Phân cụm dữ liệu bằng thuật toán K-means | Đồ án môn Khai phá dữ iệu
Đồ án môn Khai phá dữ liệu và kho dữ liệu với đề tài "Phân cụm dữ liệu bằng thuật toán K-means" của sinh viên trường đại học công nghệ thông tin giúp bạn tham khảo và hoàn thành tốt bài tập của mình đạt kết quả cao. Mời bạn đọc đón xem!
Môn: Khai phá dữ liệu và kho dữ liệu 16 tài liệu
Trường: Trường Đại học Công nghệ Thông tin, Đại học Quốc gia Thành phố Hồ Chí Minh 666 tài liệu
Tác giả:
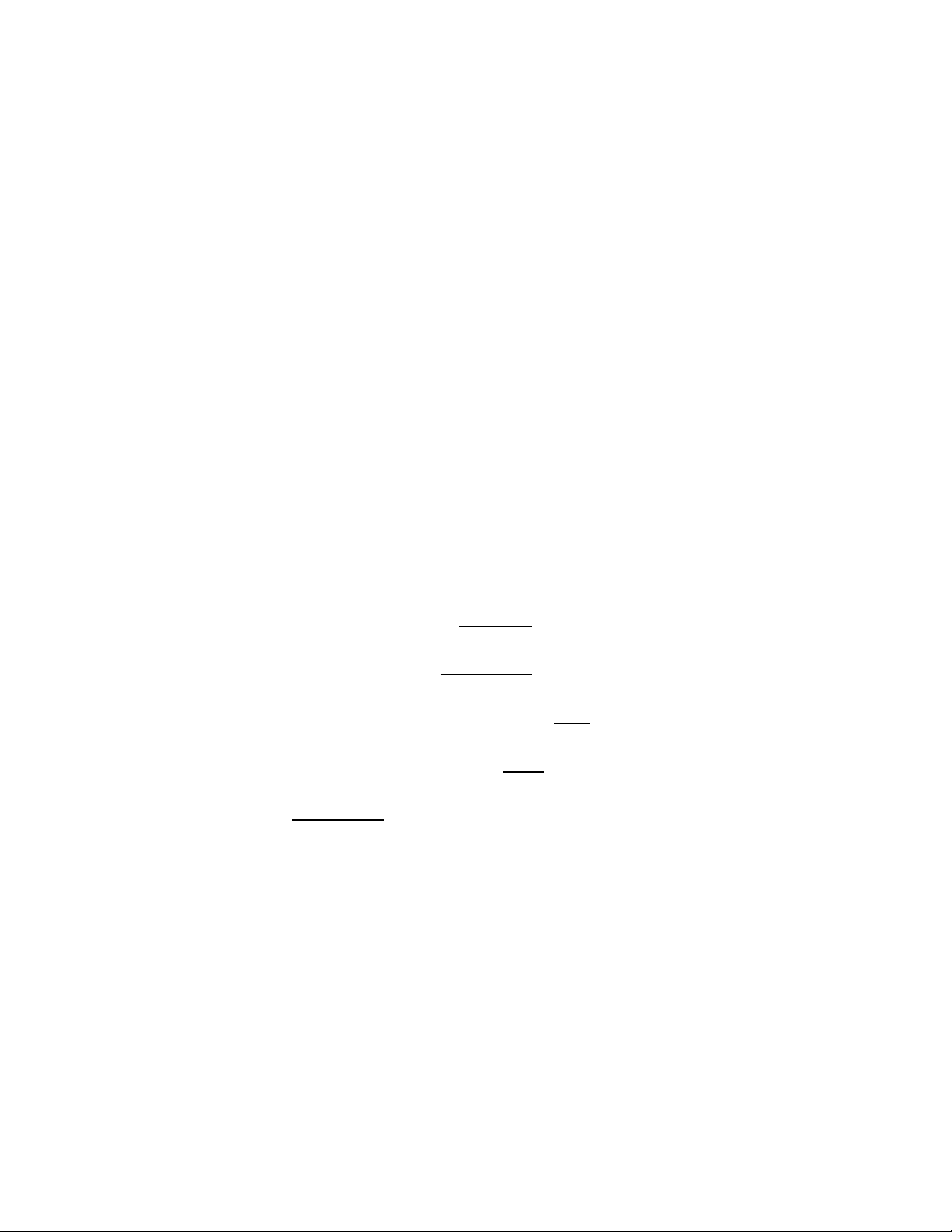
















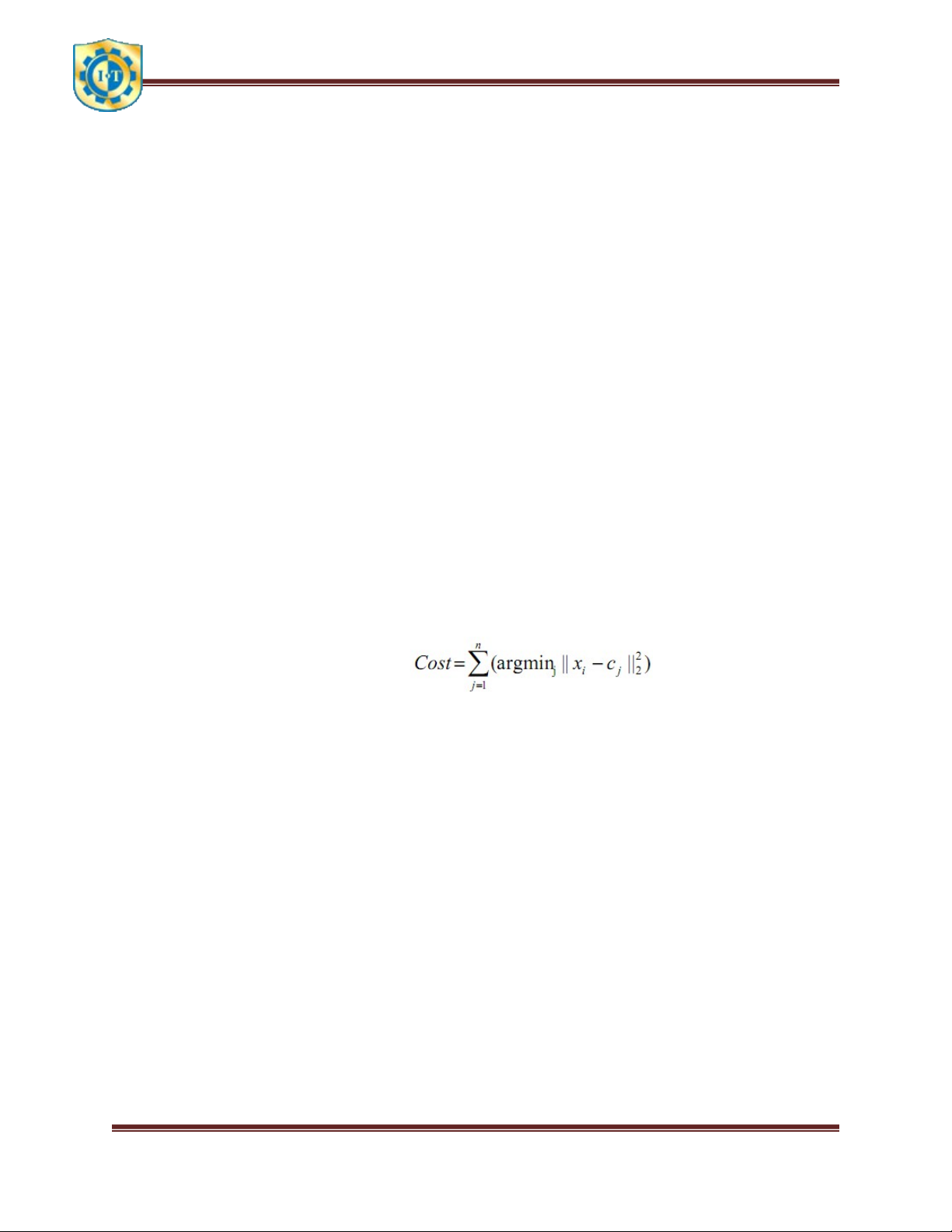



Preview text:
Đại Học Công Nghệ Thông Tin
Đại Học Quốc Gia Thành Phố Hồ Chí Minh TP. HCM 11/2012 Đề tài
Phân cụm dữ liệu bằng thuật toán K-means
GVHD: PGS.TS.Đỗ Phúc
Học viên: Trương Lê Hưng
MS: CH1101089
Lớp: Cao Học khóa 6
Môn học: Khai phá dữ liệu và kho dữ liệu
Môn học: Khai phá dữ liệu và kho dữ liệu Trang 2 Lời cảm ơn
Lời đầu tiên em xin chân thành cảm ơn thầy Đỗ Phúc đã truyền đạt cho em những
bài học thật bổ ích với những câu truyện đầy tính sáng tạo và lý thú.
Cảm ơn nhà trường đã tạo điều kiện cho em cùng các bạn trong lớp có thể học tập
và tiếp thu những kiến thức mới.
Em cũng chân thành cảm ơn các bạn trong lớp đã chia sẻ cho nhau những tài liệu
và hiểu biết về môn học để cùng hoàn thành tốt môn học này.
Trong thời gian vừa qua mặc dù em đã cố gắng rất nhiều để hoàn thành tốt đề tài
của mình, song chắc chắn kết quả không tránh khỏi những thiếu sót. Em kính mong được
sự cảm thông và tận tình chỉ bảo của thầy.
TP.Hồ Chí Minh Tháng 11/2012
Học viên thực hiện Trương Lê Hưng Lớp Cao Học khóa 6
Môn học: Khai phá dữ liệu và kho dữ liệu Trang 3 Nhận xét
------------------------------------------------------------------------------------------------------------
------------------------------------------------------------------------------------------------------------
------------------------------------------------------------------------------------------------------------
------------------------------------------------------------------------------------------------------------
------------------------------------------------------------------------------------------------------------
------------------------------------------------------------------------------------------------------------
------------------------------------------------------------------------------------------------------------
------------------------------------------------------------------------------------------------------------
------------------------------------------------------------------------------------------------------------
------------------------------------------------------------------------------------------------------------
------------------------------------------------------------------------------------------------------------
------------------------------------------------------------------------------------------------------------
------------------------------------------------------------------------------------------------------------
------------------------------------------------------------------------------------------------------------
------------------------------------------------------------------------------------------------------------
------------------------------------------------------------------------------------------------------------
------------------------------------------------------------------------------------------------------------
------------------------------------------------------------------------------------------------------------
Môn học: Khai phá dữ liệu và kho dữ liệu Trang 4 Lời mở đầu
Sự phát triển nhanh chóng của thông tin số trong nhiều lĩnh vực của đời sống, kinh
tế xã hội đã làm cho hệ thống cơ sở dữ liệu tích lũy được càng ngày càng lớn. Tuy nhiên
một phần lớn dữ liệu thu thập được không được tận dụng đúng cách để dẫn đến rất nhiều
cơ sở dữ liệu trở nên vô nghĩa.
Chính những điều đó đã đặt ra vấn đề làm sao để có những kỹ thuật và công cụ để
chuyển đổi những nguồn dữ liệu đó thành tri thức có ích cho con người sử dụng. Từ đó,
các kỹ thuật về khai mỏ dữ liệu và kho dữ liệu được chú ý nhiều hơn. Khai phá dữ liệu
đang được áp dụng rộng rãi trong nhiều lĩnh vực trong cuộc sống.
Trong nội dung bài tiểu luận này em xin được trình bày khái quát cơ sở lý thuyết
về khai phá dữ liệu và kho dữ liệu, cũng như tập trung tìm hiểu về phân cụm dữ liệu sử
dụng thuật toán K-means. Nội dung bài tiểu luận bao gồm:
Phần 1 : Cơ sở lý thuyết về khai phá dữ liệu và kho dữ liệu
Phần 2 : Phân cụm dữ liệu và các thuật toán trong phân cụm dữ liệu
Phần 3 : Thuật toán K-means Phần 4 : Demo.
Môn học: Khai phá dữ liệu và kho dữ liệu Trang 5 Mục lục
Môn học: Khai phá dữ liệu và kho dữ liệu Trang 6
Phần I . Cơ sở lý thuyết về khai phá dữ liệu và nhà kho dữ liệu 1.
Giới thiệu về khai phá dữ liệu
Khai phá dữ liệu (Data Mining) là một khái niệm ra đời vào những năm
cuối của thập kỷ 1980. Nó là quá trình trích xuất các thông tin có giá trị tiềm
ẩn bên trong lượng lớn dữ liệu được lưu trữ trong các CSDL, kho dữ liệu....
Một ví dụ hay được sử dụng là là việc khai thác vàng từ đá và cát, Dataming
được ví như công việc "Đãi cát tìm vàng" trong một tập hợp lớn các dữ liệu
cho trước. Thuật ngữ Dataming ám chỉ việc tìm kiếm một tập hợp nhỏ có giá
trị từ một số lượng lớn các dữ liệu thô. Có nhiều thuật ngữ hiện được dùng
cũng có nghĩa tương tự với từ Datamining như Knowledge Mining (khai phá
tri thức), knowledge extraction(chắt lọc tri thức), data/patern analysis(phân tích
dữ liệu/mẫu), data archaeoloogy (khảo cổ dữ liệu), datadredging(nạo vét dữ liệu),... 2.
Quá trình khám phá trí thức và khai phá dữ liệu
Các bước chính thường sử dụng trong khai phá dữ liệu:
Môn học: Khai phá dữ liệu và kho dữ liệu Trang 7
Gom dữ liệu: thu thập dữ liệu là bước đầu tiên trong việc khai phá dữ liệu.
Dữ liệu có thể lấy từ nhiều nguồn, từ các website trên mạng v.v…
Trích lọc dữ liệu: Trích chọn dữ liệu từ kho dữ liệu và phân chia theo các
tiêu chuẩn để dễ cho việc khai thác nguồn dữ liệu này.
Làm sạch, tiền xử lý dữ liệu: Loại bỏ dữ liệu nhiễu, dữ liệu dư thừa hay
các dữ liệu không đủ tính chặt chẽ, logic…
Chuyển đổi dữ liệu: Các dữ liệu được chuyển đổi sang các dạng phù hợp cho quá trình xử lý.
Khai phá dữ liệu: Là một bước quan trọng nhất, trong đó sử dụng các
thuật toán thông minh để trích ra các mẫu dữ liệu.
Đánh giá các luật và biểu diễn tri thức: là quá trình đánh giá các kết quả
tìm được, sau đó sử dụng các kỹ thuật để biểu diễn cho người dùng. 3.
Các chức năng chính của khai phá dữ liệu
Data Mining được chia thành một số hướng chính như sau:
Mô tả khái niệm (concept description): thiên về mô tả, tổng hợp và tóm tắt khái niệm.
Ví dụ: tóm tắt văn bản.
Luật kết hợp (association rules): là dạng luật biểu diễn tri thứ ở dạng khá đơn giản.
Ví dụ: “60% nam giới vào siêu thị nếu mua bia thì có tới 80% trong số họ
sẽ mua thêm thịt bò khô”. Luật kết hợp được ứng dụng nhiều trong lĩnh vực
kính doanh, y học, tài chính & thị trường chứng khoán, .v.v.
Phân lớp và dự đoán (classification & prediction): xếp một đối tượng
vào một trong những lớp đã biết trước.
Ví dụ: phân lớp vùng địa lý theo dữ liệu thời tiết. Hướng tiếp cận này
thường sử dụng một số kỹ thuật của machine learning như cây quyết định
(decision tree), mạng nơ ron nhân tạo (neural network), .v.v. Người ta còn
gọi phân lớp là học có giám sát.
Phân cụm (clustering): xếp các đối tượng theo từng cụm (số lượng cũng
như tên của cụm chưa được biết trước. Người ta còn gọi phân cụm là học không giám sát.
Khai phá chuỗi (sequential/temporal patterns): tương tự như khai phá
luật kết hợp nhưng có thêm tính thứ tự và tính thời gian. Hướng tiếp cận
Môn học: Khai phá dữ liệu và kho dữ liệu Trang 8
này được ứng dụng nhiều trong lĩnh vực tài chính và thị trường chứng
khoán vì nó có tính dự báo cao. 4.
Các ứng dụng khai phá dữ liệu
Data mining có một số ứng dụng điển hình vào các lĩnh vực như:
Thông tin thương mại: Phân tích dữ liệu bán hàng, tiếp thị. Phân tích vốn
đầu tư, chấp thuận cho vay v.v…
Thông tin sản xuất: Điều khiển và lập lịch, quản lý v.v…
Thông tin khoa học: phân tích phát hiện các dấu hiệu thời tiết bất thường, động đất v.v…
Môn học: Khai phá dữ liệu và kho dữ liệu Trang 9
Phần II. Phân cụm dữ liệu và các thuật toán phân cụm dữ liệu 1. Phân cụm dữ liệu a. Định nghĩa
Phân cụm dữ liệu(Data Clustering) hay phân cụm, cũng có thể gọi là phân
tích cụm, phân tích phân đoạn, phân tích phân loại, là quá trình nhóm một tập
các đối tượng thực thể hay trừu tượng thành lớp các đối tượng tương tự. Một
cụm là một tập hợp các đối tượng dữ liệu mà các phần tử của nó tương tự
nhau cùng trong một cụm và phi tương tự với các đối tượng trong các cụm
khác. Một cụm các đối tượng dữ liệu có thể xem như là một nhóm trong nhiều ứng dụng.
Phân cụm dữ liệu là một môn khoa học trẻ đang phát triển mạnh mẽ. Có
một số lượng lớn các bài báo nghiên cứu trong nhiều hội nghị, hầu hết trong
các lĩnh vực của khai phá dữ liệu: thống kê, học máy, cơ sở dữ liệu không gian,
sinh vật học, kinh doanh, v.v...với tầm quan trọng và các kỹ thuật khác nhau.
Do số lượng lớn các dữ liệu đã thu thập trong cơ sở dữ liệu nên phép phân tích
cụm gần đây trở thành một chủ đề tích cực cao trong nghiên cứu khai phá dữ liệu.
b. Mục tiêu của phân cụm dữ liệu
Mục tiêu của phân cụm là xác định được bản chất nhóm trong tập dữ liệu
chưa có nhãn. Nhưng để có thể quyết định được cái gì tạo thành một cụm tốt.
Nó có thể được chỉ ra rằng không có tiêu chuẩn tuyệt đối “tốt” mà có thể
không phụ thuộc vào kết quả phân cụm. Vì vậy, nó đòi hỏi người sử dụng phải
cung cấp tiêu chuẩn này, theo cách mà kết quả phân cụm sẽ đáp ứng yêu cầu.
Theo các nghiên cứu cho thấy thì hiện nay chưa có một phương pháp phân
cụm tổng quát nào có thể giải quyết trọn vẹn cho tất cả các dạng cấu trúc cụm
dữ liễu. Hơn nữa, các phương pháp phân cụm cần có cách thức biểu diễn cấu
trúc của các cụm dữ liệu, với mỗi cách thức biểu diễn khác nhau sẽ có tương
ứng một thuật toán phân cụm phù hợp. Vì vậy phân cụm dữ liệu vẫn đang là
một vấn đề khó và mở, vì phải giải quyết nhiều vấn đề cơ bản một cách trọn
Môn học: Khai phá dữ liệu và kho dữ liệu Trang 10
vẹn và phù hợp với nhiều dạng dữ liệu khác nhau, đặc biệt là đối với dữ liệu
hỗn hợp đang ngày càng tăng trong các hệ quản trị dữ liệu và đây cũng là một
trong những thách thức lớn trong lĩnh vực khai phá dữ liệu. 2.
Các ứng dụng của phân cụm dữ liệu
Phân cụm dữ liệu được ứng dụng trong nhiều lĩnh vực như:
Thương mại: Tìm kiếm nhóm các khách hàng quan trọng có đặc trưng
tương đồng và những đặc tả họ từ các bản ghi mua bán trong cơ sở dữ liệu.
Trong nghiên cứu thị trường, phân cụm dữ liệu được sử dụng để phân
đoạn thị trường và xác định mục tiêu thị trường (Chrisoppher, 1969;
Saunders, 1980, Frank and Green, 1968). Trong phân đoạn thị trường, phân
cụm dữ liệu thường được dùng để phân chia thị trường thành nhưng cụm
mang ý nghĩa, chẳng hạn như chia ra đối tượng nam giới từ 21-30 tuổi và
nam giới ngoài 51 tuổi, đối tượng nam giới ngoài 51 tuổi thường không có
khuynh hướng mua các sản phẩm mới.
Sinh học: Phân loại các gen với các chức năng tương đồng và thu được các
cấu trúc trong mẫu. Phân cụm là một trong những phân tích được sử dụng
thường xuyên nhất trong biểu diễn dữ liệu gene (Yeung et al., 2003; Eisen
at al., 1998). Dữ liệu biểu diễn gene là một tâp hợp các phép đo được lấy từ
DNA microarray (còn gọi là DNA chip hay gene chip) là một tấm thủy tinh
hoặc nhựa trên đó có gắn các đoạn DNA thành các hàng siêu nhỏ. Các nhà
nghiên cứu sử dụng các con chip như vậy để sàng lọc các mẫu sinh học
nhằm kiểm tra sự có mặt hàng loạt trình tự cùng một lúc. Các đoạn DNA
gắn trên chip được gọi là probe (mẫu dò). Trên mỗi điểm của chip có hàng
ngàn phân tử probe với trình tự giống nhau.
Thư viện: Phân loại các cụm sách có nội dung và ý nghĩa tương đồng nhau
để cung cấp cho độc giả.
Bảo hiểm: Nhận dạng nhóm tham gia bảo hiểm có chi phí bồi thường cao,
nhận dạng gian lận thương mại.
Quy hoạch đô thị: Nhận dạng các nhóm nhà theo kiểu và vị trí địa lí,...
nhằm cung cấp thông tin cho quy hoạch đô thị.
Môn học: Khai phá dữ liệu và kho dữ liệu Trang 11
Nghiên cứu trái đất: Phân cụm để theo dõi các tâm động đất nhằm cung
cấp thông tin cho nhận dạng các vùng nguy hiểm.
WWW: Có thể khám phá các nhóm tài liệu quan trọng, có nhiều ý nghĩa
trong môi trường Web. Các lớp tài liệu này trợ giúp cho việc KPTT từ dữ liệu. 3.
Những kỹ thuật tiếp cận phân cụm dữ liệu
Các kỹ thuật phân cụm có rất nhiều cách tiếp cận và các ứng dụng trong
thực tế, nó đều hướng tới hai mục tiêu chung đó là chất lượng của các cụm
khám phá được và tốc độ thực hiện của thuật toán. Hiện nay, các kỹ thuật phân
cụm có thể phân loại theo các cách tiếp cận chính sau :
Phương pháp phân cụm phân hoạch: Kỹ thuật này phân hoạch một tập
hợp dữ liệu có n phần tử thành k nhóm cho đến khi xác định số các cụm được
thiết lập. Số các cụm được thiết lập là các đặc trưng được lựa chọn trước.
Phương pháp này là tốt cho việc tìm các cụm hình cầu trong không gian
Euclidean. Ngoài ra, phương pháp này cũng phụ thuộc vào khoảng cách cơ bản
giữa các điểm để lựa chọn các điểm dữ liệu nào có quan hệ là gần nhau với
mỗi điểm khác và các điểm dữ liệu nào không có quan hệ hoặc có quan hệ là
xa nhau so với mỗi điểm khác.
Phương pháp phân cụm phân cấp: Phương pháp này xây dựng một phân
cấp trên cơ sở các đối tượng dữ liệu đang xem xét. Nghĩa là sắp xếp một tập dữ
liệu đã cho thành một cấu trúc có dạng hình cây, cây phân cấp này được xây
dựng theo kỹ thuật đệ quy. Có hai cách tiếp cận phổ biến của kỹ thuật này đó là: - Tiếp cận Bottom-Up - Tiếp cận Top-Down
Phương pháp phân cụm dựa trên mật độ: Kỹ thuật này nhóm các đối
tượng dữ liệu dựa trên hàm mật độ xác định, mật độ là số các đối tượng lân cận
của một đối tượng dữ liệu theo một nghĩa nào đó. Trong cách tiếp cận này, khi
một dữ liệu đã xác định thì nó tiếp tục được phát triển thêm các đối tượng dữ
liệu mới miễn là số các đối tuợng lân cận này phải lớn hơn một ngưỡng đã
được xác định trước. Phương pháp phân cụm dựa trên mật độ của các đối
Môn học: Khai phá dữ liệu và kho dữ liệu Trang 12
tượng để xác định các cụm dữ liệu có thể phát hiện ra các cụm dữ liệu với hình
thù bất kỳ. Kỹ thuật này có thể khắc phục được các phần tử ngoại lai hoặc giá
trị nhiễu rất tốt, tuy nhiên việc xác định các tham số mật độ của thuật toán là
rất khó khăn, trong khi các tham số này lại có tác động rất lớn đến kết quả phân cụm.
Phương pháp phân cụm dựa trên lưới: Kỹ thuật phân cụm dựa trên lưới
thích hợp với dữ liệu nhiều chiều, dựa trên cấu trúc dữ liệu lưới để phân cụm,
phương pháp này chủ yếu tập trung áp dụng cho lớp dữ liệu không gian. Mục
tiêu của phương pháp này là lượng hóa dữ liệu thành các ô tạo thành cấu trúc
dữ liệu lưới. Sau đó, các thao tác phân cụm chỉ cần làm việc với các đối tượng
trong từng ô trên lưới chứ không phải các đối tượng dữ liệu. Cách tiếp cận dựa
trên lưới này không di chuyển các đối tượng trong các ô mà xây dựng nhiều
mức phân cấp của nhóm các đối tượng trong một ô. Phương pháp này gần
giống với phương pháp phân cụm phân cấp nhưng chúng không trộn các ô,
đồng thời giải quyết khắc phục yêu cầu đối với dữ liệu nhiều chiều mà phương
pháp phân phân cụm dựa trên mật độ không giải quyết được. ưu điểm của
phương pháp phân cụm dựa trên lưới là thời gian xử lí nhanh và độc lập với số
đối tượng dữ liệu trong tập dữ liệu ban đầu, thay vào đó là chúng phụ thuộc
vào số ô trong mỗi chiều của không gian lưới.
Phương pháp phân cụm dựa trên mô hình: Phương này cố gắng khám
phá các phép xấp xỉ tốt của các tham số mô hình sao cho khớp với dữ liệu một
cách tốt nhất. Chúng có thể sử dụng chiến lược phân cụm phân hoạch hoặc
phân cụm phân cấp, dựa trên cấu trúc hoặc mô hình mà chúng giả định về tập
dữ liệu và cách chúng hiệu chỉnh các mô hình này để nhận dạng ra các phân
hoạch. Phương pháp phân cụm dựa trên mô hình cố gắng khớp giữa các dữ liệu
với mô hình toán học, nó dựa trên giả định rằng dữ liệu được tạo ra bằng hỗn
hợp phân phối xác suất cơ bản. Các thuật toán phân cụm dựa trên mô hình có
hai cách tiếp cận chính: mô hình thống kê và mạng nơron. 4.
Một số thuật toán trong phân cụm dữ liệu
Môn học: Khai phá dữ liệu và kho dữ liệu Trang 13
a. Thuật toán phân cụm phân cấp
Thuật toán CURE: Trong khi hầu hết các thuật toán thực hiện phân cụm
với các cụm hình cầu và kích thước tương tự, như vậy là không hiệu quả khi
xuất hiện các phần tử ngoại lai. Thuật toán CURE khắc phục được vấn đề này
và tốt hơn với các phần tử ngoại lai. Thuật toán này định nghĩa một số cố định
các điểm đại diệnnằm rải rác trong toàn bộ không gian dữ liệu và được chọn để
mô tả các cụm được hình thành. Các điểm này được tạo ra nhờ lựa chọn các
đối tượng nằm rải rác cho cụm và sau đó “co lại” hoặc di chuyển chúng về
trung tâm cụm bằng nhân tố co cụm. Quá trình này được lặp lại và như vậy
trong quá trình này, có thể đo tỉ lệ gia tăng của cụm. Tại mỗi bước của thuật
toán, hai cụm có cặp các điểm đại diện gần nhau (mỗi điểm trong cặp thuộc về
mỗi cụm khác nhau) được hòa nhập.
Thuật toán ANGES: Phương pháp phân hoạch ANGNES là kỹ thuật kiểu
tích tụ. ANGNES bắt đầu ở ngoài với mỗi đối tượng dữ liệu trong các cụm
riêng lẻ. Các cụm được hòa nhập theo một số loại của cơ sở luật, cho đến khi
chỉ có một cụm ở đỉnh của phân cấp, hoặc gặp điều kiện dừng. Hình dạng này
của phân cụm phân cấp cũng liên quan đến tiếp cận bottom-up bắt đầu ở dưới
với các nút lá trong mỗi cụm riêng lẻ và duyệt lên trên phân cấp tới nút gốc,
nơi tìm thấy cụm đơn cuối cùng với tất cả các đối tượng dữ liệu được chứa trong cụm đó.
Thuật toán DIANA: DIANA thực hiện đối lập với AGNES. DIANA bắt
đầu với tất cả các đối tượng dữ liệu được chứa trong một cụm lớn và chia tách
lặp lại, theo phân loại giống nhau dựa trên luật, cho đến khi mỗi đối tượng dữ
liệu của cụm lớn được chia tách hết. Hình dạng của cụm phân cấp cùng liên
quan đế tiếp cận top-down bắt đầu tại mức đỉnh nút gốc, với tất cả các đối
tượng dữ liệu, trong một cụm, và duyệt xuống các nút lá dưới cùng nơi tất cả
các đối tượng dữ liệu từng cái được chứa trong cụm của chính mình.
Thuật toán Chameleon: Phương pháp Chameleon một cách tiếp cận khác
trong việc sử dụng mô hình động để xác định các cụm nào được hình thành.
Môn học: Khai phá dữ liệu và kho dữ liệu Trang 14
Bước đầu tiên của Chameleon là xây dựng một đồ thị mật độ thưa và sau đó
ứng dụng một thuật toán phân hoạch đồ thị để phân cụm dữ liệu với số lớn
của các cụm con. Tiếp theo, Chameleon thực hiện tích tụ phân cụm phân
cấp, như AGNES, bằng hòa nhập các cụm con nhỏ theo hai phép đo, mối quan
hệ liên thông và mối quan hệ gần nhau của các nhóm con. Do đó, thuật toán
không phụ thuộc vào người sử dụng các tham số như K-means và có thể thích
nghi. Thuật toán này khảo sát mô hình động trong phân cụm phân cấp. Trong
đó, hai cụm được hòa nhập nêu giữa hai cụm có liên quan mật thiết tới quan hệ
kết và gần nhau của các đối tượng trong các cụm. Quá trình hòa nhập dễ dàng
khám phá các cụm tự nhiên và đồng nhất, ứng dụng cho tất cả các kiểu dữ liệu
miễn là hàm tương tự được xác định.
Ngoài ra còn có các thuật toán như BIRCH, ROCK v.v…
b. Thuật toán phân cụm phân hoạch
Thuật toán K-means : Thuật toán này dựa trên độ đo khoảng cách của các
đối tượng dữ liệu trong cụm. Trong thực tế, nó đo khoảng cách tới giá trị trung
bình của các đối tượng dữ liệu trong cụm. Nó được xem như là trung tâm của
cụm. Như vậy, nó cần khởi tạo một tập trung tâm các trung tâm cụm ban đầu,
và thông qua đó nó lặp lại các bước gồm gán mỗi đối tượng tới cụm mà trung
tâm gần, và tính toán tại tung tâm của mỗi cụm trên cơ sở gán mới cho các đối
tượng. Quá trình lặp này dừng khi các trung tâm hội tụ.
Ngoài ra còn có thuật toán PAM, thuật toán CLARA …
c. Thuật toán phân cụm dựa trên mật độ
Thuật toán DBSCAN: Thuật toán DBSCAN thích nghi với mật độ dầy để
phân cụm và khám phá ra các cụm có hình dạng bất kỳ trong không gian
CSDL có nhiễu. Trên thực tế DBSCAN tìm kiếm cho các cụm bằng cách kiểm
tra các đối tượng mà có số đối tượng láng giềng nhỏ hơn một ngưỡng tối thiểu,
tức là có tối thiểu MinPts đối tượng và mỗi đối tượng trong cụm tồn tại một
đối tượng khác trong cụm giống nhau với khoảng cách nhỏ một ngưỡng Eps.
Tìm tất cả các đối tượng mà các láng giềng của nó thuộc về lớp các đối tượng
đã xác định ở trên, một cụm được xác định bằng một tập tất cả các đối tượng
Môn học: Khai phá dữ liệu và kho dữ liệu Trang 15
liên thông mật độ các láng giềng của nó. DBSCAN lặp lại tìm kiếm ngay khi
các đối tượng liên lạc mật độ từ các đối tượng trung tâm, nó có thể bao gồm
việc kết hợp một số cụm có mật độ liên lạc. Quá trình kết thúc khi không tìm
được điểm mới nào có thể thêm vào bất cứ cụm nào.
Ngoài ra còn có các thuật toán OPTICS, thuật toán DENCLUE v.v…
d. Thuật toán phân cụm dựa trên lưới
Thuật toán STING: STING là kỹ thuật phân cụm đa phân giải dựa trên
lưới, trong đó vùng không gian dữ liệu được phân rã thành số hữu hạn các ô
chữ nhật, điều này có nghĩa là các ô lưới được hình thành từ các ô lưới con để thực hiện phân cụm.
Có nhiều mức của các ô chữ nhật tương ứng với các mức khác nhau của
phân giải trong cấu trúc lưới, và các ô này hình thành cấu trúc phân cấp: mỗi ô
ở mức cao được phân hoạch thành số các ô nhỏ ở mức thấp hơn tiếp theo trong
cấu trúc phân cấp. Các điểm dữ liệu được nạp từ CSDL, giá trị của các tham số
thống kê cho các thuộc tính của đối tượng dữ liệu trong mỗi ô lưới được tính
toán từ dữ liệu và lưu trữ thông qua các tham số thống kê ở các ô mức thấp
hơn. Các giá trị của các tham số thống kê gồm: số trung bình - mean, số tối đa -
max, số tối thiểu - min, số đếm - count, độ lệch chuẩn - s, ... Các đối tượng dữ
liệu lần lượt được chèn vào lưới và các tham số thống kê ở trên được tính trực
tiếp thông qua các đối tượng dữ liệu này. Các truy vấn không gian được thực
hiện bằng cách xét các ô thích hợp tại mỗi mức của phân cấp. Một truy vấn
không gian được xác định như là một thông tin khôi phục lại của dữ liệu không
gian và các quan hệ của chúng.
STING có khả năng mở rộng cao, nhưng do sử dụng phương pháp đa phân
giải nên nó phụ thuộc chặt chẽ vào trọng tâm của mức thấp nhất. Đa phân giải
là khả năng phân rã tập dữ liệu thành các mức chi tiết khác nhau. Khi hoà nhập
các ô của cấu trúc lưới để hình thành các cụm, nó không xem xét quan hệ
không gian giữa các nút của mức con không được hoà nhập phù hợp (do chúng
chỉ tương ứng với các cha của nó) và hình dạng của các cụm dữ liệu khám phá
Môn học: Khai phá dữ liệu và kho dữ liệu Trang 16
được, tất cả ranh giới của các cụm có các biên ngang và dọc, theo biên của các
ô và không có đường biên chéo được phát hiện ra.
Ngoài ra còn có thuật toán CLIQUE.
Môn học: Khai phá dữ liệu và kho dữ liệu Trang 17
Phần III Thuật toán phân cụm dữ liệu K-means 1. Thuật toán K-means
K-Means là thuật toán rất quan trọng và được sử dụng phổ biến trong kỹ
thuật phân cụm. Tư tưởng chính của thuật toán K-Means là tìm cách phân
nhóm các đối tượng (objects) đã cho vào K cụm (K là số các cụm được xác
đinh trước, K nguyên dương) sao cho tổng bình phương khoảng cách giữa các
đối tượng đến tâm nhóm (centroid ) là nhỏ nhất.
Thuật toán k-means áp dụng cho các đối tượng được biểu diễn bởi các
điểm trong không gian vectơ d chiều U = {xi | i = 1, … , N}, với xi ∈ ℜ biểu
thị đối tượng (hay điểm dữ liệu) thứ i.
Thuật toán k-means gom cụm toàn bộ các điểm dữ liệu trong U thành k
cụm C = {C1, C2, … Ck} sao cho mỗi điểm dữ liệu xi nằm trong một cụm duy
nhất. Để biết điểm dữ liệu thuộc cụm nào người ta gán cho nó một mã cụm.
Các điểm có cùng mã cụm thì ở cùng cụm, trong khi các điểm khác mã cụm thì
ở trong các cụm khác nhau. Một cụm có thể biểu thị bằng vec-tơ liên thuộc
cụm v có độ dài N, với vi là mã cụm của xi.
Giá trị k là đầu vào của thuật toán. Giá trị k dựa trên tiêu chuẩn tri thức
trước đó. Sẽ có bao nhiêu cụm thực sự xuất hiện trong U, bao nhiêu cụm được
đề nghị cho ứng dụng hiện hành, hay các kiểu cụm được tìm thấy bằng cách
dựa vào thực nghiệm với nhiều giá trị k khác nhau. Không cần thiết phải hiểu k
được chọn như thế nào khi k-means phân mảnh tập dữ liệu U, việc chọn giá trị
k như thế nào sẽ được thảo luận trong phần kế tiếp.
Trong các thuật toán gom cụm, các điểm được nhóm theo khái niệm “độ
gần” hay “độ tương tự”. Với k-means, phép đo mặc định cho “độ tương tư” là
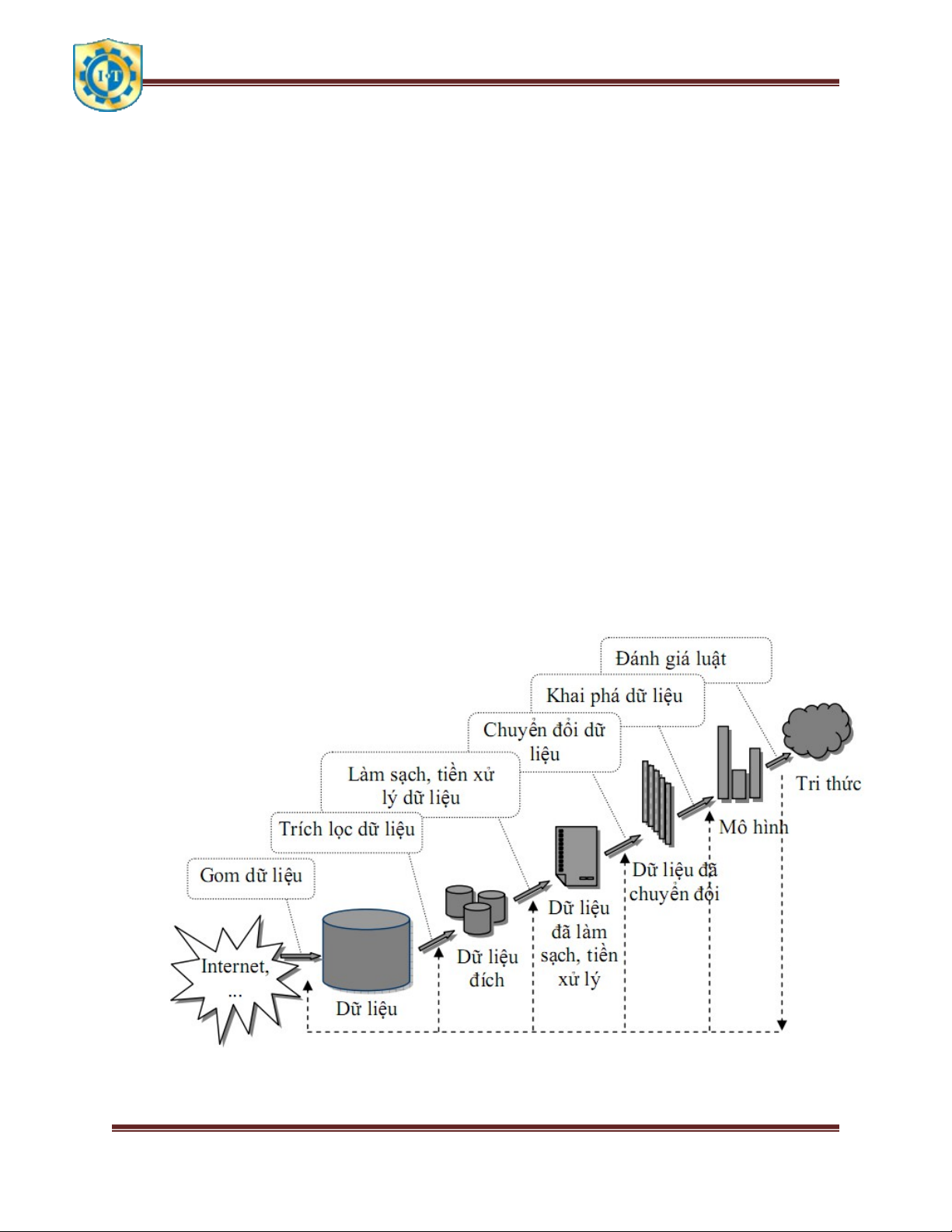
khoảng cách Euclide. Đặc biệt, có thể thấy k-means cố gắng cực tiểu hóa hàm giá trị không âm sau:
Môn học: Khai phá dữ liệu và kho dữ liệu Trang 18
Thuật toán K-Means thực hiện qua các bước chính sau:
1. Chọn ngẫu nhiên K tâm (centroid) cho K cụm (cluster). Mỗi cụm được
đại diện bằng các tâm của cụm.
2. Tính khoảng cách giữa các đối tượng (objects) đến K tâm (thường dùng khoảng cách Euclidean)
3. Nhóm các đối tượng vào nhóm gần nhất
4. Xác định lại tâm mới cho các nhóm
5. Thực hiện lại bước 2 cho đến khi không có sự thay đổi nhóm nào của các đối tượng 2. Thuật giải Thuật toán K-means:
Đầu vào: Tập dữ liệu D, số cụm k Đầu ra:
Tập thể hiện các cụm C, vec-tơ liên thuộc cụm m
Chọn ngẫu nhiên k điểm dữ liệu từ D
Xem k điểm này là tập khởi tạo các thể hiện cụm C repeat
Gán lại các điểm trong D cho trung bình cụm gần nhất
Cập nhật m sao cho mi là mã cụm của điểm thứ i trong D
Cập nhật C sao cho cj là trung bình các điểm trong cụm j
until hội tụ hàm mục tiêu:
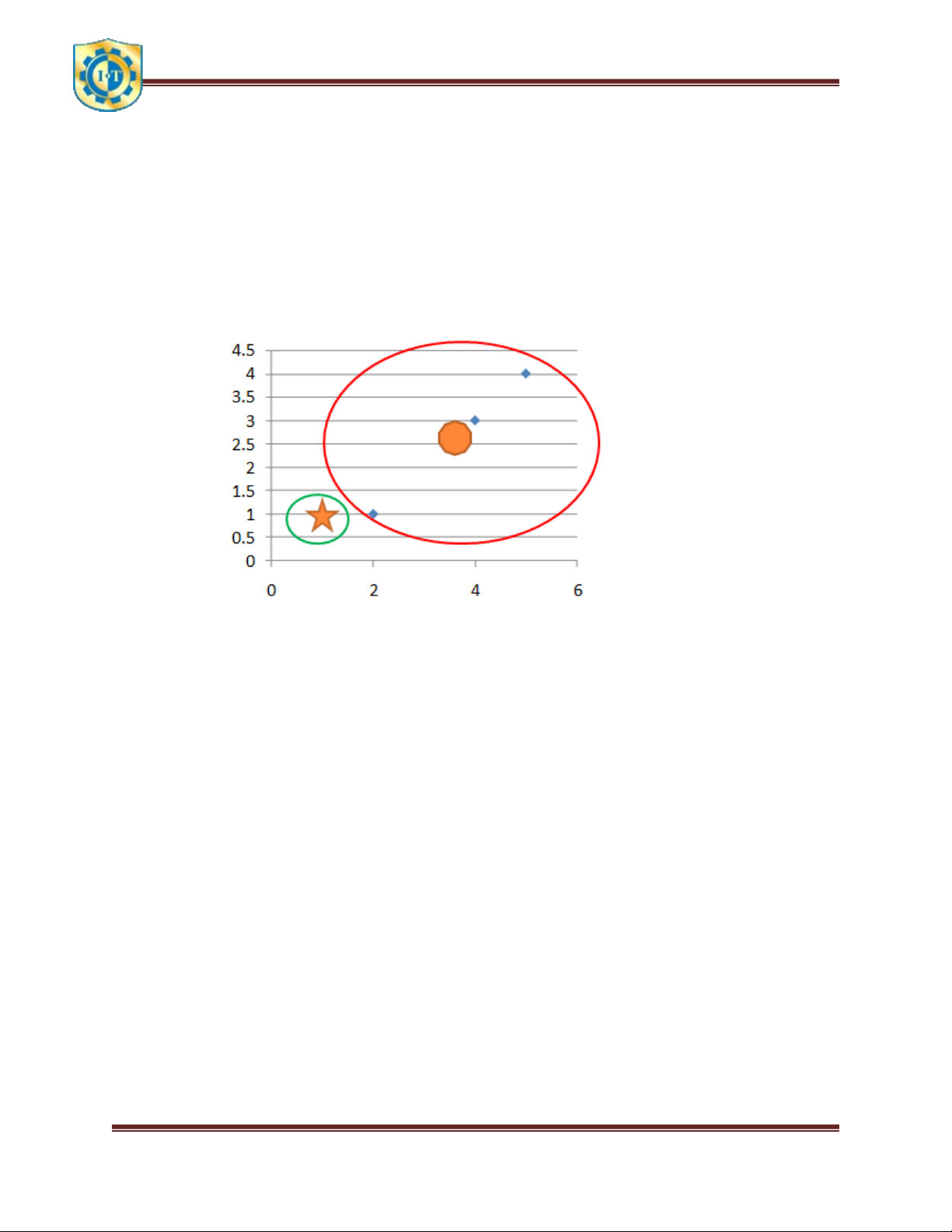
Môn học: Khai phá dữ liệu và kho dữ liệu Trang 19 3. Bài toán ví dụ Cho bảng: Đối tượng Thuộc tính 1 (X) Thuộc tính 2 (Y) A 1 1 B 2 1 C 4 3 D 5 4 Minh họa bằng sơ đồ: Bước 1:
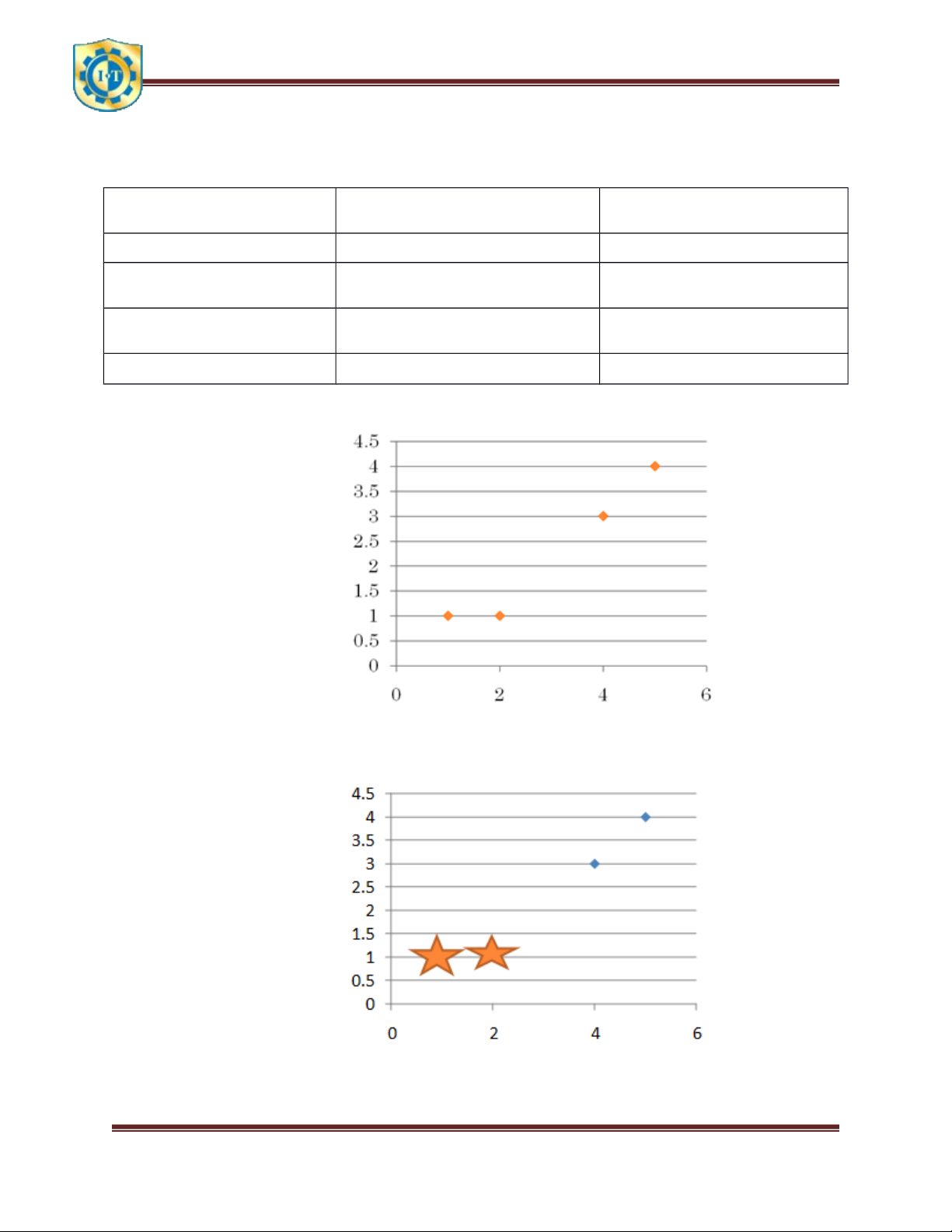
Chọn 2 trọng tâm ban đầu c1(1,1) ≡ A và c2(2,1) ≡ B, thuộc 2 cụm 1 và 2:
Bước 2: Tính khoản cách:
Môn học: Khai phá dữ liệu và kho dữ liệu Trang 20
d(C, c1) = (4 – 1)2 + (3 – 1)2 = 13
d(C, c2) = (4 – 2)2 + (3 – 1)2 = 8
d(C, c2) < d(C, c1) => C thuộc cụm 2
d(D, c1) = (5 – 1)2 + (4 – 1)2 = 25
d(D, c2) = (5 – 2)2 + (4 – 1)2 = 18
d(D, c2) < d(D, c1) => D thuộc cụm 2
Bước 3: Cập nhật lại vị trí trọng tâm:
Trọng tâm cụm 1: c1 = (1,1)
Trong tâm cụm 2: c2 = (11/3,8/3)
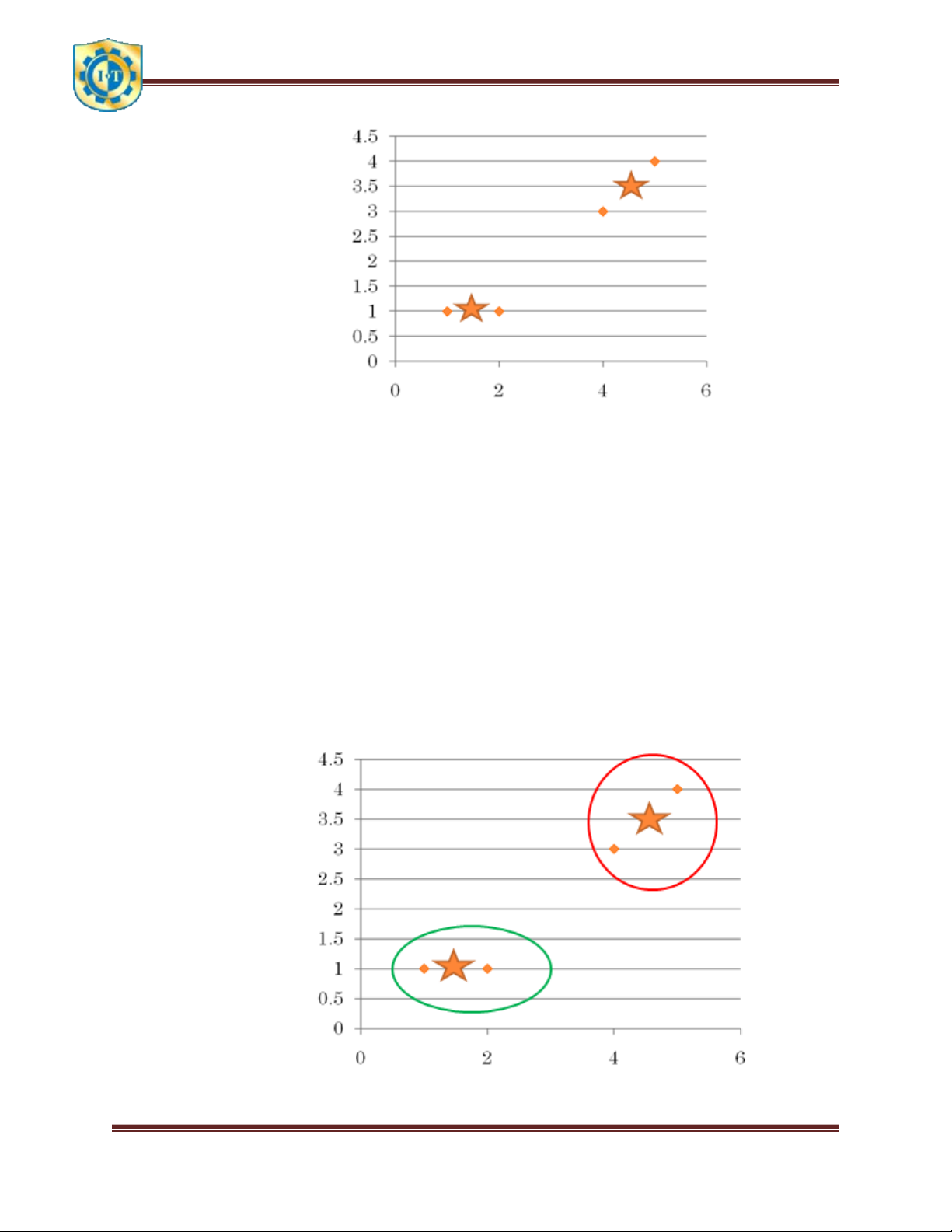
Bước 4: lặp lại bước 2:
d(A, c1 ) = 0 < d(A, c2 ) = 9.89 A thuộc cụm 1
d(B, c1 ) = 1 < d(B, c2 ) = 5.56 B thuộc cụm 1
d(C, c1 ) = 13 > d(C, c2 ) = 0.22 C thuộc cụm 2
d(D, c1 ) = 25 > d(D, c2 ) = 3.56 D thuộc cụm 2
Bước 5: lặp lại bước 3:
Cập nhật lại trọng tâm C1 = (3/2,1) C2 = (9/2,7/2)
Môn học: Khai phá dữ liệu và kho dữ liệu Trang 21
Bước 6: lặp lại bước 2:
d(A, c1 ) = 0.25 < d(A, c2 ) = 18.5 A thuộc cụm 1
d(B, c1 ) = 0.25 < d(B, c2 ) = 12.5 B thuộc cụm 1
d(C, c1 ) = 10.25 < d(C, c2 ) = 0.5 C thuộc cụm 2
d(D, c1 ) = 21.25 > d(D, c2 ) = 0.5 D thuộc cụm 2
Bước 7: Nhận xét kết quả như trước => kết luận: A thuộc cụm 1 B thuộc cụm 1 C thuộc cụm 2 D thuộc cụm 2
Môn học: Khai phá dữ liệu và kho dữ liệu Trang 22 4.
Đánh giá thuật toán - ưu điểm - nhược điểm a) Ưu điểm
Độ phức tạp: O(t . K . l) với l: số lần lặp
Có khả năng mở rộng, có thể dễ dàng sửa đổi với những dữ liệu mới.
Bảo đảm hội tụ sau 1 số bước lặp hữu hạn. Luôn có K cụm dữ liệu
Luôn có ít nhất 1 điểm dữ liệu trong 1 cụm dữ liệu.
Các cụm không phân cấp và không bị chồng chéo dữ liệu lên nhau.
Mọi thành viên của 1 cụm là gần với chính cụm đó hơn bất cứ 1 cụm nào khác. b) Nhược điểm
Không có khả năng tìm ra các cụm không lồi hoặc các cụm có hình dạng phức tạp.
Khó khăn trong việc xác định các trọng tâm cụm ban đầu.
- Chọn ngẫu nhiên các trung tâm cụm lúc khởi tạo.
- Độ hội tụ của thuật toán phụ thuộc vào việc khởi tạo các vector trung tâm cụm.
Khó để chọn ra được số lượng cụm tối ưu ngay từ đầu, mà phải qua
nhiều lần thử để tìm ra được số lượng cụm tối ưu.
Rất nhạy cảm với nhiễu và các phần tử ngoại lai trong dữ liệu.
Không phải lúc nào mỗi đối tượng cũng chỉ thuộc về 1 cụm, chỉ phù
hợp với đường biên giữa các cụm rõ. 5.
Ứng dụng của thuật toán K-means
Thuật toán K-means có rất nhiều ứng dụng từ mạng Neural network , nhận
dạng mẫu, trí tuệ nhân tạo cho đến các lĩnh vực xử lý ảnh.
Về cơ bản bất cứ bài toán nào dạng, dữ liệu gồm nhiều loại và mỗi loại có
nhiều thuộc tính riêng. Nếu muốn phân loại chúng dựa trên các thuốc tính này
thì ta có thể áp dụng thuật toán K-means với K là số nhóm (loại) muốn phân chia.
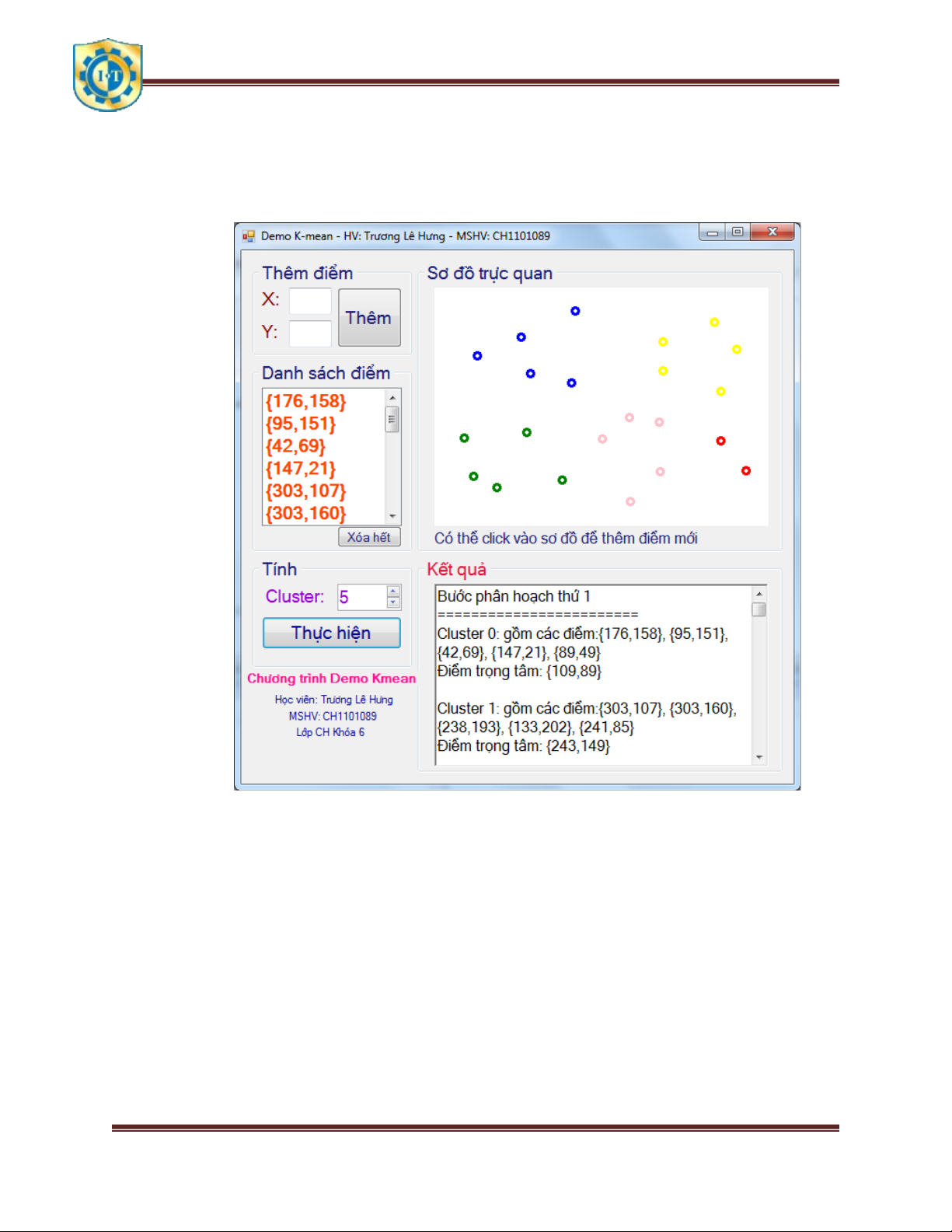
Môn học: Khai phá dữ liệu và kho dữ liệu Trang 23 Phần IV Demo 1.
Giao diện chương trình demo 2. Yêu cầu hệ thống
Chương trình Demo được phát triển bằng Visual Studio 2008.
Yêu cầu về hệ điều hành: Windows có hỗ trợ .Net framwork 2.0 trở lên. 3. Phát biểu bài toán
Bài toán yêu cầu cho phép nhập đầu vào gồm tập hợp các điểm 2 chiều: -
Thêm tọa độ điểm bằng tay -
Thêm tọa độ điểm bằng cách đánh dấu điểm vào sơ đồ Đầu ra: -
Phân cụm các tọa độ điểm theo màu sắc -
Kết quả tính toán mỗi bước 4.
Phân tích và thiết kế
Bài toán sử dụng các lớp Point để nhập và lưu các tọa độ điểm 2 chiều.
Môn học: Khai phá dữ liệu và kho dữ liệu Trang 24
Ban đầu chia đều các điểm cho số cụm
Sau đó tính toán trọng tâm các điểm ở mỗi cụm. Xét khoản cách từ mỗi
điểm đến các trọng tâm của các cụm để phân hoạch lại điểm đó thuộc cụm mà
có khoảng cách đến trọng tâm cụm đó ngắn nhất.
Lặp đi lặp lại cho đến khi các điểm thuộc các cụm không thay đổi ở hai bước liên tiếp.
Sử dụng hàm vẽ các tọa độ và chia màu các tọa độ điểm lên sơ đồ theo từng cụm.
Môn học: Khai phá dữ liệu và kho dữ liệu Trang 25 Tài liệu tham khảo
Tài liệu tiếng Việt
[1] PGS.TS. Đỗ Phúc, Tập slide bài giảng môn học khai phá dữ liệu và kho dữ liệu, ĐHCNTT, TP.HCM.
[2] Nguyễn Trung Sơn, Phương pháp phân cụm dữ liệu, Đại học Thái Nguyên 2009.
[3] An Hồng Sơn, Nghiên cứu một số phương pháp phân cụm mờ và ứng dụng,Đại học Thái Nguyên 2008.
[4] Vũ Lan Phương, Nghiên cứu và cài đặt một số giải thuật phân cụm, phân lớp, Đại học Bách Khoa Hà Nội 2006.
[5] Phạm Huyền Trang, Slide Thuật toán K-means và ứng dụng. Tài liệu tiếng Anh
[6] Anil K. Jain and Richard C. Dubes (1988), Algorithms for clustering data, Prentice- Hall, Inc., USA. Tài liệu trên Web Wikipedia
http://vi.wikipedia.org/wiki/Khai_phá_dữ_liệu
Môn học: Khai phá dữ liệu và kho dữ liệu Trang 26
Document Outline
- Phần I . Cơ sở lý thuyết về khai phá dữ liệu và nhà kho dữ liệu
- Phần II. Phân cụm dữ liệu và các thuật toán phân cụm dữ liệu
- Phần III Thuật toán phân cụm dữ liệu K-means
- Phần IV Demo
- Tài liệu tham khảo
Tài liệu liên quan:
-
Đề thi thực hành học kì I năm học 2024 - 2025 môn Cơ sở dữ liệu | Trường Đại học Công nghệ Thông tin, Đại học Quốc gia Thành phố Hồ Chí Minh
51 26 -

Đề thi thực hành học kì I môn Cơ sở dữ liệu | Trường Đại học Công nghệ Thông tin, Đại học Quốc gia Thành phố Hồ Chí Minh
58 29 -

Bài giảng Chương 5: Ràng buộc toàn vẹn môn Cơ sở dữ liệu | Trường Đại học Công nghệ Thông tin, Đại học Quốc gia Thành phố Hồ Chí Minh
44 22 -

Báo cáo thực tập Công ty TNHH Haludo | Trường Đại học Công nghệ thông tin, Đại học Quốc gia thành phố Hồ Chí Minh
60 30 -

Bài thực hành ôn tập cơ sở dữ liệu | Trường Đại học Công nghệ thông tin, Đại học Quốc gia Thành phố Hồ Chí Minh
46 23