AI – Final Report on Trí Tuệ Nhân Tạo (Artificial Intelligence) | Trường Đại học Sư phạm, Đại học Đà Nẵng
• Trí tuệ nhân tạo (AI): Là khả năng của máy tính hoặc hệ thống để thực hiện các nhiệm vụ mà trước đây cần đến trí tuệ con người, như học tập, ra quyết định, nhận dạng giọng nói, và xử lý ngôn ngữ tự nhiên. AI – Final Report on Trí Tuệ Nhân Tạo (Artificial Intelligence) | Trường Đại học Sư phạm, Đại học Đà Nẵng. Tài liệu được sưu tầm gồm 29 trang, giúp bạn tham khảo, ôn tập và đạt kết quả cao!
Môn: Công Nghệ Thông Tin (20Cntt2) 10 tài liệu
Trường: Trường Đại học Sư phạm, Đại học Đà Nẵng 72 tài liệu
Tác giả:
















Preview text:
lOMoAR cPSD| 59062190
PHẦN I: Trí tuệ nhân tạo 1. Khái niệm: •
Trí tuệ nhân tạo (AI): Là khả năng của máy tính hoặc hệ thống để thực hiện các nhiệm vụ mà
trước đây cần đến trí tuệ con người, như học tập, ra quyết định, nhận dạng giọng nói, và xử lý ngôn ngữ tự nhiên.
2. Lịch sử hình thành Trí tuệ nhân tạo (AI) •
1940-1950: Ý tưởng ban đầu về việc liệu máy móc có thể "suy nghĩ" xuất hiện. Năm 1950,
Alan Turing đề xuất Turing Test, một phương pháp để xác định khả năng trí tuệ của máy tính,
khởi đầu cho những ý tưởng về trí tuệ nhân tạo. •
1956: Thuật ngữ "Artificial Intelligence" (AI) chính thức ra đời tại hội nghị Dartmouth. Đây
được coi là khởi đầu chính thức của AI, với những tên tuổi như John McCarthy, Marvin
Minsky, và Claude Shannon. Mục tiêu ban đầu là phát triển các hệ thống có khả năng học hỏi
và suy luận như con người. •
1960-1970: Giai đoạn phát triển nhanh chóng với nhiều hệ thống AI ban đầu, như chương trình
ELIZA – một chatbot giả lập giao tiếp tự nhiên. Tuy nhiên, AI vấp phải nhiều giới hạn, đặc
biệt là việc xử lý thông tin phức tạp và thiếu sức mạnh tính toán. •
1970-1980: Mùa đông AI (AI Winter): Kỳ vọng cao nhưng không đạt được kết quả như mong
đợi, dẫn đến sự giảm sút đầu tư và quan tâm vào AI. Đây là giai đoạn AI chững lại do thiếu tiến
bộ và công nghệ hỗ trợ. •
1990-2000: AI bắt đầu phục hồi nhờ vào sự phát triển của máy tính và các phương pháp học
máy (machine learning). Sự kiện nổi bật là vào năm 1997, khi máy tính Deep Blue của IBM
đánh bại nhà vô địch cờ vua thế giới Garry Kasparov, thể hiện tiềm năng của AI trong việc xử
lý các tình huống phức tạp. lOMoAR cPSD| 59062190 •
2010 đến nay: Sự bùng nổ của AI nhờ vào học sâu (deep learning) và dữ liệu lớn (big data).
AI hiện diện trong nhiều lĩnh vực như xe tự lái, xử lý ngôn ngữ tự nhiên, nhận dạng khuôn mặt,
và nhiều ứng dụng khác. Các hệ thống như •
Google Assistant, Alexa, và ChatGPT thể hiện sự phát triển mạnh mẽ của trí tuệ nhân tạo
trong đời sống hàng ngày.
3. Các quan điểm hình thành: •
AI mạnh (Strong AI): Máy có thể tư duy và hiểu giống con người, có ý thức thực sự. •
AI yếu (Weak AI): Máy chỉ có thể thực hiện một số nhiệm vụ cụ thể mà không có ý thức.
4. Các lĩnh vực liên quan và ví dụ: Ví dụ M ối liên quan Lĩnh vực
Khoa học dữ liệu (Data thống đề xuất của
AI dùng để phân tích dữ liệu và dự đoán hành Hệ Amazon vi người dùng. Science)
Xử lý ngôn ngữ tự nhiên ợ lý ảo như Siri, Google phân tích và hiểu ngôn ngữ con người để Tr AI tương tác tự nhiên. (NLP) Assistant
Ro bot tự hành trong nhà AI giúp robot tự học và điều chỉnh hành vi Robot học (Robotics) máy theo môi trường. Thị giác máy tính
AI tự lái của Tesla nhận diện và phân tích hình ảnh từ môi Xe trường xung quanh. (Computer Vision)
5. Các ứng dụng thực tế của Trí tuệ nhân tạo (AI) 1. Chăm sóc sức khỏe:
AI hỗ trợ bác sĩ chẩn đoán bệnh qua phân tích hình ảnh y tế và dữ liệu bệnh nhân, cải thiện độ
chính xác và hiệu quả điều trị. lOMoAR cPSD| 59062190
Ví dụ: IBM Watson Health giúp phát hiện ung thư.
2. Thương mại điện tử:
AI phân tích thói quen mua sắm của khách hàng để gợi ý sản phẩm phù hợp, tăng cường trải nghiệm mua sắm.
Ví dụ: Amazon sử dụng AI để gợi ý sản phẩm cho người dùng. 3. Giao thông vận tải:
AI tối ưu hóa lộ trình di chuyển và dự báo tình trạng giao thông, giúp người dùng tiết kiệm thời gian.
Ví dụ: Google Maps sử dụng AI để tìm lộ trình nhanh nhất. 4. Giáo dục:
AI cá nhân hóa trải nghiệm học tập bằng cách theo dõi tiến độ và điều chỉnh nội dung bài học cho phù hợp.
Ví dụ: Khan Academy cung cấp bài học phù hợp với khả năng của từng học sinh. 5. Dịch vụ khách hàng:
AI tự động hóa quy trình hỗ trợ khách hàng thông qua chatbot, giúp giải đáp thắc mắc nhanh chóng.
Ví dụ: Chatbot Erica của Bank of America hỗ trợ giao dịch và hỏi đáp. 6. An ninh mạng:
AI phát hiện và ngăn chặn các mối đe dọa an ninh mạng bằng cách phân tích hành vi bất thường.
Ví dụ: Darktrace sử dụng AI để phát hiện các cuộc tấn công.
7. Nông nghiệp thông minh:
AI giúp tối ưu hóa quy trình canh tác, tưới tiêu và kiểm soát sâu bệnh để nâng cao năng suất cây trồng.
Ví dụ: John Deere áp dụng AI để phân tích dữ liệu nông nghiệp.
8. Tài chính và ngân hàng:
AI đánh giá rủi ro tín dụng và phát hiện gian lận giao dịch, giúp cải thiện an toàn tài chính. lOMoAR cPSD| 59062190
Ví dụ: JPMorgan Chase sử dụng AI để phát hiện gian lận trong giao dịch.
6. Vai trò của AI trong nền công nghiệp 4.0 •
Tự động hóa sản xuất:
AI giúp robot thay thế con người trong các nhà máy, thực hiện công việc nhanh hơn và chính
xác hơn, giảm chi phí và sai sót.
Ví dụ: Amazon sử dụng AI để quản lý kho hàng, tối ưu vận chuyển và đảm bảo giao hàng đúng hạn. • Tối ưu chuỗi cung ứng:
AI quản lý tồn kho, vận chuyển và dự báo nhu cầu, giúp hàng hóa đến đúng lúc, đúng nơi. Ví
dụ: Walmart áp dụng AI để tối ưu hóa quy trình quản lý chuỗi cung ứng, đảm bảo hàng hóa
luôn có sẵn cho khách hàng. •
Phân tích dữ liệu lớn:
AI xử lý khối lượng dữ liệu khổng lồ, tìm ra xu hướng và thông tin quan trọng giúp doanh
nghiệp đưa ra quyết định chính xác.
Ví dụ: Netflix dùng AI để phân tích thói quen xem phim của người dùng, gợi ý nội dung phù hợp. •
Cải thiện dịch vụ khách hàng:
Các chatbot và trợ lý ảo giúp trả lời tự động, tăng trải nghiệm khách hàng.
Ví dụ: HSBC sử dụng chatbot để giải đáp thắc mắc của khách hàng, tiết kiệm thời gian chờ đợi. • Y tế:
AI hỗ trợ chẩn đoán bệnh, theo dõi sức khỏe và cá nhân hóa điều trị, nâng cao hiệu quả chăm sóc y tế.
Ví dụ: IBM Watson hỗ trợ bác sĩ trong việc chẩn đoán bệnh bằng cách phân tích dữ liệu y khoa. • Thúc đẩy sáng tạo: lOMoAR cPSD| 59062190
AI gợi ý sản phẩm và công nghệ mới, giúp doanh nghiệp tạo ra sản phẩm sáng tạo, cạnh tranh.
Ví dụ: Adobe Sensei sử dụng AI để gợi ý thiết kế mới dựa trên xu hướng và dữ liệu người dùng. • An ninh mạng:
AI phát hiện và ngăn chặn các mối đe dọa an ninh, bảo vệ dữ liệu và hệ thống.
Ví dụ: Darktrace sử dụng AI để phát hiện và ngăn chặn các cuộc tấn công mạng ngay từ ban đầu. • Giáo dục:
AI cá nhân hóa lộ trình học tập, giúp học sinh học hiệu quả hơn.
Ví dụ: Duolingo cá nhân hóa bài học dựa trên tiến độ và khả năng của học viên, nâng cao hiệu quả học tập.
7. Sự khác nhau giữa lập trình hệ thống và lập trình AI: Tiêu chí Lập trình hệ thống Lập trình AI Mục êu
Xây dựng nền tảng hệ thống
Phát triển các hệ thống thông minh Phạm vi ứng dụng
H ệ điều hành, nhúng, trình điều khiển
Xử lý dữ liệu, học máy, AI Ngôn ngữ phổ biến C, C++, Rust Python, R, Julia Cách ếp cận
T ối ưu hóa hiệu suất, gần phần cứng
Học từ dữ liệu, xây dựng mô hình Thách thức
Hiệu suất phần cứng, tài nguyên
Thiếu dữ liệu, nh toán phức tạp PHẦN II: Học máy 1. Khái niệm lOMoAR cPSD| 59062190
Học máy (Machine Learning) là một lĩnh vực con của trí tuệ nhân tạo (AI) cho phép hệ thống tự động
cải thiện hiệu suất từ kinh nghiệm mà không cần lập trình cụ thể. Học máy sử dụng các thuật toán
và mô hình thống kê để phân tích và dự đoán dựa trên dữ liệu. 2. Các cơ chế học máy
Cơ chế học máy có thể chia thành ba loại chính: •
Học có giám sát (Supervised Learning) o Phương pháp: Hồi quy (Regression)
Phân loại (Classification) o Ví dụ ứng dụng:
Dự đoán giá nhà (Hồi quy)
Phân loại email thành spam hoặc không spam (Phân loại) •
Học không giám sát (Unsupervised Learning o Phương pháp: Phân cụm (Clustering)
Giảm chiều (Dimensionality Reduction) o Ví dụ ứng dụng:
Phân nhóm khách hàng trong marketing (Phân cụm)
Rút gọn dữ liệu trong phân tích (Giảm chiều) •
Học tăng cường (Reinforcement Learning) o Phương pháp: Q-Learning Deep Q-Network (DQN) lOMoAR cPSD| 59062190 o Ví dụ ứng dụng:
Robot tự động học cách di chuyển trong môi trường (Q-Learning)
Chơi trò chơi điện tử như Atari (DQN) Cây cơ chế học máy lOMoAR cPSD| 59062190
Bảng so sánh Supervised Learning và Unsupervised Learning: Tiêu chí Supervised Learning Unsupervised Learning Dữ liệu
Có gán nhãn (đầu vào - đầu ra).
Không có nhãn, chỉ có đầu vào. Mục tiêu
Dự đoán nhãn hoặc giá trị.
Tìm cấu trúc hoặc nhóm trong dữ liệu.
Ví dụ bài toán - Phân loại email (Spam/Not Spam). - Nhóm khách hàng theo hành vi mua sắm. - Dự đoán giá nhà. - Phân cụm sản phẩm. Thuật toán
Hồi quy, Random Forest, SVM.
K-Means, PCA, Hierarchical Clustering. Ứng dụng
Nhận dạng giọng nói, hình ảnh.
Phát hiện bất thường, phân cụm dữ liệu.
3. Mối liên hệ giữa học máy và TTNT: Khía cạnh Học máy (Machine Learning) Trí tuệ nhân tạo (AI) Mối liên hệ
L à nhánh của AI cho phép máy tính Lĩnh vực rộng lớn tạo ra hệ thống
Học máy là một phần cấu thành của AI. Khái niệm
tự động học từ dữ liệu. có trí thông minh.
Cung cấp khả năng học tập và cải T
hực hiện các nhiệm vụ thông minh
H ọc máy giúp AI học hỏi và cải thiện khả năng thực Chức năng thiện từ kinh nghiệm.
như nhận diện và dự đoán. hiện nhiệm vụ.
Bao gồm các công nghệ như nhận Học máy cung cấp công cụ cho AI để thực hiện các
Công nghệ hỗ trợ Sử dụng thuật toán để phân tích và công nghệ này.
rút ra thông tin từ dữ liệu.
diện giọng nói, xử lý ngôn ngữ tự nhiên, và robot. lOMoAR cPSD| 59062190 Khía cạnh Học máy (Machine Learning) Trí tuệ nhân tạo (AI) Mối liên hệ
Hệ thống học máy tự động tối ưu thể hoạt động mà không cần c máy cho phép AI tự cải thiện thông qua hả năng tự cải Có Họ
việc học từ dữ liệu mới.
hóa quy trình dựa trên dữ liệu thiện
lập trình lại liên tục. mới.
Th ng dụng ường được ứng dụng trong Đư ợc sử dụng rộng rãi trong c ứng dụng của học máy thường là các thành
phân loại, dự đoán, và phân
Cá phần của ứng dụng AI. cụm dữ liệu.
nhiều lĩnh vực như y tế, tài
chính, và tự động hóa.
Có khả năng thích ứng với dữ ng cấp giải pháp cho nhiều Học máy làm cho AI trở nên linh hoạt hơn trong nh linh hoạt liệuCu
tác vụ phức tạp và đa dạng. việc thích ứng với môi trường. và tình huống mới.
4. Các ứng dụng thực tiễn của học máy •
Nhận diện hình ảnh: Hệ thống tự động nhận diện và phân loại đối tượng trong ảnh, như trong Google Photos. •
Dự đoán tài chính: Sử dụng dữ liệu lịch sử để dự đoán xu hướng giá cổ phiếu. •
Xử lý ngôn ngữ tự nhiên: Các ứng dụng như chatbot và dịch máy tự động. •
Chẩn đoán y tế: Sử dụng phân tích dữ liệu bệnh nhân để hỗ trợ bác sĩ trong việc chẩn đoán và điều trị. lOMoAR cPSD| 59062190 •
Quảng cáo trực tuyến: Dự đoán sở thích của người tiêu dùng để tối ưu hóa quảng cáo. •
Ô tô tự lái: Học máy giúp xe tự lái nhận diện và phản ứng với môi trường xung quanh.
PHẦN III. Học có giám sát (Supervised Learning) 1. Khái niệm
Học có giám sát (Supervised Learning) là một phương pháp học máy mà trong đó mô hình học từ một
tập dữ liệu đã có sẵn nhãn (label). Mỗi dữ liệu đầu vào được gắn với một nhãn đầu ra cụ thể, và
nhiệm vụ của mô hình là học cách ánh xạ từ dữ liệu đầu vào sang nhãn đầu ra này. Sau khi huấn
luyện, mô hình có thể dự đoán nhãn cho dữ liệu mới chưa có nhãn.
Quy trình học có giám sát:
● Dữ liệu đầu vào: Tập dữ liệu huấn luyện (Training dataset) bao gồm các cặp (input, output)
mà output chính là nhãn (label).
● Mô hình: Một thuật toán học sẽ sử dụng các dữ liệu này để tìm ra mô hình dự đoán.
● Dữ liệu kiểm thử: Sau khi mô hình được huấn luyện, nó sẽ được kiểm thử trên một tập dữ
liệu mới chưa thấy trước đó để kiểm tra độ chính xác của mô hình.
2. Các ứng dụng thực tiễn cho cơ chế học có giám sát, giải thích sự ứng dụng
a. Phân loại hình ảnh (Image Classification)
● Ứng dụng: Nhận diện khuôn mặt, phân loại đối tượng trong ảnh (người, xe cộ, động vật).
● Giải thích: Trong các hệ thống nhận diện hình ảnh, học có giám sát giúp máy học cách phân
loại các đối tượng trong hình ảnh thành các nhóm cụ thể dựa trên các nhãn trước đó, như
phân loại mèo và chó từ một tập ảnh đã gắn nhãn.
b. Phân tích cảm xúc (Sentiment Analysis)
● Ứng dụng: Dự đoán cảm xúc của khách hàng từ các bình luận, đánh giá sản phẩm (tích cực, tiêu cực, trung lập). lOMoAR cPSD| 59062190
● Giải thích: Hệ thống học có giám sát được sử dụng để phân loại bình luận dựa trên cảm xúc
của người dùng. Các mô hình học từ dữ liệu các bình luận đã được gắn nhãn (tích cực hoặc
tiêu cực) để dự đoán cảm xúc của các bình luận mới.
c. Dự đoán giá nhà (House Price Prediction)
● Ứng dụng: Dự đoán giá bất động sản dựa trên các yếu tố như vị trí, diện tích, số phòng ngủ, năm xây dựng, v.v.
● Giải thích: Sử dụng dữ liệu đã gắn nhãn về giá nhà trong quá khứ và các yếu tố ảnh hưởng,
mô hình học có giám sát có thể dự đoán giá của các căn nhà mới dựa trên các yếu tố tương tự.
d. Phát hiện gian lận (Fraud Detection)
● Ứng dụng: Phát hiện các giao dịch gian lận trong hệ thống tài chính và ngân hàng.
● Giải thích: Các mô hình học có giám sát được huấn luyện từ các giao dịch tài chính bình
thường và gian lận đã được gắn nhãn, giúp phát hiện và cảnh báo các giao dịch bất thường trong tương lai.
e. Hệ thống gợi ý (Recommendation Systems)
● Ứng dụng: Đề xuất phim trên Netflix, sản phẩm trên Amazon, nhạc trên Spotify dựa trên sở
thích và hành vi của người dùng.
● Giải thích: Các hệ thống học có giám sát sử dụng dữ liệu hành vi người dùng đã được gắn
nhãn (phim đã xem, sản phẩm đã mua) để đề xuất các sản phẩm hoặc nội dung phù hợp với
sở thích cá nhân của người dùng mới. lOMoAR cPSD| 59062190
PHẦN IV: Phân lớp (Classification) 1. Khái niệm
Phân lớp (Classification) là một phương pháp học có giám sát, trong đó mục tiêu là dự đoán nhãn
(label) của các mẫu dữ liệu mới dựa trên các nhãn của dữ liệu huấn luyện đã có. Nhiệm vụ chính
của phân lớp là gán một đầu ra (nhãn) cho mỗi đối tượng đầu vào, thuộc một trong những lớp
(class) đã xác định trước.
Ví dụ: Trong bài toán nhận diện email, có hai lớp chính là "spam" và "không phải spam." Mô hình
phân lớp sẽ học cách dự đoán một email mới thuộc vào lớp nào dựa trên các đặc điểm của nó.
2. Quy trình tổng quan cho việc phân lớp
Quy trình phân lớp thường được thực hiện qua các bước sau:
1. Thu thập dữ liệu: Dữ liệu đầu vào bao gồm các mẫu (instances) đã được gắn nhãn. Mỗi
mẫu có một hoặc nhiều đặc điểm (features).
2. Xử lý dữ liệu: Làm sạch dữ liệu, chuẩn hóa các giá trị và xử lý các dữ liệu bị thiếu.
3. Chia dữ liệu: Tập dữ liệu được chia thành hai phần: tập huấn luyện (training dataset) và tập
kiểm thử (testing dataset).
4. Lựa chọn và trích xuất đặc trưng: Lựa chọn các đặc trưng quan trọng từ dữ liệu và giảm
bớt các đặc trưng không cần thiết. Điều này giúp mô hình học hiệu quả hơn.
5. Huấn luyện mô hình: Sử dụng tập huấn luyện để xây dựng mô hình phân lớp.
6. Đánh giá mô hình: Sử dụng tập kiểm thử để kiểm tra và đánh giá độ chính xác của mô hình.
7. Dự đoán: Dùng mô hình đã huấn luyện để dự đoán lớp cho các dữ liệu mới chưa được gắn nhãn.
Mô hình tổng quan cho quy trình Classification:
Dữ liệu -> Tiền xử lý -> Chia tập dữ liệu -> Huấn luyện mô hình -> Đánh giá mô hình -> Dự đoán lOMoAR cPSD| 59062190
3. Giải thích các thuật ngữ liên quan Instance/Sample/Object (Mẫu/Dữ liệu đầu vào): Một điểm dữ
liệu hoặc một đối tượng cụ thể cần được phân loại.
● Feature (Đặc trưng): Các thuộc tính hoặc đặc điểm của dữ liệu mà mô hình sử dụng để
học, ví dụ như kích thước, màu sắc, nhiệt độ.
● Label/Class (Nhãn/Lớp): Kết quả hoặc đầu ra mà mô hình cần dự đoán, ví dụ như "spam" hoặc "not spam."
● Training dataset (Tập huấn luyện): Tập dữ liệu đã có nhãn, dùng để huấn luyện mô hình.
● Testing dataset (Tập kiểm thử): Tập dữ liệu mới chưa được sử dụng trong huấn luyện,
dùng để kiểm tra độ chính xác của mô hình.
● Feature extraction (Trích xuất đặc trưng): Quá trình chọn lọc và giảm thiểu các đặc trưng
từ dữ liệu thô để cải thiện khả năng học của mô hình.
● Feature Selection (Lựa chọn đặc trưng): Chọn ra những đặc trưng quan trọng nhất trong dữ liệu.
● Feature Reduction (Giảm số lượng đặc trưng): Giảm kích thước của không gian đặc
trưng để tăng tốc độ học và giảm độ phức tạp.
● Ground truth (Sự thật chuẩn): Kết quả chính xác mà mô hình phân lớp phải dự đoán ra.
● Validation (Xác thực): Quá trình điều chỉnh mô hình dựa trên tập dữ liệu xác thực
(validation dataset) để tránh hiện tượng quá khớp (overfitting).
● Visualization (Trực quan hóa): Quá trình trình bày dữ liệu và kết quả một cách trực quan để dễ dàng phân tích.
4. Các phương pháp đánh giá độ chính xác của mô hình
a. Confusion Matrix (Ma trận nhầm lẫn)
● Khái niệm: Ma trận nhầm lẫn là bảng 2x2 (hoặc lớn hơn) dùng để so sánh kết quả phân loại
của mô hình với nhãn thực tế. lOMoAR cPSD| 59062190 ● Các tham số:
○ True Positive (TP): Dự đoán đúng lớp dương tính.
○ True Negative (TN): Dự đoán đúng lớp âm tính.
○ False Positive (FP): Dự đoán nhầm từ âm tính sang dương tính.
○ False Negative (FN): Dự đoán nhầm từ dương tính sang âm tính.
● Ví dụ minh họa: Ví dụ phân loại email spam.
b. Accuracy (Độ chính xác)
● Khái niệm: Độ chính xác là tỉ lệ số dự đoán đúng trên tổng số dự đoán. ● Công thức:
● Ví dụ: Nếu mô hình phân loại đúng 90/100 email, độ chính xác là 90%. c. Precision, Recall, F1-Score
● Precision: Tỷ lệ dự đoán đúng trên tổng số dự đoán dương tính (TP / (TP + FP)).
● Recall: Tỷ lệ dự đoán đúng trên tổng số mẫu dương tính thực sự (TP / (TP + FN)).
● F1-Score: Trung bình điều hòa giữa Precision và Recall, dùng để cân bằng giữa độ chính
xác và độ nhạy trong các bài toán có sự chênh lệch về các lớp.
PHẦN V: Trình bày các phương pháp cho bài toán phân lớp
1. Phương pháp KNN (k-Nearest Neighbor) a. Trình bày khái niệm lOMoAR cPSD| 59062190
K-Nearest Neighbor (KNN) là một thuật toán phân loại đơn giản thuộc nhóm các phương pháp
học có giám sát. Khi được cung cấp một tập huấn luyện đã được gắn nhãn, thuật toán KNN sẽ dự
đoán nhãn của một mẫu dữ liệu mới dựa trên nhãn của k mẫu gần nhất trong không gian dữ liệu.
KNN không yêu cầu mô hình nội tại mà chỉ dựa trên tính toán khoảng cách giữa các điểm.
Ví dụ: Nếu bạn muốn phân loại một quả táo là táo ngọt hay táo chua, KNN sẽ kiểm tra những quả táo
gần nhất (k lân cận) để xem loại quả nào chiếm ưu thế.
b. Giải thích các tham số
1. k: Số lượng hàng xóm gần nhất được xem xét để xác định nhãn của mẫu cần dự đoán.
2. Khoảng cách: Phương pháp tính khoảng cách giữa các điểm. Thông dụng nhất là khoảng
cách Euclide (Euclidean distance), nhưng có thể dùng các loại khoảng cách khác như
khoảng cách Manhattan hoặc khoảng cách Minkowski.
3. Lựa chọn trọng số: Một số biến thể của KNN sử dụng trọng số dựa trên khoảng cách, có
nghĩa là những điểm gần hơn sẽ có ảnh hưởng lớn hơn đến quyết định phân loại.
c. Quy trình thực hiện (thuật toán dưới dạng ngôn ngữ tự nhiên)
·Bước 1: Xác định k(3,5,7,..)(số lẻ)
·Bước 2: Tính khoảng cách theo công thức Euclib giữa hai điểm A(x1, y1) và B(x2, y2) :
·Bước 3: Sắp sếp khoảng cách từ bé đến lớn rồi lấy class của k điểm , class nhiều hơn sẽ lấy để dự
đoán cho điểm dự đoán. d. Mã giả (Pseudo-code) 1. Tải dữ liệu 2. Chọn giá trị K lOMoAR cPSD| 59062190
3.Đối với mỗi điểm dữ liệu trong dữ liệu: •
Tìm khoảng cách Euclidean đến tất cả các mẫu dữ liệu đào tạo. •
Lưu trữ khoảng cách trên một danh sách có thứ tự và sắp xếp nó. •
Chọn K mục nhập hàng đầu từ danh sách đã sắp xếp. •
Đánh dấu điểm kiểm tra dựa trên phần lớn các lớp có trong các điểm đã chọn. 4. Kết thúc.
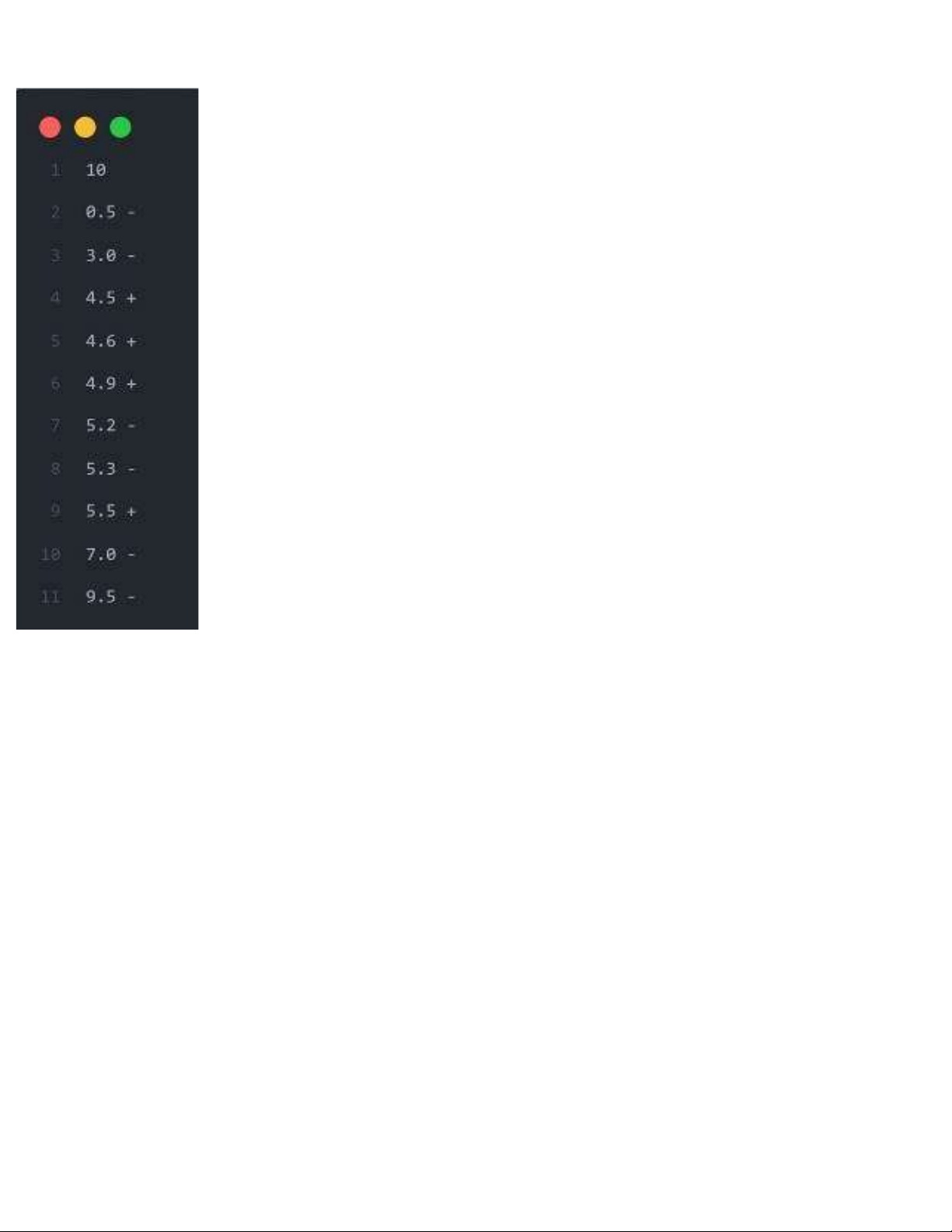
e. Ví dụ minh họa và tính tay từng bước thực hiện i. Mô tả bài toán Dữ liệu: •
Tập dữ liệu huấn luyện: Chúng ta có một tập dữ liệu gồm hai cột:
o X: Là các giá trị số.
o Y: Là nhãn lớp, có thể là "+" hoặc "-". Nhãn lớp này đại diện cho lớp mà điểm dữ liệu thuộc về. •
Điểm dữ liệu mới: Điểm này là z = 5.0, và chúng ta cần dự đoán nhãn lớp cho điểm này. Yêu cầu: •
Áp dụng KNN: Chúng ta sẽ sử dụng thuật toán KNN để dự đoán nhãn lớp cho điểm z. •
Các giá trị K: Chúng ta sẽ thực hiện dự đoán với các giá trị K khác nhau: 1, 3, 5, và 9. Giá
trị K quyết định số lượng điểm lân cận gần nhất được sử dụng để dự đoán. •
Quy tắc đa số: Sau khi tìm được K điểm lân cận gần nhất, chúng ta sẽ chọn nhãn lớp xuất
hiện nhiều nhất trong số các điểm lân cận đó làm nhãn dự đoán cho điểm z. ii. Mô tả dữ liệu
Tập huấn luyện gồm các điểm sau: lOMoAR cPSD| 59062190
iii. Tính tay từng bước: lOMoAR cPSD| 59062190 iv. Kết luận:
Với các giá trị K đã cho trong bài toán này, chúng ta đều dự đoán nhãn của điểm z = 5.0 là "+".
f. Viết chương trình cho bài toán minh họa ở mục e lOMoAR cPSD| 59062190 lOMoAR cPSD| 59062190
g. Ưu/nhược điểm của thuật toán KNN Ưu điểm:
● Đơn giản và dễ hiểu.
● Không cần huấn luyện trước, thích hợp cho các bài toán nhỏ.
● Có thể ứng dụng cho cả bài toán phân lớp và hồi quy. Nhược điểm:
● Tốc độ xử lý chậm khi dữ liệu lớn do phải tính toán khoảng cách cho tất cả các điểm.
● Hiệu suất phụ thuộc vào cách chọn k và phương pháp tính khoảng cách.
● Dễ bị ảnh hưởng bởi dữ liệu nhiễu và các đặc trưng không liên quan. 2. Thuật toán Naïve Bayes a. Khái niệm
Tài liệu liên quan:
-

Nghiên cứu Về Bug Bounties và Hackathons trong an ninh mạng | Trường Đại học Sư phạm, Đại học Đà Nẵng
94 47 -

Báo cáo giữa kỳ: Hệ thống quản lý mượn trả sách | Trường Đại học Sư phạm, Đại học Đà Nẵng
76 38 -

SRS - Tài liệu đề xuất hệ thống quản lý đặt phòng khách sạn | Trường Đại học Sư phạm, Đại học Đà Nẵng
82 41 -

Chương 6: Tính sai số chuẩn trong Công nghệ Chế tạo máy | Trường Đại học Sư phạm, Đại học Đà Nẵng
117 59 -

Khóa luận tốt nghiệp: Xây dựng hệ thống nhận diện cảm xúc qua Điện não đồ | Trường Đại học Sư phạm, Đại học Đà Nẵng
76 38