Bài giảng về Decision Trees and Bias-Variance môn Học máy | Trường Đại học Công nghệ, Đại học Quốc gia Hà Nội
Bài giảng về Decision Trees and Bias-Variance môn Học máy | Trường Đại học Công nghệ, Đại học Quốc gia Hà Nội. Tài liệu được sưu tầm giúp bạn tham khảo, ôn tập và đạt kết quả cao. Mời bạn đọc đón xem.
Môn: Học máy 10 tài liệu
Trường: Trường Đại học Công nghệ, Đại học Quốc gia Hà Nội 824 tài liệu
Tác giả:







Preview text:
Lecture 2: Decision Trees and Bias-Variance MSc. Bui Quoc Khanh
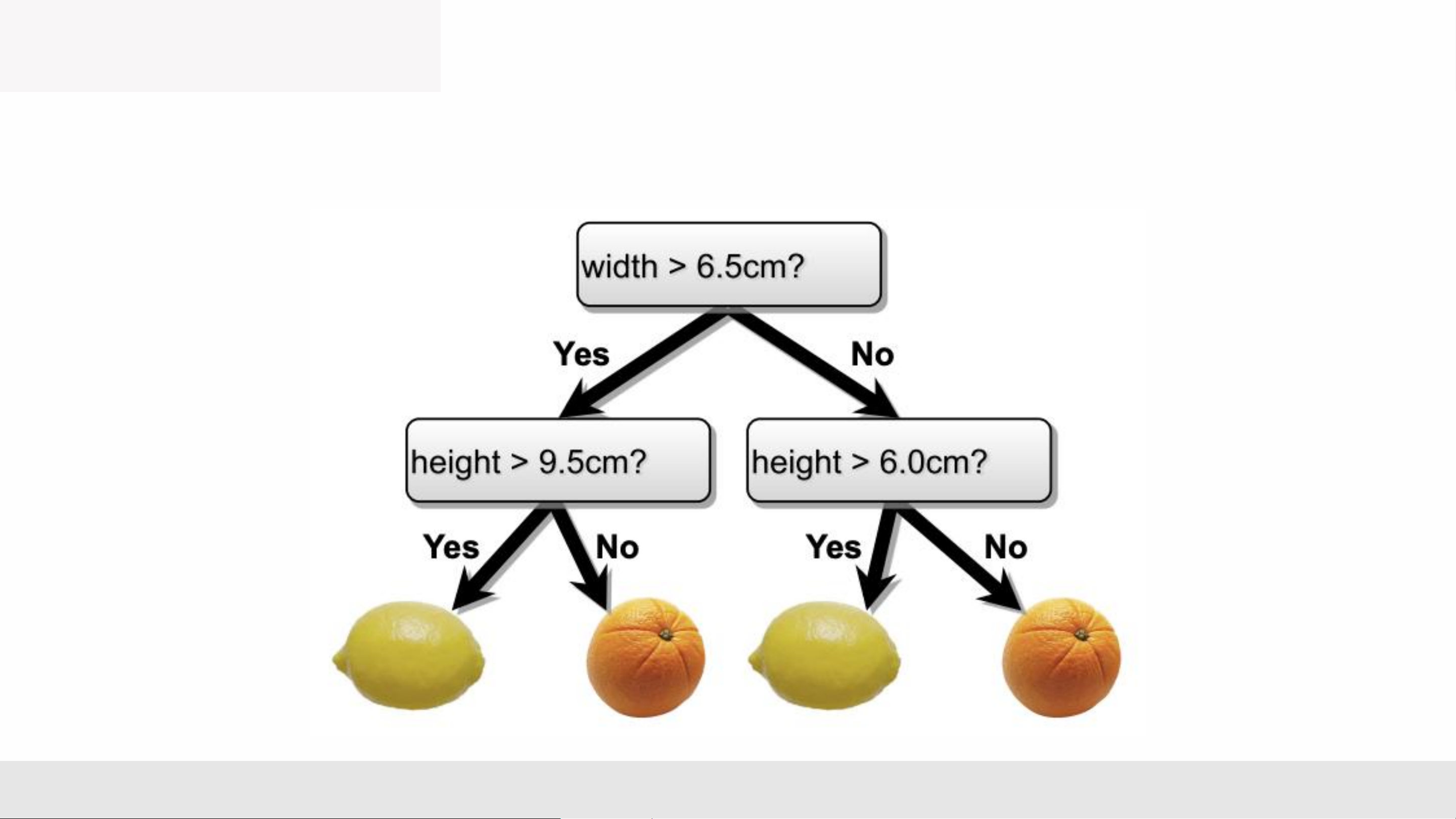
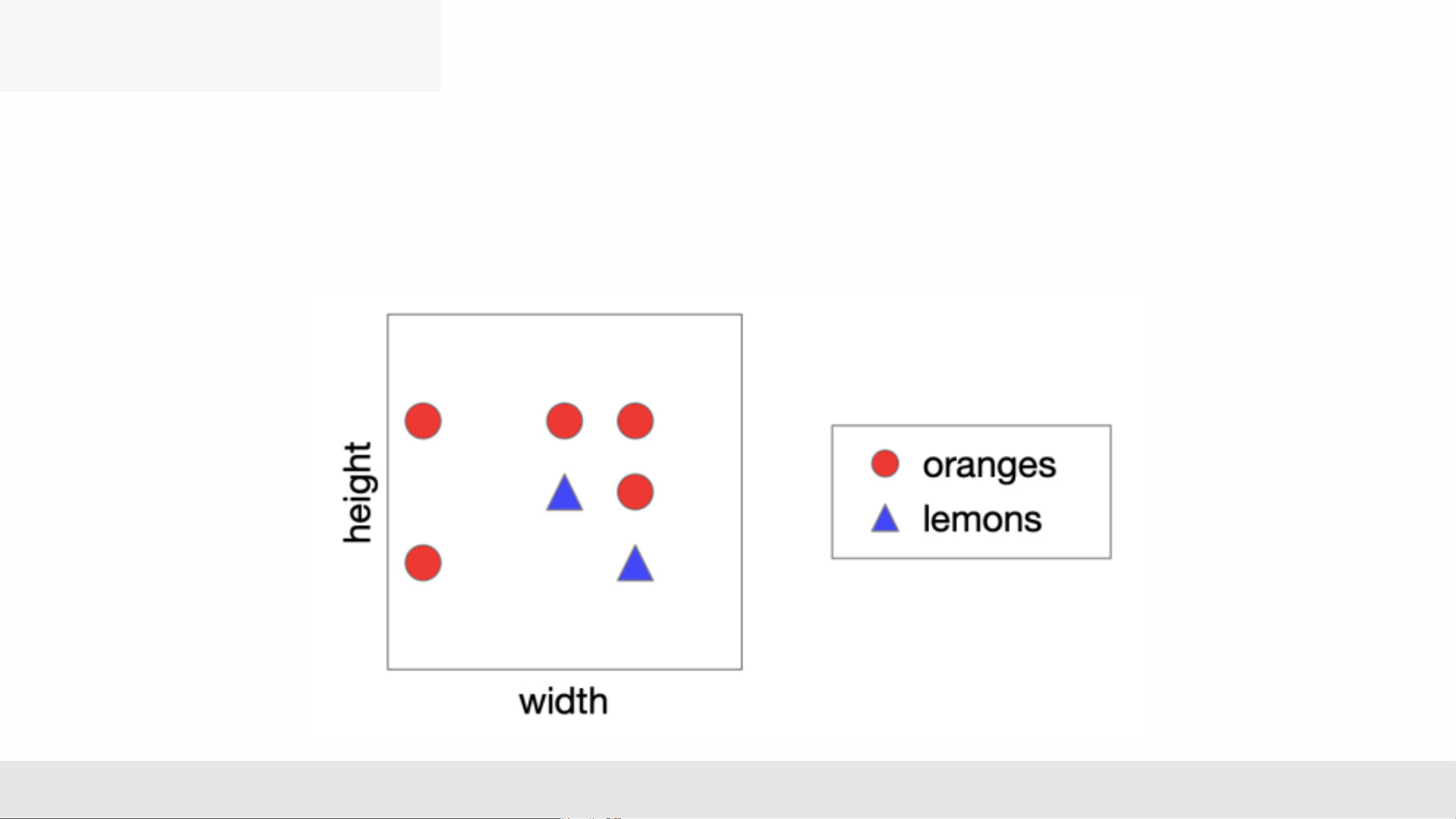
Faculty of Information Technology Fall 2025 DECISION TREE Lemons or Oranges
Scenario: You run a sorting facility for citrus fruits
• Binary classification: lemons or oranges
• Features measured by sensor on
conveyor belt: height and width MLA _Lec2 1 Decision Trees
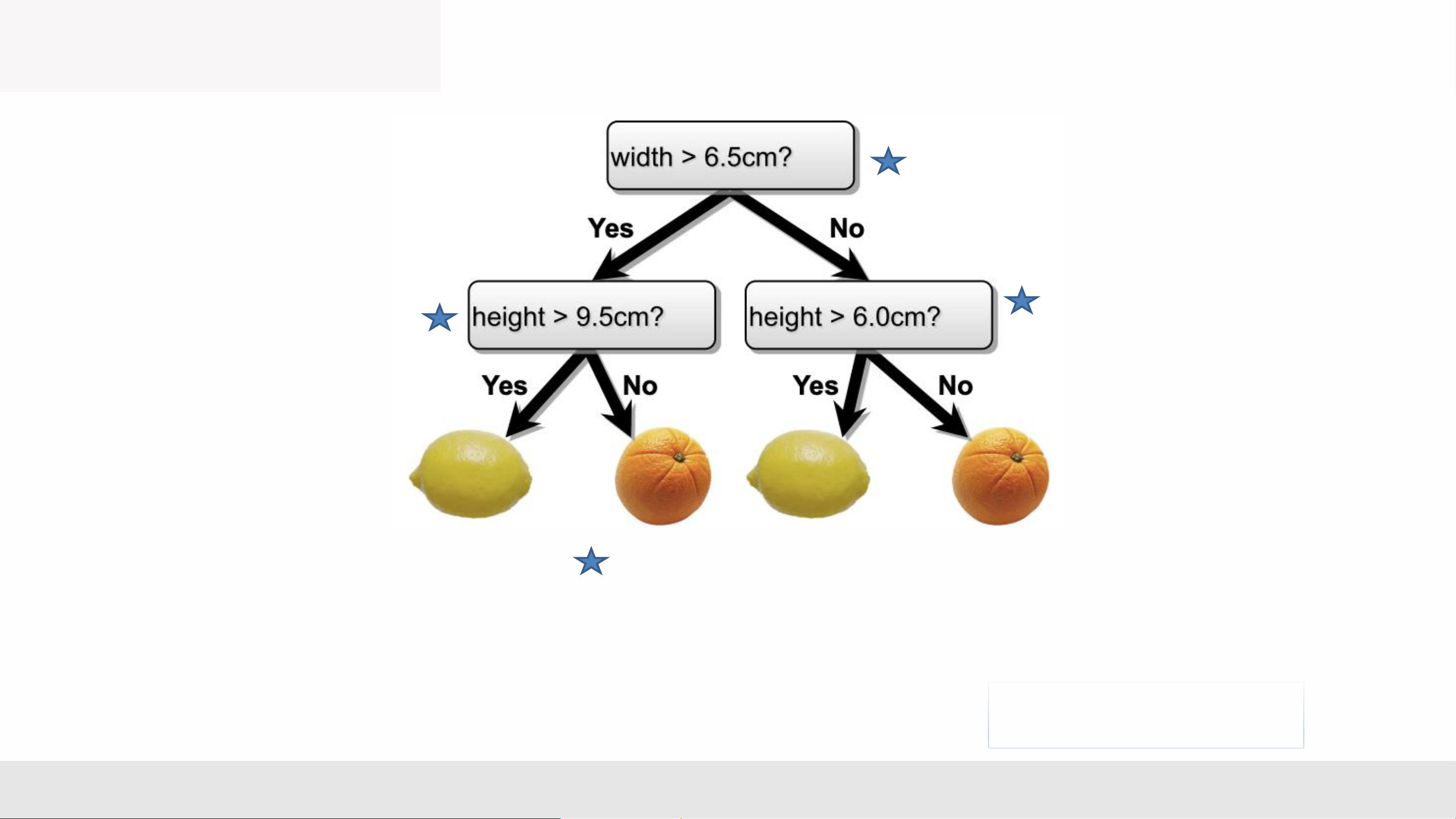
• Make predictions by splitting on features according to a tree structure. MLA _Lec2 2 Decision Trees
• Make predictions by splitting on features according to a tree structure. MLA _Lec2 3
Decision Trees—Continuous Features
• Split continuous features by checking whether that feature is greater than or less than some threshold.
• Decision boundary is made up of axis-aligned planes. MLA _Lec2 4 Decision Trees
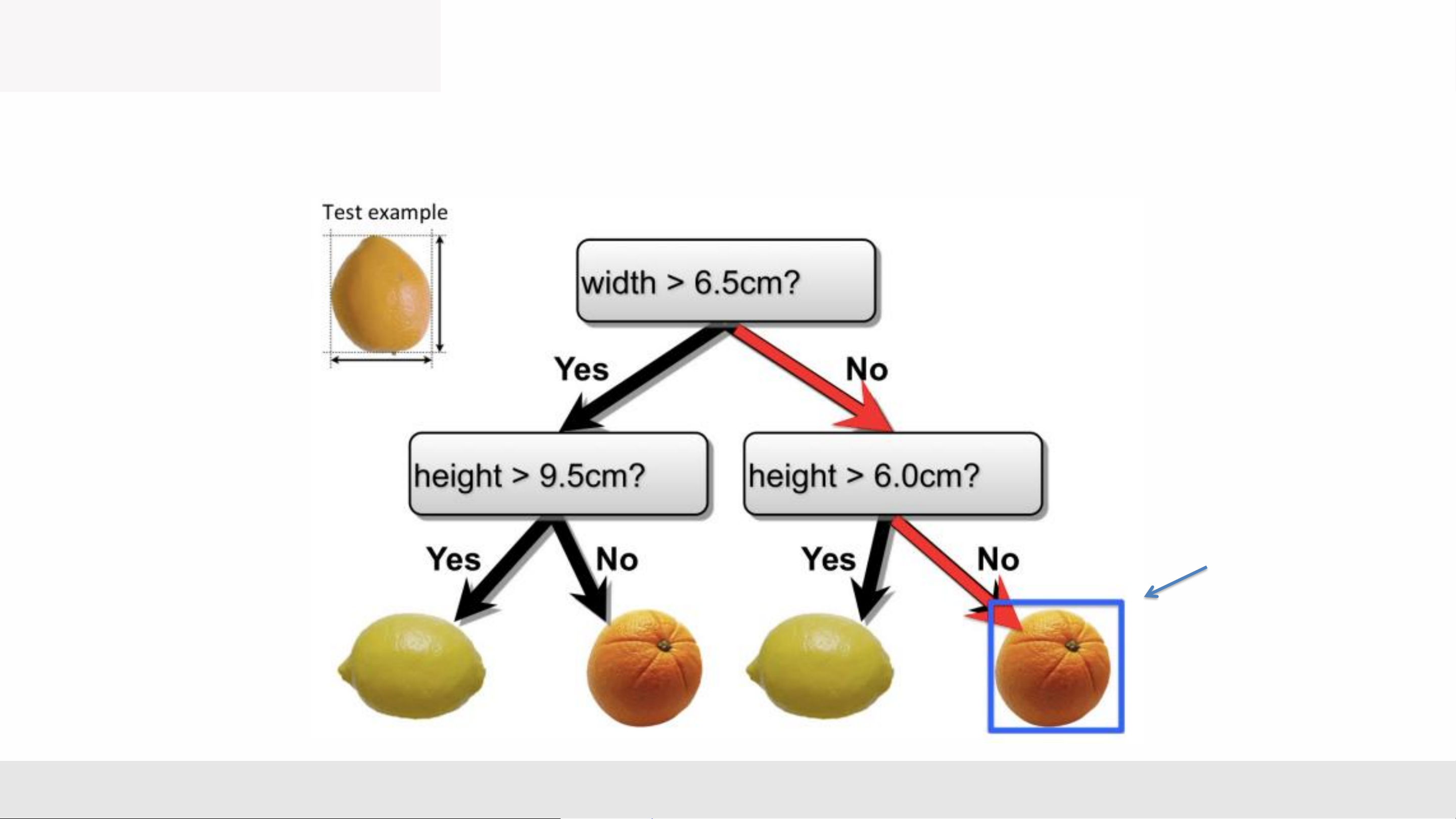
• Internal nodes test a feature
• Branching is determined by the feature value
• Leaf nodes are outputs (predictions)
Question: What are the hyperparameters of this model ? Maximum depth Hot nodes MLA _Lec2 5
Decision Trees—Classification and Regression
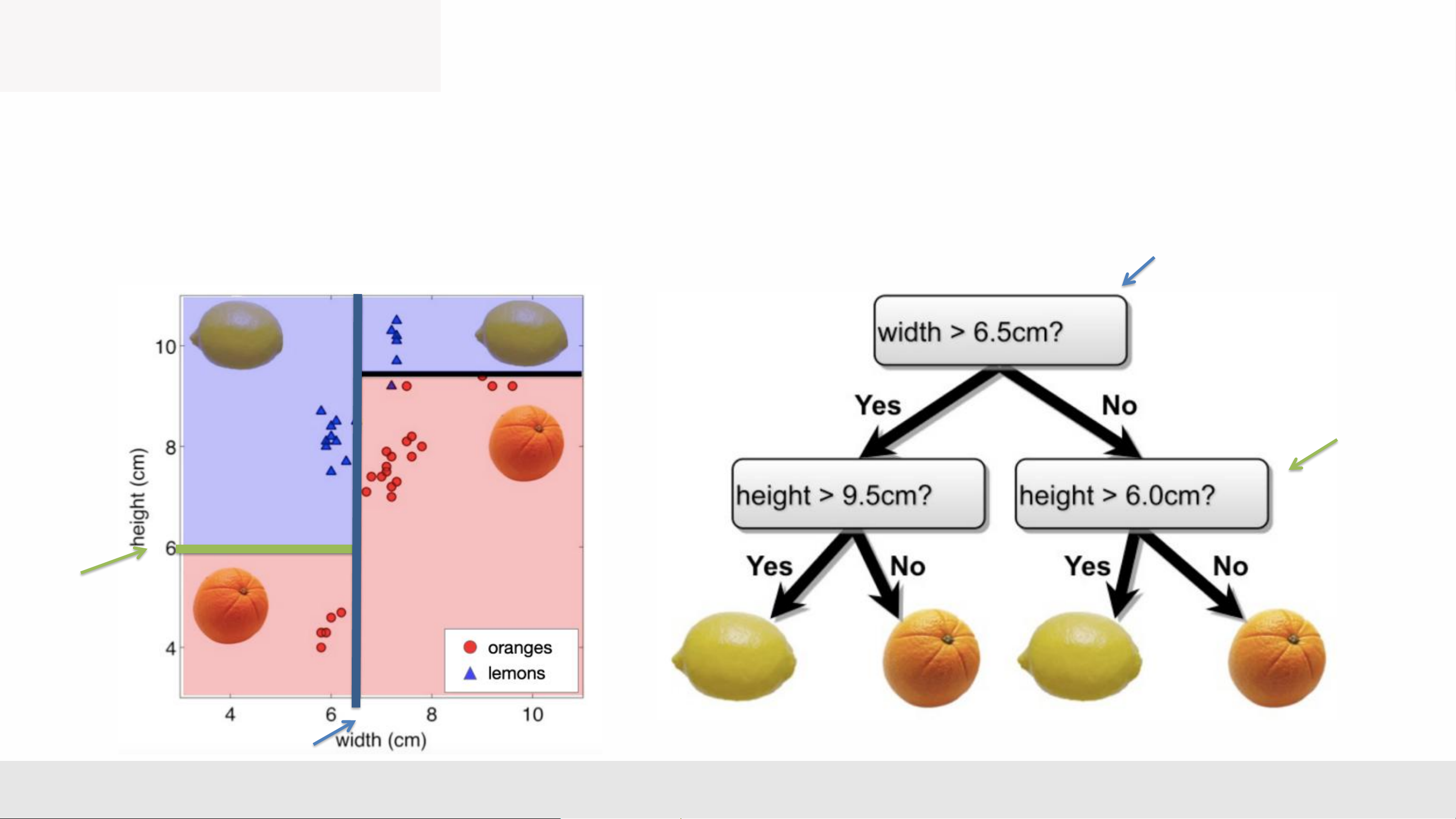
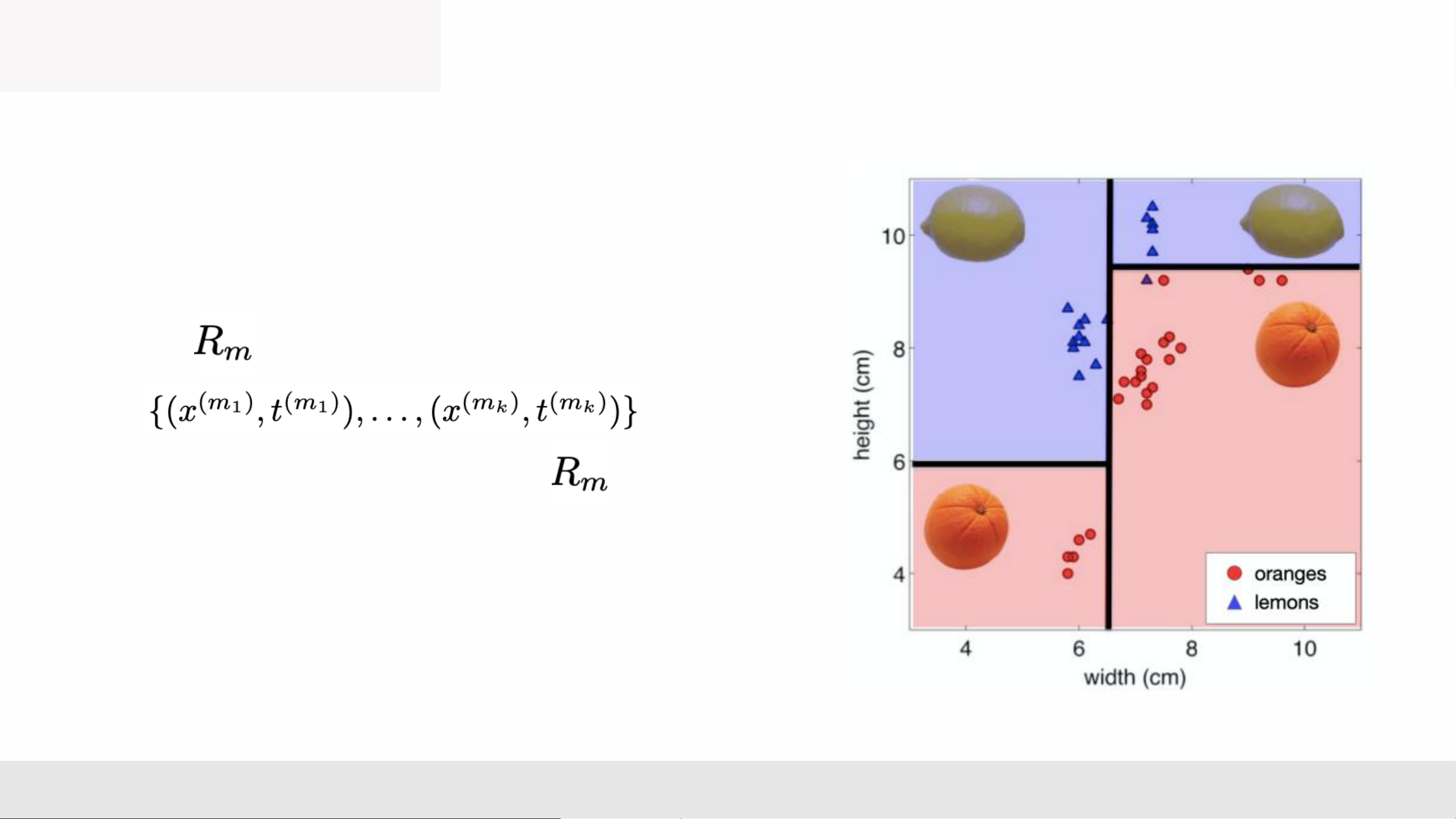
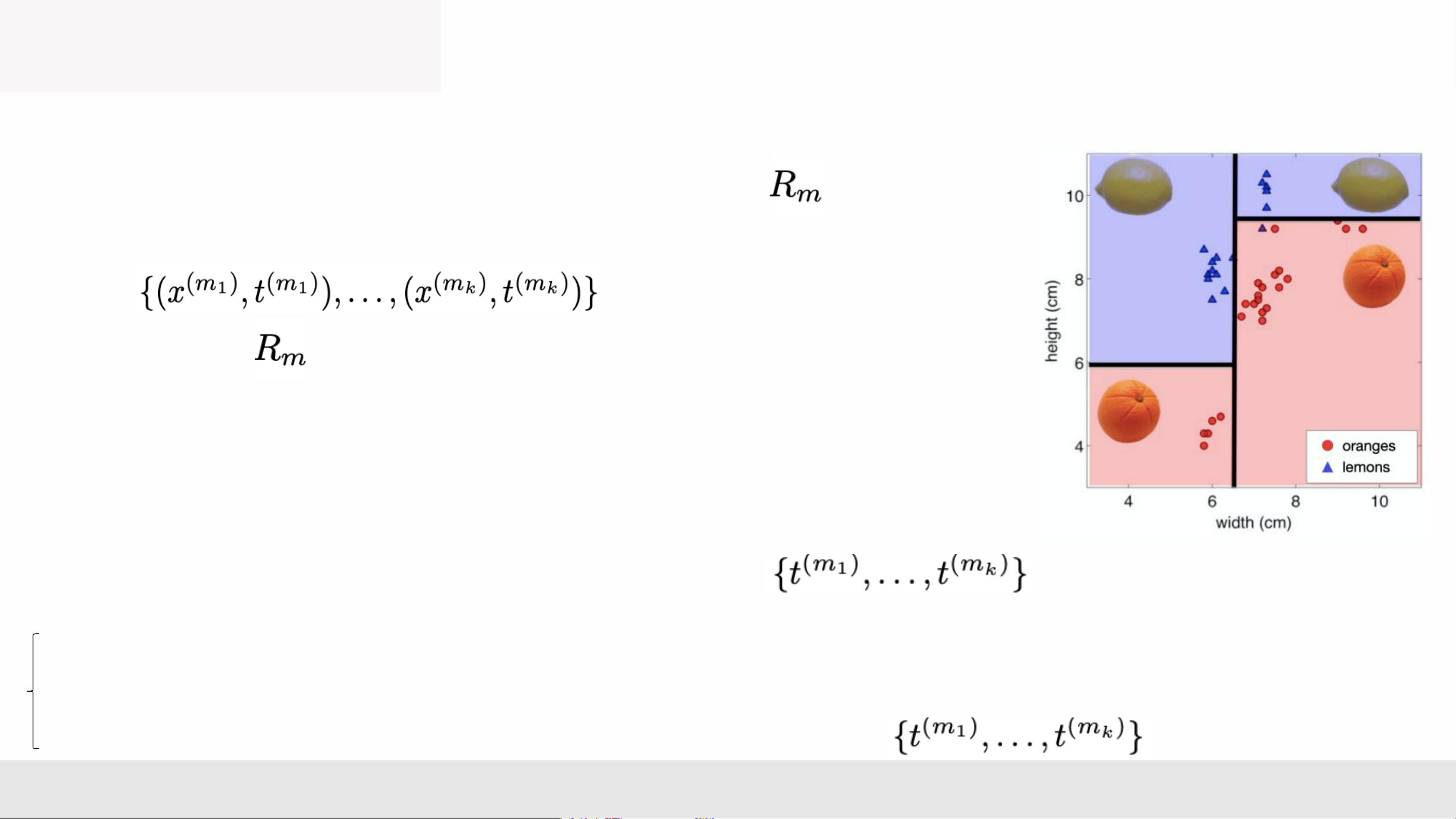
• Each path from root to a leaf defines a region of input space • Let be the training examples that fall into
• m = 4 on the right and k is the same across each region MLA _Lec2 6
Decision Trees—Classification and Regression
• Each path from root to a leaf defines a region of input space
• Let be the training examples that fall into
• m = 4 on the right and k is the same across each region • Regression tree: cây hi quy ➢ continuous output
giá tr lá y m thng c t thành giá tr trung bình trong
➢ leaf value y m typically set to the mean value in
• Classification tree (we will focus on this): cây phân loi ➢ discrete output u ra ri rc
➢ leaf value y m typically set to the most common value in t giá tr ph bin nht trong MLA _Lec2 7
Decision Trees—Discrete c dim ri rc Features
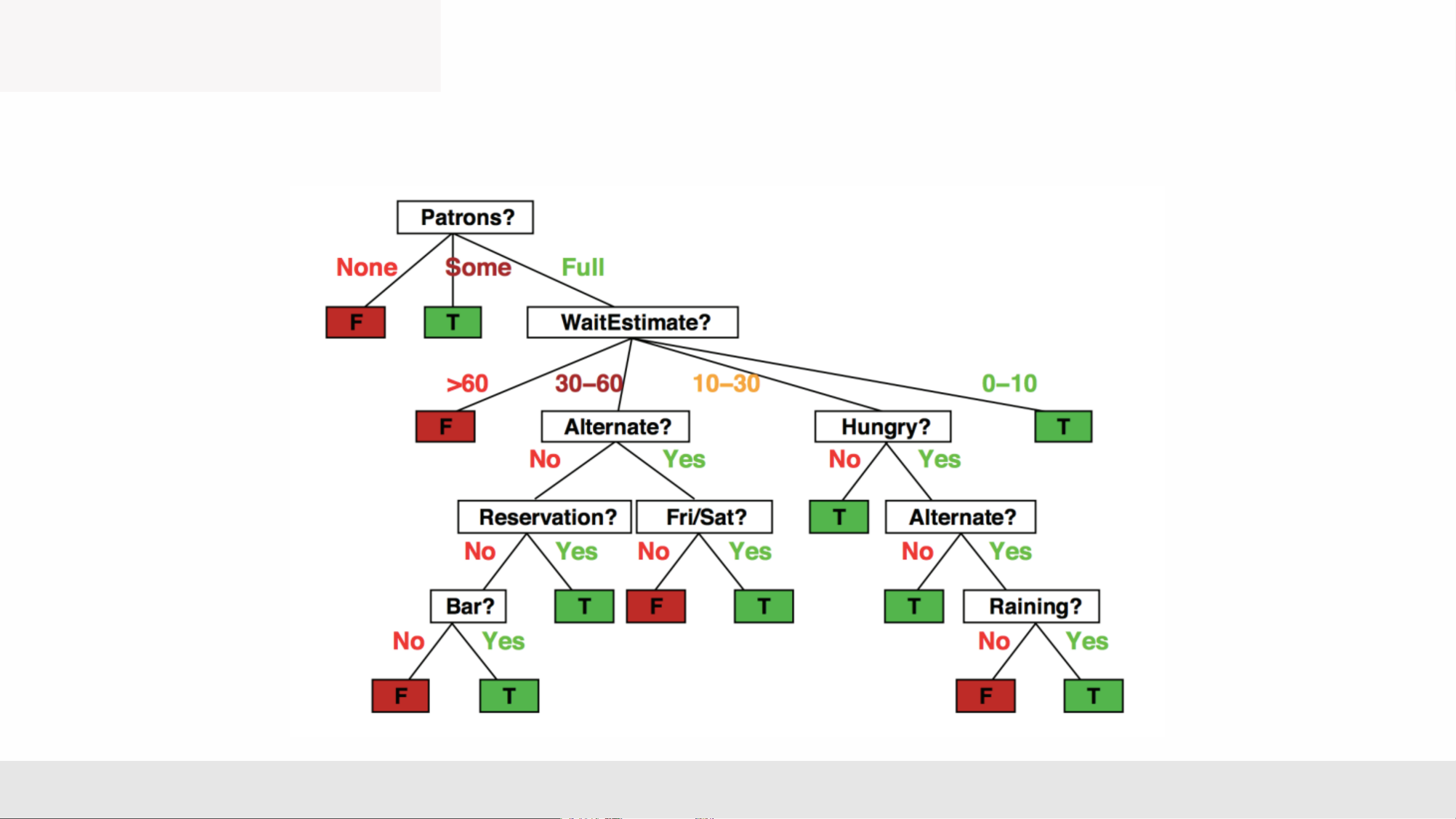
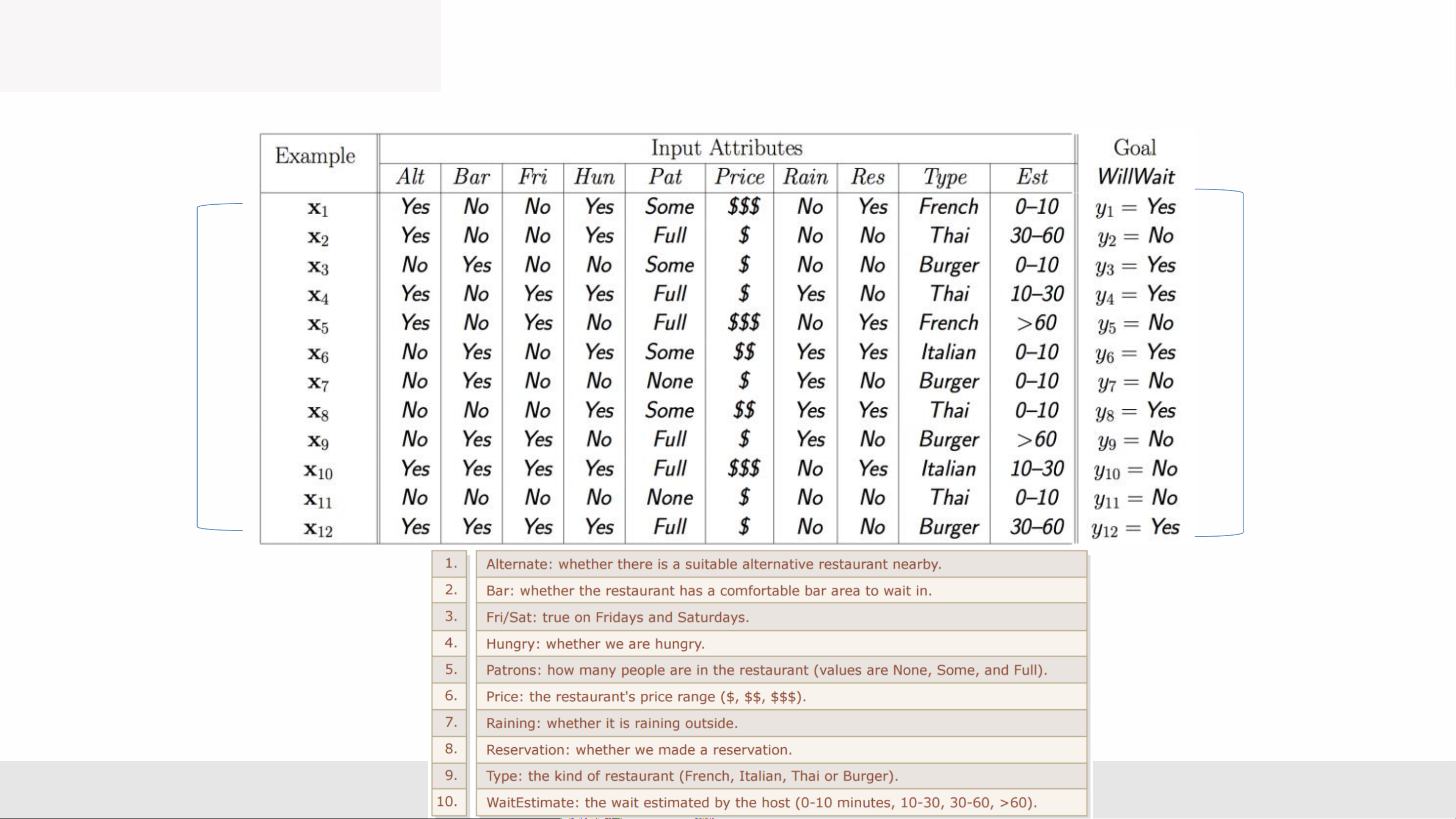
• Will I eat at this restaurant? MLA _Lec2 8
Decision Trees—Discrete Features
Chia các tính nng ri rc thành mt phân vùng các giá tr có th
• Split discrete features into a partition of possible values. Data Labels Features : MLA _Lec2 9 Learning Decision Trees
Cây quyt nh là hàm xp x ph quát
i vi bt k tp hun luyn nào, chúng ta có th xây dng mt cây quyt nh có chính xác mt lá cho mi im hun luyn, nhng nó có th s không khái quát hóa c.
• Decision trees are universal function approximators.
➢ For any training set we can construct a decision tree that has exactly the one
leaf for every training point, but it probably won’t generalize.
➢ Example : If all D features were binary, and we had N = 2 unique D training
examples, a Full Binary Tree would have one leaf per example.
• Finding the smallest decision tree that correctly classifies a training set is NP complete. (Hard problem)
➢ If you are interested, check: Hyafil & Rivest’76.
• So, how do we construct a useful decision tree? MLA _Lec2 10 Learning Decision Trees
• Resort to a greedy heuristic:
➢ Start with the whole training set and an empty decision tree.
➢ Pick a feature and candidate split that would most reduce a loss
➢ Split on that feature and recurse on subpartitions.
• What is a loss? (Metric to measure performance)
➢ When learning a model, we use a scalar number to assess whether we’re on track
➢ Scalar value: low is good, high is bad • Which loss should we use? MLA _Lec2 11 Choosing a Good Split
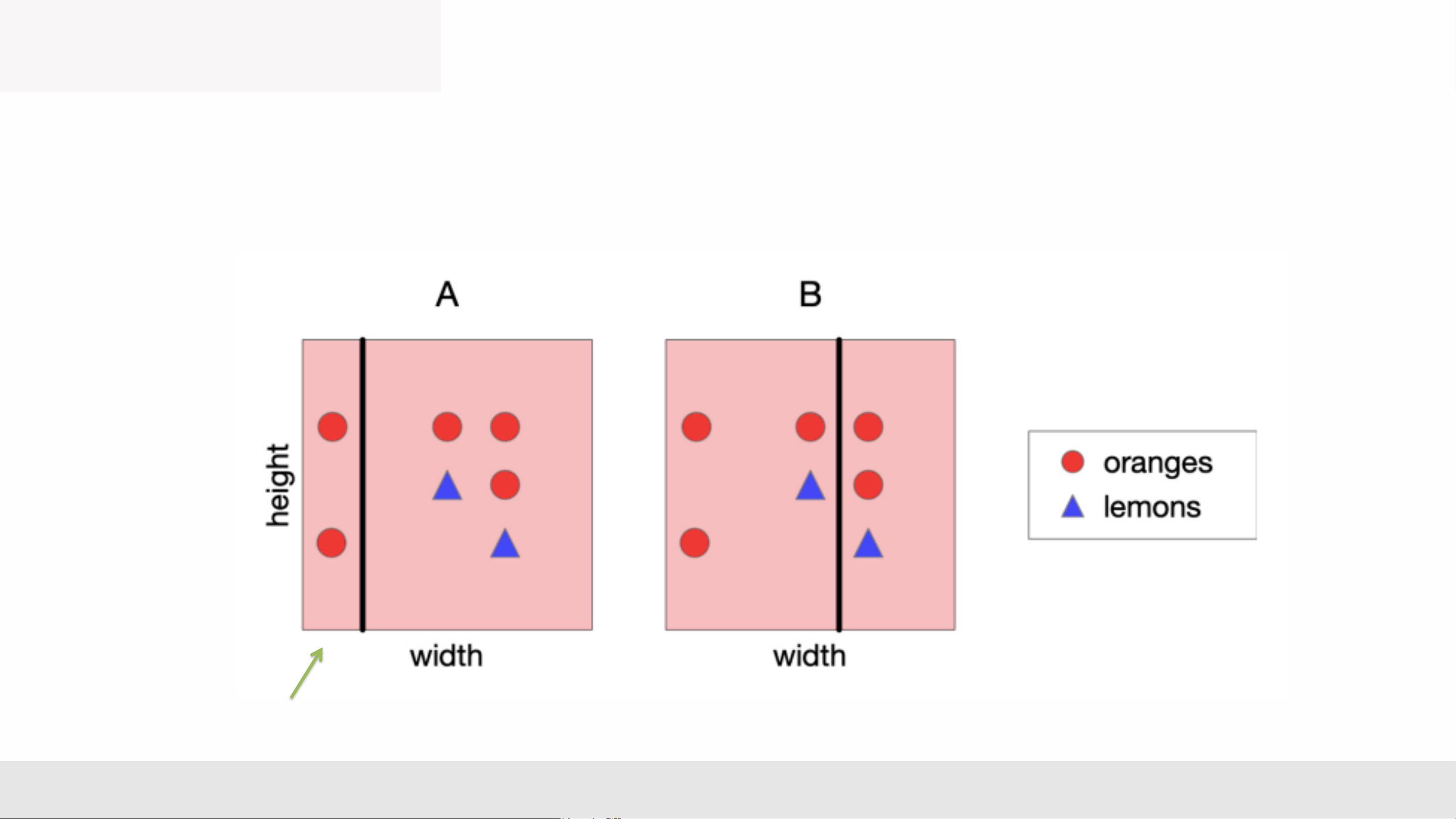
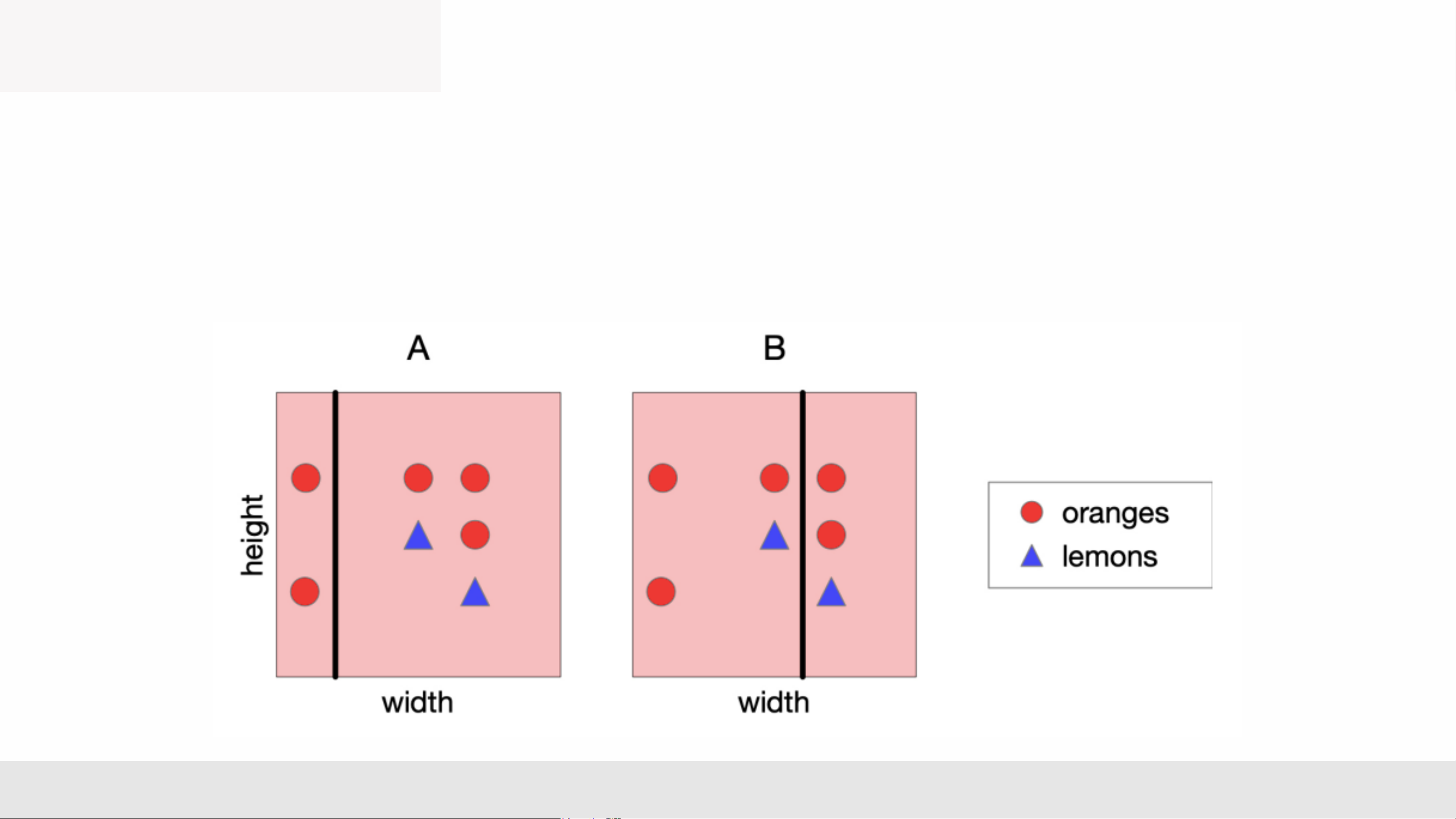
• Consider the following data. Let’s split on width. • Classify by majority. MLA _Lec2 12 Choosing a Good Split
• Which is the best split? Vote! MLA _Lec2 13 Choosing a Good Split
• A feels like a better split, because the left-hand region is very certain about whether the fruit is an orange. • Can we quantify this? nh lng MLA _Lec2 14 Choosing a Good Split
• How can we quantify uncertainty in prediction for a given leaf node?
➢ If all examples in leaf have same class: good, low uncertainty
➢ If each class has same amount of examples in leaf: bad, high uncertainty
• Idea: Use counts at leaves to define probability distributions; use a probabilistic
notion of uncertainty to decide splits.
S dng s m ti các lá xác nh phân phi xác sut; s dng khái nim xác sut v s không chc chn quyt nh phân chia.
• There are different ways to evaluate a split. We will focus on a common way: Entropy. ánh giá phép chia
• A brief detour through information theory...
Mt on ngn v lý thuyt thông tin MLA _Lec2 15 Entropy - Quantifying uncertainty
• You may have encountered the term ‘Entropy’ quantifying the state of chaos in chemical and physical systems. tính cht ca mt bin ngu nhiên
• In statistics, it is a property of a random variable.
• The entropy of a discrete random variable is a number that quantifies the uncertainty
inherent in its possible outcomes. nhng kt qu có th xy ra.
• The mathematical definition of entropy that we give in a few slides may seem arbitrary, tùy ý
but it can be motivated axiomatically.
➢ If you’re interested, check: Information Theory by Robert Ash or Elements of
Information Theory by Cover and Thomas.
• To explain entropy, consider flipping two different coins... MLA _Lec2 16
We Flip Two Different chúng ta tung hai ng xu khác nhau Coin
• Each coin is a binary random variable with outcomes 1 or 0:
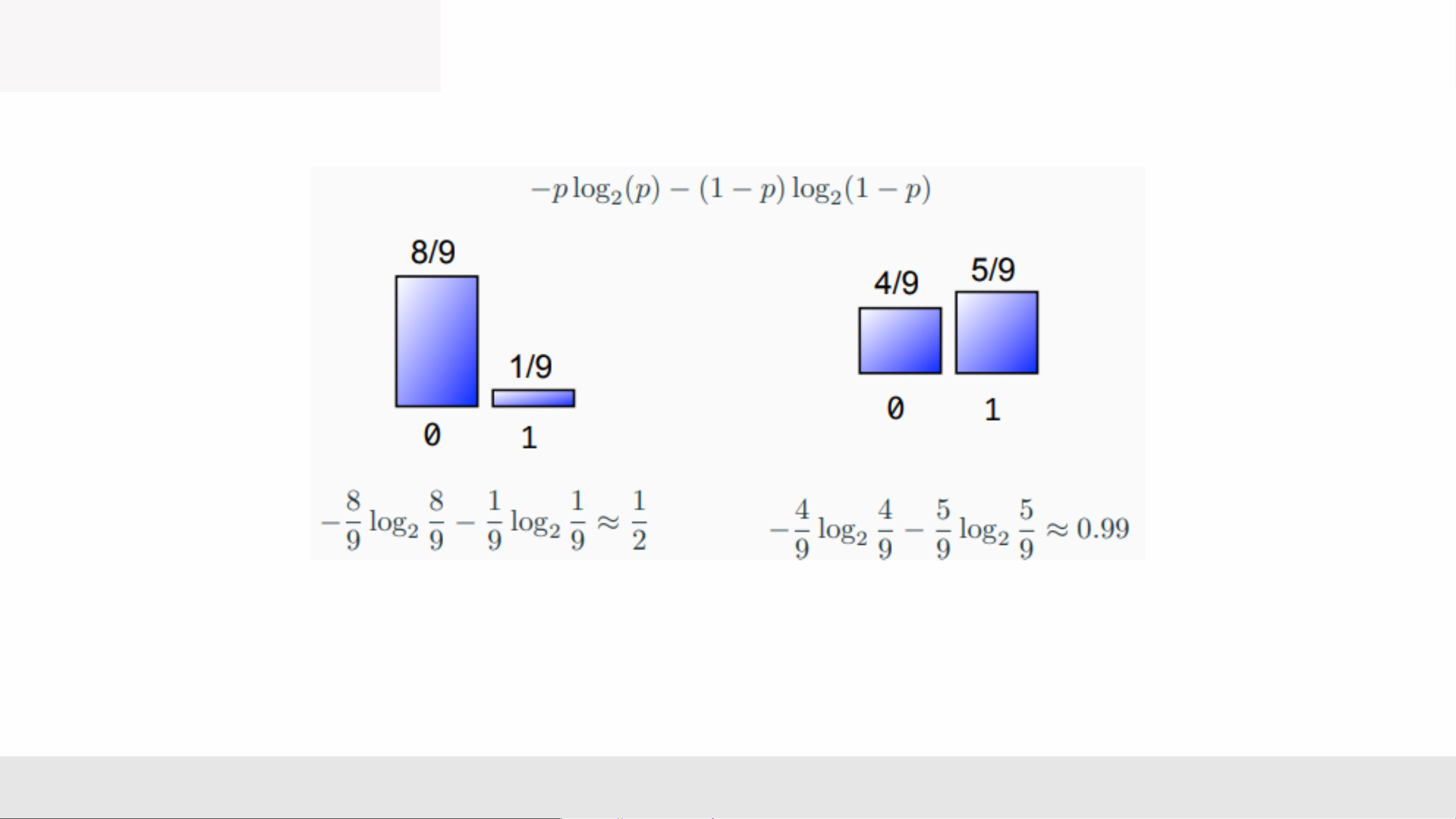
=> 1 has less uncertainty MLA _Lec2 17 Quantifying Uncertainty
Entropy ca mt ng xu có xác sut mt nga p c a ra bi
• The entropy of a loaded coin with probability p of heads is given by
• Notice: the coin whose outcomes are more certain has a lower entropy. ng xu có kt qu chc chn hn có entropy thp hn
• In the extreme case p = 0 or p = 1, we were certain of the outcome before observing.
Trong trng hp cc oan p = 0 hoc p = 1, chúng ta ã chc chn v kt qu trc khi quan sát.
So, we gained no certainty by observing it, i.e., entropy is 0. Vì vy, chúng ta không có c s chc chn nào khi quan sát nó, tc là entropy bng 0 MLA _Lec2 17
Tài liệu liên quan:
-

Bài giảng về Information Theory and Linear Regression | Trường Đại học Công nghệ, Đại học Quốc gia Hà Nội
30 15 -

Tài liệu học thuật về Deep Learning môn Học máy | Trường Đại học Công nghệ, Đại học Quốc gia Hà Nội
36 18 -

Ôn tập cuối kỳ: Regularized cost and gradient môn Học máy | Trường Đại học Công nghệ, Đại học Quốc gia Hà Nội
70 35 -

Ôn tập cuối kỳ: Logistic Regression môn Học máy | Trường Đại học Công nghệ, Đại học Quốc gia Hà Nội
65 33