Báo cáo Phân tích bình luận đánh giá chất lượng sách môn Nhập môn Khoa học dữ liệu | Học viện Công Nghệ Bưu Chính Viễn Thông
Sách đóng vai trò quan trọng trong cuộc sống, và đọc sách là thói quen tốt cần duy trì. Tuy nhiên, không phải sách nào cũng phù hợp để đọc. Việc lựa chọn sách cần được thực hiện cẩn thận. Tài liệu được sưu tầm gồm 14 trang, giúp các bạn nắm vững kiến thức, rèn luyện kỹ năng và đạt được kết quả tốt trong học tập. Mời các bạn đón xem!
Môn: Nhập môn Khoa học dữ liệu 8 tài liệu
Trường: Học viện Công Nghệ Bưu Chính Viễn Thông 1.8 K tài liệu
Tác giả:










Preview text:
lOMoAR cPSD| 58800262
HỌC VIỆN CÔNG NGHỆ BƯU CHÍNH VIỄN THÔNG
KHOA CÔNG NGHỆ THÔNG TIN 1
NHẬP MÔN KHOA HỌC DỮ LIỆU BÁO CÁO CUỐI KÌ
ĐỀ TÀI: Phân tích bình luận để đánh giá chất lượng sách
Giảng viên hướng dẫn: Vũ Hoài Nam Nhóm môn học: 02
Nhóm bài tập lớn: 08
Sinh viên : Vũ Thành Luân – B21DCCN502
Nguyễn Hoàng Nam – B21DCCN551
Phùng Bá Tùng – B21DCCN776 Hà Nội 11/2024 lOMoAR cPSD| 58800262
Phần 1: Phân tích tổng quan 1.1 Giới thiệu chung
Sách đóng vai trò quan trọng trong cuộc sống, và đọc sách là thói quen tốt cần duy trì. Tuy
nhiên, không phải sách nào cũng phù hợp để đọc. Việc lựa chọn sách cần được thực hiện cẩn thận.
Đọc sách giúp bổ sung kiến thức và phát triển tình cảm. Tuy nhiên, kiến thức và cảm xúc đó
cần phải phù hợp với lứa tuổi của người đọc. Đối với học sinh cấp một, việc học toán và văn
cần tập trung vào những kiến thức cơ bản. Còn học sinh cấp hai, với tư duy phức tạp hơn, có
thể nâng cao khả năng giải toán đa thức và viết văn sâu sắc. Chọn sách phải đồng điệu với khả
năng và nhận thức của từng độ tuổi. Việc đọc những tác phẩm không phù hợp có thể gây hiệu
ứng tiêu cực, làm mất hứng thú hoặc tạo ra tình cảm tiêu cực.
Nắm bắt được nhu cầu thiết yếu này của xã hội, chúng em đã ứng dụng thu thập dữ liệu và sử
dụng học sâu phân tích và đưa ra kết quả nhằm đưa tới cho mọi người gợi ý chính xác nhất về
từng quyển sách thông qua những dữ liệu được cung cấp từ nhiều độc giả. Từ đó có thể đưa ra
lựa chọn chính xác trong việc lựa chọn tri thức. 1.2 Phân tích bài toán
- Tên bài toán: Phân tích bình luận để đánh giá chất lượng sách
- Mục tiêu: Dựa vào các thông tin có trong bình luận về một quyển sách bất kì về phong
cách viết; cốt truyện; độ dài; nhân vật, ..... để đưa ra đánh giá về sản phẩm sách đó - Phương pháp: - Input - Output
- Các bước tiến hành o Thu thập dữ liệu o Xử lý dữ liệu thô o Gán nhãn dữ liệu o
Trích xuất đặc trưng: o Phân loại dữ liệu o Đánh giá mô hình:
Phần 2: Thu thập dữ liệu 2.1 Công cụ hỗ trợ 2.1.1 BeautifulSoup
- Là một thư viện Python phổ biến được sử dụng trong việc web scraping (thu thập dữ
liệu từ trang web) và parsing HTML/XML (phân tích cú pháp HTML/XML). Nó giúp
dễ dàng làm việc với các tài liệu HTML hoặc XML phức tạp, cho phép trích xuất thông
tin hữu ích từ chúng một cách nhanh chóng và hiệu quả. -Tính năng:
+) Dễ sử dụng:BeautifulSoup cung cấp một API đơn giản và dễ hiểu, giúp
nhanh chóng truy xuất các phần tử trong trang HTML hoặc XML mà không cần
phải hiểu sâu về cú pháp phức tạp của các tài liệu này.
+) Xử lý dữ liệu HTML/XML:Nó hỗ trợ phân tích cú pháp các tài liệu HTML
và XML không hợp lệ (broken HTML), và tự động sửa chữa các lỗi cấu trúc trong các tài liệu này.
+) Duyệt qua cây DOM: BeautifulSoup giúp duyệt qua cấu trúc cây DOM
(Document Object Model) của tài liệu HTML, tìm kiếm và trích xuất các phần
tử cần thiết như thẻ HTML, thuộc tính của thẻ, văn bản, v.v.
+) Hỗ trợ nhiều parser: BeautifulSoup có thể sử dụng nhiều parser (trình phân
tích cú pháp), bao gồm html.parser (mặc định trong Python), lxml, và html5lib,
giúp bạn lựa chọn parser phù hợp với yêu cầu và môi trường của bạn. lOMoAR cPSD| 58800262
+)Kết hợp với các công cụ khác: BeautifulSoup thường được sử dụng kết hợp
với requests (hoặc urllib) để tải các trang web và trích xuất dữ liệu. 2.1.2 API từ Tiki
- Ngoài việc thu thập dữ liệu bằng cách scraping, có thể Tiki cung cấp API cho phép
truy xuất các bình luận hoặc thông tin sản phẩm, giúp dễ dàng và chính xác hơn trong
việc thu thập dữ liệu. 2.2 Thu thập dữ liệu
- Nguồn dữ liệu: Dữ liệu được thu thập từ website Tiki, cụ thể là các bình luận của
người dùng về các sách. Đây là một dạng dữ liệu văn bản (text data) liên quan đến
đánh giá và cảm nhận của người dùng về các sản phẩm sách.
- Thu thập các file như eđể chuẩn bị cho quá trình xử lý dữ liệu thô ở phần 3 2.3 Lưu trữ:
- Sau khi thu thập các bình luận, dữ liệu sẽ được lưu trữ dưới dạng CSV. Dữ liệu này có
thể chứa các trường như username, rating, comment_text, và có thể là các thông tin
khác liên quan đến đánh giá của người dùng.
Phần 3: Xử lý dữ liệu thô 3.1 Công cụ hỗ trợ 3.1.1 PyVi
- Là một thư viện Python được sử dụng để nhận dạng và phân tích văn bản tiếng Việt,
bao gồm việc tách từ, gán nhãn từ loại (POS tagging), phân tích cú pháp và phân tích
ngữ nghĩa. Thư viện này sử dụng các mô hình học máy và quy tắc ngữ pháp để xử lý
tiếng Việt, nhằm giúp các ứng dụng NLP (Xử lý ngôn ngữ tự nhiên) hoạt động hiệu
quả hơn với ngữ liệu tiếng Việt - Tính năng:
+)Tách từ (Word segmentation): Phân chia một câu hoặc đoạn văn thành các từ riêng biệt.
+)Gán nhãn từ loại (POS tagging): Phân loại từ trong câu vào các nhóm như
danh từ, động từ, tính từ, v.v.
+)Phân tích cú pháp (Syntax parsing): Xây dựng cấu trúc cú pháp của câu để
hiểu cách các thành phần trong câu liên kết với nhau. 3.2 Xử lý dữ liệu *) Chuẩn hóa văn bản: -
Hàm concat_word_idiom: Chuyển đổi một danh sách các câu thành định dạng
mà mỗi từ trong câu được nối bằng ký tự gạch dưới (_), đồng thời loại bỏ các ký tự
không phải chữ cái hoặc khoảng trắng. lOMoAR cPSD| 58800262
+) Loại bỏ ký tự đặc biệt khỏi mỗi câu trong danh sách.
+) Chuyển toàn bộ chữ cái thành chữ thường.
+) Ghép các từ trong mỗi câu bằng ký tự _.
+) Kết quả: Một danh sách các câu đã chuyển đổi. -
Hàm pre_progcessing_idiom_data: Tiền xử lý một danh sách văn bản, bao gồm
làm sạch dữ liệu và chuẩn hóa bằng cách tách từ với công cụ ViTokenizer.
+) Loại bỏ các ký tự không phải chữ cái, dấu phẩy hoặc khoảng trắng.
+) Chuyển toàn bộ chữ thành chữ thường.
+) Sử dụng ViTokenizer để tách từ.
+) Kết quả: Danh sách các câu đã được token hóa. -
Hàm translate_text: Dịch một đoạn văn bản từ ngôn ngữ gốc sang một ngôn ngữ
đích(mặc định là tiếng Việt).
+) Sử dụng thư viện googletrans để thực hiện dịch tự động. lOMoAR cPSD| 58800262
+) Kết quả: Văn bản dịch sang ngôn ngữ đích. -
Hàm pre_progcessing_text_data: Tiền xử lý danh sách văn bản (Loại bỏ ký tự
không cần thiết, Chuẩn hóa các từ viết tắt, Thay thế các thành ngữ, Dịch các từ tiếng Anh)
+) Làm sạch văn bản: Loại bỏ ký tự không cần thiết, giảm ký tự lặp lại (ví dụ: kooooo thành ko).
+) Chuẩn hóa: Tách từ bằng ViTokenizer, Thay thế từ viết tắt bằng cụm từ đầy
đủ từ bảng viet_tat. Thay thế thành ngữ bằng cụm từ tương ứng từ bảng thanh_ngu.
+) Kết quả: Trả về danh sách câu đã xử lý.
Phần 4: Gán nhãn dữ liệu 4.1 Gán nhãn dữ liệu
- Dựa trên số sao của bình luận. Nếu bình luận có đánh giá sao là 1-2 sao, nó sẽ được
gán nhãn là tiêu cực, còn 4-5 sao sẽ được gán nhãn là tích cực.
4.2 Sử dụng GPT để gán nhãn:
- Có thể sử dụng mô hình GPT (hoặc các mô hình học sâu khác) để phân tích nội dung
bình luận và tự động gán nhãn tích cực hoặc tiêu cực, mặc dù một cách đơn giản hơn là dựa vào số sao. lOMoAR cPSD| 58800262
Phần 5: Trích xuất đặc trưng 5.1 RNN
- Mạng nơ-ron hồi quy (RNN) là một mô hình học sâu được đào tạo để xử lý và chuyển
đổi đầu vào dữ liệu tuần tự thành đầu ra dữ liệu tuần tự cụ thể. 5.1.1.SimplerRNNCell
Định nghĩa một đơn vị RNN cơ bản
+) W_xh: Trọng số từ đầu vào đến hidden state.
+) W_hh: Trọng số giữa các hidden state.
+) b_h: Bias khởi tạo bằng 0.
+) Hàm call thực hiện việc tính toán trạng thái ẩn mới (h) tại mỗi bước thời gian (time step)
dựa trên đầu vào (inputs) và trạng thái ẩn trước đó (prev_state).
+) Công thức tính toán trạng thái ẩn mới: h = tf.tanh(tf.matmul(inputs, self.W_xh)
+ tf.matmul(prev_state, self.W_hh) + self.b_h 5.1.2 Mô hình RNN *)Embedding:
- Chuyển đổi các token (số nguyên) thành vector nhúng (embedding vector) có chiều 128. lOMoAR cPSD| 58800262
- input_dim=len(dictionary)+1: Số lượng từ trong từ điển.
- output_dim=128: Kích thước vector nhúng.
*)RNN(SimpleRNNCell(32, 128)):
- Áp dụng một lớp RNN với SimpleRNNCell tự định nghĩa.
- 32: Số lượng đơn vị RNN (units).
- 128: Kích thước đầu vào.
*)Dense(12, activation='softmax'):
- Lớp đầu ra với 12 lớp (ứng với 12 nhãn trong bài toán).
- Sử dụng hàm kích hoạt softmax để dự đoán xác suất.
5.1.3 Huấn luyện mô hình
- optimizer='adam': Sử dụng thuật toán tối ưu Adam.
- loss='categorical_crossentropy': Hàm mất mát phù hợp với bài toán phân loại đa nhãn.
- metrics=['accuracy']: Theo dõi độ chính xác trong quá trình huấn luyện.
- callback=[myCallback()]: Sử dụng callback để dừng sớm hoặc kiểm tra độ chính xáctối đa. 5.1.4 Đánh giá mô hình
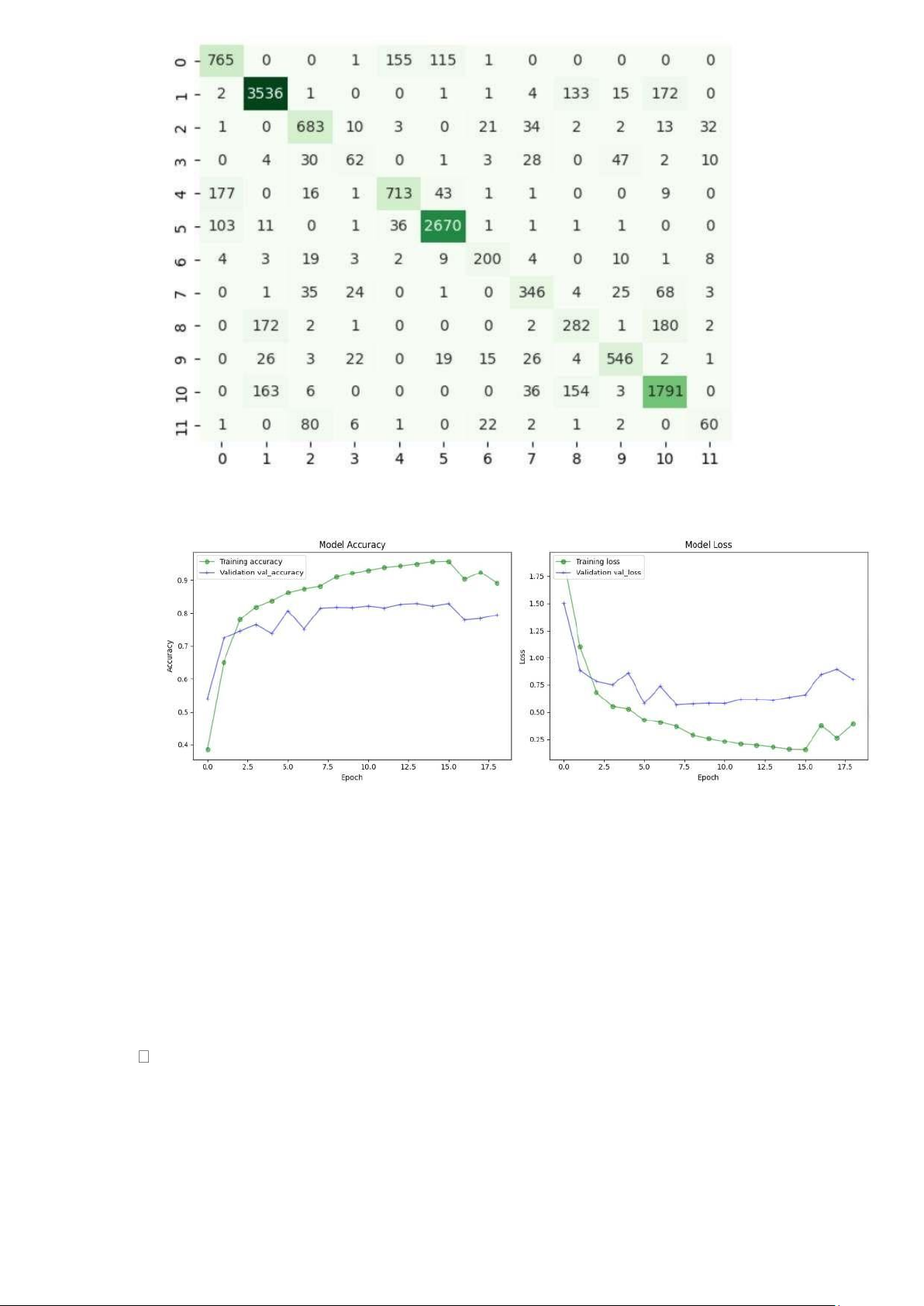
- confusion_matrix: Ma trận thể hiện sự dự đoán chính xác hoặc sai giữa các nhãn.
- sns.heatmap: Vẽ biểu đồ trực quan cho ma trận. lOMoAR cPSD| 58800262 5.2 LSTM
- LSTM là một loại mạng nơ-ron hồi quy (RNN) được thiết kế đặc biệt để giải quyết vấn
đề vanishing gradient mà các mạng RNN truyền thống gặp phải khi xử lý dữ liệu chuỗi
dài. LSTM có khả năng duy trì thông tin lâu dài và kiểm soát cách thông tin được lưu trữ
và truyền qua các bước thời gian, nhờ vào cơ chế gọi là các cổng (gates). 5.2.1 LSTMCell lOMoAR cPSD| 58800262
- W_f, W_i, W_c, W_o: Các trọng số này dùng để tính toán các cổng quên, nhập, cập
nhật và đầu ra. Kích thước của mỗi trọng số này là (input_dim + lstm_units,
lstm_units), với input_dim là số lượng đặc trưng đầu vào và lstm_units là số lượng đơn
vị LSTM (hay số chiều của trạng thái ẩn).
- b_f, b_i, b_c, b_o: Các bias được khởi tạo với giá trị bằng 0.
- add_weight: phương thức để tạo ra trọng số và bias, và tham số trainable=True cho
phép các trọng số này được huấn luyện trong quá trình huấn luyện mô hình.
- Hàm call là nơi thực hiện tính toán của một bước thời gian trong mạng LSTM. LSTM
thực hiện công việc "nhớ" và "quên" thông qua các cổng:
- Kết hợp đầu vào và trạng thái ẩn trước đó: Để thực hiện các phép toán trong LSTM,
đầu vào tại bước thời gian hiện tại inputs và trạng thái ẩn của bước thời gian trước đó
h_prev được kết hợp lại (nối lại theo chiều dọc). Điều này cho phép LSTM sử dụng
thông tin từ cả đầu vào hiện tại và trạng thái ẩn trước đó:
x_h = tf.concat([inputs, h_prev], axis=-1)
- Cổng quên (f): Cổng này quyết định phần nào của trạng thái ô (cell state) trước đó sẽ bị
loại bỏ. Đầu vào của cổng quên là sự kết hợp giữa đầu vào và trạng thái ẩn trước đó,
qua một phép nhân với trọng số W_f và cộng với bias b_f. Hàm kích hoạt của cổng này
là hàm sigmoid, đưa ra một giá trị trong khoảng [0, 1].
f = tf.sigmoid(tf.matmul(x_h, self.W_f) + self.b_f)
- Cổng nhập (i): Quyết định phần nào của trạng thái ô mới sẽ được ghi vào trạng thái ô.
Tương tự như cổng quên, đầu vào của cổng nhập cũng là sự kết hợp của đầu vào và
trạng thái ẩn, nhưng trọng số và bias khác nhau.
i = tf.sigmoid(tf.matmul(x_h, self.W_i) + self.b_i)
- Cổng cập nhật (c_): Cổng cập nhật giúp tính toán giá trị mới của trạng thái ô (cell
state). Đầu vào của cổng này là sự kết hợp giữa đầu vào và trạng thái ẩn, và giá trị được lOMoAR cPSD| 58800262
tính thông qua một phép nhân với trọng số W_c và cộng với bias b_c. Hàm kích hoạt của cổng này là tanh
c_ = tf.tanh(tf.matmul(x_h, self.W_c) + self.b_c)
- Cổng đầu ra (o): Cổng đầu ra quyết định phần nào của trạng thái ô sẽ ảnh hưởng đến
trạng thái ẩn hiện tại. Tính toán tương tự như các cổng trên, với trọng số W_o và bias
b_o, sử dụng hàm kích hoạt sigmoid o = tf.sigmoid(tf.matmul(x_h, self.W_o) + self.b_o)
- Cập nhật trạng thái ô (c): Trạng thái ô mới c được tính bằng cách kết hợp cổng quên và
cổng nhập, cho phép mạng LSTM "quên" một phần thông tin cũ và "ghi" thông tin mới vào trạng thái ô. c = f * c_prev + i * c_
- Tính trạng thái ẩn (h): Trạng thái ẩn mới h được tính bằng cách nhân cổng đầu ra với
tanh(c), tức là áp dụng hàm tanh lên trạng thái ô mới c và sau đó nhân với cổng đầu ra. h = o * tf.tanh(c) 5.2.2 Xây dựng mô hình
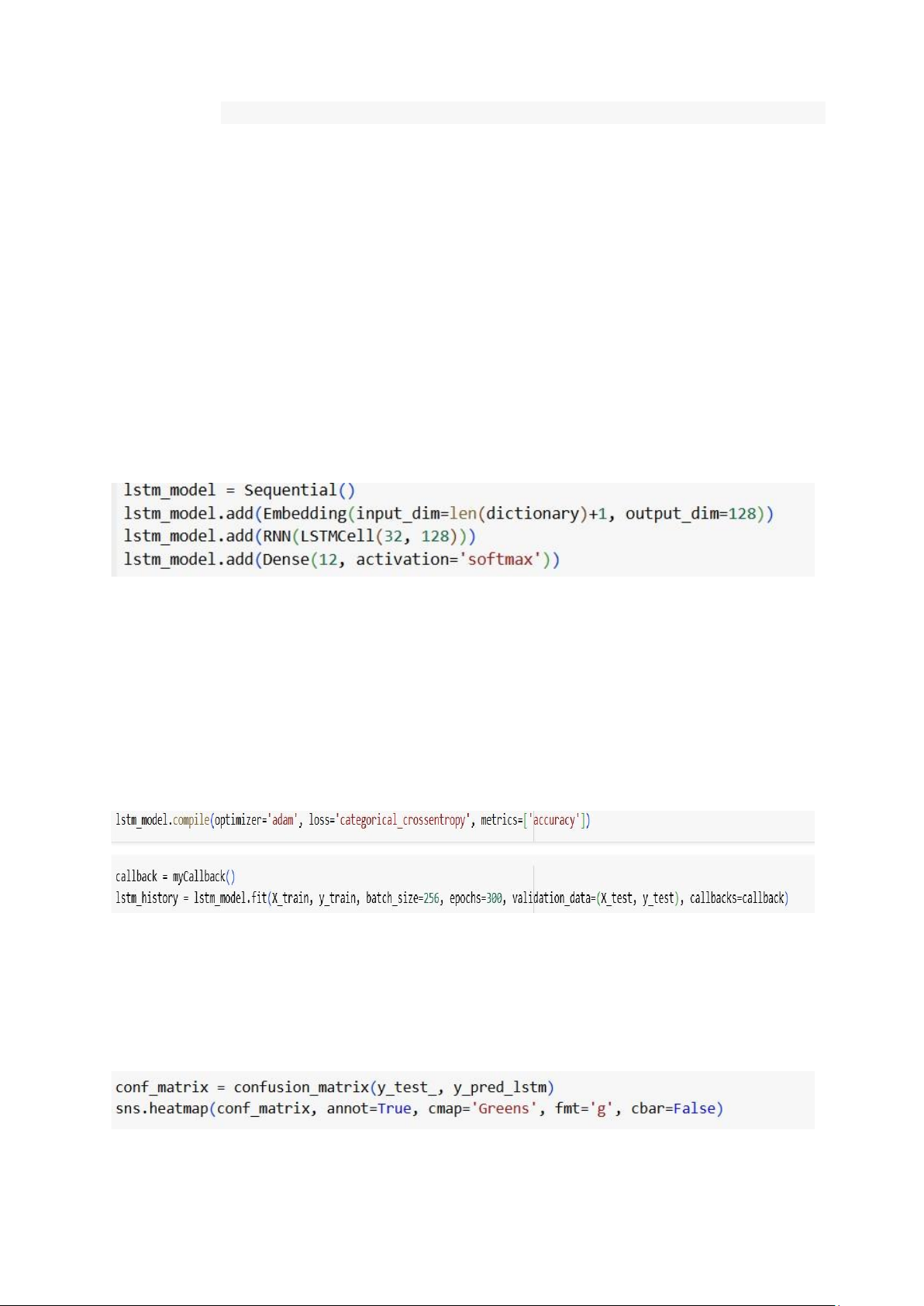
Mô hình LSTM được xây dựng sử dụng lớp LSTMCell đã được định nghĩa ở trên.
- Embedding: Lớp này chuyển đổi các từ thành vector nhúng, với input_dim là số lượng
từ trong từ điển và output_dim=128 là chiều của không gian nhúng.
- RNN(LSTMCell(32, 128)): Lớp RNN dùng LSTMCell để xây dựng một mạng LSTM
với 32 đơn vị LSTM. Lớp này nhận đầu vào có chiều dài 128.
- Dense: Lớp fully connected với 12 đơn vị, dùng hàm kích hoạt softmax để phân loại thành 12 lớp.
5.2.3 Huấn luyện mô hình
- Biên dịch mô hình: Sử dụng bộ tối ưu adam và hàm mất mát categorical_crossentropy
cho bài toán phân loại nhiều lớp.
- Huấn luyện: Mô hình được huấn luyện trên dữ liệu X_train và y_train với 300 epoch,
mỗi lần huấn luyện có batch size là 256. 5.2.4 Đánh giá
- Sau khi huấn luyện, mô hình sẽ dự đoán các nhãn cho tập kiểm tra X_test.
- Dự đoán được tính bằng np.argmax để chọn nhãn có xác suất cao nhất.
- Ma trận nhầm lẫn được tạo ra để đánh giá độ chính xác của mô hình. 5.3 GRU lOMoAR cPSD| 58800262
- Là một dạng của mạng nơ-ron hồi quy (RNN), được phát triển để cải thiện hiệu suất của
RNN trong các bài toán học chuỗi dài. GRU, giống như LSTM (Long Short-Term
Memory), giải quyết vấn đề vanishing gradient trong quá trình huấn luyện với chuỗi
dài, giúp mạng "nhớ" thông tin lâu hơn mà không bị mất mát.
- Tuy nhiên, GRU đơn giản hơn LSTM vì nó chỉ có hai cổng: cổng cập nhật (update gate)
và cổng đặt lại (reset gate). Các cổng này giúp mạng quyết định những phần nào của
trạng thái ẩn cần được "cập nhật" và "đặt lại". 5.3.1 GRUCell
- Cổng cập nhật (z): Quyết định mức độ thông tin từ trạng thái ẩn trước đó được giữ lại.
- Cổng đặt lại (r): Quyết định phần nào của trạng thái ẩn trước đó sẽ bị bỏ qua khi tính
toán trạng thái ẩn mới.
- Cổng ứng dụng mới (h_tilde): Tính toán trạng thái ẩn mới tiềm năng, sử dụng cổng đặt lại r
- Kết hợp đầu vào và trạng thái ẩn trước đó: Cả đầu vào hiện tại và trạng thái ẩn trước đó
được kết hợp lại để tính toán các cổng.
x_h_prev_reset = tf.concat([inputs, r * prev_state], axis=-1)
- Tính to án các cổng:
+) Cổng cập nhật zt sử dụng hàm sigmoid.
+)Cổng đặt lại rt sử dụng hàm sigmoid.
+)Cổng ứng dụng mới h_tilde sử dụng hàm tanh
z = tf.sigmoid(tf.matmul(x_h_prev, self.W_z) + self.b_z) r = tf.sigmoid(tf.matmul(x_h_prev,
self.W_r) + self.b_r) x_h_prev_reset = tf.concat([inputs, r * prev_state], axis=-1) h_tilde =
tf.tanh(tf.matmul(x_h_prev_reset, self.W_h) + self.b_h) lOMoAR cPSD| 58800262
- Tính toán trạng thái ẩn mới: Trạng thái ẩn mới new_state được tính bằng cách kết hợp
cổng cập nhật zt và cổng ứng dụng mới h_tilde.
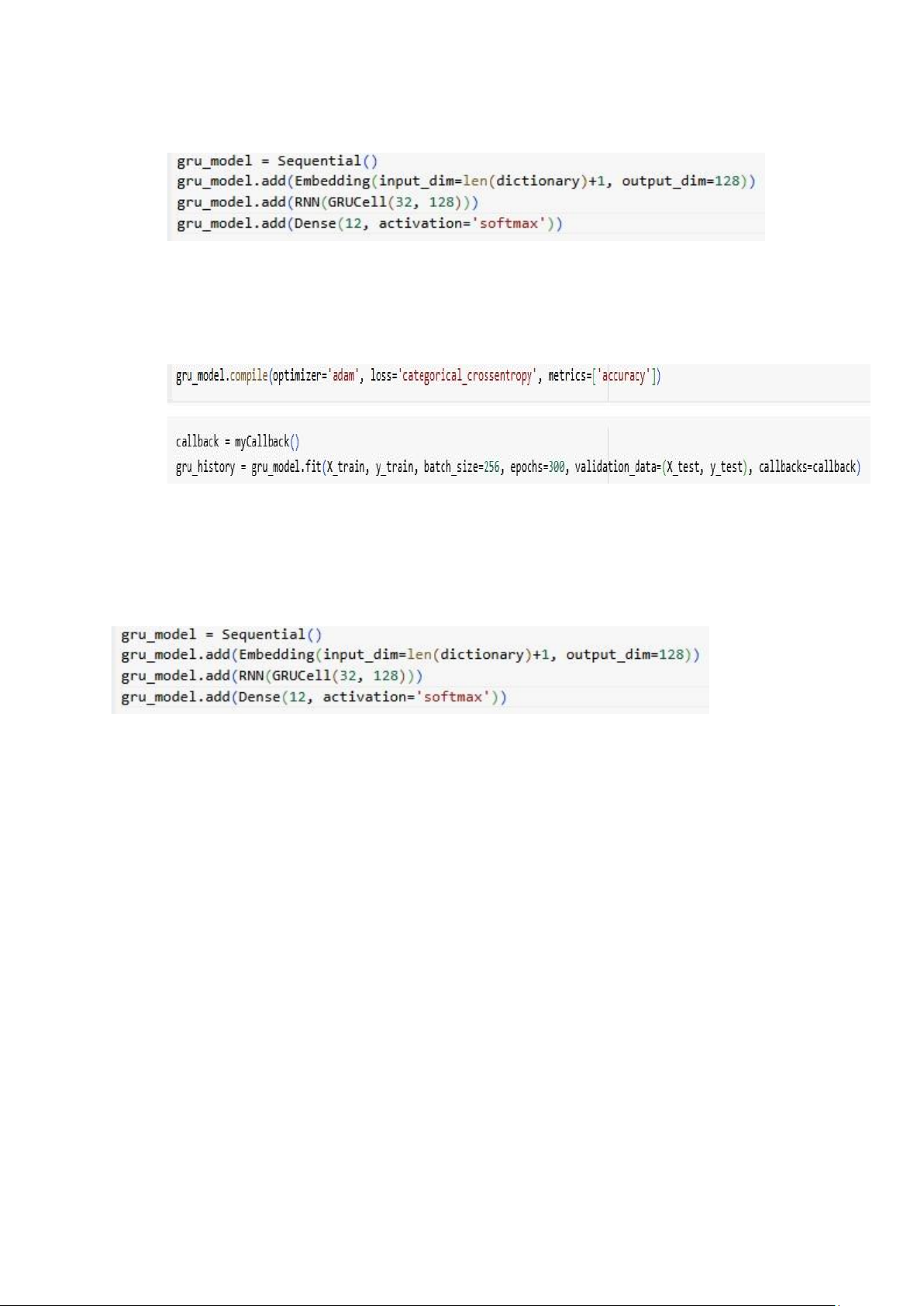
new_state = z * prev_state + (1 - z) * h_tilde 5.3.2 Xây dựng mô hình
- Embedding: Lớp nhúng chuyển các từ trong từ điển thành các vector nhúng.
- RNN với GRUCell: Lớp này sử dụng GRUCell để xây dựng mô hình GRU.
- Dense: Lớp fully connected với 12 lớp phân loại, sử dụng hàm kích hoạt softmax để dự
đoán xác suất cho từng lớp.
5.3.3 Huấn luyện mô hình
- Mô hình được biên dịch với optimizer là adam và hàm mất mát
categorical_crossentropy. Sau đó, mô hình được huấn luyện với dữ liệu huấn luyện và kiểm tra.
Phần 6: Phân loại dữ liệu
- Sử dụng lớp Dense để phân thành 12 lớp do phần Sản phẩm quy định có 3 mức( -1:
Tệ, 0: Trung bình , 1: Tốt), phần Dịch vụ có 4 mức (-1: Tệ, 0: Trung bình , 1: Tốt, 2:
Không đề cập) từ đó tạo thành ma trận đánh giá với 12 vector
- Sử dụng hàm kích hoạt Softmax chuyển các giá trị đầu ra thành xác suất, sao cho tổng
các xác suất của các lớp là 1. Mỗi neuron trong lớp sẽ trả về một giá trị từ 0 đến 1, và
lớp có giá trị cao nhất sẽ được chọn là dự đoán của mô hình. lOMoAR cPSD| 58800262
Phần 7: Đánh giá mô hình
- Trục x (Epoch): Biểu diễn số lần lặp lại quá trình huấn luyện.
- Trục y (Accuracy): Biểu diễn độ chính xác (accuracy) của mô hình.
7.1. Model Accuracy (Biểu đồ bên trái): -
Training Accuracy (đường màu xanh lá): Độ chính xác tăng nhanh ở các epoch
đầu tiên và đạt giá trị gần 1 (tức là 100%) ở cuối quá trình huấn luyện. -
Validation Accuracy (đường màu xanh dương): Ban đầu cũng tăng lên nhưng
sau đó chững lại, dao động quanh một mức cụ thể. Điều này cho thấy mô hình có thể đã
đạt mức tối ưu trên dữ liệu kiểm tra.
Kết luận: Mô hình có dấu hiệu overfitting, vì độ chính xác trên tập huấn luyện cao hơn
đáng kể so với tập kiểm tra (validation).
7.2. Model Loss (Biểu đồ bên phải):
- Training Loss (đường màu xanh lá): Giảm đều đặn, gần như hội tụ về một giá trị rất thấp.
- Validation Loss (đường màu xanh dương): Ban đầu giảm mạnh nhưng sau đó tăng lên,
điều này cho thấy mô hình không còn cải thiện trên dữ liệu kiểm tra. lOMoAR cPSD| 58800262
Kết luận: Tập kiểm tra (validation) có dấu hiệu overfitting loss, tức là mô hình hoạt động
kém trên tập dữ liệu không thấy trước. 7.3 Kết luận
- Overfitting: Mô hình đã bắt đầu overfit sau epoch ~10.
7.4 Giải pháp đề xuất:
- Early Stopping: Dừng huấn luyện tại epoch mà validation loss đạt giá trị thấp nhất (khoảng epoch 8-10).
- Regularization: Thêm kỹ thuật như Dropout hoặc L2 Regularization để giảm overfitting.
- Data Augmentation: Tăng tính đa dạng của dữ liệu huấn luyện để mô hình học khái quát tốt hơn.
- Learning Rate Adjustment: Sử dụng lịch giảm learning rate để cải thiện việc tối ưu.
Tài liệu liên quan:
-

Đồ án tốt nghiệp - Triển khai hệ thống Cloud trên nền tảng mã nguồn mở Openstack sử dụng Kolla-Ansible | Học viện Công Nghệ Bưu Chính Viễn Thông
42 21 -

Tiểu luận: Ứng dụng khai phá dữ liệu trong phân tích bộ dữ liệu giá nhà và dự đoán giá nhà môn Nhập môn khoa học dữ liệu | Học viện Công Nghệ Bưu Chính Viễn Thông
55 28 -

Mẫu bài tập lớn môn Nhập môn Khoa học dữ liệu | Học viện Công Nghệ Bưu Chính Viễn Thông
219 110 -

Kiến thức và ứng dụng cơ bản môn Nhập môn Khoa học dữ liệu | Học viện Công Nghệ Bưu Chính Viễn Thông
244 122