Báo cáo cuối kỳ Điện toán đám mây | Trường Đại học Sư phạm Kỹ thuật Thành phố Hồ Chí Minh
Báo cáo cuối kỳ Điện toán đám mây | Trường Đại học Sư phạm Kỹ thuật Thành phố Hồ Chí Minh. Tài liệu được sưu tầm giúp bạn tham khảo, ôn tập và đạt kết quả cao. Mời bạn đọc đón xem.
Môn: Điện toán đám mây (CLCO332779) 12 tài liệu
Trường: Trường Đại học Sư phạm Kỹ thuật Thành phố Hồ Chí Minh 4.4 K tài liệu
Tác giả:










Preview text:
TRƯỜNG ĐẠI HỌC CÔNG NGHỆ KĨ THUẬT TP.HCM
KHOA CÔNG NGHỆ THÔNG TIN
BÁO CÁO ĐỒ ÁN NHÓM 45: Data Engineering
BỘ MÔN: Điện toán đám mây
HỌC KỲ 1 – NĂM HỌC 2025-2026
GVHD:TS. Huỳnh Xuân Phụng
MÃ LỚP HỌC :251CLCO332779_25_1_08
Sinh viên thực hiện: MSSV Họ và tên 23110360
Nguyễn Đăng Tường 23110338
Nguyễn Hữu Thưởng
Thành phố Hồ Chí Minh, Tháng 2 năm 2026
BÁO CÁO MÔN HỌC ĐIỆN TOÁN ĐÁM MÂY
HỌC KỲ I NĂM HỌC 2025 - 2026
1. Mã lớp môn học: 251CLCO332779_25_1_08
2. Giảng viên hướng dẫn: TS. Huỳnh Xuân Phụng
3. Tên đề tài: Data Engineering 4. Danh sách sinh viên: Sinh viên thực hiện MSSV Tỉ lệ % tham gia Nguyễn Hữu Thưởng 23110338 100% Nguyễn Đăng Tường 23110360 100%
Nhận xét và đánh giá của giảng viên:
…………………………………………………………………………………………
…………………………………………………………………………………………
…………………………………………………………………………………………
…………………………………………………………………………………………
…………………………………………………………………………………………
…………………………………………………………………………………………
…………………………………………………………………………………………
…………………………………………………………………………………………
…………………………………………………………………………………………
TP. Hồ Chí Minh, ngày … tháng 12 năm 2025 Giảng viên hướng dẫn MỤC LỤC
DANH MỤC HÌNH ẢNH .............................................................................................. 5
CHƯƠNG 1. TỔNG QUAN VỀ DATA ENGINEERING ............................................ 1
1.1 Giới thiệu về kỹ thuật dữ liệu (Data Engineering) ............................................... 1
1.2. Vai trò của Data Engineer .................................................................................... 1
1.3. Quy trình xử lý dữ liệu trong Data Engineering .................................................. 2
1.4 Mô hình ETL và ELT trong Data Engineering ..................................................... 3
1.5. Giải pháp lưu trữ và ngôn ngữ lập trình trong kỹ thuật dữ liệu ........................... 4
CHƯƠNG 2. CÁC ĐẶC TÍNH CỦA BIG DATA ........................................................ 6
2.1 Tổng quan về Big Data ......................................................................................... 6
2.2 Mô hình 5V của Big Data ..................................................................................... 7
2.2.1 Volume – Khối lượng dữ liệu ........................................................................ 7
2.2.2 Variety – Sự đa dạng của dữ liệu ................................................................... 8
2.2.3 Velocity – Tốc độ phát sinh và xử lý dữ liệu ................................................. 8
2.2.4 Veracity – Độ tin cậy và chất lượng dữ liệu .................................................. 9
2.2.5 Value – Giá trị của dữ liệu ........................................................................... 10
2.3 Kết luận chương .................................................................................................. 11
CHƯƠNG 3. CÁC CHỦ ĐỀ LIÊN QUAN ĐẾN DATA ENGINEERING TRÊN
AWS CLOUD ............................................................................................................... 12
3.1 Tổng quan hệ sinh thái Data Engineering trên AWS.......................................... 12
3.2 Lớp lưu trữ dữ liệu và cơ sở dữ liệu ................................................................... 12
3.3 Thu thập và xử lý dữ liệu (Ingestion & Transformation) ................................... 13
3.4 Phân tích dữ liệu và Business Intelligence ......................................................... 14
3.5 Quản trị dữ liệu, bảo mật và giám sát hệ thống .................................................. 15
3.6 Kết luận chương .................................................................................................. 15
CHƯƠNG 4. MỘT SỐ USE CASE ÁP DỤNG DATA ENGINEERING TRÊN AWS
CLOUD ......................................................................................................................... 16
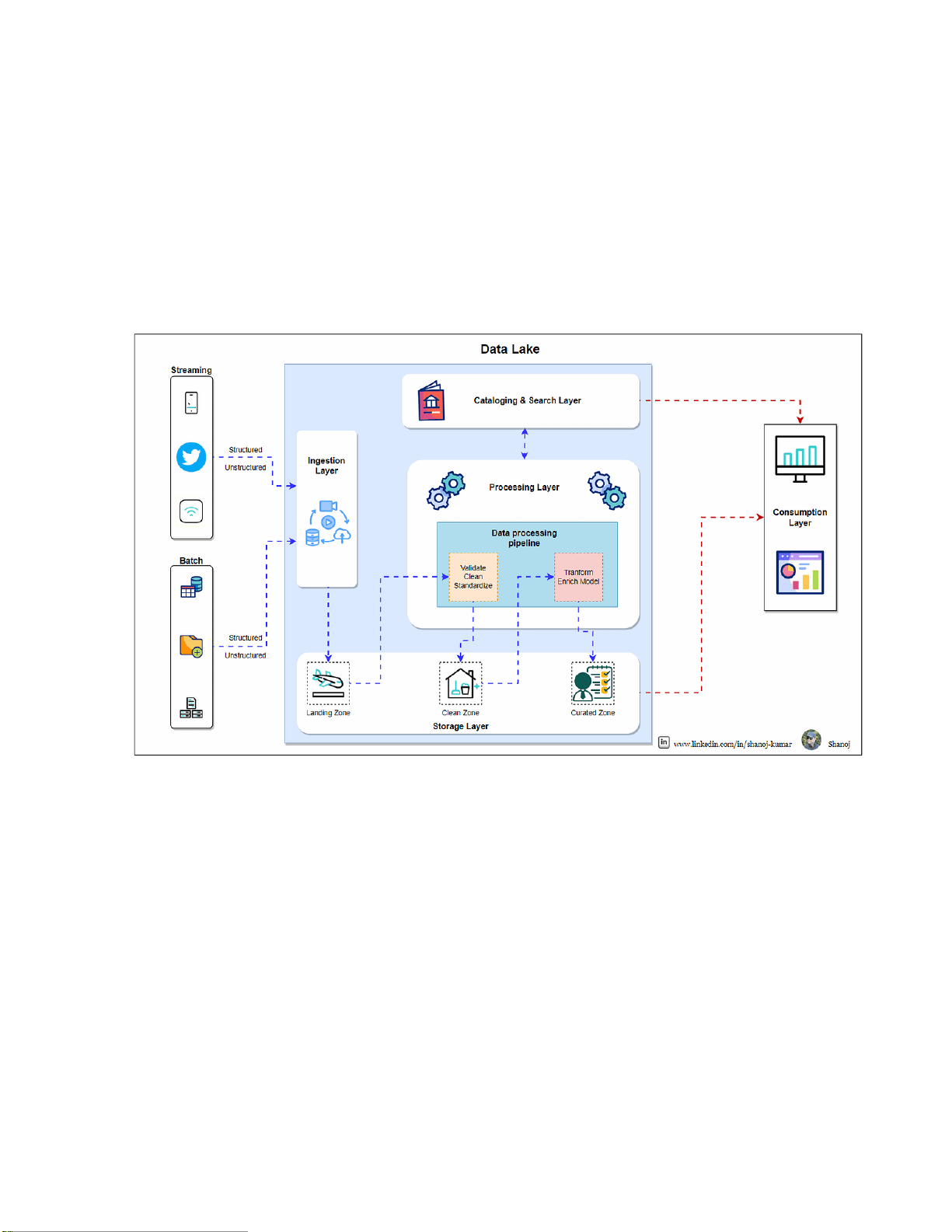
4.1 Xây dựng hệ thống Data Lake tập trung trên AWS ............................................ 16
4.2 Phân tích hành vi người dùng theo thời gian thực (Real-time Analytics) .......... 17
4.3 Chuẩn bị dữ liệu và Feature Engineering cho hệ thống AI/ML ......................... 17
4.4 Hệ thống báo cáo điều hành và Business Intelligence ........................................ 18
4.5 Kiểm soát chất lượng dữ liệu trong Data Pipeline .............................................. 18
4.6 Kết luận chương .................................................................................................. 19
CHƯƠNG 5. KẾT LUẬN VÀ HƯỚNG PHÁT TRIỂN.............................................. 20
5.1 Tổng kết nội dung nghiên cứu ............................................................................ 20
5.2 Ý nghĩa thực tiễn của Data Engineering trong doanh nghiệp ............................. 20
5.3 Hướng phát triển trong tương lai ........................................................................ 21
5.4 Kết luận chung .................................................................................................... 21
TÀI LIỆU THAM KHẢO ............................................................................................ 22
DANH MỤC HÌNH ẢNH
Hình 1.1. Quy trình Data Engineering Pipeline từ thu thập đến khai thác dữ liệu ......... 3
Hình 1.2. So sánh mô hình ETL và ELT trong hệ thống Data Engineering ................... 4
Hình 2.1. Mô hình 5V của Big data ................................................................................ 6
Hình 2.2. Hệ thống lưu trữ phân tán cho dữ liệu khối lượng lớn (Volume) ................... 7
Hình 2.3. Các dạng dữ liệu trong Big Data: có cấu trúc, bán cấu trúc và phi cấu trúc .. 8
Hình 2.4. So sánh xử lý dữ liệu theo lô (Batch) và thời gian thực (Streaming) ............. 9
Hình 2.5. Quy trình làm sạch và kiểm soát chất lượng dữ liệu trong Big Data............ 10
Hình 2.6. Khai thác Big Data phục vụ phân tích kinh doanh và ra quyết định ............ 11
Hình 3.1. Kiến trúc tổng thể hệ thống Data Engineering trên AWS Cloud ................. 12
Hình 3.2. Mô hình phân tầng lưu trữ dữ liệu trong Data Lake trên AWS .................... 13
Hình 3.3. Quy trình thu thập và xử lý dữ liệu Batch và Streaming trên AWS ............. 14
Hình 3.4. Hệ thống phân tích dữ liệu và báo cáo Business Intelligence trên AWS ..... 15
Hình 4.1. Kiến trúc hệ thống Data Lake trên AWS Cloud ........................................... 16
Hình 4.2. Kiến trúc phân tích dữ liệu thời gian thực trên AWS ................................... 17
Hình 4.3. Quy trình chuẩn bị dữ liệu và Feature Engineering cho mô hình AI/ML .... 18
Hình 4.4. Hệ thống kiểm soát chất lượng dữ liệu trong Data Engineering Pipeline .... 19 LỜI NÓI ĐẦU
Kính gửi thầy Huỳnh Xuân Phụng,
Em xin gửi đến thầy lời cảm ơn chân thành và sâu sắc nhất sau khi hoàn thành
khóa học Điện toán đám mây do thầy giảng dạy.
Trong suốt quá trình học tập, thầy không chỉ truyền đạt cho em những kiến thức chuyên
môn quý báu về Điện toán đám mây, từ nền tảng đến nâng cao, mà còn giúp em hiểu rõ
bản chất của vấn đề và cách vận dụng kiến thức vào thực tiễn một cách hiệu quả. Nhờ
phương pháp giảng dạy khoa học, dễ hiểu cùng sự tận tâm và kiên nhẫn của thầy, em đã
có thể củng cố vững chắc kiến thức lập trình, tự tin hơn trong việc phân tích, triển khai
và giải quyết các bài toán thực tế.
Bên cạnh kiến thức chuyên môn, em đặc biệt trân trọng những bài học mà thầy
đã truyền tải về tư duy logic, cách tiếp cận vấn đề một cách có hệ thống, sáng tạo và
khoa học. Những kỹ năng này không chỉ hữu ích trong học tập mà còn là hành trang
quan trọng cho em trong công việc và sự nghiệp sau này.
Em cảm thấy rất may mắn và biết ơn khi có cơ hội được học tập dưới sự hướng
dẫn của thầy. Những gì thầy đã dạy sẽ là nền tảng vững chắc giúp em tiếp tục học hỏi
và phát triển trong lĩnh vực công nghệ thông tin. Em hy vọng trong tương lai sẽ còn có
thêm nhiều cơ hội được học tập và trau dồi kiến thức cùng thầy.
Một lần nữa, em xin chân thành cảm ơn thầy. Kính chúc thầy luôn dồi dào sức
khỏe, nhiều niềm vui và tiếp tục gặt hái nhiều thành công trong sự nghiệp giảng dạy
CHƯƠNG 1. TỔNG QUAN VỀ DATA ENGINEERING
1.1 Giới thiệu về kỹ thuật dữ liệu (Data Engineering)
Kỹ thuật dữ liệu (Data Engineering) là lĩnh vực tập trung vào các khía cạnh thực tiễn
của việc thu thập, xử lý và lưu trữ dữ liệu, bao gồm thiết kế và xây dựng các hệ thống có
khả năng xử lý dữ liệu ở quy mô lớn. Lĩnh vực này đóng vai trò nền tảng trong hệ sinh thái
dữ liệu, giúp chuyển đổi dữ liệu thô, phân tán và không đồng nhất thành dữ liệu có cấu trúc,
đáng tin cậy và sẵn sàng cho các hoạt động phân tích và ra quyết định.
Trong bối cảnh dữ liệu lớn (Big Data) và phân tích nâng cao ngày càng phát triển,
kỹ thuật dữ liệu trở thành yếu tố cốt lõi của các hệ thống ra quyết định hiện đại. Nếu không
có hạ tầng dữ liệu được thiết kế tốt, các hoạt động phân tích dữ liệu, học máy hay trí tuệ
nhân tạo sẽ gặp nhiều hạn chế về hiệu năng, độ chính xác và khả năng mở rộng. Do đó, kỹ
thuật dữ liệu không chỉ hỗ trợ xử lý dữ liệu mà còn quyết định trực tiếp đến hiệu quả của
toàn bộ chuỗi giá trị dữ liệu trong tổ chức. Một nhiệm vụ quan trọng khác của kỹ thuật dữ
liệu là đảm bảo chất lượng, tính toàn vẹn và bảo mật dữ liệu.
Thông qua việc triển khai các cơ chế quản trị dữ liệu (data governance), kiểm soát
quyền truy cập, theo dõi luồng dữ liệu và tuân thủ các quy định pháp lý, kỹ sư dữ liệu giúp
tổ chức sử dụng dữ liệu một cách có trách nhiệm và bền vững. Điều này đặc biệt quan trọng
trong bối cảnh xử lý dữ liệu cá nhân và dữ liệu nhạy cảm, nơi các sai sót về bảo mật hoặc
chất lượng dữ liệu có thể dẫn đến rủi ro nghiêm trọng về pháp lý, tài chính và uy tín doanh
nghiệp. Trong môi trường kinh doanh dựa trên dữ liệu, kỹ thuật dữ liệu đóng vai trò xương
sống cho các ứng dụng như trí tuệ nhân tạo và học máy (AI/ML), phân tích kinh doanh
(Business Intelligence – BI) và các hệ thống phân tích dữ liệu chuyên sâu. Khả năng xử lý
nhanh chóng, chính xác và ổn định khối lượng lớn dữ liệu giúp tổ chức phát hiện sớm xu
hướng, tối ưu hóa hoạt động vận hành và phản ứng linh hoạt trước những thay đổi của thị
trường. Nhờ đó, kỹ thuật dữ liệu góp phần quan trọng trong việc tạo ra lợi thế cạnh tranh
bền vững và thúc đẩy đổi mới trong dài hạn.
1.2. Vai trò của Data Engineer
Data Engineer là người chịu trách nhiệm thiết kế, xây dựng và vận hành các hệ thống
xử lý dữ liệu trong doanh nghiệp. Công việc chính của họ xoay quanh việc thu thập, lưu 1
trữ, xử lý và quản lý dữ liệu ở quy mô lớn nhằm đảm bảo dữ liệu luôn nhất quán, chính xác và dễ dàng khai thác.
Một Data Engineer sẽ phát triển và duy trì các data pipeline, giúp chuyển đổi dữ liệu
thô từ nhiều nguồn khác nhau thành dữ liệu đã được chuẩn hóa, sẵn sàng phục vụ cho các
hoạt động phân tích, báo cáo hoặc các mô hình học máy. Họ đóng vai trò cầu nối quan
trọng, đảm bảo dữ liệu được luân chuyển hiệu quả giữa các hệ thống và có thể được sử
dụng bởi Data Analyst, Data Scientist cũng như các ứng dụng khác.
Để đảm nhiệm tốt vai trò này, Data Engineer cần có nền tảng vững chắc về khoa học
máy tính, mô hình dữ liệu và hệ thống kho dữ liệu (data warehouse). Ngoài ra, các kỹ năng
lập trình với Python, Java, SQL là không thể thiếu. Bên cạnh đó, việc am hiểu về điện toán
đám mây, hệ thống phân tán cùng các công nghệ xử lý dữ liệu lớn như Hadoop và Spark
cũng là yêu cầu quan trọng trong lĩnh vực này.
1.3. Quy trình xử lý dữ liệu trong Data Engineering
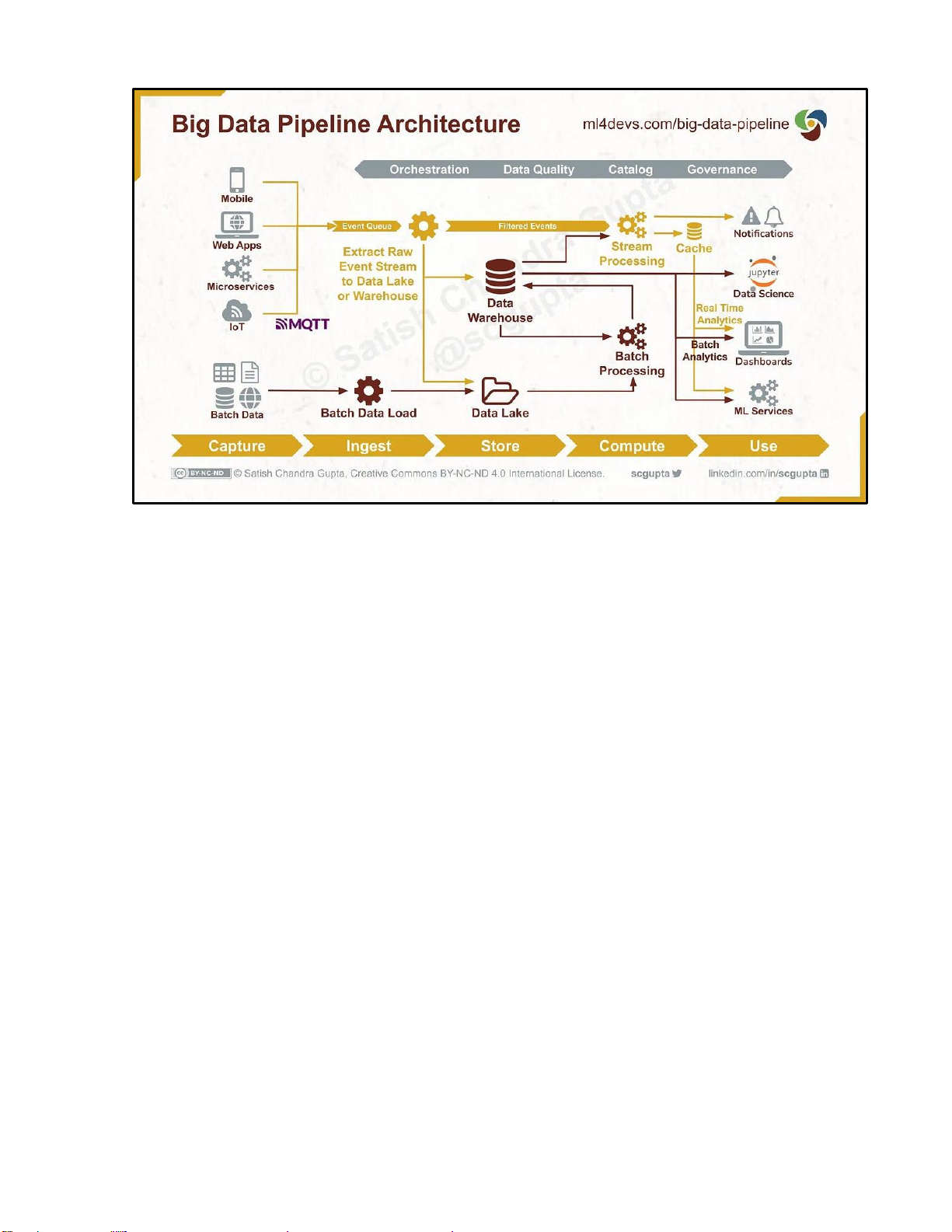
Trọng tâm của Data Engineering là hệ thống pipeline dữ liệu – chuỗi các bước tự
động hóa giúp dữ liệu được di chuyển và xử lý liên tục từ nguồn phát sinh đến hệ thống
phân tích cuối cùng. Pipeline dữ liệu đóng vai trò như “xương sống” của toàn bộ hạ tầng
dữ liệu, đảm bảo dữ liệu luôn được cập nhật, nhất quán và sẵn sàng khai thác.
Thông thường, một pipeline hoàn chỉnh bao gồm ba giai đoạn chính. Giai đoạn đầu
tiên là thu thập dữ liệu (ingestion), nơi dữ liệu được lấy từ nhiều nguồn khác nhau như cơ
sở dữ liệu nghiệp vụ, API, log hệ thống hoặc các thiết bị cảm biến. Tiếp theo là giai đoạn
chuyển đổi dữ liệu (transformation), trong đó dữ liệu được làm sạch, loại bỏ trùng lặp,
chuẩn hóa định dạng và kết hợp từ nhiều nguồn để tạo thành tập dữ liệu có cấu trúc thống
nhất. Cuối cùng là giai đoạn cung cấp dữ liệu (serving), đưa dữ liệu đã xử lý vào kho phân
tích như Data Warehouse hoặc Data Lake để phục vụ báo cáo, trực quan hóa và mô hình AI. 2
Hình 1.1. Quy trình Data Engineering Pipeline từ thu thập đến khai thác dữ liệu
Pipeline dữ liệu giúp doanh nghiệp tự động hóa toàn bộ vòng đời dữ liệu, hạn chế
phụ thuộc vào xử lý thủ công và giảm thiểu sai sót trong quá trình vận hành.
1.4 Mô hình ETL và ELT trong Data Engineering
Trong quá trình xây dựng pipeline dữ liệu, hai mô hình xử lý phổ biến nhất là ETL và ELT.
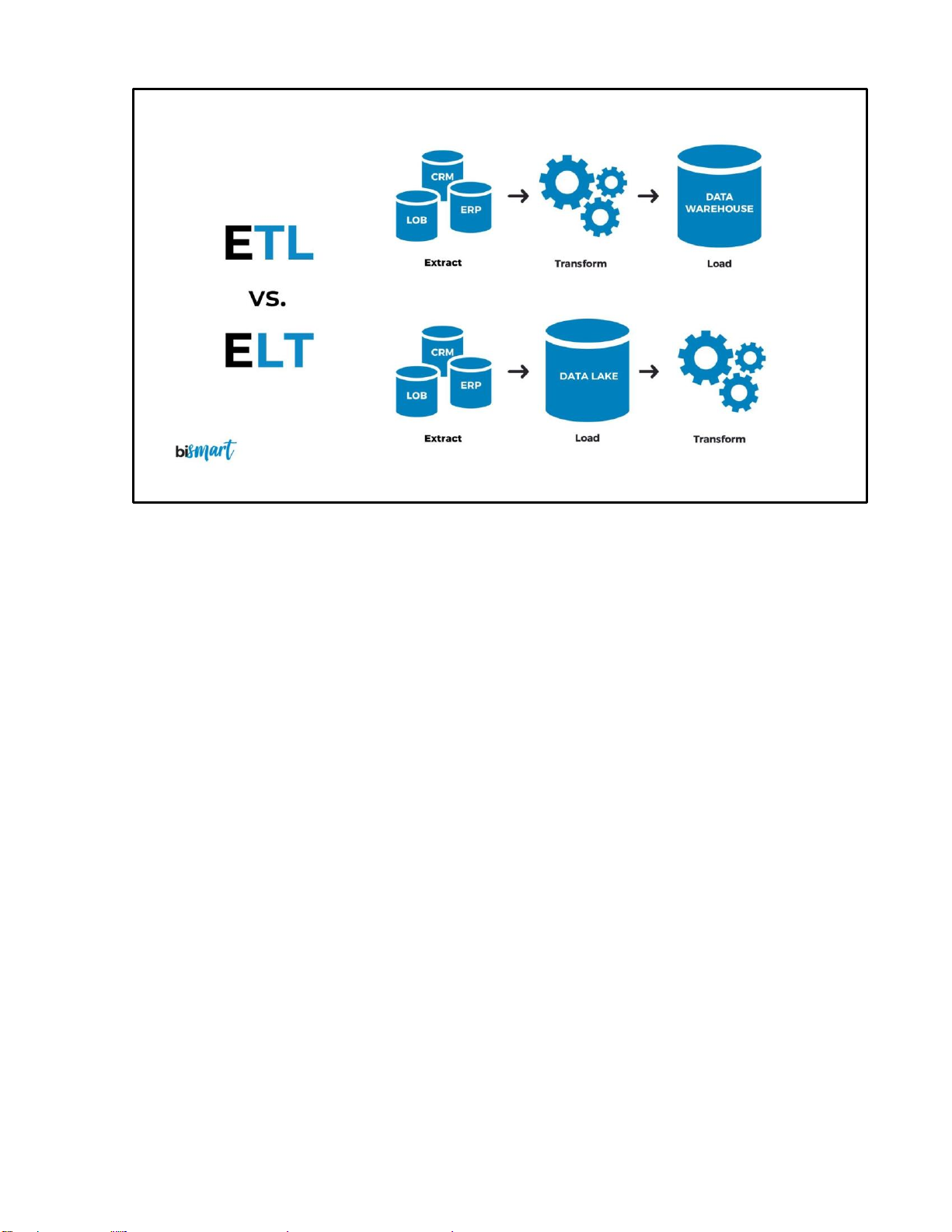
Mô hình ETL (Extract – Transform – Load) thực hiện việc trích xuất dữ liệu từ
nguồn, sau đó làm sạch và chuyển đổi dữ liệu trước khi nạp vào hệ thống lưu trữ. Phương
pháp này phù hợp với các hệ thống truyền thống, nơi tài nguyên xử lý tập trung ở tầng ETL.
Ngược lại, mô hình ELT (Extract – Load – Transform) đưa dữ liệu thô trực tiếp vào
Data Lake hoặc Data Warehouse trước, sau đó mới thực hiện chuyển đổi trên hệ thống lưu
trữ. Cách tiếp cận này tận dụng sức mạnh xử lý của các nền tảng điện toán đám mây hiện
đại và đặc biệt phù hợp với Big Data. 3
Hình 1.2. So sánh mô hình ETL và ELT trong hệ thống Data Engineering
1.5. Giải pháp lưu trữ và ngôn ngữ lập trình trong kỹ thuật dữ liệu
Hệ thống kỹ thuật dữ liệu xoay quanh các giải pháp lưu trữ dữ liệu, nơi dữ liệu được
thu thập, xử lý và lưu trữ nhằm phục vụ cho phân tích và ra quyết định. Trong bối cảnh hiện
nay, điện toán đám mây đóng vai trò trung tâm nhờ khả năng mở rộng linh hoạt, chi phí tối
ưu và độ tin cậy cao. Các nền tảng phổ biến như Amazon S3, Google Cloud Storage và
Azure Data Lake cho phép lưu trữ khối lượng dữ liệu lớn, đồng thời hỗ trợ tích hợp dễ dàng
với các công cụ xử lý và phân tích dữ liệu hiện đại. Trong hạ tầng dữ liệu, cơ sở dữ liệu
quan hệ vẫn giữ vai trò quan trọng nhờ cấu trúc bảng rõ ràng và khả năng truy vấn phức tạp
thông qua SQL, phù hợp với các hệ thống nghiệp vụ và báo cáo truyền thống.
Bên cạnh đó, cơ sở dữ liệu NoSQL mang lại sự linh hoạt cao hơn trong lưu trữ dữ
liệu phi cấu trúc hoặc bán cấu trúc, đồng thời dễ dàng mở rộng theo chiều ngang, rất phù
hợp với các hệ thống dữ liệu lớn và thay đổi nhanh. Ngoài ra, kho dữ liệu (data warehouse)
được thiết kế để hỗ trợ phân tích thời gian thực và Business Intelligence (BI), cung cấp một
nguồn dữ liệu thống nhất và đáng tin cậy cho việc ra quyết định. Ngược lại, hồ dữ liệu (data
lake) cho phép lưu trữ khối lượng lớn dữ liệu thô, bao gồm cả dữ liệu có cấu trúc và phi
cấu trúc, đặc biệt phù hợp cho các bài toán khoa học dữ liệu và học máy. Tuy nhiên, để
khắc phục hạn chế của hai mô hình này, data lakehouse đã ra đời như một giải pháp kết 4
hợp, vừa tận dụng chi phí thấp và tính linh hoạt của data lake, vừa duy trì khả năng quản trị
và hiệu năng truy vấn của data warehouse, đáp ứng hiệu quả nhu cầu BI, khoa học dữ liệu và AI/ML.
Bên cạnh hạ tầng lưu trữ, kỹ thuật dữ liệu còn đòi hỏi kiến thức vững chắc về nhiều
ngôn ngữ lập trình để xây dựng và vận hành pipeline dữ liệu. SQL là ngôn ngữ cốt lõi cho
việc truy vấn, quản lý và biến đổi dữ liệu. Python được sử dụng rộng rãi nhờ hệ sinh thái
thư viện phong phú, hỗ trợ xây dựng pipeline linh hoạt và quản lý workflow hiệu quả. Scala
đặc biệt phù hợp với xử lý dữ liệu lớn trên Apache Spark nhờ khả năng xử lý song song
mạnh mẽ, trong khi Java thường được dùng trong các hệ thống xử lý dữ liệu backend quy
mô lớn và là nền tảng của nhiều công cụ phân tích như Apache Hive. Việc thành thạo các
công nghệ này giúp kỹ sư dữ liệu xây dựng hạ tầng dữ liệu ổn định, mở rộng và đáp ứng
tốt các yêu cầu phân tích hiện đại. 5
CHƯƠNG 2. CÁC ĐẶC TÍNH CỦA BIG DATA
2.1 Tổng quan về Big Data
Big Data dùng để chỉ các tập dữ liệu có quy mô rất lớn, tốc độ phát sinh nhanh và
mức độ đa dạng cao, vượt quá khả năng xử lý của các hệ thống quản lý dữ liệu truyền thống.
Trong môi trường số hóa hiện nay, dữ liệu được tạo ra liên tục từ nhiều nguồn khác nhau
như giao dịch trực tuyến, thiết bị IoT, mạng xã hội, hệ thống doanh nghiệp và các nền tảng
điện toán đám mây. Sự bùng nổ dữ liệu này không chỉ làm gia tăng khối lượng lưu trữ mà
còn đặt ra nhiều thách thức về thu thập, xử lý, phân tích và bảo mật thông tin.
Khác với cách tiếp cận truyền thống chỉ tập trung vào lưu trữ dữ liệu, Big Data
hướng đến việc khai thác giá trị từ dữ liệu. Thông qua các công nghệ xử lý phân tán và
phân tích nâng cao, doanh nghiệp có thể phát hiện xu hướng, dự đoán hành vi khách hàng,
tối ưu hoạt động kinh doanh và nâng cao hiệu quả ra quyết định. Do đó, Big Data không
chỉ là vấn đề kỹ thuật mà còn là yếu tố chiến lược trong quá trình chuyển đổi số của tổ chức.
Để mô tả đầy đủ các đặc điểm cốt lõi của Big Data, mô hình 5V được sử dụng rộng
rãi nhằm phản ánh những thách thức và giá trị mà dữ liệu lớn mang lại.
Hình 2.1. Mô hình 5V của Big data 6
2.2 Mô hình 5V của Big Data
Mô hình 5V bao gồm năm yếu tố chính: Volume, Variety, Velocity, Veracity và
Value. Mỗi yếu tố phản ánh một khía cạnh quan trọng trong việc thu thập, xử lý và khai thác dữ liệu lớn.
2.2.1 Volume – Khối lượng dữ liệu
Volume thể hiện quy mô khổng lồ của dữ liệu được tạo ra và lưu trữ trong các hệ
thống hiện đại. Dữ liệu ngày nay không còn dừng lại ở mức gigabyte hay terabyte mà đã
mở rộng đến petabyte và thậm chí exabyte. Các doanh nghiệp thương mại điện tử, ngân
hàng, mạng xã hội và nền tảng số phải xử lý hàng triệu đến hàng tỷ bản ghi mỗi ngày.
Khối lượng dữ liệu lớn buộc các hệ thống truyền thống phải nhường chỗ cho kiến
trúc lưu trữ phân tán và điện toán đám mây. Những nền tảng như Data Lake và Data
Warehouse hiện đại cho phép lưu trữ linh hoạt, mở rộng theo nhu cầu và tối ưu chi phí.
Việc quản lý Volume hiệu quả giúp doanh nghiệp đảm bảo hiệu năng truy vấn cũng như
tránh lãng phí tài nguyên hạ tầng.
Hình 2.2. Hệ thống lưu trữ phân tán cho dữ liệu khối lượng lớn (Volume) 7
2.2.2 Variety – Sự đa dạng của dữ liệu
Variety phản ánh sự phong phú về định dạng và cấu trúc của dữ liệu. Trước đây, dữ
liệu chủ yếu tồn tại dưới dạng bảng trong các hệ quản trị cơ sở dữ liệu quan hệ. Tuy nhiên,
ngày nay dữ liệu có thể là văn bản, hình ảnh, video, âm thanh, log hệ thống hay dữ liệu cảm biến.
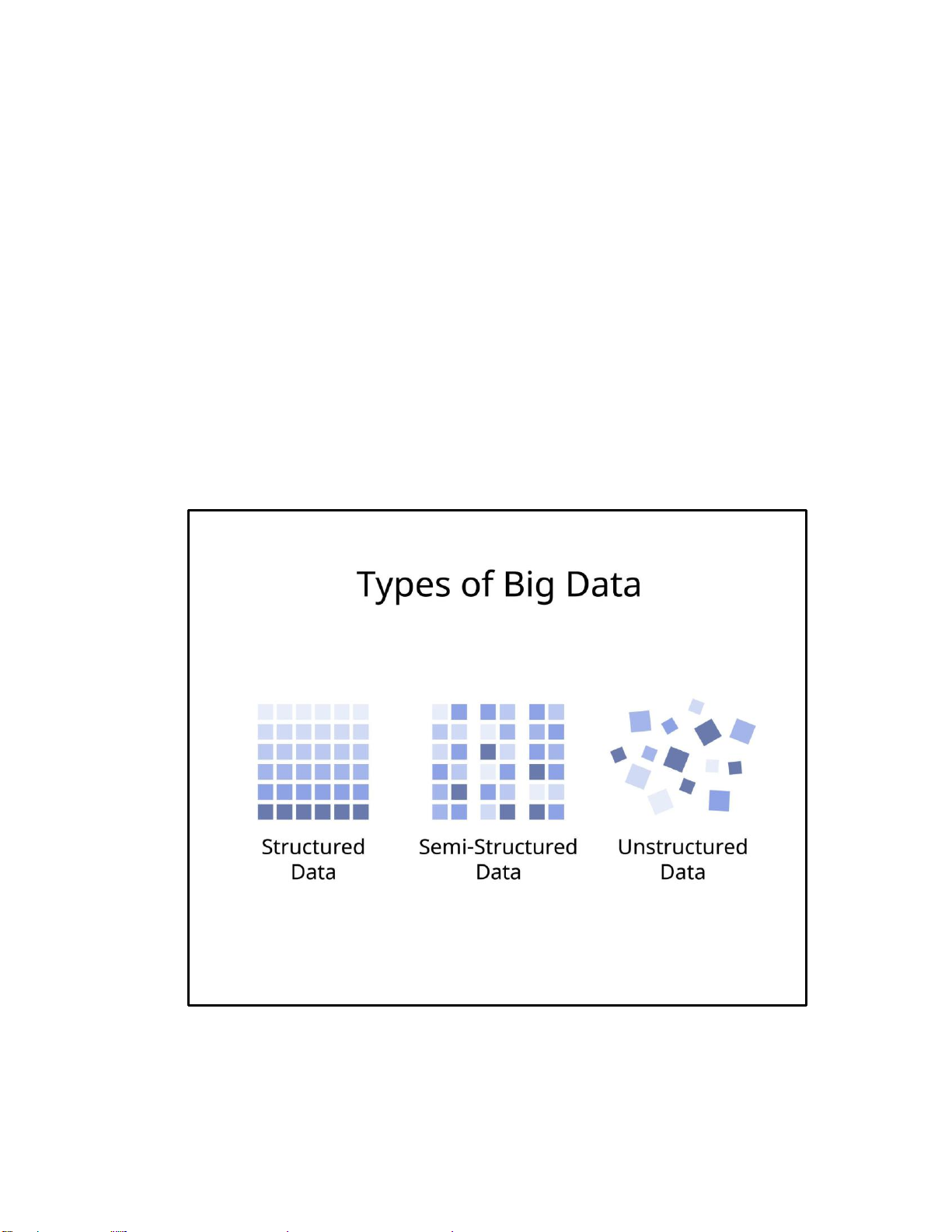
Dữ liệu được chia thành ba nhóm chính gồm dữ liệu có cấu trúc, bán cấu trúc và phi
cấu trúc. Dữ liệu có cấu trúc dễ dàng lưu trữ và truy vấn bằng SQL, trong khi dữ liệu bán
cấu trúc như JSON hay XML có schema linh hoạt hơn. Dữ liệu phi cấu trúc chiếm tỷ trọng
lớn nhất và đòi hỏi các kỹ thuật xử lý đặc biệt như xử lý ngôn ngữ tự nhiên hoặc thị giác
máy tính để khai thác giá trị.
Sự đa dạng này khiến Data Engineering phải xây dựng các pipeline linh hoạt, có khả
năng tiếp nhận và xử lý nhiều loại dữ liệu khác nhau trong cùng một hệ thống.
Hình 2.3. Các dạng dữ liệu trong Big Data: có cấu trúc, bán cấu trúc và phi cấu trúc
2.2.3 Velocity – Tốc độ phát sinh và xử lý dữ liệu
Velocity thể hiện tốc độ dữ liệu được tạo ra và yêu cầu xử lý trong hệ thống. Trong 8
nhiều lĩnh vực như tài chính, thương mại điện tử và IoT, dữ liệu được sinh ra liên tục theo
thời gian thực. Các sự kiện như giao dịch thẻ, hành vi người dùng trên website hay dữ liệu
cảm biến môi trường đều đòi hỏi phản hồi gần như ngay lập tức.
Bên cạnh xử lý theo thời gian thực (streaming), nhiều hệ thống vẫn áp dụng xử lý
theo lô (batch) cho các tác vụ tổng hợp dữ liệu lớn theo chu kỳ. Việc kết hợp linh hoạt hai
mô hình này giúp doanh nghiệp vừa đảm bảo phản ứng nhanh, vừa duy trì khả năng phân
tích lịch sử dữ liệu chuyên sâu.
Velocity cao đòi hỏi hạ tầng Data Engineering có khả năng chịu tải lớn, độ trễ thấp
và khả năng mở rộng tự động.
Hình 2.4. So sánh xử lý dữ liệu theo lô (Batch) và thời gian thực (Streaming)
2.2.4 Veracity – Độ tin cậy và chất lượng dữ liệu
Veracity phản ánh mức độ chính xác, đầy đủ và nhất quán của dữ liệu. Trong thực
tế, dữ liệu thường chứa nhiều lỗi như thiếu giá trị, trùng lặp, sai định dạng hoặc nhiễu thông
tin. Những vấn đề này nếu không được xử lý sẽ dẫn đến kết quả phân tích sai lệch, gây ảnh
hưởng nghiêm trọng đến quyết định kinh doanh.
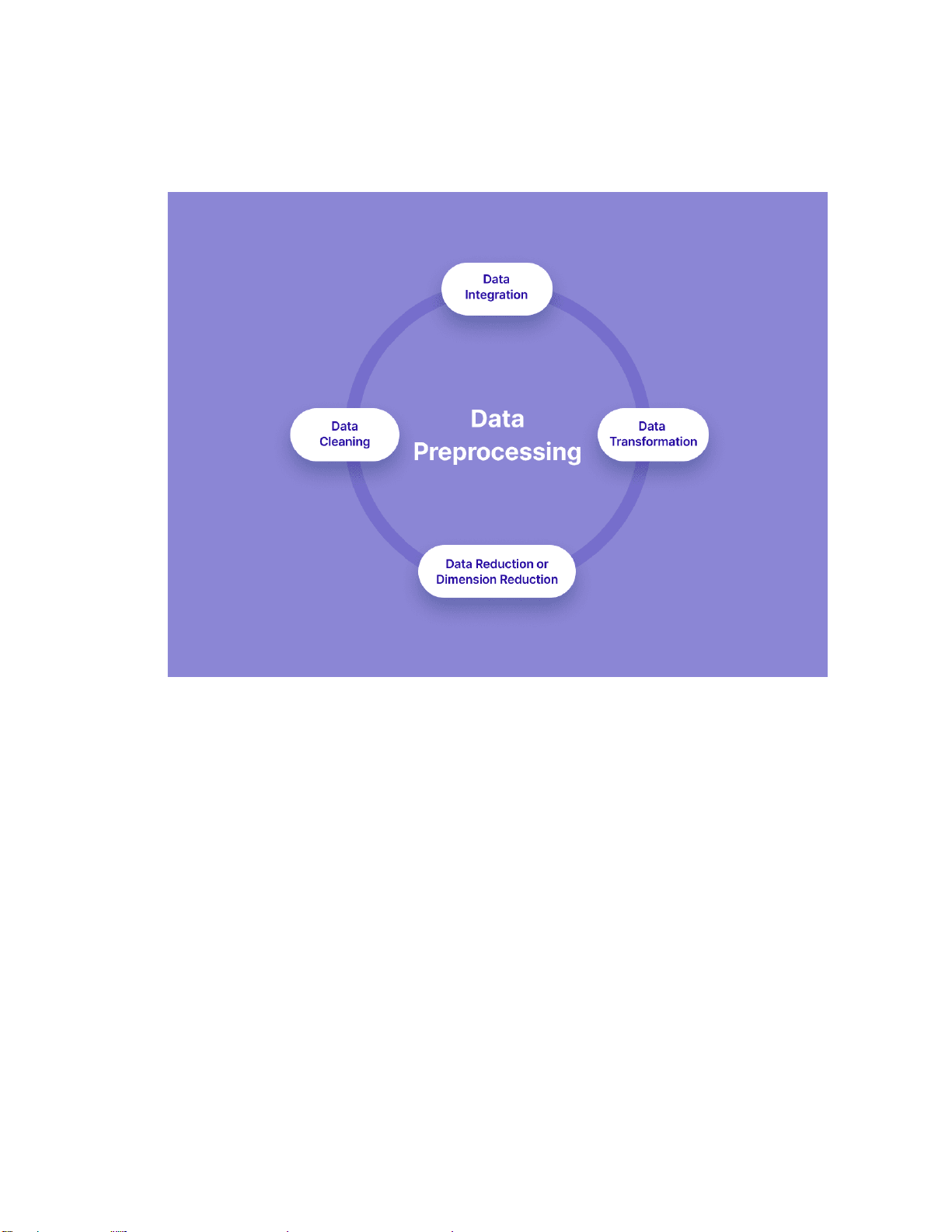
Do đó, một trong những nhiệm vụ quan trọng của Data Engineering là xây dựng các
quy trình làm sạch và kiểm soát chất lượng dữ liệu. Việc chuẩn hóa định dạng, loại bỏ dữ
liệu lỗi và phát hiện bất thường giúp đảm bảo dữ liệu đầu vào cho phân tích luôn đáng tin 9 cậy.
Chất lượng dữ liệu càng cao thì giá trị khai thác từ Big Data càng lớn, đặc biệt trong
các hệ thống học máy và trí tuệ nhân tạo.
Hình 2.5. Quy trình làm sạch và kiểm soát chất lượng dữ liệu trong Big Data
2.2.5 Value – Giá trị của dữ liệu
Value là mục tiêu cuối cùng của toàn bộ quá trình xử lý Big Data. Dữ liệu chỉ thực
sự có ý nghĩa khi mang lại lợi ích thực tế cho doanh nghiệp, chẳng hạn như cải thiện trải
nghiệm khách hàng, tối ưu chi phí vận hành, dự đoán xu hướng thị trường hoặc phát hiện gian lận.
Việc thu thập khối lượng lớn dữ liệu nhưng không khai thác hiệu quả sẽ dẫn đến
lãng phí tài nguyên và chi phí hạ tầng. Do đó, các hệ thống Data Engineering cần được thiết
kế xoay quanh mục tiêu kinh doanh cụ thể, đảm bảo dữ liệu được xử lý và phân tích theo
hướng tạo ra giá trị lâu dài. 10
Hình 2.6. Khai thác Big Data phục vụ phân tích kinh doanh và ra quyết định
2.3 Kết luận chương
Big Data được đặc trưng bởi mô hình 5V, phản ánh toàn diện các thách thức về quy
mô, tốc độ, sự đa dạng, chất lượng và giá trị dữ liệu. Việc hiểu rõ từng yếu tố trong mô hình
này giúp doanh nghiệp xây dựng kiến trúc Data Engineering phù hợp, tối ưu hạ tầng và
khai thác hiệu quả nguồn tài nguyên dữ liệu.
Big Data không chỉ là xu hướng công nghệ mà đã trở thành nền tảng cho chuyển đổi
số và cạnh tranh chiến lược trong kỷ nguyên hiện đại. 11
CHƯƠNG 3. CÁC CHỦ ĐỀ LIÊN QUAN ĐẾN DATA
ENGINEERING TRÊN AWS CLOUD
3.1 Tổng quan hệ sinh thái Data Engineering trên AWS
AWS cung cấp một hệ sinh thái dịch vụ toàn diện, hỗ trợ toàn bộ vòng đời dữ liệu
từ thu thập, lưu trữ, xử lý đến phân tích và trực quan hóa. Nhờ mô hình điện toán đám mây
linh hoạt, AWS cho phép doanh nghiệp xây dựng các hệ thống Data Engineering có khả
năng mở rộng tự động, độ tin cậy cao và tối ưu chi phí vận hành.
Trong kiến trúc Data Engineering hiện đại trên AWS, dữ liệu thường được thu thập
từ nhiều nguồn khác nhau như hệ thống giao dịch, website, thiết bị IoT và các ứng dụng
doanh nghiệp. Sau đó, dữ liệu được lưu trữ tập trung trong Data Lake, xử lý thông qua các
công cụ ETL phân tán và cuối cùng phục vụ phân tích bằng các nền tảng BI và AI.
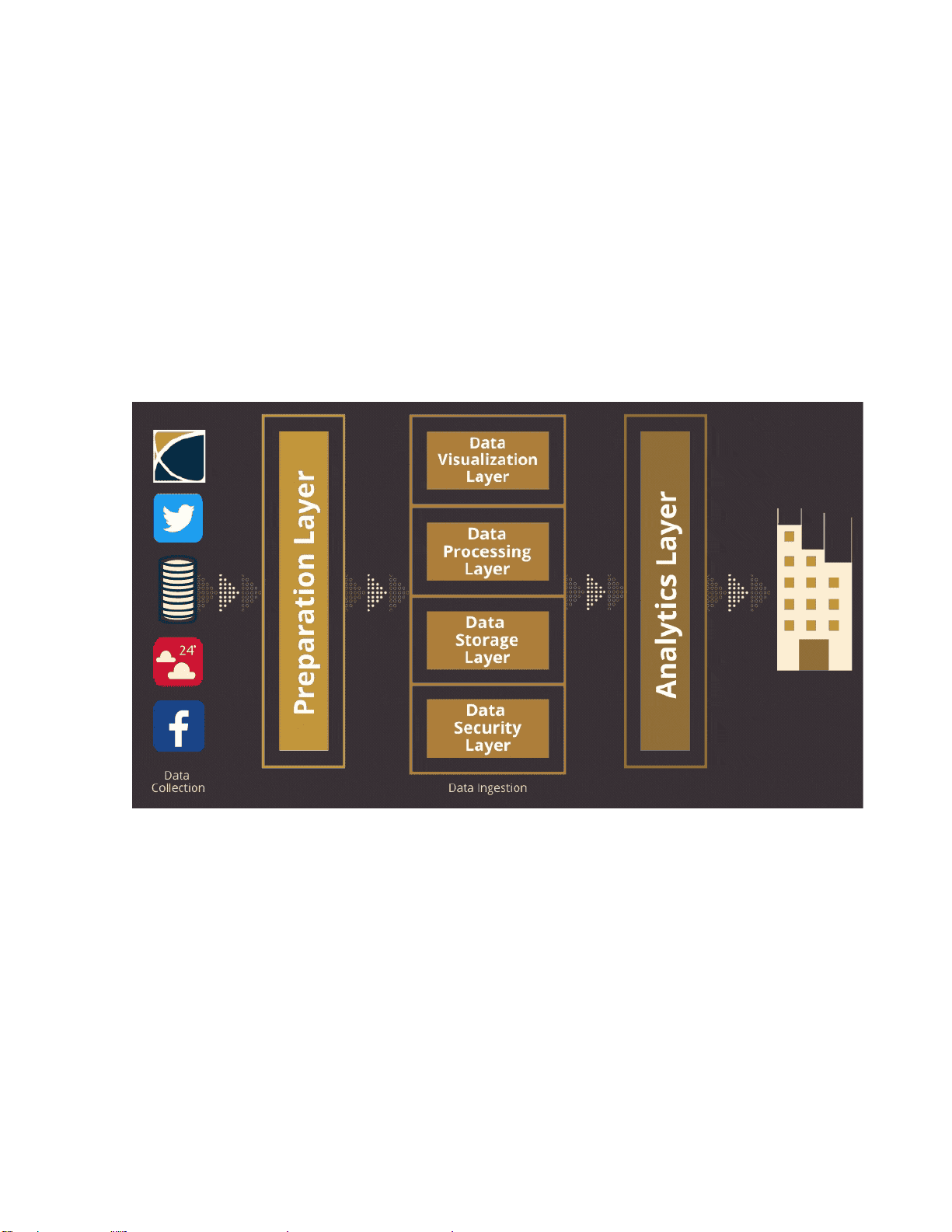
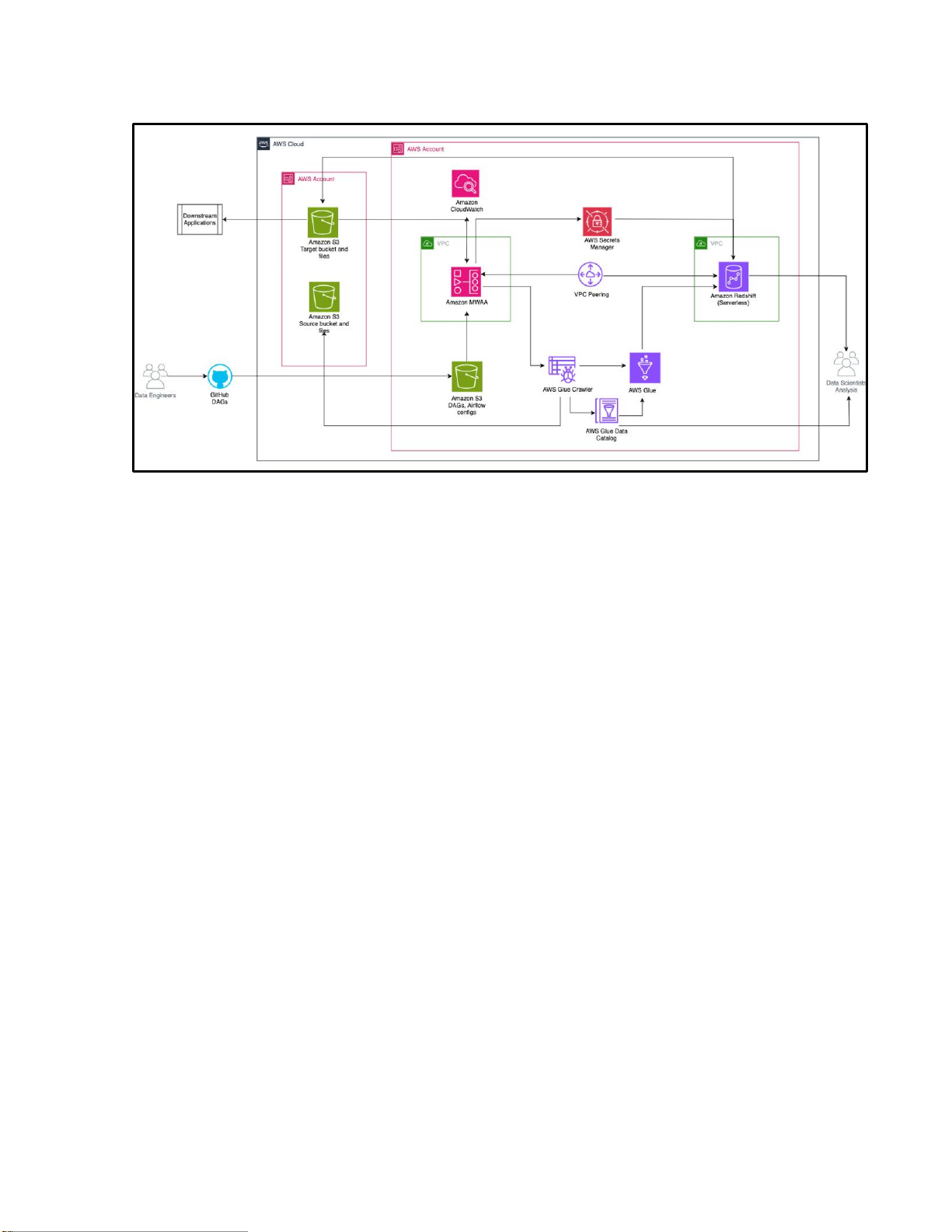
Hình 3.1. Kiến trúc tổng thể hệ thống Data Engineering trên AWS Cloud
Kiến trúc này thể hiện rõ sự liên kết giữa các lớp thu thập dữ liệu, lưu trữ trung tâm,
xử lý dữ liệu lớn và lớp phân tích cuối cùng.
3.2 Lớp lưu trữ dữ liệu và cơ sở dữ liệu
Trong hầu hết các kiến trúc Data Engineering trên AWS, lớp lưu trữ đóng vai trò
trung tâm và thường được xây dựng theo mô hình Data Lake. Data Lake cho phép lưu trữ
dữ liệu thô ở nhiều định dạng khác nhau, từ dữ liệu có cấu trúc đến dữ liệu phi cấu trúc, với 12
chi phí thấp và khả năng mở rộng gần như không giới hạn.
Bên cạnh Data Lake, AWS còn cung cấp các hệ thống Data Warehouse chuyên biệt
cho phân tích dữ liệu quy mô lớn. Các kho dữ liệu này được tối ưu cho truy vấn tổng hợp
phức tạp, phục vụ báo cáo quản trị và phân tích kinh doanh.
Ngoài ra, các cơ sở dữ liệu quan hệ và NoSQL trên AWS thường đóng vai trò nguồn
phát sinh dữ liệu giao dịch ban đầu. Data Engineering chịu trách nhiệm trích xuất dữ liệu
từ các hệ thống này để đưa vào Data Lake và Data Warehouse phục vụ phân tích.
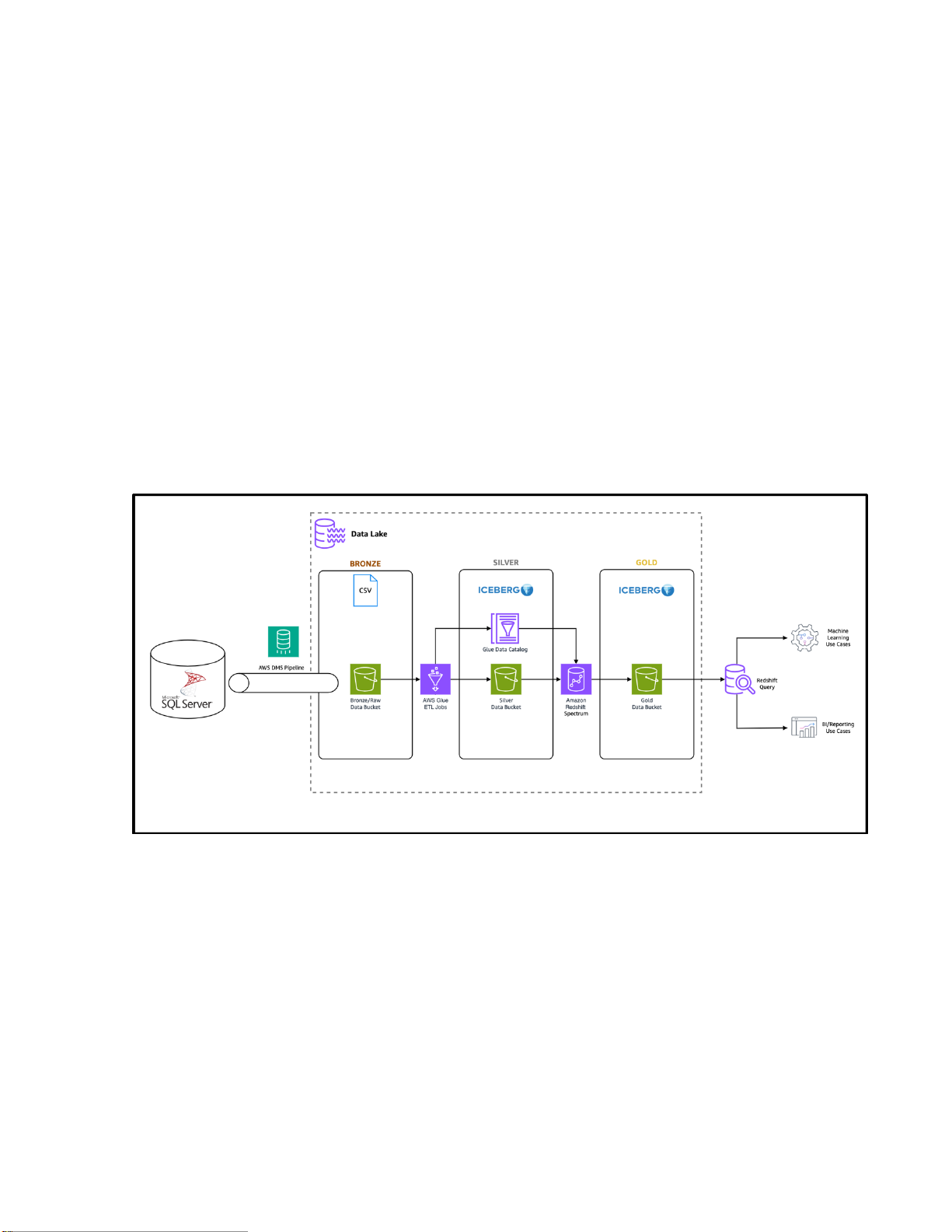
Hình 3.2. Mô hình phân tầng lưu trữ dữ liệu trong Data Lake trên AWS
Mô hình phân tầng giúp quản lý dữ liệu theo từng trạng thái xử lý, nâng cao hiệu
quả vận hành và kiểm soát chất lượng dữ liệu.
3.3 Thu thập và xử lý dữ liệu (Ingestion & Transformation)
Lớp thu thập dữ liệu trên AWS cho phép tiếp nhận dữ liệu theo cả hai mô hình batch
và streaming. Dữ liệu có thể được ingest định kỳ từ cơ sở dữ liệu doanh nghiệp hoặc tiếp
nhận liên tục từ các luồng sự kiện thời gian thực như log hệ thống và dữ liệu IoT.
Sau khi thu thập, dữ liệu được xử lý thông qua các pipeline ETL phân tán. Quá trình
này bao gồm làm sạch dữ liệu, chuẩn hóa định dạng, kết hợp nhiều nguồn dữ liệu và tối ưu
cấu trúc lưu trữ cho phân tích. Các công cụ xử lý trên AWS cho phép thực hiện khối lượng 13
công việc lớn mà không cần quản lý hạ tầng vật lý.
Hình 3.3. Quy trình thu thập và xử lý dữ liệu Batch và Streaming trên AWS
Kiến trúc này cho phép hệ thống vừa xử lý dữ liệu thời gian thực vừa duy trì khả
năng phân tích dữ liệu lịch sử quy mô lớn.
3.4 Phân tích dữ liệu và Business Intelligence
Sau khi dữ liệu được xử lý và lưu trữ, lớp phân tích đóng vai trò khai thác giá trị từ
dữ liệu. Trên AWS, dữ liệu có thể được truy vấn trực tiếp từ Data Lake hoặc từ Data
Warehouse thông qua các công cụ phân tích SQL hiệu năng cao.
Các nền tảng BI cho phép trực quan hóa dữ liệu thành dashboard, báo cáo tương tác
và biểu đồ quản trị, hỗ trợ ban lãnh đạo theo dõi hoạt động kinh doanh theo thời gian thực.
Nhờ kiến trúc cloud, hệ thống phân tích có thể mở rộng linh hoạt theo số lượng người dùng
và khối lượng truy vấn. 14
Tài liệu liên quan:
-

Báo cáo đồ án kết thúc học phần - Điện toán đám mây
40 20 -

Tổng quan về Điện toán Đám mây và Dịch vụ AWS | Môn Điện toán đám mây - Đại học Sư phạm Kỹ thuật Thành phố Hồ Chí Minh
114 57 -

Tổng quan về Điện toán đám mây và Bảo mật | Môn Điện toán đám mây - Đại học Sư phạm Kỹ thuật Thành phố Hồ Chí Minh
147 74 -

Module 9-10: AWS Cloud Architecture & Auto Scaling Principles Overview | Môn Điện toán đám mây - Đại học Sư phạm Kỹ thuật Thành phố Hồ Chí Minh
183 92