Tìm hiểu về Hadoop Distributed File System (HDFS) - Báo cáo dự án. Môn Giới thiệu về Công nghệ thông tin | Trường Đại học Công nghệ, Đại học Quốc gia Hà Nội.
Tìm hiểu về Hadoop Distributed File System (HDFS) - Báo cáo dự án. Môn Giới thiệu về Công nghệ thông tin | Trường Đại học Công nghệ, Đại học Quốc gia Hà Nội.
Tài liệu gồm 23 trang giúp bạn tham khảo, củng cố kiến thức và ôn tập đạt kết quả cao trong kỳ thi sắp tới. Mời bạn đọc đón xem!
Môn: Giới thiệu về Công nghệ thông tin 5 tài liệu
Trường: Trường Đại học Công nghệ, Đại học Quốc gia Hà Nội 823 tài liệu
Tác giả:








Preview text:
lOMoAR cPSD| 59735516
ĐẠIHỌCQUỐCGIAHÀNỘI
TRƯỜNGĐẠIHỌCCÔNGNGHỆ
---------------------------------------- Báocáodựán
Đề tài: Tìm hiểu về Hadoop Distributed File System (HDFS) Thành viên Phạm Đức Dũng 21020613 Phạm Hoàng Dũng 21020614 1 lOMoAR cPSD| 59735516 Mục lục
Mục lục....................................................................................................................................................2
Chương 1: Mở đầu.................................................................................................................................3 I. Giới
thiệu........................................................................................................................................3
II. Big Data........................................................................................................................................ 3
III. Apache Hadoop........................................................................................................................... 5
Chương 2: HDFS..................................................................................................................................10 I)
Cách NameNode quản lý siêu dữ
liệu..........................................................................................10
II) Sập DataNode và cơ chế sao
chép..............................................................................................11 III) Rack Awareness trong
HDFS....................................................................................................12
IV) Cơ chế kiểm tra Checksum....................................................................................................... 13 V) Kiến trúc
HDFS..........................................................................................................................14 VI) Cơ chế đọc của
HDFS...............................................................................................................15
VII) Cơ chế viết của HDFS............................................................................................................. 16
VIII) Advantages:............................................................................................................................17
Chương 3: So sánh với các nền tảng tương tự...................................................................................18 I) HDFS và Google
Bigquery..........................................................................................................18
II) HDFS và Ceph............................................................................................................................19
Demo HDFS..........................................................................................................................................21 I) Cài đặt
Hadoop............................................................................................................................ 21 2 lOMoAR cPSD| 59735516 II)
Các thao tác với cơ sở dữ
liệu.................................................................................................... 27 Tài liệu tham
khảo............................................................................................................................... 28 Chương 1: Mở đầu I. Giới thiệu
Ngày này việc các cơ sở dữ liệu ngày càng khổng lồ kéo theo đó là việc lưu trữ, thao tác và tính toán
dựa trên lượng dữ liệu đó cũng phải phát triển theo để có thể thích ứng. Việc xử lý những dữ liệu này
không chỉ còn là việc đọc và đưa ra kết quả đơn thuần mà còn yêu cầu hiệu quả và nhanh chóng, nhận
thấy nhu cầu đó, các công ty, tập đoàn lớn đã cung nhiều nhiều công cụ để thao tác với “Dữ liệu lớn”
(Big Data) có thể kể đến như Amazon EMR (Elastic MapReduce) của Amazon, IBM InfoSphere
BigInsights của IBM, Google Cloud Dataflow của Google,... Trong giới hạn bài báo cáo này thì
chúng ta sẽ chỉ tìm hiểu về Apache Hadoop. II. Big Data
Ngày nay, dữ liệu được sản sinh ngày càng nhiều và phức tạp, các nhà nghiên cứu ước tính
có tới 328,77 triệu terabytes dữ liệu được tạo ra mỗi ngày và con số trên đang không ngừng
tăng. Dữ liệu đến từ mọi nơi như điện thoại, máy tính và các loại thiết bị IoT, dưới mọi kiểu
hình thức từ văn bản, âm thanh tới hình ảnh. Tập dữ liệu khổng lồ và phức tạp trên thường
được biết đến với tên gọi là “Big data”. Đó là khái niệm thu thập những hiểu biết hữu ích từ
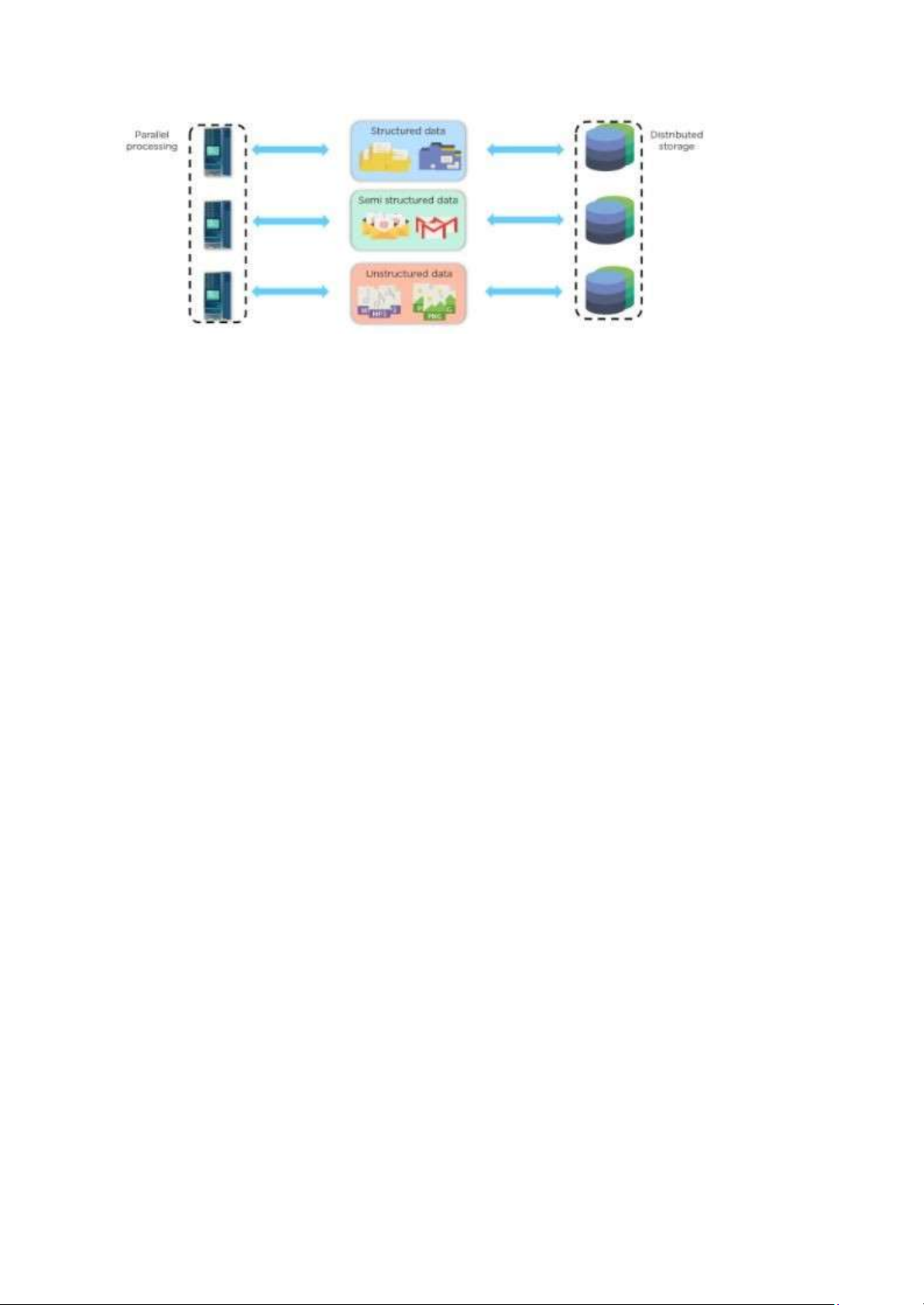
lượng lớn dữ liệu có cấu trúc, bán cấu trúc và phi cấu trúc có thể được sử dụng để ra quyết
định hiệu quả trong môi trường kinh doanh. Big data là dữ liệu có 3 đặc trưng quan trọng sau:
● Độ đa dạng: các kiểu dữ liệu khác nhau, thường là phi cấu trúc.
● Dung lượng tăng dần: trong big data, ta cần phải xử lý lượng lớn dữ liệu phân tán và phi cấu trúc.
● Tốc độ ngày càng cao: tốc độ ở đây là tốc độ dữ liệu tới hệ thống và tốc độ nó cần được xử lý tại đó.
Ngoài ra còn có 2 đặc trưng khác mới được quan tâm tới gần đây là:
● Giá trị: dữ liệu luôn có giá trị nhưng cách tận dụng giá trị đó có thể khác nhau. ●
Tính xác thực: độ tin cậy của dữ liệu.
Do các đặc trưng nói trên mà dữ liệu rất khó quản lý bằng các công cụ cơ sở dữ liệu truyền
thống. Trọng tâm của các kỹ thuật Big Data là lưu trữ và sử dụng dữ liệu một cách hiệu quả.
Một số ứng dụng của Big Data có thể kể tới bao gồm:
● Phát triển sản phẩm theo nhu cầu, thị yếu của người dùng bằng cách sử dụng dữ liệu
trong quá khứ về các mối quan tâm, thói quen của người dùng.
● Bảo trì hệ thống thiết bị bằng cách dự đoán các sự cố cơ khí bằng cách sử dụng dữ
liệu nhật kí của thiết bị, dữ liệu cảm biến, thông điệp báo lỗi hay nhiệt độ thiết bị. 3 lOMoAR cPSD| 59735516
● Học máy hiện giờ đang là một công nghệ đang phát triển vô cùng mạnh mẽ và big
data chính là nền tảng cho sự phát triển đó.
Mặc dù Big Data có rất nhiều tiềm năng, thử thách cũng đi cùng với chúng. Big Data là vô
cùng lớn, mặc dù các kỹ thuật công nghệ mới đang được phát triển liên tục, lượng thông tin
được ước tính tăng gấp đôi mỗi hai năm do vậy các tổ chức gặp khá nhiều khó khăn để bắt
kịp với nó. Việc lưu trữ dữ liệu cũng phải mang tính chọn lọc dựa theo mức độ hữu dụng của
dữ liệu đó với người dùng. Để giải quyết những vấn đề nói trên, một trong những giải pháp
phổ biến là sử dụng công nghệ Apache Hadoop. III. Apache Hadoop A. Giải pháp của Hadoop:
Hadoop là một framework sử dụng kỹ thuật lưu trữ phân tán và xử lý song song để lưu trữ và
quản lý dữ liệu lớn. Nó là phần mềm được sử dụng nhiều nhất bởi các nhà phân tích dữ liệu
để xử lý dữ liệu lớn, và kích thước thị trường của nó vẫn tiếp tục tăng trưởng. Hadoop bao
gồm ba thành phần chính: Hadoop Distributed File System (HDFS) là đơn vị lưu trữ,
Hadoop MapReduce là đơn vị xử lý và Hadoop YARN là đơn vị xử lý tài nguyên.
Vậy lưu trữ phân tán và xử lý song song là như thế nào? Trước đây khi dữ liệu còn hạn chế
việc lưu trữ và xử lý dữ liệu được thực hiện bởi một đơn vị xử lý dữ liệu và một bộ lưu trữ
duy nhất, trong khi đó với lượng dữ liệu lớn và đa dạng như hiện nay thì chỉ một đơn vị xử lý
dữ liệu là không đủ, cần đến nhiều bộ xử lý chạy song song với các đơn vị lưu trữ được phân chia cho từng bộ. 4 lOMoAR cPSD| 59735516 B. Lý do sử dụng Hadoop:
Hadoop là một công nghệ hữu ích cho các nhà phân tích dữ liệu. Một vài tính năng quan
trọng trong Hadoop khiến nó được trọng dụng có thể kể đến như:
- Hệ thống có khả năng lưu trữ và xử lý lượng dữ liệu khổng lồ với tốc độ rất nhanh.
Một tập dữ liệu bán cấu trúc, cấu trúc và không cấu trúc có thể khác nhau tùy thuộc
vào cách dữ liệu được cấu trúc.
- Hadoop hỗ trợ phân tích thời gian thực và tải công việc lịch sử, tăng cường quá trình
ra quyết định vận hành và phân tích thời gian thực.
- Dữ liệu có thể được lưu trữ bởi các tổ chức và có thể được lọc cho các mục đích phân tích cụ thể khi cần.
- Một số lượng lớn các nút có thể được thêm vào Hadoop vì nó có tính mở rộng, do đó
các tổ chức có thể thu thập nhiều dữ liệu hơn.
- Cơ chế bảo vệ ngăn các ứng dụng và quá trình xử lý dữ liệu bị ảnh hưởng bởi sự cố
phần cứng. Các nút bị ngừng hoạt động sẽ được tự động chuyển hướng đến các nút
khác, cho phép các ứng dụng hoạt động mà không bị gián đoạn. C. Các thành phần chính của Hadoop: a. Hadoop HDFS:
Dữ liệu được lưu trữ theo cách phân tán trong HDFS. Có hai thành phần của HDFS - name
node và data node. Trong đó name node là duy nhất còn data nodes thì có nhiều. HDFS được
thiết kế đặc biệt để lưu trữ bộ dữ liệu khổng lồ trong phần cứng thương mại. Phiên bản doanh
nghiệp của máy chủ có giá khoảng 10.000 USD mỗi terabyte cho toàn bộ bộ xử lý. Trong
trường hợp bạn cần mua 100 máy chủ phiên bản doanh nghiệp này, số tiền sẽ lên tới một triệu đô la.
Hadoop cho phép bạn sử dụng các máy thương mại làm nút dữ liệu của mình. Bằng cách này,
bạn không cần phải chi hàng triệu đô la chỉ cho các nút dữ liệu của mình. Tuy nhiên, name
node luôn là máy chủ doanh nghiệp. Đặc điểm của HDFS:
● Cung cấp lưu trữ phân tán
● Có thể được thực hiện trên phần cứng hàng hóa
● Cung cấp bảo mật dữ liệu
● Khả năng chịu lỗi cao - Nếu một máy bị hỏng, dữ liệu từ máy đó sẽ được chuyển sang máy tiếp theo 5 lOMoAR cPSD| 59735516
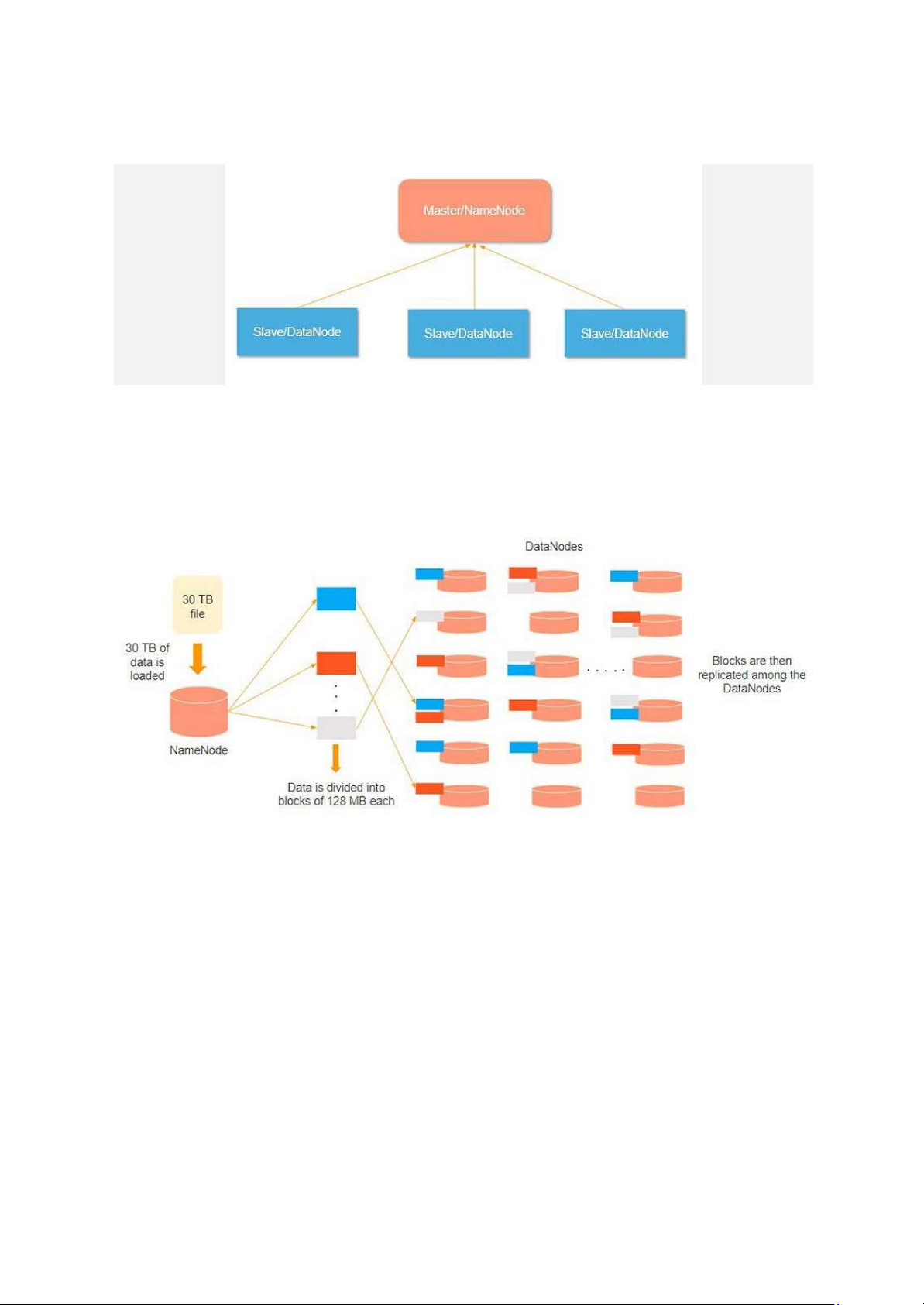
Một cụm HDFS được cấu thành nên bởi các master node và slave nodes, name node chính là
master và các data nodes là slaves.
Name node chịu trách nhiệm về hoạt động của các nút dữ liệu. Nó cũng lưu trữ siêu dữ liệu (meta data).
Các nút dữ liệu đọc, ghi, xử lý và sao chép dữ liệu. Chúng cũng gửi tín hiệu, được gọi là nhịp
tim, đến nút tên. Những nhịp tim này hiển thị trạng thái của nút dữ liệu.
Hãy xem xét rằng 30TB dữ liệu được tải vào nút tên. Name node phân phối nó trên các nút
dữ liệu và dữ liệu này được sao chép giữa các ghi chú dữ liệu. Bạn có thể thấy trong hình
trên rằng dữ liệu màu xanh lam, xám và đỏ được sao chép giữa ba nút dữ liệu.
Việc sao chép dữ liệu được thực hiện ba lần theo mặc định. Nó được thực hiện theo cách này,
vì vậy nếu máy thông thường bị lỗi, bạn có thể thay thế nó bằng một máy mới có cùng dữ liệu. b. Hadoop MapReduce
Hadoop MapReduce là đơn vị xử lý của Hadoop. Trong phương pháp MapReduce, quá trình
xử lý được thực hiện tại các nút phụ và kết quả cuối cùng được gửi đến nút chính. Theo
phương pháp truyền thống thì dữ liệu sẽ được gửi từ các Slave Nodes đến Master Nodes để
tổng hợp và xử lý. Trong khi đó thì ở Hadoop MapReduce, dữ liệu sẽ được xử lý theo cách
song song tại mỗi DataNodes trước khi được gửi đến MasterNode để tổng hợp. Đó là lý do 6 lOMoAR cPSD| 59735516
tại sao MapReduce có thể xử lý một lượng lớn dữ liệu một cách “song song và phân phối” (parallel and distributed).
Dữ liệu chứa mã được sử dụng để xử lý toàn bộ dữ liệu. Dữ liệu được mã hóa này thường rất
nhỏ so với chính dữ liệu đó. Bạn chỉ cần gửi mã có giá trị vài kilobyte để thực hiện quy trình nặng trên máy tính.
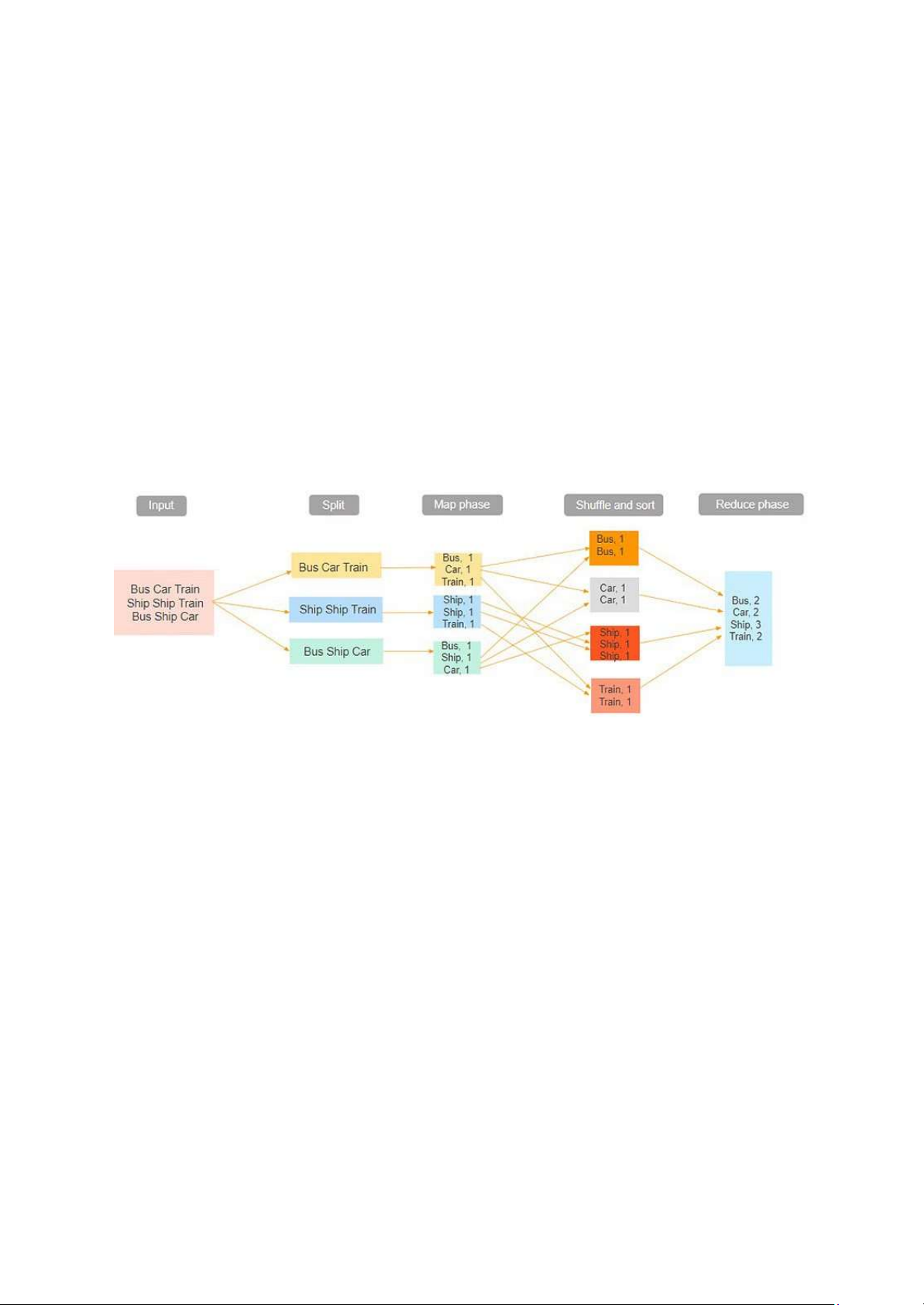
MapReduce bao gồm hai giai đoạn như chính tên gọi của nó là Map và Reduce:
- Ở giai đoạn Map, dữ liệu đầu vào sẽ được chia thành các mảnh nhỏ hơn và xử lý một
cách độc lập bởi nhiều worker nodes (hay chính là slave nodes) một cách song song.
Mỗi worker node áp dụng một hàm map vào dữ liệu đầu vào và tạo ra một cặp khóa
key-value làm giá trị đầu ra
- Dữ liệu đầu ra của giai đoạn Map được trộn và sắp xếp sau đó kết quả sẽ tiến vào giai
đoạn Reduce. Trong giai đoạn Reduce, cặp khóa key-value được tạo ra ở giai đoạn
Map được nhóm lại theo khóa (key) và hàm reduce sẽ được áp dụng cho mỗi nhóm để
tạo ra kết quả cuối cùng.
Trong ví dụ này, dữ liệu đầu vào có ba dòng văn bản với ba thực thể riêng biệt - “tàu xe
buýt”, “tàu tàu thủy”, “xe buýt tàu thủy”. Sau đó, tập dữ liệu được chia thành ba phần, dựa
trên các thực thể này và được xử lý song song.
Trong giai đoạn lập bản đồ, dữ liệu được gán một khóa và giá trị là 1. Trong trường hợp này,
chúng ta có một xe buýt, một ô tô, một con tàu và một chuyến tàu.
Các cặp khóa-giá trị này sau đó được xáo trộn và sắp xếp cùng nhau dựa trên khóa của
chúng. Ở giai đoạn rút gọn, quá trình tổng hợp diễn ra và thu được đầu ra cuối cùng. c. Hadoop Yarn:
Hadoop YARN là viết tắt của Yet Another Resource Negotiator. Đây là đơn vị quản lý tài
nguyên của Hadoop và có sẵn như một thành phần của Hadoop phiên bản 2.
● Hadoop YARN hoạt động giống như một hệ điều hành cho Hadoop. Nó là một hệ
thống tập tin được xây dựng ở trên HDFS.
● Nó chịu trách nhiệm quản lý cụm tài nguyên để đảm bảo bạn không làm quá tải một máy.
● Nó thực hiện lập kế hoạch công việc để đảm bảo rằng các công việc được sắp xếp ở đúng nơi. 7 lOMoAR cPSD| 59735516
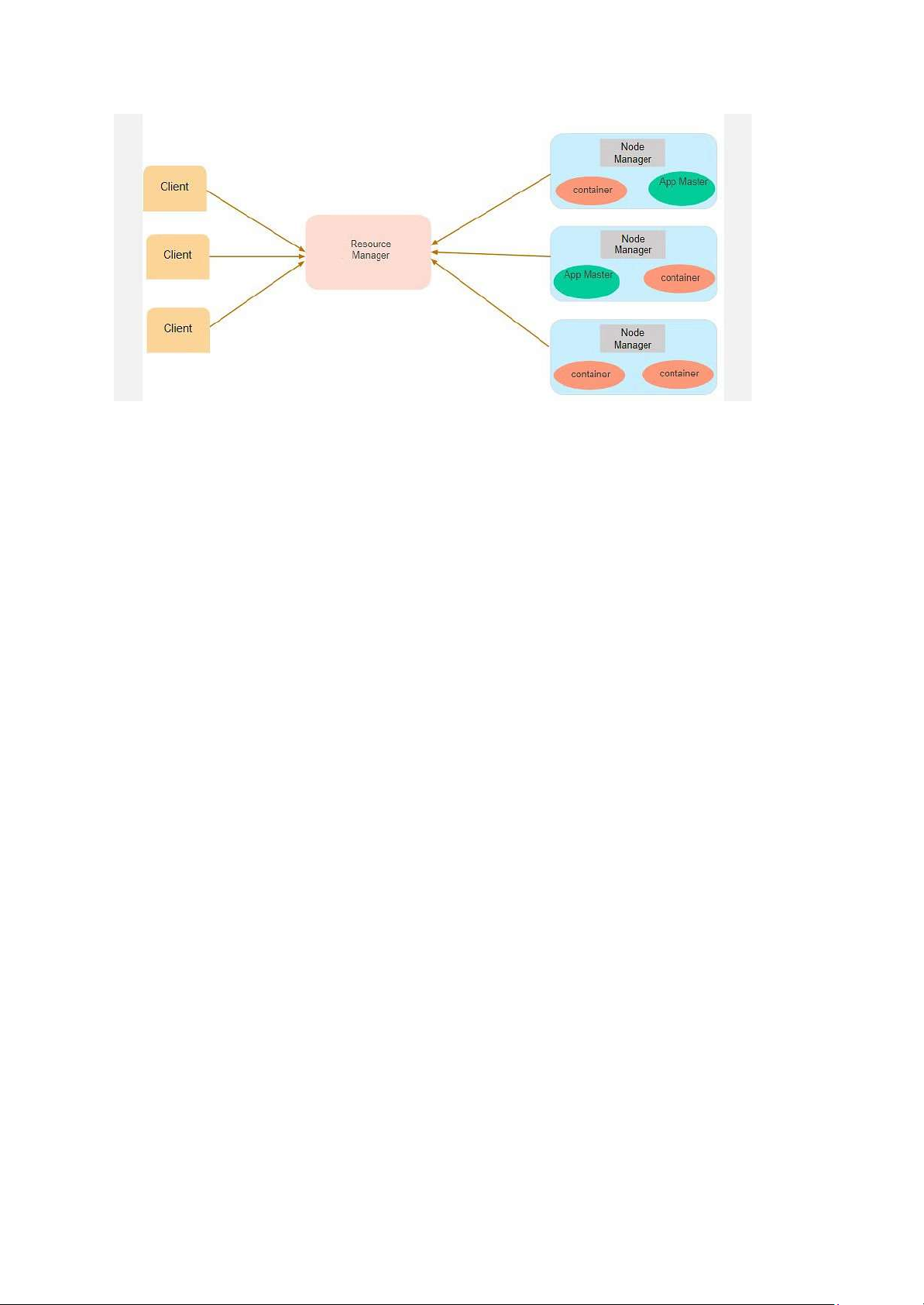
Giả sử một máy khách muốn thực hiện một truy vấn hoặc tìm nạp một số mã để phân tích dữ
liệu. Yêu cầu công việc này được chuyển đến người quản lý tài nguyên (Hadoop Yarn), chịu
trách nhiệm phân bổ và quản lý tài nguyên.
Trong phần node, mỗi node đều có node managers. Những node managers này quản lý các
nút và giám sát việc sử dụng tài nguyên trong node. Các container chứa một tập hợp các
tài nguyên vật lý, có thể là RAM, CPU hoặc ổ cứng. Bất cứ khi nào có yêu cầu công việc,
app master sẽ yêu cầu container từ node managers. Sau khi trình node managers nhận
được tài nguyên, nó sẽ quay trở lại Resource Manager. D. Cơ chế hoạt động của Hadoop:
Chức năng chính của Hadoop là xử lý dữ liệu một cách có tổ chức giữa cụm phần mềm
thương mại. Khách hàng nên gửi dữ liệu hoặc chương trình cần được xử lý. Hadoop HDFS
lưu trữ dữ liệu. YARN, MapReduce phân chia tài nguyên và phân công nhiệm vụ cho dữ liệu.
Hãy tìm hiểu chi tiết hoạt động của Hadoop.
● Dữ liệu đầu vào của máy khách được HDFS chia thành các khối 128 MB. Các khối
được sao chép theo hệ số sao chép: các DataNode khác nhau chứa các liên kết và các bản sao của chúng.
● Người dùng có thể xử lý dữ liệu sau khi tất cả các khối đã được đặt trên DataNodes HDFS.
● Máy khách gửi chương trình MapReduce cho Hadoop để xử lý dữ liệu.
● Sau đó, phần mềm do người dùng gửi được ResourceManager lên lịch trên các cụm nodes cụ thể.
● Kết quả được ghi lại vào HDFS sau khi tất cả các nút xử lý đã hoàn tất. Chương 2: HDFS
I) Cách NameNode quản lý siêu dữ liệu
NameNode lưu metadata và để quản lý metadata, NameNode duy trì 2 cấu trúc dữ liệu chính
là không gian tên (Namespace) và bản đồ khối (BlockMap). 8 lOMoAR cPSD| 59735516
Namespace là một cấu trúc cây phân cấp đại diện cho cấu trúc thư mục của hệ thống tệp. Mỗi
node trong cây đại diện cho một tệp hoặc một thư mục. Mỗi node thư mục chứa một danh
sách các nodes con, trong khi mỗi node tệp chứa thông tin như tên tệp, chủ sở hữu, quyền
truy cập và thời gian sửa đổi.
BlockMap là một ánh xạ của các khối dữ liệu tới các DataNodes lưu trữ các khối. Nó chứa
thông tin về việc DataNodes nào giữ các bản sao của từng khối và bản sao nào được coi là hợp lệ.
Như đã nói ở trên thì NameNode lưu trữ metadata, còn metadata sẽ đưa ra thông tin về vị trí
các tệp, kích cỡ các khối,...
Metadata trong HDFS được duy trì bởi hai tệp:
● editlog: Lần theo các thay đổi vừa được thực hiện ở trong HDFS
● fsimage: Lần theo mọi thay được thực hiện trong HDFS kể từ lúc bắt đầu
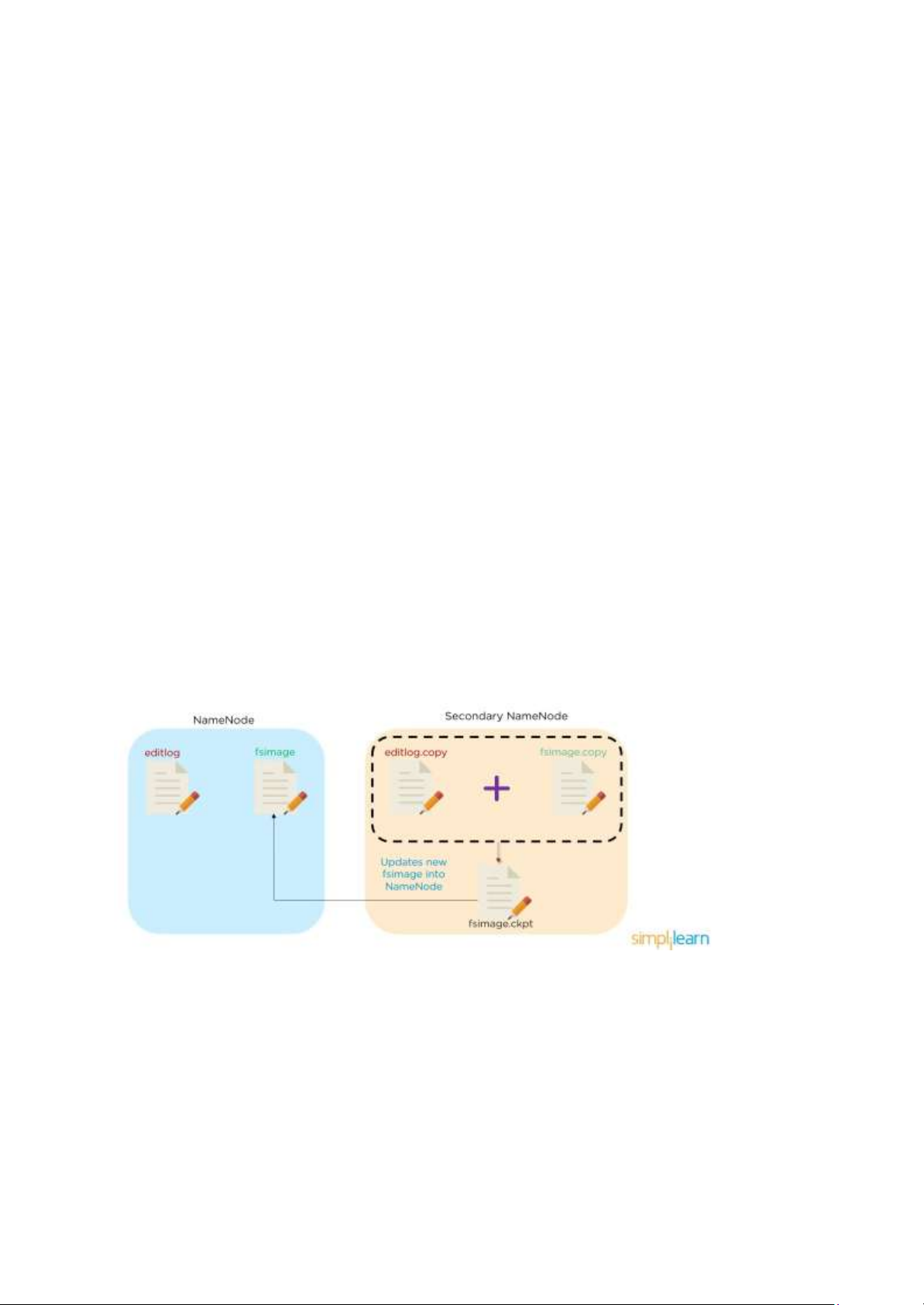
Có hai vấn đề xảy ra là khi kích cỡ của file editlog tăng lên hay là NameNode sụp đổ và giải
pháp là tạo các bản sao của editlog và fsimage (hay nói cách khác là tạo ra một NameNode
thứ 2 để duy trì bản sao của editlog và fsimage).
NameNode thứ 2 đóng vai trò quan trọng trong cơ chế Checkpoint. Sau một khoảng thời gian
được định sẵn, nó sẽ tổng hợp hai bản sao thành một tệp fsimage duy nhất sau đó cập nhật
tệp mới được tạo ra này vào tệp fsimage trên node chính. Tệp editlog trên node chính sau đó
sẽ cắt bớt để tạo chỗ cho các bản ghi thay đổi mới.
II) Sập DataNode và cơ chế sao chép
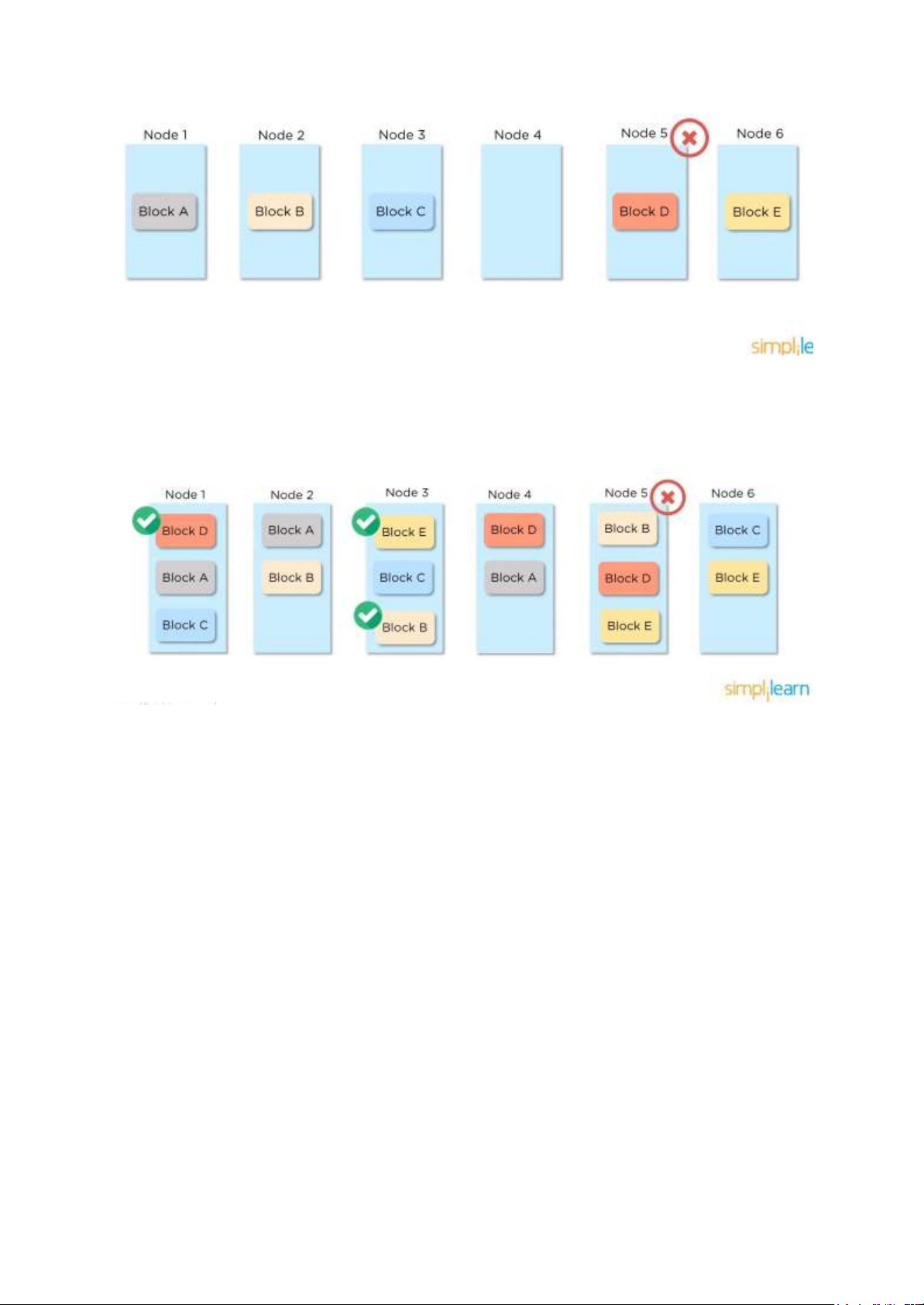
Giả sử mỗi blocks dữ liệu chỉ được lưu trữ trên một DataNode, lúc này nếu một Node bị sập
sẽ dần tới việc mất block dữ liệu do không có bản ghi nào của nó được lưu trữ trên hệ thống nữa 9 lOMoAR cPSD| 59735516
Block D bị mất khi Node 5 sập
Điều này dẫn tới giải pháp là sử dụng cơ chế sao chép: Các tệp được phân nhỏ ra thành các
blocks dữ liệu và được phân phối ra các DataNodes. Các blocks này sẽ được sao chép trên
các DataNodes khác nhau để có thể hỗ trợ khả năng chịu lỗi của hệ thống
Lúc này khi Node 5 bị sập thì các block dữ liệu có trên nó vẫn còn trên các Node khác để khôi phục
Hệ số sao chép là được đặt một cách mặc định là 3, có nghĩa là ta sẽ có tổng cộng 3 bản sao của mỗi datablock.
III) Rack Awareness trong HDFS
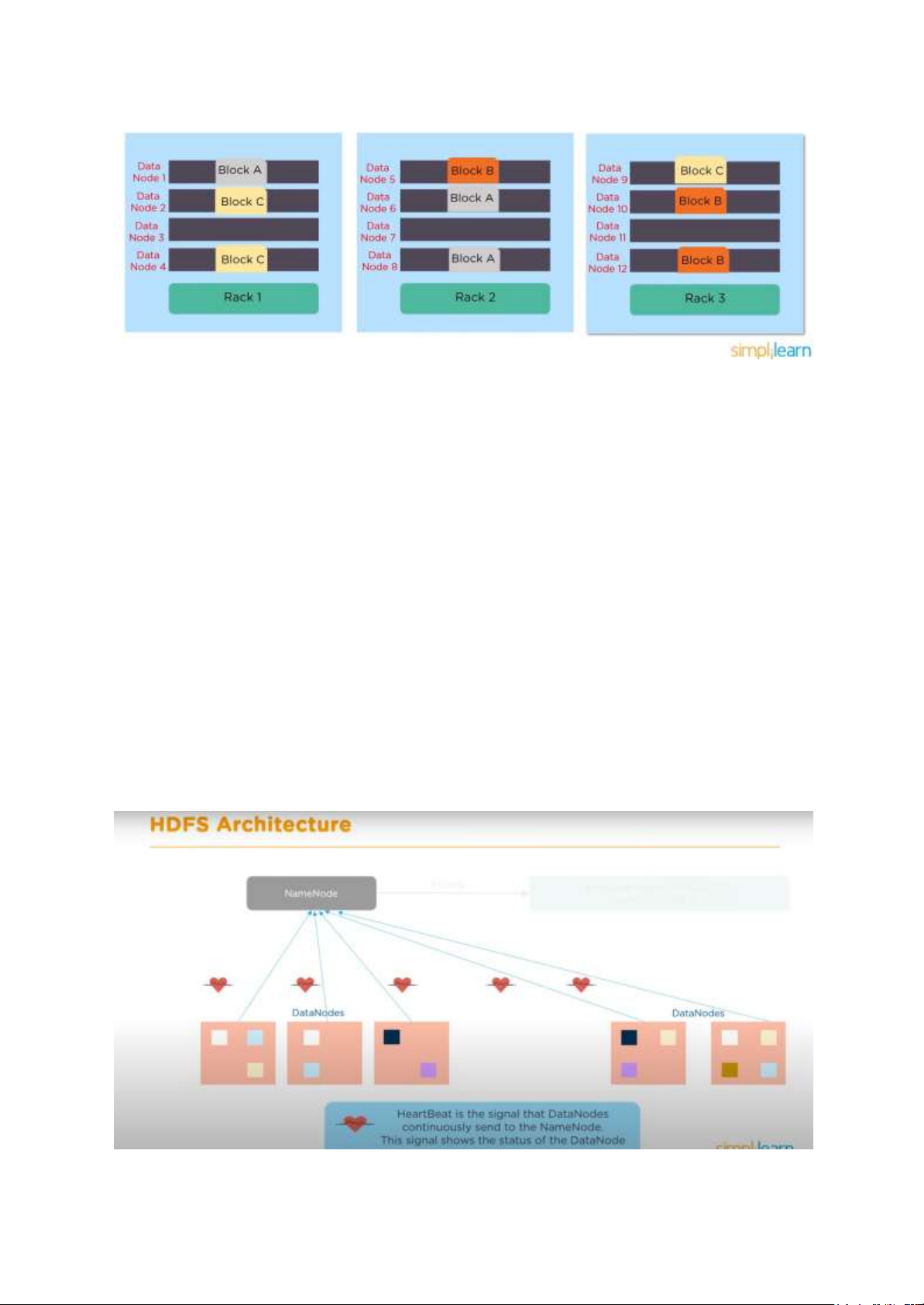
Rack là một tập hợp khoảng 30 tới 40 DataNodes. Rack Awareness là một cơ chế thiết lập để
cải thiện tính khả năng chịu lỗi và hiệu suất của hệ thống, nó giúp quyết định xem một bản
ghi của block dữ liệu nên được lưu trữ ở đâu 10 lOMoAR cPSD| 59735516
Các block được lưu trữ trên nhiều DataNode trên nhiều Rack
Mục đích của Rack Awareness là giúp cải thiện độ tin cậy, tính có sẵn của dữ liệu, tăng hiệu
quả sử dụng băng thông.
IV) Cơ chế kiểm tra Checksum
Một block dữ liệu khi lấy ra từ DataNode có thể bị hỏng (corrupted). Việc này có thể là do
thiết bị lưu trữ, đường truyền mạng hoặc xung đột phần mềm,... Phần mềm bên phía khách
của HDFS có nhiệm vụ thực hiện kiểm tra checksum trên nội dung của các tệp HDFS. Khi
bên phía khách tạo một tệp HDFS, nó tính toán checksum cho từng block của tệp và lưu trữ
các checksum này trong các tệp ẩn trong cùng một HDFS namespace. Khi phía khách lấy dữ
liệu từ tệp, nó sẽ kiểm tra xem dữ liệu nhận được từ mỗi DataNode có khớp với checksum
được lưu trữ trong tệp checksum không. Nếu không, bên phía khách sẽ có thể lấy block đó từ một DataNode khác. V) Kiến trúc HDFS 11 lOMoAR cPSD| 59735516
Kiến trúc HDFS bao gồm NameNode với DataNodes, giữa NameNode và DataNodes sử
dụng HeartBeat để giao tiếp, liên tục gửi đi tín hiệu cho biết trạng thái của DataNode.
Các DataNodes được đặt trong các rack khác nhau và trong các rack khác nhau có các phiên
bản sao chép của các DataNodes.
Tiếp đến là ta có máy client (người lập trình), ban đầu sẽ yêu cầu NameNode đọc dữ liệu.
NameNode cho phép client đọc dữ liệu được yêu cầu từ DataNodes, sau đó NameNode sẽ
cập nhật Metadata operations ở trong phần MetaData của nó và kết thúc request.
Một công việc khác của NameNode là thực thi các Block operations khi client đẩy dữ liệu
lên. Block operations bao gồm các công việc như tạo, xóa hay sao chép block.
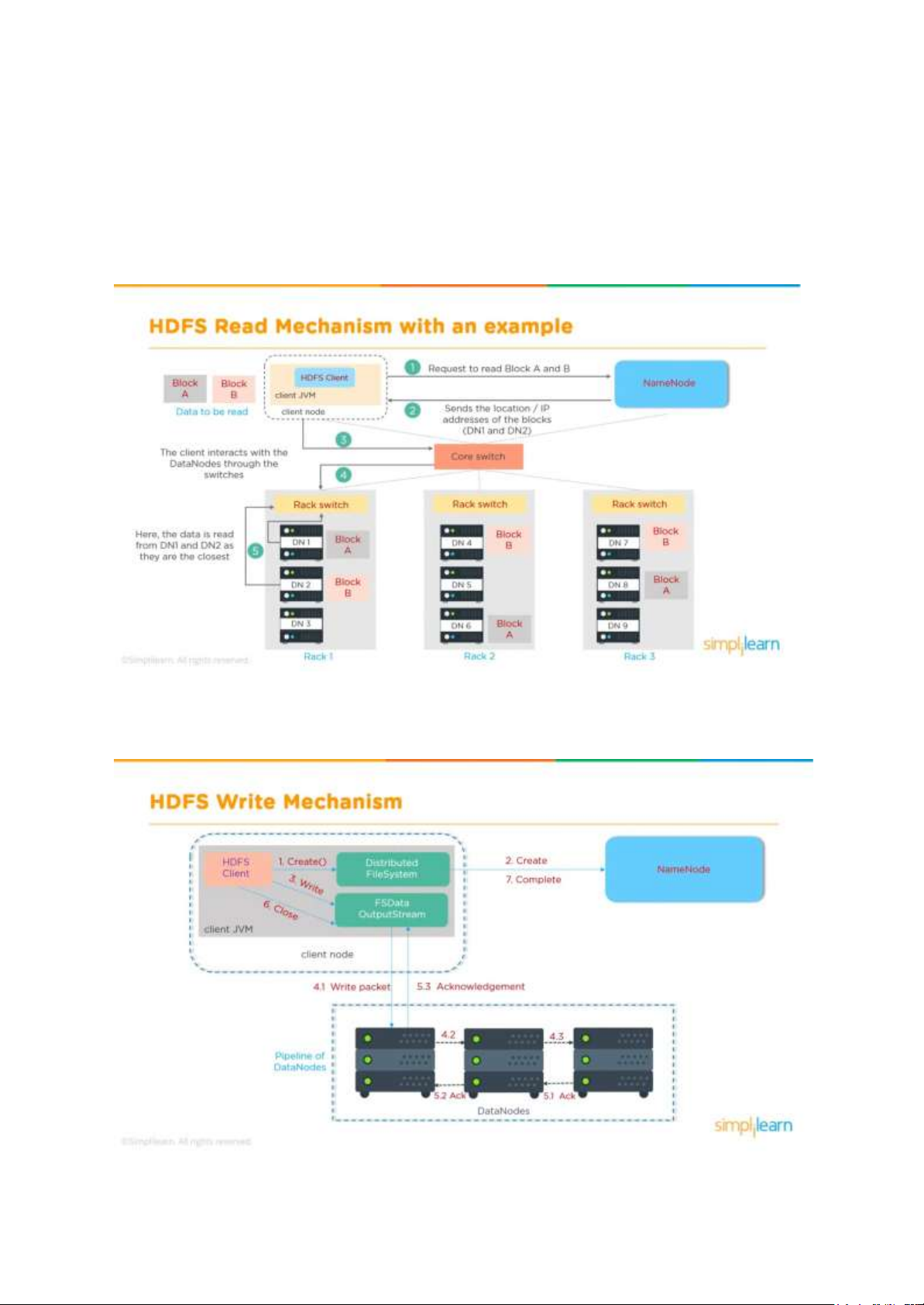
VI) Cơ chế đọc của HDFS 12 lOMoAR cPSD| 59735516
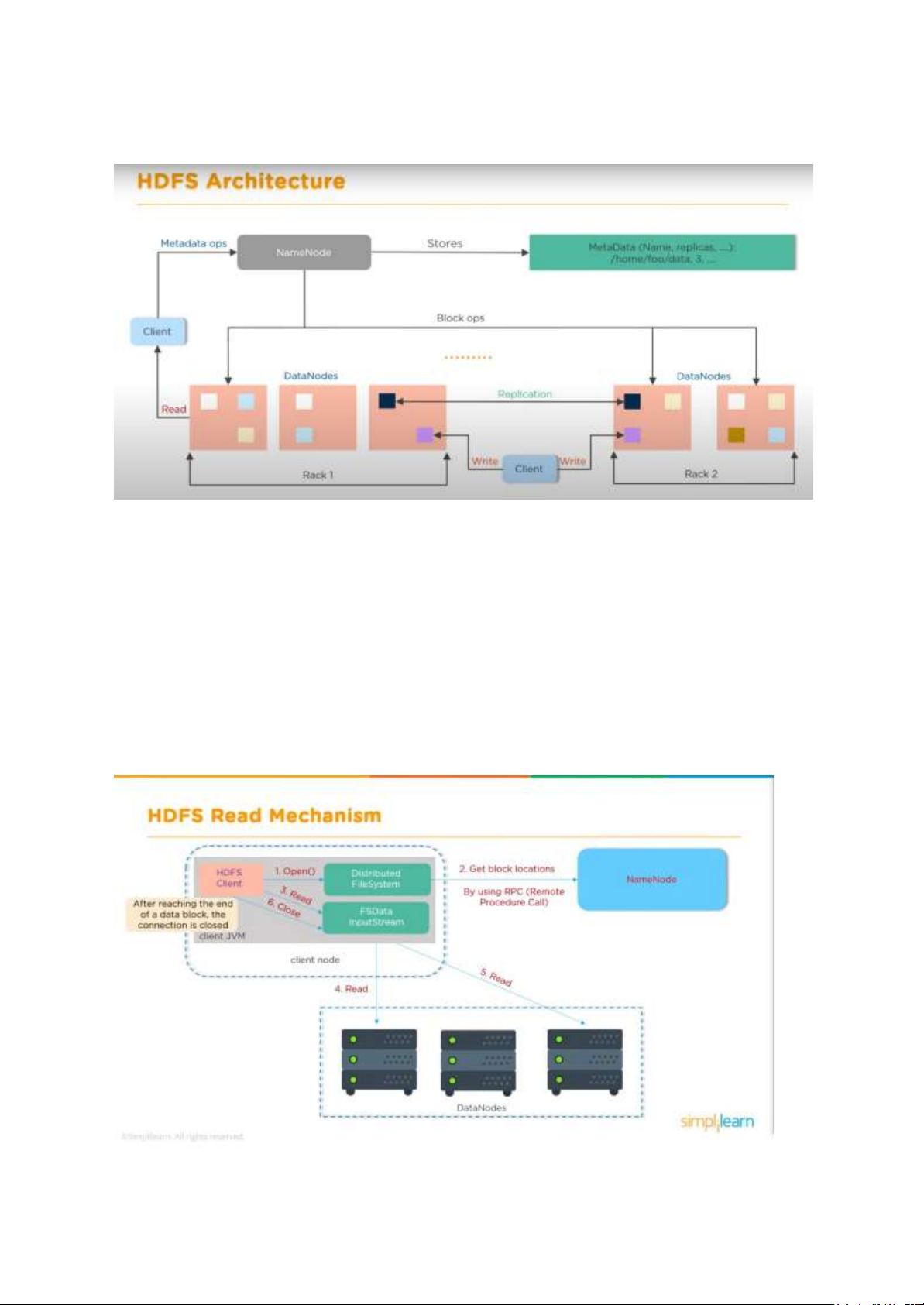
Đầu tiên HDFS client mở một kết nối tới Distributed FileSystem, gửi một yêu cầu đọc dữ
liệu tới NameNode sử dụng RPC. Khi này NameNode sẽ kiểm tra xem liệu client này có
quyền đọc dữ liệu trong yêu cầu không, nếu có NameNode sẽ cung cấp cho client vị trí của
block chứa dữ liệu đó và một token. Token này được client sử dụng để xác thực quyền được
đọc với DataNode chứa block đó. HDFS client sẽ đọc dữ liệu ở DataNodes thông qua trung
gian là FSData InputStream. Sau khi đọc xong kết nối tới FDSData InputStream sẽ được
đóng, các token sẽ bị xóa đi.
Ví dụ về cơ chế đọc của HDFS
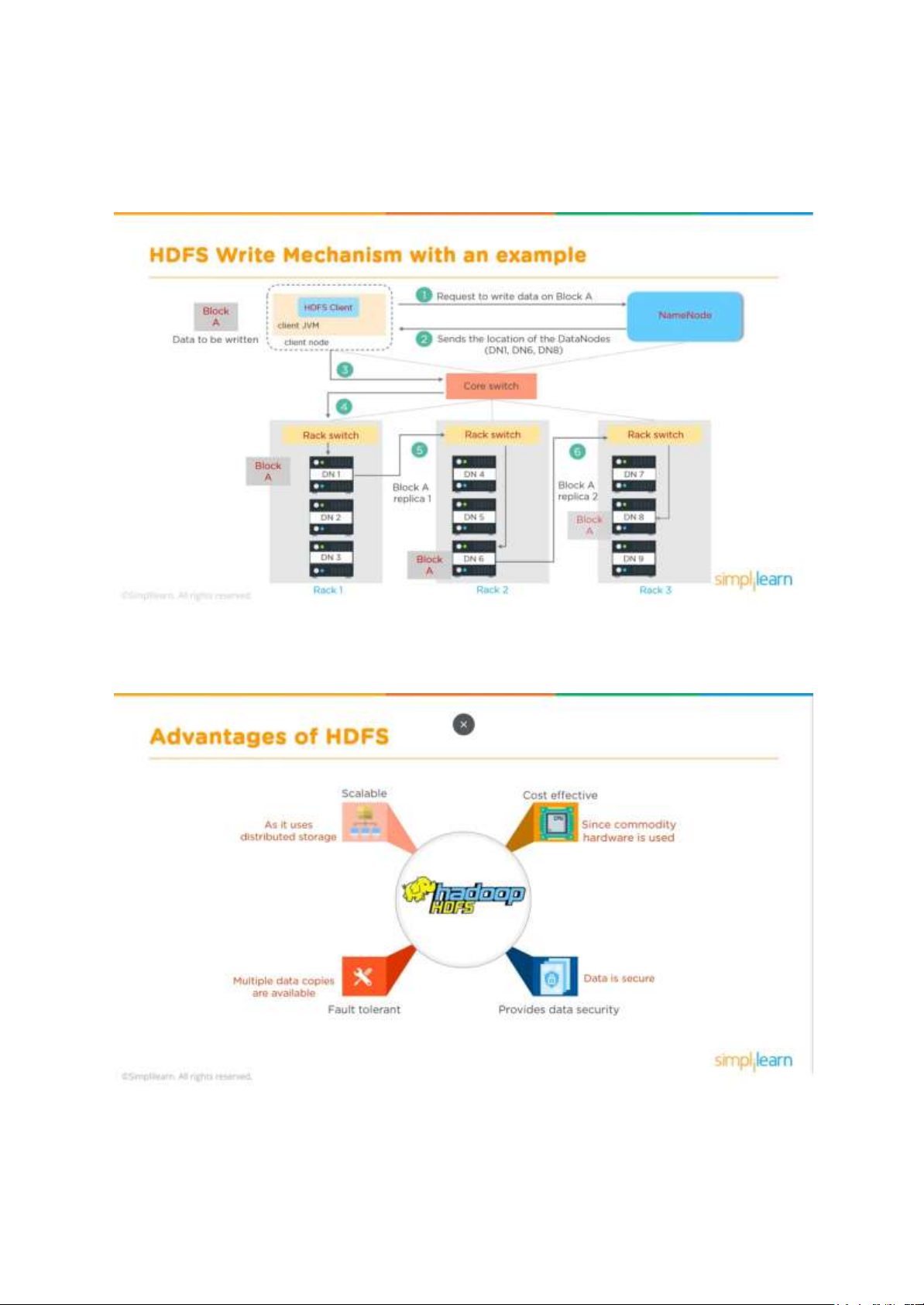
VII) Cơ chế viết của HDFS 13 lOMoAR cPSD| 59735516
HDFS Client ban đầu sẽ tạo ra một DistributedFileSystem, DFS tạo ra một NameNode. Sau
đó client sẽ viết thông qua FSData OutputStream vào một block rồi được sao chép tới các
block khác ở trong DataNode. Khi viết thành công gói tin Ack sẽ được gửi đi qua các block.
Sau khi xác nhận được gói tin Ack thì Client sẽ đóng kết nối và thông báo cho NameNode.
Ví dụ về cơ chế viết của HDFS
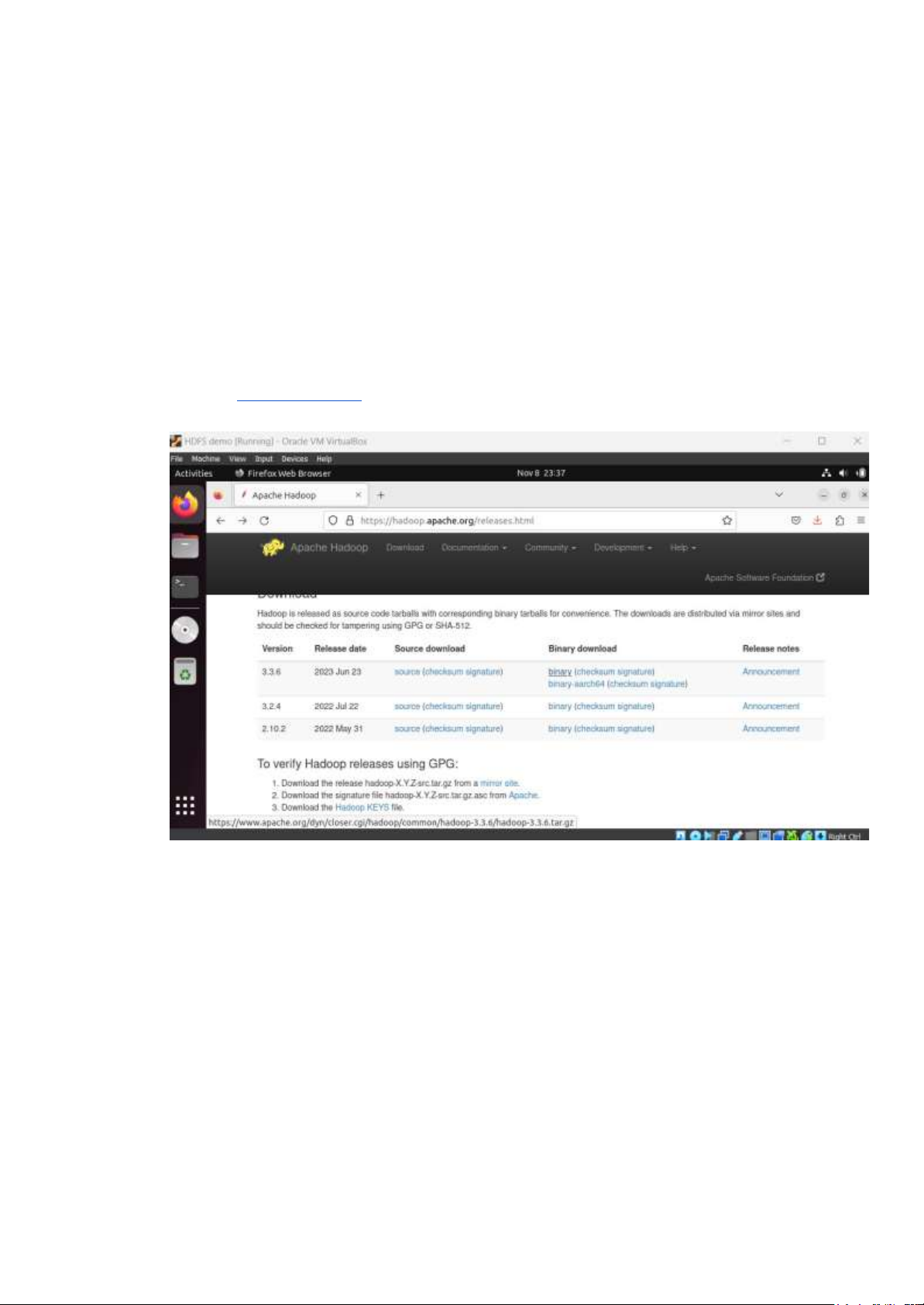
VIII) Lợi ích khi sử dụng:
Những lợi ích của HDFS có thể kể tới: 14 lOMoAR cPSD| 59735516
● Khả năng mở rộng: HDFS được thiết kế để xử lý khối lượng dữ liệu lớn. Nó có thể
mở rộng theo chiều ngang bằng cách thêm nhiều node dữ liệu hơn, điều này cho phép
nó chứa được lượng dữ liệu khổng lồ.
● Chống lỗi tốt: HDFS sao chép dữ liệu trên nhiều nút. Nếu một nút hoặc bản sao dữ
liệu bị lỗi, bản sao khác có thể được sử dụng để đảm bảo tính khả dụng của dữ liệu.
Khả năng chịu lỗi này được tích hợp vào hệ thống.
● Lưu trữ tiết kiệm chi phí: Nó được thiết kế cho phần cứng thương mại, giúp tiết kiệm
chi phí. Bạn có thể sử dụng các máy chủ rẻ tiền để xây dựng cụm Hadoop.
● Dữ liệu được bảo mật tốt: HDFS hỗ trợ xác thực quyền truy cập vào từng mục dữ liệu
của người dùng bằng Kerberos và mã hóa dữ liệu.
Chương 3: So sánh với các nền tảng tương tự
I) HDFS và Google Bigquery
Hadoop HDFS (Hadoop Distributed File System) và Google BigQuery là hai công nghệ khác
nhau được sử dụng trong việc xử lý và lưu trữ dữ liệu lớn. Dưới đây là một so sánh giữa
chúng về điểm mạnh và điểm yếu, cũng như khi nào nên sử dụng mỗi phương pháp:
HDFS: hệ thống lưu trữ phân tán sử dụng cơ sở hạ tầng vật lý Điểm mạnh:
● Lưu trữ dữ liệu lớn: Hadoop HDFS là một hệ thống lưu trữ phân tán được thiết kế để
lưu trữ và quản lý dữ liệu lớn (big data). Nó có khả năng lưu trữ petabyte dữ liệu hoặc nhiều hơn.
● Tích hợp với nhiều công cụ xử lý dữ liệu: Hadoop HDFS thường được sử dụng cùng
với các công cụ xử lý dữ liệu như Apache MapReduce, Apache Hive và Apache Spark.
● Kiểm soát hoàn toàn: Hadoop HDFS cho phép bạn có kiểm soát hoàn toàn đối với lưu
trữ và xử lý dữ liệu, điều này có thể quan trọng đối với các tổ chức có nhu cầu bảo
mật và tuân thủ nghiêm ngặt. Điểm yếu:
● Phức tạp cài đặt và quản lý: Hadoop HDFS yêu cầu kiến thức kỹ thuật cao để cài đặt
và quản lý. Điều này có thể đòi hỏi một đội ngũ IT kỹ thuật và tài nguyên đáng kể.
● Chậm cho các truy vấn phức tạp: Hadoop HDFS không phải là hệ thống truy vấn
nhanh, và việc thực hiện các truy vấn phức tạp có thể mất thời gian.
● Chi phí đầu tư cơ sở hạ tầng: tuy rằng Hadoop là mã nguồn mở miễn phí nhưng bạn
phải đầu tư xây dựng một cơ sở hạ tầng, mặc dù chúng chỉ là phần cứng, máy chủ thương mại. 15 lOMoAR cPSD| 59735516
● Đội ngũ quản lý: đi đôi với việc có thể kiểm soát hoàn toàn là yêu cầu về một đội ngũ
IT với kiến thức kỹ thuật đủ để quản lý và triển khai Hadoop.
Google BigQuery: dịch vụ truy vấn và lưu trữ dữ liệu trên đám mây Điểm mạnh
● Truy vấn nhanh và phân tích dữ liệu thời gian thực: Google BigQuery là dịch vụ truy
vấn dựa trên đám mây, cho phép bạn thực hiện truy vấn dữ liệu lớn với tốc độ nhanh.
● Không cần quản lý cơ sở hạ tầng: BigQuery loại bỏ nhu cầu cài đặt và quản lý cơ sở
hạ tầng, giúp tiết kiệm thời gian và nguồn lực.
● Tích hợp với các dịch vụ khác của Google Cloud*: BigQuery dễ dàng tích hợp với
các dịch vụ khác của Google Cloud, giúp bạn xây dựng các ứng dụng phức tạp. Điểm yếu:
● Phí sử dụng truy vấn, lưu trữ: Google BigQuery tính phí theo số lượt truy vấn và
lượng lưu trữ. Do vậy BigQuery có thể tạo ra chi phí đáng kể, đặc biệt khi bạn thực
hiện nhiều truy vấn hoặc lưu trữ lượng dữ liệu lớn.
● Không kiểm soát hoàn toàn: BigQuery là giải pháp Database-as-a-Service (DBaaS),
dữ liệu của bạn được lưu trữ trên cơ sở hạ tầng của Google, vì vậy bạn không có kiểm
soát hoàn toàn về nơi lưu trữ dữ liệu. Khi nào nên sử dụng
● Hadoop HDFS: Sử dụng Hadoop HDFS khi bạn cần lưu trữ và xử lý dữ liệu lớn, có
kiểm soát cao, và có đội ngũ IT có kiến thức kỹ thuật đủ để quản lý hệ thống.
● Google BigQuery: Sử dụng Google BigQuery khi bạn cần thực hiện truy vấn nhanh
và phân tích dữ liệu mà không muốn đầu tư nhiều vào cơ sở hạ tầng hoặc khi bạn làm
việc trên mô hình đám mây và cần tích hợp với các dịch vụ khác của Google Cloud.
Phân bố quy mô tổ chức sử dụng Google Bigquery (bên trái) với Hadoop HDFS (bên phải) II) HDFS và Ceph HDFS: Điểm mạnh:
● HDFS được tối ưu hóa cho tính toán dữ liệu lớn và có khả năng xử lý dữ liệu trong các phân tích lớn.
● Tích hợp với nhiều công cụ xử lý dữ liệu: Hadoop HDFS thường được sử dụng cùng
với các công cụ xử lý dữ liệu như Apache MapReduce, Apache Hive và Apache 16 lOMoAR cPSD| 59735516 Spark.
● Cơ chế Replication giúp đảm bảo tính toàn vẹn dữ liệu như đã được trình bày ở trên Điểm yếu:
● Khả năng lưu trữ đa dạng của HDFS không được đánh giá cao do chủ yếu dành cho
dữ liệu cấu trúc và phi cấu trúc.
● Phụ thuộc nhiều vào hệ sinh thái Hadoop do thường phải kết hợp với nhiều công cụ
khác như Hadoop MapReduce hoặc các công cụ khác để xử lý dữ liệu. Ceph: Điểm mạnh:
● Khả năng lưu trữ đa dạng của Ceph được đánh giá cao hơn do nó thích hợp với việc
lưu trữ nhiều loại dữ liệu bao gồm dữ liệu cấu trúc, phi cấu trúc và nhiều định dạng khác.
● Ceph có khả năng mở rộng rất tốt và không bị giới hạn cho việc xử lý dữ liệu lớn.
● Ceph sử dụng kiến trúc RADOS để cung cấp khả năng tự phục hồi và đảm bảo tính toàn vẹn dữ liệu. Điểm yếu:
● Triền khai và quản lý phức tạp hơn HDFS. Kh nào nên sử dụng:
● Sử dụng HDFS khi bạn có nhu cầu lưu trữ và xử lý dữ liệu lớn trong môi trường
Hadoop, và dữ liệu của bạn chủ yếu là dữ liệu cấu trúc và phi cấu trúc.
● Sử dụng Ceph khi bạn có nhu cầu lưu trữ dữ liệu đa dạng, không chỉ giới hạn cho môi
trường Hadoop, và bạn cần khả năng mở rộng và tự động phục hồi. 17 lOMoAR cPSD| 59735516 DemoHDFS I) Cài đặt Hadoop
1) Cài đặt các thành phần cần thiết để sử dụng Hadoop
- Cài đặt openjdk (ở đây chúng ta sẽ sử dụng phiên bản openjdk 11):
sudo apt install openjdk-11-jdk
- Cài đặt ssh client và server: sudo apt install ssh 2) Tải file binary Hadoop
Truy cập Apache Hadoop và tải phiên bản mới nhất (ở đây chúng ta sẽ tải về file binary phiên bản 3.3.6)
3) Giải nén file vừa tài về và đưa nó về HOME
Sử dụng lệnh: tar -zxvf ~/Downloads/hadoop-3.3.6.tar.gz
4) Configure Hadoop environment
- Truy cập vào bashrc: sudo nano .bashrc
- Thêm các dòng sau vào cuối file .bashrc:
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64
export PATH=$PATH:/usr/lib/jvm/java-11-openjdk-amd64/bin
export HADOOP_HOME=~/hadoop-3.3.6/ export
PATH=$PATH:$HADOOP_HOME/bin export
PATH=$PATH:$HADOOP_HOME/sbin export
HADOOP_MAPRED_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export 18 lOMoAR cPSD| 59735516
HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop export
HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export HADOOP_OPTS="-
Djava.library.path=$HADOOP_HOME/lib/native" export
HADOOP_STREAMING=$HADOOP_HOME/share/hadoop/tools/lib/hadoo p -streaming-3.3.6.jar
export HADOOP_LOG_DIR=$HADOOP_HOME/logs
export PDSH_RCMD_TYPE=ssh export HADOOP_CLASSPATH=$(hadoop classpath):$HADOOP_CLASSPATH
Lưu ý là các câu lệnh để configure có thể thay đổi tùy thuộc vào phiên bản openjdk và phiên
bản Hadoop được cài đặt.
5) Edit file hadoop-env.sh sudo nano hadoop-
3.3.6/etc/hadoop/hadoop-env.sh
Uncomment dòng JAVA_HOME và thay đường dẫn nó tới file openjdk
6) Edit file core-sile.xml sudo nano hadoop-
3.3.6/etc/hadoop/core-site.sml
Thêm các dòng sau vào thẻ : fs.defaultFS 19 lOMoAR cPSD| 59735516 hdfs://localhost:9000
hadoop.proxyuser.dataflair.groups *
hadoop.proxyuser.dataflair.hosts *
hadoop.proxyuser.server.hosts *
hadoop.proxyuser.server.groups *
7) Edit file hdfs-site.xml sudo nano hadoop-
3.3.6/etc/hadoop/hdfs-site.xml
Thêm các dòng sau vào thẻ : dfs.replication 1
8) Edit file mapred-site.xml sudo nano hadoop-
3.3.6/etc/hadoop/mapred-site.xml
Thêm các dòng sau vào thẻ : mapreduce.framework.name yarn
mapreduce.application.classpath
$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MA
PRED_HOME/share/hadoop/mapreduce/lib/*
9) Edit file yarn-site.xml sudo nano hadoop-
3.3.6/etc/hadoop/yarn-site.xml 20
Tài liệu liên quan:
-

tai lieu_Kỹ năng sử dụng công nghệ thông tin cơ bản
34 17 -

Tài liệu sưu tầm Công nghệ thông tin - Nguyên lý hệ điều hành
29 15 -

LÝ THUYẾT TIN HỌC CƠ SỞ - Tổng hợp nội dung và câu hỏi ôn tập. Môn Giới thiệu về Công nghệ thông tin | Trường Đại học Công nghệ, Đại học Quốc gia Hà Nội.
67 34 -

Đề thi Thực hành Giới thiệu về Công nghệ thông tin kỳ 1 năm học 2022-2023 | Trường Đại học Công nghệ, Đại học Quốc gia Hà Nội
153 77