Hướng Dẫn Sử Dụng Apache Spark Trong Azure Synapse Analytics | Môn Dữ liệu lớn - Đại học Sư phạm Kỹ thuật Thành phố Hồ Chí Minh
Azure Synapse Analytics là một dịch vụ phân tích dữ liệu tích hợp của Microsoft Azure, được thiết kế để xử lý khối lượng dữ liệu lớn, kết hợp giữa kho dữ liệu (data warehouse) và phân tích dữ liệu lớn (big data analytics). Tài liệu được sưu tầm gồm 31 trang, giúp bạn ôn tập tốt hơn. Mời các bạn đón xem.
Môn: Dữ liệu lớn (BDES333877) 10 tài liệu
Trường: Trường Đại học Sư phạm Kỹ thuật Thành phố Hồ Chí Minh 4.4 K tài liệu
Tác giả:



Preview text:
lOMoAR cPSD| 58702377 Mục lục
1. Introduction ............................................................................................................... 2
2. Get to know Apache Spark and Azure Synapse Analytics .................................... 2
2.1. Cấu trúc cụ thể của Azure Synapse Analytics .................................................. 2
2.2. How Spark works ............................................................................................... 2
2.4. Spark pool trong Azure Synapse Analytics: ..................................................... 2
3. Use Spark in Azure Synapse Analytics .................................................................... 3
3.1. Running Spark code in notebooks .................................................................... 3
3.2. Accessing data from a Synapse Spark pool ...................................................... 3
4. Cài đặt Azure Synapse Analytics ............................................................................. 3
5. Analyze data with Spark ........................................................................................... 5
5.1. Tạo Storage Account .......................................................................................... 6
5.2. Tạo Synapse Workspace................................................................................... 10
Loading data into a dataframe ............................................................................... 18
Specifying a dataframe schema ............................................................................. 24
5.4. Filtering and grouping dataframes ................................................................. 26
5.5. Using SQL expressions in
Spark....................................................................28 ................................................ 28
Creating database objects in the Spark catalog ..................................................... 28
Using the Spark SQL API to query data ............................................................... 29
Using SQL code .................................................................................................... 30 lOMoAR cPSD| 58702377
AZURE SYNAPSE ANALYTICS 1. Introduction
Azure Synapse Analytics là một dịch vụ phân tích dữ liệu tích hợp của Microsoft Azure,
được thiết kế để xử lý khối lượng dữ liệu lớn, kết hợp giữa kho dữ liệu (data warehouse)
và phân tích dữ liệu lớn (big data analytics).
Apache Spark là nền tảng mã nguồn mở dùng để xử lý song song dữ liệu lớn, phổ biến
trong các bài toán "big data". Spark có mặt trên nhiều nền tảng như Azure HDInsight,
Azure Databricks và Azure Synapse Analytics.
2. Get to know Apache Spark and Azure Synapse Analytics
2.1. Cấu trúc cụ thể của Azure Synapse Analytics
Azure Synapse Analytics kết hợp hai mô hình xử lý dữ liệu:
+ Kho dữ liệu truyền thống (Data Warehousing): Sử dụng SQL Pools (trước đây gọi là
Azure SQL Data Warehouse) để lưu trữ và xử lý dữ liệu có cấu trúc.
+ Phân tích dữ liệu lớn (Big Data Analytics): Sử dụng Spark Pools để xử lý dữ liệu phi
cấu trúc hoặc bán cấu trúc. 2.2. How Spark works
Apache Spark là nền tảng xử lý dữ liệu phân tán, cho phép phân tích dữ liệu lớn bằng
cách phân phối công việc qua nhiều nút trong cụm.
Cách hoạt động của Spark:
+ Ứng dụng Spark gồm nhiều tiến trình, được điều phối bởi SparkContext trong
chương trình chính (driver).
+ SparkContext kết nối với cluster manager (thường dùng Hadoop YARN) để xin tài
nguyên và khởi tạo các executor trên các nút trong cụm.
+ Dữ liệu được xử lý song song và lưu tạm bằng RDD (Resilient Distributed Dataset) trong bộ nhớ.
+ SparkContext chuyển ứng dụng thành DAG (directed acyclic graph) – gồm các tác
vụ thực thi song song trong executor.
2.4. Spark pool trong Azure Synapse Analytics:
Spark pool là cụm Spark được triển khai sẵn, giúp chạy các tác vụ Spark. Có thể tạo
qua Azure portal hoặc Synapse Studio. lOMoAR cPSD| 58702377
3. Use Spark in Azure Synapse Analytics
Azure Synapse Analytics hỗ trợ tích hợp Apache Spark. Spark có thể chạy nhiều loại
ứng dụng khác nhau, bao gồm mã Python, Scala, Java (JAR), và các ngôn ngữ khác.
3.1. Running Spark code in notebooks
Azure Synapse Studio cung cấp giao diện notebook tích hợp, giống như Jupyter, giúp
kết hợp mã và ghi chú Markdown
3.2. Accessing data from a Synapse Spark pool
Sử dụng Spark trong Azure Synapse Analytics để làm việc với dữ liệu từ nhiều nguồn khác nhau như:
1. Data Lake: Dữ liệu được lưu trữ trong tài khoản lưu trữ chính của Azure Synapse Analytics workspace. 2. SQL Pools.
3. Azure SQL hoặc SQL Server: Sử dụng Spark connector for SQL Server để kết nối
và làm việc với cơ sở dữ liệu SQL.
4. Azure Cosmos DB: Làm việc với cơ sở dữ liệu phân tích của Azure Cosmos DB
thông qua Azure Synapse Link for Cosmos DB.
5. Azure Data Explorer (Kusto): Kết nối với cơ sở dữ liệu Kusto được định nghĩa như
một dịch vụ liên kết trong workspace.
6. Hive Metastore: Kết nối với một Hive metastore bên ngoài được định nghĩa như
một dịch vụ liên kết.
4. Cài đặt Azure Synapse Analytics
Đăng ký tài khoản sinh viên trong Azure: Giao diện trang chủ: lOMoAR cPSD| 58702377
Vào access student benefits, tạo tài khoản sinh viên cho Azure
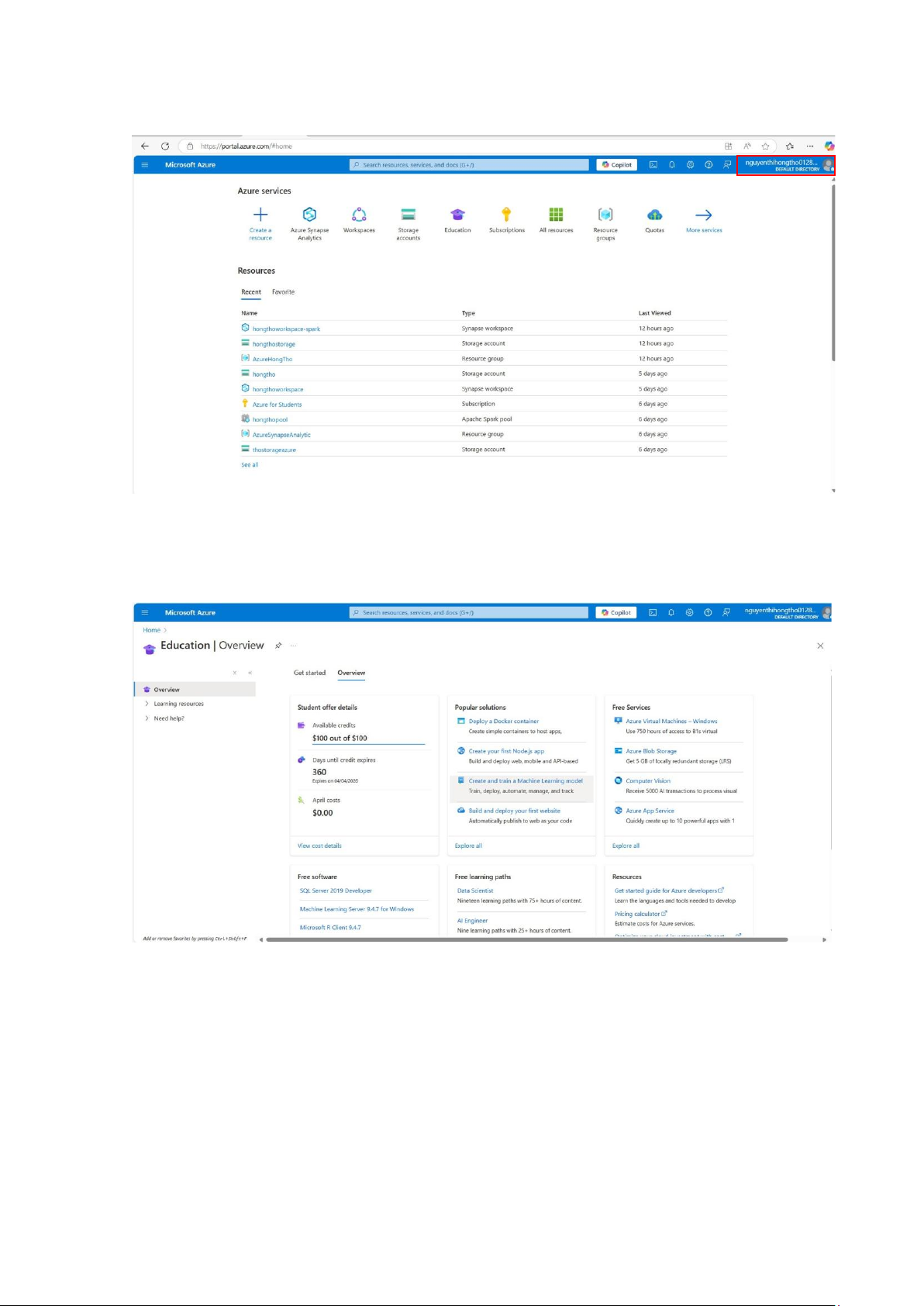
Làm theo các bước, sau khi xác thực tài khoản sinh viên thành công: lOMoAR cPSD| 58702377
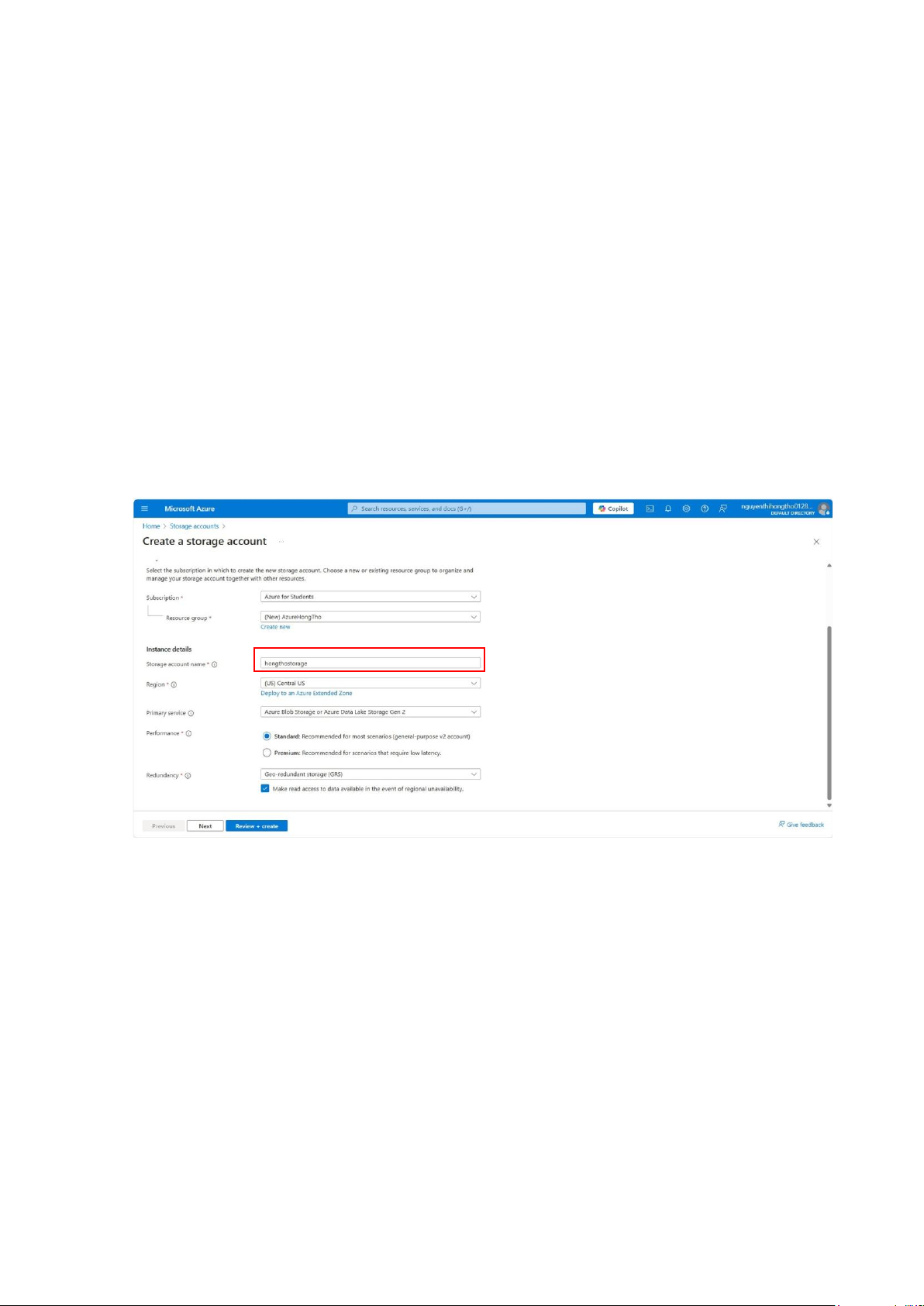
Giao diện Home sau khi đăng nhập vào tài khoản sinh viên thành công:
Đây là tài khoản sinh viên Azure liên kết với tài khoản onedrive
nguyenthihongtho0128@gmail.com
Mỗi tài khoản Education sẽ nhận được 100$.
5. Analyze data with Spark
Ngôn ngữ mặc định trong notebook của Azure Synapse là PySpark – phiên bản Python
tối ưu cho Spark. Ngoài ra, cũng có thể dùng Scala, SQL, Java, và .NET. lOMoAR cPSD| 58702377
5.1. Tạo Storage Account
Trước khi tạo workspace phải tạo a storage account vì Workspace sử dụng một Data
Lake. Synapse mặc định yêu cầu một Azure Data Lake Storage Gen2 để làm bộ lưu trữ
chính. Workspace sẽ gắn kết với storage này để xử lý và quản lý dữ liệu.
Tìm kiếm Storage account trên thanh tìm kiếm:
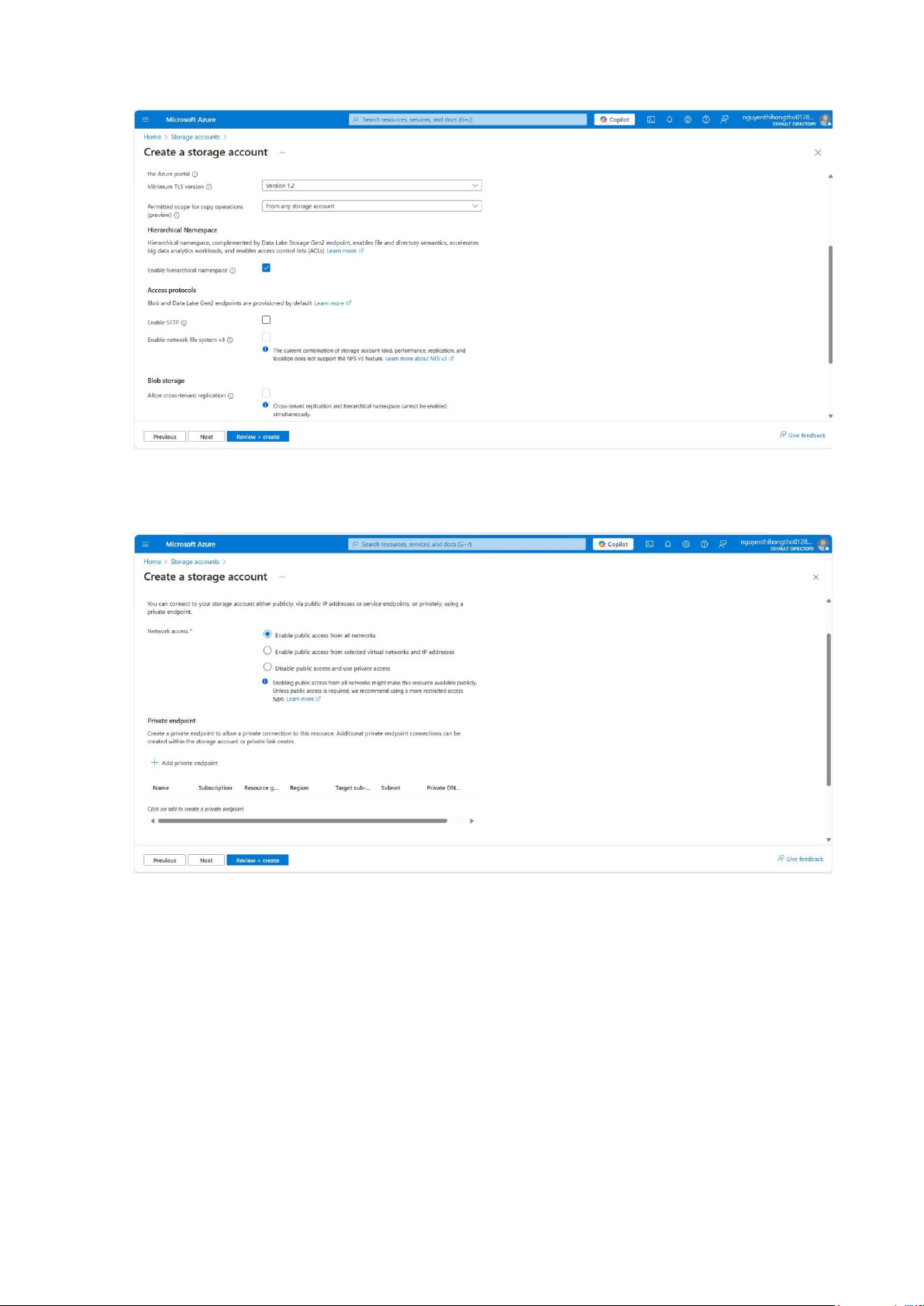
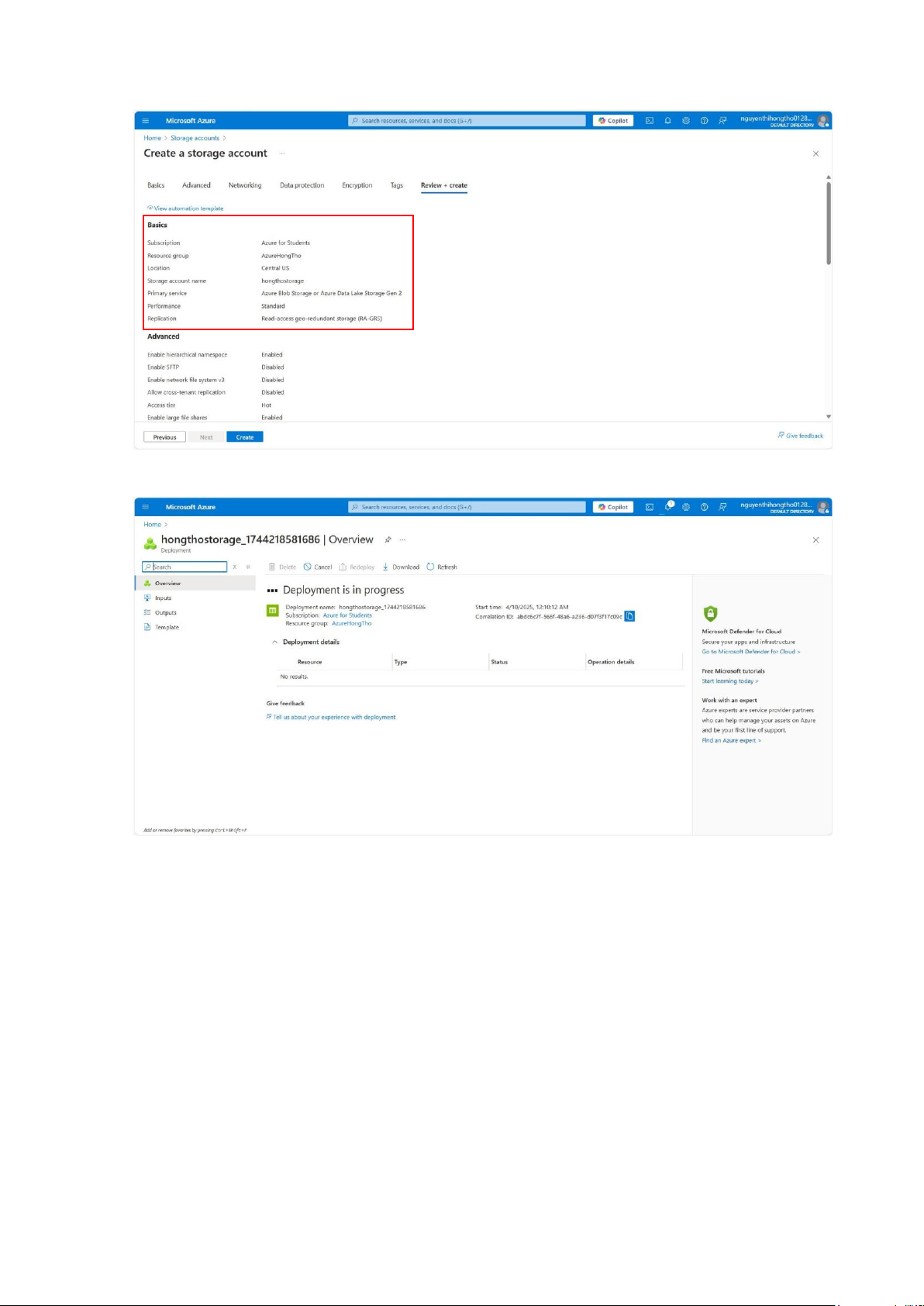
Create a storage account tên hongthostorage, nhập các thông số:
+ Subscription: Gói sử dụng Azure (Azure for Students).
+ Resource group: Nhóm quản lý các tài nguyên liên quan.
+ Storage account name: Tên tài khoản lưu trữ (phải duy nhất).
+ Region: Khu vực địa lý (chọn Central US để sử dụng các dịch vụ tối ưu hơn).
+ Primary service: chọn Gen2 do dùng với Synapse.
Chọn Next, ấn tick vào Hierarchical Namespace, bật "Hierarchical Namespace"
giúp tương thích với Synapse, dễ quản lý và xử lý dữ liệu dạng thư mục, nên rất cần
thiết khi dùng cho phân tích dữ liệu lớn: lOMoAR cPSD| 58702377
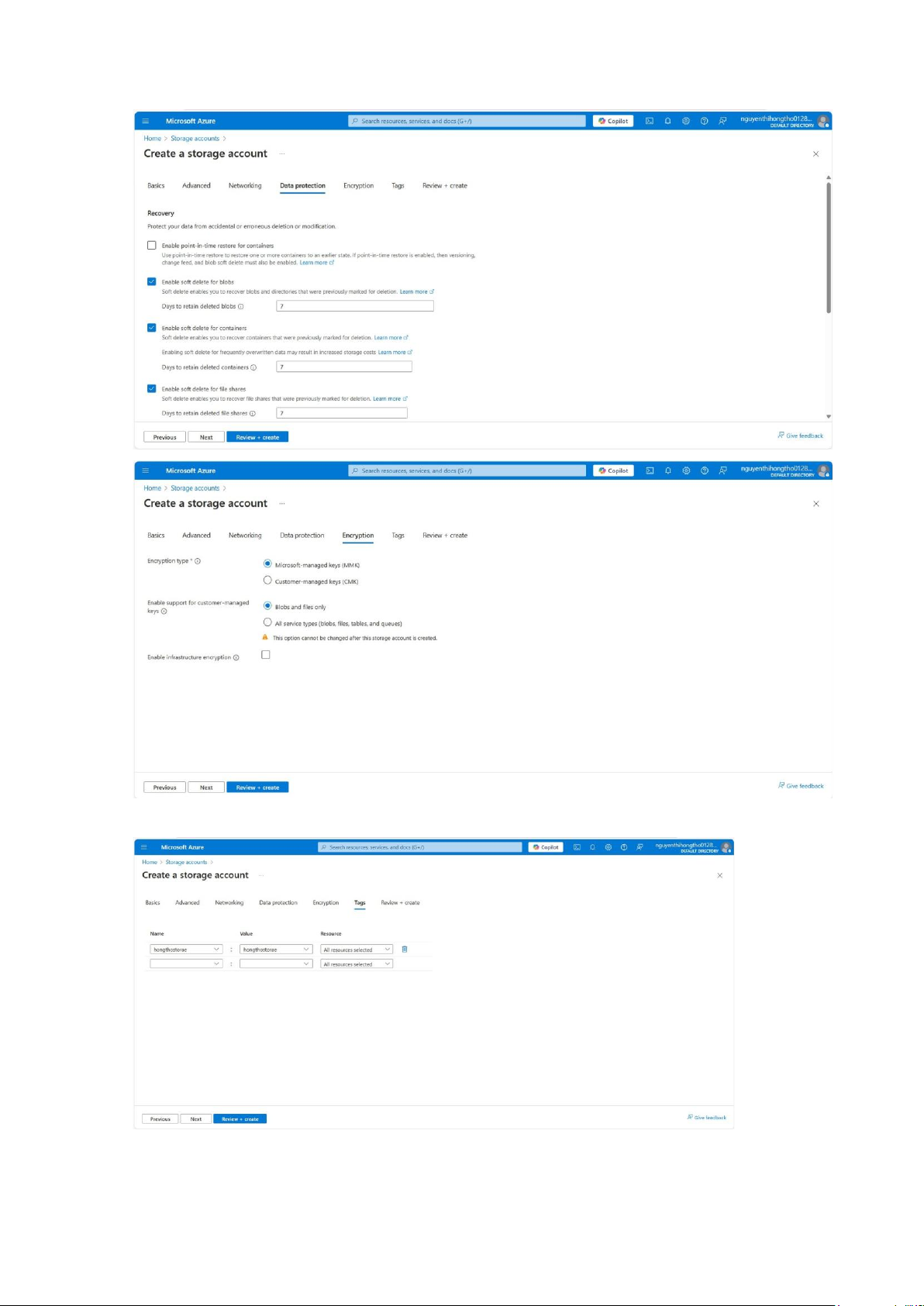
Chọn Next, để các thông số ở các tab Networking, Data protection, Encryption mặc định: lOMoAR cPSD| 58702377
Tạo tags: hongthostorage: hongthostorage Review+Code: lOMoAR cPSD| 58702377
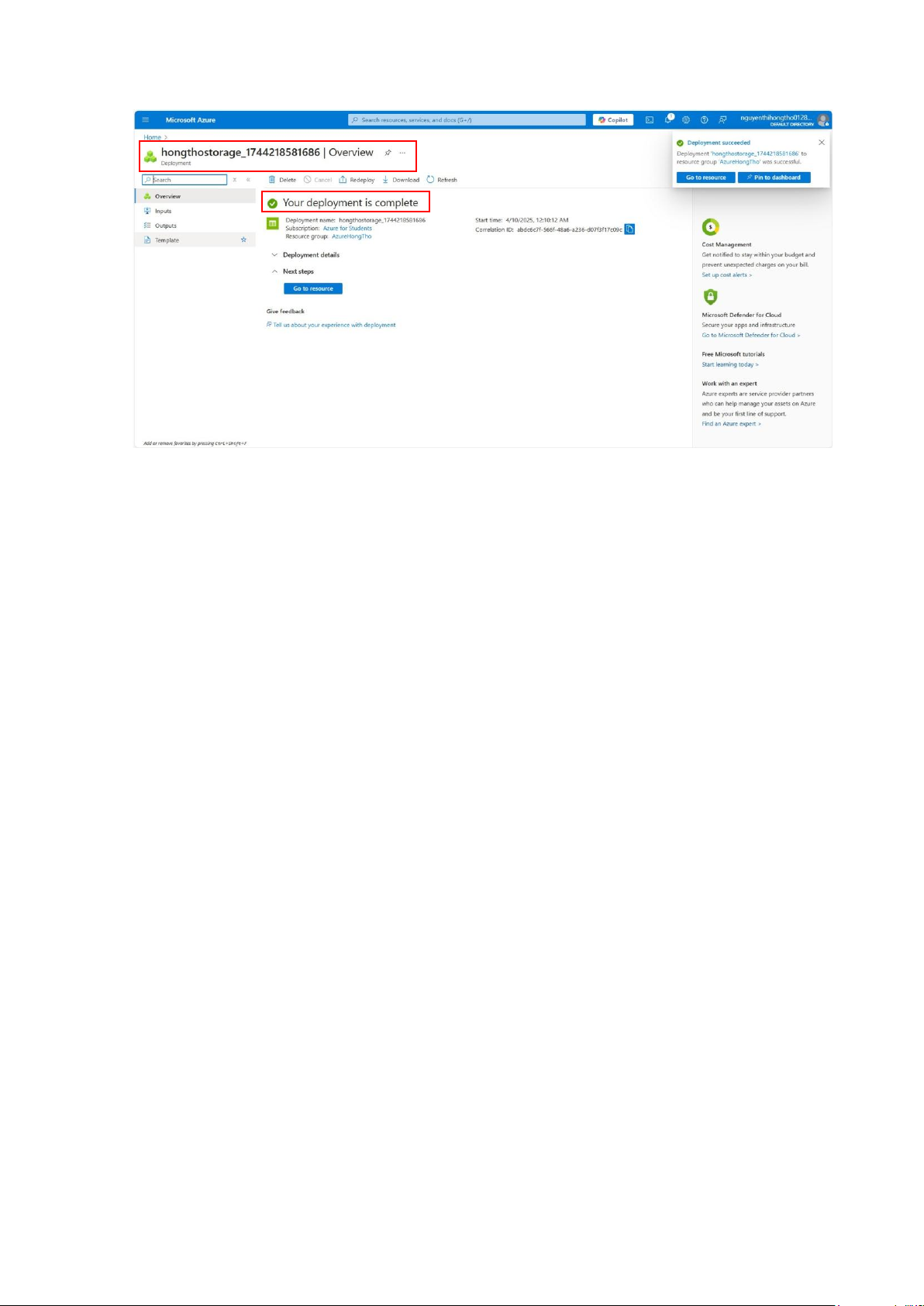
Ấn Create, chờ deploy: Tạo thành công: lOMoAR cPSD| 58702377
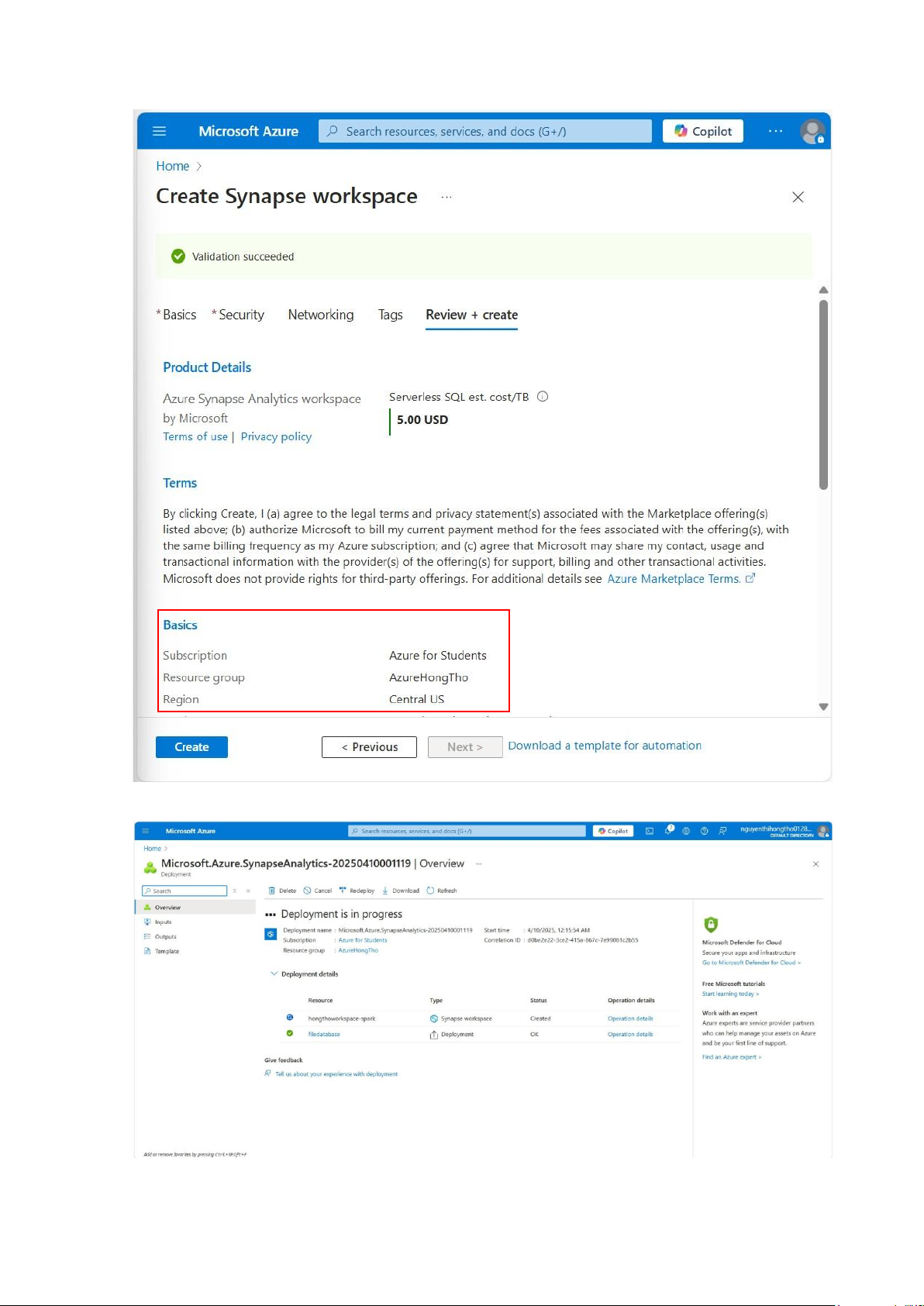
5.2. Tạo Synapse Workspace
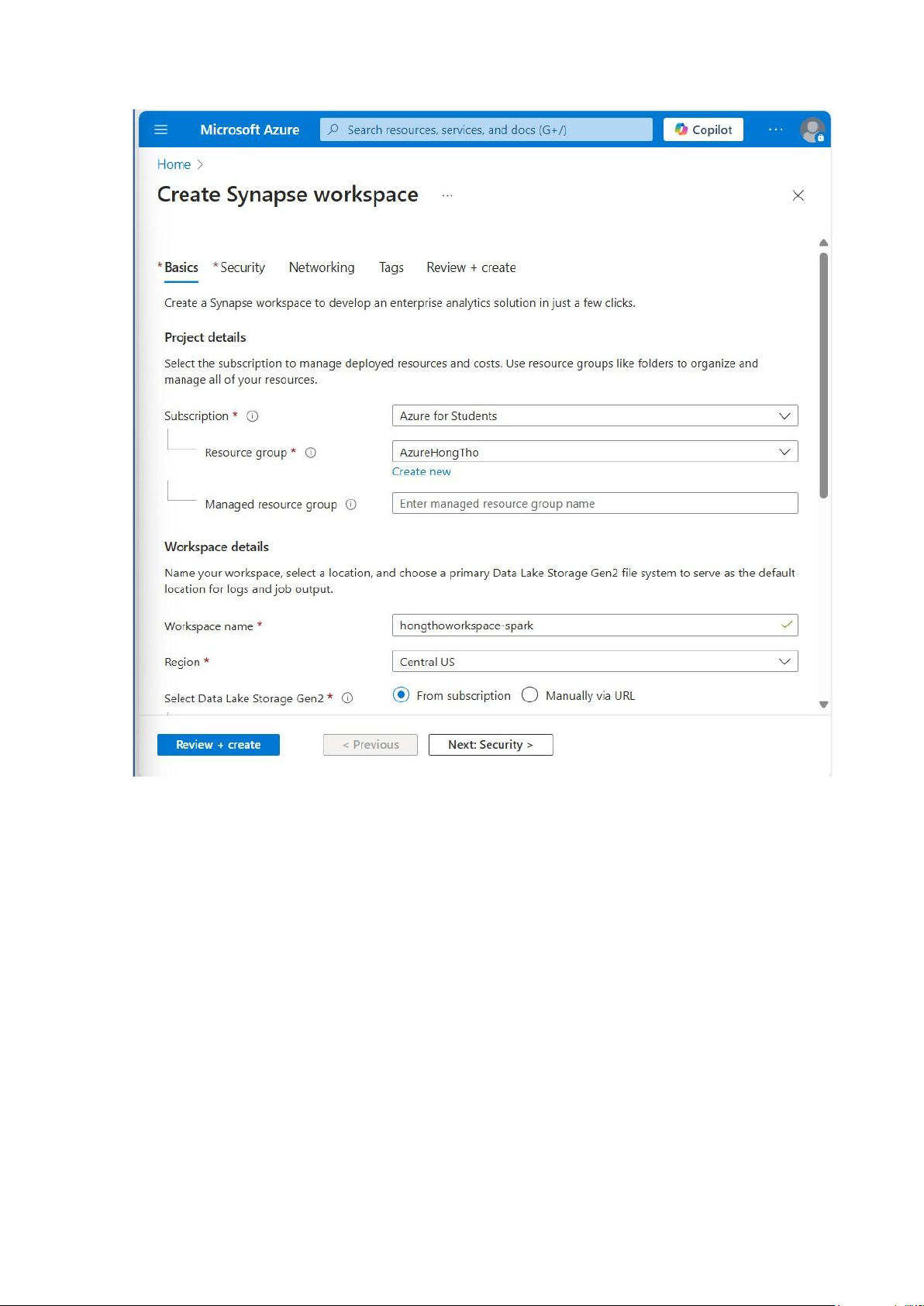
Điền các thông số để tạo workspace hongthoworkspace-spark:
+ Subscription: Azure for Students +
Resource group: AzureHongTho
+ Managed resource group: Azure tự động tạo nhóm này để quản lý tài nguyên phụ trợ cho workspace lOMoAR cPSD| 58702377 Workspace details:
+ Workspace name: Tên của Synapse workspace (hongthoworkspace-spark).
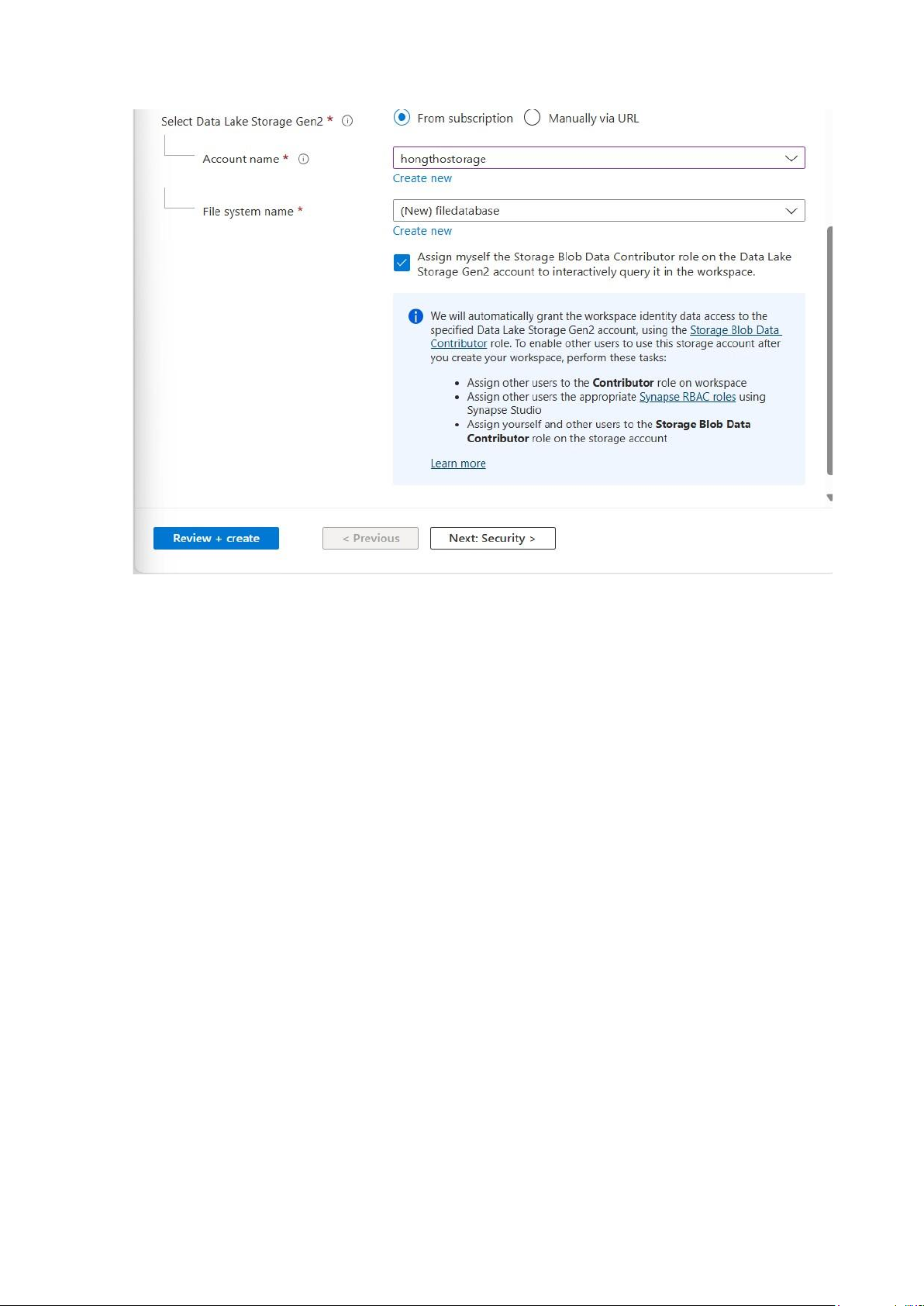
+ Region: Khu vực triển khai dịch vụ (Central US) cùng Region với Storage Account.
+ Select Data Lake Storage Gen2: From subscription - Chọn tài khoản lưu trữ đã tạo sẵn trong subscription. lOMoAR cPSD| 58702377
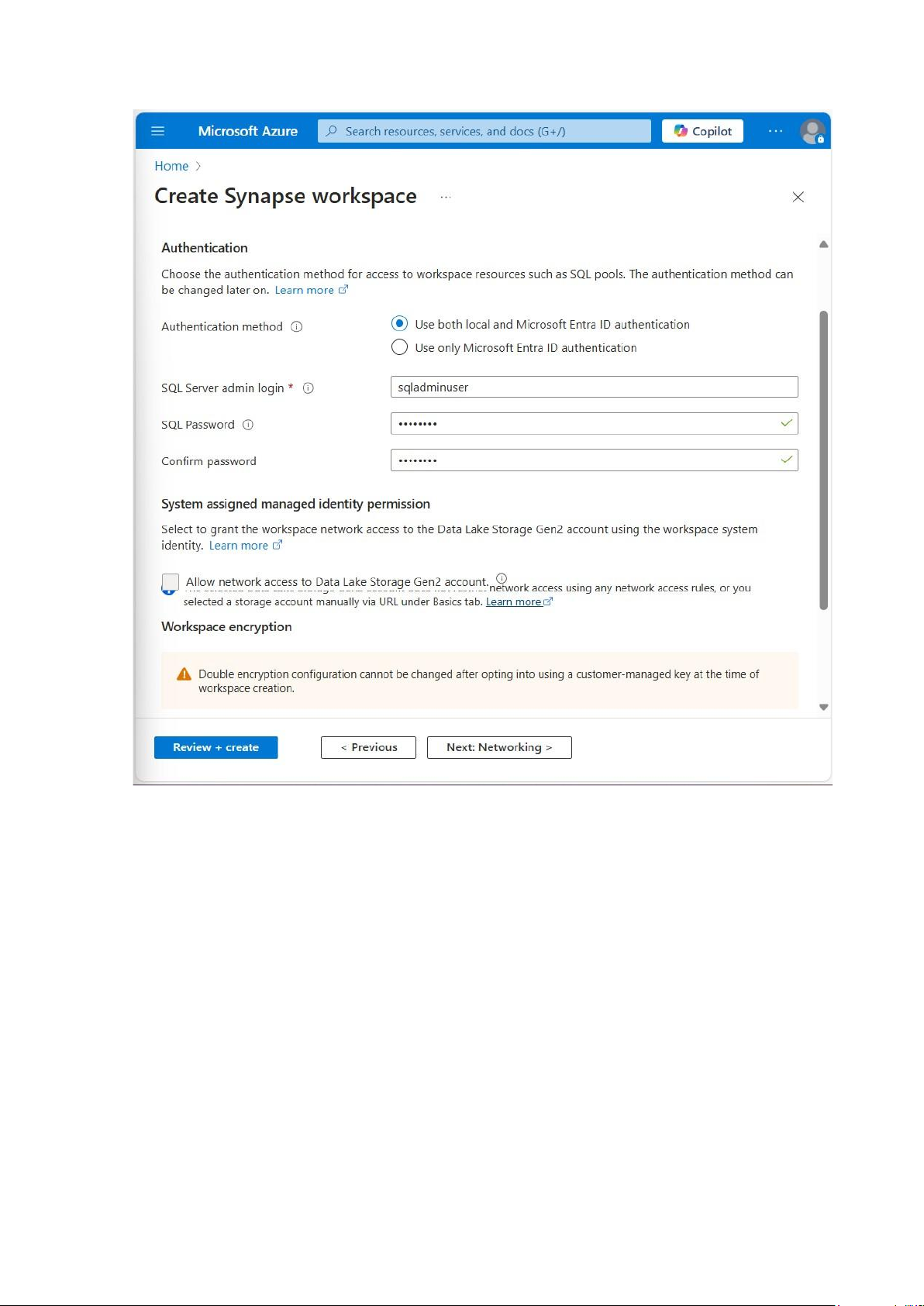
Tạo tài khoản SQL Server Admin ở Tab security: đây là tài khoản quản trị chính cho
SQL trong workspace, dùng để chạy các truy vấn trên dữ liệu: lOMoAR cPSD| 58702377
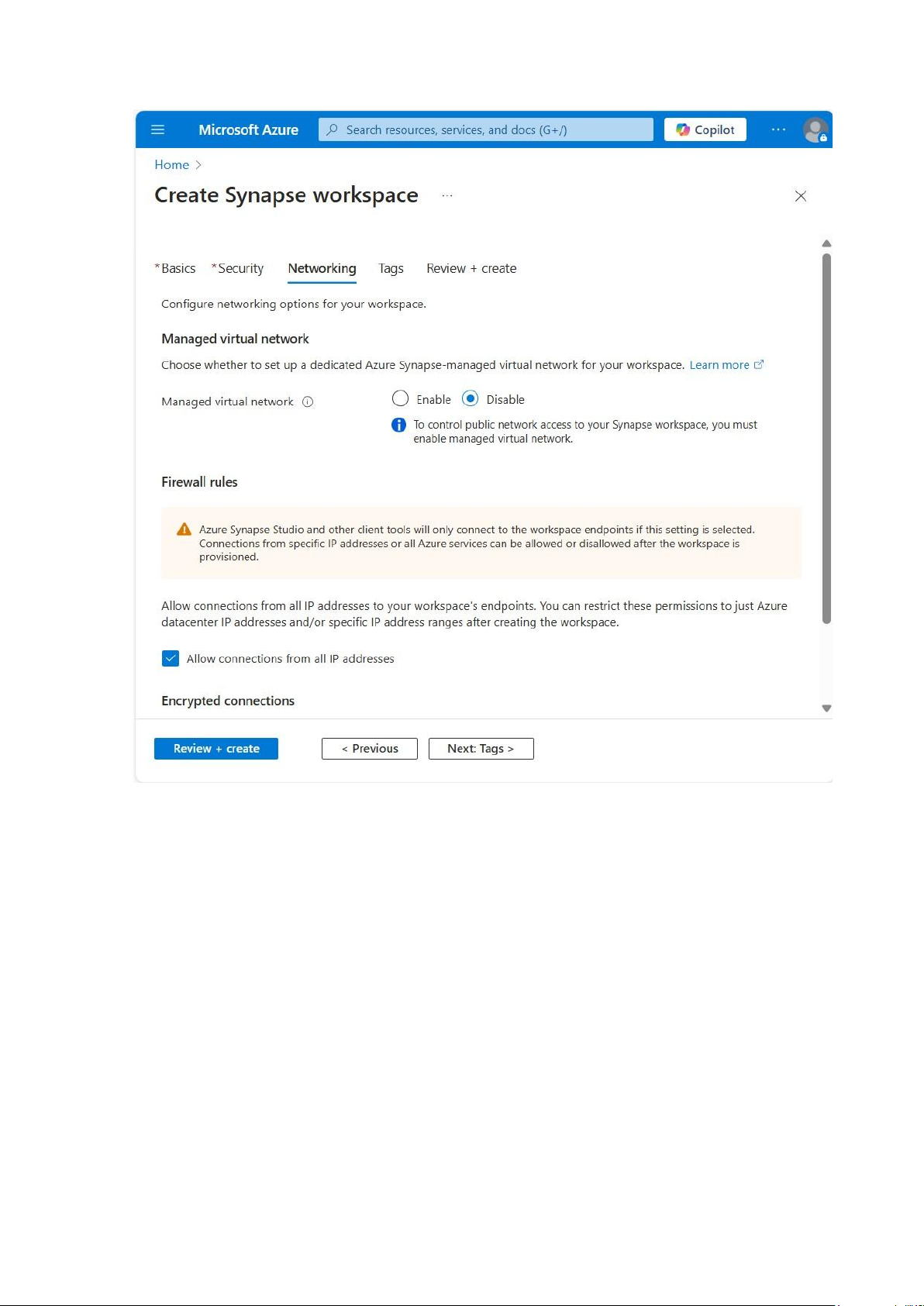
Giữ nguyên các thông số mặc định cho tabs Networking, tick chọn Allow
connections from all IP addresses: lOMoAR cPSD| 58702377
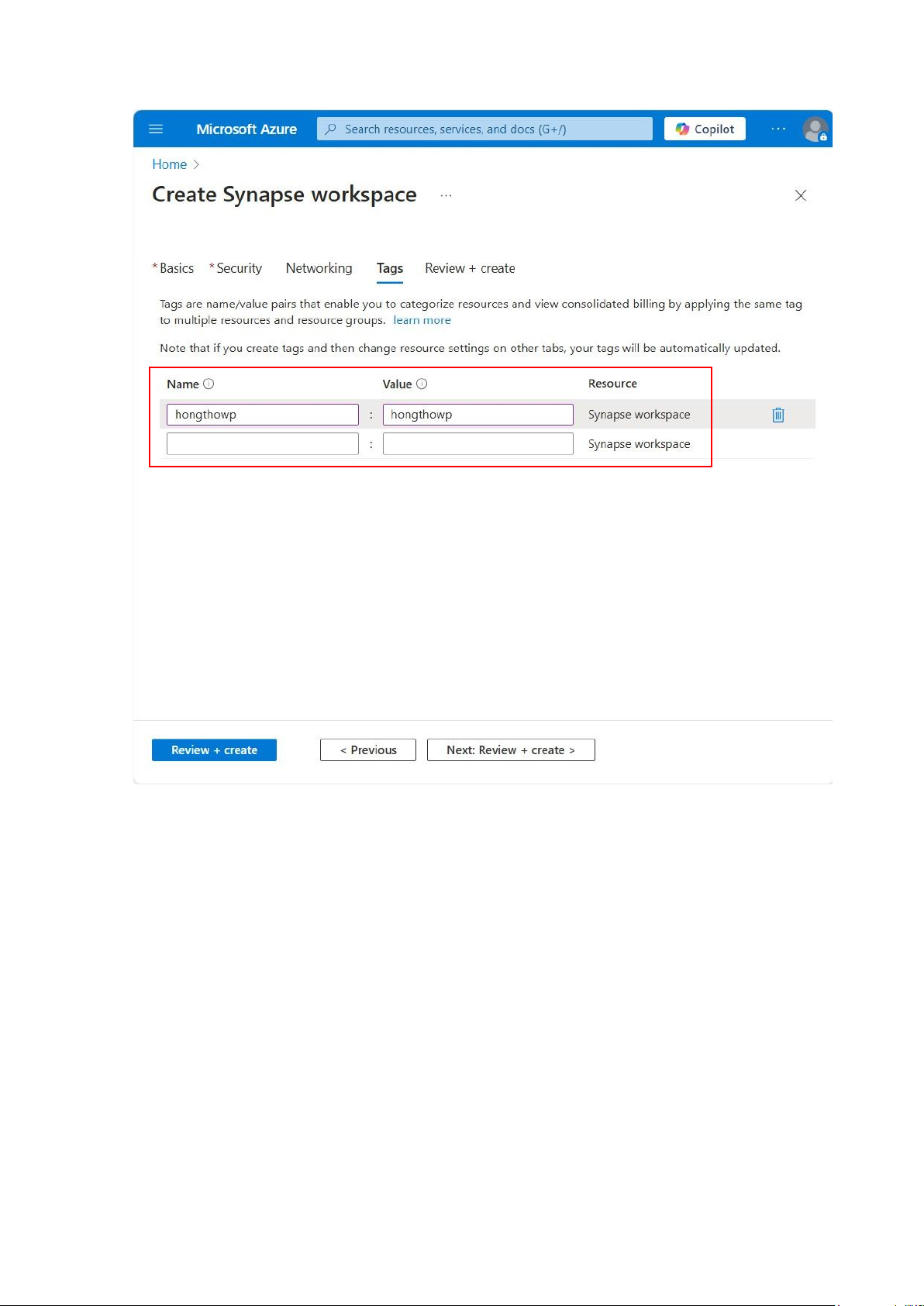
Tạo tag hongthowp:hongthowp ở Tags: lOMoAR cPSD| 58702377
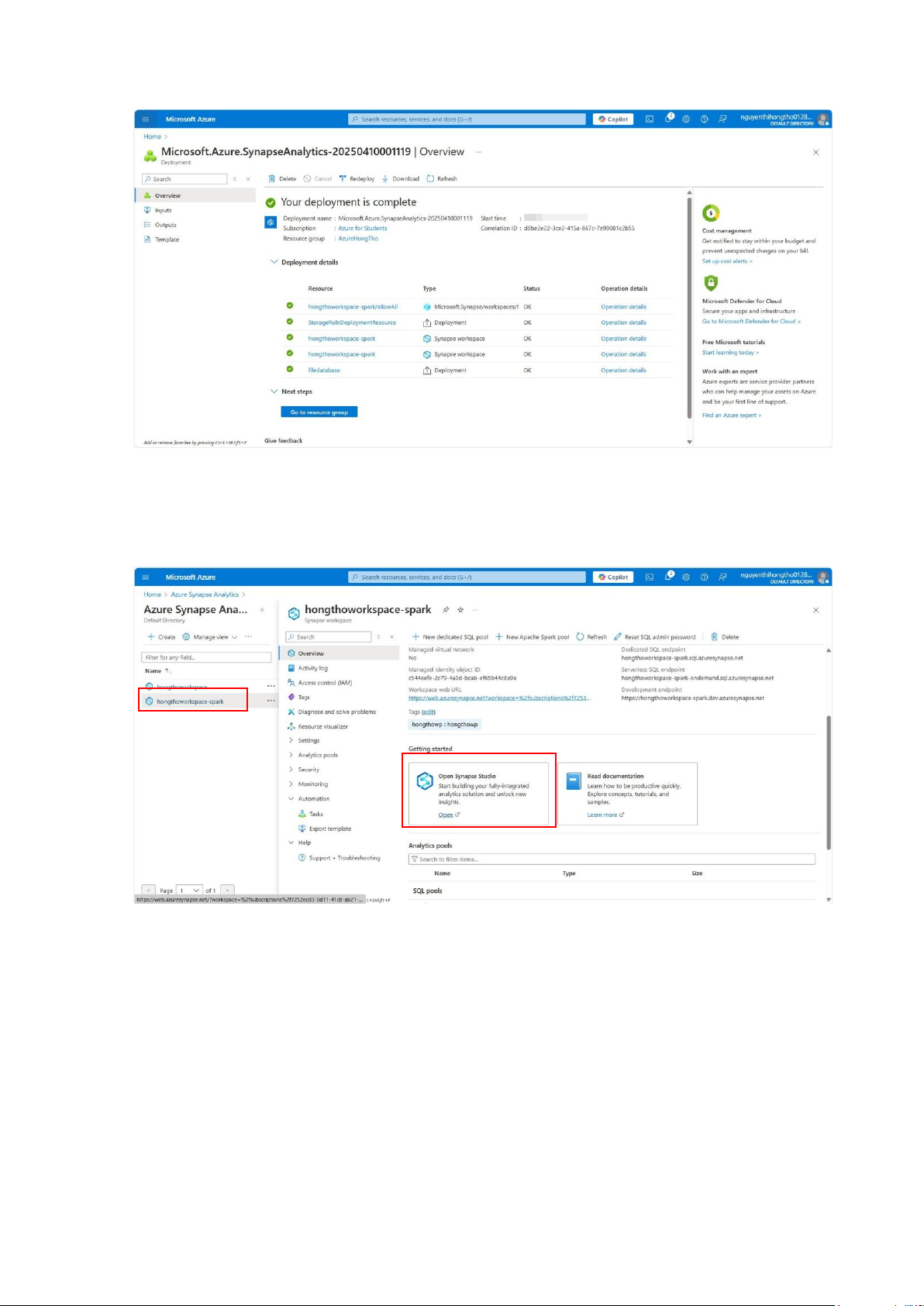
Tab Review+Create: Validation succeeded lOMoAR cPSD| 58702377 Create, chờ deploy: Deploy thành công: lOMoAR cPSD| 58702377
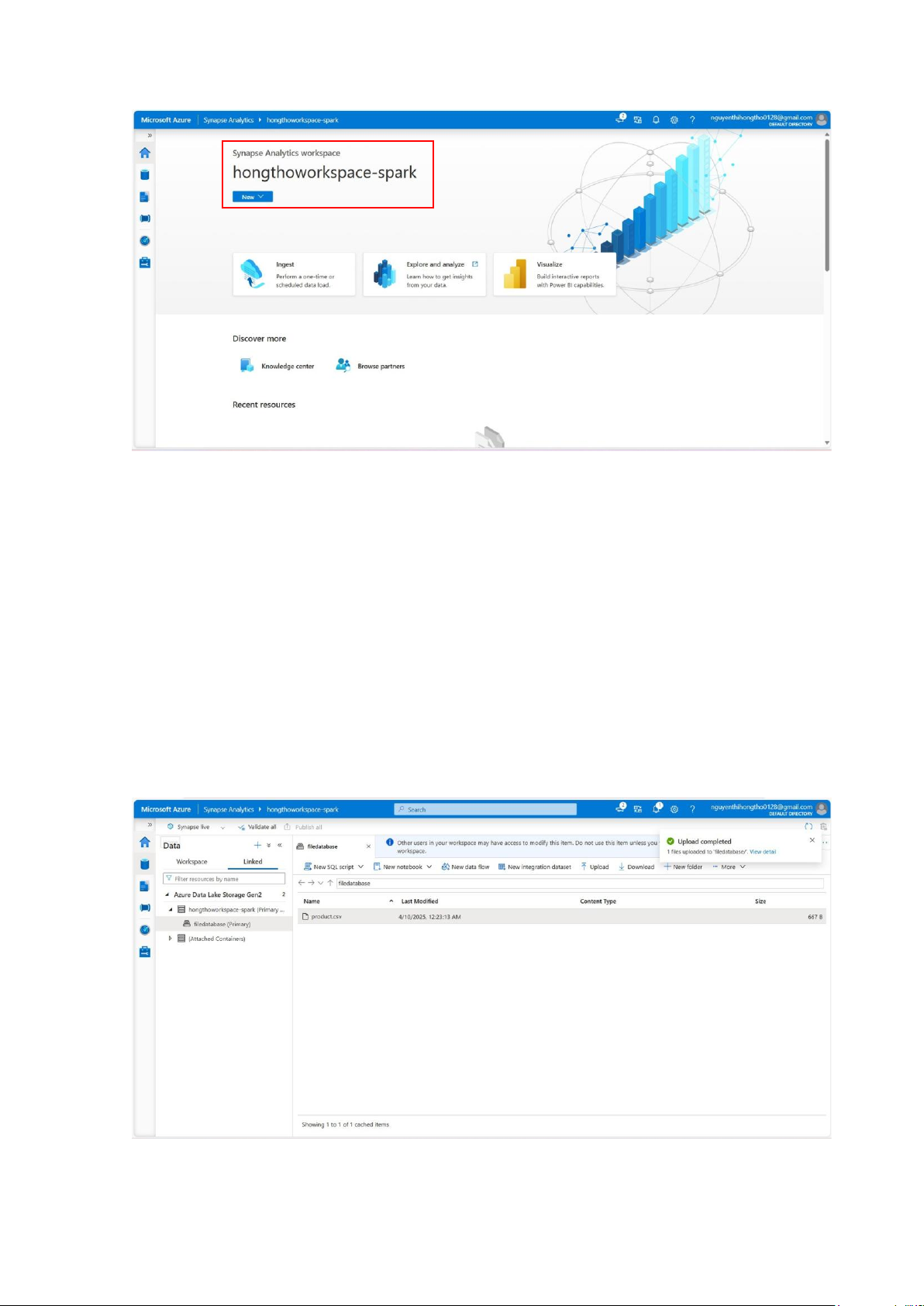
5.3. Exploring data with dataframes
Vào Azure Synapse Analytics, chọn workspace hongthoworkspace-spark vừa tạo:
Chọn Open Synapse Studio: lOMoAR cPSD| 58702377
5 .3 . Exploring data with dataframes
Loading data into a dataframe
Giả sử có tập dữ liệu product.csv:
ProductID,ProductName,Category,ListPrice
771,"Mountain-100 Silver, 38",Mountain Bikes,3399.9900
772,"Mountain-100 Silver, 42",Mountain Bikes,3399.9900
773,"Mountain-100 Silver, 44",Mountain Bikes,3399.9900 ....
Tải file products.csv lên Data Lake Storage: lOMoAR cPSD| 58702377
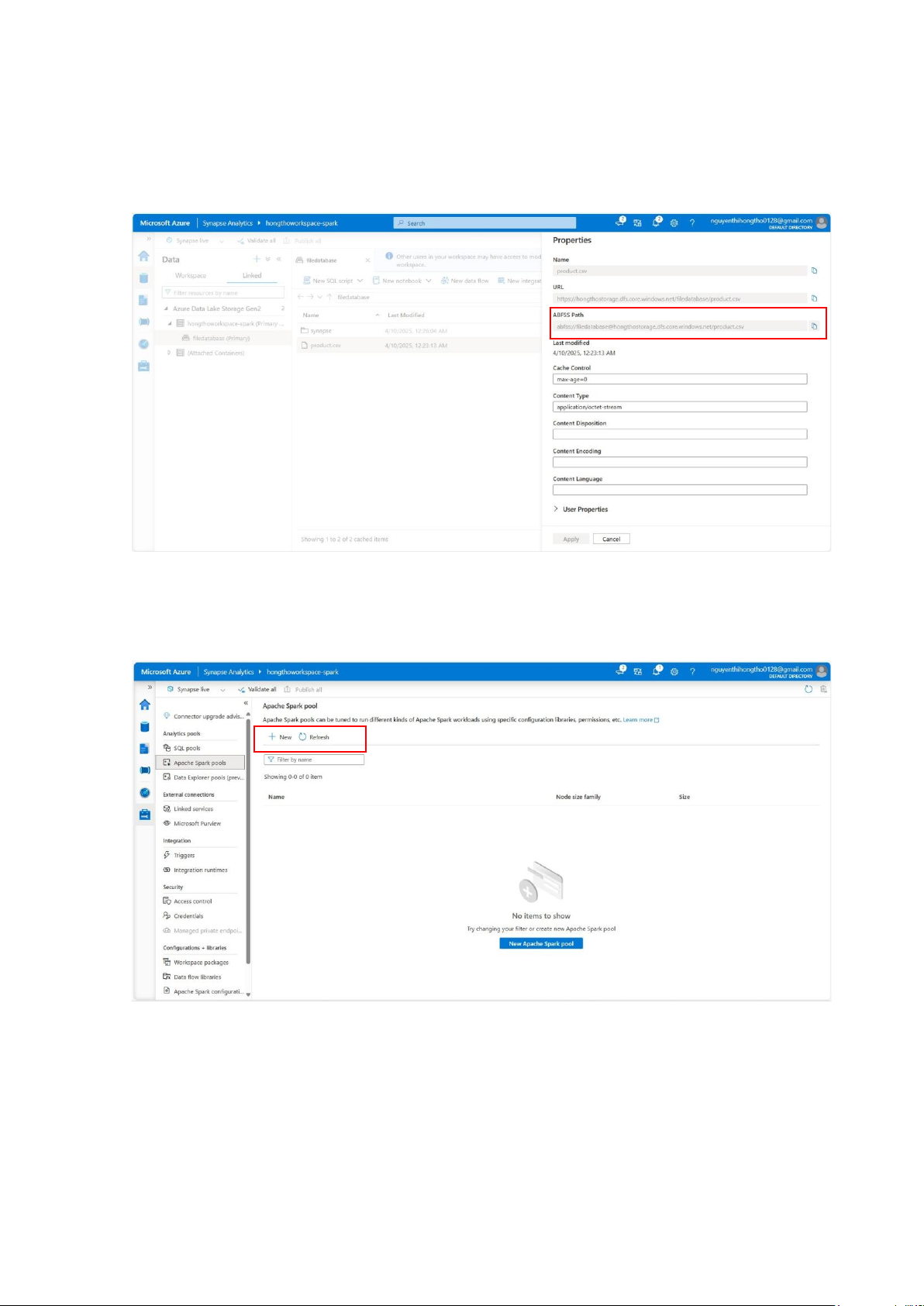
Vào properties sẽ thấy có đường dẫn ABFSS Path, ABFSS Path là đường dẫn truy cập
đến file hoặc thư mục trong Azure Data Lake Storage Gen2 qua giao thức bảo mật abfss://:
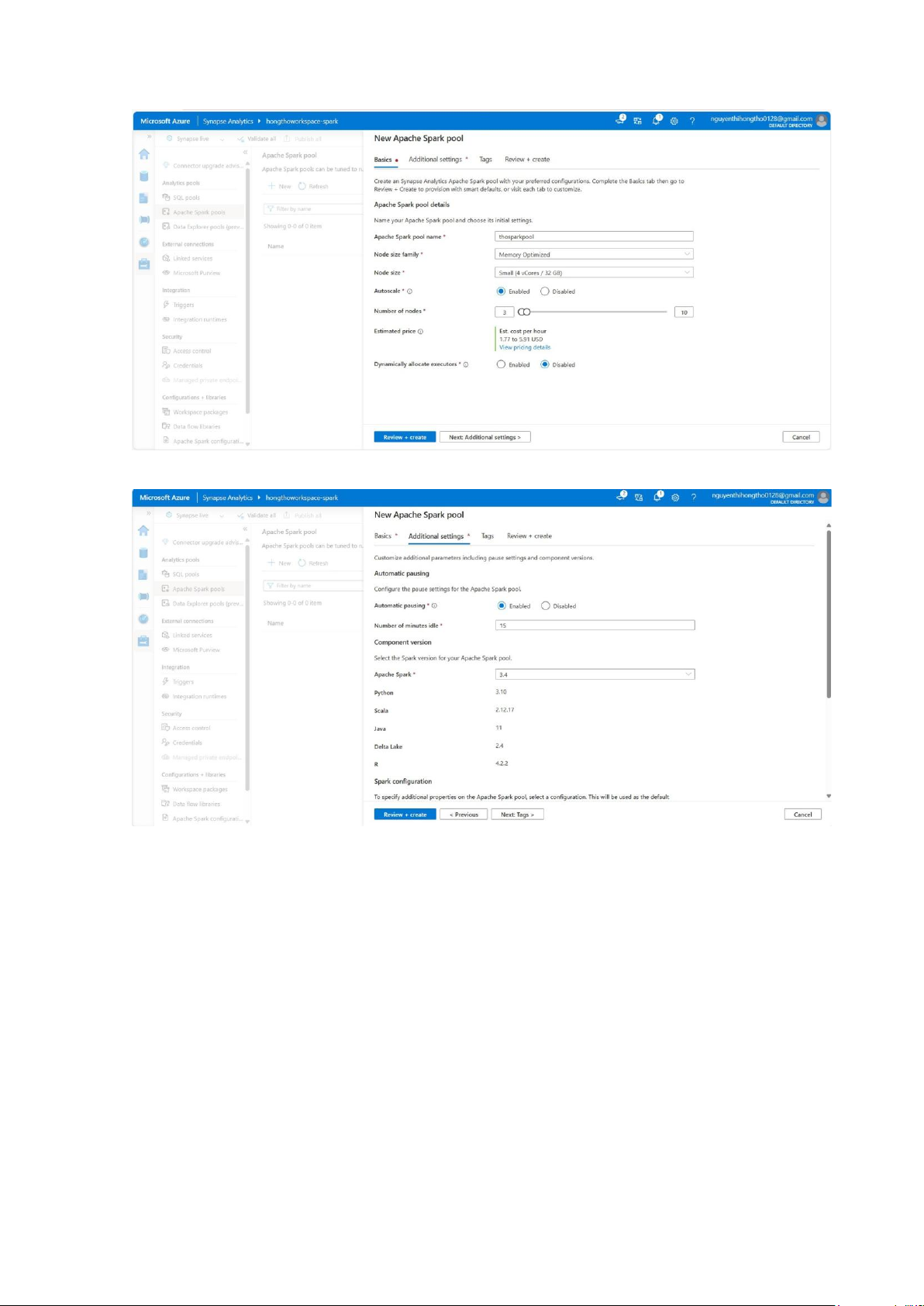
Tạo Apache Spark Pool trước khi chạy mã, vì đây là cụm tài nguyên (cluster) Spark
được tạo sẵn trong Synapse để xử lý mã PySpark, Scala, SQL... trên dữ liệu lớn.
Vào Apache Spark pools, chọn New:
Điền các thông số để tạo thosparkpool:
+ Node size family: Loại máy – chọn Memory Optimized cho xử lý dữ liệu.
+ Node size: Cỡ máy: Small: 4 core, 32 GB RAM. +
Autoscale: Tự động tăng, giảm số node theo tải.
+ Number of nodes: Số node tối thiểu, tối đa khi autoscale. lOMoAR cPSD| 58702377
Giữ các tham số mặc định cho các Tab Additional settings:
Review+Code, Vavidation succeeded:
Tài liệu liên quan:
-

Hướng dẫn cài đặt hệ thống Big Data và phân tích dữ liệu | Môn Dữ liệu lớn - Đại học Sư phạm Kỹ thuật Thành phố Hồ Chí Minh
144 72 -

Ôn tập thi giữa kì | Môn Dữ liệu lớn - Đại học Sư phạm Kỹ thuật Thành phố Hồ Chí Minh
138 69 -

Hướng dẫn cài đặt và sử dụng Apache Pig | Môn Dữ liệu lớn - Đại học Sư phạm Kỹ thuật Thành phố Hồ Chí Minh
144 72 -

Hadoop Streaming - hướng dẫn môn học | Môn Dữ liệu lớn - Đại học Sư phạm Kỹ thuật Thành phố Hồ Chí Minh
222 111 -

Hướng dẫn và câu hỏi ôn tập Chuyên sâu | Môn Dữ liệu lớn - Đại học Sư phạm Kỹ thuật Thành phố Hồ Chí Minh
133 67