Bài Tập Phân Lớp Sử Dụng Phần Mềm Orange | Các thành phần phần mềm | Trường Đại học Khoa học Tự nhiên, Đại học Quốc gia Hà Nội
Mô tả dữ liệu Attrition-Train là dữ liệu dung để nghiên cứu sự sụt giảm hay tiêu hao dần dần của lực lượng lao động với nhiều tác động như quyền chọn cổ phiếu, thu nhập hàng tháng, vai trò công việc, số năm làm việc ở công ty, tuổi tác, giới tính, độ hài long trong công việc… Tiền xử lý dữ liệu Bước 1: Mở dataset, tìm Attrition-Train Bước 2: Nhấp vào Data Table nối từ data set, dữ liệu không có missing value nên không cần tiền xử lý dữ liệu. Tài liệu được sưu tầm và soạn thảo dưới dạng file PDF để gửi tới các bạn cùng tham khảo, ôn tập đầy đủ kiến thức, chuẩn bị cho các buổi học thật tốt. Mời bạn đọc đón xem!
Môn: Các thành phần phần mềm (HUS) 11 tài liệu
Trường: Trường Đại học Khoa học tự nhiên, Đại học Quốc gia Hà Nội 1.1 K tài liệu
Tác giả:



Preview text:
Mã sinh viên Họ tên Máy số
Bài tập phân lớp sử dụng phần mềm Orange, sử dụng dữ liệu từ dataset: Attrition-Train, Attrition-
Predict. Lưu kết quả phân tích thành các tập tin:
- Mã SV-Bai Tap B4.ows (file orange)
- Mã SV-Bai Tap B4.docx (file bài làm)
- Mã SV-Bai Tap B4.xlsx (file dự báo)
1. Tiền xử lý dữ liệu (nếu cần), thống kê mô tả các biến, loại bỏ các biến không cần thiết. Mô tả dữ liệu
Attrition-Train là dữ liệu dung để nghiên cứu sự sụt giảm hay tiêu hao dần dần của lực lượng lao
động với nhiều tác động như quyền chọn cổ phiếu, thu nhập hàng tháng, vai trò công việc, số năm
làm việc ở công ty, tuổi tác, giới tính, độ hài long trong công việc… Tiền xử lý dữ liệu
Bước 1: Mở dataset, tìm Attrition-Train
Bước 2: Nhấp vào Data Table nối từ data set, dữ liệu không có missing value nên không cần tiền xử lý dữ liệu
Hình 1.1: Bảng Data Set
Thống kê mô tả các biến Bước 1: Dùng Feature
Statistics nối từ data set để thống kê dữ liệu
Hình 1.2: Các bước
thống kê mô tả
Hình 1.3: Kết quả thống kê mô tả
Loại bỏ các biến không cần thiết
Bước 1: Chọn rank để xác định các dữ liệu không có ý nghĩa/ý nghĩa thấp
Trong dữ liệu này, các dữ liệu không có ý nghĩa cao gồm: - YearsSinceLastPromotion - Education - PercentSalaryHike - Gender - PerformanceRating
Hình 1.4: Các bước loại biến
Bước 2: Dùng rank loại bỏ các biến trên
2. Sử dụng phương pháp Hồi qui logistic (Logistic Regression), SVM, cây quyết định (Tree) tiến
hành phân lớp. Chụp lại các màn hình kết quả và giải thích các lựa chọn.
Phân tích, đánh giá các phương pháp bằng ma trận nhầm lẫn và ROC? Các bước thực hiện
Bước 1: Gọi ra màn hình phương pháp Hồi qui logistic (Logistic Regression), SVM, cây quyết định (Tree)
Bươc 2: Tạo Test and Score, nối các phương pháp trên và data với Test and Score
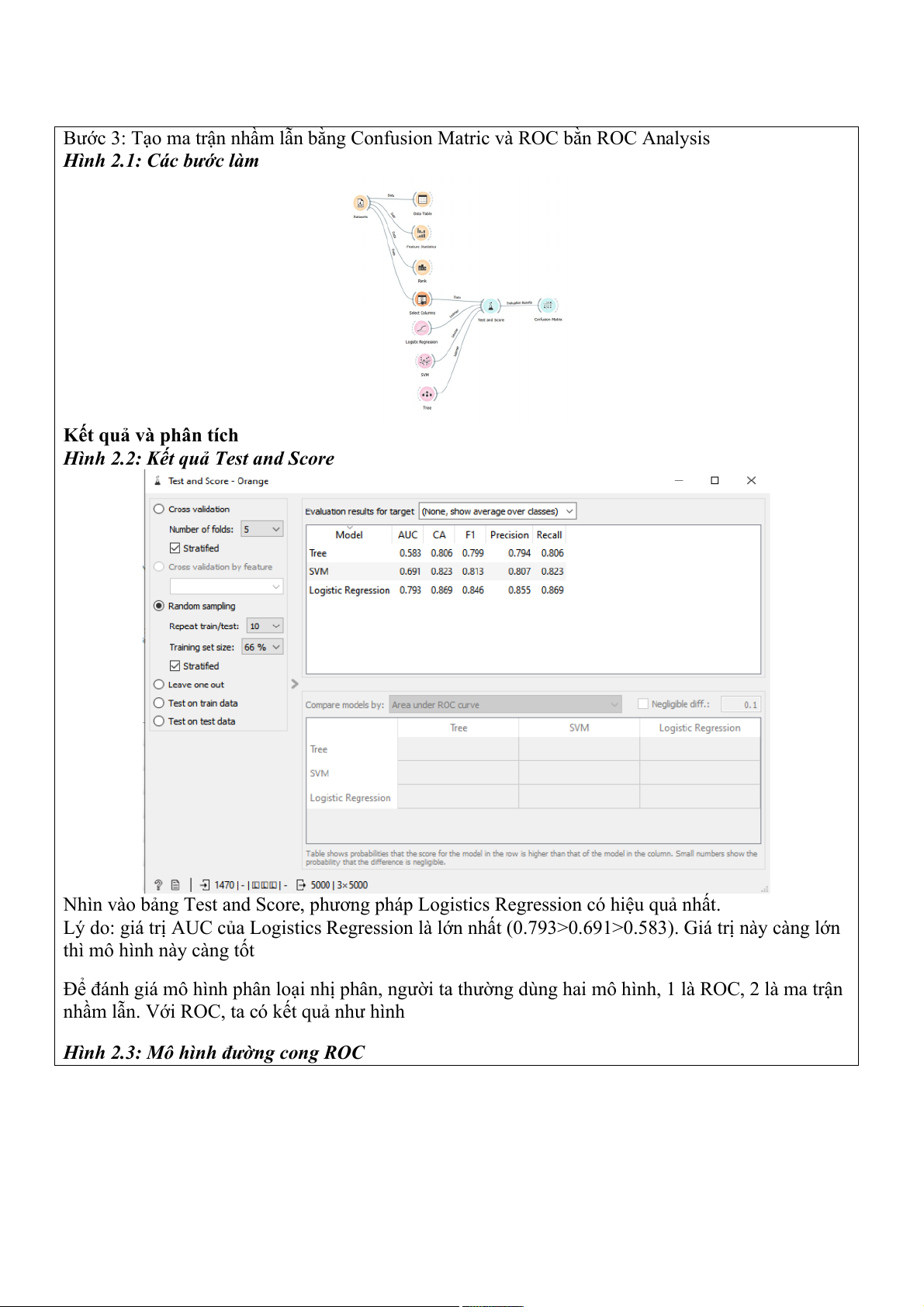
Bước 3: Tạo ma trận nhầm lẫn bằng Confusion Matric và ROC bằn ROC Analysis
Hình 2.1: Các bước làm Kết quả và phân tích
Hình 2.2: Kết quả Test and Score
Nhìn vào bảng Test and Score, phương pháp Logistics Regression có hiệu quả nhất.
Lý do: giá trị AUC của Logistics Regression là lớn nhất (0.793>0.691>0.583). Giá trị này càng lớn
thì mô hình này càng tốt
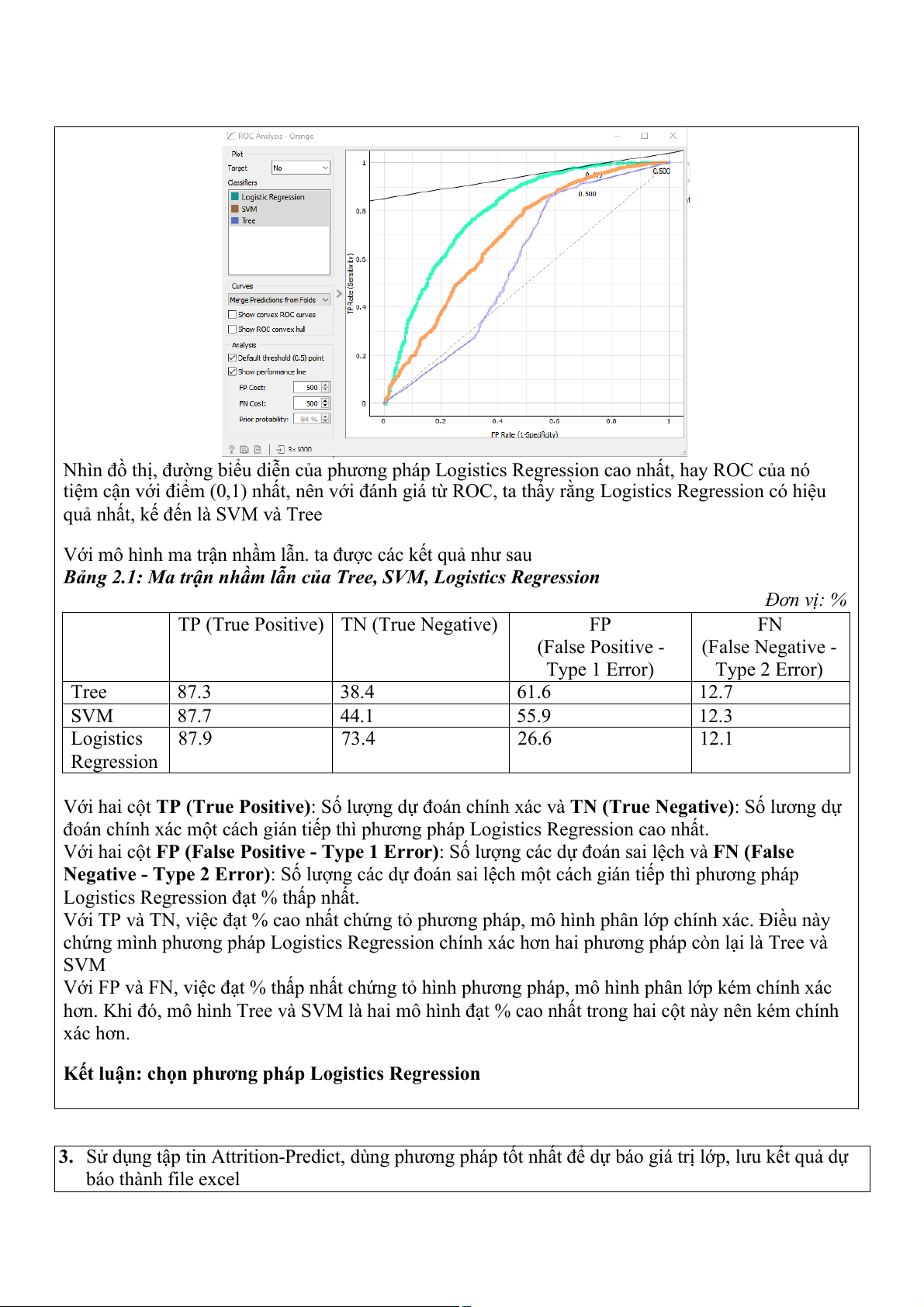
Để đánh giá mô hình phân loại nhị phân, người ta thường dùng hai mô hình, 1 là ROC, 2 là ma trận
nhầm lẫn. Với ROC, ta có kết quả như hình
Hình 2.3: Mô hình đường cong ROC
Nhìn đồ thị, đường biểu diễn của phương pháp Logistics Regression cao nhất, hay ROC của nó
tiệm cận với điểm (0,1) nhất, nên với đánh giá từ ROC, ta thấy rằng Logistics Regression có hiệu
quả nhất, kế đến là SVM và Tree
Với mô hình ma trận nhầm lẫn. ta được các kết quả như sau
Bảng 2.1: Ma trận nhầm lẫn của Tree, SVM, Logistics Regression Đơn vị: %
TP (True Positive) TN (True Negative) FP FN (False Positive - (False Negative - Type 1 Error) Type 2 Error) Tree 87.3 38.4 61.6 12.7 SVM 87.7 44.1 55.9 12.3 Logistics 87.9 73.4 26.6 12.1 Regression
Với hai cột TP (True Positive): Số lượng dự đoán chính xác và TN (True Negative): Số lương dự
đoán chính xác một cách gián tiếp thì phương pháp Logistics Regression cao nhất.
Với hai cột FP (False Positive - Type 1 Error): Số lượng các dự đoán sai lệch và FN (False
Negative - Type 2 Error): Số lượng các dự đoán sai lệch một cách gián tiếp thì phương pháp
Logistics Regression đạt % thấp nhất.
Với TP và TN, việc đạt % cao nhất chứng tỏ phương pháp, mô hình phân lớp chính xác. Điều này
chứng mình phương pháp Logistics Regression chính xác hơn hai phương pháp còn lại là Tree và SVM
Với FP và FN, việc đạt % thấp nhất chứng tỏ hình phương pháp, mô hình phân lớp kém chính xác
hơn. Khi đó, mô hình Tree và SVM là hai mô hình đạt % cao nhất trong hai cột này nên kém chính xác hơn.
Kết luận: chọn phương pháp Logistics Regression
3. Sử dụng tập tin Attrition-Predict, dùng phương pháp tốt nhất để dự báo giá trị lớp, lưu kết quả dự báo thành file excel
Bước 1: Từ dataset cho ra dữ liệu Attrition-Predict
Bước 2: Nối datasets ban đầu vào Logistics Regression, từ Logistics Regression tạo thành Prediction,
từ Prediction tạo thành Data Table -> Save Data
Bước 3: Nối Attrition-Predict vào Prediction
Bước 4: Lưu dữ liệu vào file xlsx
Hình 3.1: file excel
Hình 3.2: Bảng kết quả từ Prediction
4. Dán hình WorFlow bài làm vào khung bên dưới:
Tài liệu liên quan:
-

khoa hoc vat lieu chuan 129 tin chi
11 6 -

Yêu cầu chức năng hệ thống | Các thành phần phần mềm | Trường Đại học Khoa học Tự nhiên, Đại học Quốc gia Hà Nội
59 30 -

Phân Tích Phần Mềm iPOS Trong Quản Trị Kinh Doanh | Các thành phần phần mềm | Trường Đại học Khoa học Tự nhiên, Đại học Quốc gia Hà Nội
69 35 -

Mô hình hóa Kiến trúc Doanh nghiệp bằng ArchiMate | Các thành phần phần mềm | Trường Đại học Khoa học Tự nhiên, Đại học Quốc gia Hà Nội
62 31