Thuật Toán Kmeans và Phân Cụm Dữ Liệu | Báo cáo Lập trình tính toán
Trong bối cảnh hiện nay, dữ liệu lớn (Big Data) đang ngày càng trở nên phổ biến và đóng vai trò quan trọng trong việc ra quyết định trong nhiều lĩnh vực, từ marketing, tài chính, đến y tế và giáo dục. Tuy nhiên, dữ liệu thông thường chứa đựng sự phức tạp và khó hiểu, vì vậy việc phân tích và rút ra thông tin có giá trị từ dữ liệu là một thách thức lớn. Tài liệu giúp bạn tham khảo, ôn tập và đạt kết quả cao. Mời đọc đón xem!
Môn: Lập trình tính toán 1 tài liệu
Trường: Trường Đại học Sư phạm Kỹ thuật, Đại học Đà Nẵng 49 tài liệu
Tác giả:
















Preview text:
lOMoAR cPSD| 46342576
ĐẠI HỌC ĐÀ NẴNG
TRƯỜNG ĐẠI HỌC BÁCH KHOA
KHOA CÔNG NGHỆ THÔNG TIN
Tel. (+84.0236) 3736949, Fax. (84-511) 3842771
Website: http://dut.udn.vn/khoacntt, E-mail: cntt@dut.udn.vn BÁO CÁO MÔN HỌC
PBL1: LẬP TRÌNH TÍNH TOÁN ĐỀ TÀI :
THUẬT TOÁN K-MEANS VỚI BÀI TOÁN PHÂN CỤM DỮ LIỆU Họ tên sinh viên Mã sinh viên Nhóm HP Phạm Thị Ngọc Khuê 102240375 24T_Nhat2 Đậu Thùy Ngân 102240382 24T_Nhat2 Nguyễn Thị Nghĩa 102240383 24T_Nhat2
CBHD : Nguyễn Tấn Khôi
Đà nẵng, 05/06/2025 lOMoAR cPSD| 46342576 2 lOMoAR cPSD| 46342576 MỤC LỤC
CHƯƠNG 1: CƠ SỞ LÝ THUYẾT.........................................................................9 1.1.
GIỚI THIỆU THUẬT TOÁN K-MEANS....................................................9 1.2.
THUẬT TOÁN K-MEANS..........................................................................9 1.3.
MINH HỌA THUẬT TOÁN......................................................................10 1.4.
ỨNG DỤNG...............................................................................................16 1.5.
ƯU, NHƯỢC ĐIỂM CỦA THUẬT TOÁN...............................................17 1.6.
KẾT CHƯƠNG..........................................................................................18
CHƯƠNG 2: PHÂN TÍCH THIẾT KẾ HỆ THỐNG...........................................19 2.1.
PHÁT BIỂU BÀI TOÁN............................................................................19 2.2.
PHÂN TÍCH HIỆN TRẠNG......................................................................19 2.3.
PHÂN TÍCH THUẬT TOÁN.....................................................................19 2.3.1.
Nhập dữ liệu.....................................................................................19 2.3.2.
Thuật toán: Đọc dữ liệu từ file.........................................................20 2.3.3.
Thuật toán tính khoảng cách Euclid.................................................21 2.3.4.
Thuật toán chọn các tâm cụm ban đầu.............................................22 2.3.5.
Thuật toán K-means.........................................................................27 2.3.6.
Thuật toán tìm cụm gần nhất cho một điểm.....................................28 2.3.7.
Hàm sao chép các centroids cũ........................................................30 2.3.8.
Thuật toán cập nhật các tâm cụm.....................................................30 2.3.9.
Thuật toán kiểm tra hội tụ................................................................32 2.3.10.
In kết quả.........................................................................................34 2.4.
GIAO DIỆN VÀ CÔNG NGHỆ SỬ DỤNG..............................................36 2.4.1.
Giao diện..........................................................................................36 2.4.2.
Công nghệ sử dụng..........................................................................36 1 lOMoAR cPSD| 46342576 2.5. KẾT
CHƯƠNG..........................................................................................37 CHƯƠNG 3: TRIỂN KHAI VÀ ĐÁNH GIÁ KẾT
QUẢ.....................................38 3.1.
MÔ HÌNH TRIỂN KHAI...........................................................................38 3.1.1.
Môi trường triển khai.......................................................................38 3.1.2.
Các công cụ sử dụng........................................................................38 3.1.3.
Cấu hình hệ thống............................................................................38 3.2.
KẾT QUẢ THỰC NGHIỆM......................................................................38 3.2.1.
Kịch bản 1: Thu nghiem voi bo dlieu data01.txt..............................38 3.2.2.
Kịch bản 2: Thu nghiem voi bo dlieu data02.txt..............................50 3.3.
NHẬN XÉT ĐÁNH GIÁ KẾT QUẢ.........................................................56 3.4.
KẾT CHƯƠNG..........................................................................................57 2 lOMoAR cPSD| 46342576 DANH SÁCH HÌNH ẢNH
Hình 1. Khởi tạo 2 tâm cụm ban đầu.......................................................................11
Hình 2. Toạ độ tâm sau khi tính lại lần 1.................................................................13
Hình 3. Kết quả phân nhóm cuối cùng....................................................................15
Hình 4. Mẫu file data.txt..........................................................................................20
Hình 5. Mẫu file output.txt......................................................................................35
Hình 6. Dim 2..........................................................................................................36
Hình 7. Dim 3..........................................................................................................36
Hình 8. Kết quả phân cụm cuối cùng với bộ dữ liệu data01.txt...............................50
Hình 9. Đồ thị Elbow...............................................................................................52
Hình 10. Kết quả phân cụm cuối cùng với bộ dữ liệu data02.txt.............................55
BẢNG PHÂN CÔNG CÔNG VIỆC TT Công việc Người thực hiện 1
Tìm hiểu ưu điểm, ứng dụng, phân Phạm Thị Ngọc Khuê
tích thuật toán, viết thuật toán, thử
nghiệm kịch bản, đánh giá kết quả, làm bài trình chiếu 3 lOMoAR cPSD| 46342576 2
Tìm hiểu minh họa thuật toán, Đậu Thùy Ngân
nhược điểm, phân tích thuật toán,
tìm hiểu giao diện, viết thuật toán,
tìm hiểu phương pháp Elbow, làm bài trình chiếu 3
Tìm hiểu thông tin, khái niệm, phân Nguyễn Thị Nghĩa
tích hiện trạng, phát biểu bài toán,
viết thuật toán, thử nghiệm kịch bản, làm bài trình chiếu Ghi chú: •
Tất cả các thành viên đều tham gia trao đổi, góp ý nội dung và hỗ trợ lẫn nhau
trong quá trình thực hiện. •
Công việc có thể linh động điều chỉnh tùy vào tiến độ và năng lực từng thành viên. 4 lOMoAR cPSD| 46342576 MỞ ĐẦU
1. Tổng quan về đề tài
1.1. Tổng quan về đề tài
Trong bối cảnh hiện nay, dữ liệu lớn (Big Data) đang ngày càng trở nên phổ
biến và đóng vai trò quan trọng trong việc ra quyết định trong nhiều lĩnh vực, từ
marketing, tài chính, đến y tế và giáo dục. Tuy nhiên, dữ liệu thông thường chứa đựng
sự phức tạp và khó hiểu, vì vậy việc phân tích và rút ra thông tin có giá trị từ dữ liệu
là một thách thức lớn.
Một trong những phương pháp mạnh mẽ giúp giải quyết vấn đề này là phân cụm
dữ liệu (Clustering), trong đó thuật toán K-means là một trong những kỹ thuật phân
cụm phổ biến nhất. K-means giúp phân nhóm các đối tượng có đặc điểm tương tự
vào cùng một cụm, từ đó tạo ra những hiểu biết sâu sắc hơn về dữ liệu.
Thuật toán K-means được ứng dụng rộng rãi trong nhiều lĩnh vực, chẳng hạn
như phân tích khách hàng trong marketing, nhận dạng mẫu trong hình ảnh, phân tích
hành vi người dùng, và nhiều ứng dụng khác. Bằng cách phân nhóm dữ liệu thành
các cụm có đặc điểm giống nhau, thuật toán này giúp giảm bớt độ phức tạp và giúp
đưa ra các chiến lược hiệu quả hơn.
1.2. Tính cấp thiết của đề tài
Với sự phát triển nhanh chóng của công nghệ thông tin và việc thu thập dữ liệu
ngày càng gia tăng, việc phân tích và xử lý lượng lớn dữ liệu trở thành một vấn đề
cấp thiết. Các tổ chức, doanh nghiệp và nghiên cứu học thuật đang phải đối mặt với
các thách thức trong việc tìm ra cách phân nhóm, phân loại và khai thác thông tin từ
dữ liệu không có nhãn (unlabeled data). Trong bối cảnh đó, thuật toán Kmeans cung
cấp một giải pháp hiệu quả và dễ triển khai, giúp phân cụm dữ liệu một cách tự động và nhanh chóng.
Bên cạnh đó, việc chọn số lượng cụm k hợp lý trong thuật toán K-means vẫn
là một bài toán quan trọng và phức tạp. Việc lựa chọn không chính xác giá trị k có 5 lOMoAR cPSD| 46342576
thể dẫn đến kết quả phân cụm không chính xác, ảnh hưởng trực tiếp đến hiệu quả của
các ứng dụng thực tế. Do đó, nghiên cứu và cải tiến các phương pháp xác định k phù
hợp là cần thiết để tối ưu hóa kết quả phân cụm.
1.3. Các vấn đề quan trọng cần giải quyết
Trong quá trình nghiên cứu và triển khai thuật toán K-means, có một số vấn đề
quan trọng cần giải quyết, bao gồm:
Lựa chọn số lượng cụm k: Việc xác định số lượng cụm k hợp lý là một thách
thức lớn. Nếu k được chọn quá nhỏ, các nhóm sẽ không thể hiện đúng đặc điểm của
dữ liệu; ngược lại, nếu k quá lớn, dữ liệu có thể bị chia nhỏ một cách không hợp lý.
Các phương pháp như elbow method hay silhouette analysis có thể được sử dụng để
xác định giá trị k tối ưu, nhưng vẫn cần nghiên cứu thêm để cải thiện độ chính xác.
Xử lý dữ liệu ngoại lai (Outliers): K-means có thể bị ảnh hưởng mạnh bởi các
điểm ngoại lai, làm cho các centroid bị dịch chuyển và dẫn đến kết quả phân cụm
không chính xác. Do đó, việc phát hiện và xử lý các dữ liệu ngoại lai là một yếu tố
quan trọng trong việc cải thiện hiệu suất của thuật toán.
Áp dụng K-means trong các bộ dữ liệu phức tạp: K-means thường giả định
rằng các cụm có hình dạng cầu và phân bố đồng đều. Tuy nhiên, trong nhiều trường
hợp, các cụm có thể có hình dạng phức tạp hơn, và thuật toán K-means không luôn
hoạt động hiệu quả trong những trường hợp này. Các thuật toán phân cụm khác như
DBSCAN hoặc hierarchical clustering có thể được nghiên cứu để khắc phục vấn đề này.
Hiệu suất tính toán trên dữ liệu lớn: Khi bộ dữ liệu trở nên rất lớn, thuật toán
K-means có thể gặp khó khăn trong việc xử lý hiệu quả. Nghiên cứu và phát triển các
phương pháp tối ưu hóa thuật toán, chẳng hạn như tối ưu hóa bằng GPU hoặc sử dụng
parallel computing, là một hướng nghiên cứu quan trọng.
2. Mục đích và ý nghĩa của đề tài 2.1. Mục đích 6 lOMoAR cPSD| 46342576
Thuật toán K-means là một trong những thuật toán phân cụm phổ biến trong
học máy, với mục đích chính là phân chia một tập hợp các đối tượng dữ liệu thành
các nhóm (cụm) sao cho các đối tượng trong cùng một cụm có đặc điểm tương tự
nhau, trong khi các đối tượng từ các cụm khác biệt càng nhiều càng tốt. Các mục đích
chính của K-means bao gồm:
Phân nhóm dữ liệu: K-means giúp phân nhóm các điểm dữ liệu có đặc tính
tương tự nhau, giúp nhận diện và phân tích các nhóm trong một bộ dữ liệu lớn, ví dụ
như phân loại khách hàng dựa trên hành vi mua sắm, phân nhóm các văn bản theo
chủ đề, hay phân tích hình ảnh.
Giảm độ phức tạp của dữ liệu: Thông qua việc phân cụm, K-means giúp giảm
bớt sự phức tạp trong việc xử lý và phân tích dữ liệu. Việc làm việc với các nhóm dữ
liệu nhỏ và đồng nhất sẽ dễ dàng hơn thay vì làm việc với một tập hợp dữ liệu quá lớn và phức tạp.
Tìm kiếm cấu trúc trong dữ liệu: Thuật toán K-means cho phép tìm ra các
mẫu và cấu trúc trong dữ liệu mà trước đó có thể không dễ dàng nhận ra, đặc biệt
trong các bộ dữ liệu không có nhãn. 2.2. Ý nghĩa
Ứng dụng trong phân tích dữ liệu: K-means là công cụ mạnh mẽ giúp các nhà
phân tích dữ liệu chia bộ dữ liệu thành các nhóm có ý nghĩa, giúp dễ dàng hơn trong
việc nghiên cứu và hiểu về đặc điểm của dữ liệu. Ví dụ, trong marketing, Kmeans có
thể được sử dụng để phân nhóm khách hàng theo hành vi mua sắm, giúp các doanh
nghiệp xây dựng chiến lược marketing hiệu quả hơn.
Tiết kiệm chi phí và tài nguyên: Trong các bài toán phân tích dữ liệu lớn, việc
sử dụng K-means giúp giảm bớt chi phí tính toán và tài nguyên so với việc phân tích
từng điểm dữ liệu một cách riêng biệt. Các cụm dữ liệu giúp cô đọng thông tin, cho
phép phân tích và đưa ra quyết định nhanh chóng hơn.
Dễ dàng triển khai và hiệu quả: K-means là thuật toán dễ hiểu và dễ triển
khai. Dù đơn giản, nhưng nó lại có thể mang lại kết quả tốt trong nhiều ứng dụng thực 7 lOMoAR cPSD| 46342576
tế, đặc biệt khi các dữ liệu có thể được chia thành các nhóm rõ ràng. Thuật toán này
rất thích hợp trong các tình huống mà bạn không có dữ liệu nhãn (unlabeled data).
Cải thiện khả năng phân loại và nhận diện: Một trong những ứng dụng nổi
bật của K-means là phân loại dữ liệu và nhận diện mẫu, đặc biệt trong các lĩnh vực
như nhận dạng hình ảnh, nhận dạng chữ viết tay, phân tích văn bản và nhiều ứng dụng khác trong học máy.
Khả năng mở rộng: K-means có thể xử lý tốt các bộ dữ liệu lớn với hiệu suất
tốt. Khi số lượng dữ liệu tăng lên, thuật toán vẫn duy trì được hiệu quả và có thể dễ
dàng được triển khai trong các hệ thống lớn.
3. Phương pháp thực hiện
Nghiên cứu tài liệu lý thuyết về thuật toán K-means và phân cụm dữ liệu.
Triển khai thuật toán K-means bằng ngôn ngữ lập trình C.
Thực nghiệm trên các bộ dữ liệu khác nhau để đánh giá hiệu quả của thuật toán.
Phân tích kết quả và đề xuất các hướng phát triển.
4. Bố cục của báo cáo
Báo cáo bao gồm các chương chính sau:
Mở đầu: Giới thiệu về đề tài, mục đích, ý nghĩa, phương pháp thực hiện, và bố cục của báo cáo
Chương 1: Cơ sở lý thuyết
Chương 2: Phân tích thiết kế hệ thống Chương
3: Triển khai và đánh giá kết quả
Kết luận và hướng phát triển. 8 lOMoAR cPSD| 46342576
CHƯƠNG 1: CƠ SỞ LÝ THUYẾT
1.1. GIỚI THIỆU THUẬT TOÁN K-MEANS
Thuật toán phân nhóm K-means do MacQueen giới thiệu trong tài liệu “J.
Some Methods for Classification and Analysis of Multivariate Observations” năm
1967. K-Means là thuật toán rất quan trọng và được sử dụng phổ biến trong kỹ thuật phân nhóm.
K-means là một thuật toán phân nhóm (clustering) trong học máy và khai phá
dữ liệu, thuật toán này được dùng để phân các điểm dữ liệu cho trước vào các nhóm
(clusters) dựa trên tính tương đồng của chúng. Đây là thuật toán rất phổ biến trong
các bài toán phân tích dữ liệu và học máy không giám sát (unsupervised learning).
Tư tưởng chính của thuật toán K-Means là tìm kiếm cách phân nhóm các đối
tượng (objects) đã cho vào K cụm (K là số các cụm được xác đinh trước, K nguyên
dương) sao cho tổng bình phương khoảng cách giữa các đối tượng đến tâm nhóm (centroid) là nhỏ nhất.
1.2. THUẬT TOÁN K-MEANS
Đầu vào (Input): Cơ sở dữ liệu D gồm n đối tượng và k là số nhóm cần phân chia.
Đầu ra (Output): Các nhóm Ci (i=1... k) sao cho hàm tiêu chuẩn E đạt giá trị tối thiểu.
Các bước của thuật toán:
Bước 1: Khởi tạo
Chọn ngẫu nhiên k tâm(centroid) cho k nhóm(cluster). Mỗi nhóm được đại diện bằng tâm của nhóm.
Bước 2: Đối với mỗi đối tượng ai (1 ≤ i ≤ n), tính khoảng cách từ ai tới mỗi trọng
tâm cj (j=1...k) (thường dùng khoảng cách Euclidean). Bước 3: Nhóm các đối
tượng vào nhóm có trọng tâm gần nhất.
Bước 4: Xác định lại tâm mới cho các nhóm bằng cách tính trung bình cộng các thuộc
tính của các đối tượng trong nhóm. 9 lOMoAR cPSD| 46342576
Bước 5: Thực hiện lại bước 2 cho đến khi không còn sự thay đổi nào của các nhóm đối tượng.
1.3. MINH HỌA THUẬT TOÁN
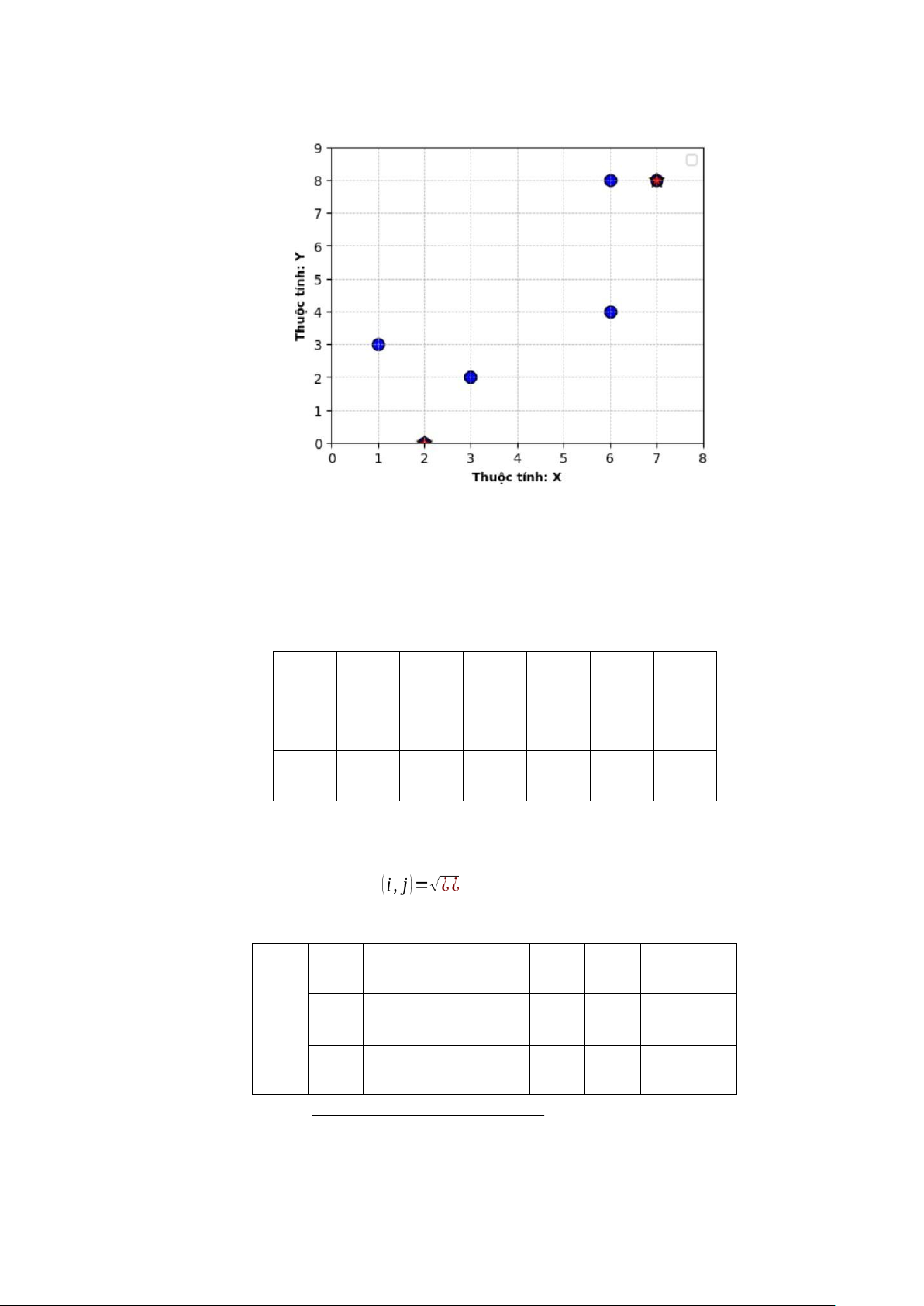
Giả sử có 6 đối tượng A, B, C, D, E, F được biểu diễn bởi 2 đặc tính X và Y.
Bảng 1.1 Thông tin đối tượng cần phân nhóm Đối tượng Đặc tính X Đặc tính Y A 1 3 B 2 0 C 6 8 D 3 2 E 7 8 F 6 4
Mục đích là phân chia các đối tượng thành 2 nhóm dựa vào các đặc tính của chúng.
Đầu vào là tập dữ liệu D có n=6 đối tượng cần phân chia thành k=2 nhóm.
Bước 1: Khởi tạo tâm cho 2 nhóm.
Giả sử chọn B là tâm của nhóm thứ nhất, vậy tọa độ tâm nhóm thứ nhất là c1(2,0) và
E là tâm của nhóm thứ hai thì toạ độ tâm nhóm thứ hai là thứ hai c2 (7,8). 10 lOMoAR cPSD| 46342576
Hình 1. Khởi tạo 2 tâm cụm ban đầu
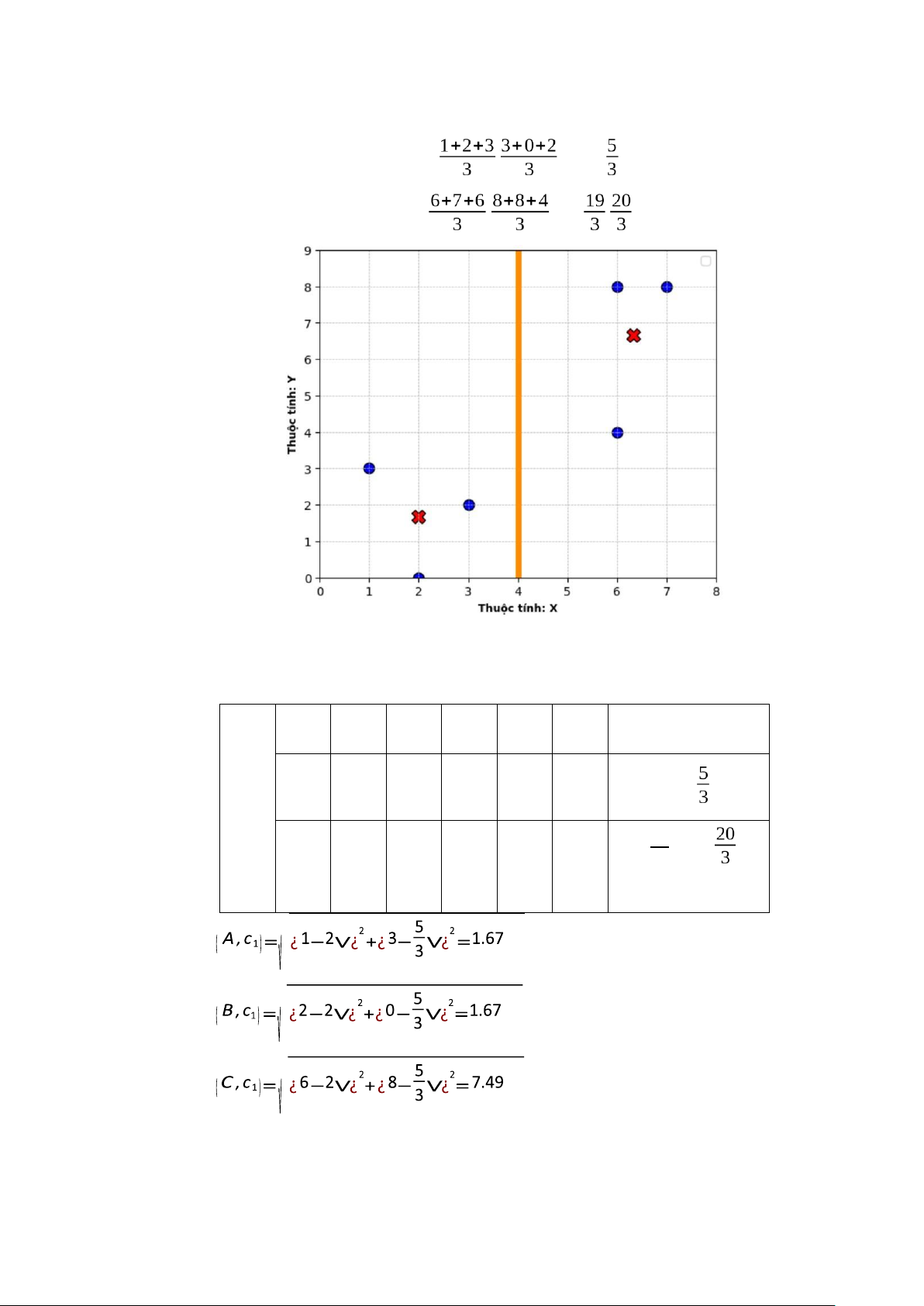
Bước 2: Tính toán khoảng cách từ các đối tượng đến tâm các nhóm (khoảng cách Euclidean).
Từ bảng 1.1 có ma trận dữ liệu: A B C D E F X 1 2 6 3 7 6 Y 3 0 8 2 8 4
Áp dụng công thức tính khoảng cách Euclidean với các đối tượng có 2 thuộc tính từ
đối tượng ai (i=1...6) đến phần tử trung tâm cj (j=1,2). d
Kết quả tính khoảng cách lần thứ nhất: D1 A B C D E F 3.16 0 8.94 2.24 9.43 5.66 c1 (2,0) 7.81 9.43 1 7.21 0 5 c2 (7,8)
d ( A,c1)=√¿1−2∨¿2+¿3−0∨¿2=3.16¿¿ 11 lOMoAR cPSD| 46342576
d (B,c1)=√¿2−2∨¿2+¿0−0∨¿2=0¿¿
d (C,c1)=√¿6−2∨¿2+¿8−0∨¿2=8.94¿¿
d (D,c1)=√¿3−2∨¿2+¿2−0∨¿2=2.24¿¿
d (E,c1)=√¿7−2∨¿2+¿8−0∨¿2=9.43¿¿
d (F,c1)=√¿6−2∨¿2+¿4−0∨¿2=5.66¿¿
d ( A,c2)=√¿1−7∨¿2+¿3−8∨¿2=7.81¿¿
d (B,c2)=√¿2−7∨¿2+¿0−8∨¿2=9.43¿¿
d (C,c2)=√¿6−7∨¿2+¿8−8∨¿2=1¿¿
d (D,c2)=√¿3−7∨¿2+¿2−8∨¿2=7.21¿¿
d (E,c2)=√¿7−7∨¿2+¿8−8∨¿2=0¿¿
d (F,c2)=√¿6−2∨¿2+¿4−1∨¿2=5¿¿
Bước 3: Nhóm các đối tượng vào nhóm gần nhất G1 A B C D E F 1 1 0 1 0 0 c1 (2,0) 0 0 1 0 1 1 c2 (7,8)
Sau vòng lặp thứ nhất, nhóm 1 có 3 đối tượng là A, B, D; nhóm 2 có 3 đối tượng là C, E, F.
Bước 4: Tính lại tọa độ tâm lần 1 cho các nhóm mới dựa vào tọa độ của các đối tượng trong nhóm. 12 lOMoAR cPSD| 46342576 c1=( ; )=(2; ) c =( 2 ; )=( ; )
Hình 2. Toạ độ tâm sau khi tính lại lần 1
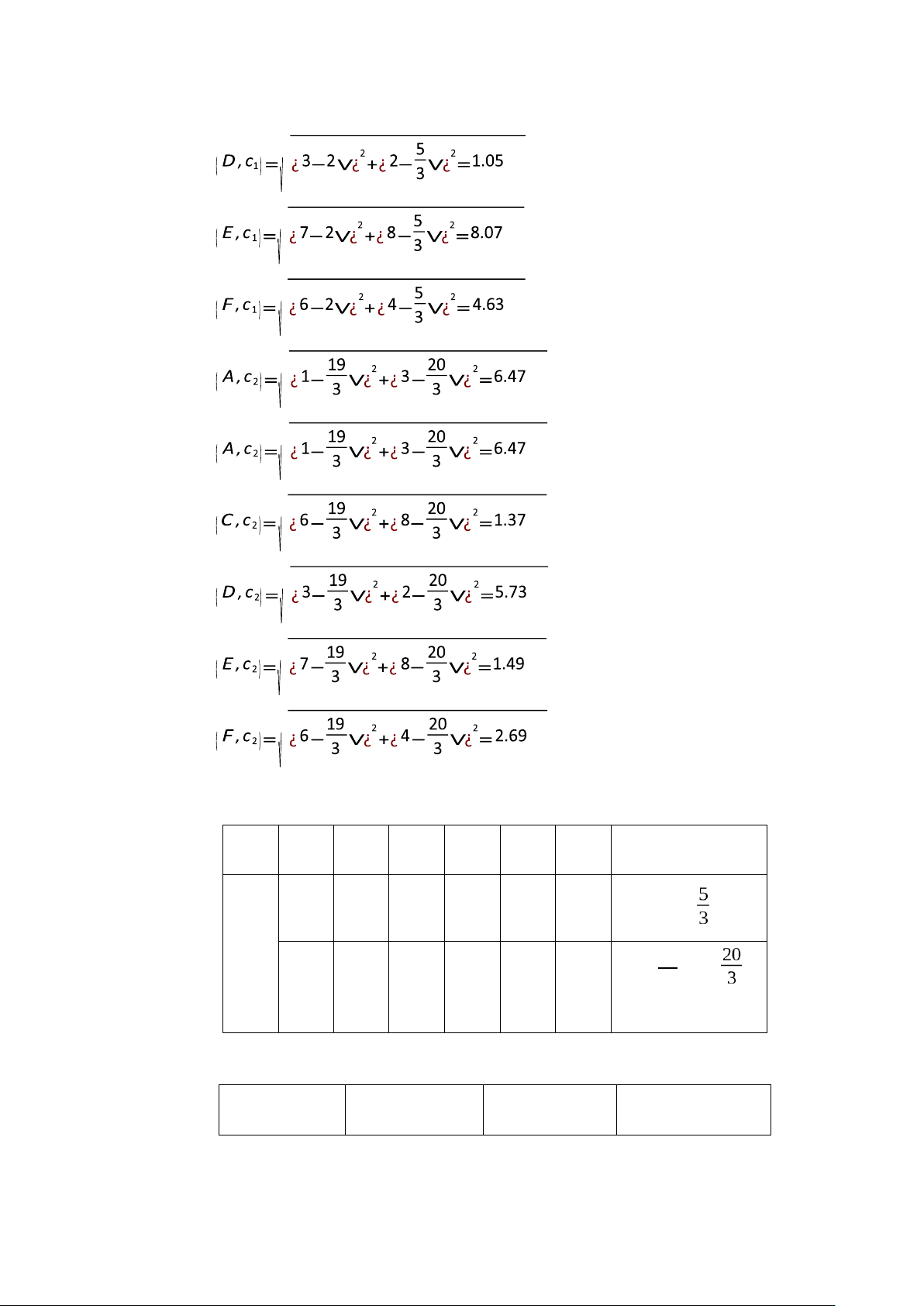
Bước 5: Tính lại khoảng cách từ các đối tượng đến tâm mới D2 A B C D E F 1.67 1.67 7.49 1.05 8.07 4.63 c ( 1 2; ) 6.47 6.47 1.37 5.73 1.49 2.69 19 c ( 2 3 ;) d ¿¿ d ¿¿ d ¿¿ 13 lOMoAR cPSD| 46342576 d ¿¿ d ¿¿ d ¿¿ d ¿¿ d ¿¿ d ¿¿ d ¿¿ d ¿¿ d ¿¿
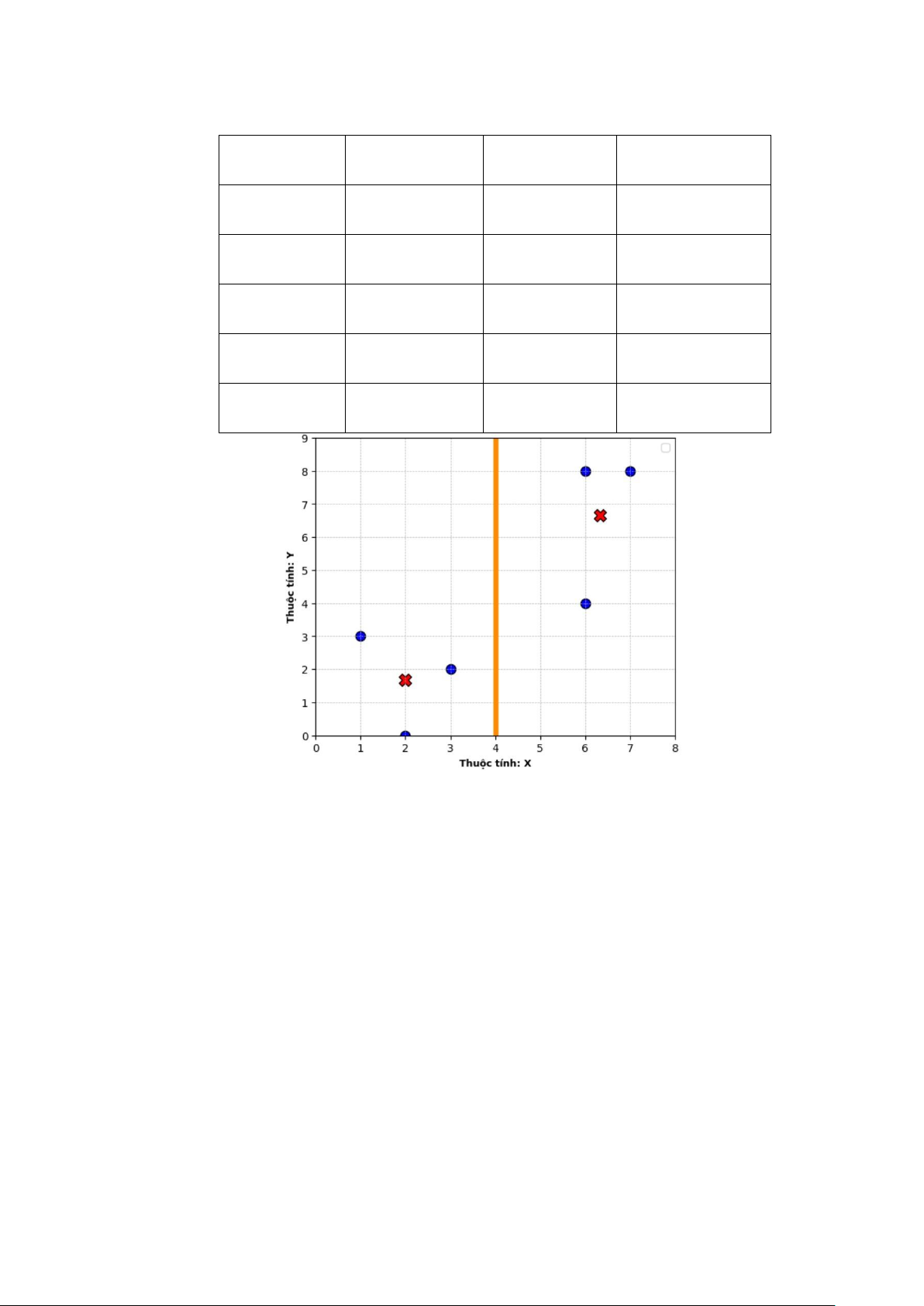
Bước 6: Nhóm các đối tượng vào nhóm gần nhất A B C D E F G2 1 1 0 1 0 0 c ( 1 2; ) 0 0 1 0 1 1 19 c ( 2 3 ;)
Kết quả nhóm các đối tượng G1 = G2 (không có sự thay đổi nhóm nào của các đối
tượng) nên thuật toán dừng và kết quả phân nhóm như sau: Đối tượng Thuộc tính X Thuộc tính Y Nhóm 14 lOMoAR cPSD| 46342576 A 1 3 1 B 2 0 1 C 6 8 0 D 3 2 1 E 7 8 0 F 6 4 0
Hình 3. Kết quả phân nhóm cuối cùng 1.4. ỨNG DỤNG
K-means là một công cụ mạnh mẽ và linh hoạt, Các lĩnh vực nghiên cứu bao
gồm khai thác dữ liệu, thống kê, học máy, công nghệ cơ sở dữ liệu không gian và
nhiều lĩnh vực ứng dụng khác như:
Phân cụm tài liệu:
Được sử dụng để phân cụm các văn bản, bài viết, và tài liệu dựa trên nội dung
của chúng. Điều này giúp trong việc tổ chức, tìm kiếm thông tin và phân loại tài liệu. Nhận dạng mẫu: 15 lOMoAR cPSD| 46342576
Được sử dụng để phân loại và nhận dạng các đối tượng trong hình ảnh, chẳng
hạn như nhận dạng khuôn mặt, phân loại các loại hoa, hay phân cụm các điểm ảnh trong một bức ảnh.
Nén dữ liệu (Data Compression):
Được sử dụng để giảm kích thước dữ liệu bằng cách nhóm các điểm dữ liệu gần
nhau lại và thay thế chúng bằng trung tâm nhóm.
Phát hiện bất thường (Anomaly Detection):
Được sử dụng để phát hiện những điểm dữ liệu bất thường bằng cách xác định
những điểm không thuộc về bất kỳ nhóm nào hoặc nằm ngoài phạm vi của các nhóm đã xác định.
Hệ thống đề xuất:
Phân nhóm người dùng hoặc sản phẩm trong hệ thống gợi ý, từ đó cung cấp các
đề xuất cá nhân hóa cho người dùng dựa trên sở thích và hành vi của các nhóm tương tự.
Nhóm các đối tượng trong dữ liệu không gian :
Sử dụng trong các ứng dụng địa lý, như phân nhóm các địa điểm, ví dụ phân
nhóm các điểm bán hàng để tối ưu hóa việc phân phối hàng hóa.
Điện toán đám mây:
Sử dụng để tối ưu hóa việc phân bố tài nguyên trong các hệ thống điện toán đám
mây, từ đó cải thiện hiệu suất và giảm chi phí.
Phân tích hành vi người dùng:
Trong lĩnh vực công nghệ thông tin, sử dụng để phân tích hành vi người dùng
trên các trang web, ứng dụng di động
Phân tích sinh học:
Phân tích dữ liệu gene, protein và các dữ liệu sinh học khác, từ đó giúp trong
nghiên cứu và phát triển các phương pháp điều trị mới. 16 lOMoAR cPSD| 46342576
Phân nhóm khách hàng:
Được sử dụng trong marketing để phân nhóm khách hàng dựa trên các đặc điểm
như độ tuổi, thu nhập, hành vi mua sắm, v.v.
Quản lý chuỗi cung ứng:
Trong lĩnh vực logistics, K-means có thể được sử dụng để tối ưu hóa vị trí của
các kho hàng và điểm phân phối dựa trên dữ liệu nhu cầu và địa lý.
Phân tích thị trường tài chính:
K-means có thể được sử dụng để phân loại các cổ phiếu, quỹ đầu tư hoặc các
tài sản tài chính khác dựa trên các chỉ số tài chính và biến động thị trường. Y học:
Phân tích dữ liệu bệnh nhân và phân loại các loại bệnh dựa trên triệu chứng và kết quả xét nghiệm.
=> Nhờ vào sự đơn giản và hiệu quả, K-means đã trở thành một công cụ rất hữu
ích trong nhiều lĩnh vực khác nhau của học máy và phân tích dữ liệu.
1.5. ƯU, NHƯỢC ĐIỂM CỦA THUẬT TOÁN Ưu điểm:
- Đơn giản, dễ triển khai. - Hiệu quả thực tế. - Hội tụ nhanh.
- Linh hoạt với các độ đo khoảng cách khác nhau. Nhược điểm:
- Cần lựa chọn k trước.
- Nhạy cảm với các điểm ngoại lai.
- Không áp dụng cho dữ liệu lớn.
- Không phù hợp với cụm có hình dạng không cầu. 1.6. KẾT CHƯƠNG 17 lOMoAR cPSD| 46342576
Chương này trình bày các cơ sở lý thuyết nền tảng liên quan trực tiếp đến nội
dung nghiên cứu của đồ án. Các khái niệm và nguyên lý được đề cập sẽ đóng vai trò
làm nền tảng cho quá trình phân tích và triển khai hệ thống trong các chương tiếp
theo. Phần phát biểu bài toán sẽ nêu rõ nội dung nghiên cứu, xác định các vấn đề cần
giải quyết, đồng thời tổng hợp, phân tích và đánh giá các giải pháp đã được đề xuất
hoặc áp dụng trong các nghiên cứu trước đó. 18