Báo cáo, tiểu luận môn nhập môn học máy | Trường đại học Điện Lực
Báo cáo, tiểu luận môn nhập môn học máy | Trường đại học Điện Lực được sưu tầm và soạn thảo dưới dạng file PDF để gửi tới các bạn sinh viên cùng tham khảo, ôn tập đầy đủ kiến thức, chuẩn bị cho các buổi học thật tốt. Mời bạn đọc đón xem!
Môn: Công nghệ thông tin(CNTT350) 109 tài liệu
Trường: Trường Đại học Điện lực 502 tài liệu
Tác giả:






































Preview text:
i
TRƯỜNG ĐẠI HỌC ĐIỆN LỰC
KHOA CÔNG NGHỆ THÔNG TIN
BÁO CÁO CHUYÊN ĐỀ HỌC PHẦN
NHẬP MÔN NHẬP MÔN HỌC MÁY ĐỀ TI:
NHẬN DIỆN CHỮ VIẾT TAY BẰNG NEUTRAL NETWORK
Sinh viên thực hiện : LÊ MINH PHÚC LÊ HỒNG PHONG NGUYỄN ĐỨC THỊNH
Giảng viên hướng dẫn : ĐO NAM ANH Ngành
: CÔNG NGHỆ THÔNG TIN Chuyên ngành
: QUẢN TRỊ AN NINH MẠNG Lớp : D13QTANM Khóa : D13
Hà Nội, tháng 10 năm 2020 ii PHIẾU CHẤM ĐIỂM ST
Họ và tên Nội dung thực hiện Điể Chữ ký T sinh viên m 1 Lê Minh
-Chỉnh sửa chung,phân công công việc . Phúc
-Làm phần:Giới thiệu bài toán nhận (Nhóm
dạng, Mô hình học sâu , Mạng nhiều trưởng) tầng MLP.
-Tìm hiểu code bài toán lớn. 2 Lê Hồng
-Làm phần: Các bước xử lý cho bài toán Phong
nhận dạng hoàn chỉnh,Mô hình và huấn
luyện trong bài toán nhận dạng.
-Tìm hiểu code bài toán lớn 3 Nguyễn
-Làm phần: Các bước xử lý cho bài toán
Đức Thịnh nhận dạng hoàn chỉnh, Giới thiệu tổng quan về neuron.
-Tìm hiểu code bài toán lớn.
Họ và tên giảng viên Chữ ký Ghi chú Giảng viên chấm 1: Giảng viên chấm 2: MỤC LỤC
LỜI CẢM ƠN........................................................................................................5
LỜI MỞ ĐẦU........................................................................................................1
CHƯƠNG 1: GIỚI THIỆU ĐỀ TÀI......................................................................3
1.1.Giới thiệu về bài toán nhận dạng....................................................................3
1.1.1.Các giai đoạn phát triển..............................................................................3
1.2.Các bước xử lý cho bài toán nhận dạng hoàn chỉnh......................................5
1.3.Kết luận chương..............................................................................................8
CHƯƠNG 2: MÔ HÌNH MẠNG NEURON VÀ MÔ HÌNH HỌC SÂU...............11
2.1.Tổng quan về mô hình mạng neuron.............................................................11
2.1.1.Giới thiệu về mạng Neuron.........................................................................11
2.1.1.1.Định nghĩa:.......................................................................................11
2.1.1.2.Lịch sử phát triển mạng neuron.......................................................11
2.1.1.3.So sánh mạng neuron với máy tính truyền thống.............................14
2.1.1.4.Hoạt động của mạng neuron............................................................15
2.1.2.Mô hình và huấn luyện trong bài toán nhận dạng.....................................26
2.1.2.1.Mạng neuron và bài toán phân loại mẫu.........................................26
2.1.2.2.Khả năng học và tổng quát hóa.......................................................27
2.1.2.3.Các phương pháp huấn luyện mạng................................................27
2.2.Mô hình học sâu............................................................................................29
2.2.1.Mạng nhiều tầng truyền thẳng (MLP).......................................................29
2.3.Kết luận chương............................................................................................34
CHƯƠNG 3: CÀI ĐẶT CHƯƠNG TRÌNH THỬ NGHIỆM...............................35
3.1.Dữ liệu thực nghiệm......................................................................................35
3.2.Huấn luyện mô hình và kết quả thực nghiệm với mô hình MLP..................35
3.2.1.Mô hình huấn luyện....................................................................................35
3.2.2.Các bước thực nghiệm...............................................................................36
KẾT LUẬN CHUNG...........................................................................................40
TÀI LIỆU THAM KHẢO.....................................................................................41 LỜI CẢM ƠN LỜI CẢM ƠN
Lời đầu tiên, em xin chân thành gửi lời cảm ơn tới các thầy cô giáo trong
Trường Đại học Điện Lực nói chung và các thầy cô giáo trong Khoa Công nghệ
thông tin nói riêng đã tận tình giảng dạy, truyền đạt cho chúng em những kiến
thức cũng như kinh nghiệm quý báu trong suốt quá trình học.
Đặc biệt, chúng em xin gửi lời cảm ơn đến Thầy Đào Nam Anh - giảng
viên Khoa Công nghệ thông tin - Trường Đại học Điện Lực. Thầy đã tận tình
theo sát giúp đỡ, trực tiếp chỉ bảo, hướng dẫn trong suốt quá trình nghiên cứu và
học tập của chúng em. Trong thời gian học tập với thầy, nhóm chúng em không
những tiếp thu thêm nhiều kiến thức bổ ích mà còn học tập được tinh thần làm
việc, thái độ nghiên cứu khoa học nghiêm túc, hiệu quả. Đây là những điều rất
cần thiết cho chúng em trong quá trình học tập và công tác sau này.
Do thời gian thực hiện có hạn kiến thức còn nhiều hạn chế nên bài làm
của chúng em chắc chắn không tránh khỏi những thiếu sót nhất định. Em rất
mong nhận được ý kiến đóng góp của thầy cô giáo và các bạn để em có thêm
kinh nghiệm và tiếp tục hoàn thiện đồ án của mình.
Chúng em xin chân thành cảm ơn! 1 LỜI MỞ ĐẦU
Nhận dạng chữ viết tay là bài toán khó trong lớp các bài toán nhận
dạng chữ, và vẫn luôn thu hút được nhiều sự quan tâm nghiên cứu của
các nhà khoa học. Đặc biệt là trong vài thập niên gần đây, do sự thúc đẩy
của quá trình tin học hóa trong mọi lĩnh vực, ứng dụng nhận dạng chữ
càng có nhiều ý nghĩa khi được sử dụng cho các bài toán trong thực tế.
Cũng như nhiều bài toán nhận dạng tiếng nói, hình ảnh… khác, thì độ
chính xác của hệ thống vẫn tiếp tục cần phải cải thiện nhằm vươn tới khả
năng nhận dạng giống như con người.
Tuy nhiên, với bài toán nhận dạng chữ viết tay thì vấn đề trở nên
phức tạp hơn nhiều so với bài toán nhận dạng chữ in thông thường ở những vấn đề sau đây:
Với chữ viết tay thì không thể có các khái niệm font chữ, kích cỡ
chữ. Các kí tự trong một văn bản chữ viết tay thường có kích thước khác
nhau. Thậm chí, cùng một kí tự trong một văn bản do một người viết
nhiều khi cũng có độ rộng, hẹp, cao, thấp khác nhau, ...
Với những người viết khác nhau chữ viết có độ nghiêng khác nhau
(chữ nghiêng nhiều/ít, chữ nghiêng trái/phải...).
Các kí tự của một từ trên văn bản chữ viết tay đối với hầu hết
người viết thường bị dính nhau vì vậy rất khó xác định được phân cách giữa chúng.
Các văn bản chữ viết tay còn có thể có trường hợp dính dòng (dòng
dưới bị dính hoặc chồng lên dòng trên).
Trong những năm gần đây, mô hình mạng Neuron theo hướng học
sâu đã cho thấy những kết quả tốt trong nhiều bài toán khác nhau, trong đó có nhận dạng chữ.
Xuất phát từ yêu cầu thực tế, đang rất cần có nhưng nghiên cứu về
vấn đề này. Chính vì vậy học viên đã chọn đề tài “Nghiên cứu mô hình
học sâu (deep-learning) và ứng dụng trong nhận dạng chữ viết tay” làm
luận văn tốt nghiệp với mong muốn phần nào áp dụng vào bài toán thực tế.
Bài toán đã đặt ra phải giải quyết được những yêu cầu sau:
Nhận dạng được các ký tự từ ảnh đầu vào
Tiến hành nhận dạng kí tự đơn lẻ sử dụng mạng Neuron nhân
tạo theo phương pháp học sâu Restricted Boltzmann machine (RBM).
Đánh giá kết quả và so sánh với mô hình mạng neuron
Với những yêu cầu đã đặt ra ở trên, cấu trúc của luận văn sẽ bao
gồm những nội dung sau đây:
Chương 1: Tổng quan về đề tài
Giới thiệu về bài toán nhận dạng chữ viết tay, tình hình nghiên cứu
trong và ngoài nước, quy trình chung để giải quyết bài toán và các
phương pháp điển hình trong việc huấn luyện nhận dạng, phạm vi của đề tài.
Chương 2: Mô hình mạng neuron và mô hình học sâu
Trình bày về cơ sở lý thuyết của mô hình neuron và huấn luyện
trong bài toán nhận dạng chữ viết tay. Cơ sở lý thuyết của mô hình học
sâu: Hopfield network, Boltzmann Machines, Restricted Boltzmann
Machines và thuật toán lan truyền ngược.
Chương 3: Kết quả thực nghiệm và đánh giá
Trình bày các kết quả thực nghiệm của hai mô hình mạng neuron
và mô hình học sâu, đưa ra kết quả đánh giá nhận dạng chữ viết tay giữa
mô hình mạng neuron và mô hình học sâu.
CHƯƠNG 1: GIỚI THIỆU ĐỀ TI
1.1.Giới thiệu về bài toán nhận dạng
Nhận dạng chữ viết tay vẫn còn là vấn đề thách thức lớn đối với
các nhà nghiên cứu. Bài toàn này chưa thể giải quyết trọn vẹn được vì
nó hoàn toàn phụ thuộc vào người viết và sự biến đổi quá đa dạng trong
cách viết và trạng thái sức khỏe, tinh thần của từng người viết.
Trong bài viết này, mình sẽ hướng dẫn các bạn xây dựng mô hình
nhận diện chữ viết trên tập dữ liệu MNIST bằng google colab.
MNIST được giới thiệu năm 1998 bởi Yann Lecun và cộng sự
nhằm đánh giá các mô hình phân lớp. MNIST là tập dữ liệu chữ viết từ 0 đến 9.
Trong đó, mỗi hình là một ảnh đen trắng chứa một số được viết tay
có kích thước là 28x28. Bộ dataset vô cùng đồ sộ với khoảng 60k data
training và 10k data test và được sử dụng phổ biến trong các thuật toán nhận dạng ảnh.
1.1.1. Các giai đoạn phát triển
Giai đoạn 1 (1900 - 1980)
Nhận dạng chữ được biết đến từ năm 1900, khi nhà khoa học người
Nga Alan Turing (1912-1954) phát triển một phương tiện trợ giúp cho những người mù.
Các sản phẩm nhận dạng chữ thương mại có từ những năm1950,
khi máy tính lần đầu tiên được giới thiệu tính năng mới về nhập và lưu
trữ dữ liệu hai chiều bằng cây bút viết trên một tấm bảng cảm ứng. Công
nghệ mới này cho phép các nhà nghiên cứu làm việc trên các bài toán
nhận dạng chữ viết tay online.
Mô hình nhận dạng chữ viết được đề xuất từ năm 1951 do phát
minh của M. Sheppard được gọi là GISMO, một robot đọc-viết.
Năm 1954, máy nhận dạng chữ đầu tiên đã được phát triển bởi J.
Rainbow dùng để đọc chữ in hoa nhưng rất chậm.
Năm 1967, Công ty IBM đã thương mại hóa hệ thống nhận dạng chữ.
Giai đoạn 2 (1980 - 1990)
Với sự phát triển của các thiết bị phần cứng máy tính và các thiết bị
thu nhận dữ liệu, các phương pháp luận nhận dạng đã được phát triển
trong giai đoạn trước đã có được môi trường lý tưởng để triển khai các
ứng dụng nhận dạng chữ.
Các hướng tiếp cận theo cấu trúc và đối sánh được áp dụng trong
nhiều hệ thống nhận dạng chữ.
Trong giai đoạn này, các hướng nghiên cứu chỉ tập trung vào các
kỹ thuật nhận dạng hình dáng chứ chưa áp dụng cho thông tin ngữ nghĩa.
Điều này dẫn đến sự hạn chế về hiệu suất nhận dạng, không hiệu quả
trong nhiều ứng dụng thực tế.
Giai đoạn 3 (1990 - nay)
Các hệ thống nhận dạng thời gian thực được chú trọng trong giai đoạn này.
Các kỹ thuật nhận dạng kết hợp với các phương pháp luận trong lĩnh
vực học máy (Machine Learning) được áp dụng rất hiệu quả.
Một số công cụ học máy hiệu quả như mạng Neuron, mô hình
Markov ẩn, SVM (Support Vector Machines) và xử lý ngôn ngữ tự nhiên...
1.2.Các bước xử lý cho bài toán nhận dạng hoàn chỉnh
Nhận dạng chữ viết tay thường bao gồm năm giai đoạn: tiền xử lý
(preprocessing), tách chữ (segmentation), trích chọn đặc trưng
(representation), huấn luyện và nhận dạng (training and recognition), hậu xử lý (postprocessing).
Hình 1- 1: Các bước trong nhận dạng chữ viết tay
Tiền xử lý (preprocessing): giảm nhiễu cho các lỗi trong
quá trình quét ảnh, hoạt động viết của con người, chuẩn hóa
dữ liệu và nén dữ liệu.
Tách chữ (segmentation): chia nhỏ văn bản thành những
thành phần nhỏ hơn, tách các từ trong câu hay các kí tự trong từ.
Trích trọn đặc trưng (representation): giai đoạn đóng vai
trò quan trọng nhất trong nhận dạng chữ viết tay. Để tránh
những phức tạp của chữ viết tay cũng như tăng cường độ
chính xác, ta cần phải biểu diễn thông tin chữ viết dưới
những dạng đặc biệt hơn và cô đọng hơn, rút trích các đặc
điểm riêng nhằm phân biệt các ký tự khác nhau. Trong luận
văn này, tôi nghiên cứu và tìm hiểu về mô hình học máy theo
chiều sâu, trong mô hình này thì khi huấn luyện và sử dụng
dữ liệu chúng ta không cần sử dụng đặc trưng của ảnh đầu
vào nên có thể bỏ qua bước trích rút đặc trưng.
Huấn luyện và nhận dạng (training and recognition):
phương pháp điển hình so trùng mẫu, dùng thống kê, mạng
neuron, mô hình markov ẩn, trí tuệ nhân tạo hay dùng
phương pháp kết hợp các phương pháp trên.Trong luận văn
này, tôi sử dụng mô hình học máy theo chiều sâu (deep
learning) để huấn luyện và nhận dạng, nội dung này sẽ được
trình bày trong các chương sau của luận văn.
Hậu xử lý (postprocessing): sử dụng các thông tin về ngữ
cảnh để giúp tăng cường độ chính xác, dùng từ điển dữ liệu.
Ban đầu các văn bản chữ viết tay được scan và đưa vào hệ thống nhận
dạng, với quá trình tiền xử lý thì ảnh sẽ được một ảnh mà do hệ thống
yêu cầu để huấn luyện và nhận dạng
Trong mô hình học máy theo chiều sâu, ảnh được sử dụng để huấn luyện
và nhận dạng là ảnh đa mức xám (các pixel được biểu diễn bởi các giá trị
từ 0 đến 255). Tại quá trình tiền xử lý thì ảnh cũng đã được xử lý lọa bỏ
nhiễu, các giá trị không cần thiết trong ảnh đầu vào.
Tại bước tách chữ thì với ảnh đã được tiền xử lý, khi đi qua bước
này sẽ được thực hiện tách dòng, tách chữ, tách kí tự để thực hiện nhận
dạng, tùy theo quy định của một hệ thống khi huấn luyện. Khi đã được
tách rời các kí tự thì việc tiếp theo ảnh để nhận dạng sẽ được lưu dưới
dạng ma trận điểm, với tùy từng vị trí của điểm ảnh mà giá trị có thể khác
nhau (từ 0 đến 255), trong mô hình Deep Learning thì ma trận điểm ảnh
sẽ được quy về dạng chuẩn là 28x28.
Sau khi qua các bước xử lý ở trên thì ảnh chính thức được đưa vào
huấn luyện và nhận dạng, trong quá trình huấn luyện và nhận dạng sẽ sử
dụng các mô hình và thuật toán cần thiết để thực hiện tính toán và xử lý,
những thuật toán và quá trình xử lý sẽ được trìn bày chi tiết trong các phần sau của luận văn.
Cuối cùng khi các ảnh đầu vào đã được đưa vào nhận dạng và cho
ra kết quả thì bước quan trọng không kém là quá trình hậu xử lý với các
kết quả ở trên, và trả lại kết quả cho người dử dụng.
1.3.Kết luận chương
Luận văn “Nghiên cứu mô hình học sâu (deep-learning) và ứng
dụng trong nhận dạng chữ viết tay” được thực hiện với mục đích giải
quyết một lớp con các bài toán nhận dạng chữ viết tay mà cụ thể nhận
dạng các kí tự đơn lẻ là các chữ từ thư viện MNIST.
Từ đó sẽ tạo cơ sở tiếp theo để có thể xây dựng tiếp mô hình nhận
dạng các chữ cái trong tiếng Việt, đây là bước cần thiết trong bài toán nhận dạng 10
chữ viết tiếng Việt các từ tiếng Việt đơn lẻ, và sẽ tiến tới xây dựng một hệ
thống nhận dạng văn bản viết tay tiếng Việt hoàn chỉnh.
Báo cáo này sẽ tập trung vào nghiên cứu về cơ sở lý thuyết mô
hình Deep Learning, các thuật toán được sử dụng, thực hiện huấn luyện
bằng mô hình Deep Learning, từ đó cài đặt chương trình mô phỏng trên ngôn ngữ Matlab, PHP, C#...
CHƯƠNG 2: MÔ HÌNH MẠNG NEURON V MÔ HÌNH HỌC SÂU
2.1. Tổng quan về mô hình mạng neuron
2.1.1. Giới thiệu về mạng Neuron
2.1.1.1. Định nghĩa:
Mạng neuron nhân tạo, Artificial Neural Network (ANN) gọi tắt là
mạng neuron, neural network, là một mô hình xử lý thông tin phỏng theo
cách thức xử lý thông tin của các hệ neuron sinh học. Nó được tạo lên từ
một số lượng lớn các phần tử (gọi là phần tử xử lý hay neuron) kết nối
với nhau thông qua các liên kết (gọi là trọng số liên kết) làm việc như
một thể thống nhất để giải quyết một vấn đề cụ thể nào đó.
Một mạng neuron nhân tạo được cấu hình cho một ứng dụng cụ thể
(nhận dạng mẫu, phân loại dữ liệu, ...) thông qua một quá trình học từ tập
các mẫu huấn luyện. Về bản chất học chính là quá trình hiệu chỉnh trọng
số liên kết giữa các neuron.
2.1.1.2. Lịch sử phát triển mạng neuron
Các nghiên cứu về bộ não con người đã được tiến hành từ hàng
nghìn năm nay. Cùng với sự phát triển của khoa học kĩ thuật đặc biệt là
những tiến bộ trong ngành điện tử hiện đại, việc con người bắt đầu
nghiên cứu các neuron nhân tạo là hoàn toàn tự nhiên. Sự kiện đầu tiên
đánh dấu sự ra đời của mạng neuron nhân tạo diễn ra vào năm 1943 khi
nhà thần kinh học Warren McCulloch và nhà toán học Walter Pitts viết
bài báo mô tả cách thức các neuron hoạt động. Họ cũng đã tiến hành xây
dựng một mạng neuron đơn giản bằng các mạch điện. Các neuron của họ
được xem như là các thiết bị nhị phân với ngưỡng cố định. Kết quả của
các mô hình này là các hàm logic đơn giản chẳng hạn như “ a OR b” hay “a AND b”.
Tiếp bước các nghiên cứu này, năm 1949 Donald Hebb cho xuất
bản cuốn sách Organization of Behavior. Cuốn sách đã chỉ ra rằng các
neuron nhân tạo sẽ trở lên hiệu quả hơn sau mỗi lần chúng được sử dụng.
Những tiến bộ của máy tính đầu những năm 1950 giúp cho việc mô
hình hóa các nguyên lý của những lý thuyết liên quan tới cách thức con
người suy nghĩ đã trở thành hiện thực. Nathanial Rochester sau nhiều
năm làm việc tại các phòng thí nghiệm nghiên cứu của IBM đã có những
nỗ lực đầu tiên để mô phỏng một mạng neuron. Trong thời kì này tính
toán truyền thống đã đạt được những thành công rực rỡ trong khi đó
những nghiên cứu về neuron còn ở giai đoạn sơ khai. Mặc dù vậy
những người ủng hộ triết lý “thinking machines” (các máy biết suy nghĩ)
vẫn tiếp tục bảo vệ cho lập trường của mình.
Năm 1956 dự án Dartmouth nghiên cứu về trí tuệ nhân tạo
(Artificial Intelligence) đã mở ra thời kỳ phát triển mới cả trong lĩnh vực
trí tuệ nhân tạo lẫn mạng neuron. Tác động tích cực của nó là thúc đẩy
hơn nữa sự quan tâm của các nhà khoa học về trí tuệ nhân tạo và quá
trình xử lý ở mức đơn giản của mạng neuron trong bộ não con người.
Những năm tiếp theo của dự án Dartmouth, John von Neumann đã
đề xuất việc mô phỏng các neuron đơn giản bằng cách sử dụng rơle điện
áp hoặc đèn chân không. Nhà sinh học chuyên nghiên cứu về neuron
Frank Rosenblatt cũng bắt đầu nghiên cứu về Perceptron. Sau thời gian
nghiên cứu này Perceptron đã được cài đặt trong phần cứng máy tính và
được xem như là mạng neuron lâu đời nhất còn được sử dụng đến ngày
nay. Perceptron một tầng rất hữu ích trong việc phân loại một tập các đầu
vào có giá trị liên tục vào một trong hai lớp. Perceptron tính tổng có
trọng số các đầu vào, rồi trừ tổng này cho một ngưỡng và cho ra một
trong hai giá trị mong muốn có thể. Tuy nhiên Perceptron còn rất nhiều
hạn chế, những hạn chế này đã được chỉ
ra trong cuốn sách về Perceptron của Marvin Minsky và Seymour Papert viết năm 1969.
Năm 1959, Bernard Widrow và Marcian Hoff thuộc trường đại học
Stanford đã xây dựng mô hình ADALINE (ADAptive LINear Elements)
và MADALINE. (Multiple ADAptive LINear Elements). Các mô hình
này sử dụng quy tắc học Least-Mean-Squares (LMS: Tối thiểu bình
phương trung bình). MADALINE là mạng neuron đầu tiên được áp dụng
để giải quyết một bài toán thực tế. Nó là một bộ lọc thích ứng có khả
năng loại bỏ tín hiệu dội lại trên đường dây điện thoại. Ngày nay mạng
neuron này vẫn được sử dụng trong các ứng dụng thương mại.
Năm 1974 Paul Werbos đã phát triển và ứng dụng phương pháp
học lan truyền ngược (back-propagation). Tuy nhiên phải mất một vài
năm thì phương pháp này mới trở lên phổ biến. Các mạng lan truyền
ngược được biết đến nhiều nhất và được áp dụng rộng dãi nhất nhất cho đến ngày nay.
Thật không may, những thành công ban đầu này khiến cho con
người nghĩ quá lên về khả năng của các mạng neuron. Chính sự cường
điệu quá mức đã có những tác động không tốt đến sự phát triển của khoa
học và kỹ thuật thời bấy giờ khi người ta lo sợ rằng đã đến lúc máy móc
có thể làm mọi việc của con người. Những lo lắng này khiến người ta bắt
đầu phản đối các nghiên cứu về mạng neuron. Thời kì tạm lắng này kéo dài đến năm 1981.
Năm 1985, viện vật lý Hoa Kỳ bắt đầu tổ chức các cuộc họp hàng
năm về mạng neuron ứng dụng trong tin học (Neural Networks for Computing).
Năm 1987, hội thảo quốc tế đầu tiên về mạng neuron của Viện các
kỹ sư điện và điện tử IEEE (Institute of Electrical and Electronic
Engineer) đã thu hút hơn 1800 người tham gia.
Ngày nay, không chỉ dừng lại ở mức nghiên cứu lý thuyết, các
nghiên cứu ứng dụng mạng neuron để giải quyết các bài toán thực tế
được diễn ra ở khắp mọi nơi. Các ứng dụng mạng neuron ra đời ngày
càng nhiều và ngày càng hoàn thiện hơn. Điển hình là các ứng dụng: xử
lý ngôn ngữ (Language Processing), nhận dạng kí tự (Character
Recognition), nhận dạng tiếng nói (Voice Recognition), nhận dạng mẫu
(Pattern Recognition), xử lý tín hiệu (Signal Processing), Lọc dữ liệu (Data Filtering),…..
2.1.1.3. So sánh mạng neuron với máy tính truyền thống
Các mạng neuron có cách tiếp cận khác trong giải quyết vấn đề so
với máy tính truyền thống. Các máy tính truyền thống sử dụng cách tiếp
cận theo hướng giải thuật, tức là máy tính thực hiện một tập các chỉ lệnh
để giải quyết một vấn đề. Vấn đề được giải quyết phải được biết và phát
biểu dưới dạng một tập chỉ lệnh không nhập nhằng. Những chỉ lệnh này
sau đó phải được chuyển sang một chương trình ngôn ngữ bậc cao và
chuyển sang mã máy để máy tính có thể hiểu được.
Trừ khi các bước cụ thể mà máy tính cần tuân theo được chỉ ra rõ
ràng, máy tính sẽ không làm được gì cả. Điều đó giới hạn khả năng của các máy
tính truyền thống ở phạm vi giải quyết các vấn đề mà chúng ta đã hiểu và
biết chính xác cách thực hiện. Các máy tính sẽ trở lên hữu ích hơn nếu
chúng có thể thực hiện được những việc mà bản thân con người không
biết chính xác là phải làm như thế nào.
Các mạng neuron xử lý thông tin theo cách thức giống như bộ não
con người. Mạng được tạo nên từ một số lượng lớn các phần tử xử lý
được kết nối với nhau làm việc song song để giải quyết một vấn đề cụ
thể. Các mạng neuron học theo mô hình, chúng không thể được lập trình
để thực hiện một nhiệm vụ cụ thể. Các mẫu phải được chọn lựa cẩn thận
nếu không sẽ rất mất thời gian, thậm chí mạng sẽ hoạt động không đúng.
Điều hạn chế này là bởi vì mạng tự tìm ra cách giải quyết vấn đề, thao tác
của nó không thể dự đoán được.
Các mạng neuron và các máy tính truyền thống không cạnh tranh
nhau mà bổ sung cho nhau. Có những nhiệm vụ thích hợp hơn với máy
tính truyền thống, ngược lại có những nhiệm vụ lại thích hợp hơn với các
mạng neuron. Thậm chí rất nhiều nhiệm vụ đòi hỏi các hệ thống sử dụng
tổ hợp cả hai cách tiếp cận để thực hiện được hiệu quả cao nhất. (thông
thường một máy tính truyền thống được sử dụng để giám sát mạng neuron
2.1.1.4. Hoạt động của mạng neuron
Một mạng neuron có thể có nhiều lớp/tầng mạng và ít nhất phải có
một lớp đó là lớp đầu ra (lớp đầu vào thường không được tính là một lớp
mạng). Mỗi lớp có thẻ có một hoặc nhiều neuron. Cấu trúc tổng quát của
mạng neuron được thể hiện trong hình 2-5 dưới đây: 20
Hinh 2- 3: Cấu trúc chung của mạng neuron
Mạng neuron với cấu trúc như hình vẽ trên có thể mô tả như sau:
Đầu vào của mạng vector có kích p : (x1, x2 ,...., x thước p ) và đầu ra
là a1,a2 ,.,aq có kích thước q. Trong vài toán phân vector loại
mẫu, kích thước đầu vào của mạng là kích thước của mẫu
đầu vào, kích thước đầu ra của mạng chính là số lớp cần
phân loại. Ví dụ, trong bài toán nhận dạng chữ số, kích
thước đầu ra của mạng là 10 tương ứng với 10 chữ số 0,…,9,
trong vài toán nhận dạng chữ cái tiếng Anh viết thường, kích
thức đầu ra của mạng là 26 tương ứng với 26 chữ cái a…z.
Lớp ẩn đầu tiên là H1 , sau đó đến lớp ẩn thứ H2 , tiếp lớp hai
tục như vậy cho đến lớp ẩn cuối cùng rồi lớp đầu ra O.
Các neuron trong các lớp có cấu trúc như trên hình 2-4, liên
kết giữa các neuron giữa các lớp có thể là liên kết đầy đủ
(mỗi neuron thuộc lớp sau liên kết với tất cả các neuron ở lớp
trước nó) hoặc liên kết chọn lọc (mỗi neuron thuộc lớp sau
liên kết với tất cả neuron ở lớp trước đó).
Đầu ra của lớp trước chính là đầu vào của lớp ngay sau nó.
tiên vector đầu vào được lan truyền qua lớp H1 . Tại lớp này, mỗi neuron
nhận vector đầu vào rồi xử lý (tính tổng có trọng số của các đầu vào rồi cho
qua hàm truyền) và cho ra kết quả tương ứng. Đầu ra của H lớp 1 chính là đầu
vào của lớp H2 , do đó sau khi lớp H1 cho kết quả ở đầu ra của mình thì lớp
H2 nhận được đầu vào và tiếp tục quá trình xử lý. Cứ như vậy cho tới khi thu
được đầu ra sau lớp O, đầu ra này chính là đầu ra cuối cùng của mạng. Mô hình mạng neuron
Mặc dù mỗi neuron đơn lẻ có thể thực hiện những chức năng xử lý
thông tin nhất định, sức mạnh của tính toán neuron chủ yếu có được nhờ
sự kết hợp các neuron trong một kiến trúc thống nhất. Một mạng neuron
là một mô hình tính toán được xác định qua các tham số: kiểu neuron
(như là các nút nếu ta coi cả mạng neuron là một đồ thị), kiến trúc kết nối
(sự tổ chức kết nối giữa các neuron) và thuật toán học (thuật toán dùng để học cho mạng).
Về bản chất một mạng neuron có chức năng như là một hàm ánh xạ
F: X → Y, trong đó X là không gian trạng thái đầu vào (input state
space) và Y là không gian trạng thái đầu ra (output state space) của
mạng. Các mạng chỉ đơn giản là làm nhiệm vụ ánh xạ các vector đầu vào x ∈ X
sang các vector đầu ra y ∈ Y
thông qua “bộ lọc” (filter) các
trọng số. Tức là y = F(x) = s(W, x), trong đó W là ma trận trọng số liên
kết. Hoạt động của mạng thường là các tính toán số thực trên các ma trận.
Các kiểu mô hình mạng neuron
Cách thức kết nối các neuron trong mạng xác định kiến trúc
(topology) của mạng. Các neuron trong mạng có thể kết nối đầy đủ (fully
connected) tức là mỗi neuron đều được kết nối với tất cả các neuron
khác, hoặc kết nối cục bộ (partially connected) chẳng hạn chỉ kết nối
giữa các neuron trong các tầng khác nhau. Người ta chia ra hai loại kiến trúc mạng chính:
Tự kết hợp (autoassociative): là mạng có các neuron đầu vào
cũng là các neuron đầu ra. Mạng Hopfield là một kiểu mạng tự kết hợp.
Hinh 2- 4: Mạng tự kết hợp
Kết hợp khác kiểu (heteroassociative): là mạng có tập neuron đầu
vào và đầu ra riêng biệt. Perceptron, các mạng Perceptron nhiều tầng
(MLP: MultiLayer Perceptron), mạng Kohonen, … thuộc loại này.
Hinh 2- 5: Mạng kết hợp khác kiểu
Ngoài ra tùy thuộc vào mạng có các kết nối ngược (feedback
connections) từ các neuron đầu ra tới các neuron đầu vào hay không,
người ta chia ra làm 2 loại kiến trúc mạng.
Kiến trúc truyền thẳng (feedforward architechture): là kiểu kiến
trúc mạng không có các kết nối ngược trở lại từ các neuron đầu ra về các neuron
đầu vào; mạng không lưu lại các giá trị output trước và các trạng thái
kích hoạt của neuron. Các mạng neuron truyền thẳng cho phép tín hiệu
di chuyển theo một đường duy nhất; từ đầu vào tới đầu ra, đầu ra của một
tầng bất kì sẽ không ảnh hưởng tới tầng đó. Các mạng kiểu Perceptron là mạng truyền thẳng.
Hinh 2- 6: Mạng truyền thẳng
Kiến trúc phản hồi (Feedback architecture): là kiểu kiến trúc
mạng có các kết nối từ neuron đầu ra tới neuron đầu vào. Mạng lưu lại
các trạng thái trước đó, và trạng thái tiếp theo không chỉ phụ thuộc vào
các tín hiệu đầu vào mà còn phụ thuộc vào các trạng thái trước đó của
mạng. Mạng Hopfield thuộc loại này. Hinh 2- 7: Mạng phản hồi Perceptron
Perceptron là mạng neuron đơn giản nhất, nó chỉ gồm một neuron,
nhận đầu vào là vector có các thành phần là các số thực và đầu ra là một
trong hai giá trị +1 hoặc -1. Hinh 2- 8: Perceptron
Đầu ra của mạng được xác định như sau: mạng lấy tổng có trọng số
các thành phần của vector đầu vào, kết quả này cùng ngưỡng b được đưa
vào hàm truyền (Perceptron dùng hàm Hard-limit làm hàm truyền) và kết
quả của hàm truyền sẽ là đầu ra của mạng.
Hoạt động của Perceptron có thể được mô tả bởi cặp công thức sau:
y f (u b)và wi xi u n 11
Và y f u b
Hardlimit u b; y nhận giá trị +1 nếu u b 0 ,
ngược lại y nhận giá trị -1.
Perceptron cho phép phân loại chính xác trong trường hợp dữ liệu
có thể phân chia tuyến tính (các mẫu nằm trên hai mặt đối diện của một
siêu phẳng). Nó cũng phân loại đúng đầu ra các hàm AND, OR và các
hàm có dạng đúng khi n trong m đầu vào của nó đúng (n ≤ m). Nó
không thể phân loại được đầu ra của hàm XOR.
Mô hình mà chúng ta hay gặp nhất là mạng neuron nhiều tầng
truyền thẳng MLP (Multi Layer Perceptrons). Mạng này có cấu trúc như
mô tả trên hình 2-6 chỉ cụ thể hơn ở chỗ: liên kết giữa các neuron ở các
lớp thường là liên kết đầy đủ. Nhiều thực nghiệm đã chứng minh rằng:
mạng MLP (chỉ cần hai lớp neuron) với thuật toán huấn luyện và thuật
toán lan truyền ngược sai số và hàm truyền sigmoid là một trong những
mô hình có thể sử dụng để giải quyết các bài toán nhận dạng chữ viết.
2.1.2. Mô hình và huấn luyện trong bài toán nhận dạng
2.1.2.1. Mạng neuron và bài toán phân loại mẫu
Một cách tổng quát, có thể nói nhiệm vụ của các hệ nhận dạng
trong các bài toán nhận dạng chính là phân loại mẫu. Có nghĩa là từ một
mẫu vào ban đầu, hệ nhận dạng cần chỉ ra nó thuộc về lớp phân loại nào.
Ví dụ, trong nhận dạng chữ viết tay, tất cả các kiểu viết khác nhau của
chữ “a” đều được quy về một lớp, lớp chữ “a” và hệ nhận dạng cần được
huấn luyện sao cho khi gặp một mẫu bất kỳ của chữ “a” nó phải chỉ ra
được đầu vào này thuộc về lớp chữ“a”. Trong hệ nhận dạng chữ cái, số
lớp phân loại là 26 lớp, tương ứng với 26 chữ cái từ “a” đến “z”.
Bên cạnh bài toán nhận dạng chữ viết, nhiều bài toán nhạn dạng
khác cũng có thể coi là bài toán phân loại mẫu như nhận dạng dấu vân
tay dùng làm mã khóa trong các hệ an ninh, nhận dạng khuôn mặt hay tiếng nói…
Câu hỏi đặt ra đối với chúng ta là sử dụng mô hình nào cho các hệ
nhận dạng này để nó không chỉ phân loại được những mẫu đã học mà còn
có thể tổng quát hóa để phân loại những mẫu chưa được học? Mang
neuron là một mô hình có thể áp dụng cho mọi bài toán nhận dạng mà bài toán đó có thể quy
về bài toán phân loại mẫu. Chính khả năng học và tổng quát hóa rất linh
hoạt của mạng neuron đã giúp nó thực hiện tốt nhiệm vụ này.
2.1.2.2. Khả năng học và tổng quát hóa
Có thể nói đặc trưng cơ bản nhất của mạng neuron là khả năng học và tổng quát hóa.
Học: là khả năng mà mạng neuron có thể phân loại chính xác
những mẫu đã được huấn luyện.
Tổng quát hóa: là khả năng mạng có thể nhận biết được những
mẫu chưa từng huấn luyện. Ví dụ, chúng ta huấn luyện mạng neuron
nhận dạng chữ viết tay trên tập mẫu do 50 người viết, và khi người khác
viết mạng vẫn nhận dạng được, đây là khả năng tổng quát hóa của mạng
neuron. Chính khả năng này tạo nên sức mạnh của mạng.
Các khả năng này có được là do việc hiệu chỉnh và cập nhật bộ
tham số mạng trong suốt quá trình huấn luyện.
2.1.2.3. Các phương pháp huấn luyện mạng
Huấn luyện mạng: là quá trình đào tạo mạng sao cho khả năng
học và tổng quát hóa mà nó đạt được là cao nhất. Bản chất của việc làm
này là hiệu chỉnh trong số liên kết giữa các neuron và ngưỡng tại các
neuron trong mạng để từ các tín hiệu vào ban đầu, sau quá trình tính toán
mạng đưa ra kết quả là giá trị mà chúng ta mong muốn. Hai kiểu huấn
luyện phổ biến là học có giám sát (supervised learning) và học không có
giám sát (unsupervised learning) với mô tả chi tiết hơn như sau:
Học có giám sát: là phương pháp học để thực hiện một công việc
nào đó dưới sự giám sát của một “thầy giáo”. Để dễ hình dung, có thể mô
tả phương pháp này như sau: chúng ta sẽ cho mạng xem một số mẫu đầu
vào và đầu ra tương ứng. Dưới sự chỉ đạo của một thuật toán huấn luyện, mạng có
nhiệm vụ tính toán, thay đổi các tham số sao cho đầu ra thực tế của
mạng gần với đầu ra mong muốn nhất.
Với phương pháp này, thuật toán huấn luyện mạng được thực hiện với
tập mẫu học có D{x , } dạng
i ti trong xi (vector p chiều trong R) là đó vector
đầu vào của mạng t và
i(vector q chiều trong R) là vector đầu ra mong muốn tương ứng x với
i . Nhiệm vụ của thuật toán là phải thiết lập được một cách
tính toán nào đó để cập nhật tham số của mạng sao cho với một đầu vào
cho trước thì sai số giữa đầu ra thực tế của mạng và đầu ra mong muốn là nhỏ nhất.
Một thuật toán điển hình trong phương pháp học có giám sát là:
thuật toán LMS (Least Mean Square error), thuật toán lan truyền ngược
sai số (Back Propagation),….
Với bài toán nhận dạng, bản chất của phương pháp học có giám sát
là học để phân lớp đầu vào trên tập mẫu huấn luyện, trong đó số lớp cần
phân loại là biết trước. Nhiệm vụ của việc học là xác định (thay đổi và
cập nhật) các tham số mạng để mỗi đầu vào sẽ được phân vào đúng lớp chứa nó.
Học không có giám sát: là phương pháp học để thực hiện một
công việc nào đó mà không cần bất kỳ sự giám sát nào.
Với cách tiếp cận này, thuật toán huấn luyện mạng được thực hiện với tạo mẫu học có D x dạng
i (vector p chiều trong R) là vector đầu {x } i với
vào của mạng. Nhiệm vụ của thuật toán là phải phân chia tập dữ liệu D
thành các nhóm con, mỗi nhóm chứa một tập vector đầu vào có các đặc
trưng giống nhau. Việc phân nhóm này cho phép tạo ra các lớp phân loại
một cách tự động và số lớp là không biết trước.
Trong thực tế, phương pháp học có giám sát được ứng dụng nhiều
hơn phương pháp học không có giám sát. Kiểu huấn luyện không có giám sát
thường không thích hợp với bài toán phân loại mẫu vì rất khó đảm bảo
chắc chắn rằng có sự tương ứng giữa các lớp được tạo ra mộ cách tự
động với các lớp dữ liệu thực sự. Phương pháp này tỏ ra thích hợp hơn
với các bài toán mô hình hóa dữ liệu.
2.2. Mô hình học sâu
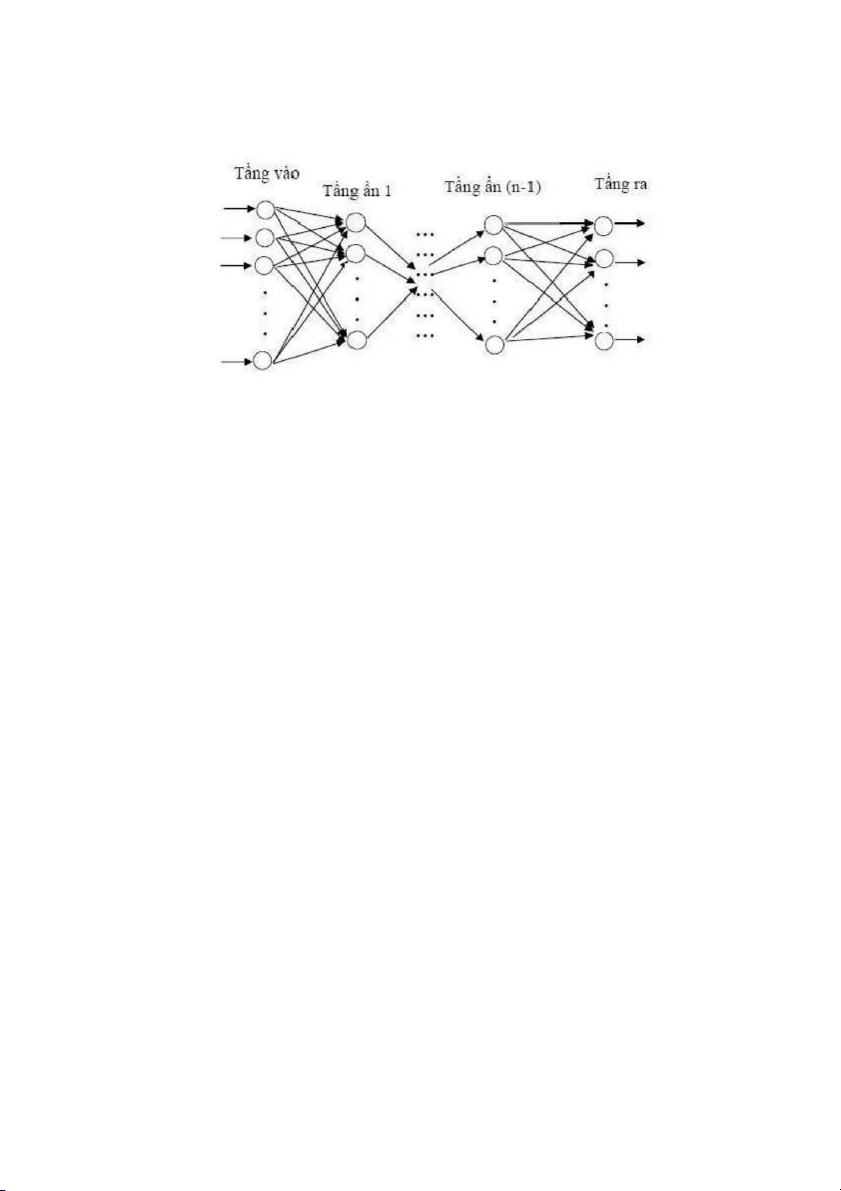
2.2.1. Mạng nhiều tầng truyền thẳng (MLP)
Mô hình mạng neuron được sử dụng rộng rãi nhất là mô hình mạng
nhiều tầng truyền thẳng (MLP: Multi Layer Perceptron). Một mạng MLP
tổng quát là mạng có n (n≥2) tầng (thông thường tầng đầu vào không
được tính đến): trong đó gồm một tầng đầu ra (tầng thứ n) và (n-1) tầng ẩn.
Hinh 2- 9: Mạng MLP tổng quát
Kiến trúc của một mạng MLP tổng quát có thể mô tả như sau:
Đầu vào là các vector
xp trong không gian p chiều, x1 , x2 , . .., đầu ra là các vector
yq trong không gian q chiều. Đối với các bài y1 , y2 , .. ., toán 31
phân loại, p chính là kích thước của mẫu đầu vào, q chính là số lớp cần
phân loại. Xét ví dụ trong bài toán nhận dạng chữ số: với mỗi mẫu ta lưu
tọa độ (x,y) của 8 điểm trên chữ số đó, và nhiệm vụ của mạng là phân
loại các mẫu này vào một trong 10 lớp tương ứng với 10 chữ số 0, 1, …,
9. Khi đó p là kích thước mẫu và bằng 8 x 2 = 16; q là số lớp và bằng 10.
Mỗi neuron thuộc tầng sau liên kết với tất cả các neuron thuộc tầng liền trước nó.
Đầu ra của neuron tầng trước là đầu vào của neuron thuộc tầng liền sau nó.
Hoạt động của mạng MLP như sau: tại tầng đầu vào các neuron nhận
tín hiệu vào xử lý (tính tổng trọng số, gửi tới hàm truyền) rồi cho ra kết
quả (là kết quả của hàm truyền); kết quả này sẽ được truyền tới các
neuron thuộc tầng ẩn thứ nhất; các neuron tại đây tiếp nhận như là tín
hiệu đầu vào, xử lý và gửi kết quả đến tầng ẩn thứ 2;…; quá trình tiếp
tục cho đến khi các neuron thuộc tầng ra cho kết quả.
Một số kết quả đã được chứng minh:
Bất kì một hàm Boolean nào cũng có thể biểu diễn được bởi một
mạng MLP 2 tầng trong đó các neuron sử dụng hàm truyền sigmoid.
Tất cả các hàm liên tục đều có thể xấp xỉ bởi một mạng MLP 2
tầng sử dụng hàm truyền sigmoid cho các neuron tầng ẩn và hàm truyền
tuyến tính cho các neuron tầng ra với sai số nhỏ tùy ý.
Mọi hàm bất kỳ đều có thể xấp xỉ bởi một mạng MLP 3 tầng sử
dụng hàm truyền sigmoid cho các neuron tầng ẩn và hàm truyền tuyến
tính cho các neuron tầng ra.
a. Xác định số neuron tầng ẩn
Câu hỏi chọn số lượng noron trong tầng ẩn của một mạng MLP thế
nào là khó, nó phụ thuộc vào bài toán cụ thể và vào kinh nghiệm của nhà 32
thiết kế mạng. Nếu tập dữ liệu huấn luyện được chia thành các nhóm với
các đặc tính tương tự nhau thì số lượng các nhóm này có thể được sử
dụng để chọn số lượng neuron ẩn. Trong trường hợp dữ liệu huấn luyện
nằm rải rác và không chứa các đặc tính chung, số lượng kết nối có thể
gần bằng với số lượng các
mẫu huấn luyện để mạng có thể hội tụ. Có nhiều đề nghị cho việc chọn
số lượng neuron tầng ẩn h trong một mạng MLP. Chẳng hạn h phải thỏa
mãn h>(p-1)/(n+2), trong đó p là số lượng mẫu huấn luyện và n là số
lượng đầu vào của mạng. Càng nhiều nút ẩn trong mạng, thì càng nhiều
đặc tính của dữ liệu huấn luyện sẽ được mạng nắm bắt, nhưng thời gian học sẽ càng tăng.
Một kinh nghiệm khác cho việc chọn số lượng nút ẩn là số lượng
nút ẩn bằng với số tối ưu các cụm mờ (fuzzy clusters). Phát biểu này đã
được chứng minh bằng thực nghiệm. Việc chọn số tầng ẩn cũng là một
nhiệm vụ khó. Rất nhiều bài toán đòi hỏi nhiều hơn một tầng ẩn để có thể giải quyết tốt.
Để tìm ra mô hình mạng neuron tốt nhất, Ishikawa and Moriyama
(1995) sử dụng học cấu trúc có quên (structural leanrning with
forgetting), tức là trong thời gian học cắt bỏ đi các liên kết có trọng số
nhỏ. Sau khi huấn luyện, chỉ các noron có đóng góp vào giải quyết bài
toán mới được giữ lại, chúng sẽ tạo nên bộ xương cho mô hình mạng neuron. b. Khởi tạo trọng
Trọng thường được khởi tạo bằng phương pháp thử sai, nó mang
tính chất kinh nghiệm và phụ thuộc vào từng bài toán. Việc định nghĩ thế
nào là một bộ trọng tốt cũng không hề đơn giản. Một số quy tắc khi khởi tạo trọng: 33
Khởi tạo trọng số sao cho mạng neuron thu được là cân bằng (với
đầu vào ngẫu nhiên thì sai số lan truyền ngược cho các ma trận trọng số là xấp xỉ bằng nhau):
W1 / W2 / W3 / W3 W1 W2 34
Nếu mạng neuron không cân bằng thì quá trình thay đổi trọng số ở một số ma
trận là rất nhanh trong khi ở một số ma trận khác lại rất chậm, thậm chí không
đáng kể. Do đó để các ma trận này đạt tới giá trị tối ưu sẽ mất rất nhiều thời gian.
Tạo trọng sao cho giá trị kết xuất của các nút có giá trị trung gian.
(0.5 nếu hàm truyền là hàm Sigmoid). Rõ ràng nếu ta không biết gì về giá
trị kết xuất thì giá trị ở giữa là hợp lý. Điều này cũng giúp ta tránh được các giá trị thái quá.
2.3. Kết luận chương
Trong chương này được trình bày chủ yếu về mô hình Mạng nhiều
tầng truyền thẳng (MLP) và mô hình học sâu (mô hình mạng neuron nhân
tạo theo phương pháp học sâu). Ngoài ra, chương này còn trình bày một
số lý thuyết về mạng neuron nhân tạo và một số đặc trung của nó. Bên
cạnh đó, trong chương này trình bày thêm về thuật toán lan truyền ngược
được ứng dụng trong quá trình huấn luyện mạng của mô hình học sâu. 35
CHƯƠNG 3: CI ĐẶT CHƯƠNG TRÌNH THỬ NGHIỆM
3.1. Dữ liệu thực nghiệm
Ở đây, chúng em đã tiến hành nhận dạng ký tự với các bộ dữ liệu của thư viện MNIST:
Cơ sở dữ liệu MNIST chứa 60.000 hình ảnh đào tạo và 10.000
hình ảnh thử nghiệm. Một nửa tập huấn luyện và một nửa tập kiểm tra
được lấy từ tập dữ liệu huấn luyện của NIST, trong khi nửa còn lại của
tập huấn luyện và nửa còn lại của tập kiểm tra được lấy từ tập dữ liệu thử
nghiệm của NIST. Những người tạo ban đầu của cơ sở dữ liệu lưu giữ
danh sách một số phương pháp được thử nghiệm trên nó. Trong bài báo
gốc, họ sử dụng máy vector hỗ trợ để có tỷ lệ lỗi là 0,8%. Một tập dữ liệu
mở rộng tương tự như MNIST có tên EMNIST đã được xuất bản vào
năm 2017, bao gồm 240.000 hình ảnh đào tạo và 40.000 hình ảnh thử
nghiệm về các ký tự và chữ số viết tay
3.2. Huấn luyện mô hình và kết quả thực nghiệm với mô hình MLP
3.2.1. Mô hình huấn luyện 36
Hình 3- 1: Mô hình huấn luyện mạng (MLP)
Trong mô hình MLP học viên sử dụng hai lớp ẩn để huấn luyện với các thông số như sau:
Lớp đầu vào (Visible Units): Với 784 nút đầu vào, mỗi một nút đầu
vào đại diện cho một điểm ảnh, với giá trị là mức xám của điểm ảnh đó (0 255).
Các lớp ẩn (Hidden Units): Tại các lớp này học viên sử dụng 2 lớp
ẩn với các lớp tương ứng với 800, 800 nút.
Lớp đầu ra (Visible Units): Gồm có 10 nút, mỗi nút tương ứng với
giá trị của các chữ cái (A, B, C, D, H, K, L, M, N, P).
3.2.2. Các bước thực nghiệm 37 38
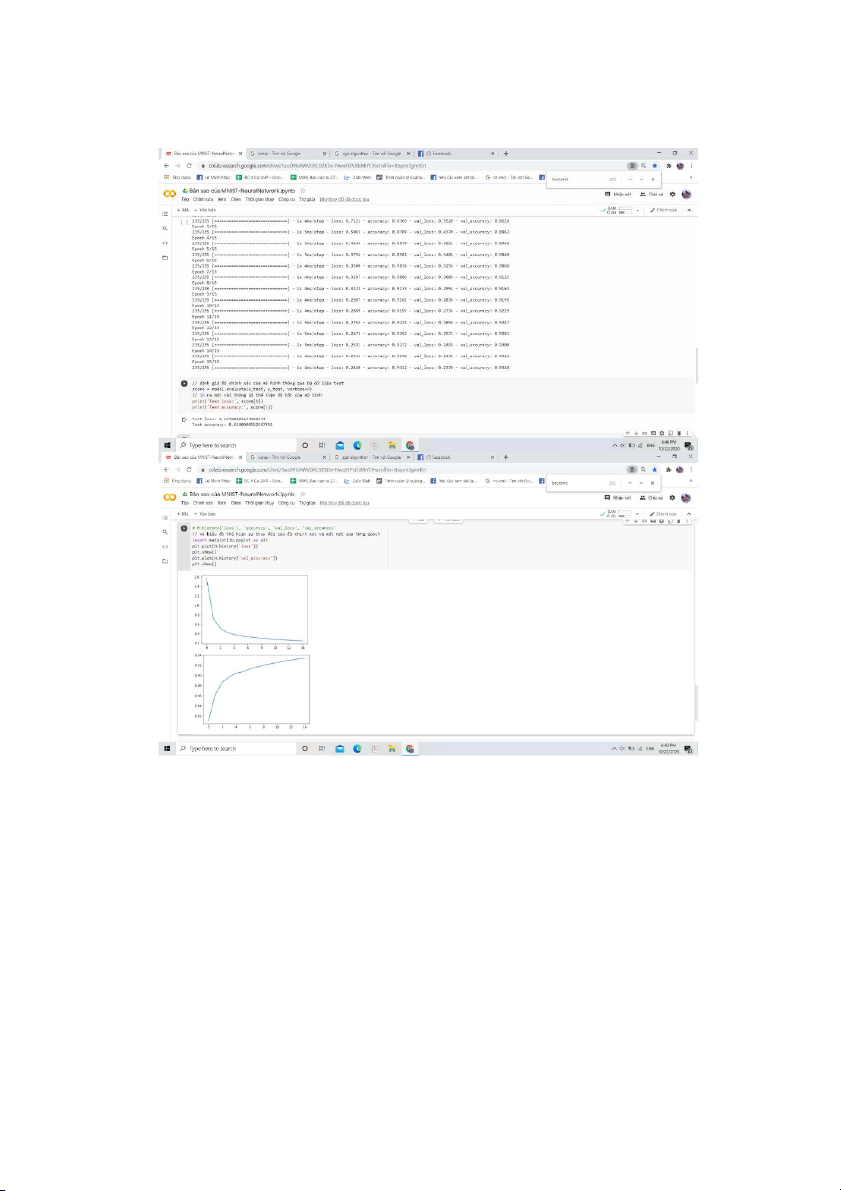
3.2.3 Kết quả thực nghiệm 39 40 KẾT LUẬN CHUNG
Trong quá trình thực hiện bài tập lớn của môn nhập môn học máy, chúng em đã
được biết thêm về các chương trình ứng dụng, nắm rõ về các phần về học máy.
Từ đó chúng em cố gắng áp dụng các kiến thức đã học vào làm bài tập để hoàn
thiện sản phẩm của mình. Trong bài tập lớn của chúng em sử dụng thuật toán
NEUTRAL NETWORK đê nhận dạng chữ viết tay. Vì trong thời gian ngắn nên
bài tập lớn của chúng em vẫn còn nhiều thiếu sót. Chúng em rất hy vọng có sự
góp ý của thầy cô, để bài tập lớn của chúng em được hoàn thiện hơn nữa ạ.
Chúng em xin chân thành cảm ơn.!
TI LIỆU THAM KHẢO Tiếng Việt [1]
Mai Văn Thủy (2015). Nghiên cứu về mô hình thống kê học sâu
và ứng dụng trong nhận dạng chữ viết tay hạn chế. Luận văn thạc
sỹ, Đại học Công nghệ thông tin và Truyền thông. [2]
Lê Minh Hoàng, một phương pháp nhận dạng văn bản tiếng Việt.
Luận văn thạc sỹ, Đại học Quốc gia Hà Nội. [3]
Đỗ Thanh Nghị, Phạm Nguyên Khang (2013). Nhận dạng kí tự số
viết tay bằng giải thuật máy học. Tạp chí khoa học Trường Đại học Cần Thơ [4]
Phạm Thị Hoàng Nhung, Hà Quang Thụy (2007). Nghiên cứu,
sử dụng mạng neuron nhân tạo trong dự báo lưu lượng nước đến
hồ Hoà Bình trước 10 ngày. Hội thảo Quốc gia Một số vấn đề
chọn lọc về Công nghệ thông tin và Truyền thông, lần thứ X, Đại Lải, Vĩnh Phúc, 9/2007. Tiếng Anh
[5] Baret O. and Simon J.C (1992). Cursiver Words Recognition. From
Pixels to Fuatures III Frontiers in Handwriting Recognition, tr.1-2.
[6] Behnk S., Pfister M. and Rojas R., (2000). Recognition of
Handwitten ZIP Codes in a Real-World Non-Standard-Letter
Sorting System. Kluwer Academic Publishers, tr.95-115.
[7] Fujasaki T., Beigi H.S.M, Tappert C.C, Ukelson M. and Wolf C.G.
(1992). Online recognition of unconstrained handprinting: a stroke-
based system and it evaluation. From Pixels to Fuatures III
Frontiers in Handwriting Recognition, tr.1-3.
[8] Hoai Vu Pham (2013), Hopfield networks and Boltzmann Machines. Byhttp://phvu.net/
[9] Hoai Vu Pham (2013), Model definition and training of
RBMs. By http://phvu.net/
[10] Hoai Vu Pham (2013), Contrastive Divergence. By http://phvu.net/
[11] LISA lab. Deep Learning 0.1 documentation. By
http://www.deeplearning.net/tutorial/contents.html
[12] Keith Kelleher (2013).Multilayer Perceptron in MATLAB / Octave. By
http://3options.net/brainannex/multilayer-perceptron-in-matlab-octave/
[13] Michael Nielsen (2014).Using neural nets to recognize handwritten digits. By
http://neuralnetworksanddeeplearning.com/chap1.html
[14] Hesham Eraqi (Updated 01 Mar 2016). MLP Neural Network with Backpropagation. By
http://www.mathworks.com/matlabcentral/fileexchange/54076- mlp-
neural-network-with-backpropagation




