Image Classification on MNIST | Báo cáo bài tập lớn học phần Thị giác máy tính | Trường Đại học Phenikaa
Các mô hình mạng của chúng tôi bao gồm nhiều lớp tích chập và một lớp được kết nối đầy đủ ở cuối. Trong mỗi lớp tích chập, một tích chập 2D được thực hiện, tiếp theo là chuẩn hóa hàng loạt 2D và kích hoạt ReLU. Tổng hợp tối đa hoặc tổng hợp trung bình không được sử dụng sau khi tích chập. Thay vào đó, kích thước của bản đồ tính năng bị giảm sau mỗi lần tích chập vì phần đệm không được sử dụng. Ví dụ: nếu chúng ta sử dụng nhân 3×3 , chiều rộng và chiều cao của hình ảnh sẽ giảm đi hai sau mỗi lớp tích chập. Cách tiếp cận tương tự được thực hiện trong các mạng khác [6, 2]. Tài liệu giúp bạn tham khảo, ôn tập và đạt kết quả cao. Mời bạn đón xem.
Môn: Thị giác máy tính 4 tài liệu
Trường: Đại học Phenika 1.3 K tài liệu
Tác giả:








Preview text:
BỘ GIÁO DỤC VÀ ĐÀO TẠO
TRƯỜNG ĐẠI HỌC PHENIKAA
TÊN BÀI TẬP/ DỰ ÁN: Image Classification on MNIST
Giảng viên: GS/PGS/TS/ThS. : Nguyễn Văn Tới Nhóm sinh viên: 6 Thành viên 1 . Hoàng Thị Hà MSV: 20010893 2 . Trần Công Danh MSV: 20010760 3 . Dương Văn Quang MSV: 20010793 4 . Nguyễn Thị Ngọc Lớp: N03
Học phần: Thị giác máy tính HÀ NỘI, 11/2022
Tóm tắt: Chúng tôi báo cáo rằng có thể đạt được độ chính xác rất cao
trên bộ thử nghiệm MNIST bằng cách sử dụng các mô hình mạng thần kinh
chuyển đổi đơn giản (CNN). Chúng tôi sử dụng ba mô hình khác nhau với kích
thước hạt nhân 3×3, 5×5 và 7×7 trong các lớp tích chập. Mỗi mô hình bao
gồm một tập hợp các lớp tích chập, theo sau là một lớp được kết nối đầy đủ
duy nhất. Mỗi lớp tích chập sử dụng chuẩn hóa hàng loạt và kích hoạt ReLU ,
trong khi không sử dụng tổng hợp. Xoay và dịch được sử dụng để tăng cường
dữ liệu đào tạo, đây là một kỹ thuật thường được sử dụng trong hầu hết các
nhiệm vụ phân loại hình ảnh. Biểu quyết theo đa số bằng cách sử dụng ba mô
hình được đào tạo độc lập trên tập huấn luyện có thể đạt được độ chính xác
lên tới 99,87% trên tập kiểm tra, đây là một trong những kết quả hiện đại nhất.
Một tập hợp hai lớp, một tập hợp không đồng nhất của ba mạng tập hợp đồng
nhất, có thể đạt được độ chính xác kiểm tra lên tới 99,91%. 1.Tổng quan
Bộ dữ liệu nhận dạng chữ số viết tay MNIST (Hình 1, [1]) là một trong những
bộ dữ liệu cơ bản nhất được sử dụng để kiểm tra hiệu suất của các mô hình mạng thần
kinh và kỹ thuật học tập. Sử dụng 60.000 hình ảnh làm tập huấn luyện, có thể dễ dàng
đạt được độ chính xác 97% -98% trên tập kiểm tra gồm 10.000 hình ảnh, với các
phương pháp học tập như k-láng giềng gần nhất (KNN), rừng ngẫu nhiên, máy vectơ
hỗ trợ (SVM) và các mô hình mạng nơ-ron đơn giản. Mạng thần kinh tích chập (CNN)
cải thiện độ chính xác này lên hơn 99% với ít hơn 100 hình ảnh bị phân loại sai trong bộ thử nghiệm.
100 hình ảnh cuối cùng khó phân loại chính xác hơn. Để cải thiện độ
chính xác sau 99%, chúng tôi cần các mô hình phức tạp hơn, điều chỉnh cẩn
thận các siêu tham số như tốc độ học và kích thước lô, các kỹ thuật chuẩn hóa
như chuẩn hóa và loại bỏ hàng loạt cũng như tăng cường dữ liệu huấn luyện.
Độ chính xác cao nhất đạt được trên bộ thử nghiệm MNIST là khoảng 99,7% đến 99,84%.
Trong bài báo này, chúng tôi báo cáo một mô hình có thể đạt được độ
chính xác rất cao trên bộ kiểm tra MNIST mà không cần các khía cạnh cấu trúc
phức tạp hoặc kỹ thuật học tập. Mô hình sử dụng một tập hợp các lớp tích chập,
theo sau là lớp được kết nối đầy đủ ở cuối, đây là một trong những kiến trúc
mô hình thường được sử dụng. Chúng tôi sử dụng các sơ đồ tăng cường dữ liệu
cơ bản, dịch và xoay. Chúng tôi đào tạo ba mô hình có kiến trúc tương tự và sử
dụng biểu quyết đa số giữa các mô hình để có được dự đoán cuối cùng. Ba mô
hình có kiến trúc tương tự nhau, nhưng có kích thước hạt nhân khác nhau trong các lớp tích chập.
Các thí nghiệm cho thấy rằng việc kết hợp các mô hình có kích thước nhân
khác nhau sẽ đạt được độ chính xác tốt hơn so với việc kết hợp các mô
hình có cùng kích thước nhân.
2.Thiết kế và đào tạo mạng
Các mô hình mạng của chúng tôi bao gồm nhiều lớp tích chập và một lớp
được kết nối đầy đủ ở cuối. Trong mỗi lớp tích chập, một tích chập 2D được
thực hiện, tiếp theo là chuẩn hóa hàng loạt 2D và kích hoạt ReLU. Tổng hợp
tối đa hoặc tổng hợp trung bình không được sử dụng sau khi tích chập. Thay
vào đó, kích thước của bản đồ tính năng bị giảm sau mỗi lần tích chập vì phần
đệm không được sử dụng. Ví dụ: nếu chúng ta sử dụng nhân 3×3 , chiều rộng
và chiều cao của hình ảnh sẽ giảm đi hai sau mỗi lớp tích chập. Cách tiếp cận
tương tự được thực hiện trong các mạng khác [6, 2]. Số lượng kênh được tăng
lên sau mỗi lớp để giảm kích thước bản đồ tính năng. Khi kích thước bản đồ
tính năng trở nên đủ nhỏ, một lớp được kết nối đầy đủ sẽ kết nối bản đồ tính
năng với đầu ra cuối cùng. Chuẩn hóa hàng loạt 1D được sử dụng ở lớp được
kết nối đầy đủ, trong khi lớp bỏ học không được sử dụng.
Chúng tôi sử dụng ba mạng khác nhau và kết hợp kết quả từ các mạng
này. Các mạng chỉ khác nhau về kích thước hạt nhân của các lớp tích chập: 3×3,
5×5 và 7×7. Vì kích thước hạt nhân khác nhau dẫn đến giảm kích thước khác
nhau trong bản đồ đặc trưng, nên số lượng lớp là khác nhau đối với mỗi mạng.
Mạng đầu tiên, M3, sử dụng 10 lớp tích chập với 16(i + 1) kênh trong
lớp tích chập thứ i. Bản đồ tính năng trở thành 8×8 với 176 kênh sau lớp thứ 10.
Mạng thứ hai, M5, sử dụng 5 lớp tích chập với 32i kênh trong lớp tích
chập thứ i. Bản đồ tính năng trở thành 8×8 với 160 kênh sau lớp thứ 5.
Mạng thứ ba, M7, sử dụng 4 lớp tích chập với 48i kênh trong lớp tích
chập thứ i . Bản đồ tính năng trở thành 4×4 với 192 kênh sau lớp thứ 4. Cấu
trúc của ba mạng được thể hiện trong Hình 2.
Khi đào tạo, chúng tôi áp dụng chuyển đổi trên dữ liệu bao gồm dịch ngẫu
nhiên và xoay ngẫu nhiên. Đối với dịch ngẫu nhiên, hình ảnh được dịch chuyển ngẫu
nhiên theo chiều ngang và chiều dọc, tối đa 20% kích thước hình ảnh theo mỗi hướng.
Để xoay ngẫu nhiên, hình ảnh được xoay tối đa 20 độ theo chiều kim đồng hồ hoặc
ngược chiều kim đồng hồ. Số lượng biến đổi khác nhau đối với từng hình ảnh và từng
kỷ nguyên, vì vậy mạng có thể xem các phiên bản khác nhau của hình ảnh trong tập
huấn luyện (Hình 3). Để đào tạo và đánh giá, các vectơ đầu vào thường là số nguyên
trong [0, 255] được chuyển đổi thành giá trị dấu phẩy động trong [-1.0, 1.0].
Các tham số mạng được khởi tạo bằng các phương thức khởi tạo mặc định
trong PyTorch [7]. Để tối ưu hóa tham số, chúng tôi sử dụng trình tối ưu hóa Adam
với chức năng mất entropy chéo. Tốc độ học bắt đầu từ 0,001 và giảm dần theo cấp
số nhânvới hệ số phân rã γ=0,98. Kích thước lô là 120 và do đó, 500 cập nhật tham
số xảy ra trong một kỷ nguyên. Chúng tôi sử dụng hàm mũ trung bình động của các
trọng số để đánh giá, điều này có thể dẫn đến khả năng khái quát hóa tốt hơn [8]. Sự
phân rã theo cấp số nhân được sử dụng cho kỷ nguyên đầu, nhưng mô hình của tất
cả các mạng trở nên giống nhau sau 50 kỷ nguyên. Bảng 1 cho thấy mức tối thiểu,
trung bình, trung bình 99,79 99,5930 ± 0,0136 99,6949 ± 0,0058 99,7667 ± 0,0084
tối đa tính toán trung bình động là 0,999. 3 thí nghiệm
3.1 Kết quả cho các Mạng và Nhóm riêng lẻ
Với mỗi loại mạng ta huấn luyện được 30 mạng với các thông số ban đầu
khác nhau. Mỗi mạng được huấn luyện để 150 kỷ nguyên, vì độ chính xác của bài
kiểm tra hầu như không được cải thiện sau thời điểm đó. Hình 4 cho thấy sự thay
đổi về độ chính xác đào tạo và độ chính xác kiểm tra trong khi đào tạo. Về độ chính
xác của thử nghiệm, các mạng có nhân lớn hơn cho thấy một số bất ổn ở độ chính
xác tối đa của 30 mạng trong khoảng từ 50 đến 150 kỷ nguyên, trong phạm vi tin
cậy 95%. Độ chính xác của M3 là cao hơn một chút, tiếp đến là M5 và M7 nhưng
mức chênh lệch không quá lớn (dưới 0,02%). Từ 50 đến 150 ở giai đoạn của 30
mạng, độ chính xác thử nghiệm cao nhất quan sát được từ M3, M5, M7 lần lượt là 99,82, 99,80 và 99,79.
Được biết, việc sử dụng tập hợp các mạng có thể cải thiện khả năng khái quát
hóa và đạt được độ chính xác kiểm tra cao hơn [9, 10, 11, 12]. Để kiểm tra hiệu suất
của các mạng đồng bộ trên tập dữ liệu MNIST, chúng tôi đã đào tạo 30 mạng cho mỗi
mạng M3, M5 và M7 và thử nghiệm bốn chiến lược tập hợp khác nhau. Trong ba
chiến lược đầu tiên, chúng tôi chọn ngẫu nhiên ba mạng từ cùng loại mạng (M3, M5
hoặc M7). Trong chiến lược thứ tư, chúng tôi chọn một mạng từ mỗi loại. Kết quả
cuối cùng thu được bằng cách sử dụng biểu quyết đa số. Nghĩa là, nếu hai mạng đồng
ý rằng một hình ảnh thuộc về một lớp cụ thể, thì lớp đó sẽ được chọn. Nếu ba mạng
bỏ phiếu cho các lớp khác nhau, thì một lớp sẽ được chọn ngẫu nhiên trong số ba
mạng. Đối với mỗi chiến lược, chúng tôi đã thử nghiệm 1000 mạng kết hợp và vẽ
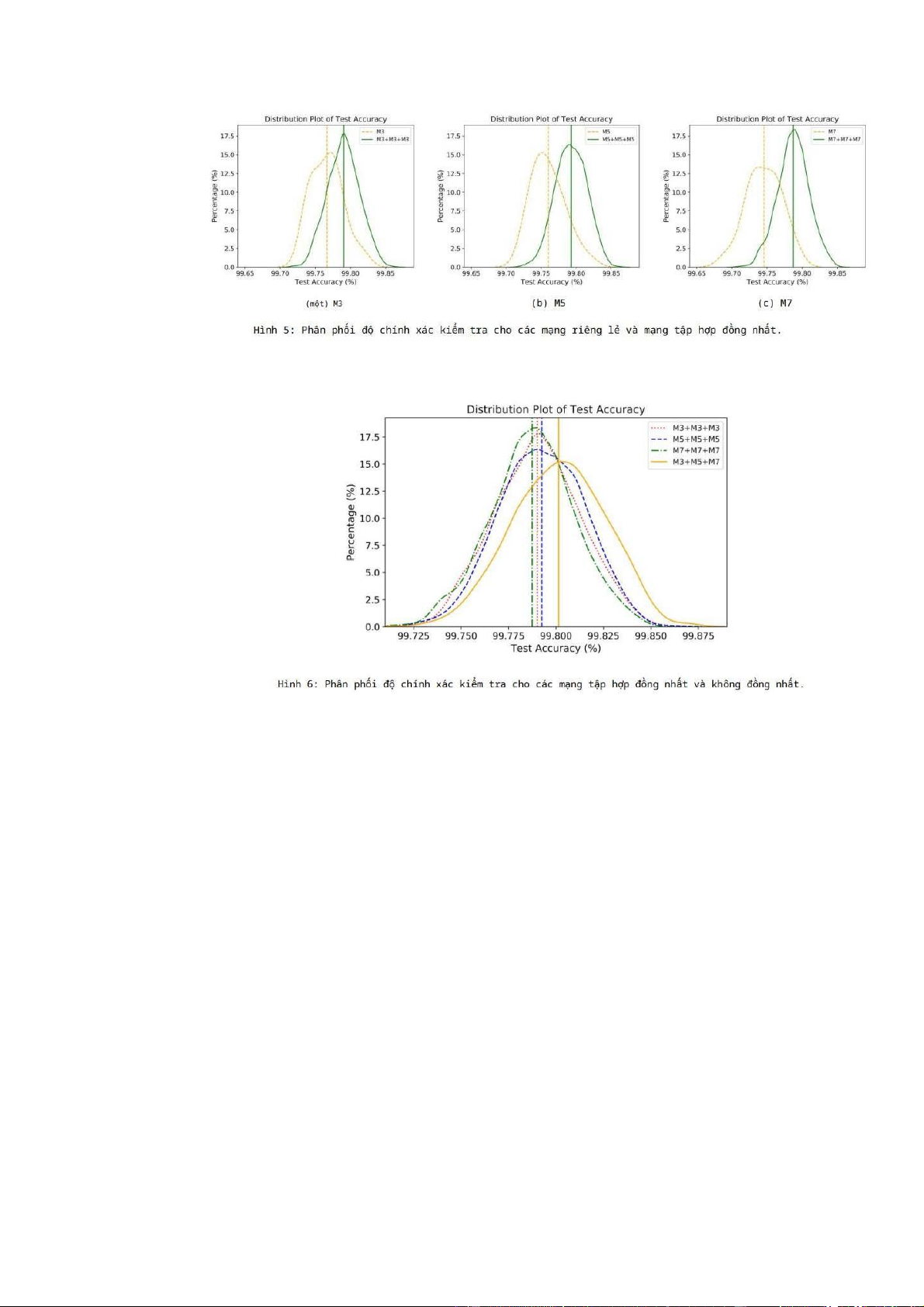
biểu đồ để biết độ chính xác của thử nghiệm. Hình 5 cho thấy lợi ích của việc sử dụng
tập hợp các mạng đồng nhất. Đối với M3, M5 và M7, có thể đạt được độ chính xác
kiểm tra cao hơn bằng cách kết hợp kết quả từ ba mạng. (Đường thẳng di chuyển sang
bên phải.) Hình 6 cho thấy độ chính xác của phép thử của bốn phương pháp kết hợp
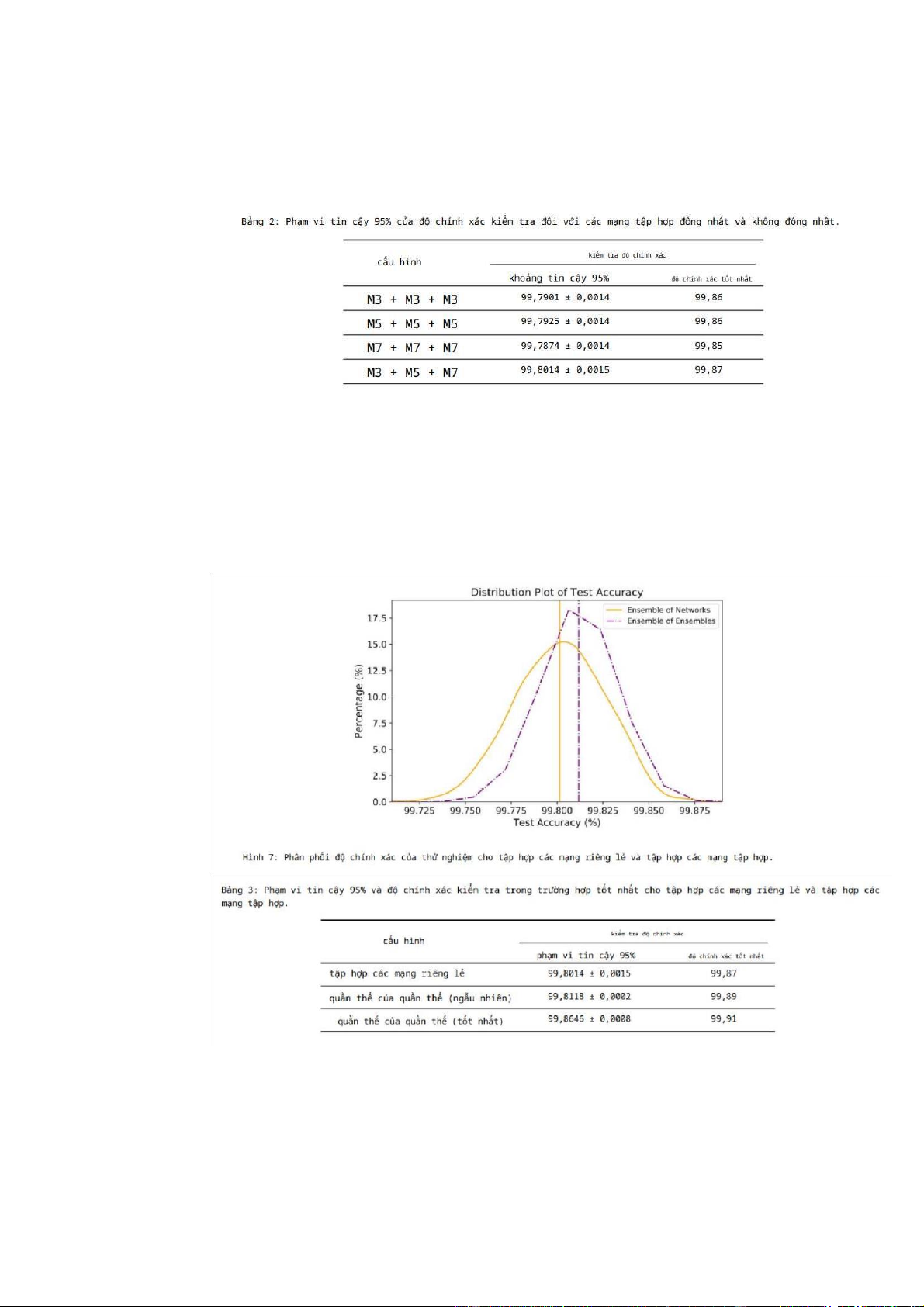
được thảo luận ở trên và Bảng 2 cho thấy phạm vi tin cậy 95% của độ chính xác của
phép thử đối với bốn phương pháp. Có thể nhận thấy rằng mặc dù độ chính xác kiểm
tra trung bình của các phương pháp tập hợp đồng nhất là tương tự nhau, nhưng
phương pháp tập hợp trong đó một mạng được chọn từ mỗi loại mạng đạt được độ chính xác cao hơn.
Từ Hình 5, chúng ta có thể thấy rằng việc sử dụng một nhóm gồm ba mạng
đồng nhất có thể cải thiện độ chính xác của phép thử.
Ngoài ra, trong Hình 6 cho thấy rằng việc kết hợp các kết quả từ các mạng
không đồng nhất cũng có thể giúp tăng độ chính xác . Chúng tôi đã thử nghiệm một
phương pháp tập hợp hai cấp độ, trong đó trước tiên chúng tôi kết hợp các kết quả từ
ba mạng đồng nhất, sau đó kết hợp các kết quả từ ba mạng tập hợp đồng nhất. Đối
với nghiên cứu này, chúng tôi đã đào tạo 3 nhóm gồm 10 mạng cho mỗi loại mạng là
M3, M5 và M7. Đối với mỗi mạng, chúng tôi đã đào tạo trong 150 kỷ nguyên và lưu
mô hình tốt nhất về độ chính xác của thử nghiệm. Sau đó, chúng tôi chọn ngẫu nhiên
3 mạng từ M3 và kết hợp kết quả của chúng bằng biểu quyết đa số. Tương tự, chúng
tôi kết hợp kết quả của ba mạng cho M5 và M7. Sau đó, chúng tôi đã sử dụng biểu
quyết đa số cho ba mạng kết hợp. Hình 7 thể hiện sự phân bổ độ chính xác của phép
thử đối với 1000 nhóm mạng riêng lẻ (M3+M5+M7) và 1000 nhóm mạng kết hợp
((M3+M3+M3)+(M5+M5+M5)+(M7+M7+M7 )).
Biểu đồ cho thấy rằng việc sử dụng tập hợp các mạng tập hợp sẽ cải thiện độ
chính xác của thử nghiệm ở mức trung bình. Bảng 3 cho thấy phạm vi tin cậy 95%
và độ chính xác tốt nhất được quan sát đối với tập hợp các mạng riêng lẻ và tập hợp các mạng tập hợp.
Ngoài lựa chọn ngẫu nhiên, chúng tôi cũng đưa ra trường hợp tốt nhất để xem
độ chính xác tốt nhất mà chúng tôi có thể đạt được là bao nhiêu. Vì trường hợp tốt
nhất, chúng tôi đã chọn 10 mạng tập hợp đồng nhất từ M3, M5 và M7 cho thấy độ
chính xác kiểm tra tốt nhất. Sau đó, chúng tôi chọn một mạng từ mỗi loại và kết hợp
kết quả của chúng. Độ chính xác tốt nhất đạt được là 99,91%.
3.2 Tác động của kiến trúc mạng
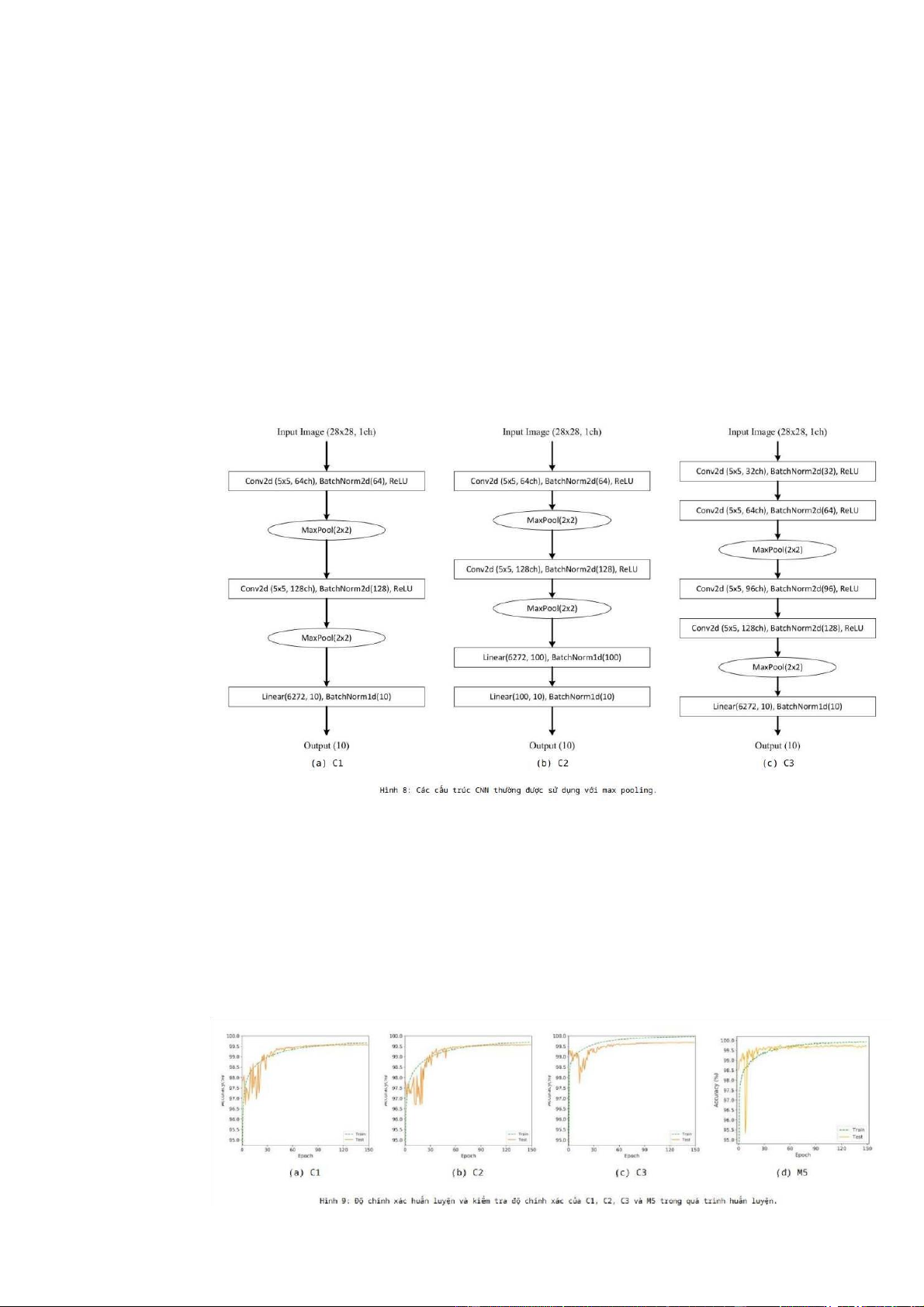
Khi xây dựng một CNN, một thực tế phổ biến là sử dụng tổng hợp, chẳng hạn
như tổng hợp tối đa hoặc tổng hợp trung bình [13]. tổng hợp là được sử dụng để có
được sự bất biến dịch thuật và cũng làm giảm kích thước của các bản đồ đặc trưng.
Một mô hình CNN thường được sử dụng bao gồm một tập hợp các lớp tích chập trong
đó mỗi lớp tích chập được theo sau bởi một lớp tổng hợp và một hoặc nhiều các lớp
được kết nối đầy đủ ở cuối. Một số mạng có hai lớp tích chập trước lớp tổng hợp.
Hình 8 cho thấy một số cấu trúc CNN thường được sử dụng và chúng tôi đặt tên cho ba mạng là C1, C2 và C3.
Hình 9 cho thấy sự thay đổi trong đào tạo và kiểm tra độ chính xác trong quá
trình đào tạo. Có thể thấy rằng đối với các mạng sử dụng tối đa gộp lại, độ chính xác
của bài kiểm tra trải qua các dao động trong giai đoạn đầu đào tạo. Mặt khác, độ chính
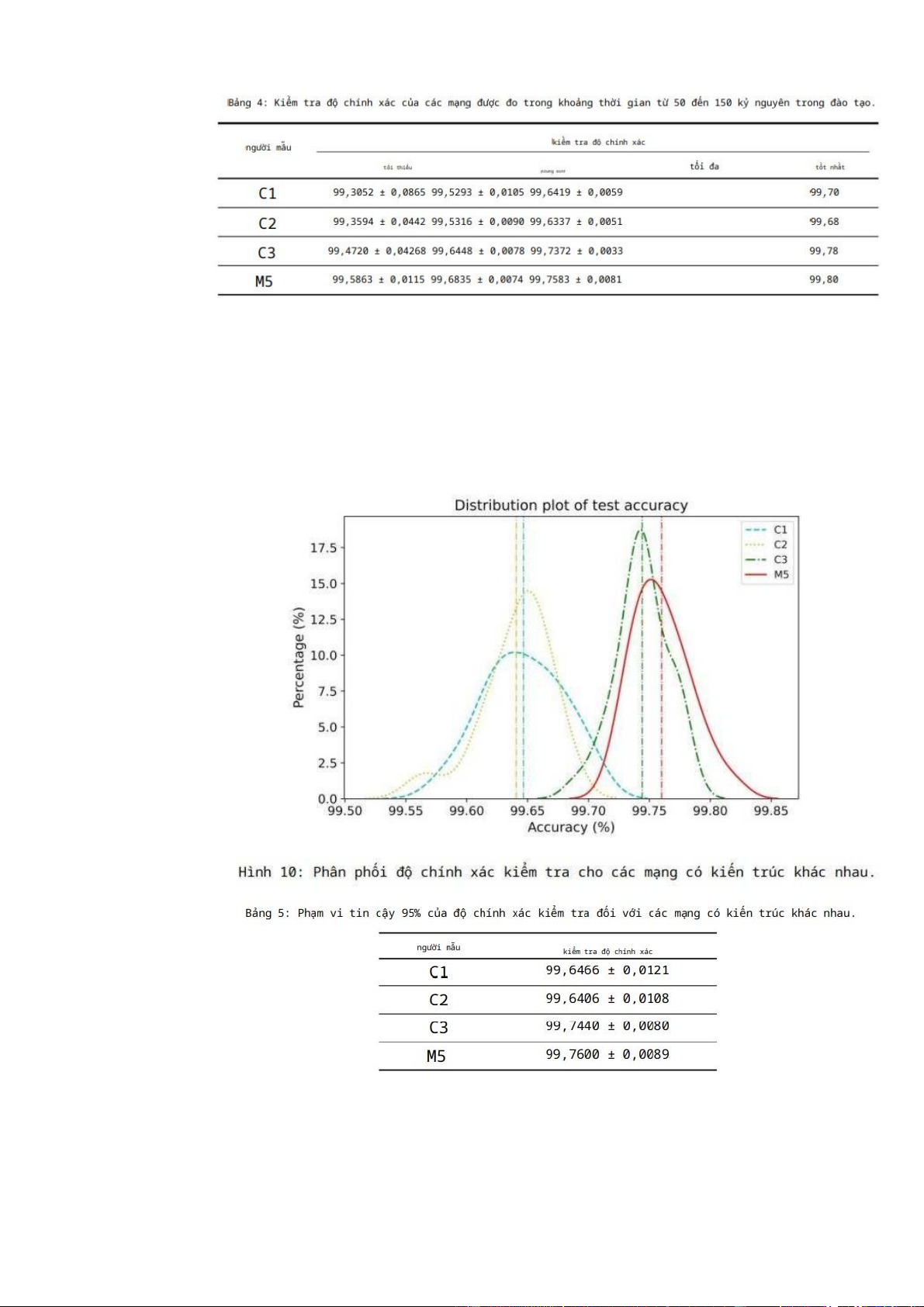
xác của phép thử của M5 tăng một cách ổn định hơn. Bảng 4 cho thấy độ chính xác
kiểm tra của 30 mạng trong khoảng thời gian từ 50 đến 150
thời đại đào tạo. Độ chính xác kiểm tra trung bình của C3 và M5 tốt hơn so
với C1 và C2, có nghĩa là sử dụng nhiều hơn các lớp tích chập có thể dẫn đến việc
học tính năng tốt hơn. Có nhiều lớp được kết nối đầy đủ hơn ở cuối không giúp được
gì, vì có thể được nhìn thấy từ độ chính xác của C1 và C2. Giữa C3 và M5, nhìn
chung M5 đạt được độ chính xác cao hơn và cũng có thể đạt độ chính xác cao hơn
trong trường hợp tốt nhất.
Hình 10 cho thấy biểu đồ phân phối của 30 mạng cho C1, C2, C3 và M5. Đối
với biểu đồ này, mỗi mạng được đào tạo trong 150 giai đoạn và mạng có độ chính xác
kiểm tra cao nhất sẽ được lưu. Có thể thấy M5 đạt bài kiểm tra tốt hơn chính xác hơn
so với các mạng khác nói chung. Bảng 5 cho thấy phạm vi tin cậy 95% của độ chính
xác kiểm tra cho từng mạng mẫu
3.3 Tác động của việc tăng cường dữ liệu
Tăng cường dữ liệu là một kỹ thuật để tăng tính đa dạng của dữ liệu đào tạo
mà không thực sự thu thập dữ liệu và ghi nhãn họ. Đây là một kỹ thuật cần thiết cho
việc học có giám sát, trong đó cần có một tập dữ liệu lớn để mô hình mạng có thể đạt
hiệu quả cao [14, 15, 16, 17, 18]. Khi đào tạo mạng được đề xuất, chúng tôi đã sử
dụng hai sơ đồ cho dữ liệu thế hệ: xoay ngẫu nhiên và dịch ngẫu nhiên. Có nhiều lược
đồ khác như cắt xén, lật và thay đổi kích thước và các sơ đồ tăng cường tốt nhất phụ
thuộc vào dữ liệu. Trong phần này, chúng tôi nghiên cứu xem liệu tăng cường dữ liệu
thực sự giúp cải thiện hiệu suất mạng. Chúng tôi đã so sánh hiệu suất của bốn mạng
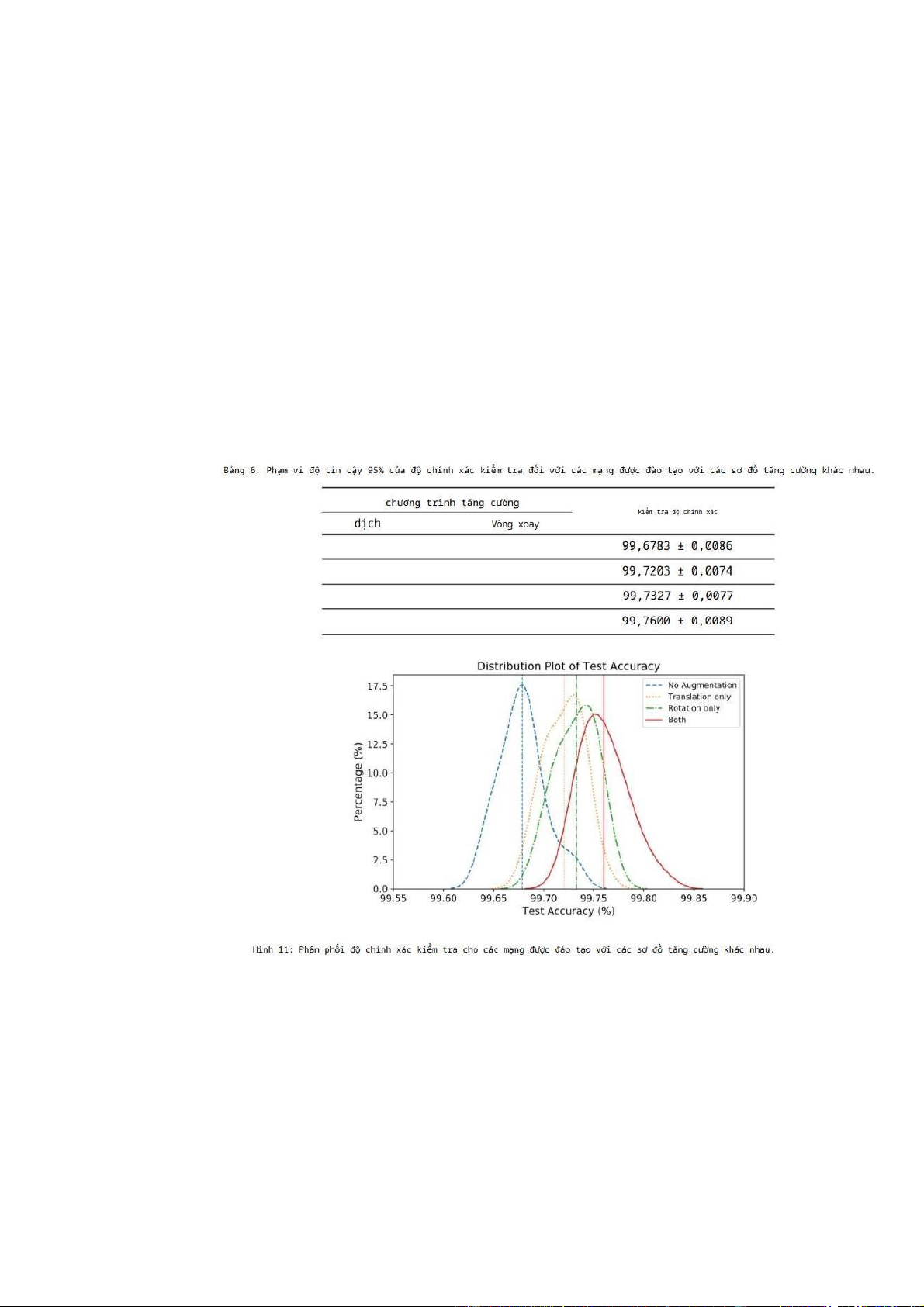
M5 với các kết hợp các chương trình tăng cường được áp dụng. Hình 11 cho thấy
biểu đồ phân phối của 30 mạng cho bốn loại khác nhau các chiến lược gia tăng. Có
thể thấy rằng việc tăng cường dữ liệu nói chung là hữu ích. Đối với tập dữ liệu MNIST,
áp dụng xoay ngẫu nhiên có đóng góp cao hơn một chút so với dịch ngẫu nhiên,
nhưng cả hai sơ đồ đều cần thiết để đạt độ chính xác tốt nhất. Bảng 6 cho thấy phạm
vi tin cậy 95% của độ chính xác kiểm tra đối với bốn chiến lược tăng cường.
3.4 Tác động của chuẩn hóa hàng loạt
Batch normalization là một kỹ thuật nổi tiếng để cải thiện hiệu suất của mạng
cũng như sự ổn định và tốc độ đào tạo [19]. Đã có báo cáo rằng hầu hết các mô hình
mạng thần kinh đều được hưởng lợi từ việc sử dụng chuẩn hóa hàng loạt [20, 21].
Trong phần này, chúng tôi nghiên cứu tác động của chuẩn hóa hàng loạt đối với hiệu
suất của mô hình mạng M5. Chúng tôi đã so sánh ba cấu hình: mô hình đầu tiên hoàn
toàn không sử dụng chuẩn hóa hàng loạt, mô hình thứ hai chỉ sử dụng chuẩn hóa hàng
loạt ở lớp được kết nối đầy đủ và mô hình thứ ba sử dụng chuẩn hóa hàng loạt ở tất
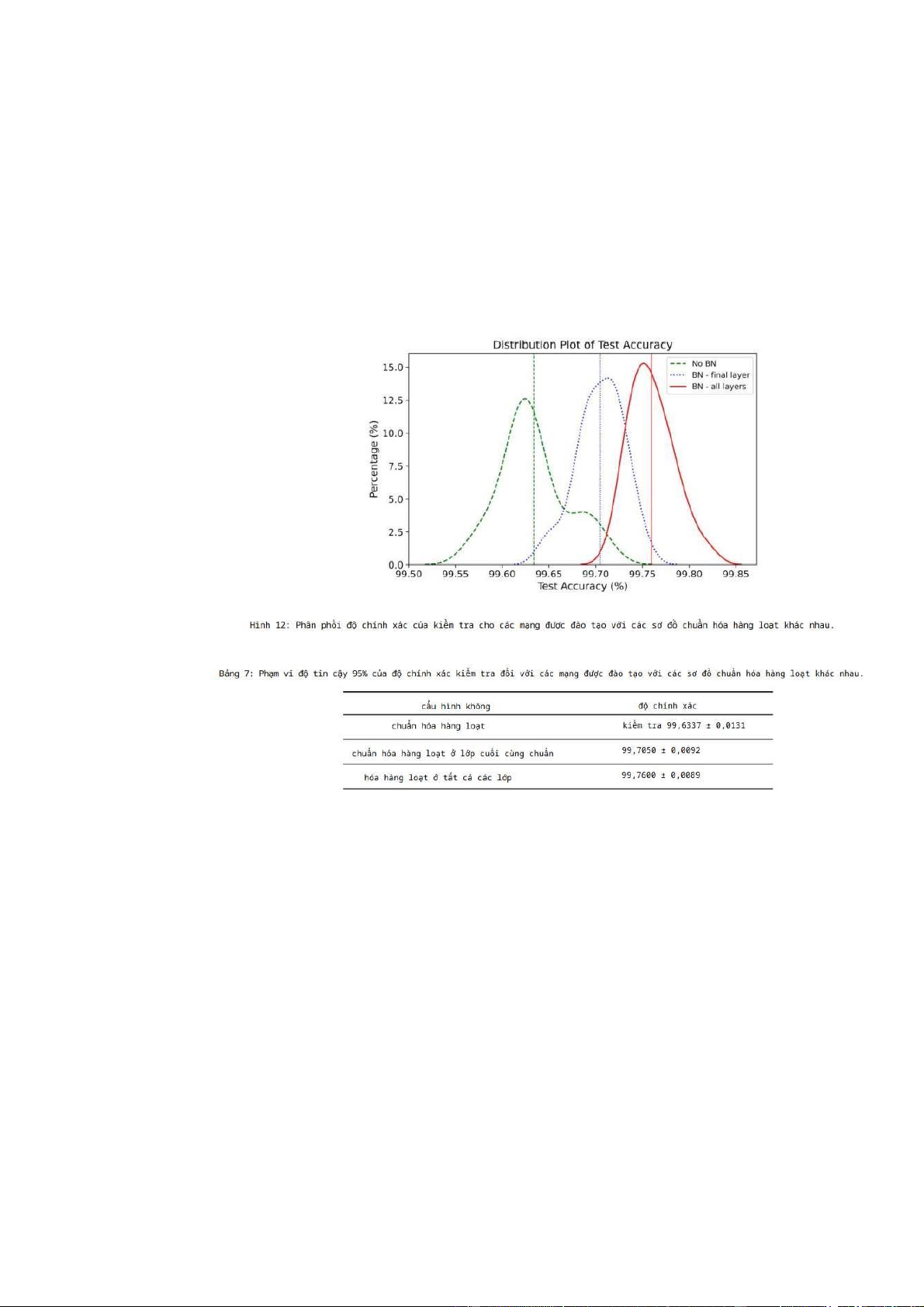
cả các lớp. Hình 12 cho thấy biểu đồ phân phối của 30 mạng cho mỗi cấu hình và
Bảng 7 cho thấy phạm vi tin cậy 95% của độ chính xác kiểm tra cho từng cấu hình.
Rõ ràng là việc sử dụng chuẩn hóa hàng loạt giúp cải thiện hiệu suất của các mô hình mạng thần kinh.
Hiệu suất tốt nhất đạt được khi chuẩn hóa hàng loạt được sử dụng ở mỗi lớp
tích chập và được kết nối đầy đủ. 4. Kết luận
Bộ dữ liệu chữ số viết tay MNIST thường được sử dụng làm bộ dữ liệu cấp
đầu vào để đào tạo và kiểm tra mạng thần kinh. Mặc dù đạt được độ chính xác 99%
trên bộ thử nghiệm khá dễ dàng, nhưng việc phân loại chính xác 1% hình ảnh cuối
cùng lại là một thách thức. Mọi người đã thử nhiều mô hình và kỹ thuật mạng khác
nhau để tăng độ chính xác của thử nghiệm và độ chính xác tốt nhất được báo cáo đạt
khoảng 99,8%. Trong bài báo này, chúng tôi đã chỉ ra rằng một mô hình CNN đơn
giản với chuẩn hóa hàng loạt và tăng cường dữ liệu có thể đạt được độ chính xác cao
nhất. Sử dụng một tập hợp các mô hình mạng đồng nhất và không đồng nhất có thể
tăng hiệu suất, độ chính xác kiểm tra lên tới 99,91%, đây là một trong những hiệu
suất tiên tiến nhất. Các nghiên cứu với nhiều cấu hình khác nhau cho thấy rằng hiệu
suất cao không đạt được bằng một kỹ thuật hoặc kiến trúc mô hình đơn lẻ mà được
đóng góp bởi nhiều kỹ thuật như chuẩn hóa hàng loạt, tăng cường dữ liệu và các phương pháp tập hợp.


