Bài tập lớn: Cài đặt và Demo Hadoop Mapreduce môn Dữ liệu lớn | Học viện Công Nghệ Bưu Chính Viễn Thông
Bài tập lớn: Cài đặt và Demo Hadoop Mapreduce môn Dữ liệu lớn. Tài liệu được sưu tầm gồm 6 trang, giúp các bạn nắm vững kiến thức, rèn luyện kỹ năng và đạt được kết quả tốt trong học tập. Mời các bạn đón xem!
Môn: Dữ liệu lớn (MUL1331) 6 tài liệu
Trường: Học viện Công Nghệ Bưu Chính Viễn Thông 1.8 K tài liệu
Tác giả:




Preview text:
lOMoAR cPSD| 58457166
BỘ KHOA HỌC VÀ CÔNG NGHỆ
HỌC VIỆN CÔNG NGHỆ BƯU CHÍNH VIỄN THÔNG
BÀI TẬP LỚN LÍ THUYẾT BIG DATA
ĐỀ TÀI: CÀI ĐẶT + DEMO HADOOP MAPREDUCE
Giảng viên hướng dẫn: Phan Thị Hà Môn học:
Cơ sở dữ liệu phân tán
Nhóm thảo luận: Nhóm 5 Thành viên:
Phạm Hải Dương (TN) Lê Quốc Toàn Vũ Thế Vinh Phạm Huy Hùng Nguyễn Đức Trung Bùi Duy Tùng Phạm Minh Đức Nguyễn Danh Toản Lưu Xuân Dũng Nguyễn Bá Dương
Hà Nội, ngày 15 tháng 4 năm 2025 lOMoAR cPSD| 58457166
Phần 0: SET UP MÔI TRƯỜNG (máy ảo ubuntu)
Bước 1: Cài đặt Java & Hadoop
Mở Terminal máy ảo và chạy: • sudo apt update •
sudo apt install openjdk-11-jdk -y Tải Hadoop: •
wget https://archive.apache.org/dist/hadoop/core/hadoop-3.3.6/hadoop-3.3.6.tar.gz • tar -xzf hadoop-3.3.6.tar.gz • mv hadoop-3.3.6 ~/hadoop
Kiểm tra Java, Hadoop: java -version • hadoop version
Bước 2: Cấu hình biến môi trường Mở file cấu hình: • nano ~/.bashrc
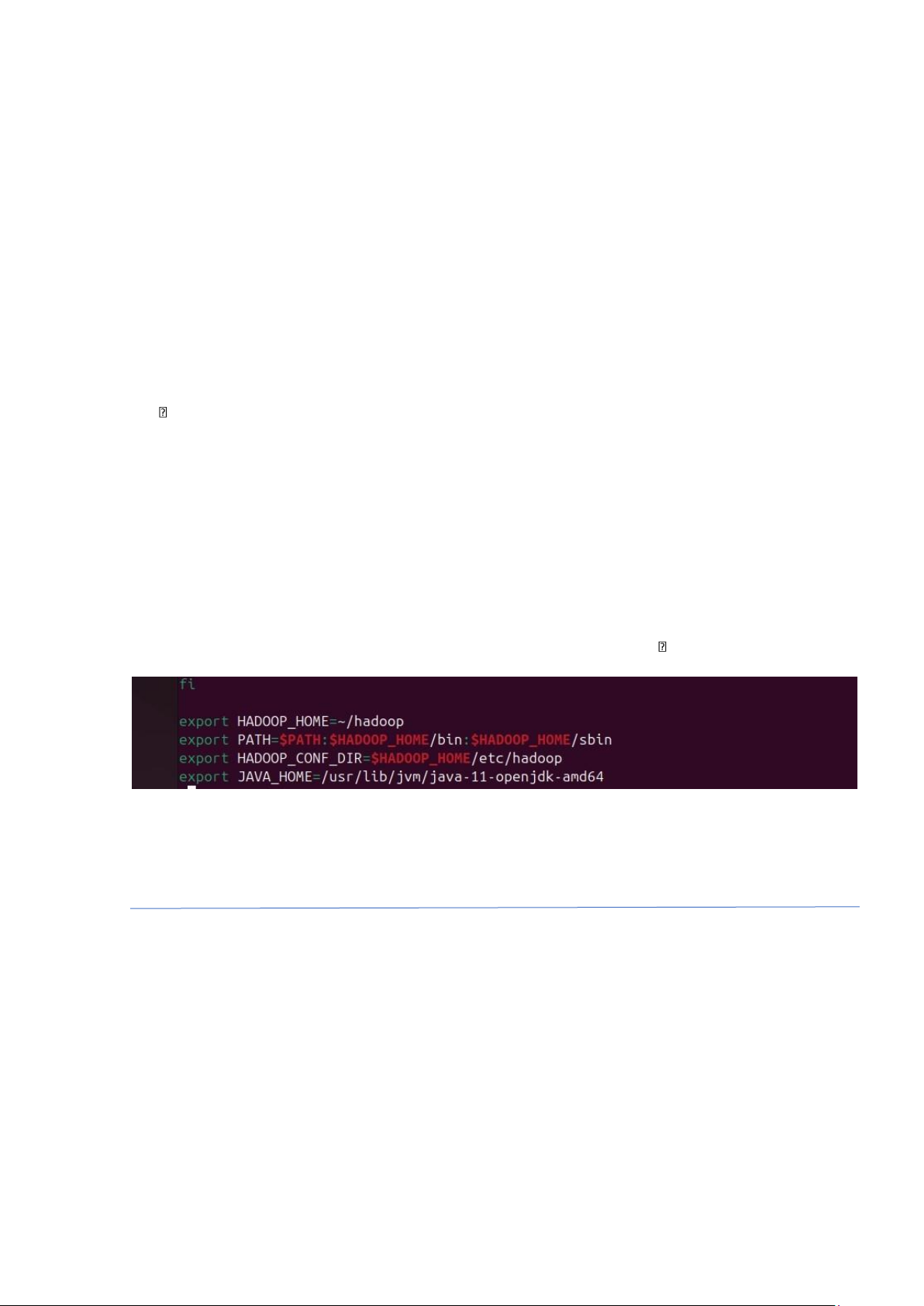
Thêm vào cuối file: • export HADOOP_HOME=~/hadoop •
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin •
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop export
JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64
Lưu lại và áp dụng: •
source ~/.bashrc Kiểm tra lệnh: • hadoop version
Phần 1: WORD COUNT HADOOP MAPREDUCE
Bước 1: Viết code Java (WordCount) Tạo file mới: • mkdir ~/mapreduce-demo • cd ~/mapreduce-demo • nano WordCount.java Dán đoạn code sau: lOMoAR cPSD| 58457166
import java.io.IOException; import java.util.StringTokenizer; import
org.apache.hadoop.conf.Configuration; import
org.apache.hadoop.fs.Path; import org.apache.hadoop.io.*; import
org.apache.hadoop.mapreduce.*; import
org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import
org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class WordCount {
public static class TokenizerMapper extends Mapper {
private final static IntWritable one = new IntWritable(1); private Text word = new Text();
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) { word.set(itr.nextToken()); context.write(word, one); } } }
public static class IntSumReducer extends Reducer {
public void reduce(Text key, Iterable values, Context context) throws
IOException, InterruptedException { int sum = 0;
for (IntWritable val : values) sum += val.get();
context.write(key, new IntWritable(sum)); } }
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1); } }
Lưu lại và thoát (Ctrl + O, Enter, Ctrl + X)
Check lại file này dùng lệnh: nano WordCount.java
Bước 2: Biên dịch và tạo jar • mkdir classes •
javac -classpath $HADOOP_HOME/share/hadoop/common/*:
$HADOOP_HOME/share/hadoop/mapreduce/* -d classes WordCount.java
jar -cvf wordcount.jar -C classes/ . lOMoAR cPSD| 58457166
Bước 3: Tạo dữ liệu đầu vào Tạo file văn bản: • mkdir input •
echo "hel o world hel o hadoop bigdata map reduce hadoop hadoop" > input/data.txt
Tạo thư mục trên HDFS: • hadoop fs -mkdir -p input •
hadoop fs -put input/data.txt input
Bước 4: Chạy chương trình MapReduce •
hadoop jar wordcount.jar WordCount input output
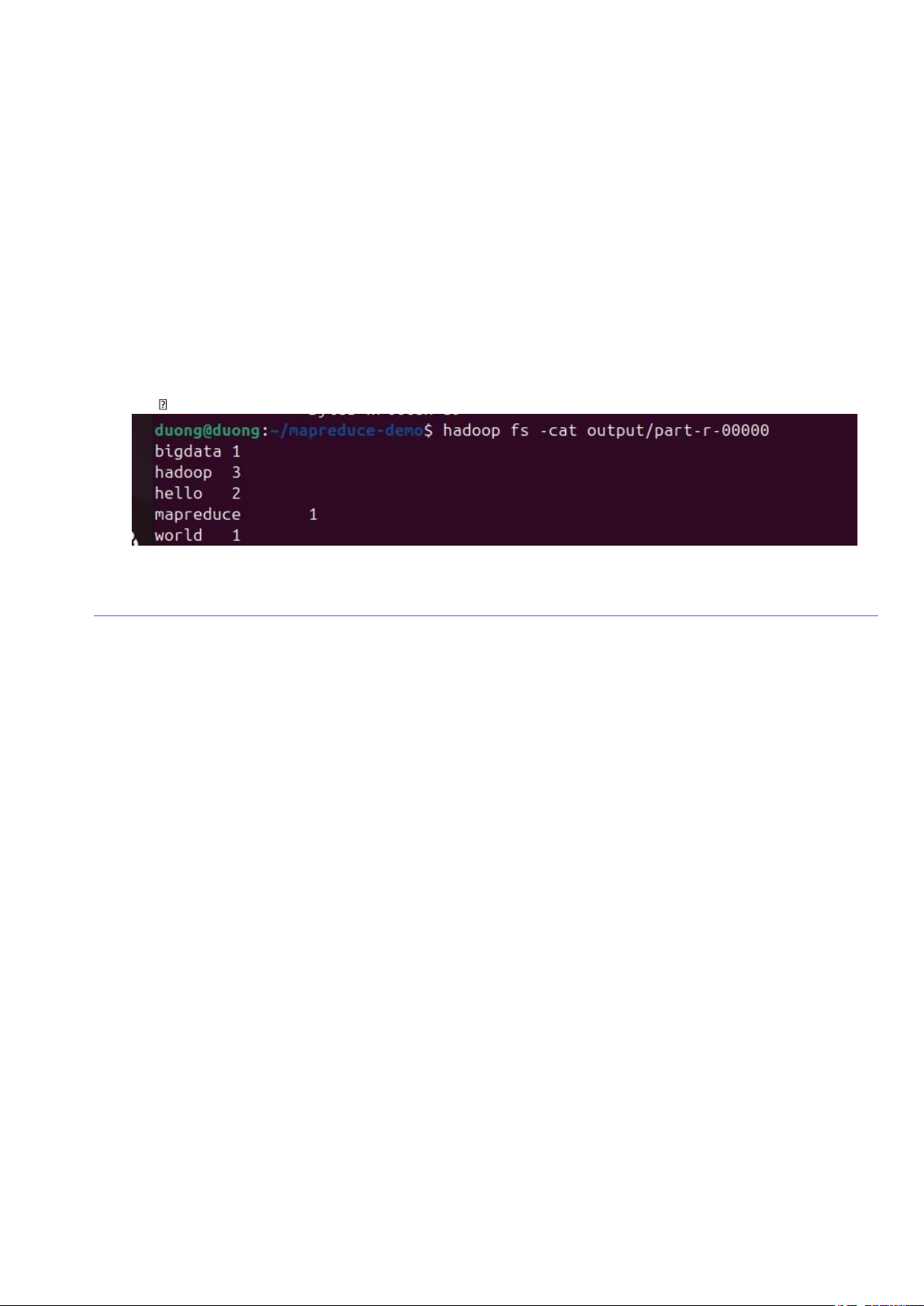
Bước 5: Xem kết quả
hadoop fs -cat output/part-r-00000
Phần 2: WORD COUNT PER LINE
Bước 1: Viết chương trình Java đếm số lượng dòng có từ Hadoop bất
kể viết hoa hay viết thường
Tạo file LineContainsKeyword.java: import java.io.IOException;
import org.apache.hadoop.conf.Configuration; import
org.apache.hadoop.fs.Path; import org.apache.hadoop.io.*; import
org.apache.hadoop.mapreduce.*; import
org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import
org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class LineContainsKeyword {
public static class LineMapper extends Mapper {
private final static IntWritable one = new IntWritable(1);
private final static Text keywordLine = new Text("Number_Of_Hadoop_Line");
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString().toLowerCase(); // bỏ qua hoa/thường
if (line.contains("hadoop")) {
context.write(keywordLine, one); } } } lOMoAR cPSD| 58457166
public static class LineReducer extends Reducer {
public void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException { int count = 0;
for (IntWritable val : values) { count += val.get(); }
context.write(key, new IntWritable(count)); } }
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "line count with keyword");
job.setJarByClass(LineContainsKeyword.class);
job.setMapperClass(LineMapper.class);
job.setCombinerClass(LineReducer.class);
job.setReducerClass(LineReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1); }
} Bước 2: Biên dịch và tạo JAR qua các câu lệnh dưới đây: •
mkdir -p classes_KeyWordPerLine • javac -classpath
"$HADOOP_HOME/share/hadoop/common/*:$HADOOP_HOME/share/hadoop/mapreduce/
*:$HADOOP_HOME/share/hadoop/hdfs/*:$HADOOP_HOME/share/hadoop/tools/lib/*" \
-d classes_KeyWordPerLine LineContainsKeyword.java jar
-cvf keywordcount.jar -C classes_KeyWordPerLine/ .
=> Sau bước này, bạn đã có file keywordcount.jar
Bước 3: Tạo dữ liệu đầu vào • mkdir -p input • nano input/data.txt
=> tạo file data.txt và thêm ND sau: This is a line about Hadoop.
Another line with hadoop inside.
This line does not have the keyword. Yet another Hadoop line. No match here. EOF Hadoop HADOOP Hadoop lOMoAR cPSD| 58457166
Bước 4: Đưa dữ liệu lên HDFS bằng câu lệnh sau: •
hadoop fs -rm -r input output # Xoá nếu đã tồn tại • hadoop fs -mkdir -p input •
hadoop fs -put input/data.txt input
Bước 5: Chạy chương trình MapReduce bằng câu lệnh sau: •
hadoop jar keywordcount.jar LineContainsKeyword input output
Bước 6: Xem kết quả bằng câu lệnh sau: •
hadoop fs -cat output/part-r-00000
Tài liệu liên quan:
-

Bài giảng Big Data | Học viện Công Nghệ Bưu Chính Viễn Thông
34 17 -

Tài liệu thiết kế kỹ thuật | Quản lý dữ liệu lớn
45 23 -

Câu hỏi ôn thi dữ liệu lớn | Học viện Công Nghệ Bưu Chính Viễn Thông
41 21 -

Kiến trúc MapReduce trong Hadoop: Cấu trúc và nguyên lý hoạt động môn Dữ liệu lớn | Học viện Công Nghệ Bưu Chính Viễn Thông
193 97