Đề thi kết thúc môn Khai phá dữ liệu dạng trắc nghiệm có đáp án
Đề thi kết thúc môn Khai phá dữ liệu dạng trắc nghiệm có đáp án giúp sinh viên tham khảo, ôn luyện và phục vụ nhu cầu học tập của mình cụ thể là có định hướng ôn tập và làm bài tốt trong những bài kiểm tra, bài tiểu luận, bài tập kết thúc học phần, từ đó học tập tốt và có kết quả cao. Mời bạn đọc đón xem!
Môn: Khai phá dữ liệu 2 tài liệu
Trường: Trường Đại học Bách khoa - Đại học Quốc gia Thành phố Hồ Chí Minh 721 tài liệu
Tác giả:








Preview text:
lOMoARcPSD| 36667950
Đại Học Quốc Gia Tp. HCM M đề thi: 01
Trường Đại Học B ch Khoa
Khoa Khoa Học v Kỹ Thuật M y T nh
Đề thi môn Khai Phá Dữ Liệu
HK1/2018-2019 - Thời gian: 90 ph t
MSMH: CO3029 - Ng y thi: 21/12/2018
(Đề thi gồm 6 trang. Sinh vi n l m phần trắc nghiệm tr n phiếu trả lời trắc nghiệm, phần tự luận ngay
tr n đề thi v nộp lại)
(Sinh vi n được ph p tham khảo t i liệu giấy) Họ v T n MSSV
Phần 1. Trắc nghiệm (7.0 điểm): Chọn 1 c u trả lời đng nhất v t v o phiếu trả lời trắc nghiệm
5. Trong kỹ thuật gom cụm dựa v o mật độ, ph t
1. Trong giải thuật Apriori biểu n o sau đy đng: a. |Ck| ≥ | Lk|
a. trong cụm chỉ c một core object, đ l trung t m b. |C cụm k| ≥ |Ck+1|
c. tập dữ liệu D sẽ được qu t m lần với m l
b. mỗi phần tử trong một cụm c t nhất MinPts
chiều d i của tập thường xuy n xuất hiện
phần tử kh c gần n (trong phạm vi b n k nh l (frequent itemset) d i nhất ε) d. c u a v c đều đng
c. khoảng c ch từ một phần tử a đến một core
2. Để kiểm tra giải thuật gradient descent với
object n o đ nhỏ hơn ε th a thuộc về cụm
d. tất cả c c c u tr n đều sai
mục ti u l cực tiểu h a h m chi ph J( )θ c hội
6. Ph t biểu n o sau đy ĐNG trong khai ph luật kết
tụ hay kh ng ta cần kiểm tra: hợp:
a. J( )θ c giảm ở mỗi bước lặp
a. support c ý nghĩa quan trọng hơn
b. J( )θ c tăng ở mỗi bước lặp confidence
c. J( )θ =0 sau 10,000 lần lặp
b. support_count(A => B) l số lần xuất hiện
đồng thời của A v B trong tập dữ liệu D
d. hệ số học α c được thiết lập đủ lớn, v dụ
c. support(A => B) lu n lớn hơn bằng 0.1 confidence(A=> B)
3. Khi ph n loại dữ liệu d ng c y quyết định, độ đ
d. tất cả c c c u tr n đều sai
o n o sau đy gi p tr nh tạo ra c c ph n hoạch 7. Giải thuật FP-Growth c qu t đối tượng
a. qu t tập dữ liệu D (tập dữ liệu lớn) m lần với a. Information Gain
m l số d ng trong header table b. GainRatio
b. thường chạy chậm hơn giải thuật Apriori c. GiniIndex
c. tập hợp c c node tr n một nh nh của FP-tree
d. tất cả c c c u tr n đều sai
phải xuất hiện t nhất k lần trong D, với k l số
4. Phương ph p gom cụm n o sau đy gi p ph t
đếm (count) của node l trong nh nh đang x t
hiện được c c cụm c dạng h nh ống (pipe) tốt
d. tất cả c c c u tr n đều sai nhất
Dữ kiện dưới đy d ng cho 3 c u sau đy: a. K-Means
Cho T chứa 500,000 giao dịch trong đ số giao dịch b. K-Medoids
chứa b nh m, chứa mứt v chứa đồng thời b nh m v mứt c. DBSCAN
lần lượt l 20000, 30000 v 10000. d. BIRCH 1/6 lOMoARcPSD| 36667950
8. Độ hỗ trợ (support) của ph t biểu "ai mua 2/6 lOMoARcPSD| 36667950
mứt đều sẽ mua b nh m" l : b. ph n hoạch (partition) a. 2%
c. trộn (agglomerative) dữ liệu dựa v o c y ph n b. 33.33% cấp c. 50%
d. ph n cụm dựa v o mật độ
d. Tất cả c c c u tr n đều sai
15. Trong web mining, để hiểu được thứ tự c c URL
9. Độ tin cậy (confidence) của ph t biểu "ai mua
được truy cập, ta thường d ng phương ph p n o
mứt đều sẽ mua b nh m" l :
a. ph n t ch chuỗi tuần tự (sequetial analysis) a. 66.66%
b. khai ph luật kết hợp (association rule) b. 33.33%
c. ph n lớp (classification) c. 45%
d. ph n t ch tương quan (correlation analysis) d. 50%
16. C c mẫu điều kiện cơ sở (conditional pattern base)
10. Khi số lượng giao dịch trong T tăng l n được tạo ra
10,000,000 nhưng số lượng giao dịch mua mứt
a. cho mỗi frequent item trong header table
v b nh m n u ở tr n kh ng đổi th ph t biểu "ai
b. bằng c ch duyệt c y FP-Tree (từ dưới l n), xuất ph
mua mứt đều sẽ mua b nh m" sẽ
t từ node đầu ti n trong danh s ch node link của
a. thay đổi độ hỗ trợ
item đang x t v phải duyệt hết c c node trong danh
b. thay đổi độ tin cậy s ch n y
c. cả độ hỗ trợ v độ tin cậy đều thay đổi c. hai c u a v b đng
d. tất cả c c c u tr n đều sai
d. tất cả c c c u tr n đều sai
11. Sau khi chạy giải thuật FP-Growth tr n tập dữ
17. Ph t biểu n o sau đy về gom cụm dữ liệu l SAI
liệu D, trong tập kết quả c một số tập thường
a. khoảng c ch giữa c c phần tử trong c ng một cụm
xuy n xuất hiện c chiều d i l 5. Giải thuật FG- c ng nhỏ c ng tốt
Growth n y đ qu t (scan) qua D
b. khoảng c c giữa c c phần tử ở c c cụm kh c nhau c a. 1 lần ng nhỏ c ng tốt b. 2 lần
c. m h nh gom cụm tốt khi n ph t hiện được c c cụm c. 5 lần c h nh dạng bất kỳ d. t nhất l 5 lần
d. giải thuật K-means thường cho kết quả l c c
12. Logistic regression l một phương ph p d ng để
cụm c dạng h nh cầu v c k ch thước gần giống a. dự đo n (prediction) nhau
b. ph n lớp (classification)
18. Hồi qui tuyến t nh c thể được d ng để
c. m tả dữ liệu (description)
a. xử lý dữ liệu bị nhiễu
d. gom cụm dữ liệu (clustering)
b. dự đo n gi trị dữ liệu số
13. Ph t biểu n o sau đy SAI trong ph n lớp dữ liệu
c. ph n lớp dữ liệu c nh n (classification)
a. dữ liệu huấn luyện lu n phải chứa nh n (label) d. c u a v b đng
b. dữ liệu kiểm tra lu n phải chứa nh n
c. dữ liệu kiểm tra kh ng cần phải chứa nh n v
đy l tập được d ng để kiểm tra m h nh v
Dữ kiệu sau đy d ng cho hai c u sau:
nh n sẽ được tạo ra từ m h nh
Một m h nh ph n lớp (classifier) d ng h m sau
d. dữ liệu huấn luyện v kiểm tra phải c cấu tr c 1 giống nhau = h Xθ( ) −θTX
14. Kỹ thuật gom cụm n o sau đy khởi động bằng c 1+e
ch xem mỗi đối tượng dữ liệu l một cụm
l m giả thuyết (hypothesis) cho việc ph n lớp. a. K-Means 3/6 lOMoARcPSD| 36667950
19. Ph t biểu n o sau đy SAI
b. lựa chọn c c thuộc t nh dựa v o tương quan
a. X l tập dữ liệu mẫu
giữa c c thuộc t nh độc lập với thuộc t nh phụ
b. đy l h m hồi qui logistic
thuộc (v dụ thuộc t nh ph n lớp) c. đy l h m sigmoid
c. đọc dữ liệu c định dạng file l ARFF
d. hθ(X) l x c suất để Y = "1" (với Y l thuộc
d. tất cả c c c u tr n đều sai
t nh nh n v "1" l nh n m ta quan t m)
24. Ph t biểu n o sau đy SAI về mạng nơ-ron nh n tạo -
20. Ph t biểu n o sau đy ĐNG
Artificial Neural Network (ANN) a. h
a. h m k ch hoạt (activation function) thường được d θ(X) ∈ [-1, 1] ng l h m sigmoid b. hθ(X) ∈ [0, 1]
b. c thể c nhiều hơn một lớp ẩn (hidden layer)
c. X l vector c c thuộc t nh đầu v o (input
c. việc t m trọng số (weight) cho c c li n kết được
features) của tập dữ liệu mẫu (bao gồm
thực hiện dựa tr n phương ph p feedforward X0=1)
d. việc chọn hệ số học (learning rate) sẽ ảnh d. hai c u b v c đng
hưởng đến tốc độ cũng như khả năng hội tụ của
Cho bộ ph n lớp M thực hiện việc ph n loại dữ giải thuật
liệu c ba nh n A, B v C. Kết quả ph n loại được
25. Độ đo n o được d ng đối với c c dữ liệu nhị ph n
biểu diễn bởi ma trận sai biệt (confusion matrix) a. Manhattan
như sau. H y chọn c u trả lời đng cho hai c u hỏi b. Jaccard sau đy. c. Euclidean Ph n lớp th nh d. Minkowski Thực tế A B C
26. Gọi RA,B l sự tương quan giữa hai thuộc t nh A v B A 116 13
trong tập dữ liệu D, ph t biểu n o sau đy SAI 10 a. RA,B ∈ [-1, 1] B 14 11 20
b. RA,B =1 th ta n n loại một trong hai thuộc t nh C 11 10 122
trong qu tr nh khai ph dữ liệu
c. RA,B = -1 th ta n n loại một trong hai thuộc t nh
21. Độ ch nh x c (precision) của việc ph n loại dữ
trong qu tr nh khai ph dữ liệu
liệu thuộc lớp A l (l m tr n đến 3 chữ số thập ph
d. RA,B cao thể hiện sự phụ thuộc lẫn nhau giữa A v n): B cao a. 0.823
27. Ph t biểu n o dưới đy SAI về điều kiện dừng của giải b. 0.835
thuật x y dựng c y quyết định: c. 0.803
a. Tất cả những thể hiện trong ph n hoạch D (tại n t d. 0.745
N đang x t) thuộc về c ng một lớp
22. Độ truy hồi (recall) của việc ph n loại dữ liệu
b. Kh ng c n thuộc t nh n o nữa m c c thể hiện c thể
thuộc lớp A l (l m tr n đến 3 chữ số thập ph n): được ph n hoạch th m a. 0.752
c. Việc tiếp tục lựa chọn c c thuộc t nh ph n t ch kh b. 0.835
ng l m tăng độ lợi th ng tin c. 0.803
d. Kh ng c n thể hiện n o nữa tr n nh nh đang x t, tức d. 0.829 l ph n hoạch D bị rỗng
23. Weka KH NG hỗ trợ chức năng n o sau đy?
28. Trong số c c phương ph p ph n lớp dữ liệu, phương
a. x y dựng (train) m h nh, lưu trữ m h nh v
ph p n o c t nh chất học tăng cường (incremental
sử dụng lại m h nh đ để thực thi với dữ liệu learning): mới a. C y quyết định 4/6 lOMoARcPSD| 36667950 b. Na ve Bayes c. Mạng nơ ron d. k-nearest neighbor
29. C c độ đo về sự ph n t n của dữ liệu Q1, Q2, Q3,
IQR c t c dụng trong việc:
a. Ph t hiện c c phần tử nhiễu, c c phần tử bi n
b. Cung cấp c i nh n tổng quan về ph n bố dữ liệu
c. Chuẩn h a dữ liệu, lựa chọn thuộc t nh
d. Ph n lớp dữ liệu (classification)
e. Cả hai c u a v b đều đng
30. Tri thức c thể đạt được từ qu tr nh khai ph dữ liệu l :
a. M h nh ph n loại / dự đo n
b. M h nh gom cụm / c c mối quan hệ, luật kết hợp
c. C c phần tử bi n, ngoại lai
d. Xu hướng biến dổi dữ liệu / c c mẫu thường xuy n 5/6 lOMoARcPSD| 36667950
e. Tất cả c c c u tr n đều đng 6/6 lOMoARcPSD| 36667950
31. Ph p kiểm thống k chi-square được d ng để:
so với gom cụm dựa v o c y ph n cấp l n c thể
a. T m ra những điểm chia để rời rạc h a dữ liệu
quay lại bước lặp trước đ
b. Tạo ra c c mức ý niệm để thực hiện việc tổng qu t h a dữ liệu
e. Cả hai c u a v c đều đng
c. Ph n t ch sự độc lập của c c thuộc t nh rời rạc
36. Độ lợi th ng tin (information gain) được d ng trong
d. Ph n t ch tương quan của c c thuộc t nh li n ngữ cảnh n o sau đy: tục a. Thu giảm số chiều
32. Giải ph p n o được d ng để thu giảm dữ liệu:
b. Chọn thuộc t nh ph n t ch trong việc x y dựng
a. Ph n t ch nh n tố ch nh (Principal component bộ ph n lớp dữ liệu analysis)
c. Thu giảm lượng số dữ liệu b. Histogram, Data Sampling d. Gộp khối dữ liệu
c. Kết hợp khối dữ liệu (data cube aggregation)
37. Trong giải thuật lan truyền ngược để huấn luyện d. Hai c u a v b đều đng
mạng nơ ron, mỗi lần lặp duyệt qua mọi phần tử
e. Ba c u a, b v c đều đng 33. Chọn ph t biểu
trong tập huấn luyện được gọi bằng thuật ngữ tiếng ĐNG: Anh n o sau đy:
a. H m Y = aX+b l h m hồi qui phi tuyến (a, b l a. pass th ng số) b. epoch
b. H m Y = aX1 + bX2 + cX3 + d l h m hồi qui c. stage
phi tuyến (a, b, c, d l th ng số) d. iteration
c. H m Y = a.log(bX) l h m hồi qui phi tuyến (a,
38. Th nh phần n o sau đy kh ng l th nh tố cơ bản để đặc b l th ng số)
tả t c vụ khai ph dữ liệu
d. H m Y = aXb l h m hồi qui tuyến t nh (a, b l
a. Dữ liệu cụ thể được khai ph th ng số) b. Tri thức nền e. Cả 4 c u tr n đều sai c. C c độ đo
d. Chuẩn p dụng cho việc x y dựng ứng dụng
34. C c điểm ngoại bi n (outlier) c thể ph t hiện khai ph dữ liệu.
được nhờ phương ph p n o sau đy:
a. D ng trị trung b nh v độ lệch chuẩn
39. Tri thức c thể đạt được từ qu tr nh khai ph dữ liệu l :
b. D ng gi trị IQR (interquartile range), Q1 v
a. M h nh ph n loại / dự đo n Q3
b. M h nh gom cụm / c c mối quan hệ, luật kết
c. D ng phương ph p gom cụm hợp d. Cả ba phương ph p tr n
c. C c phần tử bi n, ngoại lai
35. Chọn ph t biểu Đng trong c c c u sau:
d. Xu hướng biến dổi dữ liệu / c c mẫu thường xuy n
a. Giải thuật k-medoids giải quyết vấn đề nhiễu
e. Tất cả c c c u tr n đều đng
v điểm bi n tốt hơn k-means
b. Cả 2 giải thuật gom cụm bằng ph n hoạch
40. Mạng nơ-ron nh n tạo (ANN) l một m h nh t nh to n
(partition-based clustering) v gom cụm dựa v
a. m phỏng cơ chế hoạt động của bộ n o người
o c y ph n cấp (hierarchical clustering) đều
b. số node đầu ra (output) c thể l một hoặc
phải cho trước (input) số cụm
nhiều, phụ thuộc v o số lượng trạng th i của dữ
c. Gom cụm bằng ph n hoạch thường l m việc
liệu m hệ thống cần khảo s t
tốt với c c cụm c dạng h nh cầu
c. thường được d ng trong việc ph n lớp dữ liệu
d. Một điểm mạnh của gom cụm bằng ph n
d. tất cả c c c u tr n đều đng hoạch 7/6 lOMoARcPSD| 36667950
Phần 2: Tự luận (3.0 điểm). Sinh vi n l m b i trực tiếp tr n đề thi C u 1 (1.0
điểm) Cho một bộ dữ liệu về giỏ mua h ng như sau: TID Giỏ h ng (items bought) 1 f, a, c, d, g, i, m, 2 p a, b, c, f, l, m, o b, f , h, j, o b, c, 3 k, s, p a, f, c, e, l, 4 p, m, n 5
Vẽ FP-tree từ bộ dữ liệu n u tr n, với min_sup = 3:
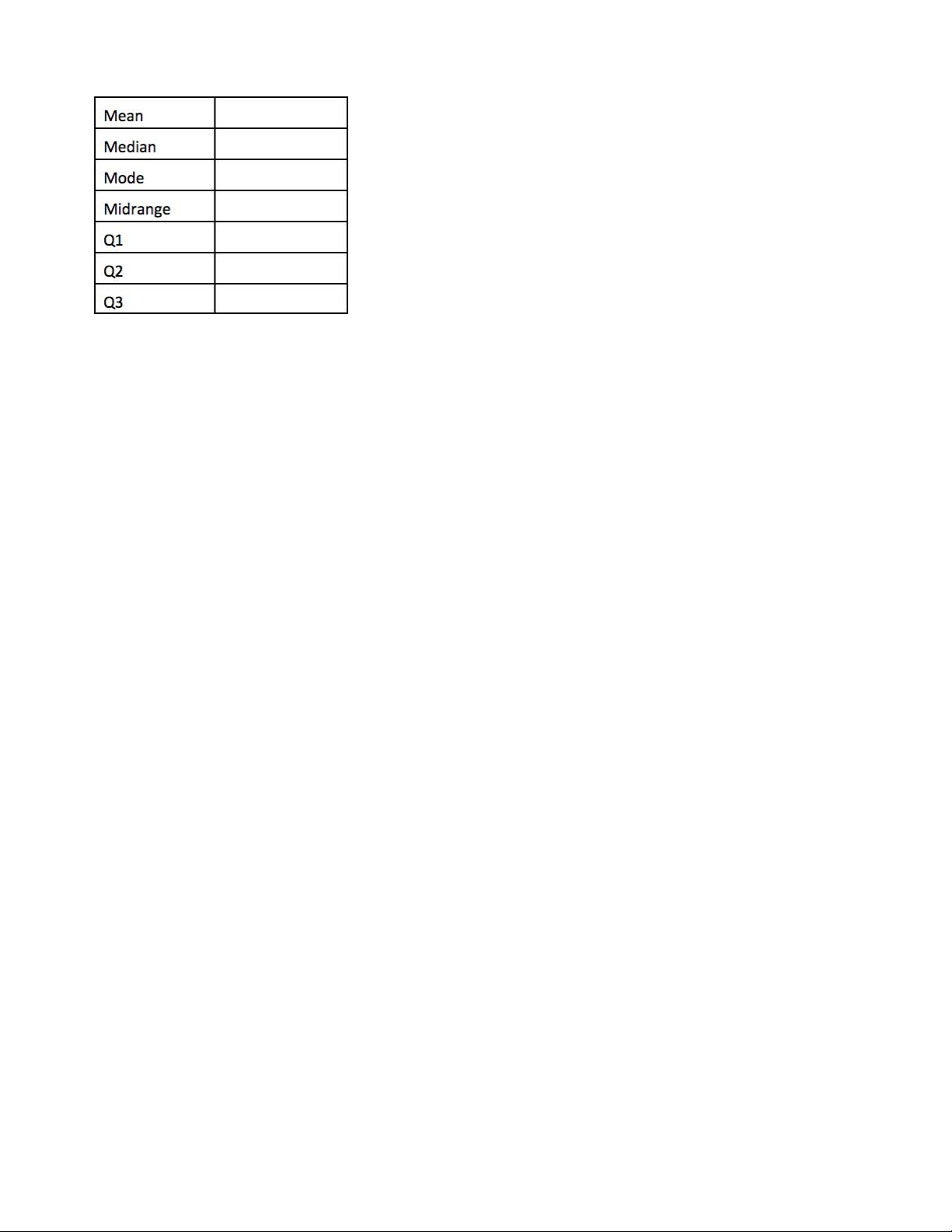
C u 2 (1.0 điểm): Cho biết tuổi của c c vận động vi n tham gia m n cờ vua như sau: 13, 15, 16, 16, 19, 20, 20,
21, 22, 22, 25, 25, 25, 25, 30, 33, 33, 35, 35, 35, 35, 36, 40, 45, 46, 52, 70. a) H y cho biết kết quả của c c gi trị sau (0.5 điểm).
b) Cho biết c c ph n tử ngoại bi n (outliers) dựa v o interquartile range (0.5 điểm). lOMoARcPSD| 36667950 5/6
C u 3 (1.0 điểm): Trong ph n lớp dữ liệu dựa v o mạng Bayesian:
a) (0.5 điểm) N u ý nghĩa của P(Ci|X) v biểu thức tổng qu t t nh P(Ci|X)
b) (0.5 điểm) N u ý nghĩa của P(X|Ci) v c ch t nh n khi X chứa đồng thời thuộc t nh rời rạc v li n tục lOMoARcPSD| 36667950
Giảng vi n ra đề Chủ nhiệm b m n
TS. Trần Minh Quang ThS. Trương Quang Hải TS. Trần Minh Quang 6/6
