Báo cáo bài tập lớn: Dịch máy với Transformer | Môn Xử lý ngôn ngữ tự nhiên - Đại học Bách Khoa Hà Nội
Transformer mô hình xử lý ngôn ngữ tự nhiên thành công nhất trong giai đoạn gần đây. Hầu hết các mô hình SOTA mới nhất đều được xây dựng dựa trên hoặc lấy ý tưởng từ Transformer và cơ chế Attention. Tài liệu được sưu tầm gồm 18 trang, giúp bạn ôn tập tốt hơn. Mời các bạn đón xem.
Môn: Xử lý ngôn ngữ tự nhiên 12 tài liệu
Trường: Đại học Bách Khoa Hà Nội 5.8 K tài liệu
Tác giả:











Preview text:
lOMoAR cPSD| 61622985 Báo cáo bài tập lớn
Học phần: XỬ LÝ NGÔN NGỮ TỰ NHIÊN
Dịch máy Anh-Việt với Transformer
Giảng viên: PGS.TS. Lê Thanh Hương Nhóm 15
Nguyễn Bình Dương – 20173062
Vũ Ngọc Hiển – 20173103
Nghiêm Văn Nghĩa – 20173283 Đặng Văn Nam - 20173268
Mục lục 1 – Tổng quan ............................................. Lỗi! Thẻ đánh dấu không được xác định.
2 – Nội dung .......................................................................................................................... 2
2.1 – Đặt vấn đề .................................................................................................................... 2
2.2 – Cơ sở lý thuyết ............................................................................................................. 4
2.3 – Đề xuất giải pháp ........................................................................................................ 10
2.4 – Thử nghiệm ................................................................................................................ 12
2.5 – Đánh giá kết quả......................................................................................................... 15
3 – Kết luận ........................................................................................................................... 18 1. Tổng quan lOMoAR cPSD| 61622985
Transformer mô hình xử lý ngôn ngữ tự nhiên thành công nhất trong giai đoạn
gần đây. Hầu hết các mô hình SOTA mới nhất đều được xây dựng dựa trên hoặc
lấy ý tưởng từ Transformer và cơ chế Attention.
Bên cạnh cơ chế self-attention làm nên thành công cho Transformer, mô hình
transformer còn có nhiều thành phần quan trọng khác cũng có khả năng ảnh
hưởng tới chất lượng mô hình cũng như tốc độ hội tụ.
Trong bài tập lớn này, nhóm chúng em đưa ra giả thuyết và thử nghiệm cải tiến
mô hình transformer với những phương pháp lập lịch cập nhật learningrate mới,
đồng thời thử nghiệm những hàm Normalization và vị trí thực hiện
normalization trong mô hình nhằm tăng mức độ ổn định. Cuối cùng, nhóm thực
hiện crawl dữ liệu tăng cường và đánh giá chất lượng mô hình sau khi được huấn
luyện với bộ dữ liệu lớn hơn. 2. Nội dung 2.1. Đặt vấn đề
2.1.1. Vấn đề warmup trong mô hình Transformer
Learning-rate warmup là một kỹ thuật lập lịch learning-rate trong
deep learning, nhằm giải quyết vấn đề “quá khớp sớm” (earlyoverfitting).
Trong quá trình huấn luyện mô hình học máy, dữ liệu thường được
chia thành các batch, các batch được huấn luyện lần lượt. Có thể
xảy ra hiện tượng những batch dữ liệu đầu tiên có những tính chất
đặc biệt, thể hiện mạnh ở batch dữ liệu đó nhưng không phải là tính
chất toàn cục của toàn bộ dataset (cực tiểu địa phương). Những
batch dữ liệu bias này có thể khiến model nhanh chóng hội tụ về
một điểm cực tiểu địa phương, dẫn đến chất lượng dự đoán của model thấp. lOMoAR cPSD| 61622985 Ví dụ bias data
1 giải pháp phổ biến để giải quyết vấn đề này là phương pháp
learning-rate warmup, trong đó ở những iteration đầu tiên của quá
trình huấn luyện, giá trị learning rate được giữ ở mức nhỏ. Kỹ thuật
này được nhóm tác giả của Transformer sử dụng, giúp cho model
không hội tụ một cách “vội vàng”. Tuy nhiên, đây cũng là sự đánh
đổi tốc độ hội tụ của model. Nếu dữ liệu được xử lý tốt, không xuất
hiện bias ở những batch đầu, warm up là không cần thiết.
Chính vì vậy, nhóm đặt ra câu hỏi liệu có thể loại bỏ kỹ thuật
warmup trong khi vẫn đảm bảo độ chính xác của model hay không?
Normalization có thể thay thế vai trò của warmup được hay không?
2.1.2. Normalization trong mô hình Transformer
Trong kiến trúc của mô hình Transformer, layer normalization là một
thành phần thiết yếu những thường ít được chú ý trong công tác
nghiên cứu tối ưu mô hình. Tuy nhiên, nhiều nghiên cứu chỉ ra rằng
normalization layer có khả năng tác động lớn tới sự hội tụ của mô hình theo 2 hướng:
- Vị trí đặt layer normalization có thể tác động tới sự hội tụ của
mô hình. Trong mô hình Transformer gốc, tác giả sử dụng
postnorm residual units (POSTNORM), trong đó layer
normalization được đặt ngay sau sub-layer và bước residual
addition. Tuy nhiên, đã có những nhà nghiên cứu đặt ra giả thuyết về việc
POSTNORM có thể gián tiếp gây ra hiệu ứng gradient vanishing/exploding đối với
mạng neural nhiều layer. Nhóm đặt ra câu hỏi: Liệu việc thay đổi vị trí của layer lOMoAR cPSD| 61622985
normalization (ví dụ: đặt layer normalization liền trước các attention sublayer) có
thể cải thiện mức độ ổn định cao hơn trong quá trinh hội tụ của model hay không?
- Lựa chọn công thức normalization có thể tác động tới sự hội tụ
của mô hình. Nhóm đề xuất thử nghiệm áp dụng các phương
pháp SCALENORM, FIXNORM tại layer normalization và quan sát
khả năng cải thiện của model.
2.1.3. Lập lịch learning rate
Nhìn chung, chiến lược lập lịch learning rate được áp dụng bởi
nhóm tác giả Transformer khá thận trọng. Nhóm tác giả sử dụng kỹ
thuật warm-up đồng thời giữ learning rate ở ngưỡng nhỏ. Cách tiếp
cận này có thể làm chậm tốc độ hội tụ của mô hình, và không xét
đến chất lượng dự đoán của mô hình trên tập validation để đưa ra
những điều chỉnh về learning rate phù hợp.
2.1.4. Vấn đề thiếu dữ liệu huấn luyện model
Dữ liệu huấn luyện đóng vai trò quan trong tới chất lượng của
model. Tuy rằng có nhiều bộ dữ liệu dịch máy Anh-Việt được công
bố trên Internet, nhóm cho rằng bên cạnh việc huấn luyện mô hình
với các dataset sẵn có, nhóm có thể tự thu thập và bổ sung các
dataset khác để bổ sung vào pipeline huấn luyện model. Nhóm dự
kiến sẽ đánh giá chất lượng mô hình trên các datatset sẵn có cũng
như dataset tự thu thập, đánh giá và giải thích sự cải thiện của mô hình (nếu có). 2.2. Cơ sở lý thuyết
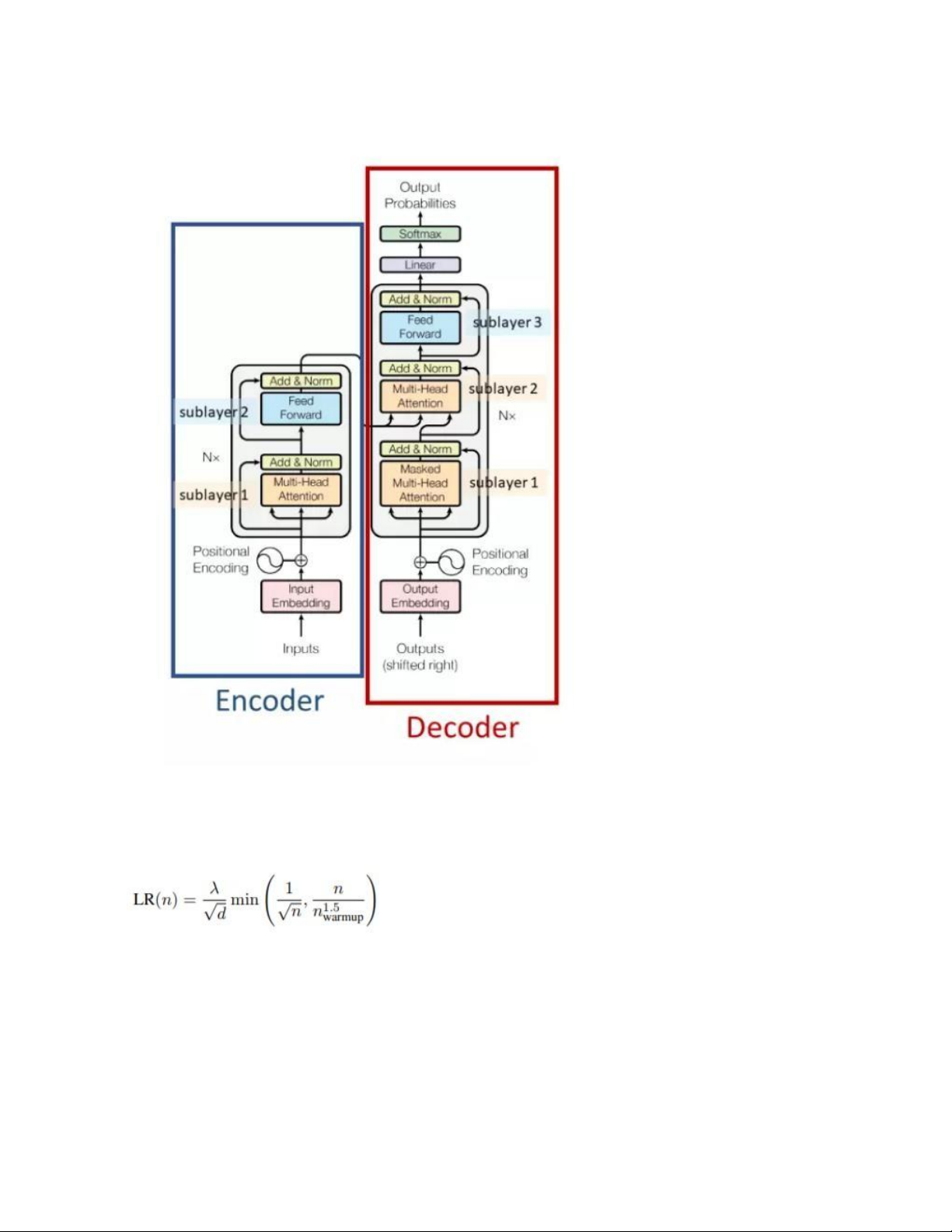
2.2.1. Tổng quan mô hình Transformer 2.2.1.1.
Vấn đề của mô hình NLP Sequence-to-Sequence truyền thống
Mô hình Sequence-to-Sequence nhận input là một sequence và
trả lại output cũng là một sequence. Ví dụ bài toán Q&A, input lOMoAR cPSD| 61622985
là câu hỏi "how are you ?" và output là câu trả lời "I am good".
Phương pháp truyền thống sử dụng RNNs cho cả encoder (phần
mã hóa input) và decoder (phần giải mã input và đưa ra output tương ứng).
Điểm yếu thứ nhất của RNNs là thời gian train rất chậm, đến
mức người ta phải sử dụng phiên bản Truncated
Backpropagation để train nó. Mặc dù vậy, tốc độ train vẫn rất
chậm do phải sử dụng CPU, không tận dụng được tính toán song song trên GPU.
Điểm yếu thứ hai là nó xử lý không tốt với những câu dài do hiện
tượng Gradient Vanishing/Exploding. Khi số lượng units càng
lớn, gradient giảm dần ở các units cuối do công thức Đạo hàm
chuỗi, dẫn đến mất thông tin/sự phụ thuộc xa giữa các units. 2.2.1.2. Kiến trúc Transformer lOMoAR cPSD| 61622985
2.2.2. Learning-rate scheduler
Trong giải pháp gốc của nhóm tác giả Transformer, kỹ thuật lập lịch
learning rate được sử dụng là inverted square root decay.
Trong đó, d là số chiều ẩn của layer self-attention, lambda và
n_warmup lần lượt là giá trị tối đa của learning rate và số bước cần
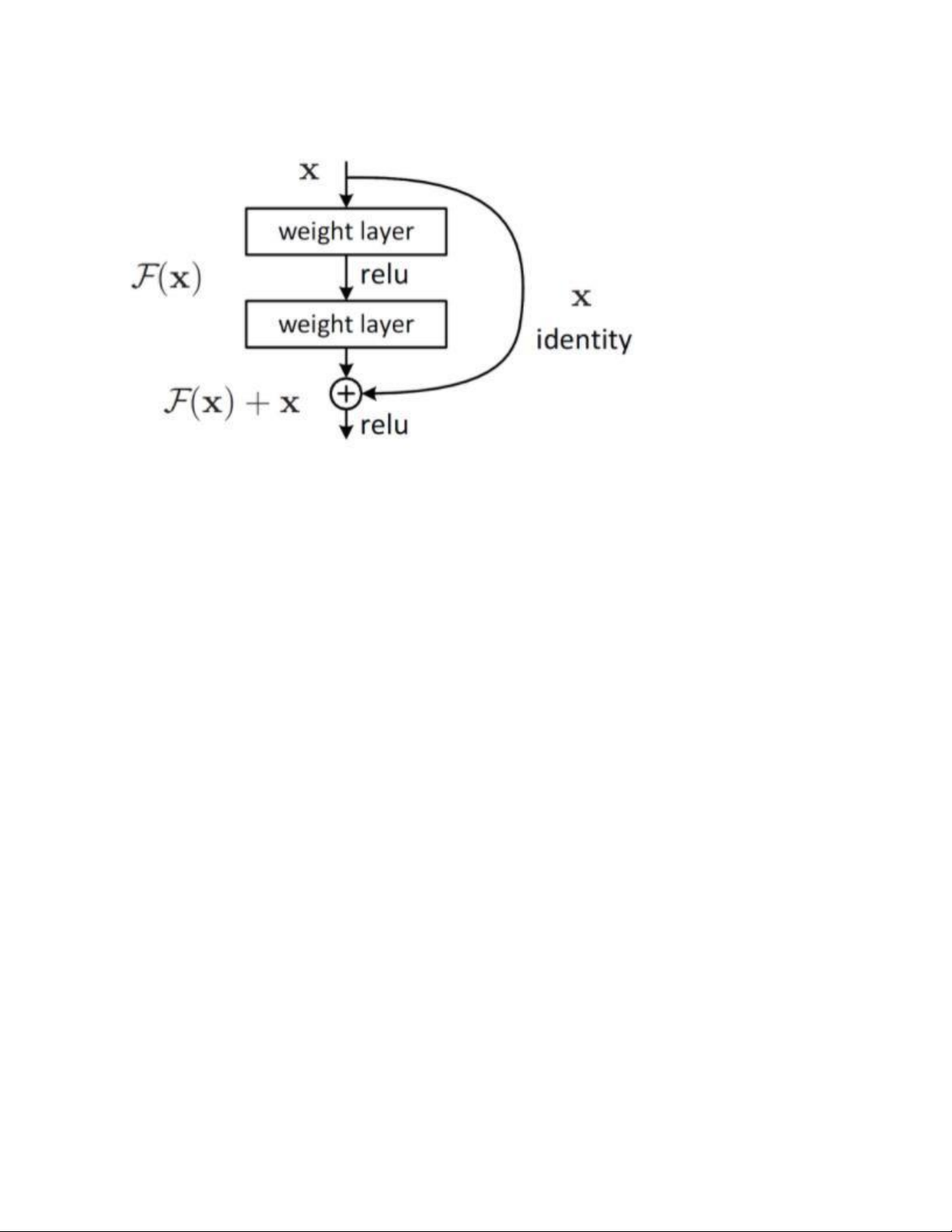
có để đạt được giá trị lambda đó. 2.2.3. Residual connection lOMoAR cPSD| 61622985 Ví dụ residual block
Residual connection là một kỹ thuật skip-connection được áp dụng
phổ biến trong các mô hình học sâu, bao gồm Transformer. Khi một
mô hình được áp dụng kỹ thuật residual connection, mô hình đó
được cấu thành bởi các residual block (hình minh họa trên). Với giả
định các layer được biểu diễn bởi hàm phi tuyến F, residual
connection thực hiện phép cộng element-wise output của stack các
layer với input của các layer: x + F(x). 2.2.4. Normalization
Trong phần này, nhóm trình bày một số phương pháp normalization được
áp dụng phổ biến trong các model SOTA, phân tích ưu/nhược điểm (trên
cơ sở lý thuyết) của các phương pháp. 2.2.4.1. LAYERNORMALIZATION (pytorch)
Đây là phương pháp normalization căn bản nhất, xuất phát trực tiếp
từ lý thuyết Phân phối chuẩn tắc. Đây cũng là phương pháp được
sử dụng bởi nhóm tác giả của mô hình Transformer. Giải pháp này
cũng được implement dưới dạng hàm của framework PyTorch.
Công thức của phương pháp LAYERNORM như sau: lOMoAR cPSD| 61622985
Trong đó, kỳ vọng và độ lệch chuẩn được tính theo chiều cuối cùng của tensor x.
Beta và gamma là các tham số của phép biến đổi affine, có tác dụng
quyết định giá trị kỳ vọng và phương sai của dữ liệu sau normalize.
Beta và gamma là 2 tham số learnable.
LAYERNORMALIZATION là phương pháp normalization được sử
dụng phổ biến do có nhiều ưu điểm, trong đó bao gồm:
- Khả năng bảo toàn hình dạng của phân phối dữ liệu. Tuy rằng giá
trị kỳ vọng và phương sai bị thay đổi, hình dạng phân phối dữ
liệu nhìn chung được giữ nguyên. Phép biến đổi affine có tính
chất bảo toàn các đường thẳng song song, các mặt phẳng trong không gian nhiều chiều.
- Linh hoạt. Các tham số beta, gamma có thể được thiết lập giá trị
tùy ý, và có thể được học và cập nhật. Điều này cho phép tận
dụng tối đa kỹ thuật gradient decent trong mô hình học sâu,
đồng thời giúp kỹ thuật normalization có thể thích ứng với nhiều
kiến trúc mô hình khác nhau.
Tuy nhiên, normalization có thể gây ra hiện tượng gradient
vanishing nếu lớp normalization được đặt ngay sau residual connection. 2.2.4.2. SCALENORM
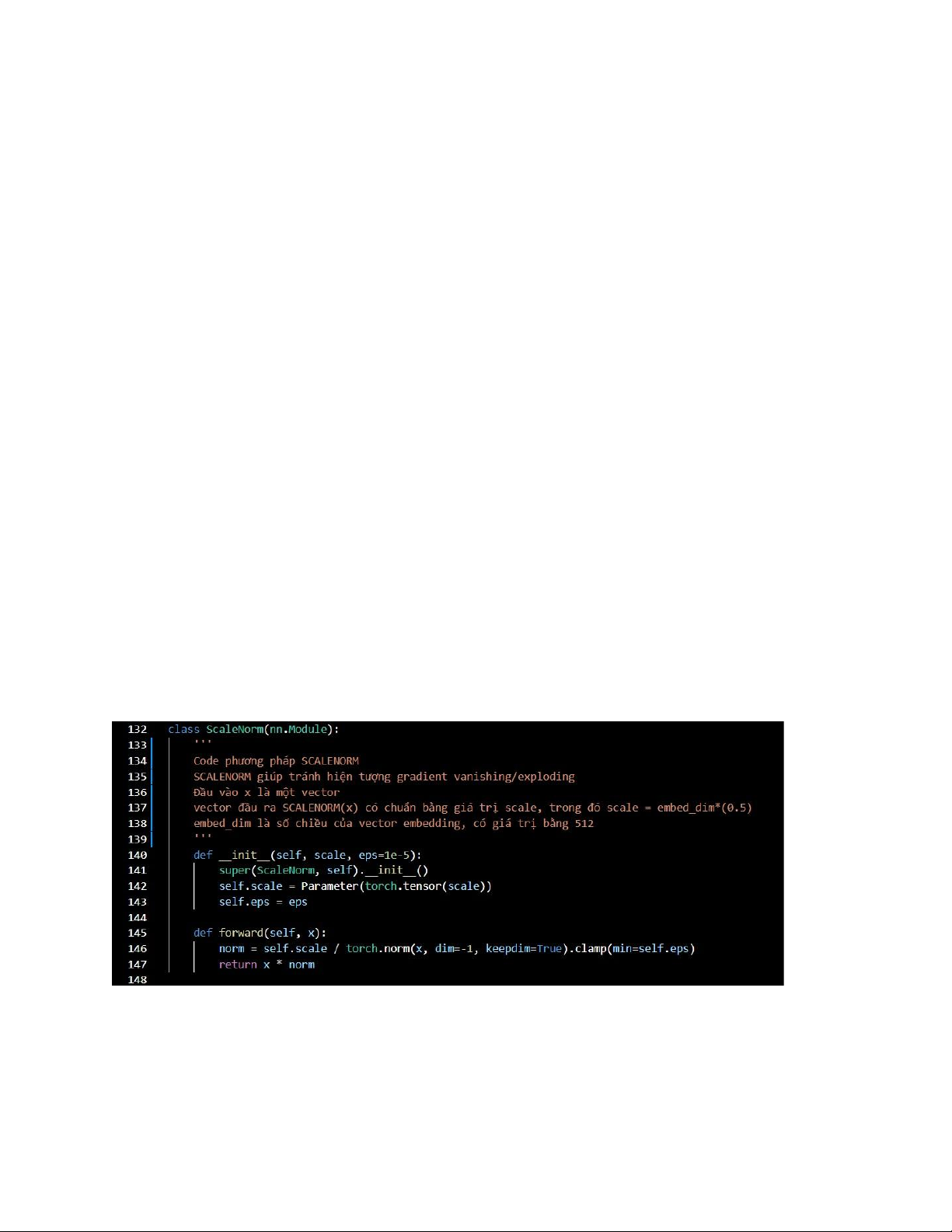
Scale Norm là một phương pháp normalization dữ liệu, đảm bảo
vector đầu ra luôn có norm = scale (scale là tham số cho trước).
Công thức cụ thể xem phần 2.2.1. 2.2.5. Data augmentation
Data augmentation là các kỹ thuật được sử dụng để tăng lượng lOMoAR cPSD| 61622985
dữ liệu bằng cách thêm các bản sao được sửa đổi nhẹ của dữ liệu
đã có hoặc dữ liệu tổng hợp mới được tạo từ dữ liệu hiện có. Nó
hoạt động như một bộ điều chỉnh và giúp làm giảm tình trạng quá
tải khi đào tạo các mô hình học máy.
- Các phương pháp làm giàu dữ liệu trong NLP:
+ Back translation: Tiến hành dịch dữ liệu từ ngôn ngữ này
sang ngôn ngữ khác và ngược lại. Điều này có thể giúp tạo
dữ liệu với các từ khác nhau trong khi văn bản mẫu bảo
toàn ngữ cảnh của dữ liệu văn bản.
+ Easy Data Augmentation: Sử dụng các phương pháp tăng
cường dữ liệu truyền thống đơn giản. EDA có thể giúp
ngăn chặn việc dữ liệu quá mức và đào tạo mô hình mạnh mẽ hơn:
● Synonym replacement: Chọn ngẫu nhiên các từ
trong câu không phải là stop words. Thay thế chúng
bằng một trong các từ đồng nghĩa được chọn ngẫu nhiên.
● Random insertion: Tìm một từ đồng nghĩa ngẫu
nhiên của một từ ngẫu nhiên trong câu không phải
stop words, chèn từ đó vào một vị trí ngẫu nhiên trong câu.
● Random swap: Chọn ngẫu nhiên hai từ trong câu và
hoán đổi vị trí của chúng.
● Random deletion: Xóa bỏ ngẫu nhiên từng từ trong câu với xác suất P. + NLP Albumentation:
● Shuffle Sentences Transform: Xáo trộn các câu để tạo ra một mẫu mới.
● Exclude duplicate transform: Nếu văn bản chứa
nhiều câu trùng lặp, tiến hành loại bỏ các câu trùng
lặp để tạo ra mẫu mới. lOMoAR cPSD| 61622985
2.3. Đề xuất giải pháp
2.3.1. Xây dựng và thử nghiệm phương pháp normalization mới
Thử nghiệm loại Normalization mới (Scale L2 Norm):
y = scale*(x/L2-norm(x)) trong đó: scale = embedding_dim^(0.5)
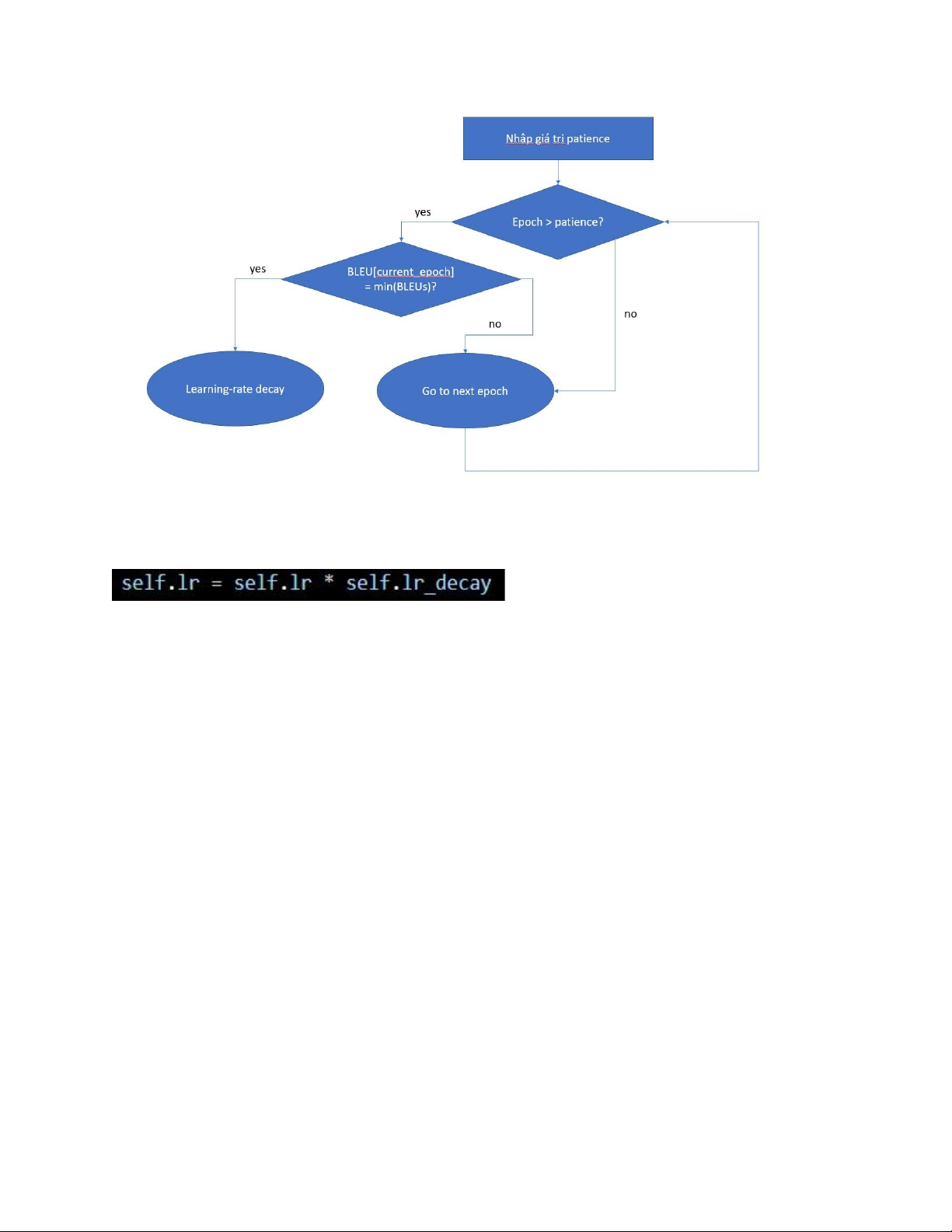
2.3.2. Thử nghiệm giải pháp Validation-based learning-rate scheduler
Nhóm chúng em áp dụng kỹ thuật lập lịch learning-rate dựa trên
thông tin từ tập dữ liệu validation. Ý tưởng của kỹ thuật như sau:
Mô hình được huấn luyện với giá trị learning-rate lớn, sau mỗi
epoch chất lượng mô hình được đánh giá lại trên tập dữ liệu
validation. Nếu mô hình cho thấy performance suy giảm,
learningrate được nhân với hệ số suy giảm alpha_decay.
Mô hình sử dụng 1 metric duy nhất để đánh giá performance qua từng epoch: BLEU
Điều kiện đánh giá sự “suy giảm” của performance được nới lỏng
bằng chiến lược patience:
Truyền vào mô hình một siêu tham số “patience”, với giá trị là một
số nguyên dương nhỏ (nhóm chọn giá trị 3). Patience đại diện cho
số epoch liền trước epoch hiện tại được đánh giá khi đưa ra quyết
định có giảm learning rate hay không.
Cụ thể, tại mỗi epoch, nếu số lượng epoch hiện tại lớn hơn patience
và giá trị BLEU trong epoch hiện tại là nhỏ nhất so với patience (VD:
3) epoch gần nhất, thì ta giảm learning rate lOMoAR cPSD| 61622985
Sơ đồ phương pháp patience
Learning rate được giảm bằng cách nhân với một hệ số decay:
Ngoài ra, nhóm cũng thử nghiệm loại bỏ bước WarmUp để đánh giá
liệu việc loại bỏ warm-up có gây ảnh hưởng tới chất lượng model hay không 2.3.3. Làm giàu dữ liệu
Trong bài toán dịch văn bản từ tiếng Anh sang tiếng Việt, lý do mà
các mô hình hiện tại cho ra được kết quả chưa được tốt cho lắm,
đặc biệt là khi xử lý các văn bản mang đậm tính ngữ cảnh, và sử
dụng các từ ngữ có tính liên kết cao, một phần lớn là do việc thiếu
dữ liệu trong quá trình huấn luyện.
Trong mô hình ban đầu mà nhóm đã xây dựng, nhóm đã xây dựng
mô hình transformer và thực hiện quá trình training trên tập dữ liệu
của Stanford, gồm 133 nghìn cặp câu tiếng Anh và tiếng Việt. 133
nghìn về mặt số lượng để cho mô hình có cơ hội hiểu và học được
những khái niệm và liên kết tổng quát về mặt ngữ nghĩa của tiếng
Việt và tiếng Anh theo đánh giá của nhóm là không nhiều. Stanford lOMoAR cPSD| 61622985
cũng đồng ý với nhận định này của nhóm với việc đánh dấu bộ dữ
liệu này là low-resource. Trên thực tế, khi thực hiện quá trình
training cho mô hình Transformer trên bộ dữ liệu trên, kết quả thu
được trên tập Validate hội tụ tại khoảng ~28 BLEU SCORE, một con
số chấp nhận được tuy nhiên vẫn khá là khiêm tốn.
Nhận thấy việc có nhiều dữ liệu từ các nguồn khác nhau ảnh hưởng
rất lớn tới kết quả của bài toán, nhóm đã quyết định dành sự quan
tâm đặc biệt tới việc thu thập dữ liệu và làm giàu dữ liệu. Trong quá
trình thu thập dữ liệu, nhóm đã bỏ rất nhiều công sức để thu thập
dữ liệu từ các nguồn khác nhau, ví dụ như các trang web sách song
ngữ, các trang web phim, các trang web về văn bản pháp luật,... và
thu được lượng khoảng 3.5 triệu cặp câu tiếng Anh và tiếng Việt.
Sau đó, nhóm thực hiện nhân bộ dữ liệu này lên trong bước làm
giàu dữ liệu bằng cách thực hiện back-translation, ghép câu
(sentence concatenating), và thực hiện kỹ thuật đánh nhãn cho các
câu này để nhân số lượng các câu lên khoảng 27 triệu cặp câu. 2.4. Thử nghiệm
2.4.1. Cài đặt Transformer với một số điều chỉnh kiến trúc -
Code phương pháp SCALENORM: File layers.py
- Code phương pháp Validation-based learning-rate decay: lOMoAR cPSD| 61622985 File controller.py
2.4.2. Huấn luyện mô hình Transformer với dữ liệu làm giàu 2.4.2.1. Dữ liệu làm giàu
Sau bước thu thập dữ liệu, nhóm đã thu thập được tổng cộng
3.5 triệu cặp câu Anh Việt, lưu trong một file json có dung lượng 1.5 GB.
Bộ từ vựng sau quá trình đếm từ tập dữ liệu này hơn là 21 nghìn
từ tiếng Anh và tiếng Việt. Số lượng như vậy theo đánh giá của
nhóm là đã đủ để thực hiện các bước tiếp theo là làm giàu và
thực hiện huấn luyện mô hình. lOMoAR cPSD| 61622985 2.4.2.2.
Huấn luyện model với dữ liệu làm giàu
Mô hình được nhóm sử dụng để huấn luyện với dữ liệu thu thập
được cùng với dữ liệu sau khi được làm giàu là Transformer của thư viện tensor2tensor.
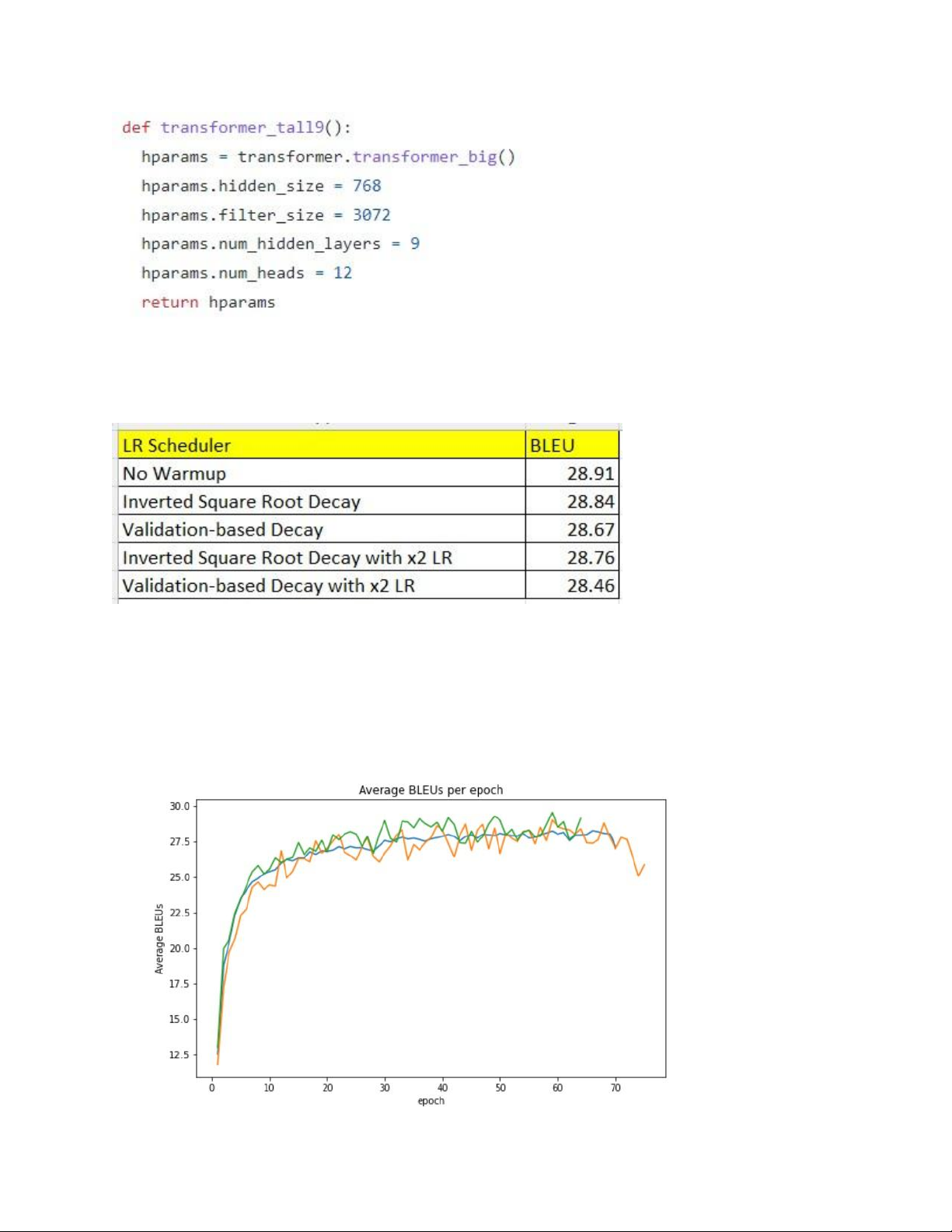
Mô hình Transformer của nhóm bao gồm có 9 lớp encoder và 9
lớp decoder, kích thước của lớp hidden là 768, kích thước filter
là 3072, số attention head của mỗi lớp là 12. lOMoAR cPSD| 61622985 2.5. Đánh giá kết quả
2.5.1. Đánh giá kết quả điều chỉnh kiến trúc Transformer
2.5.1.1. Điều chỉnh learning-rate scheduler
Không có chênh lệch đáng kể trong điểm đánh giá BLEU cuối cùng
khi so sánh các phương pháp LR Scheduler khác nhau.
Tuy nhiên, khi quan sát biến động BLEU qua từng epoch training,
nhóm nhận thấy tác động của việc loại bỏ WarmUp đối với quá trình hội tụ của mô hình: lOMoAR cPSD| 61622985
Validation-based + NoWarmUp + Decay Multiplication
Validation-based + WarmUp + InvertedSquareRootDecay
Validation-based + NoWarmUp + 2xLR
Có thể thấy việc loại bỏ WarmUp giúp model nhanh chóng hội tụ
hơn, trong khi không ảnh hưởng đến chất lượng của mô hình. Bên
cạnh đó, việc tăng gấp đôi Learning Rate cũng giúp model hội tụ
nhanh hơn. Tuy nhiên, nhóm dự đoán hiện tượng Overfitting đã xảy
ra trên model với x2 Learning Rate, do chất lượng dự đoán của
model trên training dataset tốt hơn so với x1 Learning Rate, nhưng
trên test dataset kết quả lại tệ hơn.
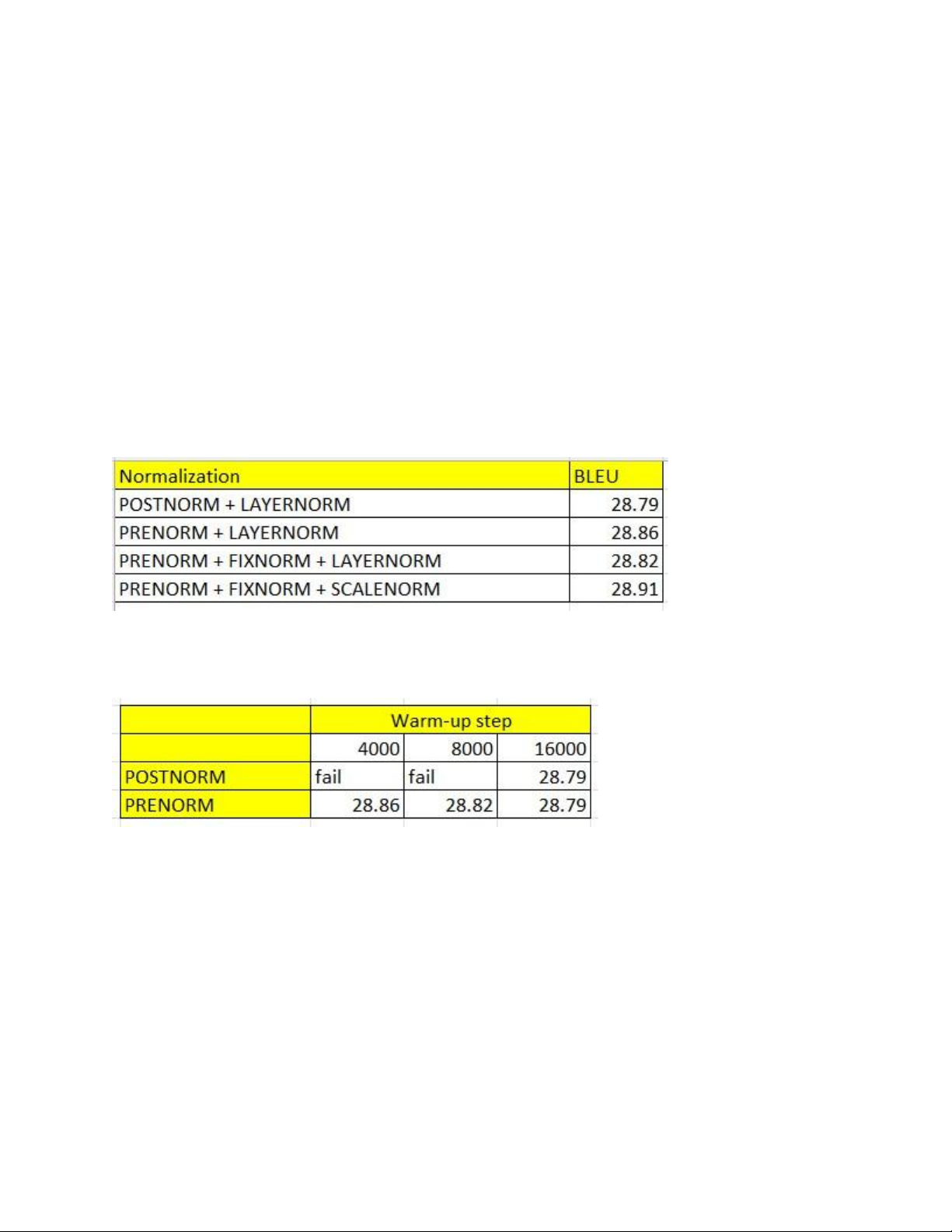
2.5.1.2. Thử nghiệm normalization
Không có sự chênh lệch đáng kể về chất lượng mô hình đánh giá
dựa trên BLEU score, tuy nhiên PRENORM cho thấy sự ổn định trong hội tụ.
Khi thay đổi số bước warm-up, ta nhận thấy với số step warm-up
nhỏ, model dễ dàng xảy ra gradient vanishing khi sử dụng POSTNORM.
Tuy nhiên PRENORM giúp model có thể hội tụ ngay cả với những
warm-up step mà POSTNORM không thể hội tụ, cho thấy mức độ
ổn định vượt trội đáng kể.
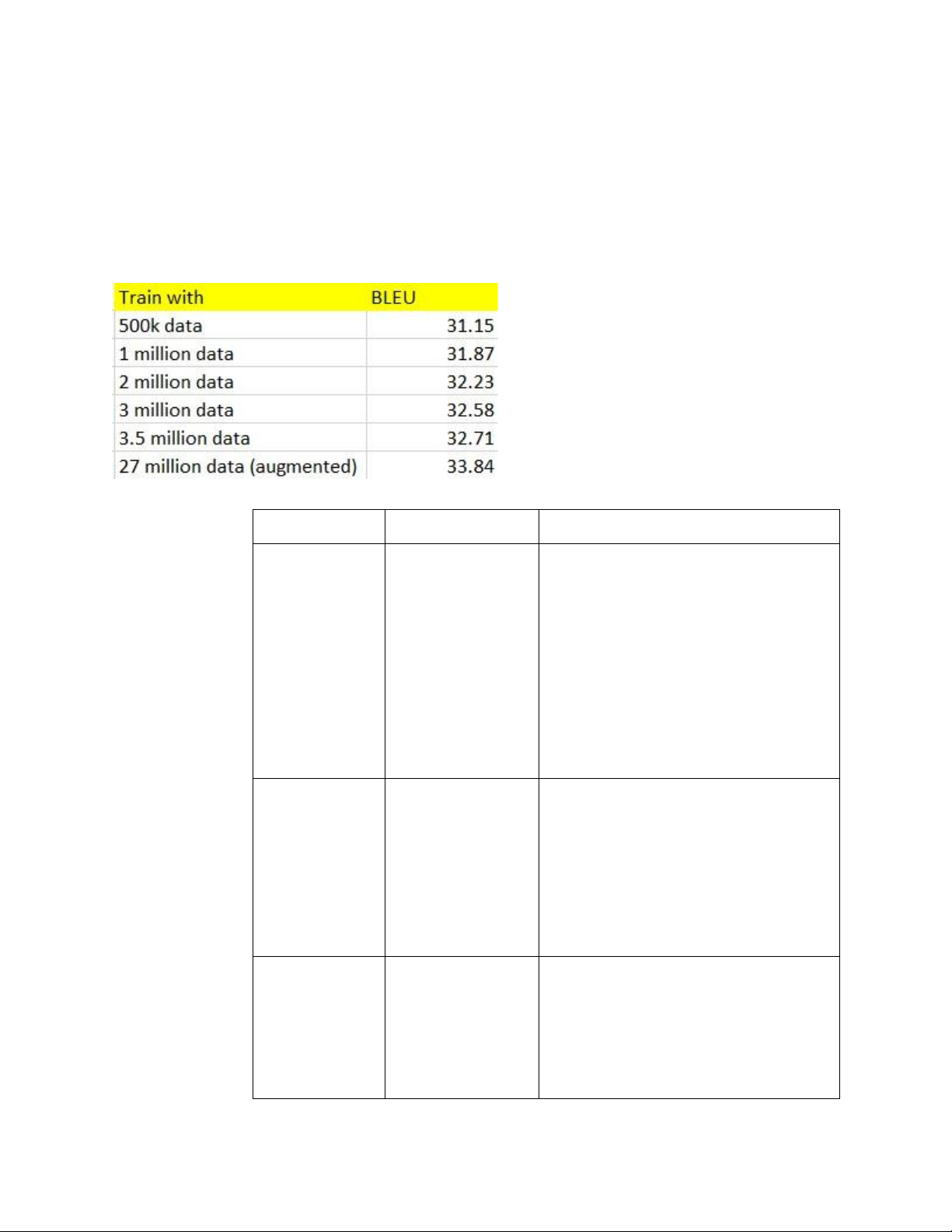
2.5.2. Đánh giá kết quả làm giàu dữ liệu (So sánh BLEU giữa các lần train với dữ liệu làm giàu) lOMoAR cPSD| 61622985
Nhóm đã thực hiện huấn luyện mô hình đối với tập dữ liệu gốc (dữ
liệu chưa được làm giàu), và thực hiện huấn luyện lại mô hình đối
với dữ liệu với dữ liệu sau khi được làm giàu, và so sánh kết quả
BLEU SCORE trung bình thu được trên tập Validate trước và sau khi
thực hiện làm giàu, và kết quả thu được trên tập Validate đã tăng
1.1 BLEU SCORE sau khi thực hiện bước làm giàu dữ liệu.
2.5.3. Phân công công việc Thành viên MSSV Nội dung công việc Nguyễn Bình 20173062 Tìm hiểu paper; Dương
Đề xuất giải pháp cải tiến; Thử nghiệm điều chỉnh LRScheduler,
ScaleNormalization; Đánh giá
kết quả, visualize kết quả, đưa
ra nhận xét; Làm báo cáo,slide và thuyết trình Vũ Ngọc Hiển 20173103
Xây dựng và huấn luyện mô
hình với augmentation data; Crawl augmentation data;
Đánh giá kết quả với mô hình
augmentation data; Chuẩn bị code demo; Đặng Văn 20173268
Tìm nguồn data bổ sung; Lập Nam
kế hoạch các giai đoạn bổ sung dữ liệu;
Thiết kế và xây dựng giải pháp crawl data; lOMoAR cPSD| 61622985 Nghiêm Văn 20173283
Xây dựng và huấn luyện mô hình Nghĩa Transfomer (2 mô hình); Thử nghiệm LR-Scheduler;
Crawl dữ liệu augmentation;
Đánh giá và tiền xử lý dữ liệu augmentation;
Huấn luyện và đánh giá mô hình với augmentation data; Làm báo cáo; 3. Kết luận
Trong bài tập lớn này, nhóm chúng em đã đặt mục tiêu hiểu rõ kiến trúc mô
hình Transformer, đồng thời nắm bắt những phương pháp cải tiến mô hình
được cộng đồng khoa học đề xuất. Chúng em cũng phối hợp với những kiến
thức học được từ “Học phần Xử lý ngôn ngữ tự nhiên” để tự đưa ra những
đề xuất cải tiến của bản thân.
Những giải pháp đề xuất được thử nghiệm chưa đem lại cải tiến đáng kể,
nhưng phần nào thể hiện được sự thống nhất giữa giả thuyết mà nhóm đề
ra với hành vi thực tế của model. Những giải pháp cải tiến cũng đem lại mức
độ ổn định đáng kể cho quá trình hội tụ của mô hình.
Nhóm cũng đã thu thập bổ sung được một lượng dữ liệu đáng kể, và chứng
minh được dữ liệu bổ sung đem lại cải thiện chất lượng cho mô hình.
Tài liệu liên quan:
-

Báo cáo Tóm tắt trích rút đơn văn bản Tiếng Việt | Môn Xử lý ngôn ngữ tự nhiên - Đại học Bách Khoa Hà Nội
74 37 -

Comprehensive overview of NLP: Parsing, MT, and QA systems môn Xử lý ngôn ngữ tự nhiên | Trường Đại học Bách Khoa Hà Nội
152 76 -

Text classification: Concepts & methods môn Xử lý ngôn ngữ tự nhiên | Trường Đại học Bách Khoa Hà Nội
106 53 -

Tóm tắt lý thuyết xử lý văn bản và âm thanh trong NLP môn Xử lý ngôn ngữ tự nhiên | Trường Đại học Bách Khoa Hà Nội
100 50