Báo cáo đề tài Trợ lý ảo PTIT môn Lập trình với Python | Học viện Công Nghệ Bưu Chính Viễn Thông
Trợ lý ảo là một ứng dụng phần mềm thông minh được thiết kế để giúp người dùng giải quyết các vấn đề cụ thể thông qua giao tiếp tự nhiên, chẳng hạn như truy vấn thông tin, thực hiện tác vụ hoặc đưa ra các đề xuất. Tài liệu được sưu tầm gồm 32 trang, giúp các bạn nắm vững kiến thức, rèn luyện kỹ năng và đạt được kết quả tốt trong học tập. Mời các bạn đón xem!
Môn: Lập trình với Python 12 tài liệu
Trường: Học viện Công Nghệ Bưu Chính Viễn Thông 1.8 K tài liệu
Tác giả:

















Preview text:
lOMoAR cPSD| 58736390
BỘ THÔNG TIN VÀ TRUYỀN THÔNG
HỌC VIỆN CÔNG NGHỆ BƯU CHÍNH VIỄN THÔNG BÁO CÁO ĐỀ TÀI TRỢ LÝ ẢO PTIT
MÔN: LẬP TRÌNH PYTHON
Giảng viên: Vũ Minh Mạnh Nhóm 18 Mã sinh viên : Họ và tên B22DCCN834
: Nguyễn Thế Thịnh B22DCCN864
: Nguyễn Tiến Trọng B22DCCN524 : Dương Nhật Minh B22DCCN085 : Ngô Văn Bộ B22DCCN786 : Nguyễn Mai Thanh Mục lục
Mở đầu ............................................................................................................................ 3
CHƯƠNG 1. CƠ SỞ LÝ THUYẾT VÀ CÔNG NGHỆ ............................................ 4
1.1. Tổng quan về hệ thống trợ lý ảo ........................................................................... 4
1.2. Các công nghệ chính sử dụng trong dự án ............................................................ 5
1.2.1. Request và BeautifulSoup – Thu thập dữ liệu từ trang web chính thức của . 5
PTIT .......................................................................................................................... 5
1.2.2. RAG (Retrieval-Augmented Generation) – Lõi AI thông minh .................... 5
1.2.3. LangChain – Xây dựng quy trình làm việc thông minh ................................. 6
1.2.4. Gemini API và Chroma Database – Hệ thống lưu trữ và truy vấn thông tin . 6
1.2.5. FastAPI – Backend hiệu suất cao ................................................................... 6
1.2.6. Vue.js – Giao diện người dùng thân thiện ...................................................... 7
1.3. Tổng kết................................................................................................................. 7
CHƯƠNG 2. THIẾT KẾ HỆ THỐNG ........................................................................ 7
2.1. Giới thiệu tổng quan hệ thống ............................................................................... 7
2.2. Kiến trúc hệ thống ................................................................................................. 8
2.3. Thiết kế chi tiết các thành phần hệ thống .............................................................. 8
2.3.1. Thu nhập dữ liệu (Thực hiện: Minh và Bộ) ................................................... 8
2.3.2. Xây dựng lõi AI cho trợ lý ảo (thực hiện: Trọng) .......................................... 9
tài liệu .................................................................................................................... 9
2.3.2.2. Kỹ Thuật Query Translation................................................................... 11
2.3.2.3. Định tuyến câu hỏi (Routing) ................................................................. 13
2.3.2.5. Truy xuất tài liệu (Retrieval) .................................................................. 15
2.3.2.6. Sinh câu trả lời (Generation) .................................................................. 16
2.3.3. Xây dựng Backend (Thực hiện: Thịnh) ........................................................ 17
2.3.4. Thiết kế giao diện (Thực hiện: Mai Thanh) ................................................. 21
CHƯƠNG 3. CHI TIẾT ỨNG DỤNG, KẾT LUẬN VÀ HƯỚNG PHÁT TRIỂN
TƯƠNG LAI ................................................................................................................ 24
3.1. Chi tiết ứng dụng trợ lý ảo .................................................................................. 24
3.2. Kết luận ............................................................................................................... 28
3.3. Hướng phát triển tương lai .................................................................................. 29
3.3.1. Cải thiện khả năng xử lý câu hỏi phức tạp ................................................... 29
3.3.2. Cập nhật dữ liệu thời gian thực .................................................................... 29
3.3.3. Tăng cường tính năng hỗ trợ và tương tác với người dùng .......................... 30
3.3.4. Phân tích và tối ưu hóa hiệu suất .................................................................. 30
3.3.5. Nghiên cứu và ứng dụng công nghệ mới ..................................................... 30
Tài liệu tham khảo ....................................................................................................... 31
2.3.2.1. Chuẩn bị dữ liệu và tạo các mô hình truy vấn tương ứng với từng loại Mở đầu
Bối cảnh và động lực của dự án:
Trong thời đại công nghệ số hiện nay, việc áp dụng công nghệ vào giáo dục đã trở
thành xu hướng tất yếu. Đặc biệt, đối với các cơ sở giáo dục đại học, việc cung cấp
thông tin nhanh chóng và chính xác cho sinh viên là một yếu tố quan trọng giúp nâng
cao chất lượng dịch vụ học tập và tuyển sinh. Tuy nhiên, với lượng thông tin lớn và đa
dạng, việc sinh viên tự tìm kiếm thông tin một cách thủ công đôi khi trở nên mất thời gian và không hiệu quả.
Tại Học Viện Công Nghệ Bưu Chính Viễn Thông (PTIT), sinh viên và các thí sinh tiềm
năng đang đối diện với nhiều khó khăn trong việc tìm kiếm thông tin về chương trình
học, các khóa học, lịch thi, cũng như các thông tin liên quan đến tuyển sinh. Điều này
tạo ra một nhu cầu cấp thiết đối với một công cụ hỗ trợ thông minh, giúp giải đáp
những thắc mắc một cách nhanh chóng và chính xác.
Để giải quyết vấn đề này, dự án “Trợ lý ảo hỗ trợ sinh viên và tư vấn tuyển sinh Học
Viện Công Nghệ Bưu Chính Viễn Thông” ra đời. Mục tiêu của dự án là xây dựng một
trợ lý ảo thông minh, có thể hỗ trợ sinh viên trong việc tìm kiếm thông tin học tập, giải
đáp các câu hỏi liên quan đến tuyển sinh và cung cấp các dịch vụ tư vấn, tất cả đều
được thực hiện tự động và hiệu quả. Mục tiêu dự án:
Mục tiêu chính của dự án là phát triển một hệ thống trợ lý ảo sử dụng công nghệ
AI, giúp hỗ trợ sinh viên PTIT trong quá trình học tập và tư vấn tuyển sinh. Cụ thể, hệ
thống này sẽ đáp ứng các mục tiêu sau: ●
Cung cấp thông tin học tập nhanh chóng và chính xác: Trợ lý ảo sẽ giúp sinh viên
tìm kiếm thông tin về lịch học, lịch thi, tài liệu học tập và các chương trình học
của PTIT một cách dễ dàng. ●
Hỗ trợ tư vấn tuyển sinh hiệu quả: Trợ lý ảo sẽ giúp thí sinh tìm hiểu thông tin
về các ngành học, yêu cầu tuyển sinh, phương thức xét tuyển, và các quy định
liên quan đến tuyển sinh của PTIT. ●
Giảm tải công việc cho các bộ phận tư vấn: Việc tự động hóa việc trả lời câu hỏi
sẽ giảm thiểu gánh nặng công việc cho các cán bộ tư vấn, giúp họ có thể tập
trung vào các nhiệm vụ quan trọng khác.
Phạm vi nghiên cứu:
Dự án này tập trung vào việc xây dựng một trợ lý ảo cho sinh viên và thí sinh của
PTIT, sử dụng các công nghệ hiện đại như Retrieval-Augmented Generation (RAG),
FastAPI và Vue.js để phát triển hệ thống. Trợ lý ảo này sẽ được triển khai dưới dạng
ứng dụng web, giúp sinh viên và thí sinh có thể dễ dàng truy cập và sử dụng bất kỳ lúc nào.
Phạm vi nghiên cứu bao gồm: Công nghệ AI (RAG): Nghiên cứu về cách thức ứng
dụng công nghệ RAG để cải thiện khả năng tìm kiếm và trả lời câu hỏi của trợ lý ảo, từ
đó tạo ra một hệ thống tự động hỗ trợ thông minh. Backend (FastAPI): Thiết kế và phát
triển hệ thống backend bằng FastAPI, đảm bảo khả năng xử lý yêu cầu nhanh chóng và
hiệu quả. Frontend (Vue.js): Tạo giao diện người dùng đơn giản, dễ sử dụng và thân
thiện với người dùng, đảm bảo trải nghiệm mượt mà trên nền tảng web.
Trợ lý ảo sẽ hỗ trợ cả hai nhóm đối tượng: Sinh viên PTIT: Tìm kiếm thông tin học
tập, chương trình học, lịch thi, và các tài liệu học tập. Thí sinh tiềm năng: Tư vấn về các
ngành học, chương trình đào tạo, phương thức xét tuyển, và các thông tin cần thiết
liên quan đến tuyển sinh.
Tầm quan trọng của dự án:
Dự án này không chỉ mang lại tiện ích cho sinh viên và thí sinh, mà còn đóng góp
vào việc cải thiện chất lượng dịch vụ của PTIT. Với việc tích hợp trợ lý ảo vào các quy
trình học tập và tuyển sinh, PTIT có thể nâng cao hiệu quả tư vấn, giảm thiểu các sai
sót trong việc cung cấp thông tin, đồng thời tạo ra một môi trường học tập và tư vấn
hiện đại, tiện lợi hơn cho người dùng.
Ngoài ra, việc ứng dụng công nghệ mới vào giáo dục cũng là một bước đi quan
trọng trong việc nâng cao hình ảnh và vị thế của PTIT trong cộng đồng giáo dục. Dự án
này có tiềm năng mở rộng ra các trường đại học khác, giúp phổ biến mô hình trợ lý ảo
trong việc hỗ trợ học tập và tuyển sinh trên toàn quốc.
CHƯƠNG 1. CƠ SỞ LÝ THUYẾT VÀ CÔNG NGHỆ
1.1. Tổng quan về hệ thống trợ lý ảo
Trợ lý ảo là một ứng dụng phần mềm thông minh được thiết kế để giúp người dùng
giải quyết các vấn đề cụ thể thông qua giao tiếp tự nhiên, chẳng hạn như truy vấn
thông tin, thực hiện tác vụ hoặc đưa ra các đề xuất. Trong giáo dục, trợ lý ảo đóng vai
trò quan trọng trong việc cung cấp thông tin nhanh chóng, giúp giảm tải công việc cho
các bộ phận hỗ trợ và tối ưu hóa trải nghiệm người dùng.
Đặc biệt, khi xây dựng một trợ lý ảo cho Học Viện Công Nghệ Bưu Chính Viễn Thông
(PTIT), hệ thống không chỉ cần khả năng cung cấp thông tin chính xác về các chương
trình học, tuyển sinh, mà còn cần tính năng tự động tư vấn, hỗ trợ sinh viên và thí sinh
một cách nhanh chóng và hiệu quả. Dự án của chúng tôi sử dụng một loạt các công
nghệ tiên tiến để xây dựng một trợ lý ảo thông minh, có khả năng thu thập dữ liệu từ
các nguồn thông tin chính thức, tích hợp các mô hình AI để tạo ra các câu trả lời tự
động, và tối ưu hóa trải nghiệm người dùng qua giao diện web thân thiện.
1.2. Các công nghệ chính sử dụng trong dự án
Dự án trợ lý ảo PTIT sử dụng một loạt các công nghệ hiện đại để xây dựng hệ thống,
từ việc thu thập dữ liệu, phát triển lõi AI, đến việc triển khai backend và frontend. Dưới
đây là các công nghệ chính mà dự án sử dụng:
1.2.1. Request và BeautifulSoup – Thu thập dữ liệu từ trang web chính thức của PTIT
Để cung cấp thông tin chính xác và cập nhật về các chương trình học, tuyển sinh và
các thông tin khác từ PTIT, hệ thống trợ lý ảo cần phải thu thập dữ liệu từ trang web
chính thức của trường. Để làm được điều này, chúng tôi sử dụng hai công nghệ phổ
biến trong việc thu thập dữ liệu từ web:
Request [1]: Đây là thư viện Python mạnh mẽ dùng để gửi yêu cầu HTTP đến các
trang web và lấy dữ liệu về. Request giúp chúng tôi dễ dàng thực hiện các yêu cầu GET
hoặc POST và lấy về nội dung của trang web dưới dạng HTML hoặc JSON.
BeautifulSoup [2]: Sau khi thu thập được dữ liệu từ trang web của PTIT, chúng tôi
sử dụng BeautifulSoup để phân tích cú pháp HTML và trích xuất các thông tin cần thiết.
BeautifulSoup là một thư viện Python rất mạnh mẽ cho việc xử lý và phân tích dữ liệu
HTML, giúp tách các phần tử trên trang web, như tiêu đề, mô tả, thông tin khóa học,
lịch thi, và các thông tin khác.
Quá trình thu thập dữ liệu từ trang web sẽ đảm bảo rằng trợ lý ảo luôn cung cấp
thông tin chính xác và kịp thời cho người dùng.
1.2.2. RAG (Retrieval-Augmented Generation) – Lõi AI thông minh
Retrieval-Augmented Generation (RAG) [3, 4] là một phương pháp mạnh mẽ kết
hợp giữa việc truy xuất thông tin từ cơ sở dữ liệu và khả năng tạo ra câu trả lời tự động.
Với RAG, hệ thống sẽ tìm kiếm các đoạn văn bản có liên quan từ một nguồn dữ liệu lớn
(như cơ sở dữ liệu của PTIT) và sử dụng những thông tin này để sinh ra các câu trả lời
chính xác, mạch lạc và phù hợp. ●
Retrieval (Truy xuất thông tin): Hệ thống tìm kiếm thông tin từ các nguồn tài liệu
có sẵn, như các trang web, cơ sở dữ liệu, tài liệu học tập và các bài giảng của PTIT. ●
Generation (Sinh ngữ nghĩa): Sau khi truy xuất được các dữ liệu liên quan, hệ
thống sử dụng mô hình sinh ngữ nghĩa để tạo ra câu trả lời cho người dùng. Quá
trình này không chỉ giúp hệ thống phản hồi các câu hỏi mà còn cải thiện tính
linh hoạt và sự phù hợp trong các câu trả lời.
Sự kết hợp giữa hai yếu tố này giúp trợ lý ảo có thể đưa ra câu trả lời chính xác hơn,
và dễ dàng đáp ứng các câu hỏi mới mà không cần phải cập nhật lại toàn bộ cơ sở dữ liệu.
1.2.3. LangChain – Xây dựng quy trình làm việc thông minh
LangChain [5] là một thư viện Python mạnh mẽ được sử dụng để tạo ra các quy
trình làm việc phức tạp cho các mô hình ngôn ngữ (language models). Thư viện này
giúp kết nối các mô hình AI với các công cụ bên ngoài (như API, cơ sở dữ liệu, hoặc các
hệ thống bên thứ ba), giúp xây dựng các quy trình tự động và thông minh trong việc
trả lời các câu hỏi hoặc thực hiện các tác vụ.
Trong dự án trợ lý ảo PTIT, LangChain sẽ được sử dụng để kết nối các mô hình ngôn
ngữ với các công cụ như Gemini API, Chroma database, và các hệ thống dữ liệu của
PTIT, tạo thành một quy trình làm việc liền mạch và tự động hóa hoàn toàn. LangChain
sẽ giúp trợ lý ảo hoạt động hiệu quả hơn trong việc xử lý các yêu cầu từ người dùng.
1.2.4. Gemini API và Chroma Database – Hệ thống lưu trữ và truy vấn thông tin
Gemini API: Đây là API của Google giúp cung cấp các mô hình ngôn ngữ tiên tiến
và các công cụ hỗ trợ xây dựng các hệ thống AI thông minh. Trong dự án trợ lý ảo PTIT,
Gemini API sẽ được sử dụng để giúp xử lý các yêu cầu ngôn ngữ tự nhiên của người
dùng, tạo ra các câu trả lời chính xác dựa trên dữ liệu được thu thập và xử lý.
Chroma Database [6]: Chroma là một cơ sở dữ liệu được tối ưu hóa cho việc lưu
trữ và truy vấn các vector embedding. Cơ sở dữ liệu này rất hiệu quả trong việc quản
lý các dữ liệu lớn và phức tạp, giúp hệ thống trợ lý ảo lưu trữ các thông tin đã xử lý từ
các bước truy xuất và sinh câu trả lời, từ đó tối ưu hóa tốc độ truy vấn và độ chính xác
của các câu trả lời. Chroma giúp duy trì các embedding của dữ liệu và hỗ trợ việc truy
xuất thông tin từ các tài liệu trong cơ sở dữ liệu một cách nhanh chóng và hiệu quả.
1.2.5. FastAPI – Backend hiệu suất cao
FastAPI [7] là một framework Python hiện đại, nhanh chóng và mạnh mẽ, được sử
dụng để xây dựng API RESTful. FastAPI cung cấp khả năng xử lý bất đồng bộ
(asynchronous), giúp tối ưu hóa hiệu suất khi phải xử lý một lượng lớn yêu cầu từ người
dùng. Đây là lý do FastAPI được chọn để xây dựng backend cho hệ thống trợ lý ảo PTIT.
FastAPI không chỉ hỗ trợ xử lý các yêu cầu nhanh chóng mà còn giúp tự động sinh
tài liệu API, giúp đội ngũ phát triển dễ dàng kiểm tra và duy trì các API của hệ thống.
Khả năng xử lý bất đồng bộ giúp FastAPI trở thành lựa chọn lý tưởng cho một hệ thống
yêu cầu phản hồi nhanh chóng và mượt mà.
1.2.6. Vue.js – Giao diện người dùng thân thiện
Vue.js [8] là một framework JavaScript mạnh mẽ được sử dụng để xây dựng giao
diện người dùng (UI) cho các ứng dụng web. Với khả năng phát triển giao diện một
cách nhanh chóng và mượt mà, Vue.js giúp hệ thống trợ lý ảo PTIT cung cấp một trải
nghiệm người dùng dễ dàng và trực quan.
Vue.js hỗ trợ xây dựng các ứng dụng đơn trang (SPA), giúp các trang web tải nhanh
hơn và mang đến một giao diện người dùng mượt mà và không gián đoạn. Nhờ vào
cấu trúc mô-đun và khả năng tái sử dụng các thành phần (components), Vue.js giúp
phát triển và duy trì giao diện một cách dễ dàng. 1.3. Tổng kết
Trong chương này, chúng ta đã điểm qua các công nghệ chính được sử dụng trong dự
án trợ lý ảo PTIT. Từ việc thu thập dữ liệu bằng Request và BeautifulSoup, đến việc xây
dựng lõi AI thông minh bằng RAG, LangChain, Gemini API, và Chroma Database, cho
đến việc xây dựng backend với FastAPI và giao diện frontend với Vue.js, tất cả các công
nghệ này kết hợp lại tạo thành một hệ thống trợ lý ảo mạnh mẽ và hiệu quả, có khả
năng hỗ trợ sinh viên và thí sinh PTIT một cách nhanh chóng, chính xác và tiện lợi.
CHƯƠNG 2. THIẾT KẾ HỆ THỐNG
2.1. Giới thiệu tổng quan hệ thống
Hệ thống trợ lý ảo PTIT được thiết kế để cung cấp một giải pháp thông minh, nhanh
chóng và chính xác cho việc hỗ trợ sinh viên và thí sinh của Học Viện Công Nghệ Bưu
Chính Viễn Thông (PTIT). Hệ thống sẽ giúp trả lời các câu hỏi liên quan đến chương
trình học, thông tin tuyển sinh, và các sự kiện của trường. Bên cạnh đó, trợ lý ảo cũng
sẽ cung cấp tư vấn tuyển sinh, giúp thí sinh dễ dàng tìm hiểu và lựa chọn ngành học phù hợp.
Hệ thống này sẽ bao gồm hai phần chính: backend (xử lý và lưu trữ dữ liệu) và
frontend (giao diện người dùng), với các công nghệ hiện đại như FastAPI cho backend
và Vue.js cho frontend. Lõi AI của hệ thống sử dụng các công nghệ như RAG (Retrieval-
Augmented Generation), LangChain, Gemini API và Chroma Database để tạo ra một trợ
lý ảo thông minh, có khả năng tương tác với người dùng qua giao diện ngôn ngữ tự nhiên.
2.2. Kiến trúc hệ thống
Hình 1. Kiến trúc hệ thống của trợ lý ảo
Hệ thống trợ lý ảo PTIT được thiết kế theo kiến trúc mô-đun, cho phép các thành
phần trong hệ thống hoạt động độc lập và dễ dàng bảo trì, mở rộng. Kiến trúc hệ thống bao gồm các lớp sau: ●
Lớp thu thập dữ liệu (Data Collection Layer): Sử dụng các công nghệ như
Request và BeautifulSoup để thu thập dữ liệu từ các trang thông tin chính thức
của PTIT. Dữ liệu được xử lý và chuyển đổi thành định dạng phù hợp để sử dụng trong hệ thống. ●
Lớp lõi AI (AI Core Layer): Sử dụng RAG, LangChain, Gemini API và Chroma
Database để phát triển khả năng hiểu và tạo câu trả lời của hệ thống. Lõi AI chịu
trách nhiệm truy xuất và sinh ngữ nghĩa từ các dữ liệu đã thu thập, cung cấp
câu trả lời thông minh và chính xác cho người dùng. ●
Lớp API (API Layer): Xây dựng bằng FastAPI, lớp này chịu trách nhiệm nhận và
xử lý các yêu cầu từ frontend. FastAPI giúp tối ưu hóa hiệu suất và tốc độ phản
hồi của hệ thống, hỗ trợ giao tiếp giữa các lớp khác nhau trong hệ thống. ●
Lớp giao diện người dùng (Frontend Layer): Được xây dựng bằng Vue.js, giao
diện người dùng sẽ cung cấp trải nghiệm thân thiện và dễ sử dụng cho sinh viên
và thí sinh. Giao diện sẽ bao gồm các tính năng như tìm kiếm thông tin, đặt câu
hỏi, xem lịch trình, và nhận các đề xuất về ngành học.
2.3. Thiết kế chi tiết các thành phần hệ thống
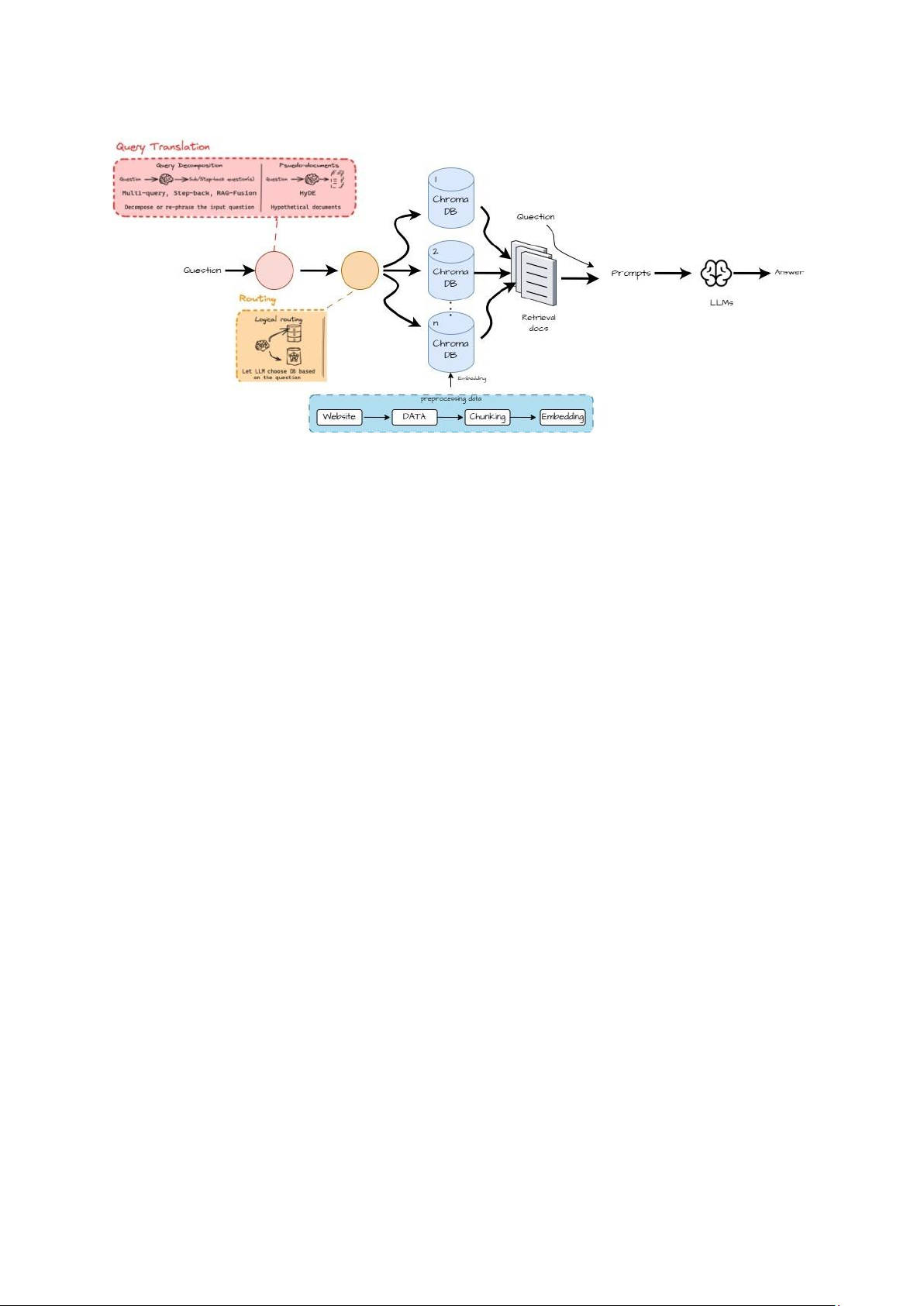
2.3.1. Thu nhập dữ liệu (Thực hiện: Minh và Bộ)
Để xây dựng một chatbot có khả năng trả lời chính xác về các thông tin liên
quan đến PTIT, việc thu thập dữ liệu từ các trang web chính thức của trường là
bước đầu tiên và rất quan trọng và tốn nhiều thời gian. Dữ liệu được thu thập từ
các nguồn đáng tin cậy sẽ đảm bảo tính chính xác và đầy đủ của thông tin mà
trợ lý ảo cung cấp. Quy trình thu thập dữ liệu bao gồm các bước sau:
1. Xác định các nguồn dữ liệu chính: Các trang web chính thống của
PTIT, bao gồm các trang về tin tức, thông báo, chương trình học, hướng
dẫn tuyển sinh và các quy định dành cho sinh viên, được chọn làm nguồn
thu thập dữ liệu. Những trang này chứa các thông tin cần thiết để đáp
ứng các câu hỏi thường gặp từ sinh viên và thí sinh.
2. Gửi yêu cầu HTTP và lấy dữ liệu HTML: Thư viện requests được sử
dụng để gửi yêu cầu HTTP đến các URL của PTIT và tải về nội dung
HTML của các trang này. Thao tác này giúp lấy được thông tin trực tiếp
từ nguồn và đảm bảo dữ liệu luôn được cập nhật khi trang web có thay đổi.
3. Phân tích và trích xuất dữ liệu với BeautifulSoup: Với nội dung
HTML nhận được, thư viện BeautifulSoup được sử dụng để phân tích cú
pháp và trích xuất các thông tin quan trọng. BeautifulSoup giúp xử lý
cấu trúc HTML phức tạp, loại bỏ các thẻ không cần thiết và chỉ lấy nội
dung cần thiết, chẳng hạn như tiêu đề, đoạn văn bản, danh sách, và các liên kết có liên quan.
4. Lưu trữ dữ liệu đã trích xuất: Các thông tin đã trích xuất được lưu dưới
dạng file .txt và để trong thư mục với nội dung tương ứng
2.3.2. Xây dựng lõi AI cho trợ lý ảo (thực hiện: Trọng)
2.3.2.1. Chuẩn bị dữ liệu và tạo các mô hình truy vấn tương ứng với từng loại tài liệu
Trước khi bắt tay vào xây dựng hệ thống trợ lý ảo PTIT, một trong những bước quan
trọng nhất là chuẩn bị dữ liệu. Dữ liệu sẽ được sử dụng để huấn luyện và hỗ trợ hệ thống
trong việc trả lời các câu hỏi của người dùng. Quá trình này bao gồm nhiều bước từ việc
tải tài liệu cho đến việc tạo ra các mô hình truy vấn để tìm kiếm và trích xuất thông tin
từ cơ sở dữ liệu. Các bước chuẩn bị dữ liệu sẽ được thực hiện theo một quy trình rõ ràng
để đảm bảo rằng thông tin được lưu trữ và truy vấn một cách chính xác và hiệu quả. a. Tải tài liệu
Bước đầu tiên trong quá trình chuẩn bị dữ liệu là tải các tài liệu cần thiết từ một
thư mục nguồn. Mỗi tài liệu sẽ thuộc một loại cụ thể (ví dụ: tài liệu tuyển sinh, chương
trình học, lịch học, quy định của trường,...) và được lưu trữ trong các thư mục riêng biệt.
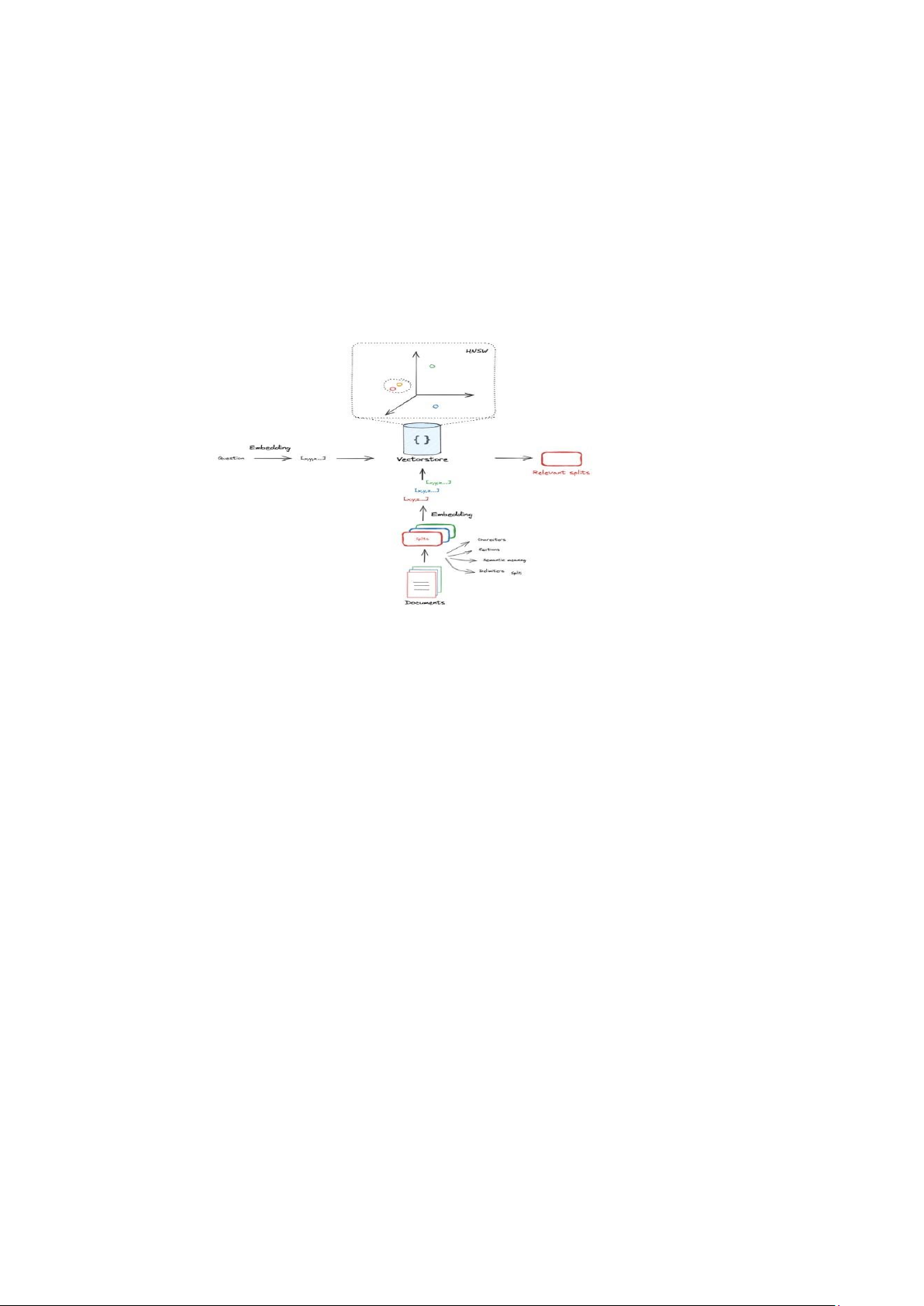
b. Cắt nhỏ tài liệu (Chunking)
Sau khi tài liệu đã được tải lên, bước tiếp theo là cắt nhỏ tài liệu thành các đoạn
(chunk) nhỏ hơn. Mỗi tài liệu có thể chứa một lượng thông tin lớn, và việc cắt nhỏ các
tài liệu giúp việc xử lý và phân tích chúng trở nên dễ dàng hơn rất nhiều. Quá trình cắt
nhỏ này giúp hệ thống chia tài liệu thành các phần nhỏ và dễ dàng được embedding
(nhúng) thành các vector, đồng thời giữ nguyên ngữ nghĩa và cấu trúc của thông tin trong mỗi phần.
Quá trình cắt nhỏ tài liệu sẽ được thực hiện dựa trên một số quy tắc nhất định.
Các yếu tố như dấu câu (dấu chấm, dấu phẩy, dấu chấm hỏi, dấu hai chấm, v.v.), ký tự
đặc biệt hoặc kích thước tối đa của mỗi chunk sẽ được sử dụng làm tiêu chí để xác
định cách cắt nhỏ. Ví dụ, mỗi chunk có thể là một đoạn văn hoặc một câu hoàn chỉnh.
Điều này không chỉ giúp giữ nguyên ý nghĩa của thông tin mà còn tạo điều kiện thuận
lợi cho quá trình embedding sau này.
Việc cắt nhỏ tài liệu không chỉ giúp tổ chức lại thông tin mà còn giúp quá trình truy
vấn trở nên hiệu quả hơn. Khi hệ thống nhận được một câu hỏi từ người dùng, các
chunk nhỏ có thể dễ dàng so sánh với câu hỏi đầu vào và trả về thông tin phù hợp. c.
Nhúng dữ liệu vào không gian vector (Embeddings)
Sau khi tài liệu đã được chia thành các chunk, mỗi chunk sẽ được chuyển đổi thành
một vector trong không gian vector thông qua quá trình nhúng (embedding). Quá trình
này sẽ giúp các chunk có thể được biểu diễn dưới dạng các vector số học, có khả năng
so sánh và tìm kiếm trong không gian vector. Hệ thống sử dụng mô hình "text-
embedding-004" của Gemini AI, một mô hình mạnh mẽ và hiệu quả trong việc xử lý
văn bản tiếng Việt. Mô hình này có khả năng hiểu ngữ nghĩa và các đặc điểm của ngôn
ngữ tự nhiên, đặc biệt là trong các ngữ cảnh tiếng Việt.
Việc nhúng văn bản vào không gian vector giúp chuyển đổi thông tin phi cấu trúc
thành dạng có thể xử lý bởi máy tính, đồng thời giữ được ngữ nghĩa của các chunk
thông qua các vector nhúng. Các vector này sẽ mang thông tin về nội dung của từng
chunk và được lưu trữ để sử dụng trong quá trình truy vấn sau này.
Gemini AI đã được chứng minh là có hiệu quả khá cao trong việc nhúng văn bản
tiếng Việt, giúp đảm bảo rằng các tài liệu sẽ được biểu diễn một cách chính xác và đầy
đủ trong không gian vector.
d. Thêm vào cơ sở dữ liệu vector (Chroma Database)
Sau khi các chunk đã được nhúng thành các vector, bước tiếp theo là lưu trữ chúng
vào cơ sở dữ liệu vector để có thể dễ dàng truy vấn và tìm kiếm thông tin. Chroma là
một cơ sở dữ liệu tối ưu hóa cho việc lưu trữ và truy xuất các vector embedding. Mỗi
chunk sẽ được gắn một doc_id độc lập để phân biệt giữa các tài liệu gốc. Doc_id này
giúp hệ thống nhận biết tài liệu gốc mà một chunk thuộc về, từ đó khi truy vấn, hệ
thống có thể trả lại toàn bộ tài liệu gốc cùng với các chunk liên quan.
Mỗi chunk sẽ được lưu trữ dưới dạng một vector trong Chroma database, và mỗi
vector sẽ được đánh dấu với doc_id tương ứng. Điều này giúp đảm bảo rằng trong quá
trình truy vấn, hệ thống có thể lấy lại toàn bộ tài liệu gốc một cách dễ dàng, đồng thời
có thể truy xuất thông tin chi tiết từ các chunk riêng biệt. Chroma database hỗ trợ việc
tìm kiếm và truy xuất thông tin với tốc độ cao, giúp hệ thống có thể cung cấp câu trả
lời một cách nhanh chóng và chính xác.
e. Khởi tạo mô hình truy vấn (Retriever)
Hình 2. Kiến trúc mô hình mô hình truy vấn dữ liệu
Cuối cùng, để có thể truy vấn và tìm kiếm thông tin từ cơ sở dữ liệu vector, hệ
thống sẽ xây dựng một mô hình truy vấn (retriever). Mô hình này sẽ giúp hệ thống
nhận diện và tìm ra các chunk hoặc tài liệu có liên quan đến yêu cầu của người dùng.
Khi người dùng nhập câu hỏi hoặc yêu cầu, mô hình truy vấn sẽ tìm kiếm trong cơ sở
dữ liệu Chroma và truy xuất những thông tin phù hợp nhất.
Mô hình truy vấn sử dụng các kỹ thuật tìm kiếm tương tự như tính toán khoảng
cách cosine giữa các vector embedding, để tìm ra những chunk có ngữ nghĩa gần nhất
với yêu cầu của người dùng. Sau khi truy vấn được thực hiện, hệ thống sẽ lấy thông tin
từ các chunk và tạo ra câu trả lời phù hợp. Điều này giúp hệ thống không chỉ tìm kiếm
thông tin mà còn tái cấu trúc câu trả lời từ nhiều chunk khác nhau để tạo ra một phản
hồi mạch lạc và đầy đủ.
2.3.2.2. Kỹ Thuật Query Translation
Trong quá trình xử lý câu hỏi từ người dùng, trợ lý ảo PTIT sử dụng các kỹ thuật
Query Translation để tối ưu hóa truy vấn, giúp tăng độ chính xác và hiệu quả trong việc
tìm kiếm thông tin. Query Translation là một bước quan trọng trong việc chuyển đổi
câu hỏi ban đầu của người dùng thành các truy vấn tối ưu, đặc biệt khi câu hỏi có thể
mang tính phức tạp, mơ hồ hoặc đa chiều. Mục tiêu của các kỹ thuật này là đảm bảo
rằng hệ thống có thể hiểu đúng ý nghĩa và nội dung của câu hỏi, từ đó cung cấp câu trả
lời phù hợp và chính xác nhất.
Để thực hiện điều này, trợ lý ảo PTIT đã triển khai ba kỹ thuật Query Translation chủ yếu sau:
a. Multi-query (Truy vấn đa dạng)
Kỹ thuật Multi-query là một phương pháp giúp mở rộng phạm vi tìm kiếm bằng
cách tạo ra nhiều truy vấn từ một câu hỏi ban đầu. Thay vì chỉ dựa vào một truy vấn
duy nhất, hệ thống sẽ biến đổi câu hỏi ban đầu thành nhiều phiên bản khác nhau hoặc
tách nhỏ các yếu tố trong câu hỏi, giúp chatbot có thể tìm kiếm từ nhiều góc độ khác nhau.
Ví dụ, nếu người dùng đặt câu hỏi “PTIT có các chương trình đào tạo nào?”, hệ
thống có thể tạo ra các truy vấn như “Các ngành học tại PTIT là gì?”, “PTIT đào tạo
những chuyên ngành nào?”, hay “Danh sách chương trình đào tạo tại PTIT”. Các truy
vấn này sẽ giúp chatbot tìm kiếm thông tin từ các dữ liệu khác nhau, mở rộng phạm vi
và tăng khả năng truy xuất chính xác hơn.
Kỹ thuật Multi-query giúp đảm bảo rằng tất cả các biến thể có thể có của câu hỏi
đều được xem xét. Điều này không chỉ giúp cải thiện khả năng truy vấn mà còn giúp
chatbot bao phủ nhiều khía cạnh của câu hỏi, từ đó tăng cơ hội tìm được câu trả lời
chính xác cho người dùng. Càng nhiều truy vấn được tạo ra từ câu hỏi ban đầu, thì khả
năng chatbot nhận diện và trả lời đúng câu hỏi càng cao. b. Decomposition (Phân tích câu hỏi)
Kỹ thuật Decomposition giúp giải quyết các câu hỏi phức tạp bằng cách chia chúng
thành các truy vấn nhỏ hơn, dễ xử lý và dễ tìm kiếm hơn. Khi người dùng đặt một câu
hỏi phức tạp hoặc có nhiều phần, hệ thống sẽ phân tích và tách câu hỏi thành các truy
vấn con. Mỗi truy vấn con sẽ tập trung vào một phần cụ thể của câu hỏi ban đầu, từ
đó tạo ra các kết quả con. Các kết quả này sau đó sẽ được hợp lại để tạo thành câu trả
lời hoàn chỉnh cho câu hỏi ban đầu của người dùng.
Ví dụ, với câu hỏi phức tạp như “Điều kiện xét tuyển vào PTIT là gì, và tôi cần chuẩn
bị những gì để đăng ký?”, hệ thống có thể chia câu hỏi này thành hai truy vấn nhỏ hơn:
một truy vấn tìm thông tin về điều kiện xét tuyển và một truy vấn khác tìm thông tin
về thủ tục đăng ký. Sau khi các truy vấn con này được xử lý, chatbot sẽ tổng hợp thông
tin từ các câu trả lời của chúng và trả lời người dùng một cách đầy đủ và chính xác.
Kỹ thuật Decomposition đặc biệt hữu ích trong việc giải quyết các câu hỏi phức tạp,
nhiều phần, hoặc yêu cầu nhiều bước phân tích. Bằng cách chia nhỏ câu hỏi, hệ thống
có thể xử lý từng phần một cách dễ dàng và chính xác hơn, từ đó tăng độ chính xác và
tính mạch lạc của câu trả lời cuối cùng.
c. HyDE (Hypothetical Document Embedding)
Kỹ thuật HyDE (Hypothetical Document Embedding) là một phương pháp mạnh mẽ
giúp tối ưu hóa khả năng tìm kiếm của trợ lý ảo bằng cách xây dựng một câu trả lời giả
định của câu hỏi. Thay vì chỉ tìm kiếm các từ khóa trong câu hỏi.
Kỹ thuật HyDE giúp tối ưu hóa khả năng truy xuất tài liệu, tăng độ chính xác của các
kết quả tìm kiếm, và giảm thiểu các vấn đề do sự thiếu khớp giữa từ khóa và nội dung
thực tế. Nó giúp hệ thống trở nên linh hoạt hơn trong việc tìm kiếm thông tin, ngay cả
khi câu hỏi của người dùng được diễn đạt khác biệt so với dữ liệu gốc.
2.3.2.3. Định tuyến câu hỏi (Routing)
Trong quá trình phát triển và vận hành trợ lý ảo PTIT, Định tuyến câu hỏi (Routing)
là một bước quan trọng giúp tối ưu hóa khả năng xử lý và phản hồi các câu hỏi từ người
dùng. Mục tiêu của quy trình Routing là đảm bảo rằng mỗi câu hỏi được chuyển đến
nguồn dữ liệu phù hợp nhất, giúp hệ thống trả lời chính xác và nhanh chóng hơn. Quy
trình này sử dụng các mô hình ngôn ngữ lớn (LLMs) để phân tích và định hướng câu
hỏi, từ đó tối ưu hóa chất lượng và độ chính xác của các câu trả lời.
Dưới đây là các bước chi tiết trong quy trình Routing của trợ lý ảo PTIT: a. Phân loại câu hỏi
Bước đầu tiên trong quy trình Routing là phân loại câu hỏi, giúp hệ thống xác định
được loại thông tin mà người dùng đang yêu cầu. Việc phân loại này rất quan trọng, vì
nó sẽ quyết định mô hình truy vấn (Retriever) và nguồn dữ liệu nào sẽ được sử dụng để trả lời câu hỏi.
Hệ thống sử dụng các mô hình ngôn ngữ lớn (LLMs) để phân tích ngữ nghĩa của
câu hỏi và xác định các chủ đề chính. Những câu hỏi có thể được phân loại theo các tiêu chí như: ●
Chủ đề: Ví dụ, câu hỏi liên quan đến ban quản lý, các chương trình học, hay
thông tin học phí các ngành sẽ được phân loại vào các nhóm khác nhau như
"Thông tin chung về Học Viện", "Chương trình đào tạo", hoặc "Thông tin các sự kiện". ●
Ngữ cảnh: Câu hỏi có thể mang ngữ cảnh yêu cầu thông tin thời gian, ví dụ như
"Thời gian nhập học năm nay là khi nào?", hay yêu cầu thông tin về các sự kiện sắp tới. ●
Từ khóa chính: Hệ thống cũng có thể nhận diện các từ khóa quan trọng trong
câu hỏi để phân loại như “học phí”, “thông tin tuyển sinh”, “chuyên ngành công nghệ thông tin”, v.v.
Sau khi phân loại, hệ thống xác định mức độ liên quan và chuyển câu hỏi đến đúng mô
hình truy vấn và nguồn dữ liệu. Nếu câu hỏi thuộc phạm vi thông tin mà hệ thống
không có, mô hình sẽ xác định rằng câu hỏi này không có tính liên quan và bỏ qua,
tránh gây nhầm lẫn và tiết kiệm tài nguyên.
b. Chọn mô hình truy vấn (Retriever) phù hợp
Khi câu hỏi đã được phân loại, bước tiếp theo là lựa chọn mô hình truy vấn
(Retriever) phù hợp. Retriever là một thành phần quan trọng trong hệ thống trợ lý ảo,
chịu trách nhiệm tìm kiếm và truy xuất thông tin từ cơ sở dữ liệu, các tài liệu, hoặc
nguồn dữ liệu khác có sẵn.
Dựa trên loại câu hỏi và phân loại đã được xác định ở bước trước, hệ thống sẽ lựa
chọn mô hình truy vấn tối ưu cho từng loại dữ liệu cụ thể. Một số ví dụ về mô hình truy
vấn có thể được sử dụng là: ●
Mô hình tìm kiếm dữ liệu chung về học viện: Dành cho các câu hỏi liên quan
đến thông tin về ban quản lý, các phòng ban , các câu lạc bộ, … trong Học Viện. ●
Mô hình tìm kiếm thông tin chương trình đào tạo: Dành cho các câu hỏi liên
quan đến các chương trình đào tạo, học phí từng chương trình, thời gian đào tạo, … ●
Mô hình tìm kiếm sự kiện: Dành cho các câu hỏi về các sự kiện hoặc chương
trình hoạt động tại PTIT, bao gồm cả lịch trình sự kiện, thông tin về các hội thảo, buổi giao lưu, v.v.
Khi mô hình truy vấn phù hợp được chọn, hệ thống sẽ tiến hành tìm kiếm và truy xuất
thông tin liên quan từ nguồn dữ liệu đã xác định, đồng thời tối ưu hóa kết quả trả về
để đảm bảo độ chính xác và tính liên quan cao nhất. c. Xử lý các câu hỏi không liên quan
Nếu câu hỏi không thể phân loại được hoặc không phù hợp với bất kỳ nguồn dữ
liệu nào trong hệ thống, mô hình sẽ xác định đây là một câu hỏi không liên quan. Trong
trường hợp này, hệ thống sẽ tự động trả lời câu hỏi theo hiểu biết của mô hình ngôn
ngữ lớn sử dụng mà không cần đến mô hình truy vấn hoặc cung cấp một thông báo
rằng không thể trả lời câu hỏi này, giúp tránh tình trạng trả lời sai hoặc gây hiểu lầm cho người dùng.
Hệ thống cũng có thể phản hồi bằng cách yêu cầu người dùng cung cấp thêm thông
tin hoặc làm rõ câu hỏi để có thể trả lời chính xác hơn, ví dụ: "Câu hỏi của bạn không
rõ ràng, vui lòng cung cấp thêm chi tiết để tôi có thể giúp bạn tốt hơn."
2.3.2.5. Truy xuất tài liệu (Retrieval)
Bước Truy Xuất Dữ Liệu (Retrieval) là một trong những giai đoạn quan trọng và
then chốt trong quá trình hoạt động của trợ lý ảo PTIT. Giai đoạn này liên quan đến
việc tìm kiếm và thu thập thông tin cần thiết từ các tài liệu đã được nhúng
(embedding), nhằm cung cấp câu trả lời chính xác và nhanh chóng cho người dùng.
Quy trình Retrieval diễn ra qua các bước sau: a. Truy xuất dữ liệu
Ở bước này, hệ thống sử dụng mô hình Retriever (được chọn trong bước Routing)
để truy xuất thông tin từ nguồn dữ liệu đã được lưu trữ. Dựa vào câu hỏi của người
dùng và kết quả phân loại câu hỏi trước đó, mô hình Retriever sẽ tìm kiếm và lấy ra các
tài liệu gốc liên quan nhất từ cơ sở dữ liệu. Các tài liệu này thường được nhúng thành
các vector trong không gian embedding, giúp hệ thống nhanh chóng xác định các tài
liệu phù hợp nhất với câu hỏi.
Quá trình truy xuất dữ liệu không chỉ dừng lại ở việc tìm kiếm các tài liệu chứa từ
khóa chính mà còn dựa trên ngữ nghĩa của câu hỏi, nhờ vào các kỹ thuật như vector
similarity. Hệ thống sẽ trả về top_k tài liệu (số lượng tài liệu có thể điều chỉnh tùy theo
cấu hình hệ thống) được cho là có mức độ liên quan cao nhất đối với câu truy vấn. Các
tài liệu này có thể là những đoạn văn bản, câu trả lời mẫu hoặc các tài liệu gốc từ trang
web chính thức của PTIT, tùy thuộc vào nội dung câu hỏi của người dùng. b. Re-ranking
Sau khi các tài liệu liên quan đã được truy xuất từ Retriever, bước tiếp theo là
Reranking – sắp xếp lại các tài liệu này theo mức độ liên quan. Mặc dù mô hình
Retriever đã chọn ra các tài liệu phù hợp nhất, không phải tất cả các tài liệu này đều có
mức độ liên quan đồng đều. Bước Re-ranking giúp xác định tài liệu nào sẽ cung cấp câu
trả lời chính xác nhất và hữu ích nhất cho người dùng. c. Chuẩn hóa dữ liệu
Sau khi đã có các tài liệu được re-ranked, bước tiếp theo là chuẩn hóa và chuyển
các tài liệu này về dạng mà hệ thống có thể sử dụng trong quá trình tạo câu trả lời. Các
tài liệu vừa được truy xuất và xếp hạng sẽ được chuyển đổi về dạng string (chuỗi văn
bản thuần túy), giúp dễ dàng đưa vào câu prompt của mô hình ngôn ngữ lớn (LLMs) ở bước tiếp theo.
Việc chuẩn hóa dữ liệu là một bước quan trọng trong quy trình, vì nó đảm bảo rằng
các tài liệu có thể được sử dụng một cách hiệu quả trong các mô hình ngôn ngữ lớn để
tạo ra các câu trả lời mạch lạc, dễ hiểu và chính xác.
2.3.2.6. Sinh câu trả lời (Generation)
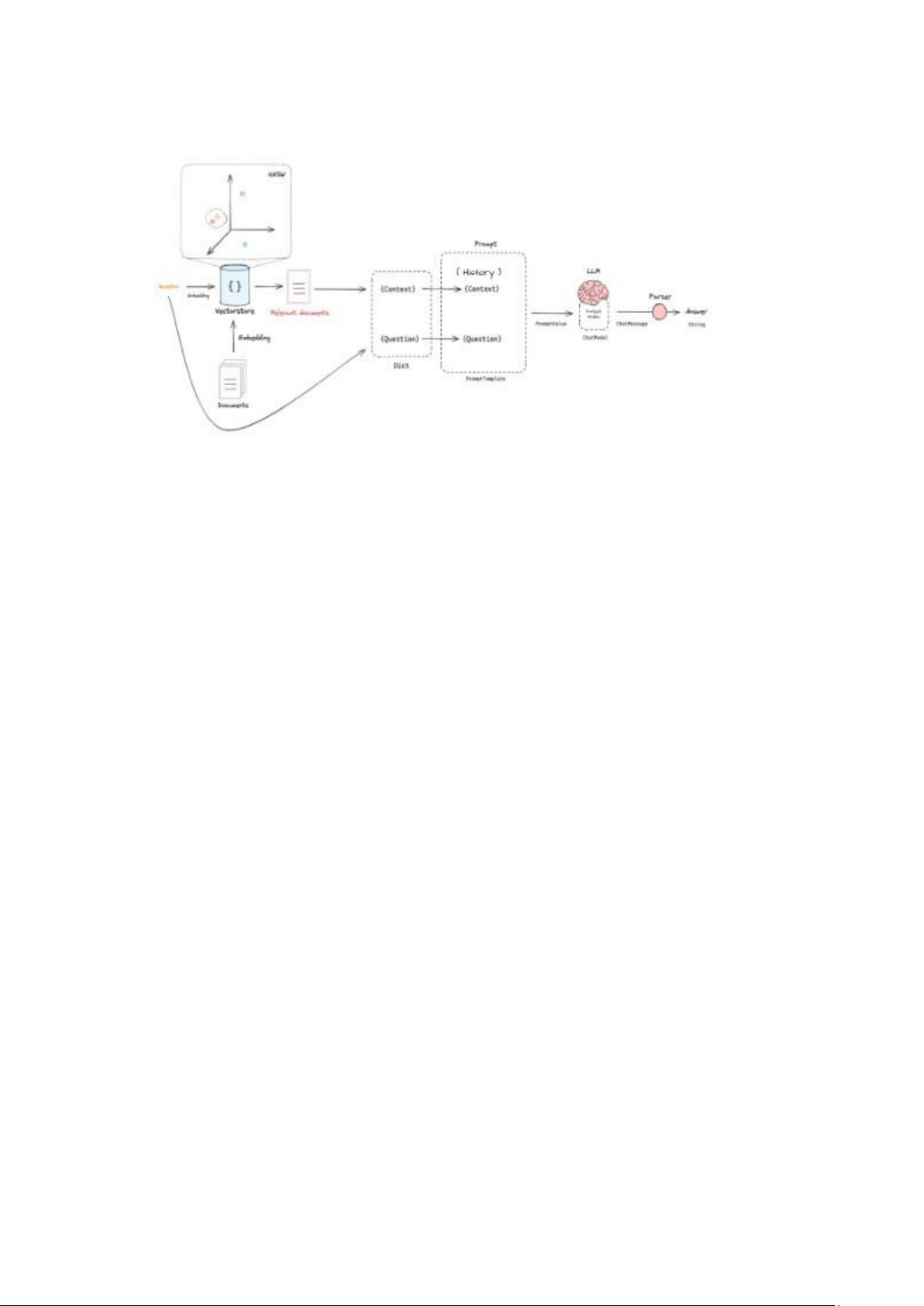
Hình 3. Quá trình sinh câu trả lời của trợ lý ảo
Bước "Sinh Câu Trả Lời" là giai đoạn cuối cùng trong quy trình xử lý yêu cầu của
người dùng trong hệ thống trợ lý ảo PTIT. Đây là bước mà hệ thống sử dụng các thông
tin đã được truy xuất từ các tài liệu, kết hợp với mô hình ngôn ngữ lớn, để tạo ra một
câu trả lời mạch lạc và chính xác, đáp ứng yêu cầu của người dùng. Quy trình Sinh Câu
Trả Lời diễn ra qua các bước sau: a. Viết câu prompt
Trước khi sinh câu trả lời, hệ thống cần tạo ra một câu prompt để truyền tải đầy
đủ thông tin cần thiết cho mô hình ngôn ngữ lớn (LLMs). Câu prompt này có vai trò
như một chỉ dẫn cho mô hình, giúp nó hiểu rõ yêu cầu của người dùng và cung cấp câu trả lời phù hợp.
Câu prompt được xây dựng bao gồm ba thành phần chính:
Question (Câu hỏi đầu vào): Đây là câu hỏi mà người dùng đã đưa ra. Mô hình sẽ
căn cứ vào câu hỏi này để tìm kiếm và tổng hợp thông tin liên quan từ các tài liệu.
Context (Các tài liệu liên quan nhất): Đây là các tài liệu đã được truy xuất và xử lý
từ bước Truy Xuất Dữ Liệu (Retrieval). Những tài liệu này chứa thông tin có liên quan
trực tiếp đến câu hỏi và sẽ được đưa vào prompt để giúp mô hình tạo ra câu trả lời chính xác.
History (Lịch sử cuộc trò chuyện): Trong trường hợp người dùng đã có cuộc trò
chuyện trước đó với trợ lý ảo, lịch sử trò chuyện sẽ được đưa vào để cung cấp bối cảnh
cho mô hình. Điều này giúp mô hình hiểu được mối liên kết giữa các câu hỏi trước đó
và câu hỏi hiện tại, đồng thời đảm bảo tính mạch lạc và liền mạch trong các phản hồi.
b. Mô hình ngôn ngữ lớn (LLMs) sử dụng
Mô hình ngôn ngữ lớn được sử dụng trong hệ thống trợ lý ảo PTIT là “gemini1.5-
flash”, một phiên bản nhỏ và nhanh của mô hình Gemini do Google phát triển. Mô hình
này được tối ưu hóa để xử lý tiếng Việt hiệu quả, đảm bảo khả năng hiểu và phản hồi
các câu hỏi từ người dùng một cách chính xác và mạch lạc.
Gemini-1.5-flash không chỉ có khả năng trả lời nhanh chóng mà còn có khả năng
học hỏi và cải thiện từ các cuộc trò chuyện trước, giúp tăng độ chính xác trong việc xử
lý các câu hỏi và yêu cầu của người dùng. Việc sử dụng mô hình này đảm bảo rằng hệ
thống sẽ trả lời câu hỏi của người dùng một cách tự nhiên, rõ ràng và phù hợp với ngữ cảnh.
c. Trả về câu trả lời
Sau khi mô hình ngôn ngữ lớn xử lý câu prompt, hệ thống sẽ sinh ra một câu trả lời
dưới dạng một xâu ký tự. Câu trả lời này được tạo ra dựa trên các thông tin truy xuất
từ các tài liệu liên quan, cũng như các thông tin bổ sung từ lịch sử cuộc trò chuyện (nếu có).
Câu trả lời này sẽ được trả về cho người dùng, giúp họ nhận được thông tin chính
xác và hữu ích. Dưới đây là một ví dụ về câu trả lời được sinh ra từ mô hình: ●
Câu hỏi: "Học phí của chương trình đào tạo cử nhân ngành Công nghệ thông tin là bao nhiêu?" ●
Câu trả lời: "Học phí của chương trình đào tạo cử nhân ngành Công nghệ thông
tin tại PTIT là 665 nghìn đồng trên một tín chỉ"
Hệ thống sẽ tiếp tục xử lý các câu hỏi tiếp theo theo cách tương tự, đảm bảo luôn cung
cấp câu trả lời phù hợp và chính xác.
2.3.3. Xây dựng Backend (Thực hiện: Thịnh)
Phần backend của ứng dụng chatbot được xây dựng bằng FastAPI, gồm nhiều thành
phần chính như xác thực người dùng, quản lý cuộc trò chuyện và lưu trữ tin nhắn. Dưới
đây là mô tả chi tiết từng phần:
a. Quản lý người dùng (User Management)
Backend sử dụng một mô hình cơ bản để quản lý thông tin người dùng: ●
Mô hình dữ liệu (User Model):
○ user_id: Khóa chính của bảng, xác định duy nhất từng người dùng.
○ username: Tên người dùng duy nhất, bắt buộc.
○ password: Mật khẩu được mã hóa.
○ email: Địa chỉ email, yêu cầu phải duy nhất.
○ full_name: Họ và tên của người dùng.
○ created_at và updated_at: Thời điểm tạo và cập nhật thông tin người dùng,
tự động ghi nhận thời gian hiện tại. ● API:
○ POST /users/: Đăng ký người dùng mới, kiểm tra tính duy nhất của username và email.
○ GET /users/: Lấy thông tin người dùng hiện tại.
○ PUT /users/: Cập nhật thông tin cá nhân của người dùng.
○ DELETE /users/{user_id}: Xóa tài khoản người dùng khi có quyền.
b. Xác thực người dùng và Quản lý phiên đăng nhập (Authentication)
Xác thực trong hệ thống được thực hiện bằng JWT (JSON Web Token) để đảm bảo an toàn trong giao tiếp: ●
Tạo token: Hàm create_access_token tạo mã token với dữ liệu người dùng,
thời gian hết hạn và mã hóa bằng SECRET_KEY. Hình 4: Hàm tạo mã token ●
Xác thực token: Hàm verify_access_token giải mã token, kiểm tra tính hợp lệ
và trả về thông tin người dùng.
Hình 5: Hàm giải mã token ●
API Login: POST /login: Đăng nhập người dùng, kiểm tra username và
password. Nếu đúng, hệ thống trả về access_token để người dùng sử dụng trong các yêu cầu tiếp theo.
c. Quản lý cuộc trò chuyện (Conversation Management)
Mô hình cuộc trò chuyện cho phép người dùng tạo và quản lý nhiều cuộc hội thoại khác nhau: ●
Mô hình dữ liệu (Conversation Model):
o conversation_id: Khóa chính, xác định duy nhất cuộc trò chuyện.
o user_id: Khóa ngoại liên kết với người dùng tạo cuộc trò chuyện. o title: Tiêu
đề của cuộc trò chuyện.
o start_time và end_time: Thời gian bắt đầu và kết thúc cuộc trò chuyện ● API:
o GET /conversations/: Lấy danh sách các cuộc trò chuyện của người dùng hiện tại.
o POST /conversations/: Khởi tạo một cuộc trò chuyện mới với tiêu đề. o PUT
/conversations/{conversation_id}/end: Kết thúc một cuộc trò chuyện
bằng cách ghi lại thời điểm kết thúc.
o DELETE /conversations/{conversation_id}: Xóa cuộc trò chuyện thuộc về người dùng hiện tại.
d. Lưu trữ tin nhắn (Message Management)
Tin nhắn giữa người dùng và chatbot được lưu trữ để có thể tái sử dụng hoặc tham khảo: ●
Mô hình dữ liệu (Message Model):
o message_id: Khóa chính của bảng, xác định duy nhất mỗi tin nhắn. o
conversation_id: Khóa ngoại liên kết với cuộc trò chuyện. o sender: Xác định
người gửi tin nhắn là user hay bot. o content: Nội dung tin nhắn.
o created_at: Thời gian gửi tin nhắn. ●
API Tin nhắn: o POST /conversations/{conversation_id}/messages: Thêm tin
nhắn mới vào cuộc trò chuyện hiện tại. o Tin nhắn từ người dùng được truyền
đến bot và được lưu vào bảng tin nhắn. o Bot trả lời lại, câu trả lời này cũng
được lưu lại trong bảng tin nhắn để duy trì lịch sử.
e. Bảo mật và Xác thực
Tài liệu liên quan:
-

Think Python - How to Think Like a Computer Scientist môn Lập trình với Python | Học viện Công Nghệ Bưu Chính Viễn Thông
108 54 -

Bài: Giới thiệu ngôn ngữ lập trình Python môn Lập trình với Python | Học viện Công Nghệ Bưu Chính Viễn Thông
100 50 -

Bài tập ôn tập môn Lập trình với Python | Học viện Công Nghệ Bưu Chính Viễn Thông
213 107 -

Đề cương bằi giảng môn Lập trình với Python | Học viện Công Nghệ Bưu Chính Viễn Thông
225 113