Kế hoạch Huấn luyện Mô hình Cây Quyết Định Phân loại Chất lượng Không khí | Iot và ứng dụng | Học viện Công nghệ Bưu chính Viễn thông
Tài liệu được sưu tầm và soạn thảo dưới dạng file PDF với mục đích hỗ trợ học tập và tham khảo. Nội dung tài liệu được trình bày rõ ràng, dễ tiếp cận, phù hợp cho việc ôn tập và củng cố kiến thức trong quá trình học đại học. Đây sẽ là nguồn tư liệu hữu ích giúp các bạn sinh viên chuẩn bị tốt hơn cho các buổi học, đồng thời mở rộng thêm hiểu biết về môn học. Hy vọng tài liệu này sẽ mang lại nhiều giá trị và hỗ trợ các bạn trong hành trình học tập. Mời bạn đọc cùng tham khảo!
Môn: IoT và ứng dụng 143 tài liệu
Trường: Học viện Công Nghệ Bưu Chính Viễn Thông 1.8 K tài liệu
Tác giả:







Preview text:
Kế hoạch Xây dựng và Huấn luyện Mô hình
Cây Quyết Định phân loại Chất lượng Không khí
1. Tải và khám phá dữ liệu
Đọc file CSV: Sử dụng thư viện pandas để tải dữ liệu giả lập từ tệp
CSV chứa thông tin chất lượng không khí. Ví dụ: df =
pd.read_csv('air_quality_data.csv'). Sau đó, in ra một vài dòng đầu
(df.head()) để kiểm tra cấu trúc dữ liệu và đảm bảo đọc đúng. Đồng
thời, sử dụng df.shape để xem kích thước (số lượng mẫu và số cột) của tập dữ liệu[1].
Thông tin các cột: Dùng df.info() để liệt kê tên cột, kiểu dữ liệu (số,
chuỗi, ...) và kiểm tra nhanh xem có giá trị thiếu (null) hay không[2].
Đảm bảo rằng các cột đầu vào (ví dụ: nồng độ PM2.5, PM10, O3, CO,
v.v.) được định dạng số, và cột nhãn chất lượng không khí (ví dụ:
Tốt, Trung bình, Xấu) có kiểu dữ liệu phù hợp (object/string). Nếu nhãn
đang là chuỗi, ta sẽ mã hóa ở bước sau.
Phân bố nhãn: Sử dụng df['TenCotNhan'].value_counts() để đếm số
lượng mẫu thuộc mỗi loại chất lượng không khí Tốt, Trung , bình . Xấu
Việc này giúp ta hiểu dữ liệu có cân bằng hay không – tức là có bị thiên
lệch về một nhãn nào không. Ví dụ, nếu kết quả cho thấy 50% mẫu là
“Tốt”, 30% “Trung bình”, 20% “Xấu”, ta biết mô hình có thể cần chú ý
hơn đến lớp ít mẫu (Xấu). Đồng thời, có thể trực quan hóa nhanh phân
bố này bằng biểu đồ cột để dễ hình dung. 2. Tiền xử lý dữ liệu
Kiểm tra giá trị thiếu: Trước khi huấn luyện, cần kiểm tra xem dữ
liệu có giá trị nào bị thiếu (NaN) không. Sử dụng df.isnull().sum() để
đếm số lượng giá trị thiếu trên mỗi cột. Nếu có cột nào có giá trị thiếu,
cần có chiến lược xử lý: loại bỏ những dòng thiếu dữ liệu hoặc điền giá
trị thay thế (trung bình, trung vị hoặc giá trị đặc biệt) tùy tình huống.
Trong trường hợp tập dữ liệu nhỏ hoặc số lượng thiếu ít, có thể loại bỏ
các dòng/ô bị thiếu. Nếu dữ liệu thiếu nhiều, có thể cân nhắc dùng
phương pháp suy luận giá trị thiếu hoặc gán bằng thống kê (ví dụ trung
bình cột). Việc xử lý giá trị thiếu đảm bảo dữ liệu “sạch” để mô hình có thể huấn luyện tốt.
Mã hóa nhãn (Label Encoding): Chuyển đổi các nhãn phân loại Tốt,
Trung bình, Xấu thành các số nguyên để mô hình có thể xử lý. Nhiều
thuật toán máy học (bao gồm cây quyết định) không làm việc trực tiếp
với dữ liệu dạng chuỗi, do đó ta cần chuyển nhãn văn bản thành số[3].
Ta có thể dùng sklearn.preprocessing.LabelEncoder để tự động gán
mã: ví dụ Tốt -> 0, Trung bình -> 1, Xấu -> 2. Thao tác với pandas
cũng được: df['LabelNumerical'] = df['Label'].map({'Tố't':0, 'Trung bình':1, 'Xấ'
u':2}). Sau khi mã hóa, nên kiểm tra lại
df['LabelNumerical'].value_counts() để đảm bảo số lượng khớp với phân bố nhãn ban đầu.
Tách đặc trưng và nhãn: Xác định cột nhãn (biến mục tiêu) và các
cột đặc trưng đầu vào. Ví dụ trong dữ liệu chất lượng không khí, cột AQI_Category hoặc Quality
là nhãn (với các giá trị Tốt/Trung
bình/Xấu), còn lại có thể là các cột chỉ số ô nhiễm (PM2.5, PM10, v.v.)
hoặc thậm chí một chỉ số AQI tổng hợp. Ta tạo biến X chứa các đặc
trưng (ví dụ df.drop('Label', axis=1)) và y là nhãn (cột label đã mã
hóa số). Kết quả thu được X là một DataFrame/tập các điểm dữ liệu, và
y là Series/mảng các nhãn tương ứng.
3. Chia dữ liệu huấn luyện và kiểm tra
Sử dụng hàm train_test_split: Để đánh giá mô hình công bằng, ta
tách dữ liệu thành hai phần: tập huấn luyện và tập kiểm tra. Dùng hàm train_test_split từ
sklearn.model_selection để thực hiện việc
này[4]. Một tỉ lệ phổ biến là 80% dữ liệu cho huấn luyện, 20% cho
kiểm tra (đảm bảo đủ dữ liệu để đánh giá)[5][6]. Ví dụ:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size=0.2, random_state=42, stratify=y)
Tham số test_size=0.2 nghĩa là 20% mẫu sẽ được giữ lại làm tập kiểm tra,
80% dùng để huấn luyện[4]. Nên sử dụng random_state (ví dụ 42) để kết quả
tách có thể tái lập (mọi lần chạy cho ra cùng một cách chia). Ngoài ra,
stratify=y giúp việc chia dữ liệu giữ nguyên tỷ lệ phân bố nhãn giữa train và
test, đặc biệt hữu ích nếu dữ liệu ban đầu không cân bằng.
Sau khi tách: Kiểm tra nhanh kích thước X_train.shape, X_test.shape
để đảm bảo việc chia đúng theo tỷ lệ mong muốn. Ví dụ, nếu ban đầu
có 1000 mẫu, tập huấn luyện ~800 mẫu và tập kiểm tra ~200 mẫu.
Đồng thời, có thể kiểm tra y_train.value_counts() vs
y_test.value_counts() để chắc chắn các nhãn phân bố tương tự nhau
(nhờ tham số stratify). Việc tách dữ liệu này đảm bảo mô hình học từ
tập huấn luyện, và ta sẽ đánh giá độ chính xác trên tập kiểm tra
chưa từng thấy để có cái nhìn khách quan về mô hình.
4. Huấn luyện mô hình Cây Quyết Định
Khởi tạo mô hình: Sử dụng DecisionTreeClassifier từ sklearn.tree.
Đầu tiên, import: from sklearn.tree import DecisionTreeClassifier.
Sau đó khởi tạo một mô hình cây quyết định trống với các tham số phù
hợp. Nếu chưa chắc chắn, có thể dùng tham số mặc định: model =
DecisionTreeClassifier(random_state=42). Để minh họa, có thể chọn
criterion="gini" (mặc định) hoặc "entropy"
(ID3/C4.5) tùy theo chỉ số
dùng để chọn nhánh[7]. Tham số random_state giúp cố định quá trình
xây dựng cây (vì thuật toán có ngẫu nhiên trong trường hợp dữ liệu
bằng nhau) – điều này hữu ích để tái lập kết quả và so sánh.
Tùy chỉnh siêu tham số (nếu cần): Để tránh cây phát triển quá
phức tạp dẫn đến overfitting, ta có thể giới hạn độ sâu hoặc số lá. Ví dụ, tham số
max_depth giới hạn chiều sâu tối đa của cây. Một cây sâu
quá mức có thể ghi nhớ dữ liệu huấn luyện và giảm khả năng tổng quát
hóa. Ngược lại, cây quá nông có thể không đủ phức tạp để học quy
luật[8]. Do đó, cần chọn max_depth hợp lý (dựa trên thử nghiệm hoặc
kiến thức miền). Tương tự, các tham số như min_samples_split (số
mẫu tối thiểu để tiếp tục chia nhánh) hay min_samples_leaf (số mẫu
tối thiểu mỗi lá) cũng có thể điều chỉnh để cây không tạo các nhánh với
quá ít mẫu. Trong bước minh họa, sinh viên có thể thử một vài giá trị
(ví dụ max_depth=3,4,5) để xem cây có dễ diễn giải hơn không và độ
chính xác thay đổi ra sao.
Huấn luyện mô hình: Sử dụng tập huấn luyện để dạy mô hình. Gọi
model.fit(X_train, y_train) để thuật toán cây quyết định tìm ra các
quy tắc phân chia dữ liệu. Quá trình này sẽ đệ quy tìm thuộc tính và
ngưỡng tối ưu tại mỗi node (theo tiêu chí entropy hoặc Gini) để tách dữ
liệu thành các nhóm “thuần” hơn về nhãn[9][10]. Ví dụ, cây có thể học
được quy tắc như: “Nếu nồng độ PM2.5 > 55 thì chất lượng không khí
là Xấu, ngược lại thì…” tùy theo cấu trúc dữ liệu. Kết quả của fit là mô
hình cây quyết định đã được huấn luyện, sẵn sàng để dự đoán nhãn
dựa trên các điều kiện đã học.
Lưu ý: Sau khi huấn luyện, có thể in ra các tham số của cây: ví dụ
model.get_depth() để xem chiều sâu, model.get_n_leaves() để xem số
lá,... nhằm hiểu độ phức tạp của cây. Nếu cây quá sâu (ví dụ > 10
tầng) thì có thể xem xét giảm max_depth hoặc tăng min_samples_split để tỉa bớt. 5. Đánh giá mô hình
Dự đoán trên tập kiểm tra: Sử dụng mô hình đã huấn luyện để dự
đoán nhãn cho X_test: y_pred = .
model.predict(X_test) Đây là bước
mô phỏng cách mô hình hoạt động với “dữ liệu mới” chưa thấy khi
huấn luyện. Thu được mảng y_pred các nhãn dự đoán (ở dạng mã số
0/1/2 tương ứng với Tốt/Trung bình/Xấu). Ta sẽ so sánh y_pred với
y_test (nhãn thực tế) để đánh giá.
Tính độ chính xác (accuracy): Độ chính xác được định nghĩa bằng tỷ
lệ phần trăm dự đoán đúng trên tổng số mẫu kiểm tra. Có thể dùng
accuracy_score(y_test, y_pred) từ sklearn.metrics để tính toán dễ
dàng. Ngoài ra, model.score(X_test, y_test) cũng trả về accuracy. In
ra kết quả này, ví dụ: “Độ chính xác trên tập kiểm tra là 92%”.
Accuracy cho biết tổng quát mô hình đúng bao nhiêu phần, nhưng
chưa cho biết chi tiết mô hình đúng-sai ra sao trên từng lớp.
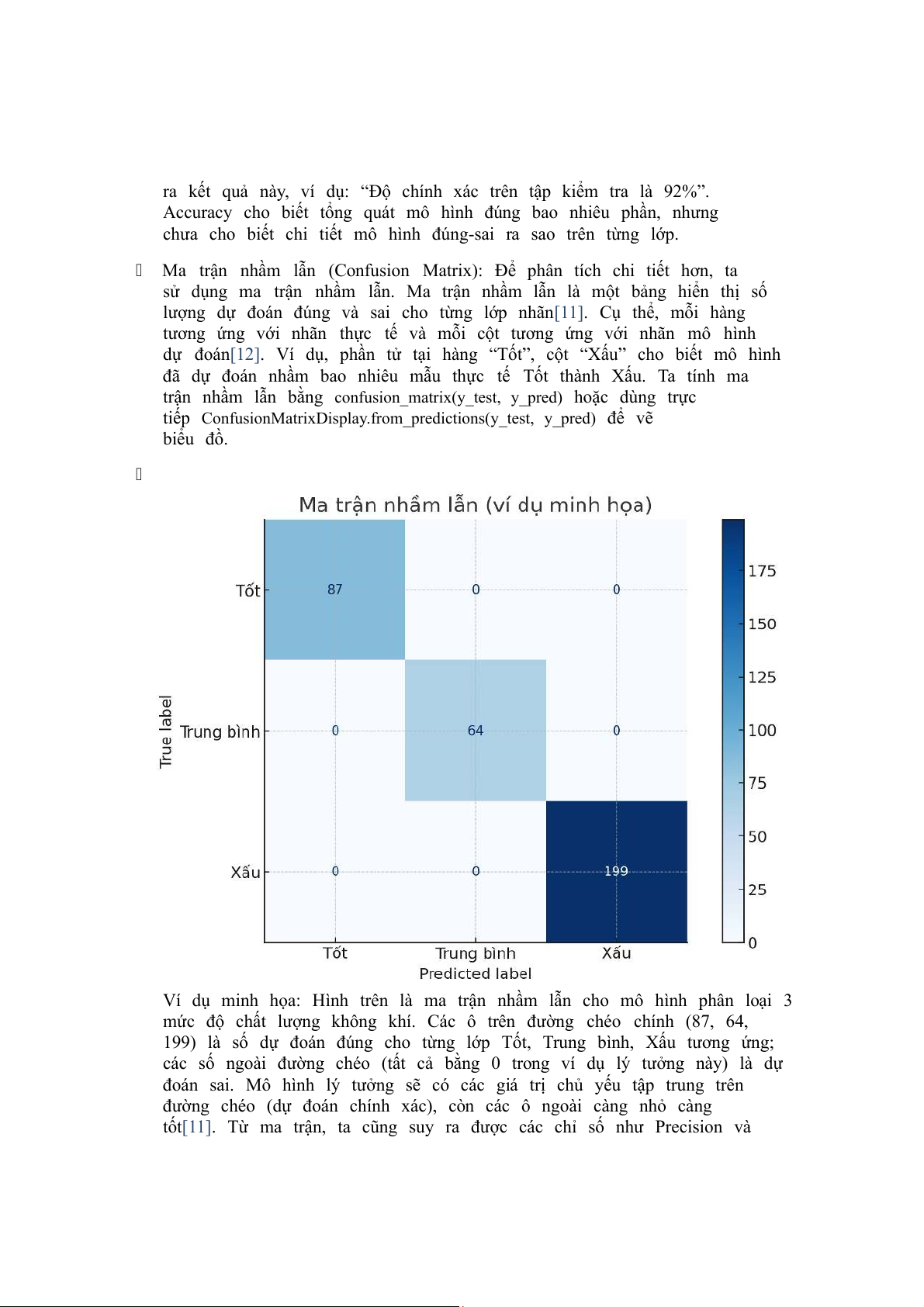
Ma trận nhầm lẫn (Confusion Matrix): Để phân tích chi tiết hơn, ta
sử dụng ma trận nhầm .
lẫn Ma trận nhầm lẫn là một bảng hiển thị số
lượng dự đoán đúng và sai cho từng lớp nhãn[11]. Cụ thể, mỗi hàng
tương ứng với nhãn thực tế và mỗi cột tương ứng với nhãn mô hình
dự đoán[12]. Ví dụ, phần tử tại hàng “Tốt”, cột “Xấu” cho biết mô hình
đã dự đoán nhầm bao nhiêu mẫu thực tế Tốt thành . Xấu Ta tính ma
trận nhầm lẫn bằng confusion_matrix(y_test, y_pred) hoặc dùng trực
tiếp ConfusionMatrixDisplay.from_predictions(y_test, y_pred) để vẽ biểu đồ.
Ví dụ minh họa: Hình trên là ma trận nhầm lẫn cho mô hình phân loại 3
mức độ chất lượng không khí. Các ô trên đường chéo chính (87, 64,
199) là số dự đoán đúng cho từng lớp Tốt, Trung bình, Xấu tương ứng;
các số ngoài đường chéo (tất cả bằng 0 trong ví dụ lý tưởng này) là dự
đoán sai. Mô hình lý tưởng sẽ có các giá trị chủ yếu tập trung trên
đường chéo (dự đoán chính xác), còn các ô ngoài càng nhỏ càng
tốt[11]. Từ ma trận, ta cũng suy ra được các chỉ số như Precision và
Recall cho từng lớp nếu cần (nhưng trong phạm vi bài toán này, chỉ
yêu cầu phân tích bằng ma trận nhầm lẫn trực quan).
Báo cáo kết quả khác: Ngoài ra, có thể in classification_report để
xem chi tiết Precision, Recall, F1-score cho từng nhãn. Điều này hữu
ích nếu muốn phân tích lớp nào model dự đoán kém (ví dụ F1 thấp) để
có hướng cải thiện. Tuy nhiên, vì mục tiêu bài toán là minh họa, ta có
thể tập trung vào ma trận nhầm lẫn và accuracy cho đơn giản.
Vẽ cây quyết định: Sử dụng sklearn.tree.plot_tree để trực quan
hóa cấu trúc cây quyết định đã huấn luyện[13]. Trước tiên, import
hàm: from sklearn.tree import plot_tree. Sau đó vẽ với tham số:
plot_tree(model, feature_names=X.columns, class_names=['Tố' t','Trung bình','Xấ' u'], filled=True, rounded=True). Tham số
feature_names giúp hiển thị tên các đặc
trưng (thay vì X[0], X[1]…), class_names để hiển thị nhãn mỗi lớp
(thay vì 0,1,2), filled=True để tô màu các node theo lớp chiếm ưu thế,
và rounded=True để khung nút bo tròn cho đẹp. Nên đặt biểu đồ kích
thước lớn một chút (plt.figure(figsize=(12,8))) để cây hiện rõ. Kết
quả sẽ là một cây phân cấp từ gốc (root) đến các lá, mỗi nút hiển thị
điều kiện phân chia (ví dụ PM2.5 <= ), 35.5 độ
impurity (độ hỗn loạn, ví
dụ entropy), số mẫu ở nút đó, và class (nhãn chiếm đa số tại nút).
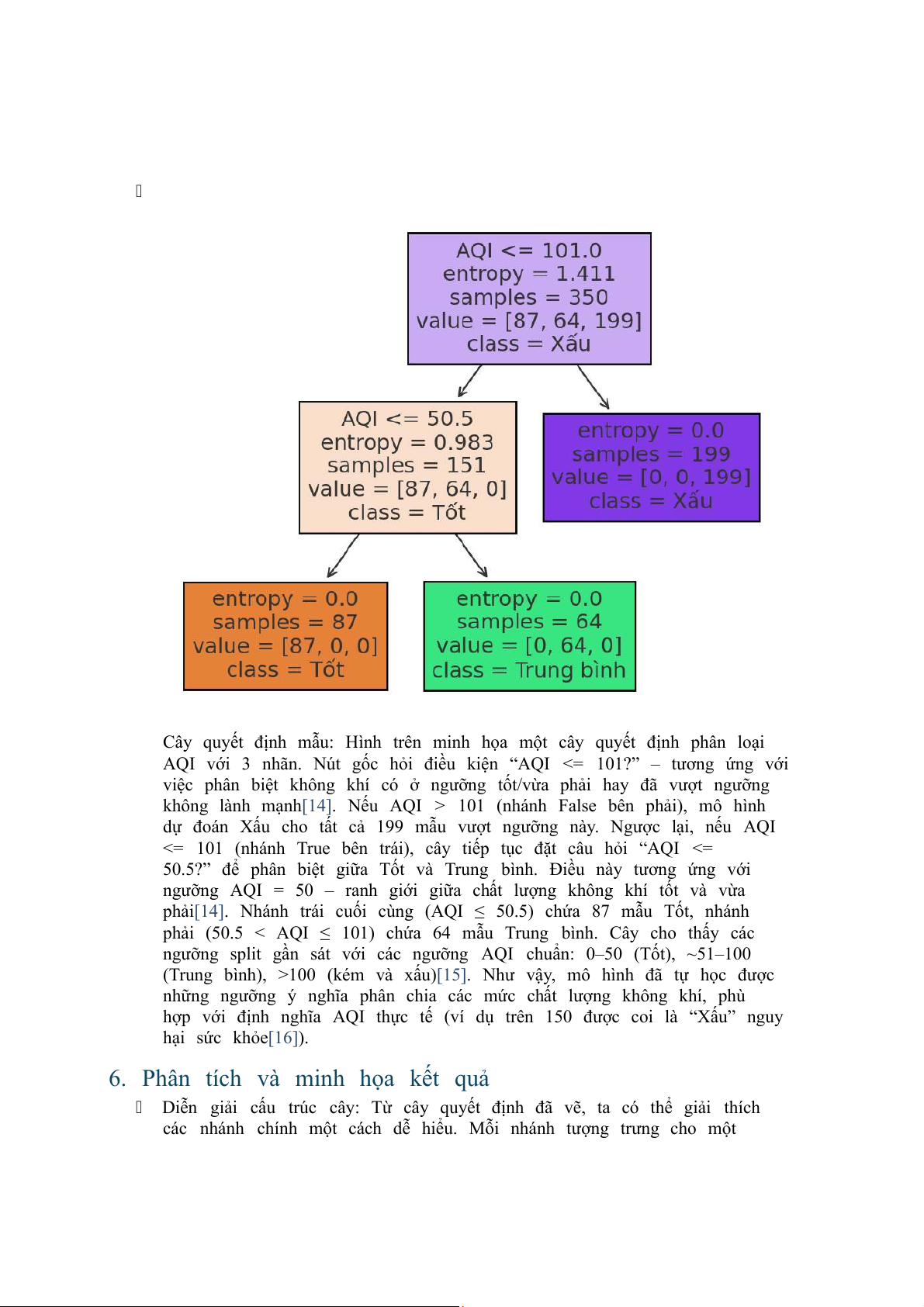
Cây quyết định mẫu: Hình trên minh họa một cây quyết định phân loại
AQI với 3 nhãn. Nút gốc hỏi điều kiện “AQI <= 101?” – tương ứng với
việc phân biệt không khí có ở ngưỡng tốt/vừa phải hay đã vượt ngưỡng
không lành mạnh[14]. Nếu AQI > 101 (nhánh False bên phải), mô hình dự đoán
Xấu cho tất cả 199 mẫu vượt ngưỡng này. Ngược lại, nếu AQI
<= 101 (nhánh True bên trái), cây tiếp tục đặt câu hỏi “AQI <=
50.5?” để phân biệt giữa Tốt và Trung .
bình Điều này tương ứng với
ngưỡng AQI = 50 – ranh giới giữa chất lượng không khí tốt và vừa
phải[14]. Nhánh trái cuối cùng (AQI ≤ 50.5) chứa 87 mẫu Tốt, nhánh
phải (50.5 < AQI ≤ 101) chứa 64 mẫu Trung . bình Cây cho thấy các
ngưỡng split gần sát với các ngưỡng AQI chuẩn: 0–50 (Tốt), ~51–100
(Trung bình), >100 (kém và xấu)[15]. Như vậy, mô hình đã tự học được
những ngưỡng ý nghĩa phân chia các mức chất lượng không khí, phù
hợp với định nghĩa AQI thực tế (ví dụ trên 150 được coi là “Xấu” nguy hại sức khỏe[16]).
6. Phân tích và minh họa kết quả
Diễn giải cấu trúc cây: Từ cây quyết định đã vẽ, ta có thể giải thích
các nhánh chính một cách dễ hiểu. Mỗi nhánh tượng trưng cho một
quy tắc if-else dựa trên một đặc trưng. Ví dụ, với dữ liệu AQI tổng
hợp, cây học được rằng ngưỡng ~100 quyết định phần lớn chất lượng
không khí: nếu AQI > ~100 thì thường rơi vào loại . Xấu Điều này hợp lý
vì theo chuẩn AQI của US EPA, chỉ số trên 100 đã cảnh báo không khí
kém chất lượng cho sức khỏe[14]. Ngưỡng tiếp theo quanh ~50 ngăn
cách Tốt và Trung bình, cũng phù hợp với chuẩn (AQI 51 bắt đầu là
Trung bình)[14]. Do dữ liệu giả lập theo chuẩn AQI, các ngưỡng mô
hình tìm được phản ánh đúng ranh giới phân loại AQI. Nếu đầu vào
có nhiều đặc trưng (PM2.5, PM10, v.v.), ta sẽ thấy thuộc tính nào quan
trọng hơn sẽ được tách ở gần gốc. Chẳng hạn, mô hình có thể chọn
PM2.5 trước (vì PM2.5 ảnh hưởng lớn đến AQI) với một ngưỡng ~35
µg/m³ tương ứng AQI~100, rồi sau đó mới xét đến chỉ số khác. Việc này
giúp ta hiểu được mô hình: Cây quyết định cung cấp giải thích
dạng luật mà sinh viên có thể trình bày: “Nếu PM2.5 > 35 thì chất
lượng không khí kém (có thể Xấu), nếu PM2.5 <= 35 nhưng PM10 >
150 thì... v.v.”. Những luật này nên được đối chiếu với kiến thức miền:
ví dụ ngưỡng PM2.5 ~35 µg/m³ chính là giới hạn giữa AQI mức Trung
bình và Xấu đối với PM2.5[17]. Như vậy, mô hình không những dự đoán
được mà còn cung cấp thông tin các ngưỡng ô nhiễm quan trọng.
So sánh dự đoán với thực tế: Để đánh giá chi tiết hơn, ta trực quan
hóa sự khác biệt giữa nhãn dự đoán và nhãn thực tế trên tập kiểm tra.
Cách làm đơn giản là vẽ biểu đồ cột so sánh số lượng mẫu mỗi loại trong
y_test và trong y_pred. Chẳng hạn, đếm y_test có bao nhiêu
“Tốt”, “Trung bình”, “Xấu” rồi so sánh với y_pred. Nếu mô hình hoàn
hảo, các con số sẽ bằng nhau cho từng lớp (mô hình dự đoán chính xác
từng trường hợp của mỗi lớp). Trong thực tế, sẽ có sự lệch: ví dụ mô
hình dự đoán thừa một số “Trung bình” thành “Tốt” chẳng hạn. Biểu đồ
so sánh này (Actual vs Predicted) giúp dễ thấy mô hình hay nhầm lẫn
loại nào. Nếu một cột “Xấu (dự đoán)” cao hơn nhiều so với “Xấu
(thực tế)” nghĩa là mô hình dự đoán nhầm quá nhiều sang Xấu, có
thể do mô hình hơi “nhạy cảm” với dấu hiệu ô nhiễm. Ngược lại, nếu
cột “Trung bình (dự đoán)” thấp hơn thực tế, nghĩa là nhiều mẫu Trung
bình bị mô hình gán nhầm sang Tốt hoặc Xấu.
Minh họa bằng biểu đồ: Sinh viên có thể tạo một DataFrame nhỏ
chứa số lượng mẫu theo từng nhãn cho
y_test và y_pred, rồi vẽ biểu
đồ nhóm. Trục hoành là các nhãn (Tốt, Trung bình, Xấu), trục tung là
số lượng mẫu. Mỗi nhóm cột có 2 cột: Thực tế và Dự , đoán với màu
sắc khác nhau. Nhìn vào biểu đồ, ta sẽ thấy mô hình dự đoán phân bổ
ra sao. Ví dụ, nếu mô hình hoàn hảo, chiều cao các cột thực tế và dự
đoán của mỗi nhóm gần như bằng nhau. Nếu có chênh lệch lớn, đó là
dấu hiệu mô hình chưa tốt ở lớp đó. Biểu đồ này bổ sung cho ma trận
nhầm lẫn: trong slide thuyết trình, nó giúp người xem nhanh chóng
hình dung tổng quát mô hình dự đoán thiếu/thừa thế nào cho mỗi loại.
Đánh giá tổng quan: Cuối cùng, tổng hợp các kết quả: độ chính xác
chung, ma trận nhầm lẫn và các phân tích trên để rút ra kết luận. Nếu
mô hình cho accuracy cao (ví dụ >90%) và hầu hết các dự đoán sai
tập trung ở các ô ngoài chéo nhỏ (ví dụ nhầm lẫn chủ yếu giữa Trung
bình với lân cận như Tốt hoặc Xấu – điều có thể hiểu được do ngưỡng),
thì mô hình được coi là đủ tốt cho mục đích minh họa. Ta cũng nhấn
mạnh lại tính trực quan: cây quyết định cho phép giải thích tại sao dự
đoán như vậy dựa trên các ngưỡng ô nhiễm. Trong báo cáo/slides, sinh
viên có thể kết luận bằng việc nhấn mạnh mô hình đã học được quy
luật phù hợp với tiêu chuẩn AQI (ví dụ: PM2.5, AQI tổng thể đều cho
thấy ngưỡng ~50 và ~100/150), qua đó minh họa thành công việc
phân loại chất lượng không khí bằng thuật toán cây quyết định.
[1] [4] Decision Trees in Python with Scikit-Learn
https://stackabuse.com/decision-trees-in-python-with-scikit-learn/
[2] Data Manipulation with pandas - Yulei's Sandbox
https://yuleii.github.io/2020/06/27/data-manipulation-with-pandas.html
[3] Label Encoding in Python - GeeksforGeeks
https://www.geeksforgeeks.org/machine-learning/ml-label-encoding-of- datasets-in-python/
[5] [6] [8] [11] Bài tập lớn: Xây dựng Mô Hình Cây Quyết Định (Classification) - Studocu
https://www.studocu.vn/vn/document/hcmc-university-of-physical-education-
and-sport/martial-arts/bai-ve-classification-dung-decision-tree/115078684
[7] Cây quyết định - Decision Tree
https://viblo.asia/p/cay-quyet-dinh-decision-tree-RnB5pXWJ5PG
[9] [10] python - how to explain the decision tree from scikit-learn - Stack Overflow
https://stackoverflow.com/questions/23557545/how-to-explain-the-decision- tree-from-scikit-learn
[12] Python Machine Learning - Confusion Matrix
https://www.w3schools.com/python/python_ml_confusion_matrix.asp
[13] plot_tree — scikit-learn 1.7.2 documentation
https://scikit-learn.org/stable/modules/generated/sklearn.tree.plot_tree.html [14] [15] [16]
Chỉ số chất lượng không khí (AQI) là gì? Ảnh hưởng sức khỏe ra sao
https://airdog.vn/tin-tuc/chi-so-chat-luong-khong-khi-aqi-la-gi?
srsltid=AfmBOoq7ylPFjS9-o5qh84hVGWyF7SvoHGSRU7GwhzVcJFgH- 6NCngOH
[17] Thang đo chỉ số chất lượng không khí và chú giải màu sắc https://aqicn.org/scale/vn/
Tài liệu liên quan:
-

Tóm tắt lý thuyết môn IoT và ứng dụng | Học viện Công Nghệ Bưu Chính Viễn Thông
23 12 -
Accelerated Corner-Detector Algorithms: GPU Implementations and Results | Iot và ứng dụng | Học viện Công nghệ Bưu chính Viễn thông
46 23 -

Đề xuất Dự án IoT: Thiết bị phát hiện chạm cho xe máy | Iot và ứng dụng | Học viện Công nghệ Bưu chính Viễn thông
35 18 -

Phân Tích và Giải Pháp FastAPI | Iot và ứng dụng | Học viện Công nghệ Bưu chính Viễn thông
30 15 -

Tăng cường pháp chế xã hội chủ nghĩa trong quản lý nhà nước | Iot và ứng dụng | Học viện Công nghệ Bưu chính Viễn thông
25 13