Comparison of Large Language Models | Tài liệu Tiếng Anh
Comparison of Large Language Models | Tài liệu Tiếng Anh
Môn: Tiếng Anh chuyên ngành 332 tài liệu
Trường: Tài liệu Tiếng Anh chuyên ngành, Tiếng Anh cho người đi làm 432 tài liệu
Tác giả:





Preview text:
See discussions, stats, and author profiles for this publication at: https://www.researchgate.net/publication/391448929
Comparison of Large Language Models (LLM)
Conference Paper · May 2025 CITATIONS READS 0 778 4 authors, including: Yuksel Celik
University at Albany, State University of New York
61 PUBLICATIONS 439 CITATIONS SEE PROFILE
All content following this page was uploaded by Yuksel Celik on 05 May 2025.
The user has requested enhancement of the downloaded file.
Comparison of Large Language Models (LLM) Yuksel Celik Lakshika Lakshika Sanjay Goel Information Security and Digital
College of Emergency Preparedness, Information Security and Digital Forensics
Homeland Security and Cybersecurity Forensics
University at Albany, State University
University at Albany, State University
University at Albany, State University of New York, Albany, NY, USA of New York, Albany, NY, USA of New York, Albany, NY, USA ycelik@abany.edu lvaishnav@abany.edu goel@albany.edu Orcid: 0000-0002-7117-9736 Sakshi Singh
University at Albany, State University
of New York College of Emergency
Preparedness, Homeland Security and
Cybersecurity, Albany, NY, USA ssingh29@albany.edu
In addition to these three major models, IBM's WatsonX
platform caters to corporate needs by providing tailored AI
Abstract—.
solutions, while Hugging Face's community-supported open-
source models, such as BLOOM[16] and Falcon[17], have
Keywords—Artificial Intelligence, Deep Learning,
become popular for research and development projects. Large Language Model
This study aims to provide an in-depth analysis of the I. INTRODUCTION
technical capacities, innovative features, and application
areas of prominent large language models. It will evaluate
The emergence of deep learning methods in the field of
which models are most suitable for specific use cases by
artificial intelligence (AI) has opened up opportunities for AI analyzing their strengths and weaknesses. This
applications across numerous domains. However, the rapid
comprehensive comparison seeks to provide a better
development of Large Language Models (LLMs) and their
understanding of the current state of AI technologies and their
exceptional capabilities has marked a transformative
potential future trajectories. The analysis serves as a guide for
milestone in the evolution of AI.
researchers and practitioners, facilitating the process of
LLMs, with their advanced features, have not only
selecting the most appropriate AI solution.
simplified many tasks in daily life but have also found
II. LARGE LANGUAGE MODELS (LLMS)
extensive use in scientific research[1], healthcare[2][3][4][5],
law[6], materials science[7], biology[8], education[9],
A. General Framework of LLMs
software development[10], autonomous systems[11], and
Large Language Models (LLMs) are deep learning-based
manufacturing[12]. OpenAI's ChatGPT[13] was the first
models trained on extensive datasets to acquire human-like
LLM to be introduced, bringing widespread adoption due to
abilities in understanding, generating, and manipulating
its creative text generation and strong logical reasoning
language. Their fundamental working principles are outlined
capabilities. Subsequently, Google developed Gemini[14], in the following stages:
which is distinguished by its multimodal capabilities,
processing textual and visual data simultaneously, making it
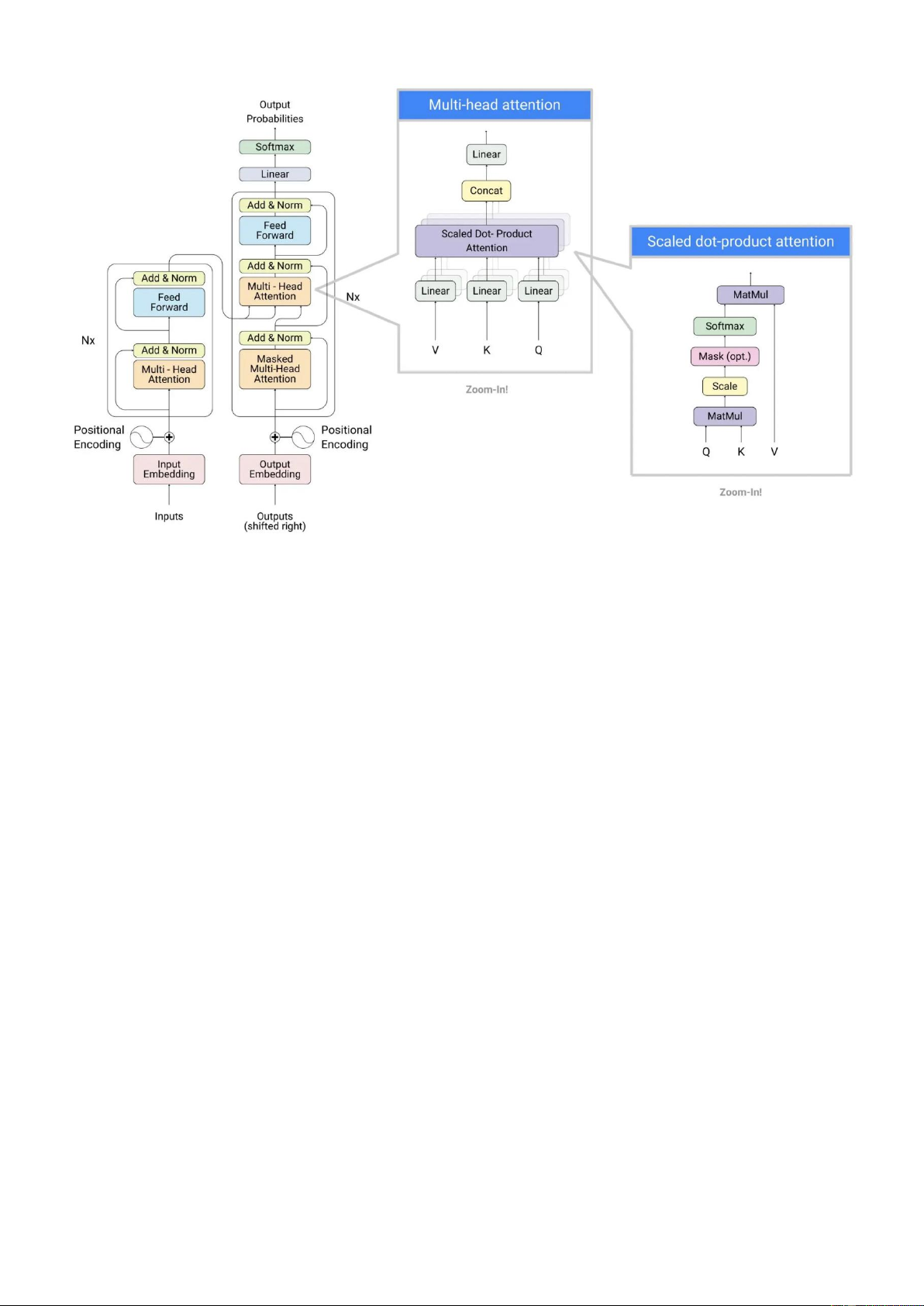
1) Transformer Architecture
particularly effective in applications such as search engines
Most LLMs are built upon the Transformer architecture, as
and creative assistants. Meta followed with the development
illustrated in Figure 1 [18]. The primary strength of this
of the LLaMA[15] models, which adopt an open-source
architecture lies in its utilization of the attention mechanism.
approach to deliver innovative solutions, especially for the
academic and research communities.
XXX-X-XXXX-XXXX-X/XX/$XX.00 ©20XX UAKK
Fig. 1 The Transformer Architecture and Multi-Head attention mechanism
Attention Mechanism: This neural network architecture
Loss Function: Cross-entropy loss is typically used to
enables a deep learning model to focus on specific and
minimize the difference between the model outputs and true
relevant aspects of the input data. It allows machines to better values.
understand the input and generate appropriate outputs. The
3) Model Parameter Size workflow includes:
Self-Attention: Enables each word (or token) in a
LLMs can contain hundreds of billions to trillions of
sentence to learn its relationship with other words, allowing
parameters. The larger the number of parameters, the better
for meaningful contextual relationships to be established.
the performance. These parameters include:
Multi-Head Attention: Facilitates parallel processing of
Weight Matrix: Learns the relationships between words
attention mechanisms across different "heads," enabling the and contexts.
model to learn various contexts simultaneously.
Number of Layers: Deeper models can learn more
Positional Encoding: Since Transformers work with complex relationships.
sequential data, positional encoding adds position
Hidden Size: Determines the information processing
information to tokens to help the model learn the order of capacity within each layer. words. 4) Prediction in LLMs
2) LLM Training Process
Once training is complete, the model can make
The initial steps in training LLMs involve data processing predictions on new data: and tokenization:
Input: A sequence of tokens is fed into the model and
Data Collection: Models are typically trained on a wide
converted into numerical vectors in the embedding layer.
variety of textual data, including web pages, books, datasets,
Contextual Processing: Inputs are processed through articles, and code.
Transformer layers to learn contextual relationships.
Tokenization: Text is divided into words or subword
Output Generation: At each step, the model generates a
units (tokens), using algorithms like Byte Pair Encoding
token probability distribution and selects the most likely
(BPE) [19] or SentencePiece [20]. token.
Language Modeling Tasks:
5) Optimization Techniques
Learning Probability Distributions: The model learns
the probability distribution of a token within its context.
Efficient training of large models involves the following
Causal Language Modeling (CLM): Predicts future techniques: tokens (e.g., GPT models).
Distributed Training: Distributes data and the model
Masked Language Modeling (MLM): Predicts
across multiple processors (GPU/TPU) for parallel
randomly masked tokens (e.g., BERT). processing.
Mixed Precision: Combines 16-bit and 32-bit operations BLOOM Transforme 176 billion CLM Text
to reduce memory and computation costs. (Hugging r base parameters Face)
Fine-Tuning: Trains the model on a broad dataset for
general knowledge and then fine-tunes it on specific tasks
In Table 1, a comparison based on architectural structures with specialized data.
reveals that all models utilize the Transformer architecture at
III. MOST POUPULAR LLMS AND COMPARISONS
their core. Their parameter counts exceed billions, and they
employ Causal Language Modeling (CLM) as the attention A. ChatGPT
mechanism. Additionally, text is observed to be the primary
OpenAI's ChatGPT series (GPT-3, GPT-3.5, GPT-4) input data for all models.
stands out for its broad language understanding and creative
Gemini stands out from the other models with its
content generation capabilities. These models are widely
multimodal capabilities in both architecture and attention
utilized in various areas, including chatbots, content creation,
mechanisms. Unlike the others, Gemini can process not only
code writing, and summarization. With a robust API
textual data but also visual data and tables as input, making it
ecosystem, ChatGPT can be seamlessly integrated into
uniquely suited for diverse applications.
different platforms, addressing the needs of users across a wide range of languages [21].
TABLE 2. MODEL TRAINING PROCESSES
B. Google DeepMind (Gemini/AlphaCode) Model Training Data Training Objecti
Google's Gemini and AlphaCode models offer advanced Dara Processing Method ve
capabilities in language understanding, code generation, and Functio
multimodal (text and visual) processing. These models are n
particularly useful for search engine enhancements, creative ChatGPT- A large text Owned and Pre- Cross 4 dataset, optimized training + Entropy
assistants, and scientific research. Their strong integration (OpenAI) books, web data Fine Loss +
with Google’s product ecosystem provides users with both pages processing tuning Human
functional and creative solutions [22]. (with Feedbac RLHF) k C. Meta (LLaMA Series) (RLHF)
Meta’s LLaMA models (LLaMA 1 and LLaMA 2) are Gemini Multimodal Specialized Pre- Cross
open-source AI models designed for research purposes. (Google) data (text + processing for training + Entropy
These models are well-suited for academic projects and images) multimodality Fine- Loss +
community-driven development efforts. Their open access to tuning Visual Loss
the research community allows for continuous improvement LLaMA Academic Academic- Pre- Cross by contributors [23]. (Meta) articles, oriented data training Entropy internet data filtering Loss
D. Hugging Face (BLOOM)
BLOOM, developed by Hugging Face, is notable for its BLOOM Open Open data and Pre- Cross
open-source and customizable nature. It is a popular choice (Hugging datasets community- training Entropy Face) based Loss
for research and development projects, supported by a large processing
developer community. The flexibility of customization
makes it applicable to a wide variety of projects [24].
An examination of Table 2 reveals that, in terms of
training methodology, ChatGPT-4 and Gemini distinguish
While the general working principles of LLMs are
themselves by incorporating fine-tuning in addition to their
similar, they differ structurally, resulting in unique
pre-training processes. This additional fine-tuning step
advantages and disadvantages depending on the application.
allows these models to achieve enhanced performance and
These differences are highlighted in the following tables:
adaptability for specific tasks compared to models that rely solely on pre-training.
Architectural Structures: Table 1,Model Training Processes:
Table 2,Performance and Competencies: Table 3,Usage
TABLE 3. PERFORMANCE AND COMPETENCIES Scenarios: Table 4,Chronological Development and
Improvements: Table 5,Languages Used in Training Data: Model Natural Code Multimo Speed Language Generation dality and Table 6 Generation Efficien cy
TABLE 1. COMPARISON ACCORDING TO ARCHITECTURAL STRUCTURES ChatGPT- Highly Advanced Text- High Model Basic Model Attention Input 4 successful level in based accuracy Architectu Architecture Mechanis Data (OpenAI) in producing coding tasks only , slower re m human-like ChatGPT- Transforme 175+ billion CLM Text text 4 r base parameters Gemini Rich content Code Ability to Very (OpenAI) (Google) production generation is process fast, Gemini Transforme 1 trillion CLM+ Text, with multi- strong but not text, powerfu (Google) r + parameters Multimodal Visual modality as strong as images, l in Multimodal , Table capabilities GPT tables context abilities combine LLaMA Transforme 7B, 13B, 65B CLM Text d with (Meta) r base (different size) visuals LLaMA Strong Limited in Text- Lighter LLaMA (Meta) 20+ Widely spoken languages, with (Meta) understandi code based and less focus on niche ones ng of text generation only faster BLOOM (Hugging 46 Multilingual inclusivity, production Face) including low-resource and context languages BLOOM Text Intermediate Text- Good (Hugging production code based perform
According to Table 6, a comparison of the languages Face) and open generation only ance on source large
included in the training data shows that ChatGPT-4 ranks first contribution data sets
with the most extensive language support, followed by Gemini.
As per Table 3, a comparison of natural language IV. DISCUSSION
processing performance indicates that ChatGPT-4 stands out
Although LLMs utilize similar AI methodologies, their
with superior performance, showcasing its ability to generate
processed data sources and structural differences result in
human-like text more effectively than its counterparts.
distinct advantages and disadvantages depending on the intended use case. TABLE 4. AREAS OF USAGE
ChatGPT stands out as a leader due to its strong language Model Chat Search Scientifi Open
generation capabilities, enabling superior human-like text Apps Engine c Source
production, broad usage scenarios, and user-friendly design. Ability Researc
However, its lack of multimodal capabilities and high h
operational costs are considered its key weaknesses.
Gemini benefits from seamless integration with the Google ChatGP Yes Limited Medium No T-4 level
ecosystem and its multimodal capabilities, enabling the (OpenAI
combination of various data types to support innovative )
applications. Despite these strengths, its weaknesses include Gemini Yes Google Powerfu No
being a closed-source model and having limited accessibility. (Google) search l
LLaMA, with its open-source and research-oriented design, integration
is a powerful tool for academic environments. However, its
limited training data and weaker performance in practical LLaMA Yes Limited Academ Yes
applications are notable disadvantages. (Meta) ically
BLOOM, supported by Hugging Face's community-driven oriented
open-source approach, offers extensive datasets and strong BLOOM Yes No Researc Yes (Huggin h-
customization capabilities, making it highly flexible for g Face) oriented
different projects. Despite these strengths, its performance
does not match that of GPT or Gemini, and it requires
According to Table 4, all models support chat
significant resources, which are key limitations
applications as a common usage scenario. However, in terms V. CONCLUSION
of search engine capabilities, Gemini stands out due to its
integration with Google's search engine, providing a
significant advantage in this area. Conversely, BLOOM lacks
search engine functionality, limiting its applications in this domain. T VI. REFERENCES
ABLE 5. LLM MODELS CHRONOLOGICAL BREAKDOWN OF THE DEVELOPMENT AND IMPROVEMENTS [1]
S. Nerella et al., “Transformers and large language Model 2021 2022 2023 2024
models in healthcare: A review,” Artif Intell Med, ChatGPT- GPT-1,2,3 ChatGPT 3.5 GPT-4 GPT-4-o vol. 154, p. 102900, Aug. 2024, doi: 4 10.1016/j.artmed.2024.102900. (OpenAI) [2]
L. Verlingue, C. Boyer, L. Olgiati, C. Brutti Gemini LaMDA Pathways Gemini 1 Gemini (Google) 1.5
Mairesse, D. Morel, and J. Y. Blay, “Artificial LLaMA n/a n/a LLaMA 1 LLaMA 2
intelligence in oncology: ensuring safe and effective (Meta)
integration of language models in clinical practice,” BLOOM n/a BLOOM BLOOM BLOOM
The Lancet Regional Health - Europe, vol. 46, p. (Hugging Face) 101064, Nov. 2024, doi: 10.1016/J.LANEPE.2024.101064. [3]
A. A. Birkun and A. Gautam, “Large Language
TABLE 6. LLM MODELS LANGUAGES INCLUDED IN THE TRAINING DATA
Model-based Chatbot as a Source of Advice on First
Aid in Heart Attack,” Curr Probl Cardiol, vol. 49, Model Approx Description Languages no. 1, p. 102048, Jan. 2024, doi: ChatGPT-4 Almost all
Best for English, supports major
10.1016/J.CPCARDIOL.2023.102048. (OpenAI) languages global languages [4]
H. Hwai, Y. J. Ho, C. H. Wang, and C. H. Huang, Gemini (Google) 100+
Extensive multilingual support
“Large language model application in emergency via Google datasets
medicine and critical care,” Journal of the Formosan
2023, Accessed: Dec. 16, 2024. [Online]. Available: Medical Association, Aug. 2024, doi:
https://inria.hal.science/hal-03850124 10.1016/J.JFMA.2024.08.032. [17]
V. Agatha and I. Setyawan, “Web Chat-based [5]
R. Bommasani et al., “On the Opportunities and
Application with Large Language Model and
Risks of Foundation Models,” Aug. 2021, Accessed:
Transformers from Hugging Face for Self-Learning Dec. 16, 2024. [Online]. Available:
on Storytelling Skills,” 2024 International
http://arxiv.org/abs/2108.07258
Electronics Symposium: Shaping the Future: Society [6]
G. Lei, R. Docherty, and S. J. Cooper, “Materials
5.0 and Beyond, IES 2024 - Proceeding, pp. 614–
science in the era of large language models: a
618, 2024, doi: 10.1109/IES63037.2024.10665795.
perspective,” Digital Discovery, vol. 3, no. 7, pp. [18]
A. Vaswani et al., “Attention is All you Need,” Adv
1257–1272, Jul. 2024, doi: 10.1039/D4DD00074A.
Neural Inf Process Syst, vol. 30, 2017. [7]
M. Bhattacharya, S. Pal, S. Chatterjee, S. S. Lee, and [19]
T. Xu and P. Zhou, “Feature Extraction for Payload
C. Chakraborty, “Large language model to
Classification: A Byte Pair Encoding Algorithm,”
multimodal large language model: A journey to
2022 IEEE 8th International Conference on
shape the biological macromolecules to biological
Computer and Communications, ICCC 2022, pp.
sciences and medicine,” Mol Ther Nucleic Acids, vol. 2441–2445, 2022, doi: 35, no. 3, p. 102255, Sep. 2024, doi:
10.1109/ICCC56324.2022.10065977. 10.1016/J.OMTN.2024.102255. [20]
S. Choo and W. Kim, “A study on the evaluation of [8]
M. Haman and M. Školník, “Using ChatGPT to tokenizer performance in natural language
conduct a literature review,” Account Res, Dec. 2023,
processing,” Applied Artificial Intelligence, vol. 37, doi: no. 1, Dec. 2023, doi:
10.1080/08989621.2023.2185514/ASSET//CMS/AS
10.1080/08839514.2023.2175112. SET/02DB9456-4A9F-4BE0-A4D1- [21]
S. S. Gill and R. Kaur, “ChatGPT: Vision and
80AE8E1B5F2E/08989621.2023.2185514.FP.PNG.
challenges,” Internet of Things and Cyber-Physical [9]
T. Alqahtani et al., “The emergent role of artificial
Systems, vol. 3, pp. 262–271, Jan. 2023, doi:
intelligence, natural learning processing, and large 10.1016/J.IOTCPS.2023.05.004.
language models in higher education and research,” [22]
R. Islam and I. Ahmed, “Gemini-the most powerful
Research in Social and Administrative Pharmacy,
LLM: Myth or Truth,” 2024 5th Information
vol. 19, no. 8, pp. 1236–1242, Aug. 2023, doi:
Communication Technologies Conference, ICTC
10.1016/J.SAPHARM.2023.05.016. 2024, pp. 303–308, 2024, doi: [10]
R. A. Husein, H. Aburajouh, and C. Catal, “Large
10.1109/ICTC61510.2024.10602253.
language models for code completion: A systematic [23]
J. Yeom et al., “Tc-llama 2: fine-tuning LLM for
literature review,” Comput Stand Interfaces, vol. 92,
technology and commercialization applications,” J p. 103917, Mar. 2025, doi:
Big Data, vol. 11, no. 1, pp. 1–31, Dec. 2024, doi: 10.1016/J.CSI.2024.103917.
10.1186/S40537-024-00963-0/TABLES/10. [11]
L. Wang et al., “A survey on large language model [24]
B. Workshop et al., “BLOOM: A 176B-Parameter
based autonomous agents,” Front Comput Sci, vol.
Open-Access Multilingual Language Model Major
18, no. 6, pp. 1–26, Dec. 2024, doi: 10.1007/S11704-
Contributors Prompt Engineering Architecture and 024-40231-1/METRICS. Objective Engineering Evaluation and [12]
S. Colabianchi, F. Costantino, and N. Sabetta,
Interpretability Broader Impacts,” 2023.
“Assessment of a large language model based digital
intelligent assistant in assembly manufacturing,”
Comput Ind, vol. 162, p. 104129, Nov. 2024, doi:
10.1016/J.COMPIND.2024.104129. [13]
B. Li, V. L. Lowell, C. Wang, and X. Li, “A
systematic review of the first year of publications on
ChatGPT and language education: Examining
research on ChatGPT’s use in language learning and
teaching,” Computers and Education: Artificial
Intelligence, vol. 7, p. 100266, Dec. 2024, doi: 10.1016/J.CAEAI.2024.100266. [14]
M. Masalkhi, J. Ong, E. Waisberg, and A. G. Lee,
“Google DeepMind’s gemini AI versus ChatGPT: a
comparative analysis in ophthalmology,” Eye 2024
38:8, vol. 38, no. 8, pp. 1412–1417, Feb. 2024, doi: 10.1038/s41433-024-02958-w. [15]
H. Touvron et al., “LLaMA: Open and Efficient
Foundation Language Models,” Feb. 2023,
Accessed: Dec. 16, 2024. [Online]. Available:
https://arxiv.org/abs/2302.13971v1 [16]
T. Le Scao et al., “BLOOM: A 176B-Parameter
Open-Access Multilingual Language Model,” Nov. View publication stats
Tài liệu liên quan:
-

Cambridge IELTS 13 Test-1 Overview and Practice Review | Tài liệu Tiếng Anh
6 3 -

IELTS Test 2 Review - Cambridge 13 Preparation Guide | Tài liệu Tiếng Anh
9 5 -

Litfocus Litreading Survey: Student Reading Interests & Habits Questionnaire | Tài liệu Tiếng Anh
9 5 -

Sách Pre-intermediate Market leader - Business English Course Book
25 13 -

Exam booster for B1 preliminary and B1 preliminary for schools with answer key
10 5