Cài đặt và cấu hình Hadoop trên máy master | Môn Mạng máy tính - Đại học Cần Thơ
Cài đặt và cấu hình Hadoop trên máy master Môn Mạng máy tính. Tài liệu được sưu tầm gồm 9 trang, giúp bạn ôn tập tốt hơn. Mời các bạn đón xem.
Môn: Mạng máy tính (CT112) 36 tài liệu
Trường: Trường Đại học Cần Thơ 804 tài liệu
Tác giả:





Preview text:
lOMoAR cPSD| 58507440
Nguyen Thi Diem Huong B2104771
**Cài ặt thông tin các máy
- Tạo ra 3 máy ảo: 1 master và 2 node (chỉ chủ yếu cài ặt thông tin tren máy master là chính)
+ gõ lệnh: sudo nano /etc/hosts: ể
ặt tên cho các máy master và node (có thể
ặt tùy ý nhưng ặt master cho dễ phân biệt
+ gõ lệnh sudo nano /etc/hostname: ể thêm các
ịa chỉ vào kết nối và ping ược với nhau 192.168.1.33 master3 192.168.1.32 node2
192.168.1.34 node4 => nếu làm trên cùng 1 máy và tạo 3 máy ảo thì dùng luôn ịa chỉ của máy ảo ó => Kiểm tra xem ã kết nối
ược chưa bằng cách ping tới add_IP hoặc tên node
- Tạo người dùng hadoop: adduser hadoop password: abc123
=> Đăng nhập vào người dùng hadoop: su hadoop {
**Cài ặt SSH trên cả 3 máy
- sudo nano apt-get update: cập nhật
- sudo nano apt-get install openssh-server: tải ssh xuống
- Tạo 1 khóa trên master: ssh-keygen -b 4096
- ***=> Có thể dùng lệnh này ể copy file chứa khóa xuống 2 máy còn lại: ssh-copy-
id -i ~/.ssh/id_rsa.pub hadoop@node2
=> khỏi làm phần còn lại
- Xem khóa bằng lệnh: less /home/hadoop/.ssh/id_rsa.pub và copy khóa vào 1 chỗ nhớ tạm trên master
- master tạo 1 tệp master.pub: sudo nano /home/hadoop/.ssh/master.pub => Dán khóa ã copy vào
- Đăng nhập vào các node2 bằng lệnh ssh node2
+ Tạo khóa bằng lệnh: ssh-keygen -b 4096
+ sudo nano /home/hadoop/.ssh/master.pub =>. Dán khóa ã copy vào
+ cat ~/.ssh/master.pub >> ~/.ssh/authorized_keys
=> làm tương tự cho node4
=> cat ~/.ssh/master.pub >> ~/.ssh/authorized_keys
** Cài ặt hadoop ở master - cd
- wget http://apache.cs.utah.edu/hadoop/common/current/hadoop-3.4.0.tar.gz : Tải hadoop xuống
- tar -xzf hadoop-3.4.0.tar.gz: Giải nén
- mv hadoop-3.4.0 hadoop : ổi tên thành hadoop
- Thêm ường dẫn vào File: /home/hadoop/.profile sudo nano /home/hadoop/.profile nội dung:
PATH=/home/hadoop/hadoop/bin:/home/hadoop/hadoop/sbin:$PATH lOMoAR cPSD| 58507440
- Thêm ường dẫn vào File: /home/hadoop/.bashrc - sudo nano /home/hadoop/.bashrc - nội dung:
export HADOOP_HOME=/home/hadoop/hadoop
export PATH=${PATH}:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin -
Sau khi chỉnh sửa cấu hình cần sài lệnh: source ~/.bashrc source ~/.profile ** Tải JDK-8 - sudo apt-get update
- sudo apt-get install openjdk-8-jdk : Tải gói jdk về
- java -version : check xem JDK
ã cài ặt thành công chưa
- update-alternatives --display java : Xem ường dẫn của JDK ã cài ặt
- Mở file sudo nano ~/hadoop/etc/hadoop/hadoop-env.sh và chỉnh sửa cho export JAVA_HOME:
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64/jre
**Set NameNode Location
- Vào file sudo ~/hadoop/etc/hadoop/core-site.xml - Thêm vào:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?> fs.default.name hdfs://master3:9000 hadoop.tmp.dir /tmp/hadoop **Set HDFS
- Vào file nano ~/hadoop/etc/hadoop/hdfs-site.xml - Thêm vào: dfs.namenode.name.dir /home/hadoop/data/nameNode dfs.datanode.data.dir /home/hadoop/data/dataNode dfs.replication 2 lOMoAR cPSD| 58507440
**Set YARN as Job Scheduler
- Vào file nano ~/hadoop/etc/hadoop/mapred-site.xml - Thêm vào: mapreduce.framework.name yarn yarn.app.mapreduce.am.env
HADOOP_MAPRED_HOME=$HADOOP_HOME mapreduce.map.env
HADOOP_MAPRED_HOME=$HADOOP_HOME mapreduce.reduce.env
HADOOP_MAPRED_HOME=$HADOOP_HOME **Set YARN
- Vào file nano ~/hadoop/etc/hadoop/yarn-site.xml - Thêm vào: yarn.acl.enable 0 yarn.resourcemanager.hostname master3 yarn.nodemanager.aux-services mapreduce_shuffle **Configure Workers
- Vào file nano ~/hadoop/etc/hadoop/workers - Thêm vào: lOMoAR cPSD| 58507440 node2 node4
* Chỉnh sửa /home/hadoop/hadoop/etc/hadoop/yarn-site.xml và thêm các dòng
sau: sudo nano ~/hadoop/etc/hadoop/yarn-site.xml Thêm những oạn này vào phía sau:
yarn.nodemanager.resource.memory-mb 1536
yarn.scheduler.maximum-allocation-mb 1536
yarn.scheduler.minimum-allocation-mb 128
yarn.nodemanager.vmem-check-enabled false
*Chỉnh sửa /home/hadoop/hadoop/etc/hadoop/mapred-site.xml và thêm các
dòng sau: sudo nano ~/hadoop/etc/hadoop/mapred-site.xml Thêm các dòng sau:
yarn.app.mapreduce.am.resource.mb 512 mapreduce.map.memory.mb 256 mapreduce.reduce.memory.mb 256 ** Nhân ôi - cd /home/hadoop
- scp hadoop-*.tar.gz node1:/home/hadoop lOMoAR cPSD| 58507440
- scp hadoop-*.tar.gz node2:/home/hadoop
=> Copy file hadoop-*.tar.gz xuống - Kết nối qua các
nút ể giải nén file ssh node2
tar -xzf hadoop-3.4.0.tar.gz mv hadoop-3.4.0 hadoop exit
- node4 làm tương tự node2
- for node in node2 node4; do
scp ~/hadoop/etc/hadoop/*
$node:/home/hadoop/hadoop/etc/hadoop/; done
=> nếu k dùng người dùng hadoop thì for node in node2 node4; do
scp ~/hadoop/etc/hadoop/*
$node:/home/student/hadoop/etc/hadoop/; done ** Format HDFS
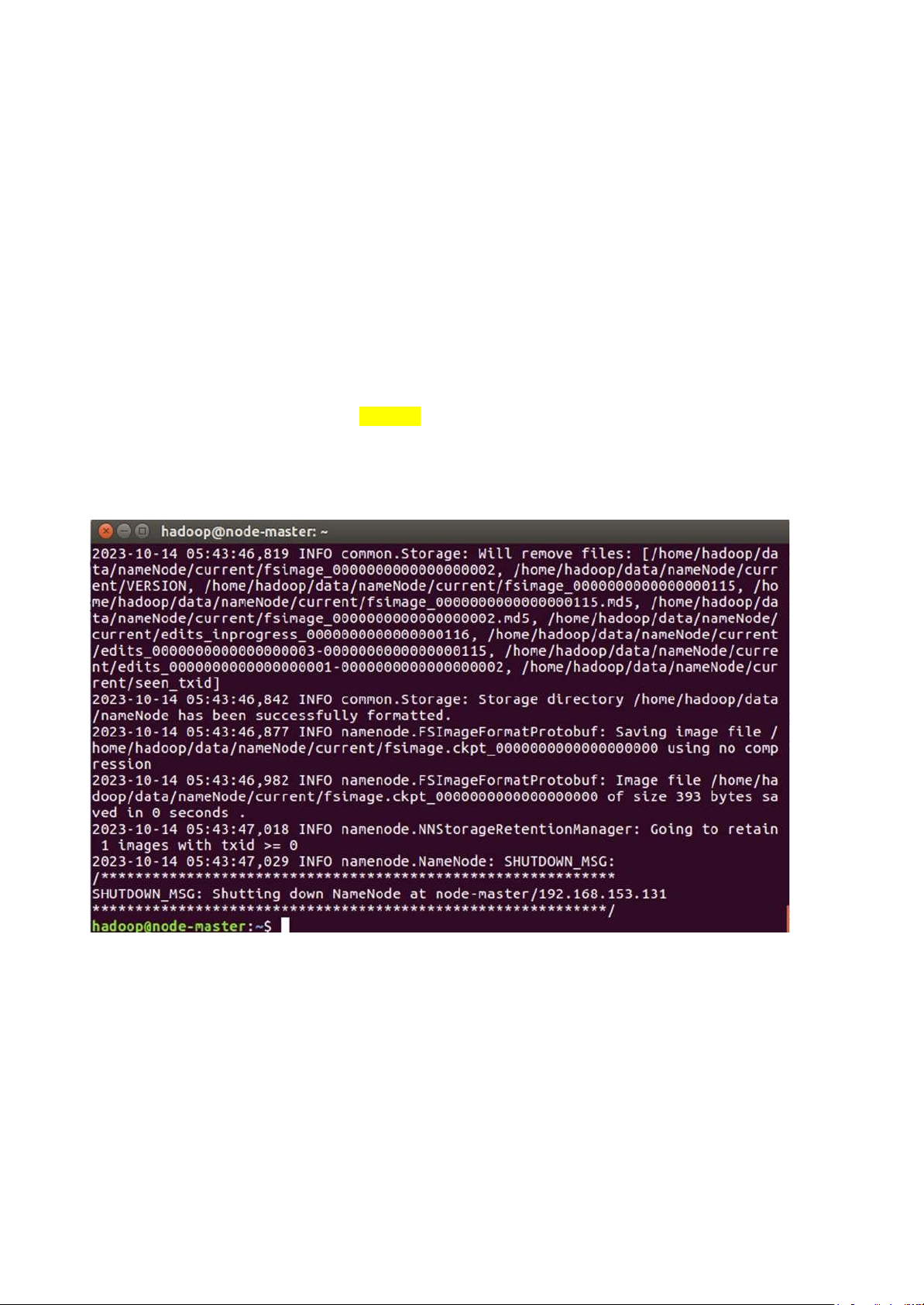
chạy trên Master: hdfs namenode -format
=> như này là thành công
**Chạy và giám sát HDFS
Start and Stop HDFS
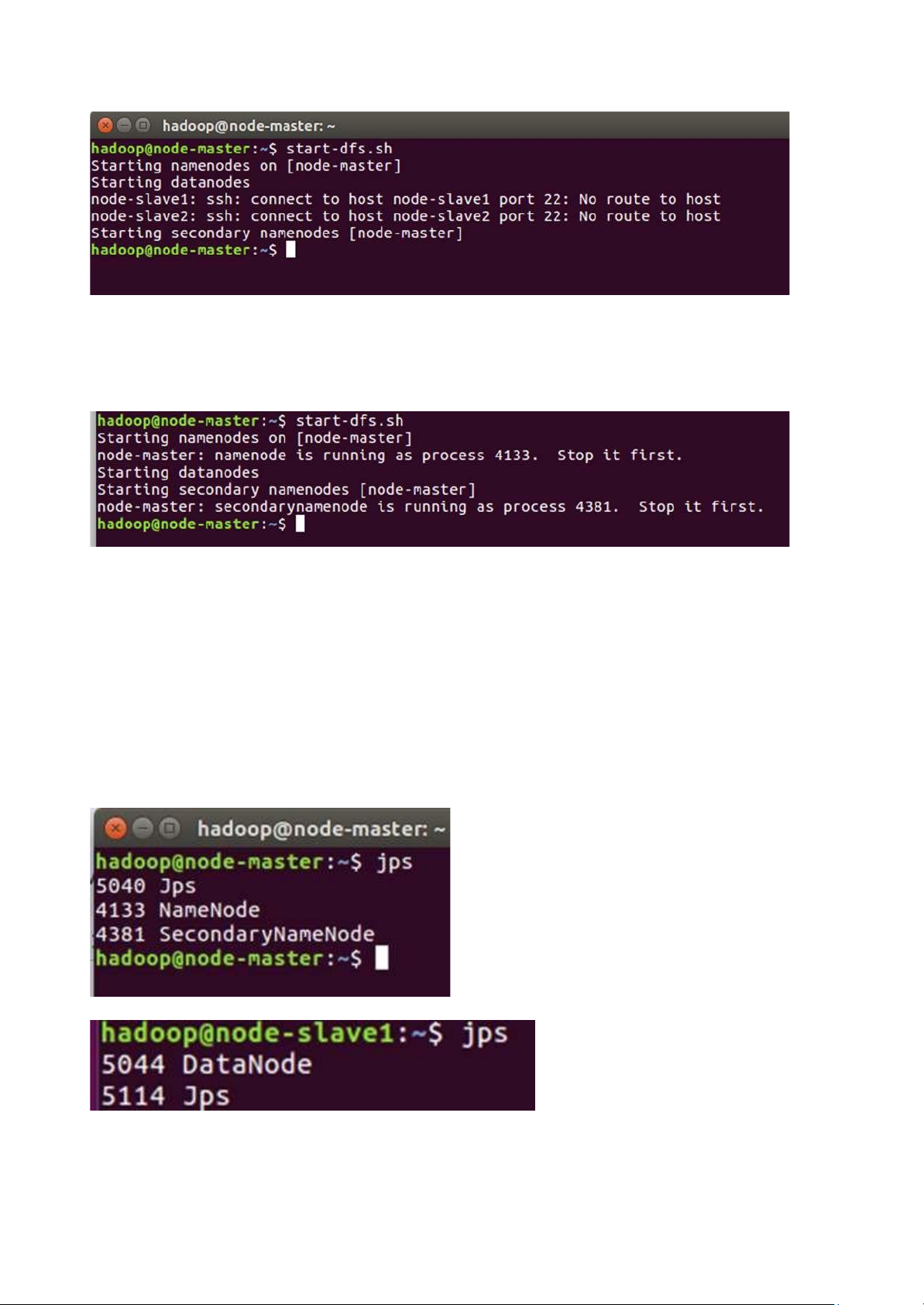
Khởi chạy HDFS bằng cách chạy tập lệnh sau từ node-master: start-dfs.sh lOMoAR cPSD| 58507440
=>Nếu nó hiển thị là no route to host tức là 2 node ang chưa có mạng, do ể lâu thì mạng tự tắt, nên qua 2 node
ó bấm vào biểu tượng mũi tên lên xuống --> bấm vào wireless connection
một lần là nó sẽ có mạng
Chạy lại lệnh start-dfs.sh
Stop it first là ã ược khởi tạo rồi
Thao tác này sẽ khởi ộng NameNode và PrimaryNameNode trên nút-master và DataNode trên
node-slave1 và node-slave2, theo cấu hình trong tệp cấu workers config file
Kiểm tra xem mọi tiến trình có
ang chạy bằng lệnh jps trên mỗi nút hay không. Trên node-
master, bạn sẽ thấy thông tin sau (số PID sẽ khác): gõ lệnh: jsp
-Kết quả trên master
-Kết quả trên node
=> Lưu ý: khi jps ở 2 node phải thấy ược DataNode xuất hiện thì start mới thành công. nếu không
thấy hãy kéo xuống chỉ dẫn cuối trang. lOMoAR cPSD| 58507440
Để dừng HDFS trên node-master and worker nodes, hãy chạy lệnh sau từ node-master: stop-dfs.sh
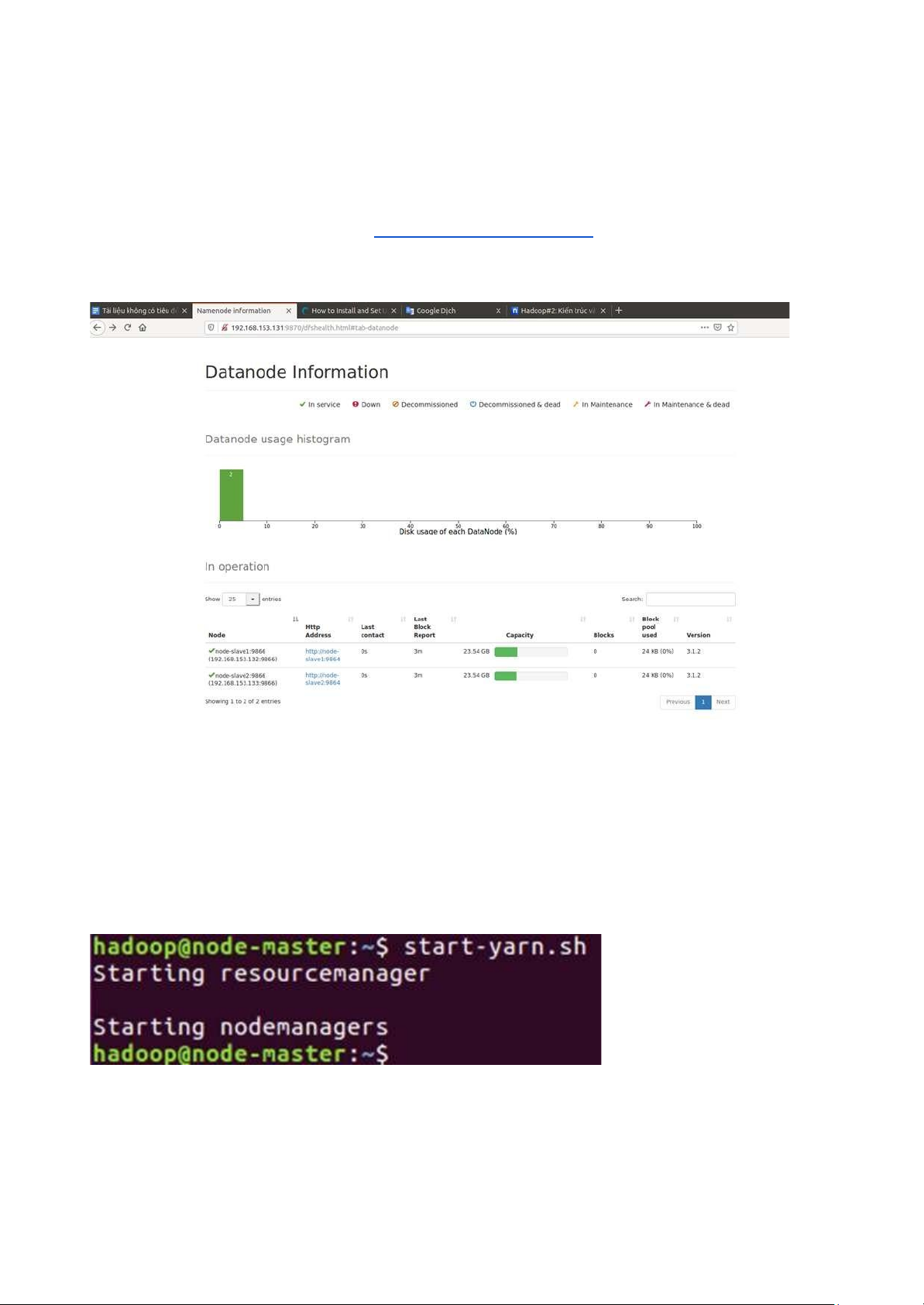
**Giám sát cụm HDFS của bạn -Lên trên web gõ
ịa chỉ của máy: http://node-master-IP:9870 -Đúng
sẽ có giao diện như này: **RUN YARN Start and Stop YARN
1. Start YARN with the script: start-yarn.sh
-Cho ra kết quả như vậy là úng, nếu chưa úng kiểm tra lại cấu hình
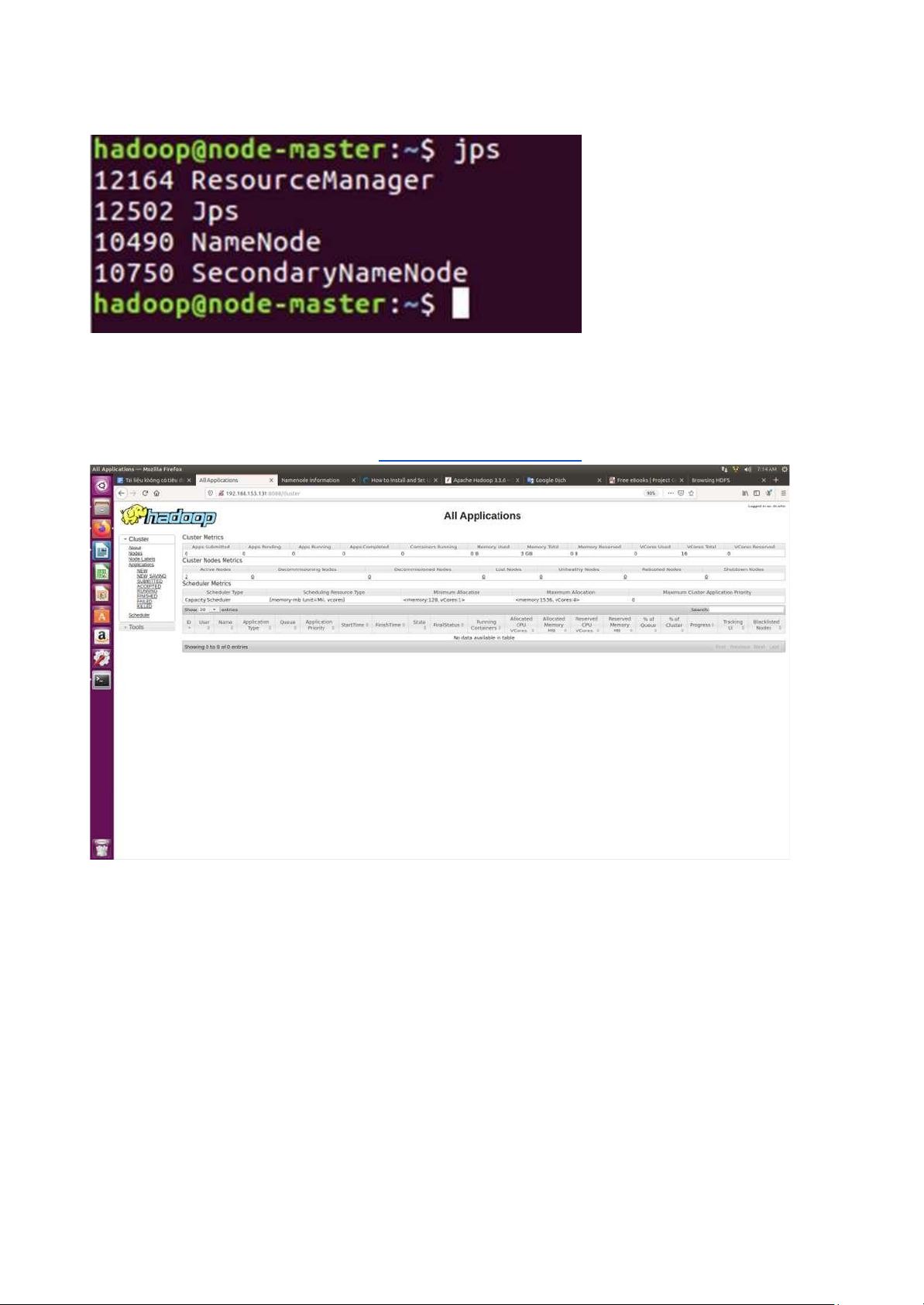
2.Kiểm tra mọi thứ có ang chạy bằng lệnh jsp
-master sẽ có thêm ResourceManager lOMoAR cPSD| 58507440
-node có thêm NodeManager
3. Để dừng YARN, hãy chạy lệnh sau trên node-master: stop-yarn.sh
4. Kiểm tra qua giao diện: lên web gõ: http://node-master-IP:8088
ĐẨY FILE TỪ MÁY CỤC BỘ LÊN HADOOP
** THỰC HÀNH BUỔI 2 Nội dung: ếm từ
1. Tạo thư mục data trên hadoop bằng cách gõ lệnh: hadoop fs -mkdir /data/ hadoop fs -
mkdir /data/input hadoop fs -mkdir /data/output 2. Tải file có dữ liệu ể ếm ặt tên là salary.txt ể trong home 3. Đẩy file
ó lên hadoop và vào thư mục /data/input/input1 lệnh: hadoop fs -put
salary.txt /data/input/input1 4. mở file ~./bashrc thêm ường dẫn này vào
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64 export
HADOOP_HOME=/home/hadoop/hadoop export
HADOOP_INSTALL=$HADOOP_HOME export lOMoAR cPSD| 58507440
HADOOP_MAPRED_HOME=$HADOOP_HOME export
HADOOP_COMMON_HOME=$HADOOP_HOME export
HADOOP_HDFS_HOME=$HADOOP_HOME export
HADOOP_YARN_HOME=$HADOOP_HOME export
HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export
PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin export
HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native" export
HADOOP_CLASSPATH=${JAVA_HOME}/lib/tools.jar 5. source ~/.bashrc
6. Tạo thư mục wc => làm ở master sudo mkdir wc cd wc
7. tải file WordCount.java của thầy xuống
ể trong thư mục wc => khi chạy sẽ có 3 file .class
hadoop com.sun.tools.javac.Main WordCount.java
8. nén 3 file .class lại: jar cf wc.jar WordCount*.class
9. chạy hadoop file hadoop jar wc.jar WordCount /data/input/input1 /data/output/wcout1
10. Để xem file chạy ra kết quả nào vào hadoop trên web chỗ Browser download file ó về và
xem bằng cách hadoop dfs -cat
/data/output/wcout1/part-*
Tài liệu liên quan:
-

Bài Thực Hành 3: Mạng LAN và Giao Thức ARP | Môn Mạng máy tính - Đại học Cần Thơ
166 83 -

Mô phỏng mạng bằng dòng lệnh | Môn Mạng máy tính - Đại học Cần Thơ
104 52 -

Mô Phỏng Mạng Ảo và Dịch Vụ Linux Bridge | Môn Mạng máy tính - Đại học Cần Thơ
182 91 -

Chương 7: Tầng Vận Chuyển trong Mạng Máy Tính | Môn Mạng máy tính - Đại học Cần Thơ
113 57 -

Chương 8: Tầng Ứng Dụng Trong Mạng | Môn Mạng máy tính - Đại học Cần Thơ
126 63