Báo cáo cuối kỳ môn Applied Machine Learning đề tài "Detecting and recognizing hand sign language"
Báo cáo cuối kỳ môn Applied Machine Learning đề tài "Detecting and recognizing hand sign language" của Đại học Sư phạm Kỹ thuật Thành phố Hồ Chí Minh với những kiến thức và thông tin bổ ích giúp sinh viên tham khảo, ôn luyện và phục vụ nhu cầu học tập của mình cụ thể là có định hướng ôn tập, nắm vững kiến thức môn học và làm bài tốt trong những bài kiểm tra, bài tiểu luận, bài tập kết thúc học phần, từ đó học tập tốt và có kết quả cao cũng như có thể vận dụng tốt những kiến thức mình đã học vào thực tiễn cuộc sống. Mời bạn đọc đón xem!
Môn: Applied Machine Learning (APML436564) 10 tài liệu
Trường: Trường Đại học Sư phạm Kỹ thuật Thành phố Hồ Chí Minh 4.4 K tài liệu
Tác giả:



















Preview text:
lOMoARcPSD| 36443508 ABSTRACT
The main aims of implementing Applied Machine Learning "YOLOv5 - Detecting
and recognizing hand sign language" we obtained both theory and practice results. It
understands how to analyze a system and apply the algorithm model to the system. We
need to get a large collection of datasets by images. lOMoARcPSD| 36443508 CONTENT
ABSTRACT .................................................................................................................... i
CONTENT ..................................................................................................................... ii
LIST OF ABBREVIATIONS ....................................................................................... iii
LIST OF FIGURE ......................................................................................................... iii
CHAPTER 1: BACKGROUND KNOWLEDGE .......................................................... 1
1.1. INTRODUCTION ........................................................................................... 1
1.2. OVERVIEW .................................................................................................... 2
1.3. YOLO ARCHITECTURE .............................................................................. 2
1.4. YOLO’s OUTPUT .......................................................................................... 3
1.5. YOLOv5 ARCHITECTURE .......................................................................... 3
1.6. HAND SYMBOL DETECTION .................................................................... 4
CHAPTER 2: DESIGN AND IMPLEMENTATION APPLICATION OF "YOLOV5 -
DETECTING AND RECOGNIZING HAND SIGN LANGUAGE" ........................... 5
2.1. DATA SET ...................................................................................................... 5
2.1.1. Images .......................................................................................................... 5
2.1.2. Labels ........................................................................................................... 6
2.2. SET UP ENVIRONMENT YOLOv5 ............................................................. 7
2.3. THE TRAINING PROCESS .......................................................................... 8
CHAPTER 3: RESULTS AND DISCUSSION ........................................................... 11
3.1. RESULTS: DETECT HAND SIGN LANGUAGE ...................................... 11
3.2. DISCUSSION ............................................................................................... 12
3.3. CONCLUSION AND RECOMMENDATION ............................................ 16 lOMoARcPSD| 36443508
APPENDIX..................................................................................................................... 17
REFERENCE..................................................................................................................1 8 LIST OF ABBREVIATIONS YOLO You Only Look Once WHO World Health Organization CNN Convolutional Neural Network CV Computer vision AI Artificial intelligence PANet Path aggregation network CSPNet Cross stage partial network FPN Feature pyramid network FLOPS
Floating-point operations per second TP True Positive FP False Positive FN False Negative TN True Negative MAP Micro-Average Precision MAR Micro-Average Recall LIST OF FIGURE
Figure 1: YOLO network architecture diagram............................................................... 2
Figure 2: The network architecture of Yolov5.................................................................4
Figure 3: Dataset............................................................................................................... 6 lOMoAR cPSD| 36443508
Figure 4: Label a Image.................................................................................................... 7
Figure 5: Parameter of ratio Frame...................................................................................7
Figure 6: Clone repository and set up all dependencies in YOLOv5 indirectly from GOOGLE
Colab................................................................................................................8 Figure 7:
Install library YOLOv5..................................................................................... 8
Figure 8: Linking datasets from GOOGLE Drive............................................................8 Figure 9: Data
collection...................................................................................................9
Figure 10: Mapping to the path site and adjust for the number of classes...................... 9
Figure 11: Start training process.......................................................................................9
Figure 12: Training process.............................................................................................. 9
Figure 13: Show the results of the training process....................................................... 10
Figure 14: The results after the training process:...........................................................11
Figure 15:The results after the detection process...........................................................12
Figure 16: Confusion Matrix.......................................................................................... 13
Figure 17: F1 Score (F1_curve)......................................................................................13
Figure 18: Precision (P_curve)....................................................................................... 14 Figure 19: Precision
(PR_curve).................................................................................... 14
Figure 20: Recall (R_curve)........................................................................................... 15
Figure 21: Results........................................................................................................... 15 lOMoARcPSD| 36443508
CHAPTER 1: BACKGROUND KNOWLEDGE 1.1. INTRODUCTION
One in every six people in the world has a hearing problem, and the number is rapidly
increasing. According to Ms. Suchitra Prasansuk, President of the World Association of
Audiologists, World Health Organization (WHO) statistics show that there were
approximately 250 million people worldwide with deafness and hearing loss in 2010,
and this number increased to approximately 360 million people in 2015. Our country
currently has 1 to 2.5 million speech and hearing impaired people, roughly the population
of a province. This demonstrates an increase in the number of people suffering from
hearing loss. The ability to communicate verbally in the deaf community is severely
limited due to impaired hearing. To replace the ability to communicate verbally, sign
language, which uses the representation of hands and body, was created.
Artificial intelligence (AI) is becoming increasingly popular and is affecting many
aspects of daily life. Computer vision (CV) is a branch of artificial intelligence that
includes digital image acquisition, processing, analysis, and recognition. Deep Learning
Networks is a discipline that examines algorithms and computer programs so that
computers may learn and make predictions in the same manner that humans do. It is used
in a variety of applications, including science, engineering, and other fields of life, as
well as object detection and classification. A good example is CNN (Convolutional
Neural Network) learning to distinguish patterns from images by successively stacking
layers on top of each other. CNN is now regarded as a model in many applications. Full
image classifier and leverages technologies in the field of computer vision to leverage machine learning.
More and more algorithms and models have been introduced for the recognition
problem, including the YOLOv5 model, which is applied specifically to hand-sign
recognition. Therefore, we choose the topic "YOLOv5 - Detecting and recognizing
hand sign language" for the final report on Applied Machine Learning. 1
Downloaded by Dylan Tran (dylantran0201@gmail.com) lOMoARcPSD| 36443508 1.2. OVERVIEW
YOLO (You Only Look Once) that is a CNN network model used to detect and
identify objects. Additionally, the convolution of layers will extract features in an image,
and give the coordinates and order of labels assigned to each frame.
Furthermore, YOLO is considered to be the fastest algorithm in object recognition
models but may not be the best.
The main purpose of YOLO is to predict labels for objects in the classification and
determine the coordinates of the object. Therefore, YOLO can detect many objects with
different labels in the fastest time.
YOLO has released 5 versions so far as v1, v2, v3, v4 and v5. Each stage of YOLO
has upgraded classification, optimized real-time label recognition and extended prediction limits for frames. 1.3. YOLO ARCHITECTURE
Base networks are convolution networks that perform feature extraction in the
YOLO architecture. The Extra Layers are used to detect objects on the base network's feature map in the back part.
The base network of YOLO is composed primarily of convolutional layers and fully
connected layers. YOLO architectures are also quite diverse and can be customized to
accommodate a wide range of input shapes.
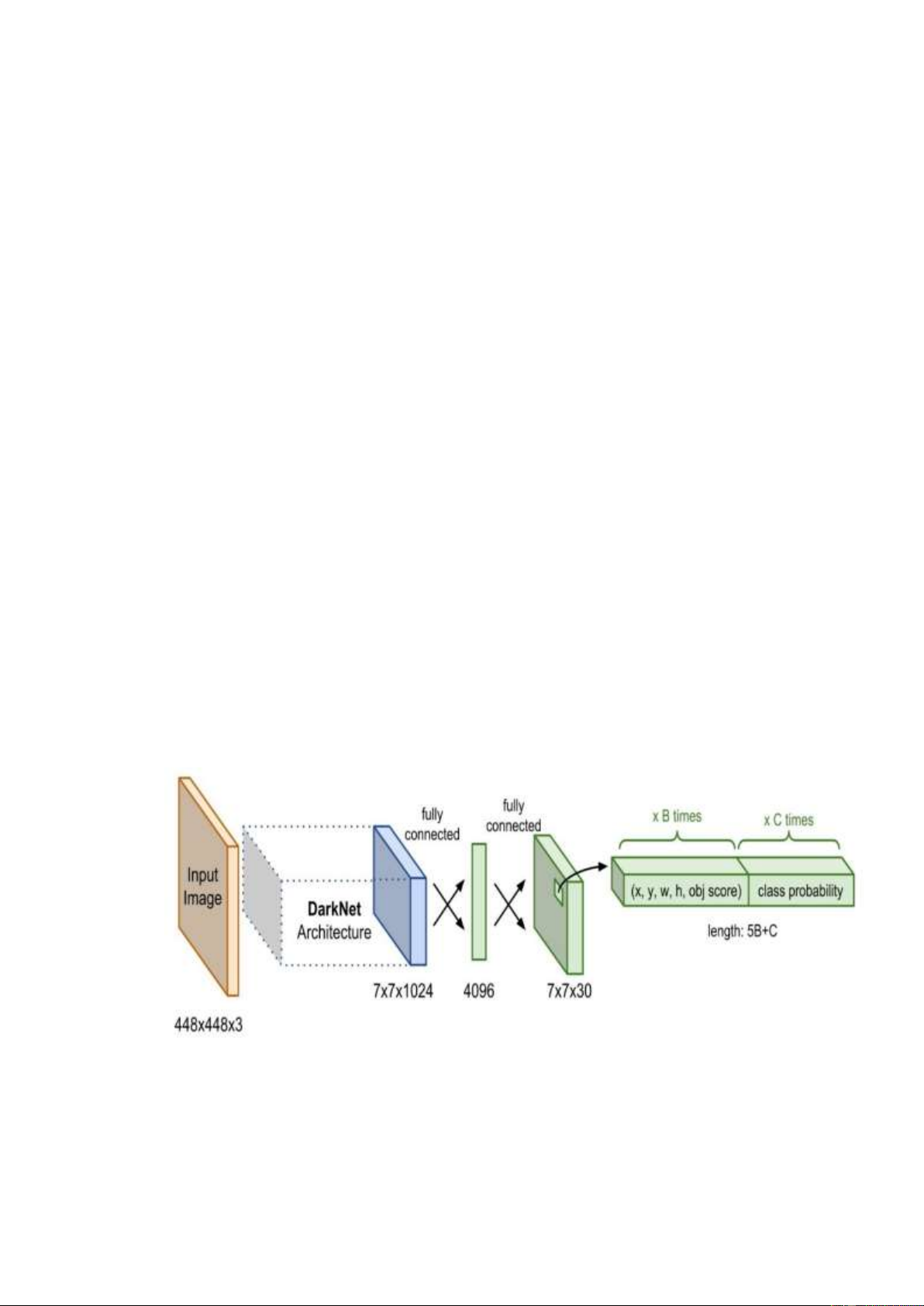
Figure 1: YOLO network architecture diagram. 2
Downloaded by Dylan Tran (dylantran0201@gmail.com) lOMoARcPSD| 36443508
The base network component of Darknet Architecture has a feature extraction effect.
The base network produces a 7x7x1024 feature map, which is used as input for Extra
layers that predict the label and bounding box coordinates of the object. 1.4. YOLO’s OUTPUT
The output of the YOLO model is a vector that will include the following components:
= [0, (, , , ℎ), (1, 2, . . . )]
0: is the predicted probability that the object will appear in the bounding box.
(, , , ℎ): help define the bounding box. where , are the coordinates of
the center and , ℎ are the width and length dimensions of the bounding box.
(1, 2, . . . ) : is the predictive probability distribution vector of classes.
1.5. YOLOv5 ARCHITECTURE
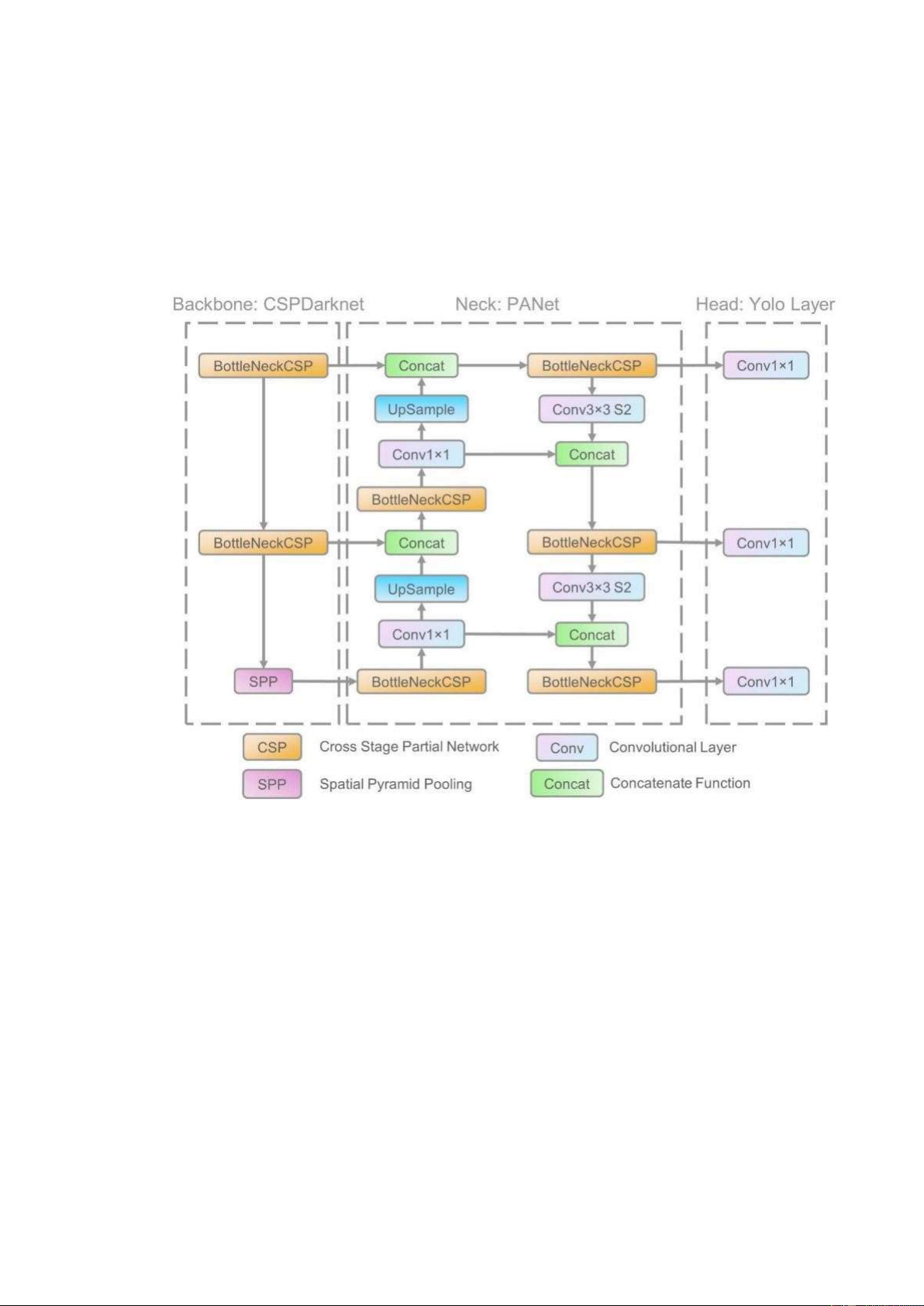
Architecturally, YOLOv5 consists of four main parts: input, backbone, neck, and output.
To begin, YOLOv5 added a cross-stage partial network (CSPNet) into Darknet,
resulting in CSPDarknet as the network's backbone. CSPNet solves the problem of
repeated gradient information in large-scale backbones by integrating gradient changes
into the feature map, reducing model parameters and floating-point operations per second
(FLOPS), ensuring inference speed and accuracy while also reducing model size.
In the hand symbol detection task, detection speed and accuracy are critical, and
compact model size influences inference efficiency on resource-constrained edge devices.
Second, to improve information flow, the YOLOv5 used a path aggregation network
(PANet) as its neck. PANet uses a new feature pyramid network (FPN) structure with an
improved bottom-up path, which improves low-level feature propagation.
Simultaneously, adaptive feature pooling, which connects the feature grid and all feature
levels, is used to ensure that useful information in each feature level propagates directly 3
Downloaded by Dylan Tran (dylantran0201@gmail.com) lOMoARcPSD| 36443508
to the next subnetwork. PANet improves the utilization of accurate localization signals
in lower layers, which obviously improves the object's location accuracy.
Third, the YOLO layer, the head of Yolov5, generates different sizes of feature maps
to achieve multi-scale prediction, allowing the model to handle small, medium, and large objects.
Figure 2: The network architecture of Yolov5.
It consists of three parts: (1) Backbone: CSPDarknet, (2) Neck: PANet, and (3) Head:
YOLO Layer. The data is first supplied into CSPDarknet, which extracts features, and
then into PANet, which fuses them. Finally, YOLO Layer outputs detection results
(class, score, location, size).
YOLOv5 include 4 different types: YOLOv5-small, YOLOv5-medium, YOLOv5-
large, YOLOv5-extraLarge. In this project, we use YOLOv5-small to train.
1.6. HAND SYMBOL DETECTION
We will use a camera and OpenCV in real-time to detect the hand symbol. It is
commonly assumed that videos are composed of still images known as frames. Hand 4
Downloaded by Dylan Tran (dylantran0201@gmail.com) lOMoARcPSD| 36443508
symbol detection was performed in every frame of a video. To detect hand symbols, we'll
utilize the YOLOv5 pre-trained model.
It is a real-time object detection algorithm. Because it has been trained to move
quickly. Furthermore, it returns the relative accuracy. It is also intended to distinguish objects in a video or image.
To begin, the detection of hand symbols involves the detection of a large number of
images. In this section, we will label the frames in each image. Then, pass them to the
model, which will train and return results.
The hand symbol variable, which contains the height and width of the rectangle as
well as the top-left corner coordinates enclosing the hand, can be used to generate a hand frame.
The method for preprocessing is the same as the method for training the model
described in the second section. The following step is to draw a rectangle on top of the
face and label it based on the predictions.
Though YOLOv5 and its variants are not as accurate. YOLOv5 performs admirably
when confronted with standard-sized objects, but it is incapable of detecting small objects.
When dealing with objects that appear to have rapidly changing properties, accuracy suffers significantly.
CHAPTER 2: DESIGN AND IMPLEMENTATION
APPLICATION OF "YOLOV5 - DETECTING AND
RECOGNIZING HAND SIGN LANGUAGE" 2.1. DATA SET 2.1.1. Images
We used images from our video to ensure that our learners could handle a variety
of hand symbols. We will use a dataset of 4,1950 images cropped from video of hand
symbols (including 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, A, B, C, D, E, F, G, H, and I LOVE U)
to prepare for the labeling and training process. A label will be attached to each image.
The images below are some examples from the dataset: 5
Downloaded by Dylan Tran (dylantran0201@gmail.com) lOMoARcPSD| 36443508 Figure 3: Dataset 2.1.2. Labels
Figure 4: Label a Image 6
Downloaded by Dylan Tran (dylantran0201@gmail.com) lOMoARcPSD| 36443508
Image input data of YOLOv5 in Darknet format with each .txt file will give an image
containing the object that we label. The .txt file will have the following format: - Each row will be an object.
- Each row will have the following format: class x_center y_center width height.
- The coordinates of the boxes will be normalized in the format x, y, w,h. - Class will start at 0.
Figure 5: Parameter of ratio Frame
2.2. SET UP ENVIRONMENT YOLOv5
To complete the hand symbol detection training, we use the Google Colab platform.
Then YOLOv5 will begin training.
We begin by download the YOLOv5 repository and installing the required dependencies to run YOLO v5.
Download indirectly from GOOGLE Colab
Figure 6: Clone repository and set up all dependencies in YOLOv5 indirectly from GOOGLE Colab
Install library YOLOv5 and supported other 7
Downloaded by Dylan Tran (dylantran0201@gmail.com) lOMoARcPSD| 36443508
Figure 7: Install library YOLOv5
2.3. THE TRAINING PROCESS
First, we link the Images and Labels datasets from Drive and extract the dataset
Figure 8: Linking datasets from GOOGLE Drive
Figure 9: Data collection
Now, classify each image with label in coco128.yaml file 8
Downloaded by Dylan Tran (dylantran0201@gmail.com) lOMoARcPSD| 36443508
Figure 10: Mapping to the path site and adjust for the number of classes Trained with 50 epoches:
Figure 11: Start training process
Figure 12: Training process
After training, we get result: 9
Downloaded by Dylan Tran (dylantran0201@gmail.com) lOMoARcPSD| 36443508
Figure 13: Show the results of the training process 10
Downloaded by Dylan Tran (dylantran0201@gmail.com) lOMoARcPSD| 36443508
CHAPTER 3: RESULTS AND DISCUSSION
3.1. RESULTS: DETECT HAND SIGN LANGUAGE
Below are some images of the results after the training process:
Figure 14: The results after the training process:
Here are some images of the results after the detection process: 11
Downloaded by Dylan Tran (dylantran0201@gmail.com) lOMoARcPSD| 36443508
Figure 15:The results after the detection process 3.2. DISCUSSION
After training, we have some discussion about the result as bellow:
Diagram: Confusion Matrix
Confusion matrix is a quantity that gives us a better view of whether data points are classified as true or false.
The model detects well when confusion_matrix is a diagonal. The correlation
between the TRUE and PREDICTED sets is 100%.
Here, there is a "FIVE" point and the FP background is matched, that is, when the
training label is TRUE but the model recognizes FALSE. At points “I” and “ONE” have
the same but the ratio is low.
A good model will produce a confusion_matrix with large values for the elements
on the main diagonal, and when represented in color, the darker the diagonal the better. 12
Downloaded by Dylan Tran (dylantran0201@gmail.com) lOMoARcPSD| 36443508
Figure 16: Confusion Matrix
Diagram: F1 Score (F1_curve)
F1 score: Accuracy of classifiers. . 1=2 +
Figure 17: F1 Score (F1_curve)
Diagram: Precision (P_curve)
Precision is the accuracy of the correct points. 13
Downloaded by Dylan Tran (dylantran0201@gmail.com) lOMoARcPSD| 36443508 = +
Figure 18: Precision (P_curve)
Diagram: Precision (PR_curve) =1 = =1( + ) =1 = =1( + ) 14
Downloaded by Dylan Tran (dylantran0201@gmail.com) lOMoARcPSD| 36443508
Figure 19: Precision (PR_curve)
Diagram: Precision (R_curve)
Recall is the accuracy of the omitted points. Recall is high which means high True
Positive Rate (TPR), which means that the rate of missing really positive points is low. = +
Figure 20: Recall (R_curve) Note:
+ True Positive(TP): The positive points are classified as positive
+ Tre Negative(TN): Negative points are classified as negative
+ False Positive(FP): The negative scores are classified as positive
+ False Negative(FN): The positive points are classified as negative Total of the Results 15
Downloaded by Dylan Tran (dylantran0201@gmail.com) lOMoARcPSD| 36443508 Figure 21: Results
3.3. CONCLUSION AND RECOMMENDATION a) Conclusion:
The model we made detected basic hand sign language.
However, with the number of images in the dataset is still small. So the accuracy is not high.
If multiple hand symbols are detected at the same time, or occur in a complex
environment, the model will ignore some of the symbols in the image. As a result, the
results will not be as accurate as when a single hand symbol is detected in the image. b) Recommendation:
In the future, we hope to develop a detection model for many hand sign languages from basic to complex.
In addition, we want to develop a device that makes it easier for people with hearing
impairment to communicate in all different situations. 16
Downloaded by Dylan Tran (dylantran0201@gmail.com) lOMoARcPSD| 36443508 REFERENCE
1. "TPH-YOLOv5: Improved YOLOv5 Based on Transformer Prediction Head
forObject Detection on Drone-captured Scenarios", Xingkui Zhu, Shuchang Lyu, Xu
Wang, Qi Zhao, https://arxiv.org/pdf/2108.11539.pdf
2. "YOLOv5", https://github.com/ultralytics/yolov5
3. "YOLOv5", https://pytorch.org/hub/ultralytics_yolov5/ 4. "Thủ ngữ – ngôn ngữ ký hiệu tay",
https://pro.edu.vn/thu-ngu-ngon-ngu-ky-hieu-tay/
Downloaded by Dylan Tran (dylantran0201@gmail.com)
Tài liệu liên quan:
-

Hướng dẫn sử dụng & lập trình màn hình 16x2 | Môn Applied Machine Learning - Đại học Sư phạm Kỹ thuật Thành phố Hồ Chí Minh
144 72 -

Yolov5 - detecting and recognizing hand sign language | Môn Applied Machine Learning - Đại học Sư phạm Kỹ thuật Thành phố Hồ Chí Minh
141 71 -

Điều khiển tự động hóa hệ thống điện công nghiệp | Môn Applied Machine Learning - Đại học Sư phạm Kỹ thuật Thành phố Hồ Chí Minh
97 49 -

Unspecific Hardware Configuration S7-1200 | Môn Applied Machine Learning - Đại học Sư phạm Kỹ thuật Thành phố Hồ Chí Minh
172 86 -

Perceptron Training and Logic Function Analysis | Môn Applied Machine Learning - Đại học Sư phạm Kỹ thuật Thành phố Hồ Chí Minh
131 66