Đề cương Hệ thống phân tán GK môn Các hệ thống phân tán và ứng dụng | Trường Đại học Bách Khoa Hà Nội
Hệ thống gồm nhiều phần tử nằm trên các máy tính khác nhau (độc lập) được nối
mạng, kết nối và phối hợp bằng truyền thông điệp – Thể hiện với người dùng là một hệ
thốngHệ thống gồm nhiều phần tử nằm trên các máy tính khác nhau (độc lập) được nối mạng, kết nối và phối hợp bằng truyền thông điệp – Thể hiện với người dùng là một hệ thống. Tài liệu được sưu tầm gồm 20 trang, giúp các bạn ôn luyện và phục vụ cho việc học tập, đạt kết quả tốt. Mời các bạn đón xem!
Môn: Hệ thống phân tán và ứng dụng 17 tài liệu
Trường: Đại học Bách Khoa Hà Nội 5.6 K tài liệu
Tác giả:













Preview text:
Ề CƯƠNG HỆ THỐNG PHÂN TÁN GK
1/ Khái niệm hệ thống phân tán
- K/n: Hệ thống gồm nhiều phần tử nằm trên các máy tính khác nhau (độc lập) được nối
mạng, kết nối và phối hợp bằng truyền thông điệp – Thể hiện với người dùng là một hệ thống - Ví dụ:
+ Mạng internet: Các máy tính trong một tổ chức kết nối với nhau để chia sẻ thông tin, công
cụ cộng tác, hệ thống hoạt động và các dịch vụ máy tính khác trong một tổ chức. +
Blockchain: Công nghệ chuỗi các bản ghi trong cơ sở dữ liệu phi tập trung, tính toán phân
tán. Mỗi máy tính tham gia vào blockchain đều ngang hàng với nhau và những quyết định
trong Blockchain phải được quyết định bởi hơn 50% người tham gia nên rất an toàn. - Đặc điểm:
+ Các máy tính trong hệ phân tán không chia sẻ bộ nhớ với nhau
+ Mỗi máy tính có HĐH riêng
+ Tính phức hợp: Đa dạng về chủng loại thiết bị phần cứng và kết nối truyền thông Một số vấn đề đặc thù:
+ Tính tương tranh của hệ thống:
+ Không đồng bộ đồng hồ trên toàn hệ thống: Rất nhiều giao dịch, yêu cầu có hiệu lực
trong thời gian nhất định, nếu các máy bị lệch nhịp đồng hồ sẽ dẫn đến các giao dịch bị lỗi khi xử lý.
+ Sự cố, lỗi độc lập của các nút trên hệ thống - Yêu cầu
+ Về năng lực tính toán: Tăng đáng kể năng lực tính toán
+ Về khả năng chịu lỗi: Hệ thống phải khả dụng, vận hành được khi xả ra sự cố ở 1 số nút.
+ Thể hiện ra ngoài như một hệ thống: o Che dấu các tổ chức nội bộ, truyền thông nội bộ
(kiến trúc bên trong) với người dùng bên ngoài.
o Cung cấp giao tiếp/giao diện chung.
+ Dễ dàng mở rộng: thêm bớt máy tính vào hệ thống
+ Tính sẵn sàng cao: Một nút gặp sự cố => các nút khác sẵn sàng đảm nhiệm công việc
+ Hỗ trợ bởi nền tảng lớp giữa. - Nhược điểm:
+ Yêu cầu phần mềm phức tạp hơn.
+ Dễ xảy ra nghẽn mạng hoặc phát sinh các vấn đề khác do lỗi mạng
+ Dễ bị mất/sửa thông tin, dễ bị tấn công/đột nhập trên mạng
- Khi xây dựng hệ thống phân tán cần phải xem xét đến các vấn đề như: Băng thông, các
điểm có thể xảy ra sự cố, bảo mật và an toàn dữ liệu, đồng bộ tiến trình.
2/ Phân loại hệ thống phân tán: khái niệm
- Điện toán cụm: Hệ thống tính toán phân cụm là 1 hệ thống máy tính cục bộ bao gồm các
máy tính độc lập và một mạng liên kết các máy tính. + Yêu cầu hệ thống điện toán cụm:
o Các máy tính có cùng loại OS
o Do các máy kết nối trong mạng cục bộ -> ổn định và hiệu năng cao o Thường có
các nút chủ(master) đóng vai trò người quản lý cụm o Nút tính toán bao gồm các phần
mềm, thư viện thực thi song song với nhau o Có quan hệ chặt chẽ, trao đổi thông tin về
trạng thái, tải. + Có 2 mô hình chính:
o Các nút có vai trò như nhau (VD: Database Oracle Cluster)
o Có nút Master đóng vai trò quản lý, còn việc xử lý, thực thi ở các nút khác + Đặc
điểm: o Hiệu quả kinh tế (so với đầu tư một máy tính có cấu hình mạnh, giá thành cao thì
đầu tư nhiều máy chủ có cấu hình thấp hơn, giá thành rẻ hơn)
o Sử dụng kỹ thuật lập trình song song
o Thường đòi hỏi hệ thống đồng nhất, quản trị phức tạp hơn
- Điện toán lưới: Điện toán lưới là cơ sở hạ tầng điện toán kết hợp các tài nguyên máy tính
trải rộng trên nhiều vị trí địa lý khác nhau để đạt được mục tiêu chung. Tất cả tài nguyên
không sử dụng trên nhiều máy tính được gộp lại với nhau và cung cấp cho một tác vụ duy nhất.
+ Không yêu cầu các nút đồng nhất: Có thể khác kiến trúc, OS, khác vùng quản trị, các cơ quan tổ chức khác nhau
+ Thường bao gồm các lớp: o Lớp ứng dụng(Application): Bao gồm các ứng dụng vận
hành trong hệ thống o Thu thập (Collective): Xử lý yêu cầu truy nhập tài nguyên o
Tài nguyên (Resource): QL các tài nguyên đơn lẻ
o Kết nối (Connectivity): Bao gồm các giao thức truyền thông để hỗ trợ cho các giao
tác lưới bao trùm toàn bộ các tài nguyên
o Kết cấu (fabric): Cung cấp giao diện để truy nhập tài nguyên cục bộ tại một trang riêng
3/ Các mục tiêu thiết kế hệ thống phân tán: - G1: tài nguyên:
▪ Hỗ trợ người sử dụng truy cập, khai thác tài nguyên ở xa: Truy cập và sử dụng các tài
nguyên phần mềm, phần cứng khi ở xa.
▪ Khả năng chia sẻ tài nguyên có kiểm soát: Có thể kiểm soát được ai - nút nào có thể truy
cập vào tài nguyên hệ thống.
▪ giảm chi phí khi chia sẻ tài nguyên đắt giá: Vd như tài nguyên tính toán
▪ Tăng hiệu năng: Khai thác được các bộ xử lý ở xa phục vụ cho việc chia sẻ công việc & tính toán song song
Bảo mật hệ thống là vấn đề đặt ra khi yêu cầu về chia sẻ tài nguyên của hệ thống (Xác thực,
định danh, phân quyền) hay đó là việc đảm bảo chia sẻ phải thuận tiện nhưng vẫn phải kiểm soát được.
- G2: tính trong suốt:
+ Khái niệm: Tính trong suốt của hệ thống của hệ phân tán được hiểu là sự che giấu đi tính
phân tán của hệ thống. Người dùng có cảm giác hệ thống là duy nhất, có giao diện giống
nhau và cách thức truy cập giống nhau tại mọi nơi, mọi thời điểm. => Thân thiện với người dùng + Các kiểu trong suốt:
-) Access: trong suốt về thể hiện dữ liệu và phương thức truy nhập nghĩa là người dùng có
thể truy nhập bằng nhiều cách khác nhau nhưng thông tin và dữ liệu nhận được vẫn phải nhất quán
-) Location: Trong suốt về nơi lưu trữ thông tin, vd: ctt thì thông tin nằm ở nhiều máy chủ
khác nhau nhưng chỉ cần vào web là có thể khai thác được thông tin
-) Migration: Trong suốt về quá trình chuyển vị trí dữ liệu, nghĩa là: Khi chúng ta khai
thác thông tin thì không cần quan tâm việc dữ liệu chuyển từ các cơ sở khác nhau mà vẫn
khai thác được đúng và đủ các thông tin của hệ thống.
-) Replication: Trong suốt quá trình tạo ra bản sao dư liệu
-) Concurrency: Trong suốt về việc chia sẻ tài nguyên cho nhiều người sử dụng, nghĩa là
trong suốt về việc hệ thống xử lý việc tương tranh giữa các nút
-) Failure: Che giấtrình chuyển dữ liệu mà không ảnh hưởng đến người dùngu lỗi và phục
hồi tài nguyên, khi hệ thống bị lỗi ở một số nút thì hệ thống vẫn hoạt động bình thường mà
không ảnh hưởng đến người dùng
-) Relocation: Trong suốt về quá trình di chuyển dữ liệu
Việc luôn để mức độ trong suốt của hệ thống lên mức cao nhất chưa chắc đã tốt. Vì tính
trong suốt và hiệu năng luôn phải đánh đổi cho nhau. Cần phân tích kỹ để đảm bảo cân
bằng giữa hiệu năng và độ trong suốt.
Ví dụ: Việc lưu trữ các bản sao ở các trung tâm dữ liệu khác nhau trên khắp mọi nơi (ví dụ
CDN) cần đảm bảo tính nhất quán. Khi một trung tâm thay đổi dữ liệu, các bản sao khác
cũng phải thay đổi theo. Cần một khoảng thời gian lan truyền về sự thay đổi đó và điều
chỉnh để thích nghi với sự thay đổi. Khoảng thời gian như vậy rất khó để che giấu người
dùng vì hệ thống gồm nhiều máy và phân tán ở vị trí địa lý xa nhau. Nếu các máy phân tán
gần nhau quá thì những người dùng ở xa sẽ phải chịu hiệu năng kém.
- G3: tính mở: HTPT có thể liên quan đến rất nhiều các cấu phần vì vậy Hệ thống cần phải
cung cấp tài nguyên, dịch vụ tuân theo các nguyên tắc tiêu chuẩn, tiêu chuẩn mở. Sử
dụng các mô tả giao tiếp, giao thức và ngôn ngữ mô tả được chuẩn hóa.
=> Như vậy, các hệ thống do các nhà CC khác nhau nhưng cùng tuân theo 1 tiêu chuẩn có
thể dễ dàng trao đổi TT, mở rộng, thay thế, sửa chữa. Tính mở giúp:
-) Tăng khả năng tương tác: giữa các tbi của các nhà CC khác nhau nhưng chỉ cần tuân theo
1 tc có thể dễ dàng trao đổi TT với nhau
-) Tăng khả năng chuyển đổi: Di trú tài nguyên từ nút này sang nút khác
-) Tăng khả năng mở rộng
- G4: khả năng mở rộng: Mục tiêu này yc hệ thống phân tán phải có khả năng Mở rộng
theo các chiều khác nhau có thể tăng - giảm theo các nhu cầu khác nhau:
-) Về kích cỡ/quy mô: Tăng số lg ứng dụng, quy mô xử lý của ht
-) Về địa lý: Cung cấp cho nhiều khu vực, quốc gia trên TG
-) Về số lượng tổ chức: HTPT có thể được quản lý bởi nhiều tổ chức khác nhau cùng
liên minh tham gia, phân vùng chính sách khác nhau 4/ Các mô hình trong hệ phân tán
- Mô hình vật lý: khái niệm
+) Khi mô tả một mô hình nào đó dưới khía cạnh vật lý, nghĩa là ta phải vẽ các mô hình để
mô tả về phần cứng và kết nối của các phần cứng và thiết bị
+) Về mô hình cơ bản: Thì ta cần phải mô tả các nút, phương thức kết nối giữa các nút này:
Kết nối mạng ntn, truyền thông điệp ntn
- Mô hình kiến trúc: thực thể, truyền thông, nhiệm vụ vai trò * Thực thể
Các thực thể trao đổi truyền thông:
+) Từ góc nhìn hệ thống:
Thông thường là các tiến trình: Biểu diễn phân tán bằng các tiến trình và truyền thông
giữa chúng, tuy nhiên trong trường hợp đơn giản vd như cá sensor: không có hệ điều hành
-> không có tiến trình thì ở đây thực thể sẽ là nút +) Từ góc nhìn phát triển, lập trình: Cần mô tả mức cao
-) Đối tượng: Sd trong tiếp cận lập trình hướng đối tượng cũng như phân tích thiết kế
hướng đối tượng. Khi đó, hệ phân tán tương đương với việc xem xét các đối tượng phân tán
và gọi các đối tượng từ xa.
-) Cấu phần - Component: Gồm tập các đối tượng, cung cấp chức năng thực thi tác vụ
nào đó khi đó gọi là hướng vấn đề. Componnent còn bao gồm mô tả sự cần hiện diện các
cấu phần khác để thực thi được tác vụ.
-) Service, web service: Điểm tương đồng object hay component: cung cấp chức năng
để thực thi tác vụ nào đó, điểm khác biệt với Object – Component: tồn tại độc lập và không
phụ thuộc vào cài đặt.
* Truyền thông:
Trong hệ phân tán ta có thể nói đến nhiều phương thức truyền thông khác nhau:
+) Ở mức thấp(Các tiến trình với nhau): Truyền thông liên tiến trình – Interprocess communication
-) Phương thức mức tương đối thấp – trao đổi giữa các tiến trình trong hệ phân tán
-) Thường dùng truyền thông điệp giữa các tiến trình – message passing
-) Do quan tâm đến 2 tiến trình gọi tới nhau như thế nào nên có thể sử dụng phương thức
truy cập API trực tiếp: socket -) Truyền thông multicast
+) Ở mức gần với người lập trình hơn(Đối tượng, service, component): Gọi từ xa – remote
revocation: Là phương thức được dùng nhiều nhất trong hệ phân tán
-) Trao đổi giữa 2 thực thể trong hệ phân tán
-) Gọi, thực thi tác vụ từ xa +) Cơ chế:
-) Request – reply: giải pháp phổ biến và dùng nhiều trong hình thức truyền thông điệp,
vd như mô hình client – server
-) RPC – remote procedure call: Hay dùng trong mô hình tương tác đối tượng phân
tán: cho phép gọi hàm của tiến trình ở xa giống như gọi hàm cục bộ, che dấu chi tiết mã
hóa tham số và đóng gói thông điệp gửi - nhận.
+) Truyền thông gián tiếp – indirect communication: Gọi thông qua 1 ứng dụng lớp giữa,
bên gửi và bên nhận không nhất thiết phải kết nối được với nhau, không phụ thuộc ở mức độ cao:
-) Bên gửi không biết bên nhận
-) Bên gửi và nhận không tồn tại song song
-) Một số cơ chế truyền thông gián tiếp: Group communication Pub – sub Queue Distributed share memory ⇨
Phải mô tả được giao tiếp giữa các nút như thế nào? Tổng hợp
thực thể, truyền thông:
*Nhiệm vụ - vai trò:
Các tiến trình, các đối tượng phân tán tương tác để thực hiện được các tác vụ => mỗi
nút có nhiệm vụ, vai trò khác nhau. Ở đây xét 2 mô hình:
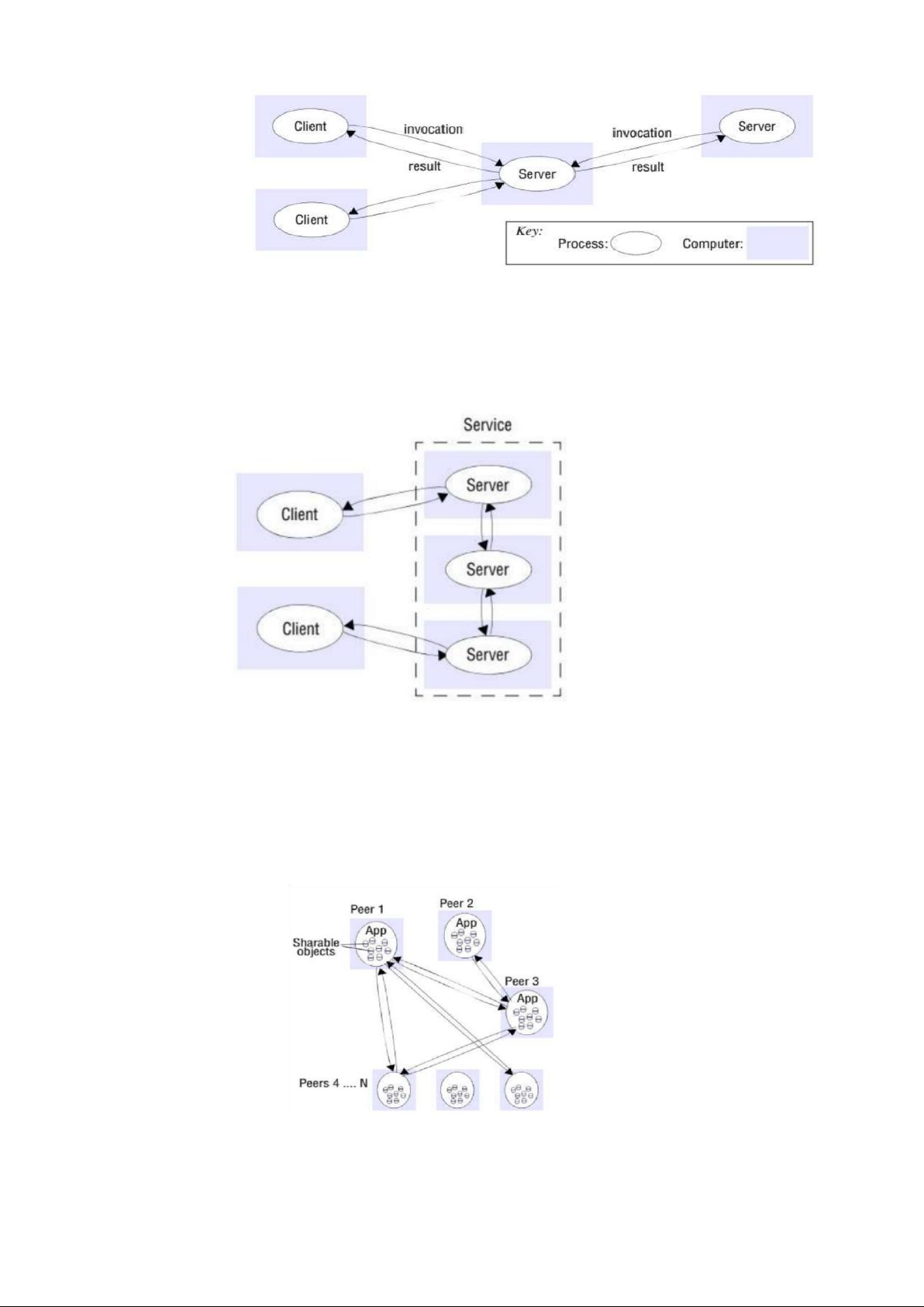
Client – Server: là kiến trúc có từ khá sớm trong hệ phân tán, vẫn đc sử dụng phổ biến
+) server: phía cung cấp tài nguyên, dịch vụ/chức năng
+) client gọi tới server (thường là trên máy ở xa) để truy cập tài nguyên do server quản lý
+) server - đến lượt mình có thể là client - gọi tới server khác để xử lý yêu cầu ví dụ:
• web browser - gọi tới web server
• web server - là client của file server (lưu các web page) • browser, web
server là client của DNS
Peer to peer: Nhiều tiến trình trên các máy
Truyền tin phụ thuộc yc mỗi nút
Dữ liệu: CSDL lớn, nhiều đối tượng được chia sẻ. Mỗi nút - chỉ lưu 1 phần
Tuy nhiên phức tạp hơn mô hình client-server, Lý do: * Vị trí
quan tâm khía cạnh về vị trí phân bố của các nút trong hệ thống
• Ánh xạ với mô hình vật lý: các nút/máy tính/ kết nối với nhau
qua hạ tầng truyền thông đa dạng
• Ảnh hưởng đến: hiệu năng, chịu lỗi, bảo mật, ... • Một số tiếp
cận thiết kế liên quan:
o Mapping service to multiple server: dịch vụ, tài nguyên có thể được phân
bố trên nhiều máy/tiến trình. các đối tượng có thể phân chia nằm trên
nhiều nút hoặc có thể duplicate-các bản sao đối tượng
o Cache: dữ liệu tạm thời được lưu gần client. Cơ chế cơ bản: lần đầu truy
cập object => object được lưu vào cache. khi yc truy cập lần tiếp =>
cache service kiểm tra => object được trả lại từ cache
o Mobile code: mã lệnh thực thi trên các thiết bị đầu cuối phân tán o
Mobile agent: mã lệnh và dữ liệu có thể di trú từ nút này tới nút khác
- Các tiếp cận thiết kế: phân lớp phân tầng, thin/thick client, proxy *
Phân lớp - Layering •
HT phức tạp => phân chia thành nhiều lớp •
Phân chia các dịch vụ thành các lớp dịch vụ ~ software abstraction •
Giao tiếp các tầng: provider & consumer •
Mỗi dịch vụ được cung cấp bởi nhiều tiến trình chạy trên các nút khác nhau •
Tương tác với nhau, và với client để thực hiện được chức năng VD: các lớp hay dùng:
SW-Middleware-OS-HW: +) Platform - nền tảng: -
Bao gồm các HW, SW ở lớp thấp -
Nhiệm vụ cung cấp dịch vụ cho các lớp ở trên => giúp các lớp ở trên độc lập với phần cứng +) Middleware - lớp giữa: -
Các lớp trung gian, che giấu sự phức tạp, cung cấp các giao diện lập trình tiêu chuẩn
để lớp trên khai thác dễ dàng hơn, -
Thường cung cấp các chức năng truyền tin, chia sẻ tài nguyên, chuyển đổi định dạng -
Có thể hoạt động như nhiều tiến trình trên nhiều nút/máy Network Time service
* Phân tầng - Tier architecture:
+) Phân tầng - bổ sung cho kiến trúc phân lớp
+) Phân lớp - quan tâm đến tổ chức các chức năng thành các lớp - trừu tượng hóa
+) Phân tầng - quan tâm đến việc đặt thực thi các chức năng trên các máy chủ nào là phù hợp * Thin client:
+) Một xu hướng trong tính toán phân tán: chuyển các tính toán phức tạp khỏi các thiết
bị đầu cuối, đặc biệt trong cloud computing => sử dụng thin client
+) thin client: có thể xem như ứng dụng đầu cuối cung cấp giao diện hiển thị và tương
tác, trong khi thực hiện tính toán phần lớn trên máy ở xa.
+) Khi thiết kế, cần xác định đặt những chức năng nào ở client (đơn giản/phức tạp,
ít/nhiều) VD: react của fb
+) Ưu điểm: Giúp tiết kiệm tài nguyên trên các thiết bị cá nhân của người dùng.
+) Nhược điểm: Yêu cầu kết nối mạng ổn định. * Thick client
+) Thực hiện phần lớn xử lý và tính toán trên máy tính cá nhân của người dùng (ngược lại với thin client).
+) Ưu điểm: Cài đặt độc lập, không phụ thuộc máy chủ và không phụ thuộc kết nối mạng.
+) Nhược điểm: Yêu cầu cấu hình phần cứng mạnh mẽ. * Proxy:
+) Cơ chế đại diện => cung cấp khả năng trong suốt về vị trí thông qua cơ chế như
remote procedure call, remote revocation. khi đó, client tương tác vs proxy, proxy tương tác vs server
+) Đóng vai trò trung gian giữa client và server chính.
+) Duy trì quyền ẩn danh của client hoặc tăng tốc độ truy cập vào tài nguyên từ server.
+) Lọc yêu cầu và phản hồi trước khi chuyển tiếp đến server.
+) Có thể cung cấp các chức năng khác như kiểm soát truy cập, cache (lưu trữ dự phòng)
- Kiến trúc cơ bản: mô hình lỗi, mô hình an ninh bảo mật * Mô hình lỗi: +) Lỗi: Failure model
Lỗi có thể xảy ra với nút (tiến trình) hoặc truyền thông +) Lỗi bỏ sót (omission):
Tiến trình gặp sự cố
-) Khi tiến trình không tiếp tục thực thi các lệnh tiếp theo - crash -) Phát
hiện tiến trình gặp sự cố => thường sử dụng probe và time out Kênh
truyền thông gặp sự cố:
-) Quá trình truyền phổ biến:
• Tiến trình gửi => gửi tới out buffer
• HĐH bên gửi: gửi qua mạng tới in buffer
• Tiến trình nhận: đọc từ in buffer
-) Sự cố: khi thông điệp không gửi được từ out buffer (bên gửi) tới in buffer (bên nhận)
+) Lỗi bất kỳ (arbitrary)
-) Có thể xảy ra bất kỳ loại lỗi nào, vd sai lệch dữ liệu
-) Với tiến trình: vd bỏ qua một số bước xử lý
-) Với truyền thông: thông điệp bị lặp
+) Lỗi thời gian/đồng hồ - Timing failures
-) Với hệ đồng bộ: có thể xảy ra lỗi về thời gian như
-) Sai lệch thời gian đồng hồ của nút quá ngưỡng
-) Thời gian xử lý yêu cầu của tiến trình quá ngưỡng
-) Thời gian truyền tin quá ngưỡng
* Mô hình an ninh - security model
+) Hệ phân tán đc xây dựng chủ yếu cho bài toán chia sẻ tài nguyên
+) Đảm bảo an ninh cho hệ phân tán liên quan đến
-) an ninh tiến trình thực thi -) an ninh kênh truyền
-) bảo vệ tài nguyên chống truy cập bất hợp pháp
+) Bảo vệ đối tượng/tài nguyên
-) đối tượng đc sử dụng bởi các người dùng khác nhau, thực hiện tác vụ khác nhau
-) kiểm soát truy cập =>dùng quyền truy cập access right
-) "người" được truy cập => principal
+) Bảo vệ tiến trình & Bảo vệ kênh truyền mô hình: xuất hiện bên thứ 3 - enemy +) Nguy cơ -) nghe trộm -) giả mạo thông điệp
+) Một số tiếp cận giải pháp -) mật mã -) mã hóa kênh
-) xác thực: server, client 5/ Truyền thông
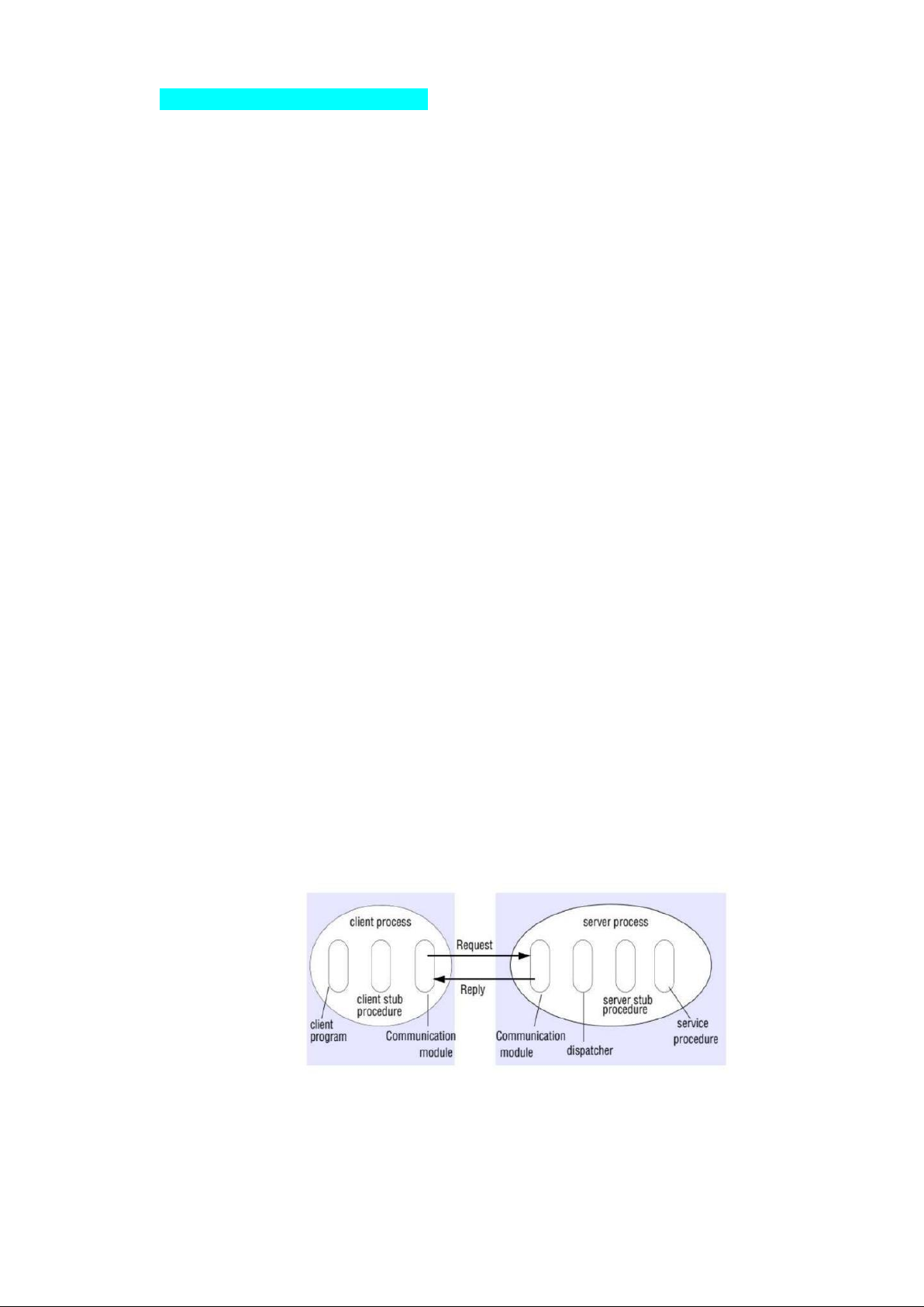
- Truyền thông trực tiếp – gọi từ xa: RPC +) Nguyên lý gọi RPC
-) che dấu quá trình thực hiện thủ tục trên tiến trình khác, truyền dữ liệu
-) cài đặt trong suốt về vị trí - location transparency
-) Tiến trình gọi: sử dụng cấu phần stub
-) Tiến trình thực thi: sử dụng cấu phần skeleton +) Thực hiện
-) Một chương trình (máy chủ) sẽ quản lý danh mục các dịch vụ
-) mỗi máy chủ & dịch vụ (hàm RPC) được gán tên, định danh, tên thủ tục, tham số...
-) Tiến trình máy client gọi thủ tục => stub -) stub đóng gói và gửi -) Skeleton mở
-) thực hiện thủ tục trên máy chủ => trả kết quả về
+) Các bước thực hiện
1. Thủ tục client gọi stub như LPC
2. Stub tạo thông điệp và gọi HĐH
3. HĐH client gửi thông điệp tới HĐH server
4. HĐH server chuyển thông điệp tới stub
5. Sub/Skeleton mở thông điệp, chuyển tới tiến trình
6. Tiến trình server thực thi, trả lại kết quả cho stub
7. Stub ở server đóng gói thông điệp kết quả => HĐH
8. HĐH server gửi tới HĐH client
9. HĐH client chuyển kết quả tới stub
10.Stub mở gói trả lại kết quả cho tiến trình client +) Các thành phần cài đặt: +) Truyền tham số
-) Một trong các vấn đề - tham số và biểu diễn tham số
-) Trong LPC: tham số có thể truyền theo giá trị, theo tham chiếu, theo con trỏ
-) truyền con trỏ: không thích hợp với gọi từ xa RPC
-) truyền tham chiếu: có thể thực hiện bằng cách tạo biến tham chiếu ở skeleton và thủ
tục server sử dụng biến tham chiếu này
-) truyền giá trị: để ý cách biểu diễn nội tại trong các BXL khác nhau (vd little endian ở
intel >< big endian ở sparc)
+) Cách gọi: đồng bộ hay dị bộ
- Truyền thông gián tiếp: Pub-sub, hàng đợi queue
+) Giữa sender và receiver không trao đổi trực tiếp => uncoupling - không phụ thuộc +)
Không phụ thuộc về không gian Space uncoupling
-) sender không cần biết định danh, vị trí của receiver và ngược lại
-) lợi ích: cho phép hệ thống dễ dàng thay đổi (vd thêm bớt thành viên) +)
Không phụ thuộc về thời gian Time uncoupling
-) độc lập về thời gian tồn tại: sender và receiver không bắt buộc cùng tồn tại trong khi thực hiện truyền thông
-) lợi ích: cho phép tạo, kết thúc tiến trình xử lý linh động (vd đăng ký học)
* Công bố & đăng ký: Pub-sub:
+) Pub-Sub: Publish-Subscribe ~ Distributed event-based systems
+) Có thể nói là mô hình được dùng phổ biến nhất trong truyền thông gián tiếp
-) trong nhiều lĩnh vực, nhất là các lĩnh vực liên quan đến phân phối sự kiện trong hệ
thống lớn: HT ngân hàng tài chính, Cung cấp dữ liệu thời gian thực, Phối hợp công việc, Theo dõi – Mornitoring
+) Đặc điểm của hệ pub-sub
-) Không đồng nhất: các cấu phần khác nhau, kh đc thiết kế tích hợp với nhau
-) Dị bộ: sự kiện và thông báo do publisher sinh ra được gửi tới các subscriber đăng ký sự kiện này asynch
+) Mô hình các hàm chức năng o publish(event) o subscribe(filter) o unsubscribe(filter) o notify(event)
Subscriber: đăng ký sự kiện dựa vào bộ lọc (filter), o channel-based: sự kiện được công
bố trên một kênh nào đó (named channel) o topic-based/subject-based: sự kiện có
các thuộc tính, trong đó có topic. Topic có thể được thiết kế phân cấp
o content-based: có thể lọc theo giá trị nhiều thuộc tính o type-
based: với đối tượng - có thuộc tính type +) Cài đặt
* Hàng đợi thông điệp - Message Queue
● Là mô hình rất phổ biến. MOM - Message Oriented Middleware
● Pub-sub: mô hình truyền thông 1-n
● Queue: truyền thông 1-1, giúp cài đặt space và time uncoupling ● Nguyên tắc vận hành
- provider: gửi dữ liệu-thông điệp tới queue
- consumer: tiếp nhận thông điệp từ queue (và xử lý)
- Thứ tự nhận/deliver thông điệp trong queue: FIFO và priority - Thông điệp thường có:
o header: các thông tin như source, dest, priority, ... o body: dữ liệu, chuỗi byte hoặc
khổ mẫu thống nhất (external representation) 6/ Đặt tên
- Đặt tên phẳng: cơ chế DHT
● Tên phẳng: phi cấu trúc, chỉ là chuỗi bit (không chứa thông tin nào hỗ trợ cho việc
xác định điểm truy cập)
● Phù hợp xử lý ở mức thấp hơn: chương trình, hệ thống
● Để xác định điểm truy cập, có thể sử dụng các kỹ thuật: o Giải pháp đơn giản -
quảng bá, nhóm o Dựa trên nguồn gốc - home based o Bảng băm ● Quảng bá, nhóm
- Gửi định danh cần tìm tới tất cả các nút (hoặc nút thành viên nhóm)
- Nút có định danh cần tìm - trả lời thông tin điểm truy cập
- đơn giản nhưng yc tất cả các nút lắng nghe
● Sử dụng nguồn gốc (home based)
- mỗi thực thể có một vị trí gốc - chứa địa chỉ hiện tại của nó
- địa chỉ của vị trí gốc - đăng ký với dịch vụ tên
* Bảng băm phân tán - DHT ● Giới thiệu -
Được sử dụng trong các hệ phân tán ngang hàng (như Napster, Freenet) -
Tổ chức tương tự bảng băm thông thường, nhưng được lưu trữ phân tán trên
nhiều nút. Do đó khi có cập nhật/thay đổi (vd các bản ghi, các nút quản lý bảng băm)
=> chỉ ảnh hưởng một số nút -
Cung cấp chức năng tìm kiếm bản ghi trong hệ phân tán -
Bản ghi: là cặp {khóa, giá trị} - {key,value} -
Chức năng tìm kiếm chính xác: theo khóa /key
● Các thành phần chính
1. Không gian giá trị khóa k, ví dụ các chuỗi 160bit khi tính khóa k bằng SHA1
2. Cách phân chia không gian khóa cho từng nút - hoạch định mỗi nút lưu phần không gian khóa nào
3. Mạng overlay: kết nối các nút, cho phép tìm ra nút nào đang quản lý khóa k cho trước
● Thực hiện lưu trữ put(key, value)
- (key,val) gửi tới nút bất kỳ
- Từ đó được truyền qua mạng overlay tới nút cuối cùng chịu trách nhiệm lưu
(dựa trên cách phân chia không gian khóa) - nút lưu lại
● Thực hiện tìm kiếm get(key)
- giá trị tìm kiếm key gửi tới nút bất kỳ
- Từ đó được truyền qua mạng overlay tới nút cuối cùng lưu key này (dựa trên cách phân chia không gian khóa)
- kết quả được trả lại cho client tìm kiếm ● Cách phân chia không gian khóa - Kỹ thuật consistent hash:
+ sử dụng hàm khoảng cách giữa 2 khóa 𝛿(𝑘1, 𝑘2)
+ mỗi nút lưu khóa: được gán định danh ID = giá trị khóa nào đó - kx
+ nút với 𝐼𝐷 = 𝑘𝑋 có nhiệm vụ lưu/quản lý các khóa ki có khoảng cách theo hàm
𝛿 tới 𝑘𝑋 là gần nhất (so với các nút ID khác)
- Ưu điểm: khi thêm, bớt nút vào mạng => chỉ làm thay đổi tập các khóa lưu trữ ở các
nút liền kề (Id), nút khác không ảnh hưởng
+ Một node ra nhập (join) hoặc rời bỏ (leave) hệ thống được quản lý như thế nào? (Cơ chế quản lý)
Tham gia- Node Join: 4 bước o Step 1: liên lạc với một node tồn tại trong DHT. o Step
2: xác định khoảng địa chỉ mà nó quản lý. o Step 3: cập nhật lại thông tin phục vụ cho
việc tìm kiếm. o Step 4: chuyển tất cả các cặp (Key, Value) thuộc quyền quản lý từ node trước về nó.
Rời bỏ-Node leave o Step 1: chuyển các cặp (Key, Value) của nó
về node trước o Step 2: Cập nhật lại các thông tin phục vụ cho việc tìm kiếm
* Giao thức Chord
• Không gian khoá: m bit => có 2^m khoá, hình dung là các điểm trên đường tròn.
• Khoảng cách 2 khoá: số điểm từ k1 đến k2 theo chiều kim đồng hồ.
• Nút: có ID ~ 1 giá trị khoá. Nút quản lý các khoá gần nó nhất.
• Với khoá k, hàm successor(k) trả lại số ID nút quản lý khoá k. * Bảng định tuyến
(finger table):
• Yêu cầu tìm khoá k gửi đến nút N.
• N tìm trong finger table dòng có giá trị khoá gần với k nhất => chuyển yêu cầu đến nút successor(k).
• Nếu không tìm thấy => khoá k được quản lý bởi nút N.
• Cách chia số dòng: thường lấy log(n).
- Đặt tên phân cấp: DNS
* Mô hình tên phân cấp
Không gian tên o Tập hợp các tên - tạo thành không gian tên - Namespace, được quản lý
và nhận biết bởi dịch vụ nào đó
o Các tên có thể quản lý với cấu trúc bên trong nào đó (vd path với file system, cơ cấu tổ
chức, hay các định danh phẳng, ...)
o Không gian tên thường tổ chức phân cấp => thuận tiện phân chia cho mục tiêu quản lý o
Cấu trúc tên, không gian tên: có thể biểu diễn dạng cây/đồ thị có hướng o Alias: bí danh,
tên mô tả cùng một thực thể với tên khác, vd Quản lý tên
o Các tên => gắn với các thuộc tính khác nhau của thực thể/đối tượng o Dịch vụ quản lý
tên: Lưu giữ các tập hợp tên và gắn với thuộc tính đối tượng o Dịch vụ thư mục - Dịch vụ tên
- Cung cấp các chức năng quản lý như tạo lập, cập nhật, truy vấn
- Microsoft AD, X509 directory service, LDAP
* Quá trình giải nghĩa tên •
Chuyển đổi từ tên thành địa chỉ, có thể thực hiện tập trung hoặc phân tán. •
DNS Server: Quản lý các bản ghi ánh xạ (tên miền và địa chỉ IP tương ứng). • DNS:
o Tổ chức miền phân cấp.
o Cấu trúc phân cấp: theo mục đích, địa lý. •
Client giải nghĩa lặp: các client hỏi nhau. •
Giải nghĩa phía server : các server hỏi nhau. 7/ Đồng hồ
- Đồng hồ vật lý, tại sao cần đồng bộ thời gian • Đồng bộ vật lý:
o Các sự kiện xảy ra theo trình tự nên cần gán nhãn thời gian. o Mỗi máy tính có đồng hồ vật
lý – bộ định thời gian. o Cấu tạo: dựa trên dao động tinh thể thạch anh.
o Mỗi dao động trừ dần giá trị reg đến khi reg = 0 => ngắt thời gian. o HĐH: từ giá trị đồng
hồ vật lý => tính toán và cung cấp giá trị thời gian cho các tiến trình. • Tại sao cần đồng bộ thời
gian: o Đảm bảo tính nhất quán dữ liệu: Đảm bảo thời điểm ghi và cập nhật dữ liệu được ghi
chính xác => ngăn chặn dữ liệu bị mất, không nhất quán.
o Xác định thứ tự sự kiện: Các sự kiện xảy ra đồng thời ở các thành phần khác nhau, đồng bộ
thời gian sẽ quyết định điều gì xảy ra trước, xảy ra sau. o Đồng bộ hoạt động: Đảm bảo các nút
thực hiện một tác vụ cùng lúc đồng thuận với nhau. o Tránh các vấn đề liên quan đến hệ điều
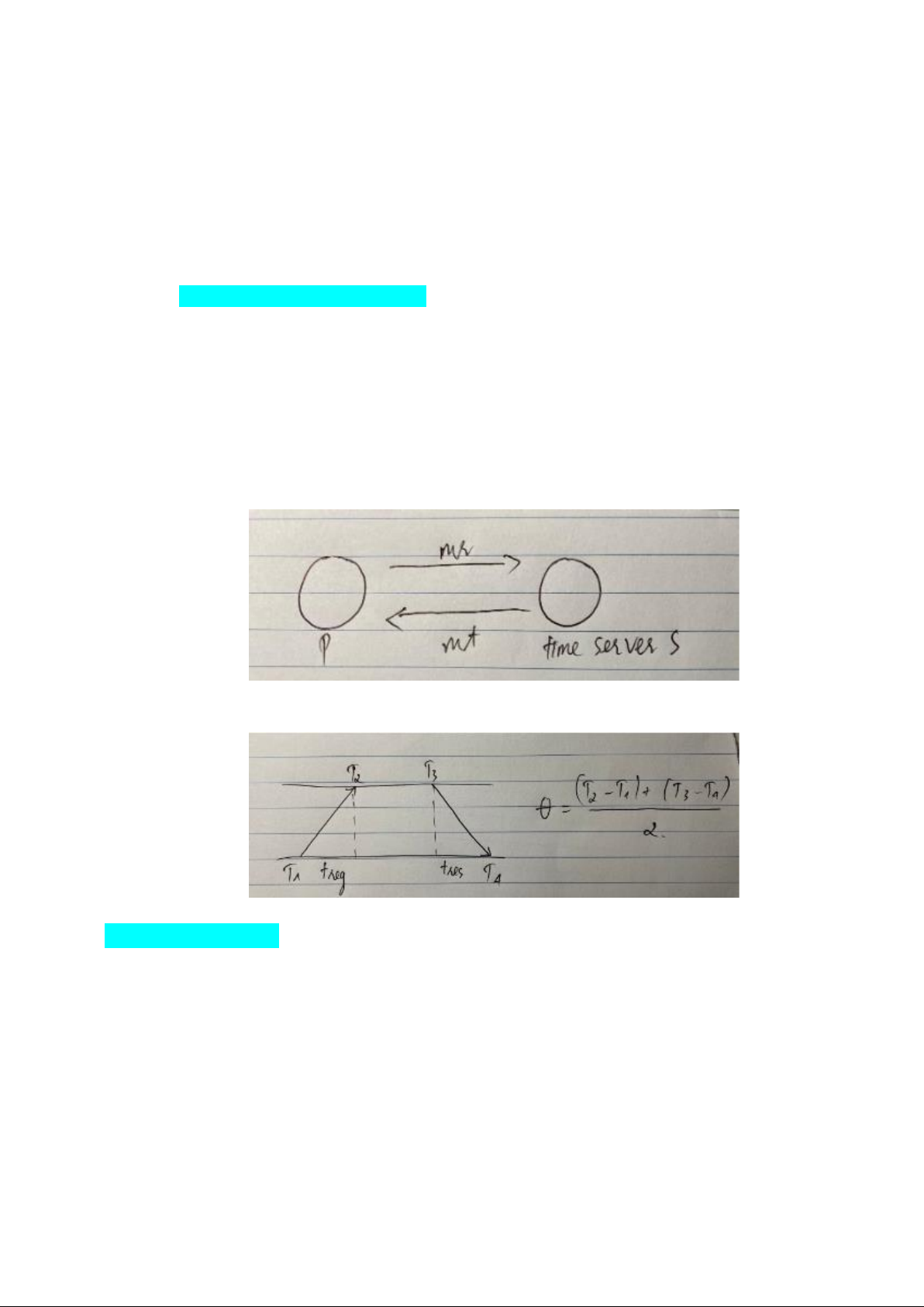
hành. - Thuật toán đồng bộ Christian
• Ý tưởng: Sử dụng một máy chủ thời gian chính xác (time server) để cung cấp thời gian hiện
tại cho các nút khác trong mạng.
• Cristian nhận thấy: mặc dù hệ là asynch, thời gian round trip của 1 message cụ thể thường đủ ngắn
• Cristian đề xuất đồng bộ với máy chủ thời gian tin cậy
○ máy client gửi yc mr tới máy chủ thời gian S
○ máy server S trả lời thời gian chuẩn trong thông điệp mt
○ client đo thời gian round trip Tr và đặt thời gian t+Tr/2 (với giả định thời gian đi và về bằng nhau)
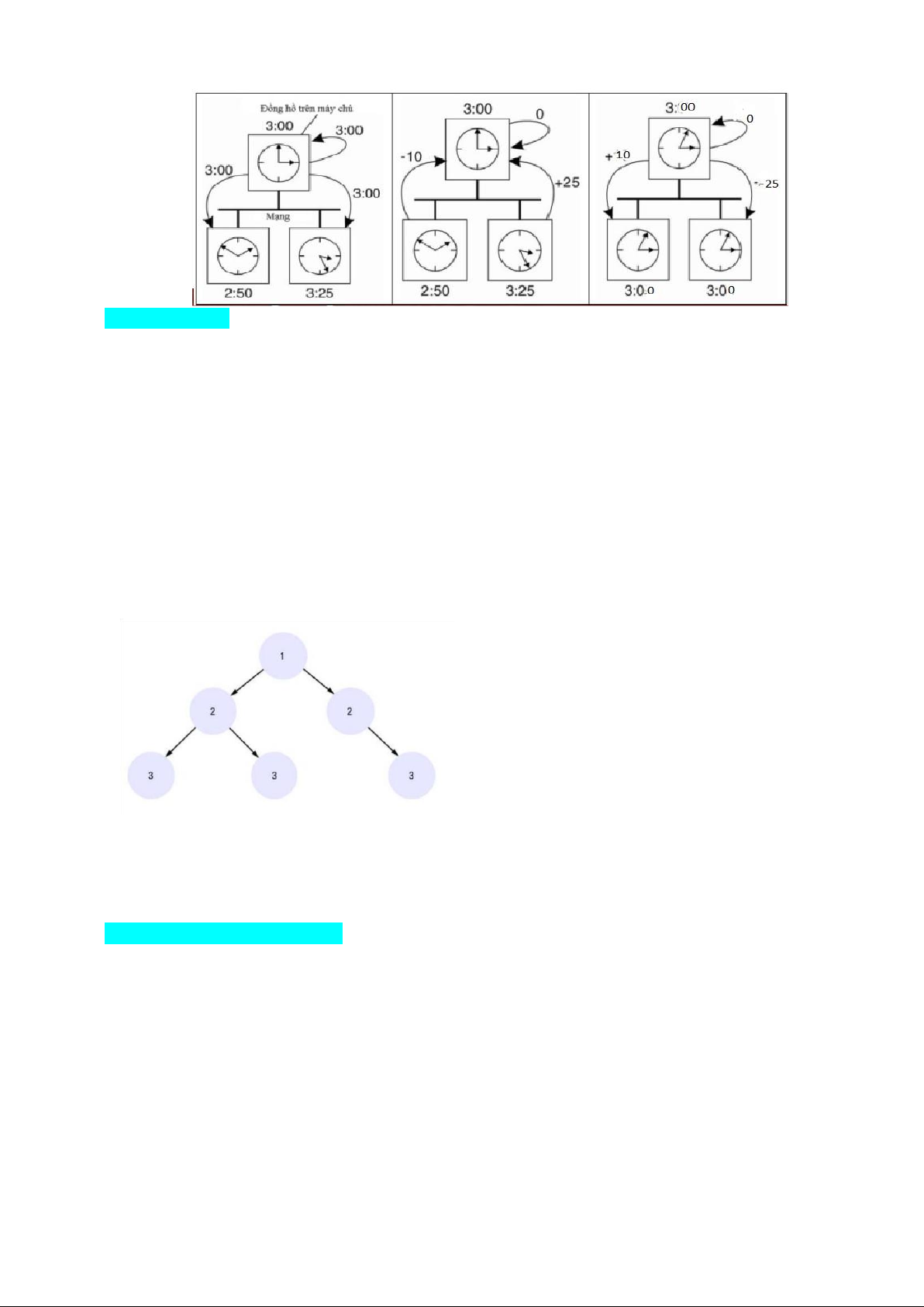
- Thuật toán Berkeley • Ý tưởng: Tự các nút điều
chỉnh thời gian với nhau.
• Có một máy điều phối – dc gọi là master
• Máy master định kỳ gửi thông điệp thời gian đến slave
• Các slave gửi thông tin thời gian local của mình tới master
• Master tính toán (có tính đến thời gian round trip) thời gian cần điều chỉnh của từng slave,
• Master gửi giá trị cần điều chỉnh tới từng slave
• Nếu master có sự cố - sẽ bình chọn master mới - Hệ thống NTP
• Mạng nội bộ: Christian, Berkeley.
• Mạng internet: thường dùng NTP.
• NTP: cung cấp dịch vụ thời gian, đồng bộ với múi giờ UTC.
• Hệ thống phân tán gồm nhiều máy chủ NTP:
o Do có thể mất kết nối trong thời gian dài => cần các máy chủ dự phòng, kết nối dự phòng.
o Hệ nhiều máy chủ => đáp ứng số lượng client.
o An ninh => sử dụng xác thực => đảm bảo dữ liệu đến từ nút tin cậy, kiểm tra địa chỉ gửi.
• Các server: tạo thành mạng đồng bộ. o Primary (root): bậc 1. o Secondary: bậc 2 và thấp
hơn nữa. o Thời gian của các server bậc thấp hơn => chính xác hơn.
• Đồng bộ thời gian: 3 chế độ.
o Multicast: thường cho LAN tốc độ cao, máy chủ gửi msg broadcast có thời gian. o
Procedure – call: thủ tục như thuật toán Christian. o Symmetric: server với server
cấp cao hơn, cần chính xác hơn.
- Đồng bộ logic, đồng bộ vecto * Đồng bộ logic
• Đồng bộ logic: Nhiều khi không cần khớp thời gian thực tế mà chỉ cần khớp về thứ tự thời gian.
• Đồng hồ Lamport: o Quan hệ tương tự nhân quả. o a -> b:
▪ (H1) a xảy ra trước b.
▪ (H2) a là sự kiện gửi msg, b là sự kiện nhận msg. ▪ (H3) bắc cầu: a -
> b, b -> c thì a -> c. • Logical clock: o
LC1: Li tăng trước khi thực hiện sự kiện ở tiến trình pi: Li = Li + 1. o LC2:
▪ Khi tiến trình pi gửi msg m, nó gắn kèm nhãn thời gian t = Li.
▪ Khi tiến trình pj nhận được (m,t) nó tính clock: Lj = max{t, Lj} và áp dụng luật LC1
trước khi gán nhãn thời gian cho sự kiện e nhận được msg m: receive(m).
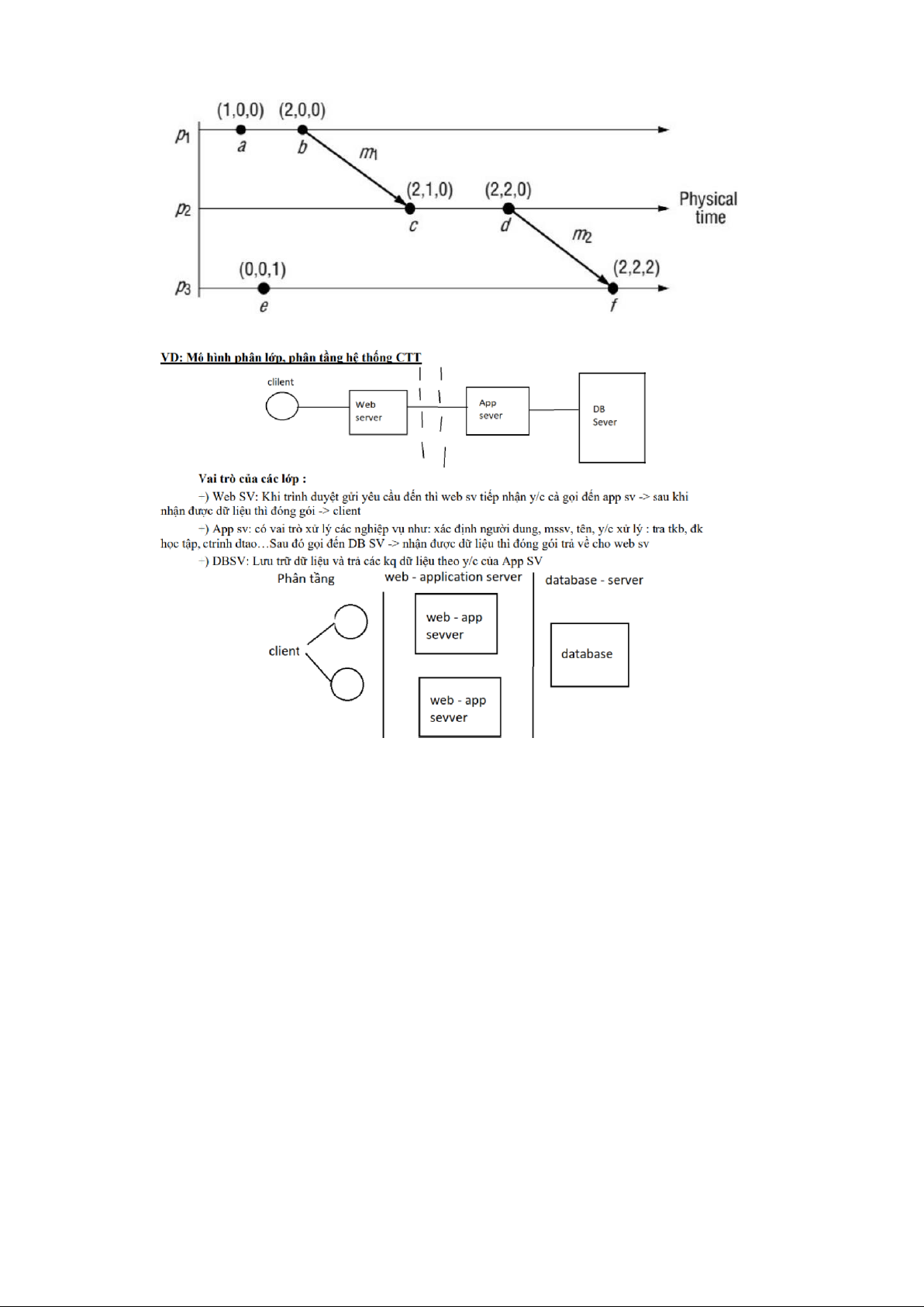
▪ Nếu e => e’ thì L(e) < L(e’) và ngược lại. - Đồng hồ vecto
• Vecto clock của tiến trình trong hệ N tiến trình là vecto N phần tử. • Quy tắc:
o VC1: tiến trình pi có clock Vi[j] = 0. o VC2: trước khi pi gán nhãn thời
gian, nó đặt Vi[i] = Vi[i] + 1. o VC3: tiến trình pi gửi kèm clock t = Vi
trong mọi msg gửi đi: (m, t).
o VC4: tiến trình nhận pj, khi nhận sẽ tính clock Vj trước khi gán nhãn cho sự
kiện nhận: Vj[k] = max{Vj[k], t[k]}. • Có thể thấy:
o Vi[i] thể hiện số sự kiện mà tiến trình thứ I – pi đã gán nhãn.
o Vi[j] thể hiện số sự kiện mà tiến trình thứ j – pj đã gán nhãn. •
Có thể so sánh 2 vecto clock:
o V = V’ ⬄ V[i] = V’[i], i = 1…n. o
V <= V’ ⬄ V[i] = V’[i], i = 1…n. o V < V’
⬄ V[i] <= V’[i] và V # V’.
Vietsub cái hình này:
+) Tại Browser: Gửi y/c đăng ký học tập (hoặc cái yêu cầu qq gì cũng được, miễn là yêu cầu)
đến Server -> Thì khi đó Thông điệp sẽ được cho vào Message Queue, gán số đếm lần xử lý t = 0.
+) Sau đó từng message được trình xử lý Processor lấy ra theo nguyên tắc FIFO (cháu nào đến
sớm thì được xử lý sớm) để xử lý yêu cầu và nếu thành công sẽ lưu kq về sever. Nếu có lỗi
phát sinh: Quá thời gian, hay cái gì gì đó nó phát sinh lỗi,… thì sẽ được trả về lại queue ban
đầu để xử lý ở các lượt sau, đồng thời tăng số đếm t lên 1 đơn vị: t = t+1. + Nếu message nào
xử lý lỗi quá số lần quy định (t^0) thì đẩy vảo Error queue
+) Để kiểm tra kết quả xử lý, brower sẽ gọi tới API hỏi kết quả xử lý yêu cầu, API truy vấn trực
tiếp tới server để kiểm tra dữ liệu request của client -> trả kết quả truy vấn về browser. Hết :V
Câu tên miền DNS: trình bày lú thuyết rồi chỗ giải thích quá trình giải nghĩa tên khi truy cập
từ BK thì tham khảo như này nhé:
DNS là hệ thống phi tập trung phân cấp. Tên Domain trên internet là phần cấp và tạo thành 1 cây.
Mỗi máy chủ DNS server phụ trách 1 vùng của cây.
Khi người dùng truy cập từ trình duyệt cục bộ ở BK, Máy chủ domain cục bộ sẽ tìm kiếm trong
kho dữ liệu xem có cơ sở dữ liệu chuyển đổi từ tên miền sang địa chỉ IP của tên miền mà người
dùng yêu cầu hay không. Do DNS tại bách khoa không quản lý tên miền gmail.com nên sẽ phải
hỏi lên DNS cấp cao đến root. Và nếu tìm thấy thì root xác định tên miền cần tìm thuộc vùng do
DNS nào quản lý rồi chỉ cho máy chủ cục bộ ở BK biết máy chủ tên miền nào đang quản lý tên
miền gmail.com. Khi đó máy chủ cục bộ BK sẽ gửi y/c đến máy chủ vừa được chỉ định => máy
chủ quản lý tên miền gmail.com sẽ trả lại IP cho máy chủ cục bộ ở BK => thu được IP của tên miền.
Cuối cùng, khi có IP thì máy chủ cục bộ BK sẽ trả về IP cho máy người dùng.
Tài liệu liên quan:
-

Bài Tập môn Hệ Thống Phân Tán
35 18 -

Bài tập chương 1 Môn Hệ thống phân tán và ứng dụng | Đại học Bách Khoa Hà Nội
67 34 -

Chương 2 Tiến Trình và Trao Đổi Thông Tin trong Hệ Phân Tán | Môn Hệ thống phân tán và ứng dụng - Đại học Bách Khoa Hà Nội
68 34 -

Chương 2 Tiến Trình và Trao Đổi Thông Tin | Môn Hệ thống phân tán và ứng dụng - Đại học Bách Khoa Hà Nội
57 29 -

Tài liệu ôn tập Môn Hệ thống phân tán và ứng dụng | Đại học Bách Khoa Hà Nội
55 28