Spark Introduction - Hệ điều hành | Trường Đại Học Tài Nguyên và Môi Trường TP HCM
Spark Introduction - Hệ điều hành | Trường Đại Học Tài Nguyên và Môi Trường TP HCM được sưu tầm và soạn thảo dưới dạng file PDF để gửi tới các bạn sinh viên cùng tham khảo, ôn tập đầy đủ kiến thức, chuẩn bị cho các buổi học thật tốt. Mời bạn đọc đón xem!
Môn: Hệ điều hành (UIT1) 10 tài liệu
Trường: Trường Đại học Tài nguyên và Môi trường Thành phố Hồ Chí Minh 30 tài liệu
Tác giả:











Preview text:
Big Data (Spark) Instructor: Trong-Hop Do November 24th 2020 S3Lab
Smart Software System Laboratory 1
“Big data is at the foundation of all the
megatrends that are happening today, from
social to mobile to cloud to gaming.”
– Chris Lynch, Vertica Systems Big i Da D t a a t 2 Introduction
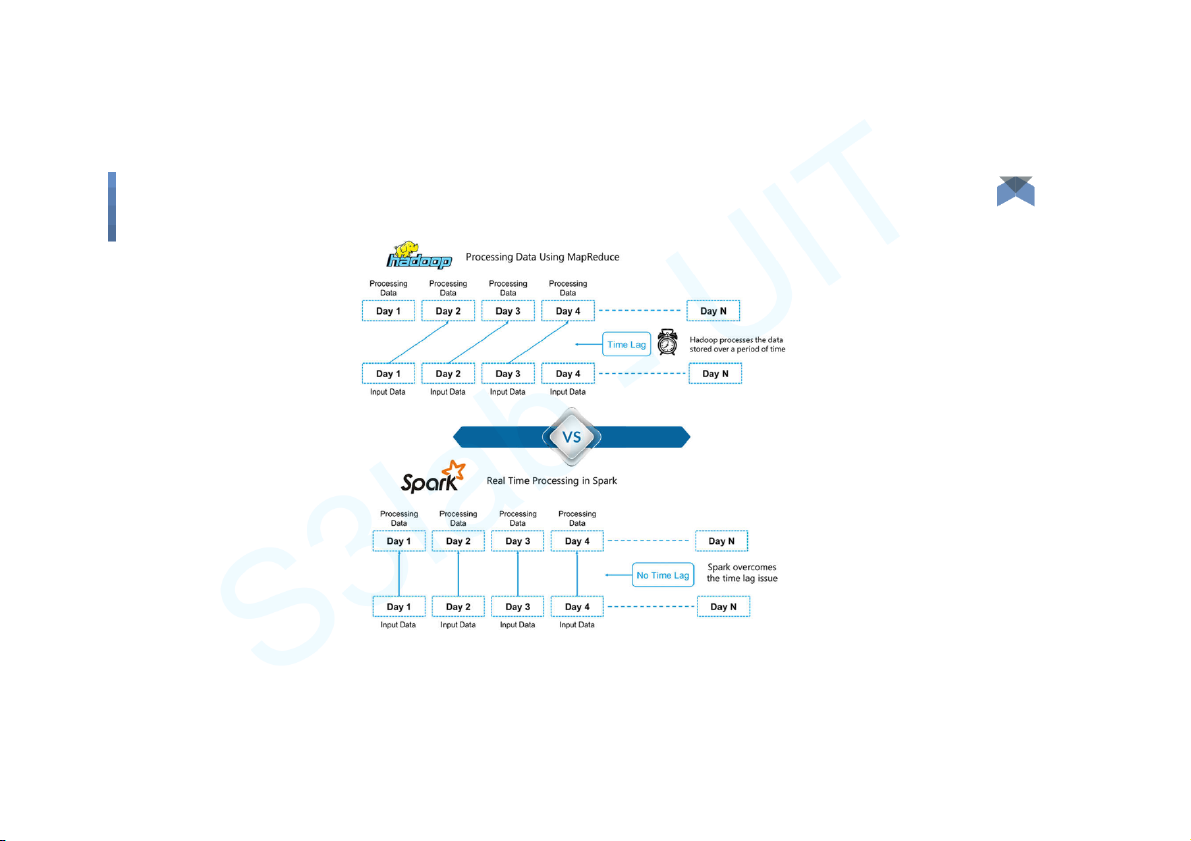
● Apache Spark is an open-source cluster computing framework for real- time processing
● Spark provides an interface for programming entire clusters with implicit
data parallelism and fault-tolerance.
● Spark is designed to cover a wide range of workloads such as batch
applications, iterative algorithms, interactive queries and streaming Big Data 3 Introduction Big Data 4 Introduction 5 Applications Big Data 6 Components
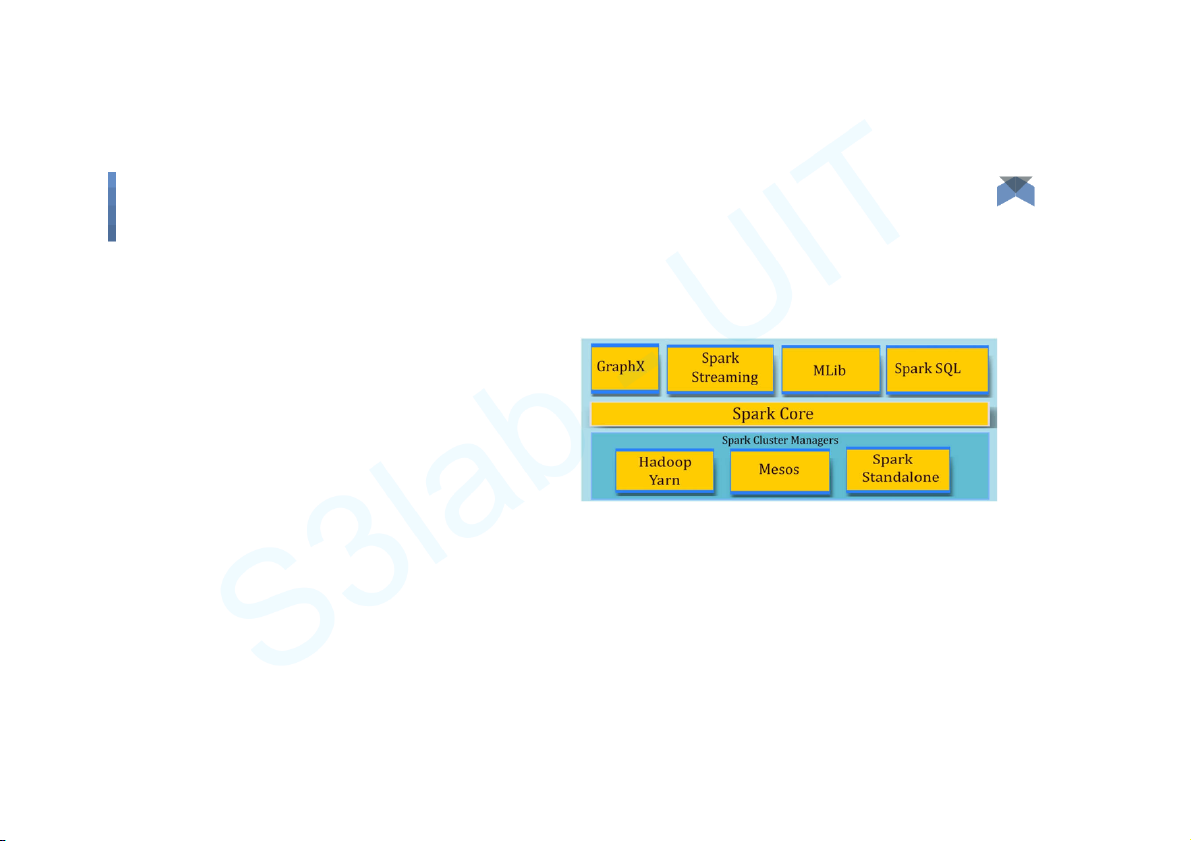
● Spark Core and Resilient Distributed Datasets or RDDs ● Spark SQL ● Spark Streaming
● Machine Learning Library or MLlib ● GraphX Big Data 7 Components Big Data 8 Components Spark Core
● The base engine for large-scale parallel and distributed data processing.
The core is the distributed execution engine and the Java, Scala, and
Python APIs offer a platform for distributed ETL application development.
Further, additional libraries which are built atop the core allow diverse
workloads for streaming, SQL, and machine learning. It is responsible for: ○
Memory management and fault recovery ○
Scheduling, distributing and monitoring jobs on a cluster ○
Interacting with storage systems Big Data 9 Components Spark Streaming
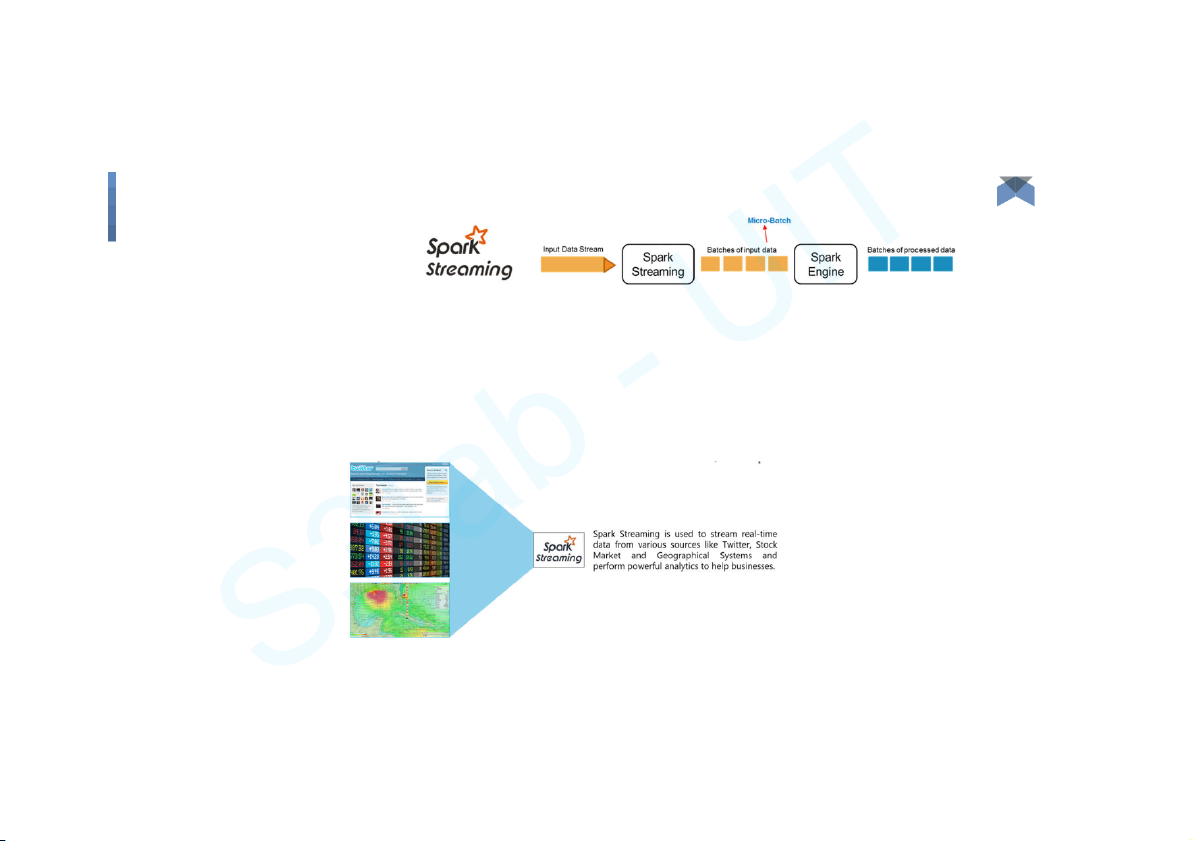
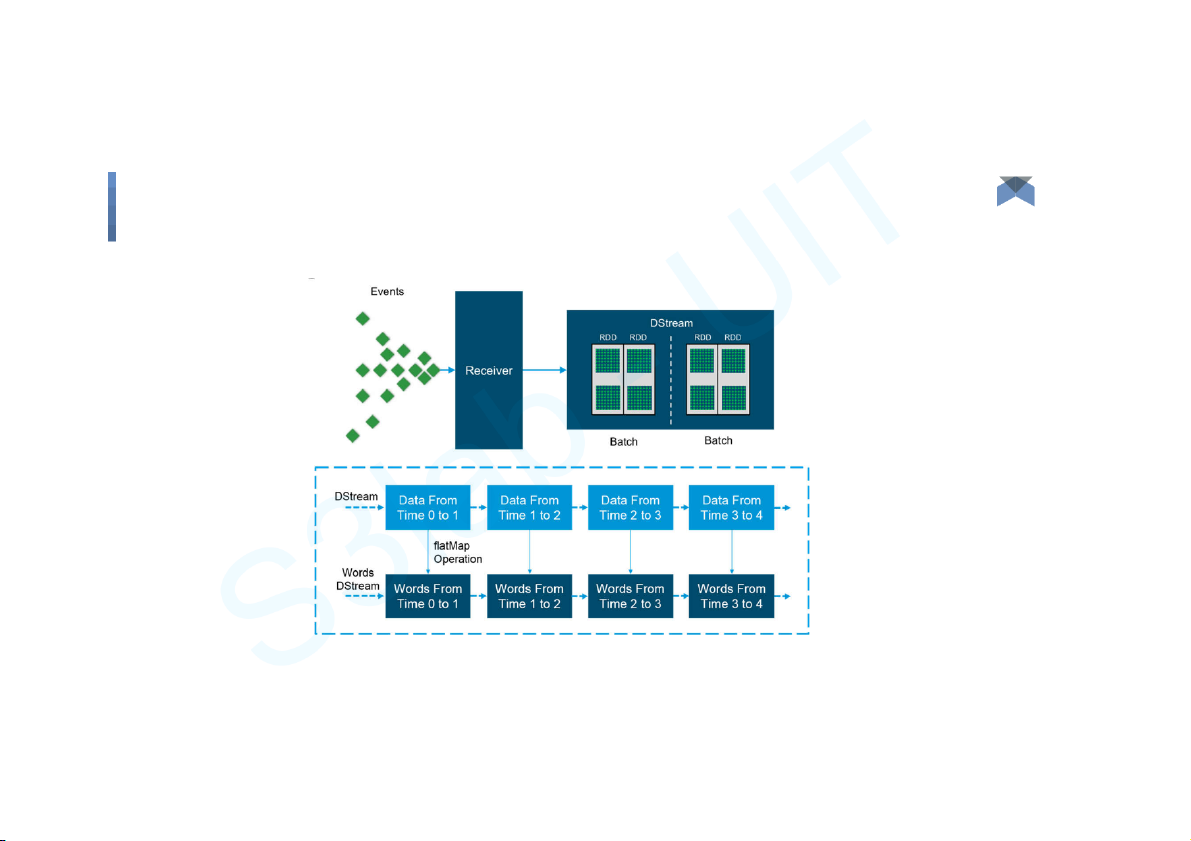
● Used to process real-time streaming data.
● It enables high-throughput and fault-tolerant stream processing of live
data streams. The fundamental stream unit is DStream which is basically
a series of RDDs (Resilient Distributed Datasets) to process the real-time data. Big Data 10 Components
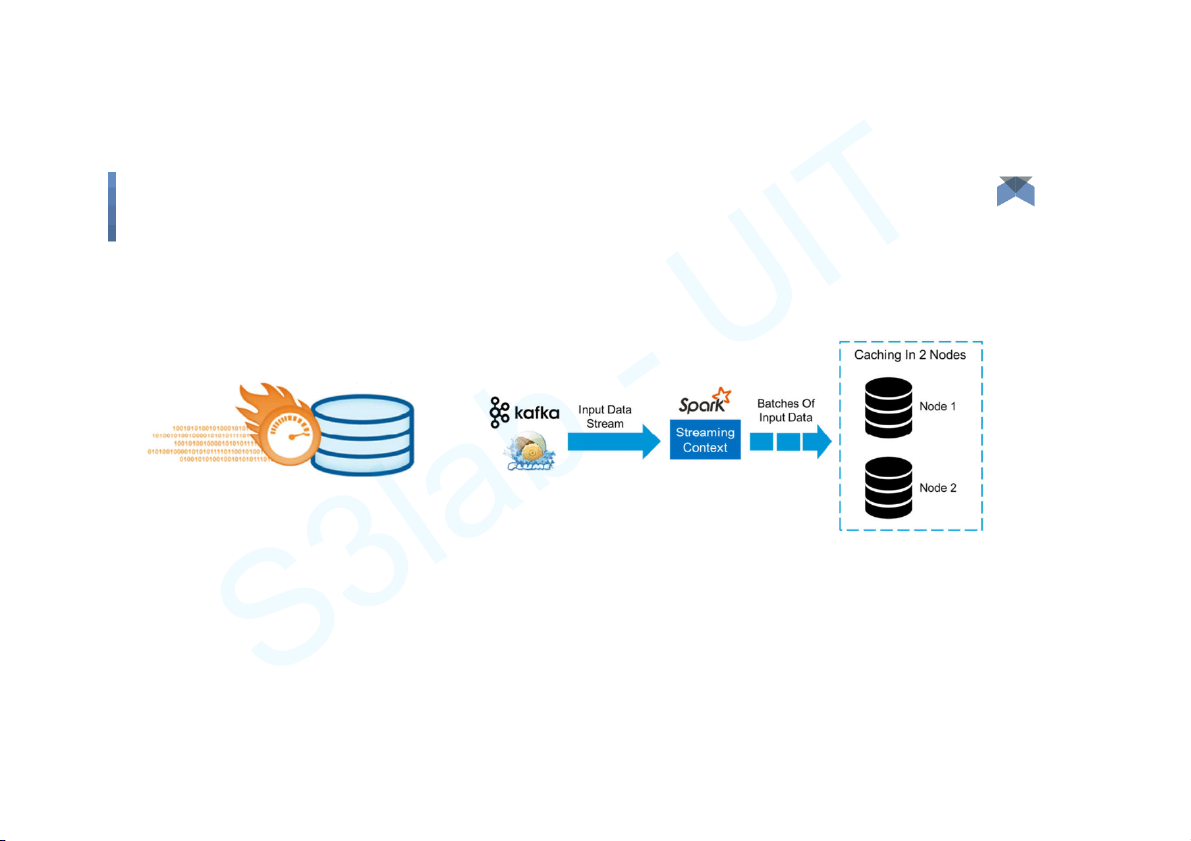
Spark Streaming - Workflow Big Data 11 Components
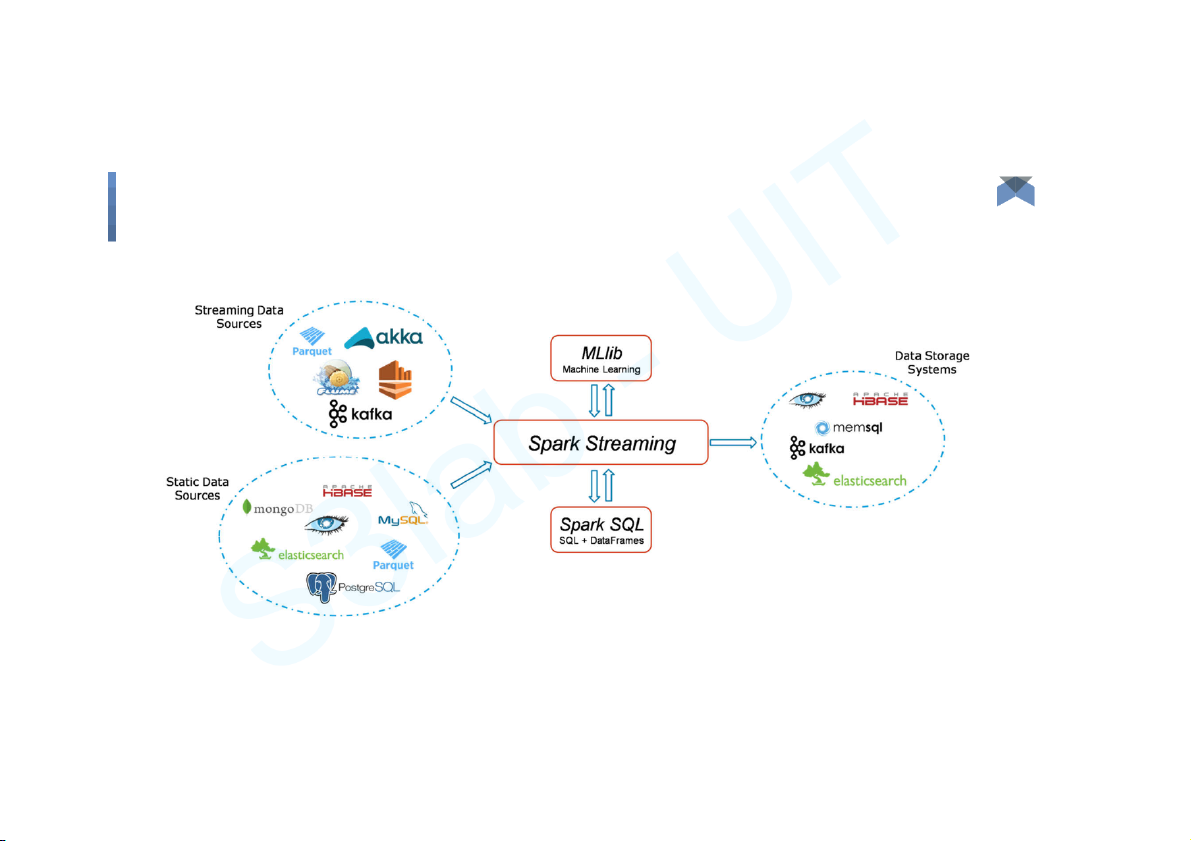
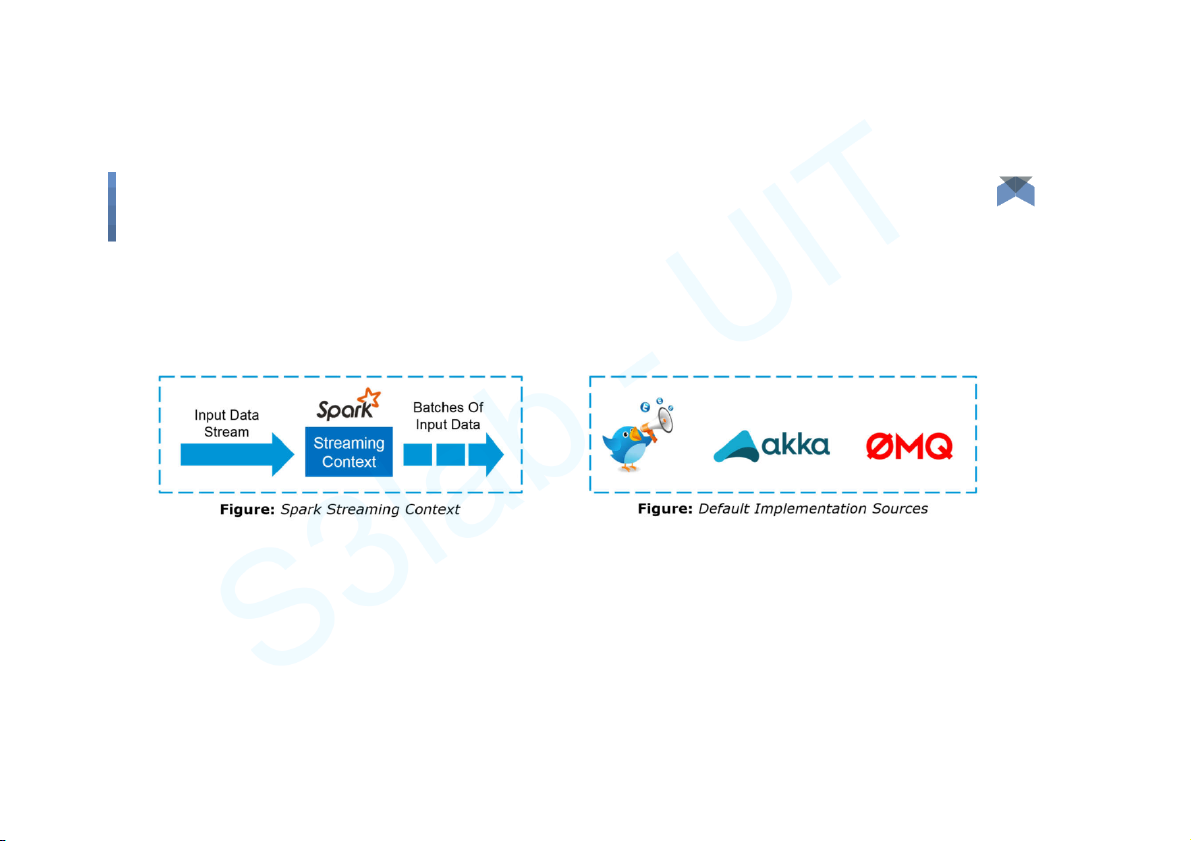
Spark Streaming - Fundamentals ● Streaming Context
● DStream (Discretized Stream) ● Caching
● Accumulators, Broadcast Variables and Checkpoints Big Data 12 Components
Spark Streaming - Fundamentals Big Data 13 Components
Spark Streaming - Fundamentals Big Data 14 Components
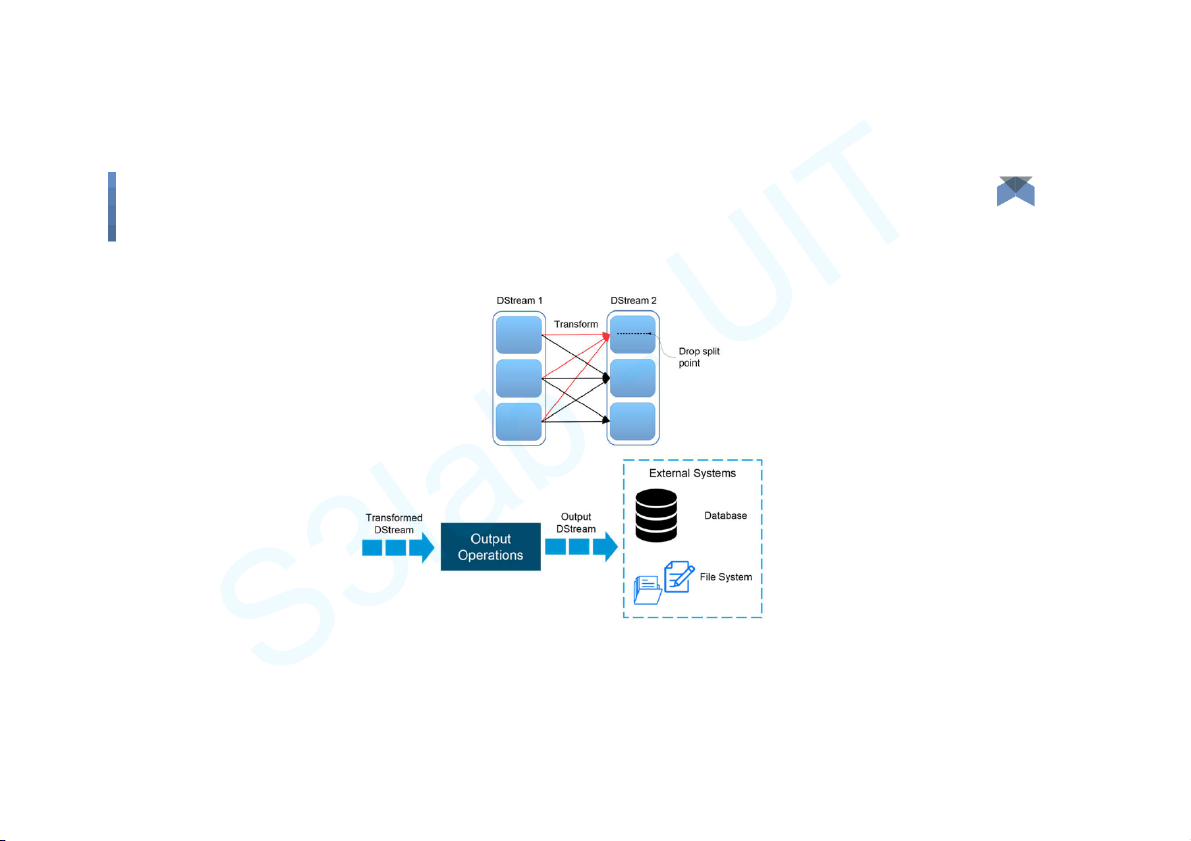
Spark Streaming - Fundamentals Big Data 15 Components
Spark Streaming - Fundamentals Big Data 16 Components Spark SQL
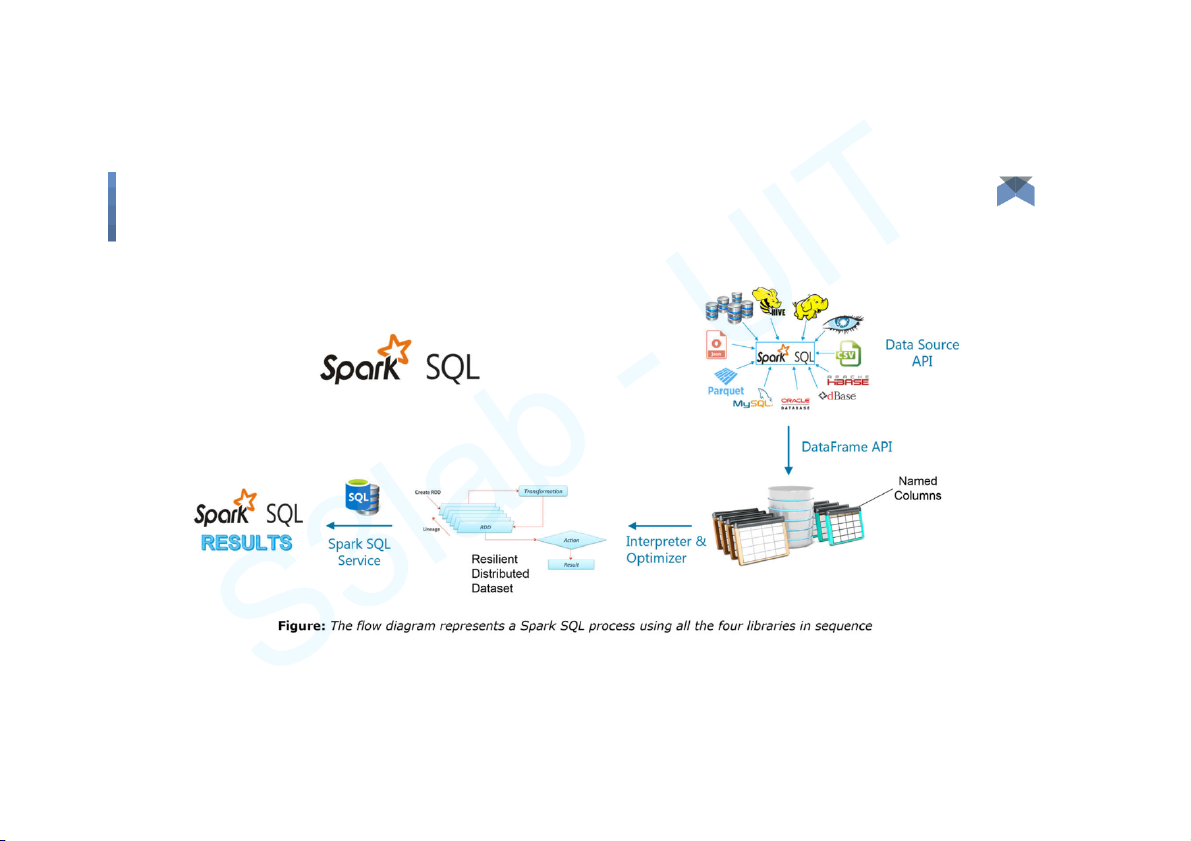
● Spark SQL integrates relational processing with Spark functional
programming. Provides support for various data sources and makes it
possible to weave SQL queries with code transformations thus resulting in
a very powerful tool. The following are the four libraries of Spark SQL. ○ Data Source API ○ DataFrame API ○ Interpreter & Optimizer ○ SQL Service Big Data 17 Components Spark SQL Big Data 18 Components
Spark SQL - Data Source API
● Universal API for loading and storing structured data. ○
Built in support for Hive, JSON, Avro, JDBC, Parquet, ect. ○
Support third party integration through spark packages ○ Support for smart sources ○
Data Abstraction and Domain Specific Language (DSL) applicable on structure and semi- structured data ○
Supports different data formats (Avro, CSV, Elastic Search and Cassandra) and storage
systems (HDFS, HIVE Tables, MySQL, etc.) ○
Can be easily integrated with all Big Data tools and frameworks via Spark-Core. ○
It processes the data in the size of Kilobytes to Petabytes on a single-node cluster to multi-node clusters. Big Data 19 Components
Spark SQL - DataFrame API
● A Data Frame is a distributed collection of data organized into named
column. It is equivalent to a relational table in SQL used for storing data into tables. Big Data 20
Tài liệu liên quan:
-

Ôn tập Các Công Thức Lý Thuyết và Bài Tập Thực Hành | Môn Hệ điều hành - Đại học Tài nguyên và Môi trường Thành phố Hồ Chí Minh
99 50 -

Ôn tập Công Thức và Câu Hỏi Thực Hành Môn Hệ điều hành | Đại học Tài nguyên và Môi trường Thành phố Hồ Chí Minh
116 58 -

Tổng hợp ôn tập Môn Hệ điều hành | Đại học Tài nguyên và Môi trường Thành phố Hồ Chí Minh
94 47 -

Câu hỏi trắc nghiệm Hệ điều hành và Quản lý tiến trình | Môn Hệ điều hành - Đại học Tài nguyên và Môi trường Thành phố Hồ Chí Minh
129 65 -

TOP câu hỏi trắc nghiệm ôn tập Môn Hệ điều hành | Đại học Tài nguyên và Môi trường Thành phố Hồ Chí Minh
88 44