Báo cáo Dự đoán tỷ lệ rời bỏ khách hàng môn Nhập môn Trí tuệ nhân tạo | Học viện Công Nghệ Bưu Chính Viễn Thông
Mô hình dự đoán tỷ lệ rời bỏ (churn prediction) được phát triển nhằm giải quyết thách thức trong việc giữ chân khách hàng, điều này rất quan trọng cho sự bền vững và phát triển của doanh nghiệp. Tài liệu được sưu tầm gồm 17 trang, giúp các bạn ôn luyện và phục vụ cho việc học tập, đạt kết quả tốt. Mời các bạn đón xem!
Môn: Nhập môn Trí tuệ nhân tạo 18 tài liệu
Trường: Học viện Công Nghệ Bưu Chính Viễn Thông 1.8 K tài liệu
Tác giả:












Preview text:
lOMoAR cPSD| 58800262
ĐỀ TÀI NHẬP MÔN TRÍ TUỆ NHÂN TẠO NHÓM 7
Build a Churn Prediction Model using Esemble Learning Developed by:
Nhóm 7 – team members: • Phạm Tiến Phúc Hưng • Nguyễn Quốc Bình • Bùi Minh Đức • Nguyễn Thành Thắng • Dương Đức Phúc • Hoàng Trọng Quyền • Trần Tiến Đạt
Lecturer: MSc. Hồ Nhựt Minh lOMoAR cPSD| 58800262 TABLE OF CONTENTS
ABSTRACT ............................................................................................................................4
1. INTRODUCTION..............................................................................................................4 1.1 Overview of the project
..................................................................................................4
1.2 Objectives and goals......................................................................................................5
1.3 Background and context...............................................................................................5
1.3.1 Learning Models ...............................................................................5
1.3.2 Dataset Description......................................................................................7
2. TECHNOLOGY REQUIREMENTS...............................................................................9
2.1 Hardware.........................................................................................................9 2.2 Sof
tware ..................................................................................................................10
3. ARCHITECTURE ...........................................................................................................10
3.1 Model Selection .................................................................................................10 3.2 EfficientNet-B0 Architecture
Overview......................................................................11
3.2.1 The EfficientNet-B0 network...................................................................11
3.2.2 Compound Scaling Method ...........................................................................11
3.2.3 Diagrams.........................................................................................................13
4. DETAILED DESIGN OF LEARNING MODEL .........................................................13
4.1 The Input ..........................................................................................14
4.2 The Output...................................................................................................14
4.3 Preprocessing........................................................................................15 4.4 Transfer Learning
Approach.......................................................................................15
5.PROJECT EXCECUTION ..............................................................................................15
5.1 DOWNLOAD DATASET ...........................................................................................15
5.2 Data Preprocessing ...................................................................................................15
5.3 Dataset Splitting.....................................................................................................16 5.4 Model Training (Computing on Colab)
.......................................................................16
5.5 Push Data and Model to DBFS - Databrick ..........................................................17 5.5.1 Cluster
Creation.....................................................................................................17
5.5.2 Running Code and Tasks ............................................................................18
5.6 Test and Evaluate Model......................................................................................18
5.6.1 Test Model ......................................................................................................18 lOMoAR cPSD| 58800262
5.6.2 Evaluate Model .....................................................................................................19
5.7 Deploy Model (via application)....................................................................................19 Page 2/27
6. IMPLEMENTATION......................................................................................................19 6.1
Purpose...........................................................................................................................19
6.2 Important coding steps .....................................................................................19
6.2.1 Load the Model ..........................................................................................19
6.2.2 Load the Leaf Image........................................................................................20
6.2.3 Image to Numbers................................................................................................20
6.2.4 Preprocessing ....................................................................................................21
6.2.5 Predict the Disease...........................................................................................21
6.2.6 Show Results.......................................................................................................21
6.2.7 Display the Image ..............................................................................................21
6.2.8 Outcome................................................................................................................21
6.3 Any challenges faced during implementation and how they were addressed ..........22
7. TESTING ..........................................................................................................................22
7.1 DETAILS ABOUT THE TESTING PROCESS ...................................................22
7.2 TEST CASES AND RESULTS..............................................................................24
7.3 Any issues encountered during testing and their resolution....................................24
8. USAGE ..............................................................................................................................24
8.1 Instructions on how to install and run the software ..................................................25
8.2 User manuals or guides..........................................................................................25 lOMoAR cPSD| 58800262
9. FURTHER IMPROVEMENT........................................................................................25
9.1 Limitations..................................................................................................................25
9.2 Improvement ...............................................................................................................26
CONTRIBUTIONS.............................................................................................27 Page 3/27 ABSTRACT
Nghiên cứu này phát triển một mô hình dự đoán tỷ lệ rời bỏ (churn) sử dụng kỹ thuật học tập tập
hợp (ensemble learning) với 15 thuộc tính liên quan đến khách hàng. Bộ dữ liệu chứa thông tin
về định danh khách hàng, nhân khẩu học, thông tin đăng ký, thói quen xem và các tương tác với
dịch vụ hỗ trợ. Bằng cách áp dụng các phương pháp học tập tiên tiến, chúng tôi đã cải thiện độ
chính xác trong việc xác định khách hàng có nguy cơ rời bỏ. Mô hình này giúp doanh nghiệp
triển khai các chiến lược giữ chân hiệu quả, nâng cao sự trung thành và giảm tỷ lệ rời bỏ.1RODUCTION
1.1 OVERVIEW OF THE PROJECT
Mô hình dự đoán tỷ lệ rời bỏ (churn prediction) được phát triển nhằm giải quyết thách thức trong
việc giữ chân khách hàng, điều này rất quan trọng cho sự bền vững và phát triển của doanh
nghiệp. Tỷ lệ rời bỏ cao không chỉ ảnh hưởng đến doanh thu mà còn gây ra khó khăn trong việc
phát triển thương hiệu. Dự án này tập trung vào việc sử dụng các kỹ thuật học tập tập hợp
(ensemble learning) để phân tích hành vi khách hàng dựa trên một bộ dữ liệu đa dạng, bao gồm
các thuộc tính như thông tin cá nhân, thói quen sử dụng dịch vụ, và mức độ tương tác với dịch vụ hỗ trợ. lOMoAR cPSD| 58800262
Dự án sử dụng thuật toán học máy để nâng cao độ chính
xác trong việc xác định khách hàng có nguy cơ rời bỏ.
Điều này giúp doanh nghiệp triển khai các chiến lược
giữ chân khách hàng hiệu quả hơn. So với các phương
pháp truyền thống như khảo sát và phân tích dữ liệu thủ
công, mô hình này tiết kiệm thời gian, tài nguyên và
tăng cường khả năng phản ứng nhanh với các dấu hiệu rời bỏ. Page 4/27
1.2 OBJECTIVES AND GOALS
Dự án này sử dụng phương pháp ensemble, bao gồm bagging và boosting, để cải thiện độ chính
xác trong việc dự đoán khách hàng có nguy cơ rời bỏ. Mục tiêu là xác định xem khách hàng của
công ty viễn thông nào đó có gia hạn đăng ký dịch vụ một năm hay không, từ đó giúp công ty
phát triển các chiến lược giữ chân hiệu quả hơn. lOMoAR cPSD| 58800262
1.3 DATASET DESCRIPTION
1.3.1 Nôi dung và cấu trúc ̣
Dataset "data_regression.csv" chứa thông tin về một công ty cung cấp dịch vụ phát video
trực tuyến, nơi họ muốn dự đoán liệu khách hàng có rời bỏ dịch vụ (churn) hay không. Tập
dữ liệu này bao gồm các thông tin liên quan đến hồ sơ của khách hàng và thói quen sử dụng dịch vụ.
1.3.2 Đăc điểm của dữ liệ u ̣
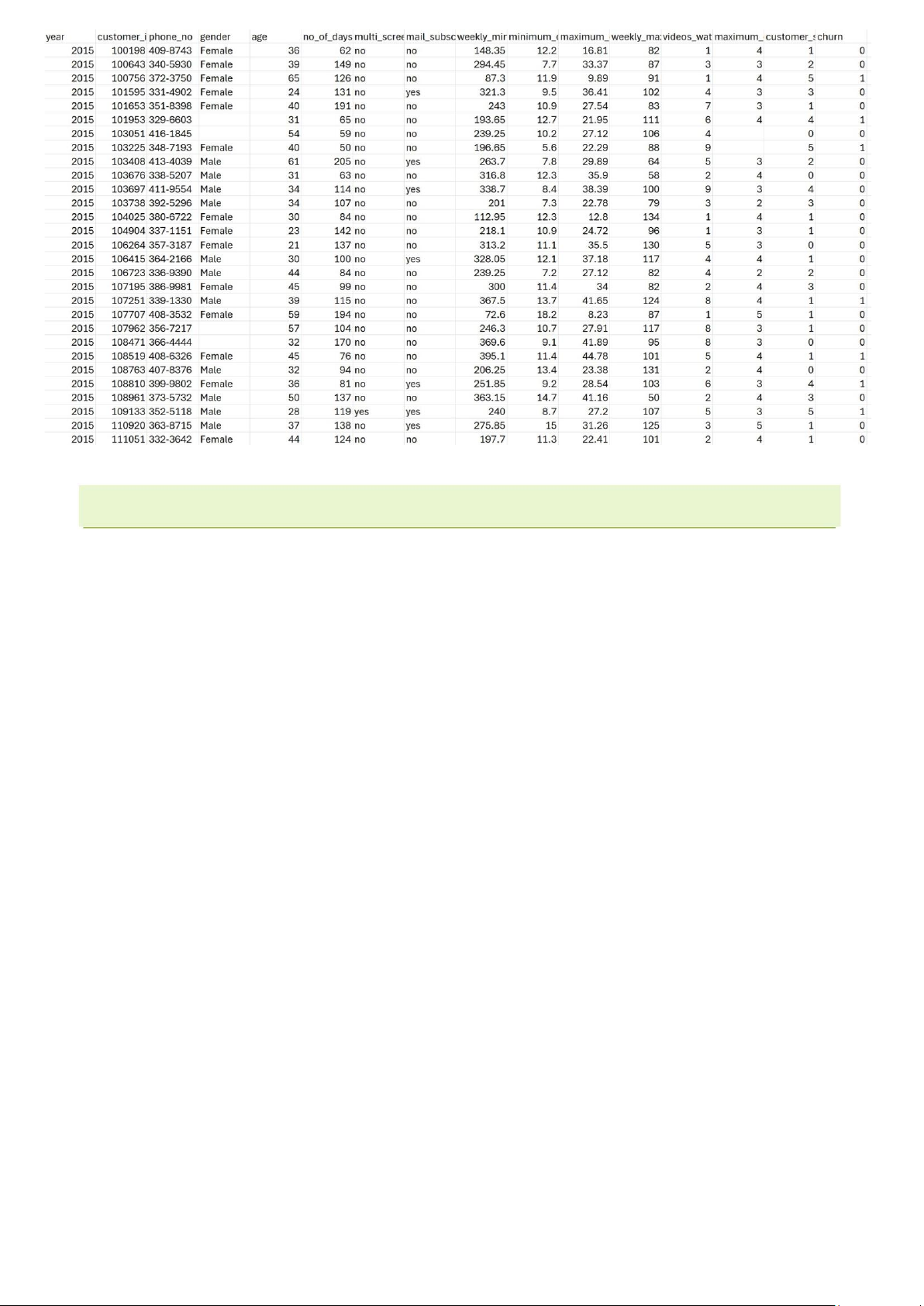
Tập dữ liệu có 16 cột với các thông tin về nhân khẩu học, hành vi sử dụng và trạng thái rời bỏ
dịch vụ của khách hàng. Mỗi hàng đại diện cho một khách hàng cụ thể:
1. year: Năm ghi nhận dữ liệu.
2. customer_id: Mã số nhận diện khách hàng (mỗi khách hàng có một mã duy nhất).
3. phone_no: Số điện thoại của khách hàng.
4. gender: Giới tính của khách hàng (Male/Female).
5. age: Tuổi của khách hàng.
6. no_of_days_subscribed: Số ngày khách hàng đã đăng ký sử dụng dịch vụ.
7. multi_screen: Khách hàng có sử dụng dịch vụ trên nhiều màn hình (Yes/No).
8. mail_subscribed: Khách hàng có đăng ký nhận email thông báo (Yes/No).
9. weekly_mins_watched: Số phút trung bình khách hàng xem nội dung trong một tuần.
10. minimum_daily_mins: Số phút ít nhất mà khách hàng xem nội dung trong một ngày.
11. maximum_daily_mins: Số phút tối đa mà khách hàng xem nội dung trong một ngày.
12. weekly_max_night_mins: Số phút tối đa khách hàng xem nội dung vào ban đêm trong một tuần.
13. videos_watched: Số video mà khách hàng đã xem.
14. maximum_days_inactive: Số ngày tối đa mà khách hàng không sử dụng dịch vụ.
15. customer_support_calls: Số lần khách hàng gọi hỗ trợ khách hàng.
16. churn: Biến mục tiêu, biểu thị liệu khách hàng có rời bỏ dịch vụ hay không (0 -
Không rời bỏ, 1 Rời bỏ).
1.3.3 Đăc điểm của dữ liệ u ̣
Tập dữ liệu bao gồm khoảng 2000 hàng (đại diện cho 2000 khách hàng) và 16 cột. Các cột
cung cấp thông tin chi tiết về hành vi và các yếu tố có thể ảnh hưởng đến quyết định rời bỏ
của khách hàng, từ đó hỗ trợ trong việc dự đoán và phân tích.
1.3.4 Kích thước của dữ liêu ̣
Với 2000 hàng, tập dữ liệu cung cấp một lượng thông tin đủ lớn để xây dựng và thử nghiệm các
mô hình học máy nhằm dự đoán khả năng rời bỏ của khách hàng. Mặc dù đây là một tập dữ liệu
vừa phải về kích thước, nhưng nó bao gồm nhiều yếu tố quan trọng liên quan đến hành vi khách
hàng, từ đó có thể phát triển các mô hình dự đoán có độ chính xác cao. lOMoAR cPSD| 58800262
2. TECHNOLOGY R E Figure 1: Data regression 1.4 TECH TASK
Trong quá trình xây dựng và phát triển mô hình dự đoán, nhóm em sử dụng các công cụ và thư viện
từ Python để hỗ trợ phân tích dữ liệu, xử lý dữ liệu và xây dựng mô hình học máy. Các thành phần
kỹ thuật chính bao gồm: •
Ngôn ngữ lập trình:
o Python: Ngôn ngữ lập trình chính được sử dụng do khả năng mạnh mẽ trong
việc phân tích dữ liệu và hỗ trợ cho các thư viện học máy. • Các thư viện:
o NumPy: Thư viện xử lý mảng đa chiều, giúp thao tác nhanh chóng và hiệu quả với dữ liệu số.
o pandas: Công cụ chính để xử lý và thao tác dữ liệu dạng bảng (DataFrame),
hỗ trợ đọc, lọc và biến đổi dữ liệu.
o matplotlib: Thư viện trực quan hóa dữ liệu, giúp tạo các biểu đồ và đồ thị để
hiểu rõ hơn về xu hướng và phân phối dữ liệu.
o sklearn (Scikit-learn): Thư viện học máy với các công cụ để phân chia dữ
liệu, xây dựng và đánh giá mô hình, bao gồm các mô hình hồi quy và phân loại.
o pickle: Được sử dụng để lưu trữ và tải lại các mô hình đã huấn luyện hoặc các đối tượng Python khác.
o imblearn: Bộ mở rộng của Scikit-learn để xử lý dữ liệu mất cân bằng
(imbalanced data), hỗ trợ các kỹ thuật như SMOTE (Synthetic Minority Over-
sampling Technique) để cải thiện hiệu suất của mô hình trong các trường hợp dữ liệu lệch. lOMoAR cPSD| 58800262
o lime: Công cụ giải thích kết quả mô hình học máy( Local Interpretable Model-
agnostic Explanations), giúp làm sáng tỏ các quyết định của mô hình, đặc biệt
quan trọng khi xử lý các mô hình "hộp đen" như Random Forest hoặc Gradient Boosting ) 1.5 LEARNING MODEL
1.5.1 Mô hình đơn lẻ
1.5.1.1 Mô hình Logistic
Mô hình hồi quy logistic là một kỹ thuật học máy được sử dụng để dự đoán khả
năng xảy ra của một biến nhị phân (binary), tức là biến mục tiêu chỉ có hai trạng thái (ví
dụ như "có/không", "đúng/sai", "churn/không churn"). Mặc dù có tên gọi là "hồi quy",
mô hình này chủ yếu được sử dụng cho các bài toán phân loại.
Mục tiêu chính của hồi quy logistic là dự đoán xác suất xảy ra của một biến phụ
thuộc nhị phân. Ví dụ, trong bài toán churn, mô hình dự đoán xác suất khách hàng có khả
năng rời bỏ dịch vụ (churn = 1) hay không (churn = 0).
* Tiền xử lí dữ liệu • M
ục đích: Loại bỏ tấy cả các hàng có giá trị thiếu (null) trong DataFrame df lOMoAR cPSD| 58800262 • L
ý do: Các giá trị thiếu có thể gây ra lỗi hoặc làm giảm hiệu suất của mô hình. Việc loại bỏ
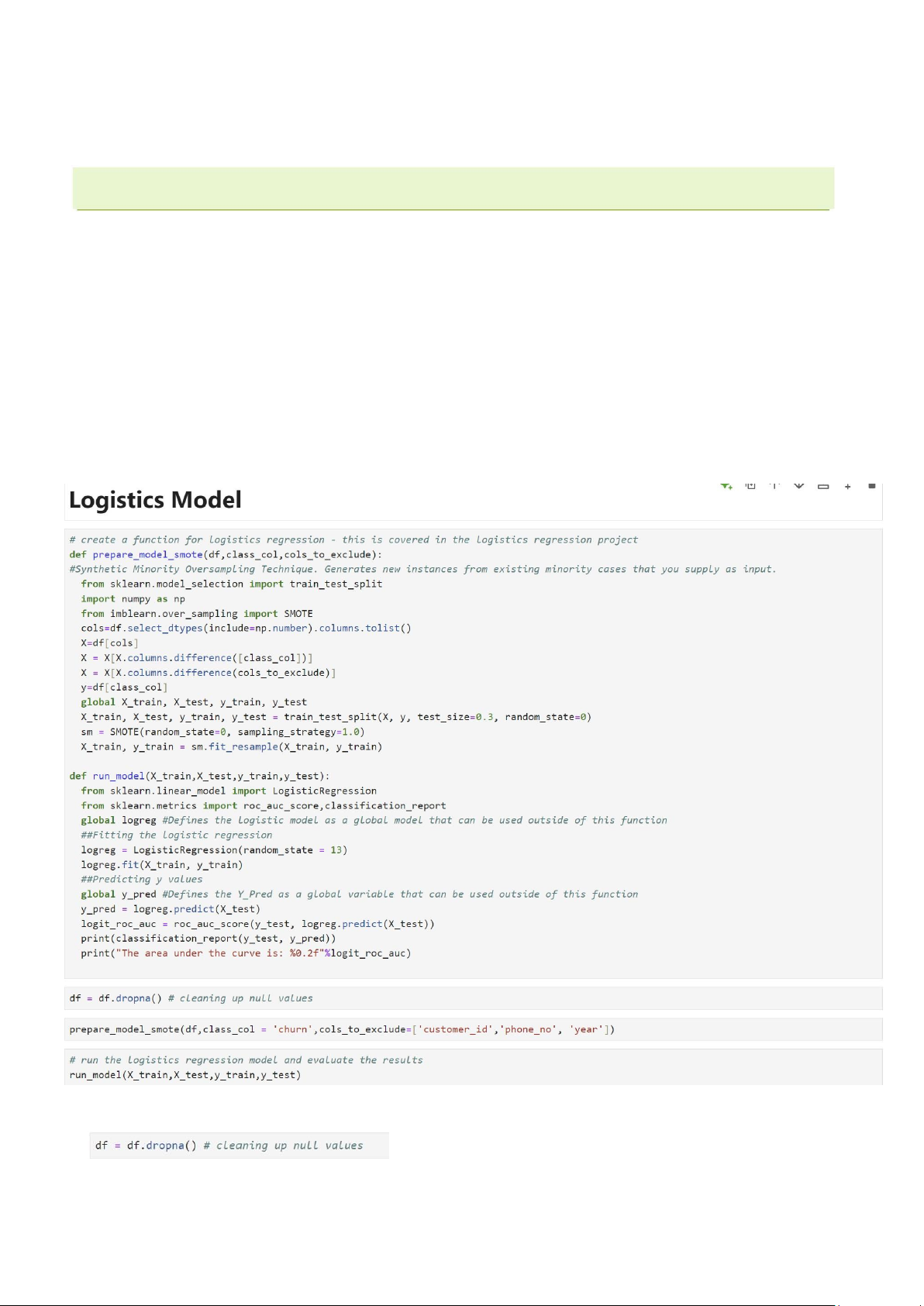
chúng giúp đảm bảo dữ liệu sạch và sẵn sàng cho việc huấn luyên mô hình * Hàm
prepare_model_smote Import thư viện: • t
rain_test_split từ sklearn.model_selection: Chia dữ liệu thành tập huấn luyện và kiểm tra. • n
umpy: Xử lý các thao tác số học. • S
MOTE từ imblearn.over_sampling: Kỹ thuật tăng cường dữ liệu cho lớp thiểu số. - Chọn các cột số: •
Lấy danh sách từ các cột trong DataFrame.
- Tách biến độc lập (X) •
Lấy các cột số, loại bỏ cột mục tiêu class_col và các cột cần loại trừ cols_to_exclude
(ví dụ: 'customer_id', 'phone_no', 'year').
- Tách biến mục tiêu (y) - Chia dữ liệu •
Chia dữ liệu thành 70% huấn luyện và 30% kiểm tra. •
Sử dụng random_state=0 để đảm bảo khả năng tái lập kết quả. - Áp dụng SMOTE •
sampling_strategy=1.0: Cân bằng tỷ lệ giữa các lớp (cả lớp đa số và lớp thiểu số đều
có số lượng bằng nhau sau SMOTE). •
fit_resample tạo ra các mẫu nhân tạo cho lớp thiểu số để cân bằng dữ liệu. * Hàm run_model - Import thư viện • L
ogisticRegression từ sklearn.linear_model: Mô hình hồi quy logistic. lOMoAR cPSD| 58800262 • r
oc_auc_score, classification_report từ sklearn.metrics: Các chỉ số đánh giá mô hình.
- Định nghĩa Mô hình Logistic Regression • K
hởi tạo mô hình với random_state=13 để đảm bảo tính tái lập. • H
uấn luyện mô hình trên tập dữ liệu huấn luyện (X_train, y_train). - Dự đoán và đánh giá • D
ự đoán giá trị y cho tập kiểm tra (X_test). • T
ính toán điểm ROC AUC để đánh giá khả năng phân biệt giữa các lớp. - In kết quả • I
n báo cáo phân loại bao gồm precision, recall, f1-score cho từng lớp. • I n điểm ROC AUC. * Chạy quy trình •
Xóa Giá Trị Thiếu: Đã thực hiện ở đầu. •
Chuẩn Bị Dữ Liệu với SMOTE: Gọi hàm prepare_model_smote để chuẩn bị dữ liệu
cân bằng. Chạy Mô Hình và Đánh Giá: Gọi hàm run_model để huấn luyện và đánh giá mô hình. Kết quả đầu ra
- Precision, Recall, F1-Score: •
Precision (Độ Chính Xác): Tỷ lệ dự đoán đúng trong tổng số dự đoán cho lớp đó. lOMoAR cPSD| 58800262
o Lớp 0.0: 0.94 (Rất cao, nghĩa là hầu hết các dự đoán lớp 0.0 đều chính xác).
o Lớp 1.0: 0.19 (Rất thấp, nghĩa là nhiều dự đoán lớp 1.0 không chính xác). •
Recall (Độ Nhạy): Tỷ lệ các mẫu thực sự thuộc lớp đó được mô hình phát hiện.
o Lớp 0.0: 0.65 (65% các mẫu lớp 0.0 được phát hiện).
o Lớp 1.0: 0.67 (67% các mẫu lớp 1.0 được phát hiện). •
F1-Score: Trung bình điều hòa giữa precision và recall.
o Lớp 0.0: 0.77 o Lớp 1.0: 0.29
- Accuracy (Độ Chính Xác Tổng Thể): 0.65 •
Tỷ lệ chính xác tổng thể của mô hình trên toàn bộ dữ liệu kiểm tra.
- Macro Avg (Trung Bình Cộng Đồng): •
Trung bình của các chỉ số (precision, recall, f1-score) của từng lớp mà không tính trọng số.
- Weighted Avg (Trung Bình Có Trọng Số): •
Trung bình các chỉ số của từng lớp, có trọng số theo số lượng mẫu trong từng lớp.
- ROC AUC (Area Under the Curve): 0.66 •
Đo lường khả năng phân biệt giữa các lớp của mô hình. Giá trị 0.66 cho thấy mô hình
có khả năng phân biệt tốt hơn ngẫu nhiên (0.5), nhưng vẫn còn không cao.
1.5.1.2 Mô hình Decision Tree
1.5.2 Mô hình Ensemble
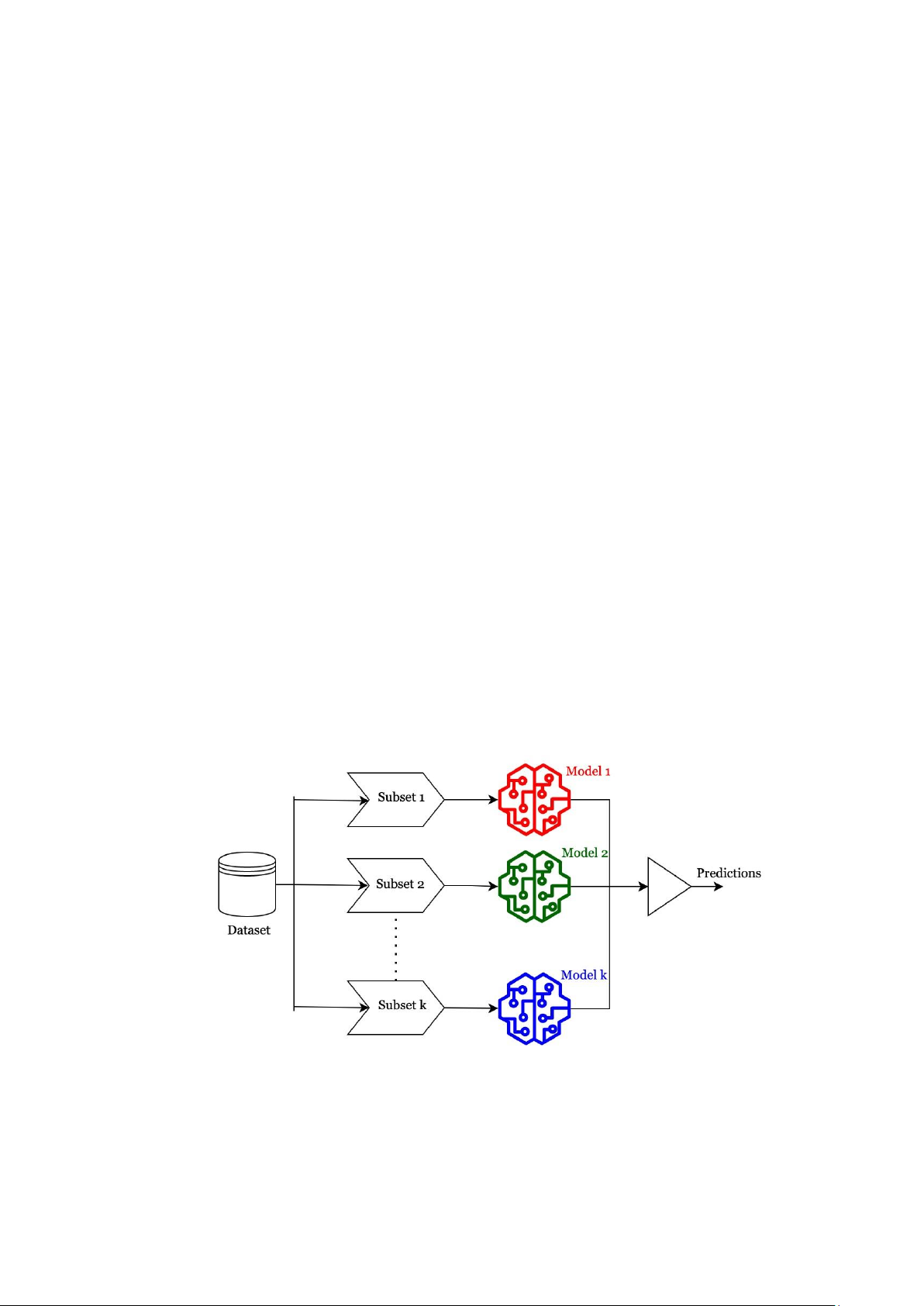
Các phương pháp Ensemble kết hợp nhiều mô hình học máy để cải thiện hiệu suất tổng thể,
giảm phương sai và tạo ra các mô hình dự đoán ổn định hơn. Trong số các mô hình ensemble
được sử dụng rộng rãi nhất là Random Forest, AdaBoost, và Gradient Boosting, cả ba đều thể
hiện sự cải thiện đáng kể so với các mô hình đơn lẻ như cây quyết định.
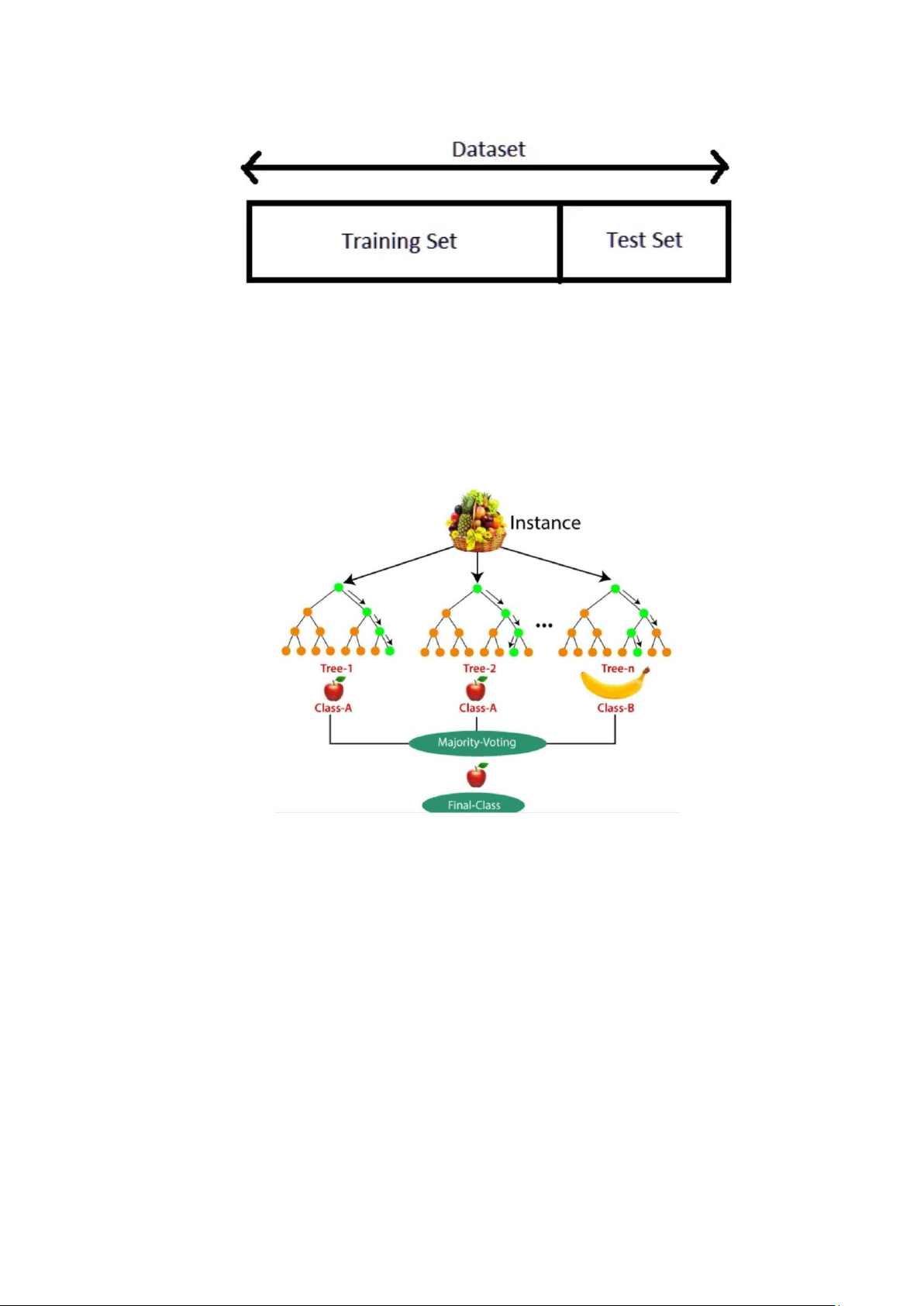
Figure 2: Ensemble model in maching learning Xây dựng mô hình 1. Chia tâp ḍ ữ liêu hụ ấn luyên ṿ à kiểm tra lOMoAR cPSD| 58800262
Để đánh giá mô hình một cách đáng tin cậy, tập dữ liệu được chia thành tập huấn luyện và
tập kiểm tra. Thông thường, ta sử dụng tỷ lệ chia 80/20 hoặc 70/30 để đảm bảo rằng mô
hình có đủ dữ liệu để huấn luyện mà vẫn còn lại đủ dữ liệu để kiểm tra khả năng tổng quát hoá của nó.
Figure 3: Training set v Testing set trong Machine learningà 2. Mô hình Random Forest
Random Forest là một kỹ thuật ensemble xây dựng nhiều cây quyết định và kết hợp chúng
để đạt được dự đoán chính xác và ổn định hơn. Nó giúp giảm tình trạng quá khớp, điều
phổ biến trong các cây quyết định đơn lẻ.
Figure 4: M hnh random forestsô ì
Kết quả: Mô hình Random Forest thường mạnh mẽ và có thể xử lý cả bài toán phân loại
và hồi quy. Ví dụ, sử dụng Random Forest Classifier có thể đạt độ chính xác khoảng 85-
90%, vượt trội hơn so với mô hình cây quyết định đơn giản vốn có thể mắc lỗi do phương sai cao. 3. Mô hình AdaBoost
AdaBoost, hay Adaptive Boosting, hoạt động bằng cách tạo ra một loạt các mô hình yếu
(thường là cây quyết định nông), mỗi mô hình tập trung nhiều hơn vào các mẫu mà các
mô hình trước đã phân loại sai lOMoAR cPSD| 58800262
Figure 5: M hnh AdaBoostô ì
Kết quả: AdaBoost có xu hướng hoạt động tốt hơn trên các tập dữ liệu nhỏ và sạch, đạt độ
chính xác khoảng 80-85% cho nhiều bài toán phân loại, mặc dù nó có thể nhạy cảm với nhiễu trong dữ liệu.
4. Mô hình Gradient Boosting
Gradient Boosting hoạt động tương tự như AdaBoost nhưng xây dựng các cây quyết định một
cách tuần tự sao cho mỗi cây mới khắc phục lỗi của các cây trước đó bằng cách sử dụng
gradient của hàm mất mát.
Kết quả: Gradient Boosting thường mang lại độ chính xác cao hơn so với AdaBoost và
Random Forest, đặc biệt trên các tập dữ liệu lớn với các mẫu phức tạp, đạt 85-95% độ chính
xác. Tuy nhiên, nó yêu cầu tính toán nhiều hơn và dễ bị quá khớp nếu không được điều chỉnh đúng cách
Hiêu suất của c ̣ ác mô hình Ensemble trên tâp dữ liệu ̣
Trong bảng dưới đây, trục dọc biểu diễn tỷ lệ chính xác, trong khi trục ngang hiển thị các
mô hình khác nhau được kiểm tra. Gradient Boosting cho thấy độ chính xác cao nhất trong số
ba mô hình, theo sau là Random Forest và AdaBoost.
Figure 6: M hnh Gradient Boostingô ì lOMoAR cPSD| 58800262
3. Phương pháp tiếp cân ̣
Quá trình phát triển mô hình dự đoán churn của khách hàng dựa trên các bước tiếp cận cụ thể,
bao gồm việc xử lý dữ liệu, xây dựng mô hình, đánh giá và cải thiện hiệu suất. Các bước thực hiện cụ thể như sau:
1. Nhập thư viện và đọc tập dữ liệu (Importing Libraries & Reading Dataset) •
Đầu tiên, chúng tôi tiến hành nhập các thư viện cần thiết như NumPy, pandas,
matplotlib, và sklearn, cũng như các thư viện bổ trợ khác để hỗ trợ trong quá trình xử
lý dữ liệu và xây dựng mô hình. •
Sau đó, dữ liệu từ tệp "data_regression.csv" được đọc vào để chuẩn bị cho các bước tiếp theo.
2. Xử lý đặc trưng (Feature Engineering) •
Loại bỏ các cột không cần thiết: Các cột không đóng góp nhiều cho quá trình dự
đoán hoặc gây nhiễu cho mô hình sẽ bị loại bỏ. Điều này giúp đơn giản hóa mô hình
và cải thiện hiệu suất. •
Ví dụ: Các cột như customer_id, phone_no có thể không liên quan trực tiếp đến dự
đoán churn nên sẽ bị loại bỏ.
3. Xây dựng mô hình (Model Building) •
Chia dữ liệu thành tập huấn luyện và kiểm tra (Train-Test Split): Dữ liệu được
chia thành hai phần, một phần dành cho huấn luyện mô hình và một phần dùng để
kiểm tra hiệu suất của mô hình. Tỷ lệ thường được sử dụng là 80% dữ liệu cho huấn
luyện và 20% dữ liệu cho kiểm tra.
Triển khai các mô hình học máy: •
Random Forest Model: Một mô hình ensemble xây dựng dựa trên nhiều cây quyết định. •
AdaBoost Model: Một mô hình boosting tạo ra các mô hình yếu và liên tục cải thiện hiệu suất. •
Gradient Boosting Model: Mô hình gradient boosting giúp tối ưu hóa việc dự đoán qua nhiều bước.
4. Đánh giá mô hình (Model Validation)
Để đánh giá hiệu suất của mô hình, chúng tôi sử dụng các chỉ số đo lường quan trọng bao gồm:
o Recall: Đo lường khả năng của mô hình trong việc phát hiện các trường hợp churn thực sự.
o Precision: Đo lường mức độ chính xác của các dự đoán churn. o F1-score:
Một thước đo cân bằng giữa precision và recall.
o ROC & AUC: Đường cong ROC và diện tích dưới đường cong AUC giúp
đánh giá khả năng phân loại của mô hình.
5. Tầm quan trọng của đặc trưng (Feature Importance) •
Một hàm được xây dựng để xác định và trực quan hóa các đặc trưng quan trọng ảnh
hưởng đến dự đoán churn. •
Sau đó, biểu đồ thể hiện tầm quan trọng của các đặc trưng sẽ được vẽ để có cái nhìn
trực quan về các yếu tố ảnh hưởng nhiều nhất. lOMoAR cPSD| 58800262
6. Triển khai LIME (LIME Implementation)
LIME (Local Interpretable Model-agnostic Explanations) được triển khai để giải
thích quyết định của mô hình trên các dự đoán cụ thể, nhằm làm sáng tỏ mô hình "hộp
đen". Chúng tôi xây dựng một hàm để áp dụng LIME lên tập dữ liệu và kiểm tra các
quyết định của mô hình. 4.1 INPUT
Giữ vai trò quan trọng trong quá trình phân tích dữ liệu. Nó chứa tất cả dữ liệu cần thiết để
thực hiện các bước tiếp theo trong mô hình dự đoán churn.
• Data_regression.csv:
o Tệp này chứa thông tin chi tiết về khách hàng của một dịch vụ video
streaming, bao gồm nhiều biến khác nhau liên quan đến hành vi sử dụng dịch
vụ và các yếu tố có thể ảnh hưởng đến việc khách hàng có quyết định rời bỏ
dịch vụ hay không (churn).
o Các cột trong tệp Data_regression.csv:
▪ year: Năm mà dữ liệu được ghi lại.
▪ customer_id: Mã định danh duy nhất của mỗi khách hàng.
▪ phone_no: Số điện thoại của khách hàng.
▪ gender: Giới tính của khách hàng (Nam, Nữ).
▪ age: Độ tuổi của khách hàng.
▪ no_of_days_subscribed: Số ngày mà khách hàng đã đăng ký dịch vụ.
▪ multi_screen: Thông tin về việc khách hàng có sử dụng nhiều màn hình hay không.
▪ mail_subscribed: Thông tin về việc khách hàng có đăng ký nhận email hay không.
▪ weekly_mins_watched: Số phút trung bình mà khách hàng xem video mỗi tuần.
▪ minimum_daily_mins: Số phút xem video ít nhất mỗi ngày.
▪ maximum_daily_mins: Số phút xem video nhiều nhất mỗi ngày.
▪ weekly_max_night_mins: Số phút tối đa mà khách hàng xem video
vào buổi tối mỗi tuần.
▪ videos_watched: Tổng số video mà khách hàng đã xem.
▪ maximum_days_inactive: Số ngày tối đa mà khách hàng không hoạt động.
▪ customer_support_calls: Số cuộc gọi hỗ trợ mà khách hàng đã thực hiện.
▪ churn: Chỉ số liệu mà khách hàng có quyết định rời bỏ dịch vụ hay không (1: có, 0: không).
• Mục tiêu của tệp dữ liệu: Mục đích chính của việc phân tích tệp
Data_regression.csv là để xây dựng một mô hình học máy có khả năng dự đoán xác
suất churn của khách hàng dựa trên các yếu tố được nêu ở trên. Bằng cách phân tích
và xử lý dữ liệu trong tệp này, chúng tôi có thể phát hiện ra các mẫu và xu hướng
hành vi của khách hàng, từ đó đưa ra những dự đoán chính xác hơn về khả năng
khách hàng sẽ rời bỏ dịch vụ. 4.2 THE OUTPUT
Đóng vai trò quan trọng trong việc lưu trữ tất cả các kết quả từ quá trình phân tích và xây
dựng mô hình. Trong phần này này, chúng tôi tổ chức thông tin thành ba mục con, mỗi mục
chứa các loại kết quả khác nhau, giúp dễ dàng quản lý và tra cứu. lOMoAR cPSD| 58800262
Nội dung của các thư mục con: • LIME_reports:
o Thư mục này chứa các báo cáo được tạo ra từ phương pháp giải thích mô hình
LIME (Local Interpretable Model-agnostic Explanations). LIME là một kỹ
thuật mạnh mẽ giúp chúng tôi hiểu rõ hơn về các quyết định mà mô hình đưa
ra bằng cách giải thích từng dự đoán cụ thể.
o Mỗi báo cáo trong thư mục này cung cấp thông tin chi tiết về các đặc trưng
quan trọng đã ảnh hưởng đến dự đoán, cũng như mức độ ảnh hưởng của
chúng. Điều này giúp chúng tôi đánh giá được tính hợp lý của các dự đoán và
cải thiện mô hình nếu cần.
o Ví dụ, báo cáo có thể bao gồm các biểu đồ trực quan hóa mức độ quan trọng
của từng đặc trưng đối với một khách hàng cụ thể, giúp đưa ra cái nhìn sâu sắc
về hành vi của khách hàng. • Models:
o Thư mục này lưu trữ tất cả các mô hình học máy đã được xây dựng cho cả ba
thuật toán (Random Forest, AdaBoost, và Gradient Boosting). Mỗi mô hình sẽ
được lưu dưới dạng tệp để có thể tái sử dụng trong tương lai mà không cần
phải huấn luyện lại từ đầu.
o Việc lưu trữ mô hình cho phép chúng tôi nhanh chóng triển khai mô hình vào
môi trường thực tế để dự đoán churn của khách hàng mới mà không cần qua
quy trình huấn luyện tốn thời gian.
o Mỗi tệp mô hình có thể bao gồm thông tin chi tiết về cấu hình của mô hình, độ
chính xác đạt được trên tập kiểm tra, cũng như các tham số mà chúng tôi đã sử
dụng trong quá trình huấn luyện. • ROC_curves:
o Thư mục này chứa các hình ảnh và dữ liệu liên quan đến đường cong ROC
(Receiver Operating Characteristic) được tạo ra cho cả ba thuật toán. Đường
cong ROC là một công cụ hữu ích để đánh giá hiệu suất của mô hình phân
loại, cho phép chúng tôi thấy được sự cân bằng giữa tỷ lệ dương tính thực tế
(True Positive Rate) và tỷ lệ dương tính giả (False Positive Rate).
o Mỗi tệp trong thư mục này sẽ cung cấp biểu đồ ROC cho từng mô hình cùng
với giá trị AUC (Area Under Curve), giúp chúng tôi so sánh hiệu suất của các
mô hình khác nhau một cách trực quan. o Việc có các đường cong ROC này
cho phép chúng tôi nhanh chóng nhận diện mô hình nào hoạt động tốt hơn
trong việc phân loại khách hàng có khả năng churn, từ đó đưa ra quyết định
hợp lý cho chiến lược kinh doanh. lOMoAR cPSD| 58800262
1.5 LEARNING MODEL
Contributions made by each team member DELIVERABLES/ TASKS PIC Tran Kim Khoi Le Minh Triet
● Project Report ( .pdf file) Nguyen Thi Tuyet Nhung Ly Le Minh
● Link of GitHub for accessing the uploaded project code Ly Le Minh ( Public access ) Nguyen Thi Tuyet Nhung □ Source code Ly Le Minh Nguyen Thi Tuyet Nhung □ Trained Model (.h5 file) Ly Le Minh Nguyen Thi Tuyet Nhung Tran Kim Khoi
□ Test Data Used in the Project Ly Le Minh Le Minh Triet □ File ReadMe.doc Ly Le Minh
● Link of Published Blog Tran Kim Khoi Tran Kim Khoi □ Problem Definition Le Minh Triet Le Minh Triet □ Design Specifications Nguyen Thi Tuyet Nhung □ User Flow Diagram Tran Kim Khoi
□ Project Installation Instructions Ly Le Minh Ly Le Minh Le Minh Triet
□ Detailed Steps to Execute the Project Nguyen Thi Tuyet Nhung
● Link Youtube video and an .mp4 file demonstrating the working Ly
Le Minh of the application, including all the functionalities of the project. Le Minh Triet Page 14/27

