Bài Tập Lớn Mạng GoogLeNet: Xây Dựng Mạng Lenet5 và Ứng Dụng | Môn Kiến trúc máy tính 1 - Đại học Xây Dựng Hà Nội
Trong những năm qua, chủ yếu là nhờ những tiến bộ của mô hình học sâu (deep learning), các mô hình mạng nơ-ron tích chập (CNN), sự chất lượng trong việc nhận dạng hình ảnh và phát hiện đối tượng đã được cải tiến với tốc độ chóng mặt. Tài liệu được sưu tầm gồm 9 trang, giúp bạn ôn tập tốt hơn. Mời các bạn đón xem.
Môn: Kiến trúc máy tính 1 (structural analysys 1) 23 tài liệu
Trường: Trường Đại học Xây Dựng Hà Nội 540 tài liệu
Tác giả:


Preview text:
lOMoAR cPSD| 58950985 MẠNG GoogLeNet 1. Giới thiệu
- Trong những năm qua, chủ yếu là nhờ những tiến bộ của mô hình học sâu(deep learning), các mô
hình mạng nơ-ron tích chập(CNN), sự chất lượng trong việc nhận dạng hình ảnh và phát hiện đối
tượng đã được cải tiến với tốc độ chóng mặt. Một điều đáng để tâm là sự cải tiến này không chỉ là
kết quả của việc phần cứng trở nên mạnh hơn, bộ dữ liệu và mô hình lớn hơn mà chủ yếu đến từ
kết quả của những ý tưởng, thuật toán mới và sự cải tiến kiến trúc mạng. Trong đó, GoogLeNet là
một ví dụ tiêu biểu trong việc cái tiến kiến trúc mạng
- GoogLeNet (hay Inception_V1) được đề xuất bởi các nhà nghiên cứu tại Google (với sự hợp tác
của nhiều trường đại học khác nhau) vào năm 2014 trong bài nghiên cứu có tiêu đề “Going Deeper
with Convolutions”. Kiến trúc này đã chiến thắng trong thử thách phân loại hình ảnh
ILSVRC 2014. Nó đã giúp tỷ lệ lỗi giảm đáng kể so với những người chiến thắng trước đó AlexNet
(Người chiến thắng ILSVRC 2012) và ZF-Net (Người chiến thắng ILSVRC 2013) và tỷ lệ lỗi ít
hơn đáng kể so với VGG (Á quân năm 2014).
2. Cơ sở lý thuyết
2.1 Convolution(Tích chập)
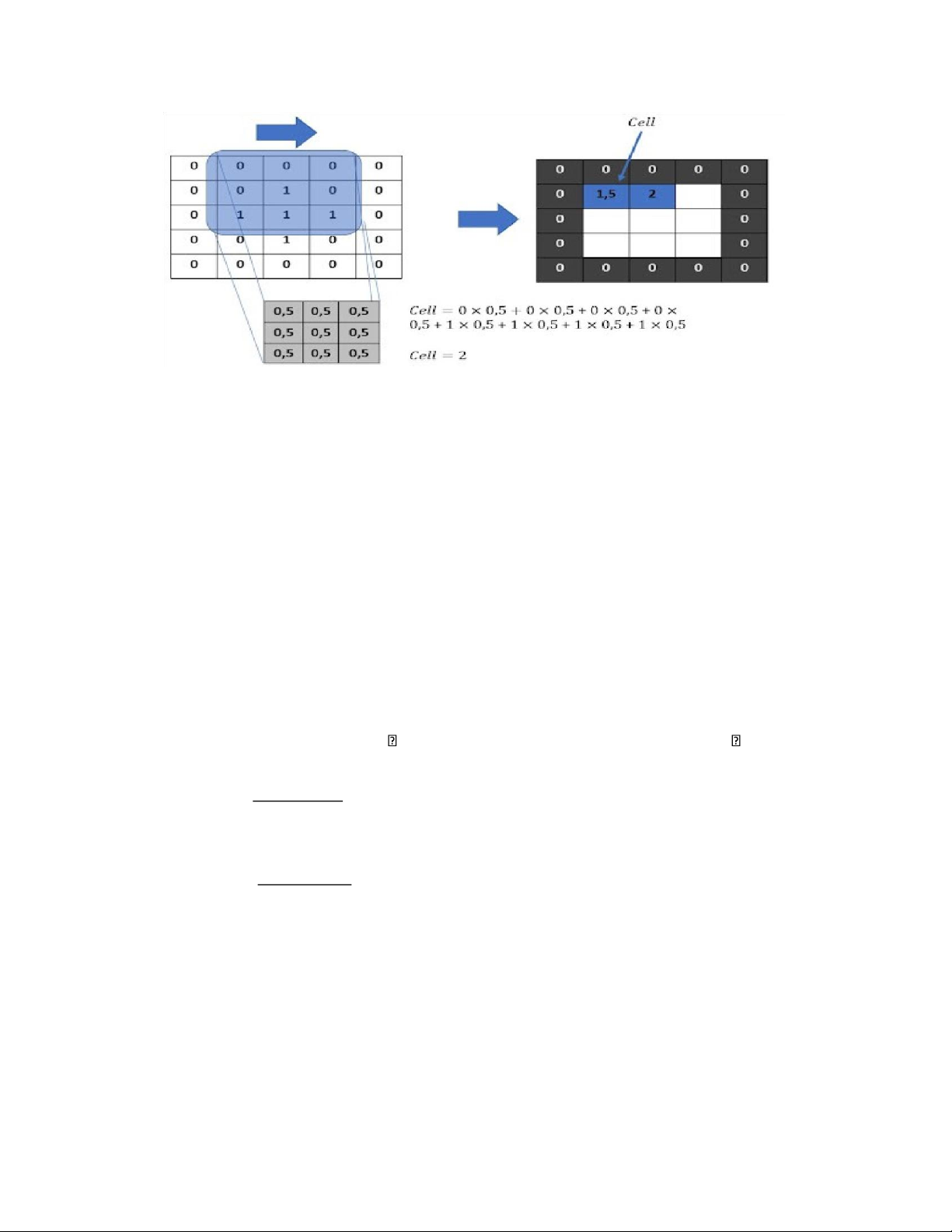
- Trong xử lý hình ảnh, tích chập(Convolution) là quá trình biến đổi hình ảnh bằng cách áp dụng hạt
nhân(kernel) trên mỗi pixel và các lân cận cục bộ của nó, trên toàn bộ hình ảnh.
- Quá trình tích chập bao gồm các bước:
(1) Nó đặt Ma trận hạt nhân(kernel) trên mỗi pixel của hình ảnh (đảm bảo rằng toàn bộ hạt nhânnằm
trong hình ảnh), nhân từng giá trị của hạt nhân với pixel tương ứng mà nó trải qua.
(2) Sau đó, tính tổng các giá trị của phép nhân ở bước (1) và trả về giá trị kết quả mới của pixeltrung tâm.
(3) Quá trình này được lặp lại trên toàn bộ hình ảnh. lOMoAR cPSD| 58950985
Hình ảnh mình họa
Công thúc 琀 nh kích thước đầu ra của ảnh sau khi áp dụng 琀 ch chập: H '=
H−Fh+2P+1 S W '=
W−Fw +2P+1 S
• H, W là chiều dài và chiều rộng của ảnh đầu vào
• H’, W’ là chiều dài và chiều rộng của ảnh đầu ra
• P là Padding(phần đệm), S là stride(bước), Fh là chiều dài của hạt
nhân, Fw là chiều rộng của hật nhân lOMoAR cPSD| 58950985 2.2 Pooling
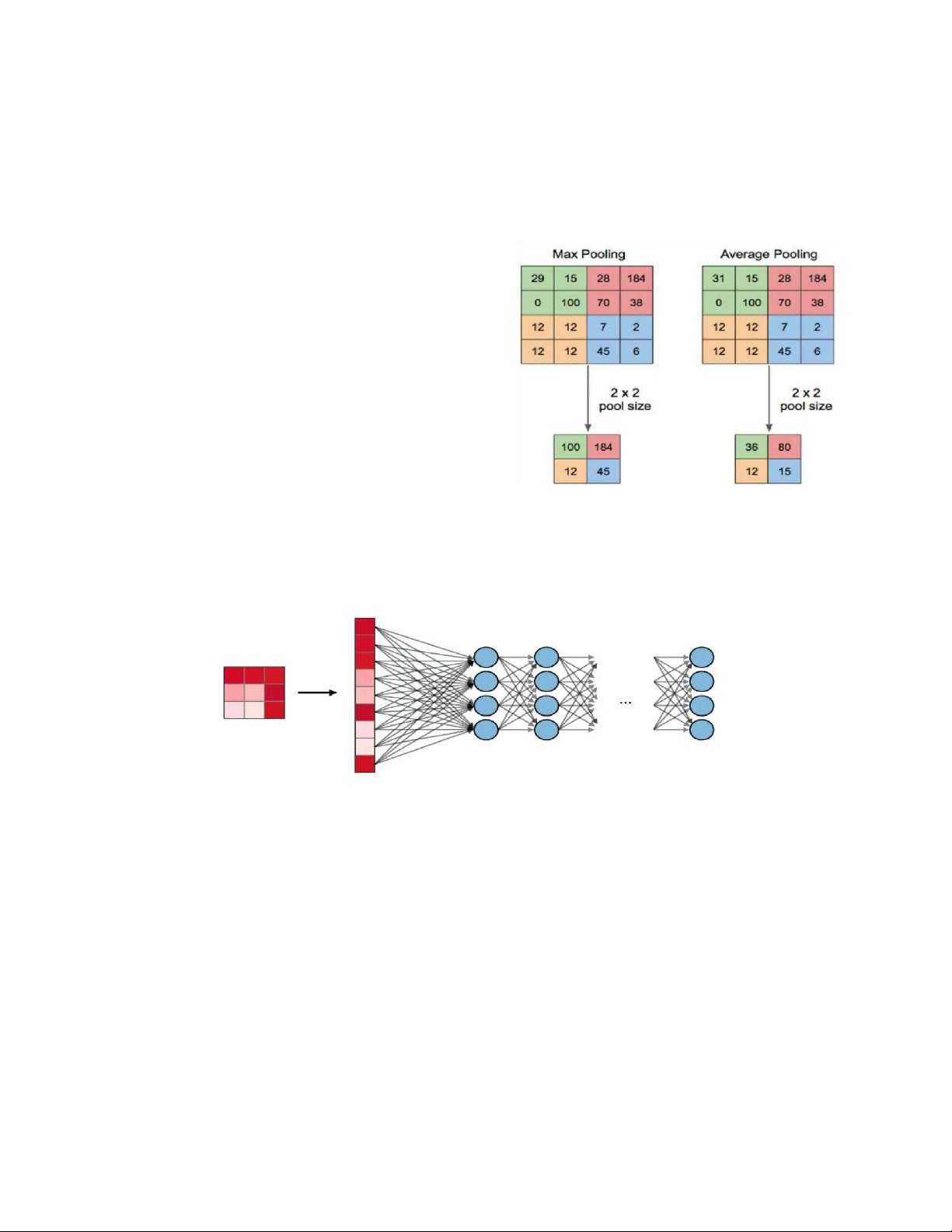
- Pooling là quá trình trích xuất các đặc điểm từ đầu ra hình ảnh của lớp tích chập. Điều này cũng sẽ
tuân theo quy trình tương tự khi trượt qua hình ảnh với kích thước nhóm/kích thước hạt nhân được chỉ định. - Có 2 loại Pooling
1. Max Pooling: giữ giá trị cao nhất trong nhóm
2. Average Pooling: tính trung bình các giá trị
trung nhóm(lấy phần chẵn)
2.3 Fully Connected (FC)
Tầng kết nối đầy đủ (FC) nhận đầu vào là các dữ liệu đã được làm phẳng, mà mỗi đầu vào đó được
kết nối đến tất cả neuron. Trong mô hình mạng CNNs, các tầng kết nối đầy đủ thường được tìm
thấy ở cuối mạng và được dùng để tối ưu hóa mục tiêu của mạng ví dụ như độ chính xác của lớp.
2.4 Softmax và ReLU Activation(Hàm kích hoạt) 1) ReLU -
Công thức: f(x) = max(0,x)
Hàm ReLU đang được sử dụng khá nhiều trong những năm gần đây khi huấn luyện các mạng
neuron. ReLU đơn giản lọc các giá trị < 0. Nhìn vào công thức chúng ta dễ dàng hiểu được cách hoạt động của nó. lOMoAR cPSD| 58950985 2) Softmax
- Softmax Function dịch ra Tiếng Việt là hàm trung bình mũ. Hàm softmax tính toán xác suất xảy ra
của một sự kiện. Nói một cách khái quát, hàm softmax sẽ tính khả năng xuất hiện của một class
trong tổng số tất cả các class có thể xuất hiện. Sau đó, xác suất này sẽ được sử dụng để xác định
class mục tiêu cho các input.
- Từ định nghĩa về hàm softmax, chúng ta có thể đoán được tính chất của nó. Dưới đây là một vài
tính chất của hàm softmax:
o Xác suất sẽ luôn nằm trong khoảng (0:1]. o Tổng tất cả các xác suất bằng 1. o Công thức: ez i σ(z)i= K ∑ez j j=1
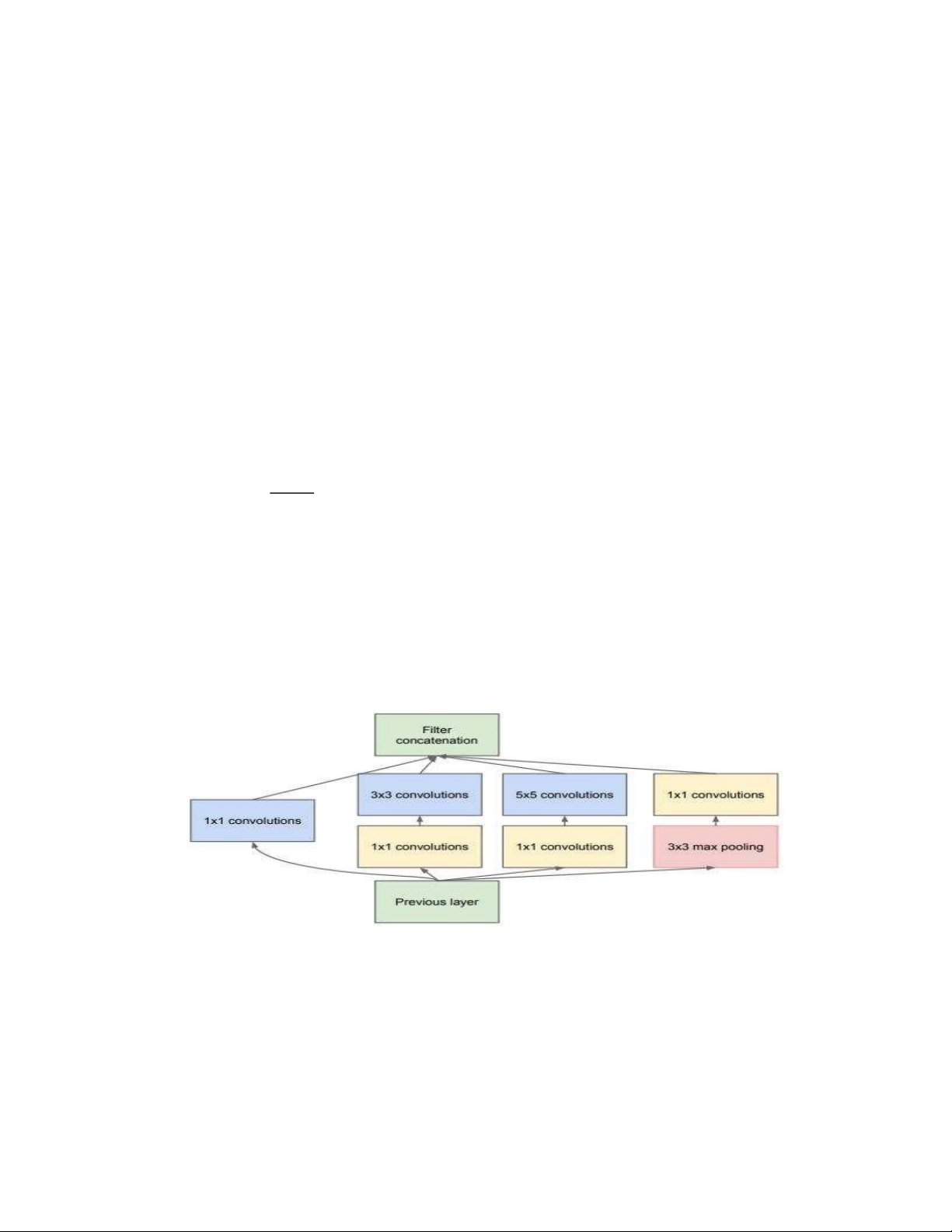
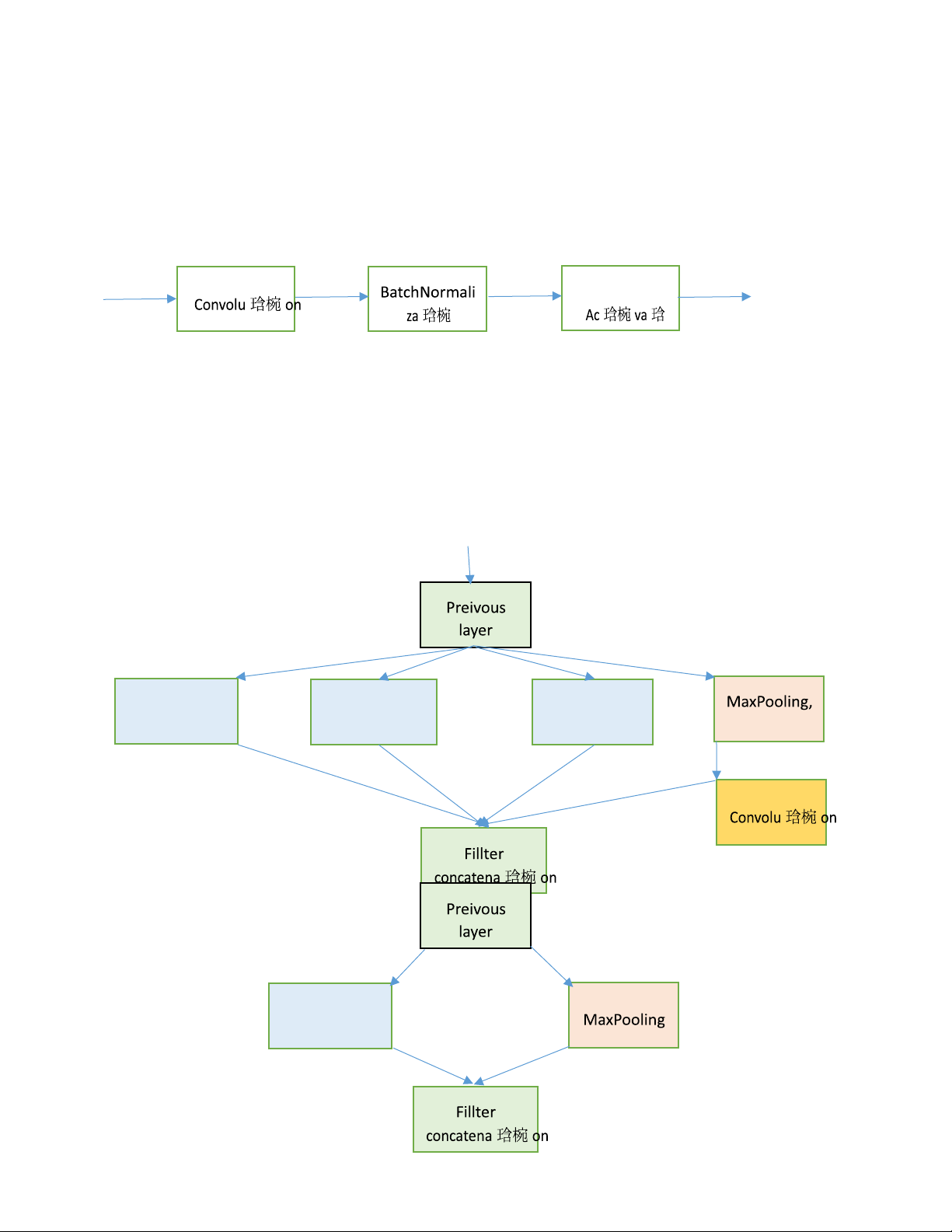
2.5 Khối Inception(Inception module with dimension reductions)
Khối tích chập cơ bản trong mô hình GoogLeNet được gọi là Inception, nhiều khả năng được đặt
tên dựa theo câu nói “Chúng ta cần đi sâu hơn” (“We Need To Go Deeper”) trong bộ phim Inception,
sau này đã tạo ra một trào lưu lan rộng trên internet.
Như mô tả ở hình trên, khối Inception bao gồm bốn nhánh song song với nhau. Ba nhánh đầu sử
dụng các tầng tích chập với kích thước cửa sổ trượt lần lượt là 1×1 , 3×3 , và 5×5 để trích xuất
thông tin từ các vùng không gian có kích thước khác nhau. Hai nhánh giữa thực hiện phép tích chập
1×1 trên dữ liệu đầu vào để giảm số kênh đầu vào, từ đó giảm độ phức tạp của mô hình. Nhánh thứ
tư sử dụng một tầng gộp cực đại kích thước 3×3 , theo sau là một tầng tích chập 1×1 để thay đổi lOMoAR cPSD| 58950985
số lượng kênh. Cả bốn nhánh sử dụng phần đệm phù hợp để đầu vào và đầu ra của khối có cùng
chiều cao và chiều rộng. Cuối cùng, các đầu ra của mỗi nhánh sẽ được nối lại theo chiều kênh để
tạo thành đầu ra của cả khối. Các tham số thường được tinh chỉnh của khối Inception là số lượng kênh đầu ra mỗi tầng.
2.6 Dropout(bỏ học)
thuật ngữ “dropout” đề cập đến việc bỏ qua các đơn vị (unit) (cả hai hidden unit và visible unit)
trong mạng neural network. Hiểu đơn giản là, trong mạng neural network, kỹ thuật dropout là việc
chúng ta sẽ bỏ qua một vài unit trong suốt quá trình train trong mô hình, những unit bị bỏ qua được
lựa chọn ngẫu nhiên. Ở đây, chúng ta hiểu “bỏ qua - ignoring” là unit đó sẽ không tham gia và đóng
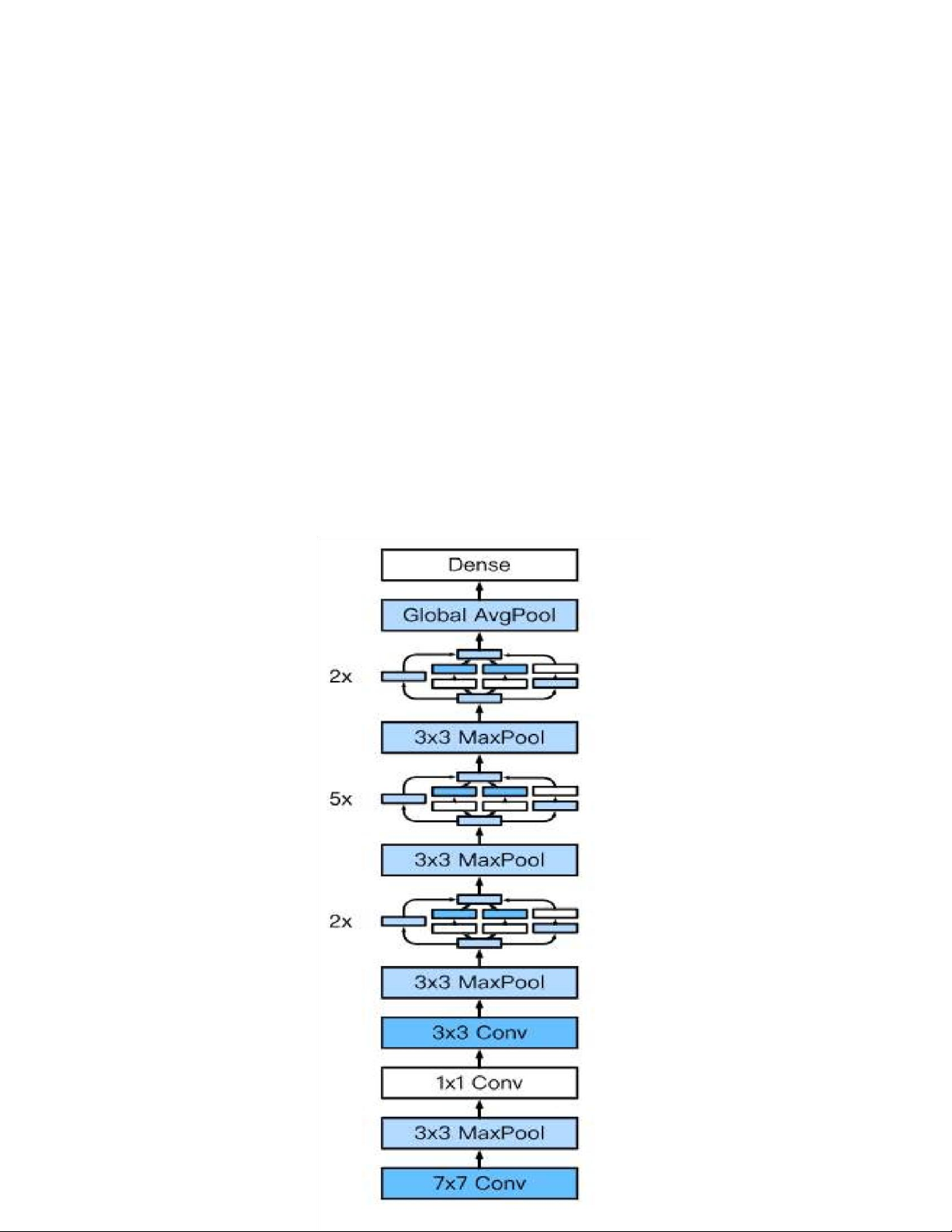
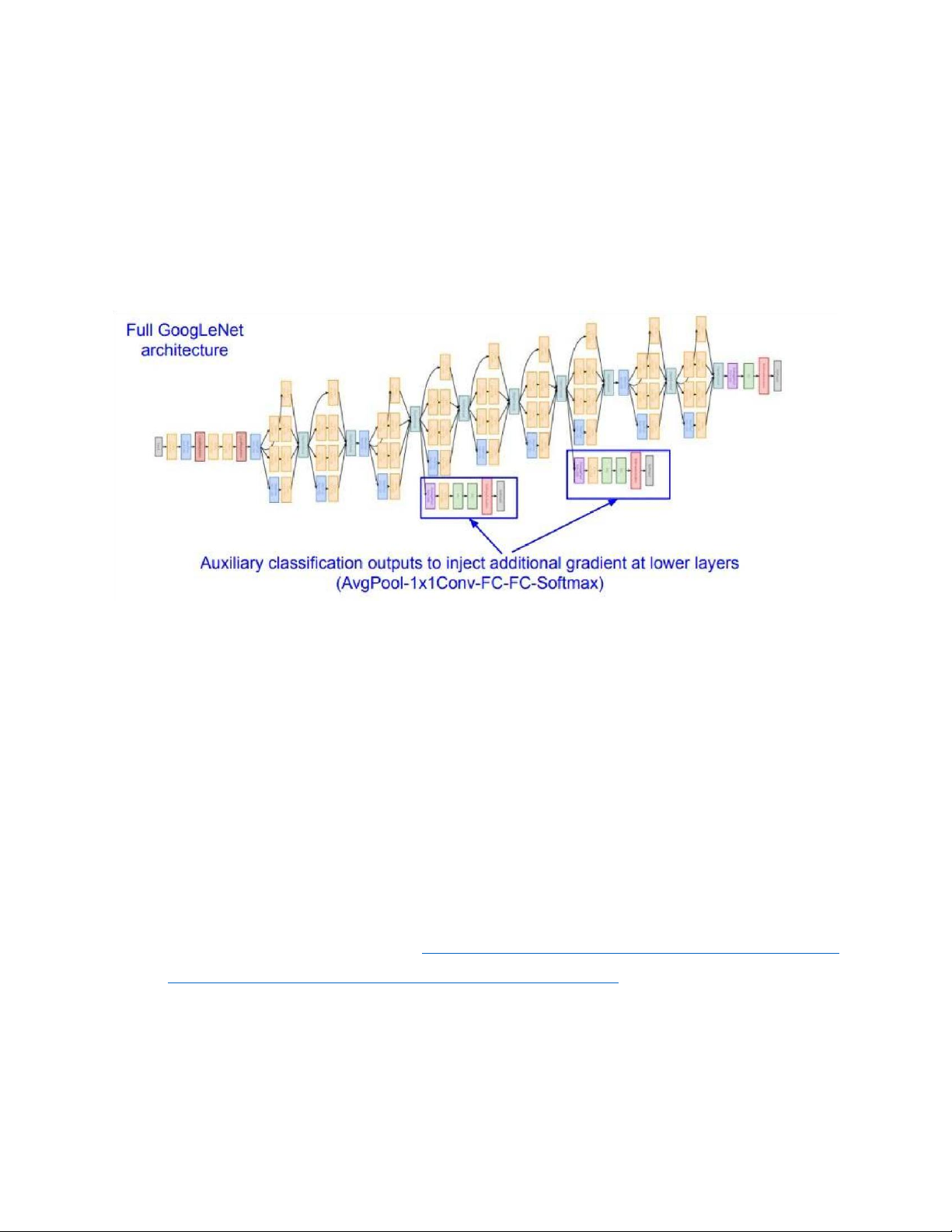
góp vào quá trình huấn luyện (lan truyền tiến và lan truyền ngược). 2.7 Mô hình kiến trúc GoogLeNet 1) Tổng Quan Mô hìnhGoogLeNet sử dụng tổng cộng 9 khốiinception và tầng gộp trung bình toàn cụcxếp chồng lên nhau. Phép gộp cựcđại(max pooling) giữa các khối inceptioncó tác dụng làm giảm kích thước
chiều.Phần đầu tiên của GoogleNet giốngAlexNet và LeNet, có các khối xếp
chồnglên nhau kế thừa từ thiết kế của VGG vàphép gộp trung bình toàn cục giúp tránh
phảisử dụng nhiều tầng
kết nối đầy đủ liên
tiếpở cuối. Cấu trúc của mô hình được mô tảnhư dưới đây. Mô hình GoogLeNet lOMoAR cPSD| 58950985
2) Chi tiết mô hình kiến trúc GoogLeNet(Dữ liệu đầu vào là 224x224x3) type patch size/ output size depth #1x1 #3x3 reduce #3x3 #5x5 reduce #5x5 pool proj stride convolution 7x7/2 112x112x64 1 max pool 3x3/2 56x56x64 0 convolution 3x3/1 56x56x192 2 64 192 max pool 3x3/2 28x28x192 0 inception (3a) 28x28x256 2 64 96 128 16 32 32 inception (3b) 28x28x480 2 128 128 192 32 96 64 max pool 3x3/2 14x14x480 0 inception (4a) 14x14x512 2 192 96 208 16 48 64 inception (4b) 14x14x512 2 160 112 224 24 64 64 inception (4c) 14x14x512 2 128 128 256 24 64 64 inception (4d) 14x14x528 2 112 144 288 32 64 64 inception (4e) 14x14x832 2 256 160 320 32 128 128 max pool 3x3/2 7x7x832 0 inception (5a) 7x7x832 2 256 160 320 32 128 128 inception (5b) 7x7x1024 2 384 192 384 48 128 128 avg pool 7x7/1 1x1x1024 0 dropout (40%) 1x1x1024 0 linear 1x1x1000 1 softmax 1x1x1000 0
- Trong mô hình GoogLeNet nguyên bản, tất cả các phép tính tích chập(Convolution), bao gồm cả
các tích chập ở trong các tích chập ở trong các khối Inception, hàm kích hoạt(activation) được sử dụng là hàm ReLU.
- “#3×3 reduce” và “#5×5 reduce” là viết tắt của số lượng hạt nhân 1x1 được sử dụng trước khi tính
toán tích châp 3x3 và 5v5 ở nhánh 2 và 3
- Pool proj” là viết tắt của số lương hạt nhân sử dụng sau khi thực hiện phép gộp cực đại(max pooling) ở nhánh 4 lOMoAR cPSD| 58950985
- Để tăng hiệu quả của việc lan truyên ngược để tính loss, chúng ta thêm các bộ phân loại
phụ(auxiliary classifiers) được kết nối với các lớp trung gian. Các bộ phân loại này có dạng các
mạng tích chập nhỏ hơn được đặt trên đầu ra của các Inception (4a) và (4d), cấu trúc là:
1. Average Pooling 5x5, stride = 3 2. Convolution 1x1x128
3. Fully Connected với 1024 unit 4. Dropout layer với tỉ lệ 70%
5. Áp dụng Softmax để phân loại
3. Phương pháp thực hiện
- Trong phần trên, chúng ta đã được giới thiệu qua những cơ sở lý thuyết cần có để thực hiện kiến
trúc mạng GoogLeNet. Qua đó chúng ta có thể áp dụng mô hình trên để thực hiện hiện phân loại
ảnh của tập dữ liệu Cifar-10
- Trước hết, chúng ta cần lưu ý rằng, mục địch ban đầu của mô hình GoogLeNet là để phân loại ảnh
trong tập dữ liệu ImageNet, có kích thước ảnh là 224x224.Trong khi đó, kích thước ảnh của tập dữ
liệu Cifar-10 là 32x32. Vì thế nếu chúng ta bê nguyên mô hình đã được giới thiệu ở phần 2 để phân
loại tập Cifar-10 thì sẽ không nhận được hiệu quả tốt
- Chính vì vậy, để có thể áp dụng Mô hình GoogLeNet lên tập dữ liệu Cifar-10 chúng ta cần thay đổi
kiến trúc khối Inception, cùng với các thông số sao cho phù hợp. - Tài liệu tham khảo:
https://machinelearningknowledge.ai/googlenet-architecture-
implementationin-keras-with-cifar-10-dataset/#Inception_Module
3.1 Xử lý dữ liệu lOMoAR cPSD| 58950985
a) “Trung bình hóa”(mean normalization) ở tiền xử lý dữ liệu 1.
Tính giá trị trung bình (mean) của mỗi cột trong ma trận dữ liệu
X: mean = np.mean(X, axis=0) 2. Trừ giá trị trung bình (mean) từng
phần tử trong từng cột của X: X -= mean b) Batch Normalization
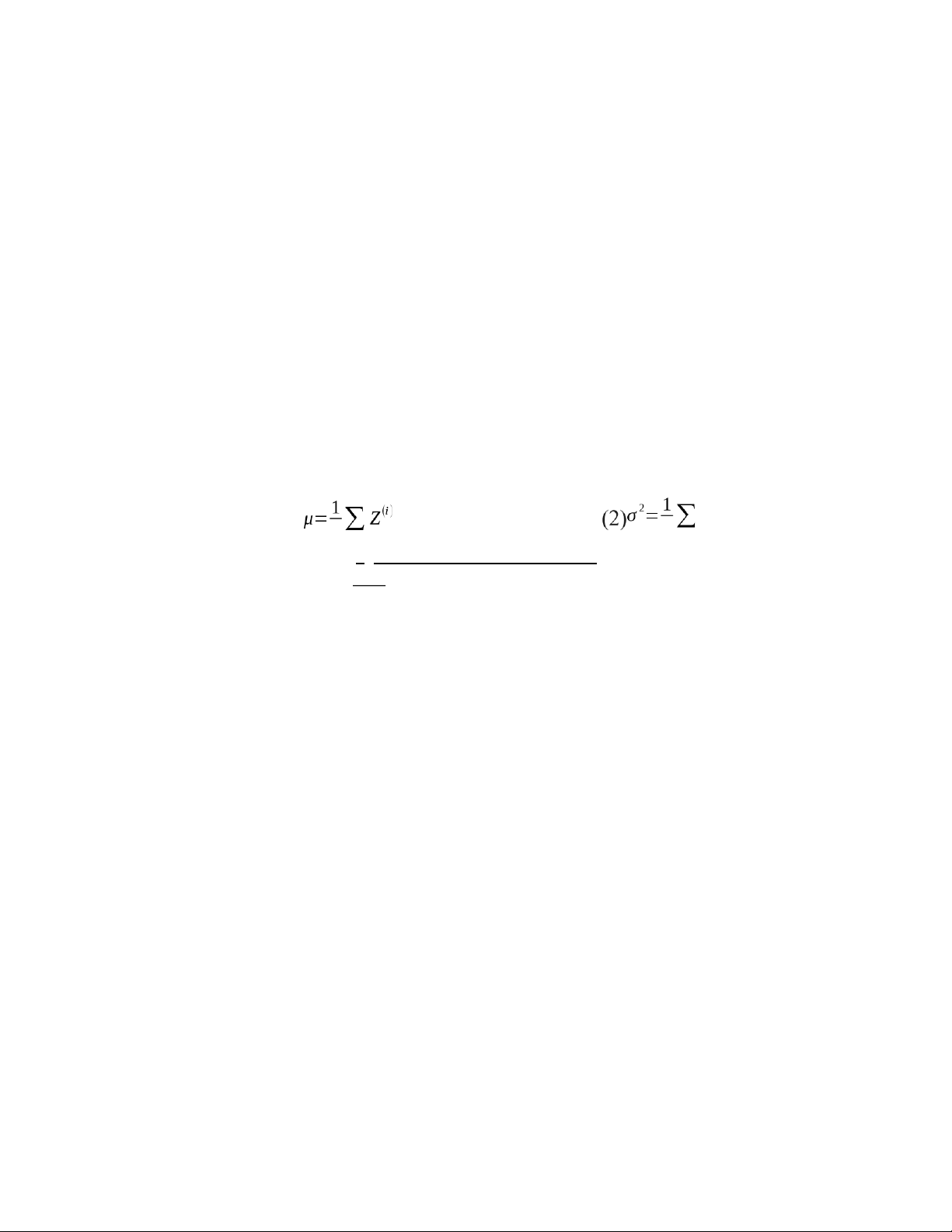
- Batch-Normalization (BN) là phương pháp khiến cho việc huấn luyện mạng nơ rông sâu (Deep
Nearon Network, DNN) nhanh và ổn định hơn.
- Nó bao gồm chuẩn hoá các vectors của lớp ẩn (hidden layers) sử dụng trung bình và phương sai
(mean và variance) của batch hiện tại. Bước chuẩn hoá có thể được áp dụng ngay trước hoặc ngay
sau một hàm phi tuyến tính. - Công thức: (1) n i n i ¿¿¿ (i)
Z(i)−μ
(4¿Z°=w×Z (normi) +β) (3)Znorm= 2−ϵ √σ lOMoAR cPSD| 58950985
- Code python: ta có thể sử dụng hàm BatchNormalization trong keras
3.2 Kiến trúc GooGleNet áp dụng cho Cifar-10
1) Convolutional Module(Gọi tắt là Conv_modul) ReLU 2) Inception Module Conv_module Conv_module Conv_module stride = 1 3) Downsample Module Conv_module
Tài liệu liên quan:
-

Tính Thời Vụ Trong Du Lịch: Nhận Diện & Giải Pháp Khắc Phục
17 9 -

Ngành Hạt Trần - Gymnospermae: Đặc Điểm và Phân Loại Chi Tiết
29 15 -

Tài liệu về Mô hình Cấu trúc Tuyến tính SEM (CB-SEM, PLS-SEM)
26 13 -

BÀI GIẢI MẪU XÂY DỰNG HỆ THỐNG THÔNG TIN CHO TRUNG TÂM THUÊ BĂNG ĐĨA
28 14 -
Giải bài tập LTM2: Đáp án cho mạch điện lý thuyết và thực hành
31 16