Dự Đoán Khả Năng Sống Sót Sau Thảm Họa Titanic - Nhập Môn Học Máy 2024 | Đại học điện lực
Học máy (Machine Learning) là một lĩnh vực. Dự Đoán Khả Năng Sống Sót Sau Thảm Họa Titanic - Nhập Môn Học Máy 2024 | Đại học điện lực. Tài liệu sưu tầm gồm 20 trang, giúp bạn tham khảo, ôn tập và đạt kết quả cao.
Môn: Nhập môn học máy 10 tài liệu
Trường: Trường Đại học Điện lực 502 tài liệu
Tác giả:











Preview text:
lOMoARcPSD| 59629529
BỘ CÔNG THƯƠNG OMoARcPSD| 59629529
TRƯỜNG ĐẠI HỌC ĐIỆN LỰC
KHOA CÔNG NGHỆ THÔNG TIN
BÁO CÁO CHUYÊN ĐỀ HỌC PHẦN NHẬP
MÔN HỌC MÁY ĐỀ TÀI :
DỰ ĐOÁN NGƯỜI SỐNG SÓT SAU THẢM HỌA
TRÊN TÀU TITANIC BẰNG LOGISTIC REGRESSION
Giảng viên hướng dẫn :ThS. Vũ Văn Định
Sinh viên thực hiện :Nguyễn Công Lập
Nguyễn Thị Thương Phạm Bảo Yến Ngành
:CÔNG NGHỆ THÔNG TIN Chuyên ngành
:Công Nghệ Phần Mềm Lớp :D16CNPM5 Khóa học :2021-2026
Hà Nội, tháng 4 năm 2024 lOMoARcPSD| 59629529 PHIẾU CHẤM ĐIỂM
Sinh viên thực hiện
Họ và tên Chữ ký Ghi Chú Nguyễn Công Lập Nguyễn Thị Thương Phạm Bảo Yến
Giảng viên chấm
Họ và tên Chữ ký Ghi chú Giảng viên chấm 1 Giảng viên chấm 2 MỤC LỤC
LỜI MỞ ĐẦU................................................................................................................4
CHƯƠNG 1:..................................................................................................................5
TỔNG QUAN VỀ HỌC MÁY VÀ THUÂT TOÁN LOGISTIC REGRESSION........5̣
I. Tổng quan về học máy.............................................................................................5
1. Khái niệm về học máy................................................................................................5
2. Các loại học máy........................................................................................................5
3. Ứng dụng của học máy.............................................................................................10
II. Logistic Regression..............................................................................................11
1. Logistic Regression là gì?........................................................................................11
2. Hàm sigmoid............................................................................................................11 lOMoARcPSD| 59629529
3. Hàm Mất Mát (Loss Function).................................................................................12
4. Tối Ưu Hóa Trọng Số và Đào Tạo Mô Hình:..........................................................12 4.1 Tối Ưu Hóa Trọng Số
(Optimization):...................................................................12 4.2 Quá Trình Đào Tạo Mô
Hình:................................................................................12 4.3 Learning
Rate:........................................................................................................12
4.4 Regularization:................................................................................................. .......135. Cross Validation và Đánh Giá Mô
Hình..................................................................13
CHƯƠNG 2: THỰC HIỆN VÀ ĐÁNH GIÁ BÀI TOÁN..........................................14
Phát biểu bài toán:.....................................................................................................14 1. Nhập thư viện sử
dụng...............................................................................................15
2. Đọc Dữ Liệu:............................................................................................................16 3. Xác định biến độc lập (features) và biến phụ thuộc
(target):.............................................16 4. Tiền xử loại dữ
liêụ :..................................................................................................17 5. Chia dữ liêụ
và chuẩn hóa dữ liệu:............................................................................17 6. Tạo và
huấn luyện mô hình hồi quy logistic............................................................17
7. Đánh giá mô hình.....................................................................................................18
CHƯƠNG 3: SO SÁNH MÔ HÌNH............................................................................19
I. Mô hình KNN (K-Nearest Neighbors)......................................................................19
II. So sánh 2 mô hình....................................................................................................20
1. Mô Hình Hồi Quy Logistic:.....................................................................................20
2. Mô Hình K-Nearest Neighbors:...............................................................................21
KẾT LUẬN..................................................................................................................23
TÀI LIỆU THAM KHẢO............................................................................................24 LỜI MỞ ĐẦU
Trong thế kỷ 21 hiện nay, dữ liệu đã trở thành một tài nguyên quý giá, và khả
năng phân tích dữ liệu để rút ra thông tin hữu ích đã trở thành một công cụ quan trọng
đối với nhiều lĩnh vực khác nhau. Trí tuệ nhân tạo và học máy đã mở ra những cánh
cửa mới, mở rộng khả năng của chúng ta trong việc hiểu và dự đoán từ dữ liệu. lOMoARcPSD| 59629529
Trong môn học này, chúng ta sẽ đặt chân vào thế giới của học máy với một trong
những đề tài thú vị và mang tính lịch sử - dự đoán khả năng sống sót sau thảm họa trên
tàu Titanic. Sự cố đắm tàu Titanic năm 1912 đã để lại những dấu vết đau lòng, nhưng
cũng cung cấp cho chúng ta một bài toán thực tế để áp dụng học máy.
Chúng ta sẽ tiếp cận vấn đề này thông qua Logistic Regression, một phương pháp
phổ biến trong học máy. Logistic Regression không chỉ giúp chúng ta hiểu mối quan
hệ giữa các biến đầu vào và đầu ra, mà còn cho phép chúng ta dự đoán kết quả dựa trên
các đặc trưng đã biết trước.
Trong đề tài này, chúng ta sẽ tiếp cận bước đầu của học máy, từ việc tiền xử lý
dữ liệu, huấn luyện mô hình, đánh giá và tinh chỉnh mô hình để dự đoán khả năng sống
sót của hành khách trên tàu Titanic. Chúng ta sẽ nhìn nhận cách mà học máy có thể áp
dụng vào thực tế thông qua việc xử lý dữ liệu thô và biến nó thành thông tin có ý nghĩa.
Mục tiêu của chúng ta không chỉ là áp dụng một kỹ thuật học máy cụ thể để dự
đoán sống sót sau thảm họa trên tàu Titanic. Chúng ta cũng cần hiểu rõ hơn về các bước
cơ bản từ việc xử lý dữ liệu, xây dựng mô hình và đánh giá hiệu suất của mô hình
Logistic Regression. Bằng cách này, chúng ta sẽ có cơ sở vững chắc hơn để tiếp cận và
giải quyết những vấn đề phức tạp và thực tế trong học máy CHƯƠNG 1:
TỔNG QUAN VỀ HỌC MÁY VÀ THUÂṬ TOÁN LOGISTIC REGRESSION
I. Tổng quan về học máy
1.Khái niệm về học máy
Học máy (Machine Learning) là một lĩnh vực của trí tuệ nhân tạo (AI) tập
trung vào việc phát triển các thuật toán và mô hình máy tính có khả năng học từ
dữ liệu và trải nghiệm để tự điều chỉnh và cải thiện hiệu suất mà không cần phải
được lập trình cụ thể. lOMoARcPSD| 59629529
Ở cơ bản, học máy cho phép máy tính học từ dữ liệu mẫu và trải nghiệm,
từ đó có khả năng dự đoán, phân loại hoặc đưa ra quyết định trên dữ liệu mới mà
không cần phải có quy tắc rõ ràng. Nó tập trung vào việc xác định mô hình hoặc
thuật toán tối ưu để giải quyết vấn đề cụ thể bằng cách sử dụng các kỹ thuật từ
thống kê, toán học và khoa học máy tính.
Các thuật toán học máy chủ yếu được chia thành ba loại chính: -
Học máy giám sát (Supervised Learning) -
Học máy không giám sát (Unsupervised Learning) -
Học máy bán giám sát (Semi-supervised Learning): Kết hợp cả hai
loại trên, sử dụng cả dữ liệu có nhãn và không nhãn để huấn luyện mô hình.
2.Các loại học máy
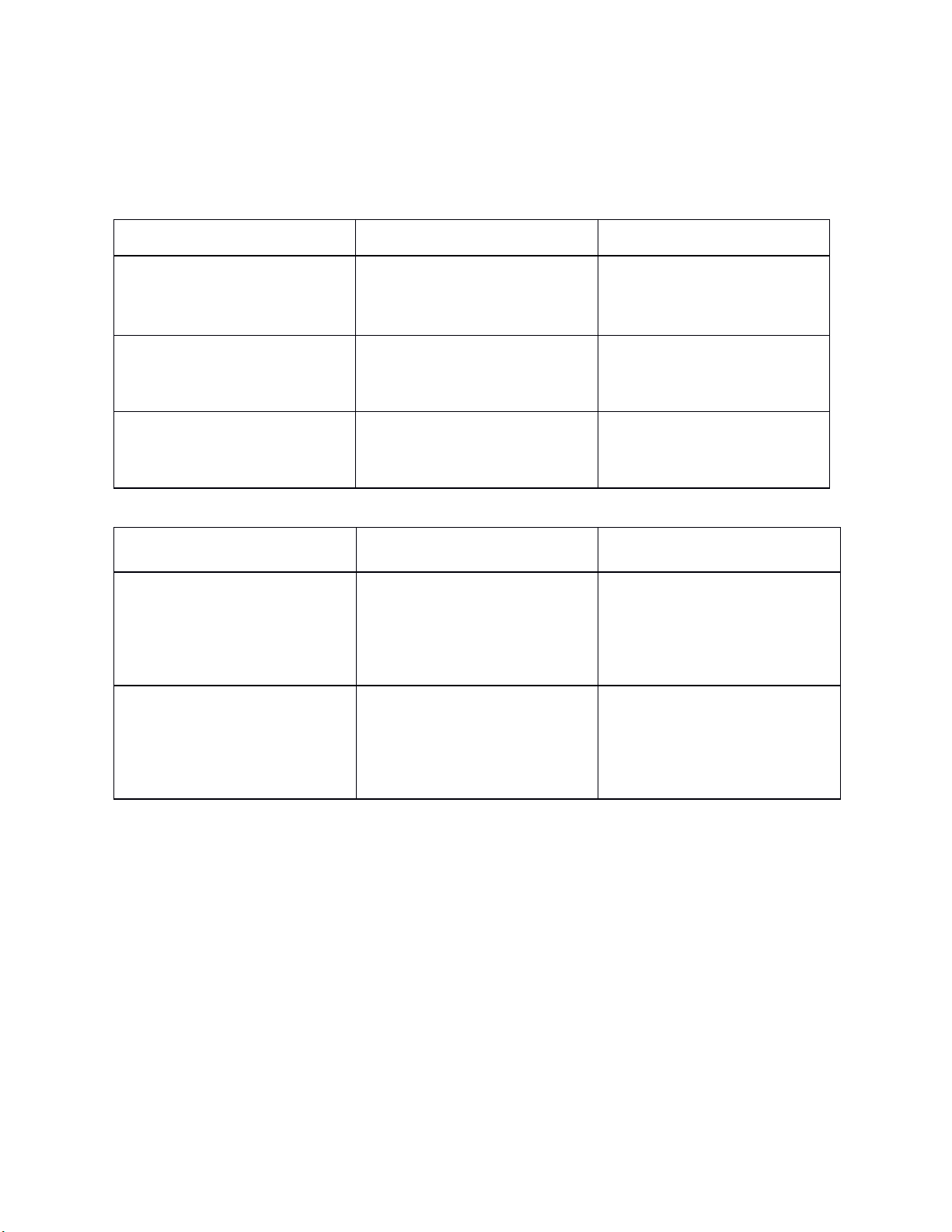
2.1 Học có giám sát (Supervised Learning)-SL
Học máy giám sát (Supervised Learning) là một trong những phương pháp
chính của học máy, trong đó mô hình được huấn luyện trên dữ liệu đã được gán
nhãn. Điều này có nghĩa là mỗi mẫu dữ liệu trong tập huấn luyện đã được gán
một kết quả mong muốn hoặc một nhãn. lOMoARcPSD| 59629529
Mục tiêu chính của học máy giám sát là học mối quan hệ giữa các đặc trưng
(features) hoặc biến đầu vào và kết quả dự đoán (outcome) hoặc nhãn (label). Mô
hình học máy sau khi được huấn luyện sẽ sử dụng thông tin từ các dữ liệu huấn luyện
này để dự đoán kết quả cho dữ liệu mới, chưa được nhìn thấy trước đó.
Các ví dụ phổ biến của học máy giám sát bao gồm: -
Hồi quy (Regression): Dự đoán giá nhà dựa trên các đặc trưng như diện
tích, vị trí, số phòng, vv. -
Phân loại (Classification): Phân loại email là spam hay không spam, phân
loại ảnh là chó, mèo hoặc chim, vv.
Thuật toán học máy giám sát cơ bản bao gồm các phương pháp như:
•Linear Regression: Sử dụng để dự đoán giá trị liên tục dựa trên các đặc trưng.
•Logistic Regression: Phân loại dữ liệu vào các nhóm hoặc lớp khác nhau.
•Support Vector Machines (SVM): Tìm ra ranh giới phân chia tốt nhất giữa các nhóm dữ liệu.
•Decision Trees và Random Forests: Tạo ra các cây quyết định để phân loại dữ liệu.
•Neural Networks (Mạng nơ-ron): Mô phỏng cấu trúc của não người để học và phân loại dữ liệu.
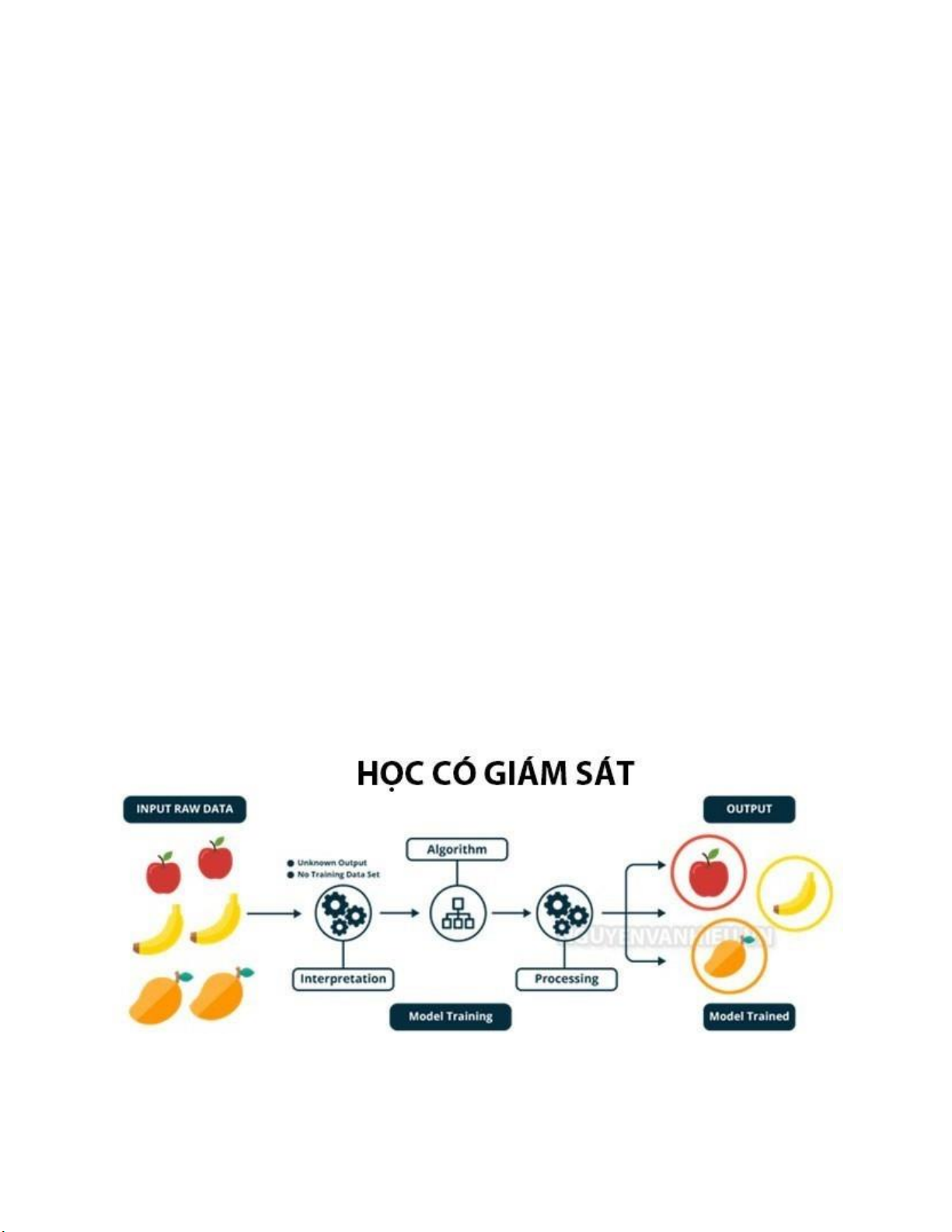
2.2. Học không giám sát (Unsupervised Learning)-UL
Học máy không giám sát (Unsupervised Learning) là một phương pháp trong
học máy mà mô hình được huấn luyện trên dữ liệu không có nhãn hoặc không có
đầu ra mong muốn được gán trước.
Trong học máy không giám sát, mục tiêu chính không phải là dự đoán hoặc
phân loại dữ liệu, mà là khám phá cấu trúc ẩn, mối quan hệ hoặc các nhóm tự nhiên
trong dữ liệu. Điều này giúp chúng ta hiểu rõ hơn về cấu trúc tự nhiên của dữ liệu
mà không cần có sự can thiệp của con người để gán nhãn. lOMoARcPSD| 59629529
Các phương pháp thông dụng trong học máy không giám sát bao gồm:
•Phân cụm (Clustering): Phân nhóm các điểm dữ liệu có tính chất tương tự nhau
vào các cụm khác nhau mà không cần biết trước thông tin về nhãn. •
Phân tích thành phần chính (Principal Component Analysis - PCA):
Giảm chiều dữ liệu thông qua việc tìm ra các thành phần chính quan trọng nhất để
giảm thiểu sự mất mát thông tin. •
Khám phá luật kết hợp (Association Rule Learning): Tìm ra các mẫu
hoặc quy tắc thường xuất hiện cùng nhau trong dữ liệu.
Học máy không giám sát thường được sử dụng trong các trường hợp như phân
tích dữ liệu, nén dữ liệu, xử lý dữ liệu không có nhãn, phát hiện bất thường trong
dữ liệu, và những tác vụ mà việc đánh giá mô hình không phụ thuộc vào dữ liệu
huấn luyện đã có nhãn. Phương pháp này giúp tạo ra cái nhìn toàn diện hơn về dữ
liệu và cấu trúc ẩn bên trong nó mà không cần sự can thiệp cụ thể từ con người
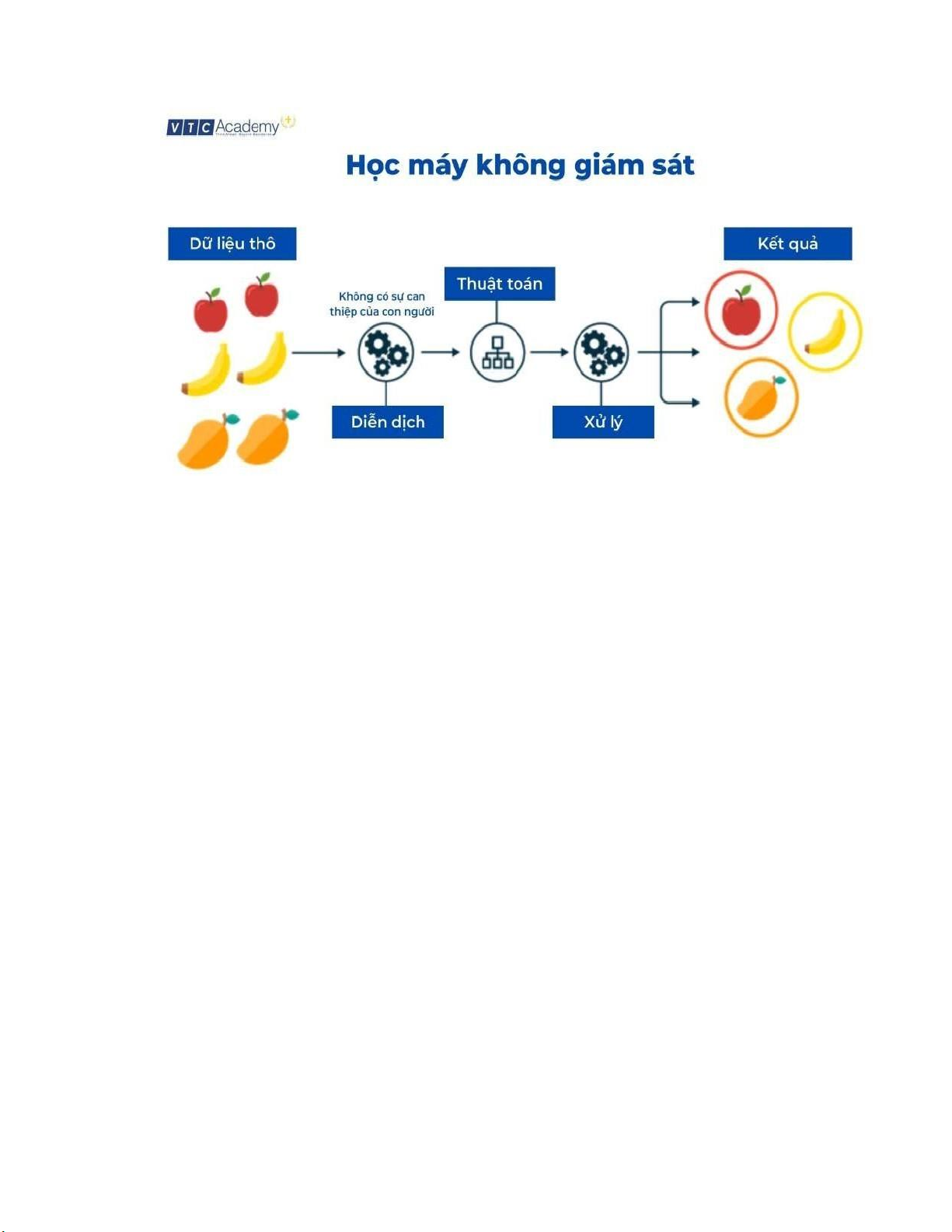
2.3. Học máy bán giám sát
Học máy bán giám sát (Semi-supervised Learning) là một phương pháp kết
hợp cả học máy giám sát và không giám sát. Trong loại học này, một phần của dữ
liệu được gán nhãn và một phần còn lại không có nhãn. lOMoARcPSD| 59629529
Mục tiêu của học máy bán giám sát là sử dụng cả dữ liệu có nhãn và không
nhãn để huấn luyện mô hình có khả năng dự đoán hoặc phân loại dữ liệu mới. Bằng
việc sử dụng thông tin từ dữ liệu có nhãn và áp dụng nó vào dữ liệu không nhãn,
mô hình có thể học được các đặc trưng và mối quan hệ phức tạp hơn trong dữ liệu.
Các phương pháp phổ biến của học máy bán giám sát bao gồm:
•Mô hình hóa trực tuyến (Self-training): Sử dụng mô hình đã được
huấn luyện từ dữ liệu có nhãn để gắn nhãn cho dữ liệu không nhãn và sau đó sử dụng
dữ liệu này để huấn luyện mô hình lại.
•Truyền tải học (Transfer Learning): Sử dụng thông tin được học từ
một tác vụ cụ thể và chuyển giao kiến thức này sang một tác vụ khác có liên quan mà
không cần nhiều dữ liệu mới.
•Kết hợp học máy giám sát và không giám sát: Kết hợp thông tin từ
cả dữ liệu có nhãn và không nhãn để tạo ra một mô hình mạnh mẽ hơn.
Học máy bán giám sát thường được áp dụng trong các tình huống khi có ít dữ
liệu được gán nhãn và nhiều dữ liệu không được gán nhãn. Phương pháp này có thể
giúp tận dụng được thông tin từ dữ liệu không nhãn để cải thiện hiệu suất dự đoán lOMoARcPSD| 59629529
của mô hình, đồng thời giảm thiểu sự phụ thuộc vào việc có sẵn dữ liệu được gán nhãn.
3. Ứng dụng của học máy
Học máy (Machine Learning) có rất nhiều ứng dụng trong nhiều lĩnh vực khác
nhau. Dưới đây là một số ứng dụng phổ biến của học máy:
- Xử lý ngôn ngữ tự nhiên (NLP):
• Dịch máy: Google Translate, các ứng dụng dịch trực tiếp.
• Phân loại văn bản: Phân loại email là spam hay không spam.
• Tóm tắt văn bản: Tự động tạo tóm tắt cho văn bản dài.
- Nhận diện hình ảnh và video: •
Nhận diện khuôn mặt: Hệ thống nhận diện khuôn mặt trong ảnh hoặc video. •
Phân loại đối tượng: Xác định và phân loại đối tượng trong hình ảnhhoặc video.
- Dự đoán và phân tích dữ liệu:
• Dự đoán thị trường tài chính: Dự đoán giá cổ phiếu, thị trường bất động sản.
• Dự đoán y tế: Dự đoán nguy cơ bệnh lý, chuẩn đoán và điều trị bệnh.
• Gợi ý sản phẩm: Hệ thống gợi ý sản phẩm dựa trên lịch sử mua hàng và
sởthích của người dùng.
- Tự lái xe và ô tô tự lái:
• Xe tự lái: Sử dụng học máy để nhận diện và phản ứng với các tình huống giao thông.
- Công nghiệp và tối ưu hóa quy trình: •
Dự đoán sản xuất: Dự đoán lượng hàng tồn kho và nhu cầu sản phẩm. lOMoARcPSD| 59629529 •
Tối ưu hóa quy trình: Sử dụng học máy để tối ưu hóa chuỗi cung ứng, lên
kếhoạch sản xuất hiệu quả.
- Y tế và dược phẩm: •
Dự đoán bệnh lý: Sử dụng học máy để dự đoán khả năng mắc các loại
bệnhdựa trên dữ liệu y tế. •
Khám phá dược phẩm: Sử dụng mô hình học máy để phát hiện và thiết
kếcác phương pháp điều trị mới.
- Cá nhân hóa và Marketing: •
Marketing định hướng cá nhân: Tùy chỉnh quảng cáo dựa trên hành vi
trựctuyến của người dùng. •
Đề xuất sản phẩm: Gợi ý sản phẩm dựa trên lịch sử mua sắm và sở thích củangười dùng.
Những ứng dụng này chỉ là một phần nhỏ trong rất nhiều cách mà học máy
được áp dụng rộng rãi trong nhiều lĩnh vực khác nhau, đem lại hiệu quả và giá trị
từ dữ liệu mà trước đây có thể không được tận dụng tối đa
II. Logistic Regression
1. Logistic Regression là gì?
Hồi quy Logistic là một mô hình thống kê được sử dụng để phân loại nhị phân,
tức dự đoán một đối tượng thuộc vào một trong hai nhóm. Hồi quy Logistic làm việc
dựa trên nguyên tắc của hàm sigmoid – một hàm phi tuyến tự chuyển đầu vào của
nó thành xác suất thuộc về một trong hai lớp nhị phân. 2. Hàm sigmoid lOMoARcPSD| 59629529
Hàm sigmoid là một hàm số có dạng đường cong hình "S" hay còn gọi là
đường cong sigmoid. Một ví dụ phổ biến của một hàm sigmoid là hàm Lôgit, được
thể hiện trong hình đầu tiên và có công thức định nghĩa như sau:
3. Hàm Mất Mát (Loss Function)
Hàm mất mát log-likelihood được xây dựng dựa trên nguyên lý của xác suất.
Mục tiêu là tối đa hóa xác suất dự đoán đúng cho các điểm thuộc vào lớp tích cực
(yi=1) và xác suất dự đoán đúng cho các điểm thuộc vào lớp tiêu cực (yi=0). Hàm
mất mát này không chỉ đo lường sự chênh lệch giữa dự đoán và thực tế mà còn thúc
đẩy mô hình học từ dữ liệu thông qua quá trình tối ưu hóa.
4. Tối Ưu Hóa Trọng Số và Đào Tạo Mô Hình:
4.1 Tối Ưu Hóa Trọng Số (Optimization):
Gradient Descent: Một phương pháp phổ biến để tối ưu hóa trọng số.
Gradient descent điều chỉnh trọng số dựa trên độ dốc của hàm mất mát, giảm
thiểu hàm mất mát bằng cách di chuyển ngược hướng của độ dốc.
4.2 Quá Trình Đào Tạo Mô Hình:
Khởi Tạo Trọng Số: Gán giá trị ban đầu cho các trọng số của mô hình.
Lặp Lại Quá Trình Tối Ưu Hóa: Thực hiện nhiều vòng lặp để cập nhật trọng
số và tối ưu hóa mô hình.Dừng Lặp: Các tiêu chí như số lượng vòng lặp tối đa hoặc
sự hội tụ của trọng số có thể được sử dụng để dừng quá trình đào tạo.
4.3 Learning Rate: lOMoARcPSD| 59629529
Đây là một siêu tham số quan trọng trong gradient descent, quyết định kích
thước của bước di chuyển trong quá trình tối ưu hóa. Việc chọn learning rate phù
hợp là quan trọng để đảm bảo mô hình hội tụ một cách nhanh chóng mà không gặp
vấn đề overshooting hoặc divergin 4.4 Regularization:
Các kỹ thuật như L1 regularization (Lasso) hoặc L2 regularization (Ridge) có
thể được áp dụng để kiểm soát overfitting và giảm độ phức tạp của mô hình.
5. Cross Validation và Đánh Giá Mô Hình
K-fold Cross Validation: Đánh giá mô hình trên nhiều tập dữ liệu kiểm thử để
đảm bảo tính khái quát và giảm thiểu tình trạng overfitting hoặc underfitting.
Đánh Giá Hiệu Suất: Sử dụng các độ đo như độ chính xác, ma trận nhầm lẫn,
precision, recall, F1-score để đánh giá khả năng phân loại của mô hình trên dữ liệu thực tế. lOMoARcPSD| 59629529
CHƯƠNG 2: THỰC HIỆN VÀ ĐÁNH GIÁ BÀI TOÁN
Phát biểu bài toán:
Titanic là một con tàu nổi tiếng đã chìm vào năm 1912 sau khi va
chạm với một tảng băng. Trong thảm họa này, có một số yếu tố đã ảnh hưởng đến
khả năng sống sót của hành khách, chẳng hạn như giới tính, tuổi tác, lớp hành khách,
số lượng anh chị em hay vợ/chồng đi cùng, số lượng cha mẹ hoăc ̣ con cái đi cùng
và giá vé . Bài toán dự đoán người sống sót trên tàu Titanic dựa trên các thông tin này.
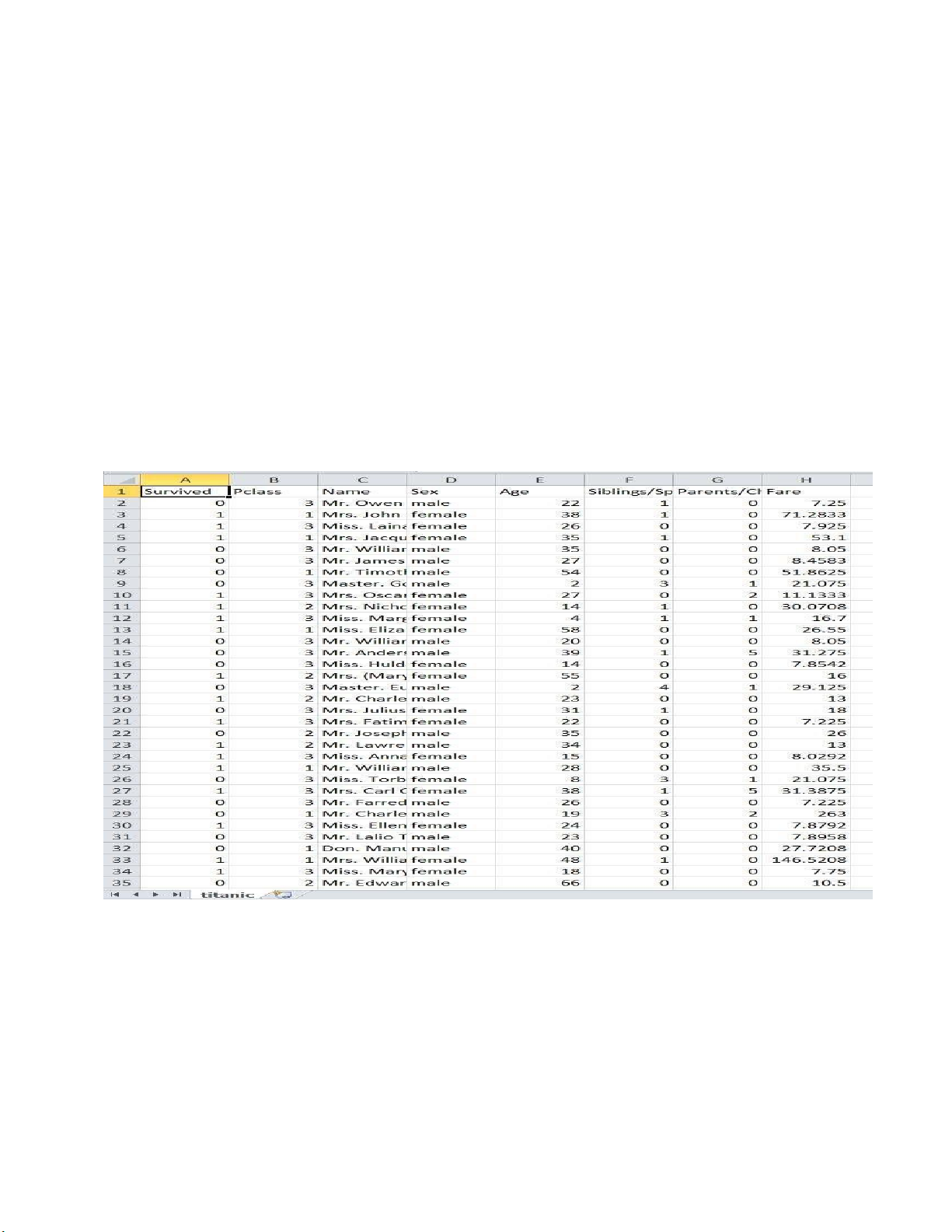
Bô ̣dữ liêụ titanic.csv gồm 888 hàng và 8 côt :̣
-Survived: Dữ liệu thể hiện sự sống sót ( 0: không sống sót – 1: sống sót)
-Pclass: Lớp hành khách trên tàu -Name: Tên hành khách -Sex : Giới tính lOMoARcPSD| 59629529 -Age: Đô ̣ tuổi
-Siblings/Spouses Aboard: số lượng anh chị em hay vợ/chồng đi cùng
- Parents/Children Aboard: Số lượng cha mẹ hoặc con cái đi cùng - Fare: giá vé
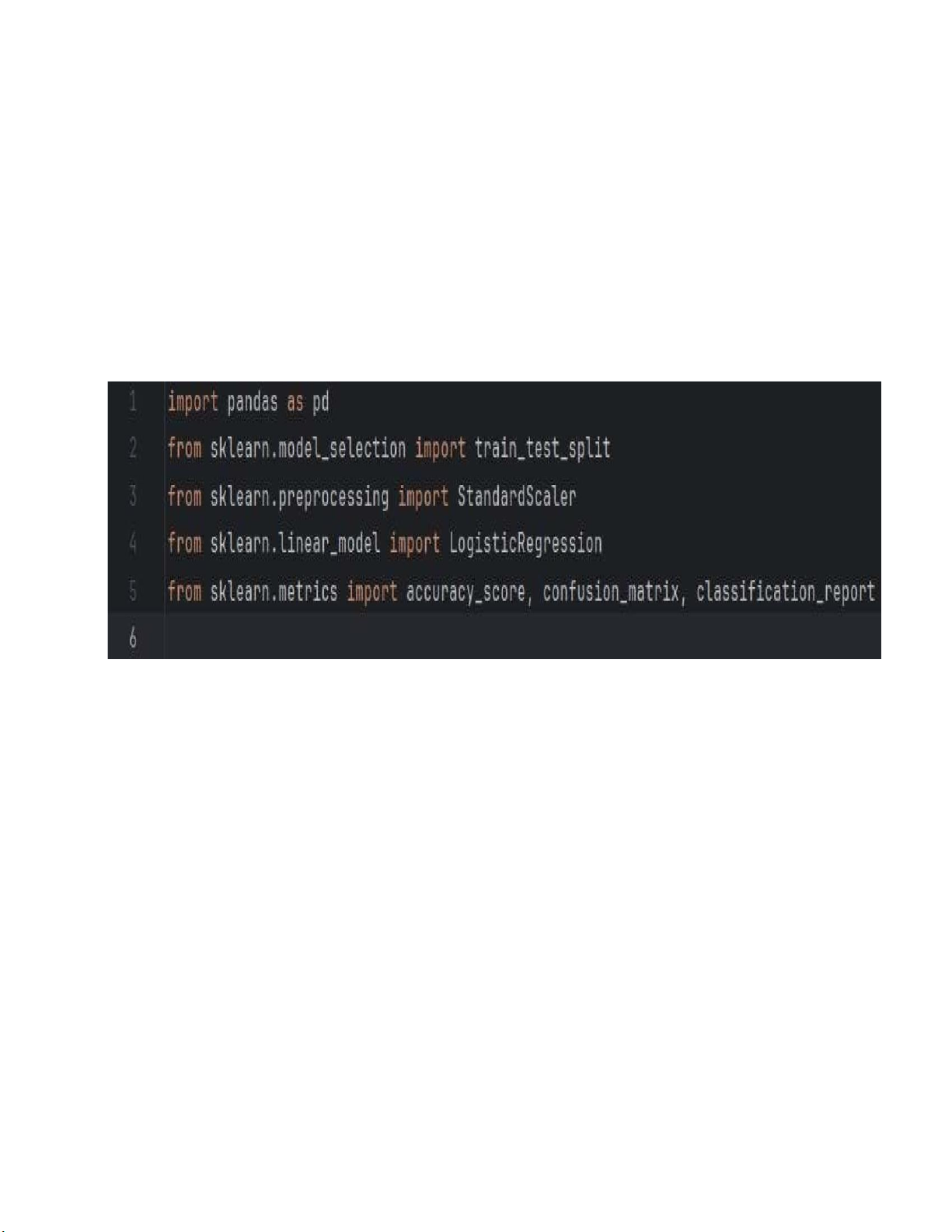
1. Nhập thư viện sử dụng
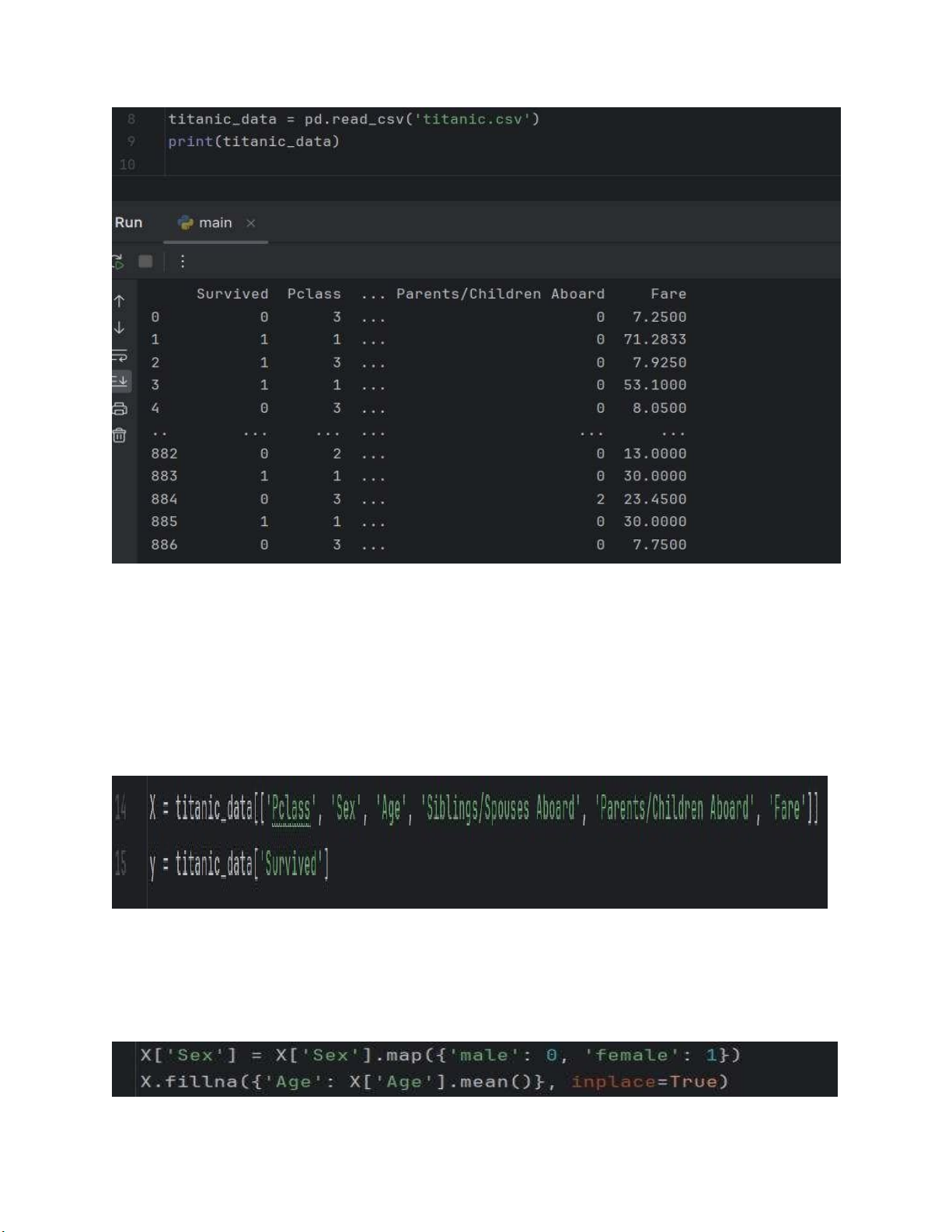
2. Đọc Dữ Liệu:
Dữ liệu được đọc từ tập tin CSV 'titanic.csv' và lưu vào DataFrame 'titanic_data'. lOMoARcPSD| 59629529
3. Xác định biến độc lập (features) và biến phụ thuộc (target): • Biến độc lập
(features) bao gồm 'Pclass', 'Sex', 'Age',
'Siblings/Spouses Aboard', 'Parents/Children Aboard', và 'Fare'.
• Biến phụ thuộc (target) là 'Survived'.
4. Tiền xử loại dữ liêụ :
• Chuyển đổi biến phân loại 'Sex' thành biến số.
• Điền giá trị thiếu của cột 'Age' bằng giá trị trung bình. lOMoARcPSD| 59629529
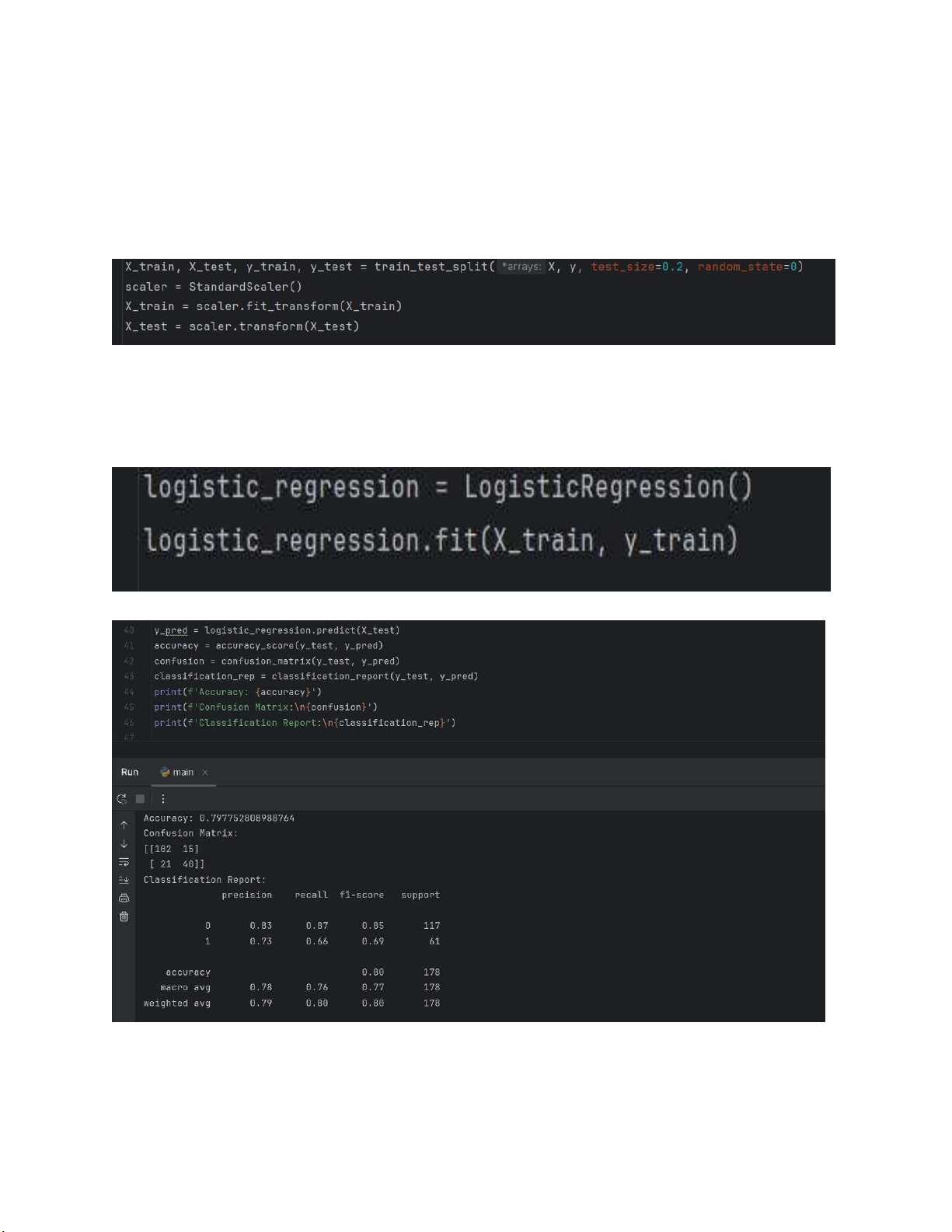
5. Chia dữ liêụ và chuẩn hóa dữ liệu:
• Dữ liệu được chia thành tập huấn luyện và tập kiểm thử (80-20).
• Chuẩn hóa dữ liệu sử dụng StandardScaler để đảm bảo các biến có cùng thang đo.
6. Tạo và huấn luyện mô hình hồi quy logistic
• Mô hình Logistic Regression được khởi tạo và huấn luyện trên tập huấn luyện (X_train, y_train).
7. Đánh giá mô hình lOMoARcPSD| 59629529
CHƯƠNG 3: SO SÁNH MÔ HÌNH
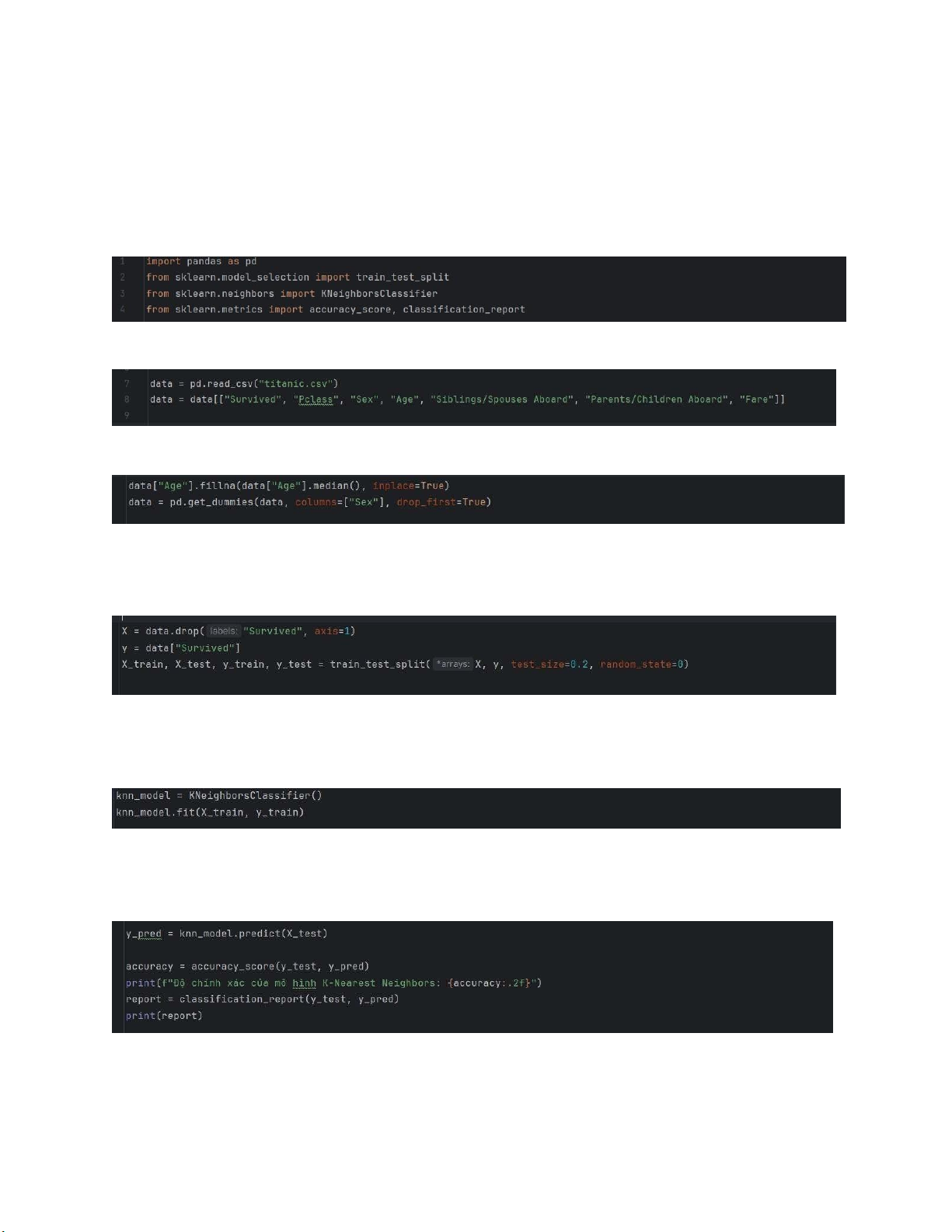
I. Mô hình KNN (K-Nearest Neighbors) Thư viện sử dụng Đọc Dữ Liệu Tiền Xử Lý Dữ Liệu
Chia Dữ Liệu và Tạo Tập Huấn Luyện và Tập Kiểm Thử
Huấn Luyện Mô Hình K-Nearest Neighbors Đánh Giá Hiệu Suất Chạy chương trình lOMoARcPSD| 59629529
II. So sánh 2 mô hình
1. Mô Hình Hồi Quy Logistic:
• Tiền Xử Lý Dữ Liệu:
• Chuyển đổi giới tính thành biến nhị phân (0 và 1).
• Điền giá trị trung bình cho các giá trị thiếu trong cột "Age". • Chia Dữ Liệu:
• Tập huấn luyện chiếm 80% và tập kiểm thử chiếm 20% của dữ liệu.
• Dữ liệu được chuẩn hóa sử dụng StandardScaler. • Mô Hình:
• Sử dụng mô hình hồi quy logistic từ thư viện scikit-learn. • Kết Quả:
• Độ chính xác trên tập kiểm thử: 79.8%.
2. Mô Hình K-Nearest Neighbors:
• Tiền Xử Lý Dữ Liệu: lOMoARcPSD| 59629529
• Giá trị trung bình của "Age" được sử dụng để điền vào các giá trị thiếu.
• Tạo biến nhị phân từ cột "Sex" bằng phương thức pd.get_dummies. • Chia Dữ Liệu:
• Tập huấn luyện chiếm 80% và tập kiểm thử chiếm 20% của dữ liệu. • Mô Hình:
• Sử dụng mô hình K-Nearest Neighbors từ thư viện scikit-learn với giá trị mặc định K=5. • Kết Quả:
• Độ chính xác trên tập kiểm thử: 71%. So Sánh: • Độ Chính Xác:
• Mô hình hồi quy logistic có độ chính xác cao hơn so với mô hình K-
Nearest Neighbors trên tập kiểm thử.
• Thời Gian Huấn Luyện:
• Mô hình hồi quy logistic thường có thời gian huấn luyện nhanh hơn so
với K-Nearest Neighbors, đặc biệt là trên tập dữ liệu lớn. • Độ Phức Tạp:
• Mô hình K-Nearest Neighbors có thể có độ phức tạp cao hơn khi kích
thước dữ liệu tăng, đặc biệt là khi cần tính toán khoảng cách giữa các điểm dữ liệu.
Tóm lại, mặc dù mô hình hồi quy logistic có độ chính xác cao hơn trên tập
kiểm thử, việc lựa chọn giữa hai mô hình còn phụ thuộc vào yêu cầu cụ thể của vấn
đề và sự cân nhắc về thời gian và độ phức tạp của mô hình. lOMoARcPSD| 59629529 KẾT LUẬN
Tất cả những gì chúng em đã đạt được trong quá trình làm báo cáo môn nhập môn
học máy không thể phủ nhận là một hành trình học hỏi đầy ý nghĩa. Chúng em đã dành
nhiều thời gian để tìm hiểu và áp dụng các chương trình ứng dụng cũng như logistic
regression trong lĩnh vực học máy vào bài toán dự đoán sống sót trên tàu Titanic.
Tuy nhiên, dù đã cố gắng hết sức, bài báo cáo của chúng em không thể tránh khỏi
những hạn chế và thiếu sót. Trong quá trình nghiên cứu và thực hiện, chúng em đã gặp
phải một số thách thức, bao gồm thời gian hạn chế, giới hạn về kiến thức cũng như kỹ
năng kỹ thuật. Do đó, bài báo cáo không thể đạt được mức độ hoàn thiện như mong muốn.
Với lòng mong muốn học hỏi và cải thiện, chúng em rất trân trọng mọi phản hồi và
góp ý từ phía thầy cô. Chúng em mong muốn nhận được sự chỉ dẫn và hướng dẫn chi tiết
hơn về cách cải thiện bài báo cáo của mình, giúp chúng em hiểu rõ hơn về những điểm cần
cải thiện và phát triển trong công việc nghiên cứu và trình bày của mình. Mọi đóng góp và
hỗ trợ từ phía thầy cô sẽ giúp chúng em tiến bộ và hoàn thiện hơn trong hành trình học tập
và nghiên cứu của mình.
Chúng em xin chân thành cảm ơn!
TÀI LIỆU THAM KHẢO
[1] Trang web: machinelearningcoban.com
Tài liệu liên quan:
-

Báo cáo chuyên đề: Ứng dụng Kmeans Clustering dự đoán Pokémon | Đại học Điện lực
150 75 -

Đánh giá xu hướng hiện đại trong Học Máy: Phân tán và Liên bang | Đại học Điện lực
87 44 -

Lý Văn Chuyển Học May - Giới Thiệu và Tình Huống Thực Tế | Đại học Điện lực
84 42 -

Báo cáo chuyên đề Nhập môn học máy - Ứng dụng CNN trong nhận diện chữ viết tay | Đại học Điện lực
171 86