Thuyết minh dự án cuối khóa HK1 năm học 2025-2026 môn Lập trình căn bản Python | Trường Đại học Sư phạm Kỹ thuật Thành phố Hồ Chí Minh
Thuyết minh dự án cuối khóa HK1 năm học 2025-2026 môn Lập trình căn bản Python | Trường Đại học Sư phạm Kỹ thuật Thành phố Hồ Chí Minh. Tài liệu được sưu tầm giúp bạn tham khảo, ôn tập và đạt kết quả cao. Mời bạn đọc đón xem.
Môn: Lập trình Python (INIT130185) 12 tài liệu
Trường: Trường Đại học Sư phạm Kỹ thuật Thành phố Hồ Chí Minh 4.4 K tài liệu
Tác giả:

















Preview text:
TRƯỜNG ĐẠI HỌC SƯ PHẠM KỸ THUYẾT MINH DỰ ÁN CUỐI KHÓA THUẬT
NĂM HỌC: HK1 - 2025 - 2026 THÀNH PHỐ HỒ CHÍ MINH
Môn: Lập trình căn bản Python KHOA KINH TẾ
Mã môn học: FUBY333808
Sinh viên: Trần Quang Đại Ngày giao: 20/12/2025 MSSV: 24126040
Ngày nộp bài: 10/01/2025 Nhóm: Vibe coder
Yêu cầu cần thực hiện:
2. Lập trình Python pandas để tạo báo cáo.
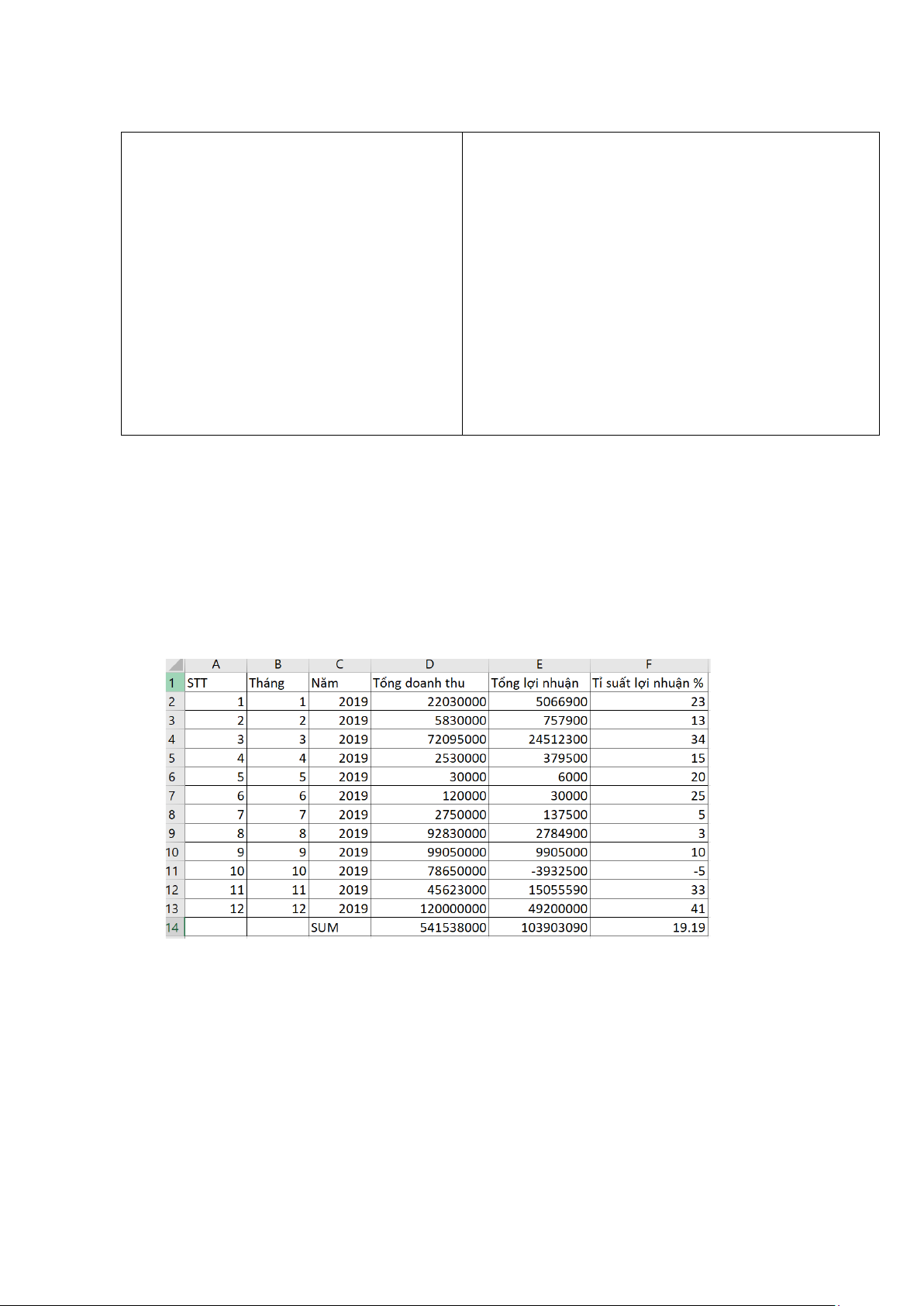
2.1. Báo cáo Doanh thu cả năm (doanhthucanam.xlsx) được tạo bằng cách đọc
baocaobanhang.xlsx và đếm xem trong từng tháng của năm được chọn tổng doanh
thu, lợi nhuận là bao nhiêu, tổng các tháng doanh thu, lợi nhuận là bao nhiêu.
2.2. Báo cáo Doanh thu theo tháng (doanhthuthang11.xlsx) được tạo bằng cách đọc
baocaobanhang.xlsx, thongtinkhachhang.xlsx, thongtinsanpham.xlsx và đếm xem
trong tháng và năm được chọn tổng doanh thu, lợi nhuận là bao nhiêu, tổng các ngày
doanh thu, lợi nhuận là bao nhiêu. Trang 1 / 57
2.3. Báo cáo Doanh số theo sản phẩm (doanhsotheosanpham.xlsx) được tạo bằng
cách đọc baocaobanhang.xlsx, thongtinkhachhang.xlsx, thongtinsanpham.xlsx và
đếm theo sản phẩm. Xếp theo thứ tự Cột tổng lợi nhuận từ cao xuống thấp.
2.4. Báo cáo Doanh số theo thị trường (doanhsotheothitruong.xlsx) được tạo bằng
cách đọc baocaobanhang.xlsx, thongtinkhachhang.xlsx, thongtinsanpham.xlsx và
đếm theo thành phố trong địa chỉ của khách hàng. Trang 2 / 57
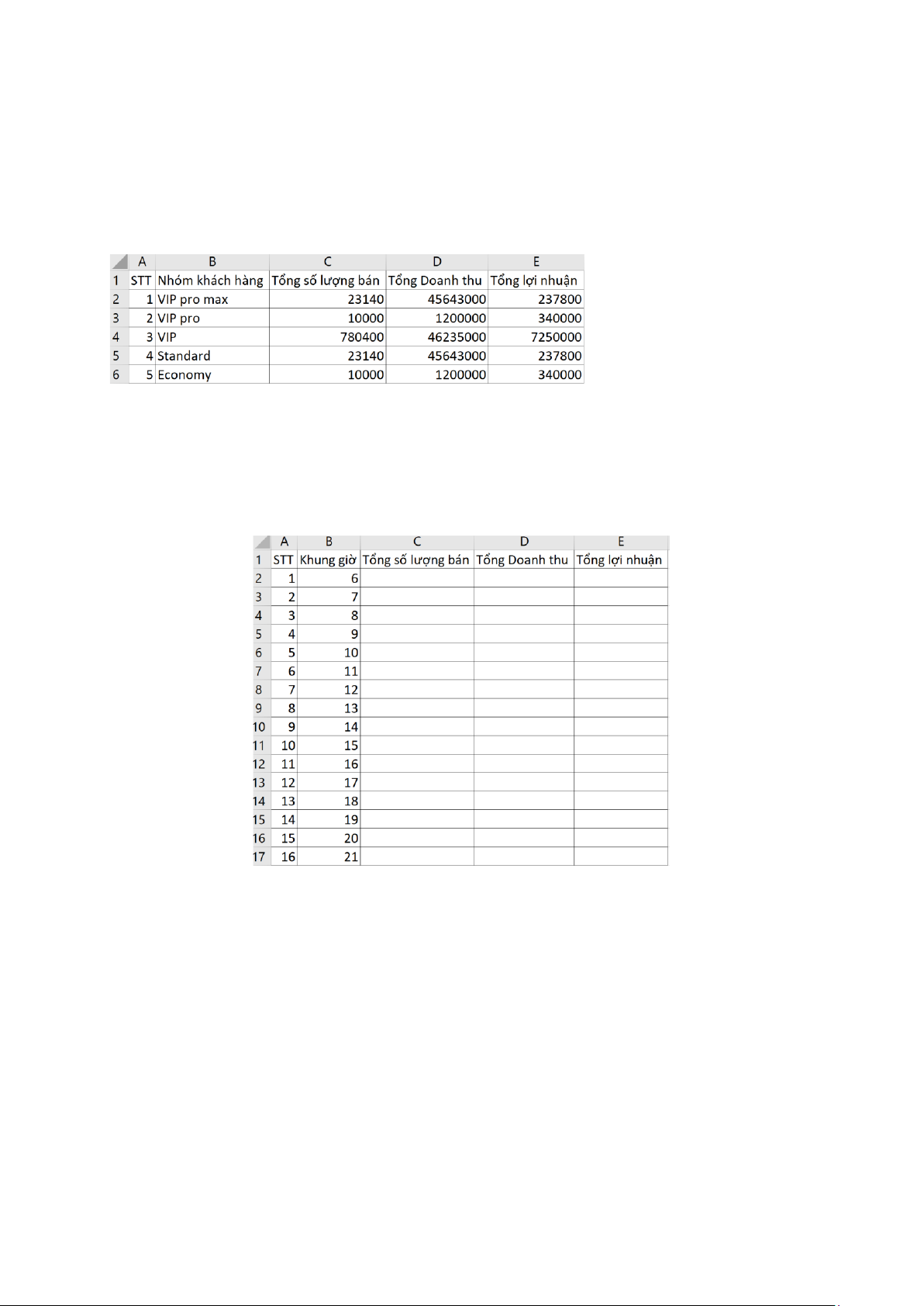
2.5. Báo cáo nhóm khách hàng (nhomkhachhang.xlsx) được tạo bằng cách đọc
baocaobanhang.xlsx, thongtinkhachhang.xlsx, thongtinsanpham.xlsx và đếm theo nhóm khách hàng
2.6. Báo cáo khung giờ bán chạy (khunggiobanchay.xlsx) được tạo bằng cách đọc
baocaobanhang.xlsx, thongtinkhachhang.xlsx, thongtinsanpham.xlsx và đếm theo
khung giờ trong ngày (từ 6 giờ đến 21 giờ) Trang 3 / 57
III. PHÂN TÍCH YÊU CẦU PHẦN MỀM
Trong phần 2 của dự án, nhóm được yêu cầu xây dựng các báo cáo thống kê
doanh số bán hàng điện thoại dựa trên dữ liệu bán hàng, dữ liệu sản phẩm và dữ liệu khách hàng.
Tổng cộng có 06 báo cáo, được đánh số từ 2.1 đến 2.6, mỗi báo cáo phục vụ một
mục tiêu phân tích khác nhau. Nội dung yêu cầu cụ thể của từng báo cáo được phân tích như sau:
2.1. Báo cáo Doanh thu cả năm
Báo cáo này có nhiệm vụ tổng hợp tổng doanh thu theo từng năm trong toàn bộ dữ
liệu bán hàng. Mục tiêu chính là giúp so sánh doanh thu giữa các năm, từ đó đánh
giá mức độ tăng trưởng hoặc suy giảm qua từng giai đoạn.
Dữ liệu sử dụng bao gồm toàn bộ các bản ghi bán hàng, trong đó cần:
• Trích xuất năm từ trường Ngày nhập.
• Tính doanh thu từng dòng dữ liệu theo công thức:
Doanh thu = Số lượng × Đơn giá.
• Nhóm dữ liệu theo năm và tính tổng doanh thu cho mỗi năm.
Kết quả đầu ra là một bảng thống kê gồm năm và tổng doanh thu tương ứng, được
sắp xếp theo thứ tự năm tăng dần để thể hiện xu hướng thời gian (hoặc sắp xếp theo
doanh thu nếu cần nhấn mạnh năm có doanh thu cao nhất).
Báo cáo được xây dựng bằng cách sử dụng thư viện Pandas, kết hợp các hàm:
• groupby() để nhóm dữ liệu theo năm,
• sum() để tính tổng doanh thu,
• insert() hoặc phép gán để thêm cột tính toán,
• to_excel() để xuất kết quả ra file Excel.
2.2. Báo cáo Doanh thu theo tháng Trang 4 / 57
Báo cáo này nhằm phân tích doanh thu theo từng tháng trong một năm cụ thể, giúp
xác định xu hướng doanh thu theo mùa vụ và nhận diện các tháng cao điểm.
Dữ liệu đầu vào là các bản ghi bán hàng của một năm được chọn. Quy trình xử lý gồm:
• Lọc dữ liệu theo năm cần phân tích.
• Trích xuất tháng từ trường Ngày nhập.
• Nhóm dữ liệu theo tháng và tính tổng doanh thu từng tháng.
Kết quả là bảng gồm 12 tháng (từ tháng 1 đến tháng 12) và tổng doanh thu tương
ứng, được sắp xếp theo thứ tự tăng dần của tháng để thuận tiện theo dõi chu kỳ trong năm.
Báo cáo được hiện thực bằng Pandas với các thao tác: • groupby() theo tháng,
• sum() để cộng doanh thu,
• to_excel() để xuất file (ví dụ: DoanhThuTheoThang2025.xlsx).
2.3. Báo cáo Doanh số theo sản phẩm
Mục tiêu của báo cáo này là tổng hợp doanh số bán ra của từng sản phẩm, qua đó
xác định các sản phẩm bán chạy (best-seller) và mức đóng góp doanh thu của từng sản phẩm.
Dữ liệu sử dụng gồm: • Mã sản phẩm, • Tên sản phẩm, • Số lượng, • Đơn giá. Trang 5 / 57
Dữ liệu được nhóm theo sản phẩm (thường sử dụng mã sản phẩm vì tính duy nhất), sau đó tính:
• Tổng số lượng bán ra,
• Tổng doanh thu của mỗi sản phẩm.
Kết quả là bảng liệt kê mỗi sản phẩm cùng với số lượng bán và doanh thu tương ứng,
được sắp xếp giảm dần theo doanh thu hoặc số lượng để dễ nhận diện sản phẩm bán chạy.
Việc xử lý được thực hiện bằng:
• groupby() trên sản phẩm,
• agg() để tính nhiều chỉ tiêu cùng lúc,
• reset_index() để đưa dữ liệu về dạng bảng,
• sort_values() để sắp xếp,
• to_excel() để xuất báo cáo (DoanhSoTheoSanPham.xlsx).
2.4. Báo cáo Doanh số theo thị trường
Báo cáo này thống kê doanh số theo từng thị trường địa lý (tỉnh/thành phố) nhằm
xác định khu vực có doanh thu cao nhất.
Dữ liệu cần kết hợp giữa:
• Bảng bán hàng (chứa tên khách hàng),
• Bảng khách hàng (chứa địa chỉ). Quy trình xử lý gồm:
• Kết nối (merge) dữ liệu bán hàng với dữ liệu khách hàng thông qua tên khách hàng.
• Tách tỉnh/thành phố từ chuỗi địa chỉ bằng cách xử lý chuỗi và áp dụng hàm apply(). Trang 6 / 57
• Nhóm dữ liệu theo tỉnh/thành phố và tính tổng doanh thu.
Các trường hợp thiếu dữ liệu địa chỉ được xử lý bằng cách:
• Loại bỏ (dropna) hoặc
• Gán giá trị mặc định như “Không xác định” (fillna) để đảm bảo thống kê không bị sai lệch.
Kết quả được sắp xếp giảm dần theo doanh thu và xuất ra file
DoanhSoTheoThiTruong.xlsx bằng to_excel().
2.5. Báo cáo Doanh số theo nhóm khách hàng
Báo cáo này phân tích doanh thu theo từng nhóm khách hàng (VIP pro max, VIP
pro, VIP, Standard, Economy, …), nhằm đánh giá hiệu quả của chính sách phân loại khách hàng.
Dữ liệu được xử lý bằng cách:
• Merge bảng bán hàng với bảng khách hàng để bổ sung cột Nhóm khách hàng.
• Xử lý giá trị thiếu bằng fillna() (ví dụ: “Chưa phân loại”).
• Nhóm dữ liệu theo nhóm khách hàng và tính tổng doanh thu.
Kết quả là bảng thống kê từng nhóm khách hàng cùng tổng doanh thu tương ứng,
được sắp xếp giảm dần theo doanh thu, phản ánh nhóm khách hàng mang lại giá trị cao nhất.
Báo cáo được xuất ra file DoanhSoTheoNhomKH.xlsx bằng to_excel().
2.6. Báo cáo Khung giờ bán chạy
Báo cáo này phân tích thời điểm bán hàng sôi động nhất trong ngày, nhằm hỗ trợ
việc tối ưu nhân sự và chiến lược bán hàng từ 6 đến 21 giờ
Quy trình thực hiện gồm:
• Trích xuất giờ (từ 6 đến 21 giờ )từ trường Ngày nhập bằng dt.hour. Trang 7 / 57
• Nhóm dữ liệu theo giờ và tính tổng số lượng sản phẩm bán ra (hoặc doanh thu).
• Sắp xếp kết quả để xác định giờ cao điểm nhất.
Kết quả là bảng gồm từ 6 đến 21 giờ và tổng số lượng bán ra tương ứng. Báo cáo
được xuất ra file KhungGioBanChay.xlsx.
Kết luận: Để xây dựng các báo cáo từ 2.1 đến 2.6, thư viện Pandas đóng vai trò trung tâm trong việc:
• Đọc và ghi dữ liệu Excel (read_excel, to_excel),
• Nhóm và tổng hợp dữ liệu (groupby, sum, agg),
• Kết nối bảng dữ liệu (merge),
• Xử lý dữ liệu thiếu (dropna, fillna),
• Chuyển đổi kiểu dữ liệu (astype),
• Sắp xếp và chuẩn hóa kết quả (sort_values, reset_index, insert, apply). Trang 8 / 57
IV. GIẢI THÍCH CÚ PHÁP CÁC HÀM VÀ THƯ VIỆN ĐƯỢC SỬ DỤNG
Để xây dựng các báo cáo thống kê doanh số bán hàng từ báo cáo 2.1 đến 2.6,
chương trình sử dụng các thư viện và hàm xử lý dữ liệu của Python nhằm thực hiện
các chức năng chính như: đọc và ghi dữ liệu Excel, làm sạch và chuẩn hóa dữ liệu,
tách thông tin thời gian, kết nối nhiều bảng dữ liệu, nhóm – tổng hợp – sắp xếp kết quả và xuất báo cáo.
Nội dung dưới đây trình bày chức năng, cú pháp, giải thích và ví dụ áp dụng của
các hàm và thư viện đã được sử dụng trong chương trình.
1. Thư viện sử dụng
1.1. Thư viện Pandas
Pandas là thư viện Python chuyên dùng để xử lý và phân tích dữ liệu dạng bảng.
Pandas cung cấp cấu trúc DataFrame, cho phép lưu trữ dữ liệu theo dạng hàng – cột
tương tự như bảng tính Excel, đồng thời hỗ trợ nhiều hàm mạnh để lọc, nhóm, tổng
hợp và làm sạch dữ liệu.
Trong dự án này, Pandas được sử dụng xuyên suốt để:
• Đọc dữ liệu từ các file Excel đầu vào.
• Chuẩn hóa và xử lý dữ liệu.
• Thực hiện các phép nhóm và thống kê.
• Kết nối dữ liệu giữa các bảng bán hàng, sản phẩm và khách hàng.
• Xuất kết quả báo cáo ra file Excel.
Pandas đóng vai trò là thư viện cốt lõi của toàn bộ chương trình.
2. Các hàm và cú pháp quan trọng 2.1. pd.read_excel()
Chức năng: Đọc dữ liệu từ file Excel (.xlsx) và đưa vào DataFrame. Cú pháp cơ bản: Trang 9 / 57
df = pd.read_excel("ten_file.xlsx", sheet_name=0) Giải thích:
• sheet_name=0: đọc sheet đầu tiên của file Excel (mặc định).
• Kết quả trả về là một DataFrame chứa toàn bộ dữ liệu trong file.
Ví dụ áp dụng trong dự án: Hàm được sử dụng để đọc:
• baocaobanhang.xlsx – dữ liệu bán hàng,
• thongtinsanpham.xlsx – thông tin sản phẩm,
• thongtinkhachhang.xlsx – thông tin khách hàng.
2.2. DataFrame.to_excel()
Chức năng: Xuất dữ liệu từ DataFrame ra file Excel. Cú pháp:
df.to_excel("output.xlsx", index=False) Giải thích:
• index=False: không ghi cột chỉ số mặc định (0,1,2,…) vào file Excel, giúp bảng
báo cáo gọn gàng và đúng chuẩn trình bày.
Ví dụ áp dụng: Sau khi hoàn thành xử lý và thống kê, mỗi báo cáo (2.1–2.6) được
xuất ra một file Excel riêng như: • doanhthucanam.xlsx • doanhthuthang11.xlsx
• doanhsotheosanpham.xlsx, …
2.3. DataFrame.groupby()
Chức năng: Nhóm dữ liệu theo một hoặc nhiều cột để phục vụ thống kê và tổng hợp
(tương tự Pivot Table trong Excel). Trang 10 / 57 Cú pháp:
df.groupby("cot_nhom")[["cot_tinh"]].sum() Giải thích:
• groupby() chỉ tạo nhóm dữ liệu, chưa tạo kết quả cuối.
• Cần kết hợp với các hàm tổng hợp như sum(), count(), agg() để tạo bảng thống kê.
Ví dụ áp dụng trong dự án:
• Nhóm theo Tháng để tính doanh thu từng tháng (báo cáo 2.1).
• Nhóm theo Ngày để tính doanh thu từng ngày trong tháng (báo cáo 2.2).
• Nhóm theo Sản phẩm, Thị trường, Nhóm khách hàng, Giờ cho các báo cáo 2.3– 2.6. 2.4. .sum() và .agg() a) .sum()
Chức năng: Tính tổng các cột dữ liệu dạng số sau khi đã nhóm. Ví dụ:
df.groupby("Tháng")[["Doanh thu", "Lợi nhuận"]].sum() b) .agg()
Chức năng: Tổng hợp nhiều chỉ tiêu khác nhau trong cùng một lần nhóm. Ví dụ:
df.groupby("Thị trường").agg({ "Số lượng": "sum", "Doanh thu": "sum",
"Khách mua hàng": "nunique" Trang 11 / 57 }) Giải thích:
• agg() cho phép tính tổng số lượng, doanh thu, lợi nhuận và đếm số khách hàng cùng lúc.
• Trong dự án, agg() đặc biệt quan trọng ở báo cáo 2.4 – Doanh số theo thị trường. 2.5. DataFrame.merge()
Chức năng: Ghép hai DataFrame dựa trên khóa chung (tương tự JOIN trong SQL). Cú pháp: df = df_ban.merge( df_khach, left_on="Khách mua hàng", right_on="Họ và tên", how="left" ) Giải thích:
• left_on, right_on: chỉ ra cột khóa ở mỗi bảng.
• how="left": giữ toàn bộ dữ liệu bán hàng; nếu không tìm thấy khách hàng tương
ứng thì các cột ghép thêm sẽ có giá trị NaN. Ví dụ áp dụng:
• Ghép bảng khách hàng để lấy Địa chỉ và Nhóm khách hàng.
• Ghép bảng sản phẩm để lấy Giá nhập, phục vụ tính lợi nhuận.
2.6. dropna() và fillna() a) dropna() Trang 12 / 57
Chức năng: Loại bỏ các dòng dữ liệu bị thiếu giá trị quan trọng. Ví dụ:
df.dropna(subset=["Ngày nhập", "Số lượng", "Đơn giá"], inplace=True) Giải thích:
• Chỉ những dòng thiếu dữ liệu cốt lõi mới bị loại bỏ, đảm bảo kết quả tính toán chính xác. b) fillna()
Chức năng: Điền giá trị thay thế cho dữ liệu bị thiếu. Ví dụ:
df["Nhóm khách hàng"] = df["Nhóm khách hàng"].fillna("Chưa phân loại") Giải thích:
Giúp giữ lại các giao dịch thiếu thông tin khách hàng khi thống kê, tránh mất dữ liệu.
2.7. astype() và pd.to_numeric()
Chức năng: Chuẩn hóa kiểu dữ liệu, đặc biệt quan trọng với dữ liệu đọc từ Excel.
• astype(str): chuẩn hóa dữ liệu chuỗi (mã sản phẩm, tên khách hàng).
• pd.to_numeric(errors="coerce"): chuyển dữ liệu về kiểu số, giá trị không hợp lệ sẽ thành NaN. Ví dụ:
df["Số lượng"] = pd.to_numeric(df["Số lượng"], errors="coerce")
df["Đơn giá"] = pd.to_numeric(df["Đơn giá"], errors="coerce") 2.8. reset_index()
Chức năng: Chuyển chỉ mục (index) sau khi groupby() thành cột thông thường. Ví dụ: Trang 13 / 57
df_bc = df.groupby("Tháng").sum(numeric_only=True).reset_index()
Giải thích:Giúp bảng dữ liệu “phẳng”, thuận tiện cho việc xuất Excel và trình bày báo cáo. 2.9. sort_values()
Chức năng:Sắp xếp dữ liệu theo tiêu chí mong muốn. Ví dụ:
df.sort_values(by="Doanh thu", ascending=False, inplace=True) Ví dụ áp dụng:
• Sắp xếp sản phẩm theo lợi nhuận giảm dần.
• Sắp xếp thị trường theo doanh thu giảm dần. 2.10. insert()
Chức năng:Chèn cột mới vào vị trí xác định trong DataFrame. Ví dụ:
df.insert(0, "STT", range(1, len(df) + 1))
Giải thích:Dùng để thêm cột STT, giúp bảng báo cáo rõ ràng và chuyên nghiệp. 2.11. round()
Chức năng:Làm tròn số, thường dùng khi tính tỷ suất lợi nhuận. Ví dụ:
df["Tỷ suất lợi nhuận (%)"] = round(100 * df["Lợi nhuận"] / df["Doanh thu"], 2)
2.12. apply() và các hàm tự định nghĩa
Chức năng:Áp dụng một hàm xử lý tùy biến lên từng phần tử của cột.
Ví dụ áp dụng trong dự án:
df["Thị trường"] = df["Địa chỉ"].apply(Tach_ThiTruong) Trang 14 / 57
Giải thích:apply() cho phép xử lý các yêu cầu không có hàm sẵn, như:
• Tách tỉnh/thành phố từ chuỗi địa chỉ,
• Tách năm, tháng, ngày, giờ từ chuỗi thời gian.
Kết luận việc sử dụng đầy đủ và hợp lý các hàm của Pandas như read_excel, merge,
groupby, sum, agg, dropna, fillna, reset_index, sort_values, insert, apply và to_excel giúp chương trình:
• Xử lý dữ liệu chính xác và đồng nhất,
• Đáp ứng đầy đủ yêu cầu của các báo cáo
• Xuất báo cáo Excel rõ ràng, chuyên nghiệp và dễ đánh giá. Trang 15 / 57
V. GIẢI THÍCH TỪNG BƯỚC PHÁT TRIỂN CHƯƠNG TRÌNH
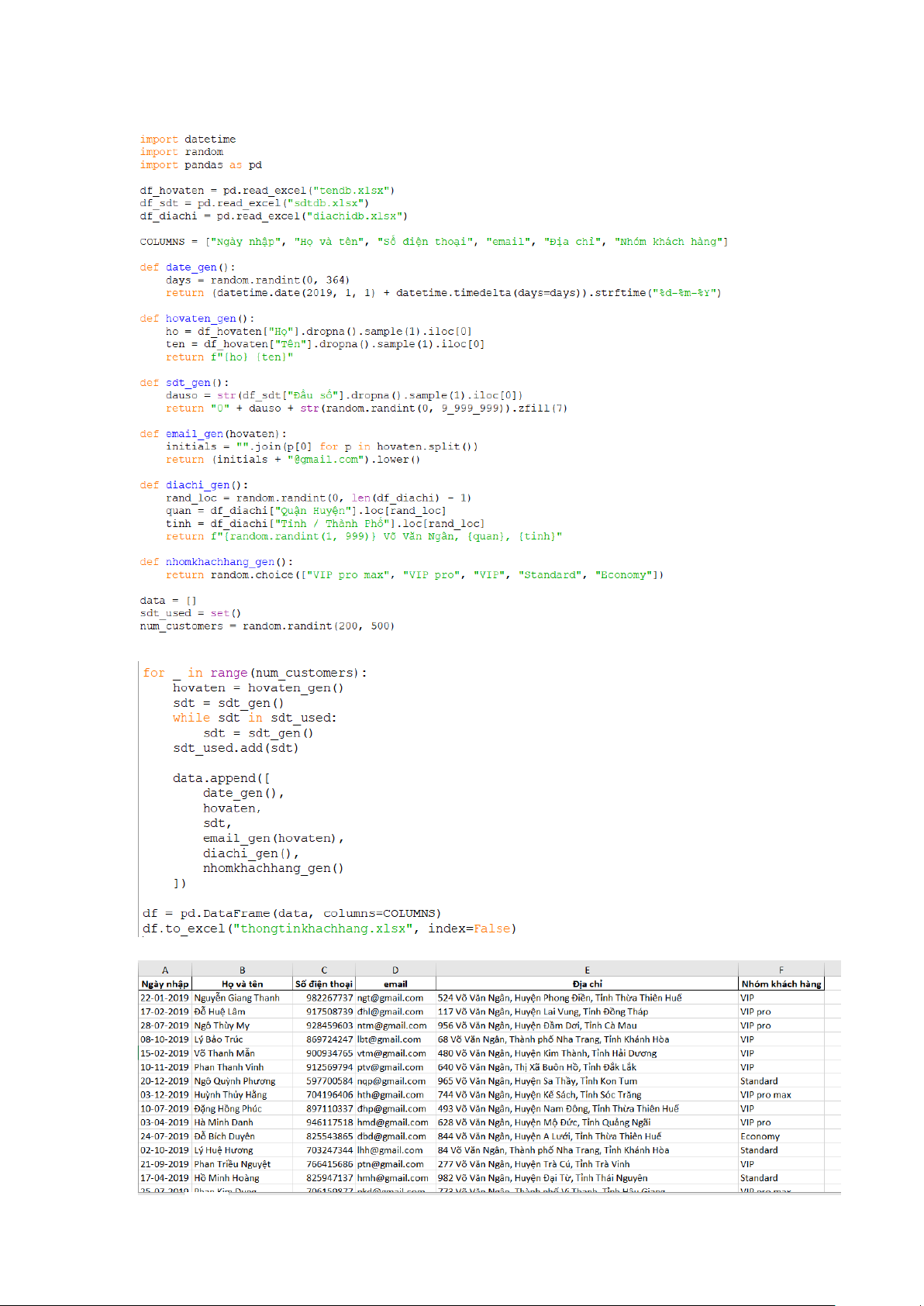
5.1. Tạo dữ liệu đầu vào phục vụ phân tích
5.1.1. Mục đích của việc tạo dữ liệu bằng Python
Trước khi tiến hành xây dựng các báo cáo thống kê (từ 2.1 đến 2.6), chương trình sử
dụng Python để tạo dữ liệu ngẫu nhiên có kiểm soát cho ba bảng chính:
• Thông tin sản phẩm (thongtinsanpham.xlsx)
• Thông tin khách hàng (thongtinkhachhang.xlsx)
• Báo cáo bán hàng (baocaobanhang.xlsx)
Việc chủ động sinh dữ liệu giúp:
• Không phụ thuộc vào dữ liệu mẫu có sẵn
• Dễ dàng kiểm tra và hiệu chỉnh thuật toán
• Đảm bảo dữ liệu phủ nhiều năm, nhiều tháng, nhiều khung giờ
• Phù hợp cho việc phân tích nhanh và đánh giá toàn diện hệ thống báo cáo
5.1.2. Sinh dữ liệu thông tin sản phẩm a) Thư viện sử dụng
Chương trình sử dụng các thư viện:
• random: sinh giá trị ngẫu nhiên
• datetime: tạo mốc thời gian
• pandas: tổ chức dữ liệu dạng bảng và xuất Excel
b) Cách sinh mã và tên sản phẩm
Mỗi sản phẩm được tạo với:
• Mã sản phẩm dạng SP0001, SP0002, …
• Tên sản phẩm được chọn từ danh sách có sẵn Trang 16 / 57
ma_sp = f"SP{str(i).zfill(4)}" Giải thích:
• SP là tiền tố cố định
• zfill(4) đảm bảo độ dài mã đồng nhất
• Giúp tránh lỗi khi merge dữ liệu giữa các bảng
c) Cách sinh giá nhập và giá bán
gia_nhap = random.randint(5_000_000, 20_000_000)
gia_ban = gia_nhap + random.randint(1_000_000, 5_000_000) Giải thích:
• Giá nhập được sinh trong khoảng hợp lý
• Giá bán luôn lớn hơn giá nhập
• Đảm bảo lợi nhuận dương, tránh sai logic khi tính toán báo cáo
d) Xuất dữ liệu sản phẩm
df.to_excel("thongtinsanpham.xlsx", index=False)
File này được sử dụng trong hàm xu_ly_du_lieu() để: • Ghép giá nhập
• Tính lợi nhuận cho từng giao dịch Trang 17 / 57
5.1.3. Sinh dữ liệu thông tin khách hàng
a) Sinh họ tên khách hàng
Tên khách hàng được tạo bằng cách ghép: • Họ • Tên đệm • Tên
ho_ten = f"{random.choice(ho)} {random.choice(ten_dem)} {random.choice(ten)}" Giải thích:
• Mô phỏng tên người Việt thực tế Trang 18 / 57
• Được dùng làm khóa ghép với bảng bán hàng
b) Sinh địa chỉ khách hàng
dia_chi = f"{random.randint(1,200)} {duong}, {quan}, {tinh}" Giải thích:
• Địa chỉ gồm số nhà – quận – tỉnh • Phục vụ cho việc: o Tách thị trường
o Báo cáo doanh số theo tỉnh/thành (2.4) c) Sinh nhóm khách hàng
nhom_kh = random.choice(["VIP", "VIP Pro", "Standard", "Economy"]) Giải thích:
• Phân loại khách hàng theo mức độ giá trị
• Dữ liệu này dùng cho báo cáo 2.5 – Doanh số theo nhóm khách hàng
d) Xuất dữ liệu khách hàng
df.to_excel("thongtinkhachhang.xlsx", index=False) Trang 19 / 57 Trang 20 / 57
Tài liệu liên quan:
-

Tuyển tập 200 bài tập Lập trình bằng ngôn ngữ Python | Trường Đại học Sư phạm Kỹ thuật Thành phố Hồ Chí Minh
36 18 -

Đề Kiểm Tra Lần 2: Quản Lý Ward và Nhân Viên | Môn Lập trình Python - Đại học Sư phạm Kỹ thuật Thành phố Hồ Chí Minh
107 54 -

Tkinter GUI Programming: Essential Code Examples and Functions | Môn Lập trình Python - Đại học Sư phạm Kỹ thuật Thành phố Hồ Chí Minh
135 68 -

Giải Thuật cho Bài Tập 2 | Môn Lập trình Python - Đại học Sư phạm Kỹ thuật Thành phố Hồ Chí Minh
104 52