Deep Learning-Based anomaly detection for time-series data | Báo cáo tổng kết học phần Khoa học máy tính
Ngày nay, Artificial Neural Network (ANN) đã được sử dụng thành công trong nhiều lĩnh vực, chẳng hạn như nhận dạng chữ viết tay, nhận dạng giọng nói, phân tích tài liệu, nhận dạng hoạt động và nhiều lĩnh vực khác; chủ yếu cho mục đích phân loại và dự đoán. Các kiến trúc ANN khác nhau đã được tận dụng thành công để phân tích chuỗi thời gian. Kỹ thuật phát hiện dị thường được đề xuất bởi Malhotra và cộng sự. Tài liệu giúp bạn tham khảo, ôn tập và đạt kết quả cao. Mời bạn đón xem.
Môn: Khoa học máy tính (Phenikaa) 1 tài liệu
Trường: Đại học Phenika 1.3 K tài liệu
Tác giả:











Preview text:
BỘ GIÁO DỤC VÀ ĐÀO TẠO
TRƯỜNG ĐẠI HỌC PHENIKAA _________________ BÁO CÁO TỔNG KẾT TÊN ĐỀ TÀI:
Deep Learning-Based anomaly detection for time-series data
Lĩnh vực: Công nghệ thông tin
Chuyên ngành: Khoa học máy tính
Sinh viên thực hiện chính: Vương Tuấn Cường Nam, Nữ: Nam
Người hướng dẫn chính: TS. Lương Văn Thiện TS. Mai Xuân Tráng
Hà Nội, tháng năm 2022 2
BỘ GIÁO DỤC VÀ ĐÀO TẠO
TRƯỜNG ĐẠI HỌC PHENIKAA BÁO CÁO TỔNG KẾT TÊN ĐỀ TÀI:
Lĩnh vực: Công nghệ thông tin
Chuyên ngành: Khoa học máy tính STT Họ và tên Lớp/Khoa Chức vụ 01 TS. Lương Văn Thiện Công nghệ thông tin Giảng viên 02 TS. Mai Xuân Tráng Công nghệ thông tin Giảng viên 03 Vương Tuấn Cường K15-KHMT Sinh viên 04 Nguyễn Chí Công K14-CNTT3 Sinh viên
Hà Nội, tháng năm 2022 3 Mục lục 1. MỞ
ĐẦẦU.........................................................................................................................................4 1.1 Khái ni m c b nệ ơ
ả ..........................................................................................................................4 1.2 M c têuụ
.......................................................................................................................................5
2. T ng quan tnh hình nghiên c u thu c lĩnh v c đêề tài.ổ ứ ộ ự
..................................................................6
2.1 T ng quan vêề các phổ ương pháp phát hi n bấất thệ
ường...........................................................6
2.2 Các phương pháp hi n đ i đệ ạ ược s d ngử ụ
...............................................................................7
3. Lý do l a ch n đê ề tàiự ọ
......................................................................................................................8 3.1 Vi ph m d li uạ ữ
ệ ......................................................................................................................8 3.2 M ng d li uạ ữ
ệ ..........................................................................................................................8
3.3 Y tê.ấ .........................................................................................................................................8 4. Phương pháp nghiên c
uứ ...............................................................................................................9
4.1 Vấấn đêề c a phát hi n bấất thủ ệ
ường trong chuỗỗi th i gianờ
.........................................................9
4.2 Phương pháp Moving Average (MA)......................................................................................9
4.3 Phương pháp Moving Median (MM)....................................................................................10
4.4 Gi i thi u vêề Convolutonal Neural Network (CNN)ớ ệ
..............................................................10
4.5 Phương pháp Seasonal and Trend decompositon using Loes (STL)......................................11
4.6 Thu t toán Spectral Residual (SR)ậ
.........................................................................................12 4.7 Kêất h p các phợ ương
pháp....................................................................................................14
5. Đỗấi tượng nghiên c
uứ ...................................................................................................................16
5.1 T p d li u DCOILBRENTEUậ ữ ệ
..................................................................................................16 5.2 T p d li u DHOILNYHậ ữ ệ
..........................................................................................................16 5.3 T p d li u OVXCLSậ ữ ệ
...............................................................................................................17 4
5.4 T p d li u DCOILWTICOậ ữ ệ
......................................................................................................17 5.5 T p d li u DHHNGSPậ ữ ệ
...........................................................................................................18 6. Kêất qu nghiên c uả
ứ .......................................................................................................................19
7. Kêất lu n và kiêấn nghậ
ị.....................................................................................................................21
7.1 Kêất lu nậ .................................................................................................................................21
7.2 Kiêấn nghị...............................................................................................................................21 Tài li u tham kh oệ
ả ................................................................................................................................22 1. MỞ ĐẦU
Trong phần này, chúng tôi muốn giới thiệu về những khái niệm cơ bản liên
quan đến đề tài trong phần 1.1, tiếp sau đó chúng tôi sẽ trình bày về mục tiêu của đề tài trong phần 1.2
1.1 Khái niệm cơ bản
Phát hiện bất thường đã là một trong những lĩnh vực nghiên cứu cốt lõi trong
một thời gian dài do tính chất phổ biến của nó. Trong đời sống hàng ngày, chúng ta
quan sát thấy những bất thường sẽ tạo cho ta những chú ý. Khi một thứ gì đó đi lệch
phần lớn so với phần còn lại của phân phối, nó được gắn nhãn là bất thường hoặc
ngoại lệ. Trong khoa học máy tính, phát hiện điểm bất thường đề cập đến các kỹ thuật
tìm kiếm các điểm dữ liệu cụ thể, không phù hợp với phân phối chuẩn của tập dữ liệu.
Grubbs đưa ra định nghĩa phù hợp nhất về sự bất thường liên quan đến khoa học máy
tính: “Quan sát ngoại lai, hay‘ ngoại lệ ’, là một quan sát có vẻ sai lệch rõ rệt so với
các thành phần khác của mẫu mà nó xảy ra”. Thuật ngữ 'anomaly (bất thường)', được
sử dụng rộng rãi và nó đề cập đến các vấn đề khác nhau trong các lĩnh vực khác nhau.
Ví dụ, sự bất thường trong hệ thống an ninh mạng có thể là một hoạt động liên quan
đến một phần mềm độc hại hoặc một nỗ lực tấn công . Trong khi đó, trong lĩnh vực sản
xuất, một sản phẩm bị lỗi được coi là một sản phẩm bất thường. Điều rất quan trọng là
phải phát hiện ra các điểm bất thường càng sớm càng tốt để tránh các vấn đề lớn như
hack hệ thống tài chính, lỗi toàn bộ máy hoặc khối u ung thư trong cơ thể người.
Các công ty từ các lĩnh vực khác nhau bao gồm sản xuất, ô tô, chăm sóc sức
khỏe, nhà nghỉ, du lịch, thời trang, thực phẩm và hậu cần đang đầu tư rất nhiều nguồn
lực, vào việc thu thập dữ liệu lớn và khám phá các mô hình bất thường tiềm ẩn trong
đó để tạo điều kiện thuận lợi cho khách hàng của họ . Trong hầu hết các trường hợp,
dữ liệu được thu thập là dữ liệu chuỗi thời gian truyền trực tuyến và do các đặc điểm
nội tại của chúng về tính chu kỳ, xu hướng, tính thời vụ và tính bất thường, nên việc
phát hiện chính xác các điểm bất thường trong chúng là một vấn đề khó khăn. Hơn 5
nữa, trong hầu hết các tình huống thực tế, thực tế không thể gắn nhãn lượng dữ liệu
khổng lồ, do đó, chúng tôi đang sử dụng phương pháp không giám sát. Mặc dù có
nhiều phương pháp không được giám sát nhưng chúng không xử lý được các đặc điểm
nội tại của dữ liệu chuỗi thời gian. Ví dụ, các kỹ thuật phát hiện điểm bất thường dựa
trên khoảng cách truyền thống không kết hợp ngữ cảnh của chuỗi thời gian, do đó
chúng không thể tìm thấy điểm bất thường xảy ra trong chu kỳ. Phương pháp không
giám sát được đề xuất kết hợp bối cảnh, tính thời vụ và xu hướng để phát hiện các
điểm bất thường. Cách tiếp cận này có thể được điều chỉnh cho các tình huống và
trường hợp sử dụng khác nhau, đồng thời hoạt động trên dữ liệu từ các miền khác nhau. 1.2 Mục tiêu
Trong đề tài này, chúng tôi muốn trình bày về các phương pháp Moving Median
(MM), Moving Average (MA), Convolutional Neural Network (CNN), Seasonal and
Trend Decomposition Procedure Based on Loess (STL), Spectral Residual (SR) và
cách chúng tôi kết hợp chúng để cho ra những kết quả tốt hơn. 6 2.
Tổng quan tình hình nghiên cứu thuộc lĩnh vực đề tài.
Trong phần này, chúng tôi muốn giới thiệu về các phương pháp để phát hiện bất
thường trong phần 2.1, các phương pháp phát hiện bất thường hiện đại được đề cập và tóm tắt trong phần 2.2. 2.1
Tổng quan về các phương pháp phát hiện bất thường
Để kết hợp các đặc điểm của chuỗi thời gian, tồn tại các kỹ thuật phát hiện bất
thường khác nhau được thiết kế để tìm các điểm bất thường dành riêng cho truyền dữ
liệu chuỗi thời gian. Chức năng phát hiện dị thường của Netflix có nguồn mở được gọi
là Robust Anomaly Detection (RAD) vào năm 2015 . Chức năng này dựa trên Robust
Principle Component Analysis (RPCA) để phát hiện các điểm bất thường. Để phát hiện
chuỗi thời gian bất thường trong tập dữ liệu nhiều terabyte, một thuật toán nhận biết
đĩa được đề xuất trong [26]. Mô hình autoregressive-moving-averge (ARMA) và các
biến thể của nó như ARIMA và ARMAX được sử dụng rộng rãi để dự đoán chuỗi thời
gian và phát hiện bất thường. Yu và cộng sự. [27] đã trình bày một kỹ thuật phát hiện
bất thường để điều khiển lưu lượng trong mạng cảm biến không dây, dựa trên mô hình
ARIMA. Họ đề xuất rằng phương pháp short step exponential weighted average là
chìa khóa để đưa ra phán đoán phát hiện bất thường tốt hơn trong lưu lượng mạng.
Trong cùng một miền, Yaacob et al. [28] đề xuất một kỹ thuật để phát hiện cảnh báo
sớm các cuộc tấn công Denial-of-Service (DoS). Bằng cách so sánh lưu lượng mạng
thực tế với các mẫu dự đoán do ARIMA tạo ra, các hành vi bất thường được xác định.
Ngày nay, Artificial Neural Network (ANN) đã được sử dụng thành công trong
nhiều lĩnh vực, chẳng hạn như nhận dạng chữ viết tay, nhận dạng giọng nói, phân tích
tài liệu, nhận dạng hoạt động và nhiều lĩnh vực khác; chủ yếu cho mục đích phân loại
và dự đoán. Các kiến trúc ANN khác nhau đã được tận dụng thành công để phân tích
chuỗi thời gian. Kỹ thuật phát hiện dị thường được đề xuất bởi Malhotra và cộng sự.
[6] dựa trên các LSTM xếp chồng lên nhau. Mô hình dự đoán của họ được đào tạo trên
các tem thời gian bình thường, được sử dụng thêm để tính toán các vectơ lỗi cho các
trình tự nhất định. Dựa trên ngưỡng lỗi, một chuỗi chuỗi thời gian được đánh dấu là
bình thường hoặc bất thường. Chauhan và Vig [8] đã sử dụng cách tiếp cận tương tự để
phát hiện sự bất thường trong dữ liệu điện tâm đồ. Họ đã sử dụng RNN, được tăng
cường với LSTM, để phát hiện 4 loại dị thường khác nhau. Một kỹ thuật phát hiện dị 7
thường dựa trên học sâu khác đã được Kanarachos và cộng sự đề xuất gần đây. [29],
trong đó họ kết hợp wavelet và biến đổi Hilbert với các mạng nơron sâu. Chúng nhằm
mục đích phát hiện những điểm bất thường trong các mẫu chuỗi thời gian. 2.2
Các phương pháp hiện đại được sử dụng
Gói phát hiện dị thường của Twitter Inc. có nguồn mở vào năm 2015, dựa trên
thuật toán Seasonal Hybrid ESD (S-H-ESD) [33]. Kỹ thuật này dựa trên kiểm tra
Generalized Extreme Studentized Deviate (ESD) [34] để xử lý nhiều hơn một giá trị
ngoại lệ và Seasonal and Trend Decomposition using Loess (STL) [35] để đối phó với
sự phân hủy dữ liệu chuỗi thời gian và xu hướng theo mùa. Tính năng Phát hiện Bất
thường trên Twitter có thể phát hiện cả những điểm bất thường toàn cầu và cục bộ. 8 3.
Lý do lựa chọn đề tài
Trong phần này, chúng tôi sẽ giới thiệu về những ứng dụng tiềm năng của phát
hiện bất thường là lý do để chúng tôi lựa chọn đề tài này. Nó có thể ứng dụng cho việc
ngăn ngừa vi phạm dữ liệu được trình bày ở phần 3.1, sử dụng trong mạng dữ liệu ở
phần 3.2, trong y tế ở phần 3.3. 3.1 Vi phạm dữ liệu
Trong thời đại của dữ liệu lớn, nơi lưu giữ những thông tin người dùng quan
trọng của các công ty, việc bảo vệ thông tin người dùng là vô cùng quan trọng. Mọi vi
phạm liên quan đến thông tin đều phải được gắn nhãn ngay lập tức. Tuy nhiên, với một
quy mô lớn như vậy, thêm việc thông tin liên tục được cập nhật và chỉnh sửa, thì việc
gắn nhãn thủ công gần như là điều bất khả thi. Qua đó, phương pháp phát hiện bất
thường trên chuỗi thời gian sẽ là một giải pháp tuyệt vời cho những công ty về việc
bảo vệ thông tin khách hàng của chính mình. 3.2 Mạng dữ liệu
Có lẽ một trong những trường hợp sử dụng quan trọng nhất mà phát hiện bất
thường đó là mạng dữ liệu. Internet là nơi lưu trữ một loạt các trang web khác nhau ở
khắp nơi trên thế giới. Thật không may, do sự dễ dàng của việc truy cập internet, nhiều
cá nhân khác nhau có thể truy cập internet với những mục đích bất chính. Tương tự
như các vụ rò rỉ dữ liệu đã được thảo luận trước đó trong bối cảnh bảo vệ dữ liệu của
công ty, tin tặc có thể thực hiện các cuộc tấn công vào các trang web khác cũng như
làm rò rỉ thông tin của họ. 3.3 Y tế
Chuyển từ kết nối mạng, phát hiện bất thường có một vai trò to lớn trong lĩnh
vực y học. Ví dụ: các mô hình có thể phát hiện những bất thường tinh tế trong nhịp tim
của bệnh nhân để phân biệt loại bệnh hoặc chúng có thể đo hoạt động sóng não để giúp
bác sĩ chẩn đoán một số tình trạng nhất định. Ngoài ra, chúng có thể giúp phân tích dữ
liệu chẩn đoán thô cho cơ quan của bệnh nhân và xử lý để chẩn đoán nhanh chóng bất
kỳ vấn đề nào có thể xảy ra ở bệnh nhân, tương tự như ví dụ về tuyến giáp đã thảo luận
trước đó.Tính năng phát hiện dị thường thậm chí có thể được sử dụng tronghình ảnh y
tế để xác định xem một hình ảnh nhất định có chứa các vật thể dị thường hay không.
Ví dụ: nếu một mô hình chỉ đượctiếp xúc với hình ảnh MRI của xương bình thường và
được hiển thị hình ảnh xương bị gãy, nó sẽ gắn cờ hình ảnh mới là bất thường. Tương
tự, phát hiện bất thường thậm chí có thể được mở rộng sang phát hiện khối u, cho phép
mô hình phân tích mọi hình ảnh trong quét MRI toàn thân và tìm kiếm sự hiện diện
của mô hình hoặc tăng trưởng bất thường. 9 4.
Phương pháp nghiên cứu
Trong phần này, chúng tôi sẽ trình bày về những vấn đề của phương pháp phát
hiện bất thường trong chuỗi thời gian ở phần 4.1. Phương pháp Moving Average (MA)
trong phần 4.2, phương pháp Moving Median (MM) trong phần 4.3, giới thiệu về
Convolutional Neural Network (CNN) trong phần 4.4, phương pháp Seasonal and
Trend Decomposition Procedure Based on Loess (STL) trong phần 4.5, phương pháp
Spectral Residual (SR) trong phàn 4.6 và cách kết hợp của các phương pháp trong phần 4.7. 4.1
Vấn đề của phát hiện bất thường trong chuỗi thời gian
Vấn đề 1: Thiếu Nhãn. Để cung cấp dịch vụ phát hiện bất thường, hệ thống phải
xử lý hàng triệu chuỗi thời gian đồng thời. Không có cách nào dễ dàng để người dùng
gắn nhãn từng chuỗi thời gian theo cách thủ công. Hơn nữa, sự phân bố dữ liệu của
chuỗi thời gian liên tục thay đổi, điều này đòi hỏi hệ thống phải nhận ra các điểm bất
thường mặc dù các mẫu tương tự chưa từng xuất hiện trước đây. Điều đó làm cho các
mô hình được giám sát không đủ dữ liệu để tập huấn.
Vấn đề 2: Tổng quát hóa. Cần phải giám sát nhiều loại chuỗi thời gian khác
nhau từ các tình huống khác nhau. Vì vậy, chúng ta cần tìm một giải pháp có tính tổng quát tốt hơn.
Vấn đề 3: Hiệu quả. Việc hệ thống phải xử lý hàng trăm triệu chuỗi thời gian
trong thời gian dẫn đến mỗi phút trong chuỗi thời gian, phát hiện bất thường cần đưa
ra kết quả trong một khoảng thời gian nhất định. Điều này dẫn đến, hiệu quả của hệ
thống là một trong những yêu cầu quan trọng đối với việc xử lý bất thường trong chuỗi
thời gian, để nó có thể cho ra những kết quả tốt. 4.2
Phương pháp Moving Average (MA)
Moving Average là một trong những kỹ thuật được biết rộng rãi được sử dụng
để dựa đoán những dữ liệu tương lai trong phân tích chuỗi thời gian. Cho đến lúc được
phát triển, có nhiều cách triển khai khác nhau được tạo ra bởi các nhà nghiên cứu. Đối
với chuỗi thời gian, mỗi điểm được nhân với trọng số riêng – chuẩn hóa các điểm
trong chuỗi thời gian – để rồi so sánh với ngưỡng, khi giá trị của dữ liệu lớn hơn 10
ngưỡng thì dữ liệu đó chính là điểm bất thường. Tuy nhiên, MA có nhược điểm của nó
khi nó dễ bị lỗi khi gặp những điểm nhiễu. 4.3
Phương pháp Moving Median (MM)
Moving Median không được phổ biến như Moving Average, tuy nhiên nó có
những ứng dụng thú vị của nó. MM sẽ cung cấp những ước tính so sánh mạnh mẽ về
hướng/chiều dữ liệu so với MA. Do đó, MM sẽ không bị ảnh hưởng bởi nhiễu vì nó sẽ
chuẩn hóa các điểm dữ liệu trong chuỗi thời gian, mà nó sẽ tác động lên ngưỡng tùy
theo dữ liệu truyền vào là như nào. 4.4
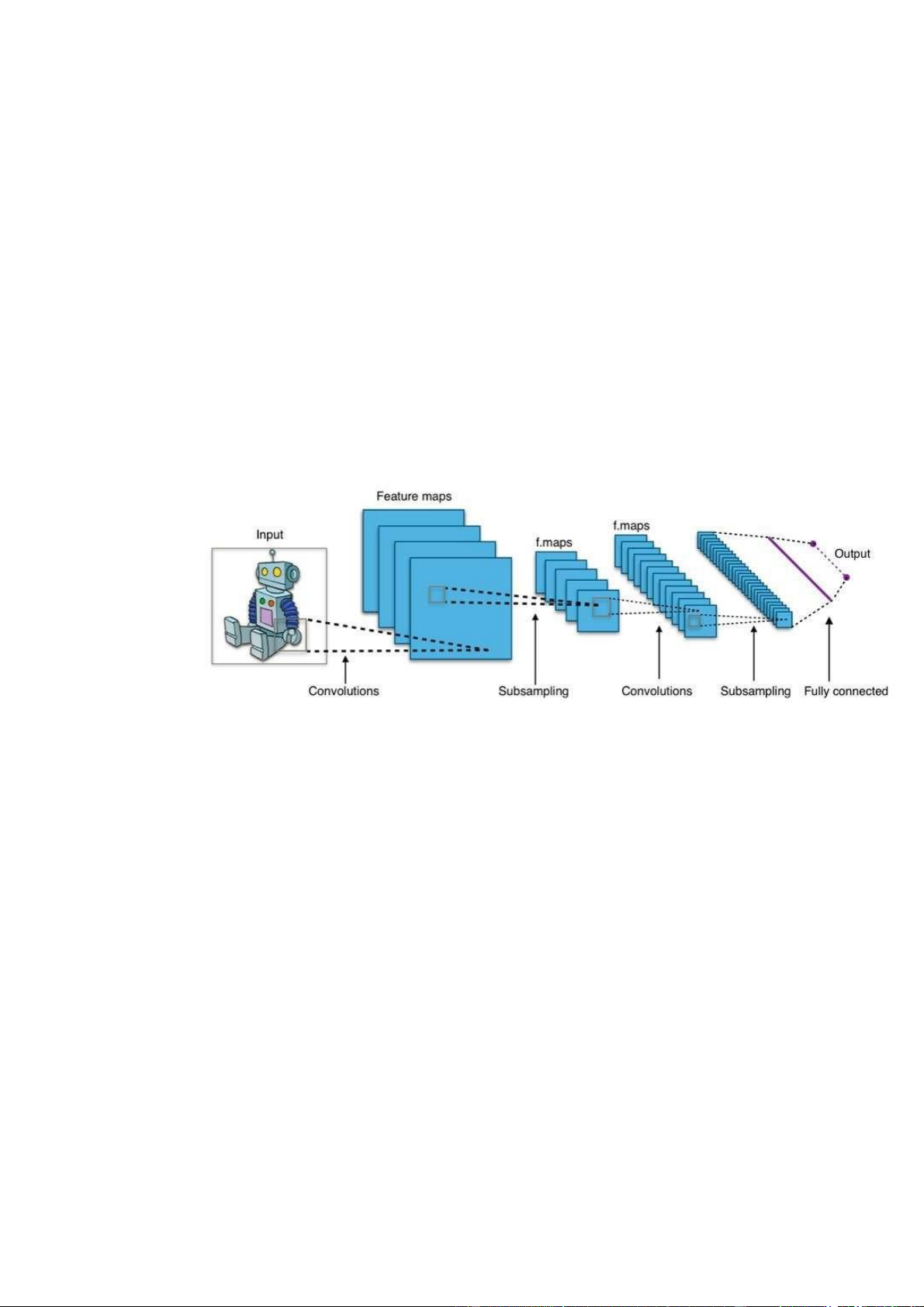
Giới thiệu về Convolutional Neural Network (CNN)
CNN là một trong những mô hình thuật toán Deep Learning.
Convolution layer – lớp tích chập là lớp đầu tiên để trích xuất các đặc tính của
dữ liệu dầu vào. Các Convolution layer có các kernel(ma trận trọng số) đã được
học để tự điều chỉnh lấy ra những thông tin chính xác nhất mà không cần lựa chọn đặc tính.
Pooling layer – lớp tổng hợp thường được sự dụng ngay sau Convolution layer
để đơn giản hóa thông tin đầu ra nhằm giảm bớt số lượng noron. Có 2 loại phổ
biến là max pooling và average pooling.
Padding – Đường viền: đôi khi dữ liệu đầu vào không phù hợp với kernel mà
ta lựa chọn. Ta có 2 cách xử lý là thêm hoặc cắt bớt số tại những điểm để tạo ra
được ma trận phù hợp.
Hàm Relu – Hàm phi tuyến là từ viết tắt của Rectified Linear Unit. Hàm Relu
quan trọng vì dữ liệu trong thế giới chúng ta tìm hiểu là các giá trị phi tuyến
không âm. Tác dụng chính của hàm Relu là mô phỏng các noron có tỷ lệ truyền
xung qua axon. Một số hàm Relu phổ biến là: Sigmoid, Tanh, Relu, ...
Fully connected layer là lớp cuối cùng trong mạng CNN. Tác dụng của lớp là
tổng hợp lại các trọng số từ đó đưa ra kết quả của mô hình. 11 4.5
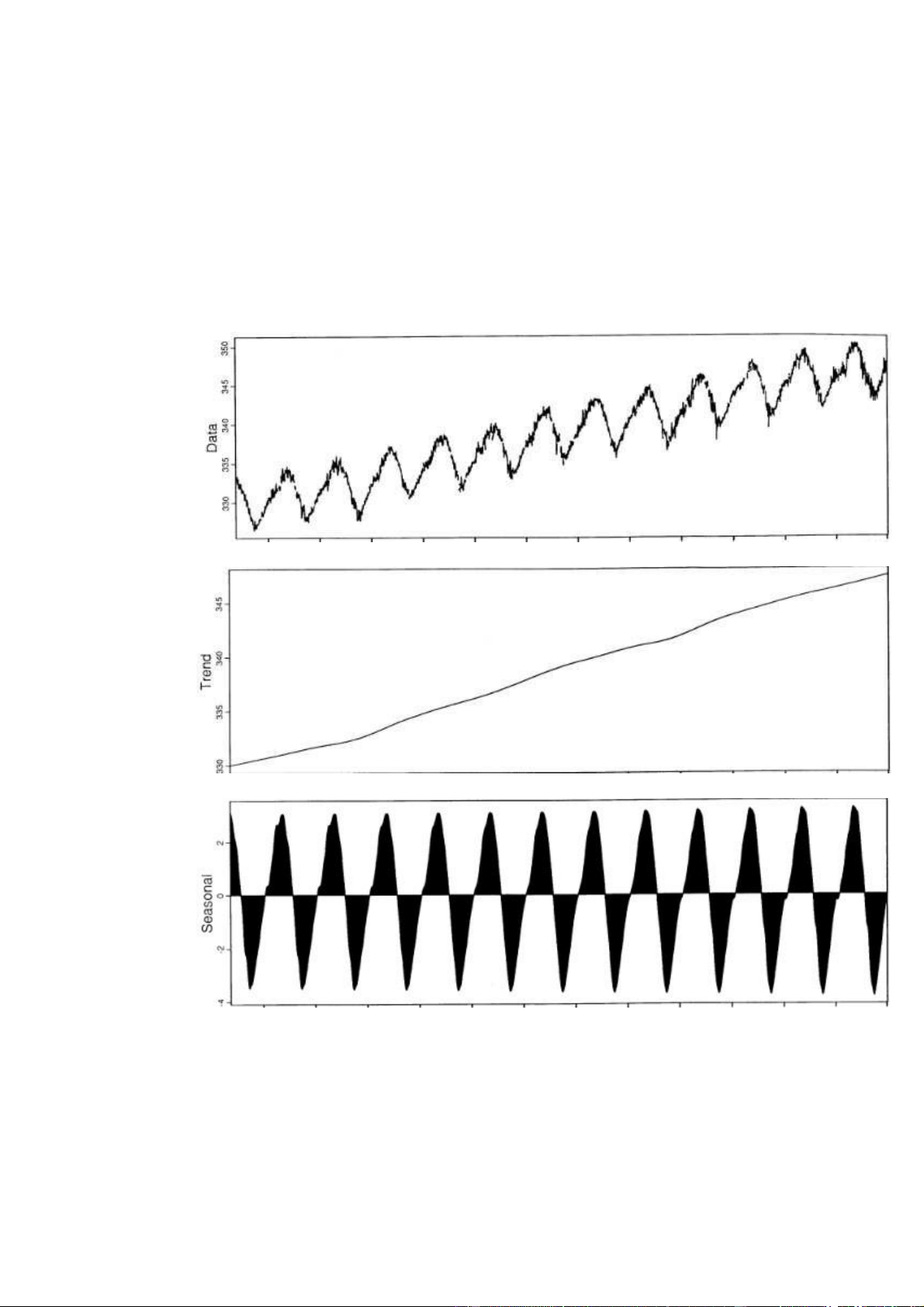
Phương pháp Seasonal and Trend decomposition using Loes (STL)
STL là một thủ tục lọc để phân tách một chuỗi thời gian thành các thành phần
xu hướng, theo mùa và phần còn lại.
Ta có thể biểu diễn nó bằng công thức sau:
Hình dưới đây sẽ mô tả kết quả quá trình khi sử dụng STL. 12
Việc sử dụng STL, giúp chúng tôi phân tách chuỗi thời gian phức tạp thành các
chuỗi thời gian có những đặc điểm riêng (theo xu hướng, theo mùa), việc này sẽ giúp
việc tính toán cho các phương pháp sau sẽ trở nên đơn giản hơn, việc kết hợp STL
cùng với các phương pháp khác nhau nó sẽ cho ra kết quả tốt hơn. 4.6
Thuật toán Spectral Residual (SR)
Thuật toán Spectral Residual (SR) được chia làm 3 bước chính:
1. Sử dụng Fourier Transform để nhận được log amplitude spectrum.
2. Tính toán spectral residual.
3. Inverse Fourier Transform để chuyển đổi chuỗi trở về không gian.
Về mặt toán học, nhận vào một chuỗi x, chúng ta sẽ có:
Ở đây, và ký hiệu của Fourier Tranform và Inverse Fourier Transform tương
ứng. là chuỗi đầu vào với kích thước , là amplitude spectrum của chuỗi . là
corresponding phase spectrum của chuỗi . là log tương ứng của . Và là average
spectrum của với sấp xỉ bằng cách convoluting chuỗi đầu vào bằng , với là một ma
trận được xác định như sau:
là spectral residual, tưng ứng, log spectrum trừ averaged log spectrum .
Spectral residual đáp ứng việc nén các chuỗi dữ liệu tương ứng trong khi việc thay đổi
một phần chuỗi ban đầu sẽ trở nên ý nghĩa hơn. Cuối cùng, chúng sẽ chuyển chuỗi trở
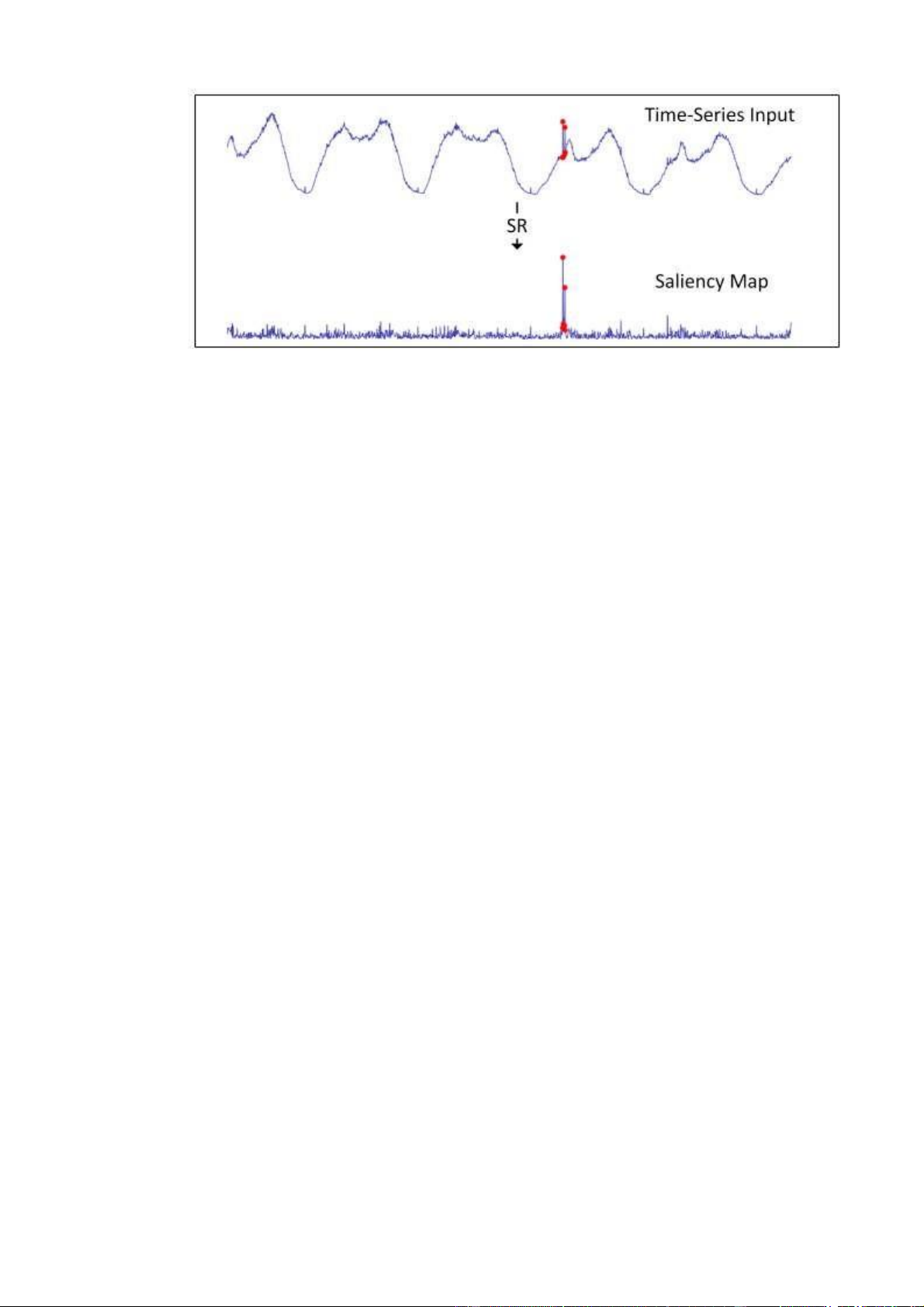
lại miền không gian đầu bằng Inverse Fourier Transform. Kết quả của chuỗi được gọi là saliency map. 13
Như hình trên là ví dụ của chuỗi thời gian ban đầu và saliency map tương ứng
sau quá trình SR. Như hình trên,, Điểm thay đổi (màu đỏ) trong saliency map đã trở
nên có ý nghĩa hơn so với chuỗi đầu vào. Dựa vào saliency map, nó có thể dễ dàng sử
dụng những quy tắc đơn giản để gán nhãn các điểm bất thường chính xác.
Chúng ta sẽ đặt một ngưỡng để gán các điểm bất thường. Lấy từ saliency map ,
đầu ra chuỗi được tính như sau:
Với đại diện cho một điểm tùy ý theo trình tự chuỗi ; là điểm tương ứng trong
saliency map; và là lân cận trung bình trước đó của điểm của . Với label 1 chính là
những điểm bất thường, label 0 là những điểm bình thường.
Trong thực tế, phép tính Fourier Transform được tiến hành trong sliding
window của chuỗi. Thêm nữa, chúng tôi mong muốn thuật toán nhận ra các điểm bất
thường với ít sự tiềm tàng hơn. Vì vậy, khi nhận một chuỗi với là những điểm lân
cận, chúng ta muốn tìm được là điểm bất thường càng sớm càng tốt. Tuy nhiên, mô
hình SR sẽ làm việc tốt hơn nếu điểm chọn nằm ở vị trí chính giữa sliding window. Do
đó, chúng ta sẽ thêm vào một estimated points sau trước đầu vào của chuỗi cho mô
hình SR. Giá trị được tính như sau:
Với ký hiệu của gradient của đường thẳng giữa điểm và điểm ; và đại điện
cho gradient trung bình của các điểm trước đó. là số lượng các điểm sinh ra trước đó,
và chúng tôi đạt trong mỗi lần triển khai. 14
Tổng kết lại, thuật toán SR chứa một số siêu tham số, sliding window cỡ , số
lượng điểm ước tính , và ngưỡng điểm bất thường . Do vậy, thuật toán SR là lựa chọn
tốt cho việc phát hiện bất thường với chuỗi thời gian. 4.7
Kết hợp các phương pháp
Nội dung các phương pháp như đã trình bày ở trên, giờ đây thử thách của chúng
tôi là lắp ghép chúng để có thể cho ra những kết quả tốt hơn.
Khi chúng tôi kết hợp STL-SR lại khi đó nó sẽ được sử dụng để làm quá trình
xử lý dữ liệu thô trước khi sử dụng để huấn luyện mô hình. Quá trình xử lý dữ liệu của
STL-SR sẽ trải qua hai giai đoạn STL xen giữa là một giai đoạn SR. Từ đó CNN sử
dụng dữ liệu đã qua xử lý để huấn luyện, từ đó kết quả sẽ tốt hơn.
Không chỉ có thể kết hợp STL-SR để xử lý data, chúng tôi cũng có thể kết hợp
SR-CNN, sở dĩ vì phương thức SR thông thường sử dụng một ngưỡng duy nhất trên
saliency map để phát hiện điểm bất thường. Tuy nhiên nó quá đơn giản để phát hiện
những điểm bất thường trong một chuỗi thời gian có độ phức tạp cao, nên để cải thiện
nó, chọn ngẫu nhiên một số điểm trong chuỗi thời gina, tính toán giá trị tiêm để thay
thế điểm gốc và lấy saliency map của nó. Giá trị của các điểm bất thường sẽ được tính toán qua:
Với là giá trị trung bình của các điểm lân cận trước đó, mean và var là giá trị
trung bình và phương sai của toàn bộ điểm dữ liệu trong lần lượt sliding window; và là mẫu ngẫu nhiên.
Chúng ta chọn CNN như là cấu trúc phân loại của mô hình. CNN thường được
sử dụng cho mô hình học có giám sát cho saliency dettection. Tuy nhiên, nó không thể
gắn nhán cho dữ liệu trong mọi trường hợp của nó, vì vậy chúng ta sẽ sử dụng nó ở
saliency map thay vì là dữ liệu thô, do vậy vấn đề về việc phát hiện bất thường nó sẽ
trở nên dễ dàng hơn. Thực tế, việc thu nhập chuỗi thời gian với điểm bất thường như là
dữ liệu đào tạo. Lợi ích của nó là máy dò có thể thích ứng với sự thay đổi của phân
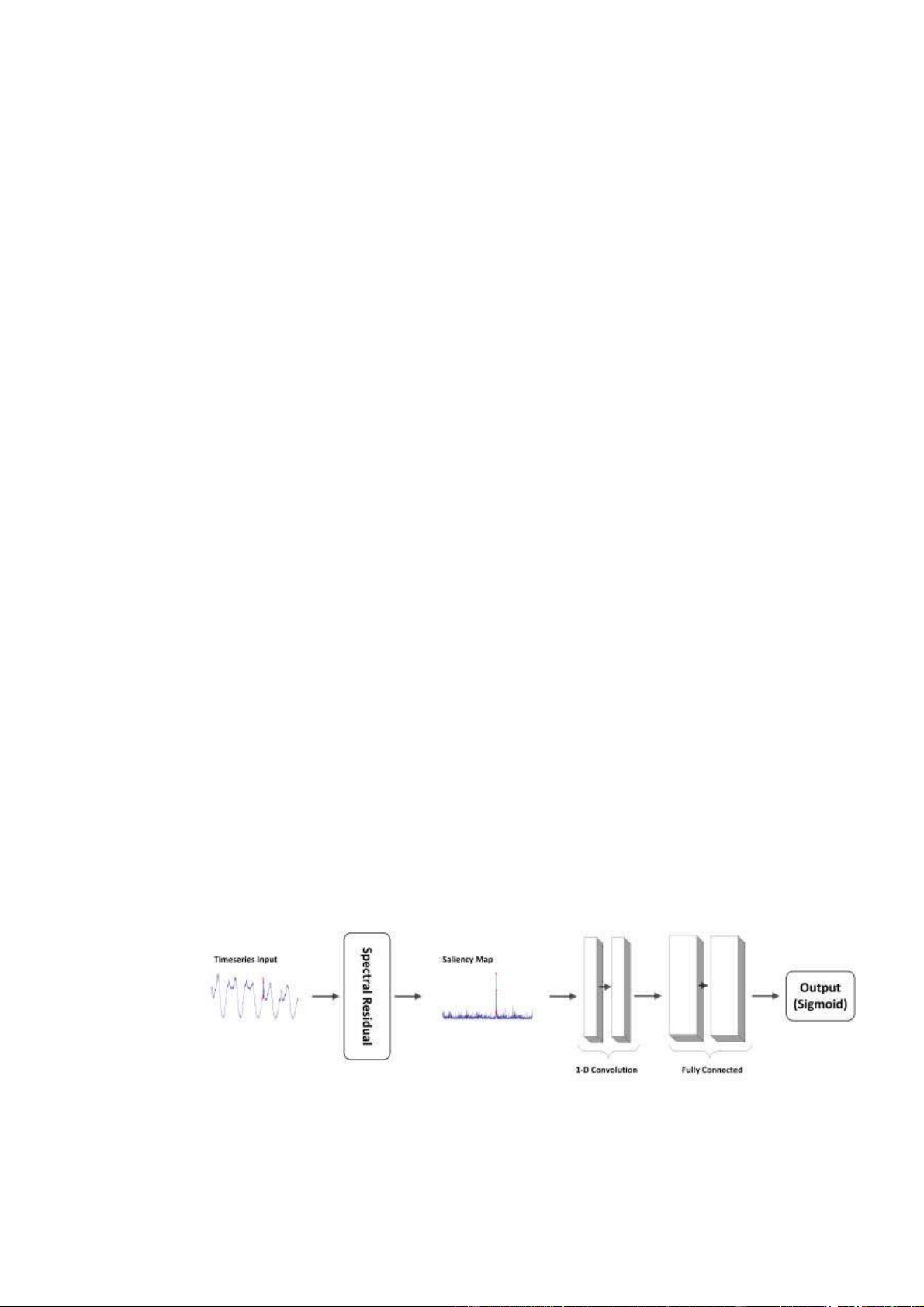
phối của chuỗi thời gian. Cấu trúc của SR-CNN sẽ được biểu diễn như trong hình sau
Mạng ở đây bao gồm hai lớp convolutional 1-D (với độ lớn filter bằng với độ lớn
window size ) và hai lớp fully connected. Độ dài channel đầu tiên của lớp
convolutional sẽ bằng ; trong khi độ lớn sẽ được gấp đôi tỏng lớp convolutional thứ
hai. Hai fully connected được trồng lên nahu trước Output(Sigmoid). Cross entropy
được dùng làm hàm mất mát; và tối ưu SGD được sử dụng trong quá trình đào tạo. 15
Không chỉ có những phương pháp hiện đại có thể kết hợp được với nhau, mà
những phương pháp truyền thống như MM hay MA cũng có thể kết hợp với những
phương pháp hiện đại để cho ra kết quả tốt hơn. Ở đây, chúng tôi kết hợp MM-STL,
kết quả của nó sẽ vượt trội so với phương pháp MM truyền thống – trình bày trong
phần 6 – với việc STL sẽ xử lý những dữ liệu thô ban đầu và nó sẽ khắc phục việc MM
thay vì phải xử lý những dữ liệu nó phức tạp thì khi chia dữ liệu thành các đặc điểm có
đặc tính riêng (theo mùa, theo xu hướng) thì MM sẽ hoạt động tốt khi các giá trị
ngưỡng sẽ luôn thay đổi nhưng với giá trị có ý nghĩa.
Tất nhiên, CNN-STL kết hợp được với nhau, khi STL sẽ được sử dụng để thu
thập những thành phần cnf lại từ dữ liệu thô của chuỗi thời gian. Sau đó, phần còn lại
được sử dụng để đào tạo mô hình CNN thay vì dữ liệu thô để có hiệu suất tốt hơn. Lưu
ý rằng dư liệu huấn luyện không chứa dữ liệu bất thường, tức là dữ liệu bình thường.
CNN-STL lấy window của chuỗi thời gian và cố gắng dự đoán và sự thất nó được so
sánh với một ngưỡng để quyết định điểm dữ liệu bất thường hay không. 16 5.
Đối tượng nghiên cứu
Trong phần này, chúng tôi sẽ trình bày về các tập dữ liệu được sử dụng để
chúng tôi kiểm tra mô hình kết hợp của mình, tập dữ liệu DCOILBRENTEU được giới
thiệu ở phần 5.1, tập dữ liệu DHOILNYH được giới thiệu ở phần 5.2, tập dữ liệu
OVXCLS được giới thiệu ở phần 5.3, tập dữ liệu DCOILWTICO được giới thiệu ở
phần 5.4, tập dữ liệu DHHNGSP được giới thiệu ở phần 5.5. 5.1
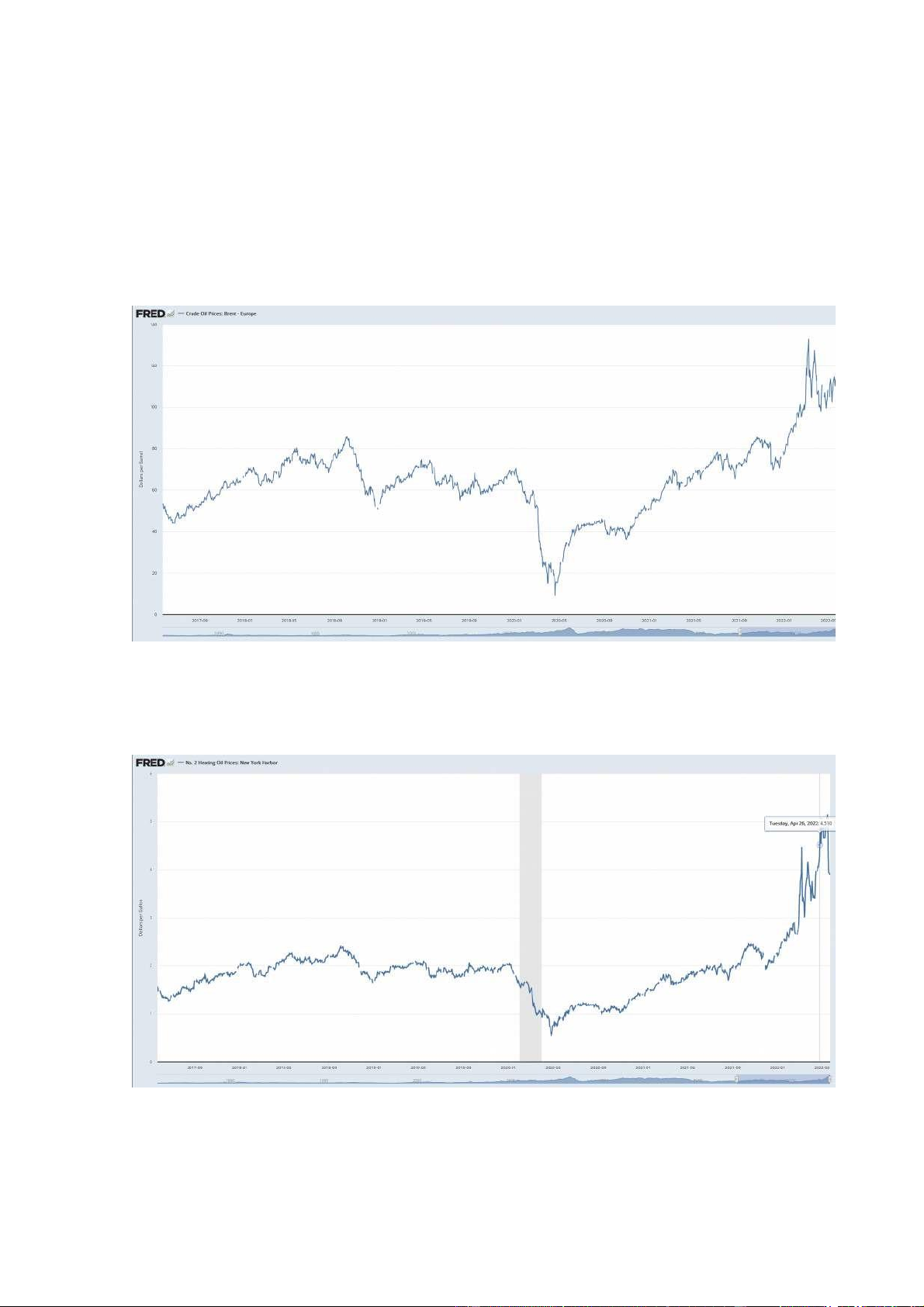
Tập dữ liệu DCOILBRENTEU
Đây là tập dữ liệu trực tuyến về giá Crude Oil của Brent – Europe tại thời điểm ngày 24/05/2022. 5.2
Tập dữ liệu DHOILNYH
Đây là tập dữ liệu trực tuyến về giá trị Heating Oil: New York Harbor tại thời điểm ngày 24/05/2022. 17 5.3
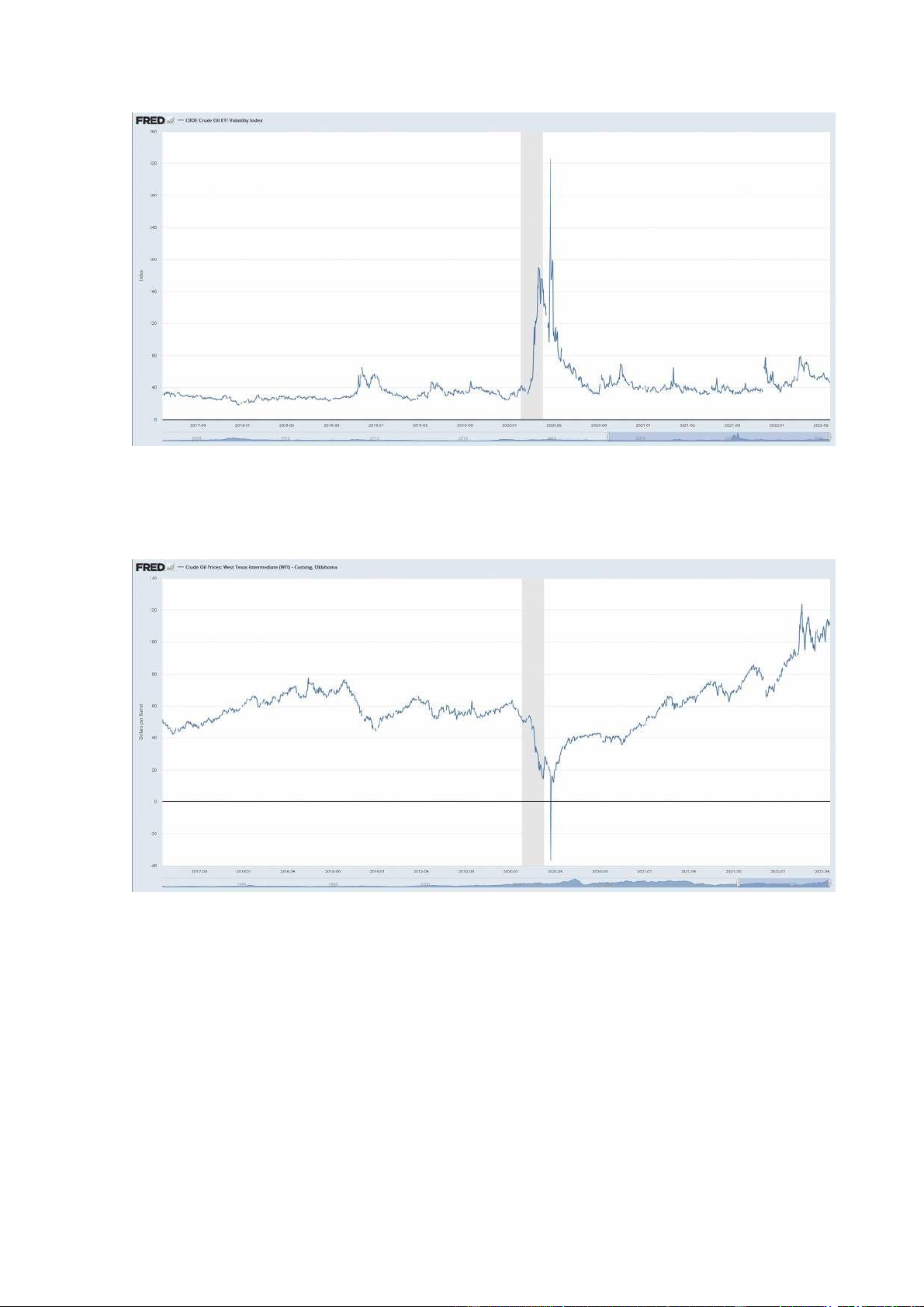
Tập dữ liệu OVXCLS
Đây là tập dữ liệu trực tuyến chỉ số biến động ETF dầu thô CBOE tại thời điểm ngày 24/05/2022. 5.4
Tập dữ liệu DCOILWTICO
Đây là tập dữ liệu trực tuyến giá trị Crude Oil: West Texas Intermediate (WTI) –
Cushing, Oklahoma vào ngày 24/05/2022 18 5.5
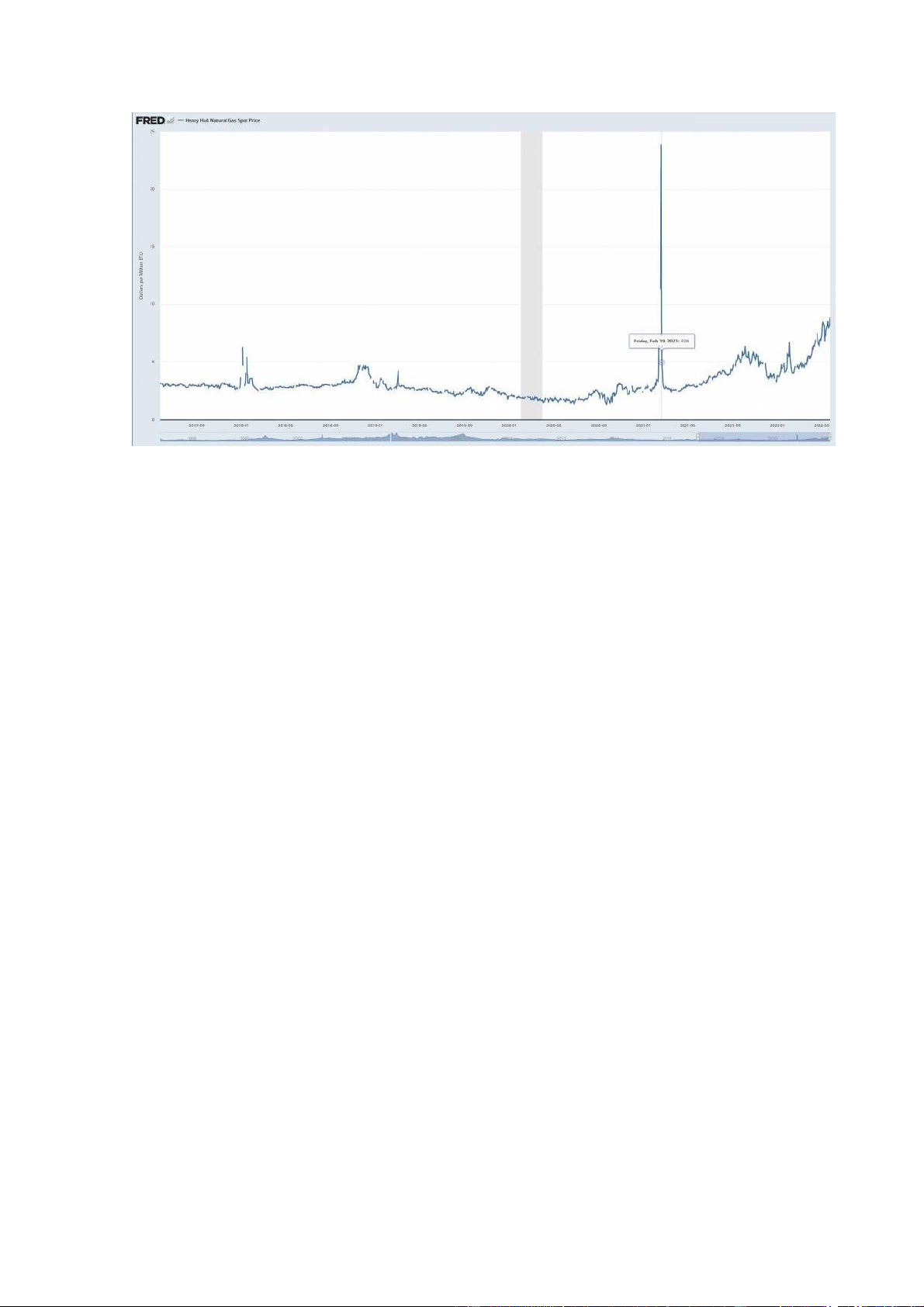
Tập dữ liệu DHHNGSP
Đây là tập dữ liệu trực tuyến về giá giao dịch khí đớt tự nhiên Henry Hub vào ngày 24/05/2022. 19 6.
Kết quả nghiên cứu CNN-STL- MM-STL CNN-STL MM MA P 0. 04 0 0. 16 67 0. 03 13 0. 20 14 0. 02 13 Dataset SR P R F1 P R F1 P R F1 P R F1 R F1
DCOIL 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
BRENT 96 87 91 92 89 91 72 77 74 52 84 69 02 02 EU
15 49 52 90 99 37 32 78 45 78 44 57 1 8
DHOIL 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. NYH
89 88 89 87 89 88 67 76 71 36 86 51 02 03
61 55 02 10 78 38 89 14 44 36 96 28 13 77 OVXC 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. LS
82 75 78 73 89 81 74 71 72 15 75 25 10 04
45 08 15 96 93 08 05 54 10 15 00 21 00 76 DCOIL 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
WTICO 93 89 91 90 83 86 71 76 73 23 78 35 12 15
57 25 27 10 28 47 90 86 98 15 54 76 31 28 DHHN 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 20
GSP 78 77 77 79 72 75 65 72 68 16 82 27 13 03 05 48 50 00 69 58 43 24 50 48 35 46 01 66
Từ bảng kết quả thực nghiệm, ta có thể thấy các mô hình truyền thống có kết quả kém
với chuỗi dữ liệu phức tạp. Nhưng chỉ cần kết hợp với một phương thức, ở đây là
MM-STL với chỉ một phương thức MM, kết quả cho ra đã hoàn toàn khác biệt. Hay
mô hình CNN-STL so với mô hình MM-STL có kết quả không tốt bằng, nhưng khi kết
hợp với CNN-STL-SR thì kết quả đã tốt hơn so với ban đầu. Điều này là bằng chứng
cho những lý thuyết đã trình bày ở phần 4.7 về việc kết hợp các phương pháp.
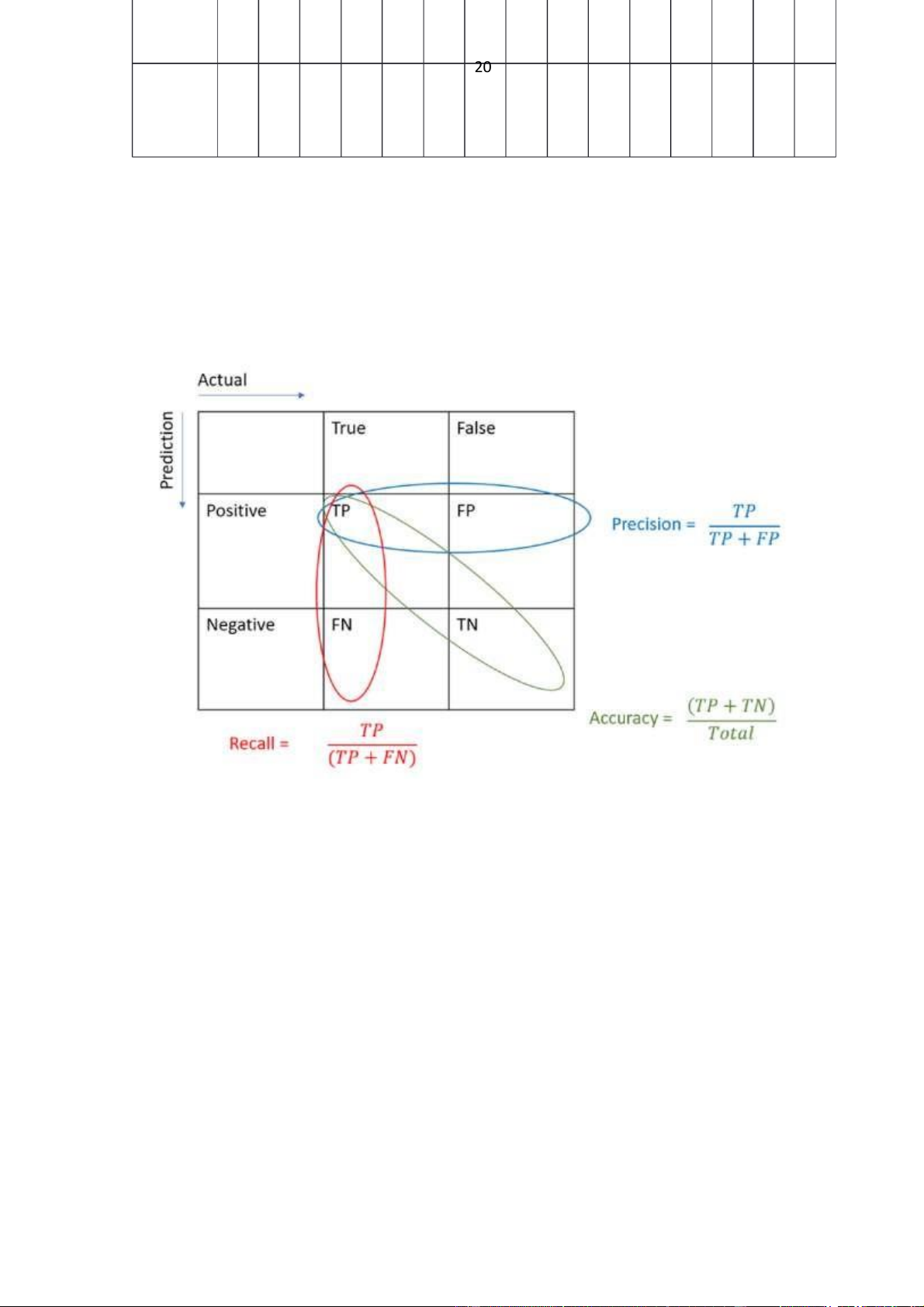
Giới thiệu về Precision (P), Recall (R) và F1 Score (F1)
Precision: là phép đo mô tả có bao nhiêu dự đoán đúng nó thực sự đúng.
Accuracy: là phép đo mô tả số lượng bạn nhận được đúng trên toàn bộ tập dữ liệu.
Recall: là phép đo mô tả số lượng bạn đã dự đoán đúng cho tất cả các điểm dữ liệu thực sự đúng.
Từ đó bạn có thể tính F1 Score: