Báo cáo bài tập nhóm môn Dữ liệu lớn đề tài "Tìm hiểu về MapReduce và ứng dụng giải quyết bài toán đếm số nguyên tố"
Báo cáo bài tập nhóm môn Dữ liệu lớn đề tài "Tìm hiểu về MapReduce và ứng dụng giải quyết bài toán đếm số nguyên tố" của Học viện Công nghệ Bưu chính Viễn thông với những kiến thức và thông tin bổ ích giúp sinh viên tham khảo, ôn luyện và phục vụ nhu cầu học tập của mình cụ thể là có định hướng ôn tập, nắm vững kiến thức môn học và làm bài tốt trong những bài kiểm tra, bài tiểu luận, bài tập kết thúc học phần, từ đó học tập tốt và có kết quả cao cũng như có thể vận dụng tốt những kiến thức mình đã học vào thực tiễn cuộc sống. Mời bạn đọc đón xem!
Môn: Dữ liệu lớn (MUL1331) 6 tài liệu
Trường: Học viện Công Nghệ Bưu Chính Viễn Thông 1.8 K tài liệu
Tác giả:









Preview text:
lOMoARcPSD| 36086670
HỌC VIỆN CÔNG NGHỆ BƯU CHÍNH VIỄN THÔNG
KHOA ĐÀO TẠO SAU ĐẠI HỌC ----- -----
BÁO CÁO BÀI TẬP NHÓM 9
MÔN: DỮ LIỆU LỚN
ĐỀ TÀI: Tìm hiểu về MapReduce và ứng dụng giải quyết
bài toán đếm số nguyên tố Giảng viên: TS. Nguyễn Ngọc Điệp Sinh viên:
B22CHIS039 - Nguyễn Hồng Anh Tấn
B22CHIS029 - Hoàng Đức Long Lớp: Hệ thống thông tin Mã lớp: M22CQIS02 – B
Downloaded by Dung Tran (tiendungtr12802@gmail.com) lOMoARcPSD| 36086670 MỤC LỤC
1. Khái niệm .............................................................................................................. 2
1.1 Hoạt động ......................................................................................................... 3
1.2 Ưu điểm và nhược điểm .................................................................................. 4
2. WordCount ........................................................................................................... 5
3. Cài đặt Hadoop .................................................................................................... 6
3.1 Sao chép repository từ GitHub ........................................................................ 6
3.2 Tạo container thông qua Docker compose ...................................................... 7
3.3 Tham gia vào nút chính “namenode” .............................................................. 7
3.4 Tạo cấu trúc thư mục để phân bổ các tập tin đầu vào ..................................... 7
4. Thực thi Mapreduce ............................................................................................ 8
4.1 MapReduce script ............................................................................................ 8
4.2 Khởi tạo dữ liệu ............................................................................................... 8
4.3 Sao chép mã MapReduce vào trong Hadoop .................................................. 8
4.4 Khởi tạo thư mục input/output ........................................................................ 8
4.5 Chạy MapReduce............................................................................................. 9
5. Bài toán đếm số nguyên tố ................................................................................ 10
5.1 Lớp Mapper: PrimeCountMapper ................................................................. 10
5.2 Lớp Reducer: PrimeCountReducer ............................................................... 11
5.3 Lớp Runner: PrimeCountRunner ................................................................... 12
Tìm hiểu về MapReduce 1. Khái niệm
MapReduce là một nền tảng được Google tạo ra để quản lý dữ liệu của họ.
Nhiệm vụ của MapReduce là tiếp nhận một khối lượng dữ liệu lớn. Sau đó sẽ tiến
hành tách các dữ liệu này ra thành những phần nhỏ theo một tiêu chuẩn nào đó. Từ
đó sẽ sắp xếp, trích xuất các tệp dữ liệu con mới phù hợp với yêu cầu của người
dùng. Đây cũng là cách mà thanh tìm kiếm của Google hoạt động trong khi chúng ta sử dụng hằng ngày. lOMoARcPSD| 36086670
MapReduce bao gồm hai hàm chính là hàm Map và hàm Reduce. Đây là hai
hàm được chính người dùng định nghĩa và nó cũng chính là hai giai đoạn nối tiếp
nhau trong quy trình xử lý dữ liệu của Mapreduce. Các hàm này có nhiệm vụ chính cụ thể như sau:
• Hàm Map: Hàm này có nhiệm vụ là xử lý một cặp key (key, value) để tạo ra
một cặp key mới (keyl, valuel), lúc này cặp key (keyl, valuel) sẽ đóng vai trò
là trung gian. Sau đó, người dùng chỉ cần ghi dữ liệu xuống đĩa cứng và nhanh
chóng tiến hành thông báo cho hàm Reduce để dữ liệu đi vào input của Reduce.
• Hàm Reduce: Hàm này có nhiệm vụ là tiếp nhận cặp từ khoá trung gian và
giá trị tương ứng với lượng từ khoá đó (keyl, valuel) để tạo thành một tập
khoá khác nhau bằng cách tiến hành ghép chúng lại. Các cặp khoá/giá trị này
sẽ được đưa vào các hàm Reduce thông qua một con trỏ vị trí. Quá trình này
sẽ giúp cho các lập trình viên dễ dàng quản lý được một lượng danh sách lớn
cũng như phân bổ giá trị phù hợp với bộ nhớ hệ thống.
Ngoài ra, ở giữa Map và Reduce còn một bước trung gian khác mang tên
Shuffle. Sau khi Map hoàn thành xong nhiệm vụ của mình thì Shuffle sẽ tiếp tục
công việc thu thập cũng như tổng hợp cặp từ khoá/giá trị trung gian đã được tạo ra
bởi Map trước đó và chuyển nó đến Reduce để tiếp tục xử lý.
Hình 1: Các hàm của MapReduce 1.1 Hoạt động
Mapreduce hoạt động dựa vào nguyên tắc chính là "Chia để trị", như sau:
1. Phân chia các dữ liệu cần xử lý thành nhiều phần nhỏ trước khi thực hiện.
Downloaded by Dung Tran (tiendungtr12802@gmail.com) lOMoARcPSD| 36086670
2. Xử lý các vấn đề nhỏ theo phương thức song song trên các máy tính rồi
phântán hoạt động theo hướng độc lập.
3. Tiến hành tổng hợp những kết quả thu được để đề ra được kết quả sau cùng.
Các bước hoạt động của MapReduce:
1. Tiến hành chuẩn bị các dữ liệu đầu vào để cho Map() có thể xử lý.
2. Lập trình viên thực thi các mã Map() để xử lý.
3. Tiến hành trộn lẫn các dữ liệu được xuất ra bởi Map() vào trong ReduceProcessor
4. Tiến hành thực thi tiếp mã Reduce() để có thể xử lý tiếp các dữ liệu cầnthiết.
5. Thực hiện tạo các dữ liệu xuất ra cuối cùng.
1.2 Ưu điểm và nhược điểm Ưu điểm:
• Xử lý dữ liệu lớn: MapReduce được thiết kế đặc biệt để xử lý và tính toán trên
các tập dữ liệu lớn, chẳng hạn như petabyte hoặc exabyte dữ liệu.
• Tính toán phân tán: Hệ thống MapReduce phân tán công việc xử lý dữ liệu
trên nhiều máy chủ, giúp tận dụng sức mạnh tính toán của nhiều máy tính.
• Khả năng mở rộng: Bạn có thể thêm máy chủ vào hệ thống MapReduce để
tăng hiệu suất xử lý dữ liệu một cách dễ dàng khi cần.
• Tính chịu lỗi: MapReduce có khả năng xử lý lỗi một cách hiệu quả thông qua
việc tự động chuyển công việc đến các máy tính khác nếu máy chủ gặp sự cố.
• Dễ dàng lập trình: Có nhiều khung lập trình, chẳng hạn như Apache Hadoop,
Apache Spark, và Flink, hỗ trợ MapReduce, giúp người lập trình viết mã một cách dễ dàng. Nhược điểm:
• Khó triển khai và cấu hình: Cài đặt và cấu hình một hệ thống MapReduce có
thể phức tạp và đòi hỏi kiến thức kỹ thuật đáng kể.
• Tốc độ chậm cho các công việc nhỏ: MapReduce không phải lựa chọn tốt cho
các công việc xử lý nhỏ hoặc truy cập dữ liệu tần suất thấp, do overhead của
quá trình tạo và tải các tập dữ liệu trên đĩa.
• Lưu trữ trung gian: MapReduce thường đòi hỏi lưu trữ trung gian trên đĩa,
điều này có thể tạo ra hiệu suất kém và tăng độ trễ. lOMoARcPSD| 36086670
• Không phù hợp cho các loại công việc khác nhau: MapReduce chủ yếu thích
hợp cho các công việc tính toán phân tán và có mô hình dữ liệu phù hợp. Đối
với các loại công việc khác nhau, chẳng hạn như xử lý dữ liệu đồ thị, có thể
cần sử dụng các công cụ khác.
• Khó phân tích dữ liệu thời gian thực: MapReduce không phải là lựa chọn tốt
cho các ứng dụng đòi hỏi phản hồi thời gian thực và xử lý dữ liệu liên tục. 2. WordCount
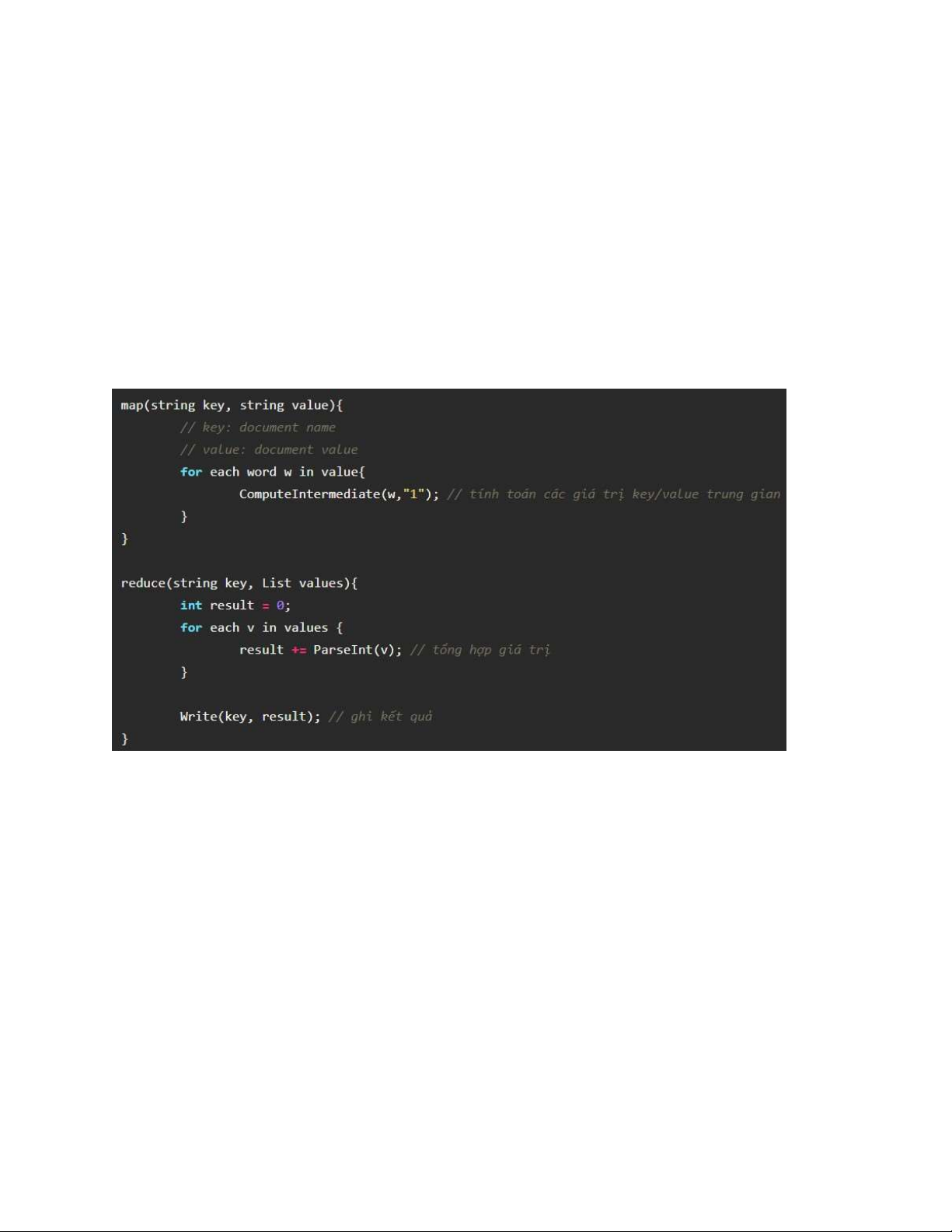
WordCount là một bài toán điển hình để minh họa cho MapReduce, ý tưởng
của MapReduce được viết giống với đoạn mã giả sau:
Ví dụ bây giờ chúng ta cần thực hiện 1 task là đếm số lần xuất hiện của mỗi từ
trong 1 văn bản. Đầu tiên chúng ta sẽ chia tách văn bản đó thành các dòng, mỗi dòng
sẽ được đánh 1 số thứ tự. Đầu vào của hàm Map sẽ là các cặp key/value chính là số
thứ tự dòng / đoạn văn bản trên dòng đó.
Trong Map chúng ta sẽ xử lý tách từng từ trong 1 dòng ra và gán cho chúng
giá trị tần suất suất hiện ban đầu là 1.
Sẽ có một tiến trình ở giữa giúp việc gộp các output đầu ra của Map có cùng key với
nhau thành 1 mảng các giá trị.
Đầu vào của Reduce sẽ là cặp key/value là từ / và 1 mảng là tần suất xuất hiện
của từ đó. Trong Reduce chúng ta chỉ cần thực hiện cộng các giá trị trong mảng và
đưa ra kết quả chính là số lần xuất hiện của từng từ trong văn bản đầu vào.
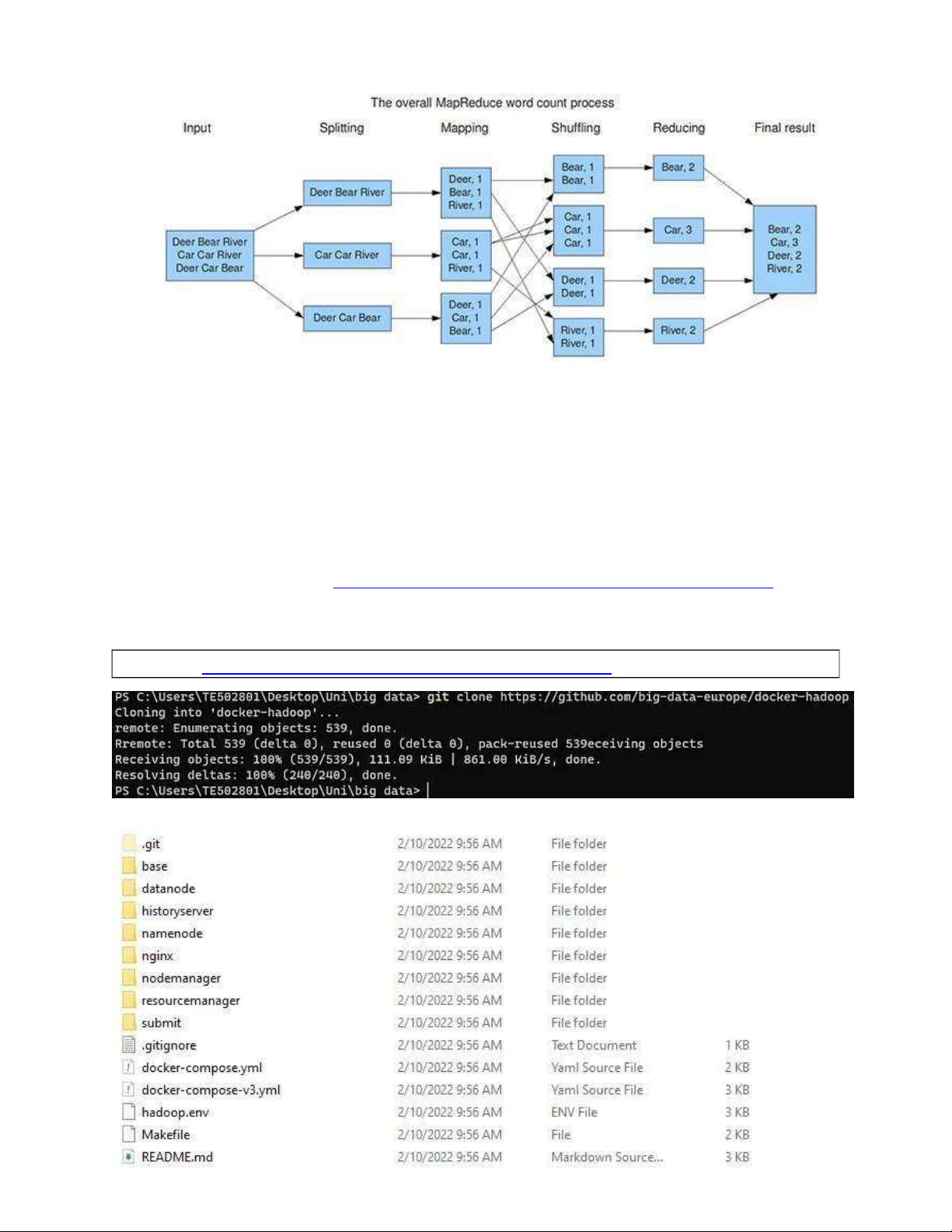
Để hình dung rõ hơn, bạn có thể xem hình ảnh sau:
Downloaded by Dung Tran (tiendungtr12802@gmail.com) lOMoARcPSD| 36086670
Hình 2: Ví dụ về WordCount trong Mapreduce 3. Cài đặt Hadoop
Điều kiện: Đã cài đặt Git và Docker
3.1 Sao chép repository từ GitHub
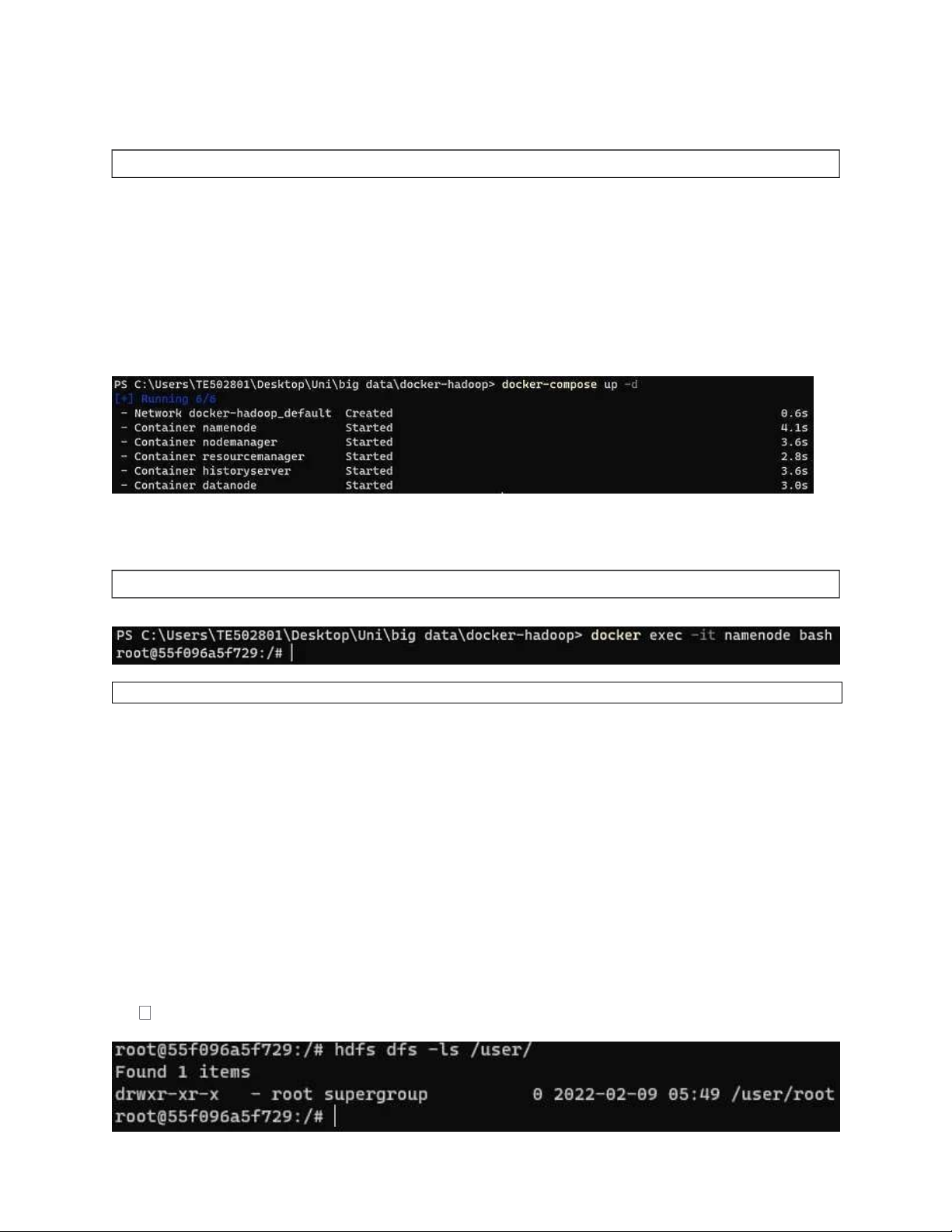
Truy cập liên kết: https://github.com/big-data-europe/docker-hadoop và sao
chép kho lưu trữ, nếu bạn đang sử dụng bảng điều khiển, bạn có thể gõ lệnh tiếp theo:
git clone https://github.com/big-data-europe/docker-hadoo p
Và bạn sẽ nhận được cấu trúc thư mục tiếp theo: lOMoARcPSD| 36086670
3.2 Tạo container thông qua Docker compose Chạy lệnh tiếp theo: docker-compose up -d
Thao tác này sẽ bắt đầu 05 container cần thiết (nếu đây là lần đầu tiên bạn thực
hiện việc này, bạn sẽ phải đợi cho đến khi quá trình tải xuống hoàn tất).
Docker Compose cho phép chúng ta chạy các ứng dụng Docker nhiều
container và sử dụng nhiều lệnh chỉ bằng tệp YAML. Vì vậy, việc gọi lệnh trước đó
sẽ chạy tất cả các dòng trong tệp docker-compose.yml và sẽ tải xuống các hình ảnh cần thiết, nếu cần.
Bạn có thể kiểm tra xem tất cả năm container có đang chạy hay không bằng cách gõ lệnh docker ps
3.3 Tham gia vào nút chính “namenode”
docker exec -it namenode bash
3.4 Tạo cấu trúc thư mục để phân bổ các tập tin đầu vào
Đầu tiên, có thể liệt kê tất cả các tệp trong hệ thống HDFS • hdfs dfs -ls
Tiếp theo, chung ta tạo một tệp /user/root/, vì hadoop hoạt động với cấu trúc được xác định này
• hdfs dfs -mkdir -p /user/root
Chúng ta có thể xác minh xem nó có được tạo chính xác không hdfs dfs -ls /user/
Downloaded by Dung Tran (tiendungtr12802@gmail.com) lOMoARcPSD| 36086670 4. Thực thi Mapreduce 4.1 MapReduce script
Tải về hadoop-mapreduce-examples-2.7.1-sources.jar tại
https://repo1.maven.org/maven2/org/apache/hadoop/hadoop- mapreduceexamples/2.7.1/
Đây là ví dụ về MapReduce cho bài toán Word count
4.2 Khởi tạo dữ liệu
Hầu hết chúng ta sẽ sử dụng Hadoop để xử lý một tệp khá lớn, có thể vài
gigabyte, nhưng trong trường hợp này, chúng tôi sẽ sử dụng tệp 1 MB, cuốn sách
kinh điển “Don Quijote de La Mancha” làm văn bản thuần túy, bạn có thể sử dụng
bất kỳ văn bản nào bạn muốn.
Bạn có thể tải xuống tệp văn bản tôi đã sử dụng ở đây:
https://gist.github.com/jsdario/6d6c69398cb0c73111e49f1218960f79#fileel_ quijotetxt
4.3 Sao chép mã MapReduce vào trong Hadoop
Đầu tiên, di chuyển chúng từ nơi bạn đã tải xuống và đặt chúng vào thư mục
kho lưu trữ nhân bản. Sau đó gõ lệnh tiếp theo (bạn phải ở trong terminal bình
thường, không phải bên trong container nút tên, bạn có thể sử dụng lệnh “exit”).
docker cp hadoop-mapreduce-examples-2.7.1-sources.jar namenode:/tmp
Làm tương tự với file .txt
4.4 Khởi tạo thư mục input/output Vào lại container namenode
• docker exec -it namenode bash Sau đó
• hdfs dfs -mkdir /user/root/input lOMoARcPSD| 36086670
Sao chép tệp .txt từ /tmp sang tệp đầu vào Đầu tiên cd tới /tmp
• hdfs dfs -put el_quijote.txt /user/root/input 4.5 Chạy MapReduce
• hadoop jar hadoop-mapreduce-examples-2.7.1-sources.jar
org.apache.hadoop.examples.WordCount input output
Bạn sẽ thấy đầu vào lớn, nhưng nếu bạn đã thực hiện đúng các bước trước đây thì mọi thứ sẽ ổn Xem kết quả
Tùy thuộc vào tệp văn bản của bạn, bạn sẽ thấy một cái gì đó như thế này
• hdfs dfs -cat /user/root/output/*
Downloaded by Dung Tran (tiendungtr12802@gmail.com) lOMoARcPSD| 36086670 5.
Bài toán đếm số nguyên tố
5.1 Lớp Mapper: PrimeCountMapper package org.example;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.*; import java.io.IOException;
import java.util.StringTokenizer;
public class PrimeCountMapper extends MapReduceBase implements MapperText, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private final static Text isPrime = new Text("Is prime");
private final static Text isNotPrime = new Text("Is not prime"); @Override public void map( LongWritable longWritable, Text text,
OutputCollector outputCollector, Reporter reporter ) throws IOException {
StringTokenizer tokenizer = new StringTokenizer(text.toString());
while (tokenizer.hasMoreTokens()) {
String number = tokenizer.nextToken(); try {
IntWritable n = new IntWritable(Integer.parseInt(number)); if (isPrime(n.get())) {
outputCollector.collect(isPrime, one); } else {
outputCollector.collect(isNotPrime, one); }
} catch (NumberFormatException e) { // TODO } } }
private boolean isPrime(int n) { if (n <= 1) { return false; }
for (int i = 2; i * i <= n; i++) { if (n % i == 0) { return false; } } return true; } } lOMoARcPSD| 36086670
Lớp Mapper thực hiện tách input từ một dòng là chuỗi string thành các token
là các số tự nhiên. Sau đó với mỗi token số tự nhiên, chương trình kiểm tra tính
nguyên tố của số tự nhiên đó. Nếu là số nguyên tố thì thêm vào Output một cặp dữ
liệu = (“Is prime”, 1), ngược lại thêm vào Output
một cặp dữ liệu = (“Is not prime”, 1).
5.2 Lớp Reducer: PrimeCountReducer package org.example;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reducer;
import org.apache.hadoop.mapred.Reporter; import java.io.IOException; import java.util.Iterator;
public class PrimeCountReducer extends MapReduceBase implements ReducerIntWritable, Text, IntWritable> { @Override
public void reduce(Text key, Iterator iterator,
OutputCollector outputCollector, Reporter reporter) throws IOException { int total = 0; while (iterator.hasNext()) {
total += iterator.next().get(); }
outputCollector.collect(key, new IntWritable(total)); } }
Lớp Reducer nhận đầu vào là key thuộc một trong hai giá trị: • “Is prime” • “Is not Prime”
Và một tập các giá trị được thêm từ Mapper thỏa mãn có key trùng với key
đang xét. Như vậy hàm Reducer cộng tổng các giá trị của key lại và trả tiếp ra output cặp tương ứng
Downloaded by Dung Tran (tiendungtr12802@gmail.com) lOMoARcPSD| 36086670
5.3 Lớp Runner: PrimeCountRunner package org.example;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.*;
public class PrimeCountRunner {
public static void main(String[] args) {
JobClient client = new JobClient();
JobConf jobConf = new JobConf(PrimeCountRunner.class);
jobConf.setJobName("SalePerCountry");
jobConf.setOutputKeyClass(Text.class);
jobConf.setOutputValueClass(IntWritable.class);
jobConf.setMapperClass(org.example.PrimeCountMapper.class);
jobConf.setReducerClass(org.example.PrimeCountReducer.class);
jobConf.setInputFormat(TextInputFormat.class);
jobConf.setOutputFormat(TextOutputFormat.class);
FileInputFormat.setInputPaths(jobConf, new Path(args[0]));
FileOutputFormat.setOutputPath(jobConf, new Path(args[1])); client.setConf(jobConf); try { JobClient.runJob(jobConf); } catch (Exception e) { e.printStackTrace(); } } }
Lớp runner cấu hình các thuộc tính cho một Job chạy trong Hadoop
Dữ liệu đầu vào: prime.txt
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 Kết quả đầu ra:
2023-10-12 19:12:13,159 INFO sasl.SaslDataTransferClient:
SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false Is not prime 9 Is prime 6
Tài liệu liên quan:
-

Bài giảng Big Data | Học viện Công Nghệ Bưu Chính Viễn Thông
34 17 -

Tài liệu thiết kế kỹ thuật | Quản lý dữ liệu lớn
45 23 -

Câu hỏi ôn thi dữ liệu lớn | Học viện Công Nghệ Bưu Chính Viễn Thông
41 21 -

Bài tập lớn: Cài đặt và Demo Hadoop Mapreduce môn Dữ liệu lớn | Học viện Công Nghệ Bưu Chính Viễn Thông
179 90 -

Kiến trúc MapReduce trong Hadoop: Cấu trúc và nguyên lý hoạt động môn Dữ liệu lớn | Học viện Công Nghệ Bưu Chính Viễn Thông
193 97