Hướng dẫn ôn tập môn Cơ sở dữ liệu | Trường Đại học Kinh tế và Quản trị Kinh doanh, Đại học Thái Nguyên
Hướng dẫn ôn tập môn Cơ sở dữ liệu | Trường Đại học Kinh tế và Quản trị Kinh doanh, Đại học Thái Nguyên. Tài liệu được biên soạn dưới dạng file PDF gồm 17 trang, giúp bạn tham khảo, ôn tập và đạt kết quả cao trong kì thi sắp tới. Mời bạn đọc đón xem!
Môn: Cơ sở dữ liệu (TN) 5 tài liệu
Trường: Trường Đại học Kinh tế và Quản trị kinh doanh, Đại học Thái Nguyên 258 tài liệu
Tác giả:








Preview text:
lOMoARcPSD| 25865958 1
MÔN: CƠ SỞ DỮ LIỆU Câu 1:
1. Anh (chị) hãy trình bày hiểu về của mình về kiến
trúc của một hệ cơ sở dữ liệu?
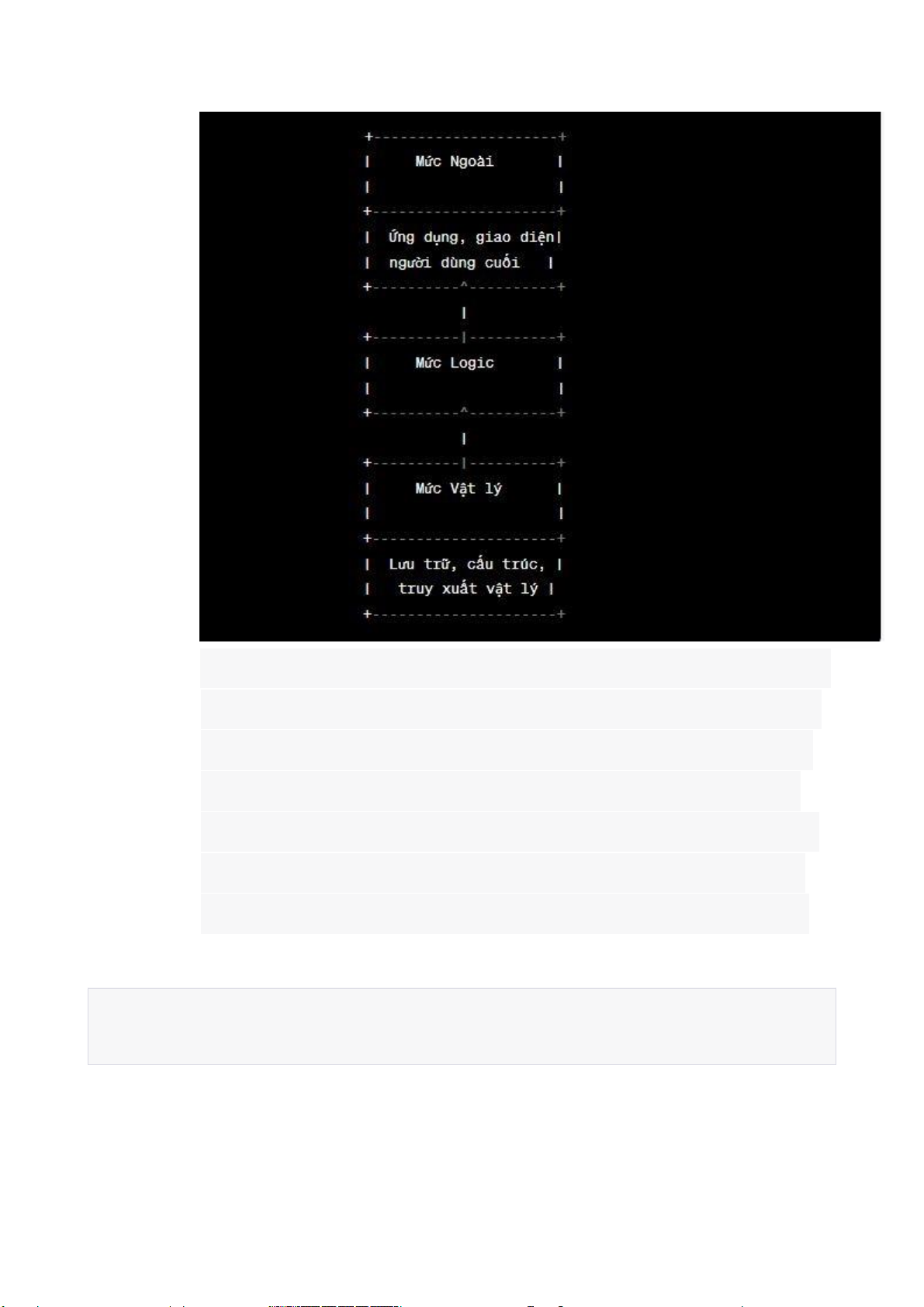
(Vẽ kiến trúc, trình bày mức ngoài, logic, vật lý)
Kiến trúc của một hệ cơ sở dữ liệu (Database System)
đóng vai trò quan trọng trong việc tổ chức và quản lý dữ
liệu trong một hệ thống. Nó bao gồm các mức khác
nhau, bao gồm mức ngoài, mức logic và mức vật lý. 1.
Mức Ngoài (External Level):
• Mức ngoài là mức giao tiếp với người dùng cuối,
bao gồm các khía cạnh của hệ thống dữ liệu mà
người dùng thấy và tương tác trực tiếp.
• Tại mức này, người dùng có thể thực hiện các hoạt
động như truy vấn dữ liệu, cập nhật, thêm, xóa dữ
liệu và thực hiện các thao tác khác liên quan đến dữ liệu.
• Mức ngoài cung cấp một giao diện dễ sử dụng cho
người dùng và ẩn đi chi tiết về cấu trúc và lưu trữ của dữ liệu. 2.
Mức Logic (Conceptual Level):
• Mức logic là mức trung gian giữa mức ngoài và mức vật lý.
• Tại mức này, ta mô tả cấu trúc tổ chức dữ liệu trong
cơ sở dữ liệu một cách trừu tượng và độc lập với
các chi tiết về lưu trữ vật lý. lOMoARcPSD| 25865958 2
• Mức logic bao gồm các khái niệm như các thực thể (entities), mối quan hệ
(relationships), ràng buộc (constraints) và các luật
kết nối (integrity rules).
• Mức logic định nghĩa một mô hình dữ liệu ảo
(conceptual schema) cho toàn bộ hệ thống cơ sở dữ liệu. 3.
Mức Vật lý (Physical Level):
• Mức vật lý là mức thấp nhất trong kiến trúc của hệ cơ sở dữ liệu.
• Tại mức này, ta quản lý chi tiết về cách dữ liệu được
lưu trữ và truy xuất trên các thiết bị lưu trữ vật lý như ổ cứng.
• Mức vật lý xác định cách dữ liệu được phân tán, bố
trí và cấu trúc bên trong các file và các cấu trúc dữ
liệu khác nhau như bảng, chỉ mục và các phương
pháp truy xuất dữ liệu.
Dưới đây là biểu đồ mô tả kiến trúc của một hệ cơ sở dữ liệu: lOMoARcPSD| 25865958 3
Trên biểu đồ, mức ngoài tương tác trực tiếp với
người dùng cuối và cung cấp giao diện cho việc
truy xuất dữ liệu. Mức logic là mức trung gian,
nơi mô hình dữ liệu được xác định và các quy
tắc và ràng buộc dữ liệu được định nghĩa. Mức
vật lý là mức thấp nhất, quản lý chi tiết về lưu
trữ và truy xuất dữ liệu trên các thiết bị vật lý.
2. Ưu nhược điểm của mô hình dữ liệu quan hệ
Mô hình dữ liệu quan hệ là một mô hình dữ liệu phổ
biến và được sử dụng rộng rãi trong các hệ cơ sở dữ
liệu. Dưới đây là ưu nhược điểm của mô hình dữ liệu quan hệ: Ưu điểm: lOMoARcPSD| 25865958 4
1. Tính mô phỏng thực tế: Mô hình dữ liệu quan hệ có
khả năng mô phỏng một cách chính xác các mối
quan hệ và liên kết giữa các đối tượng trong thế
giới thực, giúp người thiết kế dễ dàng hiểu và biểu diễn dữ liệu.
2. Đơn giản và dễ hiểu: Mô hình dữ liệu quan hệ sử
dụng các bảng và quan hệ giữa chúng để biểu diễn
dữ liệu. Cú pháp và cấu trúc của mô hình dễ hiểu và
đơn giản, giúp người thiết kế và người sử dụng dễ
dàng làm việc với dữ liệu.
3. Khả năng mở rộng: Mô hình dữ liệu quan hệ có khả
năng mở rộng để thêm mới các bảng và quan hệ
mới vào cơ sở dữ liệu mà không làm ảnh hưởng
đến các bảng và quan hệ đã tồn tại. Điều này giúp
mô hình dữ liệu quan hệ linh hoạt trong việc thay
đổi và mở rộng hệ thống.
4. Hiệu suất cao: Mô hình dữ liệu quan hệ đã được tối
ưu hóa và có các thuật toán hiệu quả để thực hiện
các thao tác truy vấn dữ liệu. Việc sử dụng chỉ mục
và các kỹ thuật tối ưu truy vấn giúp cải thiện hiệu
suất truy xuất dữ liệu. Nhược điểm:
1. Khả năng mở rộng: Mặc dù mô hình dữ liệu quan hệ
có khả năng mở rộng, nhưng khi dự án phức tạp
hơn và quy mô lớn hơn, việc thiết kế và quản lý
quan hệ giữa các bảng có thể trở nên phức tạp và khó khăn. lOMoARcPSD| 25865958 5
2. Đồng nhất dữ liệu: Mô hình dữ liệu quan hệ yêu cầu
dữ liệu trong cùng một bảng phải tuân thủ cùng
một quy tắc và có độ chính xác cao. Điều này đôi khi
khó đạt được và có thể dẫn đến sự không đồng
nhất và không nhất quán trong dữ liệu.
3. Hiệu năng và tốc độ: Mô hình dữ liệu quan hệ có
thể gặp khó khăn trong việc xử lý các truy vấn phức
tạp hoặc trong các tình huống có tải công việc cao.
Trong một số trường hợp, việc truy xuất và truy vấn
dữ liệu có thể gây ra hiệu năng chậm.
4. Khả năng mô phỏng dữ liệu không cấu trúc: Mô
hình dữ liệu quan hệ không được thiết kế để quản
lý dữ liệu không cấu trúc hoặc dữ liệu có cấu trúc
không rõ ràng. Điều này có thể làm giới hạn mô
hình trong việc làm việc với các dạng dữ liệu đa
dạng như văn bản không cấu trúc,
hình ảnh, video, và dữ liệu không có cấu trúc khác.
Tóm lại, mô hình dữ liệu quan hệ có nhiều ưu điểm,
nhưng cũng có nhược điểm. Việc áp dụng mô hình dữ
liệu quan hệ phụ thuộc vào yêu cầu và điều kiện cụ thể
của dự án để đảm bảo hiệu quả và sự phù hợp.
3. Chuẩn hóa lược đồ quan hệ, các dạng chuẩn
Chuẩn hóa lược đồ quan hệ là quá trình thiết kế và cải
tiến cấu trúc của lược đồ quan hệ trong mô hình dữ liệu
quan hệ. Mục tiêu của chuẩn hóa là loại bỏ các phụ lOMoARcPSD| 25865958 6
thuộc không mong muốn, giảm thiểu dư thừa dữ liệu và
tăng tính nhất quán và hiệu suất của hệ thống.
Dưới đây là các dạng chuẩn quan trọng trong chuẩn hóa lược đồ quan hệ: 1.
Chuẩn 1NF (First Normal Form):
• Đảm bảo mỗi thuộc tính chỉ chứa giá trị nguyên tử,
không chứa các giá trị lặp lại hoặc đa giá trị.
• Tách các thuộc tính phức tạp thành các thuộc tính
đơn giản để đảm bảo tính nguyên tử.
2. Chuẩn 2NF (Second Normal Form): Đạt được 1NF.
• Xác định các khóa chính và phụ thuộc hàm.
• Đảm bảo các thuộc tính không khóa phụ thuộc vào
một phần của khóa chính.
3. Chuẩn 3NF (Third Normal Form): Đạt được 2NF.
• Loại bỏ phụ thuộc hàm phi chính nguyên tố.
• Đảm bảo các thuộc tính không khóa không phụ thuộc lẫn nhau.
4. Chuẩn BCNF (Boyce-Codd Normal Form): • Đạt được 3NF.
• Loại bỏ các phụ thuộc hàm phi chính nguyên tố.
• Đảm bảo rằng mọi phụ thuộc hàm phi chính nguyên
tố phụ thuộc vào khóa chính.
5. Chuẩn 4NF (Fourth Normal Form): Đạt được BCNF. lOMoARcPSD| 25865958 7
• Loại bỏ các phụ thuộc đa giá trị.
• Đảm bảo tính độc lập giữa các phụ thuộc đa giá trị.
6. Chuẩn 5NF (Fifth Normal Form): Đạt được 4NF.
Loại bỏ các phụ thuộc đa giá trị phi phụ thuộc.
Ngoài ra, còn có các dạng chuẩn cao hơn như chuẩn
6NF, chuẩn Domain/Key Normal Form (DK/NF) và chuẩn 6.5NF.
Mỗi dạng chuẩn đều có mục tiêu và quy tắc riêng để
đảm bảo tính chất của dữ liệu trong lược đồ quan hệ.
Quá trình chuẩn hóa lược đồ quan hệ yêu cầu sự phân
tích cẩn thận và hiểu rõ về mối quan hệ giữa các thuộc
tính và các phụ thuộc trong cơ sở dữ liệu để đạt được
thiết kế hiệu quả và linh hoạt.
Câu 2: Cho lược đồ quan hệ r(U,F) 1. Tính bao đóng của thuộc tính
Để tính bao đóng của thuộc tính trong lược đồ quan hệ
r(U, F), ta sử dụng thuật toán bao đóng. Thuật toán này
cho phép tìm ra tập hợp các thuộc tính phụ thuộc hoàn
toàn vào một tập hợp thuộc tính khác.
Dưới đây là một bước đơn giản để tính bao đóng của
thuộc tính A trong lược đồ quan hệ r(U, F):
Bước 1: Khởi tạo bao đóng của thuộc tính A là A+ = A (bao gồm A ban đầu). lOMoARcPSD| 25865958 8
Bước 2: Lặp lại các bước sau cho đến khi không có sự
thay đổi nào trong bao đóng: a. lOMoARcPSD| 25865958 9
Đối với mỗi phụ thuộc chức năng X -> Y trong tập hợp F:
Nếu X thuộc A+ (tức là X là một tập con của A+), thêm Y
vào A+. b. Nếu A+ không thay đổi sau một vòng lặp, kết thúc thuật toán.
Kết quả cuối cùng là bao đóng của thuộc tính
A trong lược đồ quan hệ r(U, F), ký hiệu là A+.
Tính bao đóng của thuộc tính trong lược đồ quan hệ là
quan trọng để xác định các phụ thuộc chức năng và
quyết định về việc chuẩn hóa lược đồ.
2. Tìm khóa của lược đồ quan hệ Để tìm khóa của
lược đồ quan hệ r(U, F), ta có thể sử dụng thuật toán
thu gọn bao đóng (Closure Reduction Algorithm).
Dưới đây là các bước để tìm khóa của lược đồ:
Bước 1: Khởi tạo tập khóa K rỗng.
Bước 2: Với mỗi thuộc tính A trong U, thực hiện bước 3.
Bước 3: Xác định bao đóng F+ của F (bao gồm tất cả các
thuộc tính được suy ra từ F) và kiểm tra xem A có thuộc
F+ hay không. Nếu A thuộc F+, chứng tỏ A là một thuộc
tính trung gian hoặc phụ thuộc chức năng. Ta loại bỏ A
khỏi U và quay lại bước 2.
Nếu A không thuộc F+, chứng tỏ A là một thuộc tính cần
thiết để xác định khóa. Ta thêm A vào tập khóa K và
quay lại bước 2. Bước 4: Kết quả là tập khóa K, chứa tất Downloaded by 48
Nguy?n Th? Anh Th? (nguyenthianhtho2110@gmail.com) lOMoARcPSD| 25865958 10
cả các thuộc tính cần thiết để xác định mọi phụ thuộc chức năng trong F.
Tập K thu được chính là khóa của lược đồ quan hệ r(U,
F). Nếu có nhiều khóa, ta có thể thu được nhiều tập K khác nhau.
3. Tìm phủ tối thiểu
Để tìm phủ tối thiểu (Minimal Cover) của lược đồ quan
hệ r(U, F), ta có thể sử dụng thuật toán phân rã
(Decomposition Algorithm). Dưới đây là các bước để tìm phủ tối thiểu:
Bước 1: Bắt đầu với tập phụ thuộc chức năng F ban đầu.
Bước 2: Loại bỏ các phụ thuộc chức năng không cần thiết từ F.
Loại bỏ các phụ thuộc chức năng trùng lặp:
Kiểm tra xem có các phụ thuộc chức năng (X -> Y) và (X -
> Z) trong F sao cho Y và Z là tập con của nhau. Nếu có,
loại bỏ phụ thuộc chức năng dư thừa.
Loại bỏ phụ thuộc chức năng không cần thiết: Kiểm tra
xem có phụ thuộc chức năng (X -> Y) trong F sao cho Y
có thể suy ra từ các phụ thuộc chức năng khác trong F.
Nếu có, loại bỏ phụ thuộc chức năng dư thừa.
Bước 3: Xác định phủ tối thiểu của F. Tạo tập F' rỗng. lOMoARcPSD| 25865958 11
Với mỗi phụ thuộc chức năng (X -> Y) trong F, kiểm tra
xem có thể loại bỏ bất kỳ thuộc tính nào trong X mà vẫn
giữ nguyên tính chất phụ thuộc chức năng. Nếu có, loại
bỏ thuộc tính đó và thêm phụ thuộc chức năng mới vào F'.
Bước 4: Kết quả là tập phủ tối thiểu F', chứa các phụ
thuộc chức năng cần thiết để mô tả tất cả các ràng buộc
chức năng của lược đồ quan hệ r(U, F).
Tập F' thu được chính là phủ tối thiểu của lược đồ quan
hệ r(U, F). Nó là một tập con của F, chứa ít phụ thuộc
chức năng nhất để mô tả cùng một tập ràng buộc chức năng.
4. Chuẩn hóa về 3NF
Để chuẩn hóa lược đồ quan hệ r(U, F) về 3NF (Third
Normal Form), ta cần tuân theo các bước sau:
Bước 1: Xác định tập phụ thuộc chức năng không phụ
thuộc đầy đủ (Partial Dependency).
Tìm các tập con X và Y của U sao cho X -> Y là phụ thuộc
chức năng trong F và không có lOMoARcPSD| 25865958 12
tập con X' của X mà X' -> Y cũng là phụ thuộc chức năng
trong F. Đây là trường hợp phụ thuộc chức năng không phụ thuộc đầy đủ.
Bước 2: Tách các lược đồ con (Decompose the Schema).
Với mỗi phụ thuộc chức năng không phụ thuộc đầy đủ X
-> Y, tạo một lược đồ quan hệ mới có các thuộc tính trong X và Y.
Chuyển phụ thuộc chức năng của các lược đồ con vào lược đồ mới tạo.
Bước 3: Xác định tập phụ thuộc chức năng không phụ
thuộc chính quy (Transitive Dependency).
Tìm các tập con X, Y và Z của U sao cho X -> Y là phụ
thuộc chức năng trong F và Y không phụ thuộc trực
tiếp vào X, nhưng có Z là tập con của U sao cho Z -> Y là
phụ thuộc chức năng trong F. Đây là trường hợp phụ
thuộc chức năng không phụ thuộc chính quy. Bước 4:
Tách lược đồ con mới (Decompose the New Schema).
Với mỗi phụ thuộc chức năng không phụ thuộc chính
quy X -> Y, tạo một lược đồ quan hệ mới có các thuộc
tính trong X và Y. Chuyển phụ thuộc chức năng của các
lược đồ con vào lược đồ mới tạo.
Bước 5: Kiểm tra và lặp lại.
Kiểm tra lược đồ quan hệ mới để đảm bảo rằng không
còn phụ thuộc chức năng không phụ thuộc đầy đủ hoặc
không phụ thuộc chính quy. lOMoARcPSD| 25865958 13
Lặp lại các bước trên nếu cần cho đến khi không còn
phụ thuộc chức năng không phụ thuộc đầy đủ và không
phụ thuộc chính quy nữa.
Sau khi hoàn thành các bước trên, lược đồ quan hệ r(U,
F) sẽ được chuẩn hóa về 3NF, đảm bảo tính toàn vẹn dữ
liệu và loại bỏ các phụ thuộc chức năng không cần thiết. Câu 3:
1. Cú pháp của ngôn ngữ định nghĩa dữ liệu gồm
những gì?; Nêu bộ lệnh tổng quát của SQL được áp
dụng trên cơ sở dữ liệu (Database), cho ví dụ minh họa. Cú pháp: Create object_Name Alter object_Name
Drop object_Name create database:
tạo cơ sở dữ liệu create database
HoSoSinhViencreate drop database: xóa
cơ sở dữ liệu drop database HoSoSinhVien
alter database: sửa các thông tin của cơ sở
dữ liệu alter database HoSoSinhVien lOMoARcPSD| 25865958 14
2. Nêu bộ lệnh tổng quát của SQL được áp dụng trên
bảng (Table), cho ví dụ minh họa.
create table: tạo bảng create table SinhVien (MaSV
int,TenSV nchar(50)) drop
table: xóa bảng drop table SinhVien
alter table..add: thêm cột Thêm cột bằng
cách dùng lệnh alter table alter table
SinhVienadd QueQuan int alter table..drop
column: xóa cột alter table SinhVien drop column QueQuan
alter table..alter column: thêm thuộc tính not null lOMoARcPSD| 25865958 15
alter table SinhVienalter column
TenSV nchar(50) not null alter table..add primary key: thêm khóa chính
3. Phân tích ưu nhược điểm của ngôn ngữ truy
vấn dữ liệu SQL server Ưu điểm:
Dữ liệu có ở mọi nơi: Dữ liệu xuất hiện ở mọi nơi
trên màn hình từ laptop đến điện thoại của bạn.
Việc học tập và tìm hiểu SQL sẽ giúp bạn biết được
cách thức hoạt động của những dữ liệu này.
Thêm, sửa, đọc và xóa dữ liệu dễ dàng: với SQL, các
thao tác xử lý dữ liệu trở nên dễ dàng hơn bao giờ
hết. Bạn chỉ cần thực hiện một số thao tác với dữ
liệu đơn giản trên SQL thay vì phải dùng nhiều câu
lệnh phức tạp trên các loại ngôn ngữ khác.
SQL giúp công việc lập trình dễ dàng hơn: bạn có
thể lưu nhiều dữ liệu cho nhiều ứng dụng khác
nhau trên cũng một cơ sở dữ liệu và việc truy cập
các cơ sở dữ liệu này trở lên đơn giản hơn nhờ một cách thức giống nhau.
Được sử dụng và hỗ trợ bởi nhiều công ty lớn: tất
cả các công ty lớn về công nghệ trên thế giới hiện
nay như Microsoft, IBM, Oracle… đều hỗ trợ việc
phát triển ngôn ngữ SQL. lOMoARcPSD| 25865958 16
Lịch sử hơn 40 năm: với lịch sử phát triển hơn 40
năm từ 1970, SQL vẫn tồn tại và trụ vững đến ngày
nay. Điều này cho thấy vị trí của SQL hiện tại rất khó
bị thay thế bởi bất kỳ một ngôn ngữ máy tính nào khác. Nhược điểm:
Giao diện khó dùng: SQL có giao diện phức tạp
khiến một số người dùng khó truy cập.
Không được toàn quyền kiểm soát: Các lập trình
viên sử dụng SQL không có toàn quyền kiểm soát cơ sở dữ liệu.
Thực thi: Hầu hết các chương trình cơ sở dữ liệu
SQL đều có phần mở rộng độc quyền riêng.
Giá cả: Chi phí vận hành của một số phiên bản SQL
khá cao khiến một số lập trình viên gặp khó khăn khi tiếp cận.
4. Cú pháp cơ bản của lệnh truy vấn trong SQL sever là
gì? Có những lựa chọn nào cho mệnh đề Select? SELECT [tính chất] FROM Lựa chọn: SELECT *
Để lấy tất cả dữ liệu ở một hoặc nhiều Table ta sử
dụng SELECT * với cú pháp :
SELECT * FROM , < tên table2>,… lOMoARcPSD| 25865958 17 SELECT * FROM dbo.BOMON SELECT DISTINCT
Trong table, ngoài khóa chính, các column khác đều
có thể chứa giá trị trùng lặp, để lấy ra những dữ
liệu hoàn toàn riêng biệt.
Để đảm bảo điều này ta dùng từ khóa DISTINCT SELECT DISTINCT FROM SELECT TOP
Với những table có số lượng record lên đến hàng
nghìn, trăm nghìn, thì việc truy xuất một số lượng
lớn dữ liệu như vậy có thể gây ảnh hưởng đến hiệu
suất. Việc sử dụng mệnh đề SELECT TOP giúp trả về
một lượng record theo yêu cầu, hữu ích hơn cho hệ thống.
Truy xuất n tập tin theo column SELECT TOP FROM table>
Tài liệu liên quan:
-

Cấu trúc và Lệnh Cơ Bản Môn Cơ sở dữ liệu | Đại học Kinh tế và Quản trị kinh doanh, Đại học Thái Nguyên
45 23 -

Giới thiệu Cơ sở Dữ liệu và Phân loại Dữ liệu | Môn Cơ sở dữ liệu - Đại học Kinh tế và Quản trị kinh doanh, Đại học Thái Nguyên
45 23 -

Ôn Tập Môn Cơ sở dữ liệu | Đại học Kinh tế và Quản trị kinh doanh, Đại học Thái Nguyên
45 23 -

Bài tập Môn Cơ sở dữ liệu | Đại học Kinh tế và Quản trị kinh doanh, Đại học Thái Nguyên
49 25