SLIDE Week 14 (Revision and prepare for last exam) Kiến Trúc Máy Tính | Trường Đại học Công nghệ, Đại học Quốc gia Hà Nội
SLIDE Week 14 (Revision and prepare for last exam) Kiến Trúc Máy Tính | Trường Đại học Công nghệ, Đại học Quốc gia Hà Nội . Tài liệu được sưu tầm và biên soạn dưới dạng PDF gồm 19 trang giúp bạn tham khảo, củng cố kiến thức và ôn tập đạt kết quả cao trong kỳ thi sắp tới. Mời bạn đọc đón xem!
Môn: Kiến Trúc Máy Tính (UET) 20 tài liệu
Trường: Trường Đại học Công nghệ, Đại học Quốc gia Hà Nội 824 tài liệu
Tác giả:






Preview text:
ELT3047 Computer Architecture Lecture 14: Summary Hoang Gia Hung
Faculty of Electronics and Telecommunications
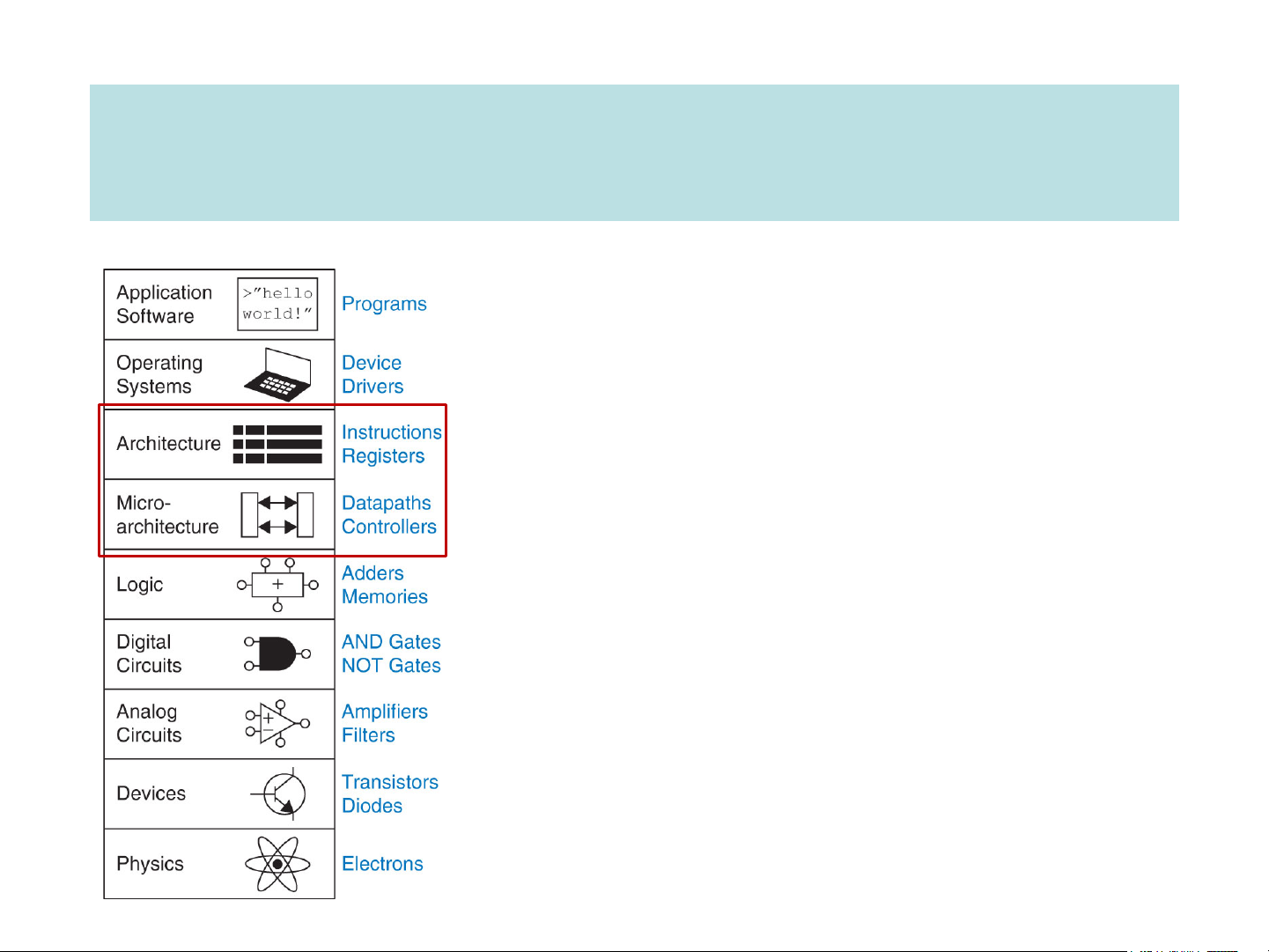
University of Engineering and Technology, VNU Hanoi Computer Architecture ❑ Architecture (ISA)
programmer/compiler view
➢ “functional appearance to its immediate user/system programmer”
➢ Data storage, addressing mode,
instruction set, instruction formats & encodings. ❑ µ-architecture processor designer view
➢ “logical structure or organization that performs the architecture”
➢ Pipelining, functional units, caches, physical registers The 5 Aspects in ISA Design C = A + B
❑ Instruction: operation (verb) applied to operands (objects)
❑ Data storage: where do we store oprerands & results?
➢ Stack, Accumulator, GPR (), Memory.
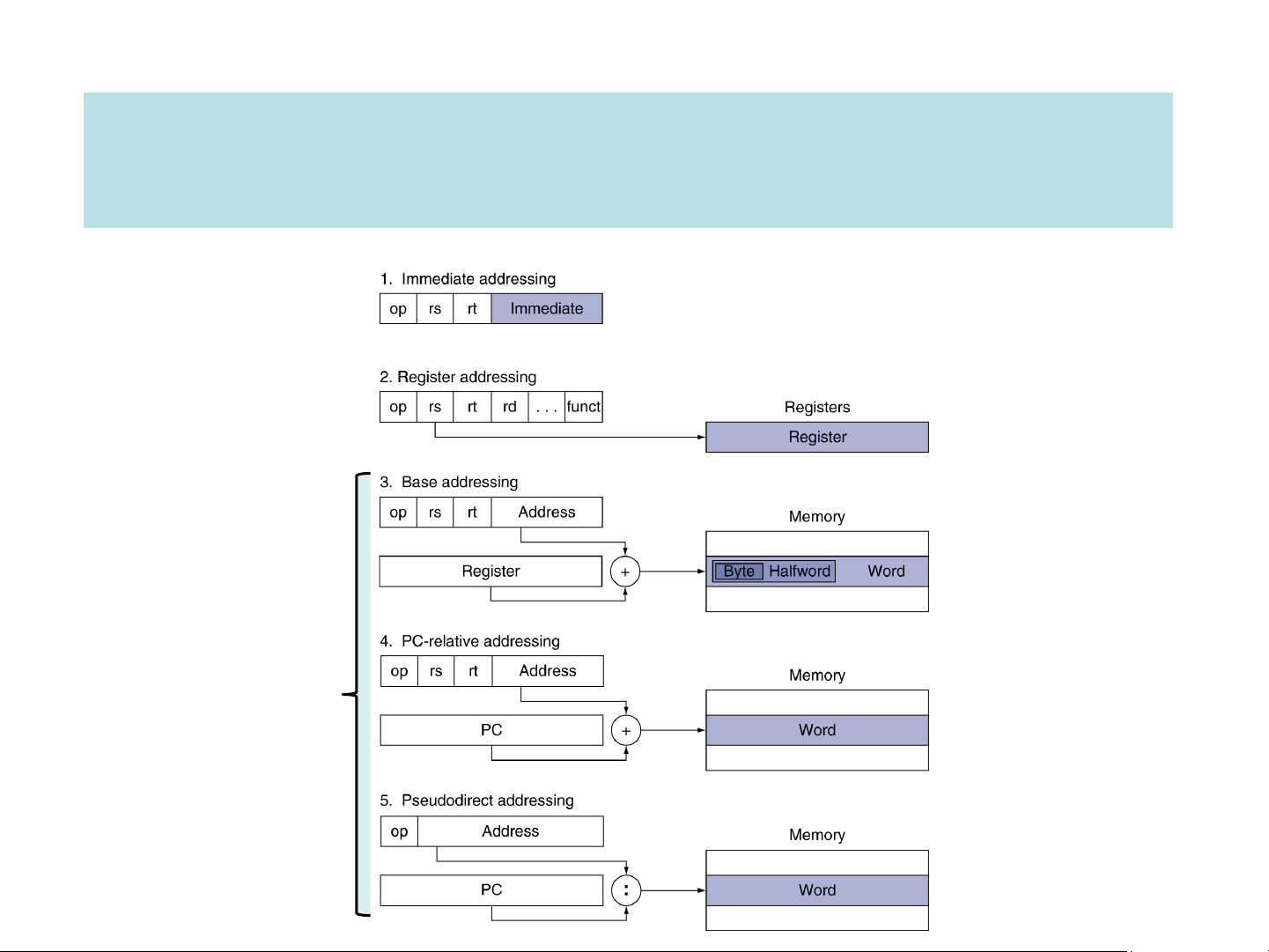
❑ Memory addressing modes: how do we specify the data?
➢ Register, immediate, displacement
❑ Operations in instruction set: which one should be supported?
➢ CISC vs RISC (arithmetic & logical, data transfer (load/store), control (branching & jump)).
❑ Instruction encoding: how inst. are represented in binary?
➢ Fixed vs variable length ❑ Compiler support
➢ Regularity, simplicity, register allocation (≥16 GPR’s) Practical examples addi $s1, $s2, 100
add $s1, $s2, $s3/sub $s1, $s2, $s3
lw $s1, 100($s2)/sw $s1, 100($s2)
beq $s1, $s2, 25/bne $s1, $s2, 25 Displacement addressing j 2500 ISA performance ❑ 1
𝑃𝑒𝑟𝑓𝑜𝑟𝑚𝑎𝑛𝑐𝑒𝑋 = 𝐸𝑥𝑒𝑐𝑢𝑡𝑖𝑜𝑛 𝑡𝑖𝑚𝑒𝑋
➢ Relative performance: 𝑃𝑒𝑟𝑓𝑜𝑟𝑚𝑎𝑛𝑐𝑒𝑋
𝐸𝑥𝑒𝑐𝑢𝑡𝑖𝑜𝑛 𝑡𝑖𝑚𝑒 = 𝑌 = 𝑛
𝑃𝑒𝑟𝑓𝑜𝑟𝑚𝑎𝑛𝑐𝑒𝑌
𝐸𝑥𝑒𝑐𝑢𝑡𝑖𝑜𝑛 𝑡𝑖𝑚𝑒𝑋 ❑ CPU time 𝐶𝑃𝑈 𝑇𝑖𝑚𝑒 =
𝐶𝑃𝑈 𝐶𝑙𝑜𝑐𝑘 𝐶𝑦𝑐𝑙𝑒𝑠 × 𝐶𝑙𝑜𝑐𝑘 𝐶𝑦𝑐𝑙𝑒 𝑇𝑖𝑚𝑒
𝐶𝑃𝑈 𝐶𝑙𝑜𝑐𝑘 𝐶𝑦𝑐𝑙𝑒𝑠 =
𝐶𝑙𝑜𝑐𝑘 𝑅𝑎𝑡𝑒 =
𝐼𝐶 × 𝐶𝑃𝐼 × 𝐶𝑙𝑜𝑐𝑘 𝑝𝑒𝑟𝑖𝑜𝑑 𝐼𝐶 × 𝐶𝑃𝐼 =
𝐶𝑙𝑜𝑐𝑘 𝑟𝑎𝑡𝑒
➢ Algorithm affects IC, possibly CPI
➢ Programming language affects IC, CPI ➢ Compiler affects IC, CPI
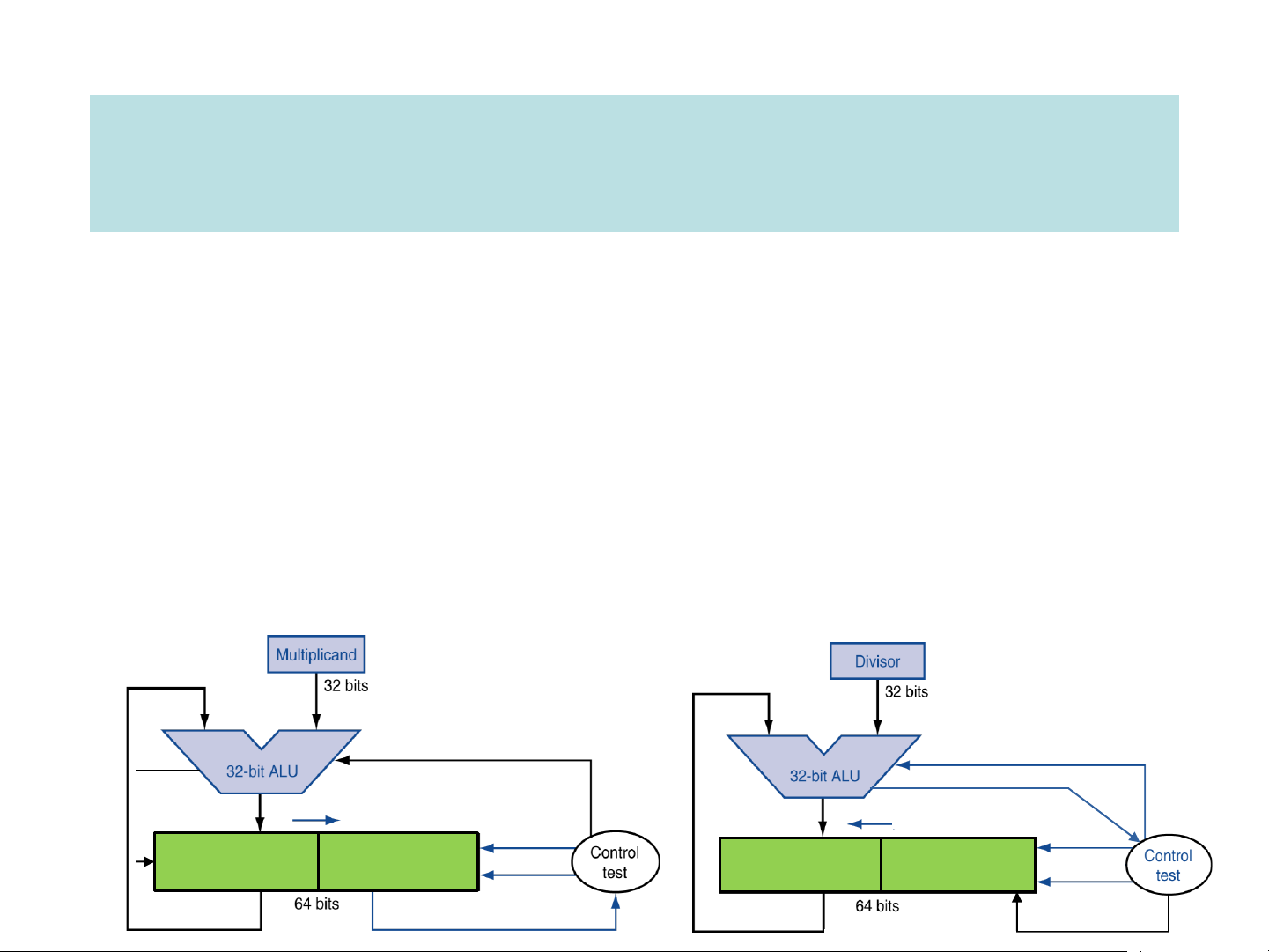
➢ ISA affects IC, CPI, Clock cycle time Arithmetic processing unit implementation ❑ Operations on integers
➢ Addition and subtraction (carry vs overflow)
➢ Multiplication and division ➢ Floating-Point Addition ❑ Implementation
➢ Sequential Unsigned Multiplication ➢ Signed Integer Multiplier
➢ Sequential Unsigned Division Add/sub sub sign sign shift right HI LO write HI LO write (remainder) (quotient) shift left LO[0] set lsb
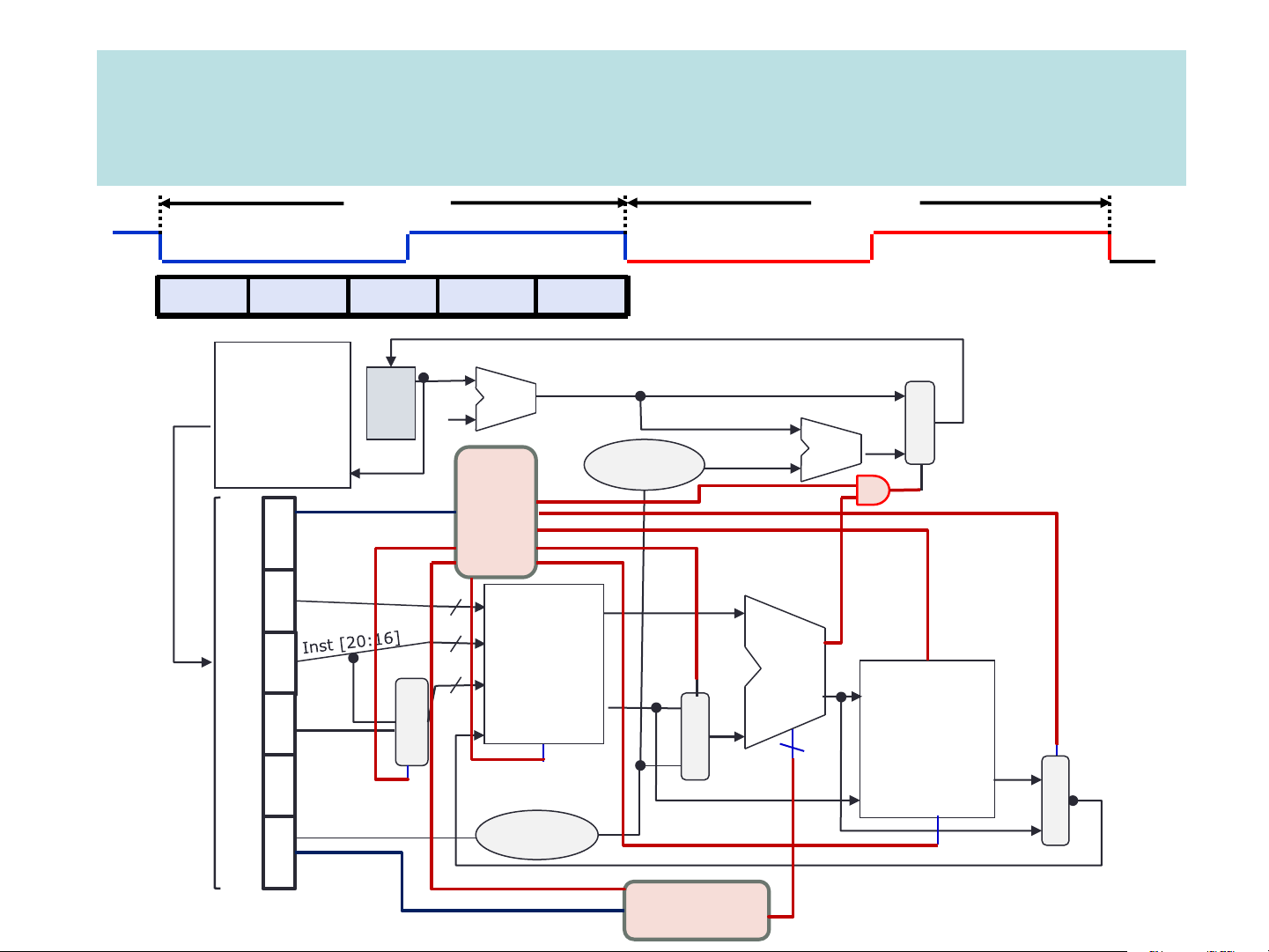
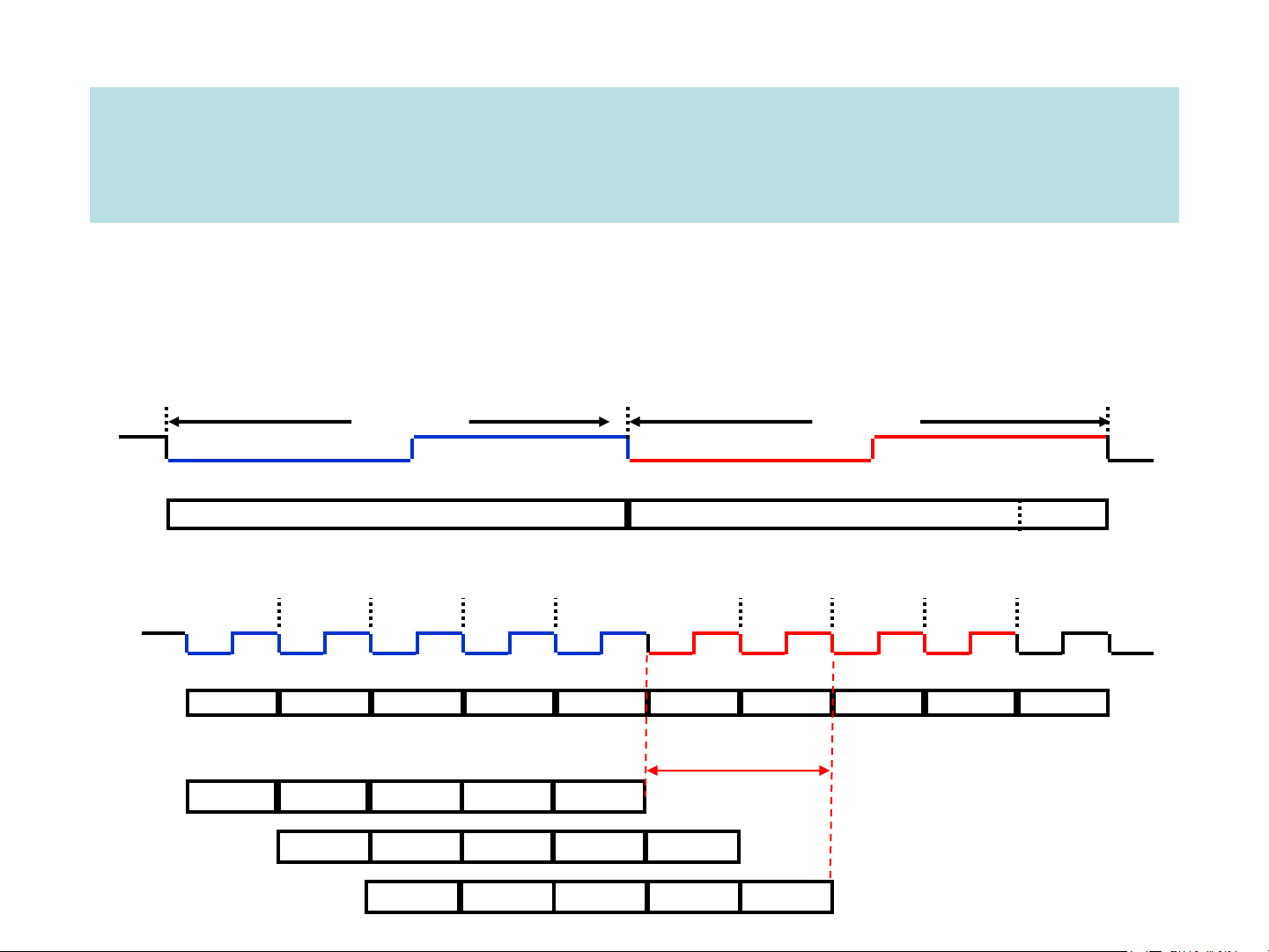
Building the datapath & control for a single cycle processor Cycle 1 Cycle 2 IF ID Exec Mem Wr Instruction Memory PC Add M Instruction 4 U Add Control X Left Shift 2-bit Address PCSrc opcode Branch 31:26 000000 Inst [31:26] 25:21 01001 rs Inst [25:21] 5 RR1 RD1 20:16 01010 5 rt RR2 is0? MemWrite Registers ALU 5 ALUSrc 15:11 01000 M WR ALU Address rd RD2 M result U WD Data MemToReg Inst U shamt 000000 X 4 Memory 10:6 [15:11] X RegWrite ALUcontrol Read M RegDst Write Data Data U funct 100000 Inst [15:0] 5:0 Sign Extend X MemRead Inst [5:0] ALUop ALU Control Pipelining principle
❑ Five stages, one step per stage
➢ Each step requires 1 clock cycle → steps enter/leave pipeline at the rate of one step per clock cycle
Single Cycle Implementation: Cycle 1 Cycle 2 Clk lw sw Waste
Multiple Cycle Implementation:
Cycle 1 Cycle 2 Cycle 3 Cycle 4 Cycle 5 Cycle 6 Cycle 7 Cycle 8 Cycle 9 Cycle 10 Clk lw sw R-type IF ID EX MEM WB IF ID EX MEM IF
Pipeline Implementation: pipeline clock same as multi-cycle clock lw IF ID EX MEM WB sw IF ID EX MEM WB R-type IF ID EX MEM WB
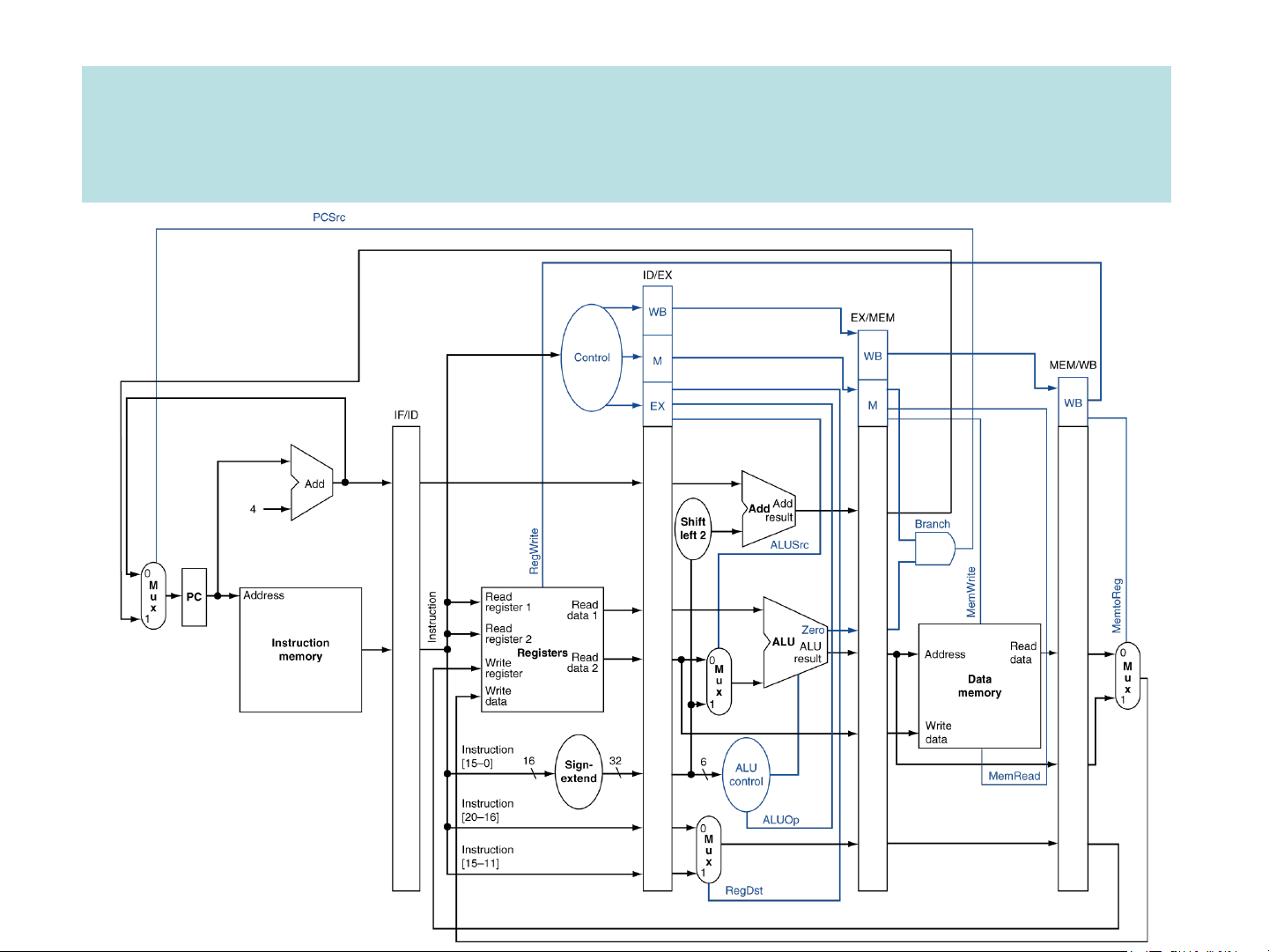
Pipeline datapath & control Pipeline hazards ❑ Issues in pipeline design
➢ structural hazards: attempt to use the same resource by two different instructions at the same time
➢ data hazards: attempt to use data before it is ready, e.g. an instruction’s
source operand(s) are produced by a prior instruction still in the pipeline
➢ control hazards: attempt to make a decision about program control flow
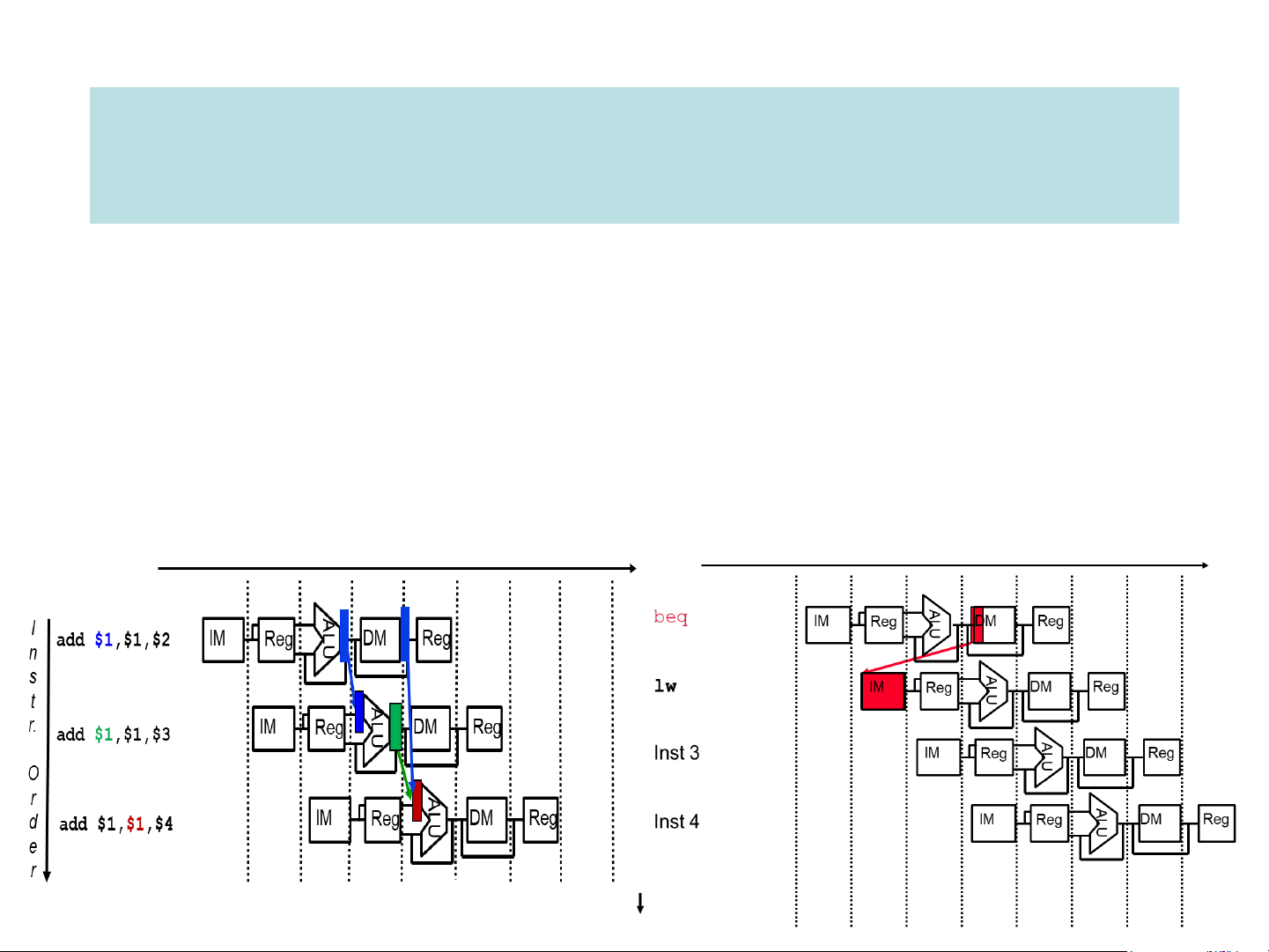
before the condition has been evaluated & new PC target address calculated data hazard control hazard Hazard handling methods
❑ General ways of handling structural hazard
1. Stall: delay access to resource by inserting nop instruction (or bubble)
between two instructions in the pipeline
2. Add more hardware resources: increase the throughput ▪
more costly, e.g. use separate memories for instructions & data
❑ Five fundamental ways of handling true data hazard
1. Stall: detect and wait
2. Forward: detect and forward/bypass data to dependent instruction
▪ Need hazard detection + forwarding units
3. Eliminate: detect and eliminate the dependence at the software level
4. Predict: predict the needed value(s), execute “speculatively”, and verify
▪ Dynamic branch prediction based on recent branching results stored in
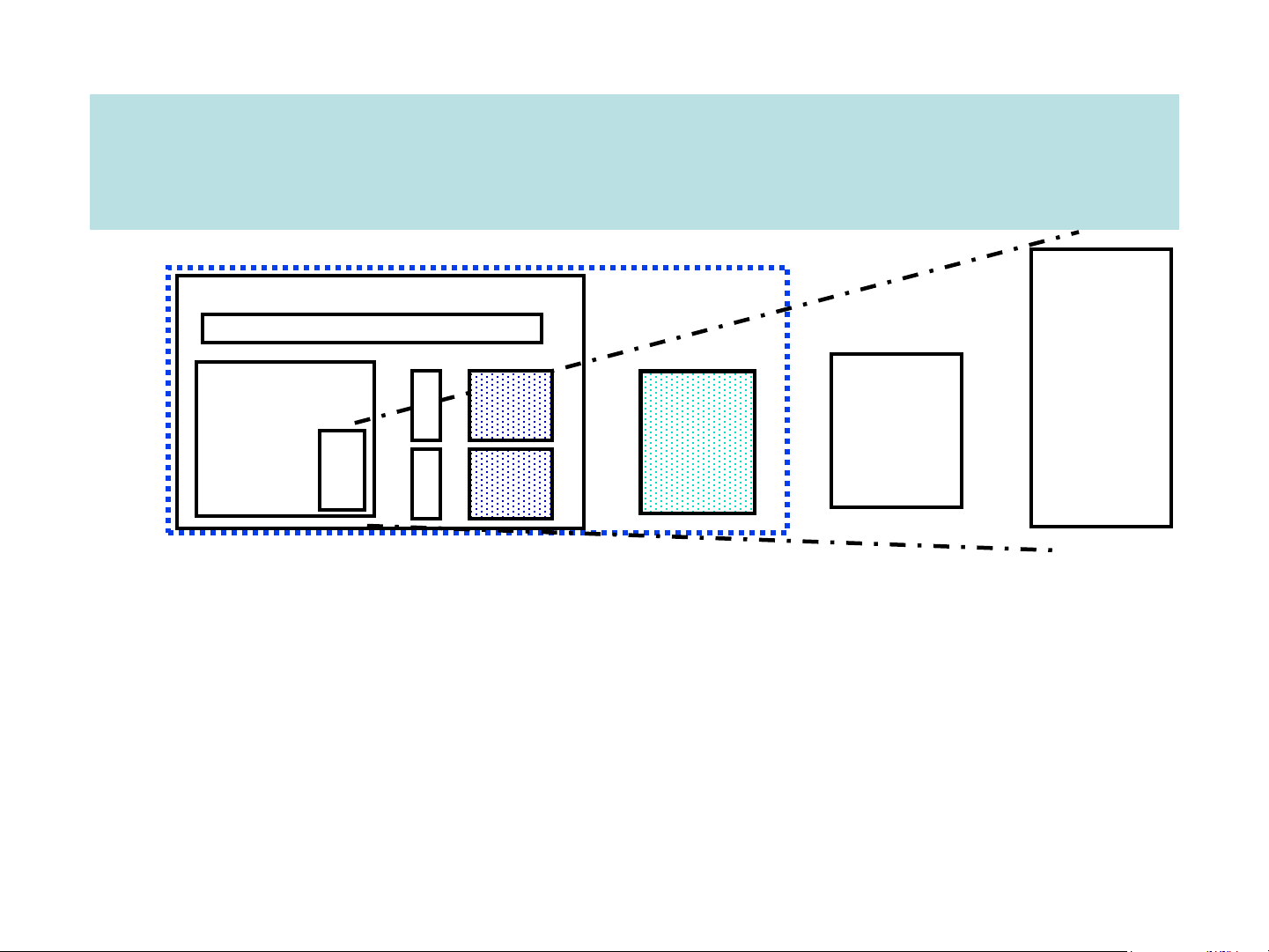
the branch target table (BTB) The memory hierachy On-Chip Components Control Cach ITLB In str Second Secondary e Main Reg Level Memory Datapath Cach DT Dat Cache Memory (Disk) Fi (DRAM) le LB a (SRAM) e Speed (%cycles): ½’s 1’s 10’s 100’s 10,000’s Size (bytes): 100’s 10K’s M’s G’s T’s Cost: highest lowest
❑ Why Does it Work? Because of locality in typical programs
➢ Temporal Locality: a program tends to reference the same memory location
many times and all within a small window of time.
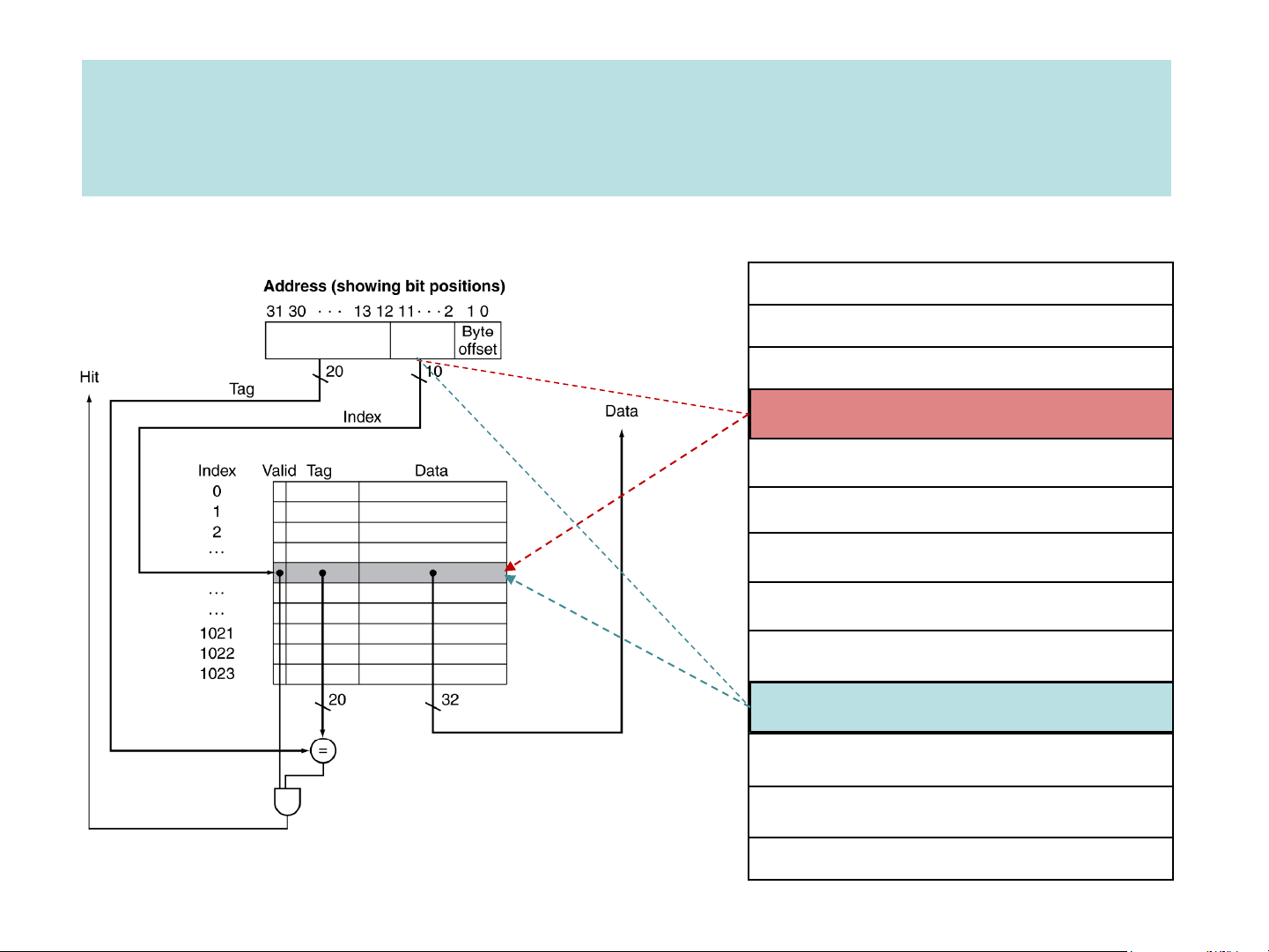
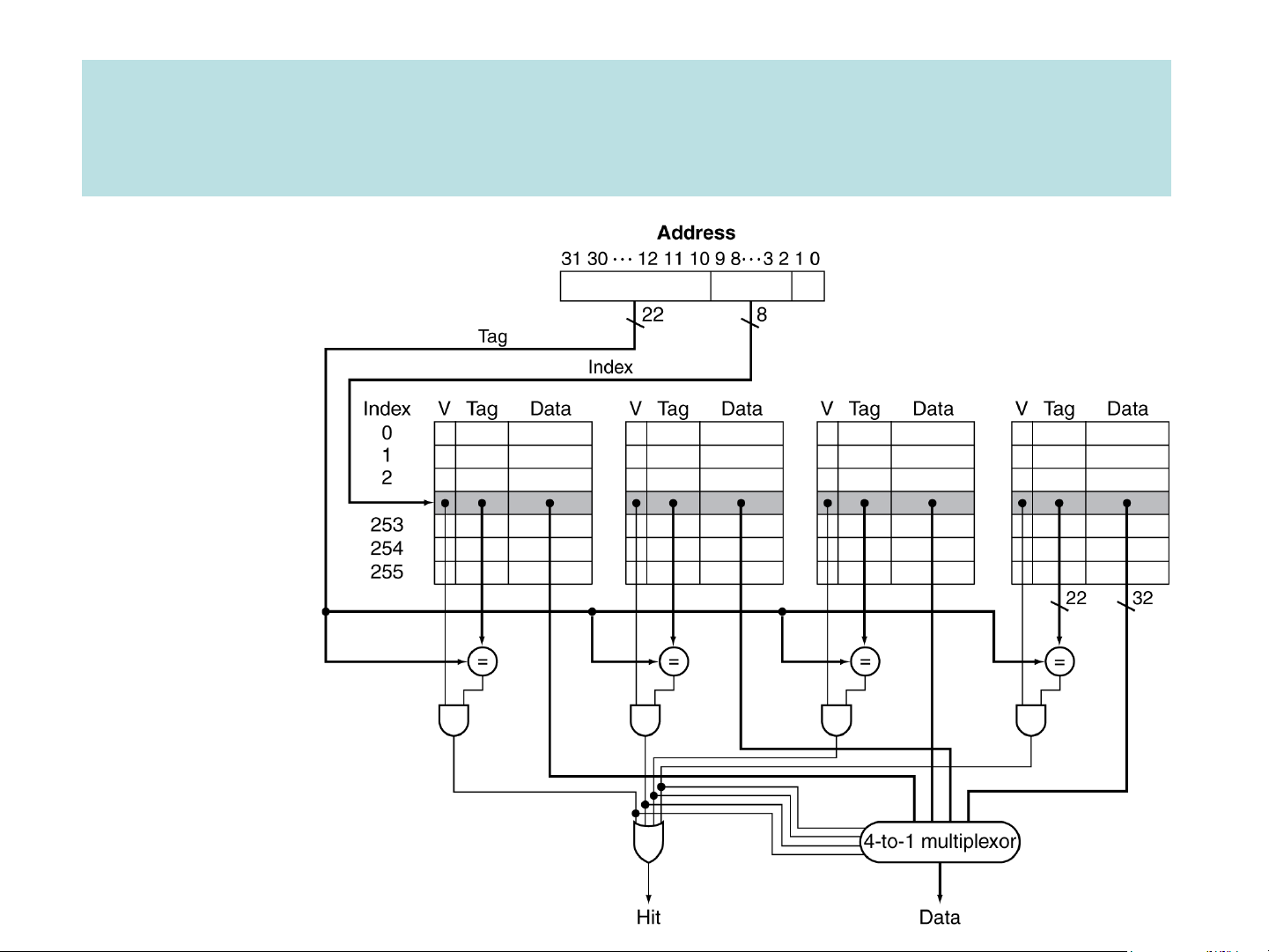
➢ Spatial Locality: a program tends to reference a cluster of memory locations at a time. Direct-map cache Four-Way Set Associative Cache 28 = 256 sets each with Way 0 Way 1 Way 2 Way 3 four ways (each with one block) Cache performance ❑ Performance measure
➢ Hit: data appears in some block in the upper level ▪ Hit rate: : #hits #accesses
➢ Miss: data needs to be retrieve from a lower level block
▪ Miss rate: #misses = 1 – (Hit rate) #accesses
▪ Miss penalty: Time to replace a block in the upper level with a block
from the lower level + Time to deliver this block’s word to the processor
❑ The processor stalls on a cache miss
➢ Memory stall cycles = I-Count x misses/instruction x miss penalty
I-Cache Miss Rate + LS Frequency × D-Cache Miss Rate
❑ Average Memory Access Time (AMAT) is the average time to
access memory considering both hits and misses.
AMAT = Hit time + Miss rate × Miss penalty Virtual Memory
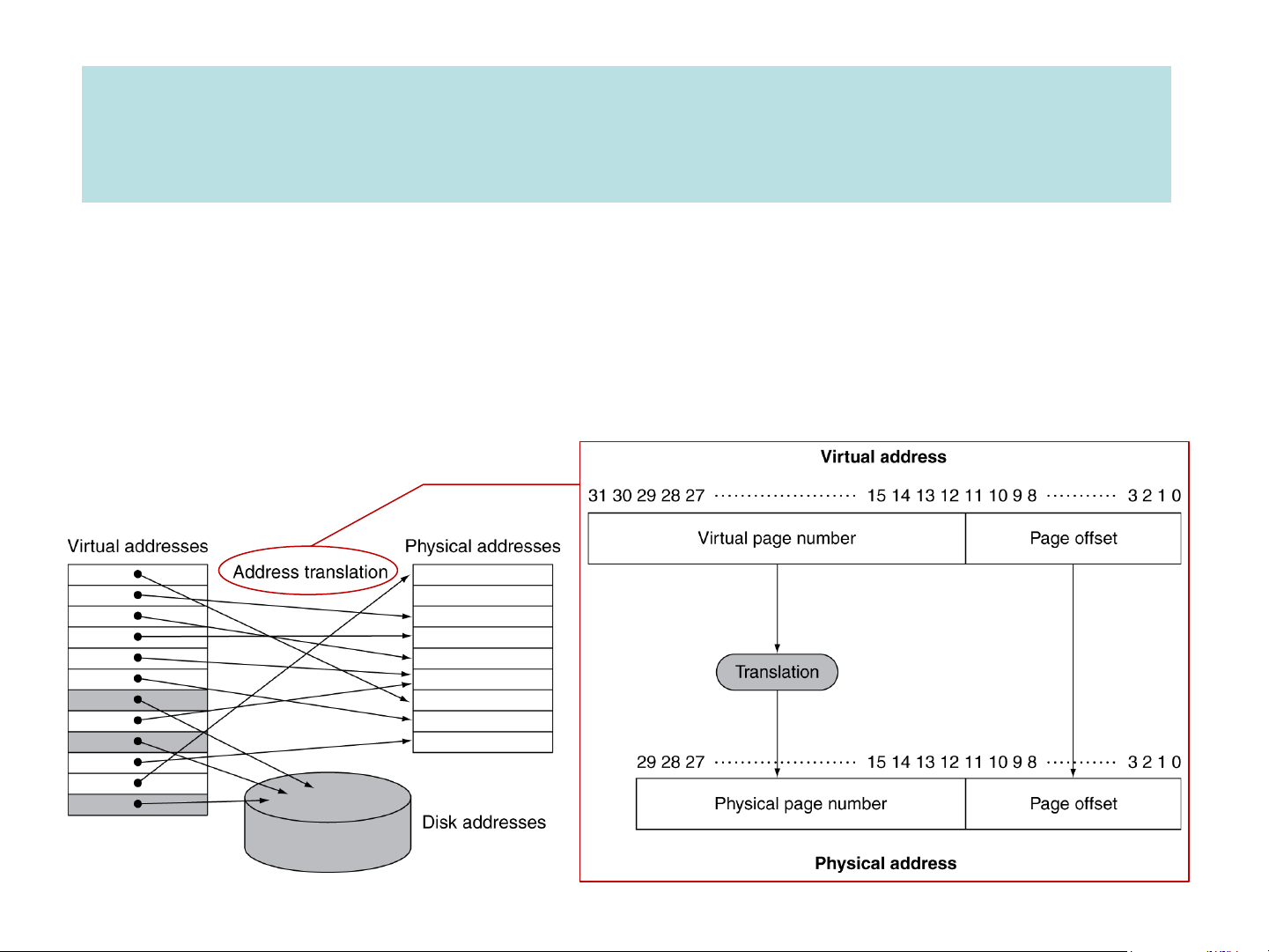
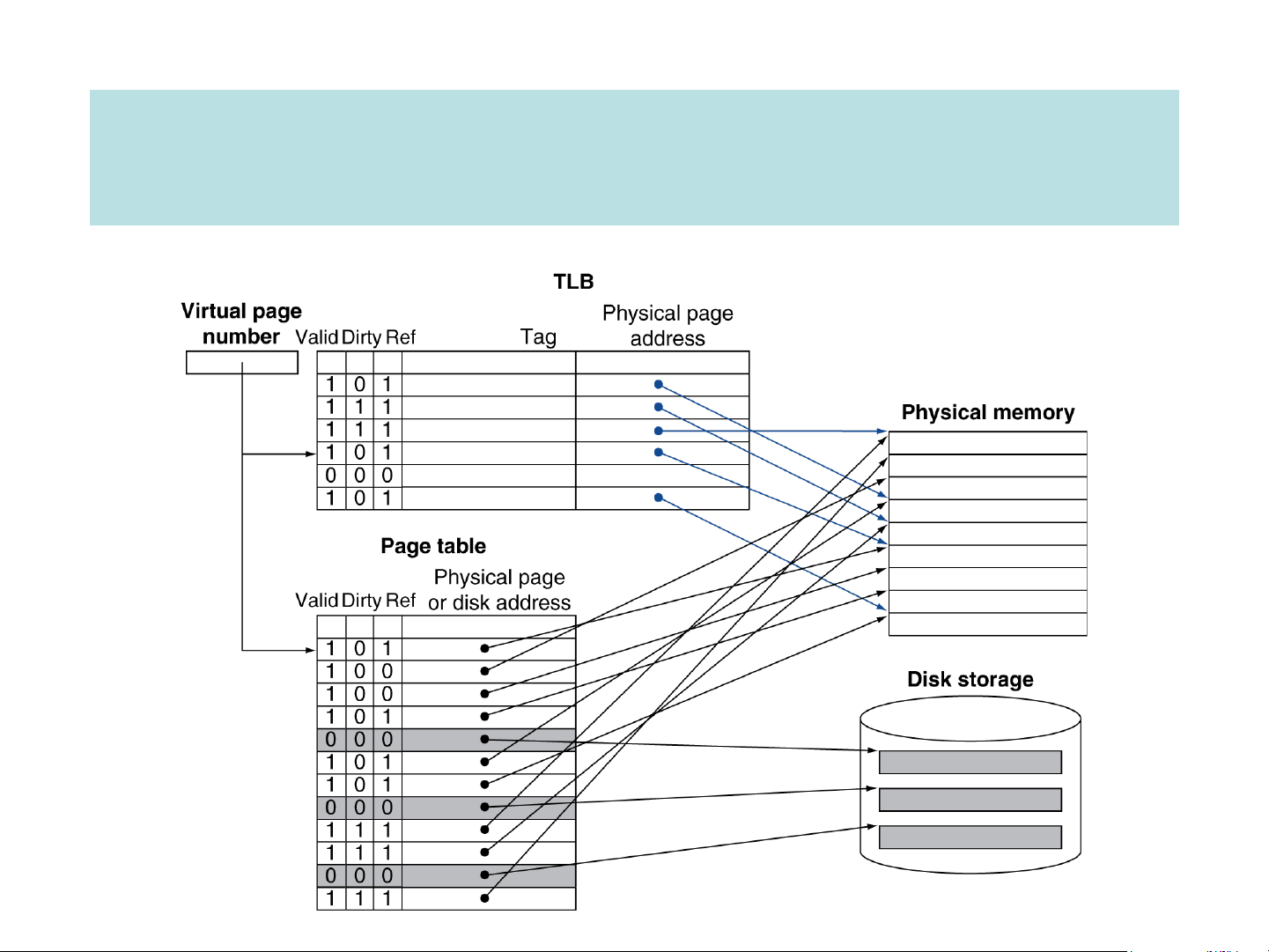
❑ A technique that uses RAM as a “cache” for secondary storage
➢ The processor generates virtual addresses while the memory is accessed
using physical addresses (real locations in main memory)
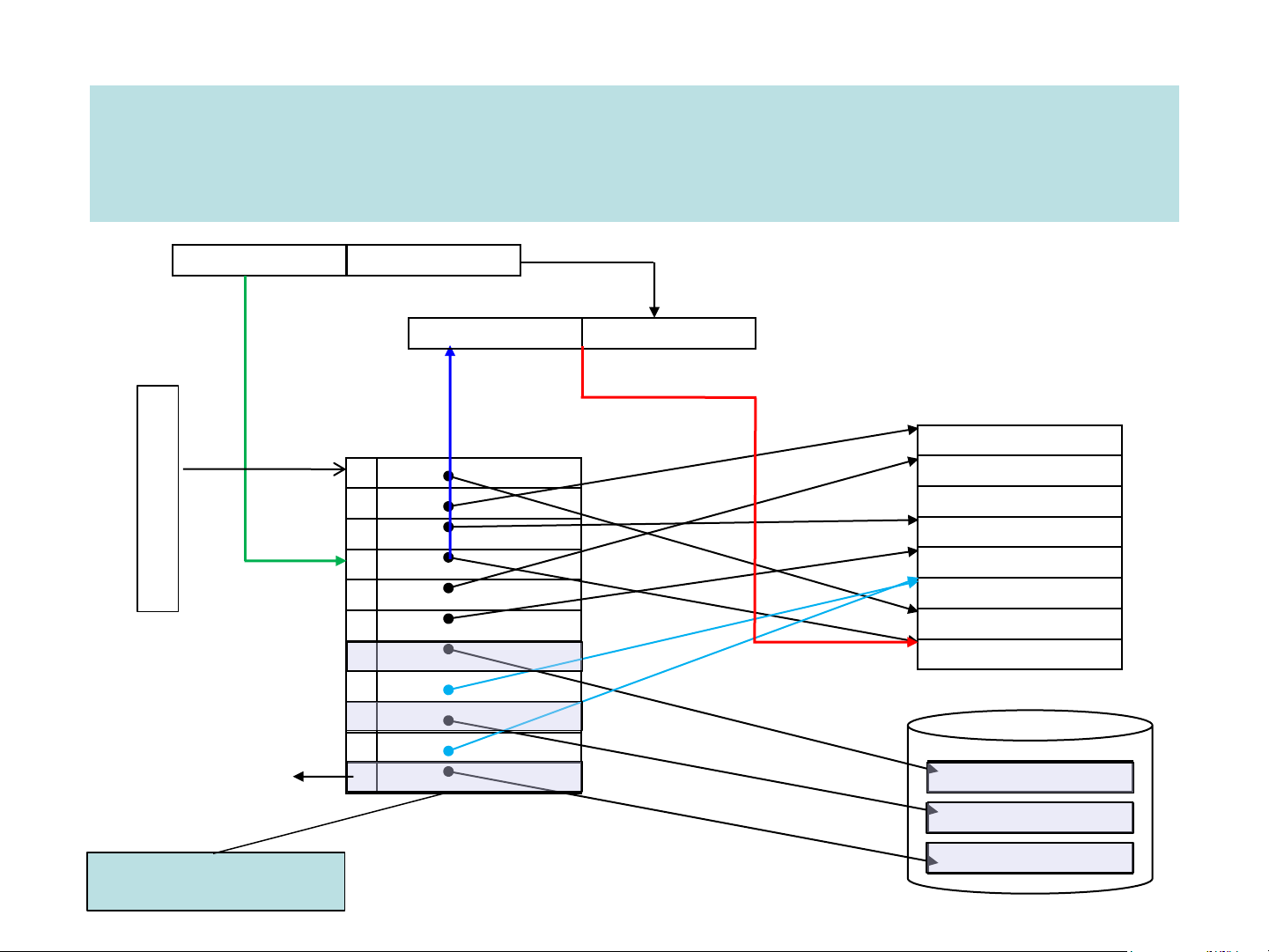
➢ A program’s address space is divided into pages. Address Translation Virtual page # Offset Physical page # Offset ret Mapping Physical page V base addr regis 1 1 able t 1 1 Page index into 1 page 1 table 0 Main memory 1 0 If valid bit is off, 1 then page is not present in 0 memory. Page Table (in main memory) 32 bits wide = V + 18 bits PPN + extra bits Disk storage
Making Address Translation Fast The epilogue
❑ The goal of exams is to check if you have learned well, getting good grades is only a symptom.
➢ When you receive a low grade, worry less about how it impacts your GPA;
worry more about the fact that you didn’t learn as well as you should.
➢ When you leave UET and have to make a real living, your GPA means
nothing if you cannot perform on the job.
❑ You cannot really “study” for the final exam in the last minute
➢ Can only “review” what you studied and learned over the whole semester.
➢ Don’t just rely on the slides, they are more like mental tabs to remind you of
what was said in the book or in the lectures.
➢ A great way to review is to work out examples given in class on your own.
❑ I enjoyed working with you this semester & good luck to all!
Tài liệu liên quan:
-

Giáo trình Đồ hoạ máy tính môn Kiến trúc máy tính | Trường Đại học Công nghệ, Đại học Quốc gia Hà Nội
23 12 -

TỔNG HỢP ĐỀ THI KTMT
49 25 -

Đề thi Kiến trúc máy tính đề số 2 năm học 2020-2021 | Trường Đại học Công nghệ, Đại học Quốc gia Hà Nội
256 128 -

Đề thi và đáp án Kiến trúc máy tính giữa kỳ 1 năm học 2021-2022 | Trường Đại học Công nghệ, Đại học Quốc gia Hà Nội
262 131 -
Đề thi Kiến trúc máy tính CLC giữa kỳ 1 năm học 2022-2023 | Trường Đại học Công nghệ, Đại học Quốc gia Hà Nội
211 106