Khai phá dữ liệu bằng kỹ thuật phân cụm
Khai phá dữ liệu bằng kỹ thuật phân cụm được biên soạn dưới định dạng file PDF cho các bạn SV tham khảo, ôn tập kiến thức, chuẩn bị cho các kì thi sắp tới. Mời bạn đọc đón xem.
Môn: Water Resources Engineering 4 tài liệu
Trường: Trường Đại học Xây Dựng Hà Nội 543 tài liệu
Tác giả:





































































Preview text:
lOMoAR cPSD| 39651089
See discussions, stats, and author profiles for this publication at: https://www.researchgate.net/publication/204753072
WEB data mining by clustering technique Thesis · January 2007 CITATIONS READS 0 7,578 1 author: Hoang Van Dung
HCMC University of Technology and Education
100 PUBLICATIONS 912 CITATIONS lOMoAR cPSD| 39651089 MỤC LỤC
MỤC LỤC ................................................................................................... i
DANH SÁCH CÁC HÌNH ......................................................................... v
DANH SÁCH CÁC BẢNG BIỂU ............................................................ vi
CÁC CỤM TỪ VIẾT TẮT........................................................................ vii
LỜI MỞ ĐẦU .............................................................................................. 1
Chương 1. TỔNG QUAN VỀ KHAI PHÁ DỮ LIỆU ................................. 3
1.1. Khai phá dữ liệu và phát hiện tri thức ......................................................... 3
1.1.1. Khai phá dữ liệu ................................................................................... 3
1.1.2. Quá trình khám phá tri thức .................................................................. 4
1.1.3. Khai phá dữ liệu và các lĩnh vực liên quan .......................................... 5
1.1.4. Các kỹ thuật áp dụng trong khai phá dữ liệu ........................................ 5
1.1.5. Những chức năng chính của khai phá dữ liệu ...................................... 7
1.1.6. Ứng dụng của khai phá dữ liệu ............................................................. 9
1.2. Kỹ thuật phân cụm trong khai phá dữ liệu ................................................ 10
1.2.1. Tổng quan về kỹ thuật phân cụm ........................................................ 10
1.2.2. Ứng dụng của phân cụm dữ liệu ......................................................... 13
1.2.3. Các yêu cầu ối với kỹ thuật phân cụm dữ liệu ................................. 13
1.2.4. Các kiểu dữ liệu và ộ o tương tự ..................................................... 15
1.2.4.1. Phân loại kiểu dữ liệu dựa trên kích thước miền ......................... 15
1.2.4.2. Phân loại kiểu dữ liệu dựa trên hệ o .......................................... 15
1.2.4.3. Khái niệm và phép o ộ tương tự, phi tương tự........................ 17
1.3. Khai phá Web ............................................................................................ 20
1.3.1. Lợi ích của khai phá Web ................................................................... 20
1.3.2. Khai phá Web ..................................................................................... 21
1.3.3. Các kiểu dữ liệu Web .......................................................................... 22
1.4. Xử lý dữ liệu văn bản ứng dụng trong khai phá dữ liệu Web .................. 23
1.4.1. Dữ liệu văn bản ................................................................................... 23
1.4.2. Một số vấn ề trong xử lý dữ liệu văn bản ......................................... 23
1.4.2.1. Loại bỏ từ dừng ............................................................................ 24
1.4.2.2. Định luật Zipf .............................................................................. 25
1.4.3. Các mô hình biểu diễn dữ liệu văn bản .............................................. 26
1.4.3.1. Mô hình Boolean ......................................................................... 26
1.4.3.2. Mô hình tần số ............................................................................. 27
1.5. Tổng kết chương 1 ..................................................................................... 30 lOMoAR cPSD| 39651089
Khai phá dữ liệu Web bằng kỹ thuật phân cụm
Chương 2. MỘT SỐ KỸ THUẬT PHÂN CỤM DỮ LIỆU ....................... 31
2.1. Phân cụm phân hoạch ................................................................................ 31
2.1.1. Thuật toán k-means ............................................................................. 32
2.1.2. Thuật toán PAM .................................................................................. 34
2.1.3. Thuật toán CLARA ............................................................................. 38
2.1.4. Thuật toán CLARANS........................................................................ 39
2.2. Phân cụm phân cấp .................................................................................... 41
2.2.1. Thuật toán BIRCH .............................................................................. 42
2.2.2. Thuật toán CURE ................................................................................ 45
2.3. Phân cụm dựa trên mật ộ ......................................................................... 47
2.3.1 Thuật toán DBSCAN ........................................................................... 47
2.3.2. Thuật toán OPTICS ............................................................................ 51
2.3.3. Thuật toán DENCLUE ....................................................................... 52
2.4. Phân cụm dựa trên lưới.............................................................................. 54
2.4.1 Thuật toán STING ............................................................................... 55
2.4.2 Thuật toán CLIQUE............................................................................. 56
2.5. Phân cụm dữ liệu dựa trên mô hình........................................................... 57
2.5.1. Thuật toán EM .................................................................................... 58
2.5.2. Thuật toán COBWEB ......................................................................... 59
2.6. Phân cụm dữ liệu mờ ................................................................................. 59
2.7. Tổng kết chương 2 ..................................................................................... 60
Chương 3. KHAI PHÁ DỮ LIỆU WEB ..................................................... 62
3.1. Khai phá nội dung Web ............................................................................. 62
3.1.1. Khai phá kết quả tìm kiếm .................................................................. 63
3.1.2. Khai phá văn bản Web ........................................................................ 63
3.1.2.1. Lựa chọn dữ liệu .......................................................................... 64
3.1.2.2. Tiền xử lý dữ liệu ......................................................................... 64
3.1.2.3. Biểu iễn văn bản ......................................................................... 65
3.1.2.4. Trích rút các từ ặc trưng ............................................................. 65
3.1.2.5. Khai phá văn bản ......................................................................... 66
3.1.3. Đánh giá chất lượng mẫu ................................................................ 68
3.2. Khai phá theo sử dụng Web ...................................................................... 69
3.2.1. Ứng dụng của khai phá theo sử dụng Web ......................................... 70 lOMoAR cPSD| 39651089
Khai phá dữ liệu Web bằng kỹ thuật phân cụm
3.2.2. Các kỹ thuật ược sử dụng trong khai phá theo sử dụng Web ........... 71
3.2.3. Những vấn ề trong khai khá theo sử dụng Web. .............................. 71
3.2.3.1. Chứng thực phiên người dùng ..................................................... 71
3.2.3.2. Đăng nhập Web và xác ịnh phiên chuyển hướng người dùng ... 72
3.2.3.3. Các vấn ề ối với việc xử lý Web log ........................................ 72
3.2.3.4. Phương pháp chứng thực phiên làm việc và truy cập Web ......... 73
3.2.4. Quá trình khai phá theo sử dụng Web ................................................ 73
3.2.4.1. Tiền xử lý dữ liệu ......................................................................... 73
3.2.4.2. Khai phá dữ liệu ........................................................................... 73
3.2.4.3. Phân tích ánh giá ........................................................................ 75
3.2.5. Ví dụ khai phá theo sử dụng Web ...................................................... 75
3.3. Khai phá cấu trúc Web .............................................................................. 77
3.3.1. Tiêu chuẩn ánh giá ộ tương tự ........................................................ 79
3.3.2. Khai phá và quản lý cộng ồng Web .................................................. 80
3.3.2.1. Thuật toán PageRank ................................................................... 81
3.3.2.2. Phương pháp phân cụm nhờ thuật toán HITS ............................. 82
3.4. Áp dụng thuật toán phân cụm dữ liệu trong tìm kiếm và PCDL Web ...... 85
3.4.1. Hướng tiếp cận bằng kỹ thuật phân cụm ............................................ 85
3.4.2. Quá trình tìm kiếm và phần cụm tài liệu ............................................ 87
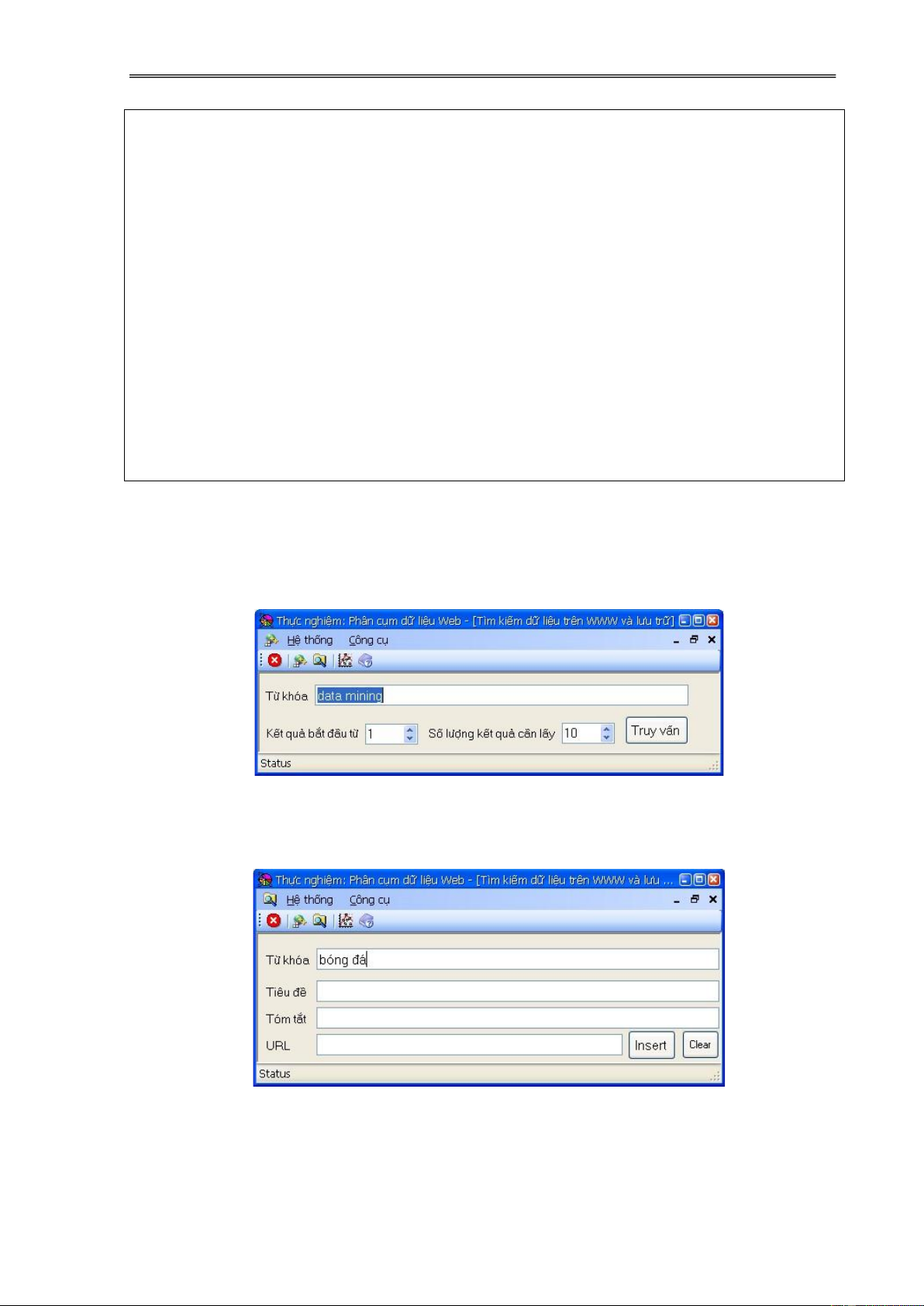
3.4.2.1. Tìm kiếm dữ liệu trên Web .......................................................... 87
3.4.2.2. Tiền xử lý dữ liệu ......................................................................... 88
3.4.2.3. Xây dựng từ iển .......................................................................... 89
3.4.2.4. Tách từ, số hóa văn bản và biểu diễn tài liệu ............................... 90
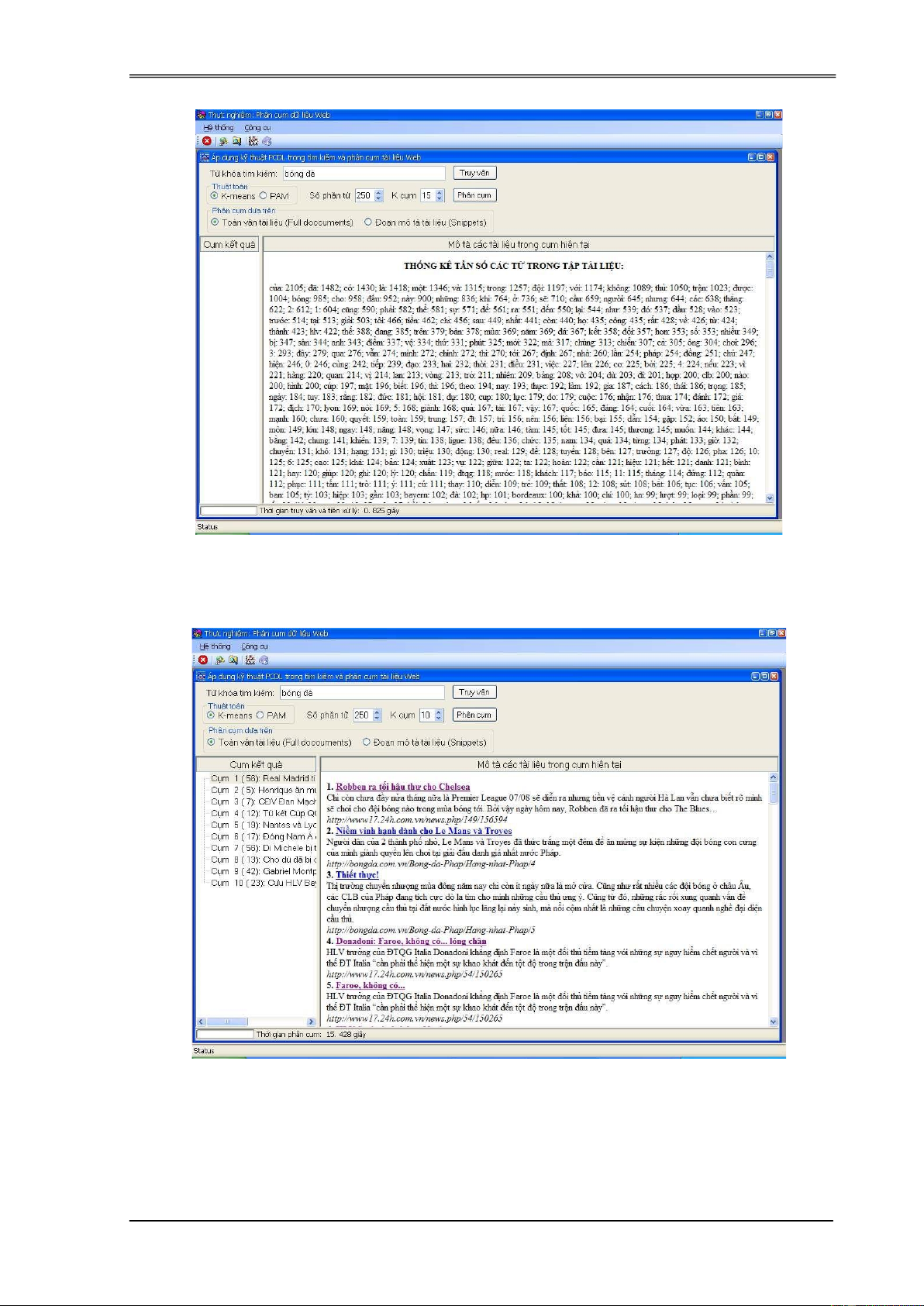
3.4.2.5. Phân cụm tài liệu .......................................................................... 90
3.4.6. Kết quả thực nghiệm ........................................................................... 92
3.5. Tổng kết chương 3 ..................................................................................... 93
KẾT LUẬN VÀ HƯỚNG PHÁT TRIỂN ................................................... 94
PHỤ LỤC ................................................................................................... 96
TÀI LIỆU THAM KHẢO ......................................................................... 102 DANH SÁCH CÁC HÌNH lOMoAR cPSD| 39651089
Khai phá dữ liệu Web bằng kỹ thuật phân cụm
Hình 1.1. Quá trình khám phá tri thức ........................................................... 4
Hình 1.2. Các lĩnh vực liên quan ến khám phá tri thức trong CSDL .......... 6
Hình 1.3. Trực quan hóa kết quả KPDL trong Oracle ................................ 10
Hình 1.4. Mô phỏng sự PCDL ..................................................................... 11
Hình 1.5. Phân loại dữ liệu Web.................................................................. 22
Hình 1.6. Lược ồ thống kê tần số của từ theo Định luật Zipf ................... 26
Hình 1.7. Các ộ o tương tự thường dùng ................................................. 29
Hình 2.1. Thuật toán k-means ..................................................................... 32
Hình 2.2. Hình dạng cụm dữ liệu ược khám phá bởi k-means ................. 33
Hình 2.3. Trường hợp Cjmp=d(Oj,Om,2) – d(Oj, Om) không âm .................... 35
Hình 2.4. Trường hợp Cjmp= (Oj,Op)- d(Oj, Om) có thể âm hoặc dương ..... 36
Hình 2.5. Trường hợp Cjmp bằng không ....................................................... 36
Hình 2.6. Trường hợp Cjmp= (Oj,Op)- d(Oj, Om,2) luôn âm .......................... 37
Hình 2.7. Thuật toán PAM .......................................................................... 37
Hình 2.8. Thuật toán CLARA ..................................................................... 38
Hình 2.9. Thuật toán CLARANS ................................................................ 40
Hình 2.10. Các chiến lược phân cụm phân cấp ........................................... 42
Hình 2.11. Cây CF ược sử dụng bởi thuật toán BIRCH ........................... 43
Hình 2.12. Thuật toán BIRCH ..................................................................... 44
Hình 2.13. Ví dụ về kết quả phân cụm bằng thuật toán BIRCH ................. 44
Hình 2.14. Các cụm dữ liệu ược khám phá bởi CURE ............................. 45
Hình 2.15. Thuật toán CURE ...................................................................... 46
Hình 2.16. Một số hình dạng khám phá bởi phân cụm dưa trên mật ộ ..... 47 lOMoAR cPSD| 39651089
Khai phá dữ liệu Web bằng kỹ thuật phân cụm
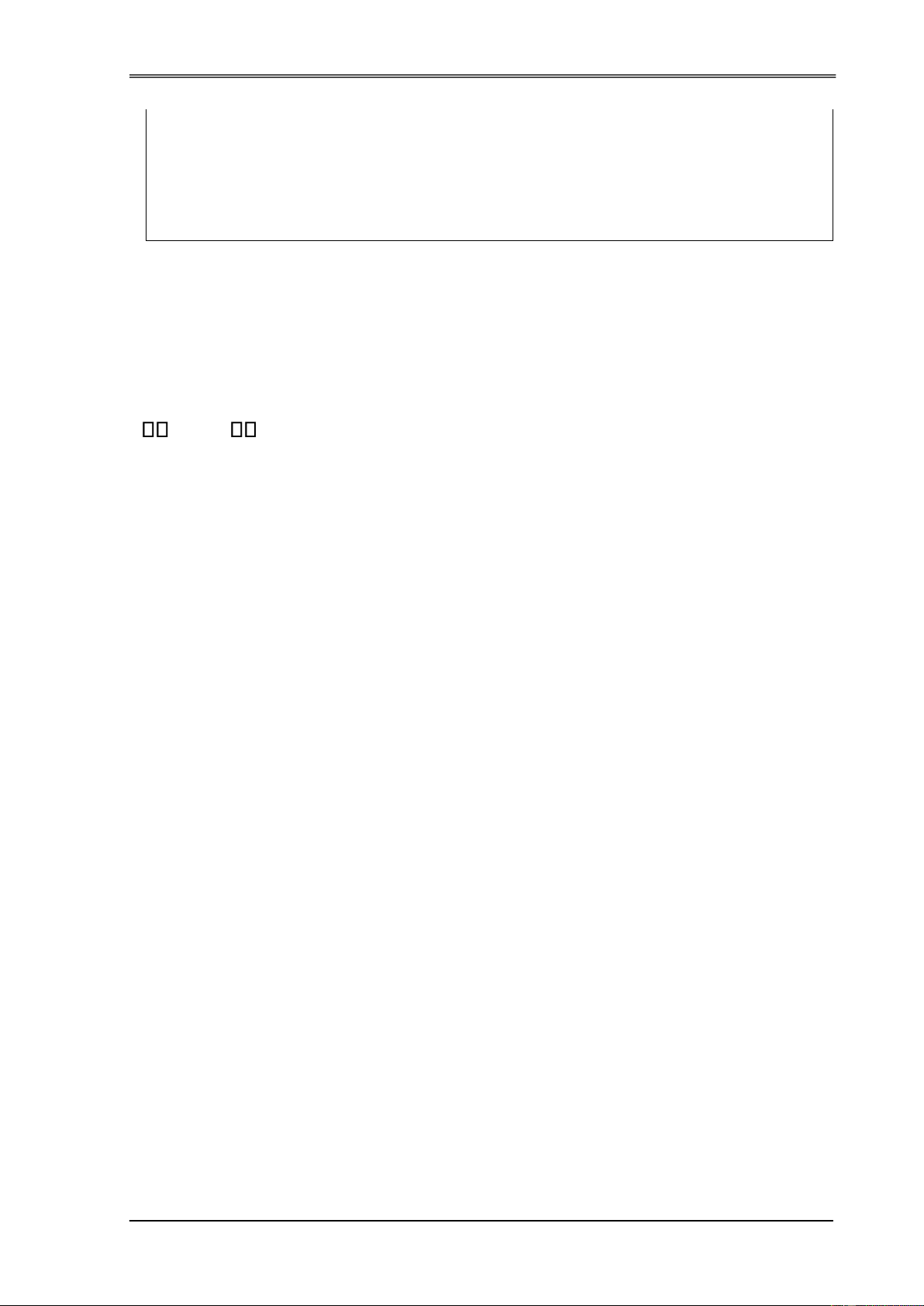
Hình 2.17. Lân cận của P với ngưỡng Eps .................................................. 48
Hình 2.18. Mật ộ - ến ược trực tiếp ....................................................... 49
Hình 2.19. Mật ộ ến ược ........................................................................ 49
Hình 2.20. Mật ộ liên thông ....................................................................... 49
Hình 2.21. Cụm và nhiễu ............................................................................. 50
Hình 2.22. Thuật toán DBSCAN ................................................................. 51
Hình 2.23. Thứ tự phân cụm các ối tượng theo OPTICS .......................... 52
Hình 2.24. DENCLUE với hàm phân phối Gaussian ..................................
53 Hình 2.25. Mô hình cấu trúc dữ liệu lưới
.................................................... 55
Hình 2.26. Thuật toán CLIQUE .................................................................. 56
Hình 2.27. Quá trình nhận dạng các ô của CLIQUE ................................... 57
Hình 3.1. Phân loại khai phá Web ............................................................... 62
Hình 3.2. Quá trình khai phá văn bản Web ................................................. 64
Hình 3.3. Thuật toán phân lớp K-Nearest Neighbor ...................................
67 Hình 3.4. Thuật toán phân cụm phân cấp
.................................................... 67
Hình 3.5. Thuật toán phân cụm phân hoạch ................................................ 68
Hình 3.6. Kiến trúc tổng quát của khai phá theo sử dụng Web .................. 70
Hình 3.7. Minh họa nội dung logs file ......................................................... 72
Hình 3.8. Phân tích người dùng truy cập Web ............................................ 77
Hình 3.9. Đồ thi liên kết Web ...................................................................... 78
Hình 3.10. Quan hệ trực tiếp giữa 2 trang ................................................... 79
Hình 3.11. Độ tương tự ồng trích dẫn ....................................................... 79 lOMoAR cPSD| 39651089
Khai phá dữ liệu Web bằng kỹ thuật phân cụm
Hình 3.12. Độ tương tự chỉ mục .................................................................. 79
Hình 3.13. Cộng ồng Web ......................................................................... 80
Hình 3.14. Kết quả của thuật toán PageRank .............................................. 81
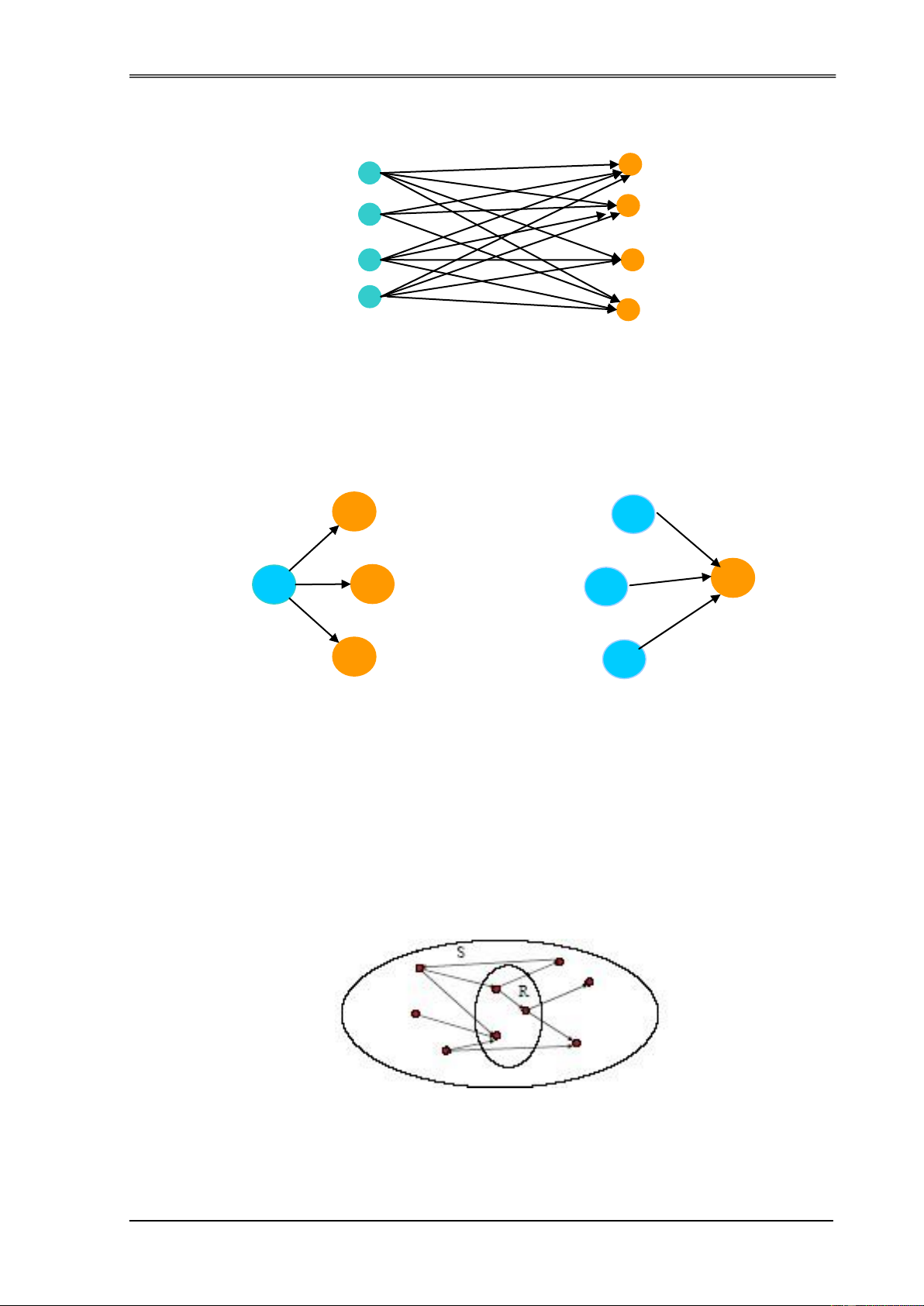
Hình 3.15. Đồ thị phân ôi của Hub và Authority ...................................... 82
Hình 3.16. Sự kết hợp giữa Hub và Authority ............................................ 83
Hình 3.17. Đồ thị Hub-Authority ................................................................ 84
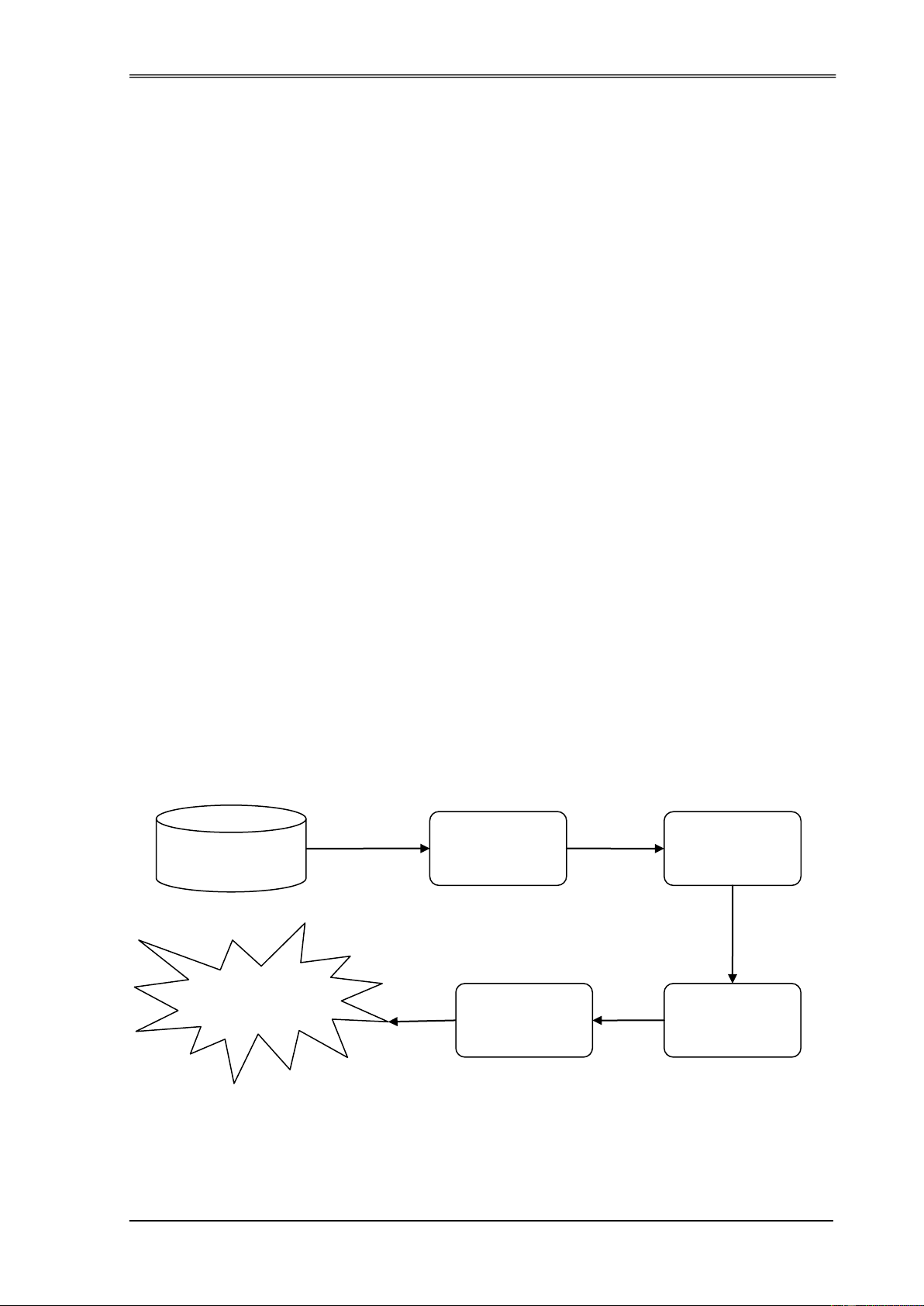
Hình 3.18. Giá trị trọng số các Hub và Authority ....................................... 84
Hình 3.19. Thuật toán ánh trọng số cụm và trang ..................................... 86
Hình 3.20. Các bước phân cụm kết quả tìm kiếm trên Web ....................... 87
Hình 3.21. Thuật toán k-means trong phân cụm nội dung tài liệu Web ..... 91
DANH SÁCH CÁC BẢNG BIỂU Bảng 1.1. Bảng tham số thuộc tính nhị
phân ......................................................................... Error! Bookmark not defined.
Bảng 1.2. Thống kê các từ tần số xuất hiện cao .......................................... 23
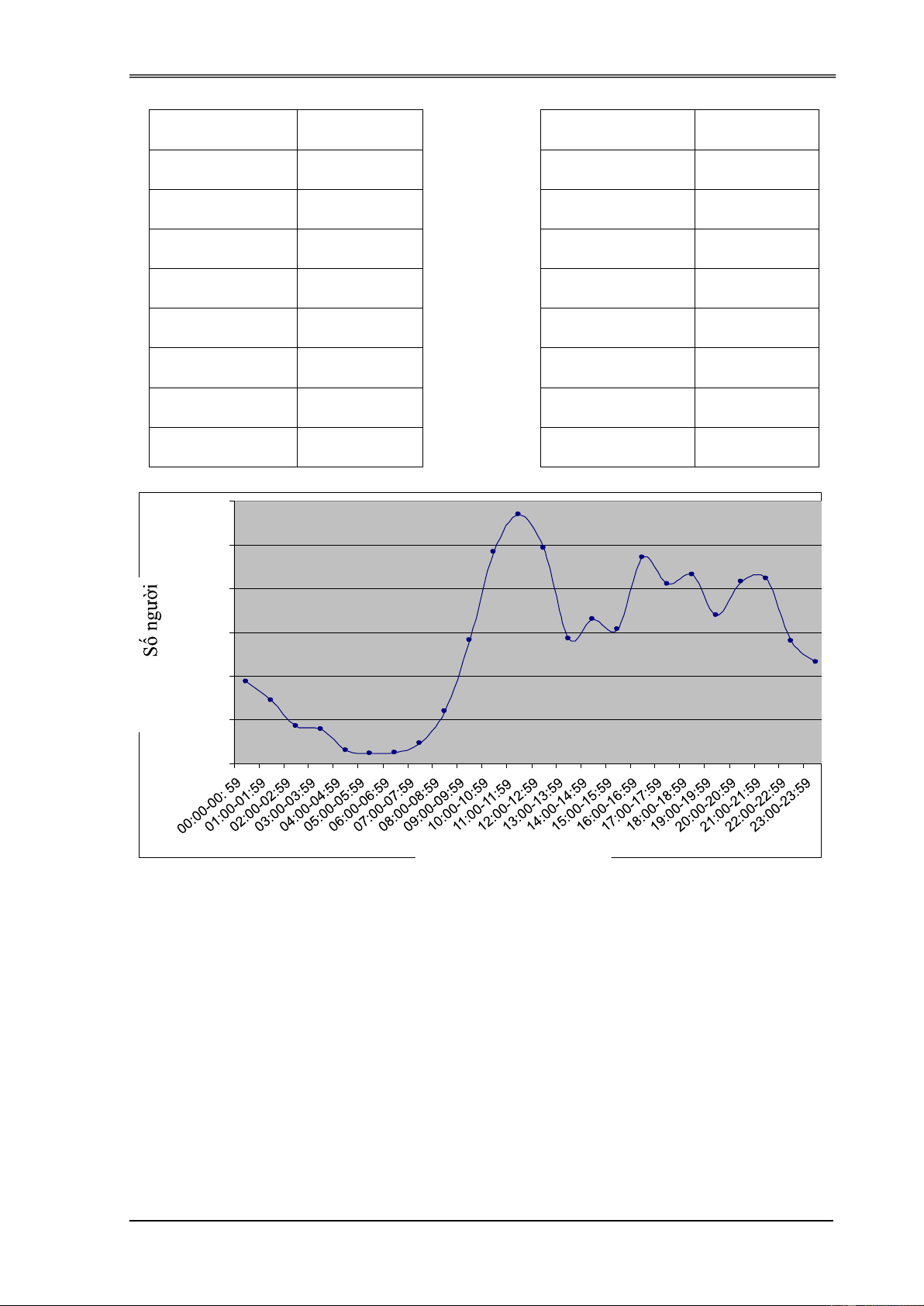
Bảng 3.1. Thống kê số người dùng tại các thời gian khác nhau ................. 72
Bảng 3.2. Bảng o thời gian thực hiện thuật toán phân cụm ........................ 87
CÁC CỤM TỪ VIẾT TẮT
STT Viết tắt
Cụm từ tiếng Anh
Cụm từ tiếng Việt 1 CNTT Information Technology Công nghệ thông tin 2 CSDL Database Cơ sở dữ liệu Khám phá tri thức trong 3
KDD Knowledge Discovery in Database cơ sở dữ liệu lOMoAR cPSD| 39651089
Khai phá dữ liệu Web bằng kỹ thuật phân cụm 4 KPDL Data mining Khai phá dữ liệu 5 KPVB Text Mining Khai phá văn bản 6 PCDL Data Clustering Phân cụm dữ liệu lOMoAR cPSD| 39651089 Khai
phá dữ liệu Web bằng kỹ thuật phân cụm LỜI MỞ ĐẦU
Trong những năm gần ây cùng với phát triển nhanh chóng của khoa học kỹ
thuật là sự bùng nỗ về tri thức. Kho dữ liệu, nguồn tri thức của nhân loại cũng trở
nên ồ sộ, vô tận làm cho vấn ề khai thác các nguồn tri thức ó ngày càng trở nên
nóng bỏng và ặt ra thách thức lớn cho nền công nghệ thông tin thế giới.
Cùng với những tiến bộ vượt bậc của công nghệ thông tin là sự phát triển
mạnh mẽ của mạng thông tin toàn cầu, nguồn dữ liệu Web trở thành kho dữ liệu
khổng lồ. Nhu cầu về tìm kiếm và xử lý thông tin, cùng với yêu cầu về khả năng
kịp thời khai thác chúng ể mạng lại những năng suất và chất lượng cho công tác
quản lý, hoạt ộng kinh doanh,… ã trở nên cấp thiết trong xã hội hiện ại. Nhưng
vấn ề tìm kiếm và sử dụng nguồn tri thức ó như thế nào ể phục vụ cho công việc
của mình lại là một vấn ề khó khăn ối với người sử dụng. Để áp ứng phần nào yêu
cầu này, người ta ã xây dựng các công cụ tìm kiếm và xử lý thông tin nhằm giúp
cho người dùng tìm kiếm ược các thông tin cần thiết cho mình, nhưng với sự rộng
lớn, ồ sộ của nguồn dữ liệu trên Internet ã làm cho người sử dụng cảm thấy khó
khăn trước những kết quả tìm ược.
Với các phương pháp khai thác cơ sở dữ liệu truyền thống chưa áp ứng ược
các yêu cầu ó. Để giải quyết vấn ề này, một hướng i mới ó là nghiên cứu và áp
dụng kỹ thuật khai phá dữ liệu và khám phá tri thức trong môi trường Web. Do ó,
việc nghiên cứu các mô hình dữ liệu mới và áp dụng các phương pháp khai phá
dữ liệu trong khai phá tài nguyên Web là một xu thế tất yếu vừa có ý nghĩa khoa
học vừa mang ý nghĩa thực tiễn cao.
Vì vậy, tác giả chọn ề tài “Khai phá dữ liệu Web bằng kỹ thuật phân cụm” ể
làm luận văn tốt nghiệp cho mình.
Bố cục luận văn gồm 3 chương:
Chương 1 trình bày một cách tổng quan các kiến thức cơ bản về khai phá dữ
liệu và khám phá tri thức, khai phá dữ liệu trong môi trường Web; một số vấn ề
về biểu diễn và xử lý dữ liệu văn bản áp dụng trong khai phá dữ liệu Web. lOMoAR cPSD| 39651089 Khai
phá dữ liệu Web bằng kỹ thuật phân cụm
Chương 2 giới thiệu một số kỹ thuật phân cụm dữ liệu phổ biến và thường
ược sử dụng trong lĩnh vực khai phá dữ liệu và khám phá tri thức.
Chương 3 trình bày một số hướng nghiên cứu trong khai phá dữ liệu Web
như khai phá tài liệu Web, khai phá theo sử dụng Web, khai phá cấu trúc Web và
tiếp cận theo hướng sử dụng các kỹ thuật phân cụm dữ liệu ể giải quyết bài toán
khai phá dữ liệu Web. Trong phần này cũng trình bày một mô hình áp dụng kỹ
thuật phân cụm dữ liệu trong tìm kiếm và phân cụm tài liệu Web.
Phần kết luận của luận văn tổng kết lại những vấn ề ã nghiên cứu, ánh giá kết
quả nghiên cứu, hướng phát triển của ề tài.
Phần phụ lục trình bày một số oạn mã lệnh xử lý trong chương trình và một
số giao diện trong chương trình mô phỏng.
Chương 1. TỔNG QUAN VỀ KHAI PHÁ DỮ LIỆU
1.1. Khai phá dữ liệu và phát hiện tri thức
1.1.1. Khai phá dữ liệu
Cuối thập kỷ 80 của thế kỷ 20, sự phát triển rộng khắp của các CSDL ã tạo
ra sự bùng nổ thông tin trên toàn cầu, vào thời gian này người ta bắt ầu ề cập ến
khái niệm khủng hoảng trong việc phân tích dữ liệu tác nghiệp ể cung cấp thông
tin với yêu cầu chất lượng ngày càng cao cho người làm quyết ịnh trong các tổ
chức chính phủ, tài chính, thương mại, khoa học,…
Đúng như John Naisbett ã cảnh báo “Chúng ta ang chìm ngập trong dữ liệu
mà vẫn ói tri thức”. Lượng dữ liệu khổng lồ này thực sự là một nguồn tài nguyên
có nhiều giá trị bởi thông tin là yếu tố then chốt phục vụ cho mọi hoạt ộng quản
lý, kinh doanh, phát triển sản xuất và dịch vụ, … nó giúp người iều hành và quản
lý có những hiểu biết về môi trường và tiến trình hoạt ộng của tổ chức mình trước
khi ra quyết ịnh ể tác ộng ến quá trình hoạt ộng nhằm ạt ược các mục tiêu một
cách hiệu quả và bền vững.
KPDL là một lĩnh vực mới ược nghiên cứu, nhằm tự ộng khai thác thông tin,
tri thức mới hữu ích, tiềm ẩn từ những CSDL lớn cho các ơn vị, tổ chức, doanh Hoàng Văn Dũng 2 lOMoAR cPSD| 39651089 Khai
phá dữ liệu Web bằng kỹ thuật phân cụm
nghiệp,…. từ ó làm thúc ẩy khả năng sản xuất, kinh doanh, cạnh tranh cho các ơn
vị, tổ chức này. Các kết quả nghiên cứu khoa học cùng những ứng dụng thành
công trong KDD cho thấy KPDL là một lĩnh vực phát triển bền vững, mang lại
nhiều lợi ích và có nhiều triển vọng, ồng thời có ưu thế hơn hẵn so với các công
cụ tìm kiếm phân tích dữ liệu truyền thống. Hiện nay, KPDL ã ứng dụng ngày
càng rộng rãi trong các lĩnh vực như thương mại, tài chính, y học, viễn thông, tin – sinh,….
Các kỹ thuật chính ược áp dụng trong lĩnh vực KPDL phần lớn ược thừa kế
từ lĩnh vực CSDL, học máy, trí tuệ nhân tạo, lý thuyết thông tin, xác suất thống kê
và tính toán hiệu năng cao,...
Như vậy ta có thể khái quát hóa khái niệm KPDL là một quá trình tìm kiếm,
phát hiện các tri thức mới, hữu ích, tiềm ẩn trong CSDL lớn.
KDD là mục tiêu chính của KPDL, do vậy hai khái niệm KPDL và KDD ược
các nhà khoa học trên hai lĩnh vực xem là tương ương với nhau. Thế nhưng nếu
phân chia một cách chi tiết thì KPDL là một bước chính trong quá trình KDD.
1.1.2. Quá trình khám phá tri thức
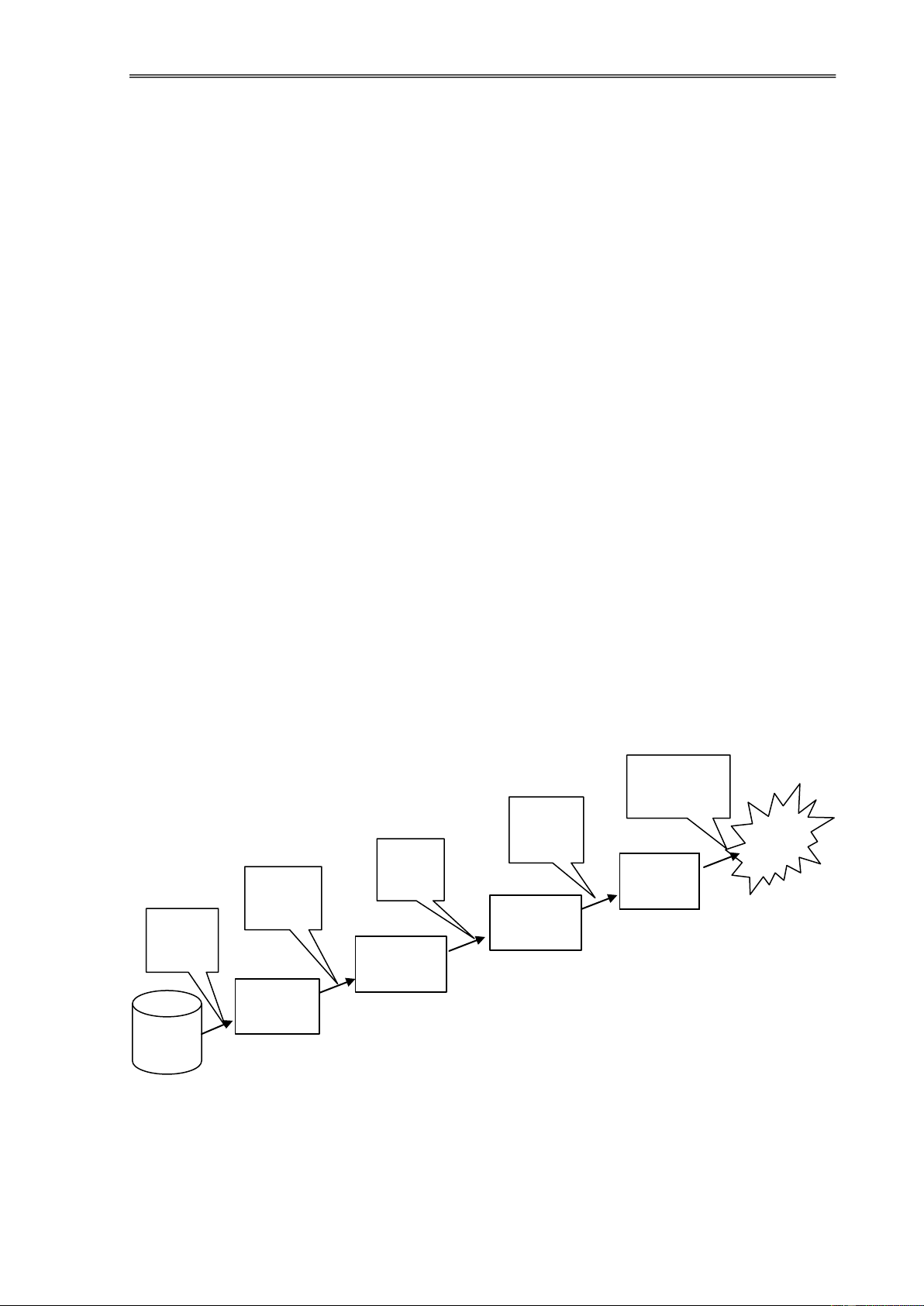
Quá trình khá phá tri thức có thể chia thành 5 bước như sau [10]: Đánh giá, biểu diễn Khai Tri phá Biến thức Các mẫu Tiền ổi xử lý Dữ liệu Trích biến ổi chọn Dữ liệu tiền xử lý Dữ liệu lựa chọn Dữ liệu thô
Hình 1.1. Quá trình khám phá tri thức Quá
trình KPDL có thể phân thành các giai oạn sau [10]:
Trích chọn dữ liệu: Đây là bước trích chọn những tập dữ liệu cần ược khai
phá từ các tập dữ liệu lớn ban ầu theo một số tiêu chí nhất ịnh. lOMoAR cPSD| 39651089 Khai
phá dữ liệu Web bằng kỹ thuật phân cụm
Tiền xử lý dữ liệu: Đây là bước làm sạch dữ liệu (xử lý những dữ liệu không
ầy ủ, nhiễu, không nhất quán,...), rút gọn dữ liệu (sử dụng hàm nhóm và tính tổng,
các phương pháp nén dữ liệu, sử dụng histograms, lấy mẫu,...), rời rạc hóa dữ liệu
(rời rạc hóa dựa vào histograms, dựa vào entropy, dựa vào phân khoảng,...). Sau
bước này, dữ liệu sẽ nhất quán, ầy ủ, ược rút gọn và ược rời rạc hóa.
Biến ổi dữ liệu: Đây là bước chuẩn hóa và làm mịn dữ liệu ể ưa dữ liệu
về dạng thuận lợi nhất nhằm phục vụ quá trình khai phá ở bước sau.
Khai phá dữ liệu: Đây là bước áp dụng những kỹ thuật phân tích (như các kỹ
thuật của học máy) nhằm ể khai thác dữ liệu, trích chọn ược những mẫu thông tin,
những mối liên hệ ặc biệt trong dữ liệu. Đây ược xem là bước quan trọng và tốn
nhiều thời gian nhất của toàn quá trình KDD.
Đánh giá và biểu diễn tri thức: Những mẫu thông tin và mối liên hệ trong dữ
liệu ã ược khám phá ở bước trên ược biến ổi và biểu diễn ở một dạng gần gũi với
người sử dụng như ồ thị, cây, bảng biểu, luật,... Đồng thời bước này cũng ánh giá
những tri thức khám phá ược theo những tiêu chí nhất ịnh.
1.1.3. Khai phá dữ liệu và các lĩnh vực liên quan
KPDL là một lĩnh vực liên quan tới thống kê, học máy, CSDL, thuật toán,
tính toán song song, thu nhận tri thức từ hệ chuyên gia và dữ liệu trừu tượng. Đặc
trưng của hệ thống khám phá tri thức là nhờ vào các phương pháp, thuật toán và
kỹ thuật từ những lĩnh vực khác nhau ể KPDL.
Lĩnh vực học máy và nhận dạng mẫu trong KDD nghiên cứu các lý thuyết và
thuật toán của hệ thống ể trích ra các mẫu và mô hình từ dữ liệu lớn. KDD tập
trung vào việc mở rộng các lý thuyết và thuật toán cho các vấn ề tìm ra các mẫu
ặc biệt (hữu ích hoặc có thể rút ra tri thức quan trọng) trong CSDL lớn.
Ngoài ra, KDD có nhiều iểm chung với thống kê, ặc biệt là phân tích dữ liệu
thăm dò (Exploratory Data Analysis - EDA). Hệ thống KDD thường gắn những
thủ tục thống kê cho mô hình dữ liệu và tiến trình nhiễu trong khám phá tri thức nói chung. Hoàng Văn Dũng 4 lOMoAR cPSD| 39651089 Khai
phá dữ liệu Web bằng kỹ thuật phân cụm
Một lĩnh vực liên quan khác là phân tích kho dữ liệu. Phương pháp phổ biến
ể phân tích kho dữ liệu là OLAP (On-Line Analytical Processing). Các công cụ
OLAP tập trung vào phân tích dữ liệu a chiều.
1.1.4. Các kỹ thuật áp dụng trong khai phá dữ liệu
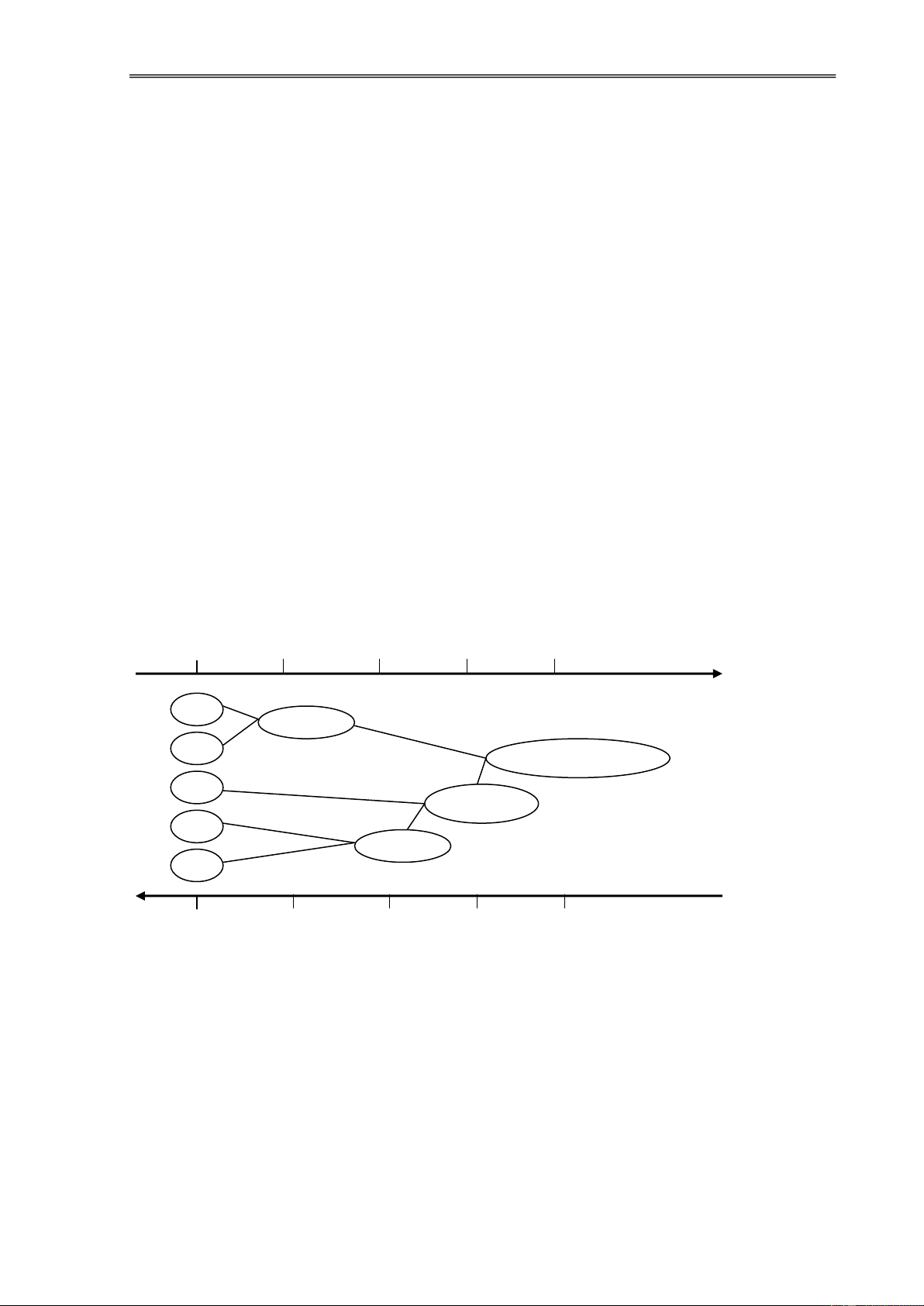
KDD là một lĩnh vực liên ngành, bao gồm: Tổ chức dữ liệu, học máy, trí tuệ
nhân tạo và các khoa học khác. Sự kết hợp này có thể ược diễn tả như sau: Các lĩnh vực khoa học khác Học máy và Tổ chức dữ liệu trí tuệ nhân tạo
Hình 1.2. Các lĩnh vực liên quan ến khám phá tri thức trong CSDL
Đứng trên quan iểm của học máy, thì các kỹ thuật trong KPDL, bao gồm:
Học có giám sát: Là quá trình gán nhãn lớp cho các phần tử trong CSDL dựa
trên một tập các ví dụ huấn luyện và các thông tin về nhãn lớp ã biết.
Học không có giám sát: Là quá trình phân chia một tập dữ liệu thành các lớp
hay cụm dữ liệu tương tự nhau mà chưa biết trước các thông tin về lớp hay tập các
ví dụ huấn luyện.
Học nửa giám sát: Là quá trình phân chia một tập dữ liệu thành các lớp dựa
trên một tập nhỏ các ví dụ huấn luyện và các thông tin về một số nhãn lớp ã biết trước.
+ Nếu căn cứ vào lớp các bài toán cần giải quyết, thì KPDL bao gồm các kỹ thuật áp dụng sau [10]:
Phân lớp và dự báo: Xếp một ối tượng vào một trong những lớp ã biết trước.
Ví dụ như phân lớp các dữ liệu bệnh nhân trong hồ sơ bệnh án. Hướng tiếp cận
này thường sử dụng một số kỹ thuật của học máy như cây quyết ịnh, mạng nơron
nhân tạo,... Phân lớp và dự báo còn ược gọi là học có giám sát. lOMoAR cPSD| 39651089 Khai
phá dữ liệu Web bằng kỹ thuật phân cụm
Luật kết hợp: Là dạng luật biểu diễn tri thức ở dạng khá ơn giản. Ví dụ: “60
% nữ giới vào siêu thị nếu mua phấn thì có tới 80% trong số họ sẽ mua thêm son”.
Luật kết hợp ược ứng dụng nhiều trong lĩnh vực kinh doanh, y học, tinsinh, tài
chính và thị trường chứng khoán,...
Phân tích chuỗi theo thời gian: Tương tự như khai phá luật kết hợp nhưng có
thêm tính thứ tự và tính thời gian. Hướng tiếp cận này ược ứng dụng nhiều trong
lĩnh vực tài chính và thị trường chứng khoán vì nó có tính dự báo cao.
Phân cụm: Xếp các ối tượng theo từng cụm dữ liệu tự nhiên. Phân cụm còn
ược gọi là học không có giám sát.
Mô tả và tóm tắt khái niệm: Thiên về mô tả, tổng hợp và tóm tắt khái niệm,
ví dụ như tóm tắt văn bản.
Do KPDL ược ứng dụng rộng rãi nên nó có thể làm việc với rất nhiều kiểu
dữ liệu khác nhau. Sau ây là một số dạng dữ liệu iển hình: Dữ liệu quan hệ, dữ
liệu a chiều, dữ liệu dạng giao dịch, dữ liệu quan hệ - hướng ối tượng, dữ liệu
không gian và thời gian, dữ liệu chuỗi thời gian, dữ liệu a phương tiện, dữ liệu văn bản và Web,…
1.1.5. Những chức năng chính của khai phá dữ liệu
Hai mục tiêu chính của KPDL là mô tả và dự báo. Dự báo là dùng một số
biến hoặc trường trong CSDL ể dự oán ra các giá trị chưa biết hoặc sẽ có của các
biến quan trọng khác. Việc mô tả tập trung vào tìm kiếm các mẫu mà con người
có thể hiểu ược ể mô tả dữ liệu. Trong lĩnh vực KDD, mô tả ược quan tâm nhiều
hơn dự báo, nó ngược với các ứng dụng học máy và nhận dạng mẫu mà trong ó
việc dự báo thường là mục tiêu chính. Trên cơ sở mục tiêu chính của KPDL, các
chức năng chính của KDD gồm:
Mô tả lớp và khái niệm: Dữ liệu có thể ược kết hợp trong lớp và khái niệm.
Thí dụ, trong kho dữ liệu bán hàng thiết bị tin học, các lớp mặt hàng bao gồm máy
tính, máy in,…và khái niệm khách hàng bao gồm khách hàng mua sỉ và khách
mua lẻ. Việc mô tả lớp và khái niệm là rất hữu ích cho giai oạn tổng hợp, tóm lược
và chính xác hoá. Mô tả lớp và khái niệm ược bắt nguồn từ ặc trưng hoá dữ liệu
và phân biệt dữ liệu. Đặc trưng hoá dữ liệu là quá trình tổng hợp những ặc tính Hoàng Văn Dũng 6 lOMoAR cPSD| 39651089 Khai
phá dữ liệu Web bằng kỹ thuật phân cụm
hoặc các thành phần chung của một lớp dữ liệu mục tiêu. Phân biệt dữ liệu là so
sánh lớp dữ liệu mục tiêu với những lớp dữ liệu ối chiếu khác. Lớp dữ liệu mục
tiêu và các lớp ối chiếu là do người dùng chỉ ra và tương ứng với các ối tượng dữ
liệu nhận ược nhờ truy vấn.
Phân tích sự kết hợp: Phân tích sự kết hợp là khám phá các luật kết hợp thể
hiện mối quan hệ giữa các thuộc tính giá trị mà ta nhận biết ược nhờ tần suất xuất
hiện cùng nhau của chúng. Các luật kết hợp có dạng X Y , tức là A1 .... An B1
..... Bm , trong ó Ai (i=1,..., n) và Bj (j=1,...,m) là các cặp thuộc tính giá trị. Luật
kết hợp dạng X Y có thể ược hiểu là “dữ liệu thoã mãn các iều kiện của X thì cũng
sẽ thoả các iều kiện của Y”.
Phân lớp và dự báo: Phân lớp là quá trình tìm kiếm một tập các mô hình
hoặc chức năng mà nó mô tả và phân biệt nó với các lớp hoặc khái niệm khác.
Các mô hình này nhằm mục ích dự báo về lớp của một số ối tượng. Việc xây dựng
mô hình dựa trên sự phân tích một tập các dữ liệu ược huấn luyện có nhiều dạng
thể hiện mô hình như luật phân lớp (IF-THEN), cây quyết ịnh, công thức toán học
hay mạng nơron,... Sự phân lớp ược sử dụng ể dự oán nhãn lớp của các ối tượng
trong dữ liệu. Tuy nhiên trong nhiều ứng dụng, người ta mong muốn dự oán những
giá trị khuyết thiếu nào ó. Thông thường ó là trường hợp dự oán các giá trị của dữ
liệu kiểu số. Trước khi phân lớp và dự báo, có thể cần thực hiện phân tích thích
hợp ể xác ịnh và loại bỏ các thuộc tính không tham gia vào quá trình phân lớp và dự báo.
Phân cụm: Không giống như phân lớp và dự báo, phân cụm phân tích các ối
tượng dữ liệu khi chưa biết nhãn của lớp. Nhìn chung, nhãn lớp không tồn tại
trong suốt quá trình huấn luyện dữ liệu, nó phân cụm có thể ược sử dụng ể ưa ra
nhãn của lớp. Sự phân cụm thực hiện nhóm các ối tượng dữ liệu theo nguyên tắc:
Các ối tượng trong cùng một nhóm thì giống nhau hơn các ối tượng khác nhóm.
Mỗi cụm ược tạo thành có thể ược xem như một lớp các ối tượng mà các luật ược
lấy ra từ ó. Dạng của cụm ược hình thành theo một cấu trúc phân cấp của các lớp
mà mỗi lớp là một nhóm các sự kiện tương tự nhau. lOMoAR cPSD| 39651089 Khai
phá dữ liệu Web bằng kỹ thuật phân cụm
Phân tích các ối tượng ngoài cuộc: Một CSDL có thể chứa các ối tượng
không tuân theo mô hình dữ liệu. Các ối tượng như vậy gọi là ối tượng ngoài cuộc.
Hầu hết các phương pháp KPDL ều coi các ối tượng ngoài cuộc là nhiễu và loại
bỏ chúng. Tuy nhiên trong một số ứng dụng, chẳng hạn như phát hiện nhiễu, thì
sự kiện hiếm khi xảy ra lại ược chú ý hơn những gì thường xuyên gặp phải. Sự
phân tích dữ liệu ngoài cuộc ược coi như là sự khai phá các ối tượng ngoài cuộc.
Một số phương pháp ược sử dụng ể phát hiện ối tượng ngoài cuộc: sử dụng các
test mang tính thống kê trên cơ sở một phân phối dữ liệu hay một mô hình xác
suất cho dữ liệu, dùng các ộ o khoảng cách mà theo ó các ối tượng có một khoảng
cách áng kể ến cụm bất kì khác ược coi là ối tượng ngoài cuộc, dùng các phương
pháp dựa trên ộ lệch ể kiểm tra sự khác nhau trong những ặc trưng chính của các nhóm ối tượng.
Phân tích sự tiến hoá: Phân tích sự tiến hoá thực hiện việc mô tả và mô hình
hoá các qui luật hay khuynh hướng của những ối tượng mà hành vi của chúng thay
ổi theo thời gian. Phân tích sự tiến hoá có thể bao gồm cả ặc trưng hoá, phân biệt,
tìm luật kết hợp, phân lớp hay PCDL liên quan ến thời gian, phân tích dữ liệu theo
chuỗi thời gian, so sánh mẫu theo chu kỳ và phân tích dữ liệu dựa trên ộ tương tự.
1.1.6. Ứng dụng của khai phá dữ liệu
KPDL là một lĩnh vực ược quan tâm và ứng dụng rộng rãi. Một số ứng dụng
iển hình trong KPDL có thể liệt kê như sau: Phân tích dữ liệu và hỗ trợ ra quyết
ịnh, iều trị y học, KPVB, khai phá Web, tin-sinh, tài chính và thị trường chứng khoán, bảo hiểm,...
Thương mại: Như phân tích dữ liệu bán hàng và thị trường, phân tích ầu tư,
phát hiện gian lận, chứng thực hóa khách hàng, dự báo xu hướng phát triển,...
Thông tin sản xuất: Điều khiển, lập kế hoạch, hệ thống quản lý, phân tích thử nghiệm,...
Thông tin khoa học: Dự báo thời tiết, bảo lụt, ộng ất, tin sinh học,...
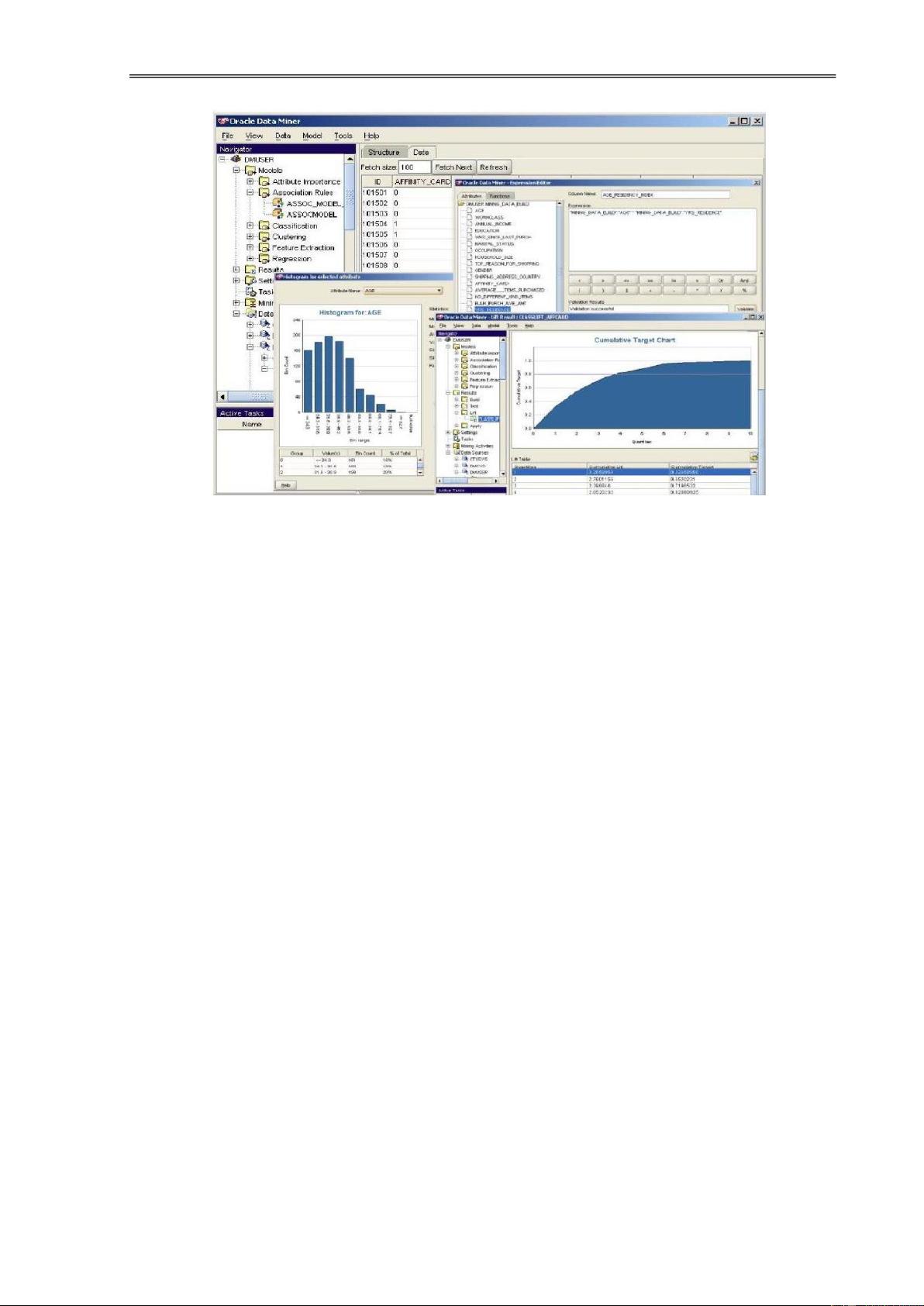
Hiện nay các hệ quản trị CSDL ã tích hợp những modul ể KPDL như SQL
Server, Oracle, ến năm 2007 Microsoft ã cung cấp sẵn công cụ KPDL tích hợp
trong cả MS-Word, MS-Excel,.. Hoàng Văn Dũng 8 lOMoAR cPSD| 39651089 Khai
phá dữ liệu Web bằng kỹ thuật phân cụm
Hình 1.3. Trực quan hóa kết quả KPDL trong Oracle
1.2. Kỹ thuật phân cụm trong khai phá dữ liệu
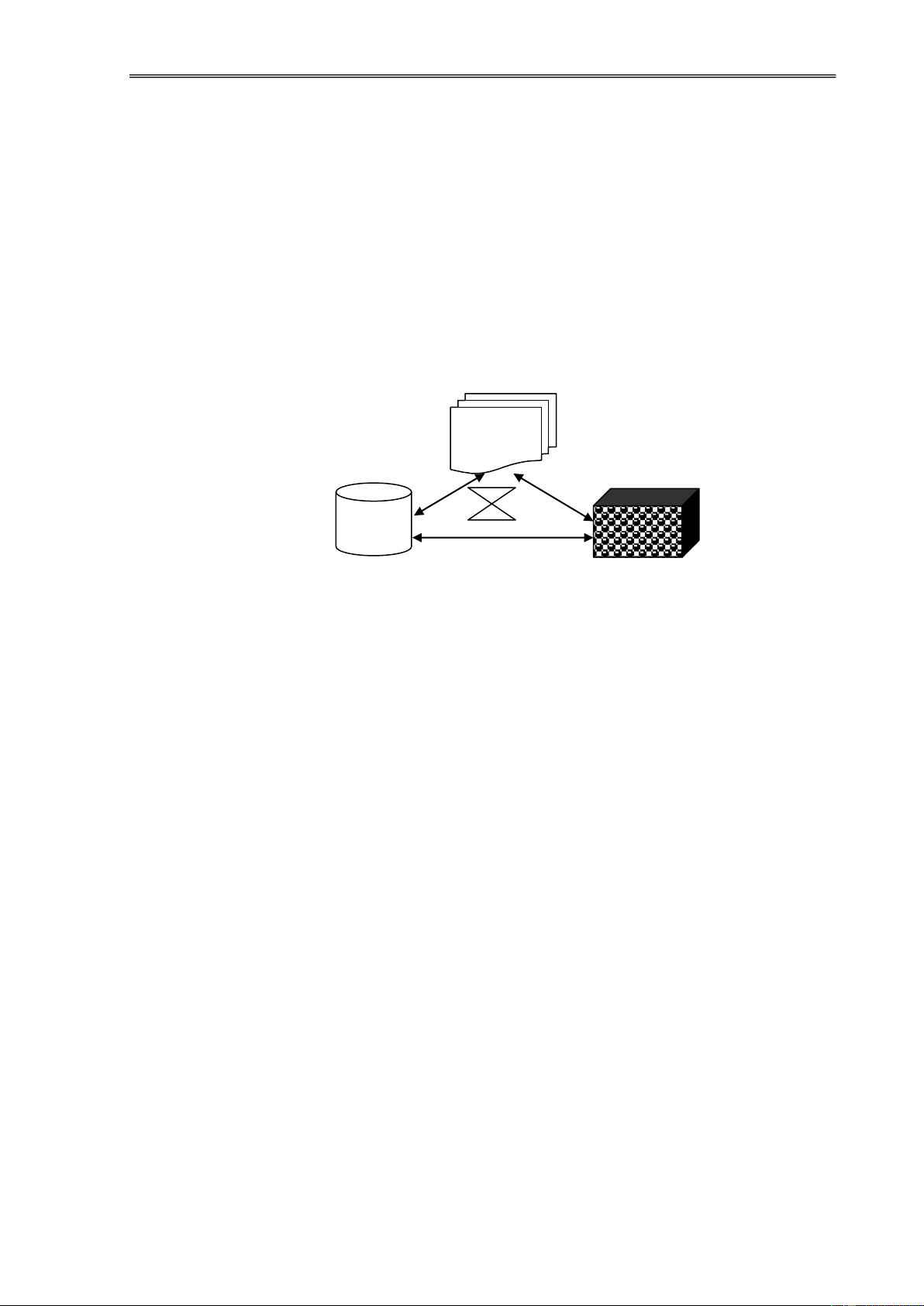
1.2.1. Tổng quan về kỹ thuật phân cụm
Mục ích chính của PCDL nhằm khám phá cấu trúc của mẫu dữ liệu ể thành
lập các nhóm dữ liệu từ tập dữ liệu lớn, theo ó nó cho phép người ta i sâu vào phân
tích và nghiên cứu cho từng cụm dữ liệu này nhằm khám phá và tìm kiếm các
thông tin tiềm ẩn, hữu ích phục vụ cho việc ra quyết ịnh. Ví dụ “nhóm các khách
hàng trong CSDL ngân hàng có vốn các ầu tư vào bất ộng sản cao”… Như vậy,
PCDL là một phương pháp xử lý thông tin quan trọng và phổ biến, nó nhằm khám
phá mối liên hệ giữa các mẫu dữ liệu bằng cách tổ chức chúng thành các cụm.
Ta có thể khái quát hóa khái niệm PCDL [10][19]: PCDL là một kỹ thuật
trong KPDL, nhằm tìm kiếm, phát hiện các cụm, các mẫu dữ liệu tự nhiên, tiềm
ẩn, quan trọng trong tập dữ liệu lớn từ ó cung cấp thông tin, tri thức hữu ích cho việc ra quyết ịnh.
Như vậy, PCDL là quá trình phân chia một tập dữ liệu ban ầu thành các cụm
dữ liệu sao cho các phần tử trong một cụm "tương tự" với nhau và các phần tử
trong các cụm khác nhau sẽ "phi tương tự" với nhau. Số các cụm dữ liệu ược phân
ở ây có thể ược xác ịnh trước theo kinh nghiệm hoặc có thể ược tự ộng xác ịnh
của phương pháp phân cụm. lOMoAR cPSD| 39651089 Khai
phá dữ liệu Web bằng kỹ thuật phân cụm
Độ tương tự ược xác ịnh dựa trên giá trị các thuộc tính mô tả ối tượng. Thông
thường, phép o khoảng cách thường ược sử dụng ể ánh giá ộ tương tự hay phi tương tự.
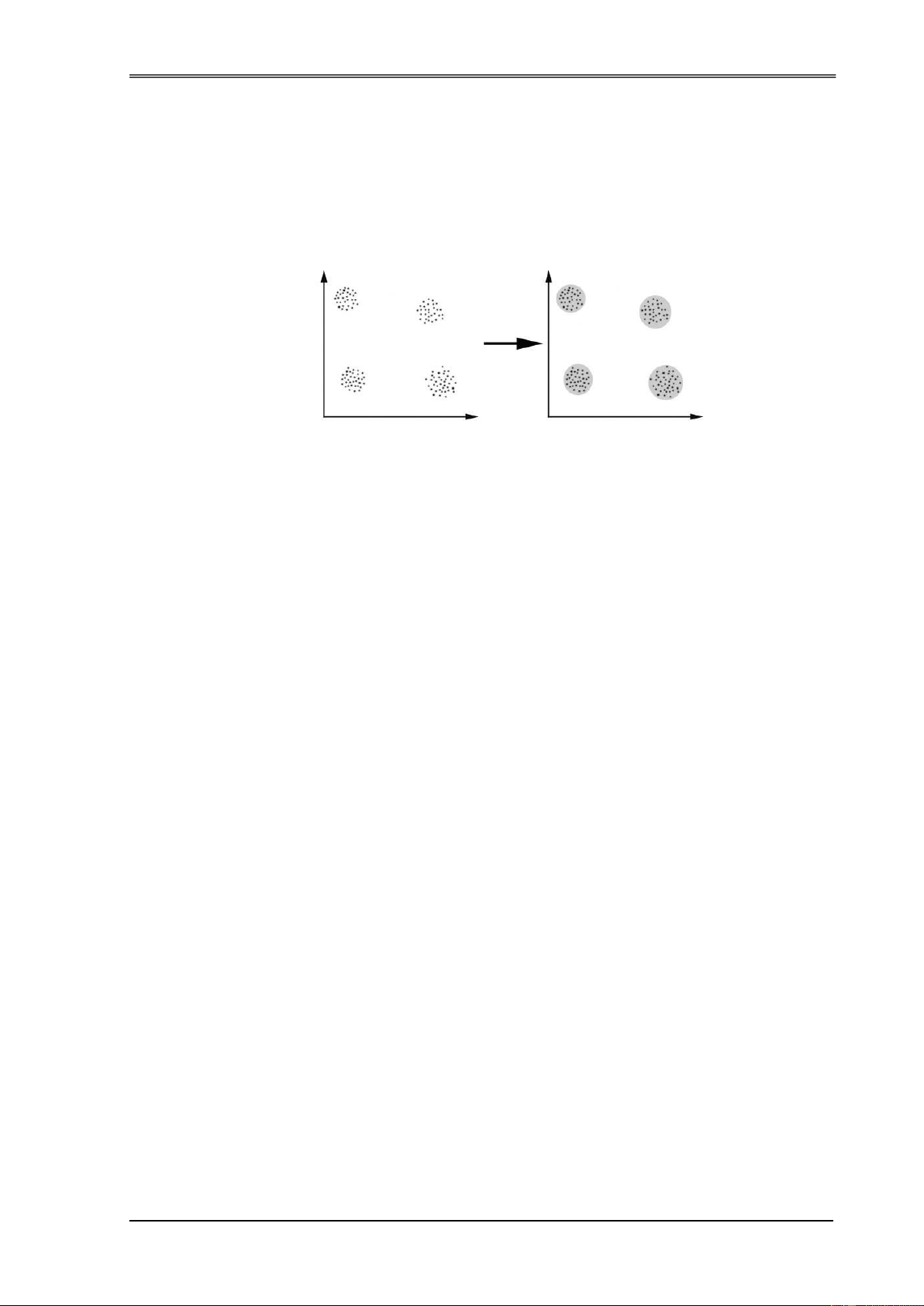
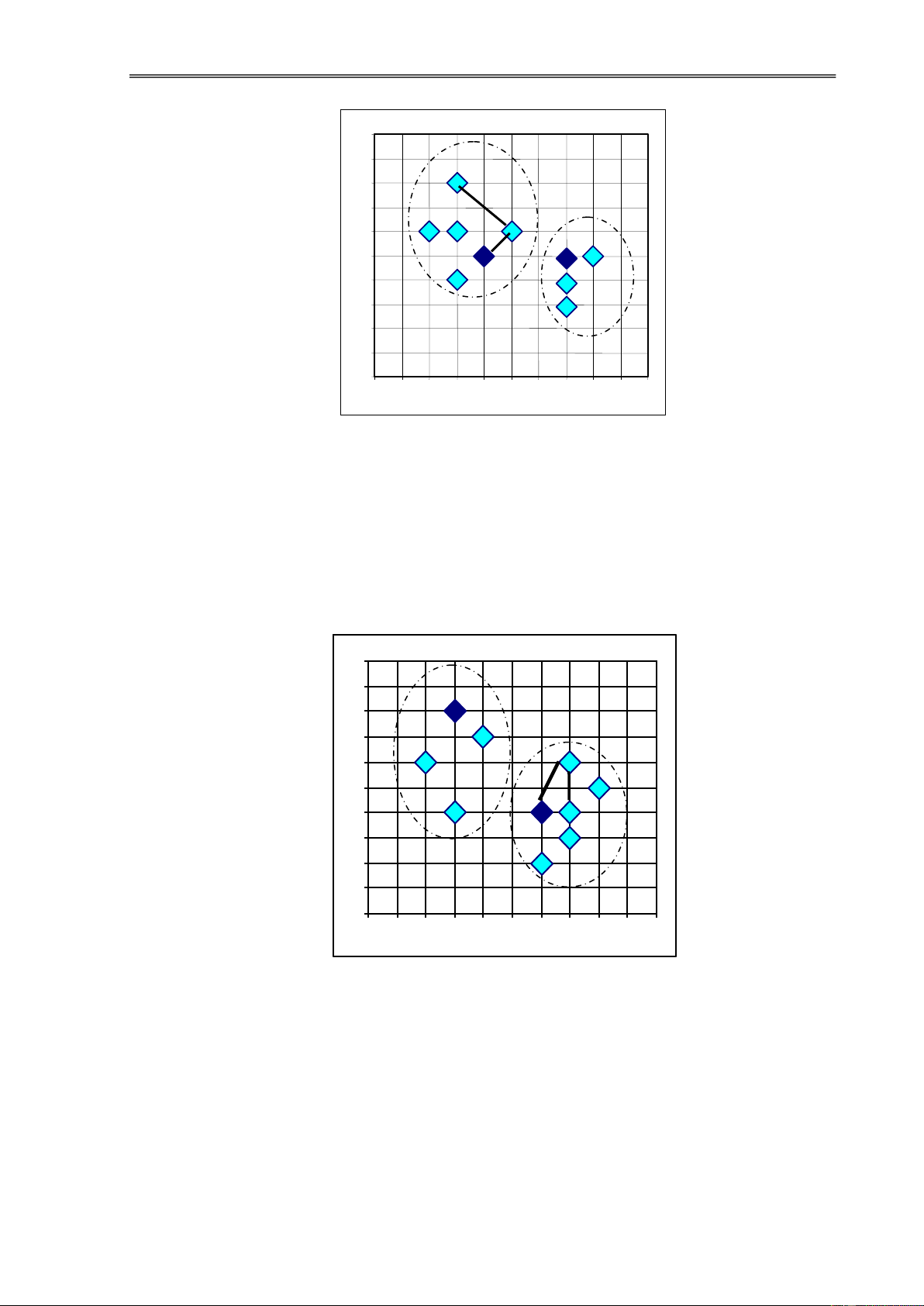
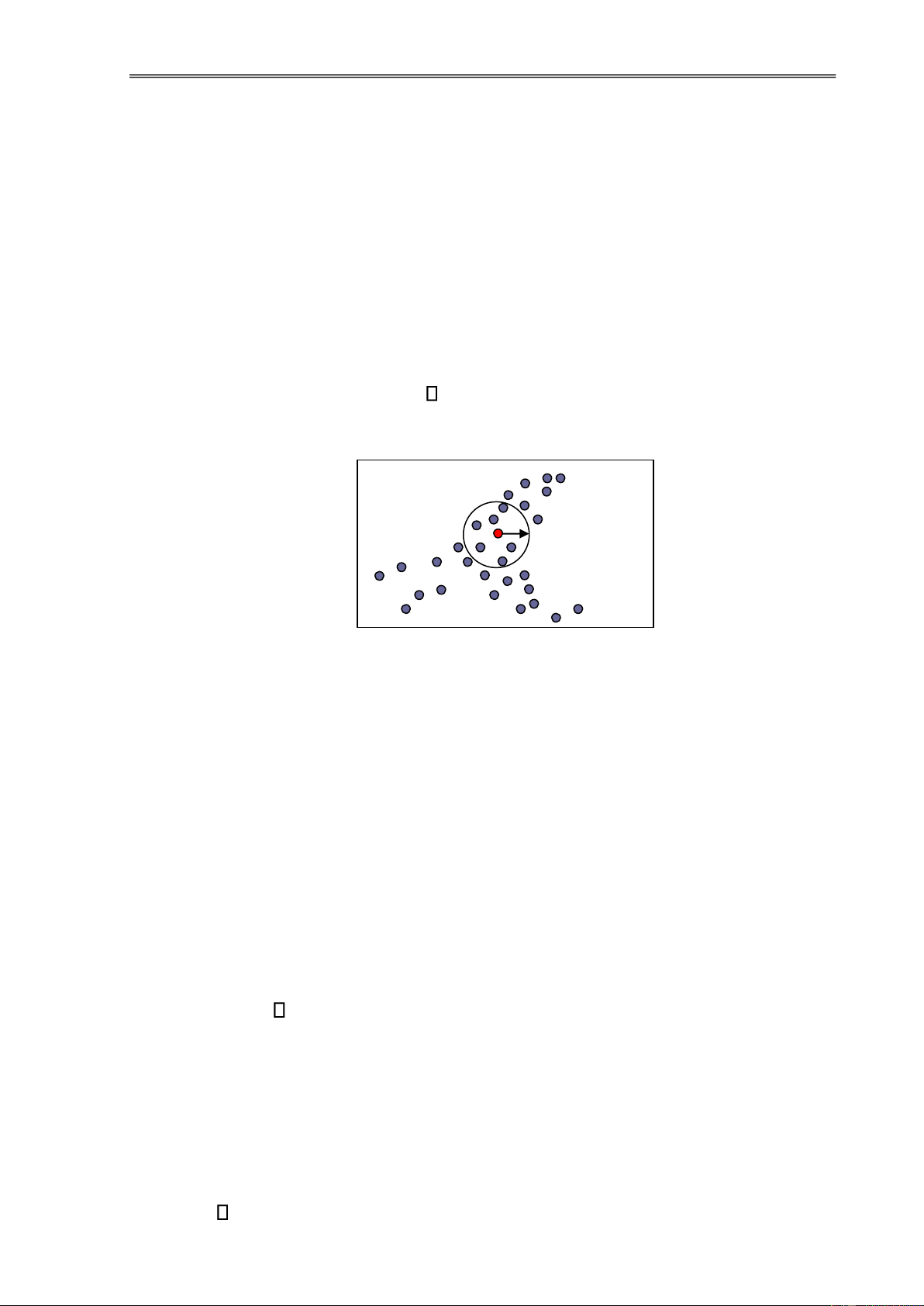
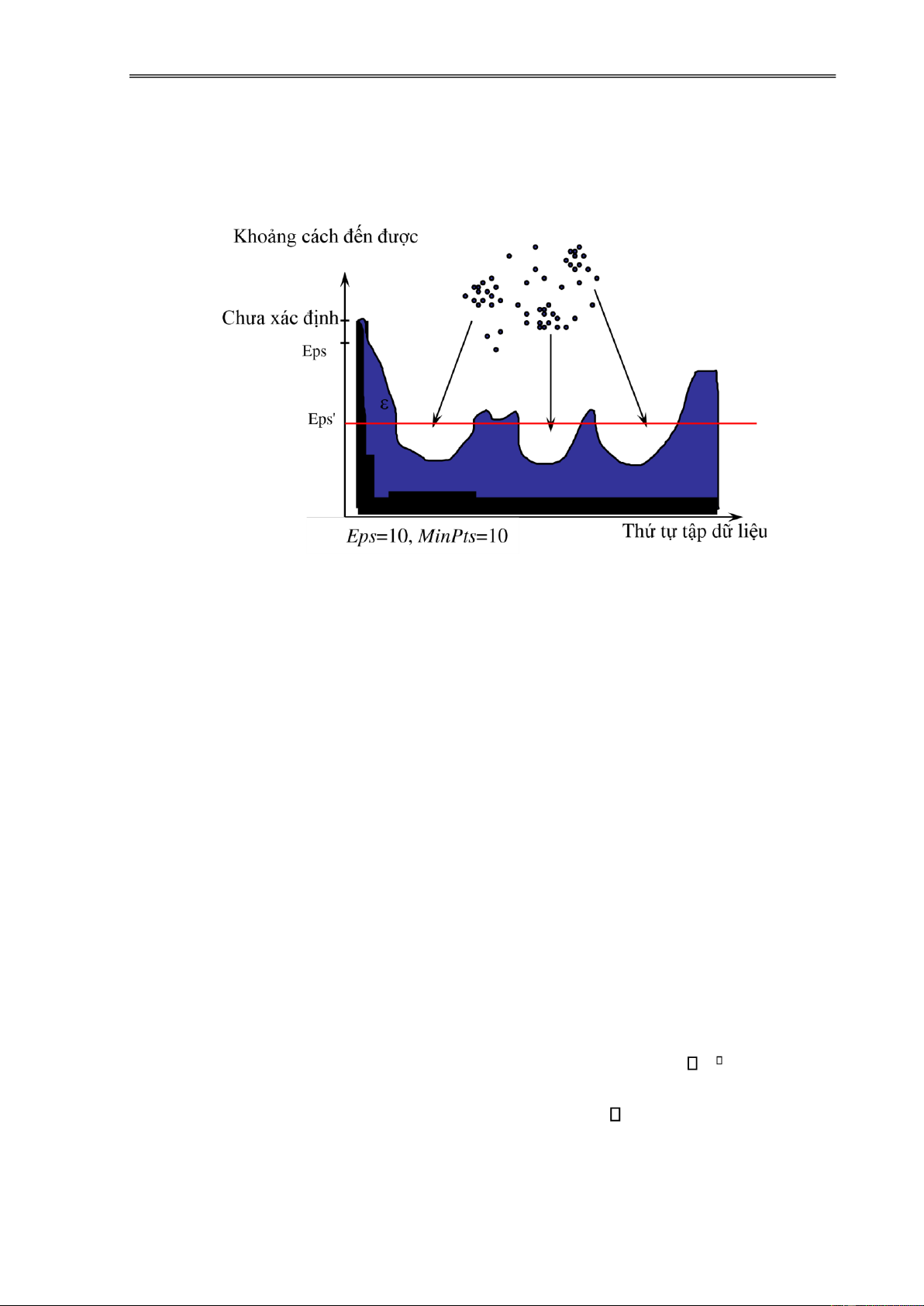
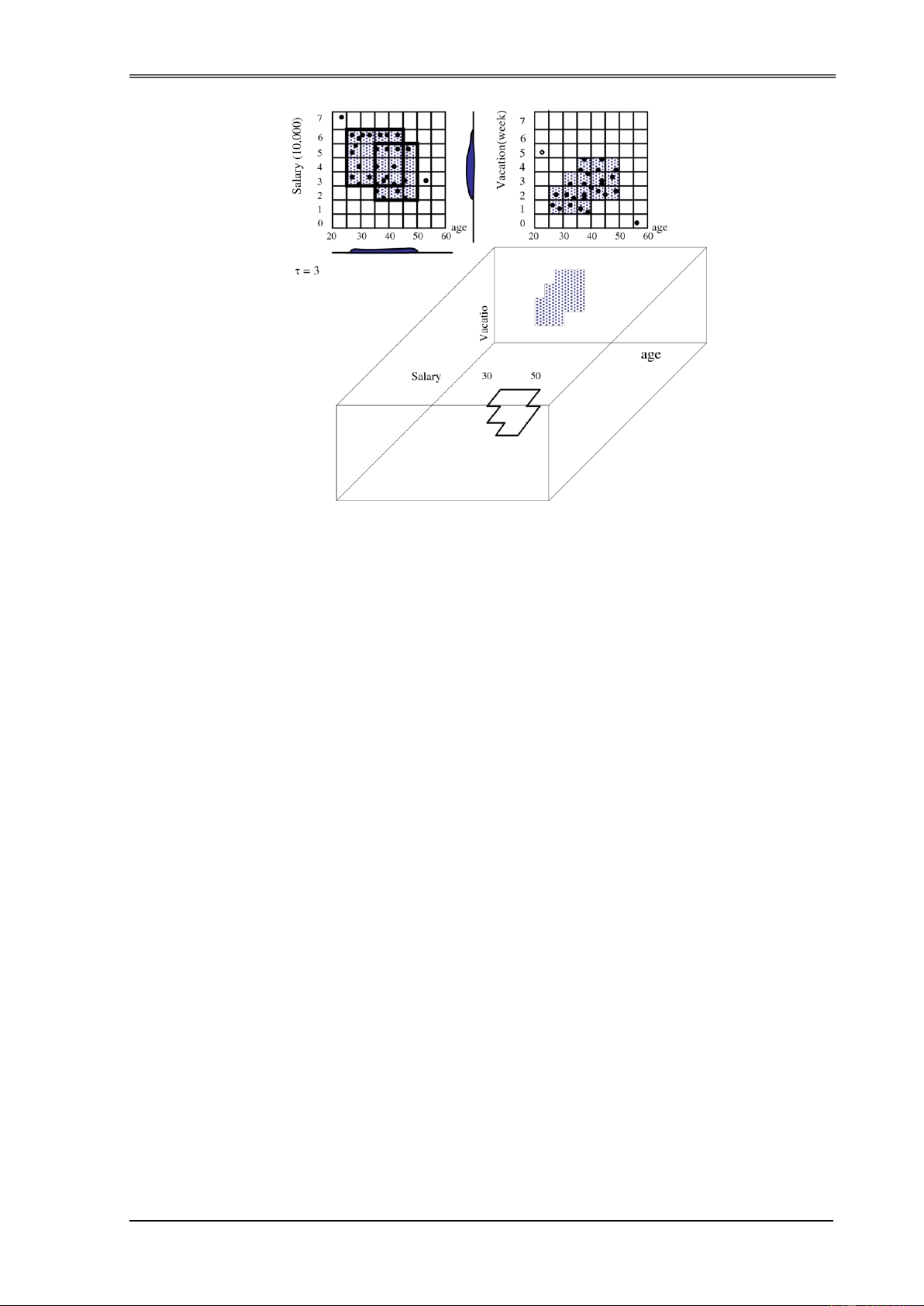
Ta có thể minh hoạ vấn ề phân cụm như hình sau ây:
Hình 1.4. Mô phỏng sự PCDL
Trong hình trên, sau khi phân cụm ta thu ược bốn cụm trong ó các phần tử
"tương tự" thì ược xếp vào một cụm, các phần tử "phi tương tự" thì chúng thuộc về các cụm khác nhau.
Trong PCDL khái niệm, hai hoặc nhiều ối tượng cùng ược xếp vào một cụm
nếu chúng có chung một ịnh nghĩa về khái niệm hoặc chúng xấp xỉ với các khái
niệm mô tả cho trước. Như vậy, PCDL không sử dụng ộ o “tương tự” như ã trình bày ở trên.
Trong học máy, PCDL ược xem là vấn ề học không có giám sát, vì nó phải
giải quyết vấn ề tìm một cấu trúc trong tập hợp dữ liệu chưa biết trước các thông
tin về lớp hay các thông tin về tập huấn luyện. Trong nhiều trường hợp, nếu phân
lớp ược xem là vấn ề học có giám sát thì PCDL là một bước trong phân lớp dữ
liệu, PCDL sẽ khởi tạo các lớp cho phân lớp bằng cách xác ịnh các nhãn cho các nhóm dữ liệu.
Một vấn ề thường gặp trong PCDL là hầu hết các dữ liệu cần cho phân cụm
ều có chứa dữ liệu "nhiễu" do quá trình thu thập thiếu chính xác hoặc thiếu ầy ủ,
vì vậy cần phải xây dựng chiến lược cho bước tiền xử lý dữ liệu nhằm khắc phục
hoặc loại bỏ "nhiễu" trước khi bước vào giai oạn phân tích PCDL. "Nhiễu" ở ây
có thể là các ối tượng dữ liệu không chính xác hoặc các ối tượng dữ liệu khuyết
thiếu thông tin về một số thuộc tính. Một trong các kỹ thuật xử lý nhiễu phổ biến Hoàng Văn Dũng 10 lOMoAR cPSD| 39651089 Khai
phá dữ liệu Web bằng kỹ thuật phân cụm
là việc thay thế giá trị của các thuộc tính của ối tượng "nhiễu" bằng giá trị thuộc
tính tương ứng của ối tượng dữ liệu gần nhất.
Ngoài ra, dò tìm phần tử ngoại lai là một trong những hướng nghiên cứu quan
trọng trong PCDL, chức năng của nó là xác ịnh một nhóm nhỏ các ối tượng dữ
liệu "khác thường" so với các dữ liệu khác trong CSDL - tức là các ối tượng dữ
liệu không tuân theo các hành vi hoặc mô hình dữ liệu - nhằm tránh sự ảnh hưởng
của chúng tới quá trình và kết quả của PCDL. Khám phá các phần tử ngoại lai ã
ược phát triển và ứng dụng trong viễn thông, dò tìm gian lận thương mại…
Tóm lại, PCDL là một vấn ề khó vì người ta phải i giải quyết các vấn ề con cơ bản như sau: - Biểu diễn dữ liệu.
- Xây dựng hàm tính ộ tương tự.
- Xây dựng các tiêu chuẩn phân cụm.
- Xây dựng mô hình cho cấu trúc cụm dữ liệu.
- Xây dựng thuật toán phân cụm và xác lập các iều kiện khởi tạo.
- Xây dựng các thủ tục biểu diễn và ánh giá kết quả phân cụm.
Theo các nghiên cứu thì ến nay chưa có một phương pháp phân cụm tổng
quát nào có thể giải quyết trọn vẹn cho tất cả các dạng cấu trúc cụm dữ liệu. Hơn
nữa, các phương pháp phân cụm cần có cách thức biểu diễn cấu trúc các cụm dữ
liệu khác nhau, với mỗi cách thức biểu diễn khác nhau sẽ có một thuật toán phân
cụm phù hợp. PCDL ang là vấn ề mở và khó vì người ta cần phải i giải quyết nhiều
vấn ề cơ bản như ã ề cập ở trên một cách trọn vẹn và phù hợp với nhiều dạng dữ
liệu khác nhau. Đặc biệt ối với dữ liệu hỗn hợp, ang ngày càng tăng trưởng không
ngừng trong các hệ quản trị dữ liệu, ây cũng là một trong những thách thức lớn
trong lĩnh vực KPDL trong những thập kỷ tiếp theo và ặc biệt là trong lĩnh vực KPDL Web.
1.2.2. Ứng dụng của phân cụm dữ liệu
PCDL là một trong những công cụ chính của KPDL ược ứng dụng trong
nhiều lĩnh vực như thương mại và khoa học. Các kỹ thuật PCDL ã ược áp dụng
cho một số ứng dụng iển hình trong các lĩnh vực sau [10][19]: lOMoAR cPSD| 39651089 Khai
phá dữ liệu Web bằng kỹ thuật phân cụm
Thương mại: PCDL có thể giúp các thương nhân khám phá ra các nhóm
khách hàng quan trọng có các ặc trưng tương ồng nhau và ặc tả họ từ các mẫu mua bán trong CSDL khách hàng.
Sinh học: PCDL ược sử dụng ể xác ịnh các loại sinh vật, phân loại các Gen
với chức năng tương ồng và thu ược các cấu trúc trong các mẫu.
Phân tích dữ liệu không gian: Do sự ồ sộ của dữ liệu không gian như dữ liệu
thu ược từ các hình ảnh chụp từ vệ tinh, các thiết bị y học hoặc hệ thống thông tin
ịa lý (GIS), …làm cho người dùng rất khó ể kiểm tra các dữ liệu không gian một
cách chi tiết. PCDL có thể trợ giúp người dùng tự ộng phân tích và xử lý các dữ
liêu không gian như nhận dạng và chiết xuất các ặc tính hoặc các mẫu dữ liệu quan
tâm có thể tồn tại trong CSDL không gian.
Lập quy hoạch ô thị: Nhận dạng các nhóm nhà theo kiểu và vị trí ịa lý,…
nhằm cung cấp thông tin cho quy hoạch ô thị.
Nghiên cứu trái ất: Phân cụm ể theo dõi các tâm ộng ất nhằm cung cấp thông
tin cho nhận dạng các vùng nguy hiểm.
Địa lý: Phân lớp các ộng vật, thực vật và ưa ra ặc trưng của chúng.
Khai phá Web: PCDL có thể khám phá các nhóm tài liệu quan trọng, có nhiều
ý nghĩa trong môi trường Web. Các lớp tài liệu này trợ giúp cho việc khám phá tri
thức từ dữ liệu Web, khám phá ra các mẫu truy cập của khách hàng ặc biệt hay
khám phá ra cộng ồng Web,…
1.2.3. Các yêu cầu ối với kỹ thuật phân cụm dữ liệu
Việc xây dựng, lựa chọn một thuật toán phân cụm là bước then chốt cho việc
giải quyết vấn ề phân cụm, sự lựa chọn này phụ thuộc vào ặc tính dữ liệu cần phân
cụm, mục ích của ứng dụng thực tế hoặc xác ịnh ộ ưu tiên giữa chất lượng của các
cụm hay tốc ộ thực hiện thuật toán,…
Hầu hết các nghiên cứu và phát triển thuật toán PCDL ều nhằm thoả mãn các
yêu cầu cơ bản sau [10][19]:
Có khả năng mở rộng: Một số thuật toán có thể ứng dụng tốt cho tập dữ liệu
nhỏ (khoảng 200 bản ghi dữ liệu) nhưng không hiệu quả khi áp dụng cho tập dữ
liệu lớn (khoảng 1 triệu bản ghi). Hoàng Văn Dũng 12 lOMoAR cPSD| 39651089 Khai
phá dữ liệu Web bằng kỹ thuật phân cụm
Thích nghi với các kiểu dữ liệu khác nhau: Thuật toán có thể áp dụng hiệu
quả cho việc phân cụm các tập dữ liệu với nhiều kiểu dữ liệu khác nhau như dữ
liệu kiểu số, kiểu nhị phân, dữ liệu ịnh danh, hạng mục,... và thích nghi với kiểu dữ liệu hỗn hợp.
Khám phá ra các cụm với hình thù bất kỳ: Do hầu hết các CSDL có chứa
nhiều cụm dữ liệu với các hình thù khác nhau như: hình lõm, hình cầu, hình que,…
Vì vậy, ể khám phá ược các cụm có tính tự nhiên thì các thuật toán phân cụm cần
phải có khả năng khám phá ra các cụm dữ liệu có hình thù bất kỳ.
Tối thiểu lượng tri thức cần cho xác ịnh các tham số vào: Do các giá trị ầu
vào thường ảnh hưởng rất lớn ến thuật toán phân cụm và rất phức tạp ể xác ịnh
các giá trị vào thích hợp ối với các CSDL lớn.
Ít nhạy cảm với thứ tự của dữ liệu vào: Cùng một tập dữ liệu, khi ưa vào xử
lý cho thuật toán PCDL với các thứ tự vào của các ối tượng dữ liệu ở các lần thực
hiện khác nhau thì không ảnh hưởng lớn ến kết quả phân cụm.
Khả năng thích nghi với dữ liệu nhiễu cao: Hầu hết các dữ liệu phân cụm
trong KPDL ều chứa ựng các dữ liệu lỗi, dữ liệu không ầy ủ, dữ liệu rác. Thuật
toán phân cụm không những hiệu quả ối với các dữ liệu nhiễu mà còn tránh dẫn
ến chất lượng phân cụm thấp do nhạy cảm với nhiễu.
Ít nhạy cảm với các tham số ầu vào: Nghĩa là giá trị của các tham số ầu vào
khác nhau ít gây ra các thay ổi lớn ối với kết quả phân cụm.
Thích nghi với dữ liệu a chiều: Thuật toán có khả năng áp dụng hiệu quả cho
dữ liệu có số chiều khác nhau.
Dễ hiểu, dễ cài ặt và khả thi.
Các yêu cầu này ồng thời là các tiêu chí ể ánh giá hiệu quả của các phương
pháp PCDL, ây là những thách thức cho các nhà nghiên cứu trong lĩnh vực PCDL.
1.2.4. Các kiểu dữ liệu và ộ o tương tự
Trong phần này ta phân tích các kiểu dữ liệu thường ược sử dụng trong
PCDL. Trong PCDL, các ối tượng dữ liệu cần phân tích có thể là con người, nhà
cửa, tiền lương, các thực thể phần mềm,… Các ối tượng này thường ược diễn tả
dưới dạng các thuộc tính của nó. Các thuộc tính này là các tham số cần cho giải
quyết vấn ề PCDL và sự lựa chọn chúng có tác ộng áng kể ến các kết quả của phân
cụm. Phân loại các kiểu thuộc tính khác nhau là một vấn ề cần giải quyết ối với
hầu hết các tập dữ liệu nhằm cung cấp các phương tiện thuận lợi ể nhận dạng sự lOMoAR cPSD| 39651089 Khai
phá dữ liệu Web bằng kỹ thuật phân cụm
khác nhau của các phần tử dữ liệu. Dưới ây là cách phân lớp dựa trên hai ặc trưng
là: kích thước miền và hệ o.
1.2.4.1. Phân loại kiểu dữ liệu dựa trên kích thước miền
- Thuộc tính liên tục: Nếu miền giá trị của nó là vô hạn không ếm ược, nghĩa
là giữa hai giá trị tồn tại vô số giá trị khác. Thí dụ như các thuộc tính về màu, nhiệt
ộ hoặc cường ộ âm thanh.
- Thuộc tính rời rạc: Nếu miền giá trị của nó là tập hữu hạn hoặc ếm ược.
Thí dụ như các thuộc tính về số serial của một cuốn sách, số thành viên trong một gia ình,…
1.2.4.2. Phân loại kiểu dữ liệu dựa trên hệ o
Giả sử ta có hai ối tượng x, y và các thuộc tính xi, yi tương ứng với thuộc tính
thứ i của chúng. Chúng ta có các lớp kiểu dữ liệu như sau:
- Thuộc tính ịnh danh: Dạng thuộc tính khái quát hoá của thuộc tính nhị phân,
trong ó miền giá trị là rời rạc không phân biệt thứ tự và có nhiều hơn hai phần tử
- nghĩa là nếu x và y là hai ối tượng thuộc tính thì chỉ có thể xác ịnh là x y hoặc
x = y. Thí dụ như thuộc tính về nơi sinh.
- Thuộc tính có thứ tự: Là thuộc tính ịnh danh có thêm tính thứ tự, nhưng
chúng không ược ịnh lượng. Nếu x và y là hai thuộc tính thứ tự thì ta có thể xác
ịnh là x y hoặc x = y hoặc x > y hoặc x < y. Thí dụ như thuộc tính Huy chương
của vận ộng viên thể thao.
- Thuộc tính khoảng: Nhằm ể o các giá trị theo xấp xỉ tuyến tính. Với thuộc
tính khoảng, ta có thể xác ịnh một thuộc tính là ứng trước hoặc ứng sau thuộc tính
khác với một khoảng là bao nhiêu. Nếu xi > yi thì ta nói x cách y một khoảng |xi –
yi| tương ứng với thuộc tính thứ i. Ví dụ: thuộc tính số Serial của một ầu sách trong
thư viện hoặc thuộc tính số kênh trên truyền hình.
- Thuộc tính tỉ lệ: Là thuộc tính khoảng nhưng ược xác ịnh một cách tương
ối so với iểm mốc, thí dụ như thuộc tính chiều cao hoặc cân nặng lấy giá trị 0 làm mốc. Hoàng Văn Dũng 14 lOMoAR cPSD| 39651089 Khai
phá dữ liệu Web bằng kỹ thuật phân cụm
Trong các thuộc tính dữ liệu trình bày ở trên, thuộc tính ịnh danh và thuộc
tính có thứ tự gọi chung là thuộc tính hạng mục, thuộc tính khoảng và thuộc tính
tỉ lệ ược gọi là thuộc tính số.
Người ta còn ặc biệt quan tâm ến dữ liệu không gian. Đây là loại dữ liệu có
các thuộc tính số khái quát trong không gian nhiều chiều, dữ liệu không gian mô
tả các thông tin liên quan ến không gian chứa ựng các ối tượng, thí dụ như thông
tin về hình học,… Dữ liệu không gian có thể là dữ liệu liên tục hoặc rời rạc:
Dữ liệu không gian rời rạc: Có thể là một iểm trong không gian nhiều chiều
và cho phép ta xác ịnh ược khoảng cách giữa các ối tượng dữ liệu trong không gian.
Dữ liệu không gian liên tục: Bao gồm một vùng trong không gian.
Thông thường, các thuộc tính số ược o bằng các ơn vị xác ịnh như là
Kilogams hoặc Centimeter. Tuy nhiên, các ơn vị o có ảnh hưởng ến các kết quả
phân cụm. Thí dụ như thay ổi ộ o cho thuộc tính cân nặng từ Kilogams sang Pound
có thể mang lại các kết quả khác nhau trong phân cụm. Để khắc phục iều này
người ta phải chuẩn hoá dữ liệu, tức là sử dụng các thuộc tính dữ liệu không phụ
thuộc vào ơn vị o. Thực hiện chuẩn hoá phụ thuộc vào ứng dụng và người dùng,
thông thường chuẩn hoá dữ liệu ược thực hiện bằng cách thay thế mỗi một thuộc
tính bằng thuộc tính số hoặc thêm các trọng số cho các thuộc tính.
1.2.4.3. Khái niệm và phép o ộ tương tự, phi tương tự
Khi các ặc tính của dữ liệu ược xác ịnh, người ta tìm cách thích hợp ể xác ịnh
"khoảng cách" giữa các ối tượng (phép o ộ tương tự dữ liệu). Đây là các hàm ể o
sự giống nhau giữa các cặp ối tượng dữ liệu, thông thường các hàm này hoặc là ể
tính ộ tương tự hoặc là tính ộ phi tương tự giữa các ối tượng dữ liệu. Giá trị của
hàm tính ộ o tương tự càng lớn thì sự giống nhau giữa ối tượng càng lớn và ngược
lại, còn hàm tính ộ phi tương tự tỉ lệ nghịch với hàm tính ộ tương tự. Độ tương tự
hoặc ộ phi tương tự có nhiều cách ể xác ịnh, chúng thường ược o bằng khoảng
cách giữa các ối tượng. Tất cả các cách o ộ tương tự ều phụ thuộc vào kiểu thuộc
tính mà ta phân tích. Thí dụ, ối với thuộc tính hạng mục người ta không sử dụng
ộ o khoảng cách mà sử dụng một hướng hình học của dữ liệu. lOMoAR cPSD| 39651089 Khai
phá dữ liệu Web bằng kỹ thuật phân cụm
Tất cả các ộ o dưới ây ược xác ịnh trong không o gian metric. Bất kỳ một
metric nào cũng là một ộ o, nhưng iều ngược lại không úng. Để tránh sự nhầm
lẫn, thuật ngữ ộ o ở ây ề cập ến hàm tính ộ tương tự hoặc ộ phi tương tự. Một
không gian metric là một tập trong ó có xác ịnh các "khoảng cách" giữa từng cặp
phần tử, với những tính chất thông thường của khoảng cách hình học. Nghĩa là,
một tập X (các phần tử của nó có thể là những ối tượng bất kỳ) gồm các ối tượng
dữ liệu trong CSDL D gọi là một không gian metric nếu với mỗi cặp phần tử x, y
thuộc X ều xác ịnh một số thực δ(x,y), ược gọi là khoảng cách giữa x và y thoả
mãn hệ tính chất sau: (i) δ(x, y)
> 0 nếu x ≠ y; (ii) δ(x,y)= 0 nếu x = y; (iii) δ(x, y) = δ(y, x) với mọi x, y; (iv) δ(x, y)
≤ δ(x, z)+ δ(z,y).
Hàm δ(x, y) ược gọi là một metric của không gian. Các phần tử của X ược
gọi là các iểm của không gian này.
Một số phép o ộ tương tự áp dụng ối với các kiểu dữ liệu khác nhau [10][17][27]:
+ Thuộc tính khoảng: Sau khi chuẩn hoá, ộ o phi tương tự của hai ối tượng
dữ liệu x, y ược xác ịnh bằng các metric như sau: 1/ y
Khoảng cách Minskowski:d x y( , ) ( n1|xi
i| )qq, với q là số nguyên dương. i
Khoảng cách Euclide: d x y( , ) n i 1 (xi
yi)2 , (trường hợp ặc biệt của
khoảng cách Minskowski trong trường hợp q =2).
Khoảng cách Manhattan: d x y( , )
n | xi yi |, (trường hợp ặc biệt của i 1
khoảng cách Minskowski trong trường hợp q=1). Hoàng Văn Dũng 16 lOMoAR cPSD| 39651089 Khai
phá dữ liệu Web bằng kỹ thuật phân cụm
Khoảng cách cực ại: d x y( , ) Max ni 1| xi yi |, ây là trường hợp của khoảng
cách Minskowski trong trường hợp q .
+ Thuộc tính nhị phân: Trước hết ta có xây dựng bảng tham số sau: y: 1 y: 0 x: 1 + x: 0 + + +
Bảng 1.1. Bảng tham số thuộc tính nhị phân
Trong ó: = + + + , các ối tượng x, y mà tất cả các thuộc tính của nó ều
là nhị phân biểu thị bằng 0 và 1. Bảng trên cho ta các thông tin sau:
- là tổng số các thuộc tính có giá trị là 1 trong cả hai ối tượng x, y.
- là tổng số các giá trị thuộc tính có giá trị là 1 trong x và 0 trong y.
- là tổng số các giá trị thuộc tính có giá trị là 0 trong x và 1 trong y.
- là tổng số các giá trị thuộc tính có giá trị là 0 trong x và y.
Các phép o ộ tương tự ối với dữ liệu thuộc tính nhị phân ược ịnh nghĩa như sau:
- Hệ số ối sánh ơn giản: d x y( , )
, ở ây cả hai ối tượng x và y có
vai trò như nhau, nghĩa là chúng ối xứng và có cùng trọng số.
- Hệ số Jacard: d x y( , )
, tham số này bỏ qua số các ối sánh
giữa 0-0. Công thức tính này ược sử dụng trong trường hợp mà trọng số của các
thuộc tính có giá trị 1 của ối tượng dữ liệu có giá trị cao hơn nhiều so với các
thuộc tính có giá trị 0, như vậy các thuộc tính nhị phân ở ây là không ối xứng.
+ Thuộc tính ịnh danh: Độ o phi tương tự giữa hai ối tượng x và y ược ịnh
nghĩa như sau: d x y( , ) p m , trong ó m là số thuộc tính ối sánh p
tương ứng trùng nhau và p là tổng số các thuộc tính.
+ Thuộc tính có thứ tự: Phép o ộ phi tương tự giữa các ối tượng dữ liệu với
thuộc tính thứ tự ược thực hiện như sau, ở ây ta giả sử i là thuộc tính lOMoAR cPSD| 39651089 Khai
phá dữ liệu Web bằng kỹ thuật phân cụm
thứ tự có Mi giá trị (Mi kích thước miền giá trị):
Các trạng thái Mi ược sắp thứ tự như sau: [1…Mi], ta có thể thay thế mỗi giá
trị của thuộc tính bằng giá trị cùng loại ri, với ri {1,…,Mi}.
Mỗi một thuộc tính thứ tự có các miền giá trị khác nhau, vì vậy ta chuyển ổi
chúng về cùng miền giá trị [0,1] bằng cách thực hiện phép biến ổi sau cho mỗi thuộc tính: z 1 i( )j Mri( )j i
1, với i=1,..,Mi
Sử dụng công thức tính ộ phi tương tự của thuộc tính khoảng ối với các giá trị z ( )j i
, ây cũng chính là ộ phi tương tự của thuộc tính có thứ tự.
+ Thuộc tính tỉ lệ: Có nhiều cách khác nhau ể tính ộ tương tự giữa các thuộc
tính tỉ lệ. Một trong những số ó là sử dụng công thức tính logarit cho mỗi thuộc
tính xi, thí dụ qi = log(xi), lúc này qi óng vai trò như thuộc tính khoảng. Phép biến
ổi logarit này thích hợp trong trường hợp các giá trị của thuộc tính là số mũ.
Trong thực tế, khi tính ộ o tương tự dữ liệu, người ta chỉ xem xét một phần
các thuộc tính ặc trưng ối với các kiểu dữ liệu hoặc ánh trọng số cho cho tất cả
các thuộc tính dữ liệu. Trong một số trường hợp, người ta loại bỏ ơn vị o của các
thuộc tính dữ liệu bằng cách chuẩn hoá chúng hoặc gán trọng số cho mỗi thuộc
tính giá trị trung bình, ộ lệch chuẩn. Các trọng số này có thể sử dụng trong các ộ
o khoảng cách trên, thí dụ với mỗi thuộc tính dữ liệu ã ược gán trọng số tương
ứng wi (1 i k ), ộ tương tự dữ liệu ược xác ịnh như sau: d x y( , ) i n1 wi (xi yi)2 .
Người ta có thể chuyển ổi giữa các mô hình cho các kiểu dữ liệu trên, thí dụ
dữ liệu kiểu hạng mục có thể chuyển ổi thành dữ liệu nhị phân và ngược lại. Nhưng
giải pháp này rất tốt kém về chi phí tính toán, cần phải cân nhắc khi áp dụng cách thức này.
Tuỳ từng trường hợp dữ liệu cụ thể mà người ta sử dụng các mô hình tính ộ
tương tự khác nhau. Việc xác ịnh ộ tương tự dữ liệu thích hợp, chính xác, ảm bảo Hoàng Văn Dũng 18 lOMoAR cPSD| 39651089 Khai
phá dữ liệu Web bằng kỹ thuật phân cụm
khách quan là rất quan trọng và góp phần xây dựng thuật toán PCDL có hiệu quả
cao trong việc ảm bảo chất lượng cũng như chi phí tính toán của thuật toán. 1.3. Khai phá Web
1.3.1. Lợi ích của khai phá Web
Với sự phát triển nhanh chóng của thông tin trên www, KPDL Web ã từng
bước trở nên quan trọng hơn trong lĩnh vực KPDL, người ta luôn hy vọng lấy ược
những tri thức hữu ích thông qua việc tìm kiếm, phân tích, tổng hợp, khai phá
Web. Những tri thức hữu ích có thể giúp ta xây dựng nên những Web site hiệu quả
ể có thể phục vụ cho con người tốt hơn, ặc biệt trong lĩnh vực thương mại iện tử.
Khám phá và phân tích những thông tin hữu ích trên www bằng cách sử dụng
kỹ thuật KPDL ã trở thành một hướng quan trọng trong lĩnh vực khám phá tri
thức. Khai phá Web bao gồm khai phá cấu trúc Web, khai phá nội dung Web và
khai phá các mẫu truy cập Web.
Sự phức tạp trong nội dung của các trang Web khác với các tài liệu văn bản
truyền thống [16]. Chúng không ồng nhất về cấu trúc, hơn nữa nguồn thông tin
Web thay ổi một cách nhanh chóng, không những về nội dung mà cả về cấu trúc
trang. Chẳng hạn như tin tức, thị trường chứng khoán, thông tin quảng cáo, trung
tâm dịch vụ mạng,... Tất cả thông tin ược thay ổi trên Web theo từng giai oạn. Các
liên kết trang và ường dẫn truy cập cũng luôn thay ổi. Khả năng gia tăng liên tục
về số lượng người dùng, sự quan tâm tới Web cũng khác nhau, ộng cơ người dùng
rất a dạng và phong phú. Vậy làm thế nào ể có thể tìm kiếm ược thông tin mà
người dùng cần? Làm thế nào ể có ược những trang Web chất lượng cao?...
Những vấn ề này sẽ ược thực hiện hiệu quả hơn bằng cách nghiên cứu các
kỹ thuật KPDL áp dụng trong môi trường Web. Thứ nhất, ta sẽ quản lý các Web
site thật tốt; thứ hai, khai phá những nội dung mà người dùng quan tâm; thứ ba,
sẽ thực hiện phân tích các mẫu sử dụng Web.
Dựa vào những vấn ề cơ bản trên, ta có thể có những phương pháp hiệu quả
cao ể cung cấp những thông tin hữu ích ối với người dùng Web và giúp người
dùng sử dụng nguồn tài nguyên Web một cách hiệu quả. lOMoAR cPSD| 39651089 Khai
phá dữ liệu Web bằng kỹ thuật phân cụm 1.3.2. Khai phá Web
Có nhiều khái niệm khác nhau về khai phá Web, nhưng có thể tổng quát hóa
như sau [5][30]: Khai phá Web là việc sử dụng các kỹ thuật KPDL ể tự ộng hóa
quá trình khám phá và trích rút những thông tin hữu ích từ các tài liệu, các dịch
vụ và cấu trúc Web. Hay nói cách khác khai phá Web là việc thăm dò những thông
tin quan trọng và những mẫu tiềm năng từ nội dung Web, từ thông tin truy cập
Web, từ liên kết trang và từ nguồn tài nguyên thương mại iện tử bằng việc sử dụng
các kỹ thuật KPDL, nó có thể giúp con người rút ra những tri thức, cải tiến việc
thiết kế các Web site và phát triển thương mại iện tử tốt hơn. Lĩnh vực này ã thu
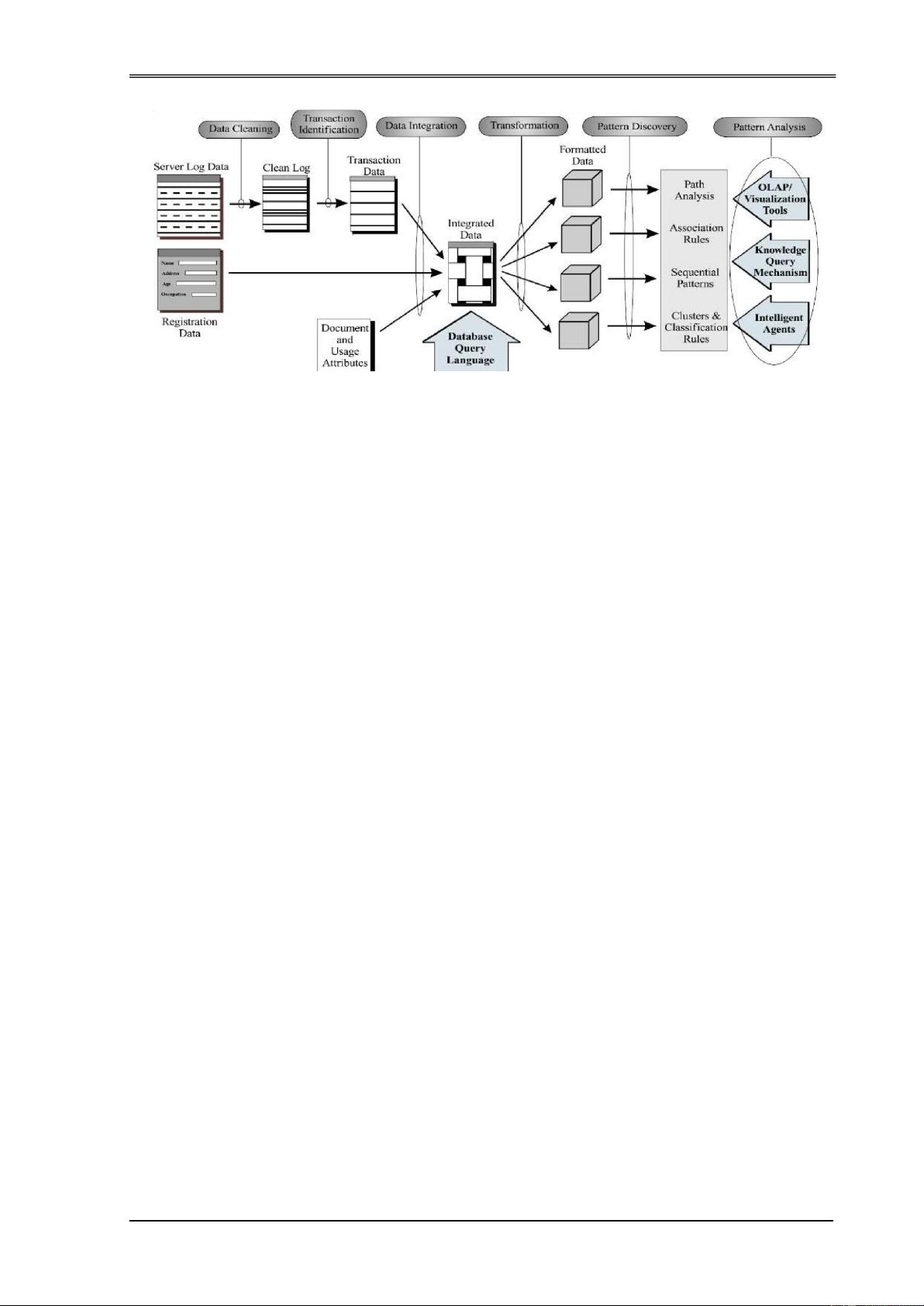
hút ược nhiều nhà khoa học quan tâm. Quá trình khai phá Web có thể chia thành
các công việc nhỏ như sau:
i. Tìm kiếm nguồn tài nguyên: Thực hiện tìm kiếm và lấy các tài liệu Web
phục vụ cho việc khai phá.
ii. Lựa chọn và tiền xử lý dữ liệu: Lựa chọn và tiền xử lý tự ộng các loại
thông tin từ nguồn tài nguyên Web ã lấy về.
iii. Tổng hợp: Tự ộng khám phá các mẫu chung tại các Web site riêng lẽ
cũng như nhiều Website với nhau.
iv. Phân tích: Đánh giá, giải thích, biểu diễn các mẫu khai phá ược.
1.3.3. Các kiểu dữ liệu Web
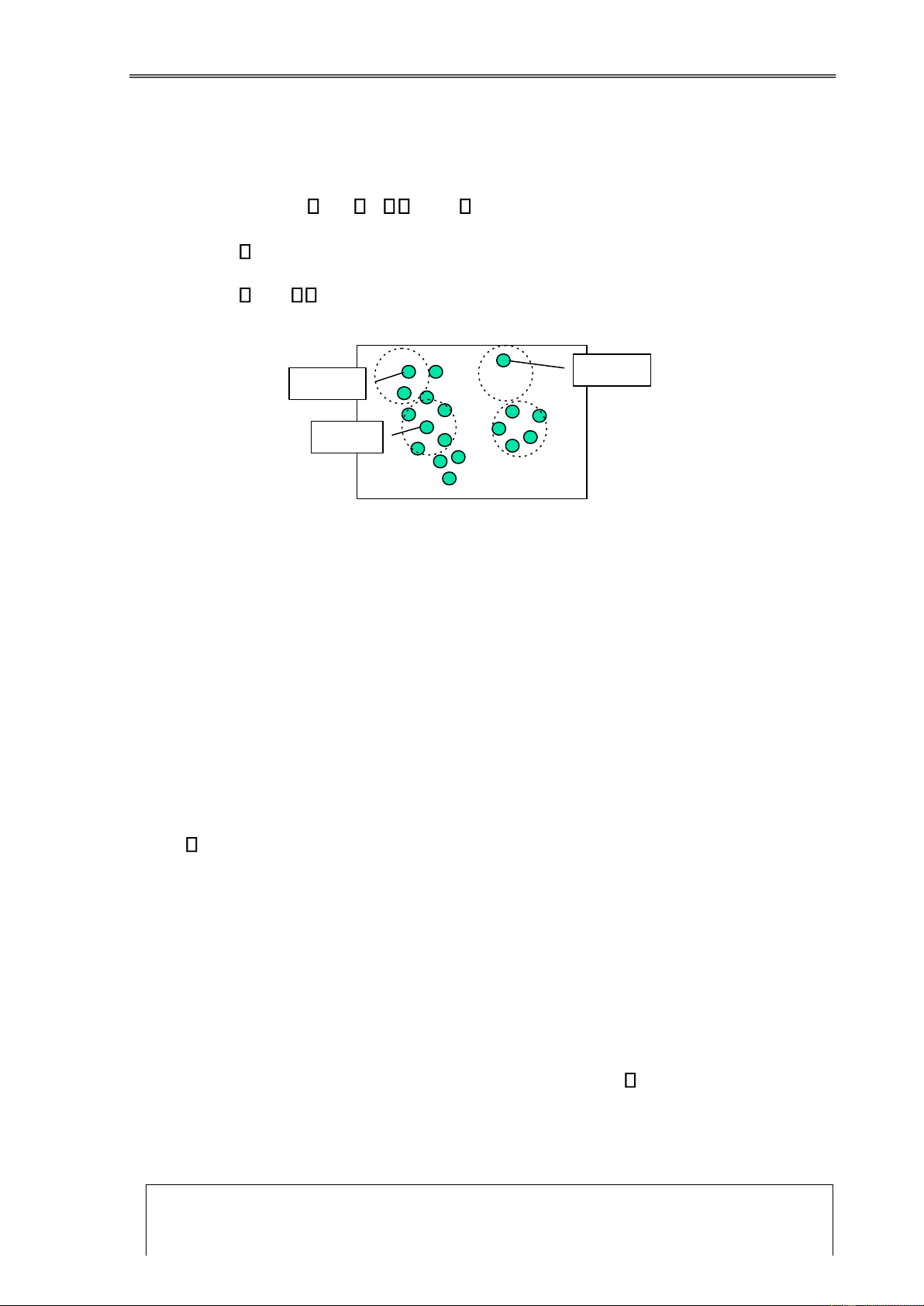
Ta có thể khái quát bằng sơ ồ sau: Free Text HTML file Content data XML file Dynamic content Multimedia Web data Static link Structure data Usage data Dynamic link User Profile data
Hình 1.5. Phân loại dữ liệu Web Hoàng Văn Dũng 20 lOMoAR cPSD| 39651089 Khai
phá dữ liệu Web bằng kỹ thuật phân cụm
Các ối tượng của khai phá Web bao gồm [5][16]: Server logs, Web pages,
Web hyperlink structures, dữ liệu thị trường trực tuyến và các thông tin khác.
Web logs: Khi người dùng duyệt Web, dịch vụ sẽ phân ra 3 loại dữ liệu ăng
nhập: sever logs, error logs, và cookie logs. Thông qua việc phân tích các tài liệu
ăng nhập này ta có thể khám phá ra những thông tin truy cập.
Web pages: Hầu hết các phương pháp KPDL Web ược sử dụng trong Web pages là theo chuẩn HTML.
Web hyperlink structure: Các trang Web ược liên kết với nhau bằng các siêu
liên kết, iều này rất quan trọng ể khai phá thông tin. Do các siêu liên kết Web là
nguồn tài nguyên rất xác thực.
Dữ liệu thị trường trực tuyến: Như lưu trữ thông tin thương mại iện tử trong
các site thương mại iện tử.
Các thông tin khác: Chủ yếu bao gồm các ăng ký người dùng, nó có thể
giúp cho việc khai phá tốt hơn.
1.4. Xử lý dữ liệu văn bản ứng dụng trong khai phá dữ liệu Web
1.4.1. Dữ liệu văn bản
Trong các loại dữ liệu hiện nay thì văn bản là loại dữ liệu phổ biến nhất và
nó có mặt khắp mọi nơi, ặc biệt là ối với dữ liệu trên Web. Do vậy, các bài toán
xử lý văn bản ã ược ặt ra từ rất sớm và hiện nay nó vẫn là vấn ề rất ược nhiều nhà
nghiên cứu quan tâm, một trong những bài toán ó là tìm kiếm và trích dẫn văn
bản, biểu diễn và phân loại văn bản,….
CSDL văn bản có thể chia làm 2 loại chính [14][20]:
+ Dạng không có cấu trúc: Đây là những tài liệu văn bản thông thường mà ta
ọc thường ngay trên các sách, báo, internet,… ây là dạng dữ liệu của ngôn ngữ tự
nhiên của con người và nó không theo một khuôn mẫu ịnh sẵn nào cả.
+ Dạng nữa cấu trúc: Đây là những văn bản ược tổ chức dưới dạng cấu trúc
lỏng, nhưng vẫn thể hiện nội dung chính của văn bản, như văn bản HTML, Email,..
1.4.2. Một số vấn ề trong xử lý dữ liệu văn bản
Mỗi văn bản ược biểu diễn bằng một vector Boolean hoặc vector số. Những
vector này ược xét trong một không gian a chiều, trong ó mỗi chiều tương ứng với lOMoAR cPSD| 39651089 Khai
phá dữ liệu Web bằng kỹ thuật phân cụm
một từ mục riêng biệt trong tập văn bản. Mỗi thành phần của vector ược gán một
hàm giá trị f, nó là một số chỉ mật ộ tương ứng của chiều ó trong văn bản. Nếu
thay ổi giá trị hàm f ta có thể tạo ra nhiều trọng số khác nhau.
Một số vấn ề liên quan ến việc biểu diễn văn bản bằng mô hình không gian vector:
+ Không gian vector là một tập hợp bao gồm các từ.
+ Từ là một chuỗi các ký tự (chữ cái và chữ số); ngoại trừ các khoảng trống
(space, tab), ký tự xuống dòng, dấu câu (như dấu chấm, phẩy, chấm phẩy, dấu
cảm,...). Mặt khác, ể ơn giản trong quá trình xử lý, ta không phân biệt chữ hoa và
chữ thường (nếu chữ hoa thì chuyển về chữ thường).
+ Cắt bỏ từ: Trong nhiều ngôn ngữ, nhiều từ có cùng từ gốc hoặc là biến thể
của từ gốc sang một từ khác. Việc sử dụng từ gốc làm giảm áng kể số lượng các từ
trong văn bản (giảm số chiều của không gian), nhưng việc cắt bỏ các từ lại rất khó
trong việc hiểu văn bản.
Ngoài ra, ể nâng cao chất lượng xử lý, một số công trình nghiên cứu ã ưa ra
một số cải tiến thuật toán xem xét ến ặc tính ngữ cảnh của các từ bằng việc sử
dụng các cụm từ/văn phạm chứ không chỉ xét các từ riêng lẽ [31]. Những cụm từ
này có thể ược xác ịnh bằng cách xem xét tần số xuất hiện của cả cụm từ ó trong tài liệu.
Bằng phương pháp biểu diễn không gian vector, ta có thể thấy rõ ràng là
chiều của một vector sẽ rất lớn bởi số chiều của nó ược xác ịnh bằng số lượng các
từ khác nhau trong tập hợp từ. Chẳng hạn, số lượng các từ có thể từ 103 ến 105 ối
với các tập văn bản nhỏ. Vấn ề ặt ra là làm sao ể giảm số chiều của vector mà vẫn
ảm bảo việc xử lý văn bản úng và chính xác, ặc biệt là trong môi trường www, ta
sẽ xem xét ến một số phương pháp ể giảm số chiều của vector.
1.4.2.1. Loại bỏ từ dừng
Trước hết ta thấy trong ngôn ngữ tự nhiên có nhiều từ chỉ dùng ể biểu diễn
cấu trúc câu chứ không biểu ạt nội dung của nó. Như các giới từ, từ nối,... những
từ như vậy xuất hiện nhiều trong các văn bản mà không liên quan gì tới chủ ề hoặc Hoàng Văn Dũng 22 lOMoAR cPSD| 39651089 Khai
phá dữ liệu Web bằng kỹ thuật phân cụm
nội dung của văn bản. Do ó, ta có thể loại bỏ những từ ó ể giảm số chiều của vector
biểu diễn văn bản, những từ như vậy ược gọi là những từ dừng.
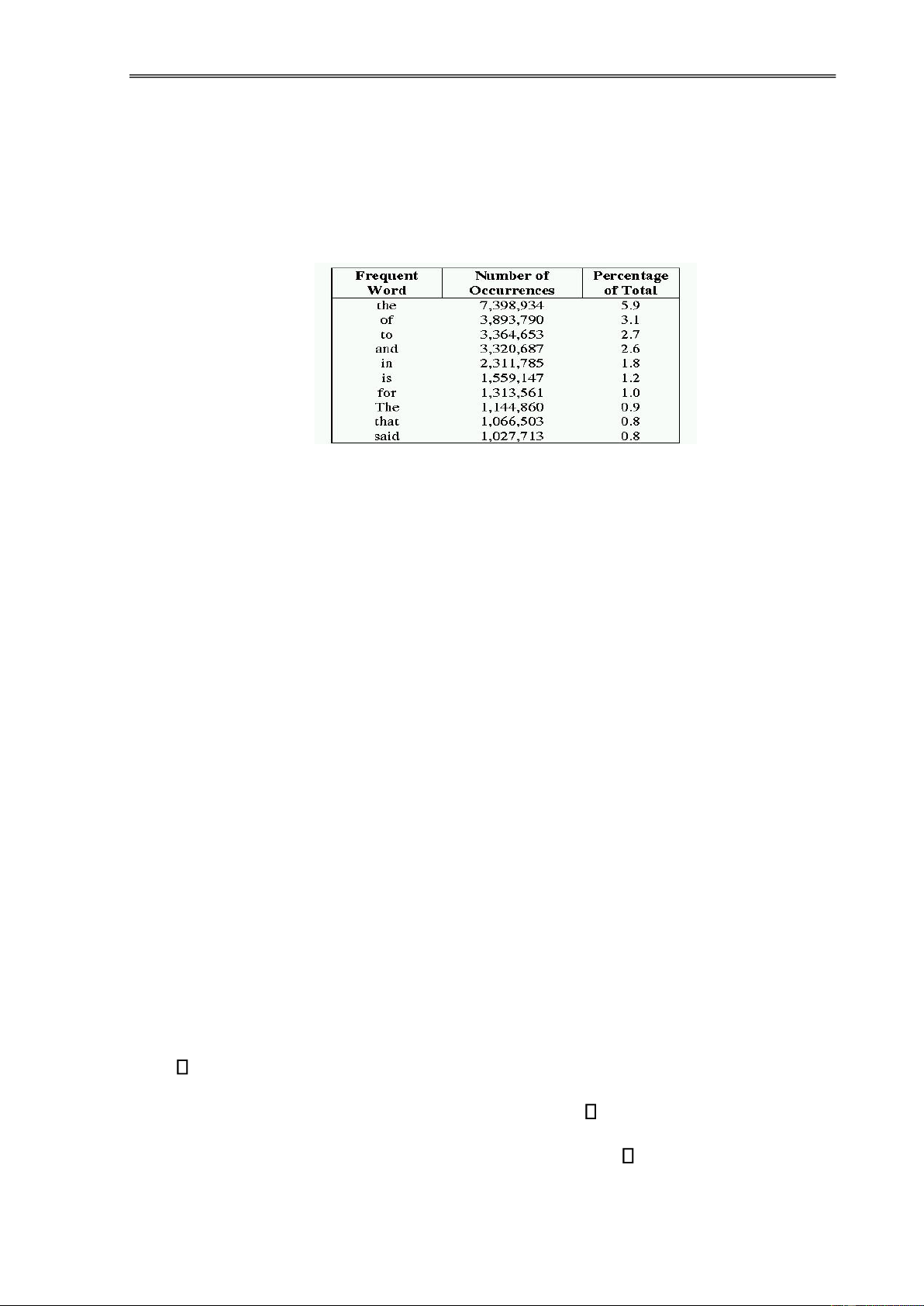
Sau ây là ví dụ về tần số xuất hiện cao của một số từ (tiếng Anh) trong
336,310 tài liệu gồm tổng cộng 125.720.891 từ, 508.209 từ riêng biệt.
(thống kê của B. Croft, UMass)
Bảng 1.2. Thống kê các từ tần số xuất hiện cao
1.4.2.2. Định luật Zipf
Để giảm số chiều của vector biểu diễn văn bản hơn nữa ta dựa vào một quan
sát sau: Nhiều từ trong văn bản xuất hiện rất ít lần, nếu mục tiêu của ta là xác ịnh
ộ tương tự và sự khác nhau trong toàn bộ tập hợp các văn bản thì các từ xuất hiện
một hoặc hai lần (tần số xuất hiện nhỏ) thì ảnh hưởng rất bé ến các văn bản.
Tiền ề cho việc lý luận ể loại bỏ những từ có tần suất nhỏ ược ưa ra bởi Zipf
năm 1949. Zipf phát biểu dưới dạng một quan sát nhưng ngay trong thời iểm ó,
quan sat ó ã ược gọi là ịnh luật Zipf, mặc dù nó thực sự không phải là một ịnh luật
mà úng hơn ó là một hiện tượng xấp xỉ toán học.
Để mô tả ịnh luật Zipf, ta gọi tổng số tần số xuất hiện của từ t trong tài liệu
D là ft. Sau ó sắp xếp tất cả các từ trong tập hợp theo chiều giảm dần của tần số
xuất hiện f và gọi thứ hạng của mỗi từ t là rt.
Định luật Zipf ược phát biểu dưới dạng công thức như sau: rt.ft
K (với K là một hằng số).
Trong tiếng Anh, người ta thấy rằng hằng số K N/10 trong ó N là số các từ
trong văn bản. Ta có thể viết lại ịnh luật Zipf như sau: rt K/ ft
Giả sử từ ti ược sắp xếp ở vị trí thấp nhất với tần số xuất hiện là b nào ấy và
từ tj cũng ược sắp ở vị trí thấp kế tiếp với một tần số xuất hiện là b+1. Ta có thể lOMoAR cPSD| 39651089 Khai
phá dữ liệu Web bằng kỹ thuật phân cụm
thu ược thứ hạng xấp xỉ của các từ này là rti K/b và rtj K/(b+1), trừ 2 biểu thức
này cho nhau ta xấp xỉ ối với các từ riêng biệt có tần số xuất hiện là b.
rti- rtj K/b-K/(b+1)
Ta xấp xỉ giá trị của từ trong tập hợp có thứ hạng cao nhất. Một cách tổng
quát, một từ chỉ xuất hiện một lần trong tập hợp, ta có rmax=K.
Xét phân bố của các từ duy nhất xuất hiện b lần trong tập hợp, chia 2 vế cho
nhau ta ược K/b. Do ó, ịnh luật Zipf cho ta thấy sự phân bố áng chú ý của các tự
riêng biệt trong 1 tập hợp ược hình thành bởi các từ xuất hiện ít nhất trong tập hợp.
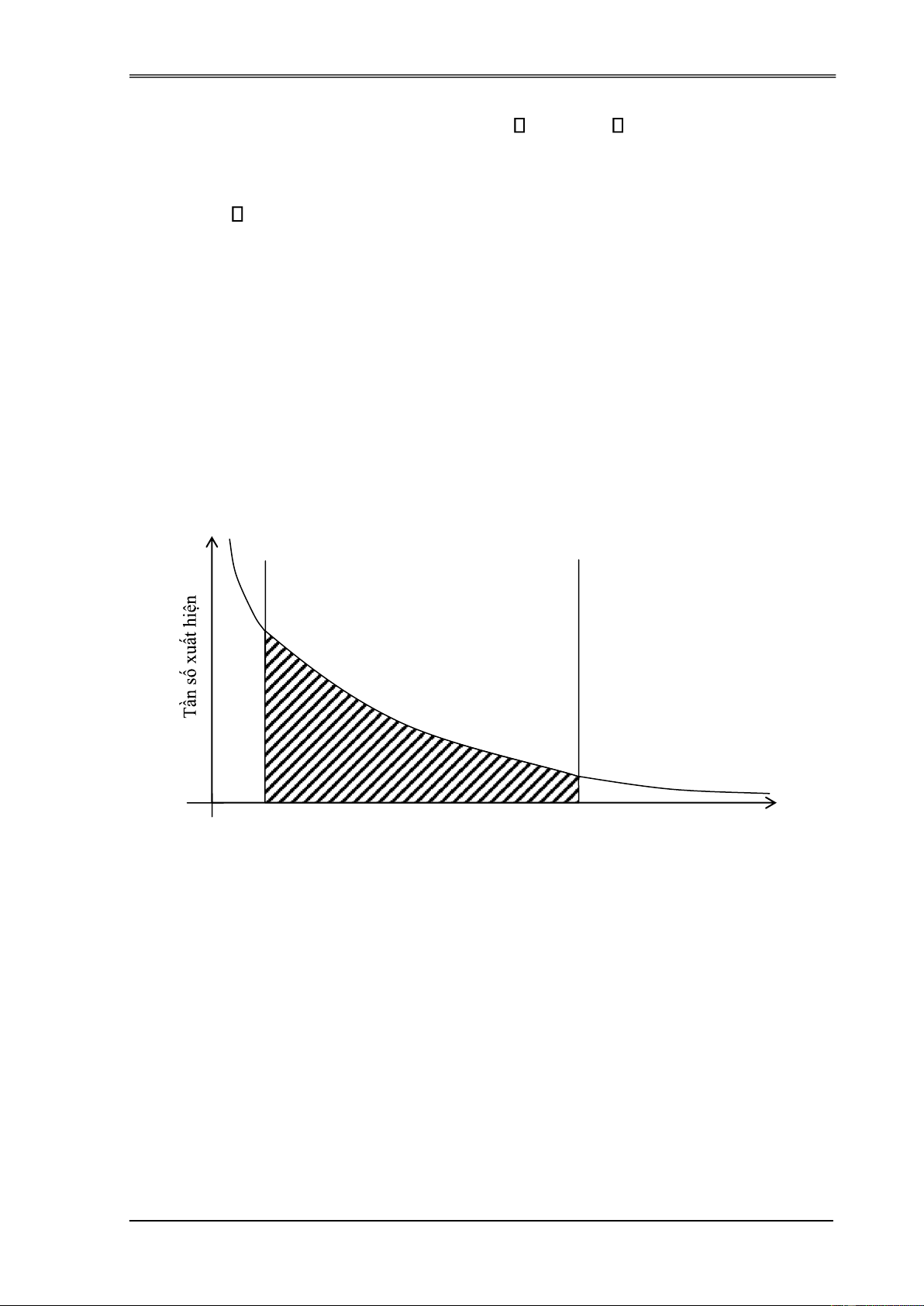
Năm 1958 Luhn ề xuất những từ “phổ biến” và “hiếm” và không cần thiết
cho quá trình xử lý như sau. f vùng cao Vùng những từ Vùng thấp mang ý nghĩa Thứ hạng của từ r
Hình 1.6. Lược ồ thống kê tần số của từ theo Định luật Zipf
1.4.3. Các mô hình biểu diễn dữ liệu văn bản
Trong các bài toán xử lý văn bản, ta thấy rằng vai trò của biểu diễn văn bản
rất lớn, ặc biệt trong các bài toán tìm kiếm, phân cụm,…
Theo các nghiên cứu về cách biểu diễn khác nhau trong xử lý văn bản thì
cách biểu diễn tốt nhất là bằng các từ riêng biệt ược rút ra từ tài liệu gốc và cách
biểu diễn này ảnh hưởng tương ối nhỏ ối với kết quả.
Các cách tiếp cận khác nhau sử dụng mô hình toán học khác nhau ể tính toán,
ở ây ta sẽ trình bày một số mô hình phổ biến và ược ăng nhiều trong các bài báo gần ây [14][22]. Hoàng Văn Dũng 24 lOMoAR cPSD| 39651089 Khai
phá dữ liệu Web bằng kỹ thuật phân cụm
1.4.3.1. Mô hình Boolean
Đây là mô hình biểu diễn vector với hàm f nhận giá trị rời rạc với duy nhất
hai giá trị úng/sai (true/false). Hàm f tương ứng với thuật ngữ ti sẽ cho giá trị úng
khi và chỉ khi ti xuất hiện trong tài liệu ó.
Giả sử rằng có một CSDL gồm m văn bản, D={d1, d2, ..., dm}. Mỗi văn bản
ược biểu diễn dưới dạng một vector gồm n thuật ngữ T={t1, t2,...,tn}. Gọi W={wij}
là ma trận trọng số, wij là giá trị trọng số của thuật ngữ ti trong tài liệu dj.
Mô hình Boolean là mô hình ơn giản nhất, nó ược xác ịnh như sau: 1 nếu ti dj Wij= 0 nếu ti dj
1.4.3.2. Mô hình tần số
Mô hình này xác ịnh giá trị trọng số các phần tử trong ma trận W(wij) các giá
trị là các số dương dựa vào tần số xuất hiện của các từ trong tài liệu hoặc tần số
xuất hiện của tài liệu trong CSDL. Có 2 phương pháp phổ biến:
1.4.3.2.1. Mô hình dựa trên tần số xuất hiện các từ
Trong mô hình dưa trên tần số xuất hiện từ (TF-Term Frequency) giá trị của
các từ ược tính dựa vào số lần xuất hiện của nó trong tài liệu, gọi tfij là số lần xuất
hiện của từ ti trong tài liệu dj, khi ó wij có thể ược tính theo một trong các công thức sau [31]: - Wij = tfij
- Wij = 1+log(tfij) - Wij = tfij
Với mô hình này, trọng số wij ồng biến với số lần xuất hiện của thuật ngữ ti
trong tài liệu dj. Khi số lần xuất hiện thuật ngữ ti trong tài liệu dj càng lớn thì có
nghĩa là dj càng phụ thuộc nhiều vào thuật ngữ ti, nói cách khác thuật ngữ ti mang
nhiều thông tin hơn trong tài liệu dj.
1.4.3.2.2. Phương pháp dựa trên tần số văn bản nghịch ảo
Trong mô hình dưa trên tần số văn bản nghịch ảo (IDF-Inverse Document
Frequency) giá trị trọng số của từ ược tính bằng công thức sau [31]: lOMoAR cPSD| 39651089 Khai
phá dữ liệu Web bằng kỹ thuật phân cụm )
n log(n) log(hi ) nếu ti dj Wij= log( i h
nếu ngược lại (ti dj) 0
Trong ó, n là tổng số văn bản trong CSDL, hi là số văn bản chứa thuật ngữ ti.
Trọng số wij trong công thức trên ược tính dựa vào ộ quan trọng của thuật
ngữ ti trong tài liệu dj. Nếu ti xuất hiện càng ít trong các văn bản thì nó càng quan
trọng, do ó nếu ti xuất hiện trong dj thì trọng số của nó càng lớn, nghĩa là nó càng
quan trọng ể phân biệt dj với các tài liệu khác và lượng thông tin của nó càng lớn.
1.4.3.2.3. Mô hình kết hợp TF-IDF
Trong mô hình TF-IDF [31], mỗi tài liệu dj ược xét ến thể hiện bằng một ặc
trưng của (t1, t2,.., tn) với ti là một từ/cụm từ trong dj. Thứ tự của ti dựa trên trọng
số của mỗi từ. Các tham số có thể ược thêm vào ể tối ưu hóa quá trình thực hiện
nhóm. Như vậy, thành phần trọng số ược xác ịnh bởi công thức sau, nó kết hợp
giá trị trọng số tf và giá trị trọng số idf.
Công thức tính trọng số TF-IDF là:
tfij idfij [1 log(fij )] log(n ) nếu ti dj Data Wij= hi set 0
nếu ngược lại (ti dj) Trong ó:
tfij là tần số xuất hiện của ti trong tài liệu dj idfij là
nghịch ảo tần số xuất hiện của ti trong tài liệu dj. hi là số
các tài liệu mà ti xuất hiện trong CSDL.
n là tổng số tài liệu trong CSDL.
Từ công thức này, ta có thể thấy trọng số của mỗi phần tử là dựa trên nghịch
ảo của tần số tài liệu trong CSDL mà ti và tần số xuất hiện của phần tử này trong tài liệu.
Thông thường ta xây dựng một từ iển từ ể lấy i những từ rất phổ biến và
những từ có tần số xuất hiện thấp. Ngoài ra ta phải lựa chọn m (Zemir sử dụng
500) phần tử có trọng số cao nhất như là những từ ặc trưng. Hoàng Văn Dũng 26 lOMoAR cPSD| 39651089 Khai
phá dữ liệu Web bằng kỹ thuật phân cụm
Phương pháp này kết hợp ược ưu iểm của cả 2 phương pháp trên. Trọng số
wij ược tính bằng tần số xuất hiện của thuật ngữ ti trong tài liệu dj và ộ “hiếm” của
thuật ngữ ti trong toàn bộ CSDL. Tùy theo ràng buộc cụ thể của bài toán mà ta sử
dụng các mô hình biểu diễn văn bản cho phù hợp.
Tính toán ộ tương tự giữa 2 vector
Xét 2 vector X={x1, x2,..., xm} và Y={y1, y2,..., ym}.
Trong mô hình TF-IDF, ta có thể lựa chọn công thức nào ó ể tính toán ộ tương
tự giữa các cặp tài liệu hoặc các cụm. Sau ây là các ộ o tương tự phổ biến [5][14][31]:
2 m (xi yi )
Dice: S im(X Y, ) i 1 m m xi2 yi2 i 1 i 1 Jaccard : m (xi yi ) Sim( X Y, ) m im 1 m xi2 yi2 X Y (xi yi ) i 1 i 1 i 1
m (xi yi ) Cosine: Sim( , ) i 1 m xi2 m yi2
i 1 i 1 i 1 i 1
m (xi yi ) Sim( X Y, ) Euclidean:
Sim( X Y, ) Dis(X Y, )
Overlap: i 1m m
m (xi yi )2 min( xi2, yi2 ) 1 i
Manhattan : Sim( X Y, ) Dis(X Y, ) m | xi yi | i 1
Hình 1.7. Các ộ o tương tự thường dùng lOMoAR cPSD| 39651089 Khai
phá dữ liệu Web bằng kỹ thuật phân cụm
Với xi và yj ại diện một cặp từ hoặc cụm từ trong tài liệu. Sử dụng các công
thức này và với một ngưỡng thích hợp, ta có thể dễ dàng xác ịnh mức ộ tương tự
của các tài liệu trong CSDL. Ý tưởng sử dụng mô hình TF-IDF ể biểu diễn tài liệu
có nhiều từ thông dụng giữa 2 tài liệu thì có nhiều khả năng chúng tương tự nhau.
Kỹ thuật phân cụm phân cấp và phân cụm phân hoạch (k-means) là 2 kỹ
thuật phân cụm thường ược sử dụng cho phân cụm tài liệu với mô hình TF-IDF.
1.5. Tổng kết chương 1
Chương 1 trình bày những kiến thức cơ bản về khai phá dữ liệu và khám phá
tri thức trong CSDL, các kỹ thuật áp dụng trong khai phá dữ liệu, những chức
năng chính, ứng dụng của nó trong xã hội,...
Chương này cũng trình bày một hướng nghiên cứu và ứng dụng trong khai
phá dữ liệu là phân cụm dữ liệu, gồm tổng quan về kỹ thuật phân cụm, các ứng
dụng của phân cụm, các yêu cầu ối với kỹ thuật phân cụm, các kiểu dữ liệu và ộ o tương tự,...
Một hướng tiếp cận mới trong khai phá dữ liệu là khai phá dữ liệu trong môi
trường Web. Phần này trình bày khái niệm và lợi ích của khai phá Web, một số
mô hình biểu diễn và xử lý dữ liệu văn bản áp dụng trong khai phá Web như mô
hình Boolean, mô hình tần số (TF), mô hình tần số nghịch ảo văn bản (IDF), mô
hình kết hợp TF-IDF và các ộ o ể xác ịnh ộ tương tự văn bản.
Chương 2. MỘT SỐ KỸ THUẬT PHÂN CỤM DỮ LIỆU
Các kỹ thuật áp dụng ể giải quyết vấn ề PCDL ều hướng tới hai mục tiêu
chung: Chất lượng của các cụm khám phá ược và tốc ộ thực hiện của thuật toán.
Tuy nhiên, các kỹ thuật PCDL có thể ược phân loại thành một số loại cơ bản dưa
trên các phương pháp tiếp cận như sau [10][19]: Hoàng Văn Dũng 28 lOMoAR cPSD| 39651089 Khai
phá dữ liệu Web bằng kỹ thuật phân cụm
2.1. Phân cụm phân hoạch
Ý tưởng chính của kỹ thuật này là phân một tập dữ liệu có n phần tử cho
trước thành k nhóm dữ liệu sao cho mỗi phần tử dữ liệu chỉ thuộc về một nhóm
dữ liệu và mỗi nhóm dữ liệu có tối thiểu ít nhất một phần tử dữ liệu. Các thuật
toán phân hoạch có ộ phức tạp rất lớn khi xác ịnh nghiệm tối ưu toàn cục cho vấn
ề PCDL, vì nó phải tìm kiếm tất cả các cách phân hoạch có thể ược. Chính vì vậy,
trên thực tế người ta thường i tìm giải pháp tối ưu cục bộ cho vấn ề này bằng cách
sử dụng một hàm tiêu chuẩn ể ánh giá chất lượng của các cụm cũng như ể hướng
dẫn cho quá trình tìm kiếm phân hoạch dữ liệu. Với chiến lược này, thông thường
người ta bắt ầu khởi tạo một phân hoạch ban ầu cho tập dữ liệu theo phép ngẫu
nhiên hoặc theo heuristic và liên tục tinh chỉnh nó cho ến khi thu ược một phân
hoạch mong muốn, thoả mãn các iều kiện ràng buộc cho trước. Các thuật toán
phân cụm phân hoạch cố gắng cải tiến tiêu chuẩn phân cụm bằng cách tính các
giá trị o ộ tương tự giữa các ối tượng dữ liệu và sắp xếp các giá trị này, sau ó thuật
toán lựa chọn một giá trị trong dãy sắp xếp sao cho hàm tiêu chuẩn ạt giá trị tối
thiểu. Như vậy, ý tưởng chính của thuật toán phân cụm phân hoạch tối ưu cục bộ
là sử dụng chiến lược ăn tham ể tìm kiếm nghiệm.
Lớp các thuật toán phân cụm phân hoạch bao gồm các thuật toán ề xuất ầu
tiên trong lĩnh vực KPDL cũng là các thuật toán ược áp dụng nhiều trong thực tế
như k-means, PAM, CLARA, CLARANS. Sau ây là một số thuật toán kinh iển
ược kế thừa sử dụng rộng rãi.
2.1.1. Thuật toán k-means
Thuật toán phân cụm k-means do MacQueen ề xuất trong lĩnh vực thống kê
năm 1967, mục ích của thuật toán k-means là sinh ra k cụm dữ liệu {C1, C2,…,
Ck} từ một tập dữ liệu ban ầu gồm n ối tượng trong không gian d chiều
Xi =(xi1, xi2, …,xid) (i 1,n), sao cho hàm tiêu chuẩn: E k
i 1 x Ci D2(x m i ) ạt giá trị
tối thiểu. Trong ó: mi là trọng tâm của cụm Ci, D là khoảng cách giữa hai ối tượng. lOMoAR cPSD| 39651089 Khai
phá dữ liệu Web bằng kỹ thuật phân cụm
Trọng tâm của một cụm là một vector, trong ó giá trị của mỗi phần tử của nó
là trung bình cộng các thành phần tương ứng của các ối tượng vector dữ liệu trong
cụm ang xét. Tham số ầu vào của thuật toán là số cụm k, tập CSDL gồm n phần
tử và tham số ầu ra của thuật toán là các trọng tâm của các cụm dữ liệu. Độ o
khoảng cách D giữa các ối tượng dữ liệu thường ược sử dụng dụng là khoảng cách
Euclide, bởi vì ây là mô hình khoảng cách dễ ể lấy ạo hàm và xác ịnh các cực trị
tối thiểu. Hàm tiêu chuẩn và ộ o khoảng cách có thể ược xác ịnh cụ thể hơn tuỳ
vào ứng dụng hoặc các quan iểm của người dùng.
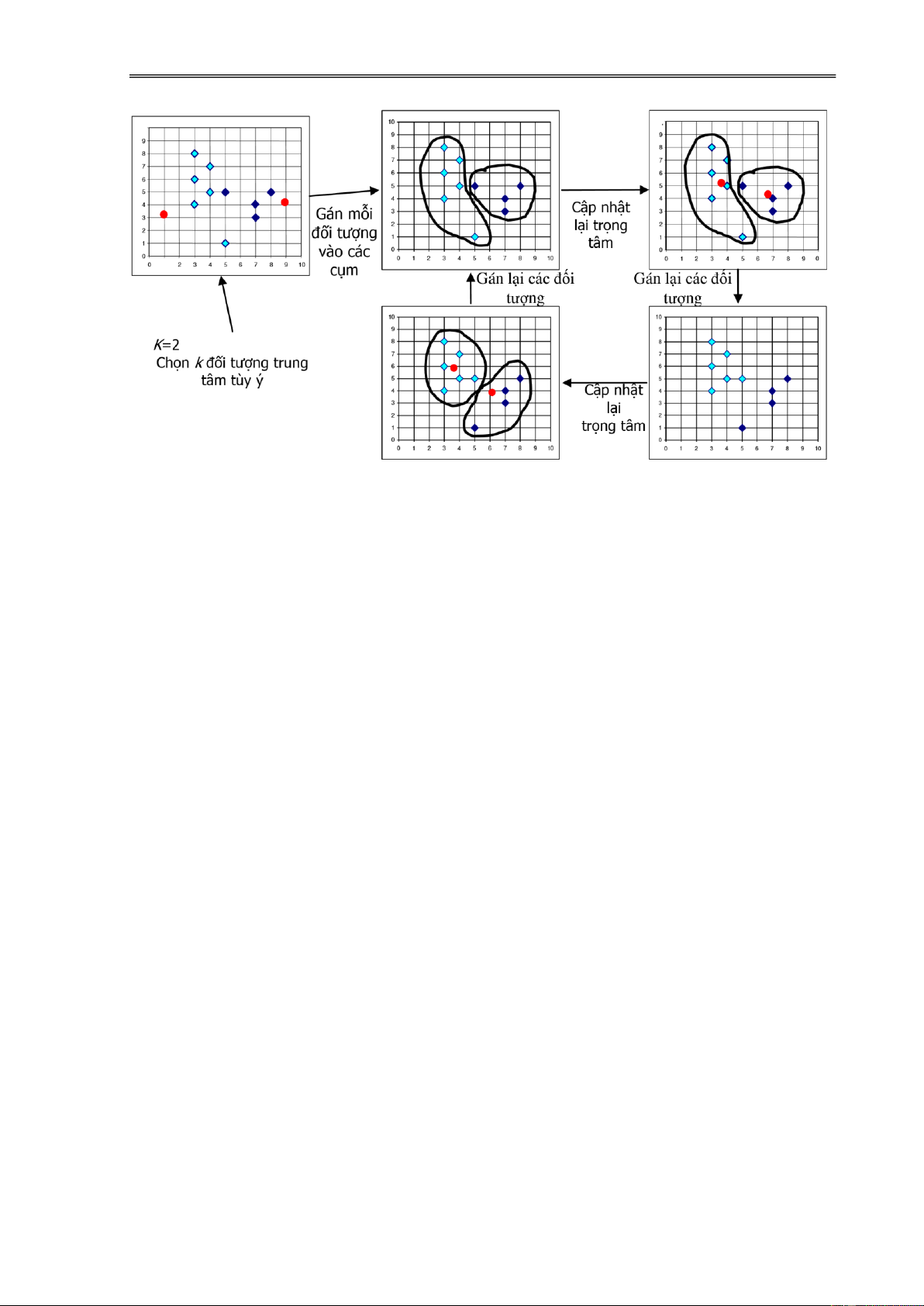
Thuật toán k-means bao gồm các bước cơ bản như sau:
INPUT: Một CSDL gồm n ối tượng và số các cụm k.
OUTPUT: Các cụm Ci (i=1,..,k) sao cho hàm tiêu chuẩn E ạt giá trị tối thiểu. Bước 1: Khởi tạo
Chọn k ối tượng mj (j=1...k) là trọng tâm ban ầu của k cụm từ tập dữ liệu
(việc lựa chọn này có thể là ngẫu nhiên hoặc theo kinh nghiệm). Bước 2: Tính toán khoảng cách
Đối với mỗi ối tượng Xi (1 i n) , tính toán khoảng cách từ nó tới mỗi
trọng tâm mj với j=1,..,k, sau ó tìm trọng tâm gần nhất ối với mỗi ối tượng. Bước 3:
Cập nhật lại trọng tâm
Đối với mỗi j=1,..,k, cập nhật trọng tâm cụm mj bằng cách xác ịnh trung bình
cộng của các vector ối tượng dữ liệu.
Bước 4: Điều kiện dừng
Lặp các bước 2 và 3 cho ến khi các trọng tâm của cụm không thay ổi.
Hình 2.1. Thuật toán k-means
Thuật toán k-means ược chứng minh là hội tụ và có ộ phức tạp tính toán là: O((n k d )
T flop ). Trong ó: n là số ối tượng dữ liệu, k là số cụm dữ liệu, d
là số chiều, là số vòng lặp, T flop là thời gian ể thực hiện một phép tính cơ sở như
phép tính nhân, chia, …Như vậy, do k-means phân tích phân cụm ơn giản nên có
thể áp dụng ối với tập dữ liệu lớn. Tuy nhiên, nhược iểm của kmeans là chỉ áp
dụng với dữ liệu có thuộc tính số và khám phá ra các cụm có dạng hình cầu, k-
means còn rất nhạy cảm với nhiễu và các phần tử ngoại lai trong dữ liệu. Hình sau
diễn tả môi phỏng về một số hình dạng cụm dữ liệu khám phá ược bởi k-means: Hoàng Văn Dũng 30 lOMoAR cPSD| 39651089 Khai
phá dữ liệu Web bằng kỹ thuật phân cụm
Hình 2.2. Hình dạng cụm dữ liệu ược khám phá bởi k-means
Hơn nữa, chất lượng PCDL của thuật toán k-means phụ thuộc nhiều vào các
tham số ầu vào như: số cụm k và k trọng tâm khởi tạo ban ầu. Trong trường hợp,
các trọng tâm khởi tạo ban ầu mà quá lệch so với các trọng tâm cụm tự nhiên thì
kết quả phân cụm của k-means là rất thấp, nghĩa là các cụm dữ liệu ược khám phá
rất lệch so với các cụm trong thực tế. Trên thực tế người ta chưa có một giải pháp
tối ưu nào ể chọn các tham số ầu vào, giải pháp thường ược sử dụng nhất là thử
nghiệm với các giá trị ầu vào k khác nhau rồi sau ó chọn giải pháp tốt nhất.
Đến nay, ã có rất nhiều thuật toán kế thừa tư tưởng của thuật toán k-means
áp dụng trong KPDL ể giải quyết tập dữ liệu có kích thước rất lớn ang ược áp
dụng rất hiệu quả và phổ biến như thuật toán k-medoid, PAM, CLARA,
CLARANS, k- prototypes, …
2.1.2. Thuật toán PAM
Thuật toán PAM (Partitioning Around Medoids) ược Kaufman và Rousseeuw
ề xuất 1987, là thuật toán mở rộng của thuật toán k-means, nhằm có khả năng xử
lý hiệu quả ối với dữ liệu nhiễu hoặc các phần tử ngoại lai. Thay vì sử dụng các
trọng tâm như k-means, PAM sử dụng các ối tượng medoid ể biểu diễn cho các
cụm dữ liệu, một ối tượng medoid là ối tượng ặt tại vị trí trung tâm nhất bên trong
của mỗi cụm. Vì vậy, các ối tượng medoid ít bị ảnh hưởng của các ối tượng ở rất lOMoAR cPSD| 39651089 Khai
phá dữ liệu Web bằng kỹ thuật phân cụm
xa trung tâm, trong khi ó các trọng tâm của thuật toán k-means lại rất bị tác ộng
bởi các iểm xa trung tâm này. Ban ầu, PAM khởi tạo k ối tượng medoid và phân
phối các ối tượng còn lại vào các cụm với các ối tượng medoid ại diện tương ứng
sao cho chúng tương tự với ối tượng medoid trong cụm nhất.
Để xác ịnh các medoid, PAM bắt ầu bằng cách lựa chọn k ối tượng medoid
bất kỳ. Sau mỗi bước thực hiện, PAM cố gắng hoán chuyển giữa ối tượng medoid
Om và một ối tượng Op không phải là medoid, miễn là sự hoán chuyển này nhằm
cải tiến chất lượng của phân cụm, quá trình này kết thúc khi chất lượng phân cụm
không thay ổi. Chất lượng phân cụm ược ánh giá thông qua hàm tiêu chuẩn, chất
lượng phân cụm tốt nhất khi hàm tiêu chuẩn ạt giá trị tối thiểu.
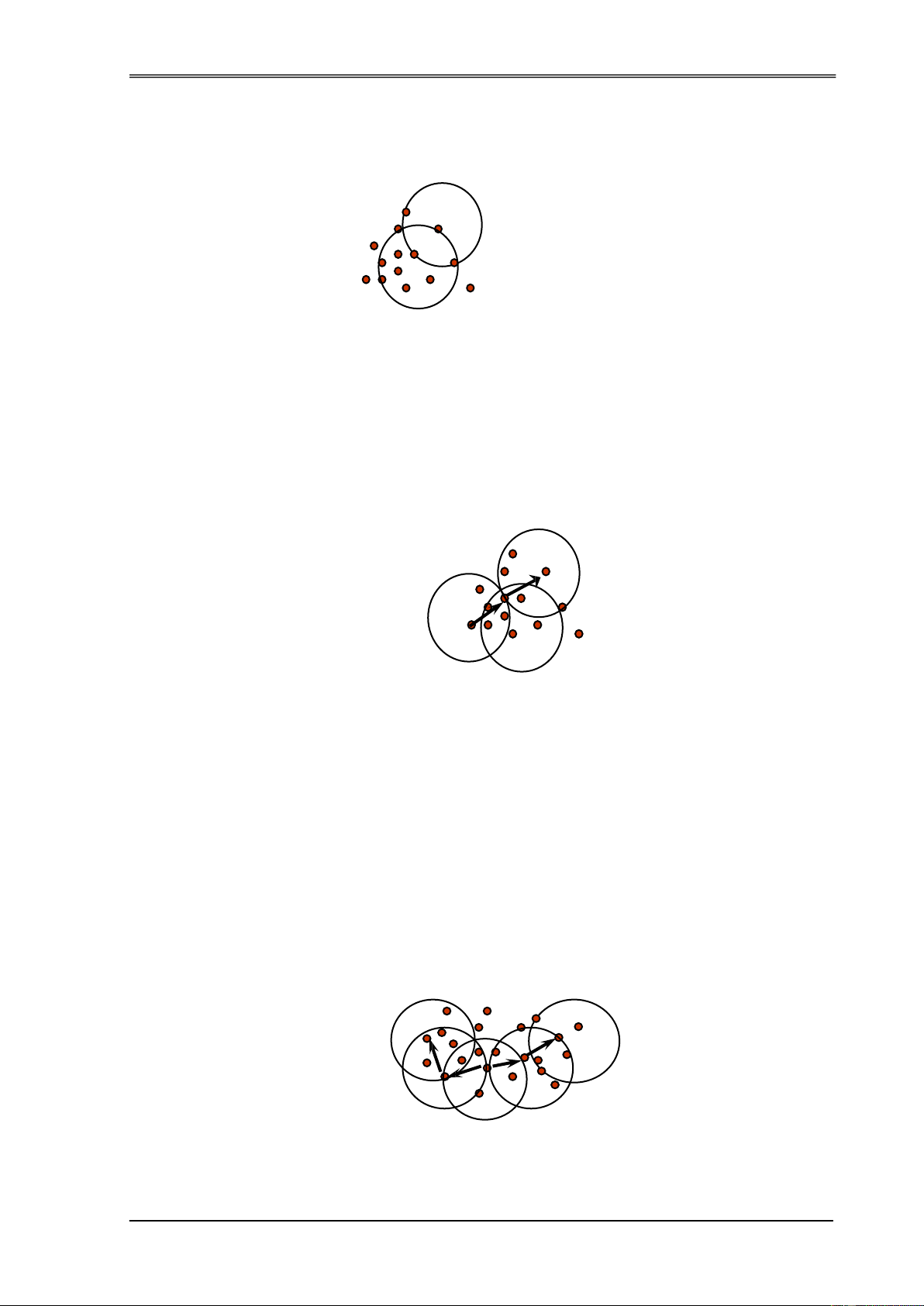
Để quyết ịnh hoán chuyển hai ối tượng Om và Op hay không, thuật toán PAM
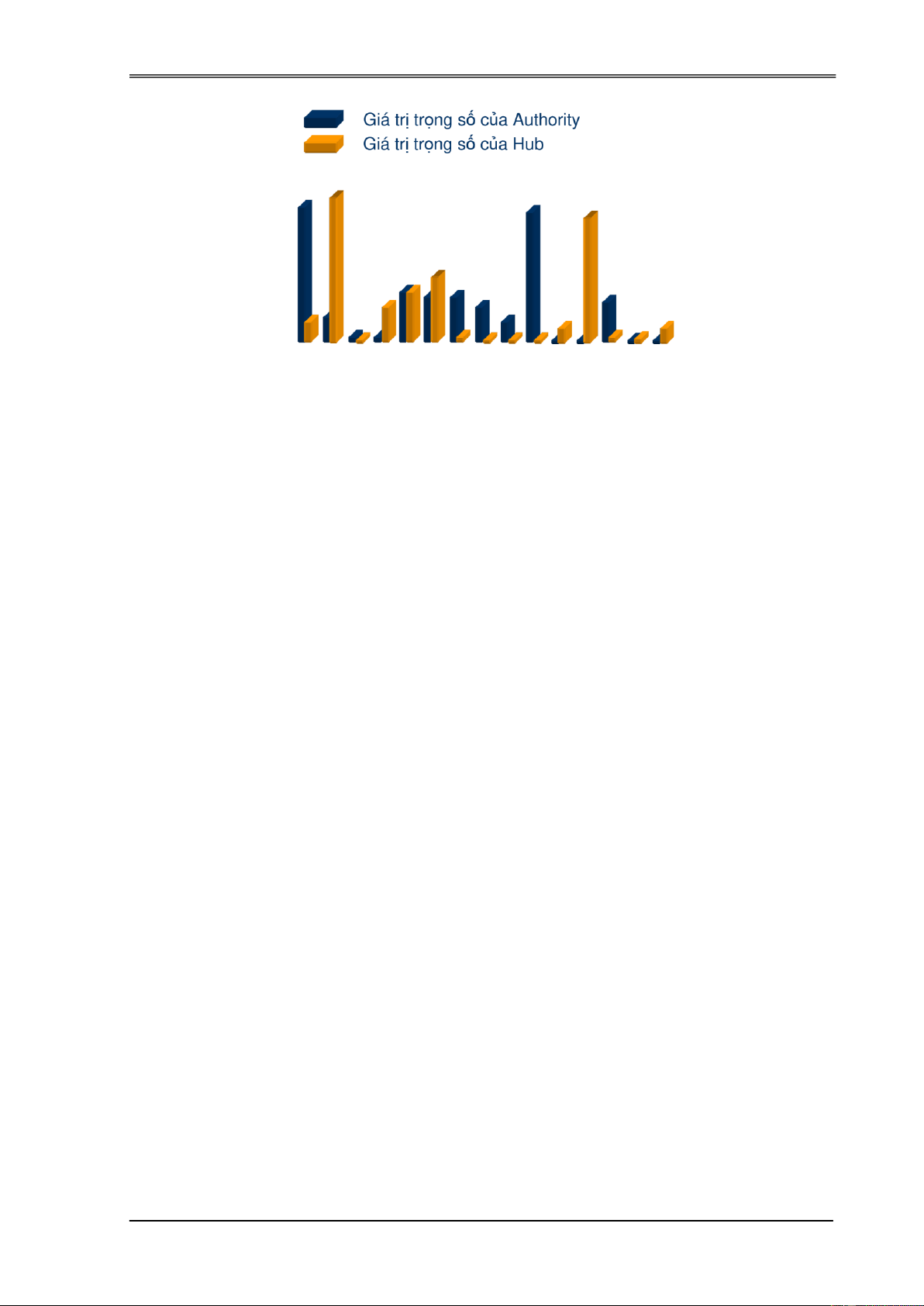
sử dụng giá trị tổng chi phí hoán chuyển Cjmp làm căn cứ:
- Om: Là ối tượng medoid hiện thời cần ược thay thế
- Op: Là ối tượng medoid mới thay thế cho Om;
- Oj: Là ối tượng dữ liệu (không phải là medoid) có thể ược di chuyển sang cụm khác.
- Om,2: Là ối tượng medoid hiện thời khác với Om mà gần ối tượng Oj nhất.
Bốn trường hợp như mô tả trong thí dụ trên, PAM tính giá trị hoán ổi Cjmp
cho tất cả các ối tượng Oj. Cjmp ở ây nhằm ể làm căn cứ cho việc hoán chuyển giữa
Om và Op. Trong mỗi trường hợp Cjmp ược tính với 4 cách khác nhau như sau:
- Trường hợp 1: Giả sử Oj hiện thời thuộc về cụm có ại diện là Om và Oj
tương tự với Om,2 hơn Op (d(Oj, Op) d(Oj, Om,2)). Trong khi ó, Om,2 là ối tượng
medoid tương tự xếp thứ 2 tới Oj trong số các medoid. Trong trường hợp này, ta
thay thế Om bởi ối tượng medoid mới Op và Oj sẽ thuộc về cụm có ối tượng ại diện
là Om,2. Vì vậy, giá trị hoán chuyển Cjmp ược xác ịnh như sau:
Cjmp = d(Oj, Om,2) – d(Oj, Om). Giá trị Cjmp là không âm. Hoàng Văn Dũng 32 lOMoAR cPSD| 39651089 Khai
phá dữ liệu Web bằng kỹ thuật phân cụm 10 9 8
O p 7
O j 6
O m,2 5 4
O m 3 2 1 0 0 1 2 3 4 5 6 7 8 9 10
Hình 2.3. Trường hợp Cjmp=d(Oj,Om,2) – d(Oj, Om) không âm
- Trường hợp 2: Oj hiện thời thuộc về cụm có ại diện là Om, nhưng Oj ít
tương tự với Om,2 so với Op (d(Oj,Op)< d(Oj,Om,2)). Nếu thay thế Om bởi Op thì Oj
sẽ thuộc về cụm có ại diện là Op. Vì vậy, giá trị Cjmp ược xác ịnh như sau:
Cjmp=(Oj,Op)- d(Oj, Om). Cjmp ở ây có thể là âm hoặc dương. 10 9 8
O m2 7
O j 6 5 4
O m
O p 3 2 1 0 0 1 2 3 4 5 6 7 8 9 10
Hình 2.4. Trường hợp Cjmp= (Oj,Op)- d(Oj, Om) có thể âm hoặc dương
- Trường hợp 3: Giả sử Oj hiện thời không thuộc về cụm có ối tượng ại diện
là Om mà thuộc về cụm có ại diện là Om,2. Mặt khác, giả sử Oj tương tự với Om,2
hơn so với Op, khi ó, nếu Om ược thay thế bởi Op thì Oj vẫn sẽ ở lại trong cụm có
ại diện là Om,2. Do ó: Cjmp= 0. lOMoAR cPSD| 39651089 Khai
phá dữ liệu Web bằng kỹ thuật phân cụm 10 9
O j O 8 m2 7 6 5
O p 4 3
O m 2 1 0 0 1 2 3 4 5 6 7 8 9 10
Hình 2.5. Trường hợp C jmp bằng không
- Trường hợp 4: Oj hiện thời thuộc về cụm có ại diện là Om,2 nhưng Oj ít
tương tự tới Om,2 hơn so với Op. Vì vậy, nếu ta thay thế Om bởi Op thì Oj sẽ chuyển
từ cụm Om,2 sang cụm Op. Do ó, giá trị hoán chuyển Cjmp ược xác ịnh là: Cjmp=
(Oj,Op)- d(Oj, Om,2). Cjmp ở ây luôn âm. 1 9 8 O 7 m 6
O p 5
O j 4 3 2
O m2 1 0 0 1 2 3 6 7 8 9 1 4 5
Hình 2.6. Trường hợp Cjmp= (Oj,Op)- d(Oj, Om,2) luôn âm
- Kết hợp cả bốn trường hợp trên, tổng giá trị hoán chuyển Om bằng Op ược
xác ịnh như sau: TCmp = C jmp . j
Thuật toán PAM gồm các bước thực hiện chính như sau: Hoàng Văn Dũng 34 lOMoAR cPSD| 39651089 Khai
phá dữ liệu Web bằng kỹ thuật phân cụm
INPUT: Tập dữ liệu có n phần tử, số cụm k
OUTPUT: k cụm dữ liệu sao cho chất lượng phân hoạch là tốt nhất.
Bước 1: Chọn k ối tượng medoid bất kỳ;
Bước 2: Tính TCmp cho tất cả các cặp ối tượng Om, Op. Trong ó Om là ối tượng medoid
và Op là ối tượng không phải là modoid.
Bước 3: Với mỗi cặp ối tượng Om và Op. Tính minOm, minOp, TCmp.
Nếu TCmp là âm, thay thế Om bởi Op và quay lại bước 2. Nếu TCmp dương, chuyển sang bước 4.
Bước 4: Với mỗi ối tượng không phải là medoid, xác ịnh ối tượng medoid tương tự
với nó nhất ồng thời gán nhãn cụm cho chúng.
Hình 2.7. Thuật toán PAM
Trong bước 2 và 3, có PAM phải duyệt tất cả k(n-k) cặp Om, Op. Với mỗi cặp,
việc tính toán TCmp yêu cầu kiểm tra n-k ối tượng. Vì vậy, ộ phức tạp tính toán của
PAM là O(I k (n-k)2), trong ó I là số vòng lặp. Như vậy, thuật toán PAM kém
hiệu quả về thời gian tính toán khi giá trị của k và n là lớn.
2.1.3. Thuật toán CLARA
CLARA (Clustering LARge Application) ược Kaufman và Rousseeuw ề xuất
năm 1990, thuật toán này nhằm khắc phục nhược iểm của thuật toán PAM trong
trường hợp giá trị của k và n lớn. CLARA tiến hành trích mẫu cho tập dữ liệu có
n phần tử và áp dụng thuật toán PAM cho mẫu này và tìm ra các các ối tượng
medoid của mẫu này. Người ta thấy rằng, nếu mẫu dữ liệu ược trích một cách ngẫu
nhiên, thì các medoid của nó xấp xỉ với các medoid của toàn bộ tập dữ liệu ban
ầu. Để tiến tới một xấp xỉ tốt hơn, CLARA ưa ra nhiều cách lấy mẫu rồi thực hiện
phân cụm cho mỗi trường hợp này và tiến hành chọn kết quả phân cụm tốt nhất
khi thực hiện phân cụm trên các mẫu này. Để cho chính xác, chất lượng của các
cụm ược ánh giá thông ộ phi tương tự trung bình của toàn bộ các ối tượng dữ liệu
trong tập ối tượng ban ầu. Kết quả thực nghiệm chỉ ra rằng, 5 mẫu dữ liệu có kích
thước 40+2k cho các kết quả tốt. Các bước thực hiện của thuật toán CLARA như sau: lOMoAR cPSD| 39651089 Khai
phá dữ liệu Web bằng kỹ thuật phân cụm
INPUT: CSDL gồm n ối tượng, số cụm k.
OUTPUT: k cụm dữ liệu
1. For i = 1 to 5 do Begin
2. Lấy một mẫu có 40 + 2k ối tượng dữ liệu ngẫu nhiên từ tập dữ liệu và áp dụng
thuật toán PAM cho mẫu dữ liệu này nhằm ể tìm các ối tượng medoid ại diện cho các cụm.
3. Đối với mỗi ối tượng Oj trong tập dữ liệu ban ầu, xác ịnh ối tượng medoid
tương tự nhất trong số k ối tượng medoid.
4. Tính ộ phi tương tự trung bình cho phân hoạch các ối tượng dành ở bước
trước, nếu giá trị này bé hơn giá trị tối thiểu hiện thời thì sử dụng giá trị này thay cho
giá trị tối thiếu ở trạng thái trước, như vậy tập k ối tượng medoid xác ịnh ở bước này
là tốt nhất cho ến thời iểm hiện tại. End;
Hình 2.8. Thuật toán CLARA
Độ phức tạp tính toán của thuật toán là O(k(40+k)2 + k(n-k)), và CLARA có
thể thực hiện ối với tập dữ liệu lớn. Chú ý ối với kỹ thuật tạo mẫu trong PCDL:
kết quả phân cụm có thể không phụ thuộc vào tập dữ liệu khởi tạo nhưng nó chỉ ạt tối ưu cục bộ.
2.1.4. Thuật toán CLARANS
Thuật toán CLARANS (A Clustering Algorithm based on RANdomized
Search) ược Ng & Han ề xuất năm 1994, nhằm ể cải tiến chất lượng cũng như mở
rộng áp dụng cho tập dữ liệu lớn. CLARANS là thuật toán PCDL kết hợp thuật
toán PAM với chiến lược tìm kiếm kinh nghiệm mới. Ý tưởng cơ bản của
CLARANS là không xem xét tất cả các khả năng có thể thay thế các ối tượng tâm
medoids bởi một ối tượng khác, nó ngay lập tức thay thế các ối tượng medoid này
nếu việc thay thế có tác ộng tốt ến chất lượng phân cụm chứ không cần xác ịnh
cách thay thể tối ưu nhất. Một phân hoạch cụm phát hiện ược sau khi thay thế ối
tượng trung tâm ược gọi là một láng giềng của phân hoạch cụm trước ó. Số các
láng giềng ược hạn chế bởi tham số do người dùng ưa vào là Maxneighbor, quá
trình lựa chọn các láng giềng này là hoàn toàn ngẫu nhiên. Tham số Numlocal cho
phép người dùng xác ịnh số vòng lặp tối ưu cục bộ ược tìm kiếm. Không phải tất
các láng giềng ược duyệt mà chỉ có Maxneighbor số láng giềng ược duyệt. Hoàng Văn Dũng 36 lOMoAR cPSD| 39651089 Khai
phá dữ liệu Web bằng kỹ thuật phân cụm
Một số khái niệm sử dụng trong thuật toán CLARANS ược ịnh nghĩa như sau:
Giả sử O là một tập có n ối tượng và M
là tập các ối tượng medoid, NM
M là tập các ối tượng không phải medoid. Các ối tượng dữ liệu sử dụng
trong thuật toán CLARANS là các khối a diện. Mỗi ối tượng ược diễn tả bằng một
tập các cạch, mỗi cạnh ược xác ịnh bằng 2 ỉnh. Giả sử P R3 là một tập tất cả
các iểm. Nói chung, các ối tượng ở ây là các ối tượng dữ liệu không gian và ta ịnh
nghĩa tâm của một ối tượng chính là trung bình cộng toán học của tất cả các ỉnh
hay còn gọi là trọng tâm: Center: O P
Giả sử dist là một hàm khoảng cách, khoảng cách thường ược chọn ở ây
là khoảng cách Euclid: dist: P x P R + 0
Hàm khoảng cách dist có thể mở rộng cho các iểm của khối a diện thông qua hàm tâm: dist: O x O R +
0 sao cho dist (oi, oj) = dist (center(oi), center(oj))
Mỗi ối tượng ược gán cho một tâm medoid của cụm nếu khoảng cách từ trọng
tâm của ối tượng ó tới tâm medoid của nó là nhỏ nhất. Vì vậy, ta ịnh nghĩa một tâm medoid như sau: medoid: O M
Sao cho medoid (o) = mi, mi M, mj M: dist (o, mi) dist (o, mj), o O.
Cuối cùng, ta ịnh nghĩa một cụm với medoid mi tương ứng là một tập con
các ối tượng trong O với medoid(o) = mi.
Giả sử C0 là tập tất cả các phân hoạch của O. Hàm tổng ể ánh giá chất lượng
một phân hoạch ược ịnh nghĩa như sau: total_distance: C + 0 R0 sao cho total_distance(c) =
dist (o, mi) với mi M, cluster(mi).
Thuật toán CLARANS có thể ược diễn tả như sau [10][19]: lOMoAR cPSD| 39651089 Khai
phá dữ liệu Web bằng kỹ thuật phân cụm
INPUT: Tập dữ liệu gồm n ối tượng, số cụm k, O, dist, numlocal, maxneighbor;
OUTPUT: k cụm dữ liệu;
For i=1 to numlocal do Begin
Khởi tạo ngẫu nhiên k medois j = 1;
while j < maxneighbor do Begin
Chọn ngẫu nhiên một láng giềng R của S.
Tính toán ộ phi tương tự về khoảng cách giữa 2 láng giềng S và R.
Nếu R có chi phí thấp hơn thì hoán ối R cho S và j=1 ngược lại j++; End;
Kiểm tra khoảng cách của phân hoạch S có nhỏ hơn khoảng cách nhỏ nhất không,
nếu nhỏ hơn thì lấy giá trị này ể cập nhật lại khoảng cách nhỏ nhất và phân hoạch
S là phân hoạch tốt nhất tại thời iểm hiện tại. End.
Hình 2.9. Thuật toán CLARANS
Như vậy, quá trình hoạt ộng của CLARANS tương tự với quá trình hoạt ộng
của thuật toán CLARA. Tuy nhiên, ở giai oạn lựa chọn các trung tâm medoid cụm
dữ liệu, CLARANS lựa chọn một giải pháp tốt hơn bằng cách lấy ngẫu nhiên một
ối tượng của k ối tượng trung tâm medoid của cụm và cố gắng thay thế nó với một
ối tượng ược chọn ngẫu nhiên trong (n-k) ối tượng còn lại, nếu không có giải pháp
nào tốt hơn sau một số cố gắng lựa chọn ngẫu nhiên xác ịnh, thuật toán dừng và
cho kết quả phân cụm tối ưu cục bộ.
Trong trường hợp xấu nhất, CLARANS so sánh một ối tượng với tất các ối
tượng Medoid. Vì vậy, ộ phức tạp tính toán của CLARANS là O(kn2), do vậy
CLARANS không thích hợp với tập dữ liệu lớn. CLARANS có ưu iểm là không
gian tìm kiếm không bị giới hạn như ối với CLARA và trong cùng một lượng thời
gian thì chất lượng của các cụm phân ược là lớn hơn so với CLARA.
2.2. Phân cụm phân cấp
Phân cụm phân cấp sắp xếp một tập dữ liệu ã cho thành một cấu trúc có dạng
hình cây, cây phân cấp này ược xây dựng theo kỹ thuật ệ quy. Cây phân cụm có Hoàng Văn Dũng 38 lOMoAR cPSD| 39651089 Khai
phá dữ liệu Web bằng kỹ thuật phân cụm
thể ược xây dựng theo hai phương pháp tổng quát: phương pháp “trên xuống”
(Top down) và phương pháp “dưới lên” (Bottom up).
Phương pháp Bottom up: Phương pháp này bắt ầu với mỗi ối tượng ược
khởi tạo tương ứng với các cụm riêng biệt, sau ó tiến hành nhóm các ối tượng theo
một ộ o tương tự (như khoảng cách giữa hai trung tâm của hai nhóm), quá trình
này ược thực hiện cho ến khi tất cả các nhóm ược hòa nhập vào một nhóm (mức
cao nhất của cây phân cấp) hoặc cho ến khi các iều kiện kết thúc thoả mãn. Như
vậy, cách tiếp cận này sử dụng chiến lược ăn tham trong quá trình phân cụm.
Phương pháp Top Down: Bắt ầu với trạng thái là tất cả các ối tượng ược
xếp trong cùng một cụm. Mỗi vòng lặp thành công, một cụm ược tách thành các
cụm nhỏ hơn theo giá trị của một phép o ộ tương tự nào ó cho ến khi mỗi ối tượng
là một cụm hoặc cho ến khi iều kiện dừng thoả mãn. Cách tiếp cận này sử dụng
chiến lược chia ể trị trong quá trình phân cụm.
Sau ây là minh họa chiến lược phân cụm phân cấp bottom up và Top down. Bướ c 1 Bướ c 2 Bướ c 3 Bướ c 4 Bottom up
Bướ c 0 a a b b a b c d e c c d e d d e e Top Down Bước 4 Bước 3 Bước 2 Bước 1 Bước 0
Hình 2.10. Các chiến lược phân cụm phân cấp
Trong thực tế áp dụng, có nhiều trường hợp người ta kết hợp cả hai phương
pháp phân cụm phân hoạch và phương phân cụm phân cấp, nghĩa là kết quả thu
ược của phương pháp phân cấp có thể cải tiến thông quan bước phân cụm phân
hoạch. Phân cụm phân hoạch và phân cụm phân cấp là hai phương pháp PCDL cổ
iển, hiện nay ã có nhiều thuật toán cải tiến dựa trên hai phương pháp này ã ược áp
dụng phổ biến trong KPDL. Một số thuật toán phân cụm phân cấp iển hình như
CURE, BIRCH, Chemeleon, AGNES, DIANA,... lOMoAR cPSD| 39651089 Khai
phá dữ liệu Web bằng kỹ thuật phân cụm
2.2.1. Thuật toán BIRCH
BIRCH (Balanced Iterative Reducing and Clustering Using Hierarchies) do
Tian Zhang, amakrishnan và Livny ề xuất năm 1996, là thuật toán phân cụm phân
cấp sử dụng chiến lược Top down. Ý tưởng của thuật toán là không cần lưu toàn
bộ các ối tượng dữ liệu của các cụm trong bộ nhớ mà chỉ lưu các ại lượng thống
kê. Đối với mỗi cụm dữ liệu, BIRCH chỉ lưu một bộ ba (n, LS, SS), với n là số ối
tượng trong cụm, LS là tổng các giá trị thuộc tính của các ối tượng trong cụm và
SS là tổng bình phương các giá trị thuộc tính của các ối tượng trong cụm. Các bộ
ba này ược gọi là các ặc trưng của cụm CF=(n, LS, SS) (Cluster Features - CF) và
ược lưu giữ trong một cây ược gọi là cây CF.
Hình sau ây biểu thị một ví dụ về cây CF. Chúng ta thấy rằng, tất cả các nút trong
của cây lưu tổng các ặc trưng cụm CF của nút con, trong khi ó các nút lá lưu trữ
các ặc trưng của các cụm dữ liệu. Root B = 7 CF 1 CF 2 CF 3 CF 6 L = 6 child 1 child 2 child 3 child 6 Non-leaf node CF 1 CF 2 CF 3 CF 5 child 1 child 2 child 3 child 5 Leaf node Leaf node prev CF next prev next 1 CF 2 CF 6 CF 1 CF 2 CF 4
Hình 2.11. Cây CF ược sử dụng bởi thuật toán BIRCH
Cây CF là cây cân bằng, nhằm ể lưu trữ các ặc trưng của cụm. Cây CF chứa
các nút trong và nút lá. Nút trong lưu giữ tổng các ặc trưng cụm của các nút con
của nó. Một cây CF ược ặc trưng bởi hai tham số:
- Yếu tố nhánh (B): Nhằm xác ịnh số tối a các nút con của mỗi nút trong của cây; Hoàng Văn Dũng 40 lOMoAR cPSD| 39651089 Khai
phá dữ liệu Web bằng kỹ thuật phân cụm
- Ngưỡng (T): Khoảng cách tối a giữa bất kỳ một cặp ối tượng trong nút lá
của cây, khoảng cách này còn gọi là ường kính của các cụm con ược lưu tại các nút lá.
Hai tham số này có ảnh hưởng lớn ến kích thước của cây CF.
Thuật toán BIRCH thực hiện qua giai oạn sau:
INPUT: CSDL gồm n ối tượng, ngưỡng T
OUTPUT: k cụm dữ liệu
Bước 1: Duyệt tất cả các ối tượng trong CSDL và xây dựng một cây CF khởi tạo.
Một ối tượng ược chèn vào nút lá gần nhất tạo thành cụm con. Nếu ường kính của
cụm con này lớn hơn T thì nút lá ược tách. Khi một ối tượng thích hợp ược chèn
vào nút lá, tất cả các nút trỏ tới gốc của cây ược cập nhật với các thông tin cần thiết.
Bước 2: Nếu cây CF hiện thời không có ủ bộ nhớ trong thì tiến hành xây dựng một
cây CF nhỏ hơn bằng cách iều khiển bởi tham số T (vì tăng T sẽ làm hoà nhập một số
các cụm con thành một cụm, iều này làm cho cây CF nhỏ hơn). Bước này không cần
yêu cầu bắt ầu ọc dữ liệu lại từ ầu nhưng vẫn ảm bảo hiệu chỉnh cây dữ liệu nhỏ hơn.
Bước 3: Thực hiện phân cụm: Các nút lá của cây CF lưu giữ các ại lượng thống kê
của các cụm con. Trong bước này, BIRCH sử dụng các ại lượng thống kê này ể áp
dụng một số kỹ thuật phân cụm thí dụ như k-means và tạo ra một khởi tạo cho phân cụm.
Bước 4: Phân phối lại các ối tượng dữ liệu bằng cách dùng các ối tượng trọng tâm
cho các cụm ã ược khám phá từ bước 3: Đây là một bước tuỳ chọn ể duyệt lại tập dữ
liệu và gán nhãn lại cho các ối tượng dữ liệu tới các trọng tâm gần nhất. Bước này
nhằm ể gán nhãn cho các dữ liệu khởi tạo và loại bỏ các ối tượng ngoại lai
Hình 2.12. Thuật toán BIRCH
Khi hòa nhập 2 cụm ta có CF=CF1+CF2= (n1+n2, LS1+LS2, SS1+SS2).
Khoảng cách giữa các cụm có thể
o bằng khoảng cách Euclid, Manhatta,....
Ví dụ: CF (n,LS,SS), n là số ối tượng dữ liệu lOMoAR cPSD| 39651089 Khai
phá dữ liệu Web bằng kỹ thuật phân cụm
Hình 2.13. Ví dụ về kết quả phân cụm bằng thuật toán BIRCH
Sử dụng cấu trúc cây CF làm cho thuật toán BIRCH có tốc ộ thực hiện PCDL
nhanh và có thể áp dụng ối với tập dữ liệu lớn, BIRCH ặc biệt hiệu quả khi áp
dụng với tập dữ liệu tăng trưởng theo thời gian. BIRCH chỉ duyệt toàn bộ dữ liệu
một lần với một lần quét thêm tuỳ chọn, nghĩa là ộ phức tạp của nó là O(n) (n là
số ối tượng dữ liệu). Nhược iểm của nó là chất lượng của các cụm ược khám phá
không ược tốt. Nếu BIRCH sử dụng khoảng cách Euclide, nó thực hiện tốt chỉ với
các dữ liệu số. Mặt khác, tham số vào T có ảnh hưởng rất lớn tới kích thước và
tính tự nhiên của cụm. Việc ép các ối tượng dữ liệu làm cho các ối tượng của một
cụm có thể là ối tượng kết thúc của cụm khác, trong khi các ối tượng gần nhau có
thể bị hút bởi các cụm khác nếu chúng ược biểu diễn cho thuật toán theo một thứ
tự khác. BIRCH không thích hợp với dữ liệu a chiều.
2.2.2. Thuật toán CURE
Việc chọn một cách biểu diễn cho các cụm có thể nâng cao chất lượng phân
cụm. Thuật toán CURE (Clustering Using REpresentatives) ược ề xuất bởi
Sudipto Guha, Rajeev Rastogi và Kyuseok Shim năm 1998 [19] là thuật toán sử
dụng chiến lược Bottom up của kỹ thuật phân cụm phân cấp.
Thay vì sử dụng các trọng tâm hoặc các ối tượng tâm ể biểu diễn cụm, CURE
sử dụng nhiều ối tượng ể diễn tả cho mỗi cụm dữ liệu. Các ối tượng ại diện cho
cụm này ban ầu ược lựa chọn rải rác ều ở các vị trí khác nhau, sau ó chúng ược di
chuyển bằng cách co lại theo một tỉ lệ nhất ịnh. Tại mỗi bước của thuật toán, hai
cụm có cặp ối tượng ại diện gần nhất sẽ ược trộn lại thành một cụm.
Với cách thức sử dụng nhiều hơn một iểm ại diện cho các cụm, CURE có thể
khám phá ược các cụm có các dạng hình thù và kích thước khác nhau trong CSDL
lớn. Việc co các ối tượng ại diện lại có tác dụng làm giảm tác ộng của các phần tử Hoàng Văn Dũng 42 lOMoAR cPSD| 39651089 Khai
phá dữ liệu Web bằng kỹ thuật phân cụm
ngoại lai. Vì vậy, CURE có khả năng xử lý ối với các phần tử ngoại lai. Hình sau
thí dụ về các dạng và kích thước cụm dữ liệu ược khám phá bởi CURE:
Hình 2.14. Các cụm dữ liệu ược khám phá bởi CURE
Để áp dụng với CSDL lớn, CURE sử dụng lấy mẫu ngẫu nhiên và phân
hoạch. Mẫu dữ liệu ược xác ịnh ngẫu nhiên là phân hoạch ầu tiên, CURE tiến hành
phân cụm trên mỗi phân hoạch. Quá trình này lặp lại cho ến khi ta thu ược phân
hoạch ủ tốt. Các cụm thu ược sau ó lại ược phân cụm nhằm ể thu ược các cụm con
cần quan tâm. Thuật toán CURE ược thực hiện qua các bước cơ bản như sau:
Bước 1. Chọn một mẫu ngẫu nhiên từ tập dữ liệu ban ầu;
Bước 2. Phân hoạch mẫu này thành nhiều nhóm dữ liệu có kích thước bằng nhau: Ý
tưởng chính ở ây là phân hoạch mẫu thành p nhóm dữ liệu bằng nhau, kích thước của
mỗi phân hoạch là n'/p (với n' là kích thước của mẫu);
Bước 3. Phân cụm các iểm của mỗi nhóm: Ta thực hiện PCDL cho các nhóm cho ến
khi mỗi nhóm ược phân thành n'/(pq)cụm (với q>1);
Bước 4. Loại bỏ các phần tử ngoại lai: Trước hết, khi các cụm ược hình thành cho
ến khi số các cụm giảm xuống một phần so với số các cụm ban ầu. Sau ó, trong
trường hợp các phần tử ngoại lai ược lấy mẫu cùng với quá trình pha khởi tạo mẫu dữ
liệu, thuật toán sẽ tự ộng loại bỏ các nhóm nhỏ.
Bước 5. Phân cụm các cụm không gian: Các ối tượng ại diện cho các cụm di chuyển
về hướng trung tâm cụm, nghĩa là chúng ược thay thế bởi các ối tượng gần trung tâm hơn.
Bước 6. Đánh dấu dữ liệu với các nhãn tương ứng.
Hình 2.15. Thuật toán CURE
Độ phức tạp tính toán của thuật toán CURE là O(n2log(n)). CURE là thuật
toán tin cậy trong việc khám phá các cụm với hình thù bất kỳ và có thể áp dụng
tốt trên các tập dữ liệu hai chiều. Tuy nhiên, nó lại rất nhạy cảm với các tham số lOMoAR cPSD| 39651089 Khai
phá dữ liệu Web bằng kỹ thuật phân cụm
như là tham số các ối tượng ại diện, tham số co của các phần tử ại diện. Nhìn
chung thì BIRCH tốt hơn so với CURE về ộ phức tạp, nhưng kém về chất lượng
phân cụm. Cả hai thuật toán này có thể xử lý các phần tử ngoại lai tốt.
2.3. Phân cụm dựa trên mật ộ
Phương pháp này nhóm các ối tượng theo hàm mật ộ xác ịnh. Mật ộ ược ịnh
nghĩa như là số các ối tượng lân cận của một ối tượng dữ liệu theo một ngưỡng
nào ó. Trong cách tiếp cận này, khi một cụm dữ liệu ã xác ịnh thì nó tiếp tục ược
phát triển thêm các ối tượng dữ liệu mới miễn là số các ối tượng lân cận của các
ối tượng này phải lớn hơn một ngưỡng ã ược xác ịnh trước. Phương pháp phân
cụm dựa vào mật ộ của các ối tượng ể xác ịnh các cụm dữ liệu và có thể phát hiện
ra các cụm dữ liệu với hình thù bất kỳ. Tuy vậy, việc xác ịnh các tham số mật ộ
của thuật toán rất khó khăn, trong khi các tham số này lại có tác ộng rất lớn ến kết
quả PCDL. Hình minh hoạ về các cụm dữ liệu với các hình thù khác nhau dựa
trên mật ộ ược khám phá từ 3 CSDL khác nhau: CSDL 1 CSDL 2 CSDL 3
Hình 2.16. Một số hình dạng khám phá bởi phân cụm dưa trên mật ộ
Các cụm có thể ược xem như các vùng có mật ộ cao, ược tách ra bởi các vùng
không có hoặc ít mật ộ. Khái niệm mật ộ ở ây ược xem như là các số các ối tượng láng giềng.
Một số thuật toán PCDL dựa trên mật ộ iển hình như [2][3][13][20]:
DBSCAN, OPTICS, DENCLUE, SNN,….
2.3.1 Thuật toán DBSCAN
Thuật toán phân cụm dựa trên mật
ộ thông dụng nhất là thuật toán
DBSCAN (Density - Based Spatial Clustering of Applications with noise) do Hoàng Văn Dũng 44 lOMoAR cPSD| 39651089 Khai
phá dữ liệu Web bằng kỹ thuật phân cụm
Ester, P. Kriegel và J. Sander ề xuất năm 1996. Thuật toán i tìm các ối tượng mà
có số ối tượng láng giềng lớn hơn một ngưỡng tối thiểu. Một cụm ược xác ịnh
bằng tập tất cả các ối tượng liên thông mật ộ với các láng giềng của nó.
Thuật toán DBSCAN dựa trên các khái niệm mật ộ có thể áp dụng cho các
tập dữ liệu không gian lớn a chiều. Sau ây là một số ịnh nghĩa và bổ ề ược sử dụng trong thuật toán DBSCAN.
Định nghĩa 1: Các lân cận của một iểm P với ngưỡng Eps, ký hiệu NEps(p)
ược xác ịnh như sau: NEps(p) = {q D | khoảng cách Dist(p,q) ≤ Eps}, D là tập dữ liệu cho trước. Eps p
Hình 2.17. Lân cận của P với ngưỡng Eps
Một iểm p muốn nằm trong một cụm C nào ó thì NEps(p) phải có tối thiểu MinPts iểm.
Theo ịnh nghĩa trên, chỉ những iểm thực sự nằm trong cụm mới thoả mãn iều
kiện là iểm thuộc vào cụm. Những iểm nằm ở biên của cụm thì không thoả mãn
iều kiện ó, bởi vì thông thường thì lân cận với ngưỡng Eps của iểm biên thì bé hơn
lân cận với ngưỡng cũng Eps của iểm nhân .
Để tránh ược iều này, ta có thể ưa ra một tiêu chuẩn khác ể ịnh nghĩa một iểm
thuộc vào một cụm như sau: Nếu một iểm p muốn thuộc một cụm C phải tồn tại
một iểm q mà p NEps(q) và số iểm trong NEps(q) phải lớn hơn số iểm tối thiểu.
Điều này có thể ược ịnh nghĩa một cách hình thức như sau:
Định nghĩa 2: Mật ộ - ến ược trực tiếp (Directly Density - reachable)
Một iểm p ược gọi là mật ộ-ến ược trực tiếp từ iểm q với ngưỡng Eps và
MinPts trong tập ối tượng D nếu: 1) p NEps(q)
Với NEps(q) là tập con của D 2)
||NEps(q)|| ≥ MinPts Điều kiện ối tượng nhân. lOMoAR cPSD| 39651089 Khai
phá dữ liệu Web bằng kỹ thuật phân cụm
Điểm q gọi là iểm nhân. Ta thấy rằng nó là một hàm phản xạ và ối xứng ối
với hai iểm nhân và bất ối xứng nếu một trong hai iểm ó không phải là iểm nhân. MinPts = 5 p Eps = 1 cm q
Hình 2.18. Mật ộ - ến ược trực tiếp
Định nghĩa 3: Mật ộ - ến ược (Density - Reachable)
Một iểm p ược gọi là mật ộ- ến ược từ một iểm q với hai tham số
Eps và MinPts nếu tồn tại một dãy p = p
1, p2,…, pn =q sao cho pi+1 là mật ộ- ến
ược trực tiếp từ pi với i=1,..n-1. p
p 1 q
Hình 2.19. Mật ộ ến ược
Hai iểm biên của một cụm C có thể không ến ược nhau bởi vì cả hai có thể
ều không thoả mãn iều kiện nhân. Mặc dù vậy, phải tồn tại một iểm nhân trong C
mà cả hai iểm ều có thể ến ược từ iểm ó.
Định nghĩa 4: Mật ộ - liên thông (Density - Connected)
Đối tượng p là mật ộ- liên thông với iểm q theo hai tham số Eps với MinPts
nếu như có một ối tượng o mà cả hai ối tượng p, q iều là mật ộ- ến ược o theo tham số Eps và MinPts. p q o
Hình 2.20. Mật ộ liên thông
Định nghĩa 5: Cụm và nhiễu Hoàng Văn Dũng 46 lOMoAR cPSD| 39651089 Khai
phá dữ liệu Web bằng kỹ thuật phân cụm
Cho D là một tập các ối tượng dữ liệu. Một tập con C khác rỗng của D ược
gọi là một cụm theo Eps và MinPts nếu thoả mãn hai iều kiện:
1) Cực ại: Với p,q D
nếu p C và q là mật ộ- ến ược p theo Eps và
MinPts thì q C. 2) Với p,q
C, p là mật ộ-liên thông với q theo Eps và MinPts.
Mọi ối tượng không thuộc cụm nào cả thì gọi là nhiễu. Nhi ễ u Biên Nhân Eps = 1cm MinPts = 5
Hình 2.21. Cụm và nhiễu
Với hai tham số Eps và MinPts cho trước, ta có thể khám phá các cụm theo hai bước:
Bước 1: Chọn một iểm bất kỳ từ tập dữ liệu ban ầu thoả mãn iều kiện nhân.
Bước 2: Lấy tất cả các iểm ến ược mật ộ với iểm nhân ã chọn ở trên ể tạo thành cụm.
Hai bổ ề này có thể phát biểu một cách hình thức hơn như sau:
Bổ ề 1: Giả sử p là một ối tượng trong D, trong ó | NEps(p)|| ≥ MinPts, tập O
= {o|o D và o là mật ộ-ến ược từ p theo Eps và MinPts} là một cụm theo Eps và MinPts.
Như vậy, cụm C không hoàn toàn là duy nhất, tuy nhiên, mỗi một iểm trong
C ến ược mật ộ từ bất cứ một iểm nhân nào của C, vì vậy C chứa úng một số iểm
liên thông với iểm nhân tuỳ ý.
Bổ ề 2: Giả sử C là một cụm theo Eps và MinPts, p là một iểm bất kỳ trong
C với | NEps(p)|| ≥ MinPts. Khi ó C trùng với tập O = {o|o D và o là mật ộ-ến ược
từ p theo Eps và MinPts}.
Các bước của thuật toán DBSCAN như sau:
Bước 1: Chọn một ối tượng p tuỳ ý
Bước 2: Lấy tất cả các ối tượng mật ộ - ến ược từ p với Eps và MinPts. lOMoAR cPSD| 39651089 Khai
phá dữ liệu Web bằng kỹ thuật phân cụm
Bước 3: Nếu p là iểm nhân thì tạo ra một cụm theo Eps và MinPts.
Bước 4: Nếu p là một iểm biên, không có iểm nào là mật ộ - ến ược mật ộ từ p và
DBSCAN sẽ i thăm iểm tiếp theo của tập dữ liệu.
Bước 5: Quá trình tiếp tục cho ến khi tất cả các ối tượng ược xử lý.
Hình 2.22. Thuật toán DBSCAN
Nếu ta chọn sử dụng giá trị trị toàn cục Eps và MinPts, DBSCAN có thể hoà
nhập hai cụm thành một cụm nếu mật ộ của hai cụm gần bằng nhau. Giả sử khoảng
cách giữa hai tập dữ liệu S1 và S2 ược ịnh nghĩa là Dist(S1,S2) = min{dist(p,q)| p S1 và q S2}.
Thuật toán DBSCAN có thể tìm ra các cụm với hình thù bất kỳ, trong khi ó
tại cùng một thời iểm ít bị ảnh hưởng bởi thứ tự của các ối tượng dữ liệu nhập
vào. Khi có một ối tượng ược chèn vào chỉ tác ộng ến một láng giềng xác ịnh. Mặt
khác, DBSCAN yêu cầu người dùng xác ịnh bán kính Eps của các láng giềng và
số các láng giềng tối thiểu MinPts, thông thường các tham số này ược xác ịnh
bằng phép chọn ngẫu nhiên hoặc theo kinh nghiệm.
Trừ một số trường hợp ngoại lệ, kết quả của DBSCAN ộc lập với thứ tự duyệt
các ối tượng dữ liệu. Eps và MinPts là hai tham số toàn cục ược xác ịnh bằng thủ
công hoặc theo kinh nghiệm. Tham số Eps ược ưa vào là nhỏ so với kích thước
của không gian dữ liệu, thì ộ phức tạp tính toán trung bình của mỗi truy vấn là
O(nlogn).
2.3.2. Thuật toán OPTICS
Thuật toán OPTICS (Ordering Points To Identify the Clustering Structure)
do Ankerst, Breunig, Kriegel và Sander ề xuất năm 1999, là thuật toán mở rộng
cho thuật toán DBSCAN, bằng cách giảm bớt các tham số ầu vào.
Thuật toán thực hiện tính toán và sắp xếp các ối tượng theo thứ tự tăng dần
nhằm tự ộng phân cụm và phân tích cụm tương tác hơn là ưa ra phân cụm một tập
dữ liệu rõ ràng. Thứ tự này diễn tả cấu trúc dữ liệu phân cụm dựa trên mật ộ chứa
thông tin tương ương với phân cụm dựa trên mật ộ với một dãy các tham số ầu
vào. OPTICS xem xét bán kính tối thiểu nhằm xác ịnh các láng giềng phù hợp với thuật toán. Hoàng Văn Dũng 48 lOMoAR cPSD| 39651089 Khai
phá dữ liệu Web bằng kỹ thuật phân cụm
Thuật toán DBSCAN và OPTICS tương tự với nhau về cấu trúc và có cùng
ộ phức tạp: O(nLogn) (n là kích thước của tập dữ liệu). Hình sau thể hiện về một
thí dụ trong PCDL của thuật toán OPTICS:
Hình 2.23. Thứ tự phân cụm các ối tượng theo OPTICS
2.3.3. Thuật toán DENCLUE
Thuật toán DENCLUE (DENsity - Based CLUstEring) ược ề xuất bởi
Hinneburg và Keim năm 1998, ây là thuật toán PCDL dựa trên một tập các hàm
phân phối mật ộ. Ý tưởng chính của thuật toán này như sau [19]:
- Ảnh hưởng của một ối tượng tới láng giềng của nó ược xác ịnh bởi hàm ảnh hưởng.
- Mật ộ toàn cục của không gian dữ liệu ược mô hình phân tích như là tổng
tất cả các hàm ảnh hưởng của các ối tượng.
- Các cụm ược xác ịnh bởi các ối tượng mật ộ cao trong ó mật ộ cao là các
iểm cực ại của hàm mật ộ toàn cục.
Định nghĩa hàm ảnh hưởng: Cho x, y là hai ối tượng trong không gian d chiều
ký hiệu là Fd, hàm ảnh hưởng của y lên x ược xác ịnh: f y
B : Fd R0 , mà ược ịnh
nghĩa dưới dạng một hàm ảnh hưởng cơ bản f y
b : f B ( )x fb (x y, ).
Hàm ảnh hưởng là hàm tuỳ chọn, miễn là nó ược xác ịnh bởi khoảng cách d(x,y)
của các ối tượng, thí dụ như khoảng cách Euclide.
Một số thí dụ về hàm ảnh hưởng ược cho như sau: lOMoAR cPSD| 39651089 Khai
phá dữ liệu Web bằng kỹ thuật phân cụm 0 if d x y( , )
Hàm sóng ngang: f square(x y, ) = 1 if d x y( , )
, trong ó là một ngưỡng. d x y( , )2 2
Hàm Gaussian: f Gauss(x y, ) e 2
Hàm mật ộ của một ối tượng x Fd ược tính bằng tổng tất cả các hàm
ảnh hưởng tác ộng lên x. Giả sử ta có một tập dữ liệu D={x1, x2, ...,xn}.
Hàm mật ộ của x ược xác ịnh: f D x B ( )x n f B i ( )x ; i 1
Hàm mật ộ dựa trên hàm ảnh hưởng Gauss ược xác ịnh như sau: D n d x( ,xi)2 f Gauss( )d e 2 . 2 i 1
Thí dụ về kết quả PCDL của thuật toán DENCLUE với hàm chi phối
Gaussian ược biểu diễn như sau. Các cực ại mật ộ là các giá trị tại ỉnh của ồ thị.
Một cụm cho một cực ại mật ộ x* là tập con C, khi các hàm mật ộ tại x* không bé hơn : Data set
Hình 2.24. DENCLUE với hàm phân phối Gaussian
Thuật toán DENCLUE phụ thuộc nhiều vào ngưỡng nhiễu (Noise
Threshold) và tham số mật ộ , nhưng nó có các ưu iểm sau:
- Có cơ sở toán học vững chắc
- Có khả năng xử lý các phần tử ngoại lai tốt. Hoàng Văn Dũng 50 lOMoAR cPSD| 39651089 Khai
phá dữ liệu Web bằng kỹ thuật phân cụm
- Cho phép khám phá ra các cụm với hình thù bất kỳ ngay cả ối với các dữ liệu a chiều.
Độ phức tạp tính toán của thuật toán DENCLUE là O(nlogn). Các thuật toán
dựa trên mật ộ không thực hiện kỹ thuật phân mẫu trên tập dữ liệu như trong các
thuật toán phân cụm phân hoạch, vì iều này có thể làm tăng thêm ộ phức tạp do
có sự khác nhau giữa mật ộ của các ối tượng trong mẫu với mật ộ của toàn bộ dữ liệu.
2.4. Phân cụm dựa trên lưới
Kỹ thuật phân cụm dựa trên mật ộ không thích hợp với dữ liệu nhiều chiều,
ể giải quyết cho òi hỏi này, người ta ã sử dụng phương pháp phân cụm dựa trên
lưới. Đây là phương pháp dựa trên cấu trúc dữ liệu lưới ể PCDL, phương pháp
này chủ yếu tập trung áp dụng cho lớp dữ liệu không gian. Thí dụ như dữ liệu ược
biểu diễn dưới dạng cấu trúc hình học của ối tượng trong không gian cùng với các
quan hệ, các thuộc tính, các hoạt ộng của chúng. Mục tiêu của phương pháp này
là lượng hoá tập dữ liệu thành các ô (Cell), các ô này tạo thành cấu trúc dữ liệu
lưới, sau ó các thao tác PCDL làm việc với các ối tượng trong từng ô này. Cách
tiếp cận dựa trên lưới này không di chuyển các ối tượng trong các ô mà xây dựng
nhiều mức phân cấp của nhóm các ối tượng trong một ô. Trong ngữ cảnh này,
phương pháp này gần giống với phương pháp phân cụm phân cấp nhưng chỉ có
iều chúng không trộn các ô. Do vậy các cụm không dựa trên ộ o khoảng cách (hay
còn gọi là ộ o tương tự ối với các dữ liệu không gian) mà nó ược quyết ịnh bởi
một tham số xác ịnh trước. Ưu iểm của phương pháp PCDL dựa trên lưới là thời
gian xử lý nhanh và ộc lập với số ối tượng dữ liệu trong tập dữ liệu ban ầu, thay
vào ó là chúng phụ thuộc vào số ô trong mỗi chiều của không gian lưới. Một thí
dụ về cấu trúc dữ liệu lưới chứa các ô trong không gian như hình sau: lOMoAR cPSD| 39651089 Khai
phá dữ liệu Web bằng kỹ thuật phân cụm Tầng 1 . Mức 1 (mức cao nhất ) .
có thể chỉ chứa một ô . . . . Ô mức i-1 có thể tương Tầng i- 1 ứng với 4 ô của mức i
Hình 2.25. Mô hình cấu trúc dữ liệu lưới
Một số thuật toán PCDL dựa trên cấu trúc lưới iển hình như [13][20]: STING, WaveCluster, CLIQUE,…
2.4.1 Thuật toán STING
STING (STatistical INformation Grid) do Wang, Yang và Muntz ề xuất năm
1997, nó phân rã tập dữ liệu không gian thành số hữu hạn các cell sử dụng cấu
trúc phân cấp chữ nhật. Có nhiều mức khác nhau cho các cell trong cấu trúc lưới,
các cell này hình thành nên cấu trúc phân cấp như sau: Mỗi cell ở mức cao ược
phân hoạch thành các cell mức thấp hơn trong cấu trúc phân cấp.
Giá trị của các tham số thống kê (như các giá trị trung bình, tối thiểu, tối a)
cho các thuộc tính của ối tượng dữ liệu ược tính toán và lưu trữ thông qua các
tham số thống kê ở các cell mức thấp hơn ( iều này giống với cây CF).
Các tham số này bao gồm: tham số ếm count, tham số trung bình means,
tham số tối a max tham số tối thiểu min, ộ lệch chuẩn s,… .
Các ối tượng dữ liệu lần lượt ược chèn vào lưới và các tham số thống kê ở
trên ược tính trực tiếp thông qua các ối tượng dữ liệu này. Các truy vấn không
gian ược thực hiện bằng cách xét các cell thích hợp tại mỗi mức của phân cấp.
Một truy vấn không gian ược xác ịnh như là một thông tin khôi phục lại của dữ
liệu không gian và các quan hệ của chúng. STING có khả năng mở rộng cao,
nhưng do sử dụng phương pháp a phân giải nên nó phụ thuộc chặt chẽ vào trọng Hoàng Văn Dũng 52 lOMoAR cPSD| 39651089 Khai
phá dữ liệu Web bằng kỹ thuật phân cụm
tâm của mức thấp nhất. Đa phân giải là khả năng phân rã tập dữ liệu thành các
mức chi tiết khác nhau. Khi hoà nhập các cell của cấu trúc lưới ể hình thành các
cụm, các nút của mức con không ược hoà nhập phù hợp (do chúng chỉ tương ứng
với các cha của nó) và hình thù của các cụm dữ liệu khám phá ược có các biên
ngang và dọc, theo biên của các cell. STING sử dụng cấu trúc dữ liệu lưới cho
phép khả năng xử lý song song, STING duyệt toàn bộ dữ liệu một lần nên ộ phức
tạp tính toán ể tính toán các ại lượng thống kê cho mỗi cell là O(n), trong ó n là
tổng số ối tượng. Sau khi xây dựng cấu trúc dữ liệu phân cấp, thời gian xử lý cho
các truy vấn là O(g) với g là tổng số cell tại mức thấp nhất (g<<n).
2.4.2 Thuật toán CLIQUE
Thuật toán CLIQUE do Agrawal, Gehrke, Gunopulos, Raghavan ề xuất năm
1998, là thuật toán tự ộng phân cụm không gian con với số chiều lớn, nó cho phép
phân cụm tốt hơn không gian nguyên thủy. Các bước chính của thuật toán như sau:
Bước 1: Phân hoạch tập dữ liệu thành các hình hộp chữ nhật và tìm các hình hộp
chữ nhật ặc (nghĩa là các hình hộp này chứa một số các ối tượng dữ liệu trong số các
ối tượng láng giềng cho trước).
Bước 2: Xác ịnh không gian con chứa các cụm ược sử dụng nguyên lý Apriori.
Bước 3: Hợp các hình hộp này tạo thành các cụm dữ liệu.
Bước 4: Xác ịnh các cụm: Trước hết nó tìm các cell ặc ơn chiều, tiếp ến chúng tìm
các hình chữ nhật 2 chiều, rồi 3 chiều,…, cho ến khi hình hộp chữ nhật ặc k chiều ược tìm thấy.
Hình 2.26. Thuật toán CLIQUE lOMoAR cPSD| 39651089 Khai
phá dữ liệu Web bằng kỹ thuật phân cụm
Hình 2.27. Quá trình nhận dạng các ô của CLIQUE
CLIQUE có khả năng áp dụng tốt ối với dữ liệu a chiều, nhưng nó lại rất
nhạy cảm với thứ tự của dữ liệu vào, ộ phức tạp tính toán của CLIQUE là O(n).
2.5. Phân cụm dữ liệu dựa trên mô hình
Phương pháp này cố gắng khám phá các phép xấp xỉ tốt của các tham số mô
hình sao cho khớp với dữ liệu một cách tốt nhất. Chúng có thể sử dụng chiến lược
phân cụm phân hoạch hoặc chiến lược phân cụm phân cấp, dựa trên cấu trúc hoặc
mô hình mà chúng giả ịnh về tập dữ liệu và cách mà chúng tinh chỉnh các mô hình
này ể nhận dạng ra các phân hoạch.
Phương pháp PCDL dựa trên mô hình cố gắng khớp giữa dữ liệu với mô hình
toán học, nó dựa trên giả ịnh rằng dữ liệu ược tạo ra bằng hỗn hợp phân phối xác
suất cơ bản. Các thuật toán phân cụm dựa trên mô hình có hai tiếp cận chính: Mô
hình thống kê và Mạng Nơron. Một số thuật toán iển hình như EM, COBWEB,...
2.5.1. Thuật toán EM
Thuật toán EM (Expectation - Maximization) ược nghiên cứu từ 1958 bởi
Hartley và ược nghiên cứu ầy ủ bởi Dempster, Laird và Rubin công bố năm 1977.
Thuật toán này nhằm tìm ra sự ước lượng về khả năng lớn nhất của các tham số
trong mô hình xác suất (các mô hình phụ thuộc vào các biến tiềm ẩn chưa ược Hoàng Văn Dũng 54 lOMoAR cPSD| 39651089 Khai
phá dữ liệu Web bằng kỹ thuật phân cụm
quan sát), nó ược xem như là thuật toán dựa trên mô hình hoặc là mở rộng của
thuật toán k-means. EM gán các ối tượng cho các cụm ã cho theo xác suất phân
phối thành phần của ối tượng ó. Phân phối xác suất thường ược sử dụng là phân
phối xác suất Gaussian với mục ích là khám phá lặp các giá trị tốt cho các tham
số của nó bằng hàm tiêu chuẩn là hàm logarit khả năng của ối tượng dữ liệu, ây là
hàm tốt ể mô hình xác suất cho các ối tượng dữ liệu.
Thuật toán gồm 2 bước xử lý: Đánh giá dữ liệu chưa ược gán nhãn (bước E)
và ánh giá các tham số của mô hình, khả năng lớn nhất có thể xẩy ra (bước M).
Cụ thể thuật toán EM ở bước lặp thứ t thực hiện các công việc sau:
1) Bước E: Tính toán ể xác ịnh giá trị của các biến chỉ thị dựa trên mô hình hiện tại và dữ liệu:
zij( )t E (zij | x) Pr ( zij 1| x)
fkj (xi ) ( )xi ( )j t g1fg g
2) Bước M: Đánh giá xác suất ( 1)jt
n zij( )t /n i 1
EM có thể khám phá ra nhiều hình dạng cụm khác nhau, tuy nhiên do thời
gian lặp của thuật toán khá nhiều nhằm xác ịnh các tham số tốt nên chí phí tính
toán của thuật toán là khá cao. Đã có một số cải tiến ược ề xuất cho EM dựa trên
các tính chất của dữ liệu: có thể nén, có thể sao lưu trong bộ nhớ và có thể huỷ bỏ.
Trong các cải tiến này, các ối tượng bị huỷ bỏ khi biết chắc chắn ược nhãn phân
cụm của nó, chúng ược nén khi không bị loại bỏ và thuộc về một cụm quá lớn so
với bộ nhớ và chúng sẽ ược lưu lại trong các trường hợp còn lại.
2.5.2. Thuật toán COBWEB
COBWEB ược ề xuất bởi Fisher năm 1987. Các ối tượng ầu vào của thuật
toán ược mô tả bởi cặp thuộc tính-giá trị, nó thực hiện phân cụm phân cấp bằng
cách tạo cây phân lớp, các cấu trúc cây khác nhau. lOMoAR cPSD| 39651089 Khai
phá dữ liệu Web bằng kỹ thuật phân cụm
Thuật toán này sử dụng công cụ ánh giá heuristic ược gọi là công cụ phân
loại CU (Category untility) ể quản lý cấu trúc cây. Từ ó cấu trúc cây ược hình
thành dựa trên phép o ộ tương tự mà phân loại tương tự và phi tương tự, cả hai có
thể mô tả phân chia giá trị thuộc tính giữa các nút trong lớp.
Cấu trúc cây có thể hợp nhất hoặc phân tách khi chèn một nút mới vào cây.
Các bước chính của thuật toán: 1)
Khởi tạo cây bắt ầu bằng một nút rỗng. 2)
Sau khi thêm vào từng nút một và cập nhật lại cây cho phù hợp tại mỗi thời iểm. 3)
Cập nhật cây bắt ầu từ lá bên phải trong mỗi trường hợp, sau ó cấu trúc lại cây. 4)
Quyết ịnh cập nhật dựa trên sự phân hoạch và các hàm tiêu chuẩn phân loại.
Tại mỗi nút, nó xem xét 4 khả năng xảy ra (Insert, Create, Merge, Split) và
lựa chọn một khả năng có hàm giá trị CU ạt ược tốt nhất của quá trình.
Một số hạn chế của COBWEB là nó thừa nhận phân bố xác suất trên các
thuộc tính ơn lẻ là ộc lập thống kê và chi phí tính toán phân bố xác suất của các
cụm khi cập nhật và lưu trữ là khá cao.
Các phương pháp cải tiến của thuật toán COBWEB là CLASSIT, AutoClass.
2.6. Phân cụm dữ liệu mờ
Thông thường, mỗi phương pháp PCDL phân một tập dữ liệu ban ầu thành
các cụm dữ liệu có tính tự nhiên và mỗi ối tượng dữ liệu chỉ thuộc về một cụm dữ
liệu, phương pháp này chỉ phù hợp với việc khám phá ra các cụm có mật ộ cao và
rời nhau. Tuy nhiên, trong thực tế, các cụm dữ liệu lại có thể chồng lên nhau (một
số các ối tượng dữ liệu thuộc về nhiều các cụm khác nhau), người ta ã áp dụng lý
thuyết về tập mờ trong PCDL ể giải quyết cho trường hợp này, cách thức kết hợp
này ược gọi là phân cụm mờ. Trong phương pháp phân cụm mờ, ộ phụ thuộc của
ối tượng dữ liệu xk tới cụm thứ i (uik) có giá trị thuộc khoảng [0,1]. Ý tưởng trên
ã ược giới thiệu bởi Ruspini (1969) và ược Dunn áp dụng năm 1973 nhằm xây
dựng một phương pháp phân cụm mờ dựa trên tối thiểu hoá hàm tiêu chuẩn. Hoàng Văn Dũng 56 lOMoAR cPSD| 39651089 Khai
phá dữ liệu Web bằng kỹ thuật phân cụm
Bezdek (1982) ã tổng quát hoá phương pháp này và xây dựng thành thuật toán
phân cụm mờ c-means có sử dụng trọng số mũ [10][13][20].
c-means là thuật toán phân cụm mờ (của k-means). Thuật toán c-means mờ
hay còn gọi tắt là thuật toán FCM (Fuzzy c- means) ã ược áp dụng thành công
trong giải quyết một số lớn các bài toán PCDL như trong nhận dạng mẫu, xử lý
ảnh, y học, … Tuy nhiên, nhược iểm lớn nhất của thuật toán FCM là nhạy cảm với
các nhiễu và phần tử ngoại lai, nghĩa là các trung tâm cụm có thể nằm xa so với
trung tâm thực tế của cụm.
Đã có nhiều các phương pháp ề xuất ể cải tiến cho nhược iểm trên của thuật
toán FCM bao gồm: Phân cụm dựa trên xác suất (keller, 1993), phân cụm nhiễu
mờ (Dave, 1991), Phân cụm dựa trên toán tử LP Norm (Kersten, 1999).
Thuật toán - Insensitive Fuzzy c-means ( FCM-không nhạy cảm mờ c- means).
2.7. Tổng kết chương 2
Chương này trình bày một số phương pháp phân cụm dữ liệu phổ biến như
phân cụm phân hoạch, phân cụm phân cấp, phân cụm dưa trên mật ộ, phân cụm
dựa trên lưới, phân cụm dựa trên mô hình và phương pháp tiếp cận mới trong PCDL là phân cụm mờ.
Phương pháp phân cụm phân hoạch dựa trên ý tưởng ban ầu tạo ra k phân
hoạch, sau ó lặp lại nhiều lần ể phân bố lại các ối tượng dữ liệu giữa các cụm nhằm
cải thiện chất lượng phân cụm. Một số thuật toán iển hình như k-means, PAM, CLARA, CLARANS,...
Phương pháp phân cụm phân cấp dựa trên ý tưởng cây phân cấp ể phân cụm
dữ liệu. Có hai cách tiếp cận ó là phân cụm dưới lên (Bottom up) và phân cụm
trên xuống (Top down). Một số thuật toán iển hình như BIRCH, CURE,..
Phương pháp phân cụm dựa trên mật ộ, căn cứ vào hàm mật ộ của các ối
tượng dữ liệu ể xác ịnh cụm cho các ối tượng. Một số thuật toán iển hình như DBSCAN, DENCLUE, OPTICS,...
Phương pháp phân cụm dựa trên lưới, ý tưởng của nó là ầu tiên lượng hoá
không gian ối tượng vào một số hữu hạn các ô theo một cấu trúc dưới dạng lưới, lOMoAR cPSD| 39651089 Khai
phá dữ liệu Web bằng kỹ thuật phân cụm
sau ó thực hiện phân cụm dựa trên cấu trúc lưới ó. Một số thuật toán tiêu biểu của
phương pháp này là STING, CLIQUE,...
Phương pháp phân cụm dựa trên mô hình, ý tưởng chính của phương pháp
này là giả thuyết một mô hình cho mỗi cụm và tìm kiếm sự thích hợp nhất của ối
tượng dữ liệu với mô hình ó, các mô hình tiếp cận theo thống kê và mạng Nơron.
Một số thuật toán iển hình của phương pháp này có thể kể ến như EM, COBWEB,...
Một cách tiếp cận khác trong PCDL ó là hướng tiếp cận mờ, trong phương
pháp phân cụm mờ phải kể ến các thuật toán như FCM, FCM,...
Chương 3. KHAI PHÁ DỮ LIỆU WEB
Tương ứng các kiểu dữ liệu Web, ta có thể phân chia các hướng tiếp cận trong khai phá Web như sau: Web mining Web content Web Structure Web Usage mining mining mining Web Page Search Result General Access Customized Content Mining Mining Pattern Tracking Usage Tracking
Hình 3.1. Phân loại khai phá Web
3.1. Khai phá nội dung Web
Khai phá nội dung Web tập trung vào việc khám phá một cách tự ộng nguồn
thông tin có giá trị trực tuyến. Không giống như khai phá sử dụng Web và cấu trúc
Web, khai phá nội dung Web tập trung vào nội dung của các trang Web, không chỉ Hoàng Văn Dũng 58 lOMoAR cPSD| 39651089 Khai
phá dữ liệu Web bằng kỹ thuật phân cụm
ơn thuần là văn bản ơn giản mà còn có thể là dữ liệu a phương tiện như âm thanh,
hình ảnh, phần biến ối dữ liệu và siêu liên kết,....
Trong lĩnh vực khai phá Web, khai phá nội dung Web ược xem xét như là kỹ
thuật KPDL ối với CSDL quan hệ, bởi nó có thể phát hiện ra các kiểu tương tự
của tri thức từ kho dữ liệu không cấu trúc trong các tài liệu Web. Nhiều tài liệu
Web là nữa cấu trúc (như HTML) hoặc dữ liệu có cấu trúc (như dữ liệu trong các
bảng hoặc CSDL tạo ra các trang HTML) nhưng phần a dữ liệu văn bản là không
cấu trúc. Đặc iểm không cấu trúc của dữ liệu ặt ra cho việc khai phá nội dung Web
những nhiệm vụ phức tạp và thách thức.
Khai phá nội dung Web có thể ược tiếp cận theo 2 cách khác nhau: Tìm kiếm
thông tin và KPDL trong CSDL lớn. KPDL a phương tiện là một phần của khai
phá nội dung Web, nó hứa hẹn việc khai thác ược các thông tin và tri thức ở mức
cao từ nguồn a phương tiện trực tuyến rộng lớn. KPDL a phương tiện trên Web
gần ây ã thu hút sự quan tâm của nhiều nhà nghiên cứu. Mục ích là làm ra một
khung thống nhất ối với việc thể hiện, giải quyết bài toán và huấn luyện dựa vào
a phương tiện. Đây thực sự là một thách thức, lĩnh vực nghiên cứu này vẫn còn là
ở thời kỳ sơ khai, nhiều việc ang ợi thực hiện.
Có nhiều cách tiếp cận khác nhau về khai phá nội dung Web, song trong luận
văn này sẽ xem xét dưới 2 góc ộ: Khai phá kết quả tìm kiếm và khai phá nội dung trang HTML.
3.1.1. Khai phá kết quả tìm kiếm
- Phân loại tự ộng tài liệu sử dụng searching engine: Search engine có thể
ánh chỉ số tập trung dữ liệu hỗn hợp trên Web. Ví dụ, trước tiên tải về các trang
Web từ các Web site. Thứ hai, search engine trích ra những thông tin chỉ mục mô
tả từ các trang Web ó ể lưu trữ chúng cùng với URL của nó trong search engine.
Thứ ba sử dụng các phương pháp KPDL ể phân lớp tự ộng và tạo iều kiện thuận
tiện cho hệ thống phân loại trang Web và ược tổ chức bằng cấu trúc siêu liên kết.
- Trực quan hoá kết quả tìm kiếm: Trong hệ thống phân loại, có nhiều tài liệu
thông tin không liên quan nhau. Nếu ta có thể phân tích và phân cụm kết quả tìm
kiếm, thì hiệu quả tìm kiếm sẽ ược cải thiện tốt hơn, nghĩa là các tài liệu “tương lOMoAR cPSD| 39651089 Khai
phá dữ liệu Web bằng kỹ thuật phân cụm
tự” nhau về mặt nội dung thì ưa chúng vào cùng nhóm, các tài liệu “phi tương tự”
thì ưa chúng vào các nhóm khác nhau.
3.1.2. Khai phá văn bản Web
KPVB là một kỹ thuật hỗn hợp. Nó liên quan ến KPDL, xử lý ngôn ngữ tự
nhiên, tìm kiếm thông tin, iều khiển tri thức,... KPVB là việc sử dụng kỹ thuật
KPDL ối với các tập văn bản ể tìm ra tri thức có ý nghĩa tiềm ẩn trong nó. Kiểu ối
tượng của nó không chỉ là dữ liệu có cấu trúc mà còn là dữ liệu nữa cấu trúc hoặc
không cấu trúc [16]. Kết quả khai phá không chỉ là trạng thái chung của mỗi tài
liệu văn bản mà còn là sự phân loại, phân cụm các tập văn bản phục vụ cho mục
ích nào ó. Cấu trúc cơ bản của khai phá thông tin văn bản ược thể hiện trong hình dưới ây [16]. Nguồn dữ Tiền Biểu diễn liệu Web xử lý dữ liệu Sử dụng các kỹ Trích rút các mẫu Đánh giá và biểu thuật khai phá dữ diễn tri thức liệu ể xử lý
Hình 3.2. Quá trình khai phá văn bản Web
3.1.2.1. Lựa chọn dữ liệu
Về cơ bản, văn bản cục bộ ược ịnh dạng tích hợp thành các tài liệu theo mong
muốn ể khai phá và phân phối trong nhiều dịch vụ Web bằng việc sử dụng kỹ thuật truy xuất thông tin.
3.1.2.2. Tiền xử lý dữ liệu
Ta thường lấy ra những metadata ặc trưng như là một căn cứ và lưu trữ các
ặc tính văn bản cơ bản bằng việc sử dụng các quy tắc/ phương pháp ể làm rõ dữ
liệu [16]. Để có ược kết quả khai phá tốt ta cần có dữ liệu rõ ràng, chính xác và
xóa bỏ dữ liệu hỗn ộn và dư thừa. Trước hết cần hiểu yêu cầu của người dùng và
lấy ra mối quan hệ giữa nguồn tri thức ược lấy ra từ nguồn tài nguyên. Thứ hai,
làm sạch, biến ổi và sắp xếp lại những nguồn tri thức này. Cuối cùng, tập dữ liệu Hoàng Văn Dũng 60 lOMoAR cPSD| 39651089 Khai
phá dữ liệu Web bằng kỹ thuật phân cụm
kết quả cuối cùng là bảng 2 chiều. Sau bước tiền xử lý, tập dữ liệu ạt ược thường
có các ặc iểm như sau [16]: -
Dữ liệu thống nhất và hỗn hợp cưỡng bức. -
Làm sạch dữ liệu không liên quan, nhiễu và dữ liệu rỗng. Dữ liệu
không bị mất mát và không bị lặp. -
Giảm bớt số chiều và làm tăng hiệu quả việc phát hiện tri thức bằng
việc chuyển ổi, quy nạp, cưỡng bức dữ liệu,... -
Làm sạch các thuộc tính không liên quan ể giảm bớt số chiều của dữ liệu.
3.1.2.3. Biểu iễn văn bản
KPVB Web là khai phá các tập tài liệu HTML, là không tự nhiên. Do ó ta sẽ
phải biến ổi và biểu diễn dữ liệu thích hợp cho quá trình xử lý. Ta có thể xử lý và
lưu trữ chúng trong mảng 2 chiều mà dữ liệu ó có thể phản ánh ặc trưng của tài
liệu. Người ta thường dùng mô hình TF-IDF ể vector hóa dữ liệu. Nhưng có một
vấn ề quan trọng là việc biểu diễn này sẽ dẫn ến số chiều vector khá lớn. Lựa chọn
các ặc trưng mà nó chắc chắn trở thành khóa và nó ảnh hưởng trực tiếp ến hiệu quả KPVB.
Phân lớp từ và loại bỏ các từ: Trước hết, chọn lọc các từ có thể mô tả ược ặc
trưng của tài liệu. Thứ hai, quét tập tài liệu nhiều lần và làm sạch các từ tần số
thấp. Cuối cùng ta cũng loại trừ các có tần số cao nhưng vô nghĩa, như các từ trong
tiếng Anh: ah, eh, oh, o, the, an, and, of, or,...
3.1.2.4. Trích rút các từ ặc trưng
Rút ra các ặc trưng là một phương pháp, nó có thể giải quyết số chiều vector
ặc trưng lớn ược mang lại bởi kỹ thuật KPVB.
Việc rút ra các ặc trưng dựa trên hàm trọng số:
- Mỗi từ ặc trưng sẽ nhận ược một giá trị trọng số tin cậy bằng việc tính toán
hàm trọng số tin cậy. Tần số xuất hiện cao của các từ ặc trưng là khả năng chắc
chắn nó sẽ phản ánh ến chủ ề của văn bản, thì ta sẽ gán cho nó một giá trị tin cậy
lớn hơn. Hơn nữa, nếu nó là tiêu ề, từ khóa hoặc cụm từ thì chắc chắn nó có giá
trị tin cậy lớn hơn. Mỗi từ ặc trưng sẽ ược lưu trữ lại ể xử lý. Sau ó ta sẽ lựa chọn
kích thước của tập các ặc trưng (kích thước phải nhận ược từ thực nghiệm). lOMoAR cPSD| 39651089 Khai
phá dữ liệu Web bằng kỹ thuật phân cụm
- Việc rút ra các ặc trưng dựa trên việc phân tích thành phần chính trong phân
tích thống kê. Ý tưởng chính của phương pháp này là sử dụng thay thế từ ặc trưng
bao hàm của một số ít các từ ặc trưng chính trong phần mô tả ể thực hiện giảm
bớt số chiều. Hơn nữa, ta cũng sử dụng phương pháp quy nạp thuộc tính dữ liệu ể
giảm bớt số chiều vector thông qua việc tổng hợp nhiều dữ liệu thành một mức cao.
3.1.2.5. Khai phá văn bản
Sau khi tập hợp, lựa chọn và trích ra tập văn bản hình thành nên các ặc trưng
cơ bản, nó sẽ là cơ sở ể KPDL. Từ ó ta có thể thực hiện trích, phân loại, phân cụm, phân tích và dự oán.
3.1.2.5.1 Trích rút văn bản
Việc trích rút văn bản là ể ưa ra ý nghĩa chính có thể mô tả tóm tắt tài liệu
văn bản trong quá trình tổng hợp. Sau ó, người dùng có thể hiểu ý nghĩa chính của
văn bản nhưng không cần thiết phải duyệt toàn bộ văn bản. Đây là phương pháp
ặc biệt ược sử dụng trong searching engine, thường cần ể ưa ra văn bản trích dẫn.
Nhiều searching engines luôn ưa ra những câu dự oán trong quá trình tìm kiếm và
trả về kết quả, cách tốt nhất ể thu ược ý nghĩa chính của một văn bản hoặc tập văn
bản chủ yếu bằng việc sử dụng nhiều thuật toán khác nhau. Theo ó, hiệu quả tìm
kiếm sẽ tốt hơn và phù hợp với sự lựa chọn kết quả tìm kiếm của người dùng.
3.1.2.5.2. Phân lớp văn bản
Trước hết, nhiều tài liệu ược phân lớp tự ộng một cách nhanh chóng và hiệu
quả cao. Thứ hai, mỗi lớp văn bản ược ưa vào một chủ ề phù hợp. Do ó nó thích
hợp với việc tìm và duyệt qua các tài liệu Web của người sử dụng.
Ta thường sử dụng phương pháp phân lớp Navie Bayesian và “K-láng giềng
gần nhất” (K-Nearest Neighbor) ể khai phá thông tin văn bản. Trong phân lớp văn
bản, ầu tiên là phân loại tài liệu. Thứ hai, xác ịnh ặc trưng thông qua số lượng các
ặc trưng của tập tài liệu huấn luyện. Cuối cùng, tính toán kiểm tra phân lớp tài liệu
và ộ tương tự của tài liệu phân lớp bằng thuật toán nào ó. Khi ó các tài liệu có ộ
tương tự cao với nhau thì nằm trong cùng một phân lớp. Độ tương tự sẽ ược o
bằng hàm ánh giá xác ịnh trước. Nếu ít tài liệu tương tự nhau thì ưa nó về 0. Nếu Hoàng Văn Dũng 62 lOMoAR cPSD| 39651089 Khai
phá dữ liệu Web bằng kỹ thuật phân cụm
nó không giống với sự lựa chọn của phân lớp xác ịnh trước thì xem như không
phù hợp. Sau ó, ta phải chọn lại phân lớp. Trong việc lựa chọn có 2 giai oạn: Huấn luyện và phân lớp.
- Lựa chọn trước ặc trưng phân lớp, Y={y1, y2,..., ym}
- Tập tài liệu huấn luyện cục bộ, X={x1, x2,...xn}, v(xj} là vector ặc trưng của xj.
- Mỗi v(yi) trong Y ược xác ịnh bằng v(xj) thông qua việc huấn luyện v(xj) trong X.
- Tập tài liệu kiểm tra, C={c1, c2,...,cp}, ck trong C là một tài liệu phân lớp mong
ợi, công việc của ta là tính toán ộ tương tự giữa v(ck) và v(yi), sim(ck,yi).
- Lựa chọn tài liệu ck mà ộ tương tự của nó với yi lớn nhất, như vậy ck nằm trong
phân lớp với yi, với max(sim(ck,yi)) i=1,...,m.
Quá trình ược thực hiện lặp lại cho tới khi tất cả các tài liệu ã ược phân lớp.
Hình 3.3. Thuật toán phân lớp K-Nearest Neighbor
3.1.2.5.3. Phân cụm văn bản
Chủ ề phân loại không cần xác ịnh trước. Nhưng ta phải phân loại các tài liệu
vào nhiều cụm. Trong cùng một cụm, thì tất cả ộ tương tự của các tài liệu yêu cầu
cao hơn, ngược lại ngoài cụm thì ộ tương tự thấp hơn. Như là một quy tắc, quan
hệ các cụm tài liệu ược truy vấn bởi người dùng là “gần nhau”. Do ó, nếu ta sử
dụng trạng thái trong vùng hiển thị kết quả searching engine bởi nhiều người dùng
thì nó ược giảm bớt rất nhiều. Hơn nữa, nếu phân loại cụm rất lớn thì ta sẽ phân
loại lại nó cho tới khi người dùng ược áp ứng với phạm vi tìm kiếm nhỏ hơn.
Phương pháp sắp xếp liên kết và phương pháp phân cấp thường ược sử dụng trong phân cụm văn bản.
- Trong tập tài liệu xác ịnh, W={w1, w2, ..,wm}, mỗi tài liệu wi là một cụm ci, tập
cụm C là C={c1, c2, ...cm}.
- Chọn ngẫu nhiên 2 cụm ci và cj, tính ộ tương tự sim(ci,cj) của chúng. Nếu ộ tương
tự giữa ci và cj là lớn nhất, ta sẽ ưa ci và cj vào một cụm mới. cuối cùng ta sẽ hình thành
ược cụm mới C={c1, c2,..cm-1}
- Lặp lại công việc trên cho tới khi chỉ còn 1 phân tử.
Hình 3.4. Thuật toán phân cụm phân cấp
Toàn bộ quá trình của phương pháp sắp xếp liên kết sẽ tạo nên một cây mà
nó phản ánh mối quan hệ lông nhau về ộ tương tự giữa các tài liệu. Phương pháp
có tính chính xác cao. Nhưng tốc ộ của nó rất chậm bởi việc phải so sánh ộ tương
tự trong tất cả các cụm. Nếu tập tài liệu lớn thì phương pháp này không khả thi. lOMoAR cPSD| 39651089 Khai
phá dữ liệu Web bằng kỹ thuật phân cụm -
Trước hết ta sẽ chia tập tài liệu thành các cụm khởi ầu thông qua việc tối
ưu hóa hàm ánh giá theo một nguyên tắc nào ó, R={R1, R2,...,Rn}, với n phải ược xác ịnh trước. -
Với mỗi tài liệu trong tập tài liệu W, W={w1, w2,..,wm}, tính toán ộ tương
tự của nó tới Rj ban ầu, sim(wi, Rj), sau ó lựa chọn tài liệu tương tự lớn nhất, ưa nó vào cụm Rj. -
Lặp lại các công việc trên cho tới khi tất cả các tài liệu ã ưa vào trong các cụm xác ịnh.
Hình 3.5. Thuật toán phân cụm phân hoạch
Phương pháp này có các ặc iểm là kết quả phân cụm ổn ịnh và nhanh chóng.
Nhưng ta phải xác ịnh trước các phần tử khởi ầu và số lượng của nó, mà chúng sẽ
ảnh hưởng trực tiếp ến hiệu quả phân cụm.
3.1.2.5.4. Phân tích và dự oán xu hướng
Thông qua việc phân tích các tài liệu Web, ta có thể nhận ược quan hệ phân
phối của các dữ liệu ặc biệt trong từng giai oạn của nó và có thể dự oán ược tương lai phát triển.
3.1.3. Đánh giá chất lượng mẫu
KPDL Web có thể ược xem như quá trình của machine learning. Kết quả của
machine learning là các mẫu tri thức. Phần quan trọng của machine learning là
ánh giá kết quả các mẫu. Ta thường phân lớp các tập tài liệu vào tập huấn luyện
và tập kiểm tra. Sau ó lặp lại việc học và kiểm thử trong tập huấn luyện và tập
kiểm tra. Cuối cùng, chất lượng trung bình ược dùng ể ánh giá chất lượng mô hình.
3.2. Khai phá theo sử dụng Web
Việc nắm bắt ược những ặc tính của người dùng Web là việc rất quan trọng
ối với người thiết Web site. Thông qua việc khai phá lịch sử các mẫu truy xuất của
người dùng Web, không chỉ thông tin về Web ược sử dụng như thế nào mà còn
nhiều ặc tính khác như các hành vi của người dùng có thể ược xác ịnh. Sự iều
hướng ường dẫn người dùng Web mang lại giá trị thông tin về mức ộ quan tâm
của người dùng ến các WebSite ó. Hoàng Văn Dũng 64 lOMoAR cPSD| 39651089 Khai
phá dữ liệu Web bằng kỹ thuật phân cụm
Dựa trên những tiêu chuẩn khác nhau người dùng Web có thể ược phân cụm
và các tri thức hữu ích có thể ược lấy ra từ các mẫu truy cập Web. Nhiều ứng dụng
có thể giúp lấy ra ược các tri thức. Ví dụ, văn bản siêu liên kết ộng ược tạo ra giữa
các trang Web có thể ược ề xuất sau khi khám phá các cụm người dùng Web, thể
hiện ộ tương tự thông tin. Thông qua việc phát hiện mối quan hệ giữa những người
dùng như sở thích, sự quan tâm của người dùng Web ta có thể dự oán một cách
chính xác hơn người sử dụng ang cần gì, tại thời iểm hiện tại có thể dự oán ược
kế tiếp họ sẽ truy cập những thông tin và họ cần thông tin gì.
Giả sử rằng tìm ược ộ tương tự về sự quan tâm giữa những người dùng Web
ược khám phá từ hiện trạng (profile) của người dùng. Nếu Web site ược thiết kết
tốt sẽ có nhiều sự tương quan giữa ộ tương tự của các chuyển hướng ường dẫn và
tương tự giữa sự quan tâm của người dùng.
Khai phá theo sử dụng Web là khai phá truy cập Web (Web log) ể khám phá
các mẫu người dùng truy nhập vào WebSite. Thông qua việc phân tích và khảo sát
những quy tắc trong việc ghi nhận lại quá trình truy cập Web ta có thể chứng thực
khách hàng trong thường mại iện tử, nâng cao chất lượng dịch vụ thông tin trên
Internet ến người dùng, nâng cao hiệu suất của các hệ thống phục vụ Web. Thêm
vào ó, ể tự phát triển các Web site bằng việc huấn luyện từ các mẫu truy xuất của
người dùng. Phân tích quá trình ăng nhập Web của người dùng cũng có thể giúp
cho việc xây dựng các dịch vụ Web theo yêu cầu ối với từng người dùng riêng lẽ ược tốt hơn.
Hiện tại, ta thường sử dụng các công cụ khám phá mẫu và phân tích mẫu. Nó
phân tích các hành ộng người dùng, lọc dữ liệu và khai phá tri thức từ tập dữ liệu
bằng cách sử dụng trí tuệ nhân tạo, KPDL, tâm lý học và lý thuyết thông tin. Sau
khi tìm ra các mẫu truy cập ta thường sử dụng các kỹ thuật phân tích tương ứng ể
hiểu, giải thích và khám phá các mẫu ó. Ví dụ, kỹ thuật xử lý phân tích trực tuyến,
tiền phân loại hình thái dữ liệu, phân tích mẫu thói quen sử dụng của người dùng.
Kiến trúc tổng quát của quá trình khai phá theo sử dụng Web như sau: lOMoAR cPSD| 39651089 Khai
phá dữ liệu Web bằng kỹ thuật phân cụm
Hình 3.6. Kiến trúc tổng quát của khai phá theo sử dụng Web
3.2.1. Ứng dụng của khai phá theo sử dụng Web
- Tìm ra những khách hàng tiềm năng trong thương mại iện tử.
- Chính phủ iện tử (e-Gov), giáo dục iện tử (e-Learning).
- Xác ịnh những quảng cáo tiềm năng.
- Nâng cao chất lượng truyền tải của các dịch vụ thông tin Internet ến người dùng cuối.
- Cải tiến hiệu suất hệ thống phục vụ của các máy chủ Web.
- Cá nhân dịch vụ Web thông quan việc phân tích các ặc tính cá nhân người dùng.
- Cải tiến thiết kế Web thông qua việc phân tích thói quen duyệt Web và phân
tích các mẫu nội dung trang quy cập của người dùng.
- Phát hiện gian lận và xâm nhập bất hợp lệ trong dịch vụ thương mại iện tử
và các dịch vụ Web khác.
- Thông qua việc phân tích chuỗi truy cập của người dùng ể có thể dự báo
những hành vi của người dùng trong quá trình tìm kiếm thông tin.
3.2.2. Các kỹ thuật ược sử dụng trong khai phá theo sử dụng Web
Luật kết hợp: Để tìm ra những trang Web thường ược truy cập cùng nhau của
người dùng những lựa chọn cùng nhau của khách hàng trong thương mại iện tử.
Kỹ thuật phân cụm: Phân cụm người dùng dựa trên các mẫu duyệt ể tìm ra
sự liên quan giữa những người dùng Web và các hành vi của họ.
3.2.3. Những vấn ề trong khai khá theo sử dụng Web. Hoàng Văn Dũng 66 lOMoAR cPSD| 39651089 Khai
phá dữ liệu Web bằng kỹ thuật phân cụm
Khai phá theo cách dùng Web có 2 việc: Trước tiên, Web log cần ược làm
sạch, ịnh nghĩa, tích hợp và biến ổi. Dựa vào ó ể phân tích và khai phá.
Những vấn ề tồn tại:
- Cấu trúc vật lý các Web site khác nhau từ những mẫu người dùng truy xuất.
- Rất khó có thể tìm ra những người dùng, các phiên làm việc, các giao tác.
Vấn ề chứng thực phiên người dùng và truy cập Web:
Các phiên chuyển hướng của người dùng: Nhóm các hành ộng ược thực hiện
bởi người dùng từ lúc họ truy cập vào Web site ến lúc họ rời khỏi Web site ó.
Những hành ộng của người dùng trong một Web site ược ghi và lưu trữ lại trong
một file ăng nhập (log file) (file ăng nhập chứa ịa chỉ IP của máy khách, ngày, thời
gian từ khi yêu cầu ược tiếp nhận, các ối tượng yêu cầu và nhiều thông tin khác
như các giao thức của yêu cầu, kích thước ối tượng,...).
3.2.3.1. Chứng thực phiên người dùng
Chứng thực người dùng: Mỗi người dùng với cùng một Client IP ược xem là cùng một người.
Chứng thực phiên làm việc: Mỗi phiên làm việc mới ược tạo ra khi một ịa
chỉ mới ược tìm thấy hoặc nếu thời gian thăm một trang quá ngưỡng thời gian cho
phép (ví dụ 30 phút) ối với mỗi ịa chỉ IP.
3.2.3.2. Đăng nhập Web và xác ịnh phiên chuyển hướng người dùng
Dịch vụ file ăng nhập Web: Một file ăng nhập Web là một tập các sự ghi lại
những yêu cầu người dùng về các tài liệu trong một Web site, ví dụ: 216.239.46.60 - - [04/April/2007:14:56:50 +0200] "GET
/~lpis/curriculum/C+Unix/ Ergastiria/Week-7/filetype.c.txt HTTP/1.0" 304 -
216.239.46.100- - [04/April/2007:14:57:33 +0200]"GET /~oswinds/top.html HTTP/ 1.0" 200 869
64.68.82.70 - - [04/April/2007:14:58:25 +0200] "GET
/~lpis/systems/rdevice/rdevice_examples.html HTTP/1.0" 200 16792
216.239.46.133 - - [04/April/2007:14:58:27 +0200] "GET
/~lpis/publications/crcchapter1. html HTTP/1.0" 304 -
209.237.238.161 - - [04/April/2007:14:59:11+0200] "GET /robots.txt HTTP/1.0" 404 276
209.237.238.161 - - [04/April/2007:14:59:12 +0200] "GET /teachers/pitas1.html HTTP/1.0" 404 286
216.239.46.43 - - [04/April/2007:14:59:45 +0200] "GET /~oswinds/publication
Nguồn từ: http://www.csd.auth.gr/ lOMoAR cPSD| 39651089 Khai
phá dữ liệu Web bằng kỹ thuật phân cụm
Hình 3.7. Minh họa nội dung logs file
3.2.3.3. Các vấn ề ối với việc xử lý Web log -
Thông tin ược cung cấp có thể không ầy ủ, không chi tiết. -
Không có thông tin về nội dung các trang ã ược thăm. -
Có quá nhiều sự ghi lại các ăng nhập do yêu cầu phục vụ bởi các proxy. -
Sự ghi lại các ăng nhập không ầy ủ do các yêu cầu phục vụ bởi proxy. -
Đặc biệt là việc lọc các mục ăng nhập: Các mục ăng nhập với tên file
mở rộng như gif, jpeg, jpg. Các trang yêu cầu tạo ra bởi các tác nhân tự ộng và
các chương trình gián iệp. -
Ước lượng thời gian thăm trang: Thời gian dùng ể thăm một trang là
một ộ o tốt cho vấn ề xác ịnh mức ộ quan tâm của người dùng ối với trang Web
ó, nó cung cấp một sự ánh giá ngầm ịnh ối với trang Web ó. -
Khoảng thời gian thăm trang: Đó là khoảng thời gian giữa hai yêu
cầu trang khác nhau liên tiếp. -
Quy lui: Nhiều người dùng rời trang bởi họ ã hoàn thành việc tìm
kiếm và họ không muốn thời gian lâu ể chuyển hướng.
3.2.3.4. Phương pháp chứng thực phiên làm việc và truy cập Web
Chứng thực phiên làm việc: Nhóm các tham chiếu trang của người dùng vào
một phiên làm việc dựa trên những phương pháp giải quyết heuristic:
Phương pháp heuristics dựa trên IP và thời gian kết thúc một phiên làm việc
(ví dụ 30 phút) ược sử dụng ể chứng thực phiên người dùng. Đây là phương pháp ơn giản nhất.
Các giao tác nội tại của phiên làm việc có thể nhận ược dựa trên mô hình
hành vi của người dùng (bao hàm phân loại tham chiếu “nội dung” hoặc “chuyển
hướng” ối với mỗi người dùng).
Trọng số ược gán cho mỗi trang Web dựa trên một số ộ o ối với sự quan tâm
của người dùng (ví dụ khoảng thời gian xem một trang, số lần lui tới trang). Hoàng Văn Dũng 68 lOMoAR cPSD| 39651089 Khai
phá dữ liệu Web bằng kỹ thuật phân cụm
3.2.4. Quá trình khai phá theo sử dụng Web
Khai phá sử dụng Web có 3 pha [22]: Tiền xử lý, khai phá và phân tích ánh
giá, biểu diễn dữ liệu.
3.2.4.1. Tiền xử lý dữ liệu
Chứng thực người dùng, chứng thực hoạt ộng truy nhập, ường dẫn ầy ủ,
chứng thực giao tác, tích hợp dữ liệu và biến ổi dữ liệu. Trong pha này, các thông
tin về ăng nhập Web có thể ược biến ổi thành các mẫu giao tác thích hợp cho việc
xử lý sau này trong các lĩnh vực khác nhau.
Trong giai oạn này gồm cả việc loại bỏ các file có phần mở rộng là gif, jpg,...
Bổ sung hoặc xóa bỏ các dữ liệu khuyết thiếu như cache cục bộ, dịch vụ proxy.
Xử lý thông tin trong các Cookie, thông tin ang ký người dùng kết hợp với IP, tên
trình duyệt và các thông tin lưu tạm.
Chứng thực giao tác: Chứng thực các phiên người dùng, các giao tác.
3.2.4.2. Khai phá dữ liệu
Sử dụng các phương pháp KPDL trong các lĩnh vực khác nhau như luật kết
hợp, phân tích, thống kê, phân tích ường dẫn, phân lớp và phân cụm ể khám phá ra các mẫu người dùng.
+ Phân tích ường dẫn [8][9][22]: Hầu hết các các ường dẫn thường ược thăm
ược bố trí theo ồ thị vật lý của trang Web. Mỗi nút là một trang, mỗi cạnh là ường
liên kết giữa các trang ó. Thông qua việc phân tích ường dẫn trong quá trình truy
cập của người dùng ta có thể biết ược mối quan hệ trong việc truy cập của người
giữa các ường dẫn liên quan. Ví dụ:
- 70% các khách hàng truy cập vào /company/product2 ều xuất phát
từ /company thông qua /company/new, /company/products và /company/product1.
- 80% khách hàng truy cập vào WebSite bắt ầu từ /company/products.
- 65% khách hàng rời khỏi site sau khi thăm 4 hoặc ít hơn 4 trang.
+ Luật kết hợp [8]: Sự tương quan giữa các tham chiếu ến các file khác nhau
có trên dịch vụ nhờ việc sử dụng luật kết hợp. lOMoAR cPSD| 39651089 Khai
phá dữ liệu Web bằng kỹ thuật phân cụm Ví dụ:
- 40% khách hàng truy cập vào trang Web có ường dẫn
/company/product1 cũng truy cập vào /company/product2.
- 30% khách hàng truy cập vào /company/special ều thông qua /company/product1.
Nó giúp cho việc phát triển chiến lược kinh doanh phù hợp, xây dựng và tổ
chức một cách tốt nhất không gian Web của công ty.
+ Chuỗi các mẫu: Các mẫu thu ược giữa các giao tác và chuỗi thời gian. Thể
hiện một tập các phần tử ược theo sau bởi phân tử khác trong thứ tự thời gian lưu hành tập giao tác.
Quá trình thăm của khách hàng ược ghi lại trên từng giai oạn thời gian. Ví dụ:
30% khách hàng thăm /company/products ã thực hiện tìm kiếm bằng Yahoo
với các từ khóa tìm kiếm.
60% khách hàng ặt hàng trực tuyến ở /company/product1 thì cũng ặt
hàng trực tuyến ở /company/product4 trong 15 ngày.
+ Quy tắc phân loại [22]: Profile của các phần tử thuộc một nhóm riêng biệt
theo các thuộc tính chung. Ví dụ như thông tin cá nhân hoặc các mẫu truy cập.
Profile có thể sử dụng ể phân loại các phần tử dữ liệu mới ược thêm vào CSDL.
Ví dụ: Khách hàng từ các vị trí ịa lý ở một quốc gia hoặc chính phủ thăm
site có khuynh hướng bị thu hút ở trang /company/product1 hoặc 50% khách hàng
ặt hàng trực tuyến ở /company/product2 ều thuộc nhóm tuổi 20-25 ở Bờ biển Tây.
+ Phân tích phân cụm: Nhóm các khách hàng lại cùng nhau hoặc các phần tử
dữ liệu có các ặc tính tương tự nhau.
Nó giúp cho việc phát triển và thực hiện các chiến lược tiếp thị khách hàng
cả về trực tuyến hoặc không trực tuyến như việc trả lời tự ộng cho các khách hàng
thuộc nhóm chắc chắn, nó tạo ra sự thay ổi linh ộng một WebSite riêng biệt ối với mỗi khách hàng. Hoàng Văn Dũng 70 lOMoAR cPSD| 39651089 Khai
phá dữ liệu Web bằng kỹ thuật phân cụm
3.2.4.3. Phân tích ánh giá
Phân tích mô hình [22]: Thống kê, tìm kiếm tri thức và tác nhân thông minh.
Phân tích tính khả thi, truy vấn dữ liệu hướng tới sự tiêu dùng của con người.
Trực quan hóa: Trực quan Web sử dụng lược ồ ường dẫn Web và ưa ra ồ thị có hướng OLAP.
Ví dụ: Querying: SELECT association-rules(A*B*C*) FROM log.data
WHERE (date>= 970101) AND (domain = ''edu'' )AND (support = 1.0) AND (confidence = 90.0)
3.2.5. Ví dụ khai phá theo sử dụng Web
Ví dụ này sử dụng phương pháp khai phá phân lớp và phân cụm, luật kết hợp
có thể ược dùng ể phân tích số lượng người dùng. Sau ó người thiết kế Web có thể
ưa ra nhiều dịch vụ khác nhau tại các thời iểm khác nhau theo các quy tắc của
người dùng truy cập Web site. Chất lượng dịch vụ tốt sẽ thúc ẩy số lượng người
dùng thăm Web site. Quá trình thực hiện như sau:
- Chứng thực người dùng truy cập vào Web site, phân tích những người dùng
ặc biệt tìm ra những người dùng quan trọng thông qua mức ộ truy cập của họ, thời
gian lưu lại trên ó và mức ộ yêu thích trang Web.
- Phân tích các chủ ề ặc biệt và chiều sâu nội dung Web. Ví dụ, hoạt ộng
thường ngày của một quốc gia, giới thiệu các tour,... Quan hệ khá tự nhiên giữa
người dùng và nội dung Web. Tìm ra những dịch vụ hấp dẫn và tiện lợi với người dùng.
Tùy theo mức ộ hiệu quả hoạt ộng truy cập Web site và iều kiện của việc
duyệt Web site ta có thể dự kiến và ánh giá nội dung Web site tốt hơn.
Dựa trên dữ liệu kiểm tra ta xác ịnh mức ộ truy xuất của người dùng qua việc
phân tích một Web site và phân tích yêu cầu phục vụ thay ổi từng giờ, từng ngày như sau [16]: Số người Số người Thời gian Thời gian truy cập truy cập 00:00-00:59 936 12:00-12:59 2466 01:00-01:59 725 13:00-13:59 1432 02:00-02:59 433 14:00-14:59 1649 lOMoAR cPSD| 39651089 Khai
phá dữ liệu Web bằng kỹ thuật phân cụm 03:00-03:59 389 15:00-15:59 1537 04:00-04:59 149 16:00-16:59 2361 05:00-05:59 118 17:00-17:59 2053 06:00-06:59 126 18:00-18:59 2159 07:00-07:59 235 19:00-19:59 1694 08:00-08:59 599 20:00-20:59 2078 09:00-09:59 1414 21:00-21:59 2120 10:00-10:59 2424 22:00-22:59 1400 11:00-11:59 2846 23:00-23:59 1163
Bảng 3.1. Thống kê số người dùng tại các thời gian khác nhau 3000 2500 2000 1500 1000 500 0 Số Thời gian người
Hình 3.8. Phân tích người dùng truy cập Web
3.3. Khai phá cấu trúc Web
WWW là hệ thống thông tin toàn cầu, bao gồm tất cả các Web site. Mỗi một
trang có thể ược liên kết ến nhiều trang. Các siêu liên kết thay ổi chứa ựng ngữ
nghĩa chung chủ ể của trang. Một siêu liên kết trỏ tới một trang Web khác có thể
ược xem như là một chứng thực của trang Web ó. Do ó, nó rất có ích trong việc
sử dụng những thông tin ngữ nghĩa ể lấy ược thông tin quan trọng thông qua phân
tích liên kết giữa các trang Web. Hoàng Văn Dũng 72 lOMoAR cPSD| 39651089 Khai
phá dữ liệu Web bằng kỹ thuật phân cụm
Sử dụng các phương pháp khai phá người dùng ể lấy tri thức hữu ích từ cấu
trúc Web, tìm ra những trang Web quan trọng và phát triển kế hoạch ể xây dựng
các WebSite phù hợp với người dùng.
Mục tiêu của khai phá cấu trúc Web là ể phát hiện thông tin cấu trúc về Web.
Nếu như khai phá nội dung Web chủ yếu tập trung vào cấu trúc bên trong tài liệu
thì khai phá cấu trúc Web cố gắng ể phát hiện cấu trúc liên kết của các siêu liên
kết ở mức trong của tài liệu. Dựa trên mô hình hình học của các siêu liên kết, khai
phá cấu trúc Web sẽ phân loại các trang Web, tạo ra thông tin như ộ tương tự và
mối quan hệ giữa các WebSite khác nhau. Nếu trang Web ược liên kết trực tiếp
với trang Web khác thì ta sẽ muốn phát hiện ra mối quan hệ giữa các trang Web
này. Chúng có thể tương tự với nhau về nội dung, có thể thuộc dịch vụ Web giống
nhau do ó nó ược tạo ra bởi cùng một người. Những nhiệm vụ khác của khai phá
cấu trúc Web là khám phá sự phân cấp tự nhiên hoặc mạng lưới của các siêu liên
kết trong các Web site của một miền ặc biệt. Điều này có thể giúp tạo ra những
luồng thông tin trong Web site mà nó có thể ại diện cho nhiều miền ặc biệt. Vì thế
việc xử lý truy vấn sẽ trở nên dễ dàng hơn và hiệu quả hơn.
+ Việc phân tích liên kết Web ược sử dụng cho những mục ích[1]:
- Sắp thứ tự tài liệu phù hợp với truy vấn của người sử dụng.
- Quyết ịnh Web nào ược ưa vào lựa chọn trong truy vấn. - Phân trang.
- Tìm kiếm những trang liên quan.
- Tìm kiếm những bản sao của Web.
+ Web ược xem như là một ồ thị [1]:
- Đồ thị liên kết: Mỗi nút là một trang, cung có hướng từ u ến v nếu có
một siêu liên kết từ trang Web u sang trang Web v. lOMoAR cPSD| 39651089 Khai
phá dữ liệu Web bằng kỹ thuật phân cụm
Hình 3.9. Đồ thi liên kết Web
- Đồ thị trích dẫn: Mỗi nút cho một trang, không có cung hướng từ u
ến v nếu có một trang thứ ba w liên kết cả u và v.
- Giả ịnh: Một liên kết từ trang u ến trang v là một thông báo ến trang
v bởi trang u. Nếu u và v ược kết nối bởi một ường liên kết thì rất có khả
năng hai trang Web ó ều có nội dung tương tự nhau.
3.3.1. Tiêu chuẩn ánh giá ộ tương tự
- Khám phá ra một nhóm các trang Web giống nhau ể khai phá, ta phải chỉ ra
sự giống nhau của hai nút theo một tiêu chuẩn nào ó.
Tiêu chuẩn 1: Đối với mỗi trang Web d1 và d2. Ta nói d1 và d2 quan hệ với
nhau nếu có một liên kết từ d1 ến d2 hoặc từ d2 ến d1. d1 d2 2
Hình 3.10. Quan hệ trực tiếp giữa 2 trang
Tiêu chuẩn 2: Đồng trích dẫn: Độ tương tự giữa d1 và d2 ược o bởi số
trang dẫn tới cả d1 và d2. Hoàng Văn Dũng 74 lOMoAR cPSD| 39651089 Khai
phá dữ liệu Web bằng kỹ thuật phân cụm d1 d2 2
Hình 3.11. Độ tương tự ồng trích dẫn
Tương tự chỉ mục: Độ tương tự giữa d1 và d2 ược o bằng số trang mà cả d1
và d2 ều trở tới. d1 d2 2
Hình 3.12. Độ tương tự chỉ mục
3.3.2. Khai phá và quản lý cộng ồng Web
Cộng ồng Web là một nhóm gồm các trang Web chia sẽ chung những vấn ề
mà người dùng quan tâm. Các thành viên của cộng ông Web có thể không biết
tình trạng tồn tại của mỗi trang (và có thể thậm chí không biết sự tồn tại của cộng
ồng). Nhận biết ược các cộng ồng Web, hiểu ược sự phát triển và những ặc trưng
của các cộng ồng Web là rất quan trọng. Việc xác ịnh và hiểu các cộng ồng trên
Web có thể ược xem như việc khai phá và quản lý Web.
Hình 3.13. Cộng ồng Web lOMoAR cPSD| 39651089 Khai
phá dữ liệu Web bằng kỹ thuật phân cụm
Đặc iểm của cộng ồng Web:
- Các trang Web trong cùng một cộng ồng sẽ “tương tự” với nhau hơn các
trang Web ngoài cộng ồng.
- Mỗi cộng ồng Web sẽ tạo thành một cụm các trang Web.
- Các cộng ồng Web ược xác ịnh một cách rõ ràng, tất cả mọi người ều biết,
như các nguồn tài nguyên ược liệt kê bởi Yahoo.
- Cộng ồng Web ược xác ịnh hoàn chỉnh: Chúng là những cộng ồng bất ngờ xuất hiện.
Cộng ồng Web ngày càng ược mọi người quan tâm và có nhiều ứng dụng
trong thực tiễn. Vì vậy, việc nghiên cứu các phương pháp khám phá cộng ồng là
rất có ý nghĩa to lớn trong thực tiễn. Để trích dẫn ra ược các cộng ồng ẩn, ta có
thể phân tích ồ thị Web. Có nhiều phương pháp ể chứng thực cộng ồng như thuật
toán tìm kiếm theo chủ ề HITS, luồng cực ại và nhát cắt cực tiểu, thuật toán PageRank,...
3.3.2.1. Thuật toán PageRank
Google dựa trên thuật toán PageRank [brin98], nó lập chỉ mục các liên kết
giữa các Web site và thể hiện một liên kết từ A ến B như là xác nhận của B bởi A.
Các liên kết có những giá trị khác nhau. Nếu A có nhiều liên kết tới nó và C có ít
các liên kết tới nó thì một liên kết từ A ến B có giá trị hơn một liên kết từ C ến B.
Giá trị ược xác ịnh như thế ược gọi là PageRank của một trang và xác ịnh thứ tự
sắp xếp của nó trong các kết quả tìm kiếm (PageRank ược sử dụng trong phép
cộng ể quy ước chỉ số văn bản ể tạo ra các kết quả tìm kiếm chính xác cao). Các
liên kết có thể ược phân tích chính xác và hiệu quả hơn ối với khối lượng chu
chuyển hoặc khung nhìn trang và trở thành ộ o của sự thành công và việc biến ối
thứ hạng của các trang. Hoàng Văn Dũng 76 lOMoAR cPSD| 39651089 Khai
phá dữ liệu Web bằng kỹ thuật phân cụm
Hình 3.14. Kết quả của thuật toán PageRank
PageRank không ơn giản chỉ dựa trên tổng số các liên kết ến. Các tiếp cận cơ
bản của PageRank là một tài liệu trong thực tế ược xét ến quan trọng hơn là các
tài liệu liên kết tới nó, nhưng những liên kết về (tới nó) không bằng nhau về số
lượng. Một tài liệu xếp thứ hạng cao trong các phần tử của PageRank nếu như có
các tài liệu thứ hạng cao khác liên kết tới nó. Cho nên trong khái niệm PageRank,
thứ hạng của một tài liệu ược dựa vào thứ hạng cao của các tài liệu liên kết tới nó.
Thứ hạng ngược lại của chúng ược dựa vào thứ hạng thấp của các tài liệu liên kết tới chúng.
3.3.2.2. Phương pháp phân cụm nhờ thuật toán HITS
Thuật toán HITS (Hypertext-Induced Topic Selection) do Kleinberg ề xuất,
là thuật toán phát triển hơn trong việc xếp thứ hạng tài liệu dựa trên thông tin liên
kết giữa tập các tài liệu. Định nghĩa: -
Authority: Là các trang cung cấp thông tin quan trọng, tin cậy dựa trên các chủ ề ưa ra. -
Hub: Là các trang chứa các liên kết ến authorities -
Bậc trong: Là số các liên kết ến một nút, ược dùng ể o ộ ủy quyền. -
Bậc ngoài: Là số các liên kết i ra từ một nút, nó ược sử dụng ể o mức ộ trung tâm.
Trong ó: Mỗi Hub trỏ ến nhiều Authority, mỗi Authority thì ược trỏ ến bởi
nhiều Hub. Chúng kết hợp với nhau tạo thành ồ thi phân ôi. lOMoAR cPSD| 39651089 Khai
phá dữ liệu Web bằng kỹ thuật phân cụm Hub Authoritie
Hình 3.15. Đồ thị phân ôi của Hub và Authority
Các Authority and hub thể hiện một quan hệ tác ộng qua lại ể tăng cường lực
lượng. Nghĩa là một Hub sẽ tốt hơn nếu nó trỏ ến các Authority tốt và ngược lại
một Authority sẽ tốt hơn nếu nó ược trỏ ến bởi nhiều Hub tốt. 5 2 1 1 3 1 6 7 7 4 h(1) = a(5) + a(6) + a(7) a(1) = h(2) + h(3) + h(4)
Hình 3.16. Sự kết hợp giữa Hub và Authority
Các bước của phương pháp HITS
Bước 1: Xác ịnh một tập cơ bản S, lấy một tập các tài liệu trả về bởi Search
Engine chuẩn ược gọi là tập gốc R, khởi tạo S tương ứng với R.
Bước 2: Thêm vào S tất cả các trang mà nó ược trỏ tới từ bất kỳ trang nào trong R.
Thêm vào S tất cả các trang mà nó trỏ tới bất kỳ trang nào trong R
Với mỗi trang p trong S: Hoàng Văn Dũng 78 lOMoAR cPSD| 39651089 Khai
phá dữ liệu Web bằng kỹ thuật phân cụm
Tính giá trị iểm số Authority: ap (vector a)
Tính giá trị iểm số Hub: hp (vector h)
Với mỗi nút khởi tạo ap và hp là 1/n (n là số các trang)
Bước 3. Trong mỗi bước lặp tính giá trị trọng số Authority cho mỗi nút trong
S theo công thức: a p hq q q: p
Bước 4. Mỗi bước lặp tính giá trị trọng số Hub ối với mỗi nút trong S theo công thức h q ap q q: p
Lưu ý rằng các trọng số Hub ược tính toán nhờ vào các trọng số Authority
hiện tạo, mà các trọng số Authority này lại ược tính toán từ các trọng số của các Hub trước ó.
Bước 5. Sau khi tính xong trọng số mới cho tất cả các nút, các trọng số ược
chuẩn hóa lại theo công thức:
(ap )2 1 and (hp )2 1 p S p S
Lặp lại bước 3 cho tới khi các hp và ap không ổi.
Ví dụ: Tập gốc R là {1, 2, 3, 4}
Hình 3.17. Đồ thị Hub-Authority
Kết quả tính ược như sau: lOMoAR cPSD| 39651089 Khai
phá dữ liệu Web bằng kỹ thuật phân cụm
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 Hình
3.18. Giá trị trọng số các Hub và Authority
KPDL Web là một lĩnh vực nghiên cứu mới, có triển vọng lớn. Các kỹ thuật
ược áp dụng rộng rãi trên thế giới như KPDL văn bản trên Web, KPDL không gian
và thời gian liên tục trên Web. Khai phá Web ối với hệ thống thương mại iện tử,
khai phá cấu trúc siêu liên kết Web,... Cho tới nay kỹ thuật KPDL vẫn phải ương
ầu với nhiều thử thách lớn trong vấn ề KPDL Web.
3.4. Áp dụng thuật toán phân cụm dữ liệu trong tìm kiếm và phân cụm tài liệu Web
Ngày nay, nhờ sự cải tiến không ngừng của các Search engine về cả chức
năng tìm kiếm lẫn giao diện người dùng ã giúp cho người sử dụng dễ dàng hơn
trong việc tìm kiếm thông tin trên web. Tuy nhiên, người sử dụng thường vẫn phải
duyệt qua hàng chục thậm chí hàng ngàn trang Web mới có thể tìm kiếm ược thứ
mà họ cần. Theo tâm lý chung, người dùng chỉ xem qua vài chục kết quả ầu tiên,
họ thiếu kiên nhẫn và không ủ thời gian ể xem qua tất cả kết quả mà các search
engine trả về. Nhằm giải quyết vấn ề này, chúng ta có thể nhóm các kết quả tìm
kiếm thành thành các nhóm theo các chủ ề, khi ó người sử dụng có thể bỏ qua các
nhóm mà họ không quan tâm ể tìm ến nhóm chủ ề quan tâm. Điều này sẽ giúp cho
người dùng thực hiện công việc của họ một cách hiệu quả hơn. Tuy nhiên vấn ề
phân cụm dữ liệu trên Web và chọn chủ ề thích hợp ể nó có thể mô tả ược nội
dung của các trang là một vấn ề không ơn giản. Trong luận văn này, ta sẽ xem khía Hoàng Văn Dũng 80 lOMoAR cPSD| 39651089 Khai
phá dữ liệu Web bằng kỹ thuật phân cụm
cạnh sử dụng kỹ thuật phân cụm ể phân cụm tài liệu Web dựa trên kho dữ liệu ã
ược tìm kiếm và lưu trữ.
3.4.1. Hướng tiếp cận bằng kỹ thuật phân cụm
Hiện nay, ể xác ịnh mức ộ quan trọng của một trang web chúng ta có nhiều
cách ánh giá như PageRank, HITS, …Tuy nhiên, các phương pháp ánh giá này
chủ yếu ều dựa vào các liên kết trang ể xác ịnh trọng số cho trang.
Ta có thể tiếp cận cách ánh giá mức ộ quan trọng theo một hướng khác là dựa
vào nội dung của các tài liệu ể xác ịnh trọng số, nếu các tài liệu "gần nhau" về nội
dung thì sẽ có mức ộ quan trọng tương ương và sẽ thuộc về cùng một nhóm.
Giả sử cho tập S gồm các trang web, hãy tìm trong tập S các trang chứa nội
dung câu hỏi truy vấn ta ược tập R. Sử dụng thuật toán phân cụm dữ liệu ể phân
tập R thành k cụm (k xác ịnh) sao cho các phần tử trong cụm là tương tự nhau
nhất, các phần tử ở các cụm khác nhau thì phi tương tự với nhau.
Từ tập S-R, chúng ta ưa các phần tử này vào một trong k cụm ã ược thiết lập
ở trên. Những phần tử nào tương tự với trọng tâm của cụm (theo một ngưỡng xác
ịnh nào ó) thì ưa vào cụm này, những phần tử không thỏa mãn xem như không
phù hợp với truy vấn và loại bỏ nó khỏi tập kết quả. Kế tiếp, chúng ta ánh trọng
số cho các cụm và các trang trong tập kết quả theo thuật toán sau:
INPUT: tập dữ liệu D chứa các trang gồm k cụm và k trọng tâm
OUTPUT: trọng số của các trang BEGIN
Mỗi cụm dữ liệu thứ m và trọng tâm Cm ta gán một trọng số tsm. Với các trọng
tâm Ci, Cj bất kỳ ta luôn có tsi>tsj nếu ti tương tự với truy vấn hơn tj.
Với mỗi trang p trong cụm m ta xác ịnh trọng số trang pwm. Với mỗi pwi, pwj
bất kỳ, ta luôn có pw1>pw2 nếu pw1 gần trọng tâm hơn pw2. END
Hình 3.19. Thuật toán ánh trọng số cụm và trang
Như vậy, theo cách tiếp cận này ta sẽ giải quyết ược các vấn ề sau:
+ Kết quả tìm kiếm sẽ ược phân thành các cụm theo các chủ ề khác nhau, tùy
vào yêu cầu cụ thể người dùng sẽ xác ịnh chủ ề mà họ cần.
+ Quá trình tìm kiếm và xác ịnh trọng số cho các trang chủ yếu tập trung vào
nội dung của trang hơn là dựa vào các liên kết trang. lOMoAR cPSD| 39651089 Khai
phá dữ liệu Web bằng kỹ thuật phân cụm
+ Giải quyết ược vấn ề từ/cụm từ ồng nghĩa trong câu truy vấn của người dùng.
+ Có thể kết hợp phương pháp phân cụm trong lĩnh vực khai phá dữ liệu với
các phương pháp tìm kiếm ã có.
Hiện tại, có một số thuật toán phân cụm dữ liệu ược sử dụng trong phân cụm
văn bản như thuật toán phân cụm phân hoạch (k-means, PAM, CLARA), thuật
toán phân cụm phân cấp (BIRCH, STC),... Trong thực tế phân cụm theo nội dung
tài liệu Web, một tài liệu có thể thuộc vào nhiều nhóm chủ ề khác nhau. Để giải
quyết vấn ề này ta có thể sử dụng thuật toán phân cụm theo cách tiếp cận mờ.
3.4.2. Quá trình tìm kiếm và phân cụm tài liệu
Về cơ bản, quá trình phân cụm kết quả tìm kiếm sẽ diễn ra theo các bước ược thể hiện như sau [31]:
- Tìm kiếm các trang Web từ các Website thỏa mãn nội dung truy vấn.
- Trích rút thông tin mô tả từ các trang và lưu trữ nó cùng với các URL tương ứng.
- Sử dụng kỹ thuật phân cụm dữ liệu ể phân cụm tự ộng các trang Web thành
các cụm, sao cho các trang trong cụm “tương tự” về nội dung với nhau hơn các trang ngoài cụm. Tìm kiếm và Dữ liệu web Tiền xử lý trích rút dữ liệu Biểu diễn kết quả Áp dụng thuật Biểu diễn toán phân cụm dữ liệu
Hình 3.20. Các bước phân cụm kết quả tìm kiếm trên Web Hoàng Văn Dũng 82 lOMoAR cPSD| 39651089 Khai
phá dữ liệu Web bằng kỹ thuật phân cụm
3.4.2.1. Tìm kiếm dữ liệu trên Web
Nhiệm vụ chủ yếu của giai oạn này là dựa vào tập từ khóa tìm kiếm ể tìm
kiếm và trả về tập gồm toàn văn tài liệu, tiêu ề, mô tả tóm tắt, URL,… tương ứng với các trang ó.
Nhằm nâng cao tốc ộ xử lý, ta tiến hành tìm kiếm và lưu trữ các tài liệu này
trong kho dữ liệu ể sử dụng cho quá trình tìm kiếm (tương tự như các Search
Engine Yahoo, Google,…). Mỗi phần tử gồm toàn văn tài liệu, tiêu ề, oạn mô tả nội dung, URL,…
3.4.2.2. Tiền xử lý dữ liệu
Quá trình làm sạch dữ liệu và chuyển dịch các tài liệu thành các dạng biểu
diễn dữ liệu thích hợp.
Giai oạn này bao gồm các công việc như sau: Chuẩn hóa văn bản, xóa bỏ các
từ dừng, kết hợp các từ có cùng từ gốc, số hóa và biểu diễn văn bản,..
3.4.2.2.1. Chuẩn hóa văn bản
Đây là giai oạn chuyển văn bản thô về dạng văn bản sao cho việc xử lý sau
này ược dễ dàng, ơn giản, thuật tiện, chính xác so với việc xử lý trực tiếp trên văn
bản thô mà ảnh hưởng ít ến kết quả xử lý. Bao gồm:
+ Xóa các thẻ HTML và các loại thẻ khác ể trích ra các từ/cụm từ.
+ Chuyển các ký tự hoa thành các ký tự thường.
+ Xóa bỏ các dấu câu, xoá các ký tự trắng dư thừa,...
3.4.2.2.2. Xóa bỏ các từ dừng
Trong văn bản có những từ mang ít thông tin trong quá trình xử lý, những từ
có tần số xuất hiện thấp, những từ xuất hiện với tần số lớn nhưng không quan
trọng cho quá trình xử lý ều ược loại bỏ. Theo một số nghiên cứu gần ây cho thấy
việc loại bỏ các từ dùng có thể giảm bởi ược khoảng 20-30% tổng số từ trong văn bản.
Có rất nhiều từ xuất hiện với tần số lớn nhưng nó không hữu ích cho quá
trình phân cụm dữ liệu. Ví dụ trong tiếng Anh các từ như a, an, the, of, and, to, on,
by,... trong tiếng Việt như các từ “thì”, “mà”, “là”, “và”, “hoặc”,... Những từ xuất
hiện với tần số quá lớn cũng sẽ ược loại bỏ. lOMoAR cPSD| 39651089 Khai
phá dữ liệu Web bằng kỹ thuật phân cụm
Để ơn giản trong ứng dụng thực tế, ta có thể tổ chức thành một danh sách các
từ dừng, sử dụng ịnh luật Zipf ể xóa bỏ các từ có tần số xuất hiện thấp hoặc quá cao.
3.4.2.2.3. Kết hợp các từ có cùng gốc
Hầu hết trong các ngôn ngữ ều có rất nhiều các từ có chung nguồn gốc với
nhau, chúng mang ý nghĩa tương tự nhau, do ó ể giảm bởt số chiều trong biểu diễn
văn bản, ta sẽ kết hợp các từ có cùng gốc thành một từ. Theo một số nghiên cứu
[5] việc kết hợp này sẽ giảm ược khoảng 40-50% kích thước chiều trong biểu diễn văn bản.
Ví dụ trong tiếng Anh, từ user, users, used, using có cùng từ gốc và sẽ ược
quy về là use; từ engineering, engineered, engineer có cùng từ gốc sẽ ược quy về là engineer.
Ví dụ xử lý từ gốc trong tiếng Anh:
- Nêu một từ kết thúc bằng “ing” thì xóa “ing”, ngoại trừ trường hợp sau khi
xóa còn lại 1 ký tự hoặc còn lại “th”.
- Nếu một từ kết thúc bằng “ies” nhưng không phải là “eies” hoặc “aies” thì
thay thế “ies” bằng “y”.....
- Nếu một từ kết thúc bằng “es” thì bỏ “s”.
- Nếu một từ kết thúc bởi "s" và ứng trước nó là một phụ âm khác “s” thì xóa “s”.
- Nếu một từ kết thúc bằng “ed”, nếu trước nó là một phụ âm thì xóa “ed”
ngoại trừ sau khi xóa từ chỉ còn lại một ký tự, nếu ứng trước là nguyên âm “i” thì
ổi “ied” thành “y”.
3.4.2.3. Xây dựng từ iển
Việc xây dựng từ iển là một công việc rất quan trọng trong quá trình vector
hóa văn bản, từ iển sẽ gồm các từ/cụm từ riêng biệt trong toàn bộ tập dữ liệu. Từ
iển sẽ gồm một bảng các từ, chỉ số của nó trong từ iển và ược sắp xếp theo thứ tự.
Một số bài báo ề xuất [31] ể nâng cao chất lượng phân cụm dữ liệu cần xem
xét ến việc xử lý các cụm từ trong các ngữ cảnh khác nhau. Theo ề xuất của Zemir
[19][31] xây dựng từ iển có 500 phần tử là phù hợp. Hoàng Văn Dũng 84 lOMoAR cPSD| 39651089 Khai
phá dữ liệu Web bằng kỹ thuật phân cụm
3.4.2.4. Tách từ, số hóa văn bản và biểu diễn tài liệu
Tách từ là công việc hết sức quan trọng trong biểu diễn văn bản, quá trình
tách từ, vector hóa tài liệu là quá trình tìm kiếm các từ và thay thế nó bởi chỉ số
của từ ó trong từ iển.
Ở ây ta có thể sử dụng một trong các mô hình toán học TF, IDF, TFIDF,... ể biểu diễn văn bản.
Chúng ta sử dụng mảng W (trọng số) hai chiều có kích thước m x n, với n là
số các tài liệu, m là số các thuật ngữ trong từ iển (số chiều), hàng thứ j là một
vector biểu diễn tài liệu thứ j trong cơ sở dữ liệu, cột thứ i là thuật ngữ thứ i trong
từ iển. Wij là giá trị trọng số của thuật ngữ i ối với tài liệu j.
Giai oạn này thực hiện thống kê tần số thuật ngữ ti xuất hiện trong tài liệu dj
và số các tài liệu chứa ti. Từ ó xây dựng bảng trọng số của ma trận W theo công thức sau:
Công thức tính trọng số theo mô hình IF-IDF: n
tfij idfij [1 log(tfij )] log( ) nếu ti dj Wij= hi 0
nếu ngược lại (ti dj) Trong ó:
tfij là tần số xuất hiện của ti trong tài liệu dj idfij là
nghịch ảo tần số xuất hiện của ti trong tài liệu dj. hi là số
các tài liệu mà ti xuất hiện.
n là tổng số tài liệu.
3.4.2.5. Phân cụm tài liệu
Sau khi ã tìm kiếm, trích rút dữ liệu và tiền xử lý và biểu diễn văn bản chúng
ta sử dụng kỹ thuật phân cụm ể phân cụm tài liệu.
INPUT: Tập gồm n tài liệu và k cụm.
OUTPUT: Các cụm Ci (i=1,..,k) sao cho hàm tiêu chuẩn ạt giá trị cực tiểu. BEGIN
Bước 1. Khởi tạo ngẫu nhiên k vector làm ối tượng trọng tâm của k cụm. lOMoAR cPSD| 39651089 Khai
phá dữ liệu Web bằng kỹ thuật phân cụm
Bước 2. Với mỗi tài liệu dj xác ịnh ộ tương tự của nó ối với trọng tâm của mỗi cụm
theo một trong các ộ o tương tự thường dùng (như Dice, Jaccard, Cosine, Overlap,
Euclidean, Manhattan). Xác ịnh trọng tâm tương tự nhất cho mỗi tài liệu và ưa tài liệu vào cụm ó.
Bước 3. Cập nhận lại các ối tượng trọng tâm. Đối với mỗi cụm ta xác ịnh lại trọng
tâm bằng cách xác ịnh trung bình cộng của các vector tài liệu trong cụm ó.
Bước 4. Lặp lại bước 2 và 3 cho ến khi trong tâm không thay ổi. END.
Hình 3.21. Thuật toán k-means trong phân cụm nội dung tài liệu Web
Vấn ề xác ịnh trọng tâm của cụm tài liệu: Xét một cụm văn bản c, trong ó
trọng tâm C của cụm c ược tính nhờ vào vector tổng D (D d ) của các d c
văn bản trong cụm c: C D | c |
Trong ó, |c| là số phần tử thuộc tập tài liệu c.
Trong kỹ thuật phân cụm, trọng tâm của các cụm ược sử dụng ể làm ại diện cho các cụm tài liệu.
Vấn ề tính toán ộ tương tự giữa 2 cụm tài liệu: Giả sử ta có 2 cụm c1, c2, khi
ó ộ tương tự giữa 2 cụm tài liệu ược tính bằng mức ộ “gần nhau” giữa 2 vector
trọng tâm C1, C2: Sim(c1,c2)= sim(C1,C2)
Ở ây, ta hiểu rằng c1 và c2 cũng có thể chỉ gồm một tài liệu vì khi ó có thể coi
một cụm chỉ gồm 1 phần tử.
Trong thuật toán k-means, chất lượng phân cụm ược ánh giá thông quan
k hàm tiêu chuẩn E i 1 x C D2 i
(x mi ) , trong ó x là các vector biểu diễn tài
liệu, mi là các trọng tâm của các cụm, k là số cụm, Ci là cụm thứ i.
- Độ phức tạp của thuật toán k-means là O((n.k.d).r).
Trong ó: n là số ối tượng dữ liệu, k là số cụm dữ liệu, d là số chiều, r là số vòng lặp.
Sau khi phân cụm xong tài liệu, trả về kết quả là các cụm dữ liệu và các trọng tâm tương ứng. Hoàng Văn Dũng 86 lOMoAR cPSD| 39651089 Khai
phá dữ liệu Web bằng kỹ thuật phân cụm
3.4.6. Kết quả thực nghiệm
+ Dữ liệu thực nghiệm là các trang Web lấy từ 2 nguồn chính sau:
- Các trang ược lấy tự ộng từ các Website trên Internet, việc tìm kiếm ược
thực hiện bằng cách sử dụng Yahoo ể tìm kiếm tự ộng, chương trình sẽ dựa vào
URL ể lấy toàn văn của tài liệu ó và lưu trữ lại phục vụ cho quá trình tìm kiếm sau
này (dưa liệu gồm hơn 4000 bài về các chủ ề “data mining”, “web mining”,
“Cluster algorithm”, “Sport”).
- Tìm kiếm có chọn lọc, phần này ược tiến hành lấy thủ công, nguồn dữ liệu
chủ yếu ược lấy từ các Web site: http://www.baobongda.com.vn/ http://bongda.com.vn/
http://vietnamnet.vn http://www.24h.com
Gồm hơn 250 bài báo chủ ề “bóng á”.
- Việc xây dựng từ iển, sau khi thống kê tần số xuất hiện của các từ trong tập
tài liệu, ta áp dụng ịnh luật Zipf ể loại bỏ những từ có tần số xuất hiện quá cao và
loại bỏ những từ có tần số quá thấp, ta thu ược bộ từ iển gồm 500 từ.
Thời gian trung bình (giây) Số tài liệu Số cụm Tiền xử lý và biểu Phân cụm tài diễn văn bản liệu 50 10 0,206 0,957 50 15 0,206 1,156 100 10 0,353 2,518 100 15 0,353 3,709 150 10 0,515 4,553 150 15 0,515 5,834 250 10 0,824 9,756 250 15 0,824 13,375
Bảng 3.2. Bảng o thời gian thực hiện thuật toán phân cụm
Ta thấy rằng thời gian thực hiện thuật toán phụ vào ộ lớn dữ liệu và số cụm
cần phân cụm. Ngoài ra, với thuật toán k-means còn phụ thuộc vào k trọng tâm
khởi tạo ban ầu. Nếu k trọng tâm ược xác ịnh tốt thì chất lượng và thời gian thực
hiện ược cải thiện rất nhiều. lOMoAR cPSD| 39651089 Khai
phá dữ liệu Web bằng kỹ thuật phân cụm
Phần giao diện chương trình và một số oạn mã code iển hình ược trình bày ở phụ lục.
3.5. Tổng kết chương 3
Chương này tác giả ã trình bày một số hướng tiếp cận trong khai phá Web
như khai phá dữ liệu toàn văn của tài liệu Web, khai phá cấu trúc Web, khai phá sử
dụng Web và một số thuật toán ang ược áp dụng trong khai phá Web.
Phần này cũng trình bày một số chức năng trong quy trình của hệ thống thực
nghiệm như tìm kiếm và trích chọn dữ liệu trên Web, tiền xử lý dữ liệu, chuẩn hoá
văn bản, xoá bỏ từ dừng, xây dựng từ iển, tách từ và biểu diễn văn bản, phân cụm
tài liệu và ánh giá kết quả thực nghiệm. Hoàng Văn Dũng 88 lOMoAR cPSD| 39651089 Khai
phá dữ liệu Web bằng kỹ thuật phân cụm
KẾT LUẬN VÀ HƯỚNG PHÁT TRIỂN
Luận văn ã nêu lên ược những nét cơ bản về khai phá dữ liệu, khám phá tri
thức và những vấn ề liên quan, kỹ thuật phân cụm dữ liệu và i sâu vào một số
phương pháp phân cụm truyền thống, phổ biến như phân cụm phân hoạch, phân
cụm phân cấp, phân cụm dựa trên mật ộ, phân cụm dựa trên lưới, phân cụm dựa
trên mô hình và theo hướng tiếp cận mờ.
Luận văn tập trung vào một hướng nghiên cứu và phát triển mới trong khai
phá dữ liệu ó là khai phá Web, một hướng ang thu hút sự quan tâm của nhiều nhà
khoa học. Phần này trình bày những vấn ề về các hướng tiếp trong khai phá Web
như khai phá tài liệu Web, khai phá cấu trúc Web và khai phá theo hướng sử dụng
Web. Một kỹ thuật trong khai phá Web ó là phân cụm dữ liệu Web. Tác giả cũng
ã trình bày một hướng tiếp cận trong việc sử dụng các kỹ thuật phân cụm trong
khai phá dữ liệu Web. Đề xuất và xây dựng một chương trình thực nghiệm phân
cụm tài liệu Web áp dụng trong tìm kiếm dữ liệu với thuật toán k-means dựa trên
mô hình vector biểu diễn văn bản TF-IDF.
Lĩnh vực khai phá Web là một vấn ề khá mới mẽ, rất quan trọng và khó, bên
cạnh những kết quả nghiên cứu ã ạt ược nó ã ặt ra những thách thức lớn ối với các
nhà nghiên cứu. Khai phá Web là một lĩnh vực ầy triển vọng, phức tạp và còn là
vấn ề mở. Hiện chưa có một thuật toán và mô hình biểu diễn dữ liệu tối ưu trong khai phá dữ liệu Web.
Mặc dù ã cố gắng, nỗ lực hết mình song do thời gian nghiên cứu, trình ộ của
bản thân có hạn và iều kiện nghiên cứu còn nhiều hạn chế nên không thể tránh
khỏi những khuyết thiếu và hạn chế, tác giả rất mong nhận ược những góp ý, nhận
xét quý báu của quý thầy cô và bạn bè ể kết quả của ề tài hoàn thiện hơn. Hướng phát triển: lOMoAR cPSD| 39651089 Khai
phá dữ liệu Web bằng kỹ thuật phân cụm
- Tiếp tục nghiên cứu, ề xuất và cải tiến một số kỹ thuật mới trong phân cụm
dữ liệu như phân cụm mờ, các thuật toán phân cụm song song,... nhằm nâng cao
hiệu suất khai phá dữ liệu trên hệ thống dữ liệu lớn, phân tán.
- Nghiên cứu các mô hình biểu diễn và xử lý văn bản mới như mô hình mờ,
mô hình tập thô,... nhằm nâng cao hiệu quả xử lý và khai phá dữ liệu ặc biệt là xử
lý dữ liệu trong môi trường Web..
- Áp dụng các kỹ thuật KPDL vào lĩnh vực thương mại iện tử, chính phủ iện tử,... PHỤ LỤC
Chương trình ược viết trên nền .NET Framework 2.0 và ngôn ngữ lập trình
Visual Basic 2005, cơ sở dữ liệu ược lưu trữ và quản lý bằng SQL Server 2005.
Sau ây là một số mã lệnh và giao diện xử lý của chương trình. Một số modul xử
lý trong cương trình
1. Chuẩn hoá xâu văn bản Hoàng Văn Dũng 90 lOMoAR cPSD| 39651089 Khai
phá dữ liệu Web bằng kỹ thuật phân cụm
Private Function Chuanhoa(ByVal S As String) As String For i = 1 To 9
S = S.Replace(Str(i) + ".", Str(i))
S = S.Replace(Str(i) + ",", Str(i)) Next i = 0 Do While i < S.Length - 1
If (Not Char.IsLetterOrDigit(S(i))) And (S(i) <> " ") Then S = S.Remove(i, 1) S = S.Insert(i, " ") Else i = i + 1 End If Loop i = 0 Do While i < S.Length - 1
If ((Char.IsDigit(S(i))) And (Not Char.IsDigit(S(i +
1)))) Or ((Not Char.IsDigit(S(i))) And
(Char.IsDigit(S(i + 1)))) Then
S = S.Insert(i + 1, " ") i = i + 1 End If i = i + 1 Loop S = S.ToLower(VN) i = 0 Do While i < S.Length - 2
If S(i) + S(i + 1) = " " Then S = S.Remove(i, 1) Else i = i + 1 End If Loop S = S.Trim Return S End Function 2. Xoá từ dừng lOMoAR cPSD| 39651089 Khai
phá dữ liệu Web bằng kỹ thuật phân cụm
Private Function XoaTuDung(ByVal S As String) As String
For i = 0 To ListTD.Count - 1
S = S.Replace(" " + ListTD.Item(i) + " ", " ") Next i i = 0 Do While i < S.Length
Do While (i < S.Length - 1) And (S(i) = " ") i = i + 1 Loop j = i + 1 Kt = False
Do While (j < S.Length) And (Not Kt)
If S(j) <> " " Then j = j + 1 Else Kt = True End If Loop If i = j - 1 Then S = S.Remove(i, 1) End If i = j Loop S = S.Trim() Return S End Function 3. Xây dựng từ iển
Private Sub XayDungTuDien(ByVal Doc As ArrayList) For Each S In Doc
list = New ArrayList(S.Split(" ")) For Each ST In list If Trim(ST) <> "" Then i = TuDien.IndexOf(ST) If (i < 0) Then TuDien.Add(Trim(ST)) TuDienTS.Add(1) Else
TuDienTS(i) = TuDienTS(i) + 1 End If End If Next Next
’Sap xep theo giam dan cua tan so tu trong tap Van ban
If (TuDien(0) = " ") Or (TuDien(0) = "") Then TuDien.RemoveAt(0) End If Hoàng Văn Dũng 92 lOMoAR cPSD| 39651089 Khai
phá dữ liệu Web bằng kỹ thuật phân cụm
QuikSort(0, TuDien.Count - 1, TuDien, TuDienTS)
Do While (TuDien.Count>500) And (TuDienTS(0) > Int(NumDoc * (MaxWork / 100))) TuDien.RemoveAt(0) TuDienTS.RemoveAt(0) Loop
Do While (TuDien.Count > MaxWork) TuDien.RemoveAt(MaxWork) TuDienTS.RemoveAt(MaxWork) Loop End Sub 4. Vector hoá văn bản
Private Sub VectorVB(ByVal Collect As ArrayList)
Vector = Array.CreateInstance(GetType(Byte), NumDoc, NumWord) i = 0 For Each S In Collect
List = New ArrayList(S.Split(" ")) For Each ST In List If Trim(ST) <> "" Then k = TuDien.IndexOf(ST) If k > 0 Then
Vector(i, k) = Vector(i, k) + 1 End If End If Next i = i + 1 Next End Sub
5. Xây dựng bảng trọng số
Private Sub XDTrongSo(ByVal Vector As
Array) Dim thongke(NumWord) As Integer
For i = 0 To NumWord - 1 thongke(i) = 0 For j = 0 To NumDoc - 1 If Vector(j, i) > 0 Then thongke(i) = thongke(i) + 1 End If Next Next
W = Array.CreateInstance(GetType(Double), NumDoc, NumWord) For i = 0 To NumDoc - 1 For j = 0 To NumWord - 1 If Vector(i, j) > 0 Then
W(i, j)=(1 + Math.Log(Vector(i,
j)))*(Math.Log(NumDoc)-Math.Log(thongke(j))) Else W(i, j) = 0.0 lOMoAR cPSD| 39651089 Khai
phá dữ liệu Web bằng kỹ thuật phân cụm End If Next Next End Sub 6. Thuật toán k-means Private Sub PhanCumKMean() Randomize(NumDoc)
’Buoc 1: KHOI TAO CAC TRONG TAM i = 0 Do While i < k
r = CInt(Int(NumDoc * Rnd())) If Not rnum.Contains(r) Then rnum.Add(r) For j = 0 To NumWord - 1 C(i, j) = W(r, j) Next i = i + 1 End If Loop For i = 0 To NumDoc - 1 Cum(i) = 0 Next check1 = True Do While check1
’Buoc 2:Tinh toan khoang cach va xac dinh cum cho cac
pt. For i = 0 To NumDoc - 1 min = Double.MaxValue Cum(i) = 0 For j = 0 To k - 1 dis = 0 For m = 0 To NumWord - 1 temp = W(i, m) - C(j, m)
dis = dis + Math.Abs(temp * temp) Next dis = Math.Sqrt(dis) If dis < min Then min = dis Cum(i) = j End If Next Next
’Buoc 3: Cap nhat lai Trong tam check1 = False
For i = 0 To k - 1 ’Cap nhat lan luot Trong tam tung cum For j = 0 To NumWord - 1 Hoàng Văn Dũng 94 lOMoAR cPSD| 39651089 Khai
phá dữ liệu Web bằng kỹ thuật phân cụm n = 0 sum = 0 For m = 0 To NumDoc - 1 If Cum(m) = i Then sum = sum + W(m, j) n = n + 1 End If Next sum = sum / n If C(i, j) <> sumThen C(i, j) = sum check1 = True End If Next Next Loop End Sub
Một số giao diện chương trình
1. Công cụ tìm kiếm tự ộng tài liệu trên Internet và lưu trữ vào CSDL
2. Công cụ tìm kiếm chọn lọc tài liệu trên Internet và lưu trữ vào CSDL
3. Trích chọn dữ liệu, tiền xử lý, xây dựng từ iển và vector hóa văn bản lOMoAR cPSD| 39651089 Khai
phá dữ liệu Web bằng kỹ thuật phân cụm
4. Phân cụm tài liệu và biểu diễn kết quả
TÀI LIỆU THAM KHẢO Tài liệu tiếng Việt [1]
Cao Chính Nghĩa, “Một số vấn ề về phân cụm dữ liệu”, Luận văn thạc sĩ,
Trường Đại học Công nghệ, ĐH Quốc gia Hà Nội, 2006. Hoàng Văn Dũng 96 lOMoAR cPSD| 39651089 Khai
phá dữ liệu Web bằng kỹ thuật phân cụm [2]
Hoàng Hải Xanh, “Về các kỹ thuật phân cụm dữ liệu trong data mining”,
luận văn thạc sĩ, Trường ĐH Quốc Gia Hà Nội, 2005 [3]
Hoàng Thị Mai, “Khai phá dữ liệu bằng phương pháp phân cụm dữ liệu”,
Luận văn thạc sĩ, Trường ĐHSP Hà Nội, 2006.
Tài liệu tiếng Anh
[4] Athena Vakali, Web data clustering Current research status & trends, Aristotle University,Greece, 2004.
[5] Bing Liu, Web mining, Springer, 2007.
[6] Brij M. Masand, Myra Spiliopoulou, Jaideep Srivastava, Osmar R. Zaiane,
Web Mining for Usage Patterns & Profiles, ACM, 2002.
[7] Filippo Geraci, Marco Pellegrini, Paolo Pisati, and Fabrizio Sebastiani, A
scalable algorithm for high-quality clustering of Web Snippets, Italy, ACM,
2006. [8] Giordano Adami, Paolo Avesani, Diego Sona, Clustering Documents
in a Web Directory, ACM, 2003.
[9] Hiroyuki Kawano, Applications of Web mining- from Web search engine to P2P filtering, IEEE, 2004.
[10] Ho Tu Bao, Knowledge Discovery and Data Mining, 2000.
[11] Hua-Jun Zeng, Qi-Cai He, Zheng Chen, Wei-Ying Ma, Jinwen Ma,
Learning to Cluster Web Search Results, ACM, 2004.
[12] Jitian Xiao, Yanchun Zhang, Xiaohua Jia, Tianzhu Li, Measuring
Similarity of Interests for Clustering Web-Users, IEEE, 2001.
[13] Jiawei Han, Micheline Kamber, Data Mining: Concepts and Techniques,
University of Illinois at Urbana-Champaign, 1999.
[14] Khoo Khyou Bun, “Topic Trend Detection and Mining in World Wide Web”, A
thesis for the degree of PhD, Japan, 2004.
[15] LIU Jian-guo, HUANG Zheng-hong , WU Wei-ping, Web Mining for
Electronic Business Application, IEEE, 2003.
[16] Lizhen Liu, Junjie Chen, Hantao Song, The research of Web Mining, IEEE,
2002 [17] Maria Rigou, Spiros Sirmakessis, and Giannis Tzimas, A Method for
Personalized Clustering in Data Intensive Web Applications, 2006.
[18] Miguel Gomes da Costa Júnior, Zhiguo Gong, Web Structure Mining:
An Introduction, IEEE, 2005.
[19] Oren Zamir and Oren Etzioni, Web document Clustering: A Feasibility
Demonstration, University of Washington, USA, ACM, 1998. lOMoAR cPSD| 39651089 Khai
phá dữ liệu Web bằng kỹ thuật phân cụm
[20] Pawan Lingras, Rough Set Clustering for Web mining, IEEE, 2002.
[21] Periklis Andritsos, Data Clusting Techniques, University Toronto,2002.
[22] R. Cooley, B. Mobasher, and J. Srivastava, Web mining:
Information and Pattern Discovery on the World Wide Web, University
of Minnesota, USA, 1998. [23] Raghu Krishnapuram, Anupam Joshi,
and Liyu Yi, A Fuzzy Relative of the
K -Medoids Algorithm with Application toWeb Document and Snippet Clustering, 2001
[24] Raghu Krishnapuram,Anupam Joshi, Olfa Nasraoui, and Liyu Yi, Low-
Complexity Fuzzy Relational Clustering Algorithms for Web Mining, IEEE, 2001.
[25] Raymond and Hendrik, Web Mining Research: A Survey, ACM, 2000 [26]
Rui Wu, Wansheng Tang,Ruiqing Zhao, An Efficient Algorithm for Fuzzy Web- Mining, IEEE, 2004.
[27] T.A.Runkler, J.C.Bezdek, Web mining with relational clustering, ELSEVIER, 2002.
[28] Tsau Young Lin, I-Jen Chiang , “A simplicial complex, a hypergraph,
structure in the latent semantic space of document clustering”, ELSEVIER, 2005.
[29] Wang Jicheng, Huang Yuan, Wu Gangshan, and Zhang Fuyan, Web
Mining: Knowledge Discovery on the Web, IEEE, 1999.
[30] WangBin, LiuZhijing, Web Mining Research, IEEE, 2003.
[31] Wenyi Ni, A Survey of Web Document Clustering, Southern Methodist University, 2004.
[32] Yitong Wang, Masaru Kitsuregawa, Evaluating Contents-Link Coupled Web
Page Clustering for Web Search Results, ACM, 2002.
[33] Zifeng Cui, Baowen Xu , Weifeng Zhang, Junling Xu, Web Documents
Clustering with Interest Links, IEEE, 2005. View publication stats Hoàng Văn Dũng 98


