Chapter 4: Lexical representations môn Xử lý ngôn ngữ tự nhiên | Trường Đại học Bách Khoa Hà Nội
Every task of NLP requires extensive knowledge about words. How to model words (or to get the base form of word)? Tài liệu được sưu tầm gồm 36 trang, giúp các bạn nắm vững kiến thức, rèn luyện kỹ năng và đạt được kết quả tốt trong học tập. Mời các bạn đón xem!
Môn: Xử lý ngôn ngữ tự nhiên 12 tài liệu
Trường: Đại học Bách Khoa Hà Nội 5.8 K tài liệu
Tác giả:













Preview text:
lOMoAR cPSD| 59703641 Natural Language Processing AC3110E 1
Lecturer: PhD. DO Thi Ngoc Diep Word
Every human language is composed of words (45
(21 letters) - the longest word “in common usage.”
“Fundamental building block of language” – of language
Word carries meaning (objective or practical meaning), can be used on its
Every task of NLP requires extensive knowledge about words
How to model words (or to get the base form of word)? Morphological parsing Normalization Stemming, Lemmatization
How to estimate the distance between words ? Edit distance calculation
https://www.grammarly.com/blog/14-of-the-longest-words-in-english/ lOMoAR cPSD| 59703641 2 main classes of morphemes:
the “main” morpheme of the word, supplying the main meaning
prefixes, suffixes, infixes, and circumfixes to say) said Ex. unbelievably 1 3 affixes un-, -able, -ly
4 ways to combine morphemes to create words Inflection Derivation Compounding Cliticization lOMoAR cPSD| 59703641
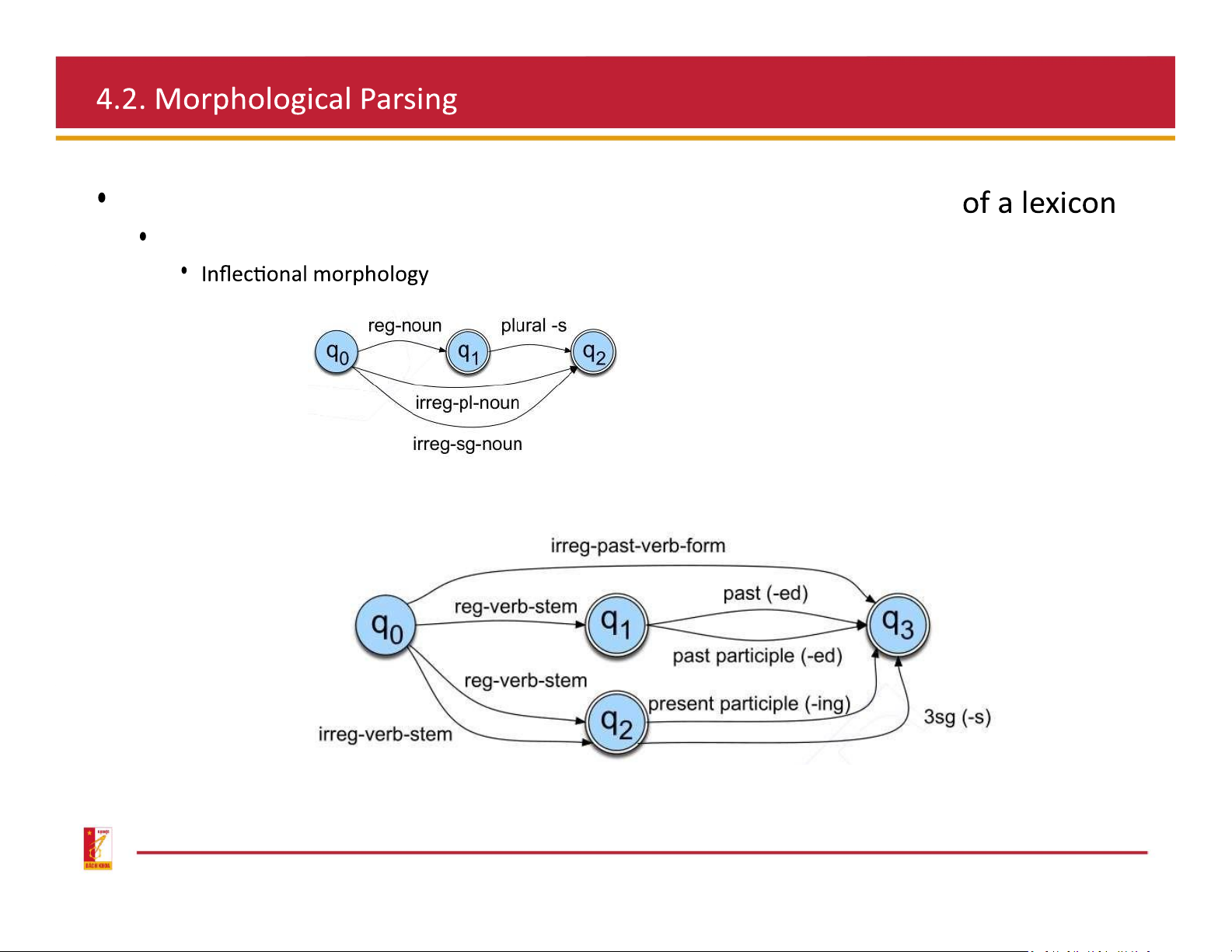
A word stem + grammatical morpheme a word of the same class
Usually filling some syntactic function like agreement Plural on nouns:
Verbal inflection: s, -ing, -ed Ex: in French
https://french.kwiziq.com/french-grammar-cefr-A0 lOMoAR cPSD| 59703641
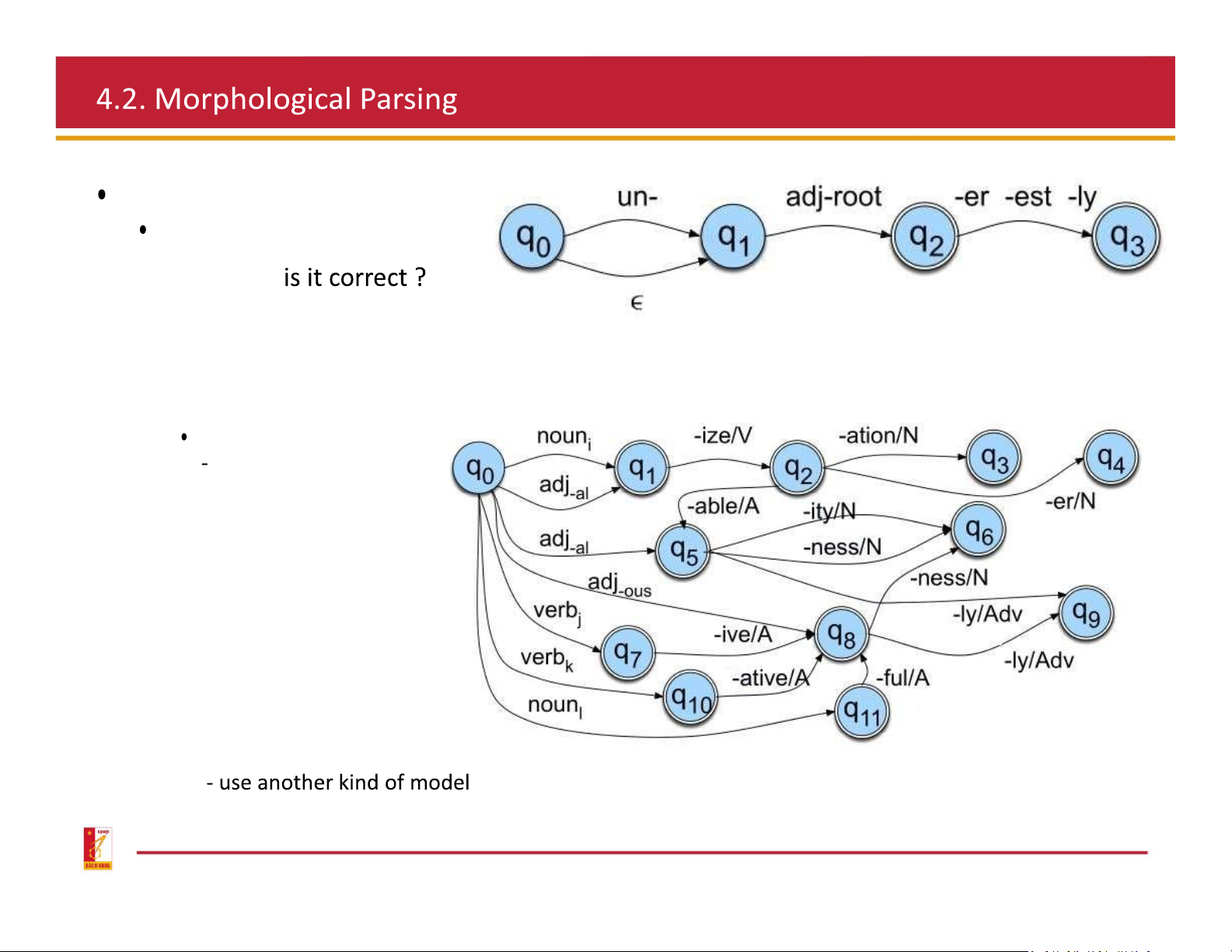
A word stem + grammatical morpheme
a word of the different class Irregular meaning change
Formation of new nouns from verbs or adjectives: -ation, -ee, -er, -ness verb + - noun
Formation of new adjectives from verbs or noun: -al, -able, -less Many paths are possible…
Combination of multiple word stems together. lOMoAR cPSD| 59703641
A word stem + a cliticization
cliticization: a morpheme that acts syntactically like a word, but reduced in form and attached to another word Ex in Arabic lOMoAR cPSD| 59703641
Some words refuse to follow the rules •Nouns:
• Irregulars : mouse/mice, goose/geese, ox/oxen
Regulars: Walk, walks, walking, walked, walked Irregulars
• Eat, eats, eating, ate, eaten caught, caught
• Cut, cuts, cutting, cut, cut lOMoAR cPSD| 59703641
convert to the stem + morphological features Need to prepare Surface form: input words
Lexicon: list of stems + affixes + class (N, V, etc.)
Morphotactics: Model of morpheme ordering N+PL, V+Past, etc. Orthographic rules:
model the changes that occur in a word city s to ambiguous !
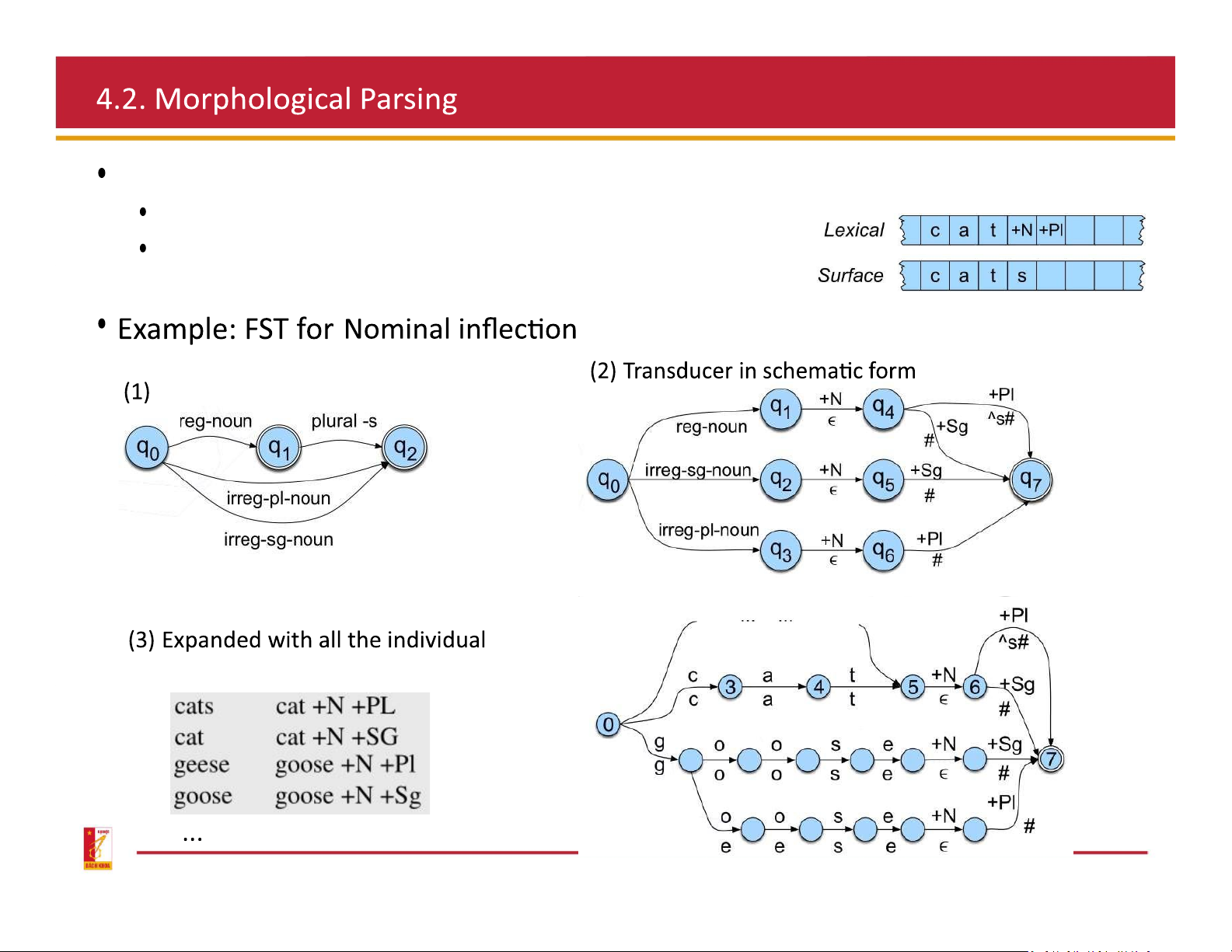
Morphotactics Modeling: represent the morphotactic structure FSA Nominal inflection Verbal inflection Morphotactics Modeling FSA
A fragment of English adjective morphology Derivation morphology: more complex Lexical Modeling:
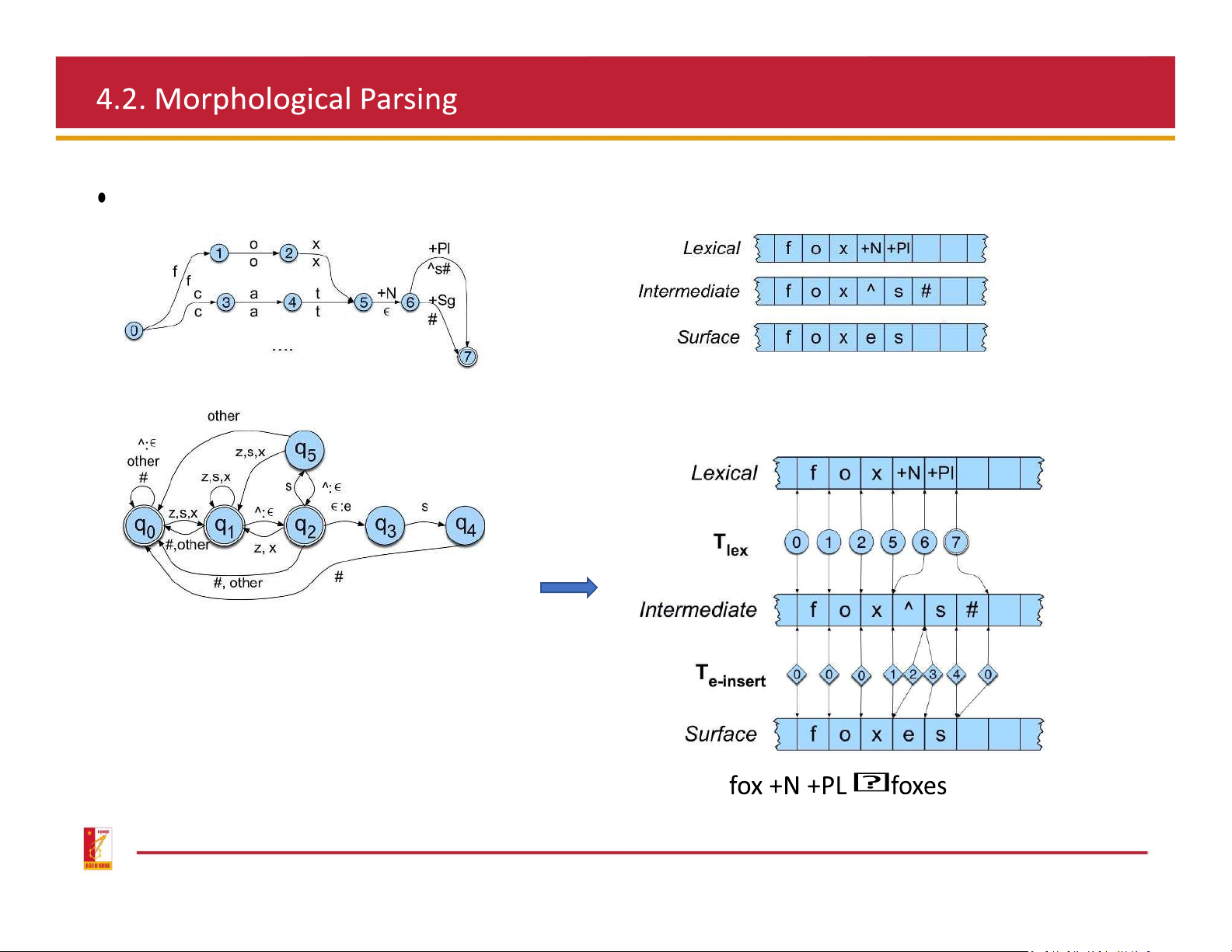
Use finite state transducer to do parsing
FST takes as input a string of letters (surface)
and products as output a string of morphemes (lexical) Morphotactic FSA above: morphological element below: surface form ˆ : morpheme boundary # : word boundary
regular and irregular noun stems
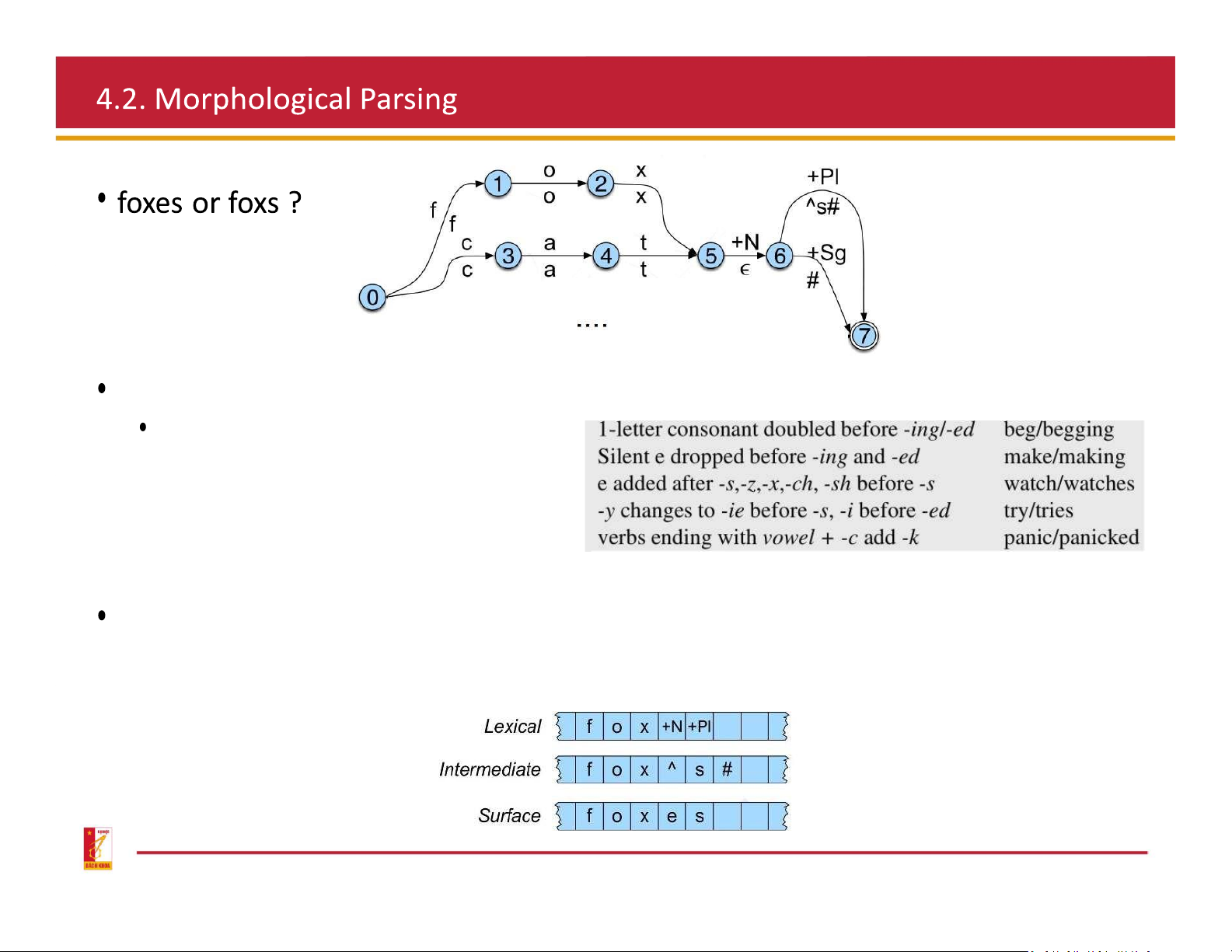
Won’t work for cases where there is a spelling change
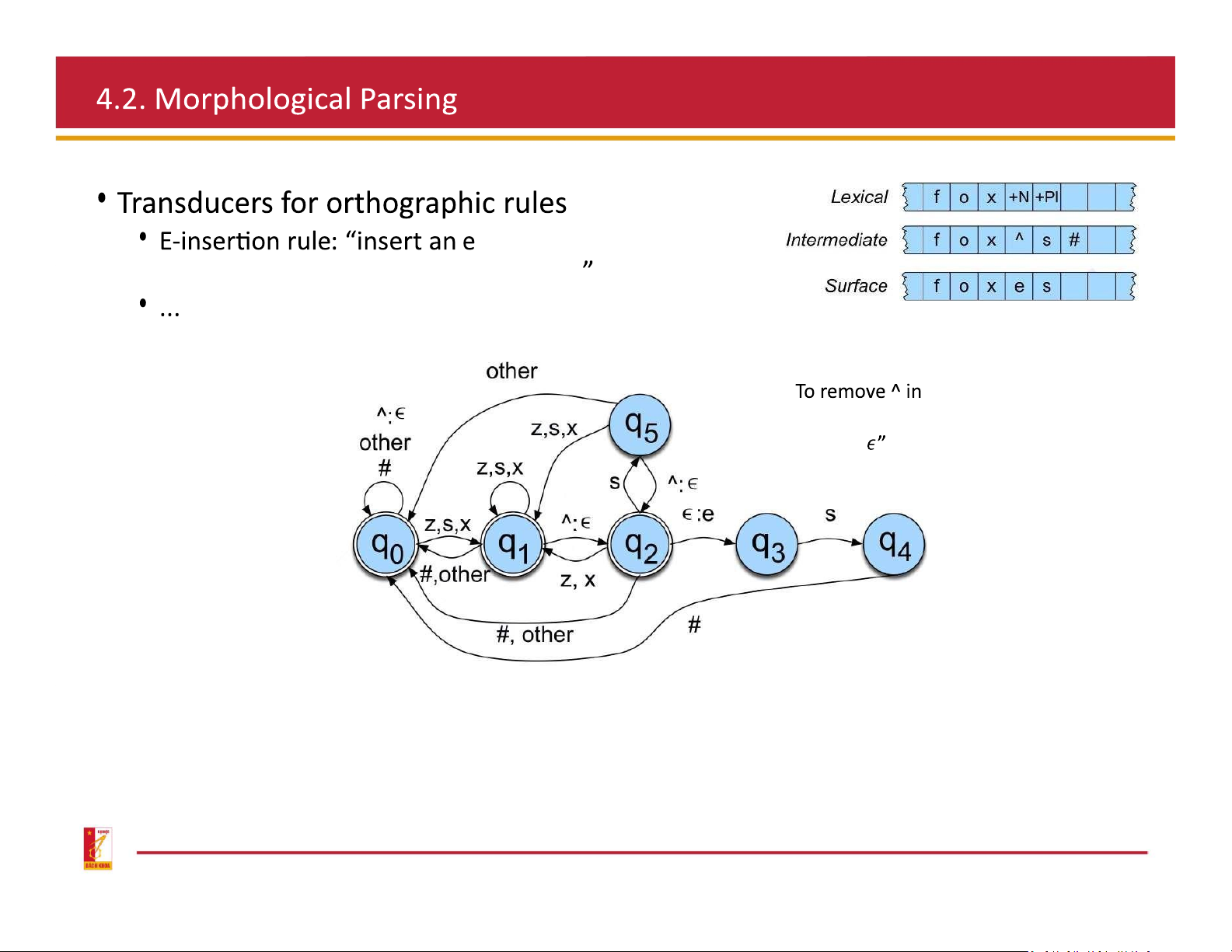
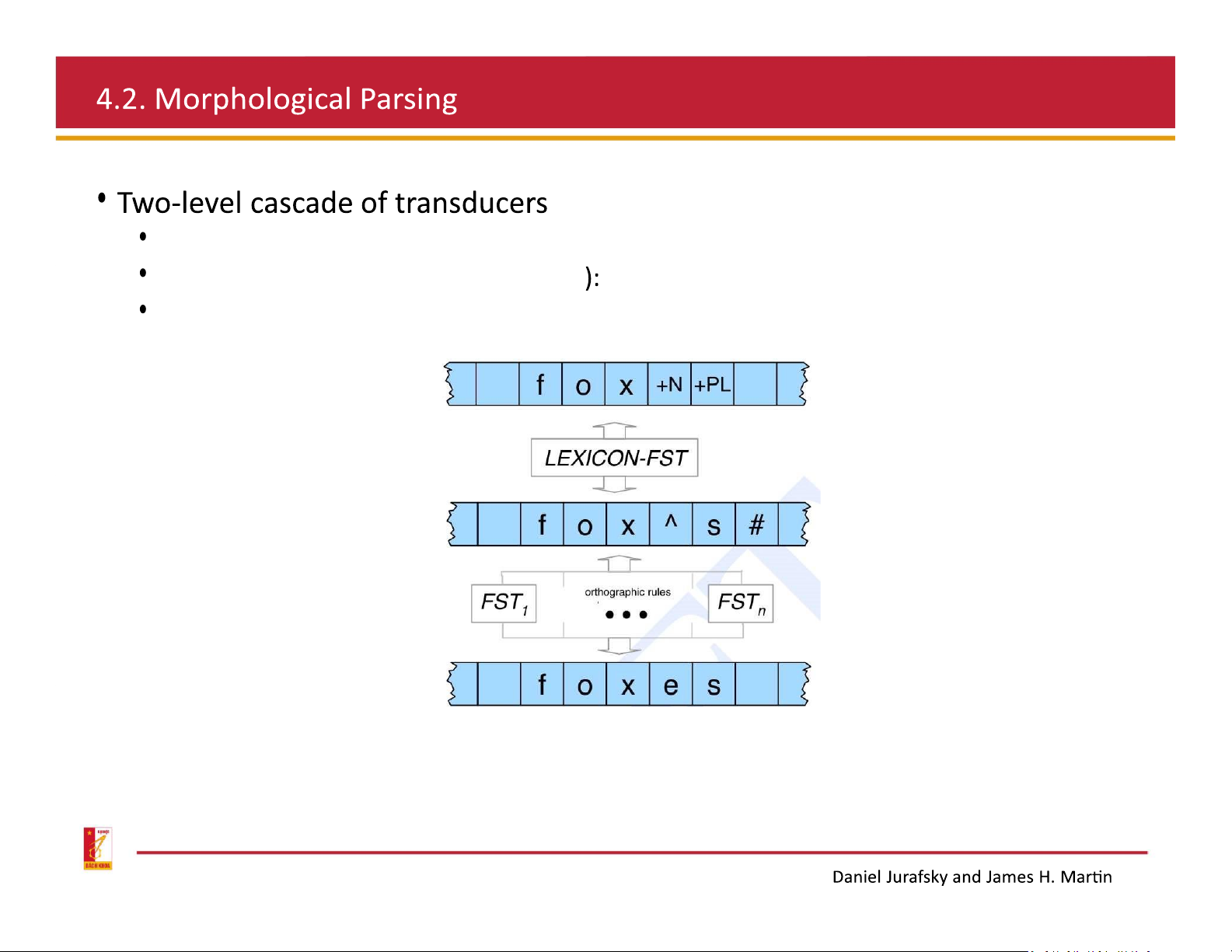
Spelling rules (orthographic rules)
To handle irregular spelling changes, add intermediate tapes with intermediate symbols after a morpheme-final
x, s, or z, and before the morpheme s
Transducer for the E-insertion rule surface: add pairs “ ˆ: Combine
Recognize strings in the language: Accept or Reject
Parse a string ( morphological analysis to find the morphology structure in it
Produce/Generate a surface form from a structure of morphology Parsing and Generating • Unionizable • Union-ize-able • Un-ion-ize-able to deal with this problem
• Simply take the first output found
• Find all the possible outputs (all paths) and return them all (without choosing)
• Bias the search so that only one or a few likely paths are explored
At around 9:25 a.m., VN-Index lost the 1,150 point mark - an important support
increasing in price by 2% or more such as SSI, SHS, VCI, HCM, MBS and FTS in What counts as a word ? Punctuation marks ? Date ( th 12 July , percentage 55
Capitalized tokens vs. uncapitalized tokens ? Abbreviation ? Filler words:
Done before almost any natural language processing of a text 1 2 . Normalizing word formats 3 . Segmenting sentences Depends on the NLP tasks
Problem of segmenting text into tokens (characters, words) Word boundary: Whitespace is sufficient ? Punctuation: “job,
/02/06, http://www.google.com Cliticization vs apostrophe: vs.
Tài liệu liên quan:
-

Báo cáo Tóm tắt trích rút đơn văn bản Tiếng Việt | Môn Xử lý ngôn ngữ tự nhiên - Đại học Bách Khoa Hà Nội
72 36 -

Báo cáo bài tập lớn: Dịch máy với Transformer | Môn Xử lý ngôn ngữ tự nhiên - Đại học Bách Khoa Hà Nội
57 29 -

Comprehensive overview of NLP: Parsing, MT, and QA systems môn Xử lý ngôn ngữ tự nhiên | Trường Đại học Bách Khoa Hà Nội
152 76 -

Text classification: Concepts & methods môn Xử lý ngôn ngữ tự nhiên | Trường Đại học Bách Khoa Hà Nội
106 53 -

Tóm tắt lý thuyết xử lý văn bản và âm thanh trong NLP môn Xử lý ngôn ngữ tự nhiên | Trường Đại học Bách Khoa Hà Nội
99 50