Báo Cáo Nhập Môn Trí Tuệ Nhân Tạo | Đại học Điện lực
Trí tuệ nhân tạo là gì. Báo Cáo Nhập Môn Trí Tuệ Nhân Tạo | Đại học Điện lực. Tài liệu sưu tầm gồm 17 trang, giúp bạn tham khảo, ôn tập và đạt kết quả cao.
Môn: Nhập môn Trí tuệ nhân tạo (EPU) 11 tài liệu
Trường: Trường Đại học Điện lực 502 tài liệu
Tác giả:














Preview text:
lOMoARcPSD| 59629529
TRƯỜNG ĐẠI HỌC ĐIỆN LỰC
KHOA CÔNG NGHỆ THÔNG TIN BÁO CÁO MÔN HỌC
Nhập môn Trí tuệ nhân tạo ĐỀ TÀI:
Sinh viên thực hiện : Đoàn Phương Nam
Phạm Quang Vinh
Giảng viên hướng dẫn : Nguyễn Thị Hồng Khánh
Chuyên ngành :
CÔNG NGHỆ PHẦN M Ề M Lớp : D16CNPM1
Hà Nội , tháng … năm 2023 lOMoARcPSD| 59629529 PHIẾU CHẤM ĐIỂM Sinh viên thực hiện: Họ và tên
Nội dung thực hiện Điểm Đoàn Phương Nam Phạm Quang Vinh Giảng viên chấm: Họ và tên Chữ ký Ghi chú Giảng viên chấm 1 : Giảng viên chấm 2 :
Chương 1: Giới thiệu
1.1. Trí tuệ nhân tạo là gì
Trí tuệ nhân tạo (Artificial Intelligence – AI) là một lĩnh vực trong
khoa học máy tính nghiên cứu và phát triển các hệ thống máy tính hoặc máy
tính tự động có khả năng thực hiện các nhiệm vụ thông minh mà trước đây
thường chỉ được thực hiện bởi con người. AI bao gồm nhiều phương pháp và lOMoARcPSD| 59629529
kỹ thuật để giúp máy tính học hỏi, đưa ra quyết định, xử lý thông tin và
tương tác với môi trường xung quanh mình. Mục tiêu của trí tuệ nhân tạo là
tạo ra máy tính hoặc hệ thống máy tính có khả năng thực hiện các nhiệm vụ
thông minh một cách tự động mà đòi hỏi sự hiểu biết, học tập và quyết định giống như con người.
1.2. Lịch sử của trí tuệ nhân tạo • Thập kỷ 1940 và 1950
Thế chiến II đã đóng một vai trò quan trọng trong việc đẩy mạnh nghiên
cứu về máy tính và tính toán. Alan Turing, một nhà toán học và nhà máy
tính học nổi tiếng, đã đưa ra khái niệm về ‘máy Turing’, một mô hình
toán học và tính toán cơ bản mà sau này trở thành cơ sở của nhiều nghiên cứu AI.
• 1956 – Hội nghị Dartmouth
Hội nghị Dartmouth College năm 1956 được xem là sự khởi đầu của trí
tuệ nhân tạo. Tại hội nghị này, những nhà khoa học hàng đầu đã đề xuất
một chương trình nghiên cứu về máy tính có khả năng thực hiện các nhiệm vụ thông minh. • Thập kỷ 1960 và 1970
Trong thời kỳ này, nghiên cứu AI tập trung vào việc phát triển các
chương trình chuyên biệt cho các nhiệm vụ cụ thể, như chơi cờ vua và
giải quyết các vấn đề trí tuệ nhân tạo đầu tiên, Logic Theorist, được tạo
ra bởi Allen Newell và Herbert A.Simon. • Thập kỷ 1980
Phát triển của khoa học máy tính (machine learning) đã tạo ra một làn
sóng mới trong nghiên cứu AI. Các phương pháp học máy trở lên phổ
biến và bắt đầu được sử dụng trong các ứng dụng thực tế. • Thập kỷ 1990 và 2000 lOMoARcPSD| 59629529
Internet và sự gia tăng vượt bậc trong sức mạnh tính toán đã cung cấp
môi trường tốt cho sự phát triển của AI. Các công ty công nghệ lớn đã
bắt đầu đầu tư mạnh mẽ vào nghiên cứu AI và phát triển các sản phẩm và
dịch vụ dựa trên trí tuệ nhân tạo.
• Thập kỷ 2010 đến nay
Học sâu (deep learning) trở thành một phần quan trọng của AI và đã giúp
tạo ra nhiều tiến bộ đáng kể trong lĩnh vực như nhận diện hình ảnh, xử lý
ngôn ngữ tự nhiên , và tự động lái xe. Các ứng dụng trí tuệ nhân tạo ngày
càng phổ biến trong cuộc sống hàng ngày, như trợ lý ảo và hệ thống tự động lái xe
1.3. Các lĩnh vực của trí tuệ nhân tạo 1.3.1. Cảm nhận
Hệ thống cần có cơ chế thu nhận thông tin liên quan tới hoạt động từ
môi trường bên ngoài. Đó có thể là camera, cảm biến âm thanh
(microphone), cảm biến siêu âm, radar, cảm biến gia tốc, các cảm biến khác.
Đó cũng có thể đơn giản hơn là thông tin do người dùng nhập vào chương
trình bằng tay. Để biến đổi thông tin nhận được về dạng có thể hiểu được,
thông tin cần được xử lý nhờ những kỹ thuật được nghiên cứu và trong
khuôn khổ các lĩnh vực sau. Thị giác máy (computer vision)
Đây là lĩnh vực thuộc trí tuệ nhân tạo có mục đích nghiên cứu về việc
thu nhận, xử lý, phân tích, nhận dạng thông tin hình ảnh thu được từ các
cảm biến hình ảnh như camera. Mục đích của thị giác máy là biến thông
tin thu được thành biểu diễn mức cao hơn để máy tính sau đó có thể hiểu
được, chẳng hạn từ ảnh chụp văn bản cần trả về mã UNICODE của các
chữ in trên văn bản đó. Biểu diễn ở mức cao hơn của thông tin từ cảm
biến hình ảnh sau đó có thể sử dụng để phục vụ quá trình ra quyết định.
Thị giác máy tính bao gồm một số bài toán chính sau: nhận dạng mẫu
(pattern recognition), phân tích chuyển động (motion analysis), tạo lập lOMoARcPSD| 59629529
khung cảnh 3D (scene reconstruction), nâng cao chất lượng ảnh (image restoration). • Nhận dạng mẫu
Đây là lĩnh vực nghiên cứu lớn nhất trong phạm vi thị giác máy. Bản
thân nhận dạng mẫu được chia thành nhiều bài toán nhỏ và đặc thù hơn
như bài toán nhận dạng đối tượng nói chung, nhận dạng các lớp đối
tượng cụ thể như nhận dạng mặt người, nhận dạng vân tay, nhận dạng
chữ viết tay hoặc chữ in. Nhận dạng đối tượng là phát hiện ra đối tượng
trong ảnh hoặc video và xác định đó là đối tượng nào. Trong khi con
người có thể thực hiện việc này tương đối đơn giản thì việc nhận dạng tự
động thường khó hơn nhiều. Hiện máy tính chỉ có khả năng nhận dạng
một số lớp đối tượng nhất định như chữ in, mặt người nhìn thẳng, với độ
chính xác gần với con người.
• Xử lý ngôn ngữ tự nhiên (natural language processing)
Đây là lĩnh vực nghiên cứu với có mục đích phân tích thông tin, dữ
liệu nhận được dưới dạng âm thanh hoặc văn bản và được trình bày dưới
dạng ngôn ngữ tự nhiên của con người. Chẳng hạn, thay vì gõ các lệnh
quy ước, ta có thể ra lệnh bằng cách nói với máy tính như với người
thường. Do đối tượng giao tiếp của hệ thống trị tuệ nhân tạo thường là
con người, khả năng tiếp nhận thông tin và phản hồi dưới dạng lời nói
hoặc văn bản theo cách diễn đạt của người sẽ rất có ích trong những
trường hợp như vậy. Xử lý ngôn ngữ tự nhiên bao gồm ba giai đoạn
chính: nhận dạng tiếng nói (speech recognition), xử lý thông tin đã được
biểu diễn dưới dạng văn bản, và biến đổi từ văn bản thành tiếng nói (text
to speech). Nhận dạng tiếng nói là quá trình biến đổi từ tín hiệu âm thanh
của lời nói thành văn bản. Nhận dạng tiếng nói còn có các tên gọi như
nhận dạng tiếng nói tự động (automatic speech recognition) hay nhận
dạng tiếng nói bằng máy tính, hay biến đổi tiếng nói thành văn bản
(speech to text – STT). Nhận dạng tiếng nói được thực hiện bằng cách lOMoARcPSD| 59629529
kết hợp kỹ thuật xử lý tín hiệu âm thanh với kỹ thuật nhận dạng mẫu,
chẳng hạn bằng cách sử dụng các mô hình thống kê và học máy.
1.3.2. Lập luận và suy diễn
Sau khi cảm nhận được thông tin về môi trường xung quanh, hệ thống
cần có cơ chế để đưa ra được quyết định phù hợp. Quá trình ra quyết định
thường dựa trên việc kết hợp thông tin cảm nhận được với tri thức có sẵn
về thế giới xung quanh. Việc ra quyết định dựa trên tri thức được thực
hiện nhờ lập luận hay suy diễn. Cũng có những trường hợp hệ thống
không thực hiện suy diễn mà dựa trên những kỹ thuật khác như tìm kiếm
hay tập hợp các phản xạ hoặc hành vi đơn giản.
• Biểu diễn tri thức (knowledge representation)
Nhiều bài toán của trí tuệ nhân tạo đòi hỏi lập luận dựa trên hình dung
về thế giới xung quanh. Để lập luận được, sự kiện, thông tin, tri thức về
thế giới xung quanh cần được biểu diễn dưới dạng máy tính có thể “hiểu”
được, chẳng hạn dưới dạng logic hoặc ngôn ngữ trí tuệ nhân tạo nào đó.
Thông thường, hệ thống cần có tri thức về: đối tượng hoặc thực thể, tính
chất của chúng, phân loại và quan hệ giữa các đối tượng, tình huống, sự
kiện, trạng thái, thời gian, nguyên nhân và hiệu quả, tri thức về tri thức
(chúng ta biết về tri thức mà người khác có) v.v. Trong phạm vi nghiên
cứu về biểu diễn tri thức, một số phương pháp biểu diễn đã được phát
triển và được áp dụng như: logic, mạng ngữ nghĩa, Frame, các luật
(chẳng hạn luật Nếu…Thì…), bản thể học (ontology).
Biểu diễn tri thức dùng trong máy tính thường gặp một số khó khăn
sau. Thứ nhất, lượng tri thức mà mỗi người bình thường có về thế giới
xung quanh là rất lớn. Việc xây dựng và biểu diễn lượng tri thức lớn như
vậy đòi hỏi nhiều công sức. Hiện nay đang xuất hiện hướng tự động thu
thập và xây dựng cơ sở tri thức tự động từ lượng dữ liệu lớn, thay vì thu
thập bằng tay. Cách xây dựng tri thức như vậy được nghiên cứu nhiều lOMoARcPSD| 59629529
trong khuôn khổ khai phá dữ liệu (data mining) hay hiện nay được gọi là
dữ liệu lớn (big data) Điển hình của cách tiếp cận này là hệ thống
Watson của IBM (sẽ được nhắc tới ở bên dưới). Thứ hai, tri thức trong
thế giới thực ít khi đầy đủ, chính xác và nhất quán. Con người có thể sử
dụng hiệu quả các tri thức như vậy, trong khi các hệ thống biểu diễn tri
thức như logic gặp nhiều khó khăn. Thứ ba, một số tri thức khó biểu
diễn dưới dạng biểu tượng mà tồn tại như các trực giác của con người.
• Tìm kiếm (search)
Nhiều bài toán hoặc vấn đề có thể phát biểu và giải quyết như bài toán
tìm kiếm trong không gian trạng thái. Chẳng hạn các bài toán tìm đường
đi, bài toán tìm trạng thái thoả mãn ràng buộc. Nhiều bài toán khác của
trí tuệ nhân tạo cũng có thể giải quyết bằng tìm kiếm. Chẳng hạn, lập
luận logic có thể tiến hành bằng cách tìm các đường đi cho phép dẫn từ
các tiền đề tới các kết luận.
Trí tuệ nhân tạo nghiên cứu cách tìm kiếm khi số trạng thái trong
không gian quá lớn và không thể thực hiện tìm kiếm bằng cách vét cạn.
Trong khuôn khổ trí tuệ nhân tạo đã phát triển một số phương pháp tìm
kiếm riêng như tìm kiếm heuristic, tìm kiếm cục bộ, bao gồm các thuật
toán tìm kiếm tiến hoá.
• Lập luận, suy diễn (reasoning hay inference)
Lập luận là quá trình sinh ra kết luận hoặc tri thức mới từ những tri
thức, sự kiện và thông tin đã có. Trong giai đoạn đầu, nhiều kỹ thuật lập
luận tự động dựa trên việc mô phỏng hoặc học tập quá trình lập luận của
con người. Các nghiên cứu về sau đã phát triển nhiều kỹ thuật suy diễn
hiệu quả, không dựa trên cách lập luận của người. Điển hình là các kỹ
thuật chứng minh định lý và suy diễn logic. Lập luận tự động thường dựa
trên tìm kiếm cho phép tìm ra các liên kết giữa tiên đề và kết quả. lOMoARcPSD| 59629529
Việc suy diễn tự động thường gặp phải một số khó khăn sau. Thứ
nhất, với bài toán kích thước lớn, số tổ hợp cần tìm kiếm khi lập luận rất
lớn. Vấn đề này được gọi là “bùng nổ tổ hợp” và đòi hỏi có phát triển các
kỹ thuật với độ phức tạp chấp nhận được. Thứ hai, lập luận và biểu diễn
tri thức thường gặp vấn đề thông tin và tri thức không rõ ràng, không
chắc chắn. Hiện nay, một trong những cách giải quyết vấn đề này là sử
dụng lập luận xác suất, sẽ được trình bầy trong chương 4 của giáo trình.
Thứ ba, trong nhiều tình huống, con người có thể ra quyết định rất nhanh
và hiệu quả thay vì lập luận từng bước, chẳng hạn co tay lại khi chạm
phải nước sôi. Hệ thống trí tuệ nhân tạo cần có cách tiếp cận khác với lập
luận truyền thống cho những trường hợp như vậy.
• Học máy (machine learning)
Học máy hay học tự động là khả năng của hệ thống máy tính tự cải
thiện mình nhờ sử dụng dữ liệu và kinh nghiệm thu thập được. Học là
khả năng quan trọng trong việc tạo ra tri thức của người. Do vậy, đây là
vấn đề được quan tâm nghiên cứu ngay từ khi hình thành trí tuệ nhân tạo.
Hiện nay, đây là một trong những lĩnh vực được quan tâm nghiên cứu
nhiều nhất với rất nhiều kết quả và ứng dụng.
Học máy bao gồm các dạng chính là học có giám sát, học không
giám sát, và học tăng cường. Trong học có giám sát, hệ thống được cung
cấp đầu vào, đầu ra và cần tìm quy tắc để ánh xạ đầu vào thành đầu ra.
Trong học không giám sát, hệ thống không được cung cấp đầu ra và cần
tìm các mẫu hay quy luật từ thông tin đầu vào. Trong học tăng cường, hệ
thống chỉ biết đầu ra cuối cùng của cả quá trình thay vì đầu ra cho từng bước cụ thể.
Học máy được phát triển trong khuôn khổ cả khoa học máy tính và
thống kê. Rất nhiều kỹ thuật học máy có nguồn gốc từ thống kê nhưng lOMoARcPSD| 59629529
được thay đổi để trở thành các thuật toán có thể thực hiện hiệu quả trên máy tính.
Học máy hiện là kỹ thuật chính được sử dụng trong thị giác máy, xử
lý ngôn ngữ tự nhiên, khai phá dữ liệu và phân tích dữ liệu lớn.
Lập kế hoạch (planning)
Lập kế hoạch và thời khoá biểu tự động, hay đơn giản là lập kế hoạch,
là quá trình sinh ra các bước hành động cần thực hiện để thực hiện một
mục tiêu nào đó dựa trên thông tin về môi trường, về hiệu quả từng hành
động, về tình huống hiện thời và mục tiêu cần đạt. Lấy ví dụ một rô bốt
nhận nhiệm vụ di chuyển một vật tới một vị trí khác. Kế hoạch thực hiện
bao gồm xác định các bước để tiếp cận vật cần di chuyển, nhấc vật lên,
xác định quỹ đạo và các bước di chuyển theo quỹ đạo, đặt vật xuống.
Khác với lý thuyết điều khiển truyền thống, bài toán lập kế hoạch
thường phức tạp, lời giải phải tối ưu theo nhiều tiêu chí. Việc lập kế
hoạch có thể thực hiện trước đối với môi trường không thay đổi, hoặc
thực hiện theo thời gian với môi trường động.
Lập kế hoạch sử dụng các kỹ thuật tìm kiếm và tối ưu, các phương
pháp quy hoạch động để tìm ra lời giải. Một số dạng biểu diễn và ngôn
ngữ riêng cũng được phát triển để thuận lợi cho việc mô tả yêu cầu và lời giải. lOMoARcPSD| 59629529 1.3.3. Hành động
Cho phép hệ thống tác động vào môi trường xung quanh hoặc đơn
giản là đưa ra thông tin về kết luận của mình.
Kỹ thuật rô bốt (robotics)
Là kỹ thuật xây dựng các cơ quan chấp hành như cánh tay
người máy, tổng hợp tiếng nói, tổng hợp ngôn ngữ tự nhiên. Đây là
lĩnh vực nghiên cứu giao thoa giữa cơ khí, điện tử, và trí tuệ nhân tạo.
Bên cạnh kỹ thuật cơ khí để tạo ra các cơ chế vật lý, chuyển động, cần
có thuật toán và chương trình điểu khiển hoạt động và chuyển động
cho các cơ chế đó. Chẳng hạn, với cánh tay máy, cần tính toán quỹ
đạo và điều khiển cụ thể các khớp nối cơ khí khi muốn di chuyển tay
tới vị trí xác định và thực hiện hành động nào đó. Đây là những thành
phần của kỹ thuật rô bốt mà trí tuệ nhân tạo có đóng góp chính. Ngoài
ra, việc xây dựng những rô bốt thông minh chính là xây dựng các hệ
thống trí tuệ nhân tạo hoàn chỉnh. lOMoARcPSD| 59629529
Chương 2: Bài toán và phương pháp tìm kiếm lời giải
2.1. Bài toán và các thành phần của bài toán
Trong lĩnh vực trí tuệ nhân tạo (AI), bài toán là một vấn đề cần giải
quyết hoặc một nhiệm vụ cần được thực hiện bằng cách sử dụng máy tính
hoặc hệ thống máy móc thông minh.
Các thành phần của bài toán bao gồm:
• Dữ liệu: Bài toán AI thường liên quan đến dữ liệu, bởi vì hệ thống AI cần
thông tin để học và đưa ra quyết định. Dữ liệu có thể là dữ liệu đầu vào
(input data), chứa thông tin về tình huống hiện tại hoặc mô tả vấn đề cần
giải quyết, cũng như dữ liệu đầu ra (output data) chứa thông tin dự đoán
hoặc hành động cần thực hiện.
• Thuật toán: Đây là phần quan trọng nhất của AI, là cách hệ thống xử lý
dữ liệu đầu vào để đưa ra kết quả. Thuật toán có thể bao gồm các phương
pháp học máy (machine learning) như học sâu (deep learning), học tăng
cường (reinforcement learning), hoặc các phương pháp trí tuệ nhân tạo khác.
• Mô hình: Mô hình trong AI là biểu đồ hoặc cấu trúc hệ thống sử dụng để
biểu diễn kiến thức hoặc cách hoạt động của bài toán. Mô hình có thể bao
gồm kiến thức ký thuyết về lĩnh vực cụ thể hoặc các biểu đồ tích hợp của
dữ liệu và thuật toán.
• Đánh giá và tối ưu hóa: Sau khi hệ thống thực hiện các bài toán, cần có
cách để đánh giá hiệu suất của nó. Điều này bao gồm việc thiết lập các
phương pháp đánh giá và chỉ số hiệu suất để đo lường chính xác, tốc độ
hoặc khả năng của hệ thống. Sau đó, có thể áp dụng các kỹ thuật tối ưu
hóa để cải thiện hiệu suất.
• Ứng dụng và triển khai: Sau khi giải quyết bài toán, kết quả có thể triển
khai trong các ứng dụng thực tế, như hệ thống tự động, ứng dụng di lOMoARcPSD| 59629529
động, hoặc các hệ thống trí tuệ nhân tạo khác để giúp giải quyết các vấn đề cụ thể.
2.2. Giải thuật tổng quát tìm kiếm lời giải
Nguyên lý chung của giải thuật tổng quát tìm kiếm lời giải: bắt đầu từ
trạng thái xuất phát, sử dụng các hàm chuyển động để di chuyển trong không
gian trạng thái cho tới khi đạt đến trạng thái mong muốn. Trả về chuỗi
chuyển động hoặc trạng thái đích tìm được tùy vào yêu cầu của bài toán.
Các ví dụ về giải thuật giải thuật tổng quát tìm kiếm lời giải bao gồm
thuật toán tìm kiếm theo chiều rộng (BFS: Breadth-First Search), thuật toán
tìm kiếm theo chiều sâu (DFS: Depth-First Search), thuật toán A*, thuật toán tìm kiếm cục bộ, ...
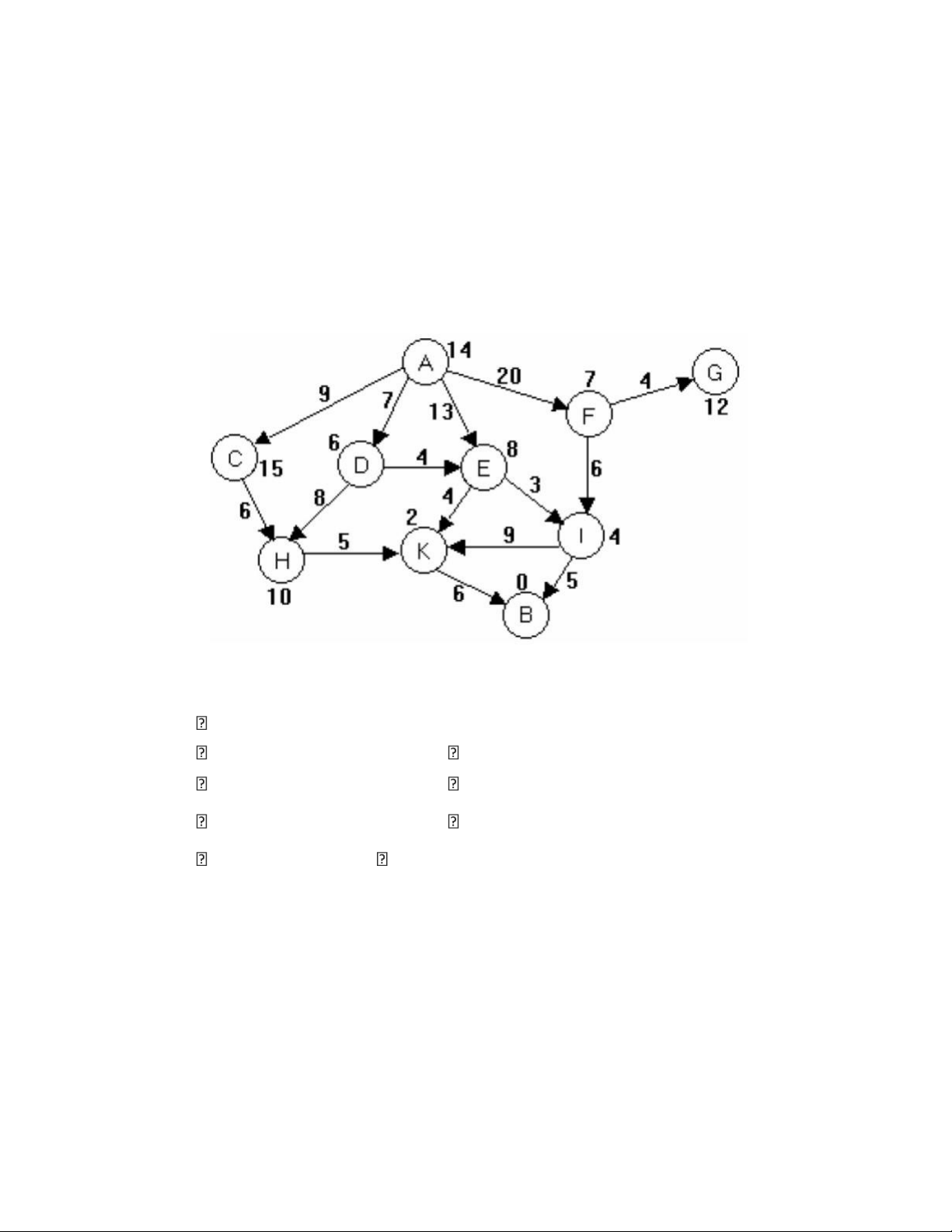
Ví dụ về thuật toán A*: Đầu vào: lOMoARcPSD| 59629529
o Trạng thái ban đầu A o Trạng thái đích B o Các giá
trị ghi trên cạnh là độ dài đường đi o Các số cạnh các đỉnh là giá trị hàm h Yêu cầu:
o Tìm đường đi ngắn nhất từ A đến B bằng A* Thực hiện:
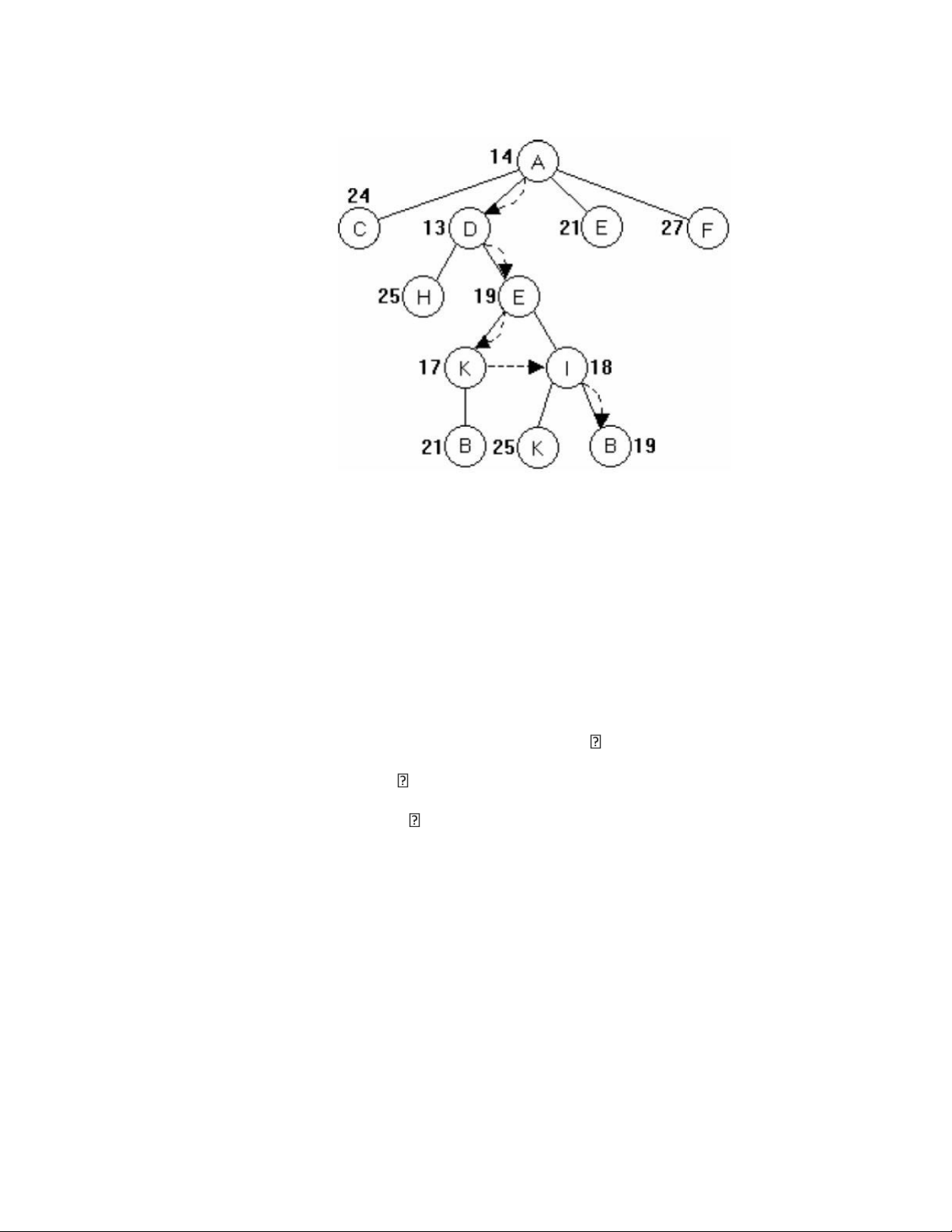
Phát triển đỉnh A sinh ra các đỉnh con C, D, E, F. g(C) = 9, h(C) = 15 → f(C) = 9 + 15 = 24 g(D) = 7, h(D) = 6 → f(D) = 7 + 6 = 13 g(E) = 13, h(E) = 8 → f(E) = 13 + 8 = 21 g(F) = 20, h(F) = 7 → f(F) = 20 + 7 = 27
→ Như vậy, đỉnh D được chọn để phát triển (f(D) = 13)
• Phát triển D, ta nhận được các đỉnh con H và E (mới). Trong đó: lOMoARcPSD| 59629529 ➢
g(H) = g(D) + độ dài cung (D, H) = 7 + 8 = 15 ➢ h(H) = 10 ➢
→f(H) = g(H) + h(H) = 15 + 10 = 25. ➢
g(E) = g(D) + độ dài cung (D, E) = 7 + 4 = 11 ➢ h(E) = 8 ➢
→f(E) = g(E) + h(E) = 11 + 8 = 19. Như vậy đỉnh E sẽ được
dùng để phát triển tiếp Tương tụ sẽ chọn được các đỉnh K, B (đích).
• Với g(B) = 19, h(B) = 0 Đường đi: A → D → E → I → B Cài đặt thuật toán A*: Begin:
Khởi tạo danh sách L chỉ chứa trạng thái ban đầu. Loop do: lOMoARcPSD| 59629529
o if L rỗng then {thông báo thất bại; stop;} o Loại trạng
thái u ở đầu danh sách L; o if u là trạng thái đích then
{thông báo thành công; stop;} o for mỗi trạng thái v kề u do
{ g(v) ← g(u) + k(u, v); f(v)
← g(v) + h(v); Đặt v vào danh sách L;
} o Sắp xếp L theo thứ tự giảm dần của hàm f sao cho trạng
thái có giá trị của hàm f nhỏ nhất ở đầu danh sách; End;
2.3. Đánh giá giải thuật tìm kiếm
Đánh giá giải thuật tìm kiếm dựa trên một số phương pháp dưới đây:
• Thời gian thực thi: Đây là một trong những tiêu chí quan trọng nhất để
đánh giá giải thuật tìm kiếm. Thời gian thực thi đo lường bằng mili giây
hoặc micro giây, và cho biết thời gian mà giải thuật cần để tìm ra giải
pháp hoặc tìm kiếm qua không gian tìm kiếm.
• Độ phức tạp thời gian: Độ phức tạp thời gian của giải thuật là một thước
đo lý thuyết về khả năng tăng tốc của giải thuật theo cỡ của dữ liệu đầu
vào. Giải thuật có độ phức tạp thời gian thấp thường được ưa chuộng.
• Số bước di chuyển hoặc trạng thái được kiểm tra: Đây là bước thể hiện sự
hiệu quả của giải thuật. Giải thuật mà cần ít bước kiểm tra thường được ưa chuộng.
• Độ chính xác: Độ chính xác của giải thuật là khả năng của nó tìm ra giải
pháp đúng. Nếu giải thuật không tìm ra giải pháp đúng thì nó thực sự không hiệu quả.
• Tính nhất quán: Giải thuật tìm kiếm nên cho kết quả tương tự cho cùng
một bài toán khi được chạy nhiều lần. Tính nhất quán là một yếu tố quan
trọng đánh giá hiệu suất của giải thuật. lOMoARcPSD| 59629529
• Tiêu tốn tài nguyên: Tiêu tốn tài nguyên như bộ nhớ, bộ thông mạng,
hoặc năng lượng cũng là một yếu tố quan trọng khi đánh giá giải thuật tìm kiếm.
• Tính thực tế: Một giải thuật tìm kiếm phải thực hiện tính thực tế và thực
hiện tốt trong những tình huống thực tế.
• Thư viện và tài liệu tham khảo: Đánh giá giải thuật cũng liên quan đến
việc sử dụng thư viện và tài liệu tham khảo có sẵn.
Chương 3: Các phương pháp tìm kiếm kinh nghiệm
3.1. Giải thuật tìm kiếm tốt nhất đầu tiên • Ý tưởng:
Tìm kiếm tốt nhất đầu tiên = Tìm kiếm theo chiều rộng + Hàm đánh giá Ý nghĩa:
Các node không được phát triển lần lượt mà được lựa chọn dựa trên hàm
đánh giá tốt nhất, đỉnh này có thể ở mức hiện tại hoặc mức trên. • Cài đặt:
Dùng hàng đợi ưu tiên. Sắp xếp các node trong hàng theo thứ tự giảm dần của hàm đánh giá. lOMoARcPSD| 59629529
3.2. Các biển thể của giải thuật tốt nhất đầu tiên
• Tìm kiếm tham lam tốt nhất đầu tiên (GBFS: Greedy Best-First Search):
Giải thuật này chỉ dựa vào hàm ước tính chi phí còn lại để quyết định
xem trạng thái nào nên mở đầu tiên, mà không quan tâm đến chi phí thực tế đã đi qua.
• A Seach * (A*): Là một biến thể nâng cao của giải thuật tìm kiếm tốt
nhất đầu tiên, sử dụng hàm ước tính chi phí (heuristic function) để ước
tính chi phí còn lại từ trạng thái hiện tại đến mục tiêu. A* sử dụng tổng
của chi phí thực tế đã đi qua và ước tính chi phí còn lại để quyết định
xem trạng thái nào nên mở đầu tiên.
• Dijkstra’s Algorithm: Thường được sử dụng để tìm đường đi ngắn nhất
trong đồ thị với trọng số không âm.
• Tìm kiếm chi phí đồng nhất (Uniform-Cost Search): Luôn chọn trạng thái
có chi phí đến hiện tại thấp nhất.
• Bidirectional Search: Là một biến thể đặc biệt, mà thực hiện tìm kiếm từ
trạng thái ban đầu và mục tiêu đồng thời và tìm cách nối chúng tại một
điểm gặp nhau. Nó có thể giảm đáng kể thời gian tìm kiếm trong một số trường hợp.
Chương 4: Các phương pháp tìm kiếm lời giải
thỏa mãn các ràng buộc
4.1. Các bài toán thỏa mãn các ràng buộc
Tài liệu liên quan:
-

Tài liệu Ôn Tập Chương Trình Dịch - Môn Học CT001
61 31 -

Bình luận về Trí tuệ Nhân tạo (AI): Tương lai hay Hủy diệt | Đại học Điện lực
74 37 -

Tiểu Luận 2 - Ứng Dụng Trí Tuệ Nhân Tạo Trong Phần Mềm | Đại học Điện lực
92 46 -

TTNT - Áp Dụng Thuật Toán Nhánh Cận Trong Bài Toán Xếp Balo | Đại học Điện lực
83 42