Road surface crack detection method based on improved YOLOV5 and vehicle-mounted images
Road surface crack detection method based on improved YOLOV5 and vehicle-mounted images. Tài liệu được sưu tầm giúp bạn tham khảo, ôn tập và đạt kết quả cao. Mời bạn đọc đón xem.
Môn: Tài liệu Tổng hợp 3.6 K tài liệu
Trường: Tài liệu khác 3.9 K tài liệu
Tác giả:







Preview text:
Measurement 229 (2024) 114443
Contents lists available at ScienceDirect Measurement
journal homepage: www.elsevier.com/locate/measurement
Road surface crack detection method based on improved YOLOv5 and vehicle-mounted images
Hongwei Hu a, Zirui Li a, Zhiyi He a,b,*, Lei Wang c, Su Cao d, Wenhua Du b
a College of Automotive and Mechanical Engineering, Changsha University of Science and Technology, Changsha Hunan 410114, China
b Shanxi Key Laboratory of Advanced Manufacturing Technology, North University of China, Taiyuan 030051, China
c College of Civil Engineering, Changsha University of Science and Technology, Changsha, Hunan 410114, China
d College of Intelligence Science and Technology, National University of Defense Technology, Changsha, Hunan,410000, China A R T I C L E I N F O A B S T R A C T Keywords:
Road surface crack detection methods using vehicle-mounted images have gained substantial attention recently. Road surface crack detection
Notably, YOLO-based techniques have exhibited effectiveness and real-time performance. However, current YOLO series
YOLO-based approaches encounter challenges like blurriness of small cracks and incomplete information Vehicle-mounted images
extraction from vehicle-mounted images. Therefore, this paper proposes a novel detection method based on the Attention mechanism Lightweight design
improved YOLOv5 and vehicle-mounted images. In this method, the Slim-Neck structure enhances crack focus
through a weighted attention mechanism while optimizing network efficiency. The integration of the C2f
structure and Decoupled Head better harnesses upper layer output information. Moreover, the SPPCSPC struc-
ture is bifurcated to augment model efficiency and accuracy. The training process is optimized by using the Silu
activation function and CIoU loss function. This approach is applied to vehicle-mounted images, with its efficacy
and feasibility affirmed through extensive comparative and ablation experiments. Importantly, compared to five
other advanced methods, notable enhancements are observed in various evaluation metrics. 1. Introduction
thus infer the location of cracks, but this entails high equipment costs
[14]. Nowadays, deep learning techniques have made remarkable
Road surface cracks [1–5]are common defects in road structures.
progress in the field of image processing. Due to their excellent perfor-
Their formation is primarily attributed to the aging and degradation of
mance, deep learning algorithms have found widespread application in
road surface materials over time, coupled with the influence of natural road surface crack detection.
climatic factors such as rain and snow [6,7]. These factors contribute to
In general, deep learning-based object detection and recognition
the emergence of various types of cracks on the road surface, which
algorithms can be categorized into two-stage detection methods based
gradually widen and lead to surface damage and structural loosening,
on classification and one-stage detection methods based on regression.
posing significant threats to both road safety and service life [8,9].
For two-stage detection methods, Girshick et al. introduced the R-CNN
Therefore, it is meaningful to conduct research on road surface crack
[15], which served as a pioneering work for deep learning-based object detection.
detection. Building on this, they improved the method for region pro-
Over the past few decades, numerous scholars and experts have
posal extraction and proposed Fast R-CNN [16] and Faster R-CNN [17].
proposed various methods to detect cracks in road surfaces. These
HE introduced an additional output branch for predicting target masks
methods include manual inspection [10], machine vision [11–13], and
during candidate object generation, leading to the development of Mask
infrared imaging [14], among others. However, these methods have
R-CNN [18]. Kim et al. [19] utilized Mask R-CNN and performed
certain limitations. Manual inspections are time-consuming, labor-
morphological operations on the detected crack masks to quantify the
intensive, and inefficient, susceptible to environmental and human
cracks. A et al. [20] utilized Transfer Learning and Dynamic-Opposite
factors [10]. Machine vision techniques enable automated detection, but
Hunger Games Search to optimize feature selection. Additionally, they
require high-quality image data and sophisticated algorithms [12].
employed an algorithm called Improved Artificial Rabbits Optimizer
Infrared imaging can detect temperature variations on road surfaces and
[21] to disregard unimportant features. While these methods have
* Corresponding author at: College of Automotive and Mechanical Engineering, Changsha University of Science and Technology, Changsha Hunan 410114, China.
E-mail address: hezhiyihnu@126.com (Z. He).
https://doi.org/10.1016/j.measurement.2024.114443
Received 10 August 2023; Received in revised form 19 February 2024; Accepted 4 March 2024 Available online 5 March 2024
0263-2241/© 2024 Elsevier Ltd. All rights reserved. H. Hu et Measurement al. 229 (2024) 114443
continuously enhanced and innovated two-stage detection techniques,
existing methods’ limitations. Section 3 presents a detailed description
their hardware requirements constrain detection speed and real-time
of the proposed method. In Section 4, comparative experiments and
capabilities, rendering them unsuitable for real-time detection.
ablation experiments are conducted to validate and analyze the pro-
To meet the real-time detection requirements, regression-based one-
posed approach. Finally, Section 5 summarizes the research findings of
stage object detection methods directly obtain the probability and po-
this paper and suggests potential directions for future improvements.
sition of the objects without the need for region proposal extraction. The
YOLO [22] series is a classic representative, with YOLOv5 [23] widely 2. Related work
applied in various domains, although it may encounter performance
bottlenecks in specific domains. Therefore, many researchers have
In this section, the YOLOv5 algorithm, which has been proposed in
conducted further studies on road surface crack detection. For instance,
recent years, is first introduced. Subsequently, the existing issues of
Li et al. [24] proposed a YOLO detection algorithm that improves
YOLOv5 in road surface crack detection are discussed in depth, and
detection accuracy, but the model size is large and fails to meet real-time
approaches to address these issues are presented.
requirements. To address this issue, Wu et al. [25] introduced an
improved YOLOv4 network with pruning techniques and EvoNorm-S0 2.1. YOLOv5
structure, which enhances detection accuracy and satisfies real-time
requirements. In other crack detection fields, such as bridge deck
The YOLOv5 object detector consists of three main components:
crack detection, Zhang et al. [26] demonstrated the effectiveness of CR-
Backbone, Neck, and Head. The Backbone is responsible for extracting
YOLO for sparsely distributed cracks but with limited performance on
the feature information from the input image. The Neck plays a crucial
complex cracks. For complex and multivariate cracks, Z et al. [27]
role in further processing and fusing the features extracted by the
developed MI-YOLO, which exhibits stronger feature extraction capa-
Backbone to enhance the accuracy and effectiveness of object detection.
bilities for light-colored and low-definition images but lower accuracy in
Finally, after being processed by the Head, YOLOv5 outputs the category identifying small cracks.
and location information of each detected object.
Although the aforementioned object detection research has initially
YOLOv5 predicts for each grid on the feature map and compares the
improved the recognition accuracy and efficiency of the models, the
predicted information with the ground truth to guide the model towards
datasets used in these studies are based on manually processed tradi-
convergence. The loss function aims to measure the discrepancy be-
tional crack images, which are not entirely suitable for the new chal-
tween the predicted information and the ground truth. A smaller loss
lenges posed by road images captured by vehicle-mounted smartphones
function value indicates that the predicted information is closer to the
for crack detection. This primarily involves two issues. Firstly, the
ground truth, which greatly determines the performance of the model.
vehicle-mounted image contains the surrounding environment of the
The loss function in YOLOv5 consists of three main components: the
road, which makes the cracks appear smaller or less prominent in the
classification loss, objectness loss, and localization loss. The formulation
image, resulting in blurred tiny cracks. Secondly, the C3 structure in the
of the loss function is as follows:
YOLO series, which is commonly studied, performs feature extraction at
earlier layers. This may lead to the loss of contextual information of tiny
Loss = λ1Lcls + λ2Lobj + λ3Lloc (1)
cracks and incomplete extraction of crack information. Due to these
Where λ corresponds to different loss weights, with default values of
circumstances, detectors struggle to accurately distinguish the subtle
0.5, 1.0, and 0.05, respectively.
differences between cracks and the surrounding background. These two
For the classification loss and objectness loss, YOLOv5 utilizes the
issues are considered the primary challenges faced by current detection
binary cross-entropy function by default. The binary cross-entropy
models, particularly when aiming to maintain excellent real-time per-
function is defined as follows:
formance while addressing these problems. {
To address the challenges mentioned above, this paper proposes a − logp, y = 1
L = − ylogp − (1 − y)log(1 − p) = (2)
novel real-time detection algorithm named Improved YOLOv5. Initially,
− log(1 − p), y = 0
a comprehensive analysis of the limitations of the current detection
Where y represents the label of the input sample (1 for positive
model is conducted. Targeted structures are selected to ensure that the
sample, 0 for negative sample), and p represents the probability pre-
choices made have a positive theoretical impact on the existing issues in
dicted by the model that the input sample is a positive sample.
the model. Subsequently, the Silu activation function and CIoU loss
As for the localization loss, YOLOv5 adopts the CIoU (Complete
function are introduced, optimizing the training process, and all struc-
Intersection over Union) loss, which is expressed by the following for-
tures are integrated. Finally, during the structural fusion and adjustment mula:
process, a layer of CBS between SPPCSPC [30] and the neck is removed
to further optimize the overall structure. Through these clever combi- ρ2(b, bgt) L + αv (3)
nations and adjustments, the challenges in crack detection in vehicle- CIoU = 1 − IoU + c2
mounted images are effectively addressed. Validated on a reorganized
Where IoU represents Intersection over Union, which is used to
dataset, the algorithm exhibits outstanding performance in the field of
measure the overlap between the predicted bounding box and the
road surface crack detection in vehicle-mounted images, as substanti-
ground truth bounding box in object detection. Assuming the predicted
ated by a wealth of experimental results.
bounding box is represented as A and the ground truth bounding box is
The following summarizes the significant contributions of this study:
represented as B, the expression for IoU is given by:
1. This paper introduces a novel real-time detection method in the field A ∩ B IoU = (4)
of road surface crack detection in vehicle-mounted images. A ∪ B
2. A new algorithm, named Improved YOLOv5, is proposed, effectively
Where b and bgt represent the center points of the predicted bounding
addressing the challenges in crack detection in vehicle-mounted
box and the ground truth bounding box, respectively. ρ denotes the
through clever combinations and adjustments.
Euclidean distance between the two center points, and c represents the
3. Reorganized datasets are used to validate and compare the proposed
diagonal distance of the minimum enclosing region of the predicted and method to well-known methods.
ground truth bounding boxes. “ gt ” is the abbreviation for ground truth.
αv is a penalty term designed to consider the consistency of aspect
The rest of this paper is organized as follows: In Section 2, a review of
ratios between two bounding boxes, aiming to focus more on the shape
the related work is provided, along with a detailed analysis of the
of the target. Let’s delve into v. Here, v is a metric used to quantify the 2 H. Hu et Measurement al. 229 (2024) 114443
consistency of aspect ratios, and its expression is as follows:
information. To mitigate the parameter count, the consideration of ( )
employing the Slim-Neck structure was made. 4 wgt w 2 v = tan− 1 − tan− 1 (5)
Regarding the second issue, in order to better utilize the information π2 hgt h
from the previous layer and address the problem of incomplete feature
In this equation, wgt and hgt represent the width and height of the
extraction in the C3 structure, a replacement with the C2f structure[50]
ground truth bounding box, while w and h represent the width and
was carried out. Furthermore, the Decoupled Head from YOLOX was
height of the currently predicted bounding box. Then, the difference in
introduced to further optimize the representation of multi-scale and
aspect ratio between the ground truth bounding box and the predicted
high-dimensional features. To further enhance the speed and accuracy of
bounding box is calculated. When computing this ratio, the arctangent
the model, the SPPCSPC structure was also introduced. Finally, by
function, denoted as tan− 1, is used to convert the aspect ratio into an
integrating the aforementioned methods and adjusting the parameter
angle. This allows for a more accurate representation of the difference
size, the method referred to as improved YOLOv5 was proposed. The
between aspect ratios. Since the range of the arctangent function is
details of this method will be elaborated in the following section.
between 0 and π/2, a scaling factor is needed to adjust the angle dif-
ference. This factor ensures that the angle difference is compared within
3. The proposed road surface crack detection method the appropriate range. The term 4
In this section, the specific steps of the proposed road surface crack
π2 in the formula acts as a scaling factor, ensuring that the
value of v stays within a reasonable range. By comparing this ratio, we
detection method is initially presented, followed by a detailed exposi-
gain insights into the consistency of the target
tion of the improved YOLOv5 utilized in this method. ’s shape.
Another crucial parameter, α, is a positive weight designed to bal-
ance the two factors of IoU and aspect ratio. Its mathematical expression
3.1. The specific steps of the proposed method is
The road surface crack detection scheme, which is based on the v α = (6)
improved YOLOv5 and proposed in this paper, is outlined in the (1 − IoU) + v
following steps. For a detailed visual representation of the process,
α nonlinearly combines v with 1 − IoU to adjust the weight. When the
readers are referred to Supplementary Fig. 1 in the supplementary
IoU is low, α increases, directing the model’s attention more towards the materials.
consistency of aspect ratios. Conversely, when the IoU is high, α de-
Step 1: Road images are captured using a vehicle-mounted smart-
creases, emphasizing the accuracy of position and size. In regression, α is
phone to establish the dataset.
given higher priority, especially when the two bounding boxes do not
Step 2: The dataset is utilized to train the improved YOLOv5 model,
overlap. This implies a greater emphasis on ensuring the precision of the resulting in weight files.
bounding box’s position and size in object detection tasks. The combi-
Step 3: The trained improved YOLOv5 weight file is subsequently
nation of these two formulas forms the calculation of CIoU, compre-
deployed on the vehicle-mounted device to perform real-time crack
hensively measuring the similarity between two bounding boxes in
detection on the road surface.
terms of position, size, and shape. This integrated metric contributes
Step 4: The detection results are generated as output.
positively to enhancing the performance and robustness of object
A simplified representation of the scheme is provided in the main detection models.
text (see Fig. 1). A comprehensive flow chart is given in the supple- mentary material.
2.2. Problems of YOLOv5 in road surface crack detection on vehicle- mounted images
Currently, YOLOv5 can be utilized in various domains. However, due
to the combined influence of factors such as dataset characteristics,
target attributes, class balance, and model optimization, YOLOv5 ex-
hibits significant differences when employed in different domains.
Through existing research and in-depth analysis of the YOLOv5 struc-
ture, the following issues have been identified in its implementation for
road surface crack detection in vehicle-mounted images:
1. The dataset used in this paper consists of road images captured by a
vehicle-mounted smartphone. In these images, cracks are often small
in size or not visually prominent, making it challenging for the
network to directly capture their subtle features. This can result in
the loss of information related to small cracks. Moreover, YOLOv5
may exhibit different performance in detecting small and large ob-
jects. When the target is small, YOLOv5 may struggle to accurately detect it.
2. The C3 structure in the YOLO series performs feature extraction at
earlier layers, which may result in the loss of contextual information
for small cracks. However, adding too many modules on top of
YOLOv5 to enhance feature extraction would significantly increase
the number of parameters, thereby sacrificing the real-time advan- tage of the original YOLOv5.
For the first issue, the addition of an attention mechanism module
was attempted to assist the model in better focusing on crack
Fig. 1. Road surface crack detection method based on improved YOLOv5. 3 H. Hu et Measurement al. 229 (2024) 114443
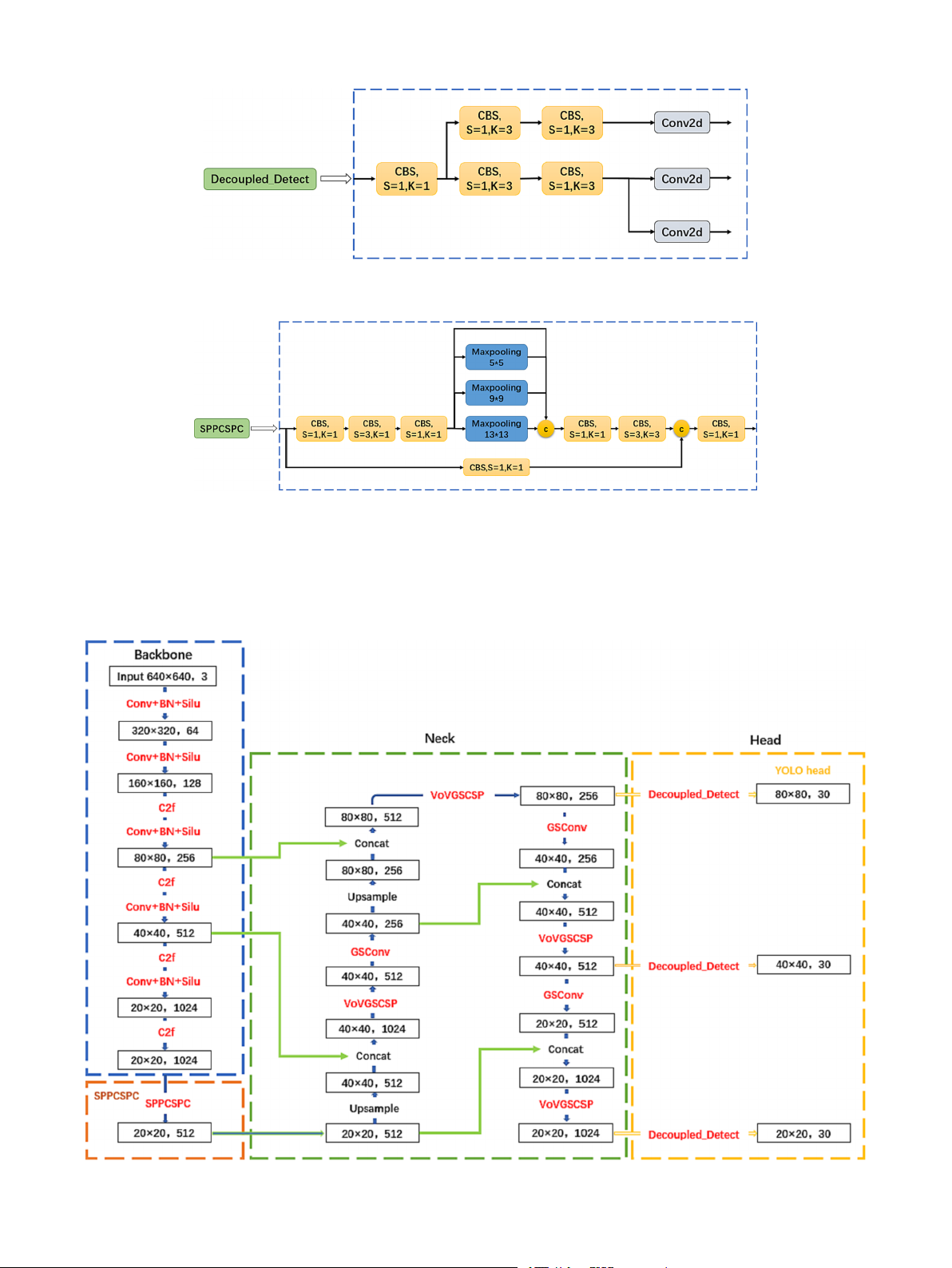
3.2. The proposed improved YOLOv5
In terms of the algorithm, the proposed improved YOLOv5 in this
paper differs from the original YOLOv5 by incorporating six key mod-
ules: Slim-Neck structure, C2f structure, Decoupled Head, SPPCSPC
structure, Silu activation function, and CIoU loss function. Each module
plays a distinct role in the model, and they will be elaborated on in
detail. The overall architecture of the improved YOLOv5 is illustrated in Fig. 2.
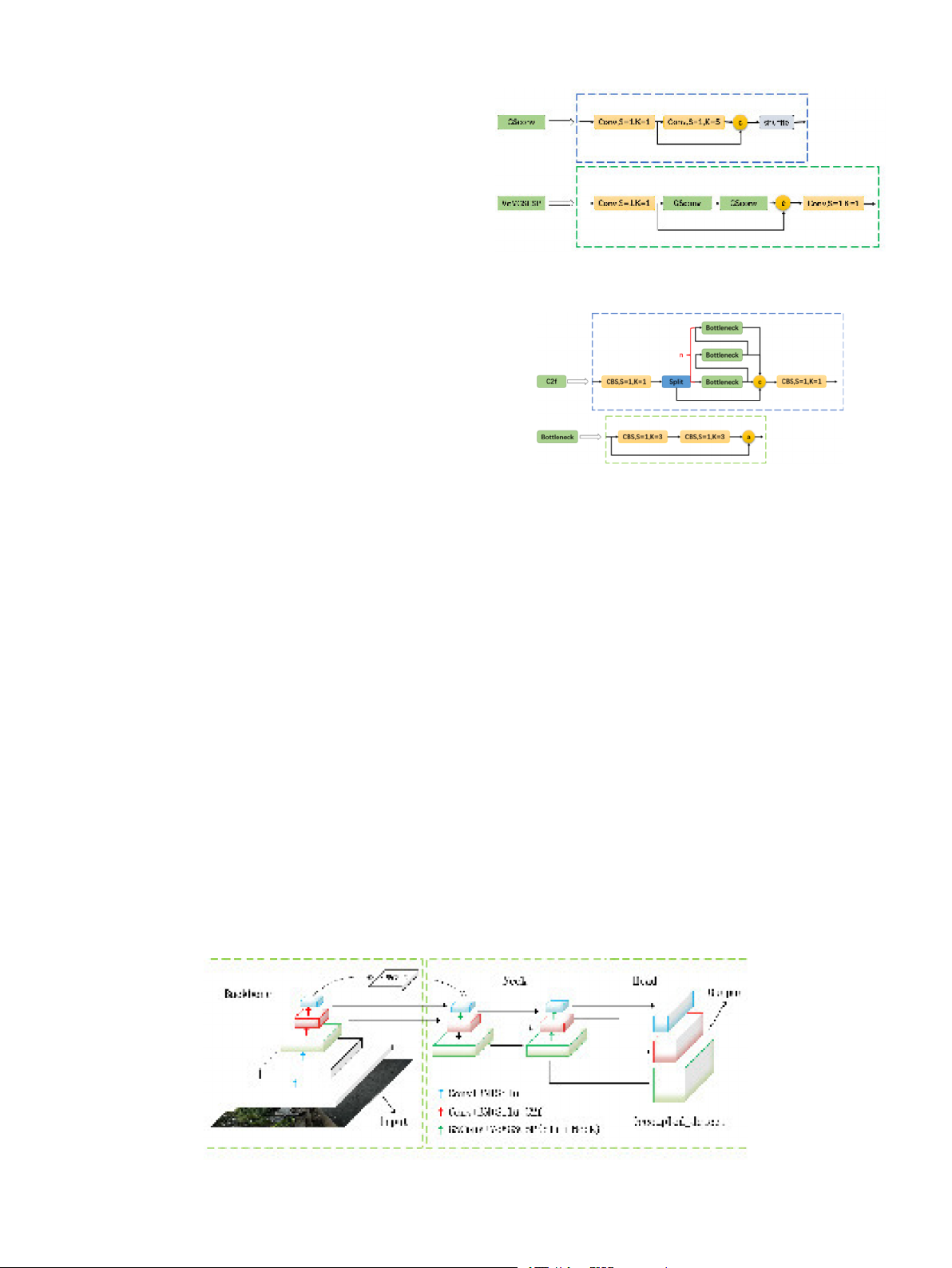
3.2.1. Slim-Neck structure
In this study, the Slim-Neck structure [26] was introduced, with
Fig. 3. Slim-Neck structure.
GSconv replacing Conv and VoVGSCSP replacing C3. Compared to the
original structure, the Slim-Neck structure incorporates lightweight
design, reducing computational complexity and model parameters,
thereby enhancing efficiency and reducing computation time and
hardware resource requirements. To meet the specific requirements of
road surface crack detection, this study integrates attention mechanisms
with convolution. Convolutional Neural Networks (CNNs) excel at
capturing local features of images, while attention mechanisms focus on
specific parts of the target, improving the accuracy of target detection.
Considering the use of vehicle-mounted images, where cracks often
appear against complex backgrounds, combining convolution and
attention mechanisms can better handle complex backgrounds, allevi- Fig. 4. C2f structure.
ating excessive attention to them. Moreover, attention mechanisms can
be employed for multi-scale feature fusion. In road surface crack
detection, the size and shape of cracks may vary significantly. By
effectively addresses issues such as class imbalance and object size
combining multi-scale features extracted by convolution with attention
variation compared to traditional detection head structures. The incor-
mechanisms, the model can better capture target information at
poration of the Decoupled Head leads to a substantial enhancement in
different scales, thereby enhancing its adaptability to scale variations. In
the model’s detection performance, improving both accuracy and speed.
summary, the introduction of the Slim-Neck structure can improve the
Additionally, the Decoupled Head enables flexible model design, such as
efficiency, accuracy, and adaptability of the model, making it an effec-
increasing the number of output classes or adjusting the detector’s
tive model improvement method. The Slim-Neck structure is illustrated
receptive field size. The Decoupled Head structure is illustrated in Fig. 5. in Fig. 3.
3.2.4. SPPCSPC structure 3.2.2. C2f structure
In order to improve the speed and accuracy of the model, the original
The proposed C2f structure in this paper is primarily used to replace
SPPF structure is replaced by the SPPCSPC structure [30] in this study.
the C3 structure in the Backbone of YOLOv5. This structure adopts the
Similar to SPPF, SPPCSPC also includes pooling layers of sizes 1x1, 5x5,
shuffling idea of CSPNet and the residual structure concept to obtain
9x9, and 13x13, but it introduces an additional 1x1 residual branch. The
richer gradient flow information and better utilization of the informa-
structure is divided into two parts, where one part is processed with
tion from the upstream. The number of stacked C2f structures is
traditional convolution and the other part is processed with the SPP controlled by the parameter
structure. Finally, these two parts are merged. This design reduces the
“n”, which can vary for models of different
scales. The specific structure of the C2f module is illustrated in Fig. 4,
computational complexity by half, thereby improving speed, while also
where CBS represents the combination of Convolution, Batch Normali-
enhancing accuracy. Additionally, the SPPCSPC structure can be com-
zation, and the Silu activation function. By replacing the C3 structure,
bined with other detection head structures, especially the previously
the C2f structure further enhances the network
proposed C2f structure and Slim-Neck structure. When situated between ’s representation capa-
bility and detection performance.
these two structures, it can better facilitate multi-scale feature fusion
and further enhance the network performance. The SPPCSPC structure is 3.2.3. Decoupled Head illustrated in Fig. 6.
In this study, the Decoupled Head [29] is introduced, which
Fig. 2. Improved YOLOv5 architecture. 4 H. Hu et Measurement al. 229 (2024) 114443
Fig. 5. Decoupled Head.
Fig. 6. SPPCSPC structure.
3.2.5. Silu activation function and CIoU loss function
crack images effectively. The smoothness and approximate linearity of
The choice of Silu activation function and CIoU loss function in this
the Silu function allow it to preserve the linear relationships of input
study is motivated by the analysis of the dataset images for crack
features and exhibit a larger dynamic range. This property may aid in
detection task. It is crucial to capture the shape, texture, and edges of
capturing subtle features in crack images and improve the accuracy of
Fig. 7. Improved yolov5 network. 5 H. Hu et Measurement al. 229 (2024) 114443
object detection. Regarding the loss function, different loss functions
4.2. Platform construction and model training
have distinct advantages for various tasks. In the case of crack detection,
the CIoU loss function provides more accurate measurement of the
The software environment and hardware environment configured for
match between predicted boxes and ground truth boxes, particularly for
model training and testing in this paper are as follows: Windows10
handling small targets. This leads to improved detection performance
operating system, Pytorch deep learning framework, CUDAv11.1,
for small targets. Therefore, the selection of Silu activation function and
Pythonv3.8.10, torchv1.9.0, GPU NVIDIA GeForce RTX 3080(10 GB),
CIoU loss function further optimizes the performance of the network.
CPU Intel(R) Xeon(R) Platinum 8255C CPU @ 2.50 GHz.
Due to the low resolution of the dataset used in this experiment,
3.2.6. Module integration optimization
which is 600*600 pixels, we selected a suitable batch size of 32 and
To better integrate the modules and enhance their effectiveness, we
trained the model for 200 epochs. As for the optimizer, we chose SGD
decided to remove a layer of CBS between the SPPCSPC structure and
and set other key parameters as follows: lr0 = 0.01, lrf = 0.01, mo-
the upsampling. This decision brings several advantages: firstly, by
mentum = 0.843, weight_decay = 0.00036.
adjusting the number of channels, we make it more adaptable to the
The model adopts a strategy of random weight initialization instead
requirements of subsequent structures. Secondly, simplifying the overall
of utilizing a pre-trained model for the initial setup. Deliberately opting
network structure helps reduce model complexity, alleviate computa-
for training from scratch, the model is designed to directly learn task-
tional burden, and thus improve inference speed. However, the key
specific features from the provided data, without relying on generic
point is that the Slim-Neck structure, designed to capture information
features learned from other datasets. Throughout the experimental
about small cracks, is located within the neck. Moreover, removing the
process, thorough training and fine-tuning have been conducted to
CBS layer before the neck reduces information loss, ensuring that critical
enhance the model’s adaptation to the specific task of road surface crack
features can be transmitted to the bottleneck stage of the network
detection. This approach allows for better control over the model’s
without interference. This measure significantly contributes to main-
structure and performance, enabling more effective addressing of chal-
taining the model’s sensitivity to details like small cracks, thereby
lenges such as the blurriness of small cracks and incomplete information
enhancing the accuracy of the detection task. The specific architecture of
extraction from vehicle-mounted images.
the improved YOLOv5 network is illustrated in Fig. 7. 4.3. Evaluation metric 4. Experiments
The evaluation metrics used in this paper for object detection include 4.1. Datasets
precision (P), recall (R), mean average precision (mAP), and F1 score as
the primary evaluation indicators for the model. Precision (P) and recall
In the field of road surface crack detection, datasets plays a crucial
(R) respectively represent the proportion of correctly predicted samples
role. The widely used dataset for complex environmental conditions in
among all detected objects and the proportion of correctly predicted
this domain is provided by the IEEE Big Data Global Road Damage
samples among all objects. The mAP is the average area under the
Detection Challenge [31]. In this study, 13,508 images were selected
precision-recall curve for all classes, and the F1 score is the harmonic
from the dataset as the refined dataset. The resolution of the images was
mean of precision and recall. Additionally, frames per second (FPS) and
set to 600x600 pixels. We focused on five categories: longitudinal
Giga floating-point operations per second (GFLOPs) are also crucial
cracks, lateral cracks, alligator cracks, potholes, and blurred white lines.
metrics for evaluating models. FPS represents the model’s capability to
Due to the disorderly nature of the annotation information in the orig-
process frames per second, while GFLOPs indicate the number of
inal dataset, a Python script was employed to transform it into a stan-
floating-point operations a device can perform per second.
dardized txt format. Subsequently, among the 13,508 txt files, we sifted
In road damage detection, both precision and recall are equally
through and retained information pertaining to five categories: longi-
important as misclassifications or false negatives can have an impact on
tudinal cracks, lateral cracks, alligator cracks, potholes, and blurred
road maintenance and safety. Therefore, this study focuses on the
white lines. These were individually labeled as D00, D10, D20, D40, and
overall performance of the model and considers the mean average pre-
D50. Following this step, data from other categories and instances of
cision (mAP) and F1 score, which combine precision and recall, as the
mislabeling were expunged. For images with missing information, we
most important evaluation metrics.
employed the image annotation tool, labelimg, to conduct additional
annotations. The refined dataset was then divided into training, vali-
4.4. Comparisons with other state-of-the-art methods
dation, and testing sets, with ratios of 0.56, 0.22, and 0.22, respectively.
During the model training process, a random shuffling technique was
To validate the superiority of improved YOLOv5 proposed in this
employed. At each epoch, images from the training and validation sets
paper, a comparison is conducted with several commonly used classical
were randomly mixed and divided into new training and validation sets
algorithms in the field of road surface crack detection, including Faster
in the same proportion. This data preparation method ensures that the
R-CNN [17], YOLOX [29], YOLOv5, u-YOLO (EM + EP) [32], YOLOv6
model is provided with high-quality and diverse data, thus improving its
[49], YOLOv7 [30], and YOLOv8 [50]. Notably, u-YOLO (EM + EP) is
accuracy and robustness. The refined dataset is illustrated in Fig. 8.
the method employed by the champion of the 2020 IEEE Big Data Global
Road Damage Detection Challenge. The evaluation metrics employed for
each algorithm include mAP, F1, and FPS. The models are trained and
Fig. 8. Some examples from the dataset. 6 H. Hu et Measurement al. 229 (2024) 114443
tested on the same dataset with identical hyperparameters. The detec-
tion results are presented in Table 1 and Fig. 9.
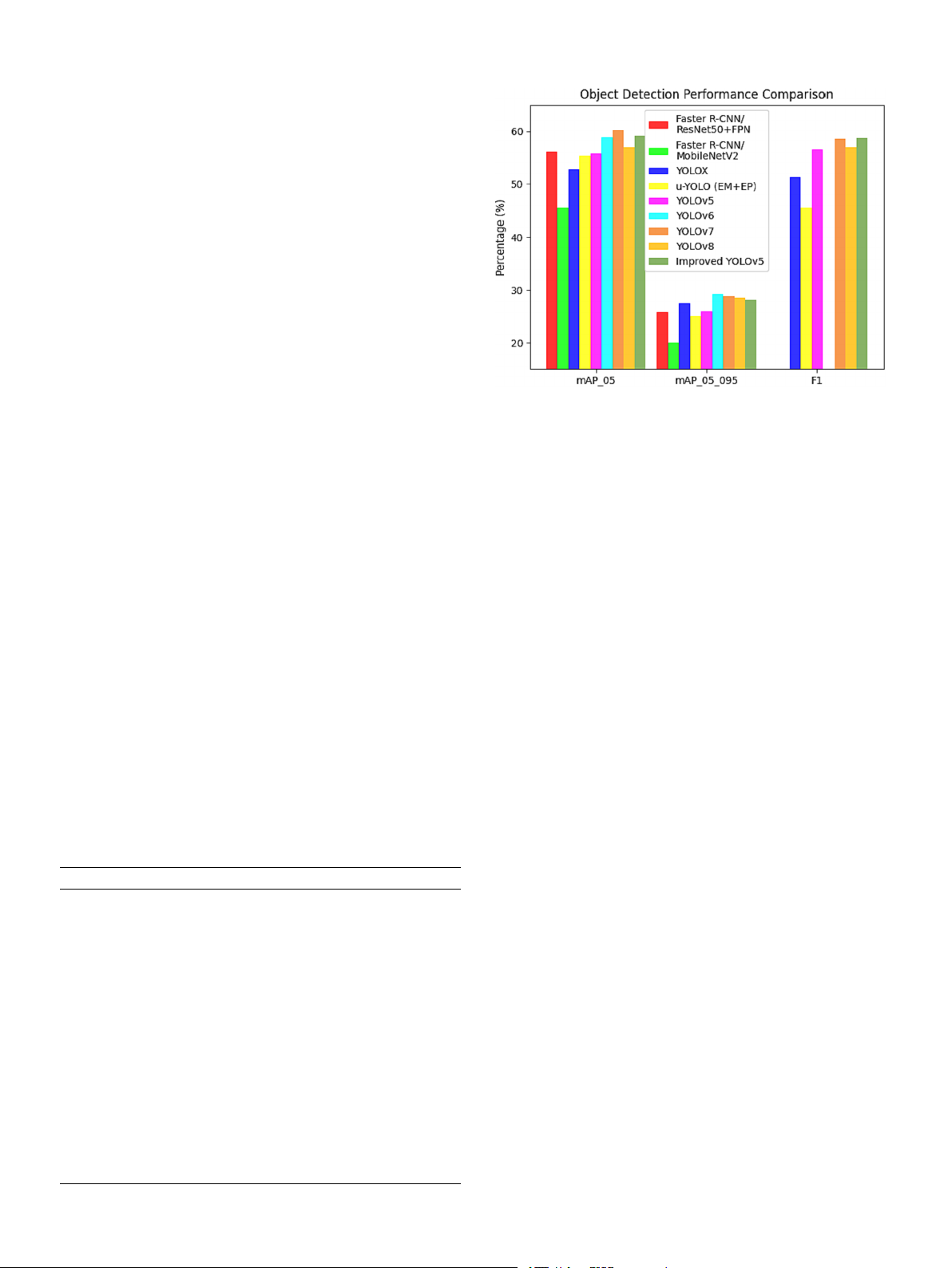
According to the analysis of the detection results in Table 1, the
improved YOLOv5 achieved an mAP@0.5 of 59.17 %, surpassing Faster
R-CNN/ResNet50 + FPN (56.10 %), Faster R-CNN/MobileNetV2 (45.50
%), YOLOX (52.82 %), u-YOLO (EM + EP) (55.40 %), YOLOv5 (55.76
%), YOLOv6 (58.80 %), and YOLOv8 (56.90 %), and approached the
performance level of YOLOv7 (60.20 %). Similarly, it demonstrated a
similar trend in F1, being higher than other detectors and approaching
the performance level of YOLOv7. Additionally, the improved YOLOv5
performed well in mAP@0.5:0.95. In terms of inference speed, the
improved YOLOv5 reached 85FPS, although lower than YOLOX (179),
YOLOv5 (114), and YOLOv8 (108) in one-stage detectors, it exceeded
all other detectors. Considering that 85FPS is sufficient for real-time
detection requirements in most scenarios, sacrificing some FPS to ach-
ieve higher performance is worthwhile without significantly affecting
overall performance. However, compared to YOLOv7, although its mAP
and F1 scores are slightly higher than the improved YOLOv5, its FPS is
only 43, which is only half of the model proposed in this paper. This is
not only unworthy but also does not meet real-time requirements.
Fig. 9. Object Detection Performance Comparison.
The proposed improved YOLOv5 algorithm in this paper is an
improvement upon YOLOv5. Compared to the original YOLOv5 algo-
terms of GFLOPs, it was successfully reduced from 15.8 (Row 1) to 12.6
rithm, the improved YOLOv5 algorithm achieved a 3.41 % improvement
(Row 8). Simultaneously, there was an improvement in accuracy. This
in mAP and a 2.25 % improvement in F1, while maintaining a FPS of 85.
highlights the effectiveness of Slim-Neck in performing road surface
When compared to other leading algorithms in this field, the improved
crack detection tasks within the model, successfully achieving the goal
YOLOv5 proposed in this paper has the highest cost-effectiveness in
of lightweighting. These results validate the previous choice of Slim- overall evaluation. Neck in the design.
Subsequently, further ablation experiments based on YOLOv5 +
Slim-Neck were performed. C2f was used as a replacement for C3, which 4.5. Ablation study
could maintain the superior receptive field of C3 while making more
effective use of the information from the previous layer, thereby further
Extensive ablation studies were also conducted on our reorganized
improving the feature extraction capability and raising the performance
dataset to validate each module of the proposed improved YOLOv5 in
from 56.7 % mAP (Row 8) to 57.3 % mAP (Row 9). When compared with
this paper. Table 2 presents the detailed roadmap from YOLOv5 to
other modules (Rows 8–12), C2f outperformed the other methods. Only improved YOLOv5.
C3TR achieved consistent performance improvement with C2f and had a
The proposed YOLOv5 + Slim-Neck in this paper improved the
smaller parameter count. However, it showed poor performance when
performance from 55.8 % mAP (Row 1) to 56.7 % mAP (Row 8),
fused with other structures (Row 14).
demonstrating the effectiveness of the introduced attention mechanism
Next, as envisioned, the Decoupled Head from YOLOX was intro-
in enhancing accuracy and focusing on cracks. Furthermore, compared
duced to further optimize multi-scale and high-dimensional feature
to other attention mechanisms (Rows 2–7), Slim-Neck not only achieved
representation. The experimental results showed an improvement in
the highest accuracy but also lightweighted the network, reducing the
performance from 57.3 % mAP (Row 9) to 58.4 % mAP (Row 13). On the
parameter count from 7,023,610 (Row 1) to 5,846,490 (Row 8), which
other hand, the introduced IDetect Head (Row 15), although having a
corresponds to a reduction of approximately 16.8 % in parameters. In
smaller parameter count, led to a significant performance drop.
Following the introduction of the SPPCSPC structure (Row 16), Table 1
which primarily introduces 1x1 residual at the outermost layer and
Comparisons with other object detection methods on our dataset. The FPS is
effectively processes regular information and SPPF structure during
tested on a single Nvidia GTX 3080 GPU.
training, this design not only improves accuracy but also maintains method mAP@0.5 mAP@0.5:0.95 F1 time FPS
speed. Additionally, the SPPFCSPC [49] structure is introduced for
comparison (Row 17). Experimental results show that both structures Two-Stage Detector: Faster R-CNN/ 56.10 % 25.90 % \ 31.8 31
have the same number of parameters, but the mAP of SPPFCSPC is ResNet50 + FPN ms
slightly higher than SPPCSPC, while the F1 score is lower. [17]
Finally, the paper removes one layer of CBS between SPPCSPC and Faster R-CNN/ 45.50 % 20.00 % \ 18.1 55
the neck (Row 19), as well as between SPPFCSPC and the neck (Row 18). MobileNetV2[33] ms One-Stage Detector:
Experimental results validate the earlier hypothesis that this measure YOLOX[29] 52.82 % 27.47 % 51.28 5.58 179
not only simplifies the overall network structure and reduces model % ms
complexity but also achieves the best performance of 59.2 % mAP and u-YOLO (EM + EP) 55.40 % 25.1 % 45.43 27.7 36
58.8 % F1 (Row 19), surpassing 57.5 % mAP and 58.7 % F1 (Row 16). [32] % ms
This further demonstrates that this measure, while improving real-time YOLOv5[23] 55.76 % 26.01 % 56.51 8.7 ms 114 %
performance, also maintains the model’s sensitivity to details such as YOLOv6[49] 58.80 % 29.20 % \ 10.77 92
small cracks, thereby enhancing the accuracy of detection tasks. ms
Compared to YOLOv5 (Row 1), although there is an increase in model YOLOv7[30] 60.20 % 28.80 % 59.55 23.1 43
parameters and GFLOPs, this may be necessary for handling pavement % ms YOLOv8[50] 56.90 % 28.60 % 56.94 9.2 ms 108
crack detection tasks. This incremental change allows for the use of more %
complex models, thereby enhancing the model’s expressive power to
Proposed YOLOv5 59.17 % 28.17 % 58.76 11.7 85
better address challenges such as the ambiguity of tiny cracks and % ms
incomplete information extraction from onboard images, which are the 7 H. Hu et Measurement al. 229 (2024) 114443 Table 2
the Silu function achieved an mAP of 59.2 % and an F1 score of 58.8 %,
A detailed ablation study of YOLO-RCD (The unchanged parts are the original
which were significantly higher than those of Sigmoid (52.5 % and 53.8 YOLOv5 parts).
%), Relu (57.5 % and 57.6 %), LeakyRelu (57.7 % and 57.7 %), Row method P R mAP F1 Parameters GFLOPs
Hardwish (58.1 % and 58.0 %), and Mish (58.7 % and 58.1 %). This
further confirms the suitability of the Silu function for crack detection 1 YOLOv5 57.1 55.9 55.8 56.5 7,023,610 15.8 2 YOLOv5 + SE 57.7 55.4 55.8 56.5 7,066,618 15.8 tasks. [34] 3 YOLOv5 + 56.2 55.8 55.2 56.0 7,090,380 16.0
4.5.2. Ablation study of loss function CBAM [35]
For the selection of the loss function, the experiments were con- 4 YOLOv5 + 57.0 56.5 55.5 56.7 7,023,622 15.8
ducted as shown in Table 4. The experimental results demonstrated that ECA [36] 5 YOLOv5 + 57.4 57.5 56.8 57.4 8,762,874 17.2
the CIoU loss function used in this study achieved an mAP of 59.2 %, GAM [37]
which was higher than that of GIoU (58.1 %), DIoU (58.1 %), and EIoU 6 YOLOv5 + 57.0 55.1 55.5 56.0 7,023,802 15.8
(58.9 %). Additionally, CIoU outperformed other loss functions in terms Shuffle [38]
of precision (P) and F1 score, with only EIoU having the highest recall 7 YOLOv5 + 57.5 56.6 56.6 57.0 6,582,650 15.2 GSConv [28]
(R). As mentioned in Section 3.5, the CIoU loss function accurately 8 YOLOv5 + 59.2 55.8 56.7 57.4 5,846,490 12.6
measures the match between predicted and ground truth boxes, partic- Slim-Neck
ularly for small objects. This superiority over GIoU and DIoU can be [28]
attributed to the CIoU’s ability. On the other hand, EIoU incorporates 9 YOLOv5 + 56.4 58.4 57.3 57.4 7,085,530 16.3
Focal Loss to address the issue of imbalanced difficulty levels in samples. Slim-Neck + C2f
However, since the dataset used in this study is relatively balanced, EIoU 10 YOLOv5 + 59.0 56.6 57.3 57.8 5,847,258 12.4
slightly underperformed compared to CIoU. Slim-Neck + C3TR [39] 11 YOLOv5 + 57.0 56.6 56.6 56.8 5,354,842 12.2
4.6. Various crack detection results Slim-Neck + C3SPP
Table 5 presents the detection results for different classes of cracks. 12 YOLOv5 + 57.1 56.9 56.3 57.0 5,228,570 12.1 Slim-Neck +
The category “all” represents all types of cracks, where D00 represents C3Ghost [40]
longitudinal cracks, D10 represents lateral cracks, D20 represents alli- 13 YOLOv5 + 58.4 57.0 58.4 57.7 14,392,794 56.7
gator cracks, D40 represents potholes, and D50 represents blurred white Slim-Neck +
lines. From Table 5, it can be observed that the proposed improved C2f + det [29]
YOLOv5 model consistently outperforms YOLOv5 in terms of evaluation 14 YOLOv5 + 58.2 56.7 57.1 57.4 13,154,522 52.8
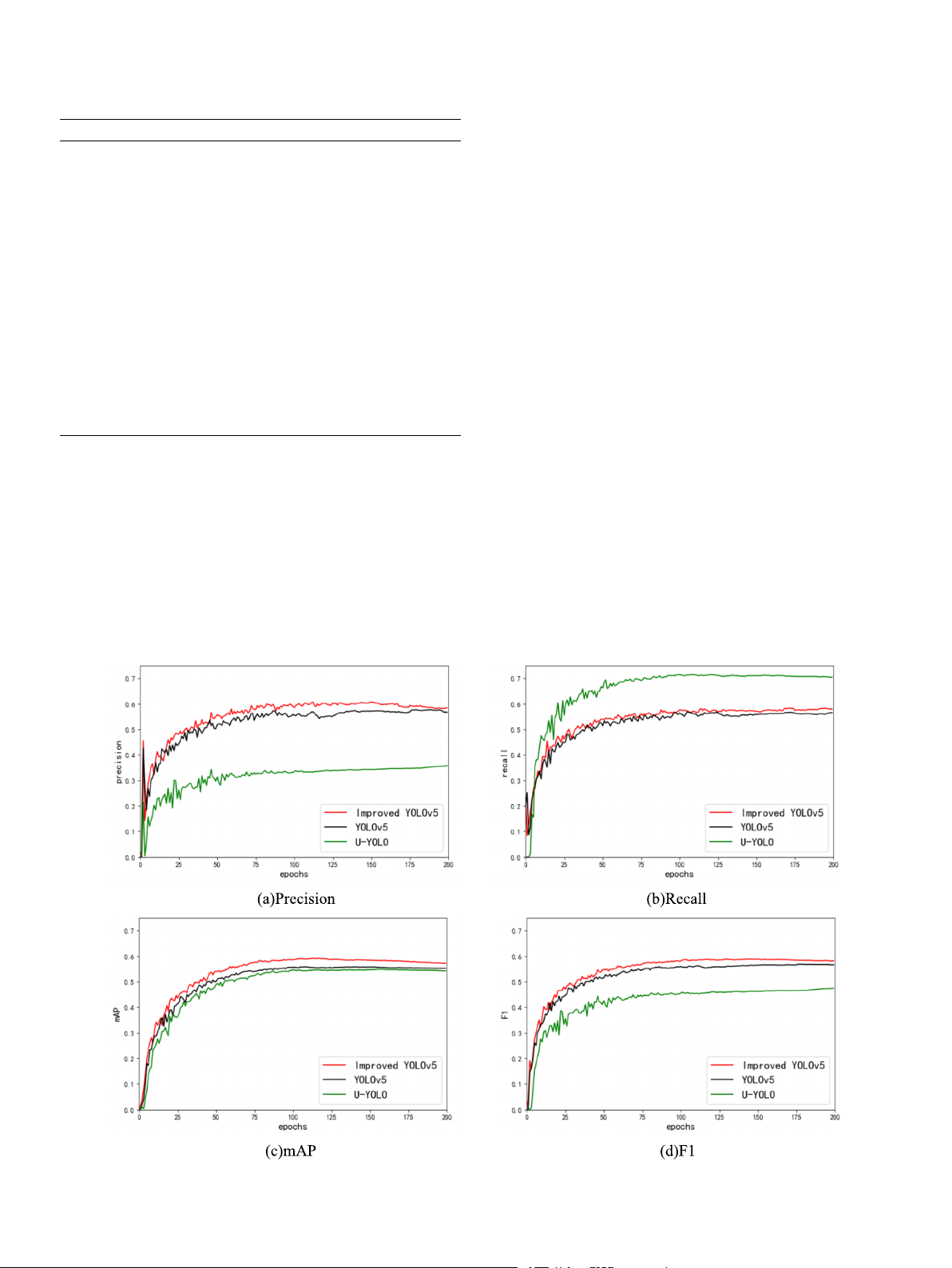
metrics for the “all” category. Throughout the 200 epochs, improved Slim-Neck +
YOLOv5 consistently leads in precision (P), recall (R), mAP, and F1, as C3TR + det
illustrated in Fig. 10. Additionally, when examining individual cate- 15 YOLOv5 + 52.3 56.8 49.1 54.5 7,086,516 16.3
gories of cracks, the improved YOLOv5 shows varying degrees of Slim-Neck + C2f + idet
improvement compared to YOLOv5, without any performance degra- [30]
dation. Notably, the most significant improvement is observed for D10, 16 YOLOv5 + 61.6 56.2 57.5 58.7 15,584,122 57.9
with a 5.9 % increase in precision, a 0.9 % increase in recall, a 4.8 % Slim-Neck +
increase in mAP, and a 2.5 % increase in F1. This signifies that our model C2f + det + SPPSCPS
is capable of better capturing and utilizing the unique features of lateral 17 YOLOv5 + 58.2 56.7 57.8 57.4 15,584,122 57.9
cracks, allowing for more accurate differentiation between lateral cracks Slim-Neck +
and other classes, thereby enhancing overall precision. These findings C2f + det +
further validate the effectiveness of the Slim-Neck architecture, as SPPFSCPS
referenced in our study. This structure focuses on the tiny details of 18 Row17-CBS 59.0 57.1 56.8 58.0 15,570,010 57.7 19 Row16-CBS 59.9 57.7 59.2 58.8 15,570,010 57.7
small cracks, contributing to addressing the issues present in the current (improved detection models. YOLOv5)
Compared to u-YOLO (EM + EP), it is evident from Table 5 and
Fig. 10 that its precision is significantly lower than YOLOv5 and
issues addressed in this paper.
Improved YOLOv5, while recall is much higher than both. This obser-
vation can be attributed to u-YOLO being an ensemble model, gener-
4.5.1. Ablation study of activation function
ating more prediction boxes with the primary aim of avoiding missed
For the selection of activation functions, the experiments were con-
detections. However, this also results in a higher false positive rate.
ducted as shown in Table 3. In Section 3.5, the Silu function was pro-
Additionally, the mAP value of u-YOLO is close to that of YOLOv5, while
posed for capturing fine features in crack images in the context of crack
the F1 score is slightly lower than YOLOv5. In conclusion, our proposed
detection tasks. To verify this proposition, five commonly used activa-
Improved YOLOv5 exhibits the best overall performance.
tion functions were compared. Based on the results presented in Table 3,
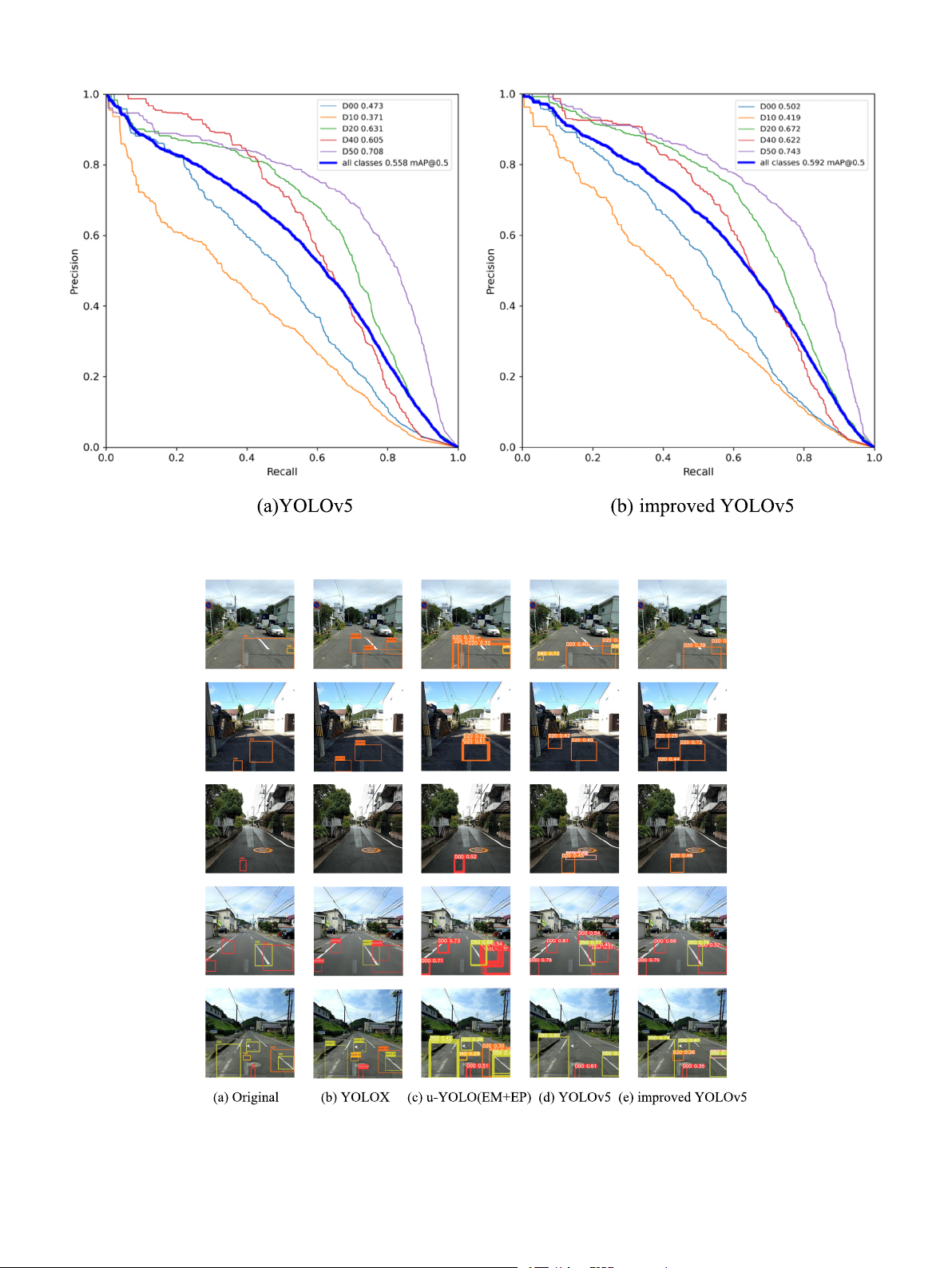
Fig. 11 illustrates the P-R curves for the two algorithms, providing a
more intuitive comparison between them. It is known that when the P-R
curve is closer to the top-right corner, it indicates that the model can Table 3
Ablation studies of the activation function. Table 4 Activation function P R mAP F1
Ablation studies of the loss function. Sigmoid 54.6 53.1 52.5 53.8 Relu [41] 57.5 57.7 57.5 57.6 Loss function P R mAP F1 LeakyRelu [42] 58.1 57.3 57.7 57.7 GIoU [46] 57.9 57.8 58.1 57.8 Hardswish [43] 59.2 56.9 58.1 58.0 DIoU [47] 59.5 57.0 58.1 58.2 Mish [44] 59.4 56.8 58.7 58.1 EIoU [48] 58.1 58.3 58.9 58.2 Silu [45] 59.9 57.7 59.2 58.8 CIoU [23] 59.9 57.7 59.2 58.8 8 H. Hu et Measurement al. 229 (2024) 114443 Table 5
4.7. Qualitative comparisons
Detection results of each class of crack. Class Labels P R mAP F1
Fig. 12 presents a qualitative comparison between improved
YOLOv5 and other state-of-the-art methods, including YOLOX [29],
u-YOLO(EM þ EP):
YOLOv5, and u-YOLO (EM + EP) [32], on our dataset. To ensure a fair all 6020 33.1 72.4 55.4 45.4 D00 1140 27.5 64.6 46.6 38.6
comparison, we trained and tested the models with the same parame- D10 1139 25.6 61.4 37.8 36.1
ters, and placed the confidence scores above the predicted boxes for D20 1768 38.9 76.2 61.4 51.5 better visualization. D40 654 30.8 75.4 61.3 43.7
YOLOX, as a more advanced algorithm in 2021, has the advantage of D50 1319 42.5 84.2 69.6 56.5 YOLOv5:
a smaller network model and very fast processing speed. From Fig. 12 all 6020 57.1 55.9 55.8 56.5
(b), it can be observed that YOLOX demonstrates certain detection ca- D00 1140 51.1 49.2 47.3 50.1
pabilities for road surface cracks, although it may have some limitations D10 1139 49.6 33.6 37.1 40.1
in detecting small cracks. However, it accurately locates, sizes, and D20 1768 67.6 60.8 63.1 64.0
classifies the predicted boxes for other types of defects, resulting in D40 654 55.1 60.6 60.5 57.7 D50 1319 62.0 75.4 70.8 68.0
overall good performance with slightly lower precision. Improved YOLOv5:
In contrast, u-YOLO (EM + EP) achieves significant improvement in all 6020 59.9 57.7 59.2 58.8
precision. However, as an ensemble model, it tends to generate more D00 1140 55.2 50.8 50.2 52.9
predicted boxes, as shown in Fig. 12 (c), which can affect its precision. D10 1139 55.5 34.5 41.9 42.6 D20 1768 68.2 63.2 67.2 65.6
YOLOv5 further enhances the performance based on u-YOLO (EM + EP) D40 654 57.4 62.1 62.2 59.7
while significantly improving speed while maintaining accuracy. D50 1319 63.1 78.0 74.3 69.8
Although Fig. 12 (d) demonstrates overall good performance, YOLOv5
tends to have more false positives, marking cracks in blank areas, which
simultaneously maintain high precision and high recall during pre-
affects the overall precision of the model.
dictions. Specifically, the P-R curves for D00 and D10 in YOLOv5 exhibit
Among the four algorithms mentioned, the proposed method based
a concave shape, while those for D00 and D10 in improved YOLOv5 are
on improved YOLOv5 performs the best. Fig. 12 (e) illustrates that the
relatively flat and convex, indicating the greater extent of improvement
predicted boxes of the improved YOLOv5 algorithm are closest to the
for D10. As for the curves of other classes, they are all convex, but the
actual position and size distribution of defects, with the highest confi-
curves in improved YOLOv5 are more convex compared to YOLOv5.
dence scores. Compared to other common algorithms, our proposed
Moreover, the curves in YOLOv5 are relatively sparser compared to the
method shows more satisfactory results in defect recognition.
improved YOLOv5, implying that our detector achieves closer detection
performance across various types of cracks, making it more practical and 5. Conclusion valuable.
This paper is based on the study of road images captured by vehicle-
Fig. 10. Comparison of three algorithms. 9 H. Hu et Measurement al. 229 (2024) 114443
Fig. 11. P-R Curve of the two algorithms.
Fig. 12. Qualitative comparison results on our dataset. 10 H. Hu et Measurement al. 229 (2024) 114443
mounted smartphones, where the widely studied YOLO series faces XJZZ202103).
challenges such as the blurring of tiny cracks and incomplete informa-
tion extraction. Therefore, a method based on improved YOLOv5 is
Appendix A. Supplementary data
proposed for road surface crack detection. First, a dataset is reorganized.
Second, the specific issues encountered by the original YOLOv5 on this
Supplementary data to this article can be found online at https://doi.
dataset are addressed by introducing the Slim-Neck structure, C2f
org/10.1016/j.measurement.2024.114443.
structure, Decoupled Head, and SPPCSPC structure, along with the
adoption of the Silu activation function and CIoU loss function. These
Appendix C. Supplementary data
improvements optimize the aforementioned two issues from various
aspects, enhancing the accuracy and comprehensiveness of target object
Supplementary data to this article can be found online at https://doi.
feature extraction while achieving lightweight results and maintaining
org/10.1016/j.measurement.2024.114443.
superior model inference speed. Experimental results demonstrate that
the proposed method based on improved YOLOv5 exhibits high detec- References
tion accuracy and real-time performance on the curated dataset. Spe-
cifically, the mAP value reaches 59.17 % and the F1 score reaches 58.76
[1] G.H. Luo, J.T. Wang, J.W. Pan, A frame work for concrete crack monitoring using
%. In comparison to the original YOLOv5, the proposed method attains a
surface wave transmission method, Measurement. 218 (2023) 113211.
[2] G. Do˘gan, B. Ergen, A new mobile convolutional neural network-based approach
3.41 % increase in mAP and a 2.25 % increase in the F1 score. Addi-
for pixel-wise road surface crack detection, Measurement. 195 (2022) 111119.
tionally, the algorithm maintains a FPS of 85, enabling fast and accurate
[3] L. Yang, J. Fan, B. Huo, E. Li, Y. Liu, A nondestructive automatic defect detection
detection of road surface cracks. Compared to other leading algorithms
method with pixelwise segmentation, Knowl-Based Syst. 242 (2022) 108338.
[4] E.M. Thompson, A. Ranieri, S. Biasotti, M. Chicchon, I. Sipiran, M. Pham,
in this field, the proposed algorithm demonstrates significant advan-
T. Nguyen-Ho, H. Nguyen, M. Tran, Shrec,, Pothole and crack detection in the road
tages in various evaluation metrics. Although this method has made
pavement using images and RGB-D data, Comput. Graph-UK 107 (2022) (2022)
optimizations for the problem addressed in this paper, it still encounters 161–171.
[5] S. Liu, Y. Han, L. Xu, Recognition of road cracks based on multi-scale Retinex fused
some remaining issues. Future work can be pursued in the following two
with wavelet transform, Array. 15 (2022) 100193.
aspects: (1) During the validation of various images using the model, it
[6] H. Zhang, J. Li, F. Kang, J. Zhang, Monitoring depth and width of cracks in
was observed that the accuracy is lower under low-light conditions. To
underwater concrete structures using embedded smart aggregates, Measurement.
further enhance the performance of the proposed detector, future 204 (2022) 112078.
[7] H. Bae, Y.K. An, Computer vision-based statistical crack quantification for concrete
research will focus on improving detection accuracy under low-light
structures, Measurement. 211 (2023) 112632.
conditions. There are plans to explore and optimize image enhance-
[8] Y. Deng, J. Gui, H. Zhang, A. Taliercio, P. Zhang, S.H.F. Wong, A. Khan, L. Li,
ment techniques to address environments with insufficient illumination.
Y. Tang, X. Chen, Study on crack width and crack resistance of eccentrically
tensioned steel-reinforced concrete members prestressed by CFRP tendons, Eng.
Simultaneously, advanced algorithms for low-light image processing Struct. 252 (2022) 113651.
will be studied and integrated to improve detection accuracy under
[9] L. Song, H. Sun, J. Liu, Z. Yu, C. Cui, Automatic segmentation and quantification of
visually challenging conditions. (2) To further enhance the overall
global cracks in concrete structures based on deep learning, Measurement. 199 (2022) 111550.
performance of the model, we plan to introduce a new loss function that
[10] H. Zhang, Y. Chen, B. Liu, X. Guan, X. Le, Soft matching network with application
better aligns with the requirements of the experimental process. Spe-
to defect inspection, Knowl-Based Syst. 225 (2021) 107045.
cifically, we intend to incorporate a mechanism for dynamically
[11] M. Hu, Q. Hu, Design of basketball game image acquisition and processing system
based on machine vision and image processor, Microprocess. Microsy. 82 (2021)
adjusting weights within the loss function. The design of this mechanism 103904.
aims to adaptively adjust the weights of various components in the loss
[12] D. Ireri, E. Belal, C. Okinda, N. Makange, C. Ji, A computer vision system for defect
function based on the characteristics of input images, enabling more
discrimination and grading in tomatoes using machine learning and image
processing, Artif. Intell, Agri. 2 (2019) 28
effective adaptation to changes in different conditions. More details and –37.
[13] Y. Tang, Z. Huang, Z. Chen, M. Chen, H. Zhou, H. Zhang, J. Sun, Novel visual crack
code are available at https://github.com/dakehe/improved-YOLO
width measurement based on backbone double-scale features for improved
v5-and-vehicle-mounted-images.
detection automation, Eng. Struct 274 (2023) 115158.
[14] T. Yu, A. Zhu, Y. Chen, Efficient crack detection method for tunnel lining surface
cracks based on infrared images, J. Comput. Civil. Eng. 31 (3) (2017) 04016067.
CRediT authorship contribution statement
[15] R. Girshick, J. Donahue, T. Darrell, J. Malik, Rich feature hierarchies for accurate
object detection and semantic segmentation, in, in: Proceedings of the IEEE Hongwei Hu: Writing
Conference on Computer Vision and Pattern Recognition, 2014, pp. 580–587.
– review & editing, Supervision. Zirui Li:
[16] R. Girshick, Fast r-cnn, in: Proceedings of the IEEE international conference on
Writing – review & editing, Writing – original draft. Zhiyi He: Super-
computer vision. 2015, pp. 1440-1448.
vision, Project administration. Lei Wang: Supervision. Su Cao: Soft-
[17] S. Ren, K. He, R. Girshick, J. Sun, Faster r-cnn: Towards real-time object detection
ware. Wenhua Du: Supervision.
with region proposal networks, in: Advances in neural information processing systems. 2015, pp. 91-99.
[18] K. He, G. Gkioxari, P. Dollar, R. Girshick, Mask r-cnn, in: Proceedings of the IEEE
Declaration of competing interest
international conference on computer vision. 2017, pp. 2961-2969.
[19] B. Kim, S. Cho, Image-based concrete crack assessment using mask and region-
based convolutional neural network, Struct. Control. Hlth. 26 (8) (2019) e2381.
The authors declare that they have no known competing financial
[20] A. Dahou, A.O. Aseeri, A. Mabrouk, R.A. Ibrahim, M.A. Al-Betar, M.A. Elaziz,
interests or personal relationships that could have appeared to influence
Optimal Skin Cancer Detection Model Using Transfer Learning and Dynamic-
the work reported in this paper.
Opposite Hunger Games Search, Diagnostics. 13 (2023) 1579.
[21] M.A. Elaziz, A. Dahou, A. Mabrouk, S. El-Sappagh, A.O. Aseeri, An efficient
artificial rabbits optimization based on mutation strategy for skin cancer Data availability
prediction, Comput Biol Med. 163 (2023) 107154.
[22] J. Redmon, S. Divvala, R. Girshick, A. Farhadi, You only look once: Unified, real-
time object detection, in, in: Proceedings of the IEEE Conference on Computer
The authors do not have permission to share data.
Vision and Pattern Recognition, 2016, pp. 779–788.
[23] X. Zhu, S. Lyu, X. Wang, Q. Zhao, TPH-YOLOv5: Improved YOLOv5 based on Acknowledgments
transformer prediction head for object detection on drone-captured scenarios, in:
In: Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 2778–2788.
This work was supported by Hunan Provincial Key Research and
[24] Y. Li, H. Sun, Y. Hu, Y. Han, Electrode defect YOLO detection algorithm based on
Development Program (Grant No. 2022GK2058), the Natural Science
attention mechanism and multi-scale feature fusion, Control and Decision (2022).
Foundation of Hunan Province (Grant Nos. 2023JJ60158,
[25] P. Wu, A. Liu, J. Fu, X. Ye, Y. Zhao, Autonomous surface crack identification of
concrete structures based on an improved one-stage object detection algorithm,
2023JJ60546, 2023JJ50237, 2022JJ40477), and the Opening Project of
Eng. Struct. 272 (2022) 114962.
Shanxi Key Laboratory of Advanced Manufacturing Technology (No. 11 H. Hu et Measurement al. 229 (2024) 114443
[26] J. Zhang, S. Qian, C. Tan, Automated bridge surface crack detection and
[38] Q.L. Zhang, Y.B. Yang Sa-net, Shuffle attention for deep convolutional neural
segmentation using computer vision-based deep learning model, Eng. Appl. Artif.
networks, in: In: ICASSP 2021–2021 IEEE International Conference on Acoustics, Intel. 115 (2022) 105225.
Speech and Signal Processing (ICASSP), 2021, pp. 2235–2239.
[27] Z. Xiaoxun, H. Xinyu, G. Xiaoxia, Y. Xing, X. Zixu, W. Yu, L. Huaxin, Research on
[39] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A.N. Gomez, L. Kaiser, L.
crack detection method of wind turbine blade based on a deep learning method,
Polosukhin, Attention is all you need, in: Advances in neural information
Appl. Energ. 328 (2022) 120241.
processing systems, 2017, pp. 5998–6008.
[28] H. Li, J. Li, H. Wei, Z. Liu, Z. Zhan, Q. Ren, Slim-neck by GSConv: A better design
[40] X. Dong, S. Yan, C. Duan, A lightweight vehicles detection network model based on
paradigm of detector architectures for autonomous vehicles, arXiv: 2206.02424
YOLOv5, Eng Appl Artif Intel 113 (2022) 104914.
Available: https://arxiv.org/abs/2206.02424.
[41] B. Xu, N. Wang, T. Chen, M. Li, Empirical evaluation of rectified activations in
[29] Z. Ge, S. Liu, F. Wang, Z. Li, J. Sun, Yolox: Exceeding yolo series in 2021, arXiv:
convolutional network, arXiv: 1505.00853 Available: https://arxiv.org/abs/
2107.08430 Available: https://arxiv.org/abs/2107.08430. 1505.00853.
[30] C.Y. Wang, A. Bochkovskiy, H.Y.M. Liao, YOLOv7: Trainable bag-of-freebies sets
[42] A.L. Maas, A.Y. Hannun, A.Y. Ng, Rectifier nonlinearities improve neural network
new state-of-the-art for real-time object detectors, in, in: Proceedings of the IEEE/
acoustic models, In:proc. Icml. (2013).
CVF Conference on Computer Vision and Pattern Recognition, 2023,
[43] A. Howard, M. Sandler, G. Chu, L.C. Chen, B. Chen, M. Tan, W. Wang, Y. Zhu, pp. 7464–7475.
R. Pang, V. Vasudevan, Q.V. Le, H. Adam, Searching for mobilenetv3, in, in:
[31] D. Arya, H. Maeda, S.K. Ghosh, D. Toshniwal, Y. Sekimoto, RDD2022: A multi-
Proceedings of the IEEE/CVF International Conference on Computer Vision, 2019,
national image dataset for automatic Road Damage Detection, arXiv: 2209.08538 pp. 1314–1324.
Available: https://arxiv.org/abs/2209.08538.
[44] D. Misra, Mish: A self regularized non-monotonic activation function, arXiv:
[32] V. Hegde, D. Trivedi, A. Alfarrarjeh, A. Deepak, S.H. Kim, C. Shahabi, Yet another
1908.08681 Available: https://arxiv.org/abs/1908.08681.
deep learning approach for road damage detection using ensemble learning, in: In:
[45] S. Elfwing, E. Uchibe, K. Doya, Sigmoid-weighted linear units for neural network
2020 IEEE International Conference on Big Data (big Data), 2020, pp. 5553–5558.
function approximation in reinforcement learning, Neural Networks 107 (2018)
[33] M. Sandler, A. Howard, M. Zhu, A. Zhmoginov, L.C. Chen, Mobilenetv 2: Inverted 3–11.
residuals and linear bottlenecks, in, in: Proceedings of the IEEE Conference on
[46] H. Rezatofighi, N. Tsoi, J. Gwak, A. Sadeghian, I. Reid, S. Savarese, Generalized
Computer Vision and Pattern Recognition, 2018, pp. 4510–4520.
intersection over union: A metric and a loss for bounding box regression, in: In:
[34] J. Hu, L. Shen, G. Sun, Squeeze-and-excitation networks, in, in: Proceedings of the
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern
IEEE Conference on Computer Vision and Pattern Recognition, 2018,
Recognition, 2019, pp. 658–666. pp. 7132–7141.
[47] Z. Zheng, P. Wang, W. Liu, J. Li, R. Ye, D. Ren, Distance-IoU loss: Faster and better
[35] S. Woo, J. Park, J.Y. Lee, I.S. Kweon, Cbam: Convolutional block attention module,
learning for bounding box regression, in: In: Proceedings of the AAAI Conference
in, in: Proceedings of the European Conference on Computer Vision (ECCV), 2018,
on Artificial Intelligence, 2020, pp. 12993–13000. pp. 3–19.
[48] Y.F. Zhang, W. Ren, Z. Zhang, Z. Jia, L. Wang, T. Tan, Focal and efficient IOU loss
[36] Q. Wang, B. Wu, P. Zhu, P. Li, W. Zuo, Q. Hu, ECA-Net: Efficient channel attention
for accurate bounding box regression, Neurocomputing 506 (2022) 146–157.
for deep convolutional neural networks, in: In: Proceedings of the IEEE/CVF
[49] C. Li, L. Li, H. Jiang, K. Wen, Y. Geng, L. Li, Z. Ke, Q. Li, M. Cheng, W. Nie,
Conference on Computer Vision and Pattern Recognition, 2020, pp. 11534–11542.
YOLOv6: A single-stage object detection framework for industrial applications,
[37] D. Guo, Y. Shao, Y. Cui, Z. Wang, L. Zhang, C. Shen, Graph attention tracking, in,
arXiv:2209.02976 Available: https://doi.org/10.48550/arXiv.2209.02976.
in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern
[50] F.M. Talaat, H. ZainEldin, An improved fire detection approach based on YOLO-v8
Recognition, 2021, pp. 9543–9552.
for smart cities, Neural Comput Appl 35 (28) (2023) 20939–20954. 12
Document Outline
- Road surface crack detection method based on improved YOLOv5 and vehicle-mounted images
- 1 Introduction
- 2 Related work
- 2.1 YOLOv5
- 2.2 Problems of YOLOv5 in road surface crack detection on vehicle-mounted images
- 3 The proposed road surface crack detection method
- 3.1 The specific steps of the proposed method
- 3.2 The proposed improved YOLOv5
- 3.2.1 Slim-Neck structure
- 3.2.2 C2f structure
- 3.2.3 Decoupled Head
- 3.2.4 SPPCSPC structure
- 3.2.5 Silu activation function and CIoU loss function
- 3.2.6 Module integration optimization
- 4 Experiments
- 4.1 Datasets
- 4.2 Platform construction and model training
- 4.3 Evaluation metric
- 4.4 Comparisons with other state-of-the-art methods
- 4.5 Ablation study
- 4.5.1 Ablation study of activation function
- 4.5.2 Ablation study of loss function
- 4.6 Various crack detection results
- 4.7 Qualitative comparisons
- 5 Conclusion
- CRediT authorship contribution statement
- Declaration of competing interest
- Data availability
- Acknowledgments
- Appendix A Supplementary data
- Appendix C Supplementary data
- References
Tài liệu liên quan:
-

Ung dung game hoa trong cac chien dich MKT
27 14 -

Bao cao Chi so TMDT Viet Nam 2025
30 15 -

Thông tư quy định về việc phân quyền, phân cấp và phân định thẩm quyền quản lý nhà nước về giáo dục cho chính quyền địa phương
32 16 -

Nghị quyết về phát huy các giá trị di sản văn hóa gắn với phát triên du lịch bền vững tỉnh Khánh Hòa đến năm 2025, định hướng đến năm 2030
34 17 -

Quyết định phê duyệt Chiến lược phát triển du lịch Việt Nam đến năm 2030
21 11