KMeans Clustering | Tiểu luận Nhập môn phân tích dữ liệu lớn
Machine learning là một lĩnh vực của trí tuệ nhân tạo (AI) mà nghiên cứu và phát triển các thuật toán và mô hình để máy tính tự động học hỏi từ dữ liệu và cải thiện hiệu suất theo thời gian. Trong machine learning, máy tính không được lập trình một cách cụ thể để giải quyết một công việc cụ thể. Tài liệu giúp bạn tham khảo, ôn tập và đạt kết quả cao. Mời đọc đón xem!
Môn: Nhập môn phân tích dữ liệu lớn 1 tài liệu
Trường: Trường Đại học Văn Lang 1.5 K tài liệu
Tác giả:









Preview text:
TRƯỜNG ĐẠI HỌC VĂN LANG KHOA CÔNG NGHỆ THÔNG TIN
NHẬP MÔN PHÂN TÍCH DỮ LIỆU LỚN
NGÀNH: CÔNG NGHỆ THÔNG TIN ĐỀ TÀI: Nhóm thực hiện:
1. Ngô Anh Tuấn - 2174802010464 2. Giảng viên: CHƯƠNG 1: MỞ ĐẦU I. Lý do chọn đề tài:
III. Giới thiệu về Machine Learning: 1. Machine Learning là gì?
Machine learning là một lĩnh vực của trí tuệ nhân tạo (AI) mà nghiên
cứu và phát triển các thuật toán và mô hình để máy tính tự động học hỏi từ dữ
liệu và cải thiện hiệu suất theo thời gian.
Trong machine learning, máy tính không được lập trình một cách cụ thể
để giải quyết một công việc cụ thể. Thay vào đó, nó được trang bị với các
thuật toán và mô hình để tự động phân tích và học từ dữ liệu đầu vào. Máy
tính sẽ tìm hiểu các mẫu và quy luật ẩn trong dữ liệu để tạo ra các dự đoán và quyết định thông minh.
Có ba loại chính của machine learning:
1. Supervised learning (học có giám sát): Thuật toán được huấn luyện bằng
cách sử dụng các cặp dữ liệu đầu vào và đầu ra đã được gán nhãn trước đó.
Mục tiêu là để xây dựng một mô hình có thể dự đoán đầu ra cho các dữ liệu mới chưa được nhãn.
2. Unsupervised learning (học không giám sát): Thuật toán không có dữ liệu
được gán nhãn trước và được sử dụng để khám phá cấu trúc và mẫu ẩn trong
dữ liệu. Mục tiêu là tìm hiểu về cấu trúc không gian của dữ liệu và phân loại chúng thành các nhóm.
3. Reinforcement learning (học tăng cường): Máy tính tương tác với một môi
trường và học từ các phản hồi (rewards) nhận được sau mỗi hành động. Mục 2
tiêu là tìm hiểu các hành động tối ưu để đạt được mục tiêu hoặc tối đa hóa
phần thưởng trong môi trường đã cho.
Machine learning có ứng dụng rộng rãi trong nhiều lĩnh vực, bao gồm
nhận dạng hình ảnh, xử lý ngôn ngữ tự nhiên, dự báo tài chính, tư vấn sản
phẩm, tự động lái xe, và nhiều lĩnh vực khác. Nó đóng vai trò quan trọng
trong việc giải quyết các vấn đề phức tạp và phát triển công nghệ thông minh.
2. Giới thiệu về giải thuật K-mean:
K-means là một thuật toán phân cụm (clustering) phổ biến trong lĩnh vực học
máy và khai phá dữ liệu. Nó được sử dụng để phân loại các điểm dữ liệu vào các
nhóm dựa trên các đặc trưng tương tự.
Trong thuật toán K-means clustering, chúng ta không biết nhãn (label) của
từng điểm dữ liệu. Mục đích là làm thể nào để phân dữ liệu thành các cụm (cluster)
khác nhau sao cho dữ liệu trong cùng một cụm có tính chất giống nhau.
Thuật toán K-means hoạt động theo các bước sau:
1. Chọn số lượng nhóm (clusters) K mà bạn muốn phân loại dữ liệu vào.
2. Chọn ngẫu nhiên K điểm dữ liệu ban đầu làm các điểm trung tâm (centroids) của từng nhóm.
3. Gán các điểm dữ liệu vào nhóm gần nhất bằng cách tính toán khoảng cách từ mỗi
điểm dữ liệu đến các điểm trung tâm.
4. Cập nhật các điểm trung tâm bằng cách tính toán trung bình của tất cả các điểm
dữ liệu trong từng nhóm.
5. Lặp lại bước 3 và 4 cho đến khi các điểm trung tâm không thay đổi hoặc đạt được tiêu chí dừng khác.
Thuật toán K-means có một số ưu điểm: 3
1. Đơn giản và hiệu quả: K-means là một thuật toán đơn giản và dễ hiểu. Nó có thể
được triển khai một cách nhanh chóng và hiệu quả trên các tập dữ liệu lớn.
2. Phân loại dữ liệu không giám sát: K-means không yêu cầu dữ liệu được gán nhãn
trước đó. Nó tự động phân loại các điểm dữ liệu vào các nhóm dựa trên đặc trưng tương tự.
3. Tính linh hoạt: K-means có thể được áp dụng cho nhiều loại dữ liệu khác nhau,
bao gồm cả dữ liệu số và dữ liệu hạng mục. Ví dụ về K-Mean:
Một công ty muốn tạo ra những chính sách ưu đãi cho những nhóm khách
hàng khác nhau dựa trên sự tương tác giữa mỗi khách hàng với công ty đó (số năm
là khách hàng; số tiền khách hàng đã chi trả cho công ty; độ tuổi; giới tính; thành
phố; nghề nghiệp; …). Giả sử công ty đó có rất nhiều dữ liệu của rất nhiều khách
hàng nhưng chưa có cách nào chia toàn bộ khách hàng đó thành một số nhóm/cụm
khác nhau. Sau khi đã phân ra được từng nhóm, nhân viên công ty đó có thể lựa
chọn ra một vài khách hàng trong mỗi nhóm để quyết định xem mỗi nhóm tương
ứng với nhóm khách hàng nào. Phần việc cuối cùng này cần sự can thiệp của con
người, nhưng lượng công việc đã được rút gọn đi rất nhiều.
Ý tưởng đơn giản nhất về cluster (cụm) là tập hợp các điểm ở gần nhau trong
một không gian nào đó (không gian này có thể có rất nhiều chiều trong trường hợp
thông tin về một điểm dữ liệu là rất lớn).
Giả sử mỗi cluster có một điểm đại diện (center) màu vàng. Và những điểm
xung quanh mỗi center thuộc vào cùng nhóm với center đó. Một cách đơn giản nhất,
xét một điểm bất kỳ, ta xét xem điểm đó gần với center nào nhất thì nó thuộc về
cùng nhóm với center đó. Tới đây, chúng ta có một bài toán thú vị: Trên một vùng
biển hình vuông lớn có ba đảo hình vuông, tam giác, và tròn màu vàng như hình
trên. Một điểm trên biển được gọi là thuộc lãnh hải của một đảo nếu nó nằm gần
đảo này hơn so với hai đảo kia . Hãy xác định ranh giới lãnh hải của các đảo. 4 5
CHƯƠNG 3: KẾT QUẢ THỰC HIỆN ĐỒ ÁN
I. Các chức năng và phạm vi của đồ án:
Hãy tưởng tượng bạn đang sở hữu một trung tâm mua sắm siêu thị và thông
qua thẻ thành viên, bạn có một số dữ liệu cơ bản về khách hàng của mình như ID
khách hàng, tuổi, giới tính, thu nhập hàng năm và điểm chi tiêu, đây là thông tin bạn
chỉ định cho khách hàng dựa trên các thông số đã xác định của bạn như hành vi của
khách hàng và dữ liệu mua hàng.
Mục đích chính của vấn đề này là tìm hiểu mục đích của các khái niệm phân
khúc khách hàng, còn được gọi là phân tích giỏ thị trường, cố gắng hiểu khách hàng
và tách họ thành các nhóm khác nhau tùy theo sở thích của họ và sau khi phân chia
xong, thông tin này có thể được cung cấp cho nhóm tiếp thị để họ có thể hoạch định chiến lược phù hợp. II. Quy trình hệ thống:
1. Tìm kiếm dữ liệu và chạy giải thuật:
- Bước 1: Thu thập dữ liệu khách hàng. 6
- Bước 2: Chạy giải thuật trên Google.Colab
2. Chức năng và các bước chạy thuật toán thực tế:
- Khai báo các thư viện cần dùng trong thuật toán: Khám phá dữ liệu:
Trong phần này, Nhóm em đang thực hiện một chút khám phá dữ liệu, kiểm
tra các giá trị null, loại dữ liệu đối tượng và những thứ khác mà Nhóm có thể xem
xét để giữ cho dữ liệu của mình sạch sẽ và có cấu trúc tốt. 7
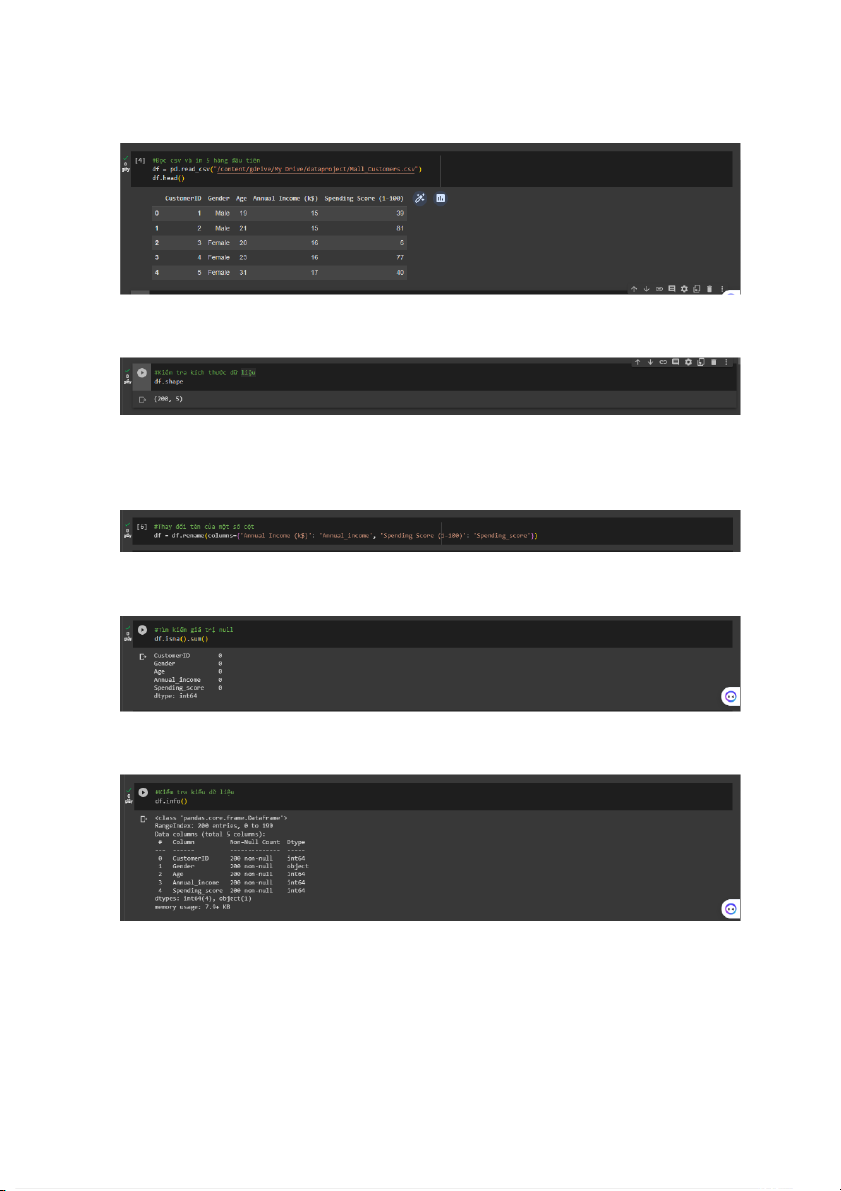
- Đọc file “Mall_customers” và in 5 hàng dữ liệu đầu tiên
- Kiểm tra kích thước dữ liệu
- Vì tên của một số cột khá phức tạp nên chúng em thay đổi thành tên đơn giản hơn
để có thể truy cập dữ liệu dễ dàng hơn - Tìm kiếm giá trị Null
- Kiểm tra kiểu dữ liệu 8
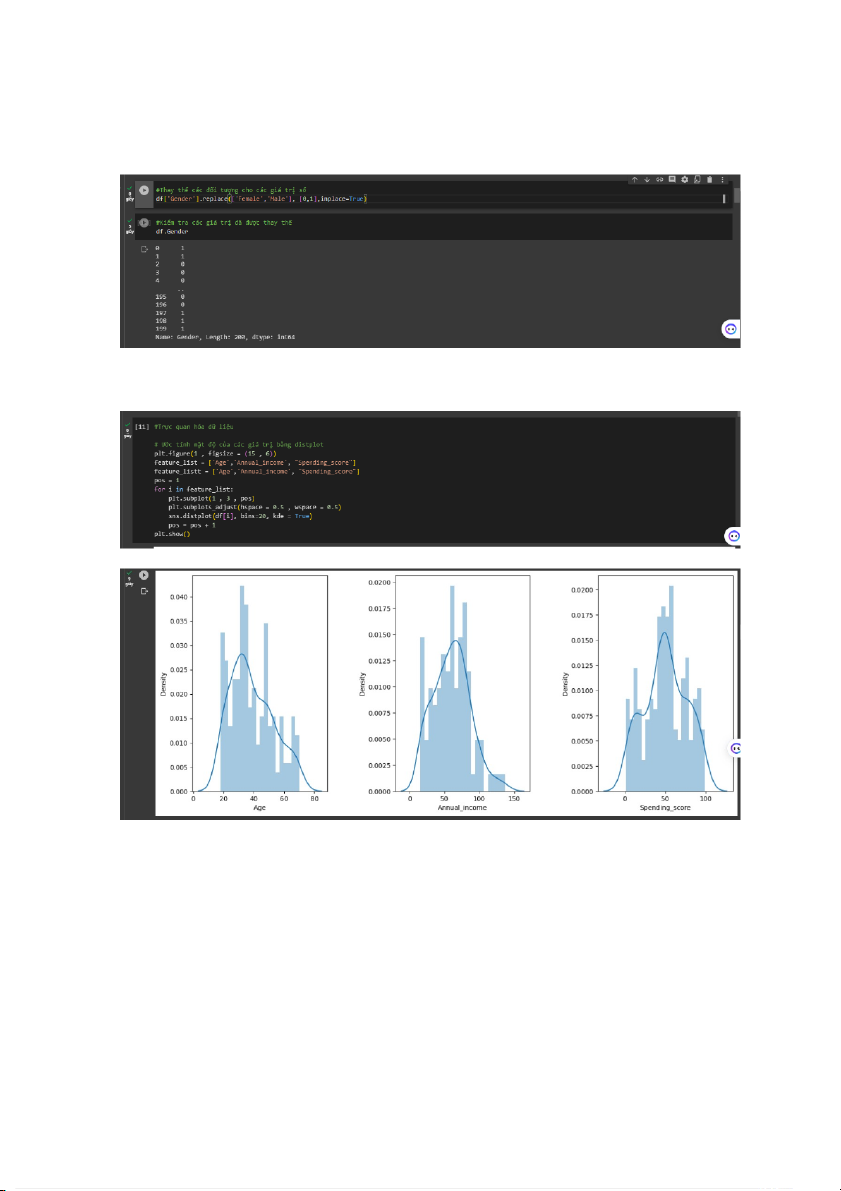
- Vì Giới tính không phải là một giá trị số mà là một đối tượng, nên Nhóm em sẽ
thay thế các giá trị này. “Nữ” sẽ là 0 và “Nam” sẽ là 1 - Trực quan hóa dữ liệu
- Trong các biểu đồ này, chúng ta có thể quan sát thấy rằng phân phối của các
giá trị này giống với phân phối Gaussian, trong đó phần lớn các giá trị nằm ở giữa
với một số ngoại lệ ở các thái cực.
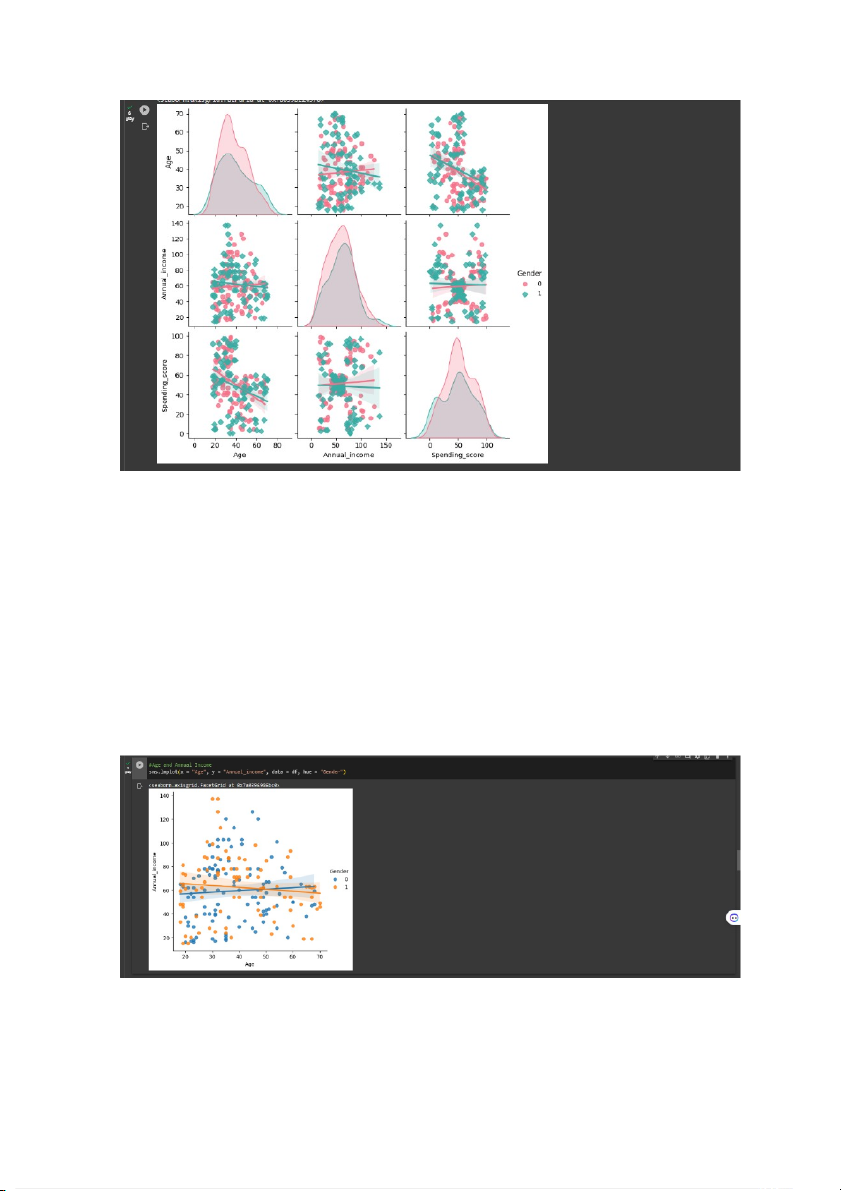
Bây giờ chúng ta đã vẽ biểu đồ phân phối giá trị thông qua biểu đồ, vẽ biểu
đồ mối quan hệ giữa các biến bằng cách sử dụng giới tính làm phân biệt lớp. Để
làm như vậy, Nhóm em đang sử dụng hàm pairplot do thư viện Seaborn cung cấp, 9
chúng tôi cũng đang sử dụng một số tham số để có thể hình dung rõ hơn sự phân tách lớp giới tính.
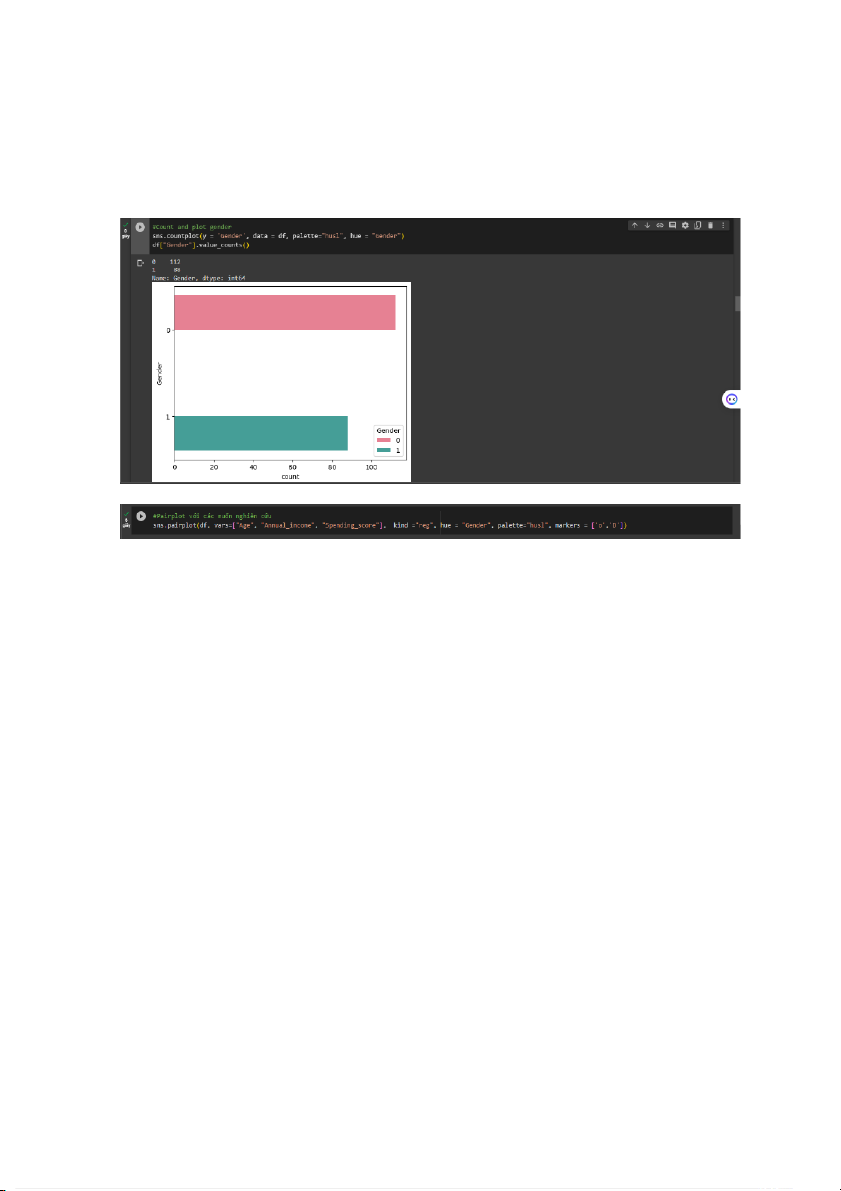
Kiểm tra xem có bao nhiêu phụ nữ và nam giới trong dữ liệu.
- Trong đồ họa biểu đồ cặp này, chúng ta có thể quan sát rõ ràng mối quan hệ
giữa các biến khác nhau mà chúng ta có trong tập dữ liệu của mình và chúng ta sẽ
giải thích rõ hơn về mối quan hệ này trong phần sau. Chúng ta có thể thấy các biểu
đồ tương tự mà chúng ta đã nghiên cứu trước đây, nhưng lần này tạo ra sự khác
biệt giữa phụ nữ và nam giới, đối với mỗi giá trị của mỗi biến, giờ đây chúng ta có
thể thấy tỷ lệ giữa nam và nữ, như chúng ta có thể quan sát, màu hồng có tỷ lệ cao
hơn màu xanh lam, vì có nhiều phụ nữ hơn nam giới, như chúng ta vừa thấy. Bây
giờ chúng ta hãy xem xét kỹ hơn một số mối quan hệ giữa các biến khác nhau này
và trích xuất một số thông tin quan trọng trước khi quá trình phân cụm diễn ra. 10
- Biểu đồ dưới đây cho chúng ta thấy rõ những người ở độ tuổi 30, 40 và 50
có xu hướng kiếm được nhiều tiền hơn hàng năm so với những người dưới 30 tuổi
hoặc trên 50 tuổi. Điều đó có nghĩa là những người có độ tuổi nằm trong khoảng từ
ba mươi đến năm mươi tuổi dường như kiếm được công việc tốt hơn vì họ có thể
được chuẩn bị tốt hơn hoặc đã có nhiều kinh nghiệm hơn những người trẻ tuổi hoặc
những người lớn tuổi hơn. Trong biểu đồ, chúng ta cũng có thể thấy nam giới có xu
hướng kiếm được nhiều tiền hơn một chút so với nữ giới, ít nhất là cho đến năm mươi tuổi. 11
- Ở đây chúng ta có thể quan sát thu nhập hàng năm tốt hơn dẫn đến việc có
điểm chi tiêu cao hơn, đặc biệt đối với phụ nữ. Tuy nhiên, mối tương quan giữa hai
biến số này không quá lớn, phần lớn những người ở mức trung bình, những người
có mức lương khá và có điểm chi tiêu khá cao.
- Trong hình cuối cùng này, những người trẻ tuổi có xu hướng chi tiêu nhiều
hơn những người lớn tuổi. Điều đó có thể do nhiều nguyên nhân: người trẻ thường
có nhiều thời gian rảnh rỗi hơn người già, các trung tâm mua sắm thường có các
cửa hàng hướng đến giới trẻ như trò chơi điện tử, cửa hàng công nghệ, v.v. 12 Selecting Number of Clusters
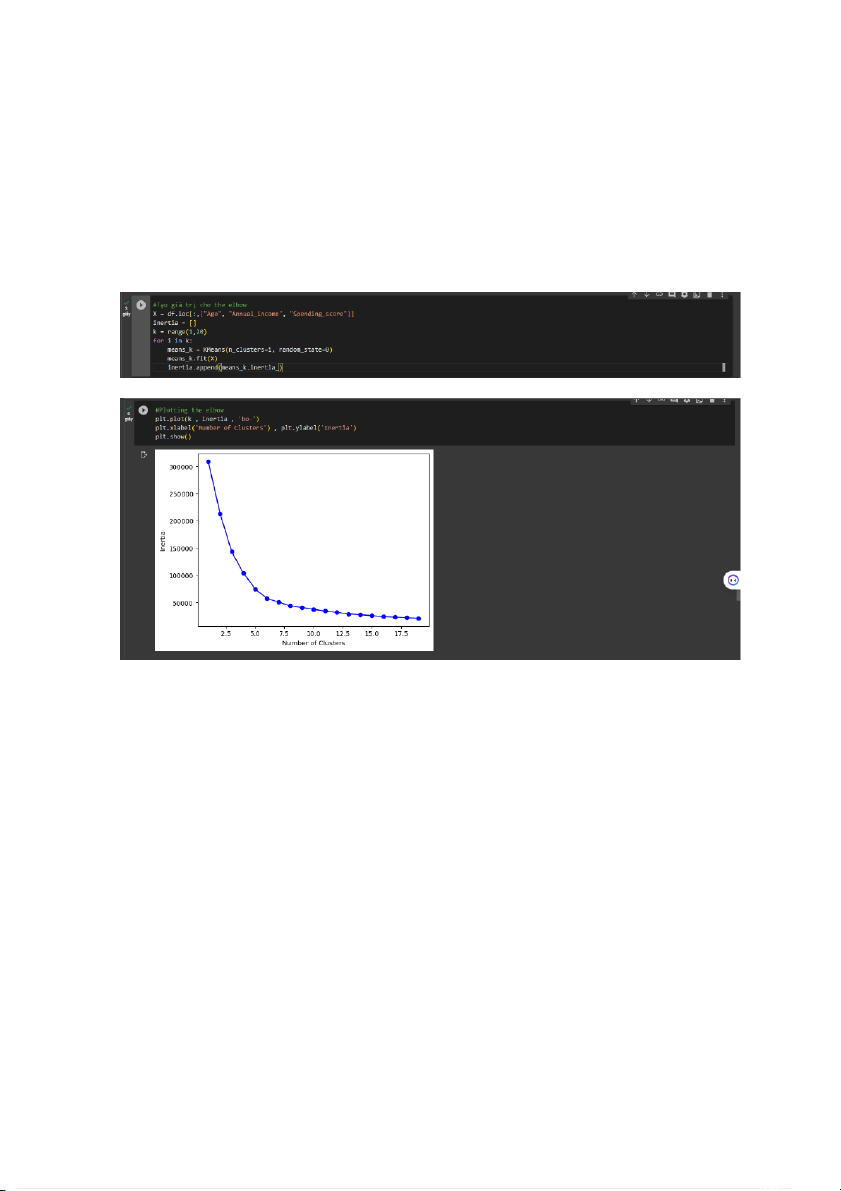
Bây giờ chúng ta đã hiểu một chút về tập dữ liệu này, quyết định số lượng cụm
mà chúng ta muốn chia dữ liệu của mình. Để làm như vậy, chúng ta sẽ sử dụng Elbow Method - Tạo giá trị cho elbow
- The elbow method được sử dụng để xác định số cụm tối ưu trong phân cụm
k-mean. The elbow method vẽ sơ đồ giá trị của hàm chi phí được tạo bởi các giá trị
khác nhau của k và người ta nên chọn một số cụm sao cho việc thêm một cụm khác
không mang lại mô hình dữ liệu tốt hơn nhiều. Trong vấn đề này, chúng tôi đang sử
dụng quán tính làm hàm chi phí để xác định tổng bình phương khoảng cách của các
mẫu đến trung tâm cụm gần nhất. Clustering
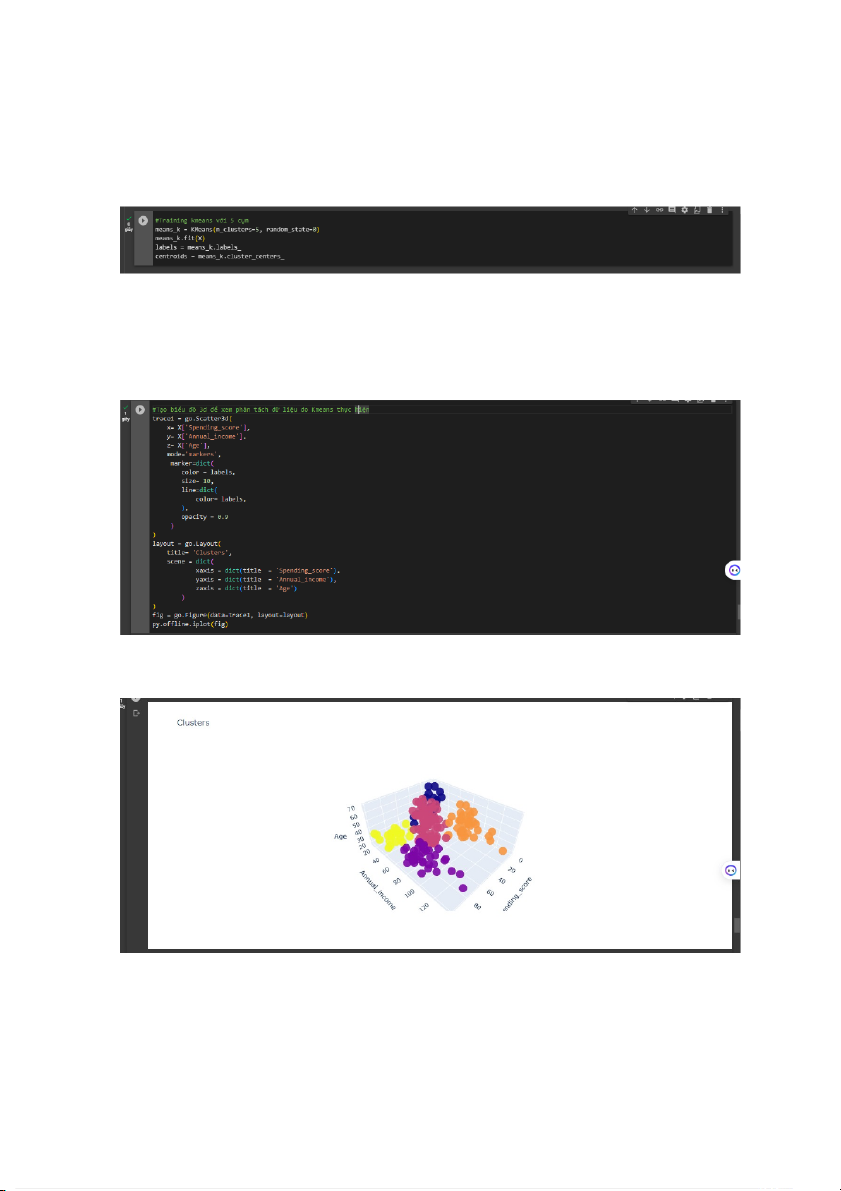
Trong quá trình phân cụm chúng ta sẽ không xét đến yếu tố giới tính. Lý do
chính đầu tiên vì sự khác biệt giữa nam và nữ trong dữ liệu này không đặc biệt cao
và việc tạo ra sự khác biệt về giới tính sẽ không cung cấp thêm thông tin nào. Lý do 13
thứ hai và không kém phần quan trọng là thực tế là các cửa hàng nói chung hầu
như không còn nhắm mục tiêu đến một giới tính cụ thể nữa, ở hầu hết các cửa hàng
trong trung tâm mua sắm đều có thể tìm thấy các sản phẩm dành cho nam và nữ.
- Thuật toán K-means đã hoàn thành và bây giờ vẽ biểu đồ kết quả mà chúng
ta thu được từ nó để chúng ta có thể hình dung các cụm khác nhau và phân tích chúng. - Mô hình 3D: 14
3. Kết quả ứng dụng giải thuật:
Phân cụm khách hàng: Thu thập dữ liệu về các khách hàng như tuổi tác, giới
tính, địa chỉ, thu nhập, sở thích,..., sử dụng giải thuật K-means để phân cụm khách
hàng thành các nhóm có đặc điểm tương tự nhau. Điều này có thể giúp doanh
nghiệp hiểu rõ hơn về khách hàng của mình và đưa ra các chiến lược marketing phù hợp.
Phân cụm sản phẩm: Thu thập dữ liệu về các sản phẩm như giá cả, thương
hiệu, tính năng,..., sử dụng giải thuật K-means để phân cụm sản phẩm thành các
nhóm có đặc điểm tương tự nhau. Điều này có thể giúp doanh nghiệp sắp xếp sản
phẩm một cách khoa học và dễ dàng tìm kiếm sản phẩm phù hợp với nhu cầu của khách hàng.
Phân cụm bài viết: Thu thập dữ liệu về các bài viết như chủ đề, nội dung, ngôn
ngữ,..., sử dụng giải thuật K-means để phân cụm bài viết thành các nhóm có đặc
điểm tương tự nhau. Điều này có thể giúp doanh nghiệp quản lý bài viết một cách
hiệu quả và dễ dàng tìm kiếm bài viết phù hợp với nhu cầu của người dùng. 15 CHƯƠNG 4: KẾT LUẬN
KMeans Clustering là một kỹ thuật mạnh mẽ để đạt được phân khúc khách hàng phù hợp.
Phân khúc khách hàng là một cách tốt để hiểu hành vi của các khách hàng
khác nhau và lập kế hoạch chiến lược tiếp thị tốt phù hợp.
Không có nhiều sự khác biệt giữa điểm số chi tiêu của phụ nữ và nam giới,
điều này khiến chúng tôi nghĩ rằng hành vi của chúng tôi khi mua sắm là khá giống nhau.
Quan sát biểu đồ phân cụm, có thể thấy rõ rằng những người chi nhiều tiền
hơn trong trung tâm thương mại là những người trẻ tuổi. Điều đó có nghĩa là họ là
mục tiêu chính khi tiếp thị, vì vậy việc nghiên cứu sâu hơn về những gì họ quan tâm
có thể dẫn đến lợi nhuận cao hơn.
Mặc dù những người trẻ tuổi dường như là những người chi tiêu nhiều nhất,
nhưng chúng ta không thể quên rằng còn có nhiều người khác mà chúng ta phải
xem xét, chẳng hạn như những người thuộc nhóm màu hồng, họ là những người mà
chúng ta thường đặt tên theo "tầng lớp trung lưu" và dường như trở thành cụm lớn nhất.
Quảng cáo giảm giá tại một số cửa hàng có thể là điều thú vị đối với những
người không thực sự chi tiêu nhiều và cuối cùng họ có thể chi tiêu nhiều hơn. 16 TÀI LIỆU THAM KHẢO
[1] Machine Learning cơ bản, machinelearningcoban.com, “tìm hiểu về machine
learning, link: https://machinelearningcoban.com/2017/01/01/kmeans/
[2] K-means Clustering: Simple Applications, machinelearningcoban.com, “Simple
Applications trong K-mean”, link:
https://machinelearningcoban.com/2017/01/04/kmeans2/?
fbclid=IwAR2bSilfNIECAaHMmakq_i2WcMHdQjE- CefMGQOl_ekKq6wRHpt_ZH8tir0
[3] Kmeans Clustering and cluster visualization in 3D, kaggle.com, “sử dụng mô
hình 3D”, link: https://www.kaggle.com/code/naren3256/kmeans-clustering-and- cluster-visualization-in-3d
[4] File bài giảng phân tích dữ liệu lớn, “Tìm hiều lý thuyết phân tích dữ liệu lớn”,
link: BaigiangNhapmonPhantichDulieuLon-20201228.doc 17