Báo cáo môn học khai phá dữ liệu | Đại học Điện lực
Trí tuệ nhân tạo ( AI ) đang ngày một phát triển mạnh, mở ra nhiều cơ hội và
thách thức mới trong công việc. Vì thế, việc áp dụng các phương pháp AI để dự
đoán và cải thiện khả năng sử dụng chỗ đậu xe trở nên cần thiết.
Bãi đỗ xe là một trong những yếu tố quan trọng nhất trong quy hoạch và quản lý giao thông đô thị. Việc cung cấp đủ chỗ đỗ xe phù hợp với nhu cầu của người dân không chỉ giúp giải tỏa tình trạng ùn tắc giao thông, mà còn ảnh hưởng trực tiếp đến hoạt động kinh tế, xã hội của cộng đồng.
Môn: Công nghệ thông tin(CNTT350) 109 tài liệu
Trường: Trường Đại học Điện lực 487 tài liệu
Tác giả:

















Preview text:
lOMoARcPSD|50662567 Data Mining - aaa
Cong nghe thong tin (Đại học Điện lực) Scan to open on Studocu
Studocu is not sponsored or endorsed by any college or university
Downloaded by B?p Tr??ng Thành (baptruongthanh@gmail.com) lOMoARcPSD|50662567
TRƯỜNG ĐẠI HỌC ĐIỆN LỰC
KHOA CÔNG NGHỆ THÔNG TIN
BÁO CÁO MÔN HỌC KHAI PHÁ DỮ LIỆU
PHÂN TÍCH VÀ DỰ ĐOÁN VỀ
TỈ LỆ CHIẾM CHỖ CỦA CÁC BÃI ĐẬU XE
Giảng viên hướng dẫn : NGUYỄN HÀ NAM
Sinh viên thực hiện
: NGUYỄN ĐÌNH QUANG MINH
: NGUYỄN QUANG QUYỀN : ĐINH LÂN DŨNG Ngành
: CÔNG NGHỆ THÔNG TIN Chuyên ngành
: CÔNG NGHỆ PHẦN MỀM Lớp : D16CNPM2
Hà Nội, tháng 5 năm 2024
Downloaded by B?p Tr??ng Thành (baptruongthanh@gmail.com) lOMoARcPSD|50662567 PHIẾU CHẤM ĐIỂM Chữ STT
Họ và tên sinh viên
Nội dung thực hiện Điểm ký Nguyễn Đình Quang 1 Minh 2 Nguyễn Quang Quyền 3 Đinh Lân Dũng
Họ và tên giảng viên Chữ ký Ghi chú Giảng viên chấm 1: Giảng viên chấm 2:
Downloaded by B?p Tr??ng Thành (baptruongthanh@gmail.com) lOMoARcPSD|50662567 MỤC LỤC
LỜI MỞ ĐẦU...........................................................................................................5
CHƯƠNG 1: TỔNG QUAN VỀ KHAI PHÁ DỮ LIỆU..........................................6
1.1.Giới thiệu về khai phá dữ liệu.......................................................................6
1.1.1 Diễn giải...............................................................................................6
1.1.2 Các phương pháp khai thác dữ liệu......................................................7
1.1.3 Một số tính năng nổi bật của khai phá dữ liệu......................................7
1.1.4 Quy trình khai phá dữ liệu....................................................................8
1.1.5 Ứng dụng khai phá dữ liệu...................................................................9
1.1.6 Các công cụ khai phá dữ liệu..............................................................10
1.2 Tiền xử lý.....................................................................................................11
1.2.1 Dữ liệu................................................................................................11
1.2.2 Làm sạch dữ liệu (data cleaning) .......................................................13
1.2.2.1 Các vấn đề của dữ liệu ..............................................................13
1.2.2.2 Nguồn gốc/lý do của dữ liệu không sạch ..................................13
1.2.2.3 Giải pháp khi thiếu giá trị của thuộc tính .................................13
1.2.2.4 Giải pháp khi dữ liệu chứa nhiễu/lỗi.........................................14
1.2.3. Tích hợp dữ liệu (data integration)....................................................14
1.2.4. Biến đổi dữ liệu (data transformation) ..............................................15
1.2.5. Thu giảm dữ liệu (data reduction) ....................................................16
CHƯƠNG 2: CHUẨN BỊ VÀ LÀM SẠCH DỮ LIỆU..........................................17
2.1.Chuẩn bị dữ liệu..........................................................................................17
2.2.Xử lý dữ liệu................................................................................................18
2.3.Code và xử lý dữ liệu...................................................................................18
2.4.Trực quan hóa tỷ lệ chiếm chỗ của tất cả bãi đỗ xe.....................................20
Downloaded by B?p Tr??ng Thành (baptruongthanh@gmail.com) lOMoARcPSD|50662567
2.5.Tương quan giữa hai bãi đỗ xe....................................................................23
CHƯƠNG 3: XÂY DỰNG MÔ HÌNH DỰ ĐOÁN...............................................25
3.1. Xây dựng mô hình dự đoán........................................................................25
3.2. Linear Regression.......................................................................................25
3.3. Random Forest Regreesion.........................................................................27
CHƯƠNG 4: XÁC ĐỊNH THUỘC TÍNH TIỀM ẨN............................................29
KẾT LUẬN.............................................................................................................31
Downloaded by B?p Tr??ng Thành (baptruongthanh@gmail.com) lOMoARcPSD|50662567 LỜI MỞ ĐẦU
Trí tuệ nhân tạo ( AI ) đang ngày một phát triển mạnh, mở ra nhiều cơ hội và
thách thức mới trong công việc. Vì thế, việc áp dụng các phương pháp AI để dự
đoán và cải thiện khả năng sử dụng chỗ đậu xe trở nên cần thiết.
Bãi đỗ xe là một trong những yếu tố quan trọng nhất trong quy hoạch và
quản lý giao thông đô thị. Việc cung cấp đủ chỗ đỗ xe phù hợp với nhu cầu của
người dân không chỉ giúp giải tỏa tình trạng ùn tắc giao thông, mà còn ảnh hưởng
trực tiếp đến hoạt động kinh tế, xã hội của cộng đồng. Tuy nhiên, quản lý hệ thống
bãi đỗ xe là một thách thức lớn đối với các thành phố hiện đại, đòi hỏi các nhà
hoạch định phải cân nhắc nhiều yếu tố khác nhau.
Trong phần này, chúng em sẽ tìm hiểu một số thuộc tính và đặc điểm quan
trọng của hệ thống bãi đỗ xe, từ đó hiểu rõ hơn về những vấn đề cần quan tâm và
các giải pháp tiềm năng để tối ưu hóa việc quản lý và sử dụng các bãi đỗ xe một
cách hiệu quả. Những thông tin này sẽ giúp các nhà hoạch định và quản lý đô thị
đưa ra các chính sách và quyết định phù hợp, nhằm đáp ứng tốt hơn nhu cầu của
người dân và thúc đẩy sự phát triển của cộng đồng.
Downloaded by B?p Tr??ng Thành (baptruongthanh@gmail.com) lOMoARcPSD|50662567
CHƯƠNG 1: TỔNG QUAN VỀ KHAI PHÁ DỮ LIỆU
1.1.Giới thiệu về khai phá dữ liệu
Khai phá dữ liệu (data mining) Là quá trình tính toán để tìm ra các mẫu
trong các bộ dữ liệu lớn liên quan đến các phương pháp tại giao điểm của máy học,
thống kê và các hệ thống cơ sở dữ liệu. Đây là một lĩnh vực liên ngành của khoa
học máy tính… Mục tiêu tổng thể của quá trình khai thác dữ liệu là trích xuất
thông tin từ một bộ dữ liệu và chuyển nó thành một cấu trúc dễ hiểu để sử dụng
tiếp. Ngoài bước phân tích thô, nó còn liên quan tới cơ sở dữ liệu và các khía cạnh
quản lý dữ liệu, xử lý dữ liệu trước, suy xét mô hình và suy luận thống kê, các
thước đo thú vị, các cân nhắc phức tạp, xuất kết quả về các cấu trúc được phát
hiện, hiện hình hóa và cập nhật trực tuyến. Khai thác dữ liệu là bước phân tích của
quá trình "khám phá kiến thức trong cơ sở dữ liệu" hoặc KDD. 1.1.1 Diễn giải
Khai phá dữ liệu là một bước của quá trình khai thác tri thức (Knowledge
Discovery Process), bao gồm:
- Xác định vấn đề và không gian dữ liệu để giải quyết vấn đề (Problem
understanding and data understanding).
- Chuẩn bị dữ liệu (Data preparation), bao gồm các quá trình làm sạch
dữ liệu (data cleaning), tích hợp dữ liệu (data integration), chọn dữ
liệu (data selection), biến đổi dữ liệu (data transformation).
- Khai thác dữ liệu (Data mining): xác định nhiệm vụ khai thác dữ
liệu và lựa chọn kỹ thuật khai thác dữ liệu. Kết quả cho ta một nguồn tri thức thô.
- Đánh giá (Evaluation): dựa trên một số tiêu chí tiến hành kiểm
tra và lọc nguồn tri thức thu được.
- Triển khai (Deployment).
- Quá trình khai thác tri thức không chỉ là một quá trình tuần tự từ bước
đầu tiên đến bước cuối cùng mà là một quá trình lặp và có quay trở lại các bước đã qua.
1.1.2 Các phương pháp khai thác dữ liệu
Downloaded by B?p Tr??ng Thành (baptruongthanh@gmail.com) lOMoARcPSD|50662567 -
Phân loại (Classification): Là phương pháp dự báo, cho phép phân loại một
đối tượng vào một hoặc một số lớp cho trước. -
Hồi qui (Regression): Khám phá chức năng học dự đoán, ánh xạ một mục dữ
liệu thành biến dự đoán giá trị thực. -
Phân nhóm (Clustering): Một nhiệm vụ mô tả phổ biến trong đó người ta tìm
cách xác định một tập hợp hữu hạn các cụm để mô tả dữ liệu. -
Tổng hợp (Summarization): Một nhiệm vụ mô tả bổ sung liên quan đến
phương pháp cho việc tìm kiếm một mô tả nhỏ gọn cho một bộ (hoặc tập hợp con) của dữ liệu. -
Mô hình ràng buộc (Dependency modeling): Tìm mô hình cục bộ mô tả các
phụ thuộc đáng kể giữa các biến hoặc giữa các giá trị của một tính năng trong tập
dữ liệu hoặc trong một phần của tập dữ liệu. -
Dò tìm biến đổi và độ lệch (Change and Deviation Dectection): Khám phá
những thay đổi quan trọng nhất trong bộ dữ liệu.
1.1.3 Một số tính năng nổi bật của khai phá dữ liệu
- Dự đoán các mẫu dựa trên xu hướng trong dữ liệu.
- Tính toán dự đoán kết quả.
- Tạo thông tin phản hồi để phân tích.
- Tập trung vào cơ sở dữ liệu lớn hơn
- Phân cụm dữ liệu trực quan
Downloaded by B?p Tr??ng Thành (baptruongthanh@gmail.com) lOMoARcPSD|50662567
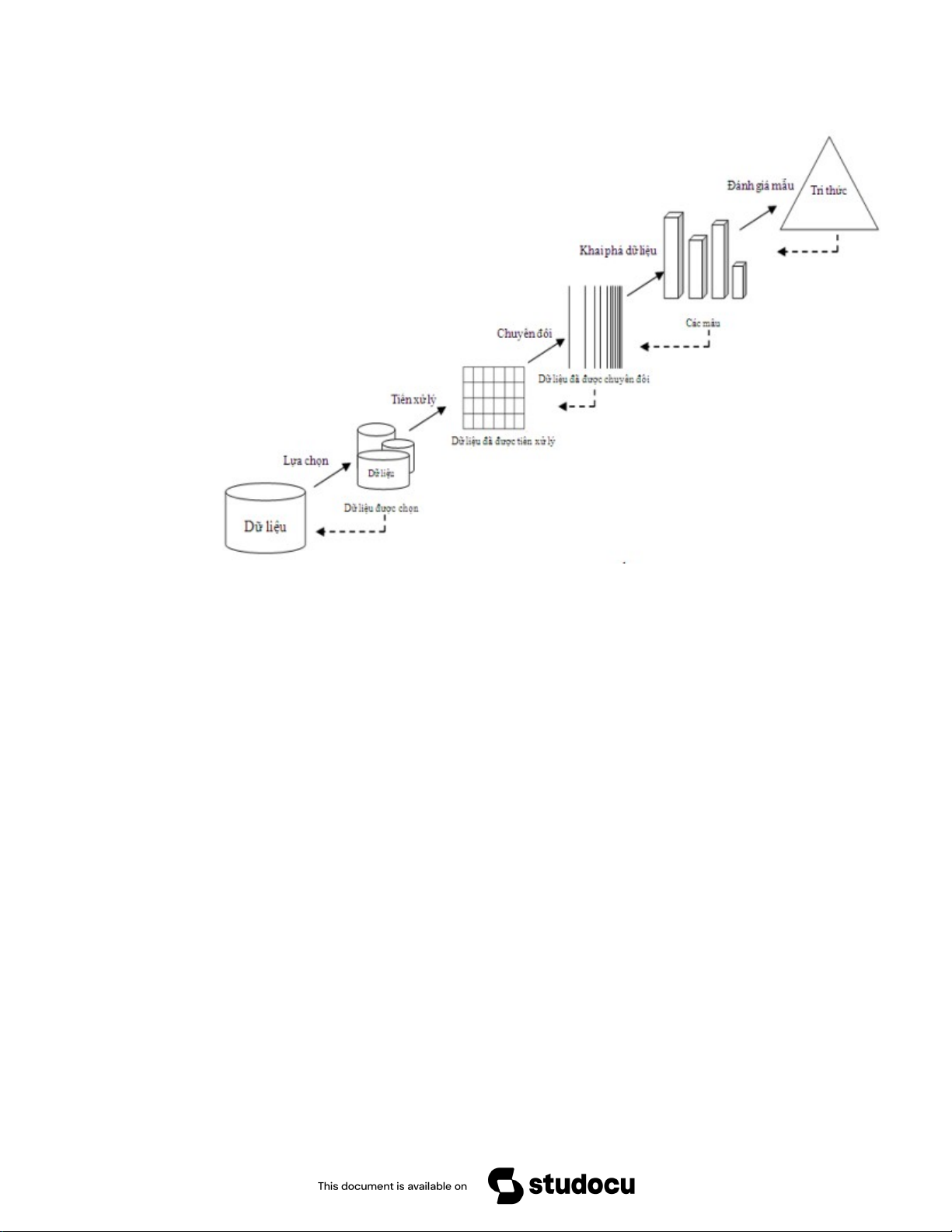
1.1.4 Quy trình khai phá dữ liệu
Các bước quan trọng khi khai phá dữ liệu bao gồm:
- Bước 1: Tiền xử lý, làm sạch dữ liệu – Trong bước này, dữ liệu được làm
sạch sao cho không có tạp âm hay bất thường trong dữ liệu.
- Bước 2: Tích hợp dữ liệu – Trong quá trình tích hợp dữ liệu, nhiều nguồn dữ
liệu sẽ kết hợp lại thành một.
- Bước 3: Lựa chọn dữ liệu – Trong bước này, dữ liệu được trích xuất từ cơ sở dữ liệu.
- Bước 4: Chuyển đổi dữ liệu – Trong bước này, dữ liệu sẽ được chuyển đổi
để thực hiện phân tích tóm tắt cũng như các hoạt động tổng hợp.
- Bước 5: Khai phá dữ liệu – Trong bước này, chúng ta trích xuất dữ liệu hữu
ích từ nhóm dữ liệu hiện có.
- Bước 6: Đánh giá mẫu – Chúng ta phân tích một số mẫu có trong dữ liệu.
- Bước 7: Trình bày thông tin – Trong bước cuối cùng, thông tin sẽ được thể
hiện dưới dạng cây, bảng, biểu đồ và ma trận. Quá trình được thực hiện qua 9 bước:
1 - Tìm hiểu lĩnh vực của bài toán (ứng dụng): Các mục đích của bài toán,
các tri thức cụ thể của lĩnh vực.
2 - Tạo nên (thu thập) một tập dữ liệu phù hợp.
3 - Làm sạch và tiền xử lý dữ liệu.
4 - Giảm kích thức của dữ liệu, chuyển đổi dữ liệu: Xác định thuộc tính quan
trọng, giảm số chiều (số thuộc tính), biểu diễn bất biến.
5 - Lựa chọn chức năng khai phá dữ liệu: Phân loại, gom cụm, dự báo, sinh ra các luật kết hợp.
6 - Lựa chọn/ Phát triển (các) giải thuật khai phá dữ liệu phù hợp.
7 - Tiến hành khai phá dữ liệu.
8 - Đánh giá mẫu thu được và biểu diễn tri thức: Hiển thị hóa, chuyển đổi,
bỏ đi các mẫu dư thừa,…
9 - Sử dụng tri thức được khai phá.
Downloaded by B?p Tr??ng Thành (baptruongthanh@gmail.com) lOMoARcPSD|50662567
Hình 1. 1: Quy trình khai phá dữ liệu
1.1.5 Ứng dụng khai phá dữ liệu
Có nhiều ứng dụng của khai phá dữ liệu thường thấy như:
Phân tích thị trường chứng khoán. - Phát hiện gian lận. -
Quản lý rủi ro và phân tích doanh nghiệp… -
Downloaded by B?p Tr??ng Thành (baptruongthanh@gmail.com) lOMoARcPSD|50662567
1.1.6 Các công cụ khai phá dữ liệu
RapidMiner: Công cụ đầu tiên phải kể tới đó là RapidMiner. Đây là công -
cụ khai phá dữ liệu khá phổ biến hiện nay. Được viết trên nền tảng JAVA
nhưng không yêu cầu mã hóa để vận hành. Ngoài ra, nó còn cung cấp các
chức năng khai thác dữ liệu khác nhau như tiền xử lý dữ liệu, biểu diễn dữ liệu, lọc, phân cụm...
Weka: Công cụ được cho ra đời tại Đại học Wichita là một phần mềm khai -
thác dữ liệu mã nguồn mở. Tương tự như RapidMiner, công cụ này không
yêu cầu mã hóa và sử dụng GUI đơn giản.
+ Sử dụng Weka, người dùng có thể gọi trực tiếp các thuật toán học máy
hoặc nhập chúng bằng mã Java. Weka được trang bị đa dạng chức năng như
trực quan hóa, tiền xử lý, phân loại, phân cụm...
Knime: Với khả năng hoạt động vô cùng mạnh mẽ tích hợp nhiều thành -
phần khác nhau của học máy và khai phá dữ liệu để cung cấp một nền tảng.
KNime hỗ trợ người dùng rất nhiều trong việc xử lý và phân tích dữ liệu,
trích xuất, chuyển đổi và tải dữ liệu.
Apache Mahout: Từ nền tảng Big Data Hadoop, người ta đã cho cho ra đời -
thêm Apache Mahout với mục đích giải quyết nhu cầu ngày càng tăng về
khai phá dữ liệu và hoạt động phân tích trong Hadoop. Nó được trang bị
nhiều chức năng học máy khác nhau như phân loại, hồi quy, phân cụm...
Oracle Data Mining: Khi sử dụng Oracle Data Mining. nó cho phép người -
dùng thực hiện khai phá dữ liệu trên cơ sở dữ liệu SQL để trích xuất các
khung hình và biểu đồ. Các phân tích sẽ hiển thị một cách trực quan giúp
người dùng dễ dàng đưa ra dự đoán cho kế hoạch tương lai.
Downloaded by B?p Tr??ng Thành (baptruongthanh@gmail.com) lOMoARcPSD|50662567
TeraData: TeraData cung cấp dịch vụ kho chứa các công cụ khai phá dữ -
liệu. Nhờ khả năng thông minh được trang bị, công cụ có thể dựa trên tần
suất sử dụng dữ liệu của người dùng và thực hiện việc cho phép truy cập nhanh hay chậm.
+ Với một dữ liệu bạn thường xuyên cần sử dụng, TeraData sẽ cho phép truy
cập nhanh hơn là một dữ liệu ít được sử dụng. Đối với dữ liệu, nhập kho là
một yêu cầu cần thiết.
- Orange: Công cụ được lập trình bằng Python với giao diện trực quan và
tương tác dễ dàng. Phần mềm Orange được biết đến bởi việc tích hợp các
công cụ khai phá dữ liệu và học máy thông minh, đơn giản 1.2 Tiền xử lý
Quá trình tiền xử lý dữ liệu, đầu tiên phải nắm được dạng dữ liệu, thuộc tính,
mô tả của dữ liệu thao tác. Sau đó tiếp hành 4 giai đoạn chính: làm sạch, tích hợp,
biến đổi, thu giảm dữ liệu. 1.2.1 Dữ liệu Tập dữ liệu:
- Một tập dữ liệu (dataset) là một tập hợp các đối tượng (object) và các thuộc tính của chúng.
- Mỗi thuộc tính (attribute) mô tả một đặc điểm của một đối tượng.
Hình 1. 2: Ví dụ dataset
Downloaded by B?p Tr??ng Thành (baptruongthanh@gmail.com) lOMoARcPSD|50662567 Các kiểu tập dữ liệu:
- Bản ghi (record): Các bản ghi trong cở sở dữ liệu quan hệ. Ma trận dữ liệu.
Biểu diễn văn bản. Hay dữ liệu giao dịch.„
- Đồ thị (graph): World wide web. Mạng thông tin, hoặc mạng xã hội
- Dữ liệu có trật tự: Dữ liệu không gian (ví dụ: bản đồ). Dữ liệu thời gian (ví
dụ: time-series data). Dữ liệu chuỗi (ví dụ: chuỗi giao dịch).
Các kiểu giá trị thuộc tính:
- Kiểu định danh/chuỗi (norminal): không có thứ tự. Ví dụ: Các thuộc tính như: Name, Profession, …
- Kiểu nhị phân (binary): là một trường hợp đăc biệt của kiểu định danh. Tập
các giá trị chỉ gồm có 2 giá trị (Y/N, 0/1, T/F).
- Kiểu có thứ tự (ordinal): Integer, Real, …
- Lấy giá trị từ một tập có thứ tự giá trị. Ví dụ: Các thuộc tính lấy giá trị số
như: Age, Height ,… Hay lấy một tập xác định, thuộc tính Income lấy giá
trị từ tập {low, medium, high}
Kiểu thuộc tính rời rạc (discrete-valued attributes): có thể là tập các giá trị của một
tập hữu hạn. Bao gồm thuộc tính có kiểu giá trị là các số nguyên, nhị phân.
Kiểu thuộc tính liên tục (continuous-valued attributes):Các giá trị là số thực.
Các đặc tính mô tả của dữ liệu:
- Giúp hiểu rõ về dữ liệu có được: chiều hướng chính/trung tâm, sự biến thiên, sự phân bố.
- Sự phân bố của dữ liệu (data dispersion):
Giá trị cực tiểu/cực đại (min/max).
Giá trị xuất hiện nhiều nhất (mode).
Giá trị trung bình (mean).
Giá trị trung vị (median).
Sự biến thiên (variance) và độ lệch chuẩn (standard deviation) .
Các ngoại lai (outliers).
Downloaded by B?p Tr??ng Thành (baptruongthanh@gmail.com) lOMoARcPSD|50662567
1.2.2 Làm sạch dữ liệu (data cleaning)
Đối với dữ liệu thu thập được, cần xác định các vấn đề ảnh hưởng là cho nó
không sạch. Bởi vì, dữ liệu không sạch (có chứa lỗi, nhiễu, không đầy đủ, có mâu
thuẫn) thì các tri thức khám phá được sẽ bị ảnh hưởng và không đáng tin cậy, sẽ
dẫn đến các quyết định không chính xác. Do đó, cần gán các giá trị thuộc tính còn
thiếu; sửa chữa các dữ liệu nhiễu/lỗi; xác định hoặc loại bỏ các ngoại lai (outliers);
giải quyết các mâu thuẫn dữ liệu.
1.2.2.1 Các vấn đề của dữ liệu
- Trên thực thế dữ liệu thu có thể chứa nhiễu, lỗi, không hoàn chỉnh, có mâu thuẫn:
Không hoàn chỉnh (incomplete): Thiếu các giá trị thuộc tính hoặc
thiếu một số thuộc tính. Ví dụ: salary = .
Nhiễu/lỗi (noise/error): Chứa đựng những lỗi hoặc các mang các giá
trị bất thường. Ví dụ: salary = “-525” , giá trị của thuộc tính không thể là một số âm.
Mâu thuẫn (inconsistent): Chứa đựng các mâu thuẫn (không thống
nhất). Ví dụ: salary = “abc” , không phù hợp với kiểu dữ liệu số của thuộc tính salary.
1.2.2.2 Nguồn gốc/lý do của dữ liệu không sạch
- Không hoàn chỉnh (incomplete): Do giá trị thuộc tính không có (not
available) tại thời điểm được thu thập. Hoặc các vấn gây ra bởi phần cứng,
phần mềm, hoặc người thu thập dữ liệu.
- Nhiễu/lỗi (noise/error): Do việc thu thập dữ liệu, hoăc việc nhập dữ liệu,
hoặc việc truyền dữ liệu.
- Mâu thuẫn (inconsistent): Do dữ liệu được thu thập có nguồn gốc khác
nhau. Hoặc vi phạm các ràng buộc (điều kiện) đối với các thuộc tính.
1.2.2.3 Giải pháp khi thiếu giá trị của thuộc tính
- Bỏ qua các bản ghi có các thuộc tính thiếu giá trị. Thường áp dụng trong các
bài toán phân lớp. Hoặc khi tỷ lệ % các giá trị thiếu đối với các thuộc tính quá lớn.
- Một số người sẽ đảm nhiệm việc kiểm tra và gán các giá trị thuộc tính còn
thiếu, nhưng đòi hỏi chi phí cao và rất tẻ nhạt.
- Gán giá trị tự động bởi máy tính:
Gán giá trị mặc định.
Downloaded by B?p Tr??ng Thành (baptruongthanh@gmail.com) lOMoARcPSD|50662567
Gán giá trị trung bình của thuộc tính đó.
Gán giá trị có thể xảy ra nhất – dựa theo phương pháp xác suất.
1.2.2.4 Giải pháp khi dữ liệu chứa nhiễu/lỗi
- Phân khoảng (binning): Sắp xếp dữ liệu và phân chia thành các khoảng
(bins) có tần số xuất hiện giá trị như nhau. Sau đó, mỗi khoảng dữ liệu có
thể được biểu diễn bằng trung bình, trung vị, hoặc các giới hạn … của các
giá trị trong khoảng đó.
- Hồi quy (regression): Gắn dữ liệu với một hàm hồi quy.
- Phân cụm (clustering): Phát hiện và loại bỏ các ngoại lai (sau khi đã xác định các cụm).
- Kết hợp giữa máy tính và kiểm tra của con người: Máy tính sẽ tự động phát
hiện ra các giá trị nghi ngờ. Các giá trị này sẽ được con người kiểm tra lại.
1.2.3. Tích hợp dữ liệu (data integration)
Tích hợp dữ liệu là quá trình trộn dữ liệu từ các nguồn khác nhau vào một
kho dữ liệu có sẵn cho quá trình khai phá dữ liệu. Khi tích hợp cần xác định thực
thể từ nhiều nguồn dữ liệu để tránh dư thừa dữ liệu.
Ví dụ: Bill Clinton ≡ B.Clinton. Việc dư thừa dữ liệu là thường xuyên xảy
ra, khi tích hợp nhiều nguồn. Bởi cùng một thuộc tính (hay cùng một đối tượng) có
thể mang các tên khác nhau trong các nguồn (cơ sở dữ liệu) khác nhau. Hay các dữ
liệu suy ra được như một thuộc tính trong một bảng có thể được suy ra từ các thuộc
tính trong bảng khác. Hay sự trùng lắp các dữ liệu. Các thuộc tính dư thừa có thể bị
phát hiện bằng phân tích tương quan giữa chúng.
Phát hiện và xử lý các mâu thuẫn đối với giá trị dữ liệu: Đối với cùng một
thực thể trên thực tế, nhưng các giá trị thuộc tính từ nhiều nguồn khác nhau lại
khác nhau. Có thể cách biểu diễn khác nhau, hay mức đánh giá, độ do khác nhau.
Yêu cầu chung đối với quá trình tích hợp là giảm thiểu (tránh được là tốt nhất) các
dư thừa và các mâu thuẫn. Giúp cải thiện tốc độ của quá trình khai phá dữ liệu và
nâng cao chất lượng của các kết quả tri thức thu được.
1.2.4. Biến đổi dữ liệu (data transformation)
Biến đổi dữ liệu là việc chuyển toàn bộ tập giá trị của một thuộc tính sang một
tập các giá trị thay thế, sao cho mỗi giá trị cũ tương ứng với một trong các giá trị mới.
Các phương pháp biến đổi dữ liệu:
Downloaded by B?p Tr??ng Thành (baptruongthanh@gmail.com) lOMoARcPSD|50662567
- Làm trơn (smoothing): Loại bỏ nhiễu/lỗi khỏi dữ liệu.
- Kết hợp (aggregation): Sự tóm tắt dữ liệu, xây dựng các khối dữ liệu.
- Khái quát hóa (generalization): Xây dựng các phân cấp khái niệm. - Chuẩn
hóa (normalization): Đưa các giá trị về một khoảng được chỉ định.
Chuẩn hóa min-max, giá trị mới nằm khoảng [new_mini , new_maxi]
Chuẩn hóa z-score, với μi , σi : giá trị trung bình và độ lệch chuẩn của thuộc tính i
Chuẩn hóa bởi thang chia 10, với j là giá trị số nguyên nhỏ nhất sao cho: max({vnew}) < 1
- Xây dựng các thuộc tính mới dựa trên các thuộc tính ban đầu.
Downloaded by B?p Tr??ng Thành (baptruongthanh@gmail.com) lOMoARcPSD|50662567
1.2.5. Thu giảm dữ liệu (data reduction)
Một kho dữ liệu lớn có thể chứa lượng dữ liệu lên đến terabytes sẽ làm cho
quá trình khai phá dữ liệu chạy rất mất thời gian, do đó nên thu giảm dữ liệu. Việc
thu giảm dữ liệu sẽ thu được một biểu diễn thu gọn, mà nó vẫn sinh ra cùng (hoặc
xấp xỉ) các kết quả khai phá như tập dữ liệu ban đầu. Các chiến lược thu giảm:
- Giảm số chiều (dimensionality reduction), loại bỏ bớt các thuộc tính không (ít) quan trọng.
- Giảm lượng dữ liệu (data/numberosity reduction)
Kết hợp khối dữ liệu. Nén dữ liệu. Hồi quy. Rời rạc hóa
Downloaded by B?p Tr??ng Thành (baptruongthanh@gmail.com) lOMoARcPSD|50662567
CHƯƠNG 2: CHUẨN BỊ VÀ LÀM SẠCH DỮ LIỆU
2.1.Chuẩn bị dữ liệu
Hình 2. 1: Dữ liệu đầu vào các bãi đậu xe
Downloaded by B?p Tr??ng Thành (baptruongthanh@gmail.com) lOMoARcPSD|50662567
Tệp file dữ liệu là file mở rộng CSV. Trong tệp dữ liệu này có 4 cột và 35718 dòng
Dữ liệu đầu vào X gồm:
- SystemCodeNumber: Mã định danh duy nhất của từng bãi đậu xe.
- Capacity: Tổng số chỗ đậu xe có sẵn tại bãi đậu xe.
- Occupancy: Số lượng xe đang đậu tại bãi đậu xe tại thời điểm nhất định.
- LastUpdated: Thời gian cập nhật cuối cùng về tình trạng chiếm dụng của bãi đậu xe.
2.2.Xử lý dữ liệu
Ở đây chúng em sử dụng logistic regression và dữ liệu lấy từ Excel(file
csv) ,google colab ,python ,để hỗ trợ quá trình training .Về cơ bản thì python đã
được tích hợp rất nhiều các thuật toán khác nhau, dễ dàng sử dụng, và giúp giảm
thời gian xây dựng các hệ thống deep learning. Đồng thời kết hợp với pandas và
numpy để phân tích, và xử lý cấu trúc data, và matplotlib dùng để về đồ thị.
2.3.Code và xử lý dữ liệu
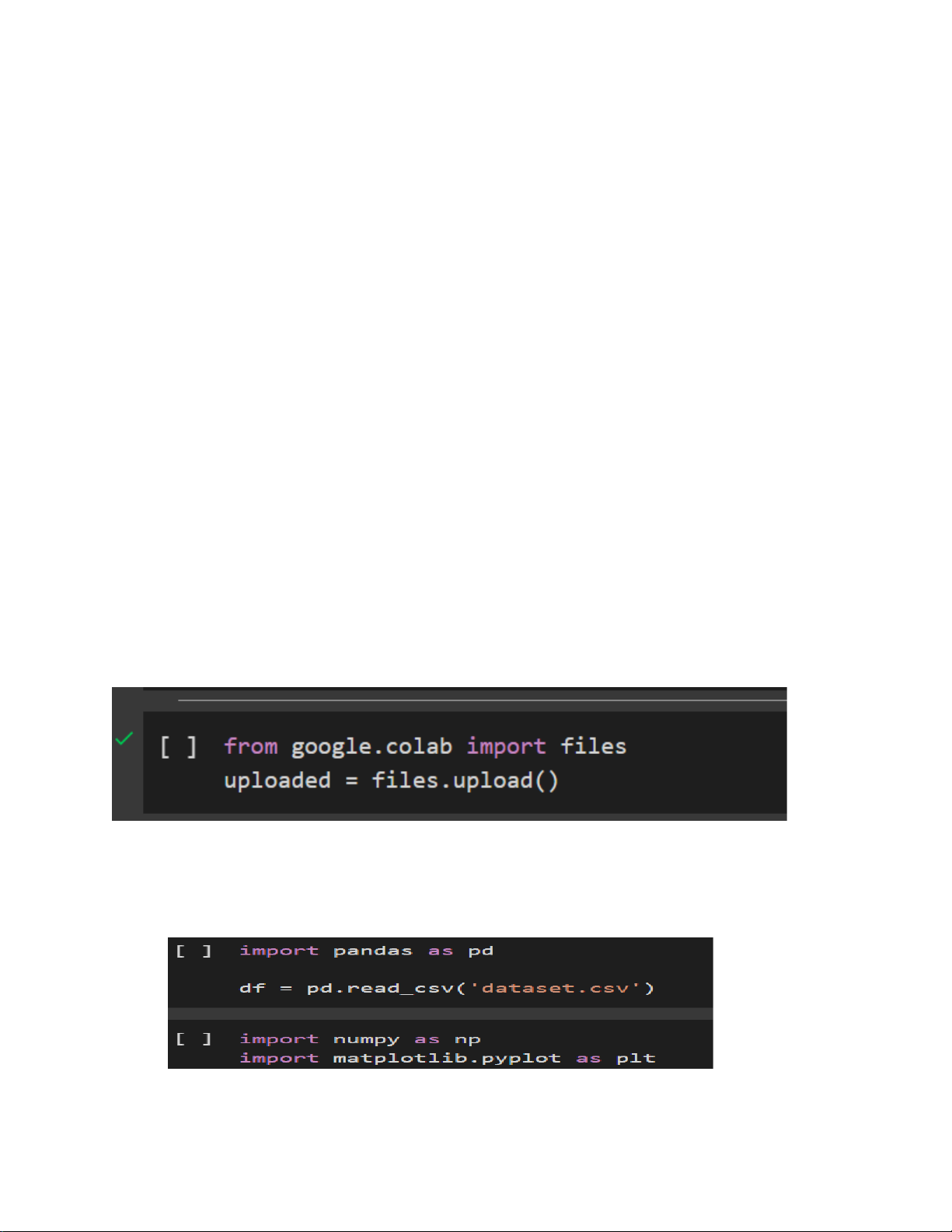
Trước tiên, ta cần uploaded file để truy cập và sử dụng files trên Colab:
Sau khi chạy đoạn mã này, bạn có thể truy cập và sử dụng tệp tin đã tải lên
trong quá trình thực hiện các tác vụ tiếp theo của mình.
Tiếp theo, chúng ta phải import các thư viện cần thiết:
Downloaded by B?p Tr??ng Thành (baptruongthanh@gmail.com) lOMoARcPSD|50662567
Thư viện pandas là một thư viện mạnh mẽ được sử dụng để làm việc với dữ
liệu dạng bảng. Nó cung cấp cấu trúc dữ liệu DataFrame linh hoạt và nhiều chức
năng để xử lý và phân tích dữ liệu. Bằng cách import pandas như import pandas as
pd, ta có thể sử dụng các chức năng và phương thức của pandas thông qua đối tượng pd.
Thư viện matplotlib là một thư viện trực quan hóa dữ liệu mạnh mẽ trong
Python. Nó cung cấp các công cụ và chức năng để tạo các biểu đồ, biểu đồ hộp,
biểu đồ phân phối và nhiều loại biểu đồ khác. Bằng cách import matplotlib.pyplot
như import matplotlib.pyplot as plt, ta có thể sử dụng các hàm và phương thức của
matplotlib.pyplot thông qua đối tượng plt.
Thư viện NumPy (Numerical Python) là một thư viện mạnh mẽ và phổ biến
trong Python, được sử dụng rộng rãi trong lĩnh vực khoa học, kỹ thuật và phân tích
dữ liệu. Nó cung cấp các chức năng và công cụ để làm việc với các mảng (arrays)
và ma trận (matrices) n chiều, cùng với nhiều phép toán số học và hàm tiện ích khác.
df = pd.read_csv('dataset.csv')
df = pd.read_csv('dataset.csv') là câu lệnh Python sử dụng thư viện Pandas
để đọc dữ liệu từ một tệp CSV (Comma-Separated Values) và lưu trữ nó trong một DataFrame Pandas.
pd.read_csv('dataset.csv'): Hàm read_csv() của Pandas được sử dụng để đọc
dữ liệu từ tệp CSV có tên "dataset.csv". Hàm này trả về một DataFrame Pandas, là
một cấu trúc dữ liệu 2 chiều với các cột (columns) và hàng (rows).
Sau khi chạy đoạn mã này, bạn sẽ có một DataFrame Pandas df chứa toàn bộ
dữ liệu từ tệp CSV "dataset.csv". Bây giờ bạn có thể sử dụng các phương thức và
thuộc tính của DataFrame Pandas để khám phá, làm sạch và phân tích dữ liệu này.
Downloaded by B?p Tr??ng Thành (baptruongthanh@gmail.com)




