Báo cáo chuyên đề học phần khai phá dự liệu - Công nghệ thông tin | Trường đại học Điện Lực
Báo cáo chuyên đề học phần khai phá dự liệu - Công nghệ thông tin | Trường đại học Điện Lực được sưu tầm và soạn thảo dưới dạng file PDF để gửi tới các bạn sinh viên cùng tham khảo, ôn tập đầy đủ kiến thức, chuẩn bị cho các buổi học thật tốt. Mời bạn đọc đón xem!
Môn: Công nghệ thông tin(CNTT350) 110 tài liệu
Trường: Trường Đại học Điện lực 511 tài liệu
Tác giả:


















Preview text:
TRƯỜNG ĐẠI HỌC ĐIỆN LỰC
KHOA CÔNG NGHỆ THÔNG TIN
BÁO CÁO CHUYÊN ĐỀ HỌC PHẦN KHAI PHÁ DỮ LIỆU ĐỀ TI:
ỨNG DỤNG THUẬT TOÁN PHÂN CỤM KMEANS CLUSTERING
ĐỂ DỰ ĐOÁN TỶ LỆ SINH V TUỔI THỌ CÁC NƯỚC Sinh viên thực
: NGUYỄN TUẤN NHẬT hiện : NGUYỄN ĐÌNH SANG : NGUYỄN ĐỨC HẢI
Giảng viên hướng : NGUYỄN THỊ THANH dẫn TÂN Ngành : CÔNG NGHỆ THÔNG TIN Chuyên ngành : CÔNG NGHỆ PHẦN MỀM Lớp : D14CNPM4 Khóa : 2019-2024
Hà Nội, tháng 12 năm 2020 PHIẾU CHẤM ĐIỂM
Sinh viên thực hiện Họ và tên Chữ ký Ghi Chú Nguyễn Tuấn Nhật Nguyễn Đình Sang Nguyễn Đức Hải Giảng viên chấm Họ và tên Chữ ký Ghi chú Giảng viên chấm 1 Giảng viên chấm 2 M'c l'c
CHƯƠNG 1. TỔNG QUAN VỀ KHAI PHÁ DỮ LIỆU.....................2
CHƯƠNG 2 THUẬT TOÁN K-MEANS CLUSTERING TRONG BI
TOÁN PHÂN CỤM........................................................................6
2.1 Tổng quan về thuật toán K-Means Clustering........................6
2.2. Thuật toán K-Means Clustering:............................................7
2.2.1. Mô hình toán học:...........................................................7
2.2.2. Độ chính xác của thuật toán:..........................................8
2.2.3. Nghiệm của thuật toán K-Means Clustering:...................8
2.2.4. Tóm tắt thuật toán:.........................................................8
CHƯƠNG 3 ỨNG DỤNG THUẬT TOÁN K-MEANS CLUSTERING
....................................................................................................10
3.1. Dữ liệu tỷ lệ sinh và tuổi thọ...............................................10
3.1.1. Phát biểu bài toán:........................................................10
3.1.2. Yêu cầu:........................................................................10
3.1.3. Bộ dữ liệu:.....................................................................10
3.1.4. Tiến hành phân c'm.....................................................11
Thực hiện hàm thuật toán K có nghĩa là......................................13
# Làm thế nào nó hoạt động:......................................................13
# 1) chọn k điểm làm số c'm......................................................13
# 2) tìm khoảng cách eucledian của mỗi điểm (x, y) trong tập dữ
liệu với k điểm-tâm đã được xác định..........................................13
# 3) chỉ định mỗi điểm dữ liệu cho tâm gần nhất bằng cách sử
d'ng khoảng cách được tìm thấy trong bước trước......................13
# 4) tìm trọng tâm mới bằng cách lấy giá trị trung bình (trung
bình) trong mỗi nhóm c'm..........................................................13
# 5) lặp lại từ 2 đến 4 cho một số lần lặp cố định hoặc cho đến khi
các trọng tâm không thay đổi......................................................13 LỜI MỞ ĐẦU
Công nghệ ngày càng phổ biến và không ai có thể phủ nhận
được tầm quan trọng và những hiệu quả mà nó đem lại cho cuộc
sống chúng ta. Bất kỳ trong lĩnh vực nào, sự góp mặt của trí tuệ
nhân tạo sẽ giúp con người làm việc và hoàn thành tốt công việc
hơn. Và gần đây, một thuật ngữ “Data Mining” rất được nhiều
người quan tâm.Thay vì phải code phần mềm với cách thức thủ
công theo một bộ hướng dẫn c' thể nhằm hoàn thành một nhiệm
v' đề ra thì máy tính sẽ tự “học hỏi” bằng cách sử d'ng một lượng
lớn dữ liệu cùng những thuật toán cho phép nó thực hiện các tác v'.
Đây là một lĩnh vực khoa học tuy không mới, nhưng cho thấy
lĩnh vực trí tuệ nhân tạo đang ngày càng phát triển và có thể tiến
xa hơn trong tương lai. Đồng thời, thời điểm này nó được xem là
một lĩnh vực “nóng” và dành rất nhiều mối quan tâm để phát triển
nó một cách mạnh mẽ, bùng nổ hơn.
Hiện nay, việc quan tâm machine learning càng ngày càng
tăng lên là vì nhờ có machine learning giúp gia tăng dung lượng
lưu trữ các loại dữ liệu sẵn, việc xử lý tính toán có chi phí thấp và
hiệu quả hơn rất nhiều.
Những điều trên được hiểu là nó có thể thực hiện tự động,
nhanh chóng để tạo ra những mô hình cho phép phân tích các dữ
liệu có quy mô lớn hơn và phức tạp hơn đồng thời đưa ra những
kết quả một cách nhanh và chính xác hơn.
Chính sự hiệu quả trong công việc và các lợi ích vượt bậc mà nó
đem lại cho chúng ta khiến machine learning ngày càng được chú
trọng và quan tâm nhiều hơn. Vì vậy chúng em đã chọn đề tài
”Ứng d'ng thuật toán K-Means để dự đoán tỷ lệ sinh và tuổi thọ
của các nước trên thế giới để làm báo cáo.
Chúng em xin chân thành gửi lời cảm ơn tới các thầy cô giáo
trong Trường Đại học Điện Lực nói chung và các thầy cô giáo trong
Khoa Công nghệ thông tin nói riêng đã tận tình giảng dạy, truyền
đạt cho chúng em những kiến thức cũng như kinh nghiệm quý báu
trong suốt quá trình học. Đặc biệt, em gửi lời cảm ơn đến Cô Trần
Thị Thanh Tâm đã tận tình theo sát giúp đỡ, trực tiếp chỉ bảo,
hướng dẫn trong suốt quá trình nghiên cứu và học tập của chúng em.
CHƯƠNG 1. TỔNG QUAN VỀ KHAI PHÁ DỮ LIỆU 1.1.1.
Tại sao lại cần khai phá dữ liệu (datamining)
Khoảng hơn một thập kỷ trở lại đây, lượng thông tin được lưu
trữ trên các thiết bị điện tử (đĩa cứng, CD-ROM, băng từ, .v.v.)
không ngừng tăng lên. Sự tích lũy dữ liệu này xảy ra với một tốc
độ bùng nổ. Người ta ước đoán rằng lượng thông tin trên toàn cầu
tăng gấp đôi sau khoảng hai năm và theo đó số lượng cũng như
kích cỡ của các cơ sở dữ liệu (CSDL) cũng tăng lên một cách
nhanh chóng. Nói một cách hình ảnh là chúng ta đang “ngập”
trong dữ liệu nhưng lại “đói” tri thức. Câu hỏi đặt ra là liệu chúng
ta có thể khai thác được gì từ những “núi” dữ liệu tưởng chừng như
“bỏ đi” ấy không ? “Necessity is the mother of invention” - Data
Mining ra đời như một hướng giải quyết hữu hiệu cho câu hỏi vừa
đặt ra ở trên []. Khá nhiều định nghĩa về Data Mining và sẽ được
đề cập ở phần sau, tuy nhiên có thể tạm hiểu rằng Data Mining
như là một công nghệ tri thức giúp khai thác những thông tin hữu
ích từ những kho dữ liệu được tích trữ trong suốt quá trình hoạt
động của một công ty, tổ chức nào đó. 1.1.2.
Khai phá dữ liệu là gì?
Khai phá dữ liệu (datamining) được định nghĩa như là một
quá trình chắt lọc hay khai phá tri thức từ một lượng lớn dữ liệu.
Một ví d' hay được sử d'ng là là việc khai thác vàng từ đá và cát,
Dataming được ví như công việc "Đãi cát tìm vàng" trong một tập
hợp lớn các dữ liệu cho trước. Thuật ngữ Dataming ám chỉ việc tìm
kiếm một tập hợp nhỏ có giá trị từ một số lượng lớn các dữ liệu
thô. Có nhiều thuật ngữ hiện được dùng cũng có nghĩa tương tự
với từ Datamining như Knowledge Mining (khai phá tri thức),
knowledge extraction(chắt lọc tri thức), data/patern analysis(phân
tích dữ liệu/mẫu), data archaeoloogy (khảo cổ dữ liệu),
datadredging(nạo vét dữ liệu),... Định nghĩa: Khai phá dữ liệu là
một tập hợp các kỹ thuật được sử d'ng để tự động khai thác và
tìm ra các mối quan hệ lẫn nhau của dữ liệu trong một tập hợp dữ
liệu khổng lồ và phức tạp, đồng thời cũng tìm ra các mẫu tiềm ẩn
trong tập dữ liệu đó. Khai phá dữ liệu là một bước trong bảy bước
của quá trình KDD (Knowleadge Discovery in Database) và KDD
được xem như 7 quá trình khác nhau theo thứ tự sau:s
1. Làm sạch dữ liệu (data cleaning & preprocessing)s: Loại bỏ
nhiễu và các dữ liệu không cần thiết.
2. Tích hợp dữ liệu: (data integration): quá trình hợp nhất dữ liệu
thành những kho dữ liệu (data warehouses & data marts) sau khi
đã làm sạch và tiền xử lý (data cleaning & preprocessing).
3. Trích chọn dữ liệu (data selection): trích chọn dữ liệu từ những
kho dữ liệu và sau đó chuyển đổi về dạng thích hợp cho quá trình
khai thác tri thức. Quá trình này bao gồm cả việc xử lý với dữ liệu
nhiễu (noisy data), dữ liệu không đầy đủ (incomplete data), .v.v.
4. Chuyển đổi dữ liệu: Các dữ liệu được chuyển đổi sang các dạng
phù hợp cho quá trình xử lý
5. Khai phá dữ liệu(data mining): Là một trong các bước quan
trọng nhất, trong đó sử d'ng những phương pháp thông minh để
chắt lọc ra những mẫu dữ liệu.
6. Ước lượng mẫu (knowledge evaluation): Quá trình đánh giá các
kết quả tìm được thông qua các độ đo nào đó.
7. Biểu diễn tri thức (knowledge presentation): Quá trình này sử
d'ng các kỹ thuật để biểu diễn và thể hiện trực quan cho người dùng. 1.1.3.
Các chức năng chính của khai phá dữ liệu
Data Mining được chia nhỏ thành một số hướng chính như sau:
• Mô tả khái niệm (concept description): thiên về mô tả, tổng
hợp và tóm tắt khái niệm. Ví d': tóm tắt văn bản.
• Luật kết hợp (association rules): là dạng luật biểu diễn tri
thứ ở dạng khá đơn giản. Ví d': “60 % nam giới vào siêu thị nếu
mua bia thì có tới 80% trong số họ sẽ mua thêm thịt bò khô”. Luật
kết hợp được ứng d'ng nhiều trong lĩnh vực kính doanh, y học, tin-
sinh, tài chính & thị trường chứng khoán, .v.v.
• Phân lớp và dự đoán (classification & prediction): xếp một
đối tượng vào một trong những lớp đã biết trước. Ví d': phân lớp
vùng địa lý theo dữ liệu thời tiết. Hướng tiếp cận này thường sử
d'ng một số kỹ thuật của machine learning như cây quyết định
(decision tree), mạng nơ ron nhân tạo (neural network), .v.v. Người
ta còn gọi phân lớp là học có giám sát (học có thầy).
• Phân c'm (clustering): xếp các đối tượng theo từng c'm (số
lượng cũng như tên của c'm chưa được biết trước. Người ta còn
gọi phân c'm là học không giám sát (học không thầy).
• Khai phá chuỗi (sequential/temporal patterns): tương tự
như khai phá luật kết hợp nhưng có thêm tính thứ tự và tính thời
gian. Hướng tiếp cận này được ứng d'ng nhiều trong lĩnh vực tài
chính và thị trường chứng khoán vì nó có tính dự báo cao. 1.1.4.
Ứng dụng của khai phá dữ liệu
Data Mining tuy là một hướng tiếp cận mới nhưng thu hút
được rất nhiều sự quan tâm của các nhà nghiên cứu và phát triển
nhờ vào những ứng d'ng thực tiễn của nó. Chúng ta có thể liệt kê
ra đây một số ứng d'ng điển hình:
• Phân tích dữ liệu và hỗ trợ ra quyết định (data analysis &
decision support) • Điều trị y học (medical treatment)
• Text mining & Web mining
• Tin-sinh (bio-informatics)
• Tài chính và thị trường chứng khoán (finance & stock market) • Bảo hiểm (insurance)
• Nhận dạng (pattern recognition) • .v.v
CHƯƠNG 2 THUẬT TOÁN K-MEANS CLUSTERING TRONG BI TOÁN PHÂN CỤM
2.1 Tổng quan về thuật toán K-Means Clustering
Với thuật toán K-Means Clustering, chúng ta không biết
nhãn (label) của từng điểm dữ liệu. M'c đích là làm thể nào để
phân dữ liệu thành các c'm (cluster) khác nhau sao cho dữ liệu
trong cùng một c'm có tính chất giống nhau. Ý tưởng đơn giản
nhất về cluster (c'm) là tập hợp các điểm ở gần nhau trong một
không gian nào đó (không gian này có thể có rất nhiều chiều
trong trường hợp thông tin về một điểm dữ liệu là rất lớn). Hình
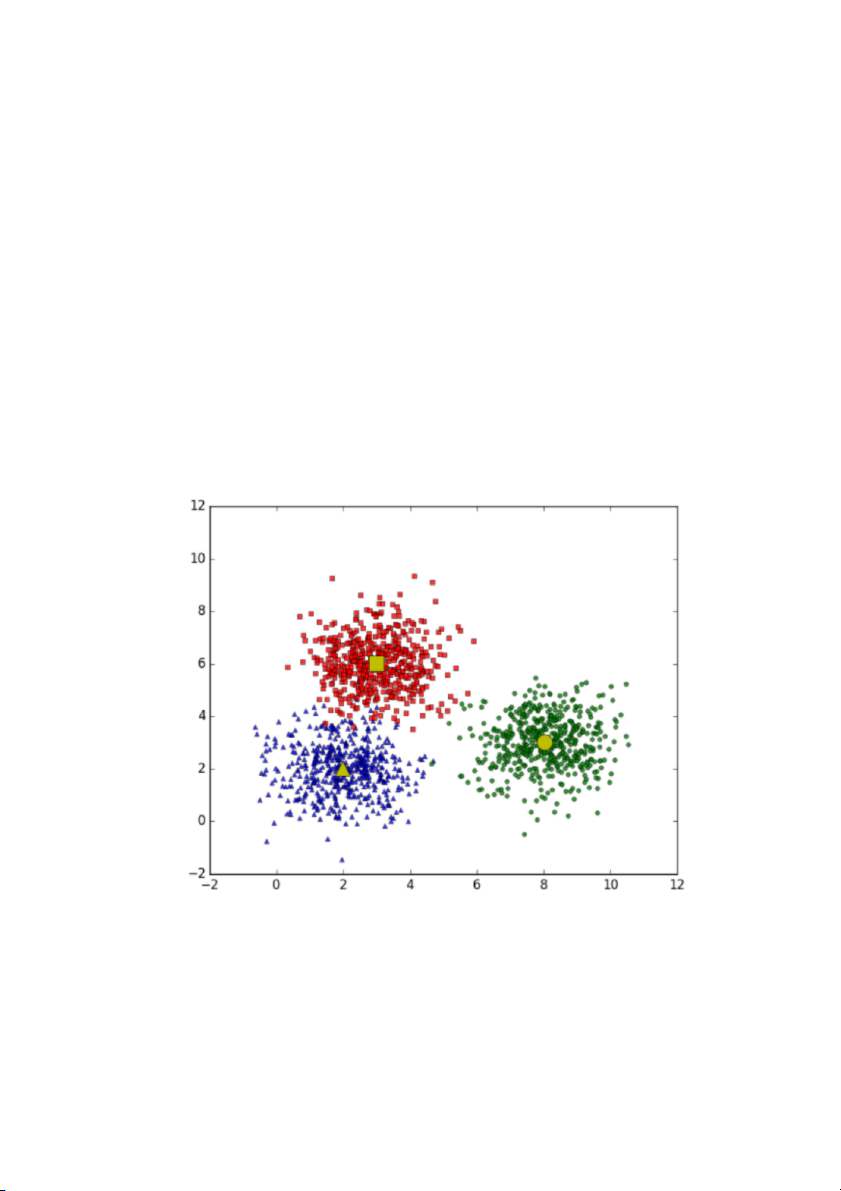
bên dưới là một ví d' về 3 c'm dữ liệu (từ giờ tôi sẽ viết gọn là cluster).
Hình 2.1: Bài toán với 3 clusters
Giả sử mỗi cluster có một điểm đại diện (center) màu
vàng. Và những điểm xung quanh mỗi center thuộc vào cùng
nhóm với center đó. Một cách đơn giản nhất, xét một điểm bất
kỳ, ta xét xem điểm đó gần với center nào nhất thì nó thuộc về
cùng nhóm với center đó.
2.2. Thuật toán K-Means Clustering: 2.2.1. Mô hình toán học:
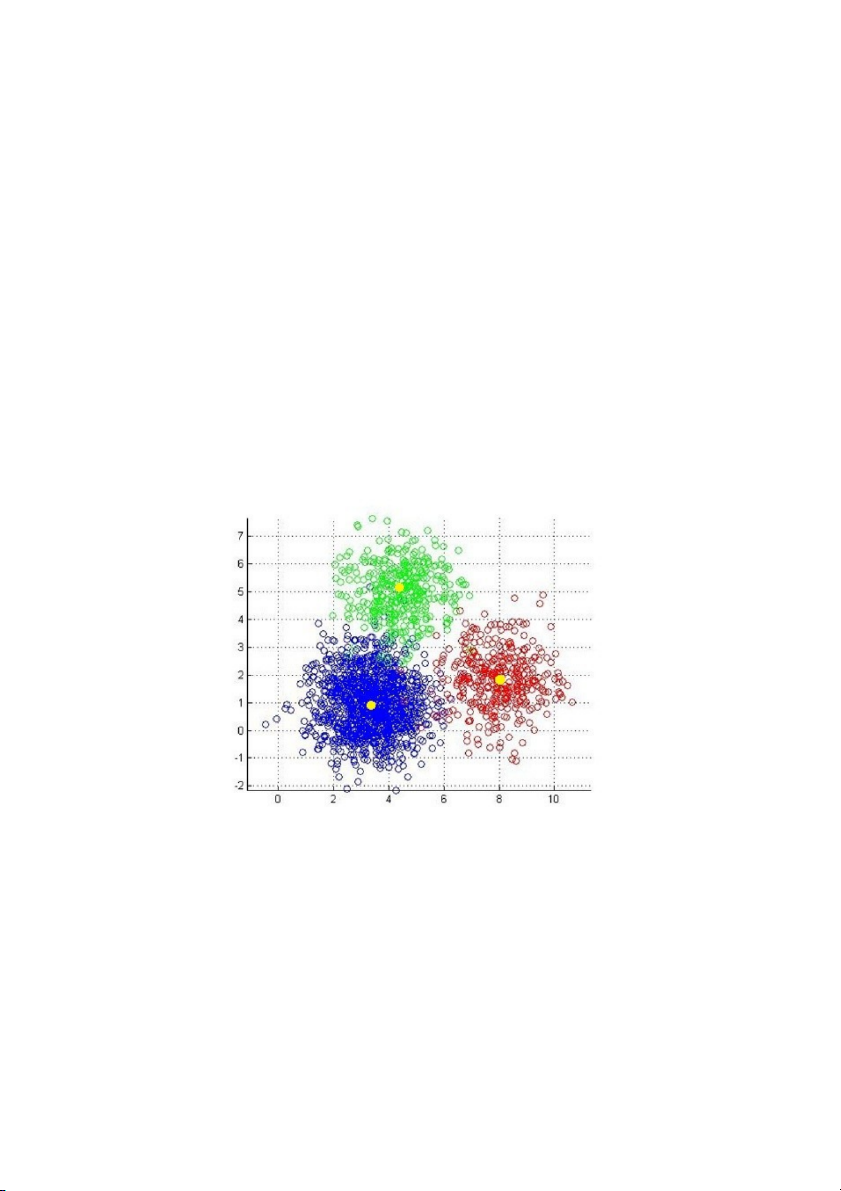
Ta gọi điểm tại vị trí trung bình của tất cả các điểm dữ liệu
trong một c'm là trung tâm cụm. Như vậy, nếu có K c'm thì
sẽ có K trung tâm c'm và mỗi trung tâm c'm sẽ nằm gần các
điểm dữ liệu trong c'm tương ứng hơn các trung tâm c'm khác.
Trong hình dưới đây, K = 3 và ta có 3 trung tâm c'm là các điểm màu vàng.
Hình 2.2: Mô hình dữ liệu được phân cụm
Để phân c'm dữ liệu bằng K-Means Clustering, trước hết ta
chọn K là số c'm để phân chia và chọn ngẫu nhiên K trong số
m dữ liệu ban đầu làm trung tâm c'm μ1, μ2, …, μK. Sau đó,
với điểm dữ liệu x(i) ta sẽ gán nó cho c'm c(i) là c'm có trung tâm c'm gần nó nhất.
Khi tất cả các điểm dữ liệu đã được gán về các c'm, bước tiếp
theo là tính toán lại vị trí các trung tâm c'm bằng trung bình
tọa độ các điểm dữ liệu trong c'm đó.
với k1, k2, …, kn là chỉ số các dữ liệu thuộc c'm thứ k. Các
bước trên được lặp lại cho tới khi vị trí các trung tâm c'm không
đổi sau một bước lặp nào đó.
2.2.2. Độ chính xác của thuật toán:
Hàm mất mát của thuật toán K-Means Clustering đặc trưng
cho độ chính xác của nó sẽ càng lớn khi khoảng cách từ mỗi
điểm dữ liệu tới trung tâm c'm càng lớn.
2.2.3. Nghiệm của thuật toán K-Means Clustering:
Trong các bước của thuật toán, thực chất bước gán các
điểm dữ liệu về trung tâm c'm gần nhất và bước thay đổi trung
tâm c'm về vị trí trung bình của các điểm dữ liệu trong c'm
đều nhằm m'c đích giảm hàm mất mát. Thuật toán kết thúc khi
vị trí các trung tâm c'm không đổi sau một bước lặp nào đó.
Khi đó hàm mất mát đạt giá trị nhỏ nhất.
Khi K càng nhỏ so với m, thuật toán càng dễ đi đến kết
quả chưa phải tối ưu. Điều này ph' thuộc vào cách chọn K trung tâm c'm ban đầu.
Để khắc ph'c điều này, ta cần lặp lại thuật toán nhiều lần
và chọn phương án có giá trị hàm mất mát nhỏ nhất.
2.2.4. Tóm tắt thuật toán:
Đầu vào: Dữ liệu XX và số lượng cluster cần tìm KK.
Đầu ra: Các center MM và label vector cho từng điểm dữ liệu YY. 1.
Chọn KK điểm bất kỳ làm các center ban đầu. 2.
Phân mỗi điểm dữ liệu vào cluster có center gần nó nhất. 3.
Nếu việc gán dữ liệu vào từng cluster ở bước 2 không
thay đổi so với vòng lặp trước nó thì ta dừng thuật toán. 4.
Cập nhật center cho từng cluster bằng cách lấy trung
bình cộng của tất các các điểm dữ liệu đã được gán vào cluster đó sau bước 2. 5. Quay lại bước 2.
CHƯƠNG 3 ỨNG DỤNG THUẬT TOÁN K-MEANS CLUSTERING
3.1. Dữ liệu tỷ lệ sinh và tuổi thọ
3.1.1. Phát biểu bài toán:
Bài toán phân loại tuổi sinh và tuổi thọ của các nước
- Giá trị input: Thông tin quốc gia, tỷ lệ sinh và tuổi thọ
- Giá trị output: tên của c'm chúng được phân vào 3.1.2. Yêu cầu:
- Lấy dữ liệu mô tả đặc tính tỷ lệ sinh và tuổi thọ
- Trích chọn đặc trưng từ tập dữ liệu lấy được
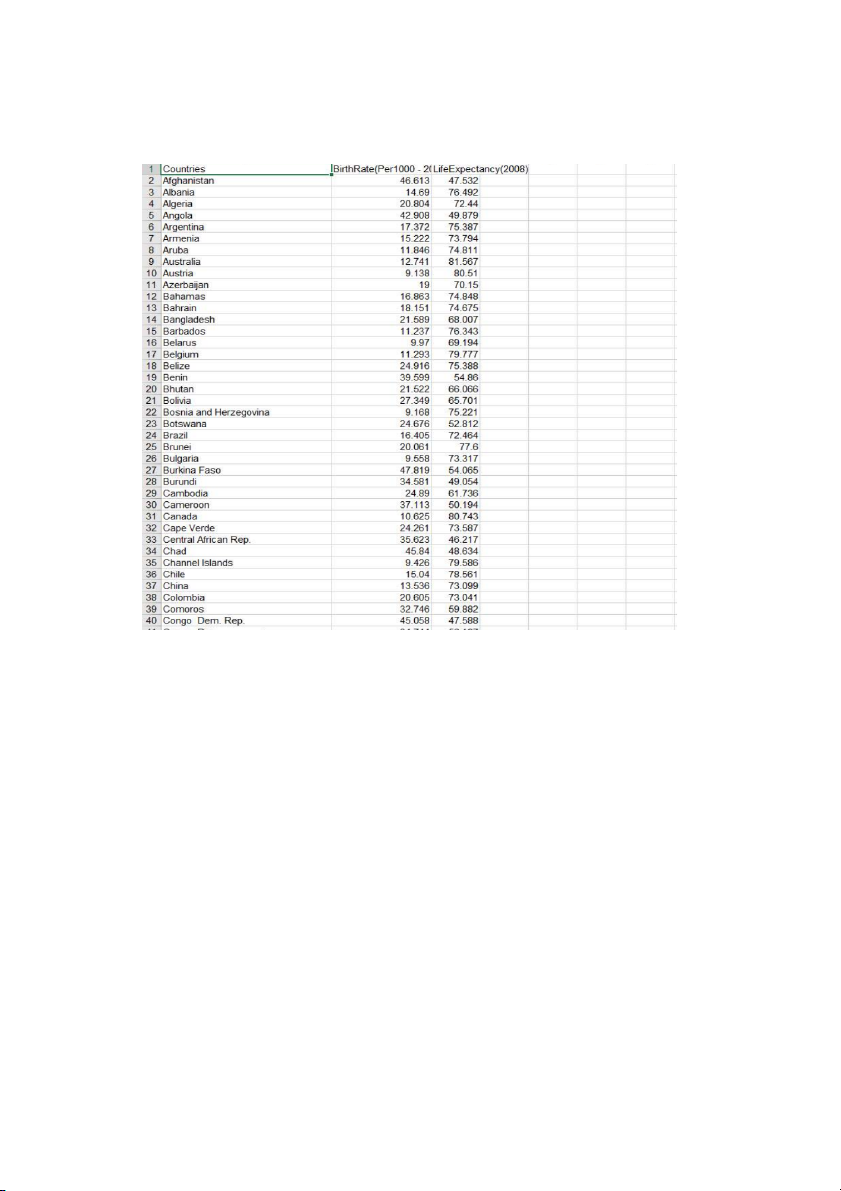
- Xử lý, làm sạch dữ liệu - Tiến hành phân c'm - Dữ liệu hóa đồ thị 3.1.3. Bộ dữ liệu:
Bộ dữ liệu bao gồm các đặc trưng là các nồng độ các
thành phần ảnh hưởng đển tỷ lệ sinh và tuổi thọ, bao gồm: - : quốc gia Countries - BirthRate): tỷ lệ sinh
- LifeExpectancy(2008): tuổi thọ
Hình 3.1: Dữ liệu cụ thể
3.1.4. Tiến hành phân cụm IMPORT THƯ VIỆN:
import matplotlib.pyplot as plt import random import numpy as np import pandas as pd import math as sqrt ĐỌC FILE DỮ LIỆU CSV:
data = pd.read_csv("data2008.csv")
HÀM KHOẢNG CÁCH TÂM CỤM VÀ VẼ # Hàm khoảng cách Euclide
def euclidean_distance(x1, x2):
return np.sqrt(np.sum((x1 - x2)**2)) # trung bình
def compute_mean(clusters, classification):
return np.average(clusters[classification], axis=0) #
def visualize_clusters(centroids, clusters):
colors = 10*['b', 'g', 'c','r', 'k'] for centroid in centroids: # plot centroids
plt.scatter(centroids[centroid][0], centroids[centroid][1],
marker="x", s=15**2, linewidths=5, label="centroid")
# vẽ các điểm dữ liệu và tô màu chúng dựa trên c'm của chúng
for classification in clusters:
color = colors[classification]
for featureset in clusters[classification]:
plt.scatter(featureset[0], featureset[1], color=color, s=30)
plt.title('2008 demographics')
plt.xlabel('BirthRate(Per1000 - 2008)')
plt.ylabel('LifeExpectancy(2008)')
plt.legend(loc='upper right') plt.show()
Thực hiện hàm thuật toán K có nghĩa là :
# 1) chọn k điểm làm số cụm
# 2) tìm khoảng cách eucledian của mỗi điểm (x, y)
trong tập dữ liệu với k điểm-tâm đã được xác định
# 3) chỉ định mỗi điểm dữ liệu cho tâm gần nhất bằng
cách sử dụng khoảng cách được tìm thấy trong bước trước
# 4) tìm trọng tâm mới bằng cách lấy giá trị trung bình
(trung bình) trong mỗi nhóm cụm
# 5) lặp lại từ 2 đến 4 cho một số lần lặp cố định hoặc
cho đến khi các trọng tâm không thay đổi.
def k_Means(DataXy, k, max_iter, tolerance = 0.0001):
# chọn centroid một cách ngẫu nhiên
centroids = {} # một từ điển lưu trữ các điểm (x, y) của centroid for i in range(k):
centroids[i] = random.choice(DataXy) # phân loại / tạo c'm
#dist = khoảng cách (DataXy, centroid) for i in range(max_iter):
clusters = {} # c'm tạm thời for i in range(k):
clusters[i] = [] #chính là giá trị centroid là tập hợp tính năng (điểm dữ liệu) for featureset in DataXy:
# tìm khoảng cách giữa điểm và c'm (centroid)
distances = [euclidean_distance(featureset,
centroids[centroid]) for centroid in centroids]
classification = distances.index(min(distances))
clusters[classification].append(featureset)
prev_centroids = dict(centroids)
# xác định lại centroid trong c'm
# centroid là trung bình của tất cả
# điểm dữ liệu thuộc c'm
for classification in clusters:
centroids[classification] = compute_mean(clusters, classification) # tối ưu hóa
# Thuật toán được hội t' nếu
# phần trăm thay đổi (cnvg) trong các giá trị centroid
thấp hơn mức chúng tôi chấp nhận
# giá trị của dung sai (0,0001) optimized = True for c in centroids:
original_centroid = prev_centroids[c]
current_centroid = centroids[c]
cnvg = np.sum((current_centroid-
original_centroid)/original_centroid*100.00)
print(f"Tính tổng trên mỗi lần lặp:: {cnvg}") if cnvg > tolerance: optimized = False if optimized: # c'm trực quan hóa
visualize_clusters(centroids, clusters)
# Một số thống kê về kết quả phân nhóm
# số quốc gia trong mỗi c'm
# danh sách các quốc gia trong mỗi c'm
# Tuổi thọ trung bình Kỳ vọng và Tỷ lệ sinh trung bình cho mỗi c'm
cnt = data['Countries'] # được sử d'ng để truy vấn các quốc gia trong tập dữ liệu
i = 1 # nhãn cho số culster trong vòng lặp
for classification in clusters:
count = 0 # đếm số lượng các c'm
countries = [] # sẽ lưu trữ các quốc gia trên mỗi c'm
meanLifExp = [] # tuổi thọ trung bình trên mỗi c'm
birthRate = [] # tỷ lệ sinh trên mỗi c'm
for featureset in clusters[classification]: count +=1
countries.append(cnt[(data['BirthRate(Per1000 - 2008)']== featureset[0])
& (data['LifeExpectancy(2008)'] == featureset[1])])
# meanLifExp lưu trữ kỳ vọng tuổi thọ cho mỗi c'm để
tính giá trị trung bình sau này
meanLifExp.append(featureset[1])
# Tỷ lệ sinh cho mỗi c'm
birthRate.append(featureset[0])
print(f"\n\n=== Số quốc gia cho c'm {i} is {count} ===")
print(f"Tuổi thọ trung bình là {np.mean(meanLifExp):.3f}")
print(f"Tỷ lệ sinh trung bình là {np.mean(birthRate):.3f}")
print(f"=== Danh sách các quốc gia và tỷ lệ sinh cho c'm {i} ===\n\n") i+=1
for country, br in zip(countries, birthRate):
print(f"{country.to_string(index=False)} {br:.3f}")
# kết thúc triển khai k_Means
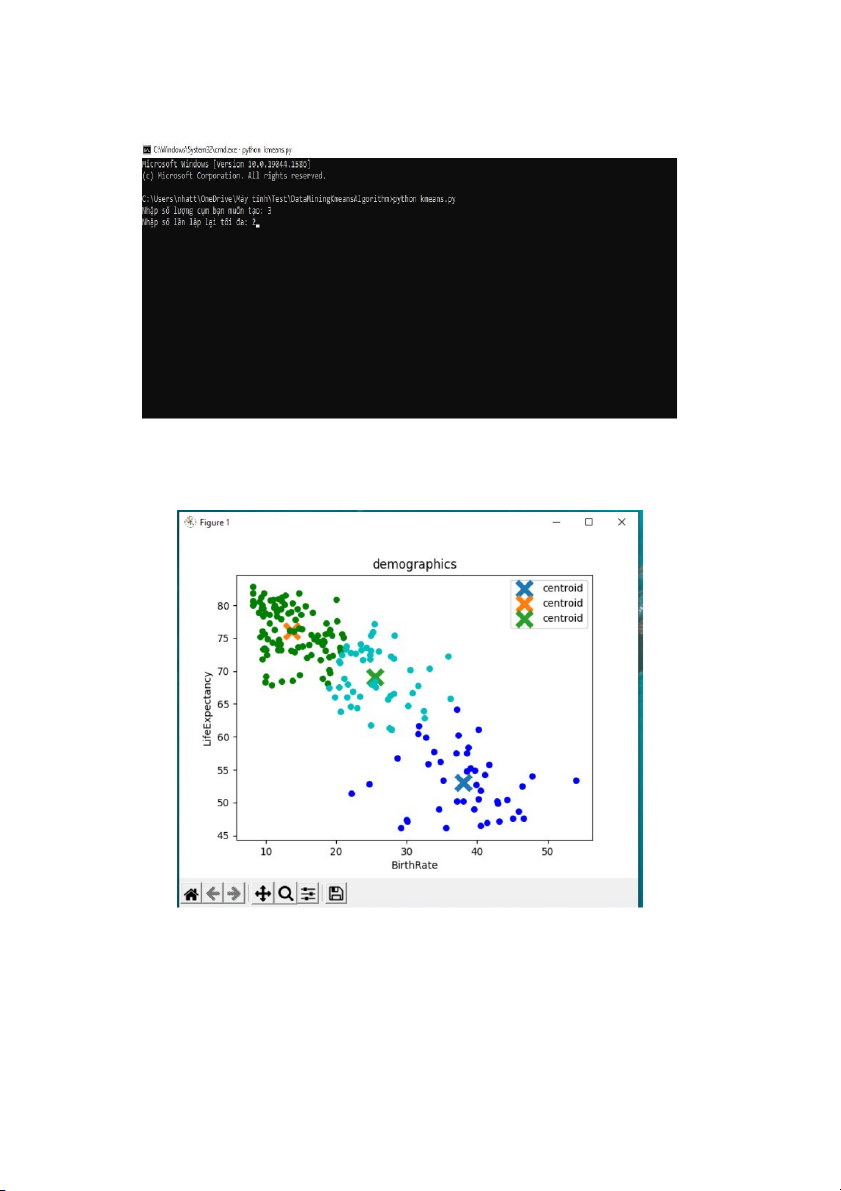
# Hỏi người dùng về số lượng c'm # và số lần lặp lại
k = int(input("Nhập số lượng c'm bạn muốn tạo: "))
n_iter = int(input("Nhập số lần lặp lại tối đa: ")) # gọi hàm k-mean k_Means(DataXy,k, n_iter)
Kết quả sau khi chạy
Ở đây cho phép nhập số lượng c'm và số lần lặp.




