Nhận diện ngôn ngữ ký hiệu | Báo cáo bài tập lớn học phần Thị giác máy tính
Dữ liệu đầu vào là các video chứa các cử chỉ và biểu hiện của ngôn ngữ ký hiệu. Mỗi video được biểu diễn dưới dạng một chuỗi các khung hình (frames), trong đó mỗi khung hình thể hiện trạng thái của ngôn ngữ ký hiệu tại một thời điểm nhất định. Để tránh tình trạng overfitting, các lớp dropout có thể được thêm vào giữa các lớp fully connected để ngẫu nhiên loại bỏ một số nơ-ron trong quá trình huấn luyện. Tài liệu giúp bạn tham khảo, ôn tập và đạt kết quả cao. Mời bạn đón xem.
Môn: Thị giác máy tính 4 tài liệu
Trường: Đại học Phenika 1.3 K tài liệu
Tác giả:












Preview text:
TRƯỜNG ĐẠI HỌC PHENIKAA
KHOA CÔNG NGHỆ THÔNG TIN --- ---
BÁO CÁO BÀI TẬP LỚN
HỌC PHẦN: THỊ GIÁC MÁY TÍNH
ĐỀ TÀI: “NHẬN DIỆN NGÔN NGỮ KÝ HIỆU” NHÓM 1
Giảng viên hướng dẫn: TS. Nguyễn Văn Tới
Sinh viên : Nguyễn Văn Hưng Trần Trọng Đài Trần Dương
Hà Nội, ngày 20 tháng 03 năm 2024 MỤC LỤC
BẢNG PHÂN CÔNG NHIỆM VỤ LÀM VIỆC .............................................. 2
CHƯƠNG I: TỔNG QUAN ............................................................................... 4
1. Đặt vấn đề ..................................................................................................... 4
2. Giải pháp ...................................................................................................... 4
3. Phạm vi đề tài ............................................................................................... 6
CHƯƠNG II: CƠ SỞ LÝ THUYẾT ................................................................. 7
1. 3D-CNN ........................................................................................................ 7
2. ConvLSTM ................................................................................................... 9
3. 2Dplus1D-CNN .......................................................................................... 10
CHƯƠNG III: TRIỂN KHAI .......................................................................... 11
1. Thu thập dữ liệu ......................................................................................... 11
2. Xử lý dữ liệu ............................................................................................... 12
3. Các mô hình thuật toán ............................................................................. 14
CHƯƠNG IV: KẾT QUẢ ................................................................................ 19
1. Kết quả ........................................................................................................ 19
2. Nhận xét ...................................................................................................... 19
3. Hướng phát triển ....................................................................................... 19
CHƯƠNG V : KẾT LUẬN .............................................................................. 20
TÀI LIỆU THAM KHẢO ................................................................................ 21
BẢNG PHÂN CÔNG NHIỆM VỤ LÀM VIỆC Mã sinh Họ và tên Nhiệm vụ viên 20010864 Nguyễn Văn Hưng
Code, chạy code, xử lý dữ liệu, tìm (Trưởng nhóm)
tài liệu, làm báo cáo, làm slide. 21011588 Trần Dương Làm slide, chạy code2d+1d. 21011589 Trần Trọng Đài
Làm báo cáo,tìm tài liệu, chạy code
CHƯƠNG I: TỔNG QUAN 1. Đặt vấn đề
Trong thế giới hiện đại, việc giao tiếp và truyền đạt thông tin là một phần không
thể thiếu của cuộc sống hàng ngày. Tuy nhiên, đối với những người khiếm thính,
việc giao tiếp qua ngôn ngữ bản ngữ có thể gặp nhiều khó khăn. Ngôn ngữ ký
hiệu đã trở thành một phương tiện quan trọng để họ truyền đạt ý nghĩa, cả trong
giao tiếp hàng ngày và trong môi trường giáo dục và làm việc. Ngôn ngữ ký hiệu
không chỉ là một hệ thống biểu đạt, mà còn là cầu nối giữa người khiếm thính và
thế giới xung quanh. Nhưng việc giao tiếp giữa người khiếm thính và người
không khiếm thính thực sự là một thách thức, đặc biệt là khi sự hiểu biết về ngôn
ngữ ký hiệu và các phương tiện giao tiếp thích hợp không phổ biến. Vì vậy, chúng
em muốn tập trung vào việc phát triển các giải pháp công nghệ như hệ thống
nhận diện ngôn ngữ ký hiệu.
Qua việc phát triển và áp dụng các công nghệ mới này, chúng em mong muốn tạo
ra những cơ hội giao tiếp mới cho người khiếm thính và giúp họ tham gia vào các
hoạt động xã hội và công việc một cách tự tin và linh hoạt hơn. Đồng thời, chúng
em cũng muốn góp phần xây dựng một cộng đồng thông cảm và hỗ trợ, nơi mọi
người đều được đón nhận và tôn trọng, không phân biệt khuyết tật. 2. Giải pháp
Qua quá trình học hỏi và tìm hiểu thì chúng em có đề xuất một số mô hình cho
việc nhận diện ngôn ngữ ký hiệu:
3DCNN (Convolutional Neural Networks 3D):
Mô tả: 3DCNN là một biến thể của mô hình CNN, được thiết kế để xử lý dữ liệu
không gian và thời gian trong các tập dữ liệu video hoặc chuỗi hình ảnh. Thay vì
chỉ sử dụng các bộ lọc 2D, 3DCNN sử dụng các bộ lọc 3D để xác định các đặc
trưng không gian và thời gian của dữ liệu. 4
Ưu điểm: 3DCNN có khả năng học các đặc trưng không gian và thời gian từ dữ
liệu video một cách hiệu quả, giúp cải thiện khả năng nhận diện trong các chuỗi
hình ảnh động như ngôn ngữ ký hiệu.
Hạn chế: 3DCNN có thể đòi hỏi lượng dữ liệu lớn và tài nguyên tính toán cao,
đặc biệt là khi xử lý các video dài.
ConvLSTM (Convolutional Long Short-Term Memory Networks): Mô tả:
ConvLSTM là một biến thể của mô hình LSTM, được kết hợp với cấu trúc
convolutional để xử lý dữ liệu không gian và thời gian. Nó giúp mô hình học
được các mẫu không gian và thời gian từ dữ liệu chuỗi một cách hiệu quả.
Ưu điểm: ConvLSTM giúp mô hình nhớ và xử lý thông tin từ quá khứ trong quá
trình dự đoán, phù hợp với việc nhận diện ngôn ngữ ký hiệu trong các video hoặc chuỗi hình ảnh động.
Hạn chế: ConvLSTM có thể đòi hỏi chi phí tính toán cao, đặc biệt là khi xử lý
các chuỗi dữ liệu lớn và phức tạp. 2DPlus1D-CNN
Mô tả: Mô hình 2DPlus1D là một phương pháp phổ biến trong lĩnh vực xử lý
video, kết hợp cả cấu trúc CNN 2D và cấu trúc Convolutional 3D để xử lý cả
thông tin không gian và thời gian. Cụ thể, 2DPlus1D sử dụng hai luồng dữ liệu:
một luồng xử lý thông tin không gian (2D CNN) và một luồng xử lý thông tin thời gian (1D Convolution).
Ưu điểm: Sự kết hợp của cả 2D CNN và 1D Convolution giúp mô hình 2DPlus1D
có khả năng học được cả các đặc trưng không gian và thời gian từ dữ liệu video
một cách hiệu quả. Đồng thời, việc tách riêng hai luồng dữ liệu cũng giúp tăng
cường khả năng hiểu biết và tinh tế trong quá trình nhận diện. Hạn chế: Mô hình
2DPlus1D có thể đòi hỏi nhiều tài nguyên tính toán hơn so với một số phương
pháp khác, đặc biệt là khi xử lý các video có độ phức tạp cao. 5
3. Phạm vi đề tài
Nghiên cứu về ngôn ngữ ký hiệu: Trong đề tài này chúng em được tìm hiểu về
ngôn ngữ ký hiệu, bao gồm các biểu hiện cử chỉ, hành động. Cụ thể là 21 từ ngữ ký hiệu khác nhau
Nghiên cứu về công nghệ: Trong đề tài này chúng em tìm hiểu các công nghệ và
các mô hình học sâu như CNN, LSTM và các biến thể của nó như 3DCNN,
2D+1D, ConvLSTM, cũng như cách áp dụng nó vào nhạn diện, phân loại video
Xây dựng mô hình nhận diện: Trong đề tài này chúng em đã ứng dụng và thử
nghiệm 3 mô hình học sâu 3DCNN, 2D+1D, ConvLSTM để nhận diện ngôn ngữ
ký hiệu từ dữ liệu đã được thu.
So sánh và đánh giá: So sánh hiệu suất của các mô hình khác nhau và đánh giá
tính khả thi và hiệu quả của từng phương pháp. Điều này giúp xác định các mô
hình có hiệu quả nhất trong việc nhận diện ngôn ngữ ký hiệu.
Hạn chế và hướng phát triển: Đánh giá các hạn chế của các phương pháp hiện tại
và đề xuất các hướng phát triển tiếp theo để cải thiện hiệu suất và ứng dụng thực
tế của nhận diện ngôn ngữ ký hiệu. 6
CHƯƠNG II: CƠ SỞ LÝ THUYẾT 1. 3D-CNN
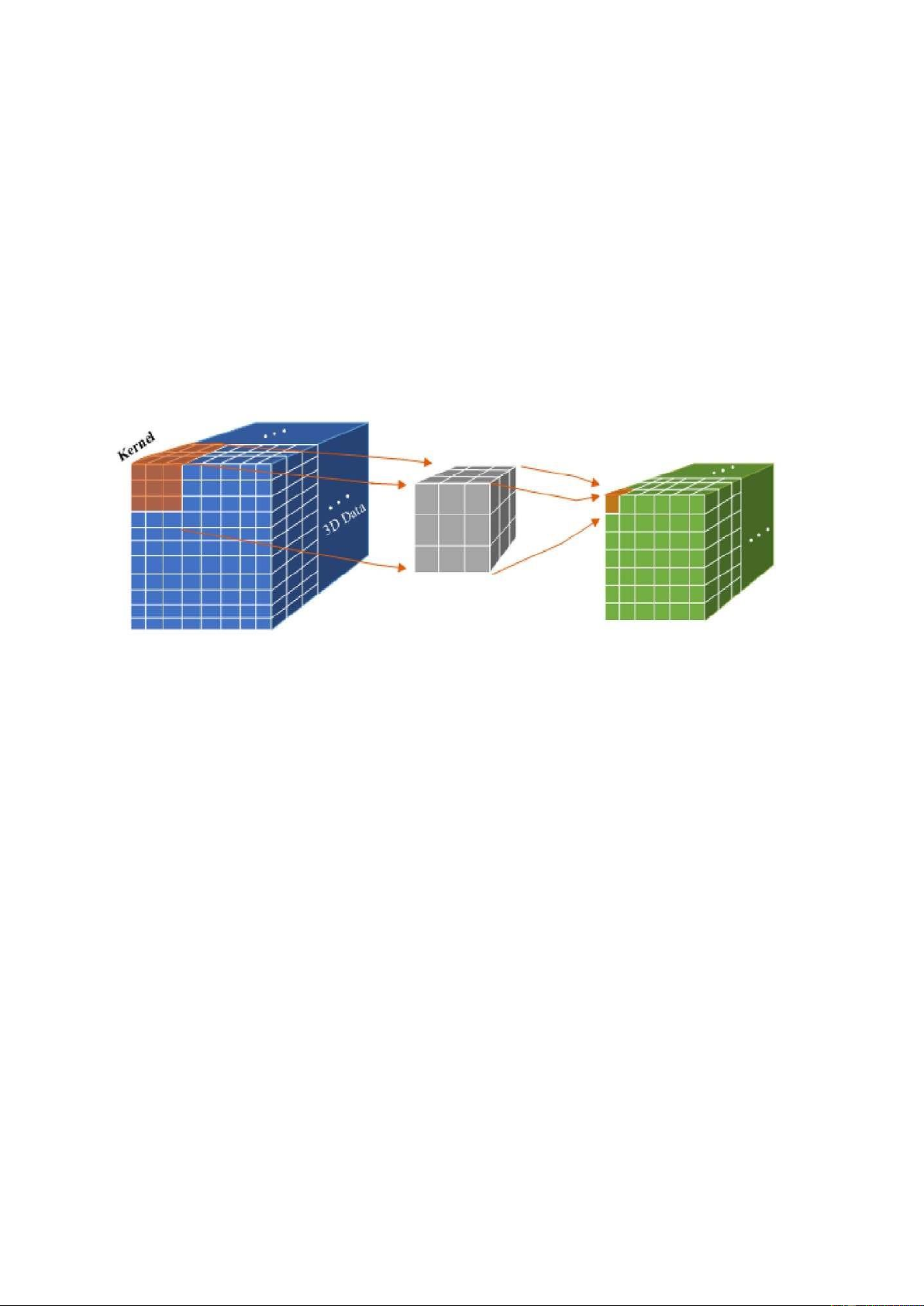
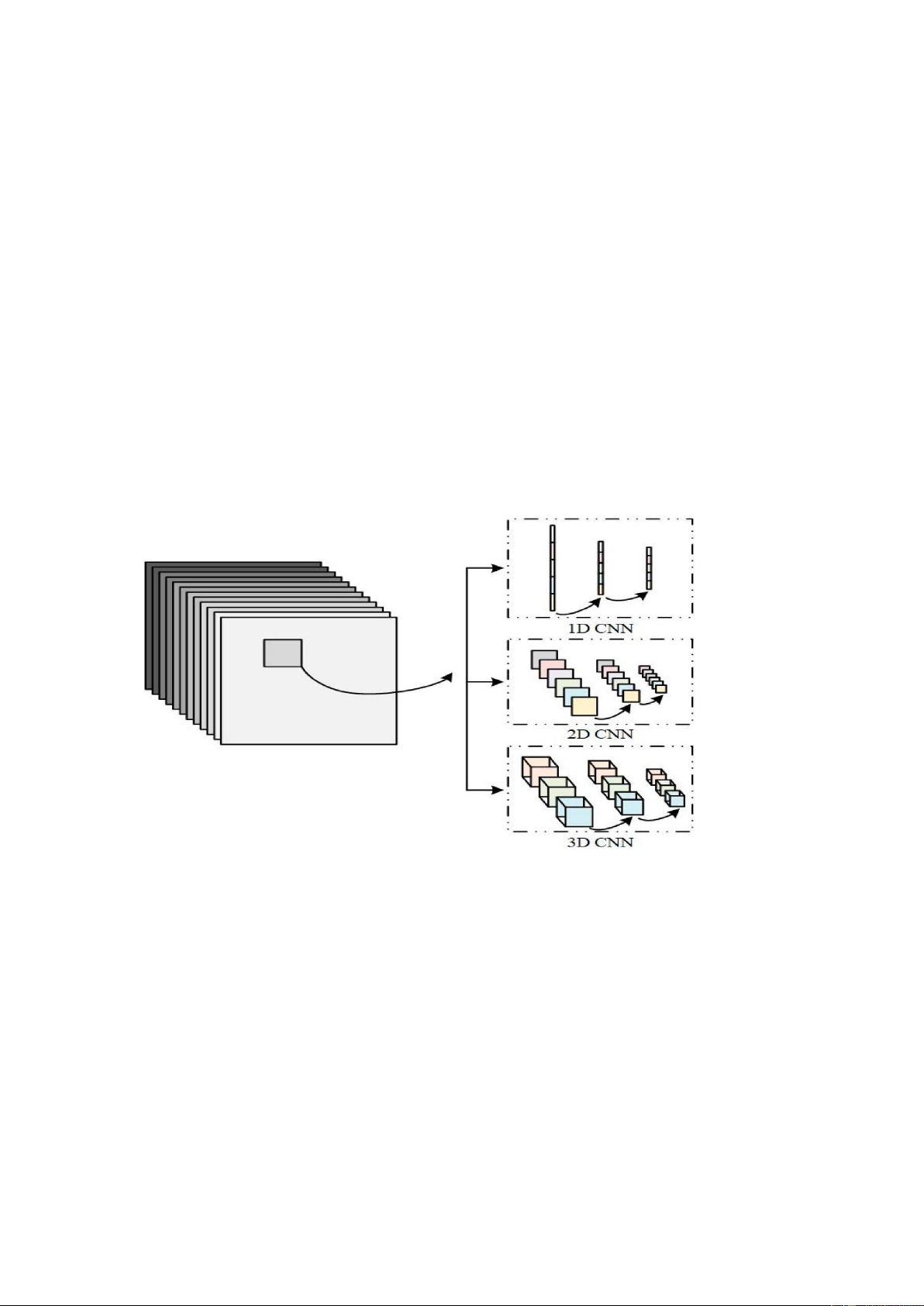
Mạng neural tích chập 3D-CNN là một mạng tích chập CNN sử dụng phép tích
chập khối (ma trận 3 chiều, thêm trục thời gian), thường được sử dụng trong các
bài toán nhận dạng (hành động, phân lớp) trong các video. Chuyển động trong
các video được hiểu là bao 9 gồm tập các hình ảnh được biểu diễn trong một trục
thời gian nhất định, do đó phát sinh thêm trục thời gian (chiều thời gian). Phép tích chập 3D-CNN
Kích thước kernel trong 3D theo thời gian là 3, các bộ kết nối cùng màu có cùng
trọng số chia sẽ (shared weights). Trong tích chập 3D, các kernel giốn nhau cùng
được áp dung khối 3D chồng lền nhau trong video đầu vào để trích xuất các tính
năng chuyển động. Trong phép tích chập 3D kernel chỉ có thể trích xuất một trong
các đặc trưng của khung hình khối lập phương đó, các trọng số kernel được tính
toán trong hình khối lập phương. Nguyên tắc chung trong mô hình CNNs là số
các feature map được tăng lên ở các lớp sau bằng cách sinh ra từ nhiều đặc trưng
từ một tập các feature map lớp trước đó. Tương tự trường hợp tích chập 2D, 3D
cũng thực hiện nhiều phép tích chập với các kernel khác nhau đến từ cùng một vị trí lớp trước đó. 7 Đầu vào (Input):
Dữ liệu đầu vào là các video chứa các cử chỉ và biểu hiện của ngôn ngữ ký hiệu.
Mỗi video được biểu diễn dưới dạng một chuỗi các khung hình (frames), trong
đó mỗi khung hình thể hiện trạng thái của ngôn ngữ ký hiệu tại một thời điểm nhất định. Convolutional Layers:
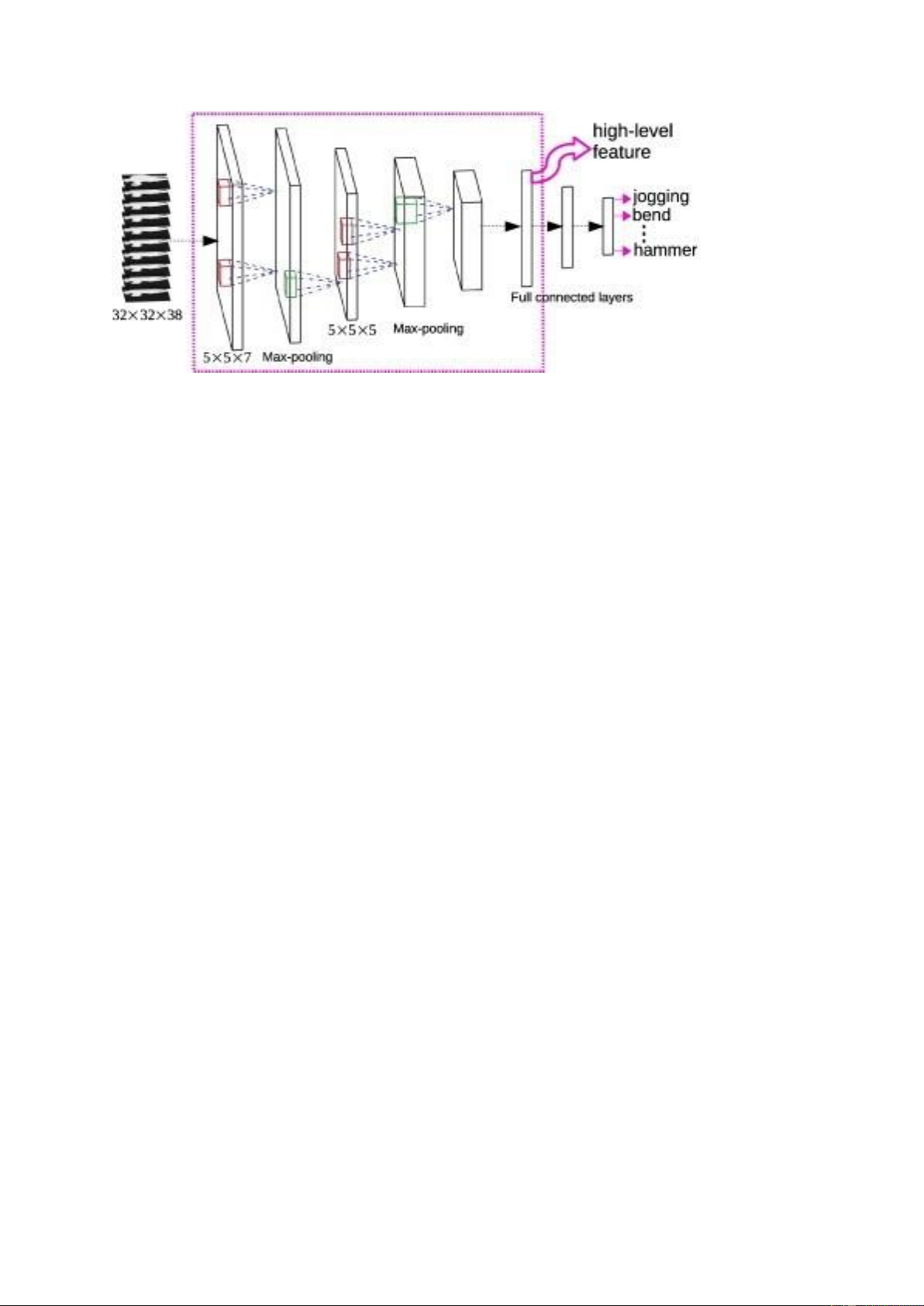
Kiến trúc 3D CNN bao gồm một chuỗi các lớp convolutional (Conv3D) để trích
xuất các đặc trưng không gian và thời gian từ dữ liệu video.
Mỗi lớp convolutional sẽ áp dụng một số lượng các bộ lọc 3D lên các khung hình
của video để tạo ra các đặc trưng phản ứng với thông tin không gian và thời gian của ngôn ngữ ký hiệu. Pooling Layers:
Sau mỗi lớp convolutional, các lớp pooling 3D (ví dụ: max pooling) thường được
sử dụng để giảm kích thước của các feature maps và tạo ra một biểu diễn sâu hơn
và thu gọn của dữ liệu. Fully Connected Layers:
Sau khi trích xuất các đặc trưng từ dữ liệu video thông qua các lớp convolutional
và pooling, các đặc trưng này sẽ được làm phẳng và đưa vào các lớp fully
connected để phân loại các ngôn ngữ ký hiệu.
Các lớp fully connected thường kết thúc bằng một lớp softmax để dự đoán xác
suất của mỗi lớp ngôn ngữ ký hiệu. 8 Dropout Layers:
Để tránh tình trạng overfitting, các lớp dropout có thể được thêm vào giữa các
lớp fully connected để ngẫu nhiên loại bỏ một số nơ-ron trong quá trình huấn luyện. Output Layer:
Lớp output của mạng 3D CNN sẽ đưa ra các dự đoán về lớp ngôn ngữ ký hiệu
của mỗi video, dựa trên xác suất từ lớp softmax.
Kiến trúc 3D CNN này cho phép mạng nơ-ron học được các đặc trưng không gian
và thời gian từ dữ liệu video và sử dụng chúng để dự đoán lớp ngôn ngữ ký hiệu
của mỗi video đầu vào. 2. ConvLSTM
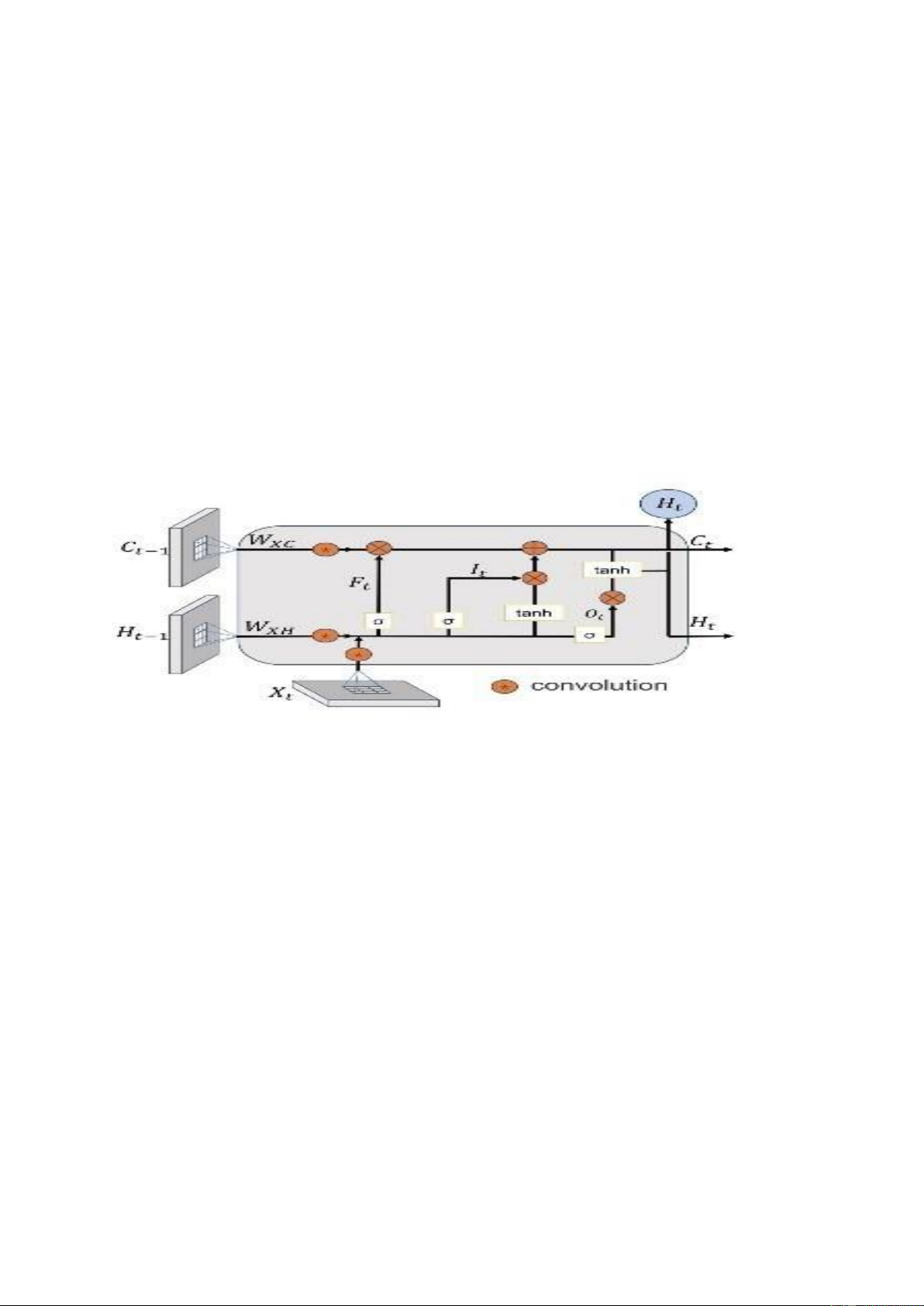
ConvLSTM là một loại mạng nơ-ron kết hợp giữa Mạng Nơ-ron Tích chập (CNN)
và mô hình Long Short-Term Memory (LSTM). CNN thường được sử dụng cho
các nhiệm vụ xử lý hình ảnh, trong đó chúng xác định và trích xuất đặc trưng từ
các hình ảnh. Mô hình LSTM, ngược lại, được sử dụng cho phân tích chuỗi thời
gian, trong đó chúng sử dụng các ô nhớ để lưu trữ thông tin qua thời gian.
ConvLSTM được thiết kế để kết hợp hai mô hình này để xử lý dữ liệu không gian
thời gian có sự phụ thuộc cả về không gian và thời gian.
ConvLSTM được giới thiệu lần đầu tiên bởi Xingjian Shi và các cộng sự trong
một bài báo năm 2015 có tựa đề "Convolutional LSTM Network: A Machine
Learning Approach for Precipitation Nowcasting." Bài báo đề xuất sử dụng mô
hình ConvLSTM để dự báo lượng mưa sử dụng hình ảnh radar, đã chứng minh 9
rằng mô hình này vượt trội hơn so với các mô hình LSTM truyền thống về độ
chính xác và xử lý dữ liệu không gian thời gian. Cách ConvLSTM Hoạt Động
Kiến trúc ConvLSTM hoạt động bằng cách duy trì thông tin không gian của đầu
vào đồng thời học các phụ thuộc thời gian. Thông thường, CNN mất thông tin
không gian khi chúng xử lý các hình ảnh đầu vào do các lớp tích chập và lớp gộp.
Mô hình LSTM, ngược lại, cần duy trì thông tin thời gian, có nghĩa là chúng yêu
cầu các chuỗi đầu vào phải được sắp xếp. Mô hình ConvLSTM sử dụng sự kết
hợp của các lớp tích chập và LSTM để duy trì cả thông tin không gian và thời gian. 3. 2Dplus1D-CNN Đầu vào (Input):
Dữ liệu đầu vào là các video, mỗi video bao gồm một chuỗi các khung hình.
Convolutional 2D Layers (2D CNN):
Các lớp Convolutional 2D được sử dụng để trích xuất các đặc trưng không gian
từ từng khung hình của video.
Các bộ lọc tích chập được áp dụng lên từng khung hình để tạo ra các bản đồ đặc trưng.
Pooling 2D Layers (2D Pooling): 10
Các lớp Pooling 2D (ví dụ: Max Pooling hoặc Average Pooling) được sử dụng
sau mỗi lớp Convolutional 2D để giảm kích thước của các bản đồ đặc trưng theo không gian.
Quá trình này giúp giảm số lượng tham số và tính toán của mô hình, đồng thời
giữ lại thông tin quan trọng trong các bản đồ đặc trưng.
Convolutional 1D Layers (1D CNN):
Các lớp Convolutional 1D được sử dụng để xử lý thông tin theo thời gian từ các
bản đồ đặc trưng đã được giảm kích thước.
Các bộ lọc tích chập 1D được áp dụng trên các bản đồ đặc trưng theo thời gian
để tạo ra các đặc trưng về sự biến đổi của video qua thời gian.
Pooling 1D Layers (1D Pooling):
Tương tự như Pooling 2D, các lớp Pooling 1D được sử dụng để giảm kích thước
của các bản đồ đặc trưng 1D. Fully Connected Layers (FC):
Các đặc trưng thu được từ các lớp Convolutional được làm phẳng và đưa vào các
lớp Fully Connected để phân loại video.
Cuối cùng, một lớp Softmax được sử dụng để dự đoán xác suất của mỗi lớp phân loại.
Kiến trúc 2DPlus1D kết hợp cả thông tin không gian và thời gian từ dữ liệu video,
giúp cải thiện hiệu suất của mô hình trong việc phân loại và hiểu biết về sự biến
đổi của video qua thời gian.
CHƯƠNG III: TRIỂN KHAI
1. Thu thập dữ liệu
Đối với đề tài này thì chúng em đã được học các từ ngữ ký hiệu khác nhau, sau
đó đối với mỗi từ thì sẽ có 10 đến 20 bạn thu hình tại cùng một địa điểm với các
thiết bị máy móc, ánh sang giống nhau. Tổng tất cả có 21 từ ngữ ký hiệu, mỗi từ
ký hiệu có trên 10 video. 11
2. Xử lý dữ liệu
Đối việc xử lý dữ liệu thì chúng em đã đọc và gán nhãn đúng cho từng video
trong, sau đó chia dữ liệu thành 3 tập train, validation, test với tỷ lệ 0.7, 0.15, 0.15.
data = [] labels = [] for i, class_name in enumerate(classes):
class_dir = os.path.join(base_dir, class_name)
for video_file in os.listdir(class_dir):
video_path = os.path.join(class_dir, video_file) data.append(video_path) labels.append(class_name)
from sklearn.model_selection import train_test_split
train_data, temp_data, train_labels, temp_labels = train_test_split(data, labels,
test_size=0.3, random_state=42)
valid_data, test_data, valid_labels, test_labels = train_test_split(temp_data,
temp_labels, test_size=0.5, random_state=42)
Sau đó chúng em xây dựng hai hàm
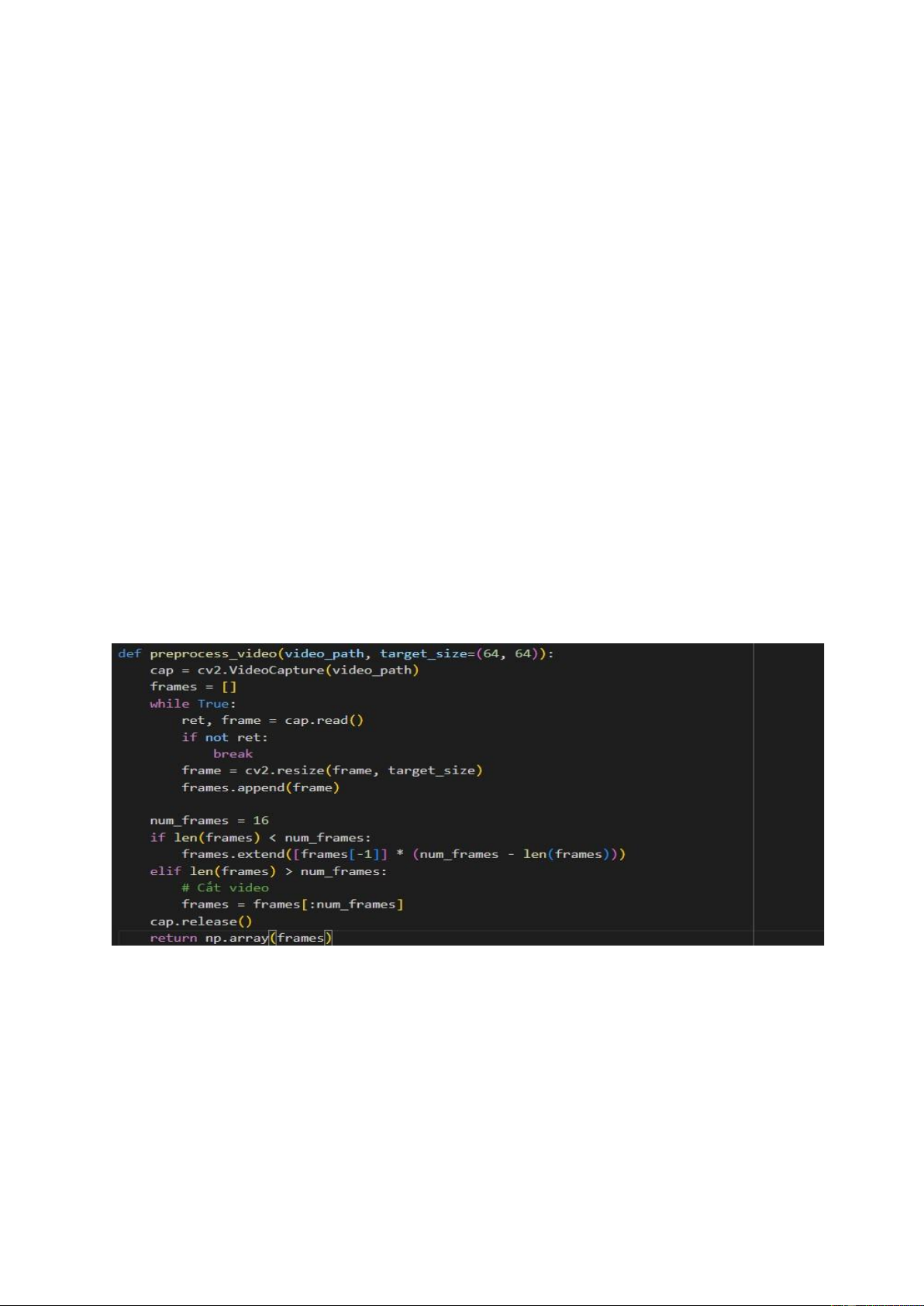
Hàm preprocess_video (video_path, target_size=(64, 64)):
Mục đích: Hàm này được sử dụng để tiền xử lý video trước khi đưa vào mô hình. Đầu vào:
video_path: Đường dẫn đến video cần xử lý.
target_size: Kích thước mục tiêu của các khung hình sau khi được resize.
Đầu ra: Một mảng các khung hình được xử lý. 12
Hàm preprocess_video đầu tiên mở video từ đường dẫn đã cho bằng OpenCV.
Sau đó, nó thực hiện quá trình resize các khung hình trong video đó về kích thước
mục tiêu (truyền vào qua tham số target_size). Nếu video có ít hơn số lượng
khung hình mong muốn (num_frames), hàm sẽ lặp lại khung hình cuối cùng cho
đến khi đủ số lượng khung hình. Nếu video có nhiều hơn num_frames, hàm sẽ
cắt bớt đi số lượng khung hình dư thừa.
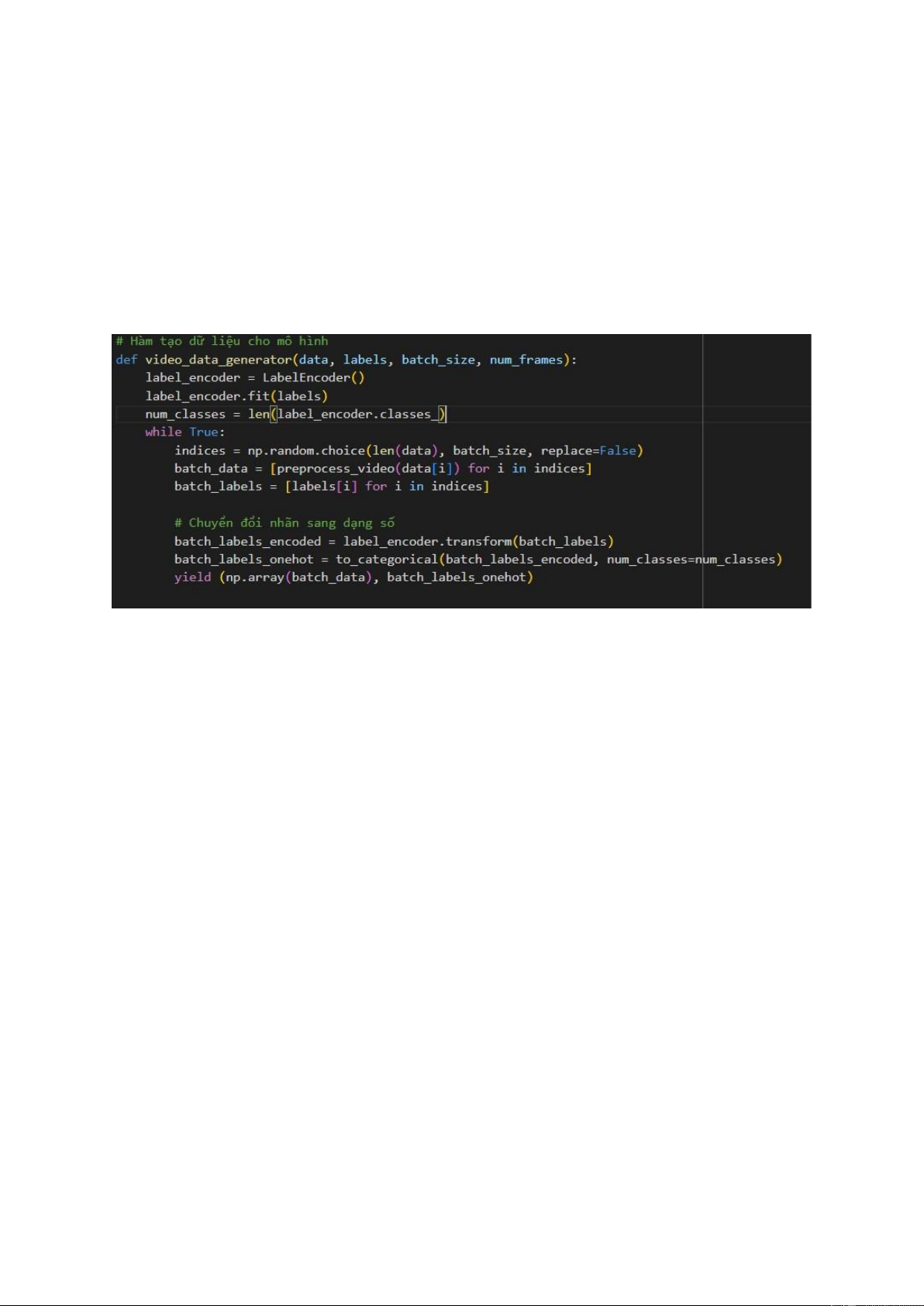
Hàm video_data_generator(data, labels, batch_size, num_frames):
Mục đích: Hàm này được sử dụng để tạo dữ liệu đầu vào cho mô hình trong quá trình huấn luyện. Đầu vào:
data: Danh sách các đường dẫn đến các video.
labels: Nhãn tương ứng với mỗi video. batch_size: Kích thước
của các batch dữ liệu. num_frames: Số lượng khung hình mong muốn trong mỗi video.
Đầu ra: Một generator tạo ra các batch dữ liệu và nhãn tương ứng cho mỗi batch.
Hàm video_data_generator tạo một generator vô hạn bằng cách lặp lại quá trình
sau: lựa chọn ngẫu nhiên một batch kích thước batch_size từ tập dữ liệu, tiền xử
lý mỗi video trong batch bằng cách gọi hàm preprocess_video, chuyển đổi nhãn
thành dạng số và one-hot encoding. Cuối cùng, generator trả về một batch dữ liệu và nhãn tương ứng. 13
3. Các mô hình thuật toán 3.1. 3D-CNN
Mô hình mạng nơ-ron này là một mô hình Convolutional Neural Network 3D
(Conv3D) được xây dựng bằng cách sử dụng Sequential API trong thư viện
Keras/TensorFlow. Dưới đây là mô tả chi tiết về các layer và cấu trúc của mô hình:
Conv3D Layer (64 filters, kernel size (3, 3, 3), activation 'relu'): Input Shape: (16, 64, 64, 3)
16: Số lượng khung hình trong mỗi video.
64x64: Kích thước của mỗi khung hình (đã được resize). 3: Số kênh màu (RGB).
64 filters với kích thước kernel là (3, 3, 3) được áp dụng trên các khung hình để
trích xuất các đặc trưng không gian và thời gian.
Activation function 'relu' được sử dụng để kích hoạt các đầu ra của layer. 14
MaxPooling3D Layer (pool_size (2, 2, 2)):
Sử dụng để giảm kích thước của các feature maps thu được từ Conv3D layer, giúp
giảm chi phí tính toán và làm tăng tính bất biến của mô hình đối với việc dịch chuyển không gian.
Pooling kích thước (2, 2, 2) được áp dụng trên các khối 3D để giảm kích thước của chúng.
Conv3D Layer (128 filters, kernel size (3, 3, 3), activation 'relu'):
Một Conv3D layer khác được thêm vào mô hình với 128 filters và kích thước kernel (3, 3, 3).
Activation function 'relu' được sử dụng.
MaxPooling3D Layer (pool_size (2, 2, 2)):
Tương tự như layer MaxPooling3D trước đó, layer này cũng giảm kích thước của
các feature maps bằng cách áp dụng pooling với kích thước (2, 2, 2). Flatten Layer:
Layer này được sử dụng để làm phẳng các feature maps thành một vector 1D,
chuẩn bị cho việc đưa vào các lớp Fully Connected (Dense).
Dense Layer (256 units, activation 'relu'):
Một lớp Dense với 256 units được thêm vào để học các đặc trưng phức tạp từ các
đặc trưng trích xuất từ Conv3D layers.
Activation function 'relu' được sử dụng.
Dropout Layer (dropout rate 0.5):
Layer Dropout với tỷ lệ dropout là 0.5, giúp tránh hiện tượng overfitting bằng
cách ngẫu nhiên loại bỏ một phần các nơ-ron trong quá trình huấn luyện.
Dense Layer (num_classes units, activation 'softmax'):
Lớp Dense cuối cùng với số lượng units bằng số lượng lớp phân loại
(num_classes), được kích hoạt bằng hàm softmax để dự đoán xác suất của mỗi lớp. Compile Model: 15
Mô hình được biên dịch với hàm mất mát là 'categorical_crossentropy', thuật toán
tối ưu hóa là 'adam', và độ đo hiệu suất là 'accuracy'. 3.2. ConvLSTM
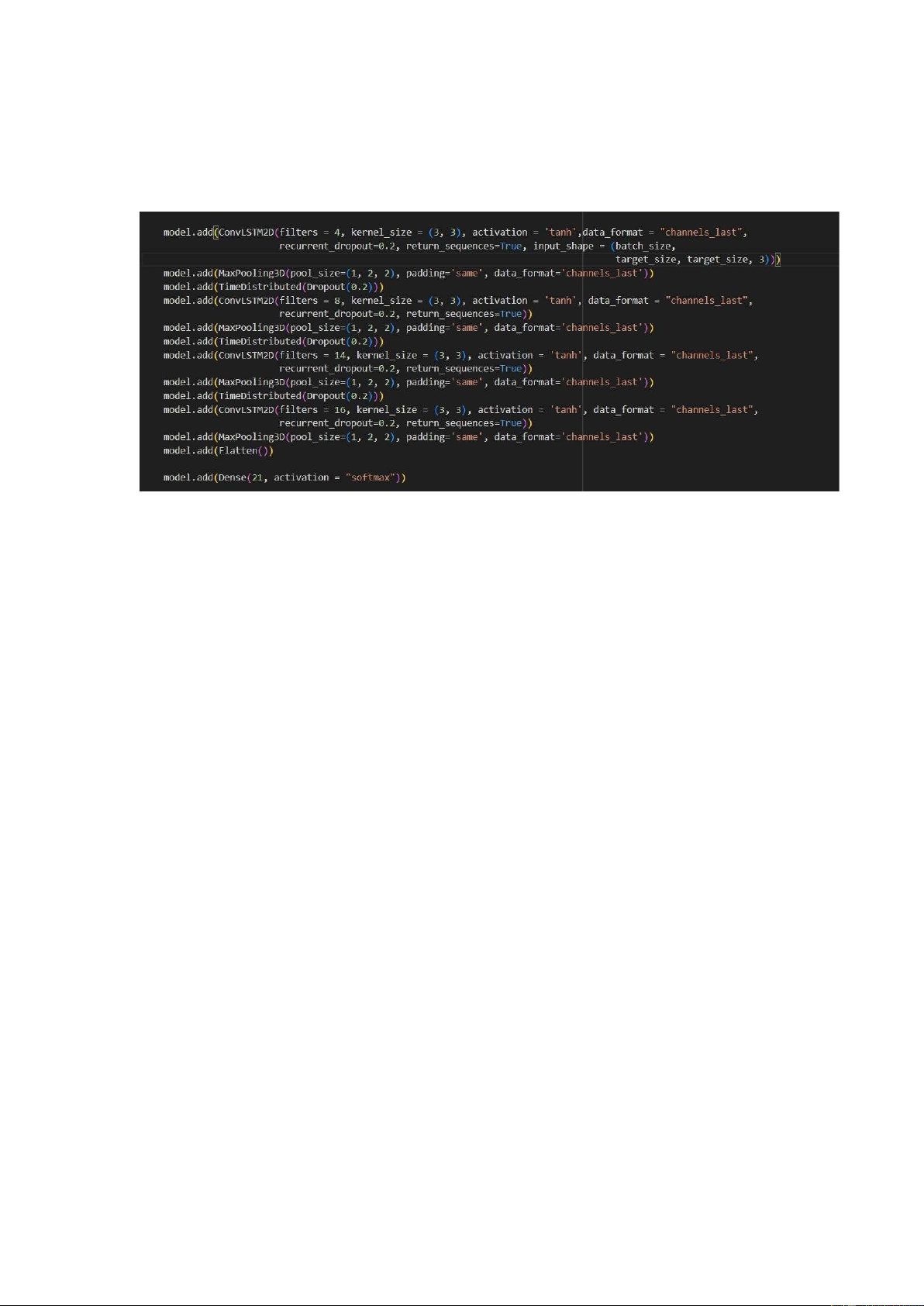
ConvLSTM2D Layer (filters = 4, kernel_size = (3, 3), activation = 'tanh'):
Input Shape: (batch_size, target_size, target_size, 3)
ConvLSTM2D với 4 filters và kích thước kernel là (3, 3).
Activation function 'tanh' được sử dụng. recurrent_dropout=0.2: Dropout được áp
dụng cho các trạng thái ẩn trong quá trình huấn luyện. return_sequences=True:
Trả về chuỗi các output thay vì chỉ output cuối cùng.
MaxPooling3D Layer (pool_size=(1, 2, 2), padding='same'):
Pooling kích thước (1, 2, 2) được áp dụng trên các khối 3D để giảm kích thước
của chúng. padding='same' được sử dụng để duy trì kích thước của đầu ra.
TimeDistributed Layer (Dropout (0.2)):
Dropout với tỷ lệ 0.2 được áp dụng lên các khung hình của mỗi video.
ConvLSTM2D Layer (filters = 8, kernel_size = (3, 3), activation = 'tanh'):
ConvLSTM2D tiếp theo với 8 filters và kích thước kernel là (3, 3).
MaxPooling3D Layer và TimeDistributed Layer (Dropout):
Lặp lại quá trình tương tự cho các lớp ConvLSTM2D tiếp theo với số filters tăng dần (14 và 16). Flatten Layer: 16
Layer này được sử dụng để làm phẳng các feature maps thành một vector 1D,
chuẩn bị cho việc đưa vào lớp Dense.
Dense Layer (21 units, activation = 'softmax'):
Lớp Dense cuối cùng với 21 units, tương ứng với số lớp phân loại.
Activation function 'softmax' được sử dụng để dự đoán xác suất của mỗi lớp. 3.3. 2Dplus1D-CNN Input Layer:
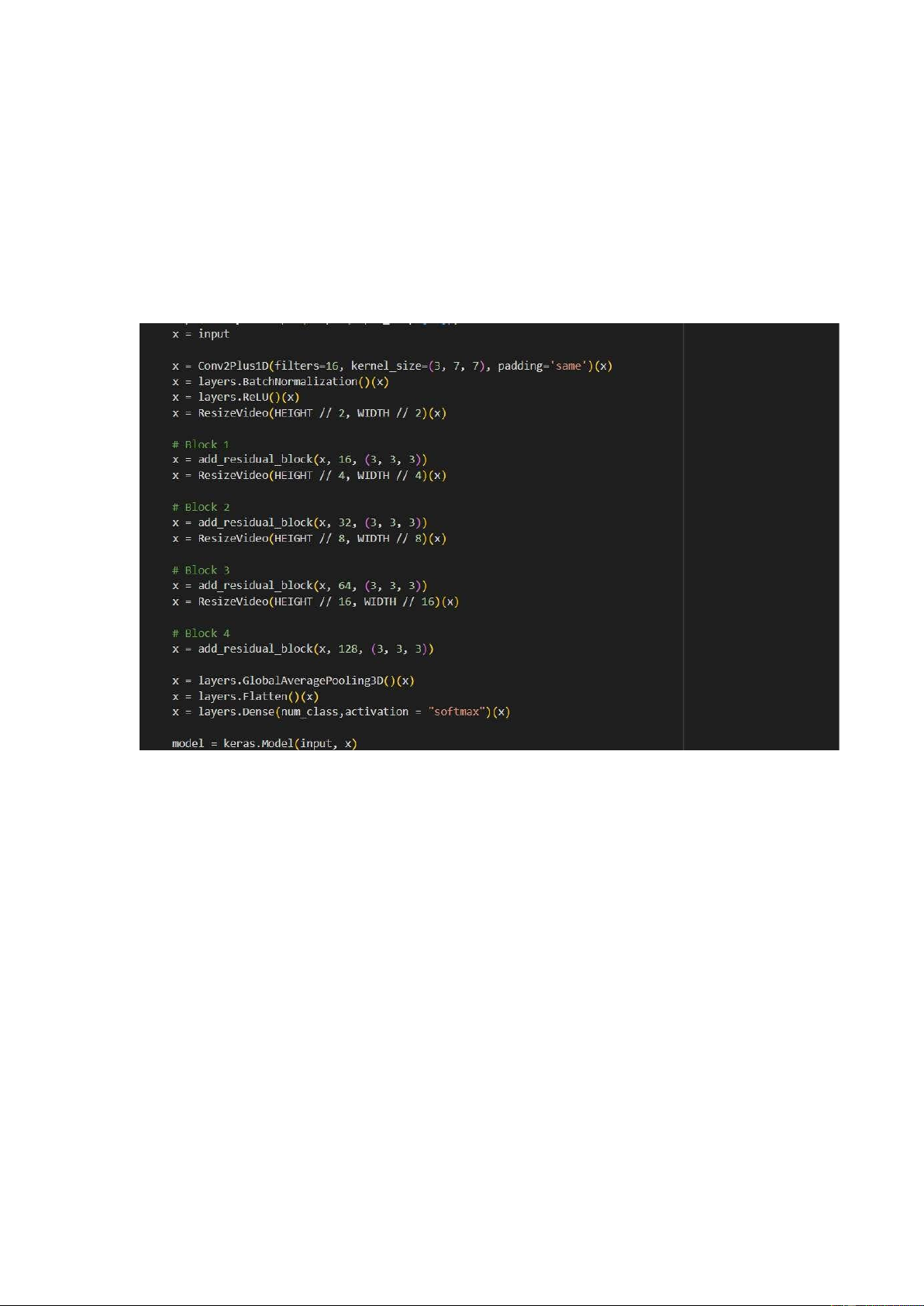
Layer đầu tiên là Input layer với shape (16, HEIGHT, WIDTH, 3) tương ứng với
kích thước của mỗi khung hình trong video.
Conv2Plus1D Layer (filters=16, kernel_size=(3, 7, 7), padding='same'):
Conv2Plus1D là một lớp Convolutional 2Dplus1D, với 16 filters và kernel_size là (3, 7, 7).
padding='same' được sử dụng để duy trì kích thước của đầu ra. BatchNormalization Layer:
BatchNormalization được sử dụng để chuẩn hóa đầu ra của Conv2Plus1D layer,
giúp tăng tốc quá trình huấn luyện và tránh hiện tượng vanishing gradient. ReLU Activation Layer: 17
Layer ReLU được sử dụng để kích hoạt các đầu ra của BatchNormalization layer. ResizeVideo Layer:
ResizeVideo được sử dụng để giảm kích thước của video đi một nửa theo chiều cao và chiều rộng.
Residual Blocks (add_residual_block):
Các Residual Blocks được thêm vào mô hình, mỗi block sử dụng kỹ thuật skip
connection để tránh hiện tượng vanishing gradient.
Mỗi block có các convolutional layers với số lượng filters tăng dần (16, 32, 64,
128) và kernel_size là (3, 3, 3). GlobalAveragePooling3D Layer:
Layer này được sử dụng để thực hiện pooling theo chiều thời gian, chiều rộng và chiều cao của đầu ra. Flatten Layer:
Layer này được sử dụng để làm phẳng đầu ra thành một vector 1 chiều, chuẩn bị
cho việc đưa vào lớp Dense.
Dense Layer (num_class units, activation='softmax'):
Lớp Dense cuối cùng với số lượng units bằng số lớp phân loại (num_class).
Activation function 'softmax' được sử dụng để dự đoán xác suất của mỗi lớp. 18 CHƯƠNG IV: KẾT QUẢ 1. Kết quả
Code được chạy trên google colab với dịch vụ điện toán T4 GPU với 10 epochs. Thuật toán Độ chính xác 1 3D-CNN 0.9 2 ConvLSTM 0.87 3 2Dplus1D-CNN 0.35 2. Nhận xét
• 3D-CNN: Độ chính xác là 0.9.
Thuật toán 3D-CNN có độ chính xác cao nhất trong ba thuật toán được đánh giá.
Điều này có thể được giải thích bởi sự khả năng của mô hình 3D-CNN trong việc
xử lý cả không gian và thời gian trong dữ liệu video.
• ConvLSTM: Độ chính xác là 0.87.
ConvLSTM đạt được một mức độ chính xác khá cao, gần bằng với 3D-CNN.
ConvLSTM có khả năng xử lý dữ liệu video theo thời gian một cách hiệu quả
nhưng có thể gặp khó khăn trong việc học các đặc trưng không gian so với 3D- CNN.
• 2Dplus1D-CNN: Độ chính xác là 0.35.
2Dplus1D-CNN có độ chính xác thấp nhất trong ba thuật toán. Có thể lý giải bởi
sự giới hạn của kiến trúc này trong việc xử lý dữ liệu video so với 3D-CNN và
ConvLSTM. Mặc dù có thể có các ưu điểm khác nhau, nhưng trong trường hợp
này, mô hình này không đạt được hiệu suất tốt nhất.
thuật toán 3D-CNN và ConvLSTM đã cho kết quả tốt hơn so với 2Dplus1DCNN
trong bài toán này. Điều này cho thấy sự ưu việt của mô hình đa chiều trong việc
xử lý dữ liệu video và nhận diện hành động cử chỉ.
3. Hướng phát triển 3.1. Tối ưu hóa mô hình
Cải thiện kiến trúc của mạng neural bằng cách thử nghiệm và tinh chỉnh các tham
số như số lượng lớp, số lượng filters, kích thước kernel, và kích thước pooling. 19
Thử nghiệm các kiến trúc mới và tiên tiến hơn như Transformer cho việc xử lý dữ liệu video. 3.2. Tăng cường dữ liệu
Thu thập dữ liệu đa dạng về không gian, thời gian, ánh sáng
Sử dụng kỹ thuật tăng cường dữ liệu như trích xuất một phần của video, thêm
nhiễu, hoặc xoay, phản chiếu, và thay đổi ánh sáng của video để tạo ra thêm dữ liệu huấn luyện. 3.3.
Kết hợp nhiều phương pháp
Kết hợp các phương pháp khác nhau như 3D-CNN, ConvLSTM, và
2Dplus1DCNN vào một mô hình duy nhất để tận dụng lợi ích từ mỗi phương
pháp. Sử dụng kỹ thuật kết hợp dự đoán từ nhiều mô hình để cải thiện chính xác
và độ tin cậy của mô hình. 3.4.
Phát triển đa ngôn ngữ
Trong tương lai không chỉ dừng lại ở ngôn ngữ tiếng Việt mà còn nhiều ngôn ngữ khác trên thế giới.
CHƯƠNG V: KẾT LUẬN
Trong quá trình nghiên cứu và phát triển các hệ thống nhận diện hành động
ngôn ngữ cử chỉ. Chúng em đã thành công trong việc áp dụng các phương
pháp học sâu và thị giác máy tính để hiểu và phân loại các biểu hiện ngôn ngữ
ký hiệu từ dữ liệu video. Hiểu được quy trình để phát triển một hệ thống từ
thu thập dữ liệu, xử lý dữ liệu, áp dụng vào mô hình thuật toán. Bên cạnh đó
chúng em tiếp tục nghiên cứu và phát triển các phương pháp mới để tối ưu
hóa hiệu suất của mô hình. Tăng cường dữ liệu huấn luyện và thử nghiệm trên
nhiều ngôn ngữ và vùng miền khác nhau để đảm bảo tính đa dạng và phong
phú của mô hình. Nắm vững và áp dụng các kỹ thuật tối ưu hóa siêu tham số
để cải thiện chính xác và hiệu suất của mô hình. Ngoài ra chúng em cần tiếp
tục học hỏi và cải thiện từng ngày để xây dựng những giải pháp thực tế và có
ý nghĩa cho cộng đồng và xã hội. 20


