Bài báo cáo học phần: Chuyên đề An ninh mạng về "Phát hiện Phishing Email sử dụng phương pháp học máy"
Bài báo cáo học phần: Chuyên đề An ninh mạng về "Phát hiện Phishing Email sử dụng phương pháp học máy" của Học viện Công nghệ Bưu chính Viễn thông với những kiến thức và thông tin bổ ích giúp sinh viên tham khảo, ôn luyện và phục vụ nhu cầu học tập của mình cụ thể là có định hướng ôn tập, nắm vững kiến thức môn học và làm bài tốt trong những bài kiểm tra, bài tiểu luận, bài tập kết thúc học phần, từ đó học tập tốt và có kết quả cao cũng như có thể vận dụng tốt những kiến thức mình đã học vào thực tiễn cuộc sống. Mời bạn đọc đón xem!
Môn: An toàn mạng (AT19) 12 tài liệu
Trường: Học viện Công Nghệ Bưu Chính Viễn Thông 1.8 K tài liệu
Tác giả:

























Preview text:
lOMoARcPSD| 37054152 Lời mở đầu
Lừa đảo vẫn là một trong những thủ đoạn tinh vi nhất có thể được tìm thấy
trong lưu lượng email độc hại. Trong kiểu tấn công này, người nhận sẽ nhận được
một email, ví dụ, được ngụy trang dưới dạng tin nhắn từ một công ty nổi tiếng yêu
cầu họ theo liên kết và đăng nhập vào một dịch vụ hoặc nhập chi tiết thẻ ngân hàng
trên một trang web giả mạo.
Trong năm 2019, hệ thống chống phishing của Kaspersky đã xác định 467 triệu
email đã cố gắng chuyển đến các trang web lừa đảo. Khoảng 10 năm trước, các từ
điển tạo thủ công được sử dụng để phát hiện lừa đảo trong lưu lượng email. Họ mô tả
tất cả các biến thể có thể có trong một email lừa đảo. Tuy nhiên, những kẻ tấn công
vẫn luôn tìm mọi cách, mọi thủ đoạn tiên tiến hơn để phục vụ cho mục đích lừa đảo
của chúng. Ngày nay, số lượng các cuộc tấn công với hình thức giả mạo các tin nhắn
độc hại qua email từ các dịch vụ trực tuyến mới chẳng hạn như khai thác các sự kiện
lớn, email xác nhận trúng thưởng hay kêu gọi ủng hộ đại dịch Covid, ...
Nội dung, hình thức của các email lừa đảo ngày càng trở nên phức tạp. Các
trang web lừa đảo có thể sử dụng giao thức https và kẻ tấn công có thể điều khiển các
botnet để thực hiện việc gửi thư. Những kẻ lừa đảo hiện có thể sử dụng nhiều mạng
botnet để tự động tạo hàng nghìn mẫu văn bản và các biến thể tiêu đề. Do đó, các
email lừa đảo trở nên khó phát hiện hơn nhiều. Việc tạo chữ ký số để chặn tất cả các
thư từ địa chỉ giả mạo không còn hữu ích với người dùng.
Để bảo vệ người dùng khỏi các cuộc tấn công như vậy cần phải có công nghệ tự động
phát hiện được các loại email giả mạo một cách nhanh chóng. Trong báo cáo này,
nhóm chúng em tìm hiểu về mô hình học máy để phát hiện email lừa đảo. Công nghệ
này sử dụng phương pháp học máy, cho phép tự động trích xuất các thông tin để phát
hiện và ngăn chặn các email lừa đảo. Nội dung báo cáo gồm 6 phần: • Phần I: Giới thiệu
• Phần II. Phương pháp học máy
• Phần III: Các kỹ thuật phát hiện phishing email
• Phần IV: Các bước nghiên cứu Phần V: Thực hiện thử nghiệm • Phần VI: Kết luận Lời cảm ơn
Trong suốt quá trình học tập và thực hành, đặc biệt là thời gian hoàn thiện bài
tập lớn này, em xin được bày tỏ, gửi lời cảm ơn chân thành đến thầy TS.Đỗ Xuân
Chợ đã tạo điều kiện, giúp đỡ và chỉ bảo để nhóm em làm tốt bài báo cáo này.
Có được bài báo cáo này, ngoài những lời động viện khích lệ từ bạn bè, người
thân. Sự tận tình hướng dẫn của các thầy cô và hơn ai hết, là người luôn theo sát, thầy lOMoARcPSD| 37054152
TS.Đỗ Xuân Chợ Đây không chỉ là sự chuyển giao và tiếp nhận kiến thức, quan trọng
hơn cả là động lực, trách nhiệm để hoàn thành. Đó là những điều em đã học thêm
được từ những người thầy của mình.
Do giới hạn kiến thức và khả năng tiếp thu còn nhiều hạn chế, nên bài báo cáo
của em không tránh khỏi sai sót , mong thầy góp ý để em có thể hoàn thành tốt hơn
những bài tập, công việc sau này.
Kính chúc thầy có thật nhiều sức khỏe và thành công hơn nữa trên con đường giảng dạy. Trân trọng cảm ơn! Mục lục
Lời mở đầu............................................................................................................2
Lời cảm ơn.............................................................................................................3
Mục lục..................................................................................................................4
Danh mục hình ảnh................................................................................................6
Danh mục bảng......................................................................................................7
Danh mục từ viết tắt..............................................................................................8
I. Giới thiệu...........................................................................................................9
1. Đặt vấn đề....................................................................................................9
2. Phishing email..............................................................................................9
2.1 Khái niệm..................................................................................................9
2.2 Các kỹ thuật phishing email....................................................................11
2.3 Hậu quả...................................................................................................13
3. Mục tiêu bài toán và phạm vi nghiên cứu..................................................13
II. Phương pháp học máy....................................................................................14
1. Khái niệm...................................................................................................14
2. Phân loại.....................................................................................................14
2.1 Học máy có giám sát...............................................................................14
2.2 Học máy không có giám sát....................................................................15 lOMoAR cPSD| 37054152
3. Một số loại học máy điển hình...................................................................16
3.1 Support Vector Machine(SVM)..............................................................17
3.2 Cây quyết định........................................................................................18
III. Các kỹ thuật phát hiện phishing email..........................................................21
1. Giới thiệu...................................................................................................21
2. Phân loại.....................................................................................................21 2.1
Phương pháp truyền thống...................................................................21 2.2
Phương pháp tự động...........................................................................22
IV. Các bước nghiên cứu.....................................................................................25
1. Tiền xử lý...................................................................................................25
2. Lựa chọn đặc trưng....................................................................................26
3. Thuật toán đánh giá....................................................................................29
4. Số liệu đánh giá............................................................................................29
V. Thực hiện thử nghiệm.....................................................................................31
1. Bộ dữ liệu dataset.......................................................................................32
2. Kết quả thử nghiệm....................................................................................32
3. So sánh.......................................................................................................37
VI. Kết luận.........................................................................................................39
Tài liệu tham khảo...............................................................................................40 lOMoARcPSD| 37054152 Danh mục hình ảnh
Hình 1 : Vòng đời của Email lừa đảo....................................................................8
Hình 2 Phishing email...........................................................................................9
Hình 3 Các loại Email lừa đảo..............................................................................9 Hình
4 Email chứa malware................................................................................11
Hình 5 Ví dụ........................................................................................................13
Hình 6 Các hình thức học máy............................................................................14
Hình 7 Thuật toán phân lớp.................................................................................15
Hình 8 Các điểm dữ liệu......................................................................................16
Hình 9 Hoạt động của thuật toán Decision Tree.................................................17
Hình 10 Các bước nghiên cứu.............................................................................22
Hình 11 Tiền xử lí dữ liệu...................................................................................23
Hình 12 Thông tin dữ liệu về các đặc trưng........................................................26
Hình 13 25 thuộc tính trong bộ dữ liệu...............................................................28
Hình 14 Kết quả thử nghiệm thuật toán Logistic Regression.............................29
Hình 15 Kết quả thử nghiệm thuật toán KNN.....................................................29
Hình 16 Kết quả thử nghiệm thuật toán Random Forest.....................................30
Hình 17 Kết quả thử nghiệm thuật toán Naïve Bayes.........................................30
Hình 18 Kết quả thử nghiệm thuật toán Decision Tree.......................................31
Hình 19 Tập hợp kết quả thử nghiệm..................................................................31
Hình 20 Cây quyết định.......................................................................................32
Hình 21 Kết quả thực nghiệm với 5 thuật toán dựa trên 25 thuộc tính...............32
Hình 22 Độ quan trọng của các thuộc tính thông qua thuật toán Random Forest33
Hình 23 Kết quả thực nghiệm với 5 thuật toán dựa trên 13 thuộc tính ở tài liệu34
Hình 24 Kết quả thực nghiệm với 5 thuật toán dựa trên 13 thuộc tính ở tài liệu34 Danh m c b nụ ả
Bảng 1 Tập dữ liệu Email ........................................................................................... 22
Bảng 2 Các đặc trưng .................................................................................................. 25
Bảng 3 Phân loại đặc trưng theo nhóm ....................................................................... 25
Bảng 4 Ma trận nhầm lẫn....................................................................................27
Bảng 5 Tổng quan bộ dữ liệu dataset..................................................................28 lOMoARcPSD| 37054152
Danh mục từ viết tắt ST Từ viết tắt Từ tiếng anh T 1 URL Uniform Resource Locator 2 SVM Support Vector Machine 3 DNS Domain Name Servers 4 IP Internet Protocol 5 CART
Classification and Regression Trees 6 DT Decision Trees Filter 7 KNN K-nearest neighbors 8 TP True positive 9
TN True negative 10 FP False positive 11 FN False negative lOMoARcPSD| 37054152 I. Giới thiệu 1. Đặt vấn đề
Từ khi bùng nổ công nghệ, hầu hết các thiết bị thông minh đều được kết nối
internet, thư điện tử (email) trở nên phổ biến, đóng vai trò quan trọng trong cuộc
sống. Nếu như trước kia, thư từ được viết tay bằng giấy, mực thì nay đã được viết hầu
hết bằng máy tính. Để chuyển thư từ người này cho người khác, trước kia sẽ cần một
bên trung gian làm công việc này. Việc vận chuyển thư thủ công này tiêu tốn nhiều
nhân lực và thời gian gây tốn chi phí, khả năng thư bị thất lạc cũng rất cao. Thư điện
tử ra đời đã làm cho việc trao đổi thư từ trở nên dễ dàng và nhanh chóng, không tốn chi phí vận chuyển.
Thư điện tử rất hữu ích nhưng cũng có rất nhiều rủi ro. Trong quá trình trao đổi
thư, những kẻ tấn công có thể sử dụng các công cụ, kỹ thuật để chặn bắt, sửa chữa và
làm lộ thông tin ra bên ngoài. Việc này đòi hỏi chúng ta phải sử dụng các phương
pháp bảo mật an toàn khi gửi thư như việc tạo chữ ký số, mã hóa thông tin trước khi
gửi, .... Ngoài ra, kẻ tấn công còn có thể sử dụng những hình thức tinh vi hơn để
chiếm đoạt thông tin người dùng. Đó là hình thức lừa đảo qua email hay còn gọi là
phishing email. Kẻ tấn công hoàn toàn có thể mạo danh một cá nhân, tổ chức hay
doanh nghiệp uy tín nhằm tạo những email mạo danh, lừa đảo để lấy cắp thông tin của nạn nhân.
Hiện nay, do diễn biến phức tạp của dịch Covid, nhiều công ty, doanh nghiệp,
tổ chức đều tiến hành làm việc online, việc trao đổi email công việc ngày càng nhiều.
Đây cũng là cơ hội cho những kẻ tấn công khai thác thông tin với mục đích chuộc lợi.
Thậm chí, kẻ tấn công còn mạo danh các tổ chức từ thiện, gửi các email giả mạo để
quyên góp từ thiện, đánh vào lòng tin của con người để chiếm đoạt tài sản bất hợp pháp, ...
Với hình thức lừa đảo tinh vi như vậy, bài toán đặt ra là phải làm sao để có thể
phát hiện, lọc và ngăn chặn được những email lừa đảo, lấy lại lòng tin của con người
vào internet và công nghệ. Một phương pháp hiệu quả hiện đã và đang được sử dụng
là mô hình Machine Learning. 2. Phishing email 2.1 Khái niệm
Phishing email là một hình thức lừa đảo trực tuyến, trong đó bọn tội phạm
mạng mạo danh các tổ chức, cá nhân hợp pháp qua email, tin nhắn văn bản, quảng
cáo hoặc các phương tiện khác để lấy thông tin nhạy cảm từ phía người dùng. lOMoARcPSD| 37054152
Hầu hết các thư lừa đảo được gửi qua email thường nhắm mục tiêu đến một cá
nhân hoặc một công ty cụ thể. Nội dung của tin nhắn lừa đảo thường rất khác nhau,
tùy theo mục đích của kẻ tấn công. Nhìn chung, phishing email được thiết kế gần
giống với giao diện ngân hàng, tổ chức. Người dùng dễ dàng bị "lừa" nếu không để ý
và tin rằng đó là email thật, sau đó họ dễ dàng cung cấp những thông tin cá nhân
quan trọng như: Mật khẩu đăng nhập hệ thống, mật khẩu giao dịch, thẻ tín dụng và
các thông tin tuyệt mật khác. Kẻ tấn công có thể sử dụng thông tin lấy cắp được để
trực tiếp lấy tiền từ nạn nhân.
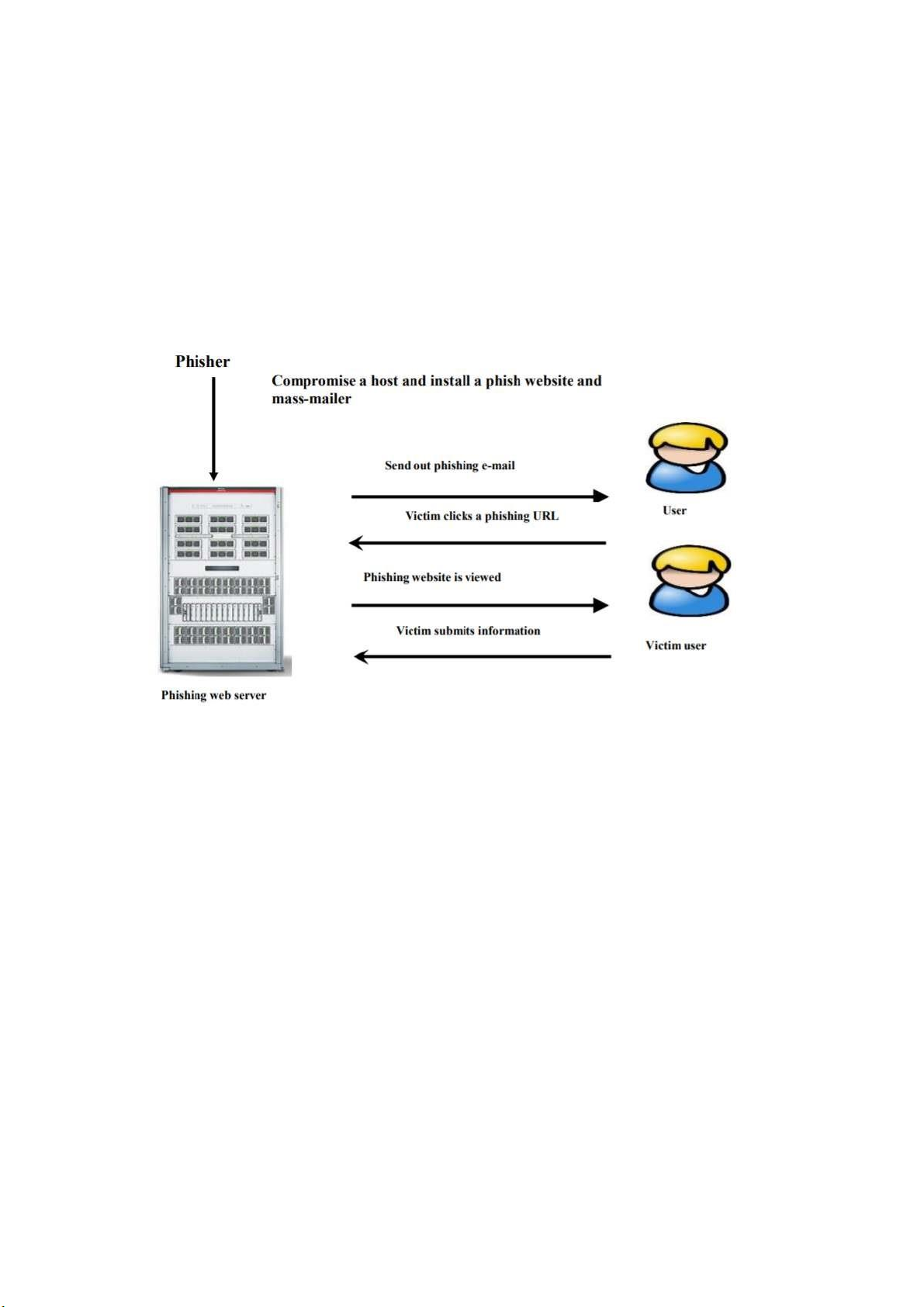
Hình 1 : Vòng đời của Email lừa đảo
Trong một email lừa đảo, nạn nhân thường được yêu cầu cung cấp thông tin về: • Ngày/tháng/năm sinh • Số an sinh xã hội • Số điện thoại
• Thông tin địa chỉ nhà
• Thông tin chi tiết về tài khoản ngân hàng, thẻ tín dụng
• Thông tin mật khẩu (các thông tin cần thiết để chúng có thể thay đổi và
đặt lại mật khẩu tài khoản của bạn), ... lOMoARcPSD| 37054152 Hình 2 Phishing email
2.2 Các kỹ thuật phishing email
Kẻ lừa đảo sử dụng hai kỹ thuật chính để đạt được mục tiêu đó là lừa đảo kỹ
thuật xã hội và phần mềm độc hại.
Hình 3 Các loại Email lừa đảo
2.2.1 Kỹ thuật xã hội
Hầu hết các kiểu lừa đảo sử dụng một hình thức đánh lừa kỹ thuật được thiết
kế làm cho một liên kết được gửi đi trong email dường như thuộc về một tổ chức mà
kẻ tấn công đang mạo danh. Đó là những liên kết gần giống với liên kết chính xác
hoặc nó đã được biến đổi từ liên kết thật bằng cách sử dụng tên miền phụ. Ví dụ như
URL sau: http://www.teckcombank.com/ . Ở đây, URL được biến đổi giả mạo URL
thật bằng cách sửa đổi 1 ký tự trong URL thật. Khi người dùng không nhìn kĩ sẽ nhấp
vào URL này, URL sẽ đưa nạn nhân đến một trang web giống hệt với trang web của lOMoARcPSD| 37054152
ngân hàng techcombank để yêu cầu nhập tài khoản, mật khẩu giao dịch và kẻ tấn
công dễ dàng lấy được thông tin tài khoản của nạn nhân.
Hầu hết các loại lừa đảo liên quan đến một số loại kỹ thuật xã hội, trong đó
người dùng bị thao túng về mặt tâm lý để thực hiện một hành động như nhấp vào liên
kết, mở tệp đính kèm hoặc tiết lộ thông tin bí mật. Ngoài việc mạo danh một cá nhân,
tổ chức hay một doanh nghiệp đáng tin cậy, kẻ tấn công còn tạo ra nội dung cấp bách,
khẩn cấp như tuyên bố tài khoản của nạn nhân sẽ bị đóng băng hoặc bị khóa nếu như
không thực hiện yêu cầu theo email mà chúng gửi. Việc này thường xảy ra với nạn
nhân sử dụng tài khoản ngân hàng hay tài khoản bảo hiểm.
Một kỹ thuật tinh xảo khác mà kẻ tấn công có thể sử dụng thay vì việc mạo
danh đó là sử dụng những bài viết giả mạo được thiết kế để kích động sự phẫn nộ từ
nạn nhân, khiến nạn nhân không do dự mà nhấp vào liên kế chúng gửi kèm trong
email. Liên kết này sẽ đưa nạn nhân đến một trang web chuyên nghiệp giống hệt với
trang web của một tổ chức hợp pháp nào đó. Khi đó, kẻ tấn công sẽ sử dụng các kỹ
thuật khác để cố gắng khai thác lỗ hổng nhằm thu thập thông tin nhạy cảm của nạn nhân.
Hiện nay, đại dịch Covid diễn biến phức tạp, kẻ tấn công đã sử dụng kỹ thuật
xã hội bằng cách lợi dụng lòng tin và tình thương của con người để gửi các email lừa
đảo để gây quỹ, ủng hộ cho người gặp khó khăn để thu lợi về mình.
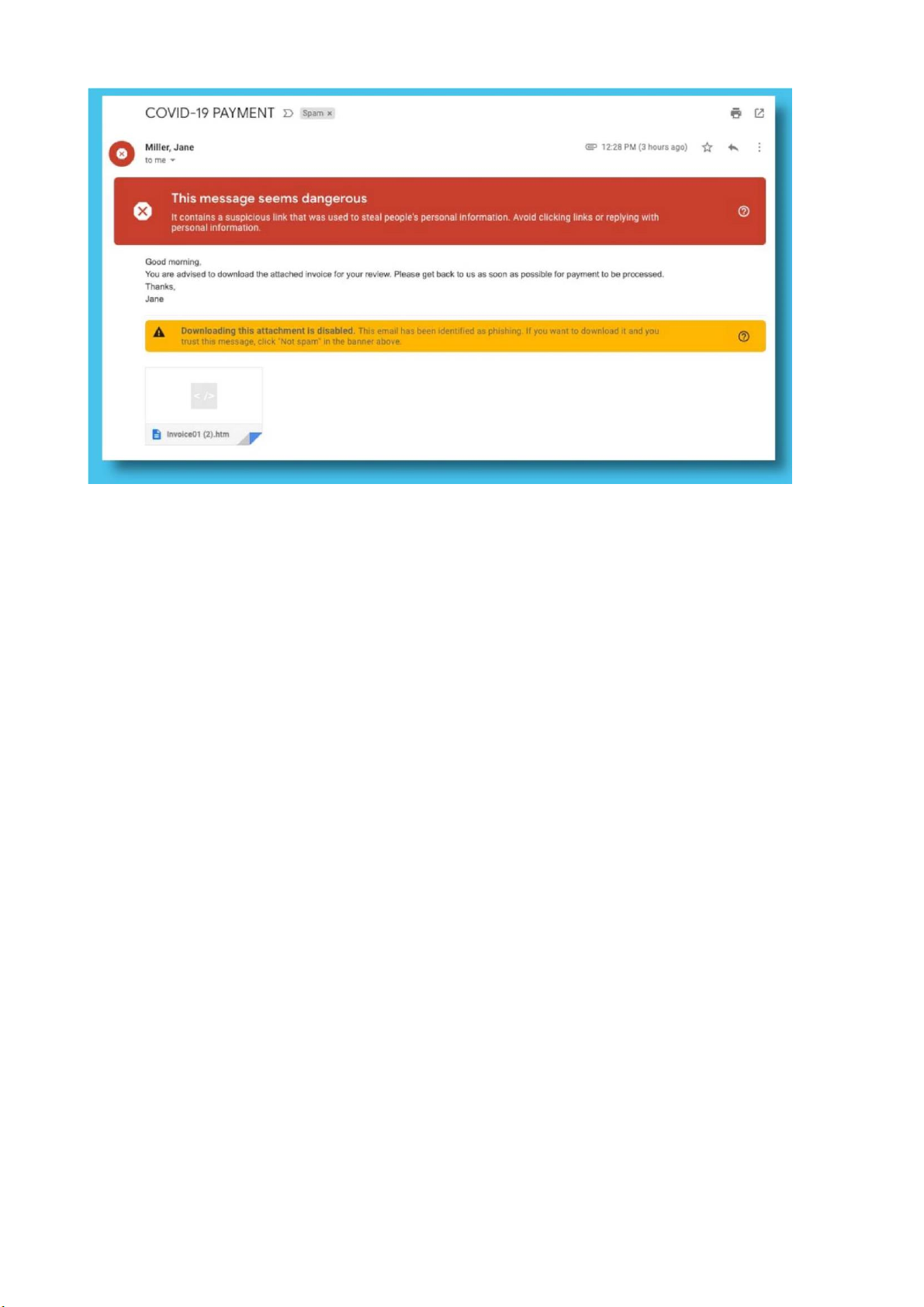
2.2.2 Phần mềm độc hại
Kỹ thuật lừa đảo dựa trên phần mềm độc hại không trực tiếp lấy thông tin của
khách hàng, thay vào đó, chúng sử dụng các loại mã độc hoặc phần mềm độc hại kết
hợp với các kỹ thuật khác. Nếu người dùng nhấp vào liên kết hoặc các tệp đính kèm
được gửi trong email thì thiết bị của nạn nhân sẽ bị nhiễm các phần mềm độc hại. Các
mã độc này sẽ khai thác các lỗ hổng trên thiết bị của nạn nhân để thực hiện lấy cắp
thông tin một cách bí mật. lOMoARcPSD| 37054152
Hình 4 Email chứa malware 2.3 Hậu quả
Lừa đảo là kỹ thuật được sử dụng để lấy cắp thông tin cá nhân cho các mục
đích khác nhau, sử dụng các email giả mạo có vẻ đến từ các tổ chức, doanh nghiệp uy
tín, hợp pháp. Điều này thường được thực hiện bằng cách gửi các email dường như
đến từ nguồn đáng tin cậy để có quyền truy cập vào thông tin bí mật và riêng tư của nạn nhân.
Email lừa đảo được coi là phương thức tội phạm trực tuyến gia tăng nhanh nhất
được sử dụng để đánh cắp dữ liệu tài chính cá nhân và đánh cắp danh tính khiến bản
thân và các tổ chức của họ gặp rủi ro:
• Gây mất niềm tin của khách hàng vào các cá nhân, tổ chức
• Lộ thông tin, kế hoạch, dự án của công ty gây thiệt hại tài sản, thậm chí là phá sản
• Mất niềm tin của người dùng vào internet, tổ chức từ thiện 3. Mục tiêu bài
toán và phạm vi nghiên cứu Mục tiêu của báo cáo:
- Xác định và đánh giá bộ tính năng được sử dụng để phát hiện email lừa đảo
- Xác định thuật toán phân loại tốt nhất để phát hiện email lừa đảo. lOMoARcPSD| 37054152
Phạm vi của báo cáo này là phát hiện email lừa đảo với bộ dữ liệu gồm 25 thuộc tính
và thử nghiệm trên các thuật toán có sẵn.
II. Phương pháp học máy 1. Khái niệm
Machine Learning chỉ đơn giản là cách máy tính “suy nghĩ” và thực hiện một
tác vụ mà không cần được lập trình. Nó là một tập hợp con của trí tuệ nhân tạo bao
gồm các thuật toán và mô hình có thể tự động phân tích và tìm hiểu dữ liệu để đưa ra
các suy luận và quyết định mà không cần sự can thiệp của con người.
Tom Michael Mitchell, một nhà khoa học máy tính người Mỹ và là tác giả của
cuốn sách Machine Learning đã đưa ra một mô tả đơn giản về hệ thống học máy:
“Một chương trình máy tính được cho là học hỏi kinh nghiệm E đối với một số loại
nhiệm vụ T và hiệu suất P nếu hiệu suất của nó ở các nhiệm vụ trong T, được đo bằng
P, sẽ cải thiện theo kinh nghiệm E. ”.
Vì vậy, nói một cách dễ hiểu, học máy mô tả cách máy tính tự thực hiện các
tác vụ bằng cách học hỏi từ những kinh nghiệm trước đó. Quá trình học hỏi kinh
nghiệm và thực hiện nhiệm vụ sử dụng một chuỗi hướng dẫn được gọi là thuật toán,
tạo thành "suy nghĩ" của máy tính.
Các thuật toán học máy được phân loại thành hai lớp chính - có giám sát và không được giám sát. 2. Phân loại
2.1 Học máy có giám sát
Trong học máy có giám sát, bạn huấn luyện hệ thống với một tập dữ liệu gồm
các ví dụ được gắn nhãn, mà hệ thống có thể dựa vào đó để đưa ra các suy luận hoặc
dự đoán. Các ví dụ được gắn nhãn này đã được gắn thẻ với các câu trả lời đúng của
chúng để giúp hệ thống thực hiện các tương quan đúng. Sau khi đào tạo đầy đủ với
một tập dữ liệu đào tạo, hệ thống có thể cung cấp các dự đoán chính xác về kết quả đầu ra.
Ví dụ: nếu một hệ thống hoặc máy móc phải giúp bạn dự đoán thời gian bạn lái
xe từ nhà đến nơi làm việc, thì nó phải được đào tạo với dữ liệu chứa thời gian bạn lái
xe đến cơ quan trong các điều kiện thời tiết khác nhau, dọc theo các tuyến đường
khác nhau, vào các thời điểm khác nhau trong ngày và vào các ngày khác nhau trong tuần. lOMoARcPSD| 37054152
Với dữ liệu đào tạo này, máy có thể suy ra những tuyến đường nào mất nhiều
thời gian hơn để đến nơi làm việc, điều kiện thời tiết nào kéo dài thời gian hoạt động
của bạn và thời gian lái xe đi làm sẽ nhanh hơn.
Tập dữ liệu này tạo thành một chuỗi “suy nghĩ” mà máy có thể cho bạn biết
bạn sẽ mất bao lâu để lái xe đi làm vào một ngày nhất định. Hình 5 Ví dụ
2.2 Học máy không có giám sát
Các thuật toán học máy không giám sát đào tạo một hệ thống bằng cách sử
dụng dữ liệu không được phân loại cũng như không được gắn nhãn. Vì vậy, trong
hình thức đào tạo máy học này, hệ thống không đưa ra câu trả lời chính xác và do đó,
không bắt buộc phải mang lại giá trị đầu ra chính xác. Thay vào đó, nó được đào tạo
để rút ra các suy luận mô tả thông tin ẩn từ dữ liệu không được gắn nhãn.
Các thuật toán học máy không được giám sát phần lớn được sử dụng trong các
ứng dụng nhận dạng hình ảnh. Ví dụ: bạn có thể xây dựng một mô hình máy có thể
xác định những người đang cười trong video mà không cần đào tạo để xác định họ.
Máy suy luận từ các mẫu người cười tương tự và liên kết các mẫu này với văn bản,
âm thanh và lời nói trong video. lOMoARcPSD| 37054152
Mặc dù mô hình không được thông báo rằng những suy luận như vậy là đúng
hay sai, nhưng ngược lại với việc học có giám sát, máy tạo sự tin tưởng và củng cố
những suy luận này khi tiếp xúc với các mô hình đó.
Hình thức học máy này phản ánh hành vi học tập không giám sát của con
người, chẳng hạn như nhận dạng trực quan. Ví dụ, một đứa trẻ nhìn thấy chiếc xe của
cha mình và xác định đó là một chiếc ô tô. Sau một vài ngày, anh ta nhìn thấy một
chiếc xe hơi của người hàng xóm và nhanh chóng cho rằng đó là một chiếc xe hơi mà
không cần biết, bằng cách quan sát các mẫu tương tự - hình dạng, đặc điểm và âm thanh.
Hình 6 Các hình thức học máy Học máy củng cố:
Loại máy học này về cơ bản là học tập dựa trên phần thưởng, nơi bạn sẽ đưa ra
phản hồi cho máy tính, tức là tích cực hoặc tiêu cực.
Nó khác với các kiểu học có giám sát khác vì máy không được tập dữ liệu mẫu
huấn luyện. Thay vào đó, nó học từ thử và sai.
Cách con người học có thể được coi là ví dụ tốt nhất cho việc học tập củng cố,
chúng ta đã được khen thưởng khi chúng ta làm được những điều tốt và cũng được
phản hồi cho những việc làm xấu của chúng ta. lOMoARcPSD| 37054152 3.
Một số loại học máy điển hình
3.1 Support Vector Machine(SVM)
Giới thiệu về thuật toán
Trong các thuật toán phân lớp trong kỹ thuật học máy giám sát thì máy véc tơ
hỗ trợ là một thuật toán hiệu quả đặc biệt trong các bài toán phân lớp dữ liệu.
Thuật toán này được đề xuất bởi Vladimir N. Vapnik, ý tưởng chính của nó là coi
các dữ liệu đầu vào như là các điểm trong một không gian n chiều và từ các dữ
liệu huấn luyện ban đầu được gán nhãn sẽ tìm ra được một siêu phẳng phân lớp
chính xác các dữ liệu này, siêu phẳng sau đó được dùng để phân lớp các dữ liệu
chưa biết cần tiên đoán.
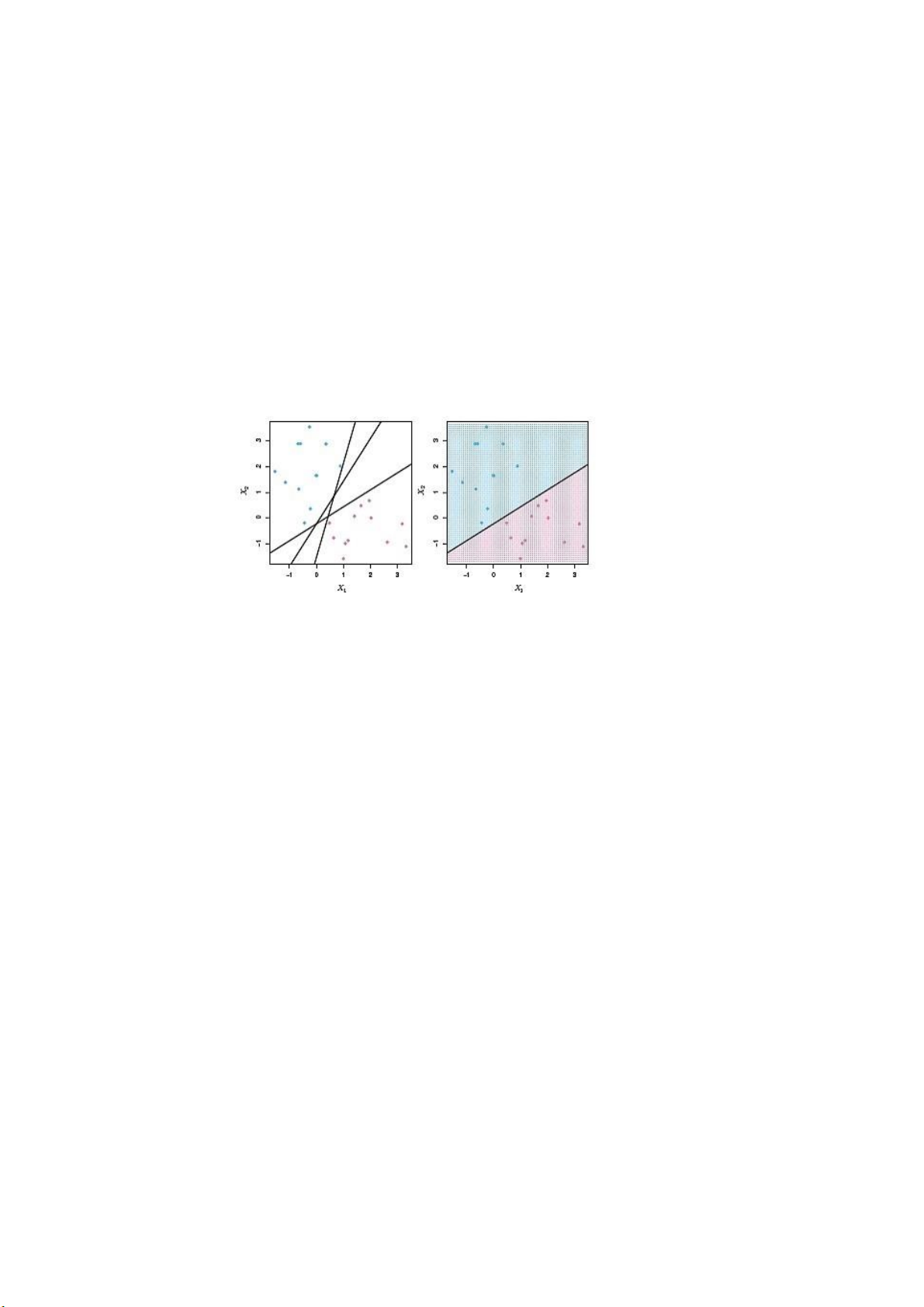
Hình 7 Thuật toán phân lớp
Xét một tập dữ liệu mẫu: = (x )…(x 1 ,y1
l , yl) , x ∈ ℝn , y ∈{-1,1}
Trong đó xi là một véc tơ đặc trưng hay một điểm (trong không gian n chiều i x
∈ ℝn) biễu diễn tập mẫu d
) biểu diễn rằng với một véc tơ đặc trưng thì được i cặp (xi , yi
gán nhãn là yi tương ứng trong đó y ∈{-1,1} hay nói cách khác với tập mẫu di sẽ được
gán nhãn cho trước là yi . Ta có phương trình một siêu phẳng được cho như sau: f (x)= w . x + b = 0
Trong đó w . x là tích vô hướng giữa véc tơ x và véc tơ pháp tuyến w ∈ ℝn
được biểu diễn trong không gian n chiều, và b ∈ ℝ là hệ số tự do.
Trên thực tế với các dữ liệu ban đầu có thể sinh ra vô số các siêu phẳng khác
nhau để phân lớp dữ liệu tuy nhiên bài toán đặt ra là trong một không gian n chiều
với các tập dữ liệu mẫu như vậy làm sao tìm được một siêu phẳng để luôn đảm bảo lOMoARcPSD| 37054152
rằng nó phân chia 32 các dữ liệu một cách tốt nhất, ta có thể hiểu rằng một siêu
phẳng tốt là một siêu phẳng mà khoảng cách từ các điểm dữ liệu được phân lớp gần
nhất với siêu phẳng đó là lớn nhất. Phương trình chứa các điểm dữ liệu này được gọi
là các lề, như vậy nói cách khác siêu phẳng tốt là siêu phẳng mà khoảng cách giữa nó
và lề càng xa càng tốt.
Hình 8 Các điểm dữ liệu
3.2 Cây quyết định
3.2.1 Giới thiệu thuật toán
Là thuật toán thuộc lại Supervised Learning, phương pháp học máy có giám
sát, kết quả hay biến mục tiêu của Decision Tree chủ yếu là biến phân loại. Các thuật
toán được xây dựng giống như hình dạng một cái cây có ngọn cây, thân cây, lá cây
kết nối bằng các cành cây, và mỗi thành phần đều có ý nghĩa riêng của nó.
Decision Tree bao gồm 3 loại nodes:
* Root node: điểm ngọn chứa giá trị của biến đầu tiên dung để phân nhánh
* Internal node: các điểm bên trong thân cây là các biến chứa các thuộc tính,
giá trị dữ liệu được dùng để xét cho các phân nhánh tiếp theo
* Leaf node: là các lá cây chứa giá trị của biến phân loại sau cùng
* Branch: là quy luật phân nhánh, nói đơn giản là mối quan hệ giữa giá trị của
Internal node và biến mục tiêu (Leaf node). 3.2.2 Ứng dụng:
Cây quyết định có cấu trúc tự nhiên nếu có thì sau đó là cách xây dựng khác
làm cho nó phù hợp với cấu trúc lập trình. Chúng cũng rất phù hợp với các vấn đề
phân loại trong đó các thuộc tính hoặc tính năng được kiểm tra một cách có hệ thống
để xác định danh mục cuối cùng. Ví dụ, một cây quyết định có thể được sử dụng một
cách hiệu quả để xác định loài của động vật. lOMoARcPSD| 37054152
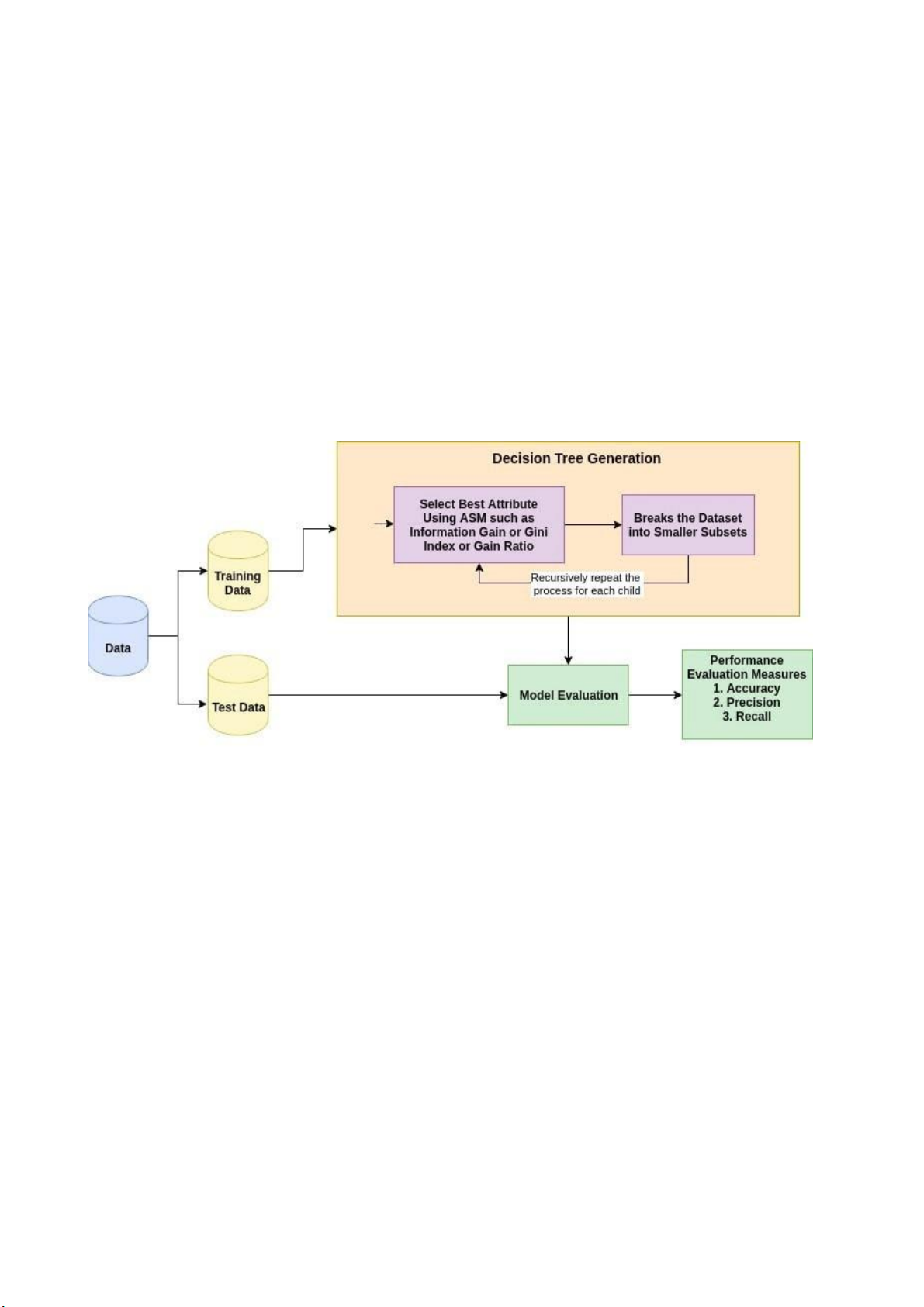
3.2.3 Các hoạt động của thuật toán Decision Tree:
1. Chọn thuộc tính tốt nhất bằng cách sử dụng các biện pháp lựa chọn thuộc tính
(ASM) để phân chia các bản ghi.
2. Biến thuộc tính đó thành nút quyết định và chia tập dữ liệu thành các tập con nhỏ hơn.
3. Bắt đầu xây dựng cây bằng cách lặp lại quy trình này một cách đệ quy cho mỗi
phần nhỏ cho đến khi một trong những điều kiện sẽ khớp:
Tất cả các bộ thuộc về cùng một giá trị thuộc tính.
Không còn thuộc tính nào nữa.
Không có nhiều trường hợp nữa.
Hình 9 Hoạt động của thuật toán Decision Tree
3.2.4 Ưu điểm và khuyết điểm của thuật toán: Ưu điểm:
Đơn giản, trực quan, không quá phức tạp, bộ dữ liệu training không cần thiết
quá lớn để xây dựng mô hình phân tích
Có khả năng xử lý dữ liệu bị missing hay bị lỗi mà không cần áp dụng phương
pháp như “imputting missing value” hay loại bỏ, ít bị ảnh hưởng bởi dữ liệu ngoại lệ.
Không sử dụng tham số nên kết quả phân tích có được khách quan nhất Khuyết điểm: lOMoARcPSD| 37054152
Hoạt động hiểu quả trên bộ dữ liệu đơn giản có ít biến dữ liệu liên hệ với nhau,
ngược lại với bộ dữ liệu phức tạp có thể dẫn đến mô hình bị overfitting lOMoARcPSD| 37054152
III. Các kỹ thuật phát hiện phishing email 1. Giới thiệu
Trong các vụ lừa đảo, email cảnh báo được gửi từ các tổ chức, văn phòng an
ninh, ngân hàng, nhà cung cấp, … Thông báo thúc giục nạn nhân trực tiếp nhập/thay
đổi thông tin cá nhân của họ. Các bộ lọc được phát triển để lọc, phát hiện và ngăn
chặn các loại email lừa đảo. Các kỹ thuật truyền thống như bảo vệ xác thực và tự
động phát hiện bằng khai phá dữ liệu hiện đại đã được đưa vào sử dụng. 2. Phân loại
2.1 Phương pháp truyền thống
Phương pháp truyền thống gồm 2 loại chính, một là bảo vệ bằng xác thực, hai
là bảo vệ mở mức mạng. Bảo vệ ở mức mạng gồm 2 loại bộ lọc, bộ lọc danh sách đen
và bộ lọc danh sách trắng được đưa vào sử dụng nhằm ngăn chặn các địa chỉ IP và
domain lừa đảo từ mạng. Ngoài ra còn có bộ lọc dựa trên quy tắc và bộ lọc so sánh đối mẫu.
• Bộ lọc danh sách đen - Blacklist Filter
Bộ lọc này giúp bảo vệ ở lớp mạng bằng cách phân loại các địa chỉ DNS, địa
chỉ IP của người nhận hoặc địa chỉ người gửi, trích xuất chi tiết header của
email rồi so sánh nó với danh sách có trước. Nếu dữ liệu có trong danh sách thì
email bị từ chối, nếu không thì email được chấp nhận.
• Bộ lọc danh sách trắng - Whitelist Filter
Đây cũng là bộ lọc giúp bảo vệ ở mức mạng. Phương pháp này sử dụng kỹ
thuật lọc so sánh dữ liệu trích xuất từ email với dữ liệu được xác định trước
trong danh sách chứa địa chỉ IP và IP tĩnh hợp pháp. Chỉ những email đến từ lOMoAR cPSD| 37054152
các địa chỉ hợp lệ có trong danh sách mới được chấp nhận, còn lại sẽ bị từ chối. • Pattern Matching Filter
Đây cũng là bộ lọc bảo vệ ở mức mạng. Bộ lọc này sử dụng dữ liệu đã được
chỉ định sẵn bao gồm cả chuỗi, từ, văn bản, ký tự được sử dụng trong nội dung
của email. Nó sử dụng để phân loại các email theo danh sách mẫu, nếu email
nhận được có lượng lớn các từ bị cấm thì sẽ bị loại bỏ.
• Xác thực email - Email verification
Hệ thống xác thực email yêu cầu việc xác nhận giữa người gửi và người nhận
email. Các email được gửi đến mà không có xác nhận giữa người gửi và người
nhận sẽ không được chuyển vào hộp thư đến. Việc sàng lọc email này mang lại
độ chính xác cao trong việc xác định thư rác nhưng sẽ mất rất nhiều thời gian
do phải đợi phản hồi từ phía người nhận. Điểm yếu nữa của là người gửi và
người nhận dễ bị mất mát thông tin.
• Bộ lọc mật khẩu - Password Filter lOMoARcPSD| 37054152
Bộ lọc là bộ lọc xác thực cấp người dùng. Bộ lọc này cho phép nhận tất cả các
email. Nếu bộ lọc phát hiện mật khẩu sai hoặc không phát hiện được mật khẩu
thì email sẽ bị từ chối.
2.2 Phương pháp tự động
Bộ phân loại tự động dựa trên học máy được sử dụng để phân loại email nhận
được có phải là thư rác hay không.
• Hồi quy logistic - logistic regression
Đây là một phương pháp tự động kiểm tra email. Nó sử dụng mô hình tuyến
tính để dự đoán các dữ liệu nhị phân 0 hoặc 1. Đây là một phương pháp đơn
giản để phân loại email.
• Cây phân loại và hồi quy - Classification and Regression Trees (CART)
Thuật toán CART là một loại thuật toán phân loại được yêu cầu để xây dựng cây quyết định.
CART là một từ bao hàm dùng để chỉ các loại cây quyết định sau:
- Cây phân loại: Khi biến mục tiêu liên tục, cây được sử dụng
để tìm "lớp" mà biến mục tiêu có nhiều khả năng rơi vào.
- Cây hồi quy: Được sử dụng để dự báo giá trị của một biến liên tục.
Mô hình này sẽ tạo ra một cây song song cho phép kết nối ghép kênh và cộng
tác đọc đơn giản giữa các chỉ số được đưa ra.
• Bộ lọc cây quyết định - Decision Trees Filter (DT)
Kênh này là một mô hình đồ họa để hỗ trợ đưa ra quyết định đúng mong muốn
dựa trên các hậu quả có thể xảy ra. Mô hình cây chứa các nút và mũi tên và nó
được khởi tạo từ nút gốc. Các quy tắc if-then nằm trong mỗi nút trong mạng.
Mũi tên biểu thị nút nào được tham chiếu tiếp theo. Cây cũng sẽ chứa các giai
đoạn phân loại khác nhau và các nút bên trong.
Các thuật ngữ khác nhau được sử dụng trong cây quyết định là:
• Trung tâm gốc: trung tâm cơ sở được gọi là trung tâm gốc mà từ
đó cây được thể hiện. lOMoARcPSD| 37054152
• Nguyên tắc if-then: mọi trung tâm bên trong hệ thống đều chứa
hướng dẫn If-then, một lớp và một phần tử.
• Mũi tên: cạnh tiếp theo được loại bỏ bằng cách sử dụng bu lông.
• Chòi lá: cây khép lại bằng tua lá hoặc bộ phận khử.
• Để tạo ra một cây, các phép tính khác nhau được kết hợp với mô
hình ID3 để xác định dữ liệu entropy nhằm đánh giá giá trị mục
tiêu. Trong cây tính toán C4.5 sẽ tạo ra các cây con trong đó mọi
trung tâm của cây đều có trung tâm cha và hơn nữa nhắc nhở một
trung tâm con. Hơn nữa, cây kết thúc với trung tâm kết thúc nói
lên kết quả khách quan của vấn đề.
• Máy vector hỗ trợ - Support Vector Machine (SVM)
Kỹ thuật này được sử dụng trong y tế để chẩn đoán bệnh, nhận dạng văn bản,
để phân loại hình ảnh và trong các lĩnh vực khác. Điều này sẽ phân chia dữ
liệu thành hai loại bằng cách sử dụng quy tắc cố định, phương trình bậc hai và
thống kê. Siêu phẳng phân tách được sử dụng để phân loại dữ liệu nhị phân và
giảm thiểu không gian của lề trên cơ sở chức năng hạt nhân. Kỹ thuật này được
sử dụng để tìm ra giải pháp tốt nhất của vấn đề. Kỹ thuật này không thành
công trong việc phân tích dữ liệu lớn.
Các phương pháp lựa chọn tính năng khác nhau là:
Mô-đun Lựa chọn tính năng dựa trên bộ lọc cung cấp nhiều thuật toán lựa chọn
tính năng để lựa chọn, chẳng hạn như mối tương quan của Pearson hoặc
Kendall, thông tin lẫn nhau, điểm số của fisher và giá trị Chi-squared. Trong
phần này, sử dụng phương pháp Chi-squared để lựa chọn đối tượng
• Tương quan Pearson: Nhãn có thể là văn bản hoặc số. Các tính năng phải là số
• Thông tin lẫn nhau: Nhãn và tính năng có thể là văn bản hoặc số.
Sử dụng phương pháp này để tính toán tầm quan trọng của tính
năng cho hai cột phân loại.
• Tương quan Kendall: Nhãn có thể là văn bản hoặc số nhưng các
đối tượng địa lý phải là số
• Tương quan Spearman: Nhãn có thể là văn bản hoặc số nhưng các
đối tượng địa lý phải là số
• Chi Squared: Các nhãn và tính năng có thể là văn bản hoặc số. Sử
dụng phương pháp này để tính toán tầm quan trọng của tính năng cho hai cột phân loại.
• Điểm Fisher: Nhãn có thể là văn bản hoặc số nhưng các đối tượng địa lý phải là số.
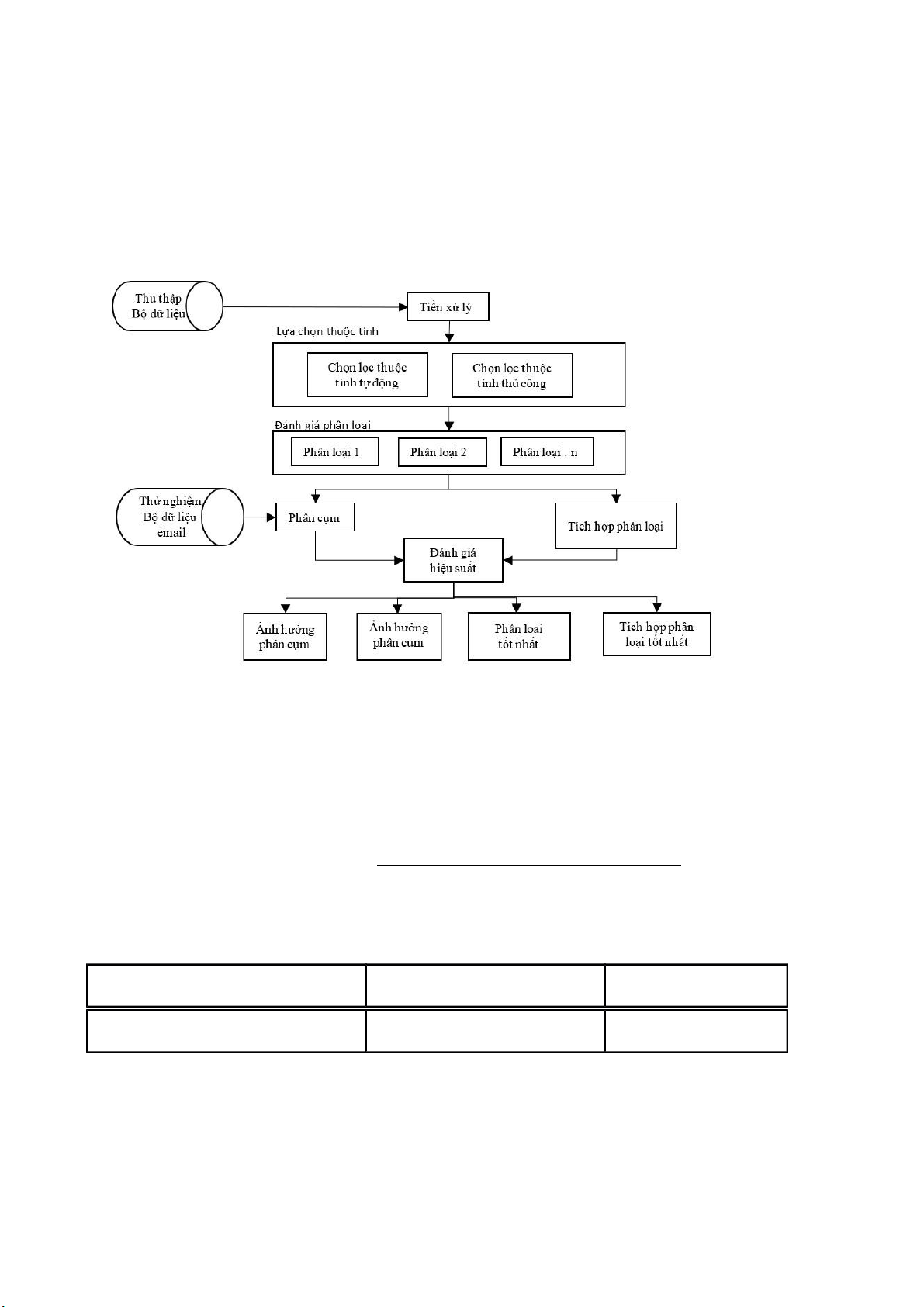
IV. Các bước nghiên cứu
Các bước nghiên cứu gồm thu thập dữ liệu (gồm cả những mail phishing và
mail thông thường). Từ đây, chúng ta tiến hành bước tiền xử lí dữ liệu để lọc ra lOMoARcPSD| 37054152
những dữ liệu cần để sử dụng. Những dữ liệu đã được lọc này sẽ được tiếp tục
chuyển sang bước tiếp theo. Tại đây chúng ta chọn lọc những thuộc tính quan trọng
để tiến hành phân loại mail. Những thuộc tính này dựa theo những đặc điểm để phân
biệt mail phishing và mail thông thường. Từ việc chọn lọc các đặc trưng để phân loại,
chúng ta được một bảng dữ liệu mới. Bảng này thể hiện các đặc trưng đã được phân
loại của mail. Cuối cùng là tính toán hiệu suất của các thuật toán phân loại trên tập
đặc trưng được trích xuất của dữ liệu được khảo sát.
Hình 10 Các bước nghiên cứu 1. Tiền xử lý
Để thực hiện dự án này, hai bộ dữ liệu thô sẽ được sử dụng:
• Bộ đầu tiên là một kho dữ liệu lớn chứa hơn 2000 email lừa đảo thực sự trong
một tệp mbox theo địa chỉ https://monkey.org/~jose/phishing/
• Bộ thứ hai là một bộ dữ liệu lớn chứa các email thông thường hoặc không lừa
đảo, từ kho dữ liệu email Enron. Đây là tập dữ liệu email 1,7 GB trong cấu trúc
thư mục được lưu gộp vào 1 file csv. phishing thường tổng 2604 7200 9804
Bảng 1 Tập dữ liệu Email
Cả hai tập dữ liệu đều ở các định dạng khác nhau và cần được thống nhất thành một file để xử lý. lOMoARcPSD| 37054152
Hình 11 Tiền xử lí dữ liệu
Khi 2 bộ dữ liệu thô được lọc và lưu dưới 2 tệp csv, nội dung dữ liệu phân biệt
rõ các phần của 1 email như subject, body, ... chúng sẽ được tiếp tục sử dụng để sử
dụng cho bước tiếp theo.
Các tệp được phân chia thành 80% -20%. 80% email sẽ được sử dụng cho mục
đích đào tạo và 20% còn lại để kiểm tra các thuật toán và đo lường hiệu quả của
chúng. Với 20% email, độ chính xác, khả năng thu hồi và độ chính xác của từng thuật
toán máy học sẽ được kiểm tra. Điều này sẽ xác định thuật toán nào hoạt động tốt
nhất trong việc xác định email lừa đảo trong bối cảnh dữ liệu và mô hình tính năng được đề xuất 2.
Lựa chọn đặc trưng
Từ các thông tin thu thập được từ 2 bộ dữ liệu lớn cũng như các đặc trưng nhận
dạng của các phishing email, chúng ta xác định được các đặc trưng sẽ được sử dụng: Tên thuộc tính Mô tả
HTML_Content Trả về 1 nếu tìm thấy html trong email, ngược lại là 0 LenSubject
Trả về số lượng từ có trong subject của email sub_wBank
Trả về 1 nếu tìm thấy từ “bank” trong subject của email, ngược lại là 0 sub_wDebit
Trả về 1 nếu tìm thấy từ “debit” trong subject của email, lOMoAR cPSD| 37054152 ngược lại là 0 sub_wVerify
Trả về 1 nếu tìm thấy từ “verify” trong subject của email, ngược lại là 0 url_wClick
Trả về 1 nếu tìm thấy từ “click” trong url của email, ngược lại là 0 url_wHere
Trả về 1 nếu tìm thấy từ “here” trong url của email, ngược lại là 0 url_wLogin
Trả về 1 nếu tìm thấy từ “login” trong url của email, ngược lại là 0 url_wUpdate
Trả về 1 nếu tìm thấy từ “update” trong url của email, ngược lại là 0 NumURL
Trả về số lượng URL trong email NumIP
Trả về số lượng IP trong URL HaveAt
Trả về 1 nếu tìm thấy kí tự “@” trong URL, ngược lại là 0 Redirection
Trả về 1 nếu tìm thấy kí tự “//” trong URL phía sau giao thức, ngược lại là 0 NumScript
Trả về số lượng các khối script trong URL Prefix-Suffix
Trả về 1 nếu tìm thấy kí tự “-“ trong URL, ngược lại là 0 Web-traffic
Trả về 1 nếu xếp hạng của web trong cơ sở dữ liệu Alexa
<100000, ngược lại là 0 httpDomain
Trả về 1 nếu tìm thấy https trong domain trong email, ngược lại là 0 tinyURL
Trả về 1 nếu tìm thấy link rút gọn trong email, ngược lại là 0 iFrame
Trả về 1 nếu iframe rỗng hoặc không tìm thấy phản hồi, ngược lại là 0 OnMouseOver
Trả về 1 nếu tìm thấy “onmouseover” hoặc không tìm
thấy phản hồi, ngược lại là 0 lOMoARcPSD| 37054152 RightClick
Trả về 1 nếu phản hồi rỗng hoặc không tìm thấy sự kiện
right click, ngược lại là 0 bodyImg
Trả về 1 nếu tìm thấy thẻ img trong body của email, ngược lại là 0 BlackList
Trả về số lượng các từ dưới đây được tìm thấy trong email:
"account", "debit", "recently", "access", "information",
"risk", "bank", "log", "security", "client", "notification",
"service", "confirm", "password", "user", "credit", "pay", "urgen" body_wDear
Trả về 1 nếu tìm thấy từ “dear” trong body của email, ngược lại là 0
body_wSuspension Trả về 1 nếu tìm thấy từ “suspension” trong body của email, ngược lại là 0
Bảng 2 Các đặc trưng
Từ bảng trên, ta có được thống kê như sau: Nhóm các đặc trưng
Số lượng các đặc trưng Tất cả các đặc trưng 25
Các đặc trưng liên quan đến body 10
Các đặc trưng liên quan đến subject 4
Các đặc trưng liên quan đến url 7
Các đặc trưng liên quan đến javaScript 4
Bảng 3 Phân loại đặc trưng theo nhóm
Sử dụng các thư viện pandas, csv, bs4, Alexa Rank để thao tác và ghi dữ liệu
vào 1 file csv duy nhất để sử dụng. Sau khi xử lí các dữ liệu để hợp nhất 2 bảng dữ
liệu phishing và enron, các thông tin thể hiện 25 đặc trưng kèm theo nhãn để đánh giá
nó có phải là email phishing hay không: lOMoARcPSD| 37054152
Hình 12 Thông tin dữ liệu về các đặc trưng
Với tập dữ liệu thu được ở trên, các thuật toán học máy khác nhau được sử dụng để
đánh giá và sau đó được kiểm tra. 3.
Thuật toán đánh giá
Năm thuật toán được chọn để đánh giá và kiểm tra độ chính xác phát hiện email
lừa đảo từ các bộ dữ liệu. Các thuật toán được sử dụng là:
• KNN (K-nearest neighbors): là một trong những thuật toán
supervisedlearning đơn giản nhất (mà hiệu quả trong một vài trường hợp)
trong Machine Learning. Khi training, thuật toán này không học một điều
gì từ dữ liệu training (đây cũng là lý do thuật toán này được xếp vào loại
lazy learning), mọi tính toán được thực hiện khi nó cần dự đoán kết quả của dữ liệu mới
• Decision tree: là thuật toán supervised learning, có thể giải quyết cả bài
toán regression và classification
• Random forest: xây dựng nhiều cây quyết định bằng thuật toán Decision
Tree, tuy nhiên mỗi cây quyết định sẽ khác nhau (có yếu tố random). Sau
đó kết quả dự đoán được tổng hợp từ các cây quyết định
• Logistic: Một thuật toán Máy học được sử dụng cho các bài toán phân loại,
nó là một thuật toán phân tích dự đoán và dựa trên khái niệm xác suất
• Naive bayes: là một kỹ thuật phân loại dựa trên Định lý Bayes với giả định
về sự độc lập giữa các yếu tố dự đoán. Naive Bayes giả định rằng sự hiện
diện của một đối tượng cụ thể trong một lớp không liên quan đến sự hiện
diện của bất kỳ đối tượng địa lý nào khác. lOMoARcPSD| 37054152
4. Số liệu đánh giá
Từ các thuật toán, ta xác định được những số liệu để đánh giá hiệu suất thu được từ
bộ dữ liệu đã được xử lí các đặc trưng
Độ chính xác: số liệu này được tính dựa trên tỷ lệ phần trăm của quyết định chính xác
trong số tất cả các mẫu thử nghiệm trong đó
• True positive (TP): Số các ca dự đoán dương tính đúng hay dương tính thật.
• True negative (TN): Số các ca dự đoán âm tính đúng hay âm tính thật.
• False positive (FP): Số các ca dự đoán dương tính sai hay dương tính giả.
False negative (FN): Số các ca dự đoán âm tính sai hay âm tính giả.
Ma trận nhầm lẫn: là một trong những kỹ thuật đo lường hiệu suất phổ biến nhất và
được sử dụng rộng rãi cho các mô hình phân loại. Nó cho phép trực quan hóa hiệu
suất của một thuật toán. Thực tế\Dự tính Dương tính Âm tính Dương tính TP FP Âm tính FN TN
Bảng 4 Ma trận nhầm lẫn
Precision: trả lời cho câu hỏi trong các trường hợp được dự báo là positive thì có bao
nhiêu trường hợp là đúng
Recall: đo lường tỷ lệ dự báo chính xác các trường hợp positive trên toàn bộ các mẫu thuộc nhóm positive
F1 Score: là trung bình điều hòa giữa precision và recall. Do đó nó đại diện hơn trong
việc đánh giá độ chính xác trên đồng thời precision và recall. lOMoARcPSD| 37054152
FPR: là tỷ lệ dự đoán sai lOMoARcPSD| 37054152
V. Thực hiện thử nghiệm 1.
Bộ dữ liệu dataset
Bộ dữ liệu chứa 9804 email, trong đó 7200 email thường và 2604 email phishing. Bộ
email được thu thập từ 2 nguồn: email phishing lấy từ website monkey.org, email
thường lấy từ web classes.cs.uchicago.edu. Dataset Phishing emails Email thường Tổng Training 2104 5739 7843 Testing 500 1461 1961
Bảng 5 Tổng quan bộ dữ liệu dataset
Từ bộ dữ liệu, ta trích xuất được 25 thuộc tính và 1 cột đại diện cho loại email (1:
phishing mail, 0: mail thường)
Hình 13 25 thuộc tính trong bộ dữ liệu 2.
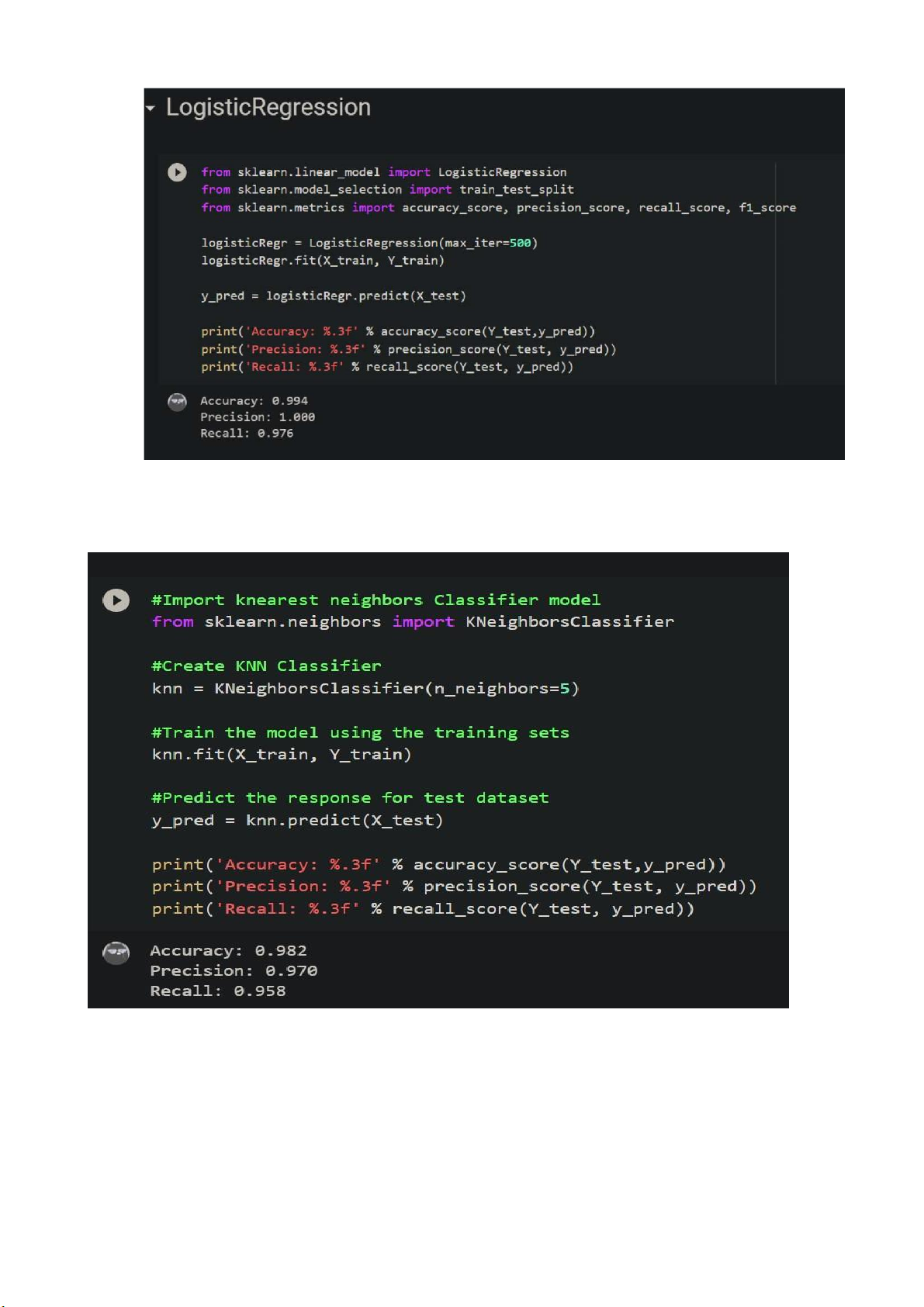
Kết quả thử nghiệm • Logistic Regression lOMoARcPSD| 37054152
Hình 14 Kết quả thử nghiệm thuật toán Logistic Regression • KNN
Hình 15 Kết quả thử nghiệm thuật toán KNN • Random Forest lOMoARcPSD| 37054152
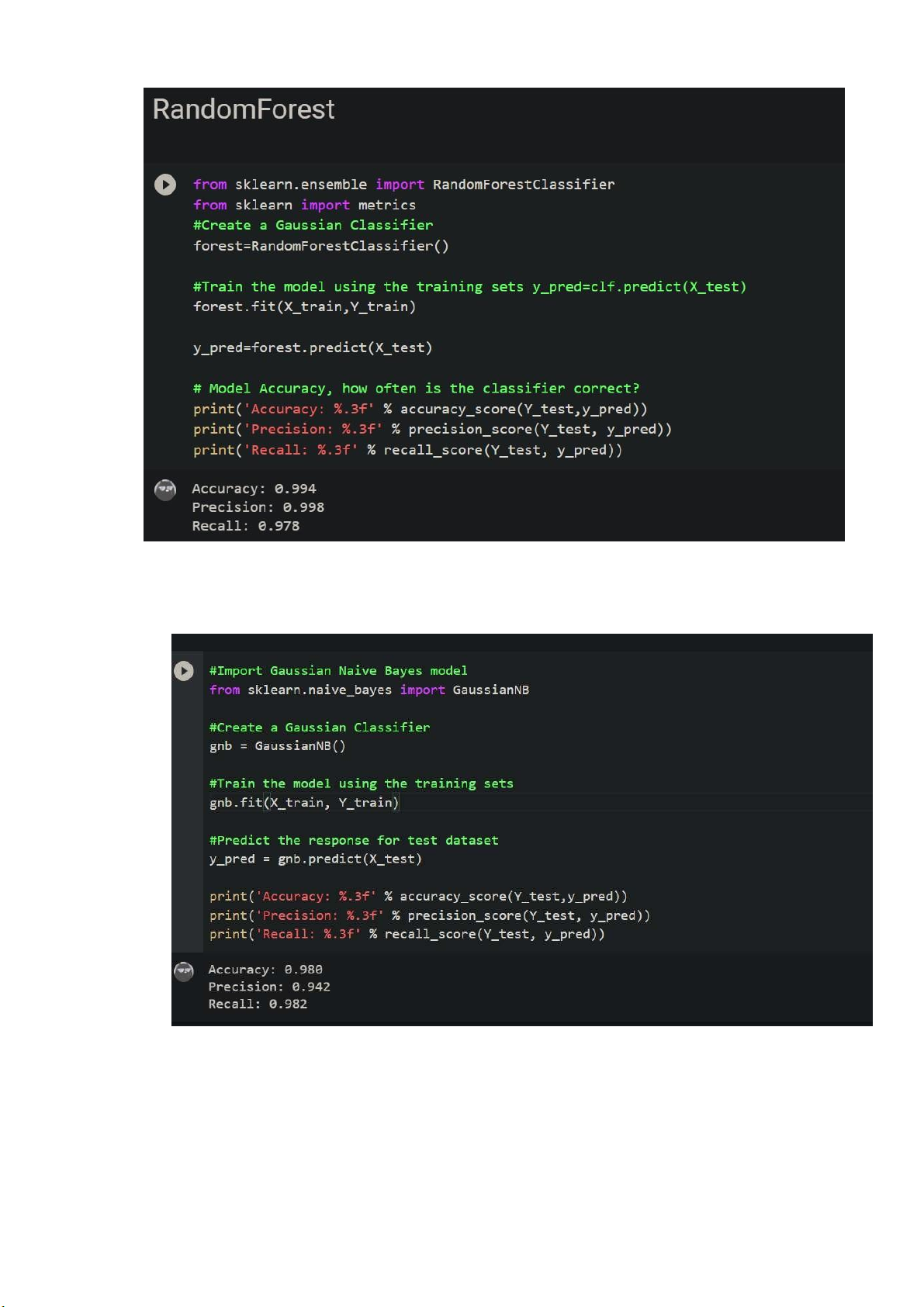
Hình 16 Kết quả thử nghiệm thuật toán Random Forest • Naive Bayes
Hình 17 Kết quả thử nghiệm thuật toán Naïve Bayes • Decision Tree lOMoARcPSD| 37054152
Hình 18 Kết quả thử nghiệm thuật toán Decision Tree
Từ đây chúng ta có bảng kết quả của 25 thuộc tính:
Hình 19 Tập hợp kết quả thử nghiệm lOMoARcPSD| 37054152
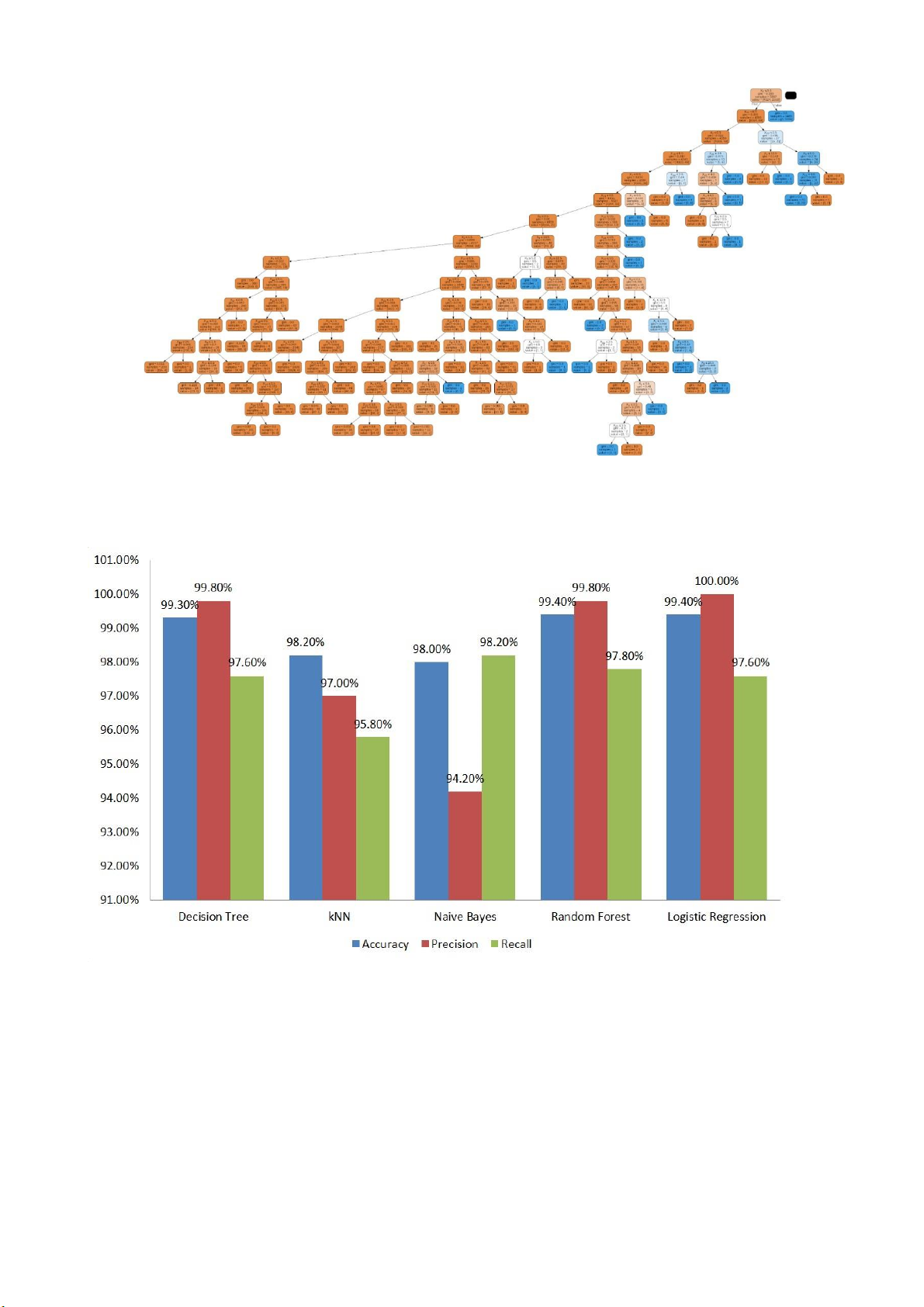
Hình 20 Cây quyết định
• So sánh 5 thuật toán được áp dụng trên 25 thuộc tính
Hình 21 Kết quả thực nghiệm với 5 thuật toán dựa trên 25 thuộc tính
• Kết quả cho thấy thuật toán Random Forests, Logistic Regression áp dụng
cho 25 thuộc tính tốt hơn các thuật toán khác như kNN, Naive Bayes, ...
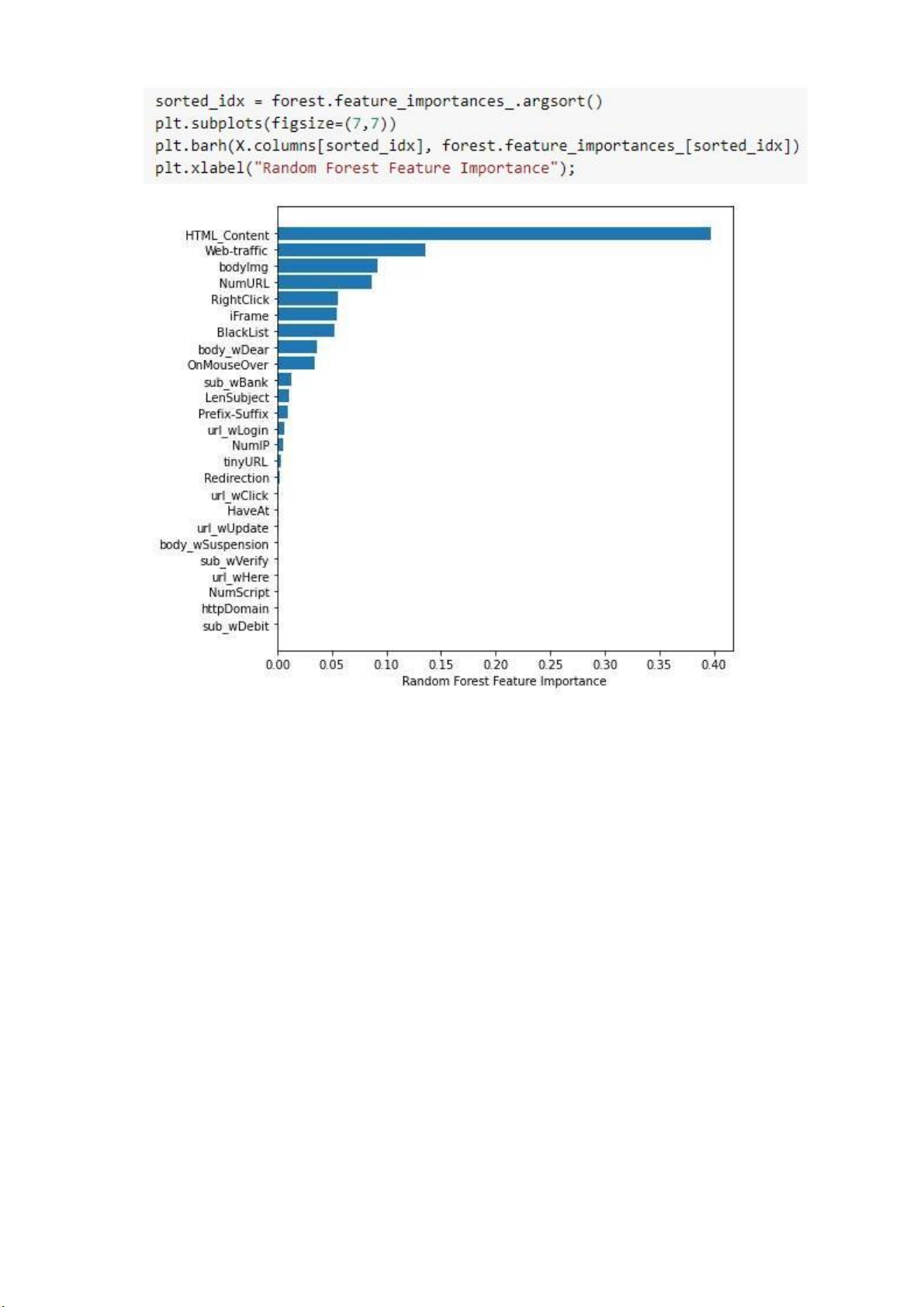
• Chỉ số quan trọng của 25 thuộc tính thông qua thuật toán Random Forest lOMoARcPSD| 37054152
Hình 22 Độ quan trọng của các thuộc tính thông qua thuật toán Random Forest
Từ sơ đồ trên ta thấy được chỉ số thuộc tính HTML_Content có chỉ số quan
trọng hơn các chỉ số khác.
Ngoài ra các chỉ số thuộc tính như Web-traffic, bodyImg cũng có chỉ số quan
trọng cao chỉ sau chỉ số thuộc tính HTML_Content. 3. So sánh
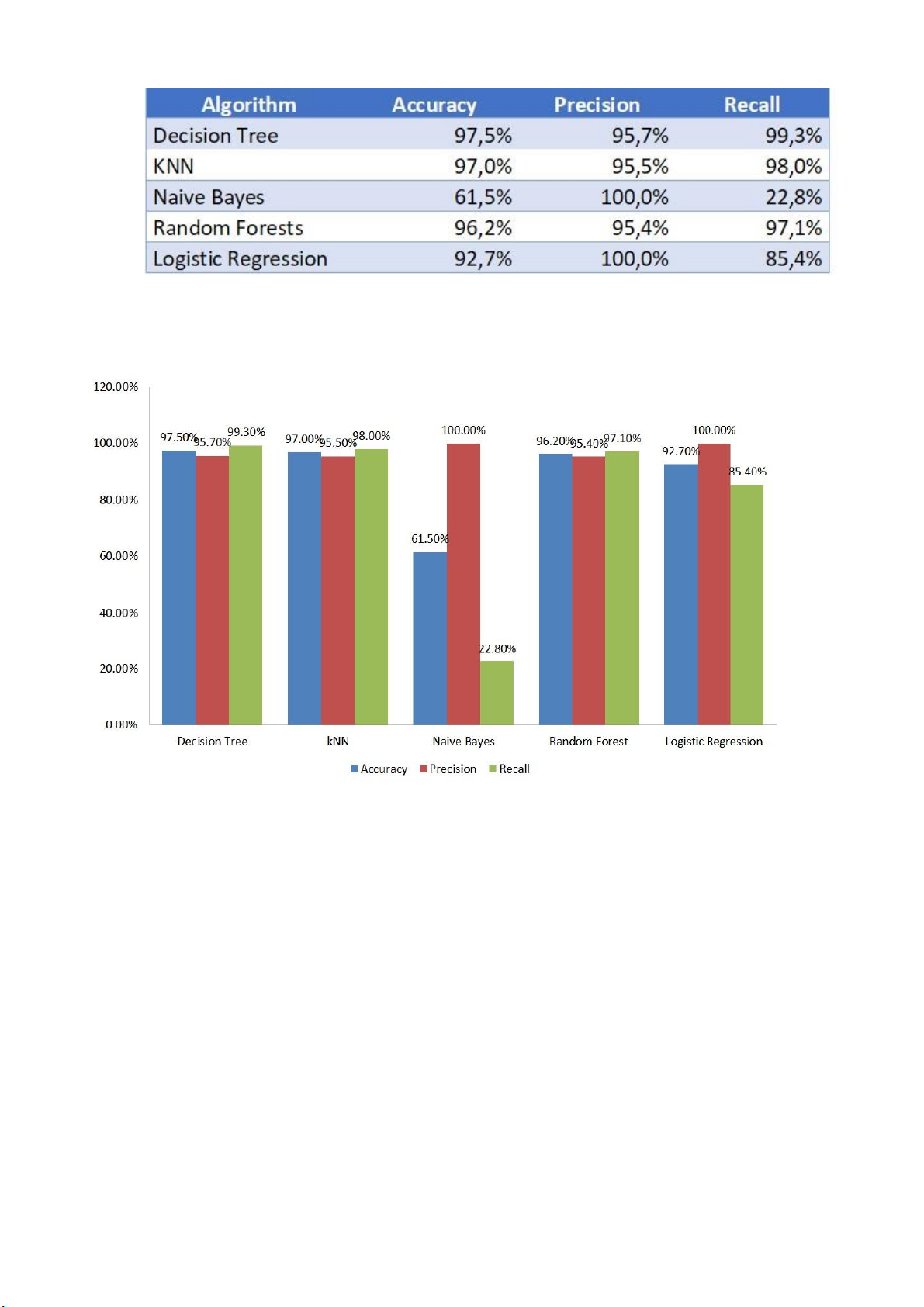
Ở nghiên cứu ở mục [], ta có kết quả của 13 đặc trưng ứng với 5 thuật toán tương ứng:
• Kết quả của 13 đặc trưng: lOMoARcPSD| 37054152
Hình 23 Kết quả thực nghiệm với 5 thuật toán dựa trên 13 thuộc tính ở tài liệu
• So sánh 5 thuật toán được áp dụng trên 13 feature
Hình 24 Kết quả thực nghiệm với 5 thuật toán dựa trên 13 thuộc tính ở tài liệu
Nhận thấy, trong một số trường hợp, kết quả của 25 thuộc tính ứng với 5 thuật toán trên cao hơn. VI. Kết luận
Các cuộc tấn công lừa đảo qua email đang trở thành mối nguy hiểm thường trực đối
với tất cả các tổ chức và quốc gia trên thế giới.
Các kết quả thực nghiệm trong bài báo cáo này cho thấy rằng các hệ thống phát hiện
email lừa đảo không nên chỉ dựa vào các phương pháp trích xuất tính năng truyền
thống. Các thuật toán học máy có thể là các nguồn hữu ích bổ sung để cải thiện hiệu
suất của các khuôn khổ phát hiện lừa đảo. lOMoARcPSD| 37054152
Đường dẫn thực hiện:
https://drive.google.com/drive/folders/1ZE6wRlYhEgrwCFqWgCq9yZXNpYLbY7b d?usp=sharing lOMoAR cPSD| 37054152
Tài liệu tham khảo
[1] "Phishing," 23 11 2021. [Online]. Available: https://en.wikipedia.org/wiki/Phishing.
[2] A. Rayan, 27 9 2021. [Online]. Available:
https://assets.researchsquare.com/files/rs921426/v1_covered.pdf?c=1632754617.
[3] waleedaliSe, 23 9 2017. [Online]. Available: https://github.com/waleedaliSe/Spam- DetectionUsing-Weka.
[4] diegoocampoh, 20 11 2017. [Online]. Available:
https://github.com/diegoocampoh/MachineLearningPhishing.
[5] 2017. [Online]. Available:
https://www.classes.cs.uchicago.edu/archive/2017/fall/121001/lecture-examples/Text-
Processing/Text_Processing.html.
[6] [Online]. Available: https://monkey.org/~jose/phishing.
Tài liệu liên quan:
-

Wireshark Network Analysis: The Official Wireshark Certified Network Analyst Study Guide (Second Edition) | Học viện Công Nghệ Bưu Chính Viễn Thông
48 24 -

Câu hỏi ôn tập an ninh mạng-PTIT
40 20 -

Bài tập lớn môn An toàn mạng truyền thông | Học viện Công nghệ Bưu chính Viễn thông
595 298 -

Đề cương ôn tập An ninh mạng nội dung chương 1 | Học viện Công nghệ Bưu chính Viễn thông
423 212 -

Bài tiểu luận môn An toàn mạng đề tài "Giải pháp an ninh mạng với Honeypot thông minh"
783 392