Báo cáo Khám Phá Dữ Liệu Với FiftyOne | Môn Trí tuệ nhân tạo - Đại học Sư phạm Kỹ thuật Thành phố Hồ Chí Minh
Trong FiftyOne, dataset là tập hợp các dữ liệu hình ảnh hoặc video mà bạn muốn phân tích hoặc đào tạo trên mô hình. Tài liệu được sưu tầm gồm 24 trang, giúp bạn ôn tập tốt hơn. Mời các bạn đón xem.
Môn: Trí tuệ nhân tạo (AI2023) 12 tài liệu
Trường: Trường Đại học Sư phạm Kỹ thuật Thành phố Hồ Chí Minh 4.4 K tài liệu
Tác giả:
















Preview text:
lOMoAR cPSD| 58778885
TRƯỜNG ĐẠI HỌC SƯ PHẠM KỸ THUẬT TP.HỒ CHÍ MINH
KHOA CƠ KHÍ CHẾ TẠO MÁY
Báo cáo trí tuệ nhân tạo lOMoAR cPSD| 58778885 Mục Lục
Chương I: Các khái niệm cơ bản và khám phá cấu trúc dữ liệu...............2
1. Khái niệm FiftyOne:.............................................................................2
2. Cấu trúc dữ liệu của FiftyOne...............................................................2
3. Phương pháp nhúng hình ảnh (image embeddings)..............................3
Chương II: Thêm dự đoán của bộ phân loại vào bộ dữ liệu và Đánh giá
mô hình phân loại......................................................................................4
1. Thêm dự đoán của bộ phân loại............................................................4
2. Đánh giá một bộ phân loại với Fiftyone..............................................6
Chương III: Tìm các mẫu bị phân loại sai và thêm dự đoán của bộ phân
loại vào bộ dữ liệu.....................................................................................7
1. Tìm các mẫu bị phân loại sai................................................................7
1.1. Tạo lỗi nhãn giả tạo............................................................................7
1.2. Thêm dự đoán mô hình......................................................................9
1.3. Tìm lỗi nhãn.....................................................................................13
2. Thêm dự đoán của bộ phân loại vào bộ dữ liệu..................................18
2.1. Đang tải tập dữ liệu phát
hiện..........................................................18 2.2. Thêm dự đoán mô
hình....................................................................21
Chương I: Các khái niệm cơ bản và khám phá cấu trúc dữ liệu
1. Khái niệm FiftyOne:
- Một bộ công cụ mã nguồn mở dùng để cải thiện hiệu suất của mô hình thị giác máy tính
- giúp người dùng xây dựng các bộ dữ liệu và mô hình chất lượng cao
- cho phép người dùng trực quan hóa, sắp xếp dữ liệu của mình một
cáchrõ ràng, tìm ra cấu trúc bên trong dữ liệu và có khả năng đánh giá
được các dự đoán mô hình trên tập dữ liệu mà bạn có.
2. Cấu trúc dữ liệu của FiftyOne lOMoAR cPSD| 58778885
- Dataset: Trong FiftyOne, dataset là tập hợp các dữ liệu hình ảnh hoặc
video mà bạn muốn phân tích hoặc đào tạo trên mô hình. Các dataset
này có thể bao gồm các hình ảnh đánh dấu hoặc chưa đánh dấu.
- Sample: là một mẫu hình ảnh hoặc video trong dataset. Mỗi mẫu
thường bao gồm hình ảnh và các thông tin liên quan đến một phần dữ
liệu nhất định, đường dẫn tới hình ảnh, và các thông tin mở rộng.
Thành phần quan trọng của một sample thường bao gồm media type, tags và metadata
- Field: đại diện cho thuộc tính của một mẫu hoặc của tập dữ liệu.
- Label: là thông tin mô tả về hình ảnh hoặc video, như là vị trí của các
đối tượng trong hình ảnh, hoặc loại của chúng. Trong FiftyOne, bạn có
thể thêm, chỉnh sửa và quản lý nhãn của các hình ảnh trong dataset.
- DatasetViews: là một tính năng quan trọng trong FiftyOne được sử
dụng để làm việc với dữ liệu. Nó sẽ tạo ra các bản sao từ tập dữ liệu
gốc, giúp người dùng có thể tiến hành các phân tích và thực nghiệm mà
không sợ ảnh hưởng đến dữ liệu ban đầu.
- Aggregations: là quá trình tổng hợp dữ liệu từ các tập dữ liệu và
chuyển hóa chúng thành các số liệu cụ thể thông qua việc tính toán,
thống kê. Từ đó người dùng có thể hiểu rõ hơn về dữ liệu và đưa ra
quyết định dựa trên các số liệu có được.
3. Phương pháp nhúng hình ảnh (image embeddings)
Đây là một phương pháp trong FiftyOne giúp người dùng có thể hiểu và
khám phá các mối quan hệ, cấu trúc, hoặc nhóm trong dữ liệu hình ảnh một cách trực quan hơn
* Quy trình cơ bản của phương pháp nhúng hình ảnh
- Bước 1: chuẩn bị dữ liệu
- Bước 2: chọn phương pháp nhúng. lOMoAR cPSD| 58778885
Có 3 phương pháp phổ biến là t-SNE, UMAP, PCA
- Bước 3: Tính toán nhúng
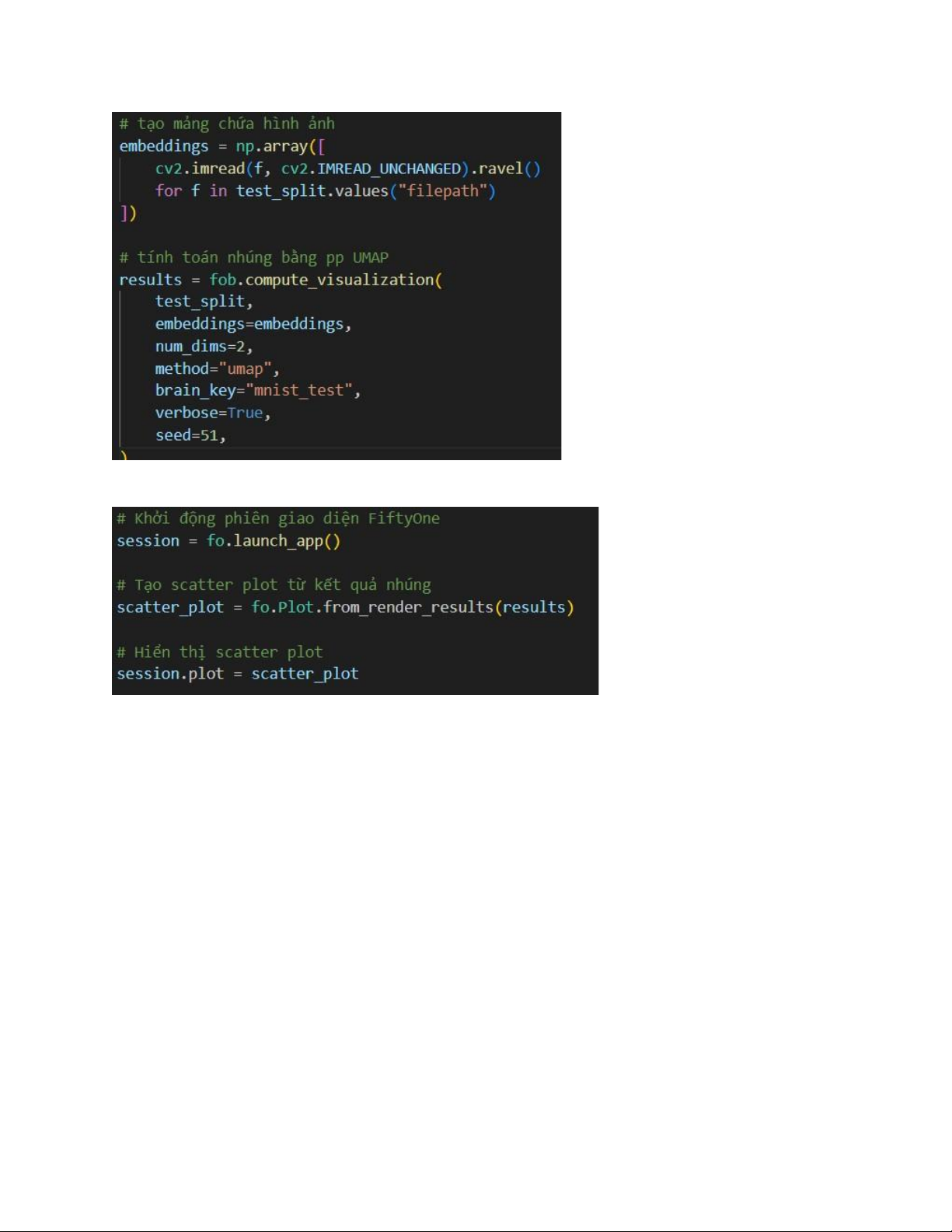
Trong FiftyOne, có thể sử dụng phương thức compute_visualization
trong module fiftyone.brain để tính toán nhúng cho các hình ảnh -
Bước 4: Hiển thị và phân tích kết quả:
Người dùng có thể hiển thị kết quả bằng cách sử dụng các công cụ trực
quan hóa có sẵn trong FiftyOne. Ví dụ: scatter_plot() (biểu đồ phân tán),
bar_chart() (biểu đồ cột),…. * Ví dụ:
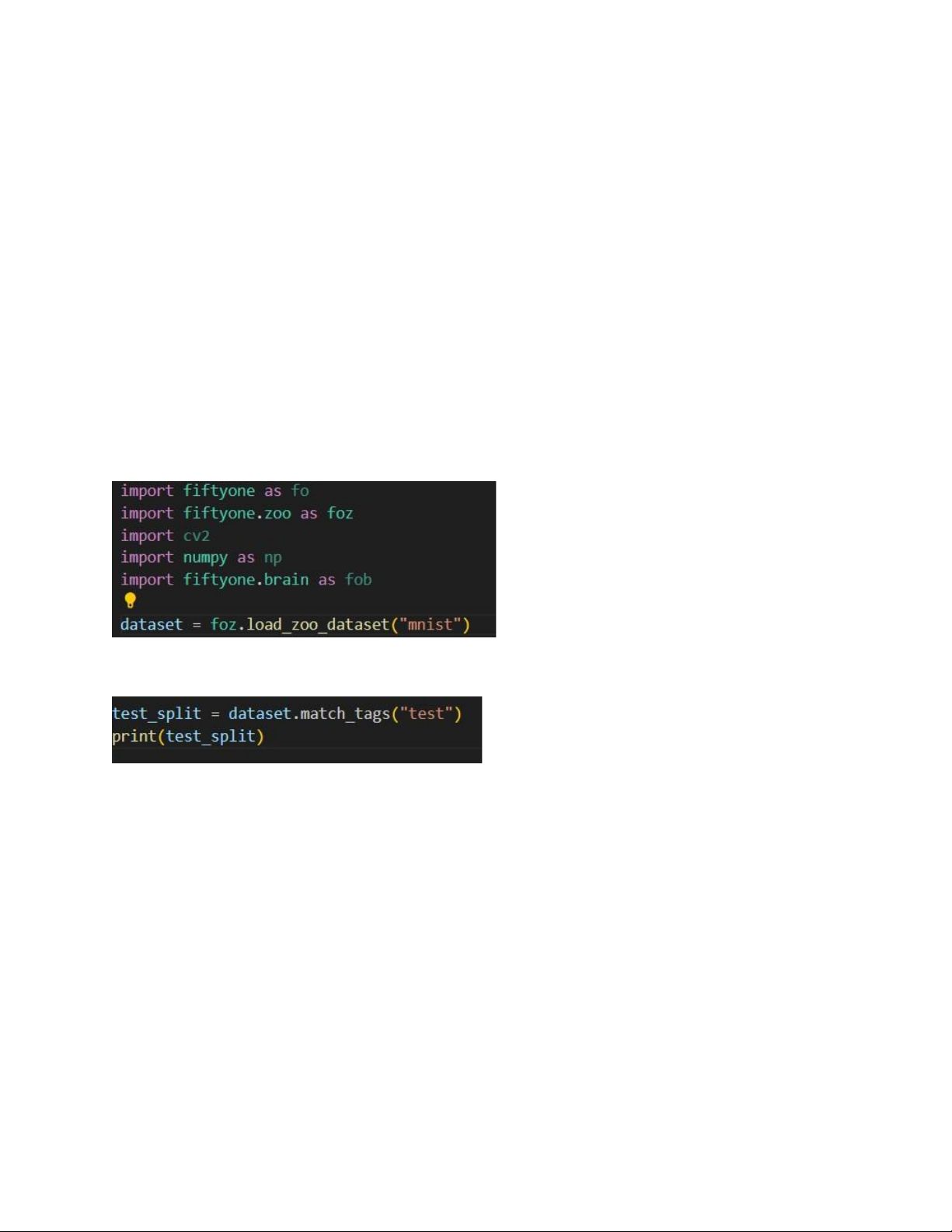
Khai báo thư viện fiftyOne và tải tập dữ liệu có tên “mnist”
Lấy một phần của tập dữ liệu ban đầu, các mẫu có tags là “test” Tính toán nhúng lOMoAR cPSD| 58778885
Hiển thị kết quả bằng scatter plot
Chương II: Thêm dự đoán của bộ phân loại vào bộ dữ liệu và Đánh
giá mô hình phân loại
1. Thêm dự đoán của bộ phân loại
Chuẩn bị Dự Đoán: Trước tiên, bạn cần có các dự đoán từ mô hình phân
loại của mình cho dữ liệu mà bạn muốn thêm vào. Đảm bảo rằng dự
đoán này được lưu trữ trong một định dạng có thể đọc được, chẳng hạn
như một tệp CSV hoặc JSON. lOMoAR cPSD| 58778885
Giả sử bạn có một tập dữ liệu phân loại hình ảnh trên đĩa theo định dạng sau:
Import các thư viện fiftyone.utils.torch được sử dụng để tạo dataset từ các hình ảnh lOMoAR cPSD| 58778885 2
. Đ ánh giá một bộ phân loại với Fiftyone -
Chạy đánh giá: chúng ta sẽ sử dụng chức năng phân loại nhị phâ n để
phân tích mô hình của chúng ta: -
Xem số liệu tổng hợp in báo cáo phân loại: results.print_report() -
sử dụng kết quả đánh giá từ results để vẽ confusion matrixvà hiển thị lOMoAR cPSD| 58778885
nó.results.plot_confusion_matrix() tạo ra một biểu đồ của ma trận nhầm
lẫn từ kết quả đánh giá. Sau đó, .show() được gọi để hiển thị biểu đồ:
plot = results.plot_confusion_matrix() plot.show()
Chương III: Tìm các mẫu bị phân loại sai và thêm dự đoán của bộ
phân loại vào bộ dữ liệu. 1. Tìm các mẫu bị phân loại sai -
Các lỗi chú thích tạo ra một giới hạn nhân tạo đối với hiệu suất của
mô hình của bạn. Tuy nhiên, việc tìm ra những lỗi này bằng tay ít nhất
cũng khó khăn như công việc chú thích ban đầu. -
FiftyOne có thể giúp bạn tìm và sửa các lỗi nhãn trong tập dữ liệu
của mình, cho phép bạn quản lý các tập dữ liệu chất lượng cao hơn và
cuối cùng là đào tạo các mô hình tốt hơn.
1.1. Tạo lỗi nhãn giả tạo: -
Trước hết, tập dữ liệu được làm giàu bằng cách thêm nhãn lỗi giả
tạo vào một phần của dữ liệu. Điều này giúp mô phỏng các lỗi nhãn có
thể xảy ra trong thực tế. - Cài đặt !pip install fiftyone # Download the software
!git clone --depth 1 --branch v2.1
https://github.com/huyvnphan/PyTorch_CIFAR10.git
# Download the pretrained model (90MB)
!eta gdrive download --public \
1dGfpeFK_QG0kV-U6QDHMX2EOGXPqaNzu \
PyTorch_CIFAR10/cifar10_models/state_dicts/resnet50.pt -
Thao tác dữ liệuimport random lOMoAR cPSD| 58778885 import fiftyone as fo import fiftyone.zoo as foz
# Load the CIFAR-10 test split
# Downloads the dataset from the web if necessary dataset
= foz.load_zoo_dataset("cifar10", split="test")
# Get the CIFAR-10 classes list classes = dataset.default_classes
# Artificially corrupt 10% of the labels
_num_mistakes = int(0.1 * len(dataset)) for
sample in dataset.take(_num_mistakes):
mistake = random.randint(0, 9) while
classes[mistake] == sample.ground_truth.label:
mistake = random.randint(0, 9)
sample.tags.append("mistake") sample.ground_truth =
fo.Classification(label=classes[mistake]) sample.save()
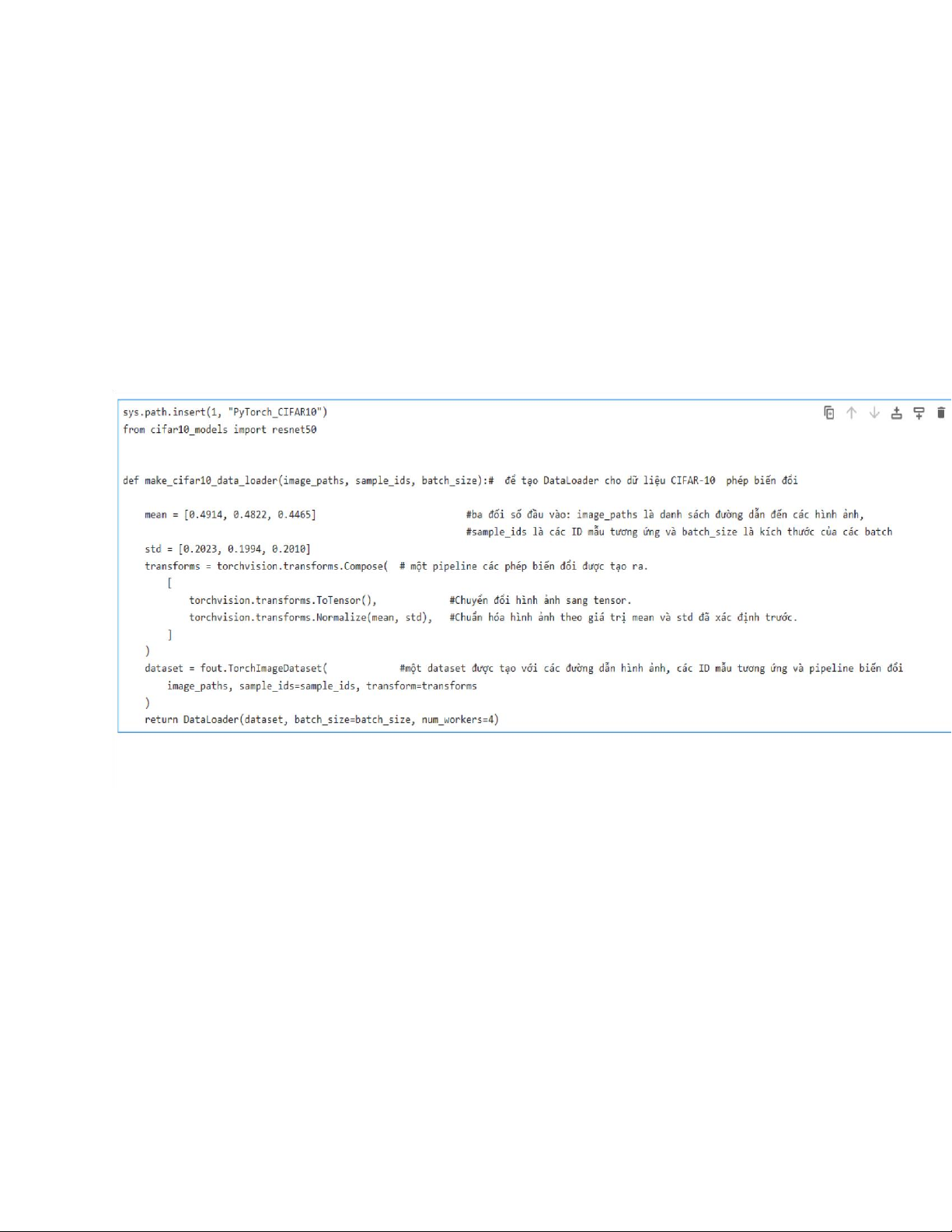
1.2. Thêm dự đoán mô hình: Một mô hình phân loại đã được huấn
luyện sẵn (trong trường hợp này là ResNet-50 trên tập dữ liệu CIFAR10)
được sử dụng để tạo dự đoán cho các mẫu trong tập dữ liệu. Các dự lOMoAR cPSD| 58778885
đoán này được thêm vào tập dữ liệu, cho phép phân tích sau này về lỗi nhãn.
- Thêm tập dự đoán vào dữ liệu import sys
import numpy as np import torch import
torchvision from torch.utils.data import DataLoader
import fiftyone.utils.torch as fout
sys.path.insert(1, "PyTorch_CIFAR10") from
cifar10_models import resnet50
def make_cifar10_data_loader(image_paths, sample_ids, batch_size):
mean = [0.4914, 0.4822, 0.4465] std =
[0.2023, 0.1994, 0.2010] transforms =
torchvision.transforms.Compose( [
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(mean, std), ] ) lOMoAR cPSD| 58778885
dataset = fout.TorchImageDataset( image_paths,
sample_ids=sample_ids, transform=transforms )
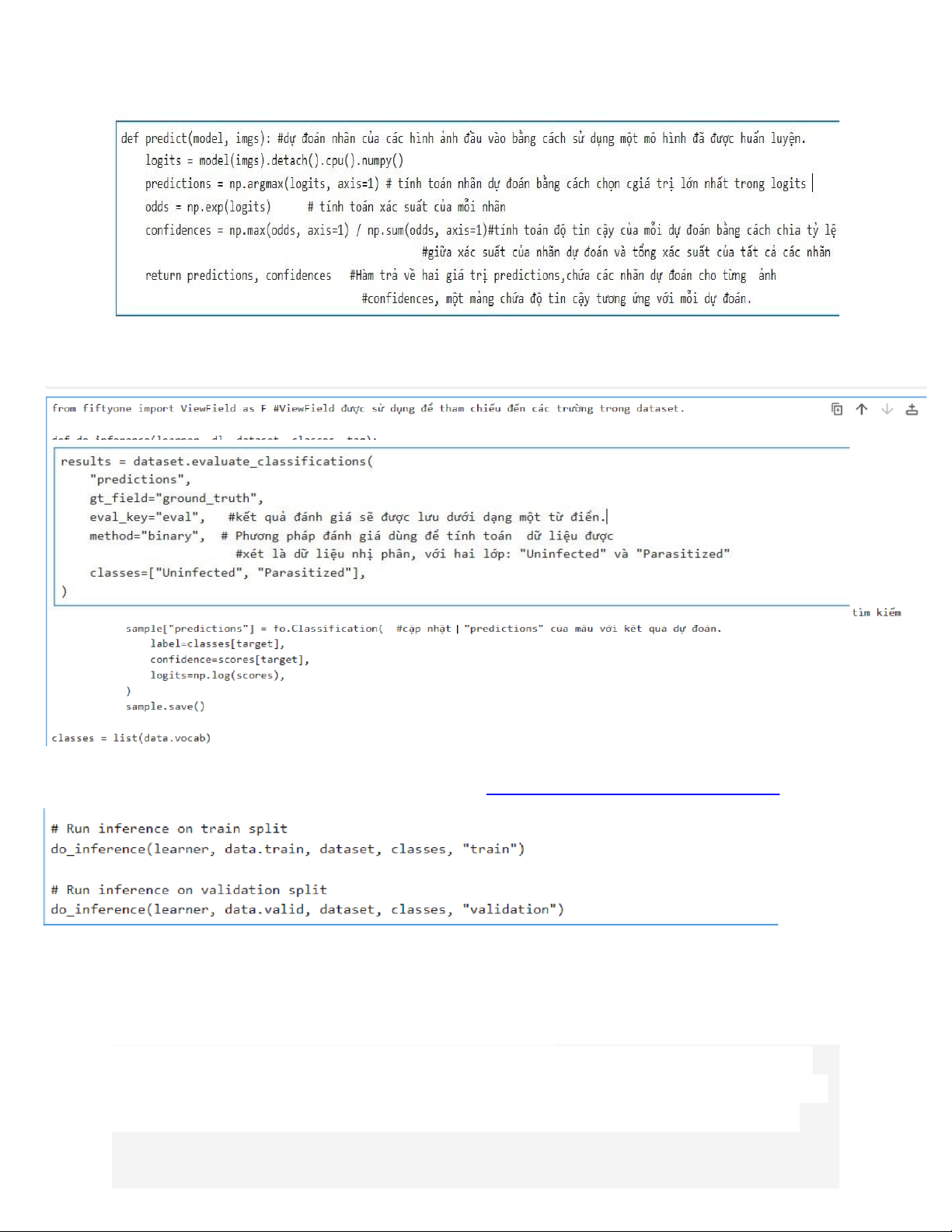
return DataLoader(dataset, batch_size=batch_size, num_workers=4) def predict(model, imgs):
logits = model(imgs).detach().cpu().numpy() predictions
= np.argmax(logits, axis=1) odds = np.exp(logits)
confidences = np.max(odds, axis=1) / np.sum(odds, axis=1)
return predictions, confidences, logits # # Load a model #
# Model performance numbers are available at:
# https://github.com/huyvnphan/PyTorch_CIFAR10 #
model = resnet50(pretrained=True) model_name = "resnet50" # lOMoAR cPSD| 58778885
# Extract a few images to process
# (some of these will have been manipulated above) #
num_samples = 1000 batch_size = 20 view =
dataset.take(num_samples) image_paths, sample_ids =
zip(*[(s.filepath, s.id) for s in view.iter_samples()]) data_loader =
make_cifar10_data_loader(image_paths, sample_ids, batch_size) #
# Perform prediction and store results in dataset #
with fo.ProgressBar() as pb: for imgs,
sample_ids in pb(data_loader):
predictions, _, logits_ = predict(model, imgs)
# Add predictions to your FiftyOne dataset for sample_id,
prediction, logits in zip(sample_ids, predictions, logits_): sample = dataset[sample_id]
sample.tags.append("processed") sample[model_name]
= fo.Classification( label=classes[prediction], logits=logits, ) lOMoAR cPSD| 58778885 sample.save()
100% |███████████████████| 50/50 [11,0 giây đã trôi qua,
còn lại 0 giây, 4,7 mẫu/s]
- In một số thông tin về các dự đoán đã được tạo và số lượng dự đoán
trong số đó tương ứng với các mẫu có nhãn sự thật cơ bản bị sai lệch
# Count the number of samples with the `processed` tag num_processed
= len(dataset.match_tags("processed"))
# Count the number of samples with both `processed` and `mistake` tags num_corrupted =
len(dataset.match_tags("processed").match_tags("mistake"))
print("Added predictions to %d samples" % num_processed) print("%d
of these samples have label mistakes" % num_corrupted) Đã thêm dự đoán vào 1000 mẫu
86 mẫu này có lỗi nhãn
1.3. Tìm lỗi nhãn: FiftyOne cung cấp các công cụ để phân tích và tìm
lỗi trong các nhãn. Một trong những phương pháp là tính toán "mức độ
nhầm lẫn" (mistakenness), dựa trên sự không phù hợp giữa nhãn thực tế
và dự đoán của mô hình. Điều này giúp xác định các mẫu có khả năng bị
phân loại sai cao. import fiftyone.brain as fob
# Get samples for which we added predictions h_view
= dataset.match_tags("processed") lOMoAR cPSD| 58778885
# Compute mistakenness fob.compute_mistakenness(h_view,
model_name, label_field="ground_truth", use_logits=True)
Tính toán sai lầm...
100% |███████████████| 1000/1000 [2,4 giây trôi qua, còn
lại 0 giây, 446,1 mẫu/s] Tính toán sai lầm hoàn tất
Phương pháp trên đã thêm mistakenness vào tất cả các mẫu mà chúng tôi
đã thêm dự đoán. Chúng ta có thể dễ dàng sắp xếp theo khả năng xảy ra lỗi từ mã:
# Sort by likelihood of mistake (most likely first) mistake_view = (dataset .match_tags("processed")
.sort_by("mistakenness", reverse=True) )
# Print some information about the view print(mistake_view)
Bộ dữ liệu: cifar10-test
Loại phương tiện: hình ảnh Số mẫu: 1000
Tags: ['lỗi', 'đã xử lý', 'kiểm tra'] Các trường mẫu: lOMoAR cPSD| 58778885
đường dẫn tệp: Fiftyone.core.fields.StringField
tags: Fiftyone.core.fields.ListField(năm
mươione.core.fields.StringField) siêu dữ liệu:
Fiftyone.core.fields.EmbeddedDocumentField(fiftyone.core.metadata.
Metadata) ground_truth:
Fiftyone.core.fields.EmbeddedDocumentField(Fiftyone.core.labels.Cla
ssification) resnet50:
Fiftyone.core.fields.EmbeddedDocumentField(Fiftyone.core.labels.Cla ssification)
nhầm lẫn: Fiftyone.core.fields.FloatField Xem các giai đoạn:
1. MatchTags(tags=['processed'])
2. SortBy(field_or_expr='nhầm lẫn', Reverse=True)
# Inspect the first few samples print(mistake_view.head()) [
'id': '6064c24201257d68b7b046d7',
'media_type': 'hình ảnh',
'filepath': '/home/ben/fiftyone/cifar10/test/data/001326.jpg',
'thẻ': BaseList(['test', 'mistake', 'processed']),
'siêu dữ liệu': Không, 'ground_truth':
'id': '6064c24c01257d68b7b0b34c', 'thẻ': BaseList([]), 'nhãn': 'tàu', lOMoAR cPSD| 58778885
'sự tự tin': Không, 'log': Không có, }>, 'resnet50':
'id': '6064c26e01257d68b7b0be64', 'thẻ': BaseList([]), 'nhãn': 'con nai',
'sự tự tin': Không,
'log': mảng([-0.925419 , -1.2076195 , -0.37321544, -0.2750331 , 6.723097 ,
-0.44599843, -0.7555994 , -0.43585306, -1.1593063 , -1.1450499 ], dtype=float32), }>,
'sự nhầm lẫn': 0,9778614850560818, }>,
'id': '6064c24201257d68b7b04977',
'media_type': 'hình ảnh',
'filepath': '/home/ben/fiftyone/cifar10/test/data/001550.jpg',
'thẻ': BaseList(['test', 'mistake', 'processed']),
'siêu dữ liệu': Không, 'ground_truth':
'id': '6064c24c01257d68b7b0b20e', 'thẻ': BaseList([]), lOMoAR cPSD| 58778885 'nhãn': 'con nai',
'sự tự tin': Không, 'log': Không có, }>, 'resnet50':
'id': '6064c26701257d68b7b0b94a', 'thẻ': BaseList([]), 'nhãn': 'ô tô',
'sự tự tin': Không,
'log': mảng([-0.6696544 , 6.331352 , -0.90380824, -0.8609426 , - 0.97413117,
-0.8693008 , -0.8035213 , -0.9215686 , -0.48488098, 0.15646096], dtype=float32), }>,
'sự nhầm lẫn': 0,967886808991774, }>,
'id': '6064c24401257d68b7b060c9',
'media_type': 'hình ảnh',
'filepath': '/home/ben/fiftyone/cifar10/test/data/003540.jpg',
'thẻ': BaseList(['test', 'processed']),
'siêu dữ liệu': Không, 'ground_truth':
'id': '6064c24401257d68b7b060c8', lOMoAR cPSD| 58778885 'thẻ': BaseList([]), 'nhãn': 'mèo',
'sự tự tin': Không, 'log': Không có, }>, 'resnet50':
'id': '6064c26e01257d68b7b0bdfe', 'thẻ': BaseList([]), 'nhãn': 'tàu',
'sự tự tin': Không,
'log': mảng([ 0.74897313, -0.7627302 , -0.79189354, -0.78844124, - 1.0206403 ,
-1.0742921 , -0.9762771 , -1.0660601 , 6.3457403 , -0.6143737 ], dtype=float32), }>,
'sự nhầm lẫn': 0,9653186284617471, }>]
2. Thêm dự đoán của bộ phân loại vào bộ dữ liệu
- Công thức này cung cấp cái nhìn thoáng qua về khả năng tích hợp
FiftyOne vào quy trình công việc ML của bạn. Cụ thể, nó bao gồm:
+ Đang tải tập dữ liệu phát hiện đối tượng từ Dataset Zoo.
+ Thêm dự đoán từ trình phát hiện đối tượng vào tập dữ liệu. lOMoAR cPSD| 58778885
+ Khởi chạy Ứng dụng FiftyOne và trực quan hóa/khám phá dữ liệu của bạn.
+ Tích hợp Ứng dụng vào quy trình phân tích dữ liệu của bạn.
2.1. Đang tải tập dữ liệu phát hiện: Trong công thức này, chúng ta sẽ
làm việc với phần phân tách xác thực của tập dữ liệu COCO , tập dữ liệu
này có sẵn để tải xuống một cách thuận tiện thông qua FiftyOne Dataset Zoo. import fiftyone as fo import fiftyone.zoo as foz dataset = foz.load_zoo_dataset(
"coco-2017", split="validation",
dataset_name="detector-recipe", )
Tách 'xác thực' đã được tải xuống
Đang tải 'coco-2017' tách 'xác thực'
100% |████████████████████| 5000/5000 [43,3 giây đã
trôi qua, còn lại 0 giây, 114,9 mẫu/s]
Tập dữ liệu 'công thức dò tìm' đã được tạo
- Kiểm tra tập dữ liệu để xem những gì chúng tôi đã tải xuống: lOMoAR cPSD| 58778885
# Print some information about the dataset print(dataset) Tên: detector-recipe
Loại phương tiện: hình ảnh Số mẫu: 5000 Liên tục: Sai
Thông tin: {'classes': ['0', 'person', 'bicycle', ...]}
Tags: ['validation'] Các trường mẫu :
đường dẫn tệp: Fiftyone.core.fields.StringField thẻ:
Fiftyone.core.fields.ListField(Fiftyone.core.fields.StringField) siêu dữ liệu:
Fiftyone.core.fields.EmbeddedDocumentField(Fiftyone.core.metadata.
Metadata) ground_truth: Fiftyone.
core.fields.EmbeddedDocumentField(năm
mươione.core.labels.Detections)
# Print a ground truth detection sample = dataset.first()
print(sample.ground_truth.detections[0])
'id': '602fea44db78a9b44e6ae129',
'thuộc tính': BaseDict({}),
Tài liệu liên quan:
-

Bài giảng Ứng dụng AI trong kinh doanh môn Trí tuệ nhân tạo | Trường Đại học Sư phạm Kỹ thuật Thành phố Hồ Chí Minh
40 20 -

Bài thuyết trình AI: Công cụ tạo tác hay năng lực thoái hóa? | Trường Đại học Sư phạm Kỹ thuật Thành phố Hồ Chí Minh
55 28 -

Bài Tập 1-5: Kiểm Tra và Huấn Luyện Dữ Liệu Fashion MNIST | Môn Trí tuệ nhân tạo - Đại học Sư phạm Kỹ thuật Thành phố Hồ Chí Minh
137 69 -

Tổng hợp Thuật Toán Simulated Annealing | Môn Trí tuệ nhân tạo - Đại học Sư phạm Kỹ thuật Thành phố Hồ Chí Minh
252 126