Chương 1: Tổng quan về Machine Learning - Học máy cơ bản | Đại học Điện lực
Tổng quan về học máy. Chương 1: Tổng quan về Machine Learning - Học máy cơ bản | Đại học Điện lực. Tài liệu sưu tầm gồm 8 trang, giúp bạn tham khảo, ôn tập và đạt kết quả cao.
Môn: Nhập môn học máy 10 tài liệu
Trường: Trường Đại học Điện lực 502 tài liệu
Tác giả:







Preview text:
lOMoARcPSD| 59629529 1
CHƯƠNG 1: TỔNG QUAN VỀ MACHINE LEARNING
1. Tổng quan về học máy
1.1. Khái niệm về học máy
Học máy là một lĩnh vực con của ngành trí tuệ nhân tạo và khoa học máy
tính liên quan đến việc xây dựng các thuật toán, dựa trên ý tưởng “bắt chước” cách
con người học và dần dần cải thiện độ chính xác của nó.
Học máy cũng có thể được định nghĩa là quá trình giải quyết một vấn đề thực tế bằng cách:
1) Thu thập một tập dữ liệu
2) Xây dựng một mô hình thống kê theo thuật toán dựa trên tập dữ liệu đó. Mô
hình thống kê đó được giả định sử dụng bằng cách nào đó để giải quyết vấn đề thực tế.
Học máy gồm 4 loại chính: học giám sát (supervised learning), bán giám sát
(semi-supervised), không giám sát và học tăng cường.
1.2. Các phương pháp học máy
1.2.1. Học máy có giám sát
Trong học máy có giám sát, tập dữ liệu là tập hợp các bản ghi được gắn nhãn, {( x N
i , yi)}i =1. Mỗi phần tử xi trong số N phần tử được gọi là một vector đặc
trưng. Vector đặc trưng là một vector trong đó mỗi chiều j = 1 , . . . , D chứa một
giá trị mô tả một thuộc tính nào đó của phần tử đó. Giá trị đó được gọi là feature
và được ký hiệu là x(j). Ví dụ: nếu mỗi x trong tập dữ liệu của chúng ta đại diện
cho một người, thì trường đầu tiên (x1) có thể chứa chiều cao tính bằng cm, trường
thứ hai (x2) chứa cân nặng của người đó và được tính bằng kg, x3 có thể chứa giới
tính, v.v.. Đối với tất cả các bản ghi trong tập dữ liệu, đối tượng ở vị trí j trong
vector đặc trưng luôn chứa cùng một loại thông tin. Có nghĩa là nếu xi2 chứa trọng
lượng tính bằng kg trong một số bản ghi, thì xk2 cũng sẽ chứa trọng lượng tính bằng
kg trong mọi bản ghi xk với k = 1 ,. . . , N. Nhãn yi có thể là một phần tử thuộc một
tập hữu hạn các lớp {1, 2 ,. . . , C}, hoặc một số thực, hoặc một cấu trúc phức tạp
hơn, như vector, ma trận, cây hoặc đồ thị. Bạn có thể xem một lớp như một danh lOMoARcPSD| 59629529 2
mục mà một bản ghi thuộc về. Ví dụ: nếu bản ghi của bạn là các email và vấn đề
của bạn là phát hiện spam, thì nhãn sẽ bao gồm hai lớp {thư rác, thư thường}.
Mục tiêu học máy có giám sát là sử dụng tập dữ liệu để tạo ra một mô hình
lấy vector đặc trưng x làm thông tin đầu vào và đầu ra cho phép dự đoán được
nhãn cho vector đặc trưng này. Ví dụ: mô hình được tạo bằng cách sử dụng tập dữ
liệu đầu vào là một vector đặc trưng mô tả một người và đầu ra là đưa ra xác suất
người đó bị tiểu đường.
1.2.2. Học máy không giám sát
Trong học máy không giám sát, tập dữ liệu là tập hợp các ví dụ không được gắn nhãn {x N
i}i =1. Một lần nữa, x là một vector đặc trưng và mục tiêu của thuật toán
học không giám sát là tạo ra một mô hình lấy một vector đặc trưng x làm đầu vào
và biến nó thành một vector khác hoặc thành một giá trị có thể được sử dụng để
giải quyết một vấn đề thực tế. Ví dụ, trong phân cụm, mô hình trả về id của cụm
tương ứng với mỗi vector đặc trưng trong tập dữ liệu. Khi thực hiện giảm kích
thước, đầu ra của mô hình là một vector đặc trưng có ít thuộc tính hơn so với vector
đầu vào x. Trong phát hiện ngoại lệ, đầu ra là một số thực cho biết mức độ mà x
khác biệt so với các ví dụ "điển hình" trong tập dữ liệu.
1.2.3. Học máy bán giám sát
Trong học bán giám sát, tập dữ liệu vừa có các bản ghi được gắn nhãn vừa
có các bản ghi không được gắn nhãn. Thông thường, số lượng bản ghi không được
gắn nhãn cao hơn nhiều so với số lượng các bản ghi được gắn nhãn. Mục tiêu của
thuật toán học bán giám sát và thuật toán học có giám sát là như nhau. Việc chúng
ta sử dụng các bản ghi không được gắn nhãn có thể giúp thuật toán tìm ra (chúng
ta có thể nói “sản xuất” hoặc “tính toán”) một mô hình tốt hơn.
Nó có thể phản trực quan rằng việc học có thể được hưởng lợi từ việc thêm
nhiều ví dụ không được gắn nhãn. Có vẻ như chúng ta thêm nhiều sự không chắc
chắn vào vấn đề. Tuy nhiên, khi bạn thêm các ví dụ không được gắn nhãn, bạn sẽ
thêm nhiều thông tin hơn về vấn đề của mình: một mẫu lớn hơn phản ánh tốt hơn
phân phối xác suất mà dữ liệu chúng ta đã gắn nhãn đến từ đó. lOMoARcPSD| 59629529 3
1.2.4. Học tăng cường
Học tăng cường là một lĩnh vực con của học máy trong đó máy tính sẽ được
đặt trong một môi trường và có khả năng nhận thức trạng thái của môi trường đó
như một vector của các đặc trưng. Máy có thể thực hiện các hành động ở mọi trạng
thái. Các hành động khác nhau mang lại phần thưởng khác nhau và cũng có thể di
chuyển máy sang trạng thái khác của môi trường. Mục tiêu của thuật toán học tăng
cường là tìm hiểu một policy.
Policy là một hàm (tương tự như mô hình trong học có giám sát) lấy vector
đặc trưng của một trạng thái làm đầu vào và đầu ra là một hành động tối ưu để
thực hiện ở trạng thái đó. Hành động là tối ưu nếu nó tối đa hóa phần thưởng trung
bình mong đợi (expected average reward).
Học máy tăng cường giải quyết một loại vấn đề cụ thể trong đó việc ra quyết
định là tuần tự và mục tiêu là lâu dài, chẳng hạn như chơi trò chơi, lập trình robot,
quản lý tài nguyên. 1.3. Vòng đời học máy
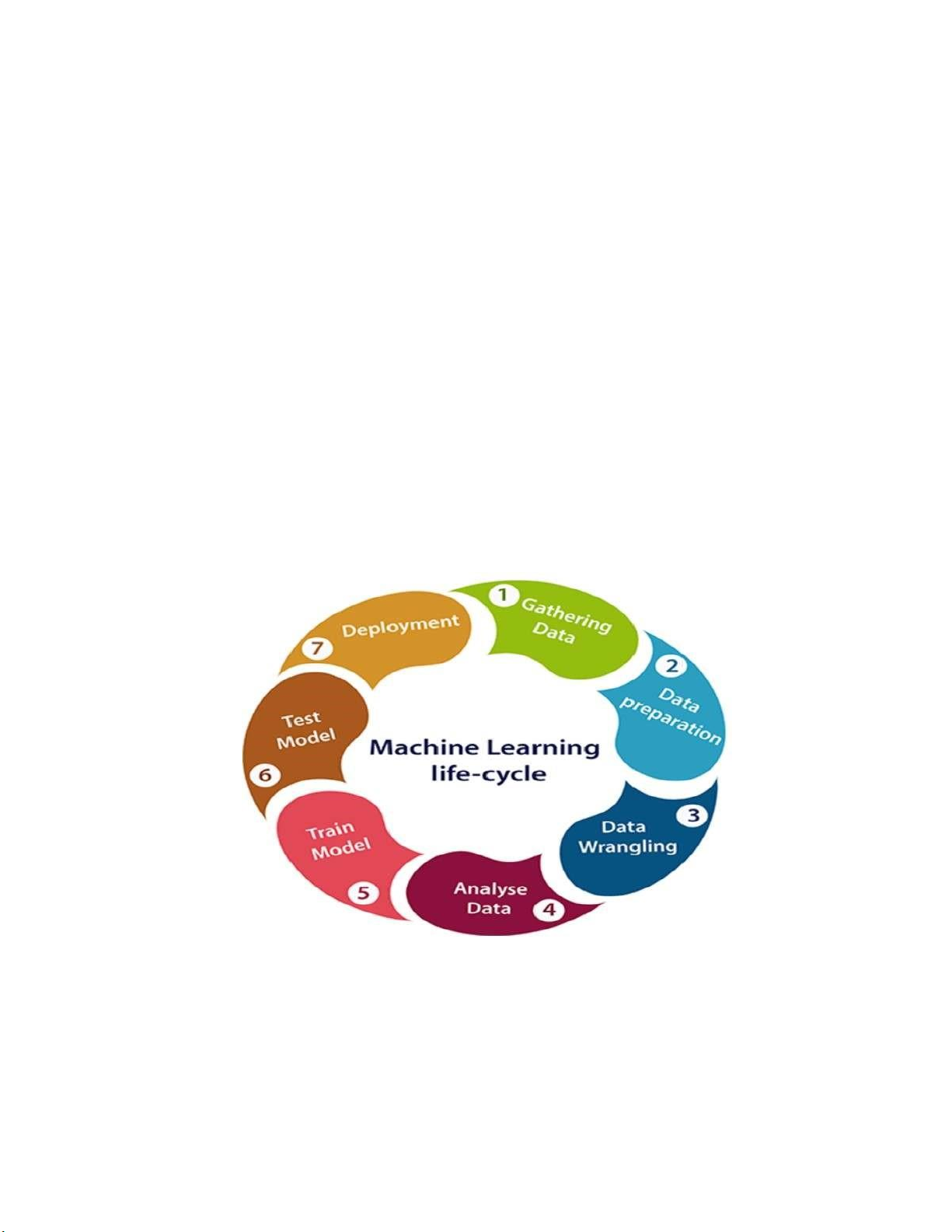
Hình 1.1 Vòng đời học máy
Bước 1: Thu thập dữ liệu
Thu thập dữ liệu là bước đầu tiên của vòng đời máy học. Mục tiêu của bước
này là xác định và thu được tất cả các vấn đề liên quan đến dữ liệu. lOMoARcPSD| 59629529 4
Trong bước này, chúng ta cần xác định các nguồn dữ liệu khác nhau, vì dữ
liệu có thể được thu thập từ nhiều nguồn khác nhau như tệp, cơ sở dữ liệu, internet
hoặc thiết bị di động. Nó là một trong những bước quan trọng nhất của vòng đời.
Số lượng và chất lượng của dữ liệu thu thập được sẽ quyết định hiệu quả của đầu
ra. Dữ liệu càng nhiều thì dự đoán càng chính xác.
Bước này bao gồm các nhiệm vụ dưới đây:
• Xác định các nguồn dữ liệu khác nhau • Thu thập dữ liệu
• Tích hợp dữ liệu thu được từ các nguồn khác nhau
Bằng cách thực hiện nhiệm vụ trên, chúng ta nhận được một tập hợp dữ liệu
nhất quán, còn được gọi là tập dữ liệu. Nó sẽ được sử dụng trong các bước tiếp theo.
Bước 2: Chuẩn bị dữ liệu
Sau khi thu thập dữ liệu, chúng ta cần chuẩn bị cho các bước tiếp theo.
Chuẩn bị dữ liệu là một bước mà chúng tôi đặt dữ liệu của mình vào một nơi thích
hợp và chuẩn bị để sử dụng trong quá trình đào tạo máy học của chúng tôi.
Trong bước này, đầu tiên, chúng tôi tập hợp tất cả dữ liệu lại với nhau, sau
đó sắp xếp thứ tự dữ liệu một cách ngẫu nhiên.
Bước này có thể được chia thành hai quá trình: • Khám phá dữ liệu:
Nó được sử dụng để hiểu bản chất của dữ liệu mà chúng ta phải làm việc.
Chúng ta cần hiểu các đặc điểm, định dạng và chất lượng của dữ liệu.
Hiểu rõ hơn về dữ liệu dẫn đến một kết quả hiệu quả. Trong phần này, chúng
tôi tìm thấy mối tương quan, xu hướng chung và ngoại lệ.
• Xử lý trước dữ liệu: bước tiếp theo là xử lý trước dữ liệu để phân tích.
Bước 3: Chuẩn hóa dữ liệu lOMoARcPSD| 59629529 5
Bao bọc dữ liệu là quá trình làm sạch và chuyển đổi dữ liệu thô thành một
định dạng có thể sử dụng được. Đây là quá trình làm sạch dữ liệu, chọn biến để sử
dụng và chuyển đổi dữ liệu theo một định dạng thích hợp để phù hợp hơn cho việc
phân tích trong bước tiếp theo. Đây là một trong những bước quan trọng nhất của
quá trình hoàn chỉnh. Làm sạch dữ liệu là cần thiết để giải quyết các vấn đề chất lượng.
Không nhất thiết phải sử dụng dữ liệu chúng tôi thu thập được vì một số dữ
liệu có thể không hữu ích. Trong các ứng dụng trong thế giới thực, dữ liệu được
thu thập có thể có nhiều vấn đề khác nhau, bao gồm: • Giá trị bị mất • Dữ liệu trùng lặp
• Dữ liệu không hợp lệ • Dữ liệu nhiễu
Vì vậy, chúng tôi sử dụng các kỹ thuật lọc khác nhau để làm sạch dữ liệu.
Bắt buộc phải phát hiện và loại bỏ các vấn đề trên vì nó có thể ảnh hưởng
tiêu cực đến chất lượng của kết quả.
Bước 4: Phân tích dữ liệu
Bây giờ dữ liệu đã được làm sạch và chuẩn bị được chuyển sang bước phân
tích. Bước này bao gồm:
• Lựa chọn các kỹ thuật phân tích • Xây dựng mô hình • Xem lại kết quả
Mục đích của bước này là xây dựng một mô hình học máy để phân tích dữ
liệu bằng các kỹ thuật phân tích khác nhau và xem xét kết quả. Nó bắt đầu với việc
xác định loại vấn đề, trong đó chúng tôi chọn các kỹ thuật học máy như: phân loại,
hồi quy, phân tích cụm, liên kết , v.v. sau đó xây dựng mô hình bằng cách sử dụng
dữ liệu đã chuẩn bị và đánh giá mô hình. lOMoARcPSD| 59629529 6
Do đó, trong bước này, chúng tôi lấy dữ liệu và sử dụng các thuật toán học
máy để xây dựng mô hình.
Bước 5: Huấn luyện mô hình
Bước tiếp theo là đào tạo mô hình, trong bước này, chúng tôi đào tạo mô
hình của mình để cải thiện hiệu suất của nó để có kết quả tốt hơn của vấn đề.
Chúng tôi sử dụng bộ dữ liệu để đào tạo mô hình bằng cách sử dụng các
thuật toán học máy khác nhau. Cần phải đào tạo một mô hình để nó có thể hiểu
các mẫu, quy tắc và tính năng khác nhau.
Bước 6: Mô hình thử nghiệm
Sau khi mô hình học máy của chúng tôi đã được đào tạo trên một tập dữ liệu
nhất định, thì chúng tôi sẽ kiểm tra mô hình. Trong bước này, chúng tôi kiểm tra
độ chính xác của mô hình bằng cách cung cấp tập dữ liệu thử nghiệm cho nó.
Kiểm tra mô hình xác định độ chính xác phần trăm của mô hình theo yêu
cầu của dự án hoặc vấn đề. Bước 7: Triển khai
Bước cuối cùng của vòng đời máy học là triển khai, nơi chúng tôi triển khai
mô hình trong hệ thống thế giới thực.
Nếu mô hình chuẩn bị ở trên tạo ra kết quả chính xác theo yêu cầu của chúng
tôi với tốc độ chấp nhận được, thì chúng tôi triển khai mô hình trong hệ thống thực.
Nhưng trước khi triển khai dự án, chúng tôi sẽ kiểm tra xem nó có đang cải thiện
hiệu suất bằng cách sử dụng dữ liệu có sẵn hay không. Giai đoạn triển khai tương
tự như lập báo cáo cuối cùng cho một dự án.
1.4. Ứng dụng của học máy
Học máy đã trở thành một công cụ mạnh mẽ được ứng dụng trong nhiều
lĩnh vực khác nhau nhờ khả năng phân tích dữ liệu, dự đoán xu hướng và tự động
hóa các tác vụ phức tạp. Một số ứng dụng tiêu biểu của học máy bao gồm: lOMoARcPSD| 59629529 7
1.4.1 Trí tuệ nhân tạo và xử lý ngôn ngữ tự nhiên (NLP)
Học máy đóng vai trò quan trọng trong việc phát triển các hệ thống trí tuệ
nhân tạo (AI), giúp máy tính có thể hiểu và tương tác với con người bằng ngôn
ngữ tự nhiên. Các ứng dụng phổ biến bao gồm: trợ lý ảo (như Siri, Google
Assistant), hệ thống chatbot, và các công cụ dịch tự động. Các mô hình học sâu
(Deep Learning) giúp cải thiện khả năng xử lý ngôn ngữ tự nhiên, như phân tích
văn bản, nhận dạng giọng nói, và tạo nội dung tự động.
1.4.2 Thị giác máy tính
Học máy được ứng dụng rộng rãi trong lĩnh vực thị giác máy tính, giúp các
hệ thống tự động phân tích và hiểu nội dung hình ảnh, video. Các ứng dụng bao
gồm: nhận dạng khuôn mặt, phát hiện đối tượng, phân loại ảnh, và xe tự hành. Các
thuật toán học máy cho phép máy tính "nhìn thấy" và "hiểu" được thông tin thị
giác, hỗ trợ nhiều ngành công nghiệp như an ninh, y tế, và giải trí.
1.4.3 Y tế và chăm sóc sức khỏe
Học máy đang mang lại những bước tiến lớn trong y học và chăm sóc sức
khỏe. Các mô hình học máy được sử dụng để chẩn đoán bệnh, dự đoán nguy cơ
sức khỏe, và tối ưu hóa điều trị cá nhân hóa cho bệnh nhân. Một ví dụ điển hình là
việc sử dụng học máy trong phân tích hình ảnh y tế (chẳng hạn như X-quang, MRI)
để phát hiện sớm các dấu hiệu của bệnh tật.
1.4.4 Tài chính và ngân hàng
Trong lĩnh vực tài chính, học máy được ứng dụng trong việc phân tích dữ
liệu lớn để dự đoán xu hướng thị trường, tự động hóa giao dịch, và phát hiện gian
lận. Các hệ thống tín dụng sử dụng học máy để đánh giá rủi ro tín dụng, trong khi
các ngân hàng và tổ chức tài chính ứng dụng học máy để cải thiện trải nghiệm
khách hàng thông qua các giải pháp cá nhân hóa.
1.4.5 Thương mại điện tử và marketing
Học máy giúp các nền tảng thương mại điện tử cải thiện trải nghiệm mua
sắm của người dùng bằng cách đưa ra các gợi ý sản phẩm cá nhân hóa dựa trên
hành vi mua sắm và sở thích của khách hàng. Học máy cũng được sử dụng để tối
ưu hóa chiến dịch marketing, dự đoán xu hướng tiêu dùng, và tăng cường hiệu quả
quảng cáo thông qua việc phân tích dữ liệu người dùng. lOMoARcPSD| 59629529 8
1.4.6 Tự động hóa và Robotics
Học máy đóng vai trò quan trọng trong việc phát triển robot tự động hóa, từ
robot trong các dây chuyền sản xuất công nghiệp cho đến robot dịch vụ. Các mô
hình học máy giúp robot học cách thực hiện các tác vụ phức tạp, điều hướng trong
môi trường không xác định, và tương tác với con người một cách thông minh và linh hoạt.
1.4.7 Mạng xã hội và truyền thông
Học máy được ứng dụng mạnh mẽ trong các nền tảng mạng xã hội để cải
thiện khả năng tương tác và gợi ý nội dung cho người dùng. Các thuật toán học
máy giúp phân tích dữ liệu lớn về hành vi người dùng để gợi ý bạn bè, nội dung,
hoặc quảng cáo phù hợp. Nó cũng hỗ trợ trong việc phát hiện và kiểm duyệt các
nội dung xấu hoặc tin giả trên mạng.
Tài liệu liên quan:
-

Dự Đoán Khả Năng Sống Sót Sau Thảm Họa Titanic - Nhập Môn Học Máy 2024 | Đại học điện lực
119 60 -

Báo cáo chuyên đề: Ứng dụng Kmeans Clustering dự đoán Pokémon | Đại học Điện lực
151 76 -

Đánh giá xu hướng hiện đại trong Học Máy: Phân tán và Liên bang | Đại học Điện lực
88 44 -

Lý Văn Chuyển Học May - Giới Thiệu và Tình Huống Thực Tế | Đại học Điện lực
85 43 -

Báo cáo chuyên đề Nhập môn học máy - Ứng dụng CNN trong nhận diện chữ viết tay | Đại học Điện lực
172 86