Báo cáo bài tập lớn: Phân loại xe máy và xe đạp môn Nhập môn Khoa học dữ liệu | Học viện Công Nghệ Bưu Chính Viễn Thông
Phân biệt xe máy và xe đạp là một bài toán phân loại ảnh trong lĩnh vực thị giác máy tính (computer vision). Tài liệu được sưu tầm gồm 13 trang, giúp các bạn ôn luyện và phục vụ cho việc học tập, đạt kết quả tốt. Mời các bạn đón xem!
Môn: Nhập môn Khoa học dữ liệu 8 tài liệu
Trường: Học viện Công Nghệ Bưu Chính Viễn Thông 1.8 K tài liệu
Tác giả:




Preview text:
lOMoAR cPSD| 58800262
HỌC VIỆN CÔNG NGHỆ BƯU CHÍNH VIỄN THÔNG
KHOA CÔNG NGHỆ THÔNG TIN
BÁO CÁO BÀI TẬP LỚN
MÔN HỌC: NHẬP MÔN KHOA HỌC DỮ LIỆU
Chủ đề: Phân loại xe máy và xe đạp Giảng viên:
Vũ Hoài Nam
Nhóm môn học: 01
Nhóm thực hiện: 03 Thành viên:
Nguyễn Trọng Hoàng - B20DCNC279
Trần Phương Nam - B20DCCN459
Lê Phúc Hoàng - B20DCCN274
Hà Nội 2023 lOMoAR cPSD| 58800262 LỜI CẢM ƠN
Chúng em xin gửi lời cảm ơn sâu sắc nhất đến Thầy Vũ Hoài Nam về sự tận tâm
và kiến thức mà Thầy đã chia sẻ trong suốt khóa học "Nhập môn khoa học dữ liệu".
Chúng em đánh giá cao cách Thầy truyền đạt kiến thức một cách sinh động và ứng
dụng thực tế, giúp chúng em hiểu rõ và ưa thích hơn trong lĩnh vực khoa học dữ
liệu. Sự hỗ trợ và sự chia sẻ kinh nghiệm của Thầy đã giúp chúng em vượt qua
những thách thức trong quá trình học tập.
Chúng em cũng muốn bày tỏ sự biết ơn đặc biệt đối với sự nhẹ nhàng và kiên nhẫn
của Thầy khi giải đáp những thắc mắc của chúng em. Nhờ vào sự hướng dẫn và
giảng dạy của Thầy, chúng em đã có được cái nhìn tổng quan và chi tiết về khoa học dữ liệu.
Chúng em rất trân trọng những giờ học với Thầy, nơi chúng em không chỉ học được
kiến thức mà còn được trải nghiệm và thực hành. Điều này giúp chúng em áp dụng
kiến thức một cách linh hoạt và hiệu quả.
Xin chúng em được bày tỏ lòng biết ơn chân thành đến Thầy Vũ Hoài Nam, người
đã đồng hành và tạo điều kiện cho sự phát triển của chúng em trong lĩnh vực học này. Mục lục
I. Giới thiệu .......................................................................................................................... 3
1. Lý do chọn đề tài ......................................................................................................... 3
2. Mục tiêu ...................................................................................................................... 3
3. Ý nghĩa ....................................................................................................................... 4
II. Xây dựng Model phân loại ............................................................................................. 4
1. Chuẩn bị dữ liệu .......................................................................................................... 4
2. Trực quan hóa dữ liệu ................................................................................................. 5
3. Tiền xử lý dữ liệu ........................................................................................................ 8
4. Model .......................................................................................................................... 9 lOMoAR cPSD| 58800262
II. Kết luận ......................................................................................................................... 12 I. Giới thiệu
1. Lý do chọn đề tài
Phân biệt xe máy và xe đạp là một bài toán phân loại ảnh trong lĩnh vực thị giác máy
tính (computer vision). Bài toán này đòi hỏi máy tính phải có khả năng nhận diện và
phân biệt hai loại phương tiện giao thông phổ biến này dựa trên các đặc trưng hình ảnh
của chúng. Đây là một bài toán không dễ dàng, vì xe máy và xe đạp có nhiều điểm
tương đồng về hình dạng, kích thước, màu sắc, và cấu tạo. Tuy nhiên, bài toán này cũng
rất quan trọng và có nhiều ứng dụng thực tế, ví dụ như:
● Giúp cải thiện an toàn giao thông. Nếu máy tính có thể phân biệt được xe máy
và xe đạp, thì nó có thể giúp các hệ thống giám sát giao thông nhận biết được
các phương tiện này trên đường và cảnh báo cho các tài xế hoặc người điều
khiển giao thông về các tình huống nguy hiểm hoặc vi phạm luật lệ.
● Giúp phát triển xe tự lái. Nếu máy tính có thể phân biệt được xe máy và xe đạp,
thì nó có thể giúp các xe tự lái nhận diện được các phương tiện này trên đường
và điều chỉnh tốc độ, hướng, và khoảng cách an toàn để tránh va chạm hoặc gây ra tai nạn.
● Giúp nâng cao trải nghiệm người dùng. Nếu máy tính có thể phân biệt được xe
máy và xe đạp, thì nó có thể giúp các ứng dụng hoặc dịch vụ liên quan đến giao
thông cung cấp các thông tin hữu ích cho người dùng, ví dụ như định vị, định
tuyến, đặt xe, thanh toán, v.v.
Do đó, chúng em quyết định chọn đề tài phân biệt xe máy và xe đạp làm đề tài cho bài
báo cáo môn khoa học dữ liệu. Phần tiếp theo, chúng em sẽ trình bày về cách thu thập,
tiền xử lý, trực quan hóa, phân tích, và khai thác dữ liệu để giải quyết bài toán này. 2. Mục tiêu
Mục tiêu của bài toán phân biệt xe máy và xe đạp là xây dựng và huấn luyện một mô
hình học sâu để nhận diện và phân loại hai loại phương tiện giao thông này dựa trên các
đặc trưng hình ảnh của chúng. Đây là một bài toán có tính thách thức cao, vì xe máy và
xe đạp có nhiều điểm tương đồng về hình dạng, kích thước, màu sắc, và cấu tạo. Để
giải quyết bài toán này, chúng em cần phải áp dụng các kiến thức và kỹ năng về thị giác lOMoAR cPSD| 58800262
máy tính, học sâu, xử lý ảnh, và khoa học dữ liệu. Bài toán này không chỉ có mục tiêu
khoa học, mà còn có mục tiêu thực tiễn, vì nó có thể ứng dụng vào nhiều lĩnh vực như
an toàn giao thông, xe tự lái, hoặc trải nghiệm người dùng. Bằng cách phân biệt được
xe máy và xe đạp, chúng em có thể giúp cải thiện chất lượng cuộc sống và bảo vệ môi trường. 3. Ý nghĩa
Phần ý nghĩa của đề tài phân biệt xe máy và xe đạp là một phần quan trọng để thể hiện
giá trị và tầm nhìn của bài toán này. Đề tài này có ý nghĩa thực tiễn cao, vì nó có thể
ứng dụng vào các lĩnh vực như: An toàn giao thông, Xe tự lái,… Nếu máy tính có thể
phân biệt được xe máy và xe đạp, thì nó có thể giúp các ứng dụng hoặc dịch vụ liên
quan đến giao thông cung cấp các thông tin hữu ích cho người dùng, ví dụ như định vị,
định tuyến, đặt xe, thanh toán, v.v. Điều này có thể nâng cao trải nghiệm người dùng,
tăng sự hài lòng và gắn kết của khách hàng, và tạo ra giá trị gia tăng cho các doanh nghiệp.
Đề tài này cũng có ý nghĩa khoa học, vì nó đòi hỏi sự sáng tạo và nghiên cứu về các kỹ
thuật và công cụ trong lĩnh vực thị giác máy tính và học sâu. Đề tài này có thể mở ra
những hướng nghiên cứu mới, khám phá những kiến thức mới, và đóng góp vào sự phát
triển của khoa học và công nghệ.
II. Xây dựng Model phân loại
1. Chuẩn bị dữ liệu
Phần chuẩn bị dữ liệu là một bước quan trọng trong quá trình phân tích và khai thác dữ
liệu. Trong bài báo cáo này, chúng em sử dụng một tập dữ liệu gồm các ảnh về các loại
xe máy và xe đạp. Để thu thập dữ liệu này, chúng em thực hiện hai bước sau:
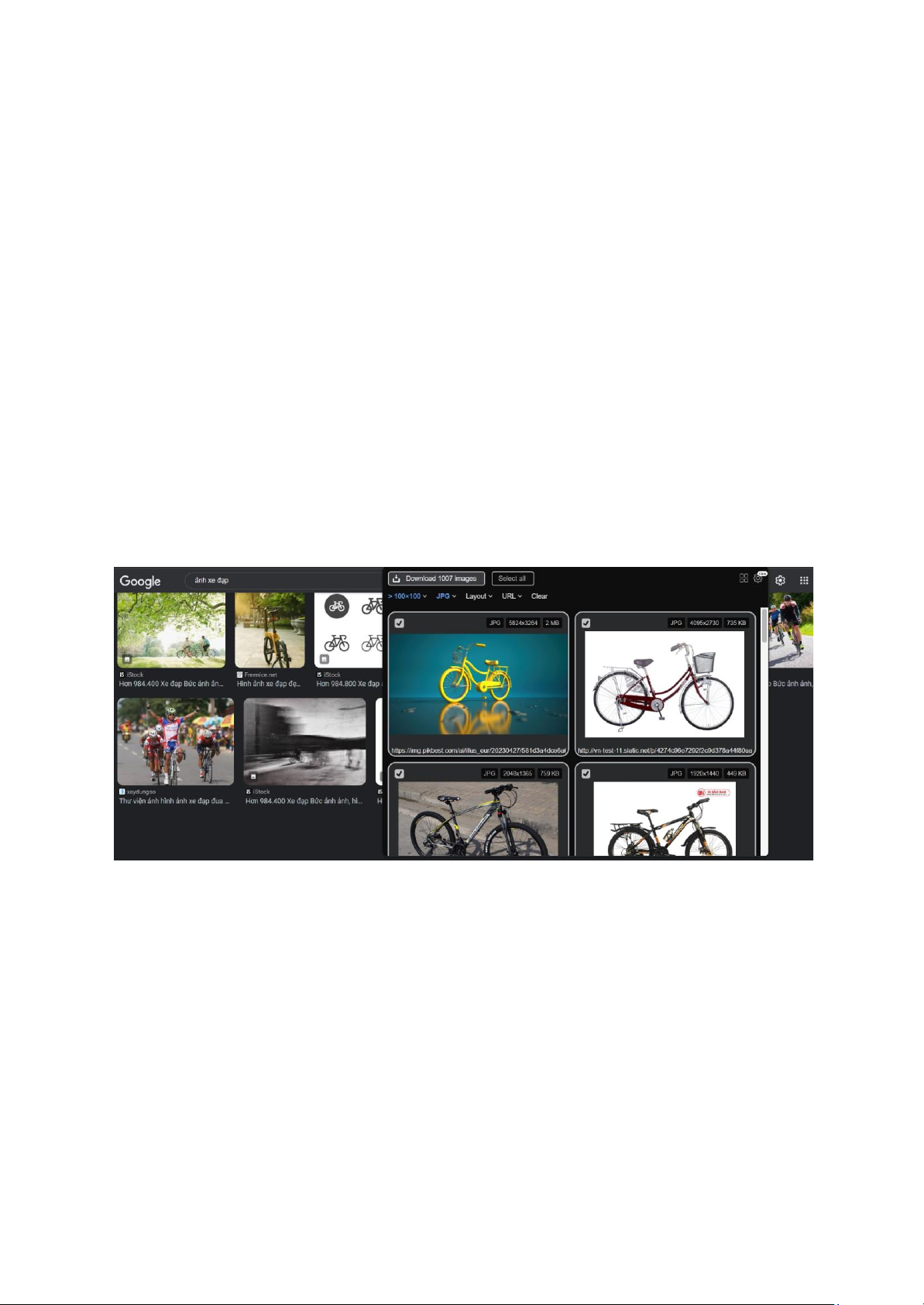
● Bước 1: Tải extension Image Downloader để tải ảnh trên Google. Extension
image downloader là một công cụ hỗ trợ người dùng tải nhiều ảnh từ một trang
web một cách nhanh chóng và dễ dàng. Chúng em cài đặt extension này trên
trình duyệt Google Chrome của chúng em. Sau đó, chúng em tìm kiếm các ảnh
về xe máy và xe đạp trên Google Images. Chúng em chọn các ảnh có chất lượng
cao, kích thước vừa và phù hợp với chủ đề. Chúng em sử dụng extension Image lOMoAR cPSD| 58800262
Downloader để tải xuống các ảnh này về máy tính của chúng em. Tổng cộng,
chúng em thu thập được khoảng 1000 ảnh về xe máy và xe đạp.
● Bước 2: Thêm dữ liệu vào thư mục và đổi tên. Sau khi tải xuống các ảnh, chúng
em cần phải sắp xếp và đặt tên lại cho chúng. Chúng em tạo một thư mục mới
trên máy tính có tên là “data”. Trong thư mục này, chúng em tạo 2 thư mục con
là “xemay” và “xedap”. Sau đó đổi tên các ảnh theo quy tắc sau: loại xe + số thứ
tự. Ví dụ: xedap_0001, xedap_0002, …, xedap_0999, … Điều này giúp chúng
em dễ dàng nhận biết và quản lý các ảnh hơn.
Như vậy, chúng em đã hoàn thành phần chuẩn bị dữ liệu cho bài toán phân loại xe máy,
xe đạp. Phần tiếp theo, chúng em sẽ tiến hành các bước tiền xử lý, phân tích, và trực
quan hóa dữ liệu để khám phá các đặc điểm và mối quan hệ của các loại xe trong tập dữ liệu của chúng em.
2. Trực quan hóa dữ liệu
Phần trực quan hóa dữ liệu là một phần quan trọng để thể hiện và khám phá các
đặc điểm và mối quan hệ của dữ liệu. Trong bài báo cáo này, chúng em sử dụng biểu đồ
scatter plot để trực quan hóa kích thước ảnh của 2 loại xe. Biểu đồ này giúp chúng em
nhìn thấy sự phân bố và biến động của kích thước ảnh trong tập dữ liệu. Chúng em vẽ
hai biểu đồ, một biểu đồ trước khi lọc các ảnh ngoài vùng trung vị và một biểu đồ sau
khi lọc. Vùng trung vị là khu vực có chiều rộng và chiều cao gần bằng với trung vị của
kích thước ảnh. Dù đã lọc qua khi tải ảnh xuống bằng Image Downloader nhưng vẫn lOMoAR cPSD| 58800262
còn có rất nhiều ảnh không tốt. Chúng em lọc các ảnh ngoài vùng trung vị vì chúng có
thể là các ảnh bị méo mó, quá dài hoặc quá rộng, hoặc không phù hợp với chủ đề.
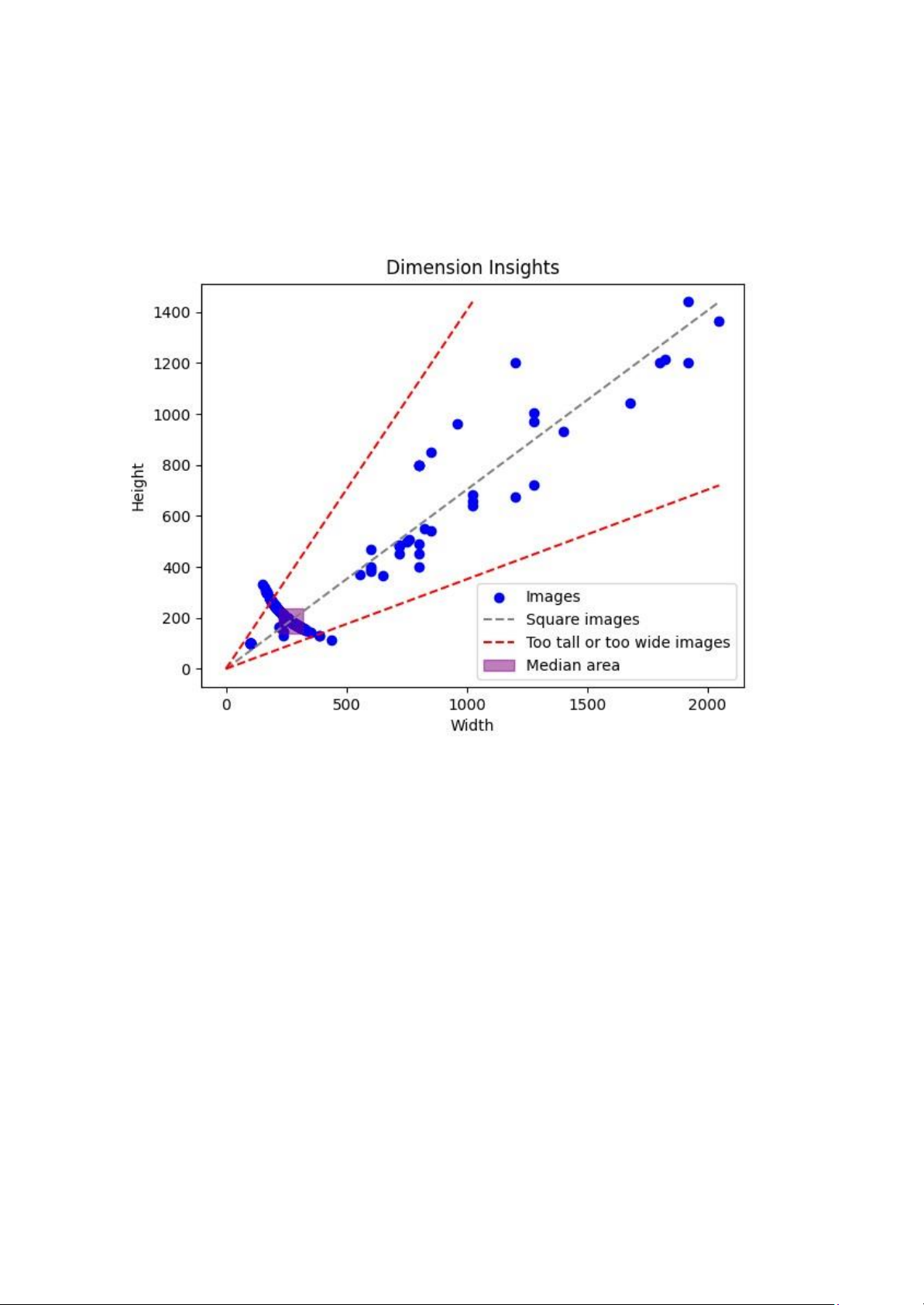
Biểu đồ trước khi lọc các ảnh ngoài vùng trung vị có thể trông như thế này:
Từ biểu đồ này, chúng em có thể thấy rằng:
● Kích thước ảnh của các loại xe có sự chênh lệch lớn, từ khoảng 100 pixel đến
khoảng 2000 pixel về cả chiều rộng và chiều cao.
● Có một số ảnh nằm trên đường chéo từ gốc tọa độ, tức là các ảnh vuông. Các
ảnh này là các ảnh có tỷ lệ cân đối và độ phân giải cao.
● Có một số ảnh nằm ngoài hai đường song song với đường chéo, tức là các ảnh
quá dài hoặc quá rộng. Các ảnh này có thể là các ảnh bị méo mó, quá kéo dài hoặc quá thu nhỏ.
● Có một số ảnh nằm trong hình chữ nhật màu tím, tức là các ảnh trong vùng trung
vị. Các ảnh này có thể là các ảnh có kích thước phù hợp và đại diện cho đa dạng của xe đạp và xe máy.
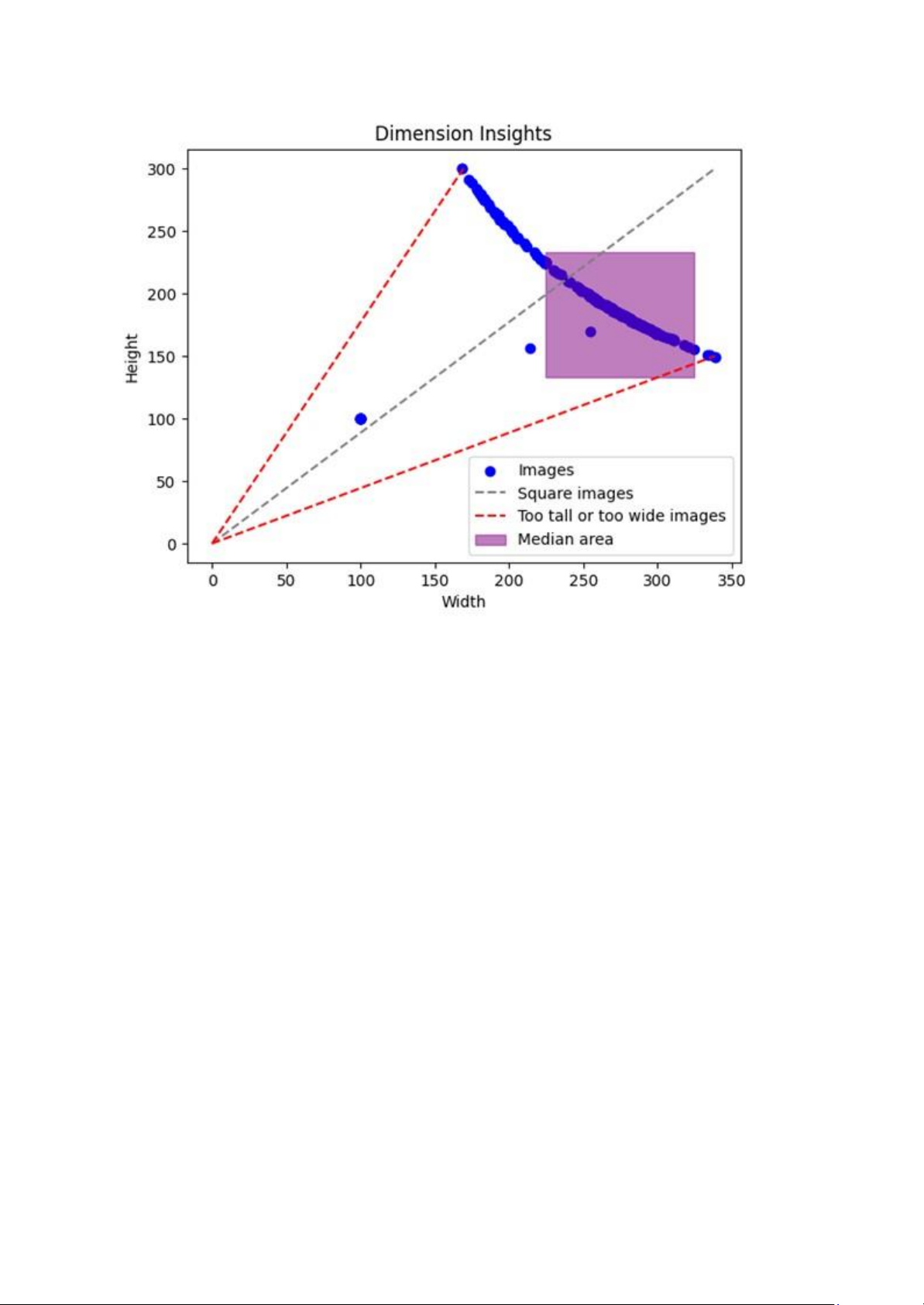
Biểu đồ sau khi lọc các ảnh ngoài vùng trung vị có thể trông như thế này: lOMoAR cPSD| 58800262
Từ biểu đồ này, chúng em có thể thấy rằng:
● Kích thước ảnh của các loại hoa có sự phân bố đều hơn, từ khoảng 150 pixel đến
khoảng 350 pixel về cả chiều rộng và chiều cao.
● Các ảnh vuông, quá dài hoặc quá rộng đã bị loại bỏ khỏi tập dữ liệu.
● Các ảnh trong vùng trung vị có thể phản ánh tốt hơn sự đa dạng và đặc trưng của
các loại hoa. Các ảnh này cũng có thể giúp chúng em tiến hành các bước tiền xử
lý, phân tích, và khai thác dữ liệu một cách hiệu quả hơn.
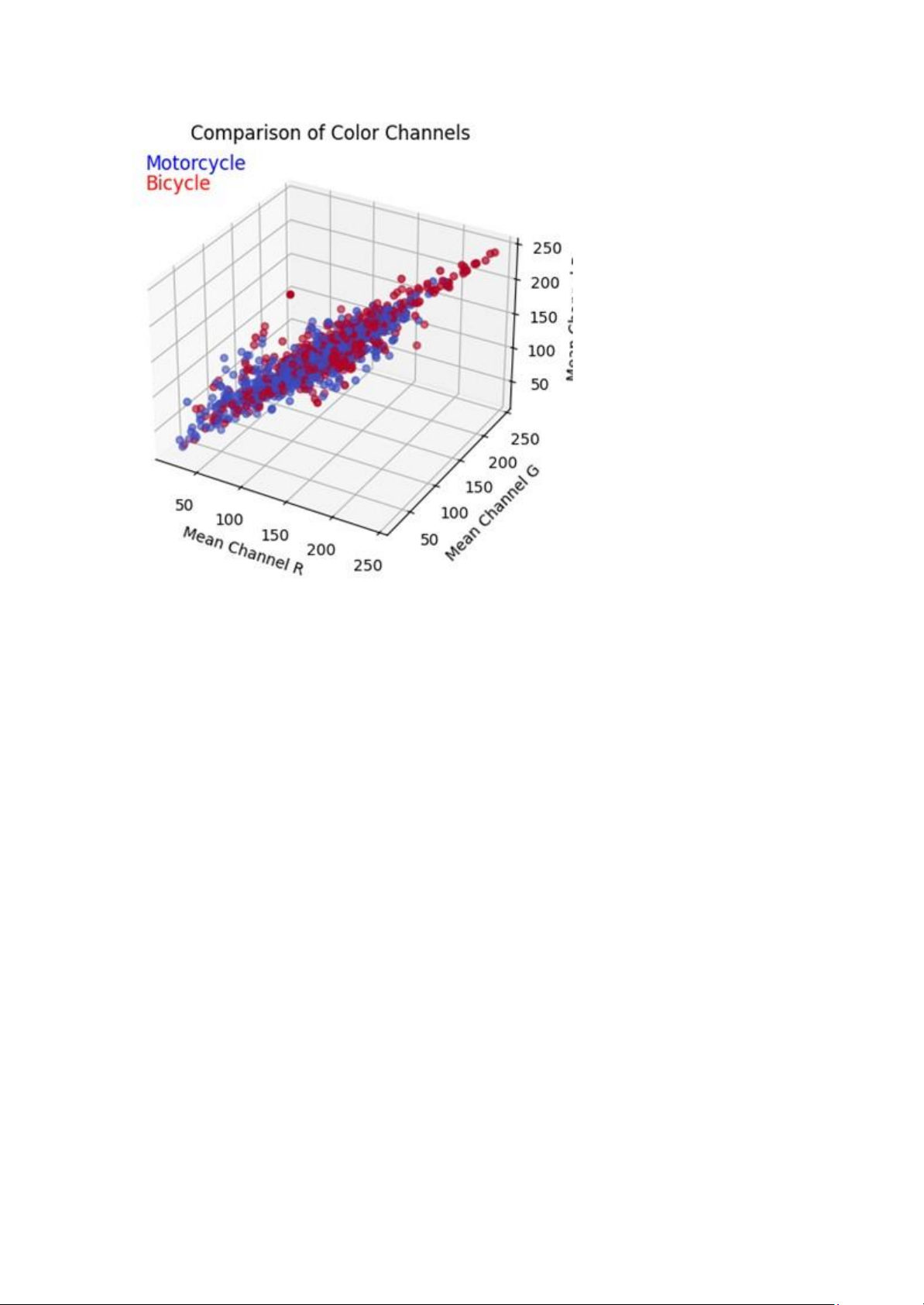
Tiếp theo, bọn em sử dụng biểu đồ scatter plot để trực quan hóa màu sắc ảnh của 2 loại
xe. Đầu tiên là chuyển ảnh về dạng numpy và tính trung bình các kênh màu của các
ảnh. Sau đó tạo một scatter plot để so sánh giá trị trung bình của mỗi kênh màu
giữa hai lớp. Mỗi điểm trên biểu đồ đại diện cho một ảnh, màu xanh dương cho xe máy, màu đỏ cho xe đạp lOMoAR cPSD| 58800262
Từ đồ thị ta thấy : xe đạp thì thiên về gam màu trắng và sáng còn xe máy thì thiên về gam màu tối.
Như vậy, chúng em đã hoàn thành phần trực quan hóa dữ liệu. Phần tiếp theo, chúng em
sẽ tiến hành các bước tiền xử lý, phân tích, và khai thác dữ liệu để khám phá các đặc
điểm và mối quan hệ của các loại xe trong tập dữ liệu.
3. Tiền xử lý dữ liệu
● Bước 1: Lọc bỏ đi những ảnh quá bé. Ở đây định nghĩa một ngưỡng kích thước
tối thiểu cho các ảnh là 64x64 pixel. Bọn em cần duyệt qua các ảnh trong bộ dữ
liệu, và xóa những ảnh có kích thước nhỏ hơn ngưỡng đã định.
● Bước 2: Sử dụng YOLOv8 để phát hiện các xe đạp và xe máy trong các ảnh. Vì
YOLOv8 có 80 class sử dụng trong các mô hình đã được huấn luyện sẵn bao
gồm cả xe máy và xe đạp nên cần chỉ cần chạy model YOLOv8 là có thể xác
định vị trí và kích thước của các xe đạp trong các ảnh. lOMoAR cPSD| 58800262
● Bước 3: Cắt ra phần ảnh chỉ chứa xe đạp và xe máy từ tọa độ của detect của
model YOLOv8. Việc này giúp xe luôn ở chính giữa ảnh và không có vật thể
không xác định xung quanh.
● Bước 4: Thay đổi kích thước các ảnh về 224x224 pixel. 4. Model
Phần model là một phần quan trọng để xây dựng và huấn luyện các mô hình học sâu để
phân loại các loại xe khác nhau. Trong bài báo cáo này, chúng em sử dụng 3 model là
VGG16, ResNet50 và ResNet101. Đây là những model được thiết kế dựa trên kiến trúc
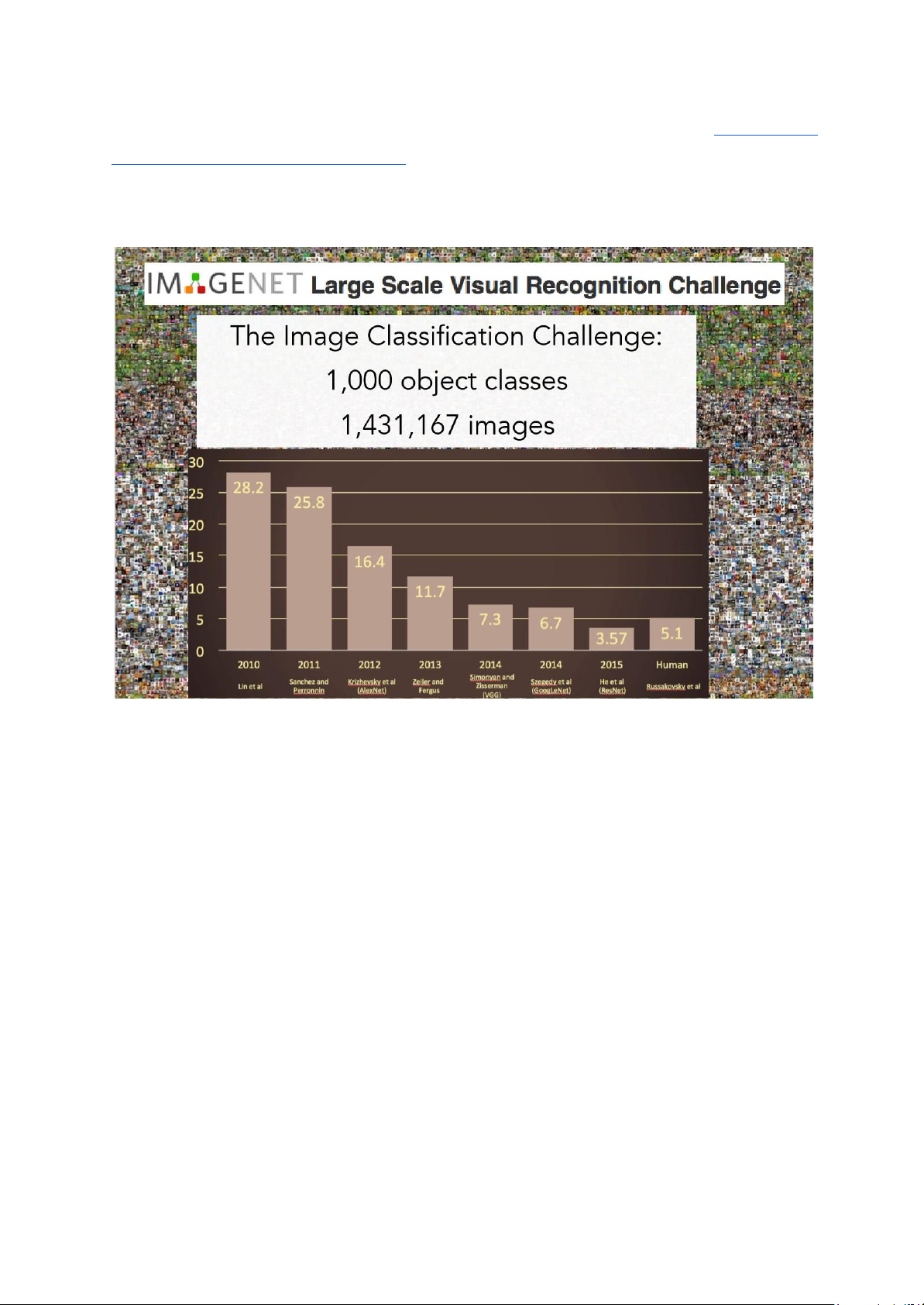
của các mạng nơ-ron tích chập (CNN) và đã được huấn luyện sẵn trên tập dữ liệu
ImageNet ((tập dữ liệu hình ảnh về phân loại đối tượng, bao gồm 14 triệu hình ảnh
thuộc 1000 lớp khác nhau). Chúng em sử dụng kỹ thuật chuyển giao học tập (transfer
learning) để tận dụng các trọng số đã được huấn luyện của các model này và thay thế
lớp phân loại cuối cùng bằng một lớp mới phù hợp với bài toán của chúng em. Sau đó,
chúng em tiến hành huấn luyện lại các model này trên tập dữ liệu của chúng em.
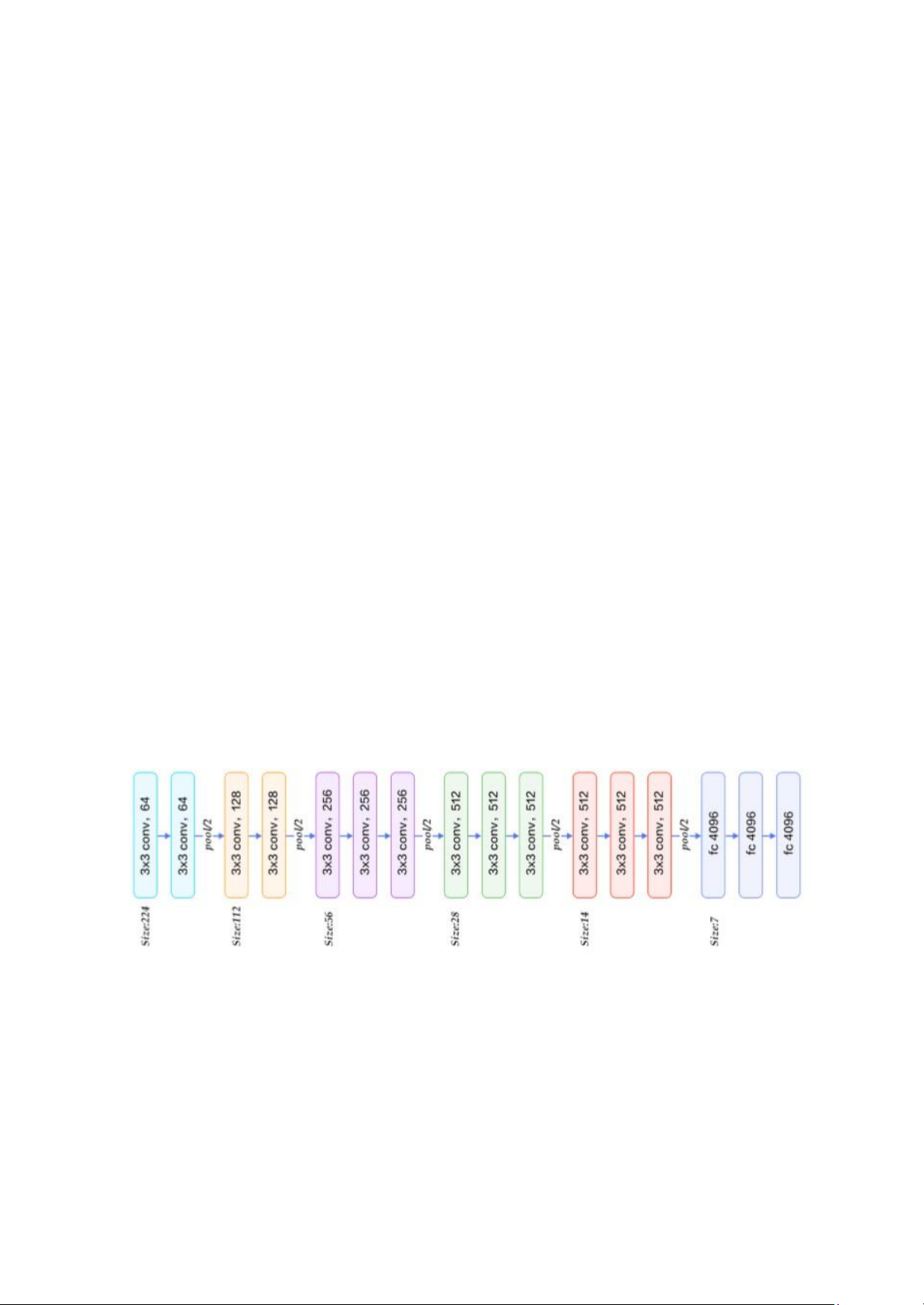
VGG16 là mạng convolutional neural network được đề xuất bởi K. Simonyan and A.
Zisserman, UniversityofOxford.Model sau khi train bởi mạng VGG 16 đạt độ chính xác
92.7% trong dữ liệu ImageNet
Model này có 16 lớp, bao gồm 13 lớp tích chập và 3 lớp kết nối đầy đủ. Model này sử
dụng các bộ lọc có kích thước 3x3 và sử dụng các lớp gộp cực đại (max pooling) để
giảm kích thước của các đặc trưng. Model này đã đạt được kết quả tốt trên tập dữ liệu
ImageNet, nhưng cũng có một số nhược điểm như số lượng tham số lớn, độ phức tạp
cao và khả năng bị quá khớp. lOMoAR cPSD| 58800262
ResNet (Residual Network) là một cấu trúc mạng CNN được giới thiệu và được đề xuất
bởi nhóm nghiên cứu của Microsoft đến công chúng vào năm 2015. Resnet đã giành
được vị trí thứ 1 trong cuộc thi ILSVRC 2015 với tỉ lệ lỗi top 5 chỉ 3.57% trên tập dữ liệu imageNet
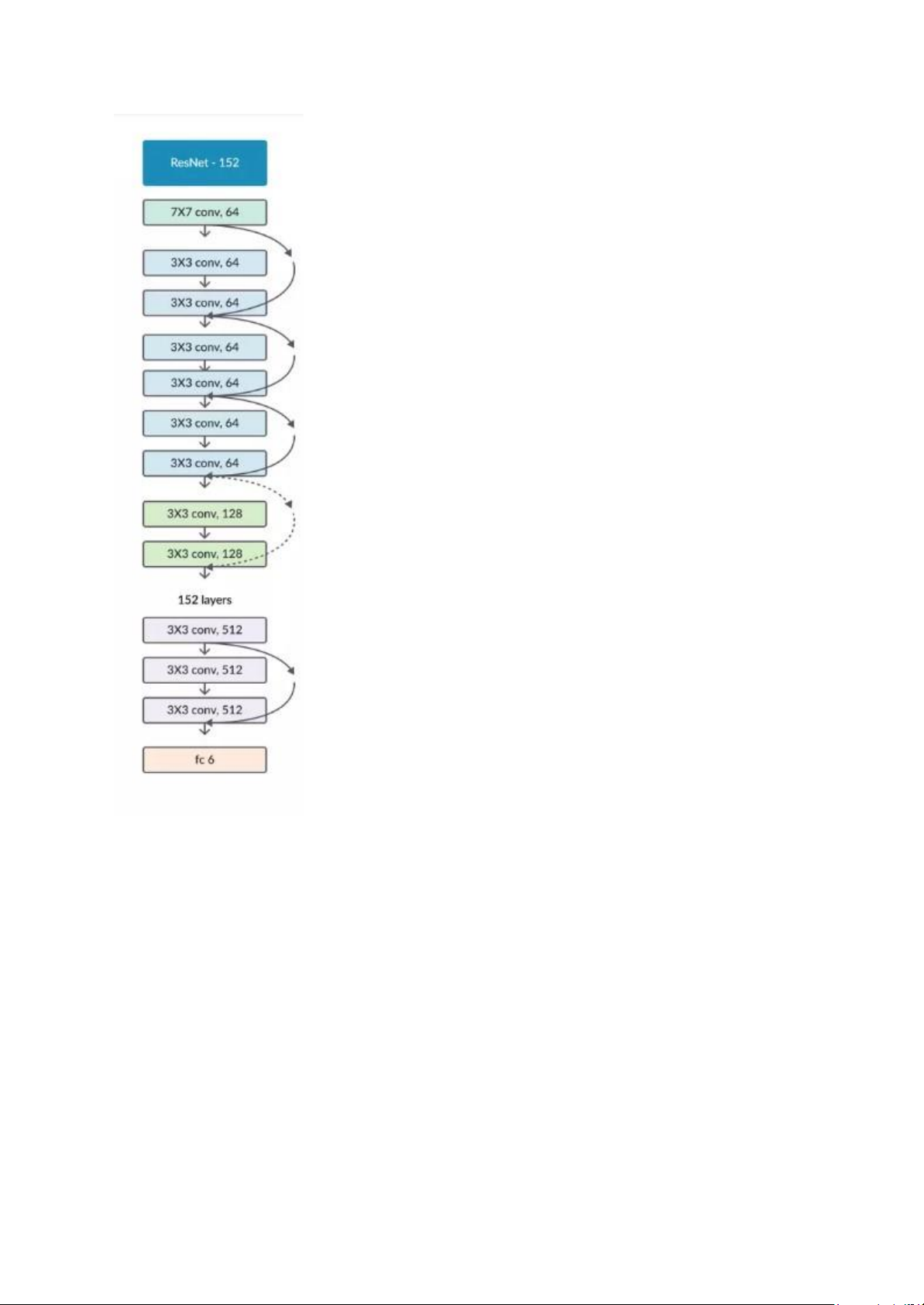
Mạng ResNet (R) là một mạng CNN được thiết kế để làm việc với hàng trăm lớp. Một
vấn đề xảy ra khi xây dựng mạng CNN với nhiều lớp chập sẽ xảy ra hiện tượng
Vanishing Gradient dẫn tới quá trình học tập không tốt. lOMoAR cPSD| 58800262
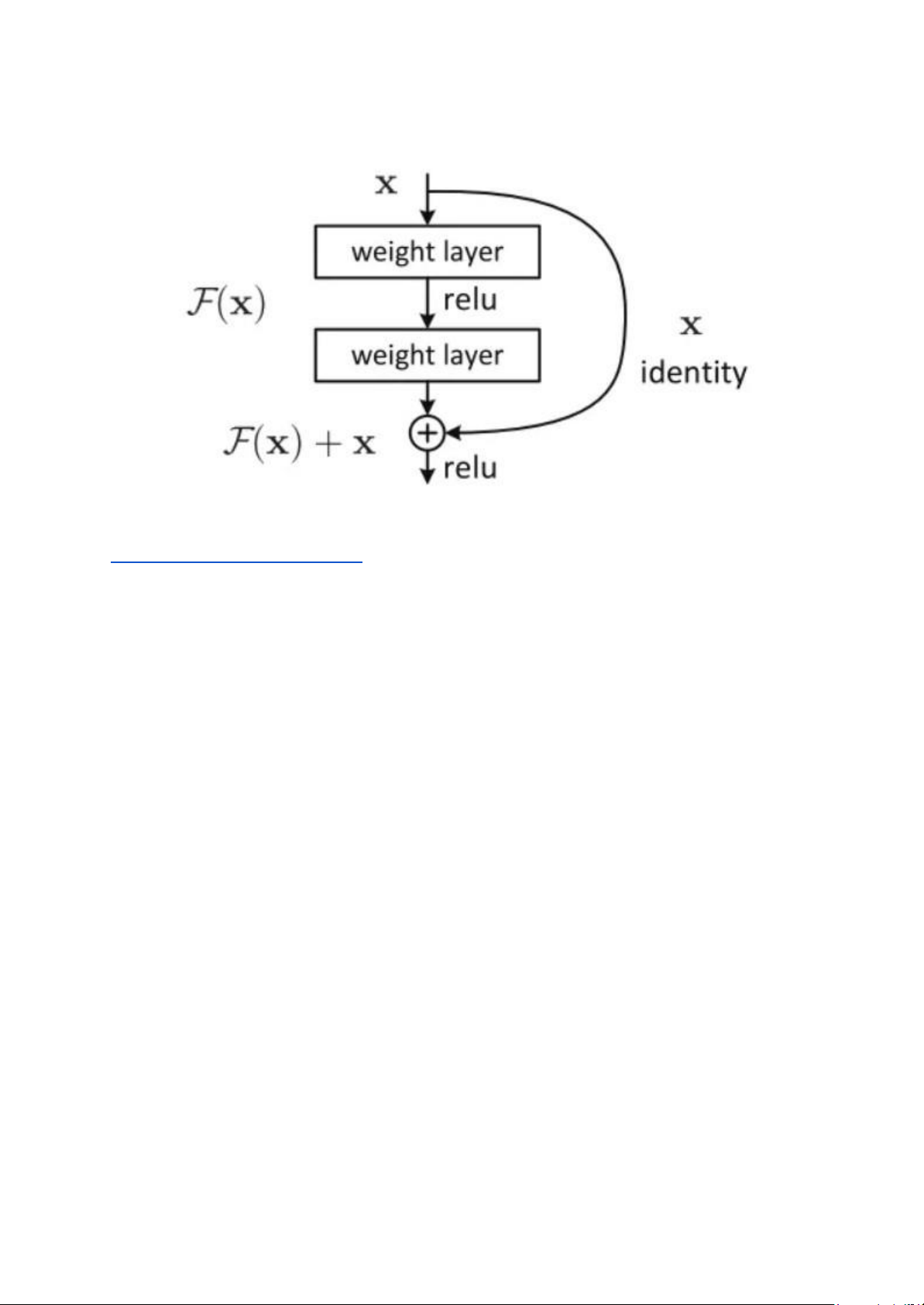
Giải pháp mà ResNet đưa ra là sử dụng kết nối "tắt" đồng nhất để xuyên qua một hay
nhiều lớp. Một khối như vậy được gọi là một khối thặng dư( Residual Block) lOMoAR cPSD| 58800262
ResNet50 và ResNet101 là hai biến thể của Resnet. Hai model này có 50 và 101 lớp,
bao gồm nhiều khối thặng dư. Mỗi khối thặng dư có một kết nối tắt (skip connection)
như trên, giúp truyền dữ liệu từ đầu vào đến đầu ra của khối mà không cần qua các lớp
tích chập. Điều này giúp giải quyết vấn đề suy giảm độ chính xác (degradation
problem) bởi mất mát đạo hàm(vanishing gradient) khi tăng số lượng lớp của mạng.
Model này đã đạt được kết quả xuất sắc trên tập dữ liệu ImageNet, và cũng có khả năng
học các đặc trưng sâu và phức tạp hơn.
Chúng em đã thử nghiệm cả 3 model trên tập dữ liệu của chúng em và đánh giá kết quả
bằng độ chính xác (accuracy) trên tập kiểm tra (test set). Kết quả cho thấy ResNet101 là
model có kết quả tốt nhất, với độ chính xác là 0.9325. ResNet50 là model có kết quả
thứ hai, với độ chính xác là 0.9007. VGG16 là model có kết quả thấp nhất, với độ chính
xác là 0.6667. Điều này cho thấy ResNet101 có khả năng học và phân loại xe đạp và xe
máy tốt hơn so với ResNet50 và VGG16. II. Kết luận
Bài toán phân loại xe máy xe đạp là một bài toán quan trọng và có nhiều ứng dụng
trong thực tế. Để giải quyết bài toán này, có thể sử dụng các mô hình học sâu, như
ResNet101, ResNet50, và VGG19. Các mô hình này đều dựa trên kiến trúc mạng nơ-
ron tích chập (CNN), và được huấn luyện trên các bộ dữ liệu lớn, như ImageNet. Các lOMoAR cPSD| 58800262
mô hình này có thể học được các đặc trưng phân biệt của các loại xe máy và xe đạp, và
phân loại chúng với độ chính xác cao.
Kết luận, bài toán phân loại xe máy xe đạp là một bài toán có nhiều thách thức và tiềm
năng. Các mô hình học sâu, như ResNet101, ResNet50, và VGG19, có thể giải quyết
bài toán này với độ chính xác cao. Tuy nhiên, các mô hình này cũng có những ưu và
nhược điểm khác nhau, và cần được lựa chọn phù hợp với bộ dữ liệu và mục tiêu của
bài toán. Theo nghiên cứu đã trình bày, ResNet101 là mô hình có hiệu năng tốt nhất
trên bài toán phân loại xe máy xe đạp, vượt trội hơn ResNet50 và VGG19.
Tài liệu liên quan:
-

Đồ án tốt nghiệp - Triển khai hệ thống Cloud trên nền tảng mã nguồn mở Openstack sử dụng Kolla-Ansible | Học viện Công Nghệ Bưu Chính Viễn Thông
42 21 -

Tiểu luận: Ứng dụng khai phá dữ liệu trong phân tích bộ dữ liệu giá nhà và dự đoán giá nhà môn Nhập môn khoa học dữ liệu | Học viện Công Nghệ Bưu Chính Viễn Thông
55 28 -

Mẫu bài tập lớn môn Nhập môn Khoa học dữ liệu | Học viện Công Nghệ Bưu Chính Viễn Thông
219 110 -

Kiến thức và ứng dụng cơ bản môn Nhập môn Khoa học dữ liệu | Học viện Công Nghệ Bưu Chính Viễn Thông
244 122 -

Báo cáo Phân tích bình luận đánh giá chất lượng sách môn Nhập môn Khoa học dữ liệu | Học viện Công Nghệ Bưu Chính Viễn Thông
113 57