Tệp cấu hình chính của IDA là ida.cfg. Sớm trong quá trình khởi động, tệp này được đọc để gán các loại
bộ xử lý mặc định cho các phần mở rộng tệp khác nhau và điều chỉnh các tham số sử dụng bộ nhớ của
IDA. Sau khi đã chỉ định một loại bộ xử lý, tệp sẽ được đọc lần thứ hai để xử lý các tùy chọn cấu hình bổ lOMoARcPSD| 36625228
sung. Các tùy chọn trong ida.cfg áp dụng cho tất cả các phiên bản của IDA bất kể giao diện người dùng đang sử dụng.
Các tùy chọn chung quan trọng trong ida.cfg bao gồm các tham số điều chỉnh bộ nhớ (VPAGESIZE), liệu
có tạo các tệp sao lưu không (CREATE_BACKUPS), và tên của trình xem đồ thị ngoài (GRAPH_VISUALIZER).
Đôi khi khi làm việc với các trường nhập rất lớn, IDA có thể báo rằng không có đủ bộ nhớ để tạo cơ sở
dữ liệu mới. Trong những trường hợp như vậy, việc tăng VPAGESIZE và sau đó mở lại tệp nhập liệu
thường là đủ để giải quyết vấn đề.
Một số lượng lớn các tùy chọn điều chỉnh định dạng dòng dịch chứa trong ida.cfg, bao gồm các giá trị
mặc định cho nhiều tùy chọn có thể truy cập qua Options -> General. Điều này bao gồm các giá trị mặc
định cho số byte opcode để hiển thị (OPCODE_BYTES), cách thức thụt lề của các lệnh
(INDENTATION), liệu có hiển thị độ lệch trỏ ngăn xếp với mỗi lệnh không (SHOW_SP), và số lượng tối
đa các tham chiếu chéo để hiển thị với một dòng dịch (SHOW_XREFS). Các tùy chọn bổ sung điều chỉnh
định dạng dòng dịch khi ở chế độ đồ thị.
Tùy chọn toàn cầu xác định độ dài tên tối đa cho các vị trí chương trình có tên (so với các biến ngăn xếp)
được chứa trong ida.cfg và được gọi là MAX_NAMES_LENGTH. Tùy chọn này mặc định là 15 ký tự và
khiến IDA tạo ra một thông báo cảnh báo mỗi khi bạn nhập một tên dài hơn giới hạn hiện tại. Độ dài mặc
định được giữ nhỏ vì một số bộ dịch không thể xử lý các tên dài hơn 15 ký tự. Nếu bạn không dự định
chạy lại một đoạn dịch IDA đã tạo qua một bộ dịch, bạn có thể an toàn tăng giới hạn này.
Tệp cấu hình GUI: idagui.cfg
Các mục cấu hình cụ thể cho phiên bản GUI của IDA được đặt trong tệp riêng của chúng:
/cfg/idagui.cfg. Tệp này được tổ chức thành khoảng ba phần chính: hành vi GUI mặc định,
ánh xạ phím tắt bàn phím, và cấu hình phần mở rộng tệp cho hộp thoại File -> Mở. Trong phần này,
chúng tôi thảo luận về một số tùy chọn thú vị hơn. Hãy xem idagui.cfg để có danh sách đầy đủ các tùy
chọn có sẵn, trong đa số trường hợp đi kèm với các chú thích mô tả mục đích của chúng.
Phiên bản GUI của IDA trên Windows cho phép chỉ định một tệp trợ giúp phụ bằng tùy chọn HELPFILE.
Bất kỳ tệp nào được chỉ định ở đây không thay thế tệp trợ giúp chính của IDA. Mục đích dự kiến của tùy
chọn này là cung cấp quyền truy cập vào thông tin bổ sung có thể áp dụng trong các tình huống phân tích
ngược cụ thể. Khi chỉ định một tệp trợ giúp bổ sung, CTRL-F1 khiến IDA mở tệp có tên và tìm kiếm một
chủ đề phù hợp với từ đang ở dưới con trỏ. Nếu không tìm thấy khớp, bạn sẽ được đưa đến chỉ mục của
tệp trợ giúp. Ví dụ, trừ khi bạn tính cả các ghi chú tự động, IDA không cung cấp bất kỳ thông tin trợ giúp
nào về các mã chỉ thị trong quá trình dịch. Nếu bạn phân tích một file nhị phân x86, bạn có thể muốn có
sẵn một tệp tham khảo mã chỉ thị x86. Nếu bạn có thể tìm được một tệp trợ giúp chứa các chủ đề cho mỗi
mã chỉ thị x86, việc truy cập trợ giúp cho bất kỳ chỉ thị nào chỉ cách nhấn một phím nóng. Lưu ý rằng
IDA chỉ hỗ trợ các tệp trợ giúp dạng WinHelp (.hlp). IDA không hỗ trợ việc sử dụng các tệp trợ giúp
HTML biên soạn (.chm) làm tệp trợ giúp phụ. LƯU Ý
Windows Vista và các phiên bản sau không cung cấp hỗ trợ tự nhiên cho các tệp WinHelp 32-bit vì tệp
WinHlp32.exe không được đi kèm với các hệ điều hành này. Vui lòng tham khảo bài viết trong cơ sở kiến
thức của Microsoft 9176073 để biết thêm thông tin. lOMoARcPSD| 36625228
Một câu hỏi phổ biến về việc sử dụng IDA là “Làm thế nào để tôi chỉnh sửa các tệp nhị phân bằng IDA?”
Nói một cách ngắn gọn, câu trả lời là “Bạn không thể”, nhưng chúng tôi sẽ trì hoãn thảo luận về chi tiết
vấn đề này cho đến Chương 14. Điều bạn có thể làm với IDA là chỉnh sửa cơ sở dữ liệu để sửa đổi lệnh
hoặc dữ liệu theo bất kỳ cách nào bạn muốn. Sau khi thảo luận về việc viết script (Chương 15), bạn sẽ
hiểu rằng việc sửa đổi cơ sở dữ liệu không quá khó khăn. Nhưng nếu bạn không quan tâm hoặc chưa sẵn
sàng để học ngôn ngữ script của IDA, IDA chứa một menu chỉnh sửa cơ sở dữ liệu không được hiển thị
mặc định. Tùy chọn DISPLAY_PATCH_SUBMENU được sử dụng để hiển thị hoặc ẩn menu chỉnh sửa
của IDA, xuất hiện dưới dạng Chỉnh sửa -> Chương trình. Các tùy chọn có sẵn trong menu này sẽ được
thảo luận trong Chương 14. .
Tệp cấu hình cho phiên bản Console: idatui.cfg
Tương đương với idagui.cfg dành cho người dùng phiên bản console của IDA là
/cfg/idatui.cfg. Tệp này rất tương tự về cấu trúc và chức năng so với idagui.cfg. Trong đó, các
chỉ định phím tắt được thực hiện theo cách tương tự như trong idagui.cfg. Vì hai tệp này tương đối giống
nhau, ở đây chúng tôi chỉ tập trung vào những điểm khác biệt.
Đầu tiên, các tùy chọn DISPLAY_PATCH_SUBMENU và DISPLAY_COMMAND_LINE không có sẵn
trong phiên bản console và không được bao gồm trong idatui.cfg. Hộp thoại File -> Open được sử dụng
trong phiên bản console đơn giản hơn nhiều so với hộp thoại được sử dụng trong phiên bản GUI, do đó,
tất cả các lệnh liên kết tệp có sẵn trong idagui.cfg đều không có trong idatui.cfg..
Các Tùy chọn Cấu hình Bổ sung của IDA
IDA có một số lượng lớn tùy chọn bổ sung phải được cấu hình thông qua giao diện người dùng của IDA.
Các tùy chọn để định dạng từng dòng disassembly đã được thảo luận trong Chương 7. Các tùy chọn IDA
bổ sung được truy cập thông qua menu Options, và trong hầu hết các trường hợp, bất kỳ tùy chọn nào bạn
sửa đổi chỉ áp dụng cho cơ sở dữ liệu hiện tại đang mở. Giá trị cho những tùy chọn đó được lưu trong tệp
cơ sở dữ liệu liên quan khi cơ sở dữ liệu được đóng. Tùy chọn Màu sắc (Options -> Colors) và Phông chữ
(Options -> Font) của IDA là hai ngoại lệ của quy tắc này vì chúng là tùy chọn toàn cầu mà một khi được
thiết lập, sẽ hiệu quả trong tất cả các phiên IDA sau này. Đối với phiên bản Windows của IDA, giá trị tùy
chọn được lưu trong registry Windows dưới registry key HKEY_CURRENT_USER\Software\Hex-Rays\
IDA. Đối với phiên bản IDA không phải Windows, các giá trị này được lưu trong thư mục home của bạn
trong một tệp định dạng độc quyền có tên là $HOME/.idapro/ida.reg.
Một thông tin khác được lưu trong registry liên quan đến các hộp thoại mà bạn có thể chọn Tắt hộp thoại
này lại lần sau. Thông điệp này đôi khi xuất hiện dưới dạng ô kiểm trong phần dưới bên phải của một số
hộp thoại thông tin mà bạn có thể không muốn nhìn thấy trong tương lai. Nếu bạn chọn tùy chọn này, một
giá trị registry sẽ được tạo trong registry key HKEY_CURRENT_USER\Software\Hex-
Rays\IDA\Hidden Messages. Nếu sau này, bạn muốn hiển thị lại một hộp thoại ẩn, bạn sẽ cần xóa giá trị
tương ứng trong registry key này.
Tab Disassembly điều khiển các màu được sử dụng cho các phần khác nhau của mỗi dòng trong cửa sổ
disassembly. Ví dụ của mỗi loại văn bản có thể xuất hiện trong disassembly được hiển thị trong cửa sổ
mẫu X. Khi bạn chọn một mục trong cửa sổ mẫu, loại mục được liệt kê tại Y. Sử dụng nút Change Color,
bạn có thể gán bất kỳ màu nào bạn muốn cho bất kỳ mục nào bạn muốn. lOMoARcPSD| 36625228
Tùy chỉnh thanh công cụ IDA
Ngoài menu và phím tắt, phiên bản GUI của IDA cung cấp một số lượng lớn nút thanh công cụ lan rộng
trên hơn hai mươi thanh công cụ. Thanh công cụ thường được ghim trong khu vực thanh công cụ chính
dưới thanh menu của IDA. Hai bố cục thanh công cụ được xác định trước có sẵn thông qua menu View ->
Toolbars là Basic mode, cho phép bảy thanh công cụ của IDA, và Advanced mode, cho phép mọi thanh
công cụ của IDA. Các thanh công cụ riêng lẻ có thể được tách ra, kéo và di chuyển đến bất kỳ vị trí nào
trên màn hình để phù hợp với sở thích cá nhân của bạn. Nếu bạn thấy không cần thiết cho một thanh công
cụ cụ thể, bạn có thể loại bỏ nó khỏi hiển thị hoàn toàn thông qua menu View -> Toolbars, như được hiển thị trong Figure 11-2.
Menu này cũng xuất hiện nếu bạn nhấp chuột phải bất kỳ nơi nào trong khu vực ghim của hiển thị IDA.
Tắt thanh công cụ Main loại bỏ tất cả các thanh công cụ khỏi khu vực ghim và hữu ích nếu bạn cần tối đa
hóa không gian màn hình dành cho cửa sổ disassembly. Bất kỳ thay đổi nào bạn thực hiện cho bố cục
thanh công cụ của mình được lưu với cơ sở dữ liệu hiện tại. Tóm tắt
Khi bắt đầu sử dụng IDA, bạn có thể hoàn toàn hài lòng với cả hành vi mặc định và bố cục GUI mặc định
của nó. Khi bạn trở nên thoải mái hơn với các tính năng cơ bản của IDA, bạn nhất định sẽ tìm cách tùy
chỉnh IDA theo sở thích riêng của mình. Mặc dù không có cách nào để cung cấp thông tin đầy đủ về mọi
tùy chọn mà IDA cung cấp trong một chương, chúng tôi đã cố gắng chỉ ra những vị trí chính mà những
tùy chọn đó có thể được tìm thấy. Chúng tôi cũng đã cố gắng nhấn mạnh những tùy chọn mà bạn có khả
năng muốn điều chỉnh tại một số thời điểm trong quá trình sử dụng IDA của bạn. Việc khám phá thêm
các tùy chọn hữu ích khác là nhiệm vụ cho các độc giả ham học hỏi.
II.NHẬN DẠNG THƯ VIỆN SỬ DỤNG CÁC CHỮ KÝ FLIRT
Tại điểm này, là lúc bắt đầu khám phá những khả năng không rõ ràng hơn của IDA và bắt đầu sự khám
phá về những gì cần làm sau khi “Quá trình phân tích tự động ban đầu đã hoàn thành.” Trong chương
này, chúng ta thảo luận về các kỹ thuật nhận dạng chuỗi mã tiêu chuẩn như mã thư viện chứa trong các
tệp nhị phân được liên kết tĩnh hoặc các hàm khởi tạo tiêu chuẩn và hàm trợ giúp được chèn bởi trình biên dịch.
Khi bạn bắt đầu thực hiện việc reverse engineering trên bất kỳ tệp nhị phân nào, điều cuối cùng bạn muốn
là không muốn lãng phí thời gian reverse engineering các hàm thư viện mà bạn có thể dễ dàng học được
hành vi của chúng đơn giản bằng cách đọc tài liệu hướng dẫn, đọc một số mã nguồn, hoặc tìm hiểu trên
internet một chút. Thách thức được đặt ra bởi các tệp nhị phân được liên kết tĩnh là chúng làm mờ sự
phân biệt giữa mã ứng dụng và mã thư viện.
Công nghệ Nhận diện và Nhận dạng Thư viện Nhanh Chóng (FLIRT)
Công nghệ Nhận diện và Nhận dạng Thư viện Nhanh Chóng, được biết đến tốt hơn với tên gọi FLIRT,
bao gồm bộ các kỹ thuật được sử dụng bởi IDA để nhận diện các chuỗi mã như mã thư viện. Ở trung tâm lOMoARcPSD| 36625228
của FLIRT là các thuật toán phù hợp mẫu (pattern-matching), cho phép IDA xác định nhanh chóng xem
một hàm đã được disassemble có khớp với một trong nhiều chữ ký được biết đến của IDA không. Thư
mục /sig chứa các tệp chữ ký được đi kèm với IDA. Đa phần, đây là các thư viện được đi kèm
với các trình biên dịch phổ biến trên Windows, tuy nhiên cũng có một số chữ ký không phải Windows được bao gồm.
Các tệp chữ ký sử dụng định dạng tùy chỉnh trong đó phần lớn dữ liệu chữ ký được nén và bao bọc trong
một tiêu đề cụ thể của IDA. Trong hầu hết các trường hợp, tên tệp chữ ký không mô tả rõ ràng chữ ký
được tạo ra từ thư viện nào. Tùy thuộc vào cách chúng được tạo ra, các tệp chữ ký có thể chứa một ghi
chú tên thư viện mô tả nội dung của chúng. Nếu chúng ta xem những dòng ASCII được trích xuất đầu
tiên từ một tệp chữ ký, thông thường ghi chú này được tiết lộ. Lệnh Unix sau đây thường hiển thị ghi chú
ở dòng thứ hai hoặc thứ ba:
Áp dụng Chữ ký FLIRT
Khi một tệp nhị phân được mở lần đầu, IDA cố gắng áp dụng các tệp chữ ký đặc biệt, được chỉ định là
chữ ký khởi động, vào điểm nhập của tệp nhị phân. Phát hiện ra rằng mã đầu vào được tạo ra bởi các trình
biên dịch khác nhau là độc đáo đến mức việc khớp chữ ký điểm nhập là một kỹ thuật hữu ích để xác định
trình biên dịch có thể đã được sử dụng để tạo ra một tệp nhị phân cụ thể.
Nếu IDA xác định được trình biên dịch được sử dụng để tạo ra một tệp nhị phân cụ thể, sau đó tệp chữ ký
cho các thư viện tương ứng với trình biên dịch đó sẽ được tải và áp dụng vào phần còn lại của tệp nhị
phân. Những chữ ký được đi kèm với IDA thường liên quan đến các trình biên dịch sở hữu như Microsoft
Visual C++ hoặc Borland Delphi. Lý do đằng sau điều này là vì một số hạn chế về số lượng thư viện nhị
phân đi kèm với những trình biên dịch này. Đối với các trình biên dịch mã nguồn mở, như GNU gcc, các
biến thể nhị phân của các thư viện tương ứng cũng phong phú như các hệ điều hành mà các trình biên
dịch đi kèm. Ví dụ, mỗi phiên bản của FreeBSD đi kèm với một phiên bản duy nhất của thư viện chuẩn
C. Để có phù hợp tối ưu với việc phân tích mẫu, các tệp chữ ký sẽ cần phải được tạo ra cho mỗi phiên bản
của thư viện. Hãy xem xét sự khó khăn trong việc thu thập mọi biến thể của libc.a đã đi kèm với mỗi
phiên bản của mỗi bản phân phối Linux. Điều này đơn giản không thực tế. Phần trong những khác biệt
này là do sự thay đổi trong mã nguồn thư viện dẫn đến mã được biên dịch khác nhau, nhưng sự khác biệt
lớn cũng đến từ việc sử dụng các tùy chọn biên dịch khác nhau, như cài đặt tối ưu hóa và việc sử dụng
các phiên bản trình biên dịch khác nhau để xây dựng thư viện. Kết quả net là IDA đi kèm với rất ít tệp
chữ ký cho các thư viện trình biên dịch mã nguồn mở CẢNH BÁO
Chỉ có các hàm được đặt tên bằng tên giả của IDA mới có thể được đặt tên tự động. Nói cách khác, nếu
bạn đã đổi tên một hàm và hàm đó sau này được phù hợp với một chữ ký, thì hàm sẽ không được đổi tên
do kết quả phù hợp đó. Do đó, việc áp dụng chữ ký càng sớm trong quá trình phân tích của bạn càng có lợi.
Hãy nhớ rằng các tệp nhị phân được liên kết tĩnh làm mờ ranh giới giữa mã ứng dụng và mã thư viện.
Nếu bạn may mắn có một tệp nhị phân liên kết tĩnh mà không bị xóa các ký hiệu của nó, bạn ít nhất cũng
sẽ có các tên hàm hữu ích (càng hữu ích càng tốt nếu lập trình viên tin cậy đã chọn tạo) để giúp bạn điều
hướng qua mã nguồn. Tuy nhiên, nếu tệp nhị phân đã bị xóa ký hiệu, bạn có thể sẽ có hàng trăm hàm, tất lOMoARcPSD| 36625228
cả đều có tên do IDA tạo ra mà không cho biết chức năng của hàm đó là gì. Trong cả hai trường hợp, IDA
chỉ có thể xác định các hàm thư viện nếu có sẵn các chữ ký (tên hàm trong tệp nhị phân chưa bị xóa
không cung cấp đủ thông tin cho IDA để xác định chính xác một hàm là hàm thư viện).
Tạo Tập Tin Chữ Ký FLIRT
Như đã thảo luận trước đó, việc IDA gửi kèm với tập tin chữ ký cho mọi thư viện tĩnh tồn tại là không
thực tế. Để cung cấp cho người dùng IDA các công cụ và thông tin cần thiết để tạo chữ ký riêng của họ,
Hex-Rays phân phối bộ công cụ Fast Library Acquisition for Identification and Recognition (FLAIR).
Các công cụ FLAIR được cung cấp trên đĩa phân phối IDA của bạn hoặc thông qua tải về từ trang web
của Hex-Rays cho khách hàng được ủy quyền. Giống như một số addon khác của IDA, các công cụ
FLAIR được phân phối trong một tệp Zip. Hex-Rays không nhất thiết phát hành một phiên bản mới của
các công cụ FLAIR với mỗi phiên bản của IDA, vì vậy bạn nên sử dụng phiên bản FLAIR mới nhất mà
không vượt quá phiên bản IDA của bạn.
Cài đặt các tiện ích FLAIR đơn giản chỉ là việc giải nén nội dung của tệp Zip tương ứng, tuy nhiên, chúng
tôi khuyến nghị mạnh mẽ bạn nên tạo một thư mục flair riêng biệt làm đích đến vì tệp Zip không được tổ
chức với một thư mục cấp cao. Bên trong bản phân phối FLAIR, bạn sẽ tìm thấy một số tệp văn bản cấu
thành tài liệu cho các công cụ FLAIR. Một số tệp đặc biệt bao gồm những tệp sau đây:
Readme.txt: Đây là tổng quan cấp cao về quy trình tạo chữ ký.
Plb.txt: Tệp này mô tả việc sử dụng trình phân tích thư viện tĩnh, plb.exe. Trình phân tích thư viện được
thảo luận chi tiết hơn trong “Tạo Tệp Mẫu” trên trang 219.
Pat.txt: Tệp này mô tả định dạng của các tệp mẫu, đại diện cho bước đầu tiên trong quá trình tạo chữ ký.
Các tệp mẫu cũng được mô tả trong “Tạo Tệp Mẫu” trên trang 219.
Sigmake.txt: Tệp này mô tả việc sử dụng sigmake.exe để tạo tệp .sig từ tệp mẫu. Vui lòng tham khảo
“Tạo Tệp Chữ Ký” trên trang 221 để biết thêm chi tiết.
Tổng quan về Tạo Chữ Ký
Quá trình cơ bản để tạo các tệp chữ ký không có vẻ phức tạp, vì nó tập trung vào bốn bước đơn giản.
1. Lấy bản sao của thư viện tĩnh mà bạn muốn tạo tệp chữ ký.
2. Sử dụng một trong các trình phân tích FLAIR để tạo một tệp mẫu cho thư viện.
3. Chạy sigmake.exe để xử lý tệp mẫu kết quả và tạo một tệp chữ ký.
4. Cài đặt tệp chữ ký mới vào IDA bằng cách sao chép nó vào /sig.
Thật không may, trong thực tế, chỉ có bước cuối cùng dễ dàng như âm thanh của nó. Trong các phần tiếp
theo, chúng ta sẽ thảo luận chi tiết hơn về ba bước đầu tiên.
Nhận Diện và Thu Thập Thư Viện Tĩnh
Bước đầu tiên trong quá trình tạo chữ ký là xác định một bản sao của thư viện tĩnh mà bạn muốn tạo chữ
ký. Điều này có thể gặp một số thách thức vì nhiều lý do. Rào cản đầu tiên là xác định thư viện bạn thực
sự cần. Nếu mã nhị phân mà bạn đang phân tích không bị loại bỏ, tên hàm, bạn có thể thấy rằng việc tìm
kiếm chuỗi thông qua dòng lệnh có thể cho ra các chuỗi đặc trưng đủ để xác định thư viện, ví dụ như
chuỗi sau đây, là một dấu hiệu rõ ràng: lOMoARcPSD| 36625228
Các thông báo bản quyền và chuỗi lỗi thường đủ đặc trưng để bạn có thể sử dụng Internet để hạn chế ứng
viên. Nếu bạn chọn chạy lệnh strings từ dòng lệnh, hãy nhớ sử dụng tùy chọn -a để buộc strings quét toàn
bộ mã nhị phân; nếu không, bạn có thể bỏ qua một số dữ liệu chuỗi có thể hữu ích.
Trong trường hợp của các thư viện mã nguồn mở, bạn có thể dễ dàng tìm thấy mã nguồn. Thật không
may, mặc dù mã nguồn có thể hữu ích trong việc giúp bạn hiểu hành vi của mã nhị phân, nhưng bạn
không thể sử dụng nó để tạo ra chữ ký của bạn. Có thể có khả năng sử dụng mã nguồn để xây dựng phiên
bản của riêng bạn cho thư viện tĩnh và sau đó sử dụng phiên bản đó trong quá trình tạo chữ ký. Tuy nhiên,
có thể rằng các biến thể trong quá trình biên dịch sẽ tạo ra đủ sự khác biệt giữa thư viện kết quả và thư
viện bạn đang phân tích để bất kỳ chữ ký nào bạn tạo ra cũng không chính xác.
Ở bước này, bạn nên có một hoặc nhiều thư viện mà bạn muốn tạo chữ ký. Bước tiếp theo là tạo tệp mẫu
cho mỗi thư viện. Tệp mẫu được tạo bằng cách sử dụng tiện ích phân tích cú pháp FLAIR phù hợp.
Tương tự như các tệp thực thi, các tệp thư viện được xây dựng theo các đặc tả định dạng tệp khác nhau.
FLAIR cung cấp các trình phân tích cú pháp cho một số định dạng tệp thư viện phổ biến. Như được mô tả
trong tệp readme.txt của FLAIR, các trình phân tích cú pháp sau có thể được tìm thấy trong thư mục bin của FLAIR:
Plb.exe/plb: Phân tích cú pháp cho các thư viện OMF (thường được sử dụng bởi trình biên dịch Borland).
Pcf.exe/pcf: Phân tích cú pháp cho các thư viện COFF (thường được sử dụng bởi trình biên dịch Microsoft).
Pelf.exe/pelf: Phân tích cú pháp cho các thư viện ELF (có trên nhiều hệ thống Unix).
Ppsx.exe/ppsx: Phân tích cú pháp cho các thư viện PlayStation PSX của Sony.
Ptmobj.exe/ptmobj: Phân tích cú pháp cho các thư viện TriMedia.
Pomf166.exe/pomf166: Phân tích cú pháp cho các tệp đối tượng Kiel OMF 166.
Tạo các tệp chữ ký.
Sau khi bạn đã tạo một tệp mẫu cho một thư viện cụ thể, bước tiếp theo trong quá trình tạo chữ ký là tạo
một tệp .sig phù hợp để sử dụng với IDA. Định dạng của tệp chữ ký trong IDA khác biệt đáng kể so với
tệp mẫu. Tệp chữ ký sử dụng một định dạng nhị phân độc quyền được thiết kế để giảm thiểu không gian
cần thiết để biểu diễn toàn bộ thông tin có trong tệp mẫu và để cho phép so khớp chữ ký với nội dung cơ
sở dữ liệu một cách hiệu quả. Một mô tả cấp cao về cấu trúc của tệp chữ ký có sẵn trên trang web của Hex-Rays LƯU Ý
Tệp tài liệu sigmake, sigmake.txt, khuyến nghị rằng tên tệp chữ ký nên tuân theo quy ước độ dài tên của
MS-DOS là 8.3. Tuy nhiên, điều này không phải là một yêu cầu cứng nhắc. Khi sử dụng tên tệp dài hơn,
chỉ có tám ký tự đầu tiên của tên cơ sở sẽ được hiển thị trong hộp thoại lựa chọn chữ ký.
Quá trình tạo chữ ký thường là một quá trình lặp lại, đặc biệt trong giai đoạn này khi xảy ra xung đột cần
được xử lý. Xung đột xảy ra khi hai hàm có các mẫu giống nhau. Nếu các xung đột không được giải quyết
một cách nào đó, không thể xác định được hàm nào đang được khớp trong quá trình áp dụng chữ ký. Do
đó, sigmake phải giải quyết mỗi chữ ký được tạo ra để tương ứng với đúng một tên hàm duy nhất. Khi
điều này không thể thực hiện được, dựa trên sự xuất hiện của các mẫu giống nhau cho một hoặc nhiều
hàm, sigmake từ chối tạo ra một tệp .sig và thay vào đó tạo ra một tệp loại trừ (exclusions). lOMoARcPSD| 36625228 CHAP 13
Mở rộng kiến thức của IDA
Hiện tại đã rõ ràng rằng một bản dịch rất chất lượng không chỉ là một danh sách các mnemonic và toán tử
được rút ra từ một chuỗi byte. Để làm cho bản dịch trở nên hữu ích, việc bổ sung thông tin được rút ra từ
việc xử lý các dữ liệu liên quan đến API như các nguyên mẫu hàm và các kiểu dữ liệu tiêu chuẩn là rất
quan trọng. Ở Chương 8, chúng ta đã thảo luận về cách IDA xử lý cấu trúc dữ liệu, bao gồm cách truy cập
vào các cấu trúc dữ liệu API tiêu chuẩn và cách xác định các cấu trúc dữ liệu tùy chỉnh của riêng bạn.
Trong chương này, chúng ta tiếp tục cuộc thảo luận về việc mở rộng kiến thức của IDA bằng cách xem
xét việc sử dụng các tiện ích idsutils và loadint của IDA. Các tiện ích này có sẵn trên đĩa phân phối IDA
của bạn hoặc có thể tải về từ trang tải về của Hex-Rays.
Bổ sung thông tin về hàm
IDA rút kiến thức về các hàm từ hai nguồn: các tệp thư viện kiểu (.til) và các tệp tiện ích IDS (.ids).
Trong giai đoạn phân tích ban đầu, IDA sử dụng thông tin được lưu trong những tệp này để cải thiện độ
chính xác của bản dịch và làm cho bản dịch dễ đọc hơn. Điều này được thực hiện bằng cách tích hợp tên
và loại tham số của hàm cũng như các ghi chú được liên kết với các hàm thư viện khác nhau.
Ở Chương 8, chúng ta đã thảo luận về tệp thư viện kiểu như cơ chế mà IDA lưu trữ cấu trúc dữ liệu phức
tạp. Tệp thư viện kiểu cũng là cách mà IDA ghi lại thông tin về quy ước gọi và thứ tự tham số của một
hàm. IDA sử dụng thông tin chữ ký hàm theo nhiều cách. Đầu tiên, khi một tệp nhị phân sử dụng thư viện
chia sẻ, IDA không biết được quy ước gọi nào có thể được sử dụng bởi các hàm trong các thư viện đó.
Trong những trường hợp như vậy, IDA cố gắng so khớp các hàm thư viện với chữ ký tương ứng trong tệp
thư viện kiểu. Nếu tìm thấy chữ ký phù hợp, IDA có thể hiểu quy ước gọi được sử dụng bởi hàm và điều
chỉnh con trỏ ngăn xếp cần thiết (ghi nhớ rằng các hàm stdcall thực hiện việc dọn dẹp ngăn xếp của riêng họ).
Sử dụng chữ ký hàm thứ hai là để chú thích các tham số được chuyển đến một hàm bằng các ghi chú chỉ
rõ chính xác tham số nào đang được đẩy vào ngăn xếp trước khi gọi hàm. Số lượng thông tin có mặt trong
ghi chú phụ thuộc vào việc thông tin nào có trong chữ ký hàm mà IDA có thể phân tích được. Hai chữ ký
sau đây đều là khai báo C hợp lệ, mặc dù chữ ký thứ hai cung cấp thêm thông tin về hàm, bởi nó cung cấp
tên tham số hình thức cùng với các kiểu dữ liệu. Các tệp .ids
IDA sử dụng các tệp .ids để bổ sung kiến thức về các hàm thư viện. Một tệp .ids mô tả nội dung của một
thư viện chia sẻ bằng cách liệt kê mọi hàm được xuất ra có trong thư viện đó. Thông tin chi tiết cho mỗi
hàm bao gồm tên hàm, số thứ tự ký hiệu liên kết, liệu hàm có sử dụng stdcall không, và nếu có, số byte
hàm xóa từ ngăn xếp khi trả về, cùng với các ghi chú tùy chọn được hiển thị khi hàm được tham chiếu
trong bản dịch. Trong thực tế, các tệp .ids thực sự là các tệp .idt được nén, với các tệp .idt chứa các mô tả
văn bản của mỗi hàm thư viện.
Khi một tệp thực thi được tải lần đầu vào cơ sở dữ liệu, IDA xác định các tệp thư viện chia sẻ mà tệp thực
thi phụ thuộc vào. Đối với mỗi thư viện chia sẻ, IDA tìm kiếm một tệp .ids tương ứng trong cấu trúc thư lOMoARcPSD| 36625228
mục /ids để có được mô tả của bất kỳ hàm thư viện nào mà tệp thực thi có thể tham chiếu.
Quan trọng để hiểu rằng các tệp .ids không nhất thiết phải chứa thông tin chữ ký hàm. Tạo các tệp IDS
Các tiện ích idsutils của IDA được sử dụng để tạo các tệp .ids. Các tiện ích này bao gồm hai trình phân
tích thư viện: dll2idt để trích xuất thông tin từ DLL Windows và ar2idt để trích xuất thông tin từ các
thư viện kiểu ar. Trong cả hai trường hợp, đầu ra là một tệp .idt văn bản chứa một dòng duy nhất cho
mỗi hàm được xuất mà ánh xạ số thứ tự ký hiệu của hàm đã được xuất tới tên của hàm. Cú pháp cho
các tệp .idt, rất đơn giản, được mô tả trong tệp readme.txt đi kèm với idsutils. Hầu hết các dòng trong
một tệp .idt được sử dụng để mô tả các hàm được xuất theo kế hoạch sau:
Bổ sung Ghi chú Định sẵn với loadint
Ở Chương 7, chúng ta đã đề cập đến khái niệm của IDA về các ghi chú tự động, khi được bật, khiến IDA
hiển thị các ghi chú mô tả mỗi lệnh ngôn ngữ hợp ngữ. Hai ví dụ về các ghi chú như vậy được hiển thị như sau:
.text:08048654 lea ecx, [esp+arg_0] ; Tải Địa chỉ Hiệu Quả
.text:08048658 and esp, 0FFFFFFF0h ; Và Logic
Nguồn của những ghi chú định sẵn này là tệp /ida.int, chứa các ghi chú được sắp xếp trước
tiên theo loại CPU và sau đó là loại lệnh. Khi ghi chú tự động được bật, IDA tìm kiếm các ghi chú liên
kết với mỗi lệnh trong bản dịch và hiển thị chúng trong lề phải nếu chúng có trong ida.int.
Các tiện ích loadint4 cung cấp khả năng cho bạn chỉnh sửa các ghi chú hiện có hoặc thêm ghi chú mới
vào ida.int. Giống như các tiện ích bổ sung khác chúng ta đã thảo luận, loadint được tài liệu trong một tệp
readme.txt đi kèm với bản phân phối loadint. Bản phân phối loadint cũng chứa các ghi chú định sẵn cho
tất cả các module xử lý của IDA dưới dạng nhiều tệp .cmt. Chỉnh sửa các ghi chú hiện có là một việc đơn
giản của việc định vị tệp ghi chú liên quan đến bộ xử lý mà bạn quan tâm (ví dụ, pc.cmt cho x86), thực
hiện các thay đổi trong bất kỳ ghi chú nào mà bạn muốn chỉnh sửa nội dung, chạy loadint để tạo lại tệp
ghi chú ida.int, và cuối cùng sao chép tệp ida.int kết quả vào thư mục chính của IDA, nơi nó sẽ được tải
vào lần khởi động IDA tiếp theo. Một lệnh chạy đơn giản để xây dựng lại cơ sở dữ liệu ghi chú có dạng như sau: Tóm tắt
Mặc dù idsutils và loadint có vẻ không ngay lập tức hữu ích với bạn, nhưng bạn sẽ học được cách đánh
giá khả năng của chúng khi bạn bắt đầu tiếp xúc với các trường hợp sử dụng của IDA không phổ biến
hơn. Với một đầu tư thời gian tương đối nhỏ, việc tạo một tệp .ids hoặc .til duy nhất có thể tiết kiệm rất
nhiều thời gian mỗi khi bạn gặp các thư viện được mô tả trong những tệp đó trong các dự án sau này. Hãy
nhớ rằng không thể mong đợi IDA có mô tả cho mọi thư viện tồn tại. Mục đích dự kiến của các công cụ
được đề cập trong chương này là cung cấp cho bạn tính linh hoạt để giải quyết các khoảng trống trong
việc mô tả thư viện của IDA mỗi khi bạn rời khỏi các ứng dụng thông thường của IDA. lOMoARcPSD| 36625228 CHAP14
PATCHING BINARIES VÀ CÁC HẠN CHẾ CỦA IDA
Một trong những câu hỏi được hỏi thường xuyên nhất từ người dùng mới hoặc tiềm năng của IDA là
“Làm cách nào để tôi sử dụng IDA để sửa đổi các tệp nhị phân?” Câu trả lời đơn giản là “Bạn không thể.”
Mục đích chính của IDA là hỗ trợ bạn trong việc hiểu hành vi của một tệp nhị phân bằng cách cung cấp
cho bạn bản dịch tốt nhất có thể. IDA không được thiết kế để làm cho việc sửa đổi các tệp nhị phân bạn
đang xem xét trở nên dễ dàng. Không muốn chấp nhận câu trả lời “không”, những người thực sự đam mê
việc sửa đổi thường theo đuổi với các câu hỏi như “Vậy cái gì về menu Edit -> Patch Program?” và “Mục
đích của File -> Produce File -> Create EXE File là gì?” Trong chương này, chúng ta sẽ thảo luận về
những dấu hiệu không rõ ràng này và xem liệu có thể thuyết phục IDA giúp chúng ta ít nhất một chút
trong việc phát triển các bản vá cho các tệp chương trình nhị phân hay không.
Chương Trình Menu Patch Nổi Tiếng
Được đề cập đầu tiên trong Chương 11, menu Edit -> Patch Program là một tính năng ẩn trong phiên bản
giao diện đồ họa của IDA mà phải được bật bằng cách chỉnh sửa tệp cấu hình idagui.cfg (menu Patch có
sẵn theo mặc định trong phiên bản console của IDA). Hình 14-1 hiển thị các tùy chọn có sẵn trên
submenu Edit -> Patch Program.
Mỗi một trong các mục submenu khiến bạn hiểu lầm rằng bạn sẽ có khả năng sửa đổi tệp nhị phân theo
các cách có thể là thú vị. Trong thực tế, những tùy chọn này cung cấp ba cách khác nhau để sửa đổi cơ sở
dữ liệu. Trên thực tế, những mục menu này, có thể nhiều hơn bất kỳ mục nào khác, làm rõ sự khác biệt
hoàn toàn giữa một cơ sở dữ liệu IDA và tệp nhị phân từ đó cơ sở dữ liệu được tạo ra. Một khi cơ sở dữ
liệu được tạo ra, IDA không bao giờ tham chiếu đến tệp nhị phân gốc. Với hành vi thực sự của nó, mục
menu này sẽ phù hợp hơn nếu được đặt tên là Patch Database.
Tuy nhiên, không phải mọi thứ đều mất đi hoàn toàn, vì các tùy chọn menu trong Hình 14-1 thực sự cung
cấp cho bạn cách dễ nhất để quan sát tác động của bất kỳ thay đổi nào bạn có thể thực hiện sau này vào
tệp nhị phân gốc. Sau này trong chương này, bạn sẽ học cách xuất các thay đổi bạn đã thực hiện và sau đó
sử dụng thông tin đó để vá tệp nhị phân gốc.
Các Tệp Output của IDA và Tạo Bản Vá
Một trong những tùy chọn menu thú vị trong IDA là menu File -> Produce File. Theo các tùy chọn trên
menu này, IDA có thể tạo ra các tệp MAP, ASM, INC, LST, EXE, DIF và HTML. Nhiều trong số này
nghe có vẻ lôi cuốn, vì vậy mỗi tùy chọn sẽ được mô tả trong các phần sau đây.
Các Tệp MAP Do IDA Tạo Ra
Một tệp .map mô tả cấu trúc tổng thể của một tệp nhị phân, bao gồm thông tin về các phần tạo nên tệp nhị
phân và vị trí của các ký hiệu trong mỗi phần. Khi tạo ra một tệp .map, bạn sẽ được yêu cầu nhập tên của
tệp mà bạn muốn tạo và các loại ký hiệu bạn muốn lưu trữ trong tệp .map. Hình 14-5 hiển thị hộp thoại
tùy chọn tệp MAP, trong đó bạn chọn thông tin mà bạn muốn bao gồm trong tệp .map. lOMoARcPSD| 36625228
Các Tệp ASM Do IDA Tạo Ra
IDA có thể tạo ra một tệp .asm từ cơ sở dữ liệu hiện tại. Ý tưởng chung là tạo ra một tệp có thể chạy qua
một trình biên dịch để tái tạo lại tệp nhị phân cơ bản. IDA cố gắng đưa ra đủ thông tin, bao gồm cả cấu
trúc, để làm cho việc biên dịch thành công trở nên có thể thực hiện được.
Các Tệp INC Do IDA Tạo Ra
Một tệp INC (include) chứa các định nghĩa của cấu trúc dữ liệu và kiểu dữ liệu được đặt tên. Điều này về
cơ bản là một dump của nội dung trong cửa sổ Structures dưới dạng có thể sử dụng được bởi một trình biên dịch.
Các Tệp LST Do IDA Tạo Ra
Một tệp LST không gì khác ngoài việc là một dump văn bản của nội dung trong cửa sổ disassembly của
IDA. Bạn có thể hạn chế phạm vi của danh sách tạo ra bằng cách chọn một phạm vi địa chỉ để dump, như
đã mô tả trước đó cho các tệp ASM.
Các Tệp EXE Do IDA Tạo Ra
Mặc dù đây là tùy chọn menu hứa hẹn nhất, nhưng không may là nó cũng là tùy chọn yếu nhất. Nó không
hoạt động cho hầu hết các loại tệp, và bạn có thể mong đợi nhận được thông báo lỗi cho biết: “Loại tệp
output này không được hỗ trợ.”
Các Tệp DIF Do IDA Tạo Ra
Một tệp DIF của IDA là một tệp văn bản thô liệt kê tất cả các byte đã được sửa đổi trong cơ sở dữ liệu của
IDA. Đây là định dạng tệp hữu ích nhất nếu mục tiêu của bạn là vá một tệp nhị phân gốc dựa trên các
thay đổi được thực hiện trong cơ sở dữ liệu của IDA. Định dạng của tệp khá đơn giản, như được thể hiện trong ví dụ.
Các Tệp HTML Do IDA Tạo Ra
IDA tận dụng khả năng đánh dấu có sẵn của HTML để tạo ra danh sách disassembly có màu sắc. Một tệp
HTML được tạo ra bởi IDA về cơ bản là một tệp LST với thẻ HTML được thêm vào để tạo ra một danh
sách được tô màu tương tự như cửa sổ disassembly thực tế của IDA. Thật không may, các tệp HTML
được tạo ra không chứa bất kỳ liên kết nào có thể làm cho việc điều hướng trong tệp dễ dàng hơn so với
việc sử dụng một danh sách văn bản tiêu chuẩn. Ví dụ, một tính năng hữu ích sẽ là việc thêm các liên kết
tới tất cả các tham chiếu tên, điều này sẽ làm cho việc theo dõi tham chiếu tên trở nên đơn giản như việc
điều hướng theo liên kết. Tóm Lược
IDA không phải là một trình chỉnh sửa tệp nhị phân. Hãy nhớ điều này bất cứ khi nào bạn nghĩ về việc vá
một tệp nhị phân bằng IDA. Tuy nhiên, đây là một công cụ đặc biệt tốt để giúp bạn nhập và hiển thị các
thay đổi tiềm năng. Bằng cách làm quen với toàn bộ tính năng của IDA và kết hợp thông tin mà IDA có
thể tạo ra với các tập lệnh hoặc chương trình bên ngoài phù hợp, việc vá tệp nhị phân trở nên dễ dàng hơn. lOMoARcPSD| 36625228
Trong các chương tiếp theo, chúng ta sẽ tìm hiểu về các cách mà khả năng của IDA có thể được mở rộng.
Đối với bất kỳ ai quan tâm đến việc tận dụng tối đa khả năng của IDA, kỹ năng viết script cơ bản và hiểu
biết về kiến trúc plug-in của IDA là cần thiết, vì chúng cung cấp cho bạn khả năng thêm các hành vi mọi
nơi mà bạn cảm thấy IDA thiếu sót.
7. PHÂN CHIA CÔNG VIỆC Họ và tên Công việc Tô Minh Tìm hiểu khái niệm Hồ Sỹ Trung Kiên Chức năng IDA cơ bản Trần Văn Sáng Chức năng IDA cơ bản Đỗ Minh Quân Chức năng IDA nâng cao
8. TÀI LIỆU THAM KHẢOhttps://github.com/nixawk/pentest-
wiki/blob/master/ReverseEngineering/The.IDA.Pro.Book.2nd.Edition. Jun.2011.pdf
Tài liệu liên quan:
-

Tìm hiểu các phần mềm mã hóa file | Môn An toàn bảo mật thông tin - Đại học Xây Dựng Hà Nội
142 71 -

Khái niệm Mạng Wifi và Lịch Sử Phát Triển | Môn An toàn bảo mật thông tin - Đại học Xây Dựng Hà Nội
101 51 -

Chương 1 Tiến Trình Phát Triển Phần Mềm | Môn An toàn bảo mật thông tin - Đại học Xây Dựng Hà Nội
230 115 -
Chương 3 - Đặc điểm và Chế độ Hệ Mật Mã Khóa Đối Xứng | Môn An toàn bảo mật thông tin - Đại học Xây Dựng Hà Nội
91 46 -

Bài tập lớn đề tài: Phát triển giao thức bảo mật ứng dụng đảm bảo quyền riêng tư trong phát hiện tấn công Web | Môn An toàn bảo mật thông tin - Đại học Xây Dựng Hà Nội
98 49