Paging: Faste Translations (TLBs) | Báo cáo bài tập lớn học phần Hệ điều hành | Trường Đại học Phenikaa
Một câu hỏi mà chúng ta cần trả lời : Ai xử lý TLB ? Có 2 câu trả lời khả thi là : Phần cứng ( hardware ) hoặc Phần mềm ( OS ). Ngày xưa, Phần cứng có các tập lệnh phức tạp ( thường được gọi là CISC, có nghĩa là complex instruction set computers ) và người đã xây dựng ra phần cứng không hoàn toàn tin tưởng vào những người làm hệ điều hành lén lút đó. Do đó , Phần cứng sẽ hoàn toàn xử lý lỗi của TLB. Để làm được điều này, Phần cứng cần phàn biết chính xác địa chỉ của bảng trang nằm ởđâu trong bộ nhớ. Tài liệu giúp bạn tham khảo, ôn tập và đạt kết quả cao. Mời bạn đón xem.
Môn: Hệ điều hành (Phenikaa) 12 tài liệu
Trường: Đại học Phenika 1.3 K tài liệu
Tác giả:














Preview text:
TRƯỜNG ĐẠI HỌC PHENIKAA KHOA CÔNG NGHỆ THÔNG TIN BÀI TẬP LỚN
Đề tài: Paging: Faste Translations (TLBs) Học Phần:
Hệ điều hành-1-2-23(N07)
Giảng Viên: TS.Trần Đăng Hoan Sinh Viên: Trần Long Khánh - 22010449 Lục Nam Tiến - 22010223 Cao Văn Trường - 22010536 Hà Nội, Tháng 3 Năm 2024 Mục lục
1 Lời Mở Đầu ............................................................................................................................... 1
2 Nội Dung .................................................................................................................................... 3
2.1 TLB Basic Algorithm ......................................................................................................... 3
2.2 EXEMPLE ACCESSING AN ARRAY ...................................................................... 4
2.3 Who Handles The TLB Miss ? ....................................................................................... 7
2.4 TLB Contents: What’s In There? ................................................................................ 10
2.5 TLB Issue: Context Switches ....................................................................................... 11
2.6 Issue: Replacement Policy ............................................................................................. 14
2.7 A Real TLB Entry .............................................................................................................. 14
3 Tổng Kết ................................................................................................................................... 16 Chương1 Lời Mở Đầu
Trong thế giới công nghệ thông tin ngày nay, hệ điều hành (OS) đóng vai
trò không thể thiếu như là bộ não điều khiển mọi hoạt động của máy tính. Từ
việc quản lý tài nguyên phần cứng đến việc cung cấp giao diện trực quan cho
người dùng, hệ điều hành là nền tảng cho mọi ứng dụng và dịch vụ. Báo cáo
này sẽ khám phá sâu hơn vào cấu trúc, chức năng, và tầm quan trọng của hệ
điều hành, cũng như cách chúng tiếp tục phát triển để đáp ứng nhu cầu ngày
càng tăng của người dùng và doanh nghiệp. 1
Dùng phân trang như một cơ chế cốt lõi để hỗ trợ bộ nhớ ảo có thể chỉ huy
bộ nhớ với hiệu suất cao. Bằng cách chia không gian bộ nhớ thành những phần
nhỏ, fixed-sized units(...), phân trang đòi hỏi một số lương lớn thông tin ánh xạ.
Bới vì thông tin ánh xạ thường được lưu trữ trong bộ nhớ vật lý, phân trang hợp
lý yêu cầu cần thêm bộ nhớ (extra memory) tra cứu cho mỗi địa chỉ ảo được tạo
ra bởi chương trình. Đi đến bộ nhớ cho mỗi thông tin dịch trước đó với mọi chỉ
dẫn để tìm hoặc tải rõ rang hoặc lưu trữ rõ ràng cực kỳ chậm. Và do đó vấn đề của chúng tôi là :
CÁCH TĂNG TỐC ĐỘ DỊCH ĐỊA CHỈ
Cách chúng tôi có thể tăng tốc độ dịch địa chỉ, và thường tránh xa tham chiếu
bộ nhớ bổ sung mà phân trang dường như yêu cầu? Cần hỗ trợ cần cứng gì ?
Cần tham gia của hệ điều hành nào ? Cái gì được gọi là TLB, Nó giúp tăng tốc
độ phân trang như thế nào?
Bộ đệm tra cứu dịch (TLB) là một loại bộ nhớ đệm lưu trữ các bản dịch gần
đây của bộ nhớ ảo sang địa chỉ vật lý để cho phép truy xuất nhanh hơn. Bộ đệm
tốc độ cao này được thiết lập để theo dõi các mục trong bảng trang (PTE) được sử dụng gần đây.
Khi chúng ta muốn nó phân trang nhanh hơn, nhu cầu sử dụng hệ điều hành
để có 1 số hỗ trợ, Và hỗ trợ thường đến từ một số người bạn cũ của Hệ Điều
Hành: Phần cứng. Để tăng tốc dịch địa chỉ, chúng tôi sẽ thêm những cái được
gọi là translation- lookaside buffer ( bộ đệm tra cứu bản dịch, hoặc TLB. TLB
là một thành phần trong chip memory-management unit( MMU ) < Đơn vị quản
lí bộ nhớ >, và chỉ đơn giản là bộ đệm phần cứng dịch địa chỉ từ bộ nhớ ảo sang
bộ nhớ vật lý phổ biến, do đó, có một cái tên tốt hơn để gọi nó là address
translation cache ( bộ đệm dịch địa chỉ ). Dựa trên mỗi tham chiếu bộ nhớ ảo,
ổ cứng sẽ kiểm tra TLB đầu tiên liệu trong đó có mong muốn giữ bản dịch hay
không, nếu vậy, bản dịch sẽ thực hiện mà không cần đến việc trao đổi với bảng trang. 2 Chương2 Nội Dung 2.1 TLB Basic Algorithm
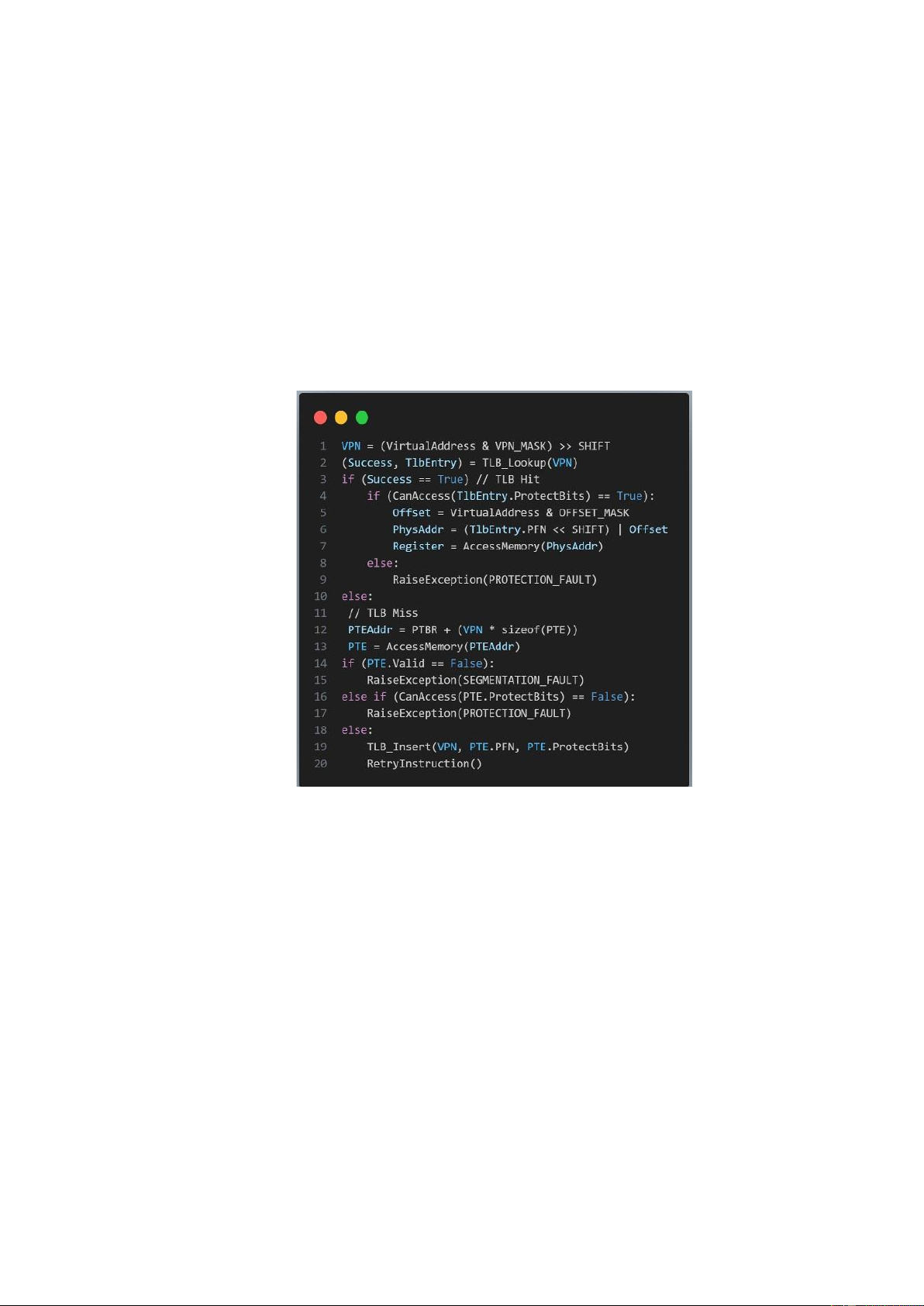
Hình 2.1: TLB Control Flow Algorithm( Thuật toán luồng điều khiển TLB)
Quan sát mã giả hình 2.1 để xem cách nào để ổ cứng có thể dịch địa chỉ ảo,
giả định một bảng phân trang tuyến tính(linear page table) đơn giản(i.e,..., bảng
trang là một mảng) và một TLB quản lý ổ cứng ( hardware managed TLB )
(phần cứng xử lý phần lớn trách nhiệm truy cập bảng trang; chúng tôi sẽ giải
thích thêm về điều này bên dưới).
Thuật toán mà phần cứng tuân theo hoạt động như sau: Đầu tiên, trích xuất
số trang ảo(VPN) từ địa chỉ ảo (Hình2.1) và kiểm tra xem TLB có giữ bản dịch
cho VPN này hay không (Dòng 2). Nếu đúng như vậy, chúng tôi có lượt truy 3
cập TLB, có nghĩa là TLB giữ bản dịch. Thành công! Bây giờ chúng ta có thể
trích xuất số khung trang (PFN) từ mục TLB có liên quan, ghép nó vào phần bù
từ địa chỉ ảo ban đầu và tạo thành địa chỉ vật lý (PA) mong muốn và bộ nhớ
truy cập (Dòng 5–7), giả sử các kiểm tra bảo vệ không thất bại (Dòng 4).
Nếu CPU không tìm thấy bản dịch trong TLB (lỗi TLB), chúng ta còn một
số việc phải làm. Trong ví dụ này, phần cứng truy cập bảng trang để tìm bản
dịch (Dòng 11–12) và giả sử rằng tham chiếu bộ nhớ ảo do quy trình tạo ra là
hợp lệ và có thể truy cập được (Dòng 13, 15), cập nhật TLB với bản dịch (Dòng
18). Tập hợp các hành động này tốn kém, chủ yếu là do cần có thêm tham chiếu
bộ nhớ để truy cập bảng trang (Dòng 12). Cuối cùng, khi TLB đã được cập nhật,
phần cứng sẽ thử lại lệnh; lần này, bản dịch được tìm thấy trong TLB và tham
chiếu bộ nhớ được xử lý nhanh chóng.
TLB, giống như tất cả các bộ nhớ đệm khác, nó được xâu dựng dựa trên
tiền đề rằng trong cách trường hợp thông thường, bản dịch có thể tìm thấy trên
các bộ nhớ đệm( tức là các lượt truy cập). Nếu vì thế, chi phí sẽ được thêm vào
một chút vì TLB được tìm thấy gần lõi xử lý và được thiết kế để hoạt động khá
nhanh. Khi xảy ra lỗi, chi phí phân trang sẽ cao; bảng trang phải được truy cập
để tìm bản dịch và kết quả tham chiếu bộ nhớ bổ sung (hoặc nhiều hơn, với các
bảng trang phức tạp hơn). Nếu điều này xảy ra thường xuyên, chương trình có
thể sẽ chạy chậm hơn đáng kể; việc truy cập bộ nhớ, so với hầu hết các lệnh
CPU, khá tốn kém và việc bỏ sót TLB dẫn đến nhiều lượt truy cập bộ nhớ hơn.
Vì vậy, chúng tôi hy vọng có thể tránh được TLB bị trượt nhiều nhất có thể. 2.2 EXEMPLE ACCESSING AN ARRAY
Để làm rõ hoạt động của một TLB, hãy nghiên cứu một dấu vết địa chỉ ảo
đơn giản và nhìn xem cách một TLB có thể cải thiện hiệu suất của nó. Trong ví
dụ sau: Giả sử chúng ta có 10 số nguyên 4 byte trong bộ nhớ, bắt đầu từ địa chỉ
ảo 100. Giả sử thêm là chúng ta có một không gian địa chỉ ảo nhỏ 8bit, với 16 4
byte trang, do đó, địa chỉ ảo chia thành một VPN 4 bit ( có 16 trang ảo ) và một
offset 4 bit ( có 16 byte trên mỗi trang ). Hình 2.2, quan sát mảng đặt ra trên 16
trang 16byte của hệ thống. Như bạn có thể thấy, Mục đầu tiên của mảng (a[0])
bắt đầu vào là VPN = 06, offset = 04; chỉ có 3 số nguyên 4byte phù hợp với 4
trang. Mảng tiếp tục vào trang tiếp theo (VPN = 07) , tiếp theo ở đây có 4 mục
được xác định vị trí ( a[3],..,a[6]) Kết thúc, 3 mục cuối cùng là a[7],...a[9] sẽ
được xác định vị trí vào trong tiếp theo của không gian địa chỉ (VPN = 08).
Hình 2.2: Example: An Array In A Tiny Address Space
Bây giờ hãy xem xét một vòng lặp đơn giản truy cập từng phần tử mảng,
trông giống như thế này trong C: 5
Để đơn giản, chúng ta sẽ giả sử rằng bộ nhớ duy nhất truy cập vào mảng mà
vòng lặp tạo ra (bỏ qua các biến i và sum, cũng như chính các lệnh). Khi phần
tử mảng đầu tiên (a[0]) được truy cập, CPU sẽ thấy tải tới địa chỉ ảo 100. Phần
cứng trích xuất VPN từ địa chỉ này (VPN=06) và sử dụng địa chỉ đó để kiểm
tra TLB xem có bản dịch hợp lệ hay không.
Giả sử đây là lần đầu tiên chương trình truy cập vào mảng thì kết quả sẽ là lỗi TLB.
Quyền truy cập tiếp theo là vào a[1] và có một số tin tốt ở đây: một cú tấn
công TLB! Bởi vì phần tử thứ hai của mảng được đóng gói bên cạnh phần tử
đầu tiên nên nó nằm trên cùng một trang; vì chúng ta đã truy cập trang này khi
truy cập phần tử đầu tiên của mảng nên bản dịch đã được tải vào TLB. Và đó
là lý do cho sự thành công của chúng tôi. Việc truy cập vào a[2] gặp phải thành
công tương tự (một lần truy cập khác), vì nó cũng nằm trên cùng một trang với a[0] và a[1].
Thật không may, khi chương trình truy cập vào [3], chúng tôi gặp phải lỗi
TLB khác. Tuy nhiên, một lần nữa, các mục tiếp theo (a[4] ... a[6]) sẽ xuất hiện
trong TLB, vì chúng đều nằm trên cùng một trang trong bộ nhớ. Cuối cùng,
quyền truy cập vào a[7] gây ra lỗi TLB cuối cùng. Phần cứng một lần nữa tra
cứu bảng trang để tìm ra vị trí của trang ảo này trong bộ nhớ vật lý và cập nhật
TLB tương ứng. Hai quyền truy cập cuối cùng (a[8] và a[9]) nhận được các lợi
ích của bản cập nhật TLB này; khi phần cứng tìm kiếm bản dịch của chúng
trong TLB, sẽ có thêm hai lần truy cập nữa. Chúng ta hãy tóm tắt hoạt động
TLB trong mười lần truy cập vào mảng: trượt, trúng, trúng, trượt, trúng, trúng,
trúng, trượt, trúng, trúng. Do đó, tỷ lệ trúng TLB của chúng tôi, tức là số lượt
truy cập chia cho tổng số lượt truy cập, là 0,7. Mặc dù con số này không quá
cao (thực sự, chúng tôi mong muốn tỷ lệ trúng đạt tới 1), nhưng nó khác 0, điều
này có thể gây ngạc nhiên. Mặc dù đây là lần đầu tiên chương trình truy cập
vào mảng nhưng TLB vẫn cải thiện hiệu suất do vị trí không gian. Các phần tử
của mảng được đóng gói chặt chẽ vào các trang (tức là chúng gần nhau trong 6
không gian) và do đó chỉ lần truy cập đầu tiên vào một phần tử trên một trang mới gây ra lỗi TLB.
Cũng lưu ý vai trò của kích thước trang trong ví dụ này. Nếu kích thước
trang chỉ đơn giản là lớn gấp đôi (32 byte, không phải 16), thì việc truy cập
mảng thậm chí còn ít bị lỗi hơn. Vì kích thước trang thông thường giống như
4KB nên các loại truy cập dựa trên mảng, dày đặc này đạt được hiệu suất TLB
tuyệt vời, chỉ gặp phải một lỗi duy nhất trên mỗi trang truy cập.
Điểm cuối cùng về hiệu suất TLB: nếu chương trình, ngay sau khi vòng lặp
này hoàn thành, truy cập lại vào mảng, chúng ta có thể sẽ thấy kết quả thậm chí
còn tốt hơn, giả sử rằng chúng ta có TLB đủ lớn để lưu vào bộ nhớ đệm các bản
dịch cần thiết: nhấn, nhấn, đánh, đánh, đánh, đánh, đánh, đánh, đánh, đánh.
Trong trường hợp này, tỷ lệ trúng TLB sẽ cao do vị trí tạm thời, tức là việc tham
chiếu nhanh các mục bộ nhớ theo thời gian. Giống như bất kỳ bộ đệm nào, TLB
dựa vào cả vị trí không gian và thời gian để thành công, đó là các thuộc tính
của chương trình. Nếu chương trình quan tâm có đặc điểm địa phương như vậy
(và nhiều chương trình cũng vậy), tỷ lệ trúng TLB có thể sẽ cao. 2.3 Who Handles The TLB Miss ?
Một câu hỏi mà chúng ta cần trả lời : Ai xử lý TLB ? Có 2 câu trả lời khả
thi là : Phần cứng ( hardware ) hoặc Phần mềm ( OS ). Ngày xưa, Phần cứng có
các tập lệnh phức tạp ( thường được gọi là CISC, có nghĩa là complex
instruction set computers ) và người đã xây dựng ra phần cứng không hoàn toàn
tin tưởng vào những người làm hệ điều hành lén lút đó. Do đó , Phần cứng sẽ
hoàn toàn xử lý lỗi của TLB. Để làm được điều này, Phần cứng cần phàn biết
chính xác địa chỉ của bảng trang nằm ở đâu trong bộ nhớ ( thông qua thanh ghi
cơ sở bảng trang, Hình 2.1). 7
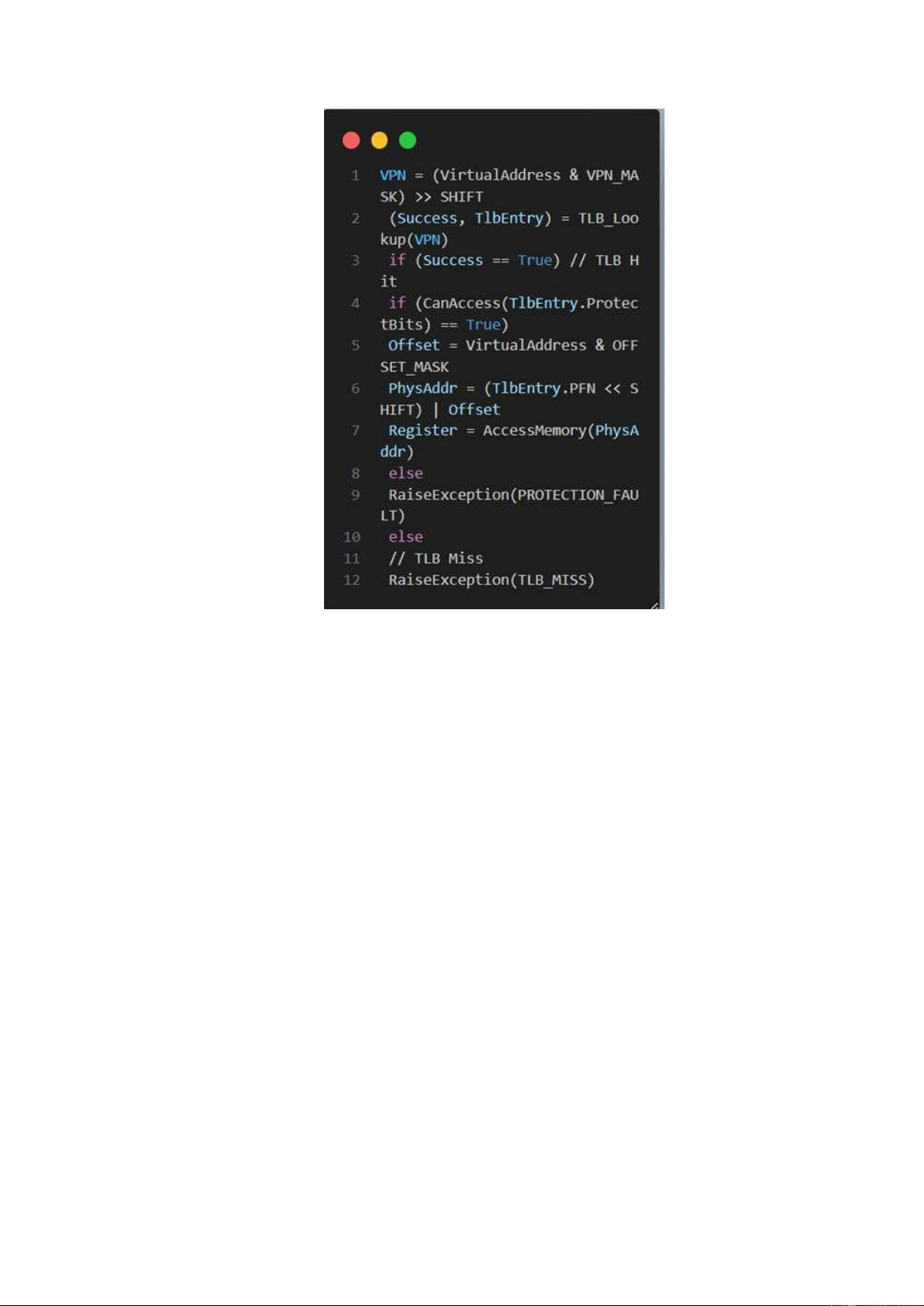
Hình 2.3: TLB Control Flow Algorithm (OS Handled)
Các kiến trúc hiện đại hơn (ví dụ: MIPS R10k [H93] hoặc SPARC v9
[WG00] của Sun, cả RISC hoặc máy tính tập lệnh rút gọn) , TLB được quản lý
bằng phần mềm. Khi xảy ra lỗi TLB, phần cứng chỉ cần đưa ra một ngoại lệ
(dòng 11 trong Hình 19.3), tạm dừng luồng lệnh hiện tại, tăng mức đặc quyền
lên chế độ kernel và chuyển sang trình xử lý bẫy. Như bạn có thể đoán, trình xử
lý bẫy này là mã trong hệ điều hành được viết với mục đích rõ ràng là xử lý các
lỗi TLB. Khi chạy, mã sẽ tra cứu bản dịch trong bảng trang, sử dụng các hướng
dẫn “đặc quyền” đặc biệt để cập nhật TLB và quay trở lại từ bẫy; tại thời điểm
này, phần cứng sẽ thử lại lệnh (dẫn đến một lần truy cập TLB).
Một vài chi tiết quan trọng:
• Đầu tiên, hướng dẫn return-from-trap cần phải khác một chút so với hướng
dẫn return-from-trap mà chúng ta đã thấy trước đây khi thực hiện lệnh gọi 8
hệ thống. Trong trường hợp sau, lệnh return-from-trap sẽ tiếp tục thực hiện
lệnh sau bẫy vào hệ điều hành, giống như lệnh quay lại từ lệnh gọi thủ tục
sẽ quay lại lệnh ngay sau lệnh gọi vào thủ tục. Trong trường hợp trước, khi
quay trở lại từ bẫy xử lý sai TLB, phần cứng phải tiếp tục thực thi theo lệnh
gây ra bẫy; do đó, lần thử lại này cho phép cấu trúc trong chạy lại, lần này
dẫn đến một lần truy cập TLB. Do đó, tùy thuộc vào cách gây ra bẫy hoặc
ngoại lệ, phần cứng phải lưu một PC khác khi bẫy vào hệ điều hành, để
tiếp tục hoạt động bình thường khi đến thời điểm thực hiện việc đó.
• Thứ hai, khi chạy mã xử lý lỗi TLB, hệ điều hành cần phải hết sức cẩn thận
để không xảy ra chuỗi lỗi TLB vô tận. Có nhiều giải pháp; ví dụ: bạn có
thể giữ các trình xử lý lỗi TLB trong bộ nhớ vật lý (nơi chúng không được
ánh xạ và không chịu sự dịch địa chỉ) hoặc dành một số mục trong TLB
cho các bản dịch hợp lệ vĩnh viễn và sử dụng một số vị trí dịch vĩnh viễn
đó cho chính mã xử lý ; những bản dịch có dây này luôn xuất hiện trong TLB.
Ưu điểm chính của cách tiếp cận được quản lý bằng phần mềm là tính linh hoạt:
• HĐH có thể sử dụng bất kỳ cấu trúc dữ liệu nào nó muốn để triển khai
bảng trang mà không cần thay đổi phần cứng.
• Một ưu điểm khác là tính đơn giản, như được thấy trong luồng điều khiển
TLB (dòng 11 trong Hình 19.3, trái ngược với dòng 11–19 trong Hình 19.1).
Phần cứng không làm được gì nhiều khi bỏ lỡ: chỉ cần đưa ra một ngoại lệ
và để trình xử lý lỗi TLB của OS thực hiện phần còn lại.
Nhược điểm: Hệ điều hành cần phải cẩn thận để tránh xảy ra chuỗi TLB vô tận.
→ Giải pháp để hệ điều hành tránh gây ra chuỗi TLB vô tận: 9
• Lưu trữ trình xử lý lỗi TLB trong bộ nhớ vật lý.
• Dành riêng một số mục trong TLB cho bản dịch vĩnh viễn hợp lệ.
• Sử dụng thuật toán dự đoán lỗi TLB để dự đoán khả năng gây lỗi trong tương lai.
• Sử dụng bộ nhớ đệm bảng trang.
• Sử dụng bảng trang đa cấp. 2.4
TLB Contents: What’s In There?
Một TLB điển hình có thể có 32, 64 hoặc 128 mục và được gọi là kết hợp
đầy đủ. Về cơ bản, điều này chỉ có nghĩa là bất kỳ bản dịch nào cũng có thể ở
bất kỳ đâu trong TLB và phần cứng sẽ tìm kiếm song song toàn bộ TLB để tìm
bản dịch mong muốn. Một mục TLB có thể trông như thế này: VNP | PFN |other bits
Lưu ý rằng cả VPN và PFN đều có trong mỗi mục nhập, vì bản dịch có thể kết
thúc ở bất kỳ vị trí nào trong số này (về mặt phần cứng, TLB được gọi là bộ
nhớ đệm liên kết đầy đủ). Phần cứng tìm kiếm các mục song song để xem có khớp không.
Thú vị hơn là những “bit khác”. Ví dụ: TLB thường có một bit hợp lệ, cho
biết mục nhập có bản dịch hợp lệ hay không. Cũng phổ biến là các bit bảo vệ,
xác định cách truy cập một trang (như trong bảng trang). Ví dụ: các trang mã
có thể được đánh dấu là đọc và thực thi, trong khi các trang heap có thể được
đánh dấu là đọc và ghi. Cũng có thể có một số trường khác, bao gồm mã định
danh không gian địa chỉ, bit bẩn, v.v. 10 2.5 TLB Issue: Context Switches
Với TLB, các vấn đề mới phát sinh khi chuyển đổi giữa các quy trình (và
do đó là không gian địa chỉ). Cụ thể, TLB chứa các bản dịch từ ảo sang vật lý
chỉ hợp lệ cho quy trình hiện đang chạy; những bản dịch này không có ý nghĩa
đối với các quá trình khác. Do đó, khi chuyển từ quy trình này sang quy trình
khác, phần cứng hoặc hệ điều hành (hoặc cả hai) phải cẩn thận để đảm bảo rằng
quy trình sắp chạy không vô tình sử dụng các bản dịch từ một số quy trình đã chạy trước đó.
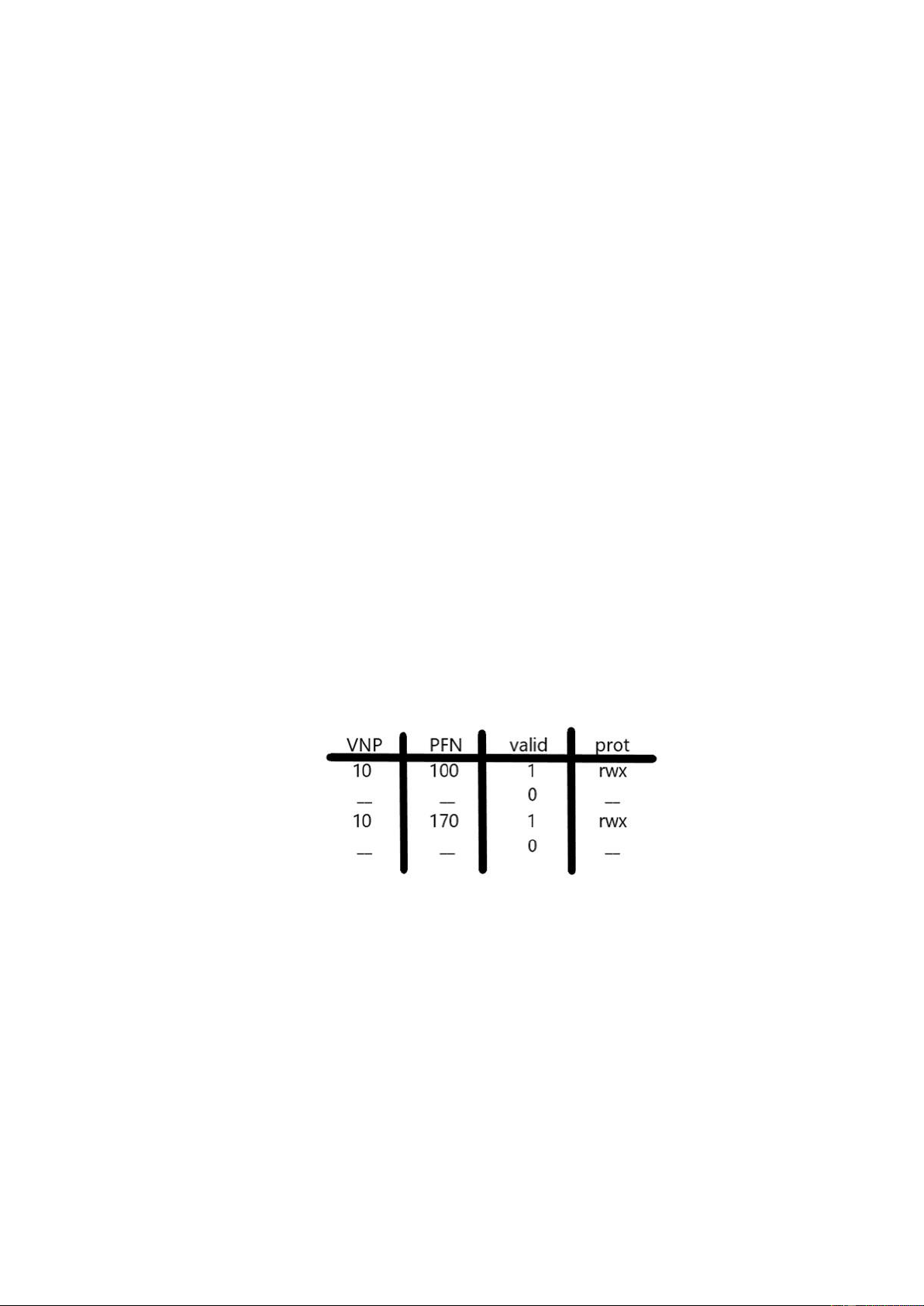
Để hiểu rõ hơn về tình huống này, chúng ta hãy xem một ví dụ. Khi một
tiến trình (P1) đang chạy, nó giả định rằng TLB có thể đang lưu vào bộ đệm các
bản dịch hợp lệ cho nó, tức là các bản dịch đến từ bảng trang của P1. Trong ví
dụ này, giả sử rằng trang ảo thứ 10 của P1 được ánh xạ tới khung vật lý 100.
Trong ví dụ này, giả sử một quy trình khác (P2) tồn tại và hệ điều hành có
thể sớm quyết định thực hiện chuyển đổi ngữ cảnh và chạy nó. Giả sử ở đây
rằng trang ảo thứ 10 của P2 được ánh xạ tới khung vật lý 170. Nếu các mục
nhập cho cả hai quy trình đều nằm trong TLB thì nội dung của TLB sẽ là:
Trong TLB ở trên, rõ ràng chúng ta có một vấn đề: VPN 10 dịch sang PFN
100 (P1) hoặc PFN 170 (P2), nhưng phần cứng không thể phân biệt mục nhập
nào dành cho quy trình nào. Vì vậy, chúng ta cần thực hiện thêm một số công
việc để TLB hỗ trợ ảo hóa một cách chính xác và hiệu quả trên nhiều quy trình.
Và do đó, một mấu chốt: 11
CÁCH QUẢN LÝ NỘI DUNG TLB TRÊN CHUYỂN ĐỔI TIẾP THEO
Khi chuyển đổi ngữ cảnh giữa các quy trình, các bản dịch trong TLB cho quy
trình cuối cùng không có ý nghĩa đối với quy trình sắp chạy. Phần cứng hoặc
hệ điều hành nên làm gì để giải quyết vấn đề này?
Có một số giải pháp khả thi cho vấn đề này. Một cách tiếp cận là chỉ cần
xóa TLB trên các công tắc ngữ cảnh, do đó làm trống nó trước khi chạy quy
trình tiếp theo. Trên hệ thống dựa trên phần mềm, điều này có thể được thực
hiện bằng lệnh phần cứng rõ ràng (và đặc quyền); với TLB được quản lý bằng
phần cứng, việc xóa có thể được thực hiện khi thanh ghi cơ sở bảng trang được
thay đổi (lưu ý rằng dù sao đi nữa, hệ điều hành cũng phải thay đổi PTBR trên
chuyển đổi ngữ cảnh). Trong cả hai trường hợp, thao tác xóa chỉ đơn giản đặt
tất cả các bit hợp lệ về 0, về cơ bản là xóa nội dung của TLB.
Bằng cách xóa TLB trên mỗi chuyển đổi ngữ cảnh, giờ đây chúng tôi
có một giải pháp hiệu quả, vì một quy trình sẽ không bao giờ vô tình gặp phải
các bản dịch sai trong TLB. Tuy nhiên, có một cái giá phải trả: mỗi khi một tiến
trình chạy, nó phải chịu lỗi TLB khi chạm vào các trang dữ liệu và mã của nó.
Nếu hệ điều hành chuyển đổi giữa các tiến trình thường xuyên thì chi phí này có thể cao.
Để giảm chi phí này, một số hệ thống bổ sung hỗ trợ phần cứng để cho phép
chia sẻ TLB qua các thiết bị chuyển mạch ngữ cảnh. Đặc biệt, một số hệ thống
phần cứng cung cấp trường nhận dạng không gian địa chỉ (ASID) trong TLB.
Bạn có thể coi ASID như một mã định danh quy trình (PID), nhưng thông
thường nó có ít bit hơn (ví dụ: 8 bit cho ASID so với 32 bit cho PID). Nếu chúng
ta lấy TLB ví dụ ở trên và thêm ASID, thì rõ ràng các quy trình có thể dễ dàng
chia sẻ TLB: chỉ cần trường ASID để phân biệt các bản dịch giống hệt nhau.
Dưới đây là mô tả về TLB có trường ASID được thêm vào: 12
Do đó, với các mã định danh không gian địa chỉ, TLB có thể giữ các bản
dịch từ các quy trình khác nhau cùng lúc mà không có bất kỳ sự nhầm lẫn nào.
Tất nhiên, phần cứng cũng cần biết quy trình nào hiện đang chạy để thực hiện
các bản dịch và do đó, hệ điều hành phải, trên một chuyển đổi ngữ cảnh, đặt
một số thanh ghi đặc quyền cho ASID của quy trình hiện tại. Ngoài ra, bạn cũng
có thể đã nghĩ đến một trường hợp khác trong đó hai mục nhập của TLB giống nhau một cách đáng kể.
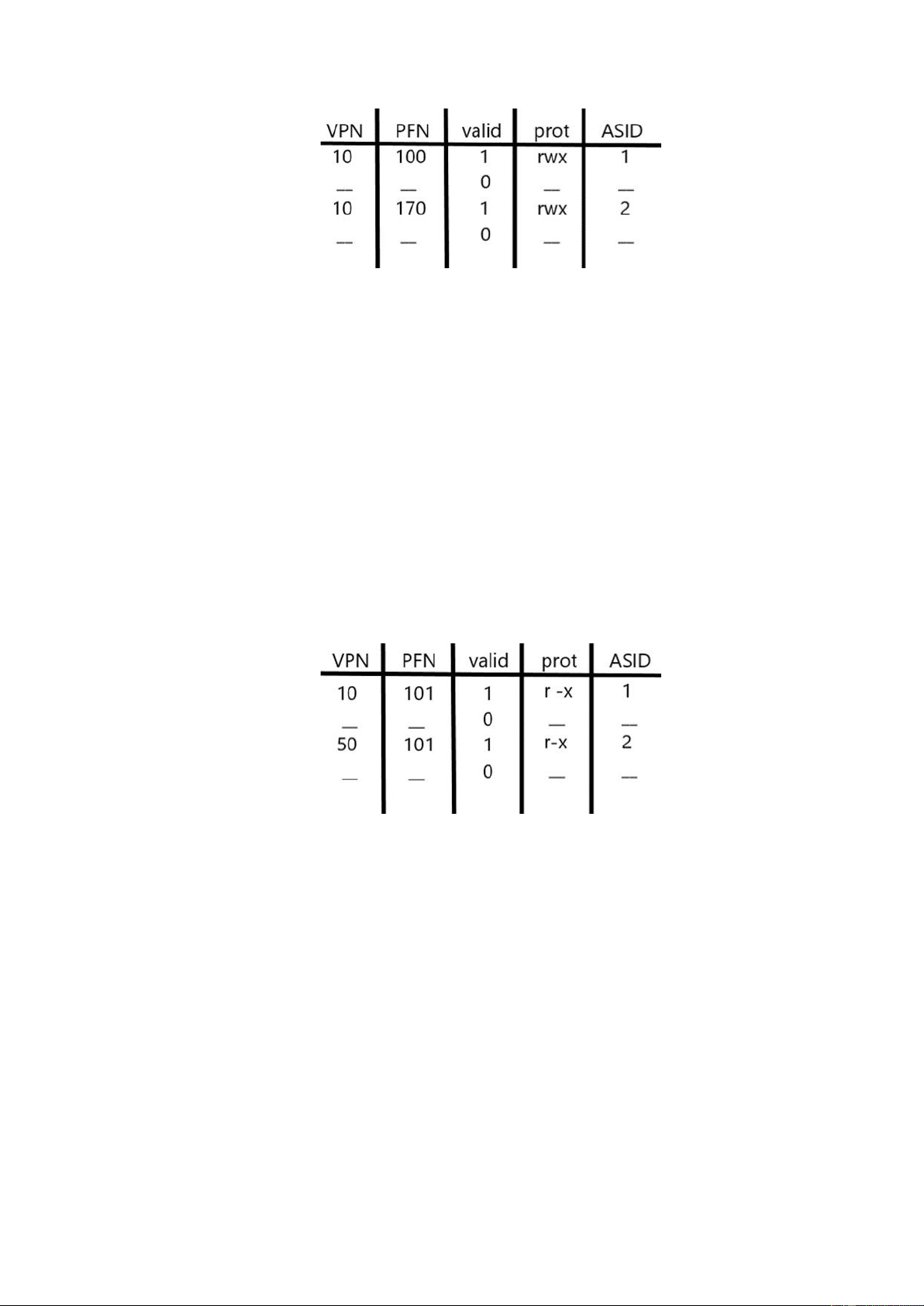
Trong ví dụ này, có hai mục nhập cho hai quy trình khác nhau với hai VPN
khác nhau trỏ đến cùng một trang vật lý:
Tình huống này có thể phát sinh, ví dụ, khi hai tiến trình chia sẻ một trang
(ví dụ: một trang mã). Trong ví dụ trên, Quy trình 1 đang chia sẻ trang 101 vật
lý với Quy trình 2; P1 ánh xạ trang này vào trang thứ 10 trong không gian địa
chỉ của nó, trong khi P2 ánh xạ nó tới trang thứ 50 trong không gian địa chỉ của
nó. Việc chia sẻ các trang mã (ở dạng nhị phân hoặc thư viện dùng chung) rất
hữu ích vì nó làm giảm số lượng trang vật lý đang được sử dụng, do đó giảm chi phí bộ nhớ. 13 2.6 Issue: Replacement Policy
• Least Recently Used ( LRU ) : Chính sách này nhắm vào việc thay thế bản
ghi TLB không được sử dụng trong thời gian giài nhất, tận dụng nguyên lý
về sự cục bộ trong các tham chiều bộ nhớ. LRU giả định rằng các bản ghi
không được sử dụng gần đây là ứng biên lý tưởng cho việc loại bỏ.
• Chính sách ngẫu nhiên : Phương pháp này sẽ loại bỏ ánh xạ TLB một cách
ngẫu nhiên. Chính sách như vậy rất hữu ích do tính đơn giản và khả năng
tránh các hành vi khó khăn. Ví dụ: một chính sách “hợp lý” như LRU hoạt
động khá bất hợp lý khi một chương trình lặp qua n
+ 1 trang với TLB có kích thước n; trong trường hợp này, LRU bỏ lỡ mọi
lần truy cập, trong khi ngẫu nhiên thì tốt hơn nhiều.
→ Tóm lại nhấn mạnh về việc lựa chọn một chính sách thay thế phù hợp cho
TLB để tối ưu hóa hiệu suất bằng các giảm thiểu tỉ lệ miss và tăng tỉ lệ hit. 2.7 A Real TLB Entry
Chúng ta hãy xem qua một ví dụ từ MIPS R4000 một hệ thống bộ nhớ sử
dụng TLB được quản lý bởi phần mềm. Hình 2.4: A MIPS TLB ENTRY
Qua hình 19.4 ta có thể thấy đó là một mục TLB MIPS đơn giản.MIPS
R4000 hỗ trợ không gian địa chỉ 32-bit với các trang 4KB. Chúng ta mong đợi
một VPN 20-bit và offset 12-bit trong địa chỉ ảo thông thường.
Tuy nhiên ta có thể thấy trong mục, chỉ có hai bit cho VPN (hóa ra địa chỉ
dự phòng sẽ đến từ một nửa không gian địa chỉ không dành cho kernel) và do 14
đó chỉ cần 19 bit của VPN. VPN chỉ đến một số khung vật lý 24-bit (PFN) nên
có thể hỗ trợ cho các hệ thống có bộ nhớ chính (vật lý) lên tới 64GB. Đây là
cách mà TLB hoạt động trong việc dịch địa chỉ ảo thành địa chỉ vật lý trong
một hệ thống máy tính.
Chúng ta thấy có 1 bit toàn cục (G) được sử dụng cho các trang nhớ được
chia sẻ toàn cục giữa các tiến trình được chia sẻ. Do đó nếu 1 bit toàn cục được
đặt thì ASID sẽ bị bỏ qua.Ta có thể thấy ASID 8 bit mà hệ điều hành dùng để
phân biệt giữa các không gian địa chỉ.
MIPS TLB thường sẽ có 32 hoặc 64 mục trong số này hầu hết chúng được
sử bởi các tiến trình của người dùng khi chạy, tuy nhiên một số được dành riêng cho hệ điều hành.
Vì MIPS TLB được quản lý bằng phần mềm nên cần có hướng dẫn để cập
nhật TLB. MIPS sẽ cung cấp 4 hướng dẫn để quản lý TLB:
• TLBP: Kiểm tra TLP để xem liệu một bản dịch cụ thể có ở đó hay không?
• TLBR: Đọc nội dung một mục TLB vào các thanh ghi
• TLBWI: Thay thế một mục TLB cụ thể
• TLBWR: Thay thế một mục TLB ngẫu nhiên
Các lệnh này cần được đặc quyền chỉ có hệ điều hành mới được sử dụng
Nếu một quá trình người dùng có thể sửa đổi nội dung của TLB, nó có thể làm
gần như bất cứ điều gì, bao gồm cả chiếm quyền kiểm soát máy, chạy hệ điều
hành độc hại riêng của mình, hoặc thậm chí làm mất đi Mặt Trời. Điều này cho
thấy tầm quan trọng của việc quản lý TLB trong việc duy trì an toàn và ổn định
của hệ thống máy tính. Chương3 15 Tổng Kết
Như vậy chúng ta có thể thấy phần cứng có thể giúp dịch địa chỉ nhanh hơn
bằng cách cung cấp một TLB nhỏ chuyên dụng trên chip làm bộ nhớ đệm dịch
địa chỉ với hy vọng hầu hết cách tham chiếu bộ nhớ sẽ xử lý mà không cần truy
cập vào bảng trang trong bộ nhớ chính. Như vậy trong những trường hợp thông
thường hiệu suất của chương trình sẽ gần như không có bộ nhớ được ảo hóa hoàn toàn.
TLB thực sự đóng một vai trò quan trọng trong việc cải thiện hiệu quả truy
cập bộ nhớ trong hệ thống máy tính bằng cách lưu vào bộ nhớ đệm các bản dịch
địa chỉ ảo được truy cập thường xuyên sang địa chỉ vật lý. Tuy nhiên nếu số
lượng trang mà một chương trình truy cập trong một thời gian ngắn vượt quá
số lượng trang phù hợp với TLB chương trình sẽ tạo ra một số lượng lớn lỗi
TLB khiến chương trình chạy khá lâu.Hiện tượng này được gọi là vượt quá
phạm vi TLB, và có thể gây vấn đề cho một số ứng dụng.Một giải pháp để giảm
thiểu vấn đề này là hỗ trợ kích thước trang lớn hơn. Bằng cách ánh xạ các cấu
trúc dữ liệu quan trọng vào các vùng của không gian địa chỉ của chương trình
sử dụng các trang lớn hơn, phạm vi TLB hiệu quả có thể được tăng. Trang lớn
thường được sử dụng bởi các chương trình như hệ thống quản lý cơ sở dữ liệu
(DBMS), chúng xử lý các cấu trúc dữ liệu lớn và được truy cập ngẫu nhiên.
Một vấn đề TLB khác đáng được đề cập : Việc truy cập TLB trở thành hạn
chế trong đường dẫn CPU. Đặc biệt là với các bộ nhớ đệm được lập chỉ mục
vật lý trong việc dịch địa chỉ phải diễn ra trước khi truy cập bộ nhớ đệm điều
này làm chậm quá trình.Để giải quyết vấn đề này người ta đã khám phá các bộ
nhớ đệm được lập chỉ mục ảo,cho phép truy cập bộ nhớ đệm bằng địa chỉ ảo
tránh dịch trong khi truy cập bộ nhớ đệm. Tuy nhiên điều này đặt ra rất nhiều
thách thức mới về thiết kế phần cứng. 16
Tóm lại mặc dù TLB cải thiện hiệu quả truy cập bộ nhớ nhưng chúng cũng
đưa ra những thách thức nhất định đòi hỏi phải cân nhắc về thiết kế quản lý phần cứng. 17
Tài liệu liên quan:
-

Giới thiệu về bảo mật trong hệ điều hành | Bài tập lớn học phần Hệ điều hành | Trường Đại học Phenikaa
506 253 -

Quản lí tiến trình trong Windows | Báo cáo bài tập lớn học phần Hệ điều hành | Trường Đại học Phenikaa
637 319 -

Deadlock và xử lý deadlock trong Windows | Báo cáo bài tập lớn học phần Hệ điều hành | Trường Đại học Phenikaa
555 278 -

Quản lý bộ nhớ trong Linux | Bài tập lớn học phần Hệ điều hành | Trường Đại học Phenikaa
699 350 -

Bài thực hành số 2 học phần Hệ điều hành | Trường Đại học Phenikaa
326 163