BÁO CÁO NHÓM 13: TÌM HIỂU VỀ HỌC SÂU (DEEP LEARNING) IT5-N. Môn Công nghệ phần mềm (CNPM) | Trường Đại học Giao thông Vận tải.
Lời nói đầu
Deep Learning, một nhánh của trí tuệ nhân tạo, đã và đang trở thành một trong những lĩnh vực nghiên cứu và ứng dụng quan trọng nhất trong công nghệ thông tin hiện nay. Với khả năng xử lý và phân tích dữ liệu phức tạp, Deep Learning đã mở ra nhiều cơ hội mới cho các lĩnh vực như thị giác máy, xử lý ngôn ngữ tự nhiên, y học, và nhiều lĩnh vực khác.
Trong báo cáo này, chúng tôi sẽ trình bày một cách chi tiết về Deep Learning, từ các nguyên lý cơ bản đến các ứng dụng thực tế, cũng như những thách thức và cơ hội mà lĩnh vực này mang lại. Chúng tôi cũng sẽ thảo luận về tương lai của Deep Learning và tầm quan trọng của nó trong việc giải quyết các vấn đề xã hội và khoa học hiện nay.
BÁO CÁO NHÓM 13: TÌM HIỂU VỀ HỌC SÂU (DEEP LEARNING) IT5-N. Môn Công nghệ phần mềm (CNPM) | Trường Đại học Giao thông Vận tải.
Tài liệu gồm 54 trang giúp bạn tham khảo, củng cố kiến thức và ôn tập đạt kết quả cao trong kỳ thi sắp tới. Mời bạn đọc đón xem!
Môn: Công nghệ phần mềm (CNPM) 10 tài liệu
Trường: Trường Đại học Giao thông vận tải 455 tài liệu
Tác giả:









{kind=link}





Preview text:
lOMoAR cPSD| 58833082
□□&□□
BỘ GIÁO DỤC VÀ ĐÀO TẠO
TRƯỜNG ĐẠI HỌC GIAO THÔNG VẬN TẢI
KHOA CÔNG NGHỆ THÔNG TIN ~~~~~~*~~~~~~ BÀI BÁO CÁO
ĐỀ TÀI TÌM HIỂU VỀ HỌC SÂU
( DEEP LEARNING )
Sinh viên thực hiện : Mã sinh viên
Hà Huy Dũng * :
21124 4250
Vũ Đức Khải :
211213620
Lớ p :
IT 5 - N06
Giáo viên hướng dẫn
: Nguyễn Đức Dư
Hà Nội - 2024 lOMoAR cPSD| 58833082
BỘ GIÁO DỤC VÀ ĐÀO TẠO TRƯỜNG ĐẠI HỌC
GIAO THÔNG VẬN TẢI KHOA CÔNG NGHỆ THÔNG TIN ~~~~~~*~~~~~~ BÀI BÁO CÁO ĐỀ TÀI
TÌM HIỂU VỀ HỌC SÂU (DEEP LEARNING)
Sinh viên thực hiện : Mã sinh viên Hà Huy Dũng* : 211244250
Vũ Đức Khải : 211213620 Lớp : IT5-N06
Giáo viên hướng dẫn :
Nguyễn Đức Dư lOMoAR cPSD| 58833082 Hà Nội - 2024 MỤC LỤC Lời nói
đầu ...............................................................................................
. 1 CHƯƠNG 1: Giới
thiệu ......................................................................... 2
I. Định nghĩa Deep learning ...........................................................................2
I. Lịch sử ......................................................................................................2
III. Một số ứng dụng ........................................................................................7
CHƯƠNG 2: Nguyên lý cơ
bản ............................................................. 7
I. Cách thức deep learning hoạt động................................................................7
1. Phương pháp deep
learning ......................................................................................... 8 II. Cơ sở lý
thuyết ............................................................................................9 1. Khái
niệm về Neural Networks (Mạng nơ-ron)....................................................... 9 2.
Các loại mô hình Deep Learning phổ biến: ............................................................... 10
2.1. Convolutional Neural Networks (CNNs) - Mạng nơ-ron tích chập ..................
10 2.2. Recurrent Neural Networks (RNN) - Mạng nơ-ron hồi
quy ............................. 16 2.3. Generative Adversarial Networks (GANs) - Mạng
nơ-ron đối đầu sinh........ 20
3.Thuật toán và phương
pháp........................................................................................... 22 3.1 Các thuật toán
DL ......................................................................................................... 22 3.3. Phương
pháp tối ưu hóa trong Deep Learning: .................................................... 30 CHƯƠNG3: Ứng
dụng ......................................................................... 36
I. Speech to text using deep learning................................................................ 37
1.1. Nguyên lí hoạt
động...................................................................................................... 37 1.2. Chuyển lOMoAR cPSD| 58833082
âm thanh thành số......................................................................................... 38 1.3.
Tiền xử lý dữ liệu mẫu âm thanh ..............................................................................
40 1.4 Nhận diện ký tự từ đoạn âm
ngắn............................................................................. 42
CHƯƠNG 4: Thách thức và hướng phát triển ................................ 43
I.Thách thức hiện tại và Cơ hội trong tương lai ............................................... 43
1. Ưu và nhược điểm của Deep
Learning......................................................................... 43 Chương 5: Tổng
kết ............................................................................... 45 lOMoAR cPSD| 58833082 1 Lời nói đầu
Deep Learning, một nhánh của trí tuệ nhân tạo, đã và đang trở thành một trong
những lĩnh vực nghiên cứu và ứng dụng quan trọng nhất trong công nghệ thông tin hiện
nay. Với khả năng xử lý và phân tích dữ liệu phức tạp, Deep Learning đã mở ra nhiều cơ
hội mới cho các lĩnh vực như thị giác máy, xử lý ngôn ngữ tự nhiên, y học, và nhiều lĩnh vực khác.
Trong báo cáo này, chúng tôi sẽ trình bày một cách chi tiết về Deep Learning, từ các nguyên
lý cơ bản đến các ứng dụng thực tế, cũng như những thách thức và cơ hội mà lĩnh vực này
mang lại. Chúng tôi cũng sẽ thảo luận về tương lai của Deep Learning và tầm quan trọng
của nó trong việc giải quyết các vấn đề xã hội và khoa học hiện nay.
Nhóm chúng em gồm hai thành viên, và sau đây là phân công nhiệm vụ trong nhóm:
Sinh viên thực hiện Mã sinh viên Công việc
Viết báo cáo và bài trình chiếu ppt Hà Huy Dũng* 211244250
Tìm hiểu về cơ sở lý thuyết Vũ Đức Khải 211213620
Tìm hiểu về nguyên lý cơ bản, ứng dụng
Báo cáo này nhằm mục đích cung cấp một cái nhìn tổng quan về Deep Learning,
giúp người đọc hiểu rõ hơn về lĩnh vực này và những ứng dụng của nó trong đời sống và
công việc. Chúng tôi hy vọng rằng báo cáo này sẽ mang lại những thông tin hữu ích và
đóng góp tích cực vào việc nghiên cứu và phát triển Deep Learning trong tương lai.
Xin chân thành cảm ơn!
CHƯƠNG 1: Giới thiệu
I. Định nghĩa Deep learning
Deep learning được xem là một lĩnh vực thuộc machine learning và trí tuệ nhân
tạo (Al), ở đó các máy tính sẽ bắt chước con người để học và cải thiện chính nó thông
qua các thuật toán. Deep learning là một yếu tố quan trọng của data science. Nó giúp cho
những nhà data science thu thập, phân tích và giải thích một lượng dữ liệu khổng lồ đơn
giản, nhanh chóng và dễ dàng.
Hiểu một cách đơn giản thì deep learning là cách để tự động hóa phân tích dự đoán. Trong
khi những thuật toán của machine learning là tuyến tính thì các thuật toán của deep learning
lại xếp chồng lên nhau theo thứ tự từ đơn giản đến phức tạp, trừu tượng. lOMoAR cPSD| 58833082 2
Bạn hãy tưởng tượng một đứa trẻ mới bắt đầu học ngôn ngữ và từ đầu tiên nó học là “chó”.
Nó sẽ chỉ vào bất cứ một đồ vật và nói “chó”. Lúc này phụ huynh sẽ đáp trả “đúng” hoặc
“không”. Sau khi nhận được phản hồi, đứa trẻ tiếp tục chỉ vào các đồ vật khác và dán nhãn
cho chúng. Bộ não của trẻ sẽ làm rõ sự trừu tượng, phức tạp của khái niệm về “chó” bằng
cách xây dựng một hệ thống phân cấp mà mức độ trừu tượng ở cấp sau được tạo ra từ kiến
thức thu được ở cấp trước. I. Lịch sử
Deep Learning (Học sâu) đã phát triển và góp phần tạo nên một bước tiến lớn
trong các ngành và lĩnh vực kinh doanh hiện nay. Học sâu là một nhánh của học máy
triển khai các thuật toán để xử lý dữ liệu và bắt chước quá trình tư duy và thậm chí phát
triển các tính năng trừu tượng.
Deep Learning sử dụng các lớp thuật toán để xử lý dữ liệu, hiểu giọng nói của con người
và nhận dạng các đối tượng một cách trực quan. Trong học sâu, thông tin được chuyển
qua từng lớp và đầu ra của lớp trước đóng vai trò là đầu vào cho lớp tiếp theo. Lớp đầu
tiên trong mạng được gọi là lớp đầu vào (input layer), trong khi lớp cuối cùng là lớp đầu
ra (output layer), các lớp ở giữa được gọi là các lớp ẩn (hidden layer).
Một điểm đặc biệt khác của học sâu là khả năng trích xuất đặc trưng, sử dụng một thuật
toán để tự động xây dựng các đặc trưng có ý nghĩa cho việc học tập, đào tạo và hiểu biết trong dữ liệu. lOMoAR cPSD| 58833082 3
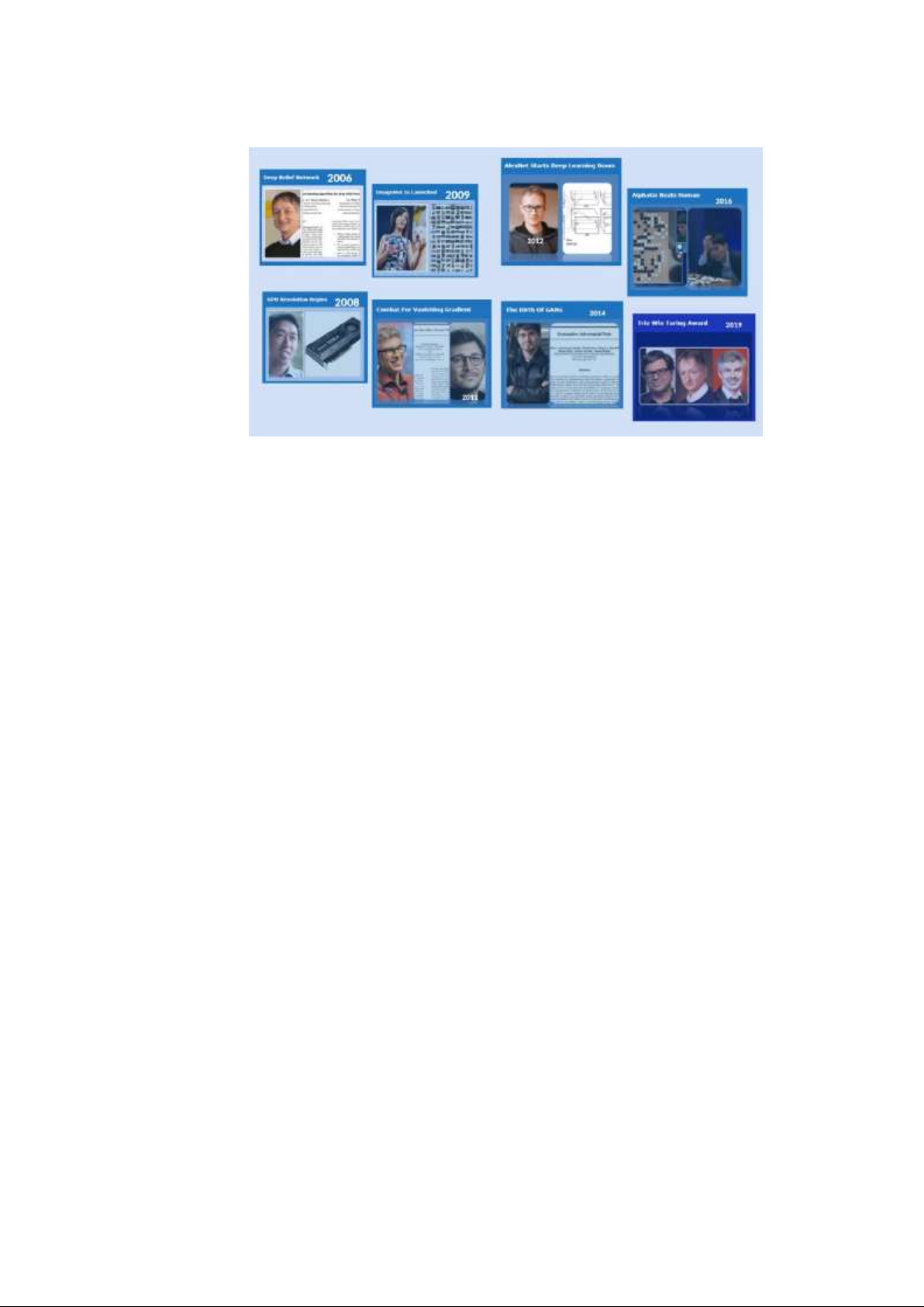
Lịch sử phát triển của Deep Learning trong nhiều năm
Thế giới hiện đang chứng kiến một cuộc cách mạng AI toàn cầu trên tất cả các lĩnh vực.
Và một trong những yếu tố thúc đẩy cuộc cách mạng AI này là Học sâu. Nhờ những gã
khổng lồ như Google và Facebook, Deep Learning giờ đây đã trở thành một thuật ngữ
phổ biến và mọi người có thể nghĩ rằng đó là một khám phá gần đây. Nhưng bạn có thể
ngạc nhiên khi biết rằng lịch sử của học sâu có từ những năm 1940.
Thật vậy, học sâu không xuất hiện trong một sớm một chiều, đúng hơn nó đã phát triển từ
từ và dần dần trong hơn bảy thập kỷ. Bài viết này nhằm giúp bạn tìm hiểu lịch sử của Deep
Learning để điểm lại những khám phá quan trọng mà các nhà nghiên cứu đã thực hiện và
tất cả những bước đi nhỏ bé này đã đóng góp như thế nào vào kỷ nguyên hiện đại của sự bùng nổ Học sâu.
Lịch sử của học sâu bắt đầu từ năm 1943 khi Warren McCulloch và Walter Pitts tạo ra một
mô hình máy tính dựa trên các mạng thần kinh mô phỏng hoạt động của não bộ con người.
Warren McCulloch và Walter Pitts đã sử dụng sự kết hợp giữa toán học và thuật toán để
bắt chước quá trình suy nghĩ. Mạng nơ-ron này có khả năng rất hạn chế và không có cơ
chế học hỏi. Tuy nhiên, nó sẽ đặt nền tảng cho mạng nơ-ron nhân tạo và Deep Learning.
• Năm 1957, trong bài báo của mình “Perceptron: A Perceiving and Recognition
Automaton” (Perceptron: Thuật toán để học có giám sát các phân loại nhị phân),
Rosenblatt cho thấy diện mạo mới của mạng nơ-ron McCulloch-Pitts – Perceptron
có khả năng học tập thực sự để tự phân loại dựa trên phép tính nhị phân. Điều này
truyền cảm hứng cho cuộc cách mạng trong nghiên cứu mạng nơ-ron nông trong
nhiều năm sau, cho đến mùa đông AI đầu tiên.
Henry J. Kelley trong bài báo của mình, “Lý thuyết Gradient về các đường bay tối
ưu” cho thấy phiên bản đầu tiên của Back Propagation Model. Mô hình của ông phù lOMoAR cPSD| 58833082 4
hợp với Lý thuyết điều khiển, nhưng nó đặt nền tảng cho việc hoàn thiện thêm mô
hình và sẽ được sử dụng trong ANN trong những năm sau đó.
• Năm 1962, ra đời Backpropagation With Chain Rule – Thuật toán Lan truyền
ngược với quy tắc chuỗi (Quy tắc chuỗi là một công thức biểu thị đạo hàm), Stuart
Dreyfus trong bài báo của mình, “Giải pháp số cho các phép tính biến phân”, (Phép
tính biến phân: là một ngành giải tích toán học sử dụng variations, là những thay
đổi nhỏ của hàm và phiếm hàm, để tìm cực đại và cực tiểu) cho thấy một thuật
toán Lan truyền ngược sử dụng quy tắc chuỗi đạo hàm đơn giản, thay vì lập trình
động mà trước đó đang sử dụng. Đây là một bước nhỏ khác giúp củng cố tương lai của Deep Learning.
• Năm 1965, khai sinh mạng Học sâu, Alexey Grigoryevich Ivakhnenko cùng với
Valentin Grigorʹevich Lapa, cho ra đời Hierarchical Representation of Neural
Network (biểu diễn phân cấp của mạng nơ-ron) sử dụng chức năng kích hoạt đa
thức và được đào tạo bằng Phương pháp xử lý dữ liệu nhóm (GMDH). Hiện nó
được coi là Perceptron nhiều lớp đầu tiên và Ivakhnenko thường được coi là cha đẻ của Deep Learning.
• Năm 1969, Sự sụp đổ của Perceptron, Marvin Minsky và Seymour Papert xuất
bản cuốn sách “Perceptrons” trong đó họ chỉ ra rằng Rosenblatt’s Perceptron
không thể giải quyết các chức năng phức tạp như XOR. Đối với các hàm
Perceptron như vậy nên được đặt trong nhiều lớp ẩn làm ảnh hưởng đến thuật toán
học Perceptron. Sự thất bại này khởi đầu một mùa đông của nghiên cứu mạng nơron.
• Năm 1970, Seppo Linnainmaa công bố phương pháp chung để phân biệt tự động
cho Backpropagation và ứng dụng nó vào trong mã máy tính. Nghiên cứu về
Backpropagation hiện đã đi rất xa, nhưng nó sẽ không được thực hiện trong mạng
nơ-ron cho mãi tới thập kỷ sau.
• Năm 1971, Alexey Grigoryevich Ivakhnenko tiếp tục nghiên cứu của mình về
Neural Network. Ông tạo ra mạng thần kinh sâu 8 lớp bằng cách sử dụng Group
Method of Data Handling (Phương pháp xử lý dữ liệu theo nhóm), viết tắt là GMDH.
• Năm 1980, mạng CNN ra đời, Kunihiko Fukushima đưa ra Neocognitron, kiến
trúc mạng nơ-ron phức hợp đầu tiên có thể nhận ra các mẫu hình ảnh chẳng hạn
như các ký tự viết tay.
• Năm 1982, ra đời Hopfield Network – tiền thân của RNN, John Hopfield tạo ra
Mạng Hopfield, không có gì khác ngoài một mạng nơ-ron tuần hoàn. Nó hoạt
động như một hệ thống bộ nhớ có thể định địa chỉ nội dung và sẽ là công cụ cho
các mô hình RNN tiếp theo.
Cùng năm này, đề xuất ứng dụng Back Propagation vào mạng ANN, Paul
Werbos, trên luận án bằng tiến sĩ của mình năm 1974, ông đề xuất việc sử dụng
Backpropagation để lan truyền lỗi trong quá trình đào tạo Mạng thần kinh. Kết quả lOMoAR cPSD| 58833082 5
từ luận án tiến sĩ của ông cuối cùng được cộng đồng nghiên cứu mạng nơ-ron được
áp dụng thực tế sau này.
• Năm 1985, ra đời Boltzmann Machine, David H. Ackley, Geoffrey Hinton và
Terrence Sejnowski đã tạo ra Boltzmann Machine là một Recurrent Neural
Network (Mạng nơ-ron lặp lại ngẫu nhiên). Mạng nơ-ron này chỉ có lớp đầu vào
và ẩn lớp nhưng không có lớp đầu ra.
• Năm 1986, ra đời NetTalk – ANN học giọng nói, Terry Sejnowski tạo ra NeTalk,
một mạng nơ-ron học cách phát âm văn bản tiếng Anh bằng cách hiển thị văn bản
dưới dạng đầu vào và khớp phiên âm để so sánh.
• Cũng trong năm này, ứng dụng Back Propagation, Geoffrey Hinton, Rumelhart và
Williams trong bài báo của họ “Learning Representations by back-propagating
errors – Học biểu diễn bằng lỗi thuật toán Lan truyền ngược” cho thấy việc triển
khai thành công quá trình lan truyền ngược trong mạng nơ-ron. Nó đã mở ra những
cánh cổng cho việc đào tạo mạng nơ-ron sâu phức tạp một cách dễ dàng hơn, vốn
là trở ngại chính trong những nghiên cứu trước đây.
Vào thời điểm này, Máy Boltzmann bị hạn chế, Paul Smolensky đưa ra một bản
nâng cấp của Boltzmann Machine không có kết nối nội bộ lớp trong đầu vào và lớp
ẩn. Nó được gọi là Máy Boltzmann hạn chế (RBM). Nó đã trở nên phổ biến trong
nhiều năm tới, đặc biệt là để xây dựng các Recommender System (Hệ thống đề xuất).
• Năm 1989, mạng CNN (Convolutional Neural Network – Mạng tích chập) sử dụng
Backpropagation, Yann LeCun sử dụng phương pháp lan truyền ngược để huấn
luyện mạng nơ-ron phức hợp để nhận dạng các chữ số viết tay. Đây là một thời điểm
đột phá vì nó đặt nền tảng của tầm nhìn máy tính hiện đại sử dụng Deep Learning.
Cùng năm, Universal Approximators Theorem – Định lý xấp xỉ phổ quát (Kết quả
thiết lập mật độ của một lớp hàm được tạo theo thuật toán trong một không gian
hàm quan tâm nhất định), George Cybenko cho ra đời phiên bản đầu tiên của mình
trong bài viết có tên “Approximation by Superpositions of a Sigmoidal function”.
Ông chứng minh rằng bổ sung mạng nơ-ron với một lớp ẩn chứa số lượng nơ-ron
hữu hạn có thể gần đúng với bất kỳ hàm liên tục nào. Nó giúp cho mạng Học sâu
trở nên đáng tin cậy hơn.
• Năm 1991, vấn đề về Vanishing Gradient xuất hiện, Sepp Hochreiter xác định vấn
đề về Vanishing Gradient có thể làm cho việc học của mạng nơron sâu trở nên cực
kỳ chậm và gần như không thực tế. Vấn đề này sẽ tiếp tục gây khó khăn cho cộng
đồng học sâu trong nhiều năm tới.
• Năm 1997, Cột mốc quan trọng của LSTM, Sepp Hochreiter và Jürgen
Schmidhuber xuất bản một bài báo quan trọng về “Long Short-Term Memory”
(LSTM). Nó là một loại kiến trúc mạng nơ-ron tuần hoàn đã tiếp tục cách mạng
hóa học sâu trong nhiều thập kỷ tới. lOMoAR cPSD| 58833082 6
• Năm 2006, xuất hiện Deep Belief Network, Geoffrey Hinton, Ruslan
Salakhutdinov, Osindero và Teh xuất bản bài báo “A fast learning algorithm for
deep belief nets”, trong đó họ xếp chồng nhiều RBM lại với nhau thành từng lớp
và gọi chúng là Deep Belief Networks. Quá trình đào tạo hiệu quả hơn nhiều đối
với lượng dữ liệu lớn.
• Năm 2008, bắt đầu GPU Revolution – Cuộc cách mạng GPU, nhóm của Andrew
NG ở Stanford bắt đầu ủng hộ việc sử dụng GPU để đào tạo Mạng thần kinh sâu
nhằm tăng tốc thời gian đào tạo lên nhiều lần. Điều này có thể mang lại tính thực
tiễn trong lĩnh vực Deep Learning để đào tạo về khối lượng dữ liệu khổng lồ một cách hiệu quả.
• Năm 2009, khởi động ImageNet, tìm đủ dữ liệu được gắn nhãn luôn là một thách
thức đối với cộng đồng Học sâu. Năm 2009, Fei-Fei Li, một giáo sư tại Stanford,
khởi chạy ImageNet, một cơ sở dữ liệu gồm 14 triệu hình ảnh được dán nhãn. Nó
sẽ là tiêu chuẩn đánh giá cho các nhà nghiên cứu Deep Learning, những người sẽ
tham gia các cuộc thi ImageNet (ILSVRC) hàng năm.
• Năm 2011, Combat For Vanishing Gradient, Yoshua Bengio, Antoine Bordes,
Xavier Glorot trong bài báo của họ “Deep Sparse Rectifier Neural Networks” cho
thấy rằng chức năng kích hoạt ReLU có thể tránh được vấn đề về Vanishing
Gradient. Điều này có nghĩa là bây giờ, ngoài GPU, cộng đồng học sâu có một
công cụ khác để giải quyết các vấn đề về thời gian đào tạo dài và không thực tế của mạng nơ-ron sâu.
• Năm 2012, bùng nổ học sâu với AlexNet, một kiến trúc mạng nơ-ron phức hợp
CNN sử dụng GPU do Alex Krizhevsky thiết kế, giành chiến thắng trong cuộc thi
phân loại hình ảnh của Imagenet với độ chính xác 84%. Đó là một bước nhảy vọt
vượt bậc so với độ chính xác 75% mà các mô hình trước đó đã đạt được. Chiến
thắng này tạo ra một sự bùng nổ học tập sâu mới trên toàn cầu.
• Năm 2014, ra đời Neural Adversarial Generative (GAN), GAN được phát triển bởi
Ian Goodfellow. Nó mở ra một cơ hội ứng dụng hoàn toàn mới của học sâu trong lOMoAR cPSD| 58833082 7
thời trang, nghệ thuật, khoa học do khả năng tổng hợp dữ liệu giống như thật của nó.
• Năm 2016, Mô hình AlphaGo, mô hình Học sâu tăng cường của Deepmind đánh
bại nhà vô địch của con người trong trò chơi cờ vây phức tạp. Trò chơi phức tạp
hơn nhiều so với cờ vua, vì vậy kỳ tích này thu hút sự quan tâm của mọi người và
nâng tầm Học sâu lên một cấp độ hoàn toàn mới.
• Năm 2019, Giải thưởng Trio Win Turing, Yoshua Bengio, Geoffrey Hinton và Yann
LeCun giành được Giải thưởng Turing 2018 vì những đóng góp to lớn của họ trong
những tiến bộ trong lĩnh vực học sâu và trí tuệ nhân tạo. Đây là một thời điểm quan
trọng đối với những người đã từng làm việc về mạng nơ-ron mà toàn bộ cộng đồng
nghiên cứu Máy học đã bỏ cuộc vào những năm 1970.
• Vì vậy, đằng sau sự tiến hóa này của Deep Learning, có rất nhiều nhà nghiên cứu
học máy đã làm việc với quyết tâm cao độ ngay cả khi không ai tin rằng mạng nơron
có bất kỳ tương lai nào.
III. Một số ứng dụng
Các ví dụ về deep learning
Những mô hình của deep learning xử lý thông tin tương tự như cách bộ não con người hoạt
động. Hiện tại deep learning được áp dụng để thay thế cho nhiều nhiệm vụ mà con người
từng thực hiện. Nó được sử dụng để nhận dạng hình ảnh, nhận dạng giọng nói và xử lý
ngôn ngữ tự nhiên. Ngoài ra nó được ứng dụng để phân tích dữ liệu lớn tập trung vào các
lĩnh vực như chẩn đoán y tế, giao dịch thị trường chứng khoán, nhận dạng hình ảnh, bảo
mật mạng. Dưới đây là những lĩnh vực cụ thể mà deep learning đang được sử dụng: •
Chatbots: Mô hình deep learning được dùng cho chatbots để tương tác với khách hàng nhanh chóng, thuận tiện. •
Text generation: Deep learning được dùng để tự động tạo văn bản mới phù hợp với
chính tả, ngữ pháp và phong cách của văn bản gốc. •
Hàng không vũ trụ và quân sự: Deep learning được dùng để phát hiện các đối tượng
vệ tinh, khu vực quan trọng, khu vực an toàn và không an toàn cho quân đội. •
Tự động hóa trong công nghiệp: Deep learning mang đến sự an toàn cho người lao
động trong nhà máy, nhà kho bằng cách phát hiện kịp thời công nhân hoặc đối tượng
nào đó đến gần máy móc. •
Adding color: Khi dùng deep learning màu sắc sẽ được thêm vào ảnh hoặc video đen
trắng tỉ mỉ, thẩm mỹ và nhanh gọn. •
Y học: Những nhà khoa học đã và đang áp dụng deep learning để phát hiện các tế bào ung thư. lOMoAR cPSD| 58833082 8 •
Computer vision: Thị giác máy tính được cải thiện rõ rệt khi dùng deep learning. Mô
hình này cung cấp cho máy tính độ chính xác cao để nó phát hiện, phân loại, khôi phục hình ảnh.
CHƯƠNG 2: Nguyên lý cơ bản
I. Cách thức deep learning hoạt động
Các chương trình máy tính sử dụng deep learning cũng trải qua quá trình tương tự
như những đứa trẻ mới tập nói. Mỗi thuật toán trong hệ thống phân cấp sẽ áp dụng một
phép biến đổi phi tuyến tính cho đầu vào của nó và dùng những kiến thức mà nó học được
để tạo một mô hình thống kê làm đầu ra. Cách thức đó cứ lặp đi lặp lại liên tục cho tới khi
có được kết quả chính xác nhất.
Trở lại với ví dụ trên ta có thể thấy đối với machine learning truyền thống lập trình viên
cần cho máy tính biết cụ thể thứ mà nó cần tìm để xác định hình ảnh có chứa “chó” hay
không. Quá trình này tốn rất nhiều công sức và sự thành công của máy tính phụ thuộc phần
lớn vào lập trình viên. Thế nhưng với deep learning máy tính sẽ tự nó phân tích và tìm ra
kết quả mà không cần giám sát. Như vậy vừa tiết kiệm thời gian vừa đạt độ chính xác cao.
Sau khi gắn nhãn “chó” hoặc “không chó” cho mỗi hình ảnh thì lập trình viên sẽ cung cấp
toàn bộ số ảnh đó cho máy tính. Chương trình sẽ dùng dữ liệu nhận được để tạo bộ tính
năng cho “chó” và xây dựng mô hình dự đoán. Trong lần dự đoán đầu tiên máy tính có thể
hiểu trong bức ảnh những con vật nào có 4 chân và có đuôi đều gắn nhãn “chó”. Sau đó
mô hình dự đoán lặp đi lặp lại và tăng mức độ phức tạp lên.
Những đứa trẻ mới tập nói phải mất vài tuần mới hiểu khái niệm về “con chó” và nhận diện
được con vật này. Thế nhưng một chương trình máy tính sử dụng deep learning thì việc
phân tích, xác định chính xác hình ảnh chứa “chó” chỉ trong vòng vài giây.
Như vậy có thể thấy deep learning có thể tạo ra các mô hình dự đoán chính xác với số
lượng dữ liệu lớn có gắn nhãn hoặc không gắn, có cấu trúc hoặc không có cấu trúc. Đó
chính là một thế mạnh để deep learning ngày càng được ứng dụng trong mọi lĩnh vực của cuộc sống con người.
1. Phương pháp deep learning
Những mô hình deep learning được tạo ra bằng nhiều phương pháp khác nhau. Có thể
kể đến như Learning rate decay, Transfer learning, Training from scratch, Dropout. • Learning rate decay
Learning rate decay là một siêu tham số quan trọng nhất của quá trình huấn luyện. Đây
là một phương pháp điều chỉnh learning rate qua mỗi bước update các tham số của mô hình.
Tỷ lệ Learning rate quá cao sẽ dẫn tới quá trình huấn luyện không ổn định. Tỷ lệ Learning lOMoAR cPSD| 58833082 9
rate quá thấp lại khiến quá trình huấn luyện kéo dài và tiềm ẩn những khó khăn. • Transfer learning
Transfer learning là một kĩ thuật chuyển giao tri thức giữa các mô hình. Tức là một mô
hình có khả năng tận dụng lại những tri thức được huấn luyện trước đó để thực hiện các
tác vụ mới với khả năng phân loại cụ thể hơn. Phương pháp này sẽ yêu cầu ít dữ liệu hơn
và giảm thời gian tính toán so với những phương pháp khác. • Training from scratch
Training from scratch yêu cầu các nhà phát triển cần thu thập một lượng dữ liệu lớn có
gắn nhãn. Bên cạnh đó cần phải thiết lập và định cấu hình cho mạng để nó có thể tìm hiểu
các tính năng và mô hình. Với các ứng dụng mới hay ứng dụng có danh mục đầu ra lớn rất
thích hợp với Training from scratch. Phương pháp này chưa phổ biến bởi quá trình huấn
luyện kéo dài hơn những phương pháp khác. • Dropout
Dropout là một phương pháp loại bỏ các nút mạng một cách ngẫu nhiên trong quá trình
huấn luyện. Bằng cách thức này đã giúp cải thiện hiệu suất của mạng nơ ron khi thực hiện
các nhiệm vụ học tập có giám sát như phân loại tài liệu, nhận dạng giọng nói, tính toán…
II. Cơ sở lý thuyết
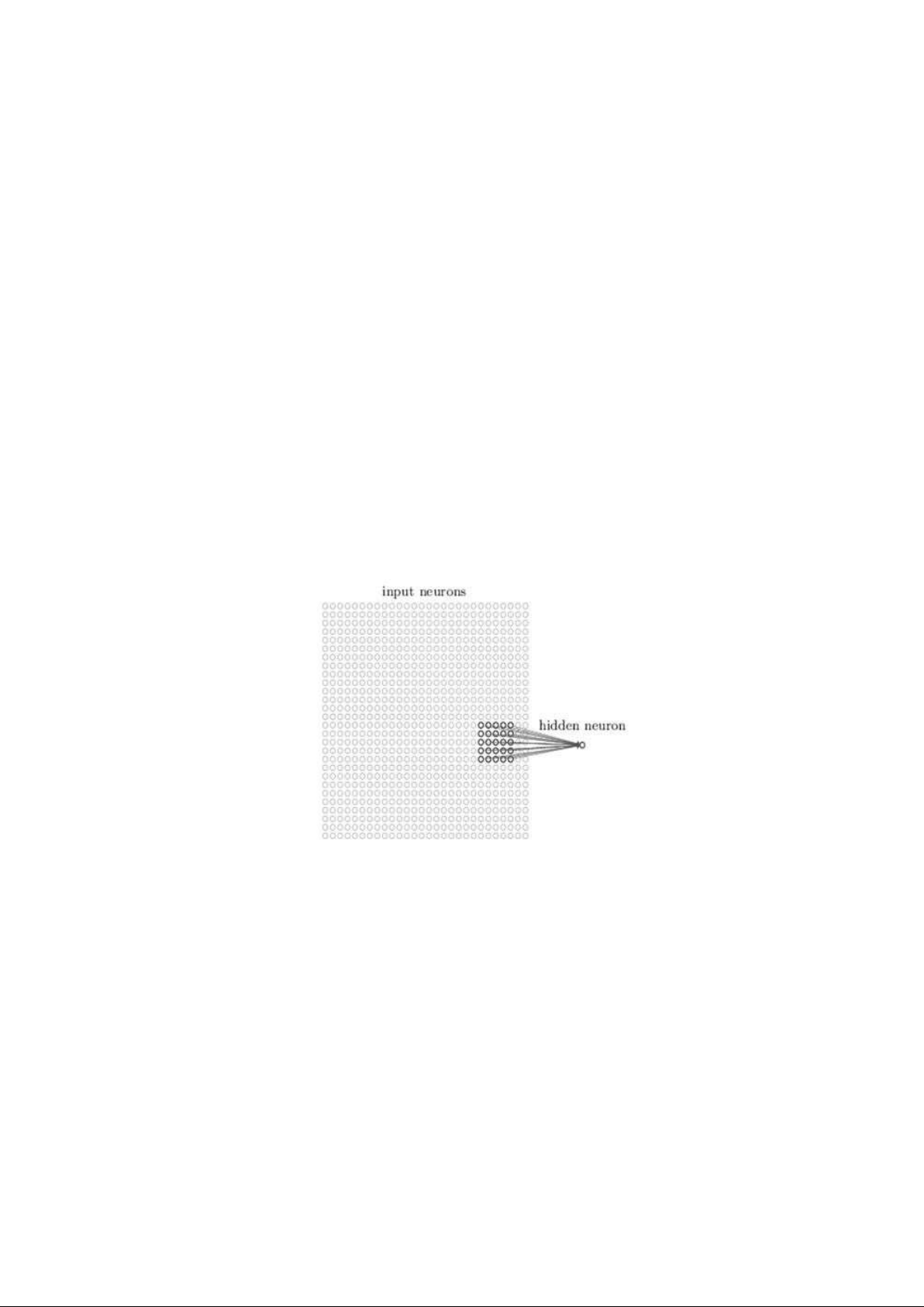
1. Khái niệm về Neural Networks (Mạng nơ-ron)
Neural Network nhân tạo được mô phỏng theo bộ não con người. Nó phân tích dữ liệu
phức tạp, hoàn thành các phép toán, tìm kiếm các mẫu và sử dụng thông tin thu thập
được để đưa ra dự đoán và phân loại. Cũng giống như bộ não con người, Neural
Network nhân tạo có một đơn vị chức năng cơ bản được gọi là nơ-ron. Những nơron
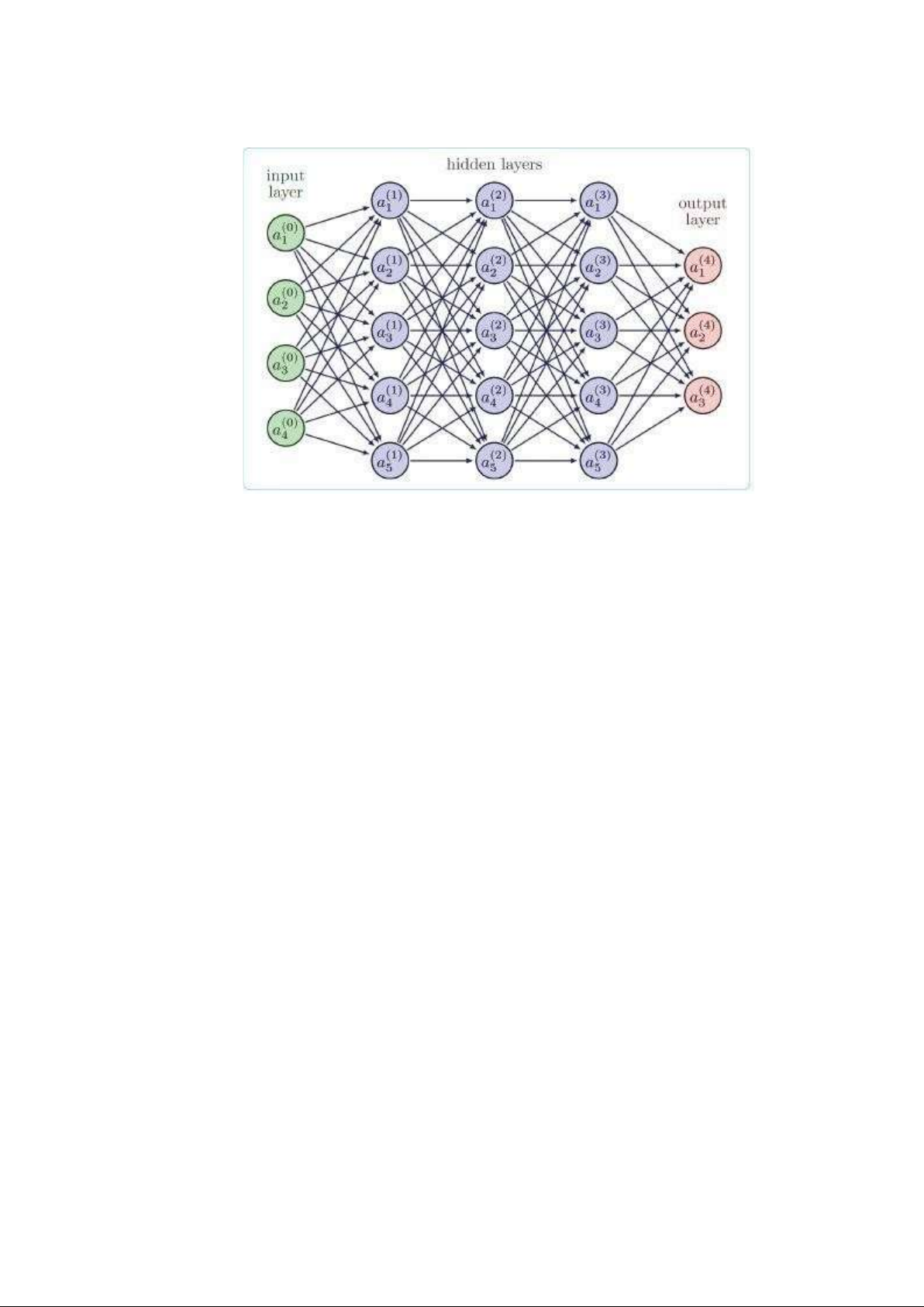
này còn được gọi là các nút, truyền thông tin trong mạng. (Hình 1) lOMoAR cPSD| 58833082 10
Một Neural Network cơ bản có các nút được kết nối với nhau trong các lớp (layer) đầu vào
(input layer), layer ẩn (hidden layer) và layer đầu ra (output layer).
Layer đầu vào xử lí và phân tích thông tin trước khi gửi nó đến layer tiếp theo.
Layer ẩn nhận dữ liệu từ layer đầu vào hoặc các layer ẩn khác. Sau đó, layer ẩn tiếp tục
xử lí và phân tích dữ liệu bằng cách áp dụng một tập hợp các phép toán để chuyển đổi và
trích xuất những tính năng có liên quan từ dữ liệu đầu vào.
Layer đầu ra cung cấp thông tin cuối cùng bằng cách sử dụng các tính năng được trích
xuất. Layer này có thể có một hoặc nhiều nút, tùy thuộc vào kiểu thu thập dữ liệu. Đối
với phân loại nhị phân, đầu ra sẽ có một nút hiển thị kết quả 1 hoặc 0.
2. Các loại mô hình Deep Learning phổ biến:
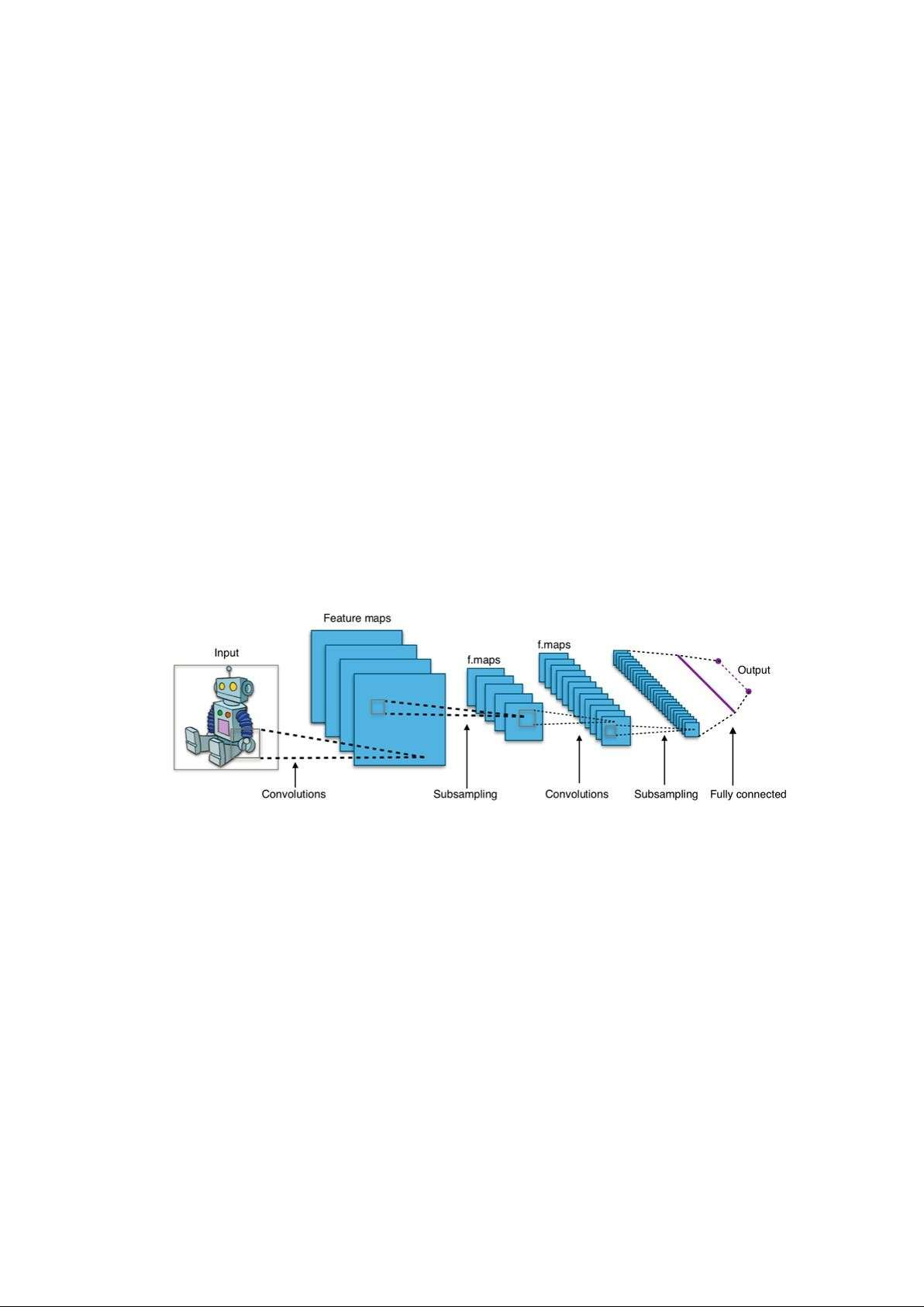
2.1. Convolutional Neural Networks (CNNs) - Mạng nơ-ron tích chập
CNN là gì? Convolutional Neural Network (CNNs – Mạng nơ-ron tích chập) là một
trong những mô hình Deep Learning tiên tiến. Nó giúp cho chúng ta xây dựng được
những hệ thống thông minh với độ chính xác cao như hiện nay.
CNN được sử dụng nhiều trong các bài toán nhận dạng các object trong ảnh. Để tìm
hiểu tại sao thuật toán này được sử dụng rộng rãi cho việc nhận dạng (detection),
chúng ta hãy cùng tìm hiểu về thuật toán này.
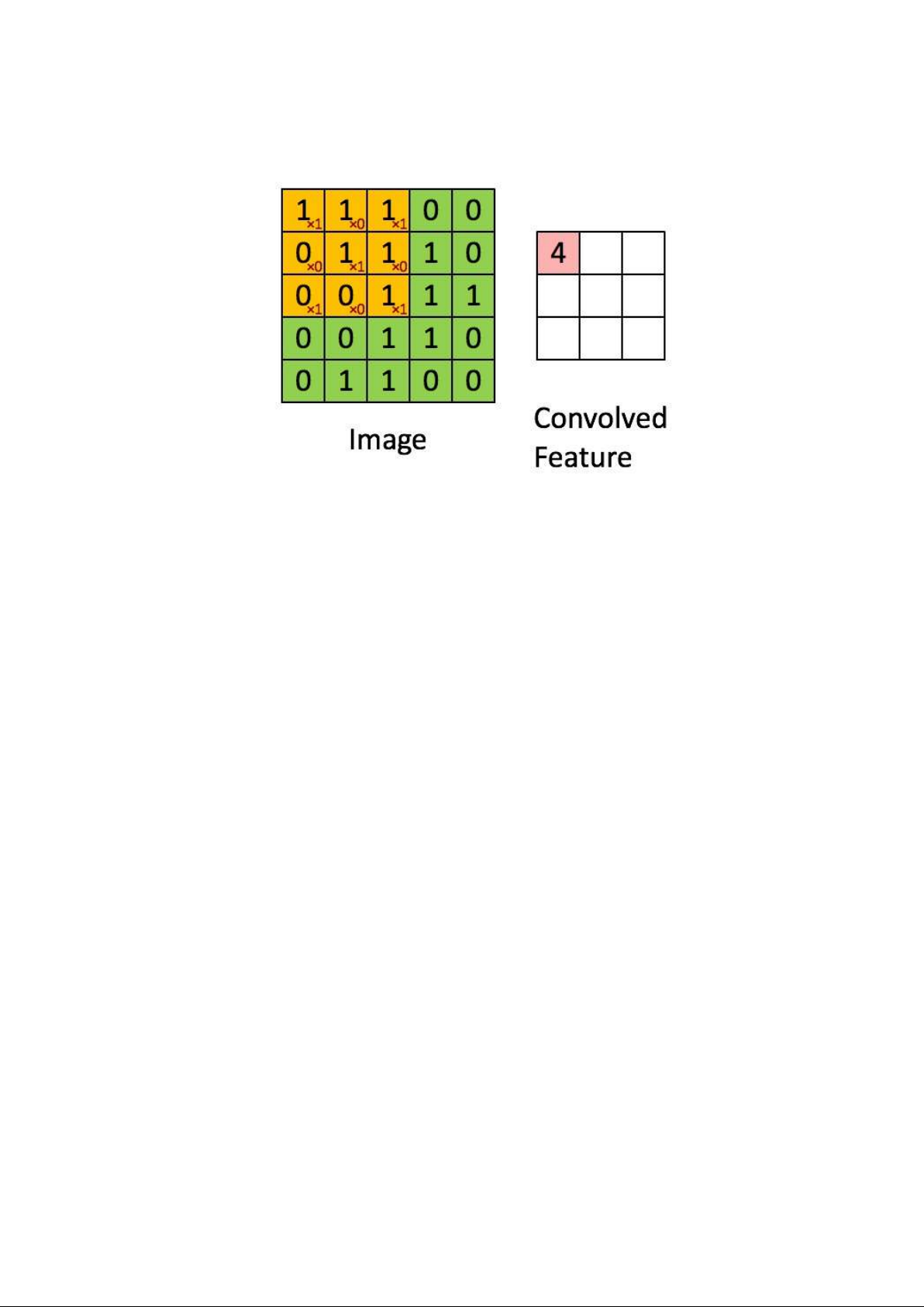
Tìm hiểu Convolutional là gì?
Là một cửa sổ trượt (Sliding Windows) trên một ma trận như mô tả hình dưới: lOMoAR cPSD| 58833082 11
Các convolutional layer có các parameter(kernel) đã được học để tự điều chỉnh lấy ra những
thông tin chính xác nhất mà không cần chọn các feature.
Trong hình ảnh ví dụ trên, ma trận bên trái là một hình ảnh trắng đen được số hóa. Ma trận
có kích thước 5×5 và mỗi điểm ảnh có giá trị 1 hoặc 0 là giao điểm của dòng và cột.
Convolution hay tích chập là nhân từng phần tử trong ma trận 3. Sliding Window hay còn
gọi là kernel, filter hoặc feature detect là một ma trận có kích thước nhỏ như trong ví dụ trên là 3×3.
Convolution hay tích chập là nhân từng phần tử bên trong ma trận 3×3 với ma trận bên
trái. Kết quả được một ma trận gọi là Convoled feature được sinh ra từ việc nhận ma trận
Filter với ma trận ảnh 5×5 bên trái. lOMoAR cPSD| 58833082 12
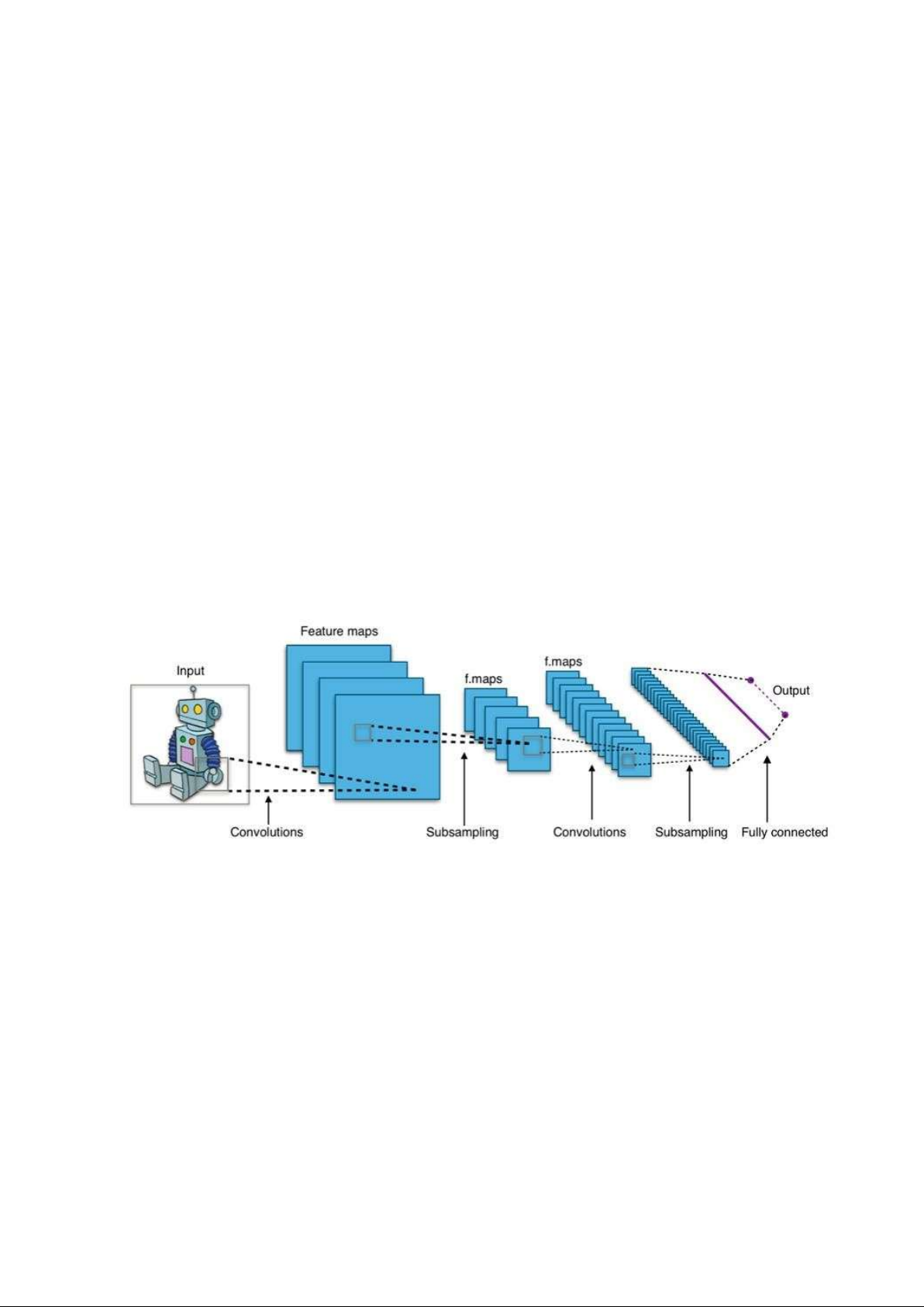
Cấu trúc mạng CNN
Mạng CNN là một tập hợp các lớp Convolution chồng lên nhau và sử dụng các hàm
nonlinear activation như ReLU và tanh để kích hoạt các trọng số trong các node. Mỗi một
lớp sau khi thông qua các hàm kích hoạt sẽ tạo ra các thông tin trừu tượng hơn cho các lớp tiếp theo.
Mỗi một lớp sau khi thông qua các hàm kích hoạt sẽ tạo ra các thông tin trừu tượng hơn
cho các lớp tiếp theo. Trong mô hình mạng truyền ngược (feedforward neural network)
thì mỗi neural đầu vào (input node) cho mỗi neural đầu ra trong các lớp tiếp theo. lOMoAR cPSD| 58833082 13
Mô hình này gọi là mạng kết nối đầy đủ (fully connected layer) hay mạng toàn vẹn
(affine layer). Còn trong mô hình CNNs thì ngược lại. Các layer liên kết được với nhau
thông qua cơ chế convolution.
Layer tiếp theo là kết quả convolution từ layer trước đó, nhờ vậy mà ta có được các kết
nối cục bộ. Như vậy mỗi neuron ở lớp kế tiếp sinh ra từ kết quả của filter áp đặt lên một
vùng ảnh cục bộ của neuron trước đó.
Mỗi một lớp được sử dụng các filter khác nhau thông thường có hàng trăm hàng nghìn
filter như vậy và kết hợp kết quả của chúng lại. Ngoài ra có một số layer khác như
pooling/subsampling layer dùng để chắt lọc lại các thông tin hữu ích hơn (loại bỏ các thông tin nhiễu).
Trong quá trình huấn luyện mạng (traning) CNN tự động học các giá trị qua các lớp filter
dựa vào cách thức mà bạn thực hiện. Ví dụ trong tác vụ phân lớp ảnh, CNNs sẽ cố gắng
tìm ra thông số tối ưu cho các filter tương ứng theo thứ tự raw pixel > edges > shapes >
facial > high-level features. Layer cuối cùng được dùng để phân lớp ảnh.
Trong mô hình CNN có 2 khía cạnh cần quan tâm là tính bất biến (Location Invariance)
và tính kết hợp (Compositionality). Với cùng một đối tượng, nếu đối tượng này được
chiếu theo các gốc độ khác nhau (translation, rotation, scaling) thì độ chính xác của thuật
toán sẽ bị ảnh hưởng đáng kể.
Pooling layer sẽ cho bạn tính bất biến đối với phép dịch chuyển (translation), phép quay
(rotation) và phép co giãn (scaling). Tính kết hợp cục bộ cho ta các cấp độ biểu diễn thông
tin từ mức độ thấp đến mức độ cao và trừu tượng hơn thông qua convolution từ các filter.
Đó là lý do tại sao CNNs cho ra mô hình với độ chính xác rất cao. Cũng giống như cách
con người nhận biết các vật thể trong tự nhiên. lOMoAR cPSD| 58833082 14
Mạng CNN sử dụng 3 ý tưởng cơ bản: •
các trường tiếp nhận cục bộ (local receptive field) • trọng số chia sẻ (shared weights)
• tổng hợp (pooling).
Trường tiếp nhận cục bộ (local receptive field)
Đầu vào của mạng CNN là một ảnh. Ví dụ như ảnh có kích thước 28×28 thì tương ứng
đầu vào là một ma trận có 28×28 và giá trị mỗi điểm ảnh là một ô trong ma trận. Trong
mô hình mạng ANN truyền thống thì chúng ta sẽ kết nối các neuron đầu vào vào tầng ảnh.
Tuy nhiên trong CNN chúng ta không làm như vậy mà chúng ta chỉ kết nối trong một vùng
nhỏ của các neuron đầu vào như một filter có kích thước 5×5 tương ứng (28- 5 + 1) 24
điểm ảnh đầu vào. Mỗi một kết nối sẽ học một trọng số và mỗi neuron ẩn sẽ học một bias.
Mỗi một vùng 5×5 đấy gọi là một trường tiếp nhận cục bộ.
Một cách tổng quan, ta có thể tóm tắt các bước tạo ra 1 hidden layer bằng các cách sau: lOMoAR cPSD| 58833082 15
B1: Tạo ra neuron ẩn đầu tiên trong lớp ẩn 1
B2: Dịch filter qua bên phải một cột sẽ tạo được neuron ẩn thứ 2.
với bài toán nhận dạng ảnh người ta thường gọi ma trận lớp đầu vào là feature map, trọng
số xác định các đặc trương là shared weight và độ lệch xác định một feature map là shared
bias. Như vậy đơn giản nhất là qua các bước trên chúng ta chỉ có 1 feature map. Tuy nhiên
trong nhận dạng ảnh chúng ta cần nhiều hơn một feature map. lOMoAR cPSD| 58833082 16
Như vậy, local receptive field thích hợp cho việc phân tách dữ liệu ảnh, giúp chọn ra những
vùng ảnh có giá trị nhất cho việc đánh giá phân lớp.
Trọng số chia sẻ (shared weight and bias)
Đầu tiên, các trọng số cho mỗi filter (kernel) phải giống nhau. Tất cả các nơ-ron trong lớp
ẩn đầu sẽ phát hiện chính xác feature tương tự chỉ ở các vị trí khác nhau trong hình ảnh đầu
vào. Chúng ta gọi việc map từ input layer sang hidden layer là một feature map. Vậy mối
quan hệ giữa số lượng Feature map với số lượng tham số là gì?
Tóm lại, một convolutional layer bao gồm các feature map khác nhau. Mỗi một feature
map giúp detect một vài feature trong bức ảnh. Lợi ích lớn nhất của trọng số chia sẻ là
giảm tối đa số lượng tham số trong mạng CNN.
Lớp tổng hợp (pooling layer)
Lớp pooling thường được sử dụng ngay sau lớp convulational để đơn giản hóa thông tin
đầu ra để giảm bớt số lượng neuron.
Thủ tục pooling phổ biến là max-pooling, thủ tục này chọn giá trị lớn nhất trong vùng đầu vào 2×2.
Tài liệu liên quan:
-

Khung câu hỏi phản biện tiểu luận CNPM - Hướng dẫn giải đáp. Môn Công nghệ phần mềm (CNPM) | Trường Đại học Giao thông Vận tải.
79 40 -

Báo cáo Phân loại Email Rác - Hệ thống và Yêu cầu Chức năng. Môn Công nghệ phần mềm (CNPM) | Trường Đại học Giao thông Vận tải.
66 33 -

Báo cáo CNPM: Thiết kế và Triển khai RESTful API với Spring Boot. Môn Công nghệ phần mềm (CNPM) | Trường Đại học Giao thông Vận tải.
104 52 -

Đặc tả yêu cầu phần mềm Cửa hàng Trang sức - CN2302C. Môn Công nghệ phần mềm (CNPM) | Trường Đại học Giao thông Vận tải.
61 31 -

Thuyết trình IT - Ảnh hưởng của Virus đến Doanh Nghiệp và Giải Pháp. Môn Công nghệ phần mềm (CNPM) | Trường Đại học Giao thông Vận tải.
58 29