CPU Scheduling | Bài tập lớn kết thúc học phần Hệ điều hành | Trường Đại học Phenikaa
Một quy trình điển hình bao gồm cả thời gian I / O và thời gian CPU. Trong một hệ thống lập trình đơn như MS-DOS, thời gian chờ đợi I / O bị lãng phí và CPU rảnh rỗi trong thời gian này. Trong nhiều hệ thống lập trình, một tiến trình có thể sử dụng CPU trong khi tiến trình khác đang đợi I / O. Điều này chỉ có thể thực hiện được khi lập lịch trình. Tài liệu giúp bạn tham khảo, ôn tập và đạt kết quả cao. Mời bạn đón xem.
Môn: Hệ điều hành (Phenikaa) 12 tài liệu
Trường: Đại học Phenika 1.3 K tài liệu
Tác giả:






Preview text:
TRƯỜNG ĐẠI HỌC PHENIKAA ---KHOA CNTT--- ⸎⸎⸎⸎⸎
BÀI TẬP LỚN KẾT THÚC HỌC PHẦN HỆ ĐIỀU HÀNH Đề số : 07 Chủ Đề: CPU Scheduling Giảng viên : NGUYỄN VĂN THỦY Sinh viên : VŨ VĂN MINH Lớp
: Hệ điều hành_1.1(14FS).2_LT Mã SV : 20010785 Mở đầu Scheduling: Introduction
Trong một hệ thống đa chương trình, thường có nhiều tiến trình cạnh tranh CPU cùng
một lúc. Khi hai hoặc nhiều quy trình đồng thời ở trạng thái sẵn sàng, phải thực hiện
lựa chọn quy trình nào sẽ chạy tiếp theo. Phần này của HĐH được gọi là Bộ lập lịch
và thuật toán được gọi là thuật toán lập lịch. Quá trình thực thi bao gồm các chu kỳ
thực thi CPU và chờ I / O. Các quá trình luân phiên giữa hai trạng thái này. Quá trình
thực thi bắt đầu với một cụm CPU, sau đó là một cụm I / O khác, tiếp theo là một cụm
I / O khác, v.v. Cuối cùng, vụ nổ CPU cuối cùng kết thúc với yêu cầu hệ thống chấm dứt thực thi.
1. Đặt vấn đề
Tại sao chúng ta cần lập lịch trình?
Một quy trình điển hình bao gồm cả thời gian I / O và thời gian CPU. Trong một hệ
thống lập trình đơn như MS-DOS, thời gian chờ đợi I / O bị lãng phí và CPU rảnh rỗi
trong thời gian này. Trong nhiều hệ thống lập trình, một tiến trình có thể sử dụng CPU
trong khi tiến trình khác đang đợi I / O. Điều này chỉ có thể thực hiện được khi lập lịch trình.
Vấn đề chúng ta gặp phải là gì?
Phân bổ CPU chưa hợp lý.
Số lượng quy trình hoàn thành việc thực thi trên một đơn vị thời gian đang còn dài
Thời gian một quy trình chờ trong hàng đợi có thể lâu có thể nhanh
HDH có thể sử dụng cơ chế ngắt để thu hồi CPU của một tiến trình đang trong trạng thái chạy
Mục tiêu của thuật toán lập lịch trình quy trình
Sử dụng CPU tối đa [Giữ CPU càng bận càng tốt] Phân bổ CPU hợp lý.
Thông lượng tối đa [Số lượng quy trình hoàn thành việc thực thi trên một đơn vị thời gian]
Thời gian quay vòng tối thiểu [Thời gian một quy trình thực hiện để kết thúc thực thi]
Thời gian chờ tối thiểu [Thời gian một quy trình chờ trong hàng đợi sẵn sàng]
Thời gian phản hồi tối thiểu [Thời gian khi một quy trình tạo ra phản hồi đầu tiên ] Thời gian đáp ứng
Tính dự đoán được [ Vòng đời, thời gian chờ đợi, thời gian đáp ứng phải ổn định,
không phụ thuộc vào tải của hệ thống ]
Tính công bằng [Các tiến trình cùng độ ưu tiên phải được đối xử như nhau ]
2. Cách giải quyết, kết quả chương trình của các giải pháp
Các giải pháp và cách giải quyết được trình bày như sau:
Lập lịch trình thuật toán:
Lên lịch phục vụ trước tiên đến trước (FIFO or FCFS): Trong thuật toán này, độ ưu tiên
phục vụ tiến trình căn cứ vào thời điểm hình thành tiến trình. Hàng đợi các tiến trình được tổ chức theo
kiểu FIFO. Mọi tiến trình đều được phục vụ theo trình tự xuất hiện cho đến khi kết thúc hoặc bị ngắt.
Ưu điểm của thuật toán này là giờ CPU không bị phân phối lại (không bị ngắt) và chi phí thực hiện thấp
nhất (vì không phải thay đổi thứ tự ưu tiên phục vụ, thứ tự ưu tiên là thứ tự của tiến trình trong hàng
đợi). Nhược điểm của thuật toán là thời gian trung bình chờ phục vụ của các tiến trình là như nhau
(không kể tiến trình ngắn hay dài), do đó dẫn tới ba điểm sau(thời gian chờ trung bình sẽ tăng vô hạn
khi hệ thống tiếp cận tới hạn khả năng phục vụ của mình, nếu độ phát tán thời gian thực hiện tiến trình
tăng thì thời gian chờ đợi trung bình cũng tăng theo, khi có tiến trình dài, ít bị ngắt thì các tiến trình
khác phải chờ đợi lâu hơn ) .
⸎Tiến trình yêu cầu CPU trước sẽ được cấp trước
⸎HDH xếp các tiến trình sẵn sàng vào hàng đợi FIFO
⸎Tiến trình mới được xếp vào cuối hàng đợi
⸎Đơn giản, đảm bảo tính công bằng
⸎Thời gian chờ đợi trung bình lớn
⸎=> Ảnh hưởng lớn tới hiệu suất chung của toàn hệ
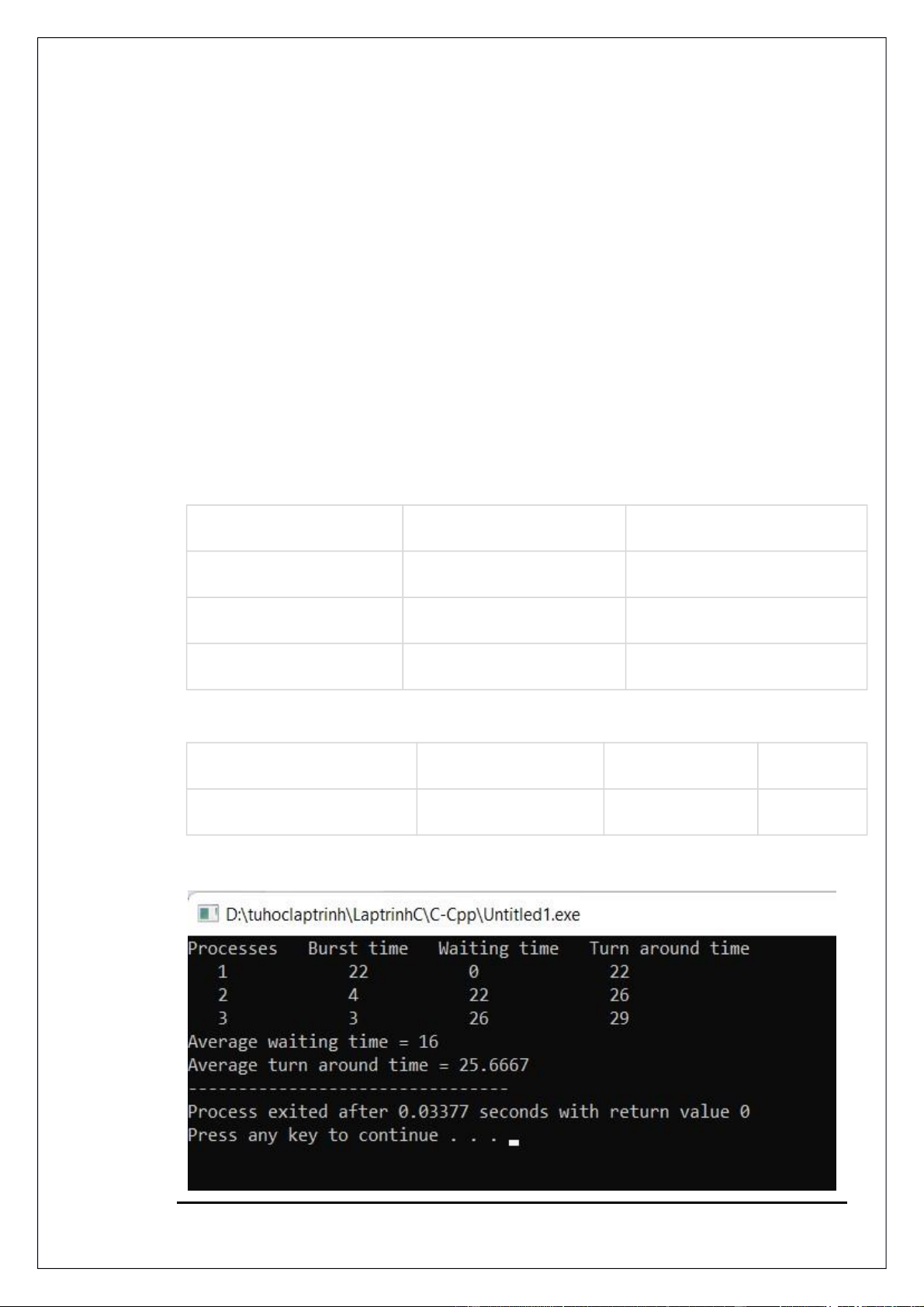
thống ⸎Thường là thuật toán điều độ không phân phối lại Ví dụ minh họa : Tiến trình Thời điểm vào Thời gian xử lí P1 0 22 P2 1 4 P3 2 3
Thứ tự cấp phát tiến trình: Tiến trình P1 P2 P3 Thời điểm 0 22 26 29
Thời gian chờ đợi trung bình: (22 + 26 ) / 3 = 16.
Lập lịch trình ngắn nhất cho công việc đầu tiên (SJF) : Quy trình có thời gian bùng nổ
ngắn nhất được lên lịch trước. Nếu hai quy trình có cùng thời gian ngắt thì FCFS được sử dụng để phá
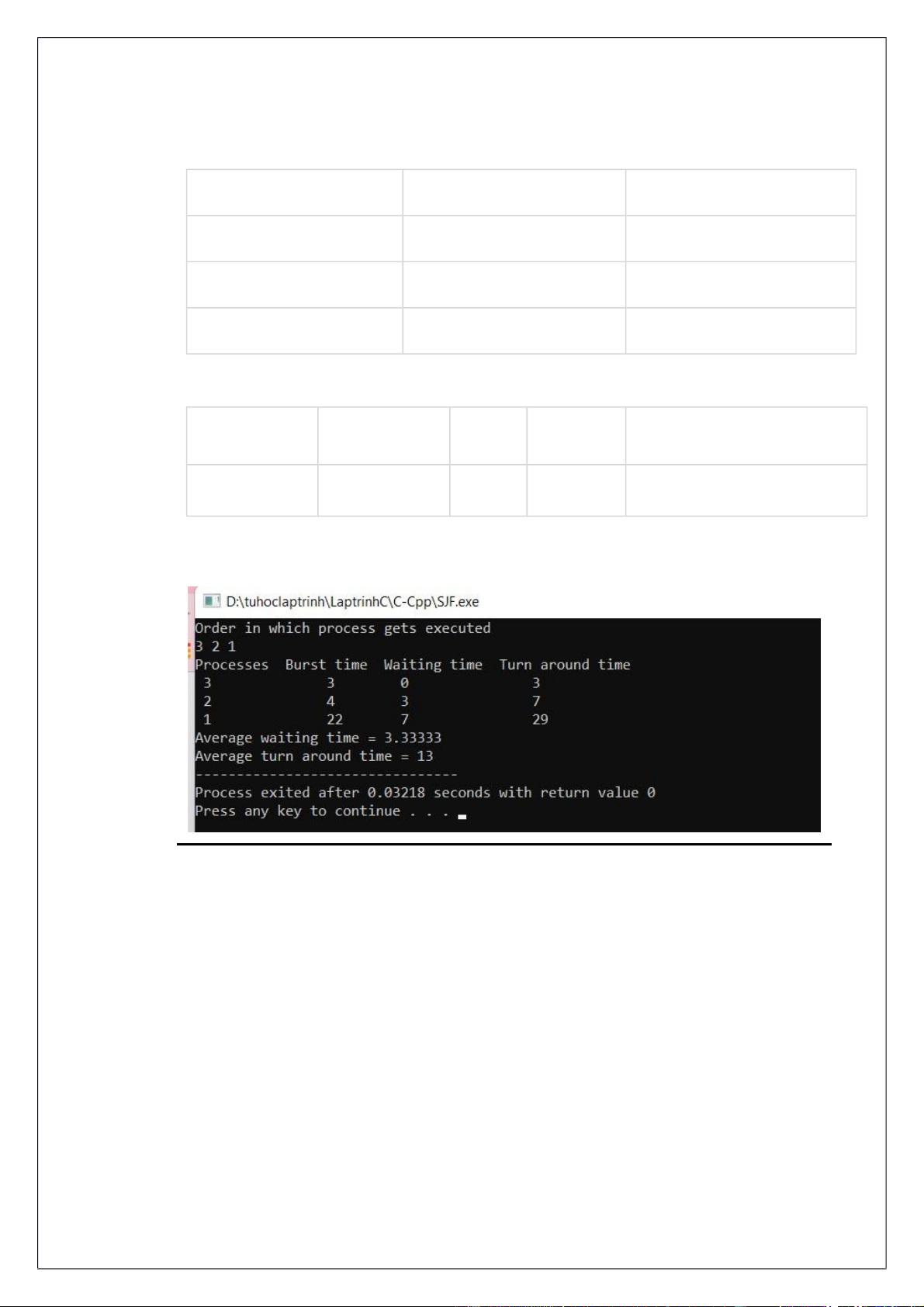
vỡ ràng buộc. Nó là một thuật toán lập lịch không ưu tiên. Ví dụ minh họa : Tiến trình Thời điểm vào Thời gian xử lí P1 0 22 P2 1 4 P3 2 3
Thứ tự cấp phát tiến trình: Tiến trình P1 P3 P2 P1 Thời điểm 0 2 5 9 29
Thời gian chờ đợi trung bình: (7 + 3 + 0 ) / 3 = 3.33. Nhận xét:
– Tối ưu thời gian chờ
– Làm sao biết được thời gian còn lại cần thực thi của một tiến trình– Không khả thi ?
– Ước lượng – sử dụng thời gian sử dụng CPU ngay trước, dùng qui luật trung bình giảm theo hàm mũ.
Thời còn lại ngắn nhất (SRTF) : việc thực hiện bất kỳ quá trình nào có thể bị dừng sau một
khoảng thời gian nhất định. Khi xuất hiện mọi quy trình, bộ lập lịch ngắn hạn lập lịch các quy trình đó
từ danh sách các quy trình có sẵn & các quy trình đang chạy có thời gian liên tục còn lại ít nhất. Sau khi
tất cả các quy trình có sẵn trong hàng đợi sẵn sàng, thì Không có quyền ưu tiên nào sẽ được thực hiện
và sau đó thuật toán sẽ hoạt động giống như lập lịch SJF. Trong Khối điều khiển quy trình, ngữ cảnh
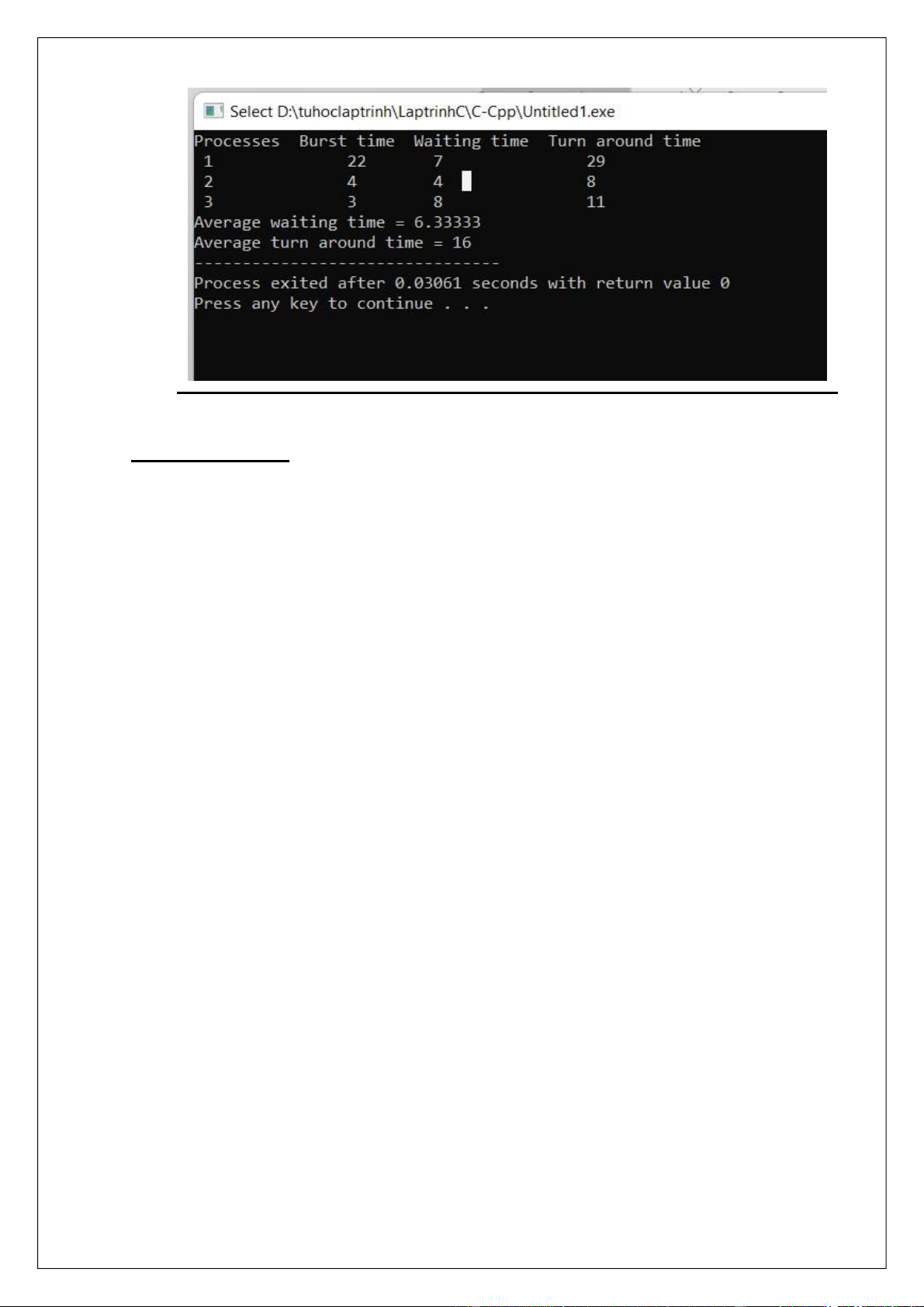
của quy trình được lưu, khi quy trình bị xóa khỏi quá trình thực thi và khi quy trình tiếp theo được lên lịch. Ví dụ minh họa : Tiến trình Thời điểm vào Thời gian xử lí P1 0 22 P2 1 4 P3 2 3
Thứ tự cấp phát tiến trình: Tiến trình P1 P2 P3 P2 P1 Thời điểm 0 1 2 5 8 29
Thời gian chờ đợi trung bình là: (7 + 0 + 3) = 3.33. Nhận xét:
SRTF là nó làm cho việc xử lý công việc nhanh hơn so với thuật toán SJF, đã đề cập rằng nó không
được tính phí trên không.
Lên lịch Round Robin (RR) : Mỗi quy trình được ấn định một thời gian cố định (Lượng tử thời
gian / Lát thời gian) theo cách tuần hoàn, nó được thiết kế đặc biệt cho hệ thống chia sẻ thời gian. Hàng
đợi sẵn sàng được coi như một hàng đợi tròn. Bộ lập lịch CPU đi xung quanh hàng đợi sẵn sàng, phân
bổ CPU cho mỗi quá trình trong một khoảng thời gian lên đến lượng tử 1 lần. Để triển khai lập lịch
Round Robin, chúng tôi giữ hàng đợi sẵn sàng như một hàng đợi FIFO của các quy trình. Các quy trình
mới được thêm vào đuôi của hàng đợi sẵn sàng. Bộ lập lịch CPU chọn quy trình đầu tiên từ hàng đợi
sẵn sàng, đặt bộ đếm thời gian để ngắt sau lượng tử 1 lần và gửi quy trình. Một trong hai điều sau đó sẽ
xảy ra. Quá trình có thể có một đợt CPU ít hơn 1 lần lượng tử. Trong trường hợp này, chính quá trình sẽ
giải phóng CPU một cách tự nguyện. Bộ lập lịch sau đó sẽ tiến hành quá trình tiếp theo trong hàng đợi
sẵn sàng. Nếu không thì, nếu đợt bùng nổ CPU của quá trình hiện đang chạy dài hơn lượng tử 1 lần, bộ
đếm thời gian sẽ tắt và gây ra gián đoạn cho hệ điều hành. Một chuyển đổi ngữ cảnh sẽ được thực thi và
quá trình này sẽ được đặt ở phần cuối của hàng đợi sẵn sàng. Sau đó, bộ lập lịch CPU sẽ chọn quá trình
tiếp theo trong hàng đợi sẵn sàng.
⸎Sửa đổi FCFS dùng cho các hệ chia sẻ thời gian
⸎Có thêm cơ chế phân phối lại bằng cách sử dụng ngắt của đồng hồ
⸎Hệ thống xác định những khoảng thời gian nhỏ gọi là lượng tử/ lát cắt thời gian t
⸎Khi CPU được giải phóng, HDH đặt thời gian của đồng hồ bằng độ dài lượng tử, lấy
tiến trình ở đầu hàng đợi và cấp CPU cho nó
⸎Tiến trình kết thúc trước khi hết thời gian t: trả quyền điều khiển cho HDH
⸎Cải thiện thời gian đáp ứng so với FIFO Ví dụ minh họa: Tiến trình thời điểm vào thời gian xử lý P1 0 22 P2 1 4 Tiến trình thời điểm vào thời gian xử lý P3 2 3 Thời gian lượng tử = 4
Thì thứ tự cấp processor cho các tiến trình lần lượt là: Tiến trình P1 P2 P3 P1 P1 P1 P1 P1 Thời điểm 0 4 8 11 15 19 23 25 29
Vậy thời gian chờ đợi trung bình sẽ là: (7+4+8)/3 = 6.33.
Như vậy RR có thời gian chờ đợi trung bình nhỏ hơn so với FIFO
3. Phần mở rộng:
Lập lịch tỷ lệ phản hồi cao nhất (HRRN) : là một thuật toán lập lịch không ưu tiên
trong hệ điều hành. Nó là một trong những thuật toán tối ưu được sử dụng để lập lịch trình. Vì
HRRN là một thuật toán lập lịch không ưu tiên nên trong trường hợp nếu có bất kỳ quá trình
nào hiện đang được thực thi với CPU và trong quá trình thực thi của nó, nếu bất kỳ quá trình
mới nào đến trong bộ nhớ với thời gian bùng nổ nhỏ hơn quá trình hiện đang chạy thì thời
gian quá trình hiện đang chạy sẽ không được đưa vào hàng đợi sẵn sàng & hoàn tất quá trình
thực thi của nó mà không bị gián đoạn. HRRN về cơ bản là sự sửa đổi của Shortest Job Next
(SJN) nhằm giảm thiểu tình trạng chết đói. Trong thuật toán lập lịch HRRN, CPU được chỉ
định cho quá trình tiếp theo có tỷ lệ phản hồi cao nhất chứ không phải cho quá trình có thời gian bùng nổ ít hơn.
Ưu điểm của Lập lịch HRNN:
⸎Thuật toán Lập lịch HRRN mang lại hiệu suất tốt hơn so với Lập lịch đầu tiên cho công việc ngắn nhất.
⸎Với thuật toán này, giảm thời gian chờ đợi cho các công việc dài hơn và nó cũng
khuyến khích các công việc ngắn hơn.
⸎Với thuật toán này, thông lượng tăng lên.
Nhược điểm của Lập kế hoạch HRNN:
⸎ Các nhược điểm của thuật toán lập lịch HRNN như sau:
⸎ Việc lập lịch HRRN trên thực tế là không thể thực hiện được vì chúng ta không thể
biết trước thời gian bùng nổ của mọi quy trình.
⸎ Trong việc lập lịch trình này, có thể xảy ra chi phí trên bộ xử lý.
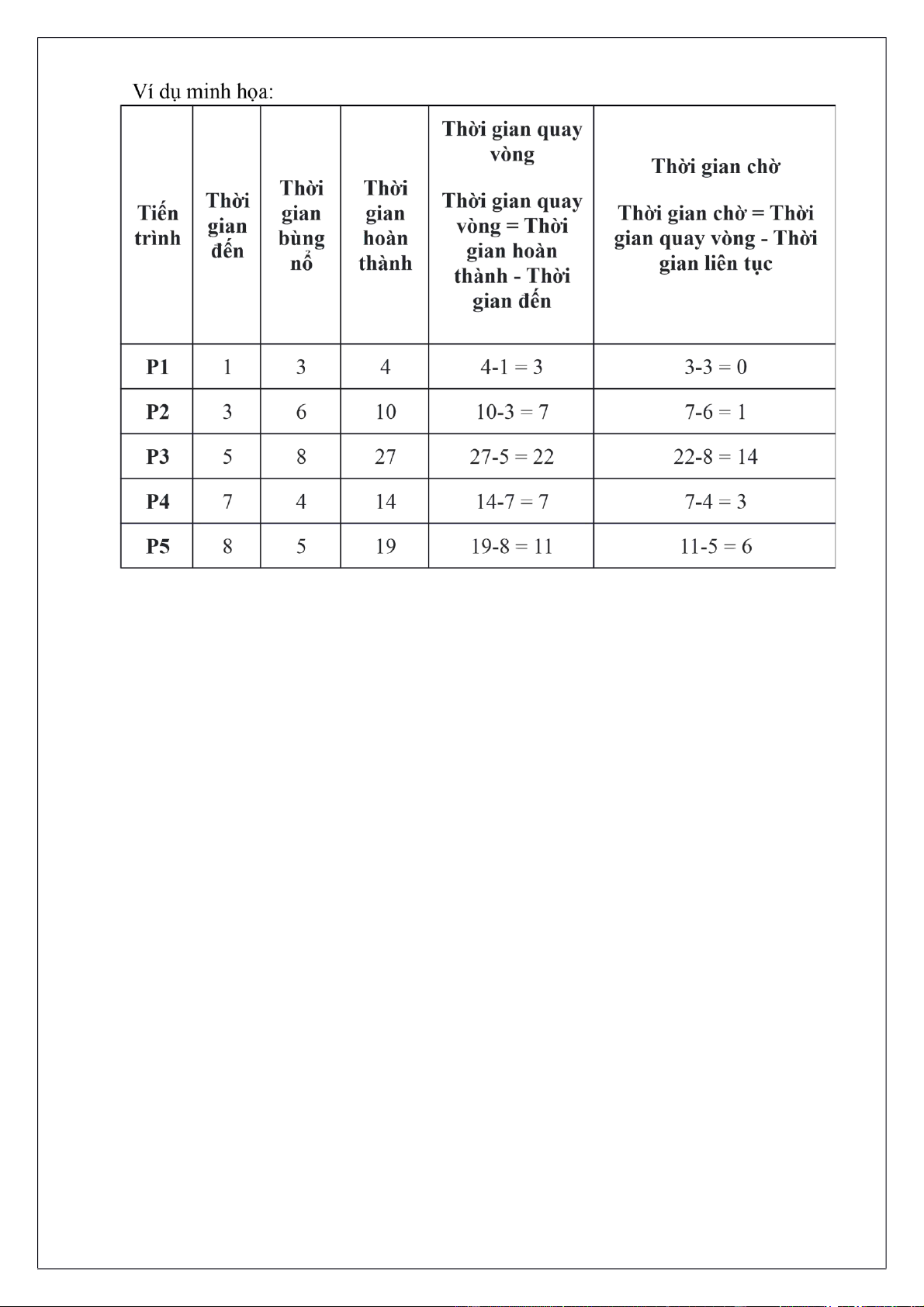
Tại thời điểm = 0, không có tiến trình nào trong hàng đợi sẵn sàng, vì vậy từ 0 đến 1 CPU
không hoạt động. Do đó 0 đến 1 được coi là thời gian nhàn rỗi của CPU.
Tại thời điểm = 1, chỉ quá trình P1 có sẵn trong hàng đợi sẵn sàng. Vì vậy, quá trình P1 thực
thi cho đến khi hoàn thành.
Sau quá trình P1, tại thời điểm = 4 chỉ có quá trình P2 đến, vì vậy quá trình P2 được thực thi
vì hệ điều hành không có bất kỳ tùy chọn nào khác.
Tại thời điểm = 10, các quá trình P3, P4 và P5 đã ở trong hàng đợi sẵn sàng. Vì vậy, để lập
lịch trình tiếp theo sau P2, chúng ta cần tính toán tỷ lệ phản hồi.
Trong bước này, chúng tôi sẽ tính toán tỷ lệ phản hồi cho P3, P4 và P5.
Code minh họa: #include struct process { char name; int at, bt, ct, wt, tt; int complete; float ntt; } p[10]; int m; void sortByArrival() { struct process temp; int i, j;
for (i = 0; i < m - 1; i++) { for (j = i + 1; j < m; j++) { if
(p[i].at > p[j].at) { temp = p[i]; p[i] = p[j]; p[j] = temp; } } } } void main() { int i, j, t, sum_bt = 0; char c; float avgwt = 0, avgtt = 0; m = 5;
int arriv[] = { 1, 3, 7, 8,5}; int burst[] = { 3, 7, 4, 2, 8};
for (i = 0, c = 'A'; i < m; i++, c++) { p[i].name = c; p[i].at = arriv[i]; p[i].bt = burst[i]; p[i].complete = 0; sum_bt += p[i].bt; } sortByArrival();
printf("\nName\tArrival Time\tBurst Time\tWaiting Time");
printf("\tTurnAround Time\t Normalized TT");
for (t = p[0].at; t < sum_bt;) { float hrr = -9999; float temp; int loc; for (i = 0; i < m; i++) {
if (p[i].at <= t && p[i].complete != 1)
{ temp = (p[i].bt + (t - p[i].at)) /
p[i].bt; if (hrr < temp) { hrr = temp; loc = i; } } } t += p[loc].bt; p[loc].wt = t - p[loc].at -
p[loc].bt; p[loc].tt = t - p[loc].at; avgtt += p[loc].tt;
p[loc].ntt = ((float)p[loc].tt / p[loc].bt); p[loc].complete = 1;
avgwt += p[loc].wt; printf("\n%c\t\t%d\t\t",
p[loc].name, p[loc].at); printf("%d\t\t%d\t\t",
p[loc].bt, p[loc].wt); printf("%d\t\t%f", p[loc].tt, p[loc].ntt);
} printf("\nThe Average waiting time:%f\n", avgwt / m);
printf("The Average Turn Around time:%f\n", avgtt / m); } Kết quả:
Tài liệu liên quan:
-

Giới thiệu về bảo mật trong hệ điều hành | Bài tập lớn học phần Hệ điều hành | Trường Đại học Phenikaa
513 257 -

Quản lí tiến trình trong Windows | Báo cáo bài tập lớn học phần Hệ điều hành | Trường Đại học Phenikaa
646 323 -

Deadlock và xử lý deadlock trong Windows | Báo cáo bài tập lớn học phần Hệ điều hành | Trường Đại học Phenikaa
558 279 -

Quản lý bộ nhớ trong Linux | Bài tập lớn học phần Hệ điều hành | Trường Đại học Phenikaa
706 353 -

Bài thực hành số 2 học phần Hệ điều hành | Trường Đại học Phenikaa
329 165