Báo cáo bài tập lớn: Tóm tắt văn bản Tiếng Việt bằng NLP môn Xử lý ngôn ngữ tự nhiên | Trường Đại học Bách Khoa Hà Nội
Tóm tắt văn bản là bài toán đưa ra đoạn nội dung tóm tắt, chứa các ý chính, cho một hoặc nhiều văn bản đầu vào. Tài liệu được sưu tầm gồm 14 trang, giúp các bạn ôn luyện và phục vụ cho việc học tập, đạt kết quả tốt. Mời các bạn đón xem!
Môn: Xử lý ngôn ngữ tự nhiên 12 tài liệu
Trường: Đại học Bách Khoa Hà Nội 5.8 K tài liệu
Tác giả:











Preview text:
lOMoAR cPSD| 59703641
ĐẠI HỌC BÁCH KHOA HÀ NỘI
TRƯỜNG CÔNG NGHỆ THÔNG TIN VÀ TRUYỀN THÔNG
──────── * ───────
Báo cáo bài tập lớn Xử lý
ngôn ngữ tự nhiên
Tóm tắt trích rút đơn văn bản Tiếng Việt
GVHD: PGS. TS. Lê Thanh Hương
Mã học phần: IT4772 - Mã lớp: 128763 Nhóm 04 Hoàng Thế Anh 20172945 Nguyễn Quang Phúc 20173304 Võ Đức Quân 20173320 Hoàng Thị Hảo 20173100
Hà Nội, tháng 01 năm 2022 Mục lục
1. Giới thiệu đề tài .......................................................................................................... 3
1.1. Giới thiệu bài toán ............................................................................................... 3
1.2. Dữ liệu sử dụng ................................................................................................... 3
2. Phương pháp thực hiện ............................................................................................... 4
2.1. Các bước thực hiện .............................................................................................. 4
2.2. Phương pháp sử dụng pretrained BERT .............................................................. 5
2.3. Phương pháp sử dụng pretrained Word2Vec ....................................................... 6
3. Đánh giá kết quả ......................................................................................................... 8
3.1. Cách tính ROUGE Score ..................................................................................... 8
3.1.1. ROUGE-N .......................................................................................................... 8
3.1.2. ROUGE-L .......................................................................................................... 9
3.2. Cách tính BERT Score ...................................................................................... 10
3.3. Kết quả với ROUGE Score ............................................................................... 12
3.3.1. Kết quả của phương pháp sử dụng pretrained Word2Vec ................................ 12
3.3.2. Kết quả của phương pháp sử dụng pretrained BERT ....................................... 12
3.4. Kết quả với BERT Score ................................................................................... 13
Tài liệu tham khảo ........................................................................................................ 14
1. Giới thiệu đề tài
1.1. Giới thiệu bài toán
Tóm tắt văn bản là bài toán đưa ra đoạn nội dung tóm tắt, chứa các ý chính, cho một
hoặc nhiều văn bản đầu vào. Bài toán có thể được phân loại theo một số cách như:
- Tóm tắt đơn văn bản: Tóm tắt nội dung của một văn bản, có thể gồm nhiều đoạn văn.
- Tóm tắt đa văn bản: Tóm tắt nội dung của nhiều văn bản.
- Tóm tắt trích rút: Nội dung của đoạn tóm tắt là các câu thuộc văn bản đầu vào.
- Tóm tắt tóm lược: Nội dung của đoạn tóm tắt là các câu được sinh ra dựa trên
việc hiểu ý nghĩa của văn bản đầu vào.
Trong đề tài này, nhóm em thực hiện bài toán “Tóm tắt trích rút đơn văn bản Tiếng
Việt”. Bài toán được thực hiện theo phương pháp học không giám sát, dựa trên việc
phân cụm các câu sau khi thực hiện mã hóa chúng bằng các mô hình vector hóa được
huấn luyện trước (pretrained word embeddings) là BERT và Word2Vec. Các câu trong
văn bản tóm tắt được lựa chọn là các câu gần tâm cụm nhất. Kết quả tóm tắt được đánh
giá, so sánh với các văn bản tóm tắt thủ công theo 2 phương pháp ROUGE Score và BERT Score.
1.2. Dữ liệu sử dụng
Dữ liệu dùng cho việc đánh giá kết quả là 200 văn bản tin tức, được tóm tắt thủ công
theo dạng tóm lược, theo 6 chủ đề khác nhau, với số lượng cụ thể như sau: Chủ đề Số lượng văn bản Khoa học công nghệ 25 Chính trị 31 Khoa học giáo dục 22 Kinh tế 53 Văn hóa 34 Xã hội 35
Bảng 1. Số lượng văn bản theo các chủ đề trong tập dữ liệu
2. Phương pháp thực hiện
2.1. Các bước thực hiện
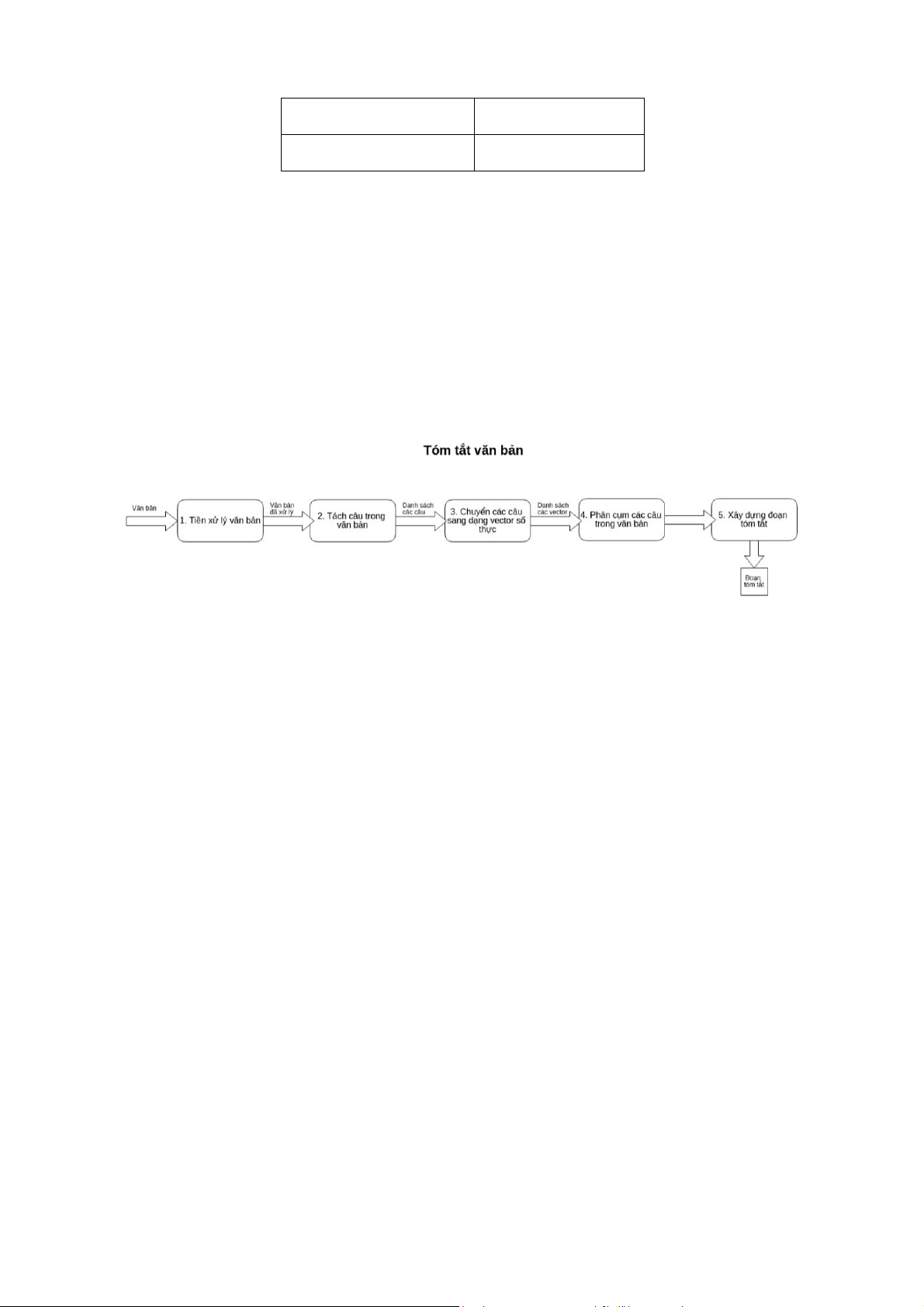
Quá trình tóm tắt một văn bản bao gồm 5 bước như sau:
Hình 1. Các bước thực hiện tóm tắt văn bản [7]
Bước 1: Tiền xử lý văn bản: Văn bản đầu vào của chúng ta có thể chứa nhiều ký tự
thừa, dấu câu thừa, khoảng trắng thừa, các từ viết tắt, viết hoa, ... điều này có thể làm
ảnh hưởng tới các bước sau này nên chúng ta cần phải xử lý nó trước. Thêm vào đó,
đơn vị từ trong tiếng Việt bao gồm từ đơn và từ ghếp nên chúng ta cần phải xác định từ
nào là từ đơn, từ nào là từ ghép trước khi đưa vào mô hình. Bởi vì mô hình của chúng
ta sẽ coi các từ là đặc trưng, tách nhau theo dấu cách. Do đó, chúng ta phải nối các từ
ghép lại thành một từ để không bị tách sai. Ví dụ: Học sinh học sinh học ⇒ Học_sinh
học sinh_học. Bài toán này là một bài toán cơ sở trong NLP – bài toán tách từ (word
tokenize). Thật may là hiện nay có khá nhiều thư viện mã nguồn mở của bài toán này.
Trong báo cáo này, chúng ta sẽ sử dụng công cụ pyvi - Python Vietnamese NLP
ToolkitSau của thầy Trần Việt Trung. Khi đã tách từ, mỗi văn bản sẽ được loại bỏ các
ký tự đặc biệt, dấu câu và cuối cùng là đưa về viết thường.
Bước 2: Tách câu trong văn bản: Ở bước này, chúng ta sẽ tách một đoạn văn bản
cần tóm tắt đã qua xử lý thành một danh sách các câu trong nó bằng thư viện nltk.
Bước 3: Chuyển các câu sang dạng vector số thực: Để phục vụ cho phương pháp
tóm tắt ở bước tiếp theo, chúng ta cần chuyển các câu văn (độ dài ngắn khác nhau) thành
các vector số thực có độ dài cố định, sao cho vẫn phải đảm bảo được độ khác nhau về ý
nghĩa giữa hai câu cũng tương tự như độ sai khác giữa hai vector tạo ra. Trong báo cáo
này, chúng ta sẽ sử dụng 2 pre-trained word embeddings là Word2Vec và BERT. Chi tiết
về cách sử dụng mỗi embedding sẽ được trình bày ở phần 2.2 và phần 2.3.
Bước 4: Phân cụm: Sau khi có được vector chúng cho từng câu, chúng ta sẽ thu
được một ma trận kích thước NxE. Trong đó, N là số câu của văn bản, E là kích thước
vector nhúng. Ma trận này sẽ là đầu vào của giải thuật K-means với số cụm là số câu
mong muốn k trong bản tóm tắt. Khi đó ta sẽ thu được các câu được chia vào từng cụm cụ thể.
Bước 5: Xây dựng đoạn văn bản tóm tắt: Sau khi đã có các cụm, trong mỗi cụm,
chúng ta sẽ chọn ra 1 câu duy nhất và gần với điểm trung tâm của cụm nhất trong cụm
đó để tạo nên văn bản được tóm tắt. Các câu này sẽ được sắp xếp theo vị trí tương đối
hoặc vị trí tuyệt đối. Câu có vị trí càng thấp thì càng được thêm vào đầu bản tóm tắt. Vị
trí tuyệt đối của một câu là vị trí cuả nó trong văn bản gốc. Vị trí tương đối của một câu
được tính bằng trung bình cộng của vị trí các câu cùng cụm với nó. Ví dụ, một cụm chứa
các câu có vị trí 2, 7 và 15 (vị trí tuyệt đối trong tập các câu). Như vậy, vị trí trung bình
của cụm này là (2+7+15) / 3 = 8. Như vậy, bằng cách thêm các câu dựa vào vị trí tương
đối hoặc vị trí tuyệt đối ta thu được bản tóm tắt trích rút với số lượng câu mong muốn
ở bản tóm tắt đúng bằng số cụm khởi tạo cho thuật toán K-means. Trong báo cáo này
chúng ta sẽ chọn cách sắp xếp theo vị trí tuyệt đối.
2.2. Phương pháp sử dụng pretrained BERT
BERT được viết tắt của Bidirectional Encoder Representations from
Transformers, một kiến trúc mới cho lớp bài toán biểu diễn ngôn ngữ được Google công
bố vào năm 2018. Không giống như các mô hình trước đó, BERT được thiết kế để tạo
ra các vector đại diện cho ngôn ngữ văn bản thông qua ngữ cảnh 2 chiều (trái và phải)
của chúng. Kết quả là, vector đại diện được sinh ra từ mô hình BERT được tinh chỉnh
với các lớp đầu ra bổ sung đã tạo ra nhiều kiến trúc cải tiến đáng kể cho các nhiệm vụ
xử lý ngôn ngữ tự nhiên như Trả lời câu hỏi (Question Answering), Suy luận ngôn ngữ
(Language Inference),... mà không cần thay đổi quá nhiều từ các kiến trúc cũ. Do hiệu
suất vượt trội của nó so với các thuật toán xử lý ngôn ngữ tự nhiên khác trong việc mã
hóa câu, nên chúng ta sẽ chọn kiến trúc BERT để biểu diễn vector cho từng câu.
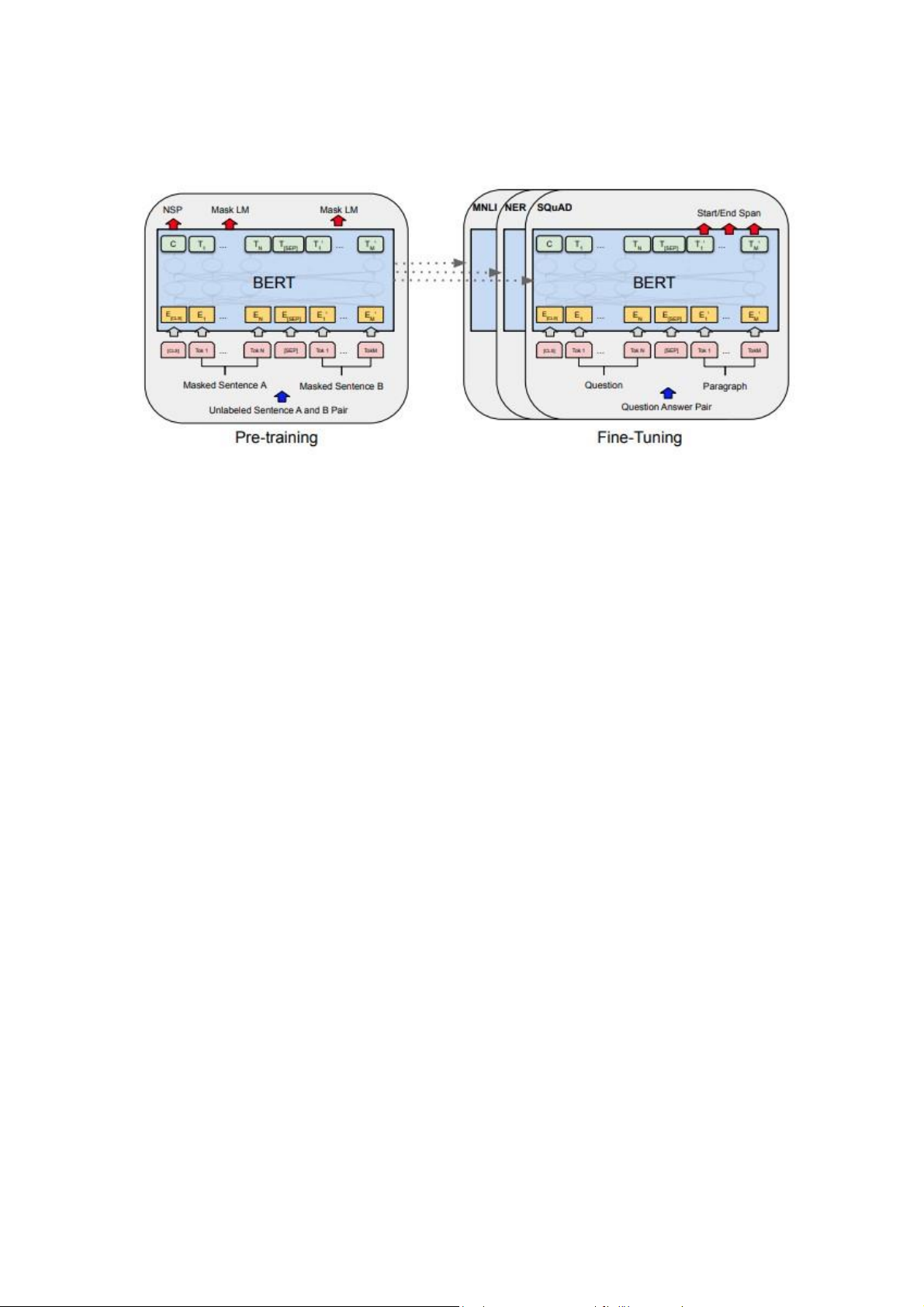
Hình 2. Tổng quan các bước pre-training và fine-tuning cho BERT Trong báo
cáo này, chúng ta sẽ sử dụng mô hình BERT đa ngôn ngữ đã được Google huấn luyện
sẵn và công bố cho cộng đồng sử dụng. Với mô hình này, chúng ta không cần phân loại
từ đơn, từ ghép trong văn bản do BERT sử dụng một bộ tokenizer riêng. Mô hình BERT
có tất cả 12 tầng, khi đầu vào là một văn bản thì mỗi tầng cho ra output là một ma trận
kích thước NxWxE, với N là số câu có trong văn bản, W là số token có trong câu và E
là số chiều của vector nhúng. Như vậy, chúng ta sẽ xây dựng embedding cho câu bằng
cách tính trung bình cộng đầu ra của mỗi token tại một trong 12 tầng và kết quả thu
được một vector nhúng có E chiều. Sau đó phân cụm và chọn ra các câu cho bản tóm tắt cuối cùng.
2.3. Phương pháp sử dụng pretrained Word2Vec
Word2Vec lần đầu được Tomas Mikolov giới thiệu vào năm 2013, là một
kỹ thuật Word embedding điển hình, được sử dụng rộng rãi trong các bài toán xử
lý ngôn ngữ tự nhiên. Trong đó, các từ sẽ được chuyển về dạng vector để xử lý.
Word2Vec có hai mô hình, đó là CBOW (Continuos bag of words) và Skip-Gram.
CBOW là mô hình dự doán từ đích dựa vào những từ ngữ cảnh xung quanh.
SkipGram thì ngược lại, nó dự đoán những từ xung quanh dựa vào một từ cho trước.
Cả hai đều có ưu, nhược điểm của mình. Theo Mikolov, Skip-Gram hoạt động tốt
với dữ liệu nhỏ và có từ hiếm. Còn CBOW lại nhanh hơn và cho ra các biểu diễn
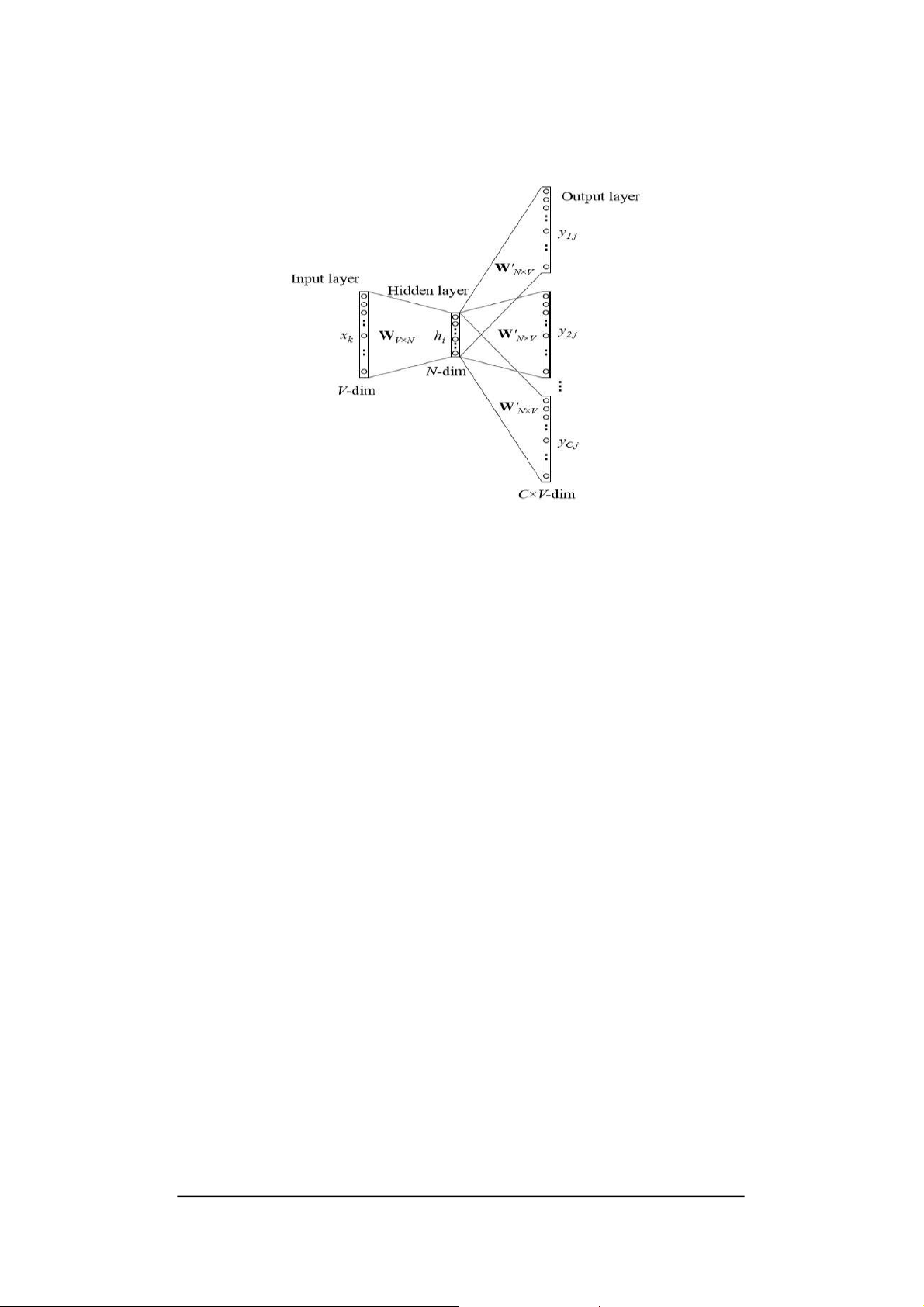
tốt hơn với bộ dữ liệu có nhiều từ có tần suất xuất hiện cao. • Kiến trúc CBOW
Xét câu sau: “It is a smart dog”. Giả sử từ “smart” là từ đích hay từ cần
được dự đoán dựa vào các từ xung quanh. Khi đó, mỗi từ xung quanh từ đích sẽ
được mã hoá dưới dạng one hot vector có số chiều là V, với V là kích thước của
từ điển. Các one hot vector này sẽ là đầu vào của mô hình mạng nơ ron một tầng
ẩn dưới đây. Sau khi nhận được kết quả từ tầng output, ta sẽ đo độ sai lệch kết quả
này so với one hot vector. Từ đó, học được biểu diễn vector của từ “smart”.
Ma trận trọng số giữa tầng đầu vào và tầng ẩn là ma trận W (có số chiều
VxN, trong đó N là số chiều lớp ẩn) có hàm phát động là tuyến tính, ma trận trọng
số giữa tầng ẩn và tầng output là W’ (có số chiều là NxV), hàm phát động của
tầng output là hàm softmax. Mô hình bên trên gồm ngữ cảnh của C từ, khi muốn
tính toán các đầu vào lớp ẩn, ta lấy trung bình trên tất cả các ngữ cảnh đầu vào của C từ.
Hình 3. Kiến trúc CBOW
• Kiến trúc Skip-Gram Skip-Gram đảo ngược cách dùng của từ đích và các từ
ngữ cảnh. Lúc này, từ đích được dùng làm đầu vào của tầng input, tầng ẩn vẫn
giữ nguyên cấu trúc như CBOW model, và tầng output của mạng sẽ điều chỉnh số
đầu ra sao cho phù hợp với số lượng từ ngữ cảnh.
Hình 4. Kiến trúc Skip-gram
Trong báo cáo này, chúng ta sẽ sử dụng mô hình Word2Vec tiếng Việt đã
được huấn luyện sẵn bằng tập dữ liệu wiki. Các câu sẽ được biểu diễn dưới dạng
vector có số chiều là 300 bằng Word2Vec. Vector của một câu bằng tổng của
vector các từ xuất hiện trong câu đó. Sau đó phân cụm và chọn ra các câu cho bản tóm tắt cuối cùng.
3. Đánh giá kết quả
3.1. Cách tính ROUGE Score
ROUGE hay Recall-Oriented Understudy for Gisting Evaluation là một phương pháp
đánh giá chất lượng của các bản tóm tắt của máy bằng cách đối sánh nó với các bản tóm
tắt của con người. Có nhiều cách tính ROUGE score khác nhau, trong đó, 2 cách tính
phổ biến nhất là ROUGE-N và ROUGE-L 3.1.1. ROUGE-N
ROUGE-N đo đạc số lượng n-grams khớp giữa văn bản tóm tắt và văn bản tham khảo.
Với một tham số n cho trước, chúng ta có thể tính toán các điểm số Recall, Precision, F1 theo công thức sau:
𝑇ổ𝑛𝑔 𝑠ố 𝑛 − 𝑔𝑟𝑎𝑚𝑠 𝑘ℎớ𝑝 𝑔𝑖ữ𝑎 𝑣ă𝑛 𝑏ả𝑛 𝑡ó𝑚 𝑡ắ𝑡 𝑣à 𝑣ă𝑛 𝑏ả𝑛 𝑡ℎ𝑎𝑚 𝑘ℎả𝑜 𝑅 =
𝑇ổ𝑛𝑔 𝑠ố 𝑛 − 𝑔𝑟𝑎𝑚𝑠 𝑡𝑟𝑜𝑛𝑔 𝑣ă𝑛 𝑏ả𝑛 𝑡ℎ𝑎𝑚 𝑘ℎả𝑜
𝑇ổ𝑛𝑔 𝑠ố 𝑛 − 𝑔𝑟𝑎𝑚𝑠 𝑘ℎớ𝑝 𝑔𝑖ữ𝑎 𝑣ă𝑛 𝑏ả𝑛 𝑡ó𝑚 𝑡ắ𝑡 𝑣à 𝑣ă𝑛 𝑏ả𝑛 𝑡ℎ𝑎𝑚 𝑘ℎả𝑜 𝑃 = 𝑅 ∗ 𝑃 𝐹 1 = 2 ∗ 𝑅 + 𝑃
𝑇ổ𝑛𝑔 𝑠ố 𝑛 − 𝑔𝑟𝑎𝑚𝑠 𝑡𝑟𝑜𝑛𝑔 𝑣ă𝑛 𝑏ả𝑛 𝑡ó𝑚 𝑡ắ𝑡 Ví dụ:
Bản tóm tắt : Con mèo đang nằm ở trên bàn
Bản tham khảo: Con mèo ở trên bàn Các cặp bigram:
Bản tóm tắt: Con mèo, mèo đang, đang nằm, nằm ở, ở trên, trên bàn
Bản tham khảo: Con mèo, mèo ở, ở trên, trên bàn Các đánh giá theo ROUGE-2 là: 𝑅 ,
𝑆ố 𝑏𝑖𝑔𝑟𝑎𝑚𝑠 𝑐ủ𝑎 𝑏ả𝑛 𝑡ℎ𝑎𝑚 𝑘ℎả𝑜 𝑃 ,
𝑆ố 𝑏𝑖𝑔𝑟𝑎𝑚𝑠 𝑐ủ𝑎 𝑏ả𝑛 𝑡ó𝑚 𝑡ắ𝑡 7 𝑅 ∗ 𝑃 1 𝐹1 = 2 ∗ = 𝑅 + 𝑃 2 3.1.2. ROUGE-L
Cho hai chuỗi X và Y, ký hiệu LCS(X,Y) là chuỗi con chung liên tiếp có độ dài lớn nhất của X và Y.
ROUGE-L đánh giá 2 văn bản có độ tương đồng càng lớn nếu LCS(X, Y) theo các từ
của chúng càng lớn. Giả sử bản tóm tắt tham khảo X có độ dài m và bản tóm tắt Y có
độ dài n, khi đó Recall, Precision và F1 của ROUGE-L được tính như sau: 𝐿𝐶𝑆(𝑋, 𝑌) 𝑅𝑙𝑐𝑠 = 𝑚 𝐿𝐶𝑆(𝑋, 𝑌) 𝑃𝑙𝑐𝑠 = 𝑛
2𝑅𝑙𝑐𝑠𝑃𝑙𝑐𝑠 𝐹𝑙𝑐𝑠 =
𝑅𝑙𝑐𝑠 + 𝑃𝑙𝑐𝑠 Ví dụ:
Bản tóm tắt S1: học_sinh đang chào một thầy_giáo
Bản tóm tắt S2: thầy_giáo đang chào một học_sinh
Bản tham khảo S0: một học_sinh chào một thầy_giáo
Ta có thể dễ dàng tính được các số điểm Recall, Precision và F1 theo ROUGE-2 của S1
và S2 so với S3 là như nhau, tuy nhiên ý nghĩa của 2 câu này lại hoàn toàn khác nhau.
Ta tính ROUGE-L của hai câu :
ROUGE-L(S1) : R = 3/5, P = 3/5, F1 = 0.6
ROUGE-L(S2) : R = 2/5, P = 2/5, F = 0.4
Do đó S1 tốt hơn so với S2
3.2. Cách tính BERT Score
Đây là một phương pháp đánh giá tự động cho các tác vụ sinh văn bản. Phương
pháp này tính toán độ tương tự giữa các token trong văn bản tóm tắt với văn bản tham
khảo, dựa trên việc mã hóa 2 văn bản theo mô hình BERT. Thực nghiệm cho thấy
BERTScore tương quan tốt hơn với các đánh giá của con người và cho hiệu quả chọn
lựa mô hình cao hơn so với phương pháp đo khác.
Các bước tính toán BERTScore cho câu tham khảo x và câu tóm tắt x’ được thực hiện như sau:
- Mã hóa x và x’ thành 𝐱 =< 𝐱𝟏, …, 𝐱𝐤 >, 𝐱′ = < 𝐱′𝟏, … 𝐱′𝐥 > sử dụng mô hình BERT.
𝐱𝐢 và 𝐱′𝐣 là các vector có cùng kích thước.
- Tính các giá trị recall, precision và F1 theo công thức: 𝑅𝐵𝐸𝑅𝑇 |𝑥|
x′j∈𝑥′ 𝐱Ti 𝐱′𝐣, 𝑃𝐵𝐸𝑅𝑇 |𝑥′|
xi∈𝑥 𝐱𝑖𝑇𝒙𝑗′,
𝐹𝐵𝐸𝑅𝑇 = 2 𝑃𝑃𝐵𝐸𝑅𝑇𝐵𝐸𝑅𝑇+∗𝑅𝑅𝐵𝐸𝑅𝑇𝐵𝐸𝑅𝑇
Độ tương đồng giữa 2 vector 𝐱𝐢 và 𝐱′𝐣 được tính theo công thức 𝐱Ti 𝐱′𝐣 thay vì công thức 𝐱Ti 𝐱′𝐣
tính độ tương đồng cosine đầy đủ |
|𝒙𝒊||.||𝐱′𝐣|| do các vector được mã hóa từ BERT đã được chuẩn hóa. • Importance Weighting.
BERT Score có thể được kết hợp với trọng số idf để tăng mức độ ảnh hưởng của các từ
ít xuất hiện. Với tập M câu tham khảo {𝑥(𝑖)}𝑀 , điểm idf của một token 𝑤 là: 𝑖=1 𝑀 𝑖𝑑𝑓
∑ 𝐼[𝑤 ∈ 𝑥(𝑖)] , 𝑀 𝑖=1
Trong đó 𝐼[𝑤 ∈ 𝑥(𝑖)] = {1, 𝑛ế𝑢 𝑤 𝑥𝑢ấ𝑡 ℎ𝑖ệ𝑛 𝑡𝑟𝑜𝑛𝑔 𝑐â𝑢 𝑥(𝑖)
0, 𝑛ế𝑢 𝑛𝑔ượ𝑐 𝑙ạ𝑖
Khi đó, Recall được tính theo công thức:
Σ𝑥𝑖∈𝑥𝑖𝑑𝑓(𝑥𝑖) max′∈𝑥′ 𝐱𝑇𝑖 𝐱𝑗′ 𝑥𝑗 𝑅𝐵𝐸𝑅𝑇 =
Σ𝑥𝑖∈𝑥𝑖𝑑𝑓(𝑥𝑖)
Hình dưới đây minh họa cách tính Recall theo BERT Score, có áp dụng trọng số idf:
Hình 5. Các bước tính Recall theo BERT Score, có áp dụng trọng số idf [6]
Ma trận trên thể hiện độ tương đồng giữa các token trong câu tham khảo x và câu tóm
tắt x’. Recall được tính theo các từ trong câu tham khảo x. Với mỗi token trong câu
tham khảo, ta chọn token có độ tương đồng lớn nhất trong câu tóm tắt, tương ứng với ô
được đánh dấu màu đỏ. • Baseline Rescaling
Với các vector mã hóa được chuẩn hóa từ các mô hình BERT, điểm số recall, precision,
f1 của BERT Score có giá trị trong khoảng [-1, 1]. Tuy nhiên, theo thực nghiệm, các
điểm số tính toán được thường rơi vào một khoảng giá trị hẹp hơn. Để chuẩn hóa lại
khoảng giá trị, các tác giả của BERT Score đã thực hiện tính toán thực nghiệm cận dưới
b cho các điểm số theo các mô hình BERT khác nhau. Các giá trị này được lưu kèm
theo thư viện bert_score [6]. Khi sử dụng “baseline rescaling” với giá trị b, điểm số
Recall được tính như sau: 𝑅𝐵𝐸𝑅𝑇′= 𝑅 𝐵𝐸𝑅𝑇 − 𝑏 1 − 𝑏
Sau phép biến đổi này, 𝑅𝐵𝐸𝑅𝑇′ sẽ nằm giữa khoảng 0 và 1. Cách biến đổi tương tự được
áp dụng cho 𝑃𝐵𝐸𝑅𝑇 và 𝐹𝐵𝐸𝑅𝑇. Phương pháp này không ảnh hưởng đến khả năng xếp hạng
và tương quan của BERTScore.
3.3. Kết quả với ROUGE Score
3.3.1. Kết quả của phương pháp sử dụng pretrained Word2Vec ROUGE Type Precision Recall F1-Score ROUGE-1
0.40428497 0.52326943 0.44264249 ROUGE-2
0.27210881 0.35200518 0.2976114 ROUGE-L
0.39386528 0.49453368 0.4297513
Bảng 2. Kết quả ROUGE Score khi sử dụng pretrained Word2Vec
3.3.2. Kết quả của phương pháp sử dụng pretrained BERT ROUGE Type Precision Recall F1-Score ROUGE-1 0.4478253 0.44006627 0.43365663 ROUGE-2
0.28460843 0.28027108 0.27609036 ROUGE-L
0.40946386 0.41959639 0.40751205
Bảng 3. Kết quả ROUGE Score khi sử dụng pretrained BERT
3.4. Kết quả với BERT Score
Kết quả BERT Score được tính dựa trên mô hình BERT đa ngôn ngữ, có sử dụng
“baseline rescaling” và trọng số idf.
Phương pháp word embeddings Precision Recall F1-Score Word2Vec
0.70179275 0.72751295 0.71341451 BERT
0.70186747 0.70750934 0.70329518
Bảng 4. Kết quả BERT Score
Tài liệu tham khảo
[1] Miller, Derek. "Leveraging BERT for extractive text summarization on lectures."
arXiv preprint arXiv:1906.04165 (2019).
[2] Devlin, Jacob, et al. "Bert: Pre-training of deep bidirectional transformers for
language understanding." arXiv preprint arXiv:1810.04805 (2018).
[3] LeCun, Yann, et al. "Gradient-based learning applied to document recognition."
Proceedings of the IEEE 86.11 (1998): 2278-2324.
[4] Chris McCormick, Nick Ryan. “BERT Word Embeddings Tutorial”
https://mccormickml.com/2019/05/14/BERT-word-embeddings-
tutorial/#3extracting-embeddings
[5] Phạm Hữu Quang. “BERT- bước đột phá mới trong công nghệ xử lý ngôn ngữ tự nhiên của Google”
https://viblo.asia/p/bert-buoc-dot-pha-moi-trong-cong-nghe-xu-ly-ngon-ngu-
tunhien-cua-google-RnB5pGV7lPG
[6] Tianyi Zhang, Varsha Kishore, Felix Wu, Kilian Q. Weinberger, and Yoav Artzi, “BERTScore: Evaluating text generation with BERT”, ICLR 2020
https://github.com/Tiiiger/bert_score
[7] Phạm Hoàng Anh, “Xây dựng chương trình tóm tắt văn bản (tiếng Việt) đơn giản
với Machine Learning”, https://viblo.asia/p/xay-dung-chuong-trinh-tom-tat-van-
ban-tieng-viet-don-gian-voimachine-learning-
YWOZrgAwlQ0?fbclid=IwAR2BqPaY2zv4xwKDYFswh4xU4NAlgw4M4XWhD Dmv5byVgQeot2d-0xtG50
Tài liệu liên quan:
-

Báo cáo Tóm tắt trích rút đơn văn bản Tiếng Việt | Môn Xử lý ngôn ngữ tự nhiên - Đại học Bách Khoa Hà Nội
72 36 -

Báo cáo bài tập lớn: Dịch máy với Transformer | Môn Xử lý ngôn ngữ tự nhiên - Đại học Bách Khoa Hà Nội
57 29 -

Comprehensive overview of NLP: Parsing, MT, and QA systems môn Xử lý ngôn ngữ tự nhiên | Trường Đại học Bách Khoa Hà Nội
152 76 -

Text classification: Concepts & methods môn Xử lý ngôn ngữ tự nhiên | Trường Đại học Bách Khoa Hà Nội
106 53 -

Tóm tắt lý thuyết xử lý văn bản và âm thanh trong NLP môn Xử lý ngôn ngữ tự nhiên | Trường Đại học Bách Khoa Hà Nội
99 50