Báo cáo tổng kết nghiên cứu độ đo tương đồng văn bản trong tiếng Việt và ứng dụng hỗ trợ đánh giá việc sao chép bài điện tử | Viện Đại học Mở Hà Nội
Báo cáo tổng kết nghiên cứu độ đo tương đồng văn bản trong tiếng Việt và ứng dụng hỗ trợ đánh giá việc sao chép bài điện tử | Viện Đại học Mở Hà Nội. Tài liệu được sưu tầm giúp bạn tham khảo, ôn tập và đạt kết quả cao. Mời bạn đọc đón xem.
Môn: Ngôn ngữ học đối chiếu (HOU) 15 tài liệu
Trường: Viện Đại học Mở Hà Nội 1.7 K tài liệu
Tác giả:



















Preview text:
BỘ GIÁO DỤC VÀ ĐÀO TẠO
VIỆN ĐẠI HỌC MỞ HÀ NỘI
------------------------------ BÁO CÁO TỔNG KẾT
ĐỀ TÀI KHOA HỌC VÀ CÔNG NGHỆ CẤP VIỆN
NGHIÊN CỨU ĐỘ ĐO TƯƠNG ĐỒNG
VĂN BẢN TRONG TIẾNG VIỆT VÀ ỨNG
DỤNG HỖ TRỢ ĐÁNH GIÁ VIỆC SAO
CHÉP BÀI ĐIỆN TỬ Mã số: V2014-33
Xác nhận của cơ quan
Chủ nhiệm đề tài chủ trì đề tài
TS. Dương Thăng Long
Hà Nội – 11/2014
Nghiên cứu độ đo tương đồng văn bản trong tiếng Việt và ứng dụng
DANH SÁCH THÀNH VIÊN
THAM GIA NGHIÊN CỨU ĐỀ TÀI
VÀ ĐƠN VỊ PHỐI HỢP
1. Danh sách thành viên tham gia nghiên cứu đề tài ThS Mai Thị Thúy Hà KS Trần Tiến Dũng
2. Các đơn vị phối hợp Khoa Đào tạo từ xa Khoa Công nghệ thông tin
Trung tâm đào tạo E-Learning
Đề tài Khoa học Công nghệ cấp Viện 2014 (mã số: V33.2014) 2
Nghiên cứu độ đo tương đồng văn bản trong tiếng Việt và ứng dụng MỤC LỤC
DANH MỤC BẢNG BIỂU ............................................................................ 4
DANH MỤC HÌNH VẼ ................................................................................. 5
DANH MỤC TỪ VIẾT TẮT ......................................................................... 6
PHẦN I: PHẦN MỞ ĐẦU ............................................................................ 7
I.1. Tính cấp thiết của đề tài .......................................................................................................7
I.2. Tình hình nghiên cứu ...........................................................................................................7
I.3. Mục đích nghiên cứu ...........................................................................................................9
I.4. Đối tượng và phạm vi nghiên cứu .....................................................................................10
I.5. Phương pháp nghiên cứu ...................................................................................................10
PHẦN II: NỘI DUNG VÀ KẾT QUẢ NGHIÊN CỨU .............................. 11
Chương 1. Các vấn đề về xử lý ngôn ngữ tự nhiên và ứng dụng ............... 11
1.1. Xử lý ngôn ngữ tự nhiên ...................................................................................................11
1.2. Vấn đề về độ tương tự trong văn bản ................................................................................14
1.3. Vấn đề về sự sao chép hay đạo văn và một số kỹ thuật ....................................................19
Chương 2. Phương pháp đánh giá độ tương đồng văn bản tiếng Việt ...... 23
2.1. Giới thiệu ..........................................................................................................................23
2.2. Phương pháp đo độ tương đồng văn bản trong tiếng Việt ................................................24
2.2.1. Độ tương tự ngữ nghĩa của văn bản ..............................................................................25
2.2.2. Độ tương tự về thứ tự các từ trong văn bản...................................................................27
2.2.3. Độ tương tự theo ma trận so sánh từng nhóm từ loại ....................................................28
2.2.4. Kết hợp giữa độ đo để đánh giá độ tương tự hai văn bản .............................................29
Chương 3. Xây dựng hệ thống ứng dụng thử nghiệm ................................ 32
3.1. Công nghệ sử dụng ...........................................................................................................32
3.1.1. Ngôn ngữ lập trình Java ................................................................................................32
3.1.2. Bộ thư viện JVNTextPro ................................................................................................34
3.1.3. Google Translate API ....................................................................................................38
3.2. Chương trình ứng dụng thử nghiệm ..................................................................................39
PHẦN III: KẾT LUẬN & KIẾN NGHỊ ..................................................... 43
III.1. Kết luận ...........................................................................................................................43
III.2. Kiến nghị.........................................................................................................................43
TÀI LIỆU THAM KHẢO ........................................................................... 44
Đề tài Khoa học Công nghệ cấp Viện 2014 (mã số: V33.2014) 3
Nghiên cứu độ đo tương đồng văn bản trong tiếng Việt và ứng dụng
DANH MỤC BẢNG BIỂU
Bảng 2.1: Các phương án kết hợp đánh giá độ tương tự văn bản ............. 30
Bảng 2.2: Kết quả các phương án kết hợp của ví dụ .................................. 31
Bảng 3.1. Kết quả thử nghiệm và so sánh với khảo sát thực tế .................. 42
Đề tài Khoa học Công nghệ cấp Viện 2014 (mã số: V33.2014) 4
Nghiên cứu độ đo tương đồng văn bản trong tiếng Việt và ứng dụng DANH MỤC HÌNH VẼ
Hình 2.1: Ví dụ về mạng từ tiếng Anh ........................................................ 15
Hình 2.2: 4 giai đoạn của quá trình phát hiện đạo văn .............................. 20
Hình 3.1 : Chương trình thử nghiệm đánh giá độ tương tự văn bản ......... 39
Hình 3.2. Biểu đồ so sánh kết quả thử nghiệm với khảo sát ....................... 42
Đề tài Khoa học Công nghệ cấp Viện 2014 (mã số: V33.2014) 5
Nghiên cứu độ đo tương đồng văn bản trong tiếng Việt và ứng dụng
DANH MỤC TỪ VIẾT TẮT Stt Từ viết tắt Ý nghĩa đầy đủ 1 NLP
Xử lý ngôn ngữ tự nhiên (Natural Language Processing) 2 IC
Hàm lượng thông tin (Information Content) 3 WordNet Mạng từ ngữ nghĩa 4 POS
Phân nhóm loại từ trong văn bản 5 LCS
Nút con chung thấp nhất (Lowest Common Subsummer) 6 LSO
Nút con chung thấp nhất (Lowest Super- Ordinate) 7 SIM
Độ tương tự (Similarity)
Đề tài Khoa học Công nghệ cấp Viện 2014 (mã số: V33.2014) 6
Nghiên cứu độ đo tương đồng văn bản trong tiếng Việt và ứng dụng
PHẦN I: PHẦN MỞ ĐẦU
I.1. Tính cấp thiết của đề tài
Xử lý ngôn ngữ tự nhiên (Natural Language Processing) là một lĩnh vực
nghiên cứu thường có sự kết hợp giữa công nghệ thông tin và ngôn ngữ học.
Trong đó, vai trò của công nghệ thông tin ngày càng chứng tỏ sức mạnh và tầm
quan trọng trong các nghiên cứu cũng như kết quả ứng dụng. Cho đến nay đã có
nhiều kết quả nghiên cứu [V1-V5, A1-A9] và triển khai ứng dụng đem lại hiệu
quả lớn cho xã hội. Trong đó, chủ yếu là xử lý ngôn ngữ tiếng Anh với các bài
toán điển hình như tóm tắt văn bản, trích chọn từ khóa, dịch tự động,… và đặc
biệt là bài toán đánh giá độ tương tự văn bản được nhiều tác giả quan tâm nghiên
cứu với hy vọng đem lại những lợi ích to lớn trong ứng dụng thực tiễn.
Hiện nay, tình trạng sao chép vi phạm bản quyền và gian dối trong các kết
quả công trình khoa học hay thậm chí là các bài viết luận diễn ra rất nhiều và
khó kiểm soát. Đặc biệt là trong lĩnh vực giáo dục – đào tạo, việc người học sao
chép bài của nhau diễn ra phổ biến với số lượng lớn, gây khó khăn và mất nhiều
thời gian cho các giảng viên trong việc phân loại, đánh giá các kết quả bài viết
luận của sinh viên. Trong khi đó, Viện Đại học Mở Hà Nội đã và đang triển khai
đào tạo các loại hình từ xa, chính quy với quy mô rất lớn và trải rộng khắp mọi
miền tổ quốc nên việc kiểm soát tình trạng này cũng gặp nhiều khó khăn.
Với tình hình trên, đề tài này hy vọng bước đầu có những nghiên cứu về
phương pháp đánh giá mức độ tương đồng văn bản tiếng Việt và đưa ra một số
đề xuất cả về mô hình cũng như thử nghiệm nhằm có những định hướng ứng
dụng hiệu quả trong việc hỗ trợ phân loại, đánh giá sơ bộ các bài viết luận, qua
đó nhằm hạn chế và tránh được những sao chép trong học thuật, góp phần nâng
cao chất lượng kết qủa học tập.
I.2. Tình hình nghiên cứu
Trong xử lý ngôn ngữ tự nhiên, các kết quả nghiên cứu về đánh giá độ tương
tự trong văn bản tiếng Anh đã và đang diễn ra rất sôi nổi, có nhiều công trình
nghiên cứu [A1-A9] và nhiều những ứng dụng hữu ích [Zha12,Abu12], đặc biệt
là trong việc phát hiện sự vi phạm bản quyền tác giả trong các bài viết. Trong
khi đó, các nghiên cứu về vấn đề này đối với tiếng Việt chiếm tỷ lệ khá khiêm
tốn [Tha14]. Hầu hết các phương pháp sử dụng đánh giá dựa trên mạng từ tiếng
Đề tài Khoa học Công nghệ cấp Viện 2014 (mã số: V33.2014) 7
Nghiên cứu độ đo tương đồng văn bản trong tiếng Việt và ứng dụng
Anh (wordnet) [Zha08,She06,She12,Pta12,Zha10], một số ít phương pháp dựa
trên kho ngữ liệu như là dữ liệu Web [Nan10] hoặc kho ngữ liệu có sẵn [Che13].
Các phương pháp mang tính thống kê dựa trên kho ngữ liệu đòi hỏi phải có một
kho ngữ liệu đủ lớn và đa dạng mới đem lại hiệu quả cao, bên cạnh đó mạng từ
tiếng Anh đã và đang được phát triển rất tốt và đem lại hiệu quả cao trong các phương pháp.
Đối với xử lý ngôn ngữ trong tiếng Việt, hiện có một số cá nhân và tổ chức
nghiên cứu xây dựng cả về lý thuyết, mô hình và triển khai ứng dụng. Trong đó
một nhánh của Đề tài Khoa học công nghệ cấp Nhà nước “Nghiên cứu, xây dựng
và phát triển một số tài nguyên và công cụ thiết yếu cho xử lý văn bản tiếng
Việt” [Tha14] đang tập trung phát triển. Tuy vậy, các phương pháp đánh giá độ
tương tự văn bản tiếng Việt chủ yếu dựa trên kho ngữ liệu với việc kế thừa các
kết quả nghiên cứu từ tiếng Anh. Trong [Tha14], các tác giả đã tổng hợp các
phương pháp đánh giá độ tương tự giữa từ với từ và trên cơ sở đó đánh giá độ
tương tự giữa câu với câu. Các ví dụ minh họa cho việc mở rộng sang đo độ
tương tự trong văn bản tiếng Việt cũng được xem xét khá chi tiết.
Bên cạnh đó, cũng có nhiều công trình nghiên cứu về lĩnh vực này và bước
đầu có những ứng dụng thử nghiệm nhất định. Điển hình như là VNQTAG, công
cụ tìm kiếm itim.vn, hoặc JVnTextPro. Trong đó:
+ VNQTAG đã được phát triển từ lâu với bộ dữ liệu nhỏ nên độ chính xác chưa cao.
+ Công cụ tìm kiếm itim.vn là một sản phẩm thương mại, hiện đang trong
giai đoạn phát triển và đưa vào sử dụng thử nghiệm, cũng chú trọng việc tách từ
trong câu văn Tiếng Việt để phục vụ cho tìm kiếm chính xác hơn. Itim.vn ghi
nhận các phản hồi của người dùng về kết quả tách từ để phục vụ cho việc thống
kê tìm kiếm kết quả của mình. Tuy nhiên vì đang trong giai đoạn thử nghiệm, độ
chính xác của việc tách từ là chưa cao.
+ JVnTextPro là hệ thống công cụ dùng lại phần lớn kết quả của đề tài VLSP.
Có thể thấy, quy mô nhất và hoàn thiện nhất là nhánh xử lý văn bản tiếng
việt trong để tài VLSP tiếp cận theo phương pháp học máy. Nhóm nghiên cứu đã
xây dựng một trang web demo, phát hành những phần mềm nguồn mở java,
công bố các tài liệu báo cáo chi tiết về công trình nghiên cứu trong các giai đoạn.
Đề tài Khoa học Công nghệ cấp Viện 2014 (mã số: V33.2014) 8
Nghiên cứu độ đo tương đồng văn bản trong tiếng Việt và ứng dụng
VLSP đã xây dựng được một thư viện dữ liệu mẫu với độ lớn và độ tin cậy cao
đó là TreeBank tiếng Việt, gồm có 90.000 câu đã được tách từ, 20.000 nghìn câu
đã được gán nhãn từ loại. Trong các phần mềm được nhóm công bố thì
JVnTager là phần mềm có chức năng tách từ và gán nhãn từ loại .
Theo thông tin của nhóm nghiên cứu, JVnTager dựa trên hai phương pháp
học máy thống kê là MaxEnt và CRFs. Để đánh giá kết quả của mình, nhóm
JVnTager sử dụng dữ liệu VietTreebank gồm 10.000 câu được chia thành 5
folds. Đánh giá gán nhãn từ loại bằng mô hình CRFs và MaxEnt với phương
pháp 5-fold-cross-validation, với tỷ lệ dữ liệu đào tạo (Train) là 80%.
Hiện nay, một số cơ sở giáo dục đã ứng dụng các hệ thống hỗ trợ kiểm tra
đánh giá việc sao chép bài luận điện tử nhằm giúp giảng viên có thể nhanh
chóng xác định, phân loại các kết quả bài luận của sinh viên. Hơn nữa, hệ thống
cũng sẽ hỗ trợ người học tự kiểm tra kết quả của mình nhằm giúp nâng cao chất
lượng kết quả học tập và chủ động tránh những hiện tượng sao chép bài điện tử.
Trong đó, điển hình là hệ thống turnitin được triển khai tại FPT Polytechnic, hệ
thống này theo giới thiệu là đã làm việc với nhiều trường đại học hàng đầu thế
giới và các trung tâm nghiên cứu lớn, bao gồm một vài tổ chức chính phủ, để
cung cấp một công cụ hiệu quả nhằm phát hiện sự vay mượn sao chép. Tại nước
Anh, chương trình triển lãm giới thiệu trên cả nước của Turnitin được chính phủ
tài trợ đã đem lại kết quả là giảm được 59% nội dung bài luận có sao chép kể từ năm 2005.
Ngoài ra, có một số hệ thống khác hỗ trợ cho việc này như Plagiarism, Dubli
Checker hay Viper Plagiarism Scanner.
I.3. Mục đích nghiên cứu
Nghiên cứu một số phương pháp đo độ tương đồng văn bản trong ngôn ngữ
tiếng Việt, thiết kế hệ thống hỗ trợ tự động đánh giá sự giống nhau về văn bản
tiếng Việt, đề xuất xây dựng thử nghiệm một số phần chức năng của hệ thống hỗ
trợ tự động đánh giá sự giống nhau của văn bản giúp cho việc xác định nhanh
chóng các kết quả bài luận dạng điện tử của sinh viên có trung thực hay không,
ứng dụng trong tổ chức quản lý đào tạo của các cơ sở giáo dục.
Đề tài Khoa học Công nghệ cấp Viện 2014 (mã số: V33.2014) 9
Nghiên cứu độ đo tương đồng văn bản trong tiếng Việt và ứng dụng
I.4. Đối tượng và phạm vi nghiên cứu
Các mô hình tính toán xác định độ đo tương đồng văn bản cả về cú pháp và
ngữ nghĩa, mức tương đồng văn bản ở các cấp độ từ, câu, đoạn văn hay toàn bộ
bài văn và ứng dụng trong tiếng Việt.
Các công cụ để lập trình và xây dựng thử nghiệm cho một mô hình được đề
xuất để đánh giá độ tương đồng hai văn bản tiếng Việt.
Hệ thống hỗ trợ tự động đánh giá sự sao chép các bài luận điện tử giúp cho
việc đánh giá sơ bộ các kết quả bài thu hoạch trong đào tạo nhanh chóng và thuận tiện.
I.5. Phương pháp nghiên cứu
Thu thập, khảo sát và hệ thống hóa các kết quả nghiên cứu đã có về vấn đề
đo độ tương đồng văn bản và các ứng dụng đối với tiếng Việt.
Nghiên cứu lý thuyết về mô hình độ đo tương đồng văn bản, ứng dụng các
mô hình vào thiết kế và xây dựng hệ thống đo độ tương đồng văn bản tiếng Việt,
kết hợp thực nghiệm trên các dữ liệu mẫu và dữ liệu thu thập thực tế để đánh giá hệ thống.
Đề tài Khoa học Công nghệ cấp Viện 2014 (mã số: V33.2014) 10
Nghiên cứu độ đo tương đồng văn bản trong tiếng Việt và ứng dụng
PHẦN II: NỘI DUNG VÀ KẾT QUẢ NGHIÊN CỨU
Chương 1. Các vấn đề về xử lý ngôn ngữ tự nhiên và ứng dụng
1.1. Xử lý ngôn ngữ tự nhiên
Xử lý ngôn ngữ tự nhiên (natural language processing - NLP), theo [Wiki],
là một nhánh của trí tuệ nhân tạo tập trung vào các ứng dụng trên ngôn ngữ của
con người. Trong trí tuệ nhân tạo thì xử lý ngôn ngữ tự nhiên là một trong những
phần khó nhất vì nó liên quan đến việc phải hiểu ý nghĩa ngôn ngữ - công cụ
hoàn hảo nhất của tư duy và giao tiếp mà con người sử dụng.
Những năm gần đây, xử lý ngôn ngữ tự nhiên (XLNNTN) đã trở thành một
lĩnh vực khoa học công nghệ được coi là mũi nhọn [Ha12], với một loạt ứng
dụng liên quan đến Internet và Web, như tìm kiếm và trích chọn thông tin trên
Web, khai phá văn bản, Web ngữ nghĩa, tóm tắt văn bản v.v. Các nghiên cứu và
ứng dụng về xử lý ngôn ngữ trên thế giới đã có một lịch sử lâu dài và được chia
thành các giai đoạn chính như sau [41]: Thời kỳ đầu tiên, bắt đầu từ những năm
1940-1950 mô hình ôtomat và các mô hình xác suất có ảnh hưởng sâu sắc đến
xử lý ngôn ngữ. Giai đoạn tiếp theo (1957-1970) xử lý ngôn ngữ được chia thành
hai nhánh tách biệt, nhánh hình thức tập trung vào các vấn đề thuộc lĩnh vực lý
thuyết ngôn ngữ hình thức và trí tuệ nhân tạo; kiểu ngẫu nhiên sử dụng trong
nhận dạng như các phương pháp Bayes. Giai đoạn 1970-1983 xuất hiện bốn
trường phái xử lý ngôn ngữ chính, đó là sử dụng phương pháp ngẫu nhiên; dựa
vào logic; hiểu ngôn ngữ tự nhiên; mô hình hóa diễn ngôn. Giai đoạn 1983-1993
việc huấn luyện các mô hình trạng thái hữu hạn, các mô hình xác suất dựa vào
dữ liệu đã xuất hiện hầu hết trong các nhiệm vụ của xử lý ngôn ngữ.
Từ những năm 1990 trở lại đây, mô hình thống kê dựa vào dữ liệu đã chứng
tỏ tính vượt trội của mình trong các công việc của xử lý ngôn ngữ [98, 99]. Công
nghệ xử lý văn bản và xử lý tiếng nói không còn cách biệt, công nghệ xử lý tiếng
nói không chỉ dựa vào các kỹ thuật xử lý tín hiệu mà còn dựa vào cả việc hiểu
ngôn ngữ. Tham số của mô hình thống kê hoặc mô hình trạng thái có thể huấn
luyện từ các kho ngữ liệu lớn, nhiều mô hình gần đây được chứng tỏ có hiệu quả
cao như Maximum Entropy Markov Model (MEMM), Conditional Random Fields (CRF), v.v.
Đề tài Khoa học Công nghệ cấp Viện 2014 (mã số: V33.2014) 11
Nghiên cứu độ đo tương đồng văn bản trong tiếng Việt và ứng dụng
Ngày nay, cùng với sự phát triển của công nghệ thông tin, dữ liệu văn bản
được sản sinh ra ngày một rất nhiều và cần phải được xử lý đáp ứng nhu cầu của
con người để tìm ra thông tin, tri thức hữu ích. Một số bài toán tiêu biểu của xử
lý ngôn ngữ với mức độ khác nhau về xử lý và sử dụng ngôn ngữ của con người như (theo [Wiki]):
- Nhận dạng chữ viết: Có hai kiểu nhận dạng, thứ nhất là nhận dạng chữ in,
ví dụ nhận dạng chữ trên sách giáo khoa rồi chuyển nó thành dạng văn bản điện
tử như dưới định dạng doc của Microsoft Word chẳng hạn. Phức tạp hơn là nhận
dạng chữ viết tay, có khó khăn bởi vì chữ viết tay không có khuôn dạng rõ ràng
và thay đổi từ người này sang người khác. Với chương trình nhận dạng chữ viết
in có thể chuyển hàng ngàn đầu sách trong thư viện thành văn bản điện tử trong
thời gian ngắn. Nhận dạng chữ viết của con người có ứng dụng trong khoa học
hình sự và bảo mật thông tin (nhận dạng chữ ký điện tử). Sản phẩm được ứng
dụng khá rộng rãi trong việc số hóa các tài liệu là VnDocR của Viện Công nghệ
thông tin – Viện hàm lâm khoa học và công nghệ Việt Nam.
- Nhận dạng tiếng nói: Nhận dạng tiếng nói rồi chuyển chúng thành văn bản
tương ứng. Giúp thao tác của con người trên các thiết bị nhanh hơn và đơn giản
hơn, chẳng hạn thay vì gõ một tài liệu nào đó bạn đọc nó lên và trình soạn thảo
sẽ tự ghi nó ra. Đây cũng là bước đầu tiên cần phải thực hiện trong ước mơ thực
hiện giao tiếp giữa con người với robot. Nhận dạng tiếng nói có khả năng trợ
giúp người khiếm thị rất nhiều.
- Tổng hợp tiếng nói: Từ một văn bản tự động tổng hợp thành tiếng nói.
Thay vì phải tự đọc một cuốn sách hay nội dung một trang web, nó tự động đọc
cho chúng ta. Giống như nhận dạng tiếng nói, tổng hợp tiếng nói là sự trợ giúp
tốt cho người khiếm thị, nhưng ngược lại nó là bước cuối cùng trong giao tiếp giữa robot với người.
- Dịch tự động (machine translate): Như tên gọi đây là chương trình dịch tự
động từ ngôn ngữ này sang ngôn ngữ khác. Một phần mềm điển hình về tiếng
Việt của chương trình này là Evtrans của Softex, dịch tự động từ tiếng Anh sang
tiếng Việt và ngược lại, phần mềm từng được trang web vdict.com mua bản
quyền, đây cũng là trang đầu tiên đưa ứng dụng này lên mạng. Tháng 10 năm
2008 có hai công ty tham gia vào lĩnh vực này cho ngôn ngữ tiếng Việt là công
ty Lạc Việt (công ty phát hành từ điển Lạc Việt) và Google, một thời gian sau đó
Đề tài Khoa học Công nghệ cấp Viện 2014 (mã số: V33.2014) 12
Nghiên cứu độ đo tương đồng văn bản trong tiếng Việt và ứng dụng
Xalo.vn cũng đưa ra dịch vụ tương tự. Tuy nhiên, vấn đề dịch tự động vẫn còn là
một bài toán khó trong lĩnh vực này bởi đặc trưng rất nhạy cảm với ngữ cảnh của ngôn ngữ tự nhiên.
- Tìm kiếm thông tin (information retrieval): Đặt câu hỏi và chương trình tự
tìm ra nội dung phù hợp nhất. Thông tin ngày càng đầy lên theo cấp số nhân, đặc
biệt với sự trợ giúp của internet việc tiếp cận thông tin trở lên dễ dàng hơn bao
giờ hết. Việc khó khăn lúc này là tìm đúng nhất thông tin mình cần giữa bề bộn
tri thức và đặc biệt thông tin đó phải đáng tin cậy. Các máy tìm kiếm dựa trên
giao diện web như Google hay Yahoo hiện nay chỉ phân tích nội dung rất đơn
giản dựa trên tần suất của từ khoá và thứ hạng của trang và một số tiêu chí đánh
giá khác để đưa ra kết luận, kết quả là rất nhiều tìm kiếm không nhận được câu
trả lời phù hợp, thậm chí bị dẫn tới một liên kết không liên quan gì do thủ thuật
đánh lừa của các trang web nhằm giới thiệu sản phẩm (có tên tiếng Anh là SEO
viết tắt của từ search engine optimization). Thực tế cho đến bây giờ chưa có máy
tìm kiếm nào hiểu được ngôn ngữ tự nhiên của con người trừ trang
www.ask.com được đánh giá là "hiểu" được những câu hỏi có cấu trúc ở dạng
đơn giản nhất. Mới đây cộng đồng mạng đang xôn xao về trang Wolfram Alpha,
được hứa hẹn là có khả năng hiểu ngôn ngữ tự nhiên của con người và đưa ra
câu trả lời chính xác. Lĩnh vực này hứa hẹn tạo ra bước nhảy trong cách thức
tiếp nhận tri thức của cả cộng đồng.
- Tóm tắt văn bản: Từ một văn bản dài tóm tắt thành một văn bản ngắn hơn
theo mong muốn nhưng vẫn chứa những nội dung thiết yếu nhất.
- Khai phá dữ liệu (data mining) và phát hiện tri thức: Từ rất nhiều tài liệu
khác nhau phát hiện ra tri thức mới. Thực tế để làm được điều này rất khó, nó
gần như là mô phỏng quá trình học tập, khám phá khoa học của con người, đây
là lĩnh vực đang trong giai đoạn đầu phát triển. Ở mức độ đơn giản khi kết hợp
với máy tìm kiếm nó cho phép đặt câu hỏi để từ đó công cụ tự tìm ra câu trả lời
dựa trên các thông tin trên web mặc cho việc trước đó có câu trả lời lưu trên web
hay không (giống như trang Yahoo! hỏi và đáp, nơi chuyên đặt các câu hỏi để
người khác trả lời), nói một cách nôm na là nó đã biết xử lý dữ liệu để trả lời câu
hỏi của người sử dụng, thay vì máy móc đáp trả những gì chỉ có sẵn trong bộ nhớ.
Đề tài Khoa học Công nghệ cấp Viện 2014 (mã số: V33.2014) 13
Nghiên cứu độ đo tương đồng văn bản trong tiếng Việt và ứng dụng
Ngoài ra, với đặc thù trong xử lý tiếng Việt, các nhóm nghiên cứu đã và
đang phát triển nhiều phương pháp để giải quyết thêm các bài toán liên quan như:
- Phân tách từ vựng tiếng Việt.
- Phân tách câu tiếng Việt.
- Tự động thêm dấu: chữ viết tiếng Việt là chữ viết có dấu thanh. Trong các
văn bản chính thống như sách, báo chí, văn bản hành chính, các dấu thanh được
viết chính xác. Tuy nhiên trong cách tình huống không chính thống như chat, gõ
tìm kiếm, người dùng thông thường không gõ các dấu thanh, dẫn tới khó khăn
nhất định cho máy tính trong việc hiểu ý nghĩa của văn bản…
Vấn đề đánh giá độ tương đồng văn bản được xem xét và nghiên cứu trong
nhiều bài toán từ mức độ thấp đến mức độ cao nhằm giải quyết hiệu quả bài toán
đó. Có thể thấy trong các bài toán như trích chọn thông tin, tóm tắt văn bản,…
đều cần đến các phương pháp đánh giá độ tương tự văn bản. Và như đã đề cập,
việc xác định mức độ giống nhau, khác nhau giữa các văn bản còn có một ứng
dụng riêng khá đặc biệt đối với bài toán chống sao chép, đạo văn.
1.2. Vấn đề về độ tương tự trong văn bản
Các độ đo độ tương đồng văn bản trong các ứng dụng của xử lý ngôn ngữ tự
nhiên và các lĩnh vực liên quan đã được sử dụng rất lâu. Một trong những ứng
dụng sớm nhất của độ tương đồng văn bản là mô hình vectơ trong tìm kiếm
thông tin, ở đó các tài liệu có liên quan nhất tới câu truy vấn đầu vào được xác
định bằng cách xếp hạng các tài liệu trong kho ngữ liệu theo thứ tự ngược của độ
tương tự (Salton & Lesk, 1971). Độ tương đồng văn bản cũng dược dùng trong
phân lớp văn bản (Rochio 1971), trích chọn văn bản (Salton et al. 1997) và
phương pháp tóm tắt văn bản (Lin &Hovy 2003). Độ đo tương đồng văn bản
cũng được sử dụng cho việc đánh giá tính chặt chẽ của văn bản (Lapata & Barzilay 2005).
Trong một số trường hợp, việc đo độ tương đồng giữa hai đoạn văn bản là
việc sử dụng so khớp từ đơn giản, và tạo ra một điểm tương tự trên số đơn vị từ
vựng xảy ra ở cả hai đoạn văn bản đầu vào. Việc loại bỏ các từ dừng, gán nhãn
từ loại, so khớp tập con dài nhất, cũng như các trọng số và các nhân tố khác đều
có thể được tích hợp để mang lại hiệu quả cho phương pháp.
Đề tài Khoa học Công nghệ cấp Viện 2014 (mã số: V33.2014) 14
Nghiên cứu độ đo tương đồng văn bản trong tiếng Việt và ứng dụng
Trong [Muf09], đề cập đến việc đánh giá độ tương tự văn bản có thể chia
thành 2 tiếp cận chính: thứ nhất là sử dụng mạng từ ngữ nghĩa (WordNet) để
trích rút các đặc trưng từ các văn bản cần đánh giá, thứ hai là sử dụng thông tin
cú pháp của văn bản. Tuy nhiên, nhiều tác đã thực hiện các nghiên cứu sâu rộng
về các phương pháp được sử dụng WordNet với mục tiêu xác định sự giống
nhau giữa các khái niệm. Các tác giả phân biệt ba khái niệm: mối quan ngữ
nghĩa, khoảng cách ngữ nghĩa, và sự tương đồng. Họ cho rằng sự giống nhau là
"một trường hợp đặc biệt của mối quan hệ ngữ nghĩa". Một ví dụ đã được đưa ra
để phân biệt giữa các mối quan ngữ nghĩa và sự tương đồng là hai từ “ô tô” và
“xăng”. Hai từ này có liên quan chặt chẽ hơn so với “ô tô” và “xe đạp”, tuy
nhiên cặp từ “ô tô” và “xe đạp” có nhiều tương tự hơn. Họ định nghĩa khái niệm
khoảng cách ngữ nghĩa như là nghịch đảo của độ tương tự ngữ nghĩa hoặc mức
độ liên quan với nhau và cho rằng "hai khái niệm gần gũi với nhau: nếu giống
nhau hoặc mối quan hệ ở mức độ cao, và ngược lại chúng rất xa nhau".
Hình 2.1: Ví dụ về mạng từ tiếng Anh
Để sử dụng mạng từ WordNet, các định nghĩa và ký hiệu sau đây được sử dụng [Muf09, Tha14]:
- Chiều dài của đường đi ngắn nhất trong WordNet từ nút (synset, hay gọi là
khái niệm) ci đến nút cj (đo bằng số cạnh hoặc số nút) được ký hiệu bằng len(ci, cj).
- Chiều sâu của một nút là độ dài của đường dẫn đến nó tính từ nút gốc,
nghĩa là độ sâu của nút, ký hiệu depth(ci) = len (root, ci).
Đề tài Khoa học Công nghệ cấp Viện 2014 (mã số: V33.2014) 15
Nghiên cứu độ đo tương đồng văn bản trong tiếng Việt và ứng dụng
- Nút cha chung thấp nhất (lowest super-ordinate) của hai nút c1 và c2 được ký hiệu là lso(c1, c2).
- Đo hàm lượng thông tin (IC – information content) của khái niệm c là:
IC(c) = − log(P(c)) ,
trong đó P(c) là xác suất của khái niệm c trong kho ngữ liệu (được tính toán
và gắn vào mỗi nút trên Wordnet). P(c) = freq(c)/N với freq(c) là tần suất của c
và N là tổng số khái niệm.
- Cho bất kỳ công thức rel(c1, c2) để tính toán mối quan hệ (hay liên hệ) ngữ
nghĩa giữa hai khái niệm c1 và c2, khi đó mối liên hệ rel (w1, w2) giữa hai từ w1
và w2 được tính như sau, rel(w , 1 w2) = {rel(c , 1 c2)} max . 1 c S ∈ ( w ) 1 , c2 S ∈ ( w2) Trong đó S( )
w là tập hợp các khái niệm trong cùng một phân loại mà ở đó
mang ý nghĩa của từ w. Như vậy, mức độ của mối liên hệ giữa hai từ là bằng mối
liên hệ gần nhất của các cặp từ mà chúng thể hiện ý nghĩa cho hai từ đó.
Sau đây chúng ta sẽ xem xét một số phương pháp xác định mối liên hệ giữ
nghĩa giữa hai từ (nói cách khác là mức độ tương tự ngữ nghĩa - sim) dựa trên
mạng từ WordNet (theo [Muf09, Nga10, Pta12]).
- Thứ nhất, phương pháp sử dụng độ dài đường nối giữa hai nút của cặp từ
cùng với trọng số của đường, tức là số lần đổi hướng trên đường nối: rel(w ,
1 w2) = C − len(w ,
1 w2) − k.turns(w , 1 w2)
trong đó, C và k là các hằng số và turns(w1,w2) là số lần đổi hướng đi trên
đường nối giữa hai từ w1 và w2.
- Thứ hai, phương pháp dựa trên độ dài đường nối hai từ và độ sâu của nút
cha chung thấp nhất giữa chúng:
2.depth(lso(c , 1 c2)) sim(c , 1 c2) = len(c , 1 lso(c ,
1 c2)) + len(c , 2 lso(c ,
1 c2)) + 2.depth(lso(c , 1 c2))
- Thứ ba, phương pháp của Wu và Palmer, độ tương tự được xác định bởi độ
sâu của hai khái niệm trong Wordnet và độ sâu của nút cha chung thấp nhất của chúng:
Đề tài Khoa học Công nghệ cấp Viện 2014 (mã số: V33.2014) 16
Nghiên cứu độ đo tương đồng văn bản trong tiếng Việt và ứng dụng
2.depth(lso(c , 1 c2)) sim(c , 1 c2) = depth(c ) 1 + depth(c2)
- Thứ tư, phương pháp Resnik, mức độ liên hệ ngữ nghĩa giữa hai khái niệm
được xác định dựa trên mức độ chia sẽ thông tin giữa chúng và nó là hàm lượng
thông tin (IC) của nút cha chung thấp nhất: sim(c ,
1 c2) = IC(lso(c , 1 c2)) .
- Thứ năm, Jiang và Conrath, cũng sử dụng khái niệm hàm lượng thông tin
nhưng ở dạng xác suất có điều kiện, tức xác suất bắt gặp một nút con khi đã có một cha: 1 sim(c , 1 c2) = . IC(c )
1 + IC(c2) − 2IC(lso(c , 1 c2))
- Thứ sáu, Yuhua Li và cộng sự, mức độ mối liên hệ ngữ nghĩa giữa hai từ là
một hàm phi tuyến mà nó kết hợp giữa độ dài đường ngắn nhất giữa hai từ và độ
sâu của nút cha chung thấp nhất, được tính như sau:
β .depth (lso ( w , 1 w2))
− β .depth (lso ( w , 1 w2)) α − − e e .len(w , 1 w2) sim(w , 1 w2) = e . ,
β .depth (lso ( w , 1 w2))
−β .depth (lso ( w , 1 w2)) e + e
trong đó α∈[0,1] và β∈(0,1] là các hằng dùng để điều chỉnh tỷ lệ giữa độ dài
đương nối hai từ và độ sâu nút cha chung thấp nhất của chúng.
Trên cơ sở các phương pháp xác định độ tương tự ngữ nghĩa giữa các cặp từ,
nhiều tác giả đã đề xuất phương pháp xác định độ tương tự giữa hai câu, chẳng
hạn S1 và S2. Trong đó, theo [Pta12], Yuhua Li và cộng sự đã đề xuất một tiếp
cận véc-tơ ngữ nghĩa (hay véc-tơ đặc trưng) để tính toán độ tương tự câu. Các
câu được dùng để xác định các vector đặc trưng theo các từ trong tập giao T gồm
các từ phân biệt của hai câu.
T = words(S )
1 ∪ words(S 2) ,
với words(S) là tập các từ vựng có trong câu S, gọi số từ của tập T là N.
Giá trị của một thành phần trong véc-tơ đặc trưng ngữ nghĩa của một câu
được xác định bởi sự tương đồng ngữ nghĩa của một từ w t
i ương ứng trong tập T
với một từ w trong câu j
đó. Từ wj được chọn là từ có độ tương tự lớn nhất với từ
w iđã xem xét. Độ tương tự này phải vượt ngưỡng quy định trước, nếu không nó
Đề tài Khoa học Công nghệ cấp Viện 2014 (mã số: V33.2014) 17
Nghiên cứu độ đo tương đồng văn bản trong tiếng Việt và ứng dụng
sẽ được thiết lập giá trị 0. Tính toán giá trị của mỗi thành phần vi trong véc-tơ đặc trưng V1={v1 : i
i=1…N} của câu S1 như sau,
v = rel(w , w ) * I (w ) * I (w ) 1 . i i 1 j i 1 j Trong đó, từ w
i ∈ T là từ thứ i trong tập T, w1j ∈S1 là từ thứ j trong câu S1,
I(w) là trọng số thông tin của từ w và được tính là, log(n + ) 1 I (w) = 1 − , log(N + ) 1
với n là tần suất xuất hiện của từ w trong cả hai câu và N là tổng số từ của cả
hai câu. Tương tự với cách tính véc-tơ đặc trưng V2 của câu S2.
Theo [Tha14], độ tương tự ngữ nghĩa của hai câu S1 và S2 có thể được tính
dựa trên véc-tơ đặc trưng V1 và V2 bằng các phương pháp sau: - Tính theo cosin: r r r r V V . ∑N v v 1 2 i= i 1 i 1 2
sim(S , S ) = cos V ( ,V ) = r r = 1 2 1 2 | , V | . | V | 1 2 ∑N v2 . v2 i 1 ∑N i=1 i= 2i 1
- Tính theo mức độ tương quan:
∑N (v −V )(v −V ) i= i 1 1 2i 1 2
sim(S , S ) = 1 2 ∑ , N N (v − V 2 ) . (v V 2 ) i 1 1 ∑ − i=1 i= 2i 1 2 - Tính theo Jaccard:
∑N min(v ,v ) i 1 i 1 2 i=
sim(S , S ) = 1 2 ∑N , max(v , v ) i= i 1 i 1 2 - Tính theo Die:
2∑N min(v , v ) i 1 i 1 2 i=
sim(S , S ) = 1 2 ∑N , (v + v ) i= i 1 i 1 2
Chúng ta có thể mở rộng cho việc đánh giá độ tương tự giữa hai đoạn văn
hoặc cả hai văn bản và sẽ được trình bày ở phần sau.
Đề tài Khoa học Công nghệ cấp Viện 2014 (mã số: V33.2014) 18
Nghiên cứu độ đo tương đồng văn bản trong tiếng Việt và ứng dụng
1.3. Vấn đề về sự sao chép hay đạo văn và một số kỹ thuật
Đạo văn, theo [Abu12], có thể được hiểu theo nhiều khía cạnh, chẳng hạn
như sao chép, cắt dán, hoặc trích tóm lược của văn bản, đạo ý tưởng, và đạo văn
thông qua việc dịch văn bản từ ngôn ngữ này sang ngôn ngữ khác. Những loại
đạo văn này rõ ràng là một trong những vấn đề nghiêm trọng trong lĩnh vực học
thuật. Một nghiên cứu [Abu12] cho thấy 70% sinh viên thú nhận đã có một vài
đạo văn, với khoảng một nửa trong đó mang hành vi phạm tội gian lận trên các
bài viết luận. Thêm vào đó, 40% sinh viên thú nhận sử dụng phương pháp "cắt
dán" để hoàn thành bài luận của mình. Phân biệt giữa các tài liệu ăn cắp ý tưởng
và tài liệu không ăn cắp ý tưởng một cách hiệu quả là một trong những vấn đề
chính trong lĩnh vực phát hiện đạo văn.
Có rất nhiều công cụ phần mềm hiện có để xác định việc đạo văn. Tuy nhiên,
nhìn chung trong thực tế những phương pháp đạo văn này là khó xác định. Một
số phương pháp bao gồm sao chép các đoạn văn bản, trích dẫn (đại diện cho
cùng một nội dung trong các từ khác nhau), sử dụng nội dung mà không trích
dẫn tham khảo, khéo léo trình bày (trình bày cùng một nội dung nhưng sử dụng
các hình thức khác nhau), sao chép mã chương trình (sử dụng mã lệnh chương
trình mà không được sự cho phép hay trích dẫn), thông tin sai lệch của tài liệu
tham khảo (thêm tham chiếu đến không chính xác hoặc không tồn tại nguồn).
Để giải quyết các loại đạo văn này cần một phiên bản nâng cao của việc kết
hợp các thuật toán là cần thiết để giảm sự không trung thực trong môi trường học thuật.
Phương pháp xác định sự sao chép hay đạo văn trong các tài liệu, theo đề
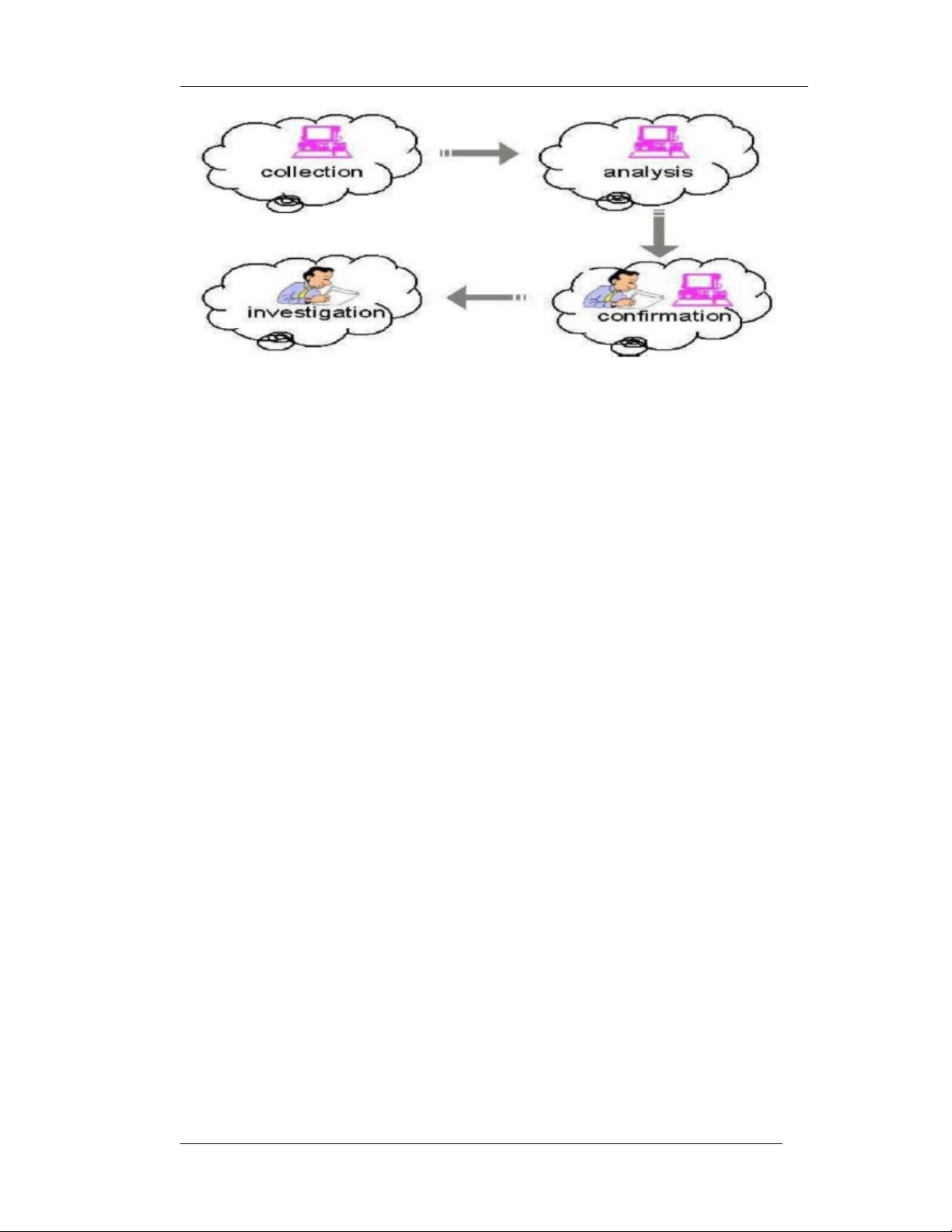
cập trong [Abu12], hai tác giả Lancaster và Culwin đã xác định các giai đoạn
quan trọng được nhiều nhà nghiên cứu sử dụng để phát hiện đạo văn như thu
thập, phân tích, xác nhận và điều tra.
Đề tài Khoa học Công nghệ cấp Viện 2014 (mã số: V33.2014) 19
Nghiên cứu độ đo tương đồng văn bản trong tiếng Việt và ứng dụng
Hình 2.2: 4 giai đoạn của quá trình phát hiện đạo văn
- Giai đoạn 1 – thu thập: Đây là giai đoạn đầu tiên của quá trình phát hiện
đạo văn, và nó đòi hỏi các sinh viên hoặc tác giả nghiên cứu tải lên các kết quả
hoặc bài viết thông qua công cụ web, các công cụ web hoạt động như một giao
diện giữa các người dùng và hệ thống. Quá trình sẽ tạo nên một kho ngữ liệu
(corpus) bao gồm nhiều các tài liệu văn bản được thu thập.
- Giai đoạn 2 – phân tích: Trong giai đoạn này tất cả các tài liệu, văn bản
trong kho ngữ liệu đã thu thập (corpus) sẽ được đưa vào một máy đánh giá độ
tương tự (engine) để xác định mức độ tương đồng giữa tài liệu này với các tài
liệu khác. Có hai loại máy đánh giá độ tương tự, thứ nhất là đánh giá trong tức
đưa ra danh sách các cặp tài liệu có mức độ tương đồng từ cao xuống thấp, thứ
hai, ngược lại, là đánh giá ngoài tức sẽ trả về kết quả những đường dẫn web có
chứa nội dung tương tự.
- Giai đoạn 3 – xác nhận: Chức năng của giai đoạn này là xác định xem các
văn bản có liên quan đã bị ăn cắp ý tưởng từ các văn bản khác hoặc xác định nếu
có một mức độ cao của sự tương đồng giữa một tài liệu và các tài liệu khác.
- Giai đoạn 4 – điều tra: Đây là giai đoạn cuối cùng của quá trình phát hiện
đạo văn và nó dựa vào sự can thiệp của con người. Trong giai đoạn này, một
chuyên gia có trách nhiệm xác định sự đúng đắn của hệ thống, tức là xem xét kết
quả đánh giá của hệ thống có thực sự đạo văn hay chỉ đơn giản là sự trích dẫn khoa học.
Tất cả bốn giai đoạn này phụ thuộc vào việc thừa nhận sự giống nhau giữa
các tài liệu và kết quả dựa trên một thuật toán hiệu quả để tìm ra những điểm
tương đồng giữa các tài liệu. Ngoài ra còn có một yếu tố phức tạp cần nhiều thời
Đề tài Khoa học Công nghệ cấp Viện 2014 (mã số: V33.2014) 20
Tài liệu liên quan:
-

Giáo trình Triết học Mác-Lênin - Ngôn ngữ học đối chiếu | Đại học Mở Hà Nội
401 201 -

The advantages of corporal punishment - Ngôn ngữ học đối chiếu | Đại học Mở Hà Nội
316 158 -

Đề kiểm tra tự luận viết Tiếng Anh 5 - Ngôn ngữ học đối chiếu | Đại học Mở Hà Nội
557 279 -

Describe one of your typical days - Ngôn ngữ học đối chiếu | Đại học Mở Hà Nội
314 157