Báo cáo bài tập lớn môn Hệ thống nhúng đa phương tiện | Đại học Bách Khoa Hà Nội
Báo cáo bài tập lớn môn Hệ thống nhúng đa phương tiện | Đại học Bách Khoa Hà Nội. Tài liệu được sưu tầm giúp bạn tham khảo, ôn tập và đạt kết quả cao. Mời bạn đọc đón xem.
Môn: Lập trình hệ nhúng 9 tài liệu
Trường: Đại học Bách Khoa Hà Nội 5.8 K tài liệu
Tác giả:
















Preview text:
Hanoi University of Science and Technology
School of Electrical and Electronic Engineering REPORT MULTIMEDIA EMBEDDED SYSTEMS Students: Nguyễn Hà Anh - 20224298
Lê Ngọc Hướng - 20224315
Nguyễn Mai Hương - 20224314 Ha Noi, January 2026
Project 20 - Smart Surveillance Camera with Voice Alerts Expected outcomes:
The system is expected to automatically detect intruders using a CNN-based person
detection model, issue real-time voice alerts via a TTS module, and enable remote
monitoring through a user application, demonstrating an integrated and responsive smart surveillance solution.
Project development page:
● Design thinking page (Figma): Link Figma
● Task management page (JIRA): Link JIRA
Number of submitted progress reports: 6 reports Obtained achievements:
This project successfully developed a Smart Surveillance Camera with Voice Alerts
prototype on Raspberry Pi 4. The system integrates real-time person detection using
YOLOv8, voice alerts via eSpeak NG, and a remote mobile monitoring application.
Through model optimization, NCNN conversion, and a multithreaded design, the system
achieves acceptable real-time performance on embedded hardware. Overall, the project
demonstrates the feasibility of combining embedded AI, text-to-speech, and remote
monitoring in a low-cost smart surveillance solution. TABLE OF CONTENT
WORK ALLOCATION...................................................................................................... 4
I. OVERVIEW......................................................................................................................5
II. IMPLEMENTATION.....................................................................................................8
Software Components...................................................................................................... 8
Data Flow......................................................................................................................... 9
UML-Based System Modeling................................................................................... 9
SystemC-Based Behavioral Modeling......................................................................10
Model Selection: YOLOv8n..................................................................................... 11
Person Detection Implementation on Raspberry Pi 4............................................... 11
III. RESULT....................................................................................................................... 17
IV. CONCLUSION.............................................................................................................19 I. OVERVIEW 1. Project summary
This project presents the development of a Smart Surveillance Camera with Voice
Alerts system designed for real-time monitoring and automated warning. The
system aims to detect human presence in surveillance scenes and immediately
respond by generating voice alerts while simultaneously sending notifications to a
remote monitoring application.
The core of the system is built on the YOLO deep learning model, which is used for
real-time person detection from video streams captured by a Logitech C930e
webcam. When a person is detected, the system triggers the eSpeak text-to-speech
engine to produce audible warning messages through a Bluetooth speaker,
providing instant on-site alerts.
In parallel, a dedicated server and remote monitoring application are developed to
receive and display detection events, enabling users to monitor the surveillance
status remotely in real time. The entire system is deployed on a Raspberry Pi 4,
which serves as the central processing unit, handling video acquisition, model
inference, alert generation, and network communication.
2. Overview of person detection and YOLO
Person detection is a fundamental task in computer vision that focuses on
identifying and localizing human presence in images or video streams. It serves as a
core component in many applications such as video surveillance, crowd analysis,
human–computer interaction, and autonomous systems. The goal of person
detection is to accurately distinguish humans from the background and other objects
under varying conditions, including changes in pose, scale, occlusion, and illumination.
YOLO (You Only Look Once) is a real-time object detection algorithm that
performs detection and classification in a single forward pass of a neural network.
Instead of separating region proposal and classification stages, YOLO formulates
object detection as a regression problem, directly predicting bounding boxes and
class probabilities from the entire input image. This unified approach enables high
processing speed while maintaining competitive accuracy, making YOLO well
suited for real-time applications such as surveillance systems, autonomous driving,
and robotics. Recent YOLO versions (e.g., YOLOv5, YOLOv8) further improve
performance by refining network architectures to better balance speed, accuracy, and deployment efficiency. 3. Overview of eSpeak
eSpeak is a compact open-source text-to-speech (TTS) engine that converts written
text into synthetic speech. Developed by Jonathan Duddington, it supports more
than 100 languages and accents and uses a formant synthesis approach instead of
large recorded speech databases, which makes it lightweight and suitable for
real-time applications on low-resource systems. eSpeak is cross-platform and
provides both command-line tools and APIs for easy integration into different
software environments. Although its synthesized voice sounds more robotic than
modern neural TTS systems, eSpeak remains popular in accessibility tools,
research, and embedded applications due to its small footprint, speed, and flexibility.
Building on these characteristics, eSpeak is particularly well suited for deployment
on the Raspberry Pi 4, a widely used single-board computer for embedded and IoT
projects. Thanks to its low CPU and memory requirements, eSpeak runs smoothly
on Raspberry Pi OS and can generate speech in real time. It can be easily integrated
into Python scripts, shell programs, and system services to enable voice output in
applications such as assistive devices, educational tools, robotics, and smart
systems. Despite its simpler and less natural voice quality, eSpeak is a practical and
reliable TTS solution for Raspberry Pi–based projects where efficiency and ease of
use are more important than high-fidelity speech.
Role of eSpeak in the System
Within the overall architecture of the project, eSpeak NG acts as the audio output
module. Its main role is to convert detection results into spoken messages, allowing
the system to communicate with users in a natural and intuitive way. When a person
is detected in the camera’s field of view, the system generates a voice alert such as
“Person detected”. This auditory feedback is particularly useful in scenarios where
users may not be constantly watching the screen, such as smart surveillance,
assistive systems, or hands-free monitoring applications.
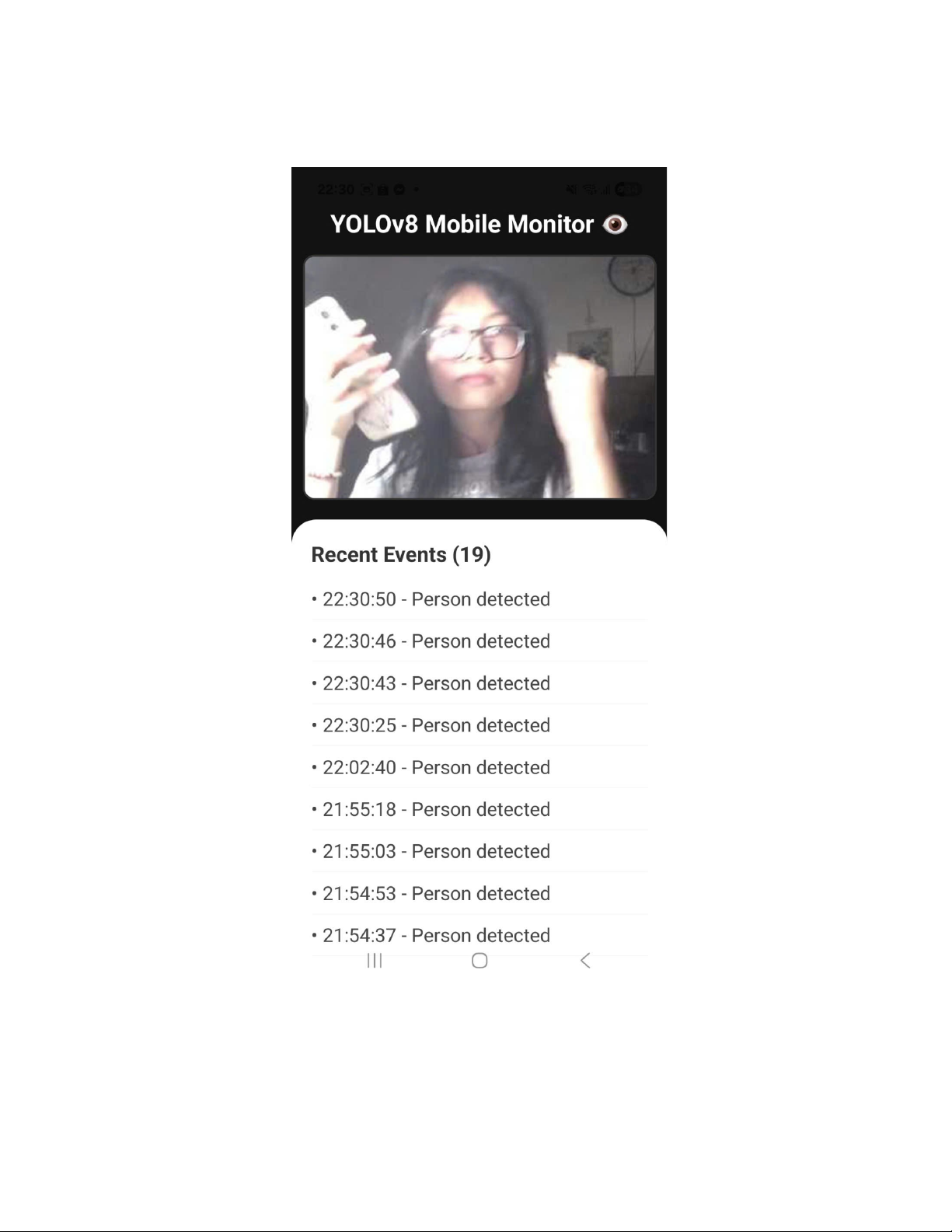
4. Overview of remote monitoring app
The remote monitoring application is a cross-platform mobile solution designed to
provide real-time oversight of the YOLOv8 detection system. Built using the React
Native framework and managed via Expo Go, the app serves as a portable
alternative to the traditional web-based dashboard, allowing users to monitor
security or operational events from any mobile device within the local network.
The core functionality of the app revolves around the seamless integration of live
visual data and textual event logs. It establishes a high-frequency connection with a
centralized Flask backend to retrieve synchronized updates. Specifically, the
application renders a live feed by decoding Base64-encoded image strings directly
from the server, while simultaneously maintaining an organized, scrollable list of
detection events (such as timestamps and identified objects). By leveraging
asynchronous data fetching and a responsive UI design, the app ensures that users
receive immediate notifications of system activities with minimal latency,
significantly enhancing the mobility and accessibility of the monitoring infrastructure. II. IMPLEMENTATION
1. Implement system modeling in UML and SystemC System design Hardware Components
- Camera: Captures live video, e.g., USB webcam or Raspberry Pi camera module.
- Speaker: Plays voice alerts when a person is detected.
- Raspberry Pi: Main processing unit running the embedded CNN model and
controlling camera & speaker.
- Network Module: Wi-Fi or Ethernet for connecting the Raspberry Pi to the remote monitoring app. Software Components
- Embedded CNN Model (Person Detection) ● Runs on Raspberry Pi.
● Receives images from the camera → predicts whether a person is present.
● Lightweight models: YOLOv8 for real-time processing. - Text-to-Speech Engine
● Triggered by the CNN detection → generates voice alert through the speaker. ● Offline engines: eSpeak. - Remote Monitoring App ● On a smartphone or PC.
● Receives live video stream from the Pi.
● Receives alerts when a person is detected.
- Control Software on Raspberry Pi
● Captures images continuously from the camera.
● Sends frames to CNN for detection.
● If a person is detected → triggers TTS → plays alert via speaker.
● Streams video and alerts to the remote app. Data Flow
- Camera captures image → Raspberry Pi.
- CNN model analyzes image → if person detected → signal sent to TTS engine.
- TTS engine generates voice alert → plays via speaker.
- Raspberry Pi sends live video stream + alert notifications to the remote
monitoring app over the network.
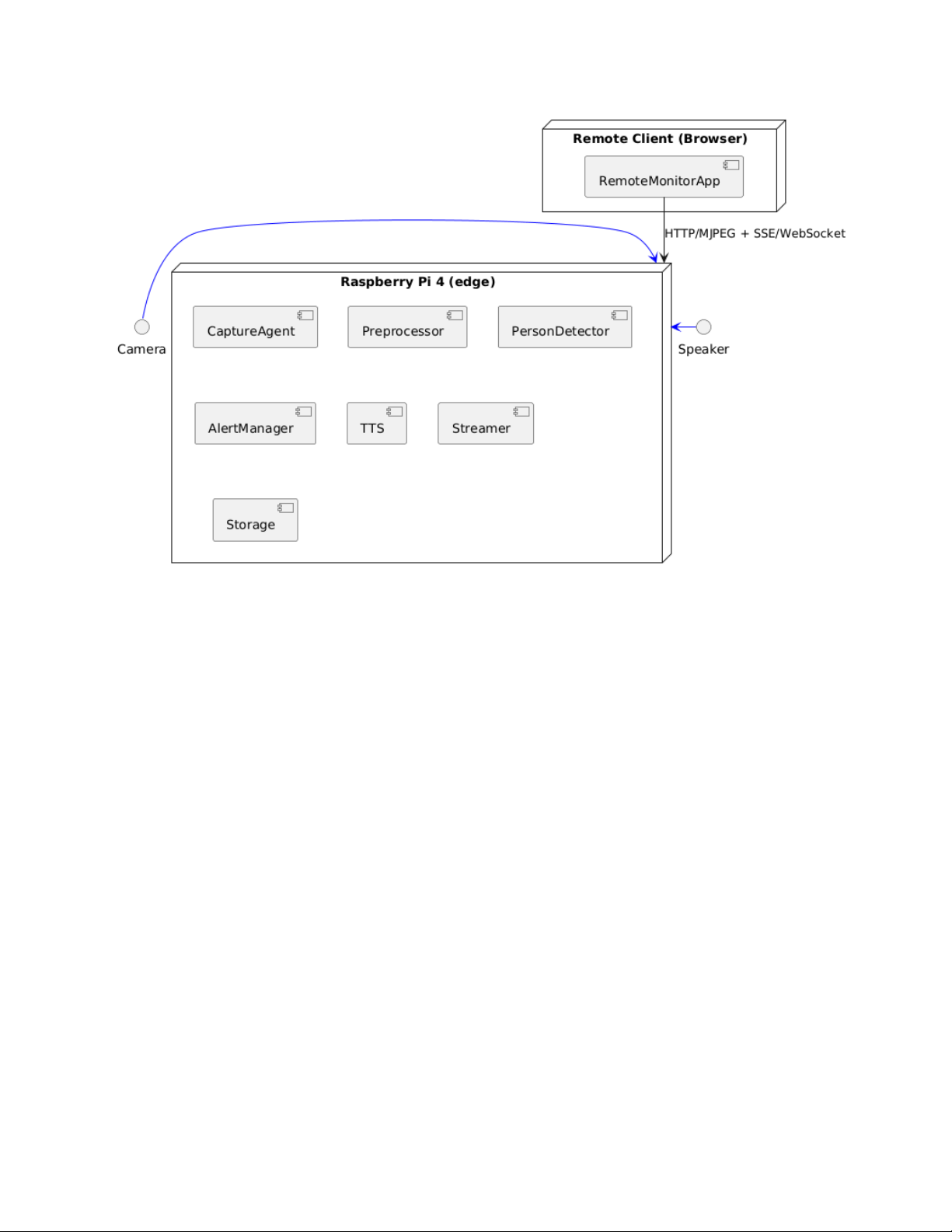
UML-Based System Modeling
The Smart Surveillance System was first modeled using Unified Modeling
Language (UML) to define the overall architecture and interactions between system
components. The UML diagrams describe a modular design consisting of video
capture, person detection, alert management, text-to-speech, and remote streaming
modules. This structure reflects an edge-computing approach, where video
processing and AI inference are executed on the embedded device, while
monitoring is handled remotely.
In addition, the UML sequence and deployment diagrams illustrate the runtime
behavior and physical distribution of the system. Video frames flow through the
detection pipeline, and detection events trigger voice alerts and remote notifications
in parallel. The deployment model places computation on the Raspberry Pi and
visualization on a web or mobile client, ensuring low latency and scalability.
SystemC-Based Behavioral Modeling
Based on the UML design, a SystemC model was implemented to simulate system
behavior and timing. The simulation includes modules for frame generation, person
detection, alert management, text-to-speech, and event streaming. Communication
between modules is implemented using sc_fifo channels, allowing realistic
modeling of data flow and concurrency.
The SystemC simulation focuses on event-driven execution and timing delays, such
as inference latency and alert generation. When a person is detected, events are
processed concurrently by the TTS and streaming modules. This approach allows
early validation of system behavior and interaction before deploying the system on real embedded hardware.
2. Implement person detection on Raspberry Pi 4
Model Selection: YOLOv8n
Person detection is implemented using the pretrained YOLOv8n model to enable
real-time human detection via a webcam. YOLOv8n is chosen due to its lightweight
architecture and fast inference speed, making it well suited for deployment on
resource-constrained devices such as the Raspberry Pi 4. The model performs
general object detection, including the person class, by predicting bounding boxes
and class labels, providing a good balance between detection accuracy and
computational efficiency for embedded surveillance applications.
Person Detection Implementation on Raspberry Pi 4
Each captured frame is passed directly to the YOLOv8n detector for inference. The
detection results are filtered to retain only the person class, and a confidence
threshold (0.8) is applied to reduce false positives. When at least one person is
detected in a frame, the system marks the frame as containing a human and triggers
subsequent actions such as alert generation or visualization. This straightforward
detection flow ensures reliable person detection while maintaining real-time
performance on the Raspberry Pi 4.
3. Implement eSpeak on Raspberry Pi 4
In this project, eSpeak NG is integrated into a Raspberry Pi 4–based system to
provide real-time text-to-speech (TTS) feedback for a person detection application.
The Raspberry Pi operates as an edge device that captures video streams, performs
object detection using a YOLO model, and announces important events through synthesized speech.
Installation of eSpeak NG on Raspberry Pi 4
eSpeak NG is installed directly on Raspberry Pi OS using the system package
manager. The installation process involves updating the package list and installing
the eSpeak NG engine and its dependencies. After installation, the tool can be tested
from the terminal to verify that audio output is working correctly through the connected speaker.
Asynchronous Speech Generation with speak_async()
The TTS functionality in the system is encapsulated in the function
speak_async(). This function is responsible for invoking the eSpeak NG engine
to synthesize speech from a given text message. Instead of running speech synthesis
directly in the main program flow, speak_async() launches the TTS process in
a separate thread. This asynchronous design has several important advantages:
● Non-blocking operation: Speech synthesis does not interrupt or delay other
tasks such as frame acquisition, YOLO inference, or visualization.
● Real-time performance: The system can continue processing new frames while audio is being played.
● Responsiveness: Voice alerts are generated immediately when events occur,
without freezing the user interface.
Triggering and Control of Speech Output
In the main processing loop, speak_async() is called only when a person is
detected. To avoid repetitive announcements when the same person remains in view,
a time-based control mechanism is applied. The system enforces a minimum
speaking interval between two consecutive alerts, ensuring that audio feedback is
informative but not intrusive.
4. Implement the remote monitoring app System Architecture
The monitoring system utilizes a Client-Server model to bridge the gap between the
detection hardware and the user's mobile device.
● Backend (Flask): Hosted on an Ubuntu workstation, serving as the central
hub to process camera frames and manage event logs received from the YOLOv8 detection module.
● Frontend (React Native/Expo): A cross-platform mobile application that
consumes the Backend APIs to provide a real-time monitoring interface.
Backend Development (Flask)
The server logic was enhanced to support mobile data transmission:
● Image Processing: Captured camera frames using OpenCV, which were then
compressed and encoded into Base64 strings.
● API Integration: Updated the /events endpoint to return a unified JSON
response containing both the latest Base64 image and the historical event list.
● Network Configuration: Configured the server to run on 0.0.0.0:5000 to
allow external connections within the local network.
Mobile App Implementation (React Native & Expo)
The mobile interface was developed to replace the original web-based monitor:
● Environment Setup: Configured a custom NPM global directory to resolve
permission errors during the Expo CLI installation.
● Data Synchronization: Implemented a Polling Mechanism using setInterval
(500ms frequency) to fetch updates from the Flask server's local IP address (192.168.0.109). ● Real-time UI Rendering:
● Utilized the component to decode and render the Base64 stream as a live video feed.
● Implemented a component to display dynamic event logs,
ensuring efficient memory usage for long lists.
● Used useState and useEffect hooks to handle the asynchronous data flow and interface updates.
5. Optimize YOLO for real time performance
a. Finetune YOLO model for person detection
To achieve real-time performance on embedded devices, the YOLO model is
optimized and fine-tuned specifically for person detection. In embedded
systems such as the Raspberry Pi, computational resources are limited, so it
is inefficient for the model to perform unnecessary calculations for object
classes that are not relevant to the application. By fine-tuning the YOLO
model to focus primarily on the person class, the overall model complexity
and inference workload are reduced. This optimization improves inference
speed, lowers latency, and ensures stable real-time performance while
maintaining sufficient detection accuracy for surveillance scenarios.
The model is finetuned using dataset People Detection on Kaggle:
https://www.kaggle.com/datasets/adilshamim8/people-detection
After fine tuning for 30 epochs, the model can focus more effectively on
detecting human presence while ignoring irrelevant object classes, resulting
in faster inference, reduced computational overhead, and improved real-time
performance on embedded devices without sacrificing detection accuracy.
b. Model Conversion (PyTorch to NCNN)
To enable efficient deployment of the YOLO-based person detection model
on the Raspberry Pi 4, the trained PyTorch model (.pt format) is converted
directly into the NCNN format. NCNN is a neural network inference
framework optimized for mobile and ARM-based devices. It provides high
performance with low memory overhead, making it particularly appropriate
for real-time applications on Raspberry Pi platforms.
Motivation for Model Conversion
The original YOLO model is trained and stored in PyTorch’s .pt format,
which is convenient for development and experimentation but not ideal for
deployment on resource-constrained hardware. Running PyTorch models
directly on Raspberry Pi 4 would introduce significant overhead in terms of
runtime size, memory usage, and inference latency. Therefore, converting the
model to NCNN allows the system to:
● Remove the dependency on the PyTorch runtime.
● Reduce model size and memory footprint.
● Improve inference speed on ARM CPUs.
● Achieve more stable real-time performance.
Direct Export from YOLO .pt to NCNN
The model conversion is performed using the YOLO framework’s built-in
export feature with the command yolo export model=yolo.pt
format=ncnn, enabling direct transformation from PyTorch to NCNN.
After export, the generated NCNN model files are transferred to the
Raspberry Pi 4, where they are loaded by the detection module and used as
the inference backend for real-time person detection.
Impact on Real-Time Performance
The direct conversion from .pt to NCNN plays a key role in achieving
real-time performance. The optimized NCNN backend allows the system to
maintain a higher frame rate and more consistent response time (the fps is
increased from ~0.2 to ~3.0), which is essential for timely detection and
voice alerts in a smart surveillance scenario.
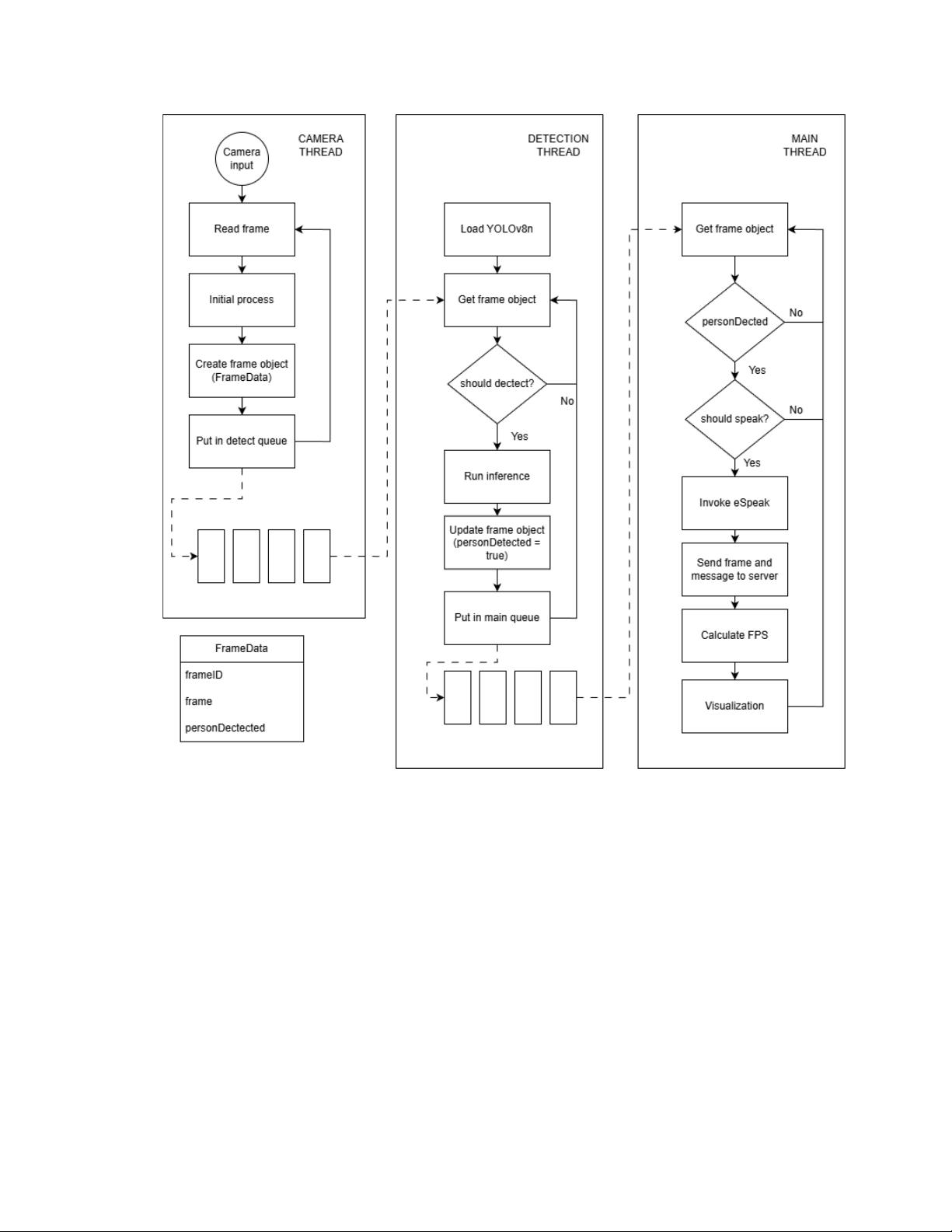
c. Performance Optimization using Multi-threading
The system adopts a multithreaded design to ensure real-time performance
on the Raspberry Pi 4 by separating time-critical and computationally
intensive tasks. Three threads operate concurrently and communicate
through bounded, thread-safe queues to control memory usage and latency.
The camera thread is responsible for continuous frame acquisition from the
webcam using OpenCV. Each captured frame is flipped and wrapped into a
FrameData object containing the raw frame and a unique frame_id.
This object is then pushed into detect_queue, which acts as a buffer
between camera input and the detection stage. The queue size is intentionally
limited to prevent frame backlog and excessive memory consumption when
downstream processing is slower than the camera frame rate.
The detection thread initializes the YOLOv8n model and retrieves
FrameData objects from detect_queue. To reduce computational load,
the detector only performs inference every predefined number of frames
(DETECT_EVERY_N). When inference is triggered, the model processes
the frame. The detection result is stored as a boolean flag
(person_detected) inside the same FrameData object, which is then
forwarded to main_queue for further handling.
The main thread consumes data from main_queue and executes
system-level logic. When a person is detected (person_detected ==
True), it triggers text-to-speech alerts with a cooldown interval to avoid
repeated notifications and sends the detected frame to a remote monitoring
server. In parallel, the thread calculates the effective FPS and overlays
system status information on the video stream for visualization. Finally, user
input is monitored to allow graceful termination of all threads.
Overall, this queue-based multithreaded pipeline ensures a clear processing
flow—capture → detect → respond—while minimizing blocking operations
and maintaining stable real-time performance on an embedded device.
Impact on Real-Time Performance
The real-time performance is improved by running YOLOv8n inference only
every N frames (DETECT_EVERY_N), which significantly reduces
computational load on the Raspberry Pi 4 and allows the video stream to
reach approximately 20 FPS. During detection frames, the stream may
briefly stutter and the FPS drops due to the inference cost; however, this
effect is minimal and does not noticeably affect overall system responsiveness. III. RESULT 1. Set up
2. Person detection result 3. Monitoring app IV. CONCLUSION
This project presents the design and implementation of a Smart Surveillance Camera with
Voice Alerts prototype that integrates real-time person detection, voice feedback, and
remote monitoring on an embedded platform. By combining YOLO-based detection,
eSpeak NG text-to-speech, and a mobile monitoring application, the system explores a
practical approach to smart surveillance using low-cost hardware.
The use of UML and SystemC modeling supported the understanding of system structure
and behavior before deployment on the Raspberry Pi 4. Through model optimization,
NCNN conversion, and a multithreaded design, the system was able to achieve acceptable
real-time performance for a prototype, although limitations in speed and accuracy still remain.
eSpeak NG provided a simple and lightweight solution for generating voice alerts, offering
timely auditory feedback despite its basic voice quality. The remote monitoring application
further demonstrates how detection results can be accessed conveniently from mobile
devices through a client–server architecture.
Overall, the project shows the feasibility of integrating computer vision, text-to-speech,
and mobile monitoring into a compact surveillance system. While the current
implementation is still preliminary, it provides a useful foundation for future
improvements in performance, robustness, and functionality toward more practical real-world applications. References
[1] How to Run YOLO Object Detection Models on the Raspberry Pi
https://www.ejtech.io/learn/yolo-on-raspberry-pi?fbclid=IwY2xjawO09ANleHRuA2FlbQI
xMABicmlkETFjM1ZKZFh2TU5sNmNia2txc3J0YwZhcHBfaWQQMjIyMDM5MTc4O
DIwMDg5MgABHnVIY31cBTAMpJm3QbqOzAY5MpXQXVPNDfVwoJLlKqwTyv4V
WMDJ398XpgDr_aem_z2O6FNk1xA4AtRTLu8onnA
[2] Optimization for YOLO model
https://www.youtube.com/watch?v=z70ZrSZNi-8
[3] How to train YOLO object detection models in Google Colab
https://youtu.be/r0RspiLG260?si=LEIaAOyBMfg2HTJZ [4] eSpeaker:
https://pypi.org/project/espeakng/
Document Outline
- I. OVERVIEW
- II. IMPLEMENTATION
- Software Components
- Data Flow
- UML-Based System Modeling
- SystemC-Based Behavioral Modeling
- Model Selection: YOLOv8n
- Person Detection Implementation on Raspberry Pi 4
- III. RESULT
- IV. CONCLUSION
Tài liệu liên quan:
-

Bài giảng IoT và Ứng dụng môn Lập trình hệ nhúng | Đại học Bách Khoa Hà Nội
18 9 -

Báo cáo thí nghiệm Lập trình vi điều khiển môn Lập trình hệ nhúng | Trường Đại học Bách Khoa Hà Nội
96 48 -

Đề thi cuối kỳ môn Lập trình hệ nhúng | Trường Đại học Bách Khoa Hà Nội
115 58 -

Bài tập lớn Thiết kế máy soát vé tàu điện tự động môn Lập trình hệ nhúng | Trường Đại học Bách Khoa Hà Nội
89 45