Tiểu luận môn học An toàn mạng đề tài "Quản lý mạng dựa trên nhận thức máy"
Tiểu luận môn học An toàn mạng đề tài "Quản lý mạng dựa trên nhận thức máy" của Học viện Công nghệ Bưu chính Viễn thông với những kiến thức và thông tin bổ ích giúp sinh viên tham khảo, ôn luyện và phục vụ nhu cầu học tập của mình cụ thể là có định hướng ôn tập, nắm vững kiến thức môn học và làm bài tốt trong những bài kiểm tra, bài tiểu luận, bài tập kết thúc học phần, từ đó học tập tốt và có kết quả cao cũng như có thể vận dụng tốt những kiến thức mình đã học vào thực tiễn cuộc sống. Mời bạn đọc đón xem!
Môn: An toàn mạng (AT19) 11 tài liệu
Trường: Học viện Công Nghệ Bưu Chính Viễn Thông 1.8 K tài liệu
Tác giả:






















Preview text:
lOMoARcPSD| 37054152 MỤC LỤC
LỜI CẢM ƠN ................................................................ Error! Bookmark not defined.
DANH MỤC HÌNH ẢNH ................................................................................................ 2
CHƯƠNG 1: GIỚI THIỆU ............................................................................................ 2
1.1. Bối cảnh và vấn đề cần giải quyết ......................................................................... 2
1.2. BDDM là gì? .......................................................................................................... 3
1.3. Các vấn đề quản lý mạng hiện tại .......................................................................... 3
1.4. Nhu cầu của người dùng và người vận hành ......................................................... 4
1.5. Chuyển nhu cầu kinh doanh sang dịch vụ mạng ................................................... 5
1.5.1. SLA là gì? ........................................................................................................ 5
1.5.2. SLA cam kết dịch vụ? ..................................................................................... 5
1.5.3. Giải pháp? ....................................................................................................... 6
1.6. Sự cần thiết phải kết hợp tính năng động............................................................... 7
1.7. Phản ứng với bối cảnh ............................................................................................ 9
1.7.1. Nhận thức ngữ cảnh ........................................................................................ 9
1.7.2. Lí luận dựa trên ngữ cảnh ............................................................................... 9
CHƯƠNG 2: NHẬN THỨC MÁY (MACHINE COGNITION) .............................10
2.1. Khái niệm và phạm vi của Nhận thức máy ..........................................................11
2.2. Vòng điều khiển thích ứng và nhận thức .............................................................12
2.3. Các khối chức năng ..............................................................................................12
2.4. Biểu diễn tri thức ..................................................................................................14
2.5. Bộ nhớ ..................................................................................................................15
CHƯƠNG 3: KIẾN TRÚC NHẬN THỨC .................................................................16
3.1. Tổng quan.............................................................................................................16
3.2. Nhà môi giới API (API Broker) ...........................................................................17
3.3 Xử lý Dữ liệu Đầu Vào và Đầu Ra .......................................................................17
3.4. Chức năng xử lý nhận thức ..................................................................................19
3.4.1 Khối chức năng nhận thức tình huống ...........................................................20
3.4.2 Khối chức năng quản lý kiến thức .................................................................20
3.4.3 Khối chức năng Quản lý Nhận thức ...............................................................21
3.4.4 Khối chức năng Học và Lý luận ....................................................................23 lOMoARcPSD| 37054152
3.4.5 Khối chức năng Quản lý Chính sách..............................................................24
3.5. Đạt được mục tiêu trong kiến trúc nhận thức ......................................................26
CHƯƠNG 4: NHẬN THỨC MÁY TRONG QUẢN LÝ MẠNG .............................27
4.1. Quy trình quản lý mạng thông qua Nhận thức máy .............................................27
4.2. Ứng dụng trong thực tiễn .....................................................................................28
4.3. Các trường hợp nghiên cứu thực tế ......................................................................29
4.4. Thách thức và giải pháp .....................................................................................30
4.5. Tương lai của quản lý mạng ...............................................................................31
KẾT LUẬN .....................................................................................................................33 lOMoARcPSD| 37054152 DANH MỤC HÌNH ẢNH Hình 1. Mô hình OSS
Hình 2. Chính sách liên tục
Hình 3. Sơ đồ khối của một trình dịch ngữ nghĩa
Hình 4. Sơ đồ khối của kiến trúc FOCALE
Hình 5. Lý luận dựa trên bối cảnh Hình 6. Nhận thức máy
Hình 7. Một tập hợp các vòng điều khiển
Hình 8. Vòng điều khiển FOCALE Hình 9. Bộ nhớ
Hình 10. Sơ đồ khối đơn giản của một hệ thống kiến trúc nhận thức
Hình 11. Kiến trúc chức năng cấp cao của mạng nhận thức
Hình 12. Khối chức năng nhận thức tình huống
Hình 13. Khối nhận thức: Tìm các bản thể học phù hợp cho phần tử mô hình
Hình 14. Khối nhận thức: Tìm các khái niệm bản thể học
Hình 15. Mô hình chính sách MEF
Hình 16. Trường Hợp Nghiên Cứu 1: AT&T's Network AI
Hình 17. Trường Hợp Nghiên Cứu 2: DeepMind's AI for Data Center Cooling
Hình 18. Trường Hợp Nghiên Cứu 3: Juniper Networks' Mist AI
CHƯƠNG 1: GIỚI THIỆU
1.1. Bối cảnh và vấn đề cần giải quyết. Bối cảnh: -
Các chức năng giám sát và cung cấp dịch vụ và quản lý mạng hiện tại ngày
càng phức tạp. Sự phổ biến của các công nghệ khác nhau cũng như cách triển khai khác
nhau từ các nhà cung cấp khác nhau đòi hỏi quá trình xử lý của con người trong vòng
lặp, việc này tốn thời gian và dễ xảy ra lỗi. Ngoài ra, người dùng đang yêu cầu các dịch
vụ phức tạp hơn (ví dụ: dịch vụ nhận biết ngữ cảnh, dịch vụ được cá nhân hóa). -
Kiến trúc quản lý mạng gặp phải tình trạng không có khả năng bảo vệ và
sử dụng các quy trình kinh doanh để thúc đẩy việc cấu hình và quản lý tài nguyên mạng
và do đó là các dịch vụ mạng. Mục đích:
Phân tích nhu cầu sử dụng các mục tiêu kinh doanh để xác định tập hợp các
dịch vụ mạng được cung cấp tại bất kỳ thời điểm nào và thảo luận tại sao việc sử dụng lOMoARcPSD| 37054152
thuật toán AI để giải quyết một phần vấn đề quản lý mạng, chẳng hạn như cải thiện thông tin đo từ xa. 1.2. BDDM là gì? -
BDDM là một mô hình cho phép các quy tắc kinh doanh quản lý việc xây dựng
các tập tin và lệnh cấu hình cho một thiết bị cũng như thực thi cách tạo, xác minh, phê
duyệt và triển khai cấu hình của một thiết bị. -
BDDM sử dụng các loại chính sách khác nhau để quản lý các khía cạnh khác
nhau của việc cung cấp dịch vụ mạng. Các chính sách này tạo thành một chuỗi liên tục
thể hiện vòng đời hoàn chỉnh (từ đặt hàng đến tạo ra cho đến phá bỏ) các dịch vụ
mạng, thu hẹp khoảng cách tự động hóa giữa các lớp dịch vụ và phần tử, đồng thời
kiểm soát các dịch vụ và tài nguyên mạng nào được phân bổ cho người dùng nào.
1.3 . Các vấn đề quản lý mạng hiện tại
Hầu hết các hệ thống hỗ trợ kinh doanh (BSS) và hệ thống hỗ trợ vận hành
(OSS) hiện nay đều được thiết kế theo kiểu ống bao gồm các hệ thống tốt nhất để thực
hiện các nhiệm vụ cụ thể. Ví dụ: thông thường có nhiều hệ thống kiểm kê, mỗi hệ
thống được thiết kế để hỗ trợ một bộ thiết bị và hệ thống mạng cụ thể.
Tuy nhiên, điều này cản trở khả năng tương tác vì mỗi hệ thống bếp như vậy sử
dụng quan điểm riêng về môi trường được quản lý. Tất nhiên điều này cản trở sự hợp
nhất thông tin từ các hệ thống khác nhau.
Hình 1. Mô hình OSS
Điều này tạo ra một số vấn đề, bao gồm những vấn đề sau:
- Các hệ thống tốt nhất có tính liên kết cao và tính liên kết thấp. Điều này có nghĩa là
một thành phần có thể phụ thuộc vào nhiều thành phần khác nên khi thay đổi sẽ ảnh
hưởng đến các thành phần khác. lOMoARcPSD| 37054152
- Không có cách nào dễ dàng để OSS này tương tác với BSS, cũng như với các thực
thể quản lý cấp thấp hơn (ví dụ: bộ điều khiển SDN hoặc trình quản lý phần tử hoặc
bộ điều phối). Điều này biến OSS thành một ống dẫn cấp hệ thống.
- Việc thiếu dữ liệu được bảo vệ chung ngăn cản các thành phần khác nhau chia sẻ và
sử dụng lại dữ liệu chung, cả trong các thành phần của chính nó và giữa các hệ thống khác.
Trong ba vấn đề trên, vấn đề phổ biến và bất lợi nhất là thiếu kiến trúc thông tin thống
nhất. Điều này gây ra một số vấn đề ngăn cản việc sử dụng thông tin từ các nguồn khác
nhau cùng nhau để tạo thành một bức tranh hoàn chỉnh hơn về môi trường. Ví dụ 1: Giả
sử rằng dữ liệu đề cập đến cùng một người có các tên khác nhau (ví dụ: JohnS so với
Strassner.John so với jstrassn). Mặc dù con người có thể đánh đồng những điều này
nhưng máy móc rất khó làm được điều đó.
Ví dụ 2: Giả sử cùng một người, khi được thể hiện trong ba hệ thống khác nhau, có ba
dạng ID khác nhau (ví dụ: ID nhân viên là 123456, EmpID là “SJ033ab” và ID là
“123456”). Ba ID khác nhau này đều có tên và kiểu dữ liệu khác nhau, khiến thiết bị gần
như không thể nhận ra rằng các ID này xác định cùng một đối tượng.
Có rất nhiều sự không tương thích về mặt kỹ thuật. Ví dụ: không có mô hình thông tin
hoặc dữ liệu nào, chưa nói đến tiêu chuẩn, để giúp dịch các lệnh SNMP sang các lệnh
giao diện dòng lệnh hoặc các mô hình mới hơn, chẳng hạn như YANG. Điều này chủ
yếu là do cú pháp và ngữ nghĩa của từng biến thể của ba cách tiếp cận này được mỗi nhà
cung cấp sử dụng là khác nhau. Ngoài ra, có hàng trăm phiên bản hệ điều hành của nhà
cung cấp. Đối với một số nhà cung cấp, hai thiết bị chạy cùng một phiên bản hệ điều
hành nhưng có khả năng sử dụng các thẻ dòng khác nhau có thể hiển thị các phản hồi
khác nhau cho cùng một lệnh.
1.4 . Nhu cầu của người dùng và người vận hành.
Sự không tương thích về mặt kỹ thuật đòi hỏi phải có một ngôn ngữ giống
Esperanto(quốc tế ngữ). Vì vậy, tất cả người dùng đều có cùng mục tiêu.
Ví dụ 1: Người dùng doanh nghiệp hiếm khi hiểu tất cả các chi tiết kỹ thuật của dịch vụ
và quản trị viên mạng hiếm khi hiểu các khái niệm như quản lý quan hệ khách hàng và
lý do tại sao nên đối xử với một khách hàng cụ thể theo cách cụ thể.
Ví dụ 2: Người dùng doanh nghiệp có thể nghĩ đến ý nghĩa kinh tế của SLA, trong khi
quản trị viên mạng có thể nghĩ đến cách lập trình các dịch vụ do SLA chỉ định. lOMoARcPSD| 37054152
Hình 2. Chính sách liên tục
Ví dụ 3: Người dùng doanh nghiệp muốn thông tin SLA và không quan tâm đến loại
hàng đợi hoặc định tuyến sẽ được sử dụng khi triển khai của dịch vụ. Ngược lại, quản
trị viên mạng có thể muốn phát triển các lệnh CLI để lập trình thiết bị và có thể cần phải
có một bản tái hiện chính sách hoàn toàn khác để phát triển các lệnh CLI xếp hàng và định tuyến.
Vì vậy, yêu cầu đặt ra là quá trình phải được coi là một chuỗi liên tục, trong đó các chính
sách khác nhau có các hình thức khác nhau và giải quyết các nhu cầu của những người dùng khác nhau.
1.5. Chuyển nhu cầu kinh doanh sang dịch vụ mạng. 1.5.1. SLA là gì?
SLA(Service Level Agreement) là một tài liệu hợp đồng hoặc một phần của một hợp
đồng giữa một nhà cung cấp dịch vụ và một khách hàng, trong đó các yêu cầu và cam
kết về mức độ chất lượng của dịch vụ được định rõ và bao gồm các yếu tố: mục tiêu chất
lượng dịch vụ(Service Level Objectives - SLO), thời gian giao dịch, quyền và nghĩa vụ
của cả hai bên, các chỉ số đo lường và theo dõi.
1.5.2. SLA cam kết dịch vụ? -
Mỗi SLA chỉ định bộ dịch vụ nào sẽ được cung cấp khi nào và ở đâu, chi phí,
hiệu suất ….. SLA thường được viết bằng ngôn ngữ và thuật ngữ kinh doanh không thể
tuân theo để lập trình trực tiếp các luồng mạng. -
SLA có thể được viết cho bất kỳ dịch vụ nào và nhiều SLA có thể được sử dụng
để xác định các đặc điểm và hành vi của một dịch vụ. Các chi tiết về chất lượng và hiệu
suất dịch vụ được xác định bằng một hoặc nhiều mục tiêu cấp độ dịch vụ (SLO) cho mỗi SLA. lOMoARcPSD| 37054152 -
Bản thân dịch vụ rất đa dạng. Ví dụ về các dịch vụ khác nhau là dịch vụ xúc giác
có độ trễ phải nhỏ hơn 10 ms hoặc dịch vụ không thành công (nghĩa là dịch vụ này
không đáp ứng các nghĩa vụ theo hợp đồng và không thể sử dụng được). Mỗi cấp xác
định các SLO khác nhau cho các ứng dụng đi kèm), trong đó mỗi cấp xác định chức
năng khác nhau dựa trên chi phí và loại dịch vụ. -
SLA có thể có một hoặc nhiều SLO. Một số SLO phụ thuộc vào ngữ cảnh (ví dụ:
vị trí địa lý, thời gian trong ngày và lưu lượng truy cập trong nước so với quốc tế) và có
thể bị hạn chế bởi các quy tắc kinh doanh của nhà cung cấp Ví dụ: ba câu lệnh sau có
thể được coi là ba phần của cùng một SLO: -
99,99% yêu cầu hệ thống của khách hàng sẽ hoàn thành trong vòng chưa đầy 15 mili giây. -
99,9% yêu cầu hệ thống của khách hàng sẽ hoàn thành trong vòng chưa đầy 5 mili giây. -
90% yêu cầu hệ thống của khách hàng sẽ hoàn thành trong vòng chưa đầy 1 mili giây.
Trong ví dụ trên, ta nhận thấy mỗi SLO có hai giá trị cấp độ dịch vụ (SLV): (1) tỷ lệ
phần trăm yêu cầu dịch vụ khách hàng (ví dụ: 99,99%, 99,9% và 90%) và (2) thời gian
hoàn thành (ví dụ: 15,5 và 1 mili giây ).
Do đó, mối quan hệ chung giữa SLA, SLO của nó và SLV liên quan là: một SLA có
nhiều SLO và mỗi SLO có nhiều SLV; mỗi SLV được đo bằng một số liệu.
1.5.3. Giải pháp?
Có hai giải pháp cho vấn đề này:
- Yêu cầu một hoặc nhiều người dịch thủ công các tài liệu kinh doanh sang dạng mà
các kỹ sư mạng có thể sử dụng.
- Sử dụng các trình phân tích cú pháp hoặc trình biên dịch để giúp tự động kết hợp quy trình.
Ở 2 giải pháp này đều có những nhược điểm:
- Ở giải pháp 1: được thực hiện thủ công và do đó làm trì hoãn việc thử nghiệm chính
thức và cung cấp dịch vụ. Loại dịch thuật này cần được thực hiện cho từng nhóm đối
tượng cần hiểu thông tin hợp đồng, chính sách quy định hoặc quy tắc kinh doanh của
tổ chức hoặc nói chung bất kỳ điều gì có thể ảnh hưởng đến việc lập kế hoạch và
quản lý dịch vụ được cung cấp. - Ở gải pháp 2:
+) Cần phân tích ngôn ngữ tự nhiên là một nhiệm vụ rất khó khăn và tốn nhiều công sức tính toán. lOMoARcPSD| 37054152
+) Không có tiêu chuẩn nào để định nghĩa các thuật ngữ có thể xuất hiện trong các
tài liệu kinh doanh này cũng như ý nghĩa của chúng.
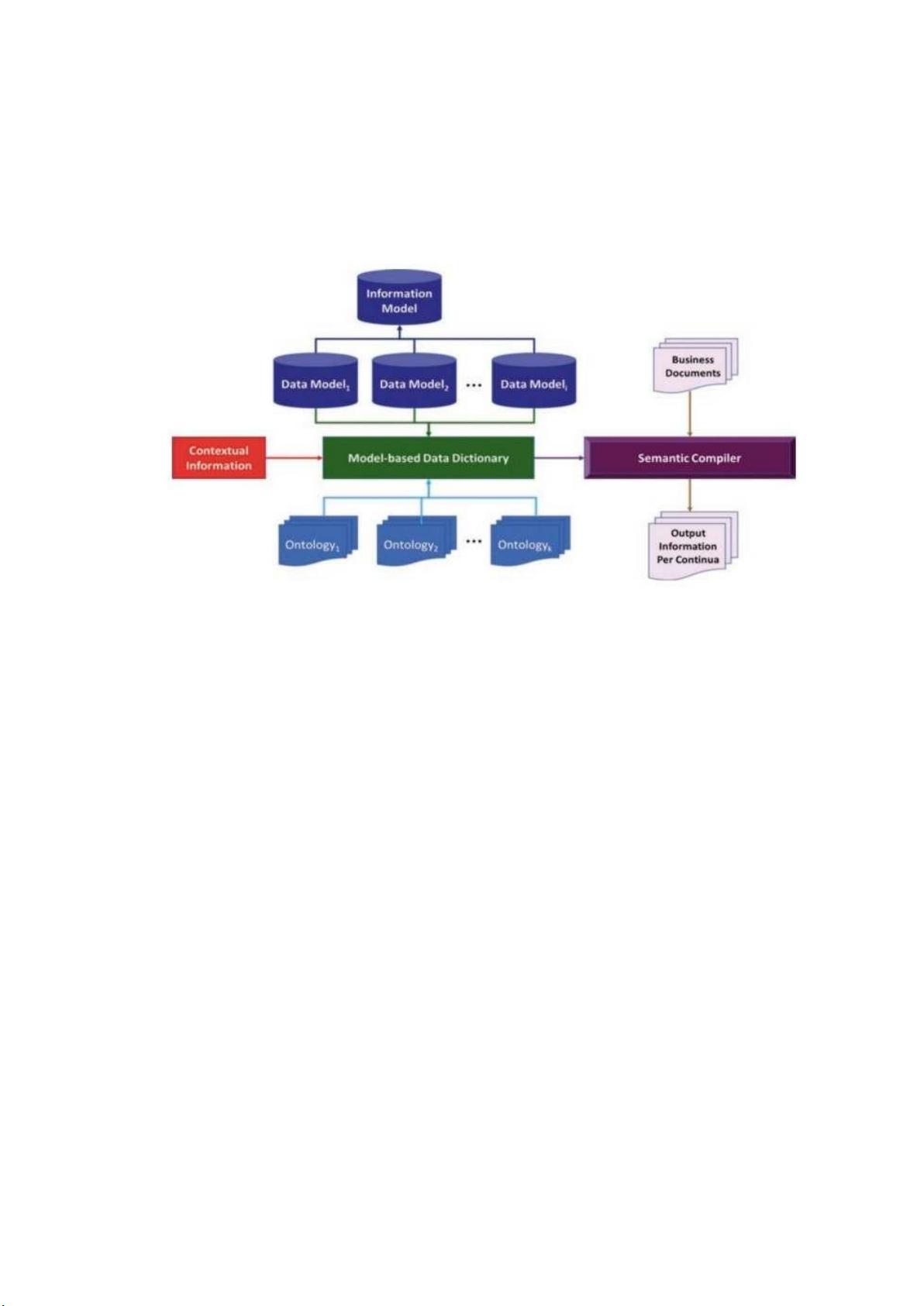
Vì vậy, sinh ra giải pháp tối ưu nhất đó là: sử dụng phương pháp kỹ thuật dựa trên mô
hình để hạn chế ngôn ngữ tự nhiên. Theo cách tiếp cận như vậy, một mô hình được sử
dụng để chứa tất cả các thuật ngữ chính dự kiến sẽ xuất hiện trong tài liệu. Sơ đồ khối
chức năng cấp cao được hiển thị trong Hình 3.
Hình 3. Sơ đồ khối của một trình dịch ngữ nghĩa
1.6. Sự cần thiết phải kết hợp tính năng động
Kỹ thuật hướng mô hình (Model-Driven Engineering - MDE) là một phương pháp kỹ
thuật phần mềm lấy mô hình làm trung tâm để xây dựng các hệ thống phần mềm có thể
được sửa đổi linh hoạt trong thời gian chạy.
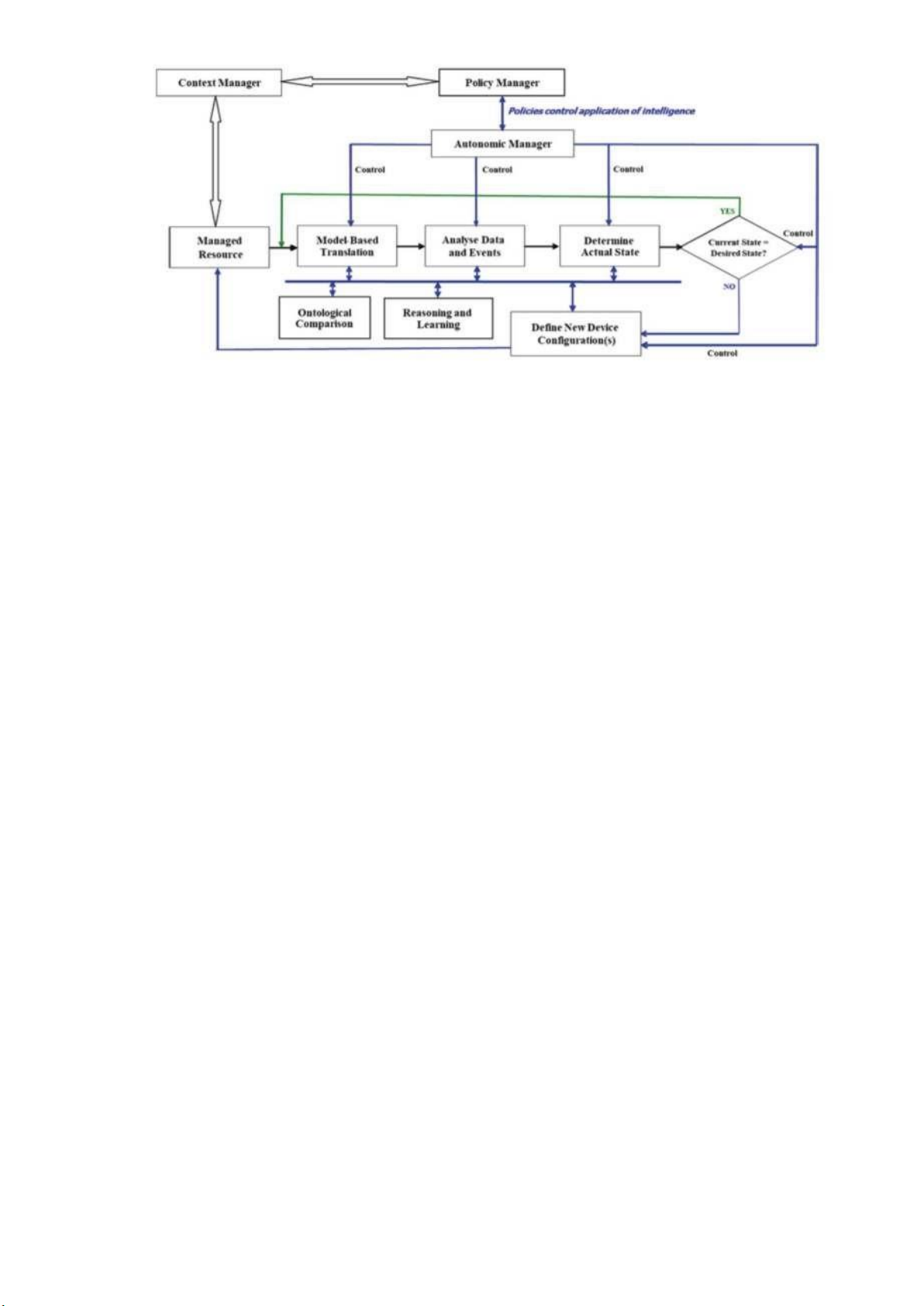
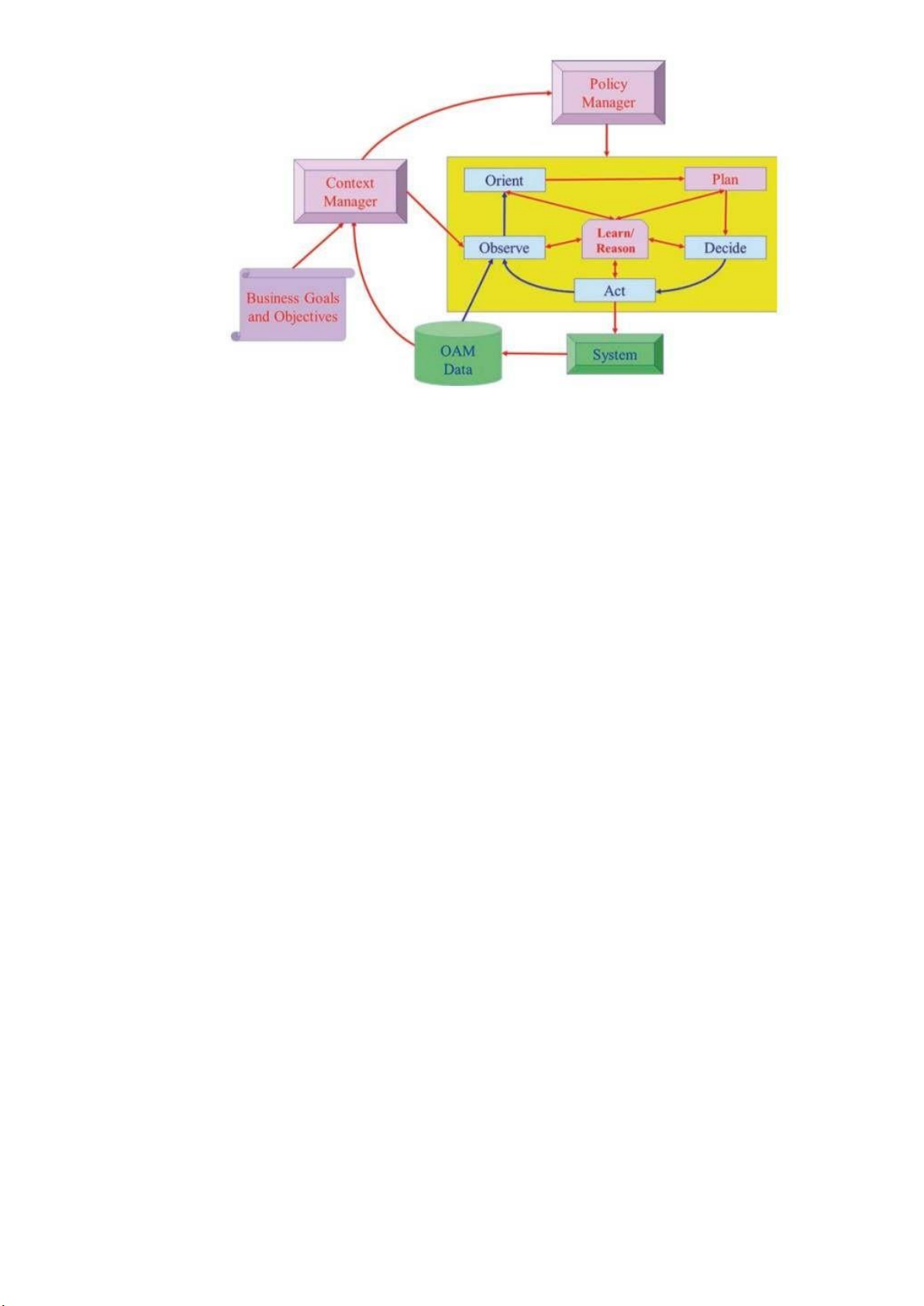
FOCALE là một kiến trúc mạng tự trị, được đề xuất lần đầu tiên vào năm 2006 và được
cải tiến qua nhiều năm. FOCALE là viết tắt của Foundation, Observe, Compare, Act,
Learn, Eason, mô tả các vòng điều khiển mới của nó. Dựa trên mô hình có nghĩa là nó
có thể tự động tạo mã để cấu hình lại các thực thể được quản lý từ các mô hình của nó
bằng cách sử dụng MDE (Hình 4). lOMoARcPSD| 37054152
Hình 4. Sơ đồ khối của kiến trúc FOCALE
Các vòng điều khiển FOCALE hoạt động như sau. Dữ liệu được truy xuất từ tài nguyên
được quản lý (ví dụ: bộ định tuyến) và được đưa vào quy trình dịch thuật dựa trên mô
hình, quy trình này sẽ dịch dữ liệu dành riêng cho nhà cung cấp và thiết bị thành dạng
chuẩn hóa bằng cách sử dụng mô hình thông tin DEN-ng và các bản thể luận làm dữ liệu
tham chiếu . Sau đó được phân tích để xác định trạng thái hiện tại của thực thể được
quản lý. Trạng thái hiện tại được so sánh với trạng thái mong muốn từ các máy trạng
thái hữu hạn(FSM). Nếu không phát hiện thấy vấn đề gì, hệ thống sẽ tiếp tục sử dụng
vòng lặp bảo trì mặt khác, vòng lặp cấu hình được sử dụng để các dịch vụ và tài nguyên
được cung cấp có thể thích ứng với những nhu cầu mới này.
Trình quản lý tự trị sử dụng bộ chính sách nhận biết ngữ cảnh hiện tại để quản lý từng
thành phần kiến trúc của vòng điều khiển, cho phép mỗi thành phần vòng điều khiển
khác nhau thay đổi cách hoạt động như một chức năng của ngữ cảnh.
Quá trình cấu hình lại sử dụng việc tạo mã động. Các mô hình thông tin và dữ liệu được
sử dụng để đưa vào các máy trạng thái, từ đó xác định hoạt động của từng thực thể mà
hệ thống tự trị đang quản lý. Thông tin quản lý mà hệ thống tự trị đang theo dõi bao gồm
dữ liệu cảm biến được ghi lại. Điều này được phân tích để rút ra trạng thái hiện tại của
tài nguyên được quản lý, cũng như để cảnh báo người quản lý tự trị về bất kỳ thay đổi
bối cảnh nào trong hoặc liên quan đến tài nguyên được quản lý.
Sau đó, người quản lý tự trị sẽ so sánh trạng thái hiện tại của các thực thể được quản lý
với trạng thái mong muốn của chúng; nếu các trạng thái bằng nhau thì việc giám sát sẽ tiếp tục.
Tuy nhiên, nếu các trạng thái không bằng nhau, trình quản lý tự trị sẽ tính toán tập hợp
chuyển đổi trạng thái tối ưu cần thiết để thay đổi trạng thái của các thực thể được quản
lý thành trạng thái mong muốn tương ứng của chúng. Trong quá trình này, hệ thống có
thể gặp phải sự thay đổi ngoài ý muốn trong bối cảnh. Do đó, hệ thống sẽ kiểm tra, như
một phần của cả vòng lặp giám sát và kiểm soát cấu hình, xem bối cảnh có thay đổi hay
không. Nếu bối cảnh không thay đổi, quá trình sẽ tiếp tục. Nếu bối cảnh đã thay đổi thì lOMoARcPSD| 37054152
trước tiên hệ thống sẽ điều chỉnh bộ chính sách đang được sử dụng để quản lý hệ thống
theo bản chất của những thay đổi bối cảnh, từ đó cung cấp thông tin mới cho máy trạng thái.
1.7. Phản ứng với bối cảnh
- Mạng có thể chứa nhiều quy tắc chính sách thuộc nhiều loại khác nhau (ví dụ: quy tắc
chính sách kinh doanh cấp cao để xác định các dịch vụ và tài nguyên được cung cấp cho
người dùng, đến quy tắc chính sách cấp thấp để kiểm soát cách thay đổi cấu hình của
thiết bị ). Mục đích của việc làm cho các quy tắc chính sách này nhận biết theo ngữ cảnh
là sử dụng ngữ cảnh để chỉ chọn những quy tắc chính sách có thể áp dụng cho nhiệm vụ
quản lý hiện tại đang được thực hiện.
1.7.1. Nhận thức ngữ cảnh -
Nhận thức ngữ cảnh cho phép một hệ thống thu thập thông tin về chính nó và
môi trường của nó. Điều này cho phép hệ thống cung cấp các dịch vụ và tài nguyên
được cá nhân hóa và tùy chỉnh tương ứng với bối cảnh đó. Quan trọng hơn, nó cho
phép hệ thống điều chỉnh hành vi của nó theo những thay đổi trong bối cảnh. -
Nhận thức ngữ cảnh cho phép dữ liệu và thông tin đa dạng dễ dàng liên kết với
nhau hơn và do đó được tích hợp vì ngữ cảnh hoạt động như một bộ lọc thống nhất. Do
đó, việc xác định thông tin theo ngữ cảnh là rất quan trọng để hiểu cả dữ liệu và thông
tin đã nhập cũng như cách dữ liệu và thông tin, cũng như kiến thức và trí tuệ hiện có,
có thể bị ảnh hưởng.
1.7.2. Lí luận dựa trên ngữ cảnh
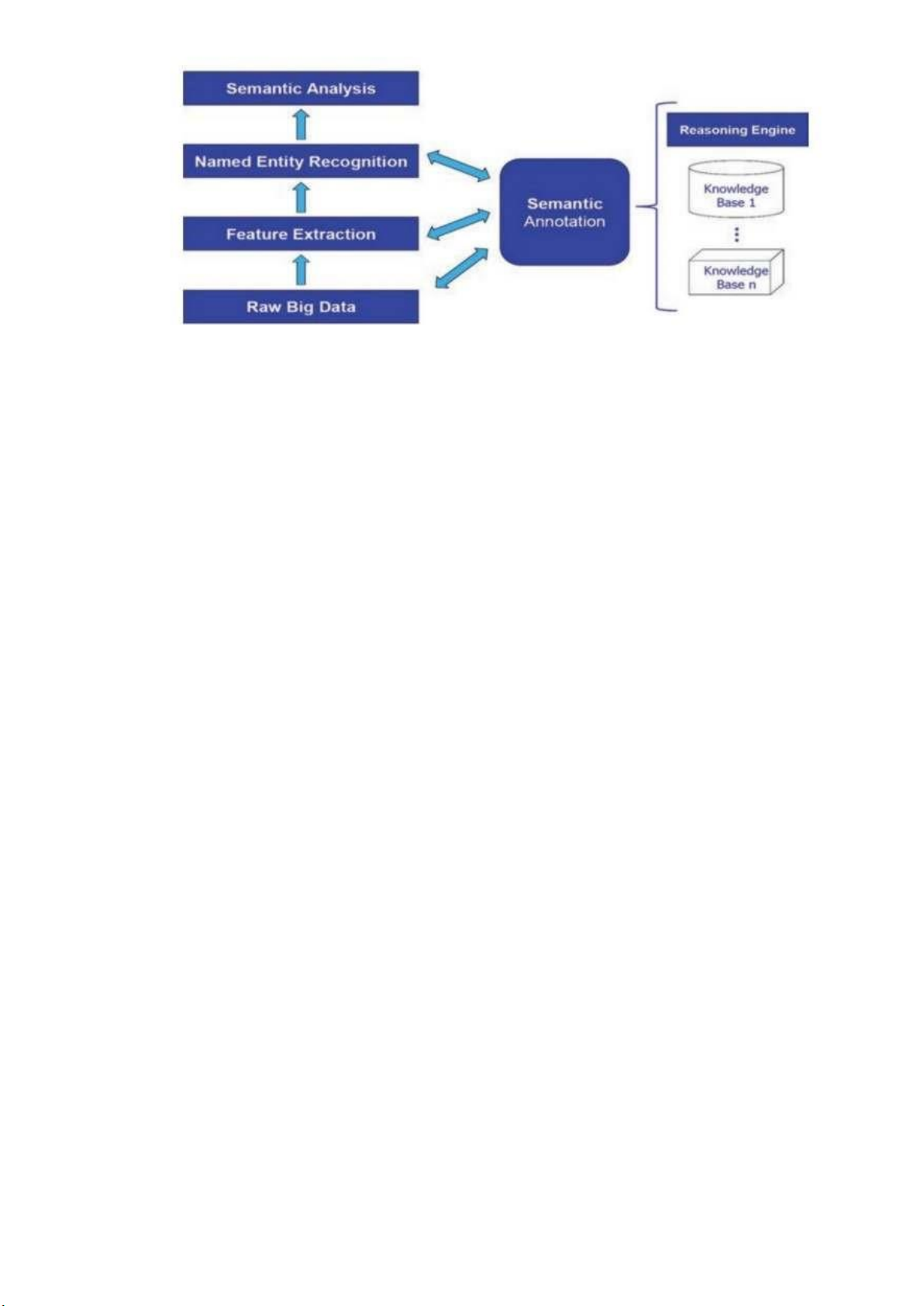
Hình 5 ta có thể hiểu như sau, bối cảnh có thể được mô hình hóa thành Dữ liệu
lớn, vì yếu tố quan trọng là trích xuất giá trị từ dữ liệu lớn. Ba thao tác trên dữ liệu mô
tả một tập hợp các thao tác ngày càng cụ thể có thể được sử dụng để chú thích thông tin
về mặt ngữ nghĩa. Phân tích ngữ nghĩa phân tích thông tin về các khái niệm ngữ nghĩa
cụ thể, tìm kiếm trên các khái niệm đó và sau đó bổ sung các mối quan hệ ngữ nghĩa bổ
sung để làm phong phú thông tin và cung cấp ý nghĩa cụ thể hơn. lOMoARcPSD| 37054152
Hình 5. Lý luận dựa trên bối cảnh
Trong học máy thì điều này tính toán các số liệu như độ tương tự về ngữ nghĩa
(nghĩa là ý nghĩa của một đối tượng được so sánh với ý nghĩa của các đối tượng khác,
trong đó việc so sánh được thực hiện bằng cách sử dụng từ đồng nghĩa, từ trái nghĩa, từ
đồng âm, siêu từ….. Đây là một cách tiếp cận thực tế và dễ tính toán hơn so với “sự hiểu biết tuyệt đối”.
CHƯƠNG 2: NHẬN THỨC MÁY (MACHINE COGNITION) lOMoARcPSD| 37054152
2.1. Khái niệm và phạm vi của Nhận thức máy
Hình 6. Nhận thức máy
Nhận thức là quá trình thu thập dữ liệu và thông tin mới, phân tích dữ liệu và
thông tin đó để hiểu ý nghĩa và tầm quan trọng của chúng, đồng thời tạo ra dữ liệu, thông
tin và kiến thức mới giúp tăng thêm sự hiểu biết về hoạt động của hệ thống và môi trường của nó.
Nhận thức máy là một tập hợp các quy trình mô phỏng theo cách bộ não con
người thu thập và hiểu dữ liệu, thông tin, đồng thời tạo ra dữ liệu, thông tin và kiến thức
mới. Máy móc thực hiện quá trình này bằng cách sử dụng nhiều loại vòng điều khiển khép kín.
Khác với Nhận thức máy thì Trí tuệ nhân tạo (AI) một khái niệm rộng hơn, đề
cập đến việc tạo ra máy móc có khả năng thực hiện các công việc mà, ở con người, yêu
cầu trí tuệ nhân tạo. AI không chỉ hạn chế trong nhận thức mà còn bao gồm cả việc mô
phỏng các năng lực như học hỏi, suy luận, thích nghi, và thậm chí cả sự sáng tạo.
Còn Học máy lại là một nhánh con của AI, tập trung vào phát triển thuật toán cho
phép máy móc học hỏi từ dữ liệu và cải thiện hiệu suất qua thời gian mà không cần lập
trình một cách rõ ràng. Đây là cốt lõi của việc phát triển khả năng nhận thức cho máy móc.
Nhận thức máy là một phần của AI chuyên sâu hơn, tập trung vào việc mô phỏng
quá trình nhận thức của con người, trong khi Học máy là phương tiện giúp đạt được khả
năng nhận thức đó. Học máy dựa trên thuật toán và dữ liệu để học hỏi, trong khi Nhận
thúc máy áp dụng những kiến thức đã học để thực hiện suy nghĩ và ra quyết định giống
như con người. Và cuối cùng, Nhận thức máy thường liên quan đến việc ứng dụng trong
các tác vụ đòi hỏi sự hiểu biết sâu sắc và quyết định phức tạp, ví dụ như chẩn đoán y tế
hoặc lái xe tự động, trong khi Học máy có thể được áp dụng trong các tác vụ rộng lớn
hơn như phân loại hình ảnh, dự đoán xu hướng thị trường, hoặc nhận dạng giọng nói. lOMoARcPSD| 37054152
2.2. Vòng điều khiển thích ứng và nhận thức
Hình 7. Một tập hợp các vòng điều khiển
Vòng điều khiển khép kín nhận thức là vòng lặp mà ở đó nó sẽ chọn dữ liệu và
hành vi để giám sát, giúp đánh giá trạng thái đạt được một tập hợp mục tiêu nhất định
và tạo ra dữ liệu, thông tin và kiến thức mới để hỗ trợ đạt được các mục tiêu đó. Vòng
điều khiển Quan sát-Định hướng-Quyết định-Hành động (viết tắt là OODA) đã được đề
xuất làm cơ sở để xây dựng các vòng điều khiển nhận thức.
Quản lý nhận thức liên kết từng khối chức năng khác nhau của hệ thống với tập
hợp các mục tiêu cuối cùng mà hệ thống đang sử dụng tại một thời điểm cụ thể. Nó cố
gắng duy trì một tập hợp các mục tiêu từ đầu đến cuối (chẳng hạn như tối ưu hóa định
tuyến, kết nối, hiệu quả, bảo mật và quản lý tin cậy) bằng cách sửa đổi chỉ thị của các khối chức năng khác.
Vòng điều khiển được hiển thị trong Hình bên trên được gọi là vòng điều khiển
khép kín thích ứng, vì chức năng điều khiển của nó thích ứng với đối tượng hoặc quá
trình được điều khiển bằng cách sử dụng tham số chưa xác định và/hoặc thay đổi theo
thời gian. Các tham số này phản ánh cả bối cảnh và tình huống đang thay đổi. Cách triển
khai ưu tiên sẽ xác định các tham số bằng cách sử dụng mô hình xác định hiệu suất vòng
kín mong muốn; điều này có thể được tăng cường bằng phân tích thống kê để xây dựng
mô hình toán học từ dữ liệu đo được. Vòng điều khiển này còn được gọi là vòng điều
khiển khép kín nhận thức, vì nó có thể chọn dữ liệu và hành vi để giám sát để giúp đánh
giá trạng thái đạt được một bộ mục tiêu và tạo ra dữ liệu, thông tin và kiến thức mới để
tạo điều kiện thuận lợi cho việc đạt được các mục tiêu đó.
2.3. Các khối chức năng lOMoARcPSD| 37054152
Hình 8. Vòng điều khiển FOCALE
Khối chức năng Quan sát chấp nhận đầu vào từ hệ thống đang được quản lý;
điều này được thể hiện bằng dữ liệu vận hành, hành chính và quản lý. Những dữ liệu này
cũng được gửi đến Trình quản lý bối cảnh để giải nghĩa theo mục tiêu hiện tại. Kết quả
được chuyển đến Trình quản lý chính sách, sau đó sẽ đưa ra các chính sách chi phối hoạt
động của tất cả sáu khối chức năng của vòng điều khiển FOCALE (hiển thị trong hình chữ nhật màu vàng).
Khối chức năng Định hướng lấy dữ liệu đầu vào đã nhập và chuẩn hóa chúng
bằng cách sử dụng một tập hợp các mô hình và bản thể luận. Về mặt khái niệm, các mô
hình cung cấp các sự kiện và các bản thể luận bổ sung ý nghĩa cho các sự kiện đó. Chức
năng này rất quan trọng vì nó cho phép dữ liệu và thông tin được tổng hợp từ nhiều
nguồn khác nhau để có được bức tranh toàn cảnh hơn về tình hình.
Ngoài ODDA thì khối Kế hoạch cung cấp quá trình xử lý phản ứng, cân nhắc và
phản ánh, đồng thời mô phỏng cách bộ não con người xử lý thông tin để nhận thức, hiểu và dự đoán hành vi.
Các quá trình phản ứng thực hiện các phản hồi ngay lập tức dựa trên việc tiếp
nhận một kích thích thích hợp từ bên ngoài. Những quá trình đó, chúng không hề hiểu
rằng các sự kiện bên ngoài là gì; đúng hơn, chúng chỉ đơn giản là phản ứng bằng bản
năng và những thứ chúng đã từng học được. Điều này cho phép hệ thống nhận thức nhận
ra tình huống đã gặp phải trước đó. Khi điều này được thực hiện, hệ thống có thể bỏ qua
nhiều phần tính toán chuyên sâu của vòng điều khiển và thay vào đó đi theo “đường tắt”
xuyên qua vòng điều khiển để đến thẳng chức năng đưa ra các hành động nhằm thay đổi
trạng thái hiện tại sang trạng thái mong muốn.
Các quy trình có chủ ý nhận dữ liệu từ đó và có thể gửi “lệnh” đến các quy trình
phản ứng; tuy nhiên, chúng không tương tác trực tiếp với thế giới bên ngoài. Quá trình
này giải quyết các mục tiêu phức tạp hơn bằng cách sử dụng bộ nhớ để tạo và thực hiện
các kế hoạch phức tạp hơn. Kiến thức này được tích lũy và khái quát hóa. Cuối cùng,
các quá trình phản ánh giám sát sự tương tác giữa các quá trình có chủ ý và phản ứng.
Các quy trình này cải tổ và điều chỉnh lại cách xử lý tình huống để lần sau
chúng sẽ có các chiến lược sáng tạo và hiệu quả hơn. Nó sẽ xem xét những dự đoán
nào đã sai, cùng với những trở ngại và hạn chế nào đã gặp phải, để ngăn chặn việc tái lOMoARcPSD| 37054152
diễn lại một lần nữa. Nó cũng bao gồm việc tự phản ánh, phân tích xem các hành động
đã được giải quyết được thực hiện tốt đến mức nào.
Một mô hình nhận thức được tạo ra dựa trên ba loại xử lý này, tạo ra một hoặc
nhiều đường dẫn. Một số đường dẫn này có thể là các đường tắt, bỏ qua một hoặc nhiều
chức năng khi đầu vào được nhận dạng và đầu ra được nhận biết hoặc có xác suất xuất
hiện đủ cao. Trong FOCALE, điều này được thực hiện bằng một tập hợp gồm một hoặc
nhiều máy trạng thái, nơi mỗi trạng thái tương ứng với một dịch vụ và một cấu hình
mạng cụ thể. Siêu dữ liệu được thêm vào các trạng thái thích hợp để bao gồm thông tin tình huống quan trọng.
Khối Hành động quyết định con đường phù hợp nhất để bảo vệ các mục tiêu
trong tình hình hiện tại. Sau đó nó sử dụng cơ chế MDE để biên dịch tập hợp các nút
trong máy trạng thái vào một loạt lệnh để cấu hình lại các tài nguyên và dịch vụ bị ảnh
hưởng, cũng như giám sát thông tin tài nguyên và dịch vụ phù hợp.
Khối Tìm hiểu/Lý do sử dụng nhận thức theo ngữ cảnh và tình huống để hiểu
dữ liệu và hành vi mới, so sánh những thông tin đầu vào mới đó với các mục tiêu hiện
tại, sau đó hình thành các hành động để bảo vệ và đạt được các mục tiêu đó, đồng thời
học hỏi từ hậu quả của các hành động đó. Nó đánh giá sự thành công hay thất bại của
việc sắp xếp các nguồn lực và dịch vụ để có thể liên kết tính hiệu quả của mỗi trạng thái
với hệ thống đang được sử dụng.
2.4. Biểu diễn tri thức
Có rất nhiều ví dụ về các hình thức biểu diễn tri thức, tuỳ mức độ phức tạp khác
nhau, từ mô hình và bản thể học đến mạng ngữ nghĩa và các hệ thống con lý luận tự
động. Về cơ bản, biểu diễn tri thức giúp cho ý định và phán đoán của một thực thể phần
mềm được thể hiện một cách phù hợp để lập luận tự động. Điều này cũng bao gồm việc
lập mô hình hành vi thông minh cho một thực thể phần mềm. Nói cách khác, biểu diễn
tri thức mô tả cách tri thức được định nghĩa và vận dụng trong trí tuệ nhân tạo. Quan
trọng nhất, việc biểu diễn tri thức không khẳng định rằng dữ liệu đó là tĩnh! Đúng hơn,
dữ liệu luôn có thể được sửa đổi hoặc tăng cường nếu có đủ bằng chứng để làm như vậy.
Có nhiều loại tri thức khác nhau:
¥ Tri thức về quy trình mô tả cách thực hiện một nhiệm vụ hoặc hoạt động và bao
gồm các quy tắc, chiến lược và quy trình.
¥ Tri thức khai báo bao gồm các khái niệm, sự kiện, đối tượng và được thể hiện bằng
một hoặc nhiều câu khai báo. Điều này tương tự như tri thức logic, thể hiện các
khái niệm, sự kiện và đối tượng theo logic hình thức.
¥ Tri thức cấu trúc mô tả thành phần và mối quan hệ giữa các khái niệm và đối tượng.
Nói chung, tất cả các loại tri thức đều có thể được sử dụng để tạo thành biểu
diễn tri thức cho một hệ thống.
Biểu diễn logic là một ngôn ngữ hình thức có thể định nghĩa các tiên đề, lý thuyết,
giả thuyết và mệnh đề mà không hề có bất kỳ sự mơ hồ nào trong cách biểu diễn của
chúng. Nó sử dụng cú pháp và ngữ nghĩa được xác định chính xác để hỗ trợ các loại suy
luận và lý luận khác nhau. Ưu điểm chính của nó là tạo điều kiện thuận lợi cho việc
chứng minh các giả thuyết về mặt toán học và có thể sử dụng suy luận để xác định các lOMoARcPSD| 37054152
đối tượng mới từ các đối tượng hiện có của nó. thông tin trong một kho lưu trữ đang
hoạt động và sẵn có trong một khoảng thời gian ngắn. Nhược điểm chính của nó là nhiều
người dùng không thành thạo sử dụng logic hình thức.
FOCALE cũng sử dụng mạng ngữ nghĩa, một loại biểu đồ tri thức. Các nút đại
diện cho các đối tượng và khái niệm, còn các cạnh mô tả mối quan hệ giữa các đối tượng
đó. Các phiên bản sau này của FOCALE đã sử dụng các mối quan hệ ngôn ngữ (ví dụ:
từ đồng nghĩa, từ trái nghĩa, từ đồng nghĩa, v.v.) bên cạnh các mối quan hệ IS-A và HAS-
A điển hình. Ưu điểm chính của nó là nó thể hiện tri thức một cách tự nhiên, dễ hiểu.
Nhược điểm chính của nó chính là khó biểu diễn các loại mối quan hệ khác nhau.
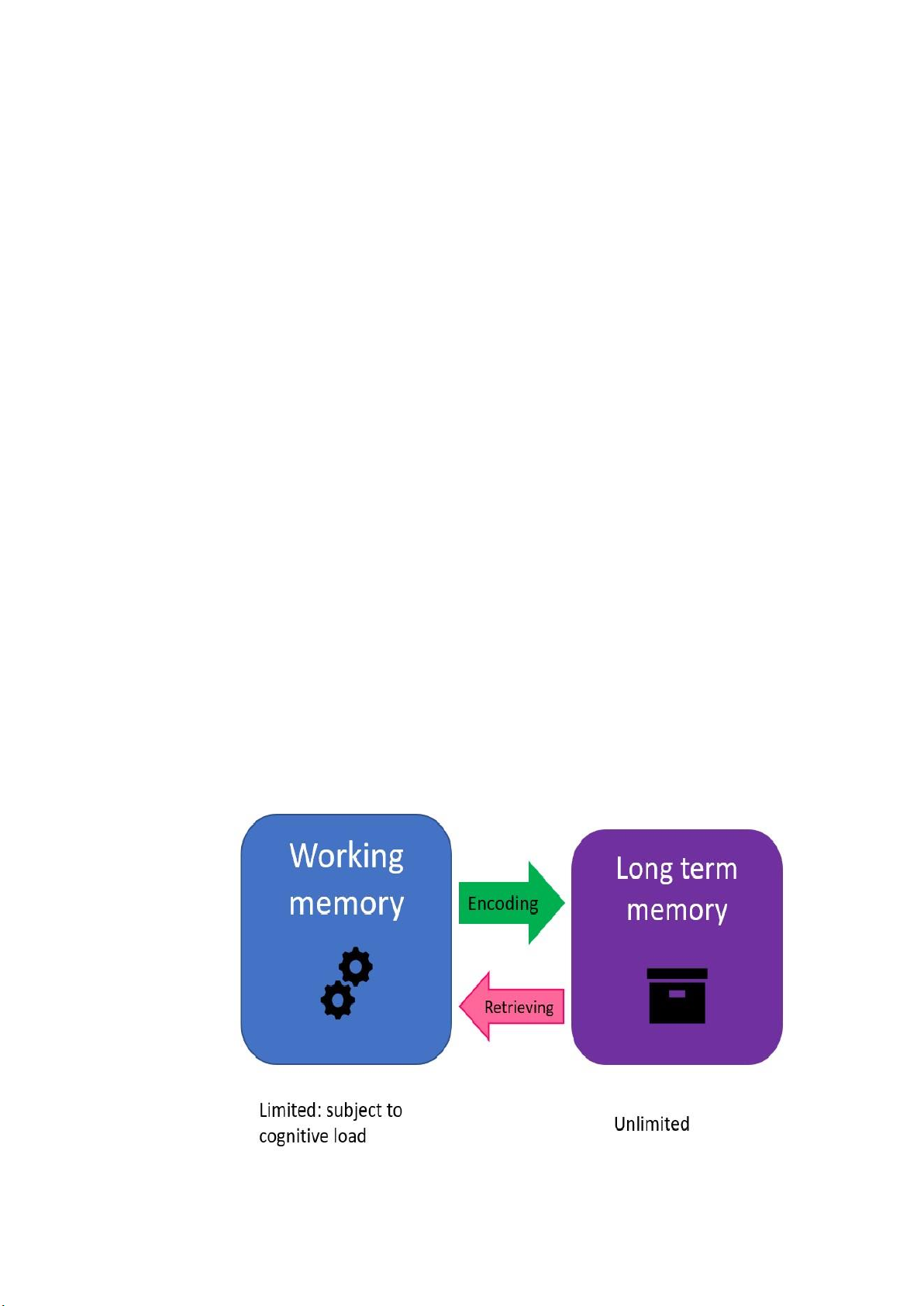
2.5. Bộ nhớ
Hệ thống nhận thức có các loại ký ức khác nhau và sử dụng chúng theo cách
tương tự như con người. Các loại bộ nhớ chính được sử dụng trong hệ thống kỹ thuật số
có thể được phân loại thành bộ nhớ ngắn hạn, bộ nhớ làm việc và bộ nhớ dài hạn.
Bộ nhớ ngắn hạn thể hiện khả năng lưu trữ một lượng nhỏ thông tin (nhưng không
thao tác được) trong một kho lưu trữ đang hoạt động trong một khoảng thời gian ngắn nhất định.
Bộ nhớ làm việc thể hiện khả năng lưu giữ và thao tác một lượng nhỏ thông tin ở
dạng dễ tiếp cận. Nó tạo điều kiện thuận lợi cho việc lập kế hoạch, tìm hiểu, lý luận và
giải quyết vấn đề. Do đó, thông tin sẽ được lưu trữ trong bộ nhớ ngắn hạn và được xử lý trong bộ nhớ làm việc.
Bộ nhớ dài hạn là nơi lưu trữ và sẽ không đả động gì đến dữ liệu và thông tin trừ khi cần thiết.
Hệ thống nhận thức thường sử dụng các kho lưu trữ hoạt động. Kho lưu trữ hoạt
động là một cơ chế lưu trữ có khả năng xử lý trước và/hoặc xử lý sau thông tin được lưu
trữ hoặc truy xuất để đáp ứng tốt hơn nhu cầu của người dùng.
Hình 9. Bộ nhớ lOMoARcPSD| 37054152
CHƯƠNG 3: KIẾN TRÚC NHẬN THỨC
Kiến trúc nhận thức là một hệ thống mô phỏng các quá trình học tập, lý luận và ra quyết
định giống con người. Nó sử dụng các cơ chế không bắt buộc để xây dựng và tạo ra kiến
thức một cách linh hoạt trong quá trình ra quyết định. Chương này tập trung vào việc
phát triển kiến trúc nhận thức cho quản lý mạng và dịch vụ. Nó giải thích kiến trúc chức
năng của hệ thống và thảo luận về những ưu điểm và lợi ích liên quan. 3.1. Tổng quan
Hệ thống nhận thức là hệ thống có thể suy luận về những hành động cần thực
hiện, ngay cả khi tình huống mà nó gặp phải không được lường trước. Nó có thể học hỏi
từ kinh nghiệm của mình để cải thiện hiệu suất. Nó cũng có thể kiểm tra khả năng của
chính mình và ưu tiên sử dụng các dịch vụ và tài nguyên của mình, đồng thời, giải thích
những gì nó đã làm nếu cần và chấp nhận các lệnh bên ngoài để thực hiện các hành động
cần thiết. Cơ bản của nhận thức là khả năng hiểu được sự liên quan của dữ liệu được
quan sát. Điều này thường được thực hiện bằng cách phân loại dữ liệu thành các biểu
diễn được xác định trước, dễ hiểu và phù hợp với tình hình hiện tại. Trí nhớ được sử
dụng để tăng khả năng hiểu biết về tình huống. Cuối cùng, các hành động được đánh giá
bằng mức độ hiệu quả mà chúng thực hiện để hỗ trợ tình huống. Từ các chức năng chính
cần được kết hợp để giải quyết các vấn đề hiện tại trong quản lý dịch vụ mạng được trình
bày ở chương 1 dẫn đến sơ đồ khối chức năng được đơn giản hóa dưới đây: .
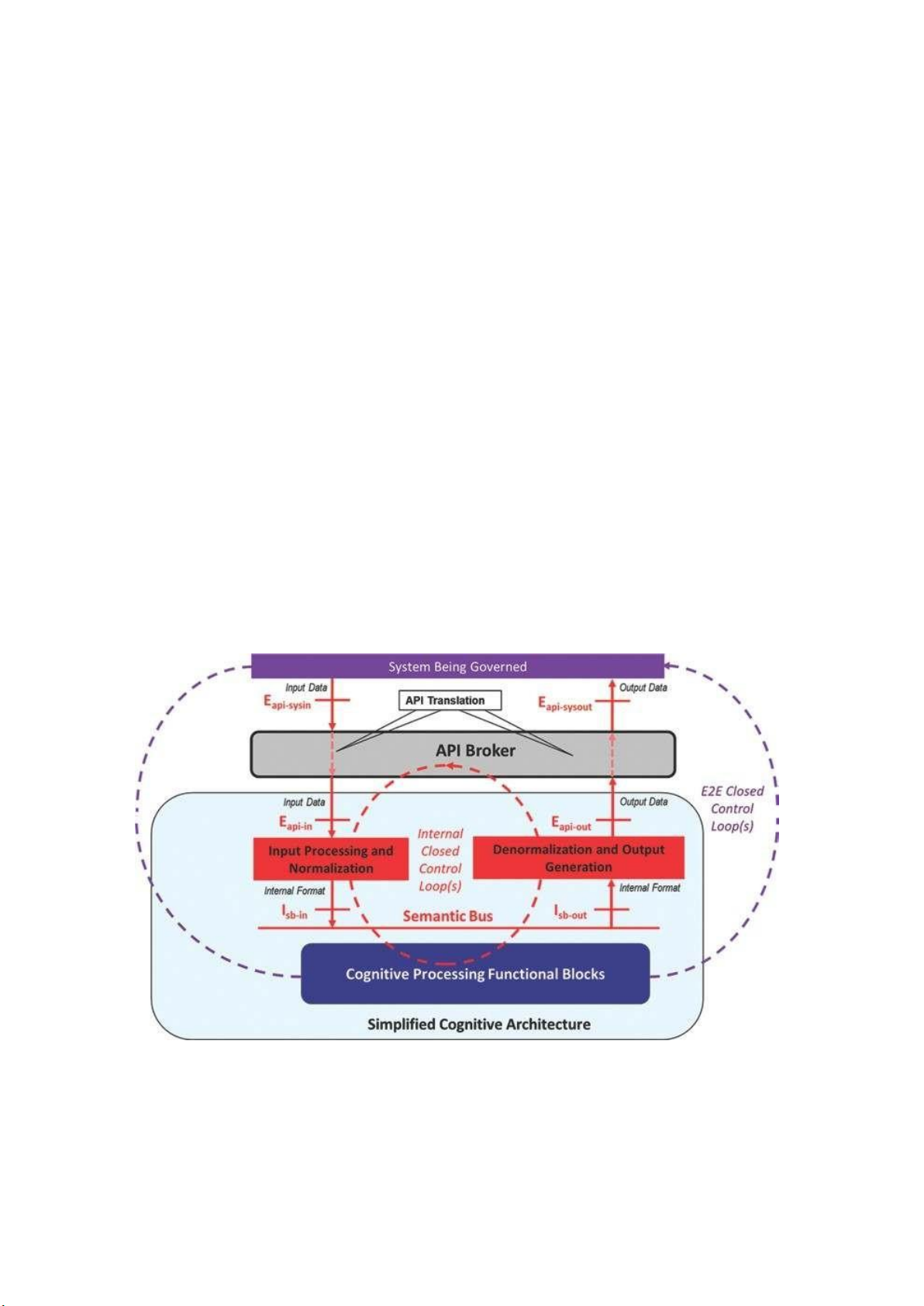
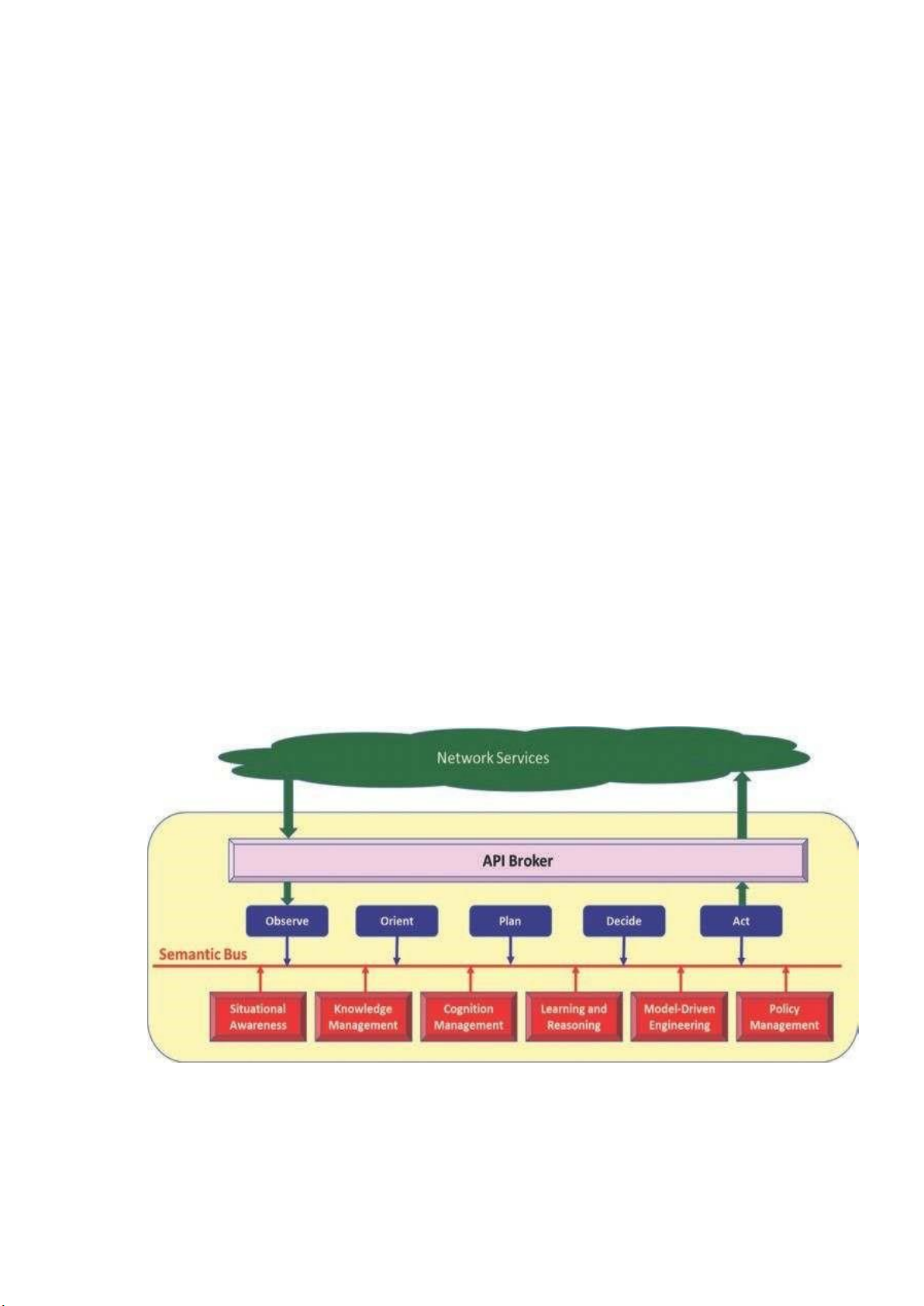
Hình 10. Sơ đồ khối đơn giản của một hệ thống kiến trúc nhận thức
Kiến trúc nhận thức được hiển thị trong Hình 10 được chia thành ba phần: Nhà
môi giới API, Phần xử lý đầu vào và đầu ra và Phần chức năng xử lý nhận thức. Có hai
vòng điều khiển khép kín khác nhau. Vòng lặp bên ngoài lấy dữ liệu từ hệ thống được
quản lý, phân tích nó và thay đổi hành vi của hệ thống được quản lý khi cần thiết để duy
trì các mục tiêu của hệ thống. Vòng lặp bên trong tối ưu hóa trạng thái của hệ thống đang
được quản lý và do đó, các dịch vụ được cung cấp tại bất kỳ thời điểm nào. lOMoARcPSD| 37054152
3.2. Nhà môi giới API (API Broker)
API Broker trong kiến trúc nhận thức là một thành phần quan trọng giúp quản lý
và tương tác với các API (Application Programming Interface) trong mô hình kiến trúc
nhận thức (Cognitive Architecture). API broker cung cấp sự liên kết giữa các thành phần
nhận thức máy khác nhau và các dịch vụ API bên ngoài Kiến trúc nhận thức thường liên
quan đến các hệ thống hoặc ứng dụng thông minh có khả năng học và thích nghi với môi trường thực tế.
Động cơ chính để sử dụng Nhà môi giới API: •
Việc sử dụng Nhà môi giới API cho phép tiếp tục phát triển kiến trúc nhận thức
để tiến hành độc lập với mọi yêu cầu cụ thể về tương tác với các thực thể bên ngoài. •
Việc sử dụng Nhà môi giới API cung cấp giải pháp có khả năng mở rộng và có
khả năng mở rộng cao hơn vì nó tạo điều kiện thuận lợi cho việc sử dụng các công nghệ
chung (ví dụ: RESTful) cũng như các phần bổ trợ tùy chỉnh để đáp ứng nhu cầu liên lạc
với các thực thể bên ngoài khác nhau.
•Việc sử dụng Nhà môi giới API cho phép sử dụng các giải pháp nâng cao, chẳng hạn như thành phần API.
Nhà môi giới API có hai chức năng chính. Đầu tiên là hoạt động như một cổng
API (tức là một thực thể có thể dịch giữa các API khác nhau). Thứ hai là cung cấp quản
lý API. Quản lý API bao gồm xác thực, ủy quyền, kế toán, kiểm toán và chức năng liên quan.
Các chức năng của Cổng API bao gồm: •
Chấp nhận các API đến được truyền qua điểm tham chiếu bên ngoài thích hợp và
định tuyến chúng đến (các) khối chức năng thích hợp của kiến trúc nhận thức •
Chấp nhận các API gửi đi được truyền qua điểm tham chiếu bên ngoài thích hợp
và định tuyến chúng đến thực thể bên ngoài thích hợp
•Chuyển đổi các giao thức được sử dụng bởi các thực thể bên ngoài thành các giao thức
được sử dụng bởi kiến trúc nhận thức và ngược lại
•Quản lý các phiên bản khác nhau của cùng một API
E api-sysin chấp nhận các yêu cầu API từ các thực thể bên ngoài Và thi hành họ,
sau đó bất kì cần thiết dịch qua các API môi giới, TRÊN các nhận thức- hoạt động ngành kiến trúc.
E api-sysout chấp nhận các yêu cầu API từ nhận thức kiến trúc và gửi chúng,
sau bất kỳ bản dịch cần thiết nào của Nhà môi giới API, tới được chỉ định các thực thể bên ngoài.
3.3 Xử lý Dữ liệu Đầu Vào và Đầu Ra
Kiến trúc nhận thức cần sẵn sàng tiếp nhận nhiều loại dữ liệu đầu vào khác nhau
được viết bằng các ngôn ngữ khác nhau. Điều này đòi hỏi biến đổi dữ liệu đầu vào này
thành một dạng chung duy nhất để làm cho quá trình xử lý trở nên hiệu quả và đồng nhất
hơn. Nếu không, mỗi khối chức năng của kiến trúc nhận thức sẽ phải hiểu mỗi loại dữ
liệu đầu vào, bao gồm cả cú pháp và ngữ nghĩa của chúng. Tương tự, định dạng (nội tại) lOMoAR cPSD| 37054152
duy nhất của kiến trúc nhận thức phải được biến đổi thành một định dạng mà các thực
thể bên ngoài có thể tiêu dùng.
Trong quá trình này, một tập hợp các nhiệm vụ chung được thực hiện trên tất cả
dữ liệu được tiếp nhận trước khi những dữ liệu này đạt đến chức năng xử lý nhận thức.
Tương tự, một tập hợp các nhiệm vụ chung được thực hiện khi các lệnh đầu ra và thông
tin được gửi từ Chức năng Xử lý Nhận thức đến bất kỳ thực thể bên ngoài nào. Điều này
là động cơ cho việc có các chức năng xử lý đầu vào và xử lý đầu ra.
Nói chung, quá trình xử lý đầu vào có thể bao gồm việc học hỏi và suy luận từ
dữ liệu thô có sẵn trong một hoặc nhiều lĩnh vực; khi những dữ liệu này được phân tích,
quá trình xử lý sẽ quyết định về kiến thức nào được chuyển tiếp đến các khối chức năng
khác. Trong một số trường hợp, quá trình xử lý có thể lưu trữ dạng thô của dữ liệu được
tiếp nhận cho việc sử dụng sau này. Ví dụ, nhiều loại xử lý xu hướng yêu cầu truy cập
đến dữ liệu thô. Trong hầu hết các trường hợp, chức năng xử lý có thể lưu trữ dạng đã
được xử lý của dữ liệu; điều này cả nhanh chóng và hiệu quả hơn. Việc lựa chọn xem có
nên lưu trữ dạng thô hay dạng đã được xử lý của dữ liệu được tiếp nhận phụ thuộc vào
ngữ cảnh hiện tại và/hoặc tình huống hiện tại và dự kiến
Quá trình này có thể bao gồm các chức năng tổng hợp và tương quan (ví dụ: để
giảm số chiều dữ liệu) cũng như học máy (ví dụ: điều này có thể dẫn đến kết quả nhanh
hơn thông qua xử lý các tập dữ liệu đáng kể nhỏ hơn và cho phép sử dụng các thuật toán
tính toán tính toán và các thuật toán lý thuyết trò chơi khác). Trong trường hợp như vậy,
dữ liệu đã chuẩn hóa cuối cùng cũng có thể chứa kiến thức về một lĩnh vực cụ thể hoặc
nhiều lĩnh vực. Xử lý đầu vào có thể bao gồm các yếu tố sau: •
Lọc dữ liệu là việc loại bỏ thông tin không cần thiết hoặc không mong
muốn. Điều này được thực hiện để đơn giản hóa và có thể tăng tốc độ của phân tích
đang được thực hiện và tương tự như việc loại bỏ nhiễu trong tín hiệu. Lọc đòi hỏi việc
xác định các quy tắc và/hoặc logic kinh doanh để xác định dữ liệu nào sẽ được bao
gồm trong phân tích. Ví dụ bao gồm việc loại bỏ các giá trị ngoại lệ, lọc theo chuỗi
thời gian, tổng hợp (ví dụ: xây dựng một luồng dữ liệu từ các phần của các luồng dữ
liệu khác nhau, chẳng hạn như việc kết hợp tên, địa chỉ IP và dữ liệu ứng dụng), xác
minh (tức là dữ liệu bị từ chối vì nó không đáp ứng các hạn chế về giá trị) và loại bỏ bản sao. •
Tương quan dữ liệu thể hiện một tập dữ liệu dưới dạng mối quan hệ với
các tập dữ liệu khác. Ví dụ, số lượng gói nâng cấp lên một loại dịch vụ cao cấp có thể
tăng do quảng cáo có mục tiêu, điều này có thể tăng thêm khi cung cấp thời gian dùng
thử miễn phí. Những dữ liệu này thường được thu thập bằng cách sử dụng các cơ chế
khác nhau và do đó, chúng bị phân tán ở các điểm thu thập khác nhau. Tương quan dữ
liệu có thể sử dụng quy tắc và/hoặc logic kinh doanh để thu thập dữ liệu phân tán và
kết hợp chúng để cải thiện phân tích. Tương quan dữ liệu là bước đầu tiên trong việc
nắm bắt sự hiểu biết gia tăng về mối quan hệ giữa dữ liệu và các đối tượng cơ bản của chúng. •
Làm sạch dữ liệu là một tập hợp các quy trình phát hiện và sau đó sửa
chữa hoặc loại bỏ dữ liệu bị hỏng, thiếu hoặc không chính xác hoặc không có liên
quan. Các giải pháp làm sạch dữ liệu cũng có thể cải thiện dữ liệu, bằng cách làm cho
nó trở nên hoàn chỉnh hơn bằng cách thêm thông tin liên quan hoặc thông qua việc
thêm dữ liệu siêu dữ liệu. Cuối cùng, việc làm sạch dữ liệu cũng có thể liên quan đến
việc điều hòa và chuẩn hóa dữ liệu. Ví dụ, các từ viết tắt có thể được thay thế bằng lOMoARcPSD| 37054152
nghĩa của chúng và dữ liệu như số điện thoại có thể được định dạng lại theo một định dạng tiêu chuẩn. •
Ẩn danh dữ liệu là quy trình loại bỏ hoặc mã hóa thông tin có thể được
sử dụng để nhận dạng các thực thể có tên từ tập dữ liệu. Trong tài liệu này, quá trình ẩn
danh được định nghĩa là cắt dữ liệu một cách không thể đảo ngược có thể được sử
dụng để nhận diện một thực thể có tên từ tập dữ liệu. Không còn khả năng xác định lại trong tương lai. •
Giả danh dữ liệu là quy trình thay thế thông tin có thể được sử dụng để
nhận dạng một thực thể có tên bằng một hoặc nhiều bộ chỉ số nhân tạo (tức là giả
danh). Lưu ý rằng quá trình giả danh có thể đảo ngược bởi một số thực thể đáng tin
cậy, vì dữ liệu nhận dạng không được loại bỏ, mà thay vào đó được thay thế bằng dữ liệu khác.
Quá trình phi chuẩn hóa là quá trình ngược với quá trình chuẩn hóa; nó sắp xếp
và định dạng dữ liệu và thông tin để đầu ra để có thể dễ dàng và hiệu quả chuyển đổi
thành một dạng mà bộ thực thể ngoại biên sẽ có thể hiểu được. Điều này có thể thực
hiện được thông qua dữ liệu gắn với dữ liệu đã tiếp nhận mô tả cách mà dữ liệu đang
được sử dụng trong kiến trúc nhận thức, và bất kỳ thông tin hay giả thuyết nào mà kiến
trúc nhận thức đã xác định dữ liệu tiếp nhận đang là một phần của nó.
Khi dữ liệu, thông tin hoặc lệnh được phi chuẩn hóa, đầu ra có thể được tạo ra.
Các kỹ thuật MDE có thể được sử dụng để hỗ trợ quá trình chuyển đổi này, vì mô hình
cung cấp các ý nghĩa thích hợp của dữ liệu, thông tin và lệnh cần được dịch.
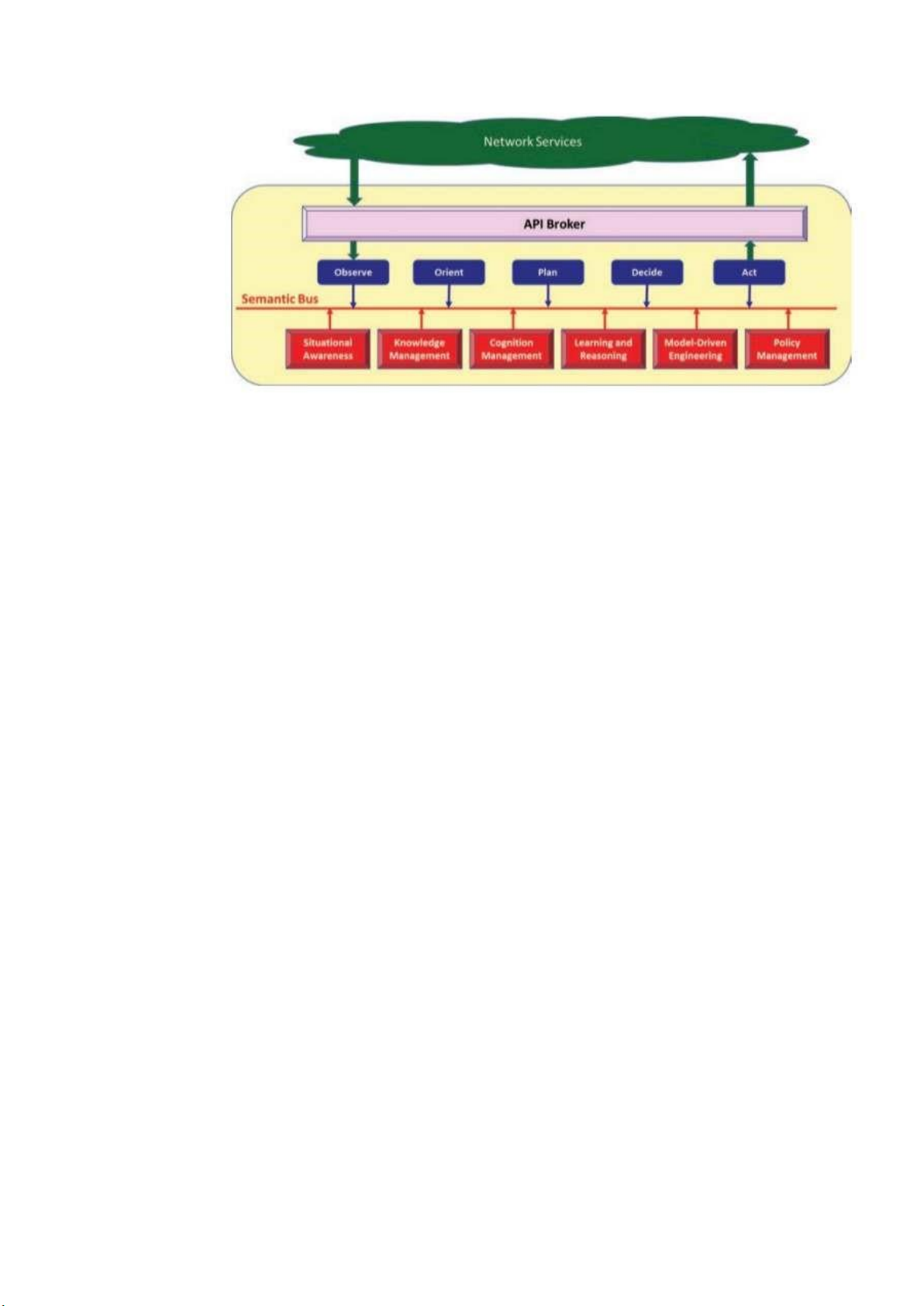
3.4. Chức năng xử lý nhận thức
Hình 11. Kiến trúc chức năng cấp cao của mạng nhận thức
Biểu đồ khối chức năng của các khối chức năng khác nhau tạo nên phần xử lý
nhận thức của kiến trúc nhận thức. Có sáu chức năng mới được yêu cầu. lOMoARcPSD| 37054152
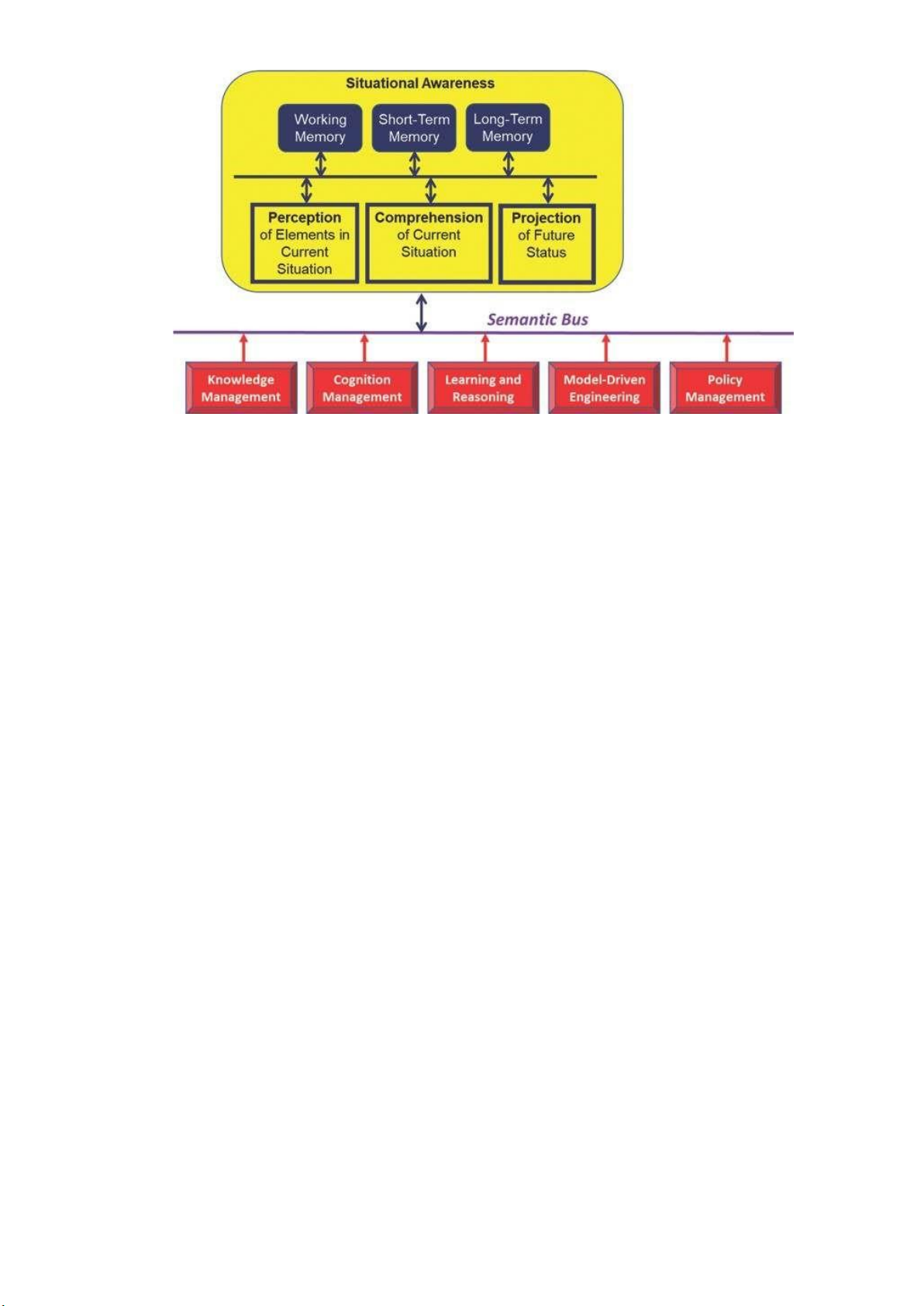
3.4.1 Khối chức năng nhận thức tình huống
Hình 12. Khối chức năng nhận thức tình huống
Khối chức năng Nhận thức Tình huống nhận dữ liệu chuẩn hóa và liên quan dữ
liệu đó đến tình huống hiện tại. Sự hiểu biết dựa trên việc kết hợp thông tin từ các yếu
tố khác nhau được tìm thấy trong tình huống. Cụ thể, sự kết hợp được thực hiện liên
quan đến cả tình huống hiện tại và các mục tiêu hệ thống áp dụng cho tình huống đó.
Việc dự đoán trạng thái tương lai dựa trên kiến thức về các đặc điểm và hành vi của các
yếu tố trong tình huống hiện tại. Khối chức năng Quản lý Nhận thức sau đó điều hướng
sự tương tác của Khối chức năng Nhận thức Tình huống với Khối chức năng Học và Ra
quyết định để xác định làm thế nào dữ liệu hiện tại đã ảnh hưởng đến cập nhật gần đây
nhất của tình huống. Nó cũng có thể xem lại các bản chụp lịch sử của tình huống để tìm
hiểu cách tình huống đã phát triển.
3.4.2 Khối chức năng quản lý kiến thức
Khối chức năng Quản lý kiến thức biến đổi dữ liệu và thông tin thành một biểu
diễn kiến thức đồng nhất mà tất cả các khối chức năng khác có thể sử dụng. Quản lý kiến
thức bao gồm các kho lưu trữ khác nhau để lưu trữ và xử lý kiến thức. Điều này bao gồm
kho lưu trữ cho mô hình, thư mục tri thức, dữ liệu và tính toán, trong đó tính toán có thể,
ví dụ, có dạng một bảng đen. Một hệ thống bảng đen sử dụng một không gian làm việc
chung mà một tập hợp các đại lý độc lập đóng góp, chứa dữ liệu đầu vào cùng với các
giải pháp đãi ngộ, thay thế và hoàn thiện. Cả bảng đen và các đại lý đóng góp đều dưới
sự kiểm soát của một thực thể quản lý có chức năng dành riêng. Mỗi đại lý có chức năng
và hoạt động được chuyên biệt và thông thường hoàn toàn độc lập với các đại lý khác
sử dụng bảng đen. Một bộ điều khiển theo dõi trạng thái của nội dung của bảng đen và
đồng bộ hóa các đại lý đang làm việc với bảng đen. Khối quản lý kiến thức có thể tạo
ra, điều chỉnh, duy trì và tăng cường quá trình lưu trữ, đánh giá, sử dụng, chia sẻ và tinh
chỉnh tài sản tri thức sử dụng biểu diễn tri thức đồng thuận. lOMoARcPSD| 37054152
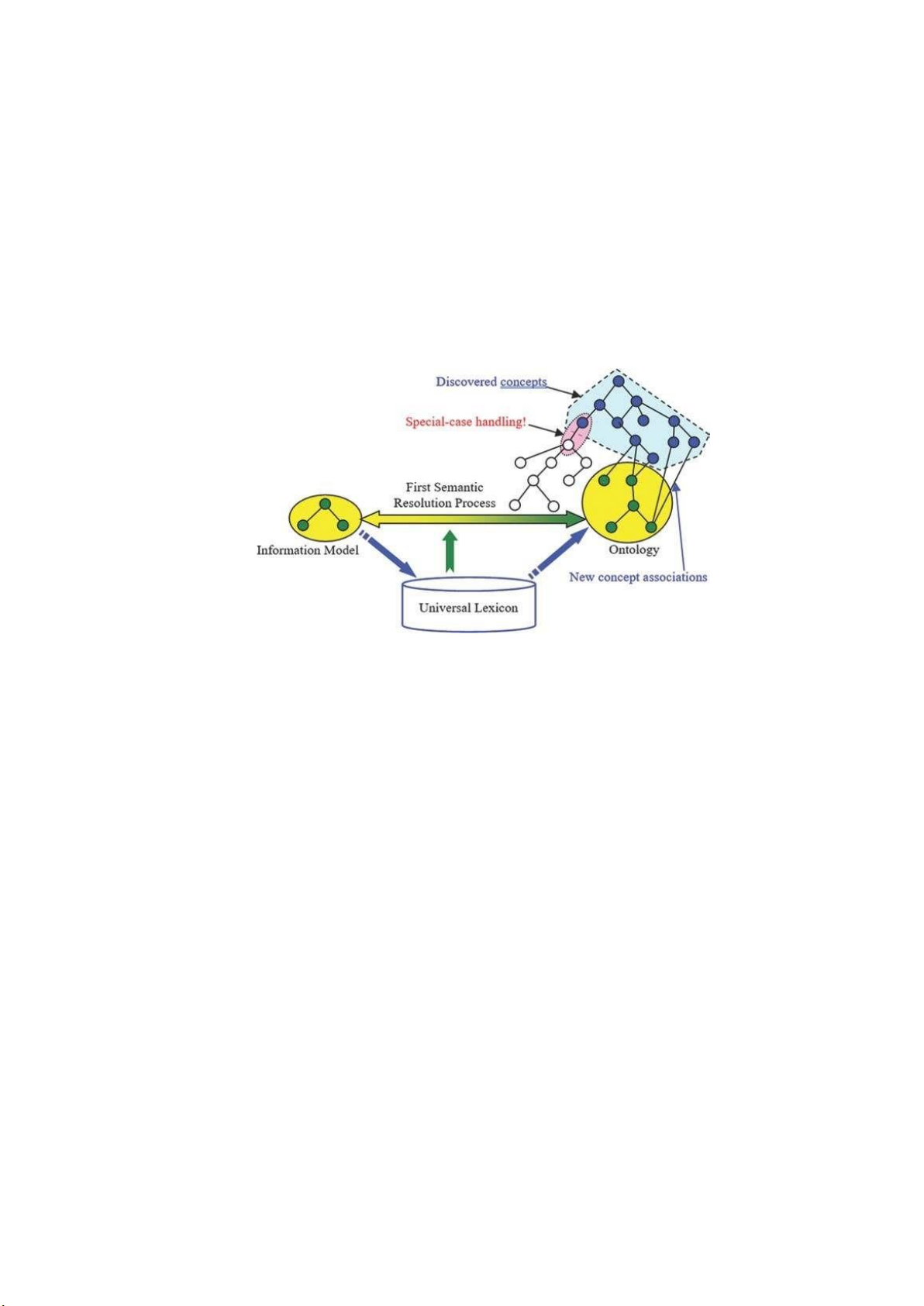
3.4.3 Khối chức năng Quản lý Nhận thức
Hình 13. Khối nhận thức: Tìm các bản thể học phù hợp cho phần tử mô hình
Khối chức năng Quản lý Nhận thức là "bộ óc" của Kiến trúc Nhận thức. Nó chịu
trách nhiệm thực hiện một mô hình nhận thức (tức là mô hình máy tính về cách thực
hiện các quá trình nhận thức, chẳng hạn như sự hiểu biết, hành động và dự đoán, và làm
thế nào các quá trình nhận thức này được thực hiện và ảnh hưởng đến các quyết định)
mà phục vụ để hướng dẫn các hành động của các khối chức năng khác. Nhận thức tập
trung vào việc biểu diễn tri thức đồng nhất và chuẩn hóa. Mô hình nhận thức của nó
được cập nhật liên tục bởi Khối chức năng Học và Ra quyết định.
Tri thức được phát triển bằng một đồ thị đa đồ thị (hoặc một tập hợp các đồ thị
đa đồ thị), như được hiển thị trong Hình 13. Theo phương pháp này, các mô hình và thư
mục tri thức đều được biểu diễn dưới dạng đồ thị; các cạnh ngữ nghĩa (tức là, mối quan
hệ có tính ngữ nghĩa, chẳng hạn như đồng nghĩa và meronymy) sau đó được tạo ra giữa
các đồ thị để xác định cách một tập hợp các khái niệm liên quan đến tập hợp khái niệm
khác. Đồ thị đa đồ thị kết quả bao gồm các mối quan hệ ngữ nghĩa kết nối mô hình ở
bên trái với tập hợp các thư mục ở bên phải; chúng được biểu thị bằng dấu mũi tên kép
trong Hình 13 kết nối chúng với nhau để đơn giản hóa. Biểu diễn ngữ nghĩa này được
xây dựng theo cách tương tác và được tóm lược bên dưới.
Quy trình trong Hình 13 có thể được đảo ngược, nhưng thông thường, một sự thật
có nhiều ý nghĩa hơn là một ý nghĩa có nhiều sự thật.
Mô hình thông tin (hoặc tập hợp các mô hình dữ liệu, nhưng sử dụng mô hình
thông tin là phổ quát hơn) cũng như tập hợp thư mục đều được biểu diễn dưới dạng một
đồ thị hướng đạo không có chu kỳ. Một từ điển là một bộ sưu tập của tất cả các từ, cụm
từ và ký hiệu được sử dụng trong một ngôn ngữ được tổ chức theo cách cho phép mỗi
từ, cụm từ hoặc ký hiệu có một tập hợp các ý nghĩa. Điều này cho phép chọn ý nghĩa
phù hợp nhất cho mỗi từ, cụm từ hoặc ký hiệu dưới ngữ cảnh đúng đắn. Từ điển đóng
vai trò như một bản đồ ánh xạ giữa các đồ thị mô hình và đồ thư mục và cần thiết vì bản
chất của tri thức trong mỗi đồ thư mục là rất khác biệt. Về cơ bản, từ điển đóng vai trò
như một cơ chế làm sáng tỏ ngữ nghĩa cho phép liên kết ý nghĩa tốt nhất từ tập hợp các
khái niệm trong đồ thư mục đối với tập hợp của các yếu tố mô hình. Điều này sau đó
được sử dụng để tìm kiếm các khái niệm có cùng ngữ nghĩa trong tập hợp các thư mục.
Hình 13 bắt đầu bằng việc xác định một hoặc nhiều yếu tố mô hình trong mô hình
thông tin. Sau đó, một hoặc nhiều công cụ khác nhau, bao gồm ngôn ngữ tính toán, tương
đương ngữ nghĩa và so khớp mẫu và cấu trúc, được sử dụng để liên quan tập hợp các
yếu tố mô hình đó đến tập hợp các thuật ngữ trong từ điển. Nói chung, tập hợp các yếu
tố mô hình có thể được liên quan đến một thuật ngữ trong từ điển, sau đó lại liên quan
đến nhiều khái niệm thuật ngữ. Mỗi mối quan hệ thường là ngôn ngữ hoặc logic, nhưng
có thể bao gồm cả các mối quan hệ khác (trong trường hợp này, chúng cần được đánh
trọng lượng thành dạng tương đương ngữ nghĩa). Để đơn giản, phần còn lại của cuộc trò
chuyện này sẽ giả định mối quan hệ ngôn ngữ (chẳng hạn, hypernyms [tức là, một đối
tượng có ý nghĩa bao gồm ý nghĩa của các đối tượng khác] và hyponyms [tức là, một
đối tượng có ý nghĩa bao gồm trong một đối tượng], holonyms [tức là, một đối tượng lOMoARcPSD| 37054152
chứa các đối tượng khác], meronyms [tức là, một đối tượng thuộc về một đối tượng
khác]) và mối quan hệ tùy chỉnh (chẳng hạn, "tương tự với", đó là mối quan hệ được gán
giá trị là mối quan hệ liên quan ngữ nghĩa giữa hai đối tượng).
Hình này cho thấy rằng quá trình tìm kiếm đã liên quan tập hợp các yếu tố mô
hình đến một khái niệm cô lập cùng với một phân cấp bao gồm bốn khái niệm, tổng cộng
là năm khái niệm, trong tập thư mục. Điều này dẫn đến việc xây dựng một đồ thị đa đồ
thị mới, bao gồm các đồ thị con gốc từ mô hình được kết nối với tập hợp các khái niệm
trong thư mục bằng cách sử dụng tập hợp các mối quan hệ ngữ nghĩa được phát hiện
trong các quy trình trên. Theo cách này, quá trình giải quyết ngữ nghĩa so sánh ý nghĩa
(tức là không chỉ là định nghĩa, mà còn cả mối quan hệ ngữ nghĩa, chẳng hạn như quan
hệ đồng nghĩa và meronymy) của mỗi yếu tố trong đồ thị con đầu với tất cả các yếu tố
trong đồ thị con thứ hai, cố gắng tìm kiếm yếu tố hoặc yếu tố tương tự nhất phù hợp với
ý nghĩa của yếu tố trong đồ thị con đầu. Thường thì không thể tìm kiếm chính
xác; vì vậy, quá trình giải quyết ngữ nghĩa cung cấp kết quả dạng tỷ lệ, cho phép xếp
hạng từng sự phù hợp theo thứ tự xấp xỉ tốt nhất cho ý nghĩa tổng hợp của đồ thị con
đầu. Bước tiếp theo được minh họa trong Hình 14.
Hình 14. Khối nhận thức: Tìm các khái niệm bản thể học
Trong bước này, mỗi khái niệm thư mục đã được xác định trong quá trình khớp
ngữ nghĩa bây giờ được kiểm tra xem nó có liên quan đến các khái niệm khác trong thư
mục này hoặc thư mục khác. Khi một khái niệm mới được tìm thấy, nó được đánh dấu
để có thể thêm vào các khái niệm hiện có đã được kết hợp từ từ điển phổ quát. Khái niệm
mới được thêm sau đó được kiểm tra xem nó có liên quan trực tiếp đến một thuật ngữ
trong từ điển phổ quát (như được thể hiện trong đa giác đứt nét trong Hình 14). Nếu nó
không liên quan trực tiếp đến một thuật ngữ trong từ điển phổ quát (như được thể hiện
trong hình oval đứt đoạn trong Hình 14), thì quá trình xử lý phức tạp hơn cần được thực
hiện, điều này vượt ra khỏi phạm vi của chương này. Việc thêm các khái niệm mới này
phục vụ hai mục đích: (1) cung cấp một tập hợp ý nghĩa tốt hơn đối với nhóm các yếu
tố mô hình và (2) xác minh rằng mỗi khái niệm mới củng cố hoặc thêm hỗ trợ bổ sung
cho khái niệm đã được chọn. Do đó, quá trình này có thể được xem như làm tăng tính
ngữ nghĩa của sự phù hợp.
Một đa đồ thị được tạo ra bằng cách định nghĩa các mối quan hệ ngữ nghĩa giữa
các đối tượng mô hình và các khái niệm trong thư mục. Những mối quan hệ ngữ nghĩa
mới này, cùng với những khái niệm mới được tìm thấy trong thư mục, có thể được sử
dụng để tìm kiếm các yếu tố mô hình mới. Bước này tương tự như bước trước, ngoại trừ
việc nó được đảo ngược. Nghĩa là, mỗi khái niệm thư mục mới trước hết được ánh xạ
thành một hoặc nhiều thuật ngữ trong từ điển phổ quát, sau đó mỗi thuật ngữ đó được
ánh xạ thành các yếu tố mô hình. Giống như trước, thuật toán cố gắng so khớp các tập lOMoARcPSD| 37054152
hợp các khái niệm liên quan với các tập hợp yếu tố mô hình liên quan. Điều này có tác
dụng gia tăng sự tương tự ngữ nghĩa giữa hai khái niệm; khi các tập hợp các khái niệm
liên quan đến các tập hợp yếu tố mô hình lớn hơn, mối tương quan mạnh hơn giữa ý
nghĩa của tập hợp khái niệm và tập hợp yếu tố mô hình được thiết lập. Điều này thực tế
là một kiểm tra tự thể hiện về sự chính xác của ánh xạ và được sử dụng để loại bỏ các
khái niệm và yếu tố mô hình phù hợp với nhau nhưng không liên quan đến thực thể đang được mô hình hoá.
3.4.4 Khối chức năng Học và Lý luận
Khối chức năng Học và Lý luận cung cấp các loại học khác nhau để cho phép sử dụng
các thuật toán học khác nhau được tùy chỉnh cho từng nhiệm vụ cụ thể:
Học thông qua kinh nghiệm, đó là tập hợp các quy trình cho phép tạo kiến thức thông qua trải nghiệm.
Học có giám sát, xác định một hàm ánh xạ từ đầu vào đến đầu ra dựa trên các cặp
ví dụ về đầu vào đã được gán nhãn và đầu ra.
Học có hướng dẫn là một thuật toán học có giám sát lặp lại, trong đó thuật toán có
thể tương tác trực tiếp với một người dùng chuyên nghiệp (ví dụ: một người chú
thích) để có được nhãn chính xác.
Học không có giám sát, xác định một hàm ánh xạ từ đầu vào đến đầu ra mà không
cần sử dụng thông tin về việc phân loại hoặc gán nhãn dữ liệu.
Học thông qua tương tác, sử dụng các tác nhân phần mềm để thực hiện các hành
động trong môi trường để tối đa hóa phần thưởng tích luỹ.
Học tính năng, phân tích dữ liệu đầu vào để học các đặc điểm quan trọng và biểu
diễn hành vi của dữ liệu, từ đó làm cho việc khám phá thông tin từ dữ liệu thô dễ
dàng hơn khi xây dựng các loại dự đoán khác nhau (ví dụ: bộ phân loại).
Học ngữ nghĩa, có khả năng học thông qua việc hiểu nghĩa của dữ liệu.
Các loại thuật toán khác nhau cho xử lý ngôn ngữ tự nhiên.
Học giám sát nên được sử dụng khi có một hoặc nhiều tập dữ liệu có các giá trị đầu
vào và đầu ra đã được gán nhãn. Các thuật toán học giám sát lý tưởng cho các nhiệm vụ
phân loại và hồi quy. Các thuật toán phân loại được sử dụng để dự đoán danh mục mà
một dữ liệu mới thuộc vào dựa trên một hoặc nhiều biến độc lập. Trong khi đó, các thuật
toán hồi quy dự đoán một giá trị số liên quan cho dữ liệu đầu vào dựa trên dữ liệu đã quan sát trước đó.
Học không giám sát nên được sử dụng khi không có dữ liệu, hoặc tập dữ liệu không
đủ, và nhiệm vụ là học cách thực hiện hành động trong tình huống cụ thể khi tương tác
với một thực thể mới. Phân cụm là một thủ tục thống kê đa biến thu thập dữ liệu chứa
thông tin về một mẫu các đối tượng sau đó sắp xếp các đối tượng thành các nhóm, trong
đó các đối tượng trong cùng một nhóm tương tự nhau hơn so với đối tượng trong các
nhóm khác. Phân cụm xác định các điểm chung trong các đối tượng trong mỗi nhóm, có
thể được sử dụng để phát hiện dữ liệu bất thường không phù hợp với bất kỳ nhóm nào.
Học chủ động là một thuật toán học có giám sát lặp lại, trong đó thuật toán có thể
tương tác trực tiếp với một chuyên gia để có thể gán nhãn chính xác. Phương pháp này
cho phép thuật toán học tương tác chọn dữ liệu mà nó sẽ học. Học có hướng dẫn lặp đi lOMoARcPSD| 37054152
lặp lại lựa chọn các ví dụ thông tin nhất để thu thập nhãn và huấn luyện một bộ phân loại
từ bộ dữ liệu đào tạo cập nhật, được bổ sung bằng các ví dụ mới được chọn. Khác với
học có giám sát truyền thống, nó cho phép một mô hình học tiến triển và thích nghi với
dữ liệu mới. Học có hướng dẫn quan tâm đến việc học các bộ phân loại chính xác bằng
cách chọn các ví dụ sẽ được gán nhãn, giảm thiểu công việc đánh dấu và chi phí đào tạo
một mô hình chính xác. Học có hướng dẫn thích hợp cho các ứng dụng học máy nơi dữ
liệu đã được gán nhãn đắt đỏ để thu thập nhưng dữ liệu chưa được gán nhãn là dồi dào.
Học có hướng dẫn đặc biệt quan trọng khi đối tượng có thể có nhiều nhãn thuộc về nhiều
danh mục khác nhau (ví dụ: một thiết bị mạng có nhiều vai trò, hoặc một hình ảnh có
thể được gán nhãn là chứa cả núi, bãi biển và biển). Thách thức chính là xác định bộ
nhãn nào phù hợp với ngữ cảnh hoặc tình huống cụ thể.
Học ngữ nghĩa sử dụng logic hình thức và/hoặc các từ điển tri thức để học dựa trên
ý nghĩa của dữ liệu so sánh với tình huống hiện tại.
Một kiến trúc nhận thức sẽ bao gồm một hoặc nhiều thuật toán xử lý ngôn ngữ tự
nhiên. Một số dữ liệu bối cảnh và tình huống có thể được tiếp thu dưới dạng ngôn ngữ
tự nhiên, tùy thuộc vào nguồn đầu vào. Các quy tắc kinh doanh, quy định chính sách và
mục tiêu hệ thống cũng có khả năng được thể hiện dưới dạng ngôn ngữ tự nhiên. Nhúng
văn bản là biểu diễn vector có giá trị thực của chuỗi ký tự, trong đó một vector dày được
xây dựng cho mỗi từ, được chọn sao cho nó tương tự với các vector của các từ xuất hiện
trong ngữ cảnh tương tự. Điều này cho phép học sâu hiệu quả trên các tập dữ liệu nhỏ
hơn, vì chúng thường là đầu vào đầu tiên cho một kiến trúc học sâu và là cách phổ biến
nhất để học chuyển đổi trong xử lý ngôn ngữ tự nhiên. Mạng lưới bộ nhớ ngắn hạn dài
(LSTM) giới thiệu cổng và một ô nhớ được xác định một cách rõ ràng. Mỗi tế bào thần
kinh có một ô nhớ và ba cổng: cổng đầu vào, cổng đầu ra và cổng quên. Chức năng của
các cổng này là bảo vệ thông tin bằng cách ngăn hoặc cho phép dòng thông tin. Cổng
đầu vào xác định mức độ thông tin từ tầng trước được lưu trữ trong ô nhớ, trong khi tầng
đầu ra xác định mức độ mà tầng tiếp theo biết về trạng thái của ô nhớ này. Cổng quên
xác định những ký tự nào sẽ bị lãng quên cho tầng xử lý tiếp theo. Hiện tại, LSTM là
mô hình mặc định cho hầu hết các nhiệm vụ gắn nhãn chuỗi. Một Transformer là một
mô hình học sâu sử dụng cơ chế chú ý, đo lường ảnh hưởng của các phần khác nhau
trong dữ liệu đầu vào. Transformer là mô hình truyền đổi đầu tiên (tức là chuyển đổi các
chuỗi đầu vào thành chuỗi đầu ra) dựa hoàn toàn vào chú ý tự thân để tính toán biểu diễn
của dữ liệu đầu vào và đầu ra mà không cần sử dụng các mạng nơ-ron đệ quy sắp xếp
theo chuỗi hoặc tích chập. Transformers được thiết kế để xử lý dữ liệu đầu vào tuần tự,
chẳng hạn như ngôn ngữ tự nhiên, nhưng không yêu cầu dữ liệu tuần tự phải được xử lý
theo trình tự. Thay vào đó, phép chú ý xác định bối cảnh cho bất kỳ vị trí nào trong chuỗi
đầu vào. Điều này cho phép triển khai mô hình của nó theo cách tự nhiên. Khối chức
năng Quản lý Chính sách là một tập hợp quy tắc được sử dụng để quản lý và kiểm soát
sự thay đổi và/hoặc duy trì trạng thái của một hoặc nhiều đối tượng quản lý. Nó cung
cấp một cơ chế thống nhất và chuẩn hóa để truyền dữ liệu.
3.4.5 Khối chức năng Quản lý Chính sách
Khối chức năng Quản lý Chính sách là một tập quy tắc được sử dụng để quản lý
và kiểm soát việc thay đổi và/hoặc duy trì trạng thái của một hoặc nhiều đối tượng được
quản lý. Nó cung cấp một cơ chế thống nhất và chuẩn hóa để trao đổi dữ liệu và lệnh
trong một hệ thống và giữa các hệ thống. Tài liệu tham khảo [7] định nghĩa một mô hình lOMoARcPSD| 37054152
thông tin hướng đối tượng UML mới lạ để đại diện cho các loại chính sách khác nhau.
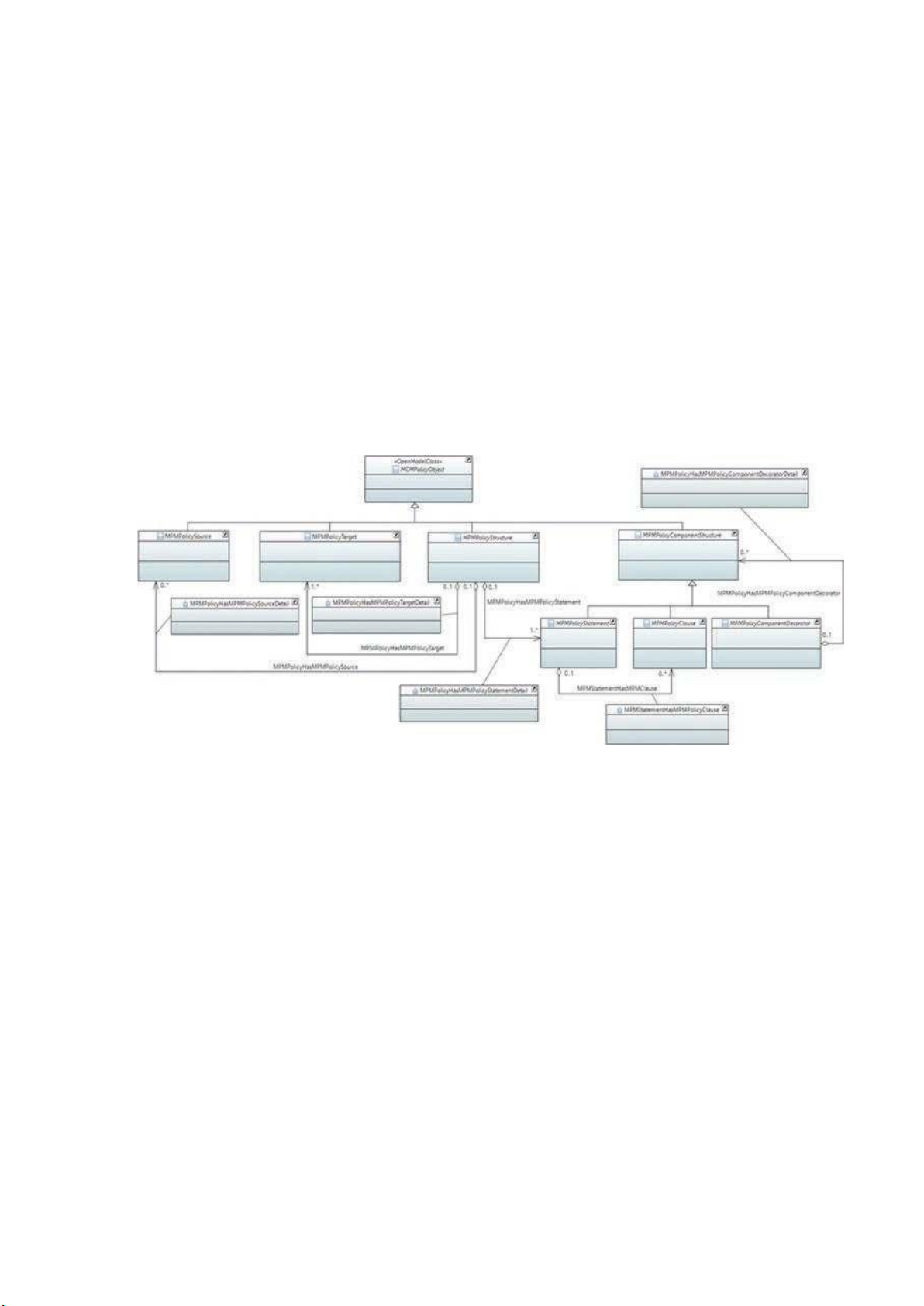
Sơ đồ lớp được thể hiện trong Hình 14.
Lớp cao nhất, MPMPolicyObject, được thừa kế từ MEF Core Model (MCM), mô
hình thông tin hướng đối tượng tổng quan này bao gồm một lớp gốc duy nhất với ba lớp
con. Các lớp con này tạo thành các hệ thống phân mảnh cho việc biểu diễn các thực thể
được quản lý và không được quản lý cùng với siêu dữ liệu (trong số các khái niệm khác).
Mô hình Chính sách MEF (MPM) [7] bao gồm bốn loại đối tượng. Hai trong số
chúng, MPMPolicyStructure và MPMPolicyComponentStructure, xác định các hệ thống
phân cấp cho việc biểu diễn chính sách và các thành phần của chính sách, một cách lần
lượt. MPMPolicySource đại diện cho một tập hợp các đối tượng đã tạo chính sách và
MPMPolicyTarget đại diện cho một tập hợp các đối tượng có thể bị ảnh hưởng bởi chính sách.
Có ba loại chính sách chính được sử dụng trong MPM: chính sách bắt buộc, chính
sách tuyên bố và chính sách mục đích. Các mô hình chính sách bổ sung (chẳng hạn như
các chức năng tiện ích) hiện đang được thiết kế.
Hình 15. Mô hình chính sách MEF
Chính sách Bắt buộc điều khiển một cách rõ ràng quá trình chuyển đổi từ một
trạng thái này sang một trạng thái khác. Trong cách tiếp cận này, chỉ có một trạng thái
mục tiêu được chọn. Một ví dụ về chính sách bắt buộc là chính sách ECA (Sự kiện-Điều
kiện-Hành động). Theo mô hình này, một chính sách bao gồm ba mệnh đề Boolean (sự
kiện, điều kiện và hành động). Ngữ nghĩa của chính sách này là:
IF: mệnh đề sự kiện là ĐÚNG
ELSE IF: mệnh đề điều kiện là ĐÚNG
Có thể xảy ra việc thực hiện các hành động trong mệnh đề hành động ENDIF ENDIF
Chính sách Bắt buộc có thể bao gồm siêu dữ liệu điều khiển cách thức thực hiện
các hành động (chẳng hạn như thực hiện hành động đầu tiên, thực hiện hành động cuối
cùng, thực hiện tất cả các hành động) và điều gì xảy ra nếu xảy ra lỗi (chẳng hạn như
ngừng thực hiện, ngừng thực hiện và quay trở lại hành động đó, ngừng thực hiện và quay
trở lại tất cả các hành động). lOMoARcPSD| 37054152
Chính sách Tuyên bố mô tả tập hợp các tính toán cần phải được thực hiện mà
không mô tả cách thực hiện các tính toán đó. Đặc biệt, không có sự xác định về luồng
điều khiển của chương trình. Vì vậy, một đặc điểm quan trọng của lập trình tuyên bố là
thứ tự thực hiện các câu lệnh không được xác định. Trong MPM, một Chính sách Tuyên
bố được viết bằng một ngôn ngữ logic hình thức, chẳng hạn như Logic Bậc 1, và là một
chương trình thực hiện theo một lý thuyết được định nghĩa trong một ngôn ngữ logic
hình thức. Do đó, một Chính sách Tuyên bố có thể chọn bất kỳ trạng thái nào thỏa mãn lý thuyết.
Chính sách Mục đích là một loại chính sách tuyên bố sử dụng các tuyên bố để
diễn tả mục tiêu của chính sách, nhưng không diễn tả cách thực hiện những mục tiêu đó.
Mỗi tuyên bố trong một Chính sách Mục đích có thể yêu cầu việc dịch một hoặc nhiều
thuật ngữ của nó sang một hình thức mà một thực thể chức năng được quản lý khác có
thể hiểu. Đặc biệt, một Chính sách Mục đích là một chính sách không thực hiện như một
lý thuyết của một ngôn ngữ logic hình thức. Chính sách Mục đích được diễn tả bằng một
ngôn ngữ tự nhiên hạn chế và yêu cầu một phép ánh xạ sang một hình thức hiểu được
bởi các thực thể chức năng được quản lý khác. Lợi ích của một Chính sách Mục đích là
khả năng diễn tả chính sách bằng các khái niệm và thuật ngữ mà một cử tri cụ thể hiểu
(chẳng hạn như được định nghĩa trong Liên tục Chính sách [2–5]). Về mặt khái niệm,
tập hợp các mô hình và ngữ cảnh được sử dụng để định nghĩa các phần tử của ngữ pháp
mà một Chính sách Mục đích được viết bằng, điều này cho phép dịch các Chính sách
Mục đích khác nhau được viết bởi các cử tri khác nhau sang một hình thức chung.
3.5. Đạt được mục tiêu trong kiến trúc nhận thức
Như được thể hiện trong Hình 11 và 12, tri thức dựa vào sự nhận thức, hiểu biết
và hành động để đạt được hoặc duy trì một tập hợp các mục tiêu hệ thống. Điều này ngụ
ý rằng kiến thức về tình huống khác với kiến thức về các hoạt động thay đổi tình huống
và thúc đẩy quá trình học thông qua trải nghiệm từ cách các thay đổi khác nhau trong hệ
thống và/hoặc môi trường ảnh hưởng đến mục tiêu của hệ thống. Ba loại cấu trúc bộ nhớ
khác nhau đóng một vai trò quan trọng trong việc củng cố điều này. Cụ thể, các mệnh
đề logic được sử dụng để liên kết các yếu tố bộ nhớ ngắn hạn như các ví dụ của các yếu
tố bộ nhớ dài hạn. Điều này cho phép mỗi yếu tố bộ nhớ ngắn hạn được gắn liền với một
mục tiêu hoặc niềm tin cơ bản. Điều này được thúc đẩy bằng cách cho phép các yếu tố
bộ nhớ dài hạn phức tạp hơn được tạo thành từ một tập hợp các yếu tố bộ nhớ dài hạn
đơn giản hơn, cung cấp một cơ sở kiến thức có tính mở rộng. Điều này quan trọng để
tạo ra một tập hợp các phụ-mục tiêu được sắp xếp để đạt được một mục tiêu cấp cao cụ
thể. Điều này yêu cầu sự mở rộng nhỏ của các máy trạng thái sử dụng, trong đó một
trạng thái cụ thể có thể cần phản ánh mối quan hệ giữa các ví dụ của bộ nhớ ngắn hạn
và dài hạn cũng như tính chất tổ hợp của một ví dụ bộ nhớ dài hạn cụ thể. lOMoARcPSD| 37054152
CHƯƠNG 4: NHẬN THỨC MÁY TRONG QUẢN LÝ MẠNG
4.1. Quy trình quản lý mạng thông qua Nhận thức máy
Bước 1: Thu Thập Dữ liệu
Thu thập dữ liệu từ các thiết bị mạng như routers, switches, tường lửa, cũng như
từ các hệ thống như IDS/IPS, hệ thống quản lý sự cố, và các dịch vụ đám mây. Sử dụng
giao thức như SNMP, NetFlow, hoặc sFlow để thu thập thông tin lưu lượng và log từ các thiết bị.
Bước 2: Tiền Xử Lý và Chuẩn Bị Dữ liệu
Làm sạch và chuẩn hóa dữ liệu, giảm nhiễu và loại bỏ thông tin không liên quan
hoặc trùng lặp. Sử dụng công cụ tiền xử lý dữ liệu, ETL (Extract, Transform, Load) và
cơ sở dữ liệu để lưu trữ dữ liệu đã được làm sạch.
Bước 3: Phân Tích và Nhận Dạng Mẫu
Sử dụng các thuật toán để phân tích dữ liệu và nhận dạng các mẫu, như dấu hiệu
của việc tắc nghẽn mạng hoặc các cuộc tấn công.
Bước 4: Dự Đoán và Đưa Ra Cảnh Báo
Dựa vào mẫu lịch sử và hiện tại, hệ thống dự đoán sự kiện tiềm ẩn và gửi cảnh
báo. Sử dụng các mô hình tiên đoán như mạng neuron nhân tạo hoặc máy vector hỗ trợ.
Bước 5: Ra Quyết Định và Hành Động Tự Động
Xác định hành động dựa trên các quy tắc hoặc các thuật toán học củng cố để tự
động hóa việc giải quyết vấn đề hoặc cải thiện hiệu suất. Tích hợp với hệ thống quản lý
mạng (NMS) hoặc hệ thống tự động hóa mạng (Network Automation Systems). Ví dụ:
¥ Giám Sát Thời Gian Thực: Sử dụng các mô hình Nhận thức máy để phân tích lưu
lượng mạng và nhận dạng các mô hình bất thường, như dấu hiệu của DDOS hoặc bị nhiễm malware.
¥ Phát Hiện Lỗ Hổng An Ninh: Áp dụng các mô hình học sâu để phân tích và phát
hiện các kỹ thuật tấn công mới và tự động hóa việc áp dụng các quy tắc bảo mật mới.
¥ Tự Động Cấu Hình Lại Mạng: Sử dụng các thuật toán để tự động cấu hình lại mạng
dựa trên nhu cầu thực tế của lưu lượng, như tự động chuyển đổi các dịch vụ sang
các đường truyền có băng thông cao. lOMoARcPSD| 37054152
Hình 16. Quản lý mạng
4.2. Ứng dụng trong thực tiễn 1. Giám Sát Mạng
a. Hệ thống giám sát tự động:
¥ Phát hiện bất thường: Sử dụng học máy để học từ dữ liệu lịch sử và nhận diện
những hành vi bất thường trong traffic mạng, có thể báo hiệu một sự kiện không
mong muốn như tấn công mạng.
¥ Phân tích dự đoán: Dự đoán và phát hiện sớm các vấn đề tiềm ẩn như cảnh báo về
tình trạng quá tải trên các thiết bị hoặc kết nối. b. Công cụ trực quan:
¥ Sử dụng các công cụ trực quan hóa dữ liệu để biểu diễn trực quan các thông số
mạng, giúp nhân viên IT nắm bắt tình hình mạng một cách dễ dàng và nhanh chóng.
2. Phát Hiện và Phản ứng với Sự Cố
a. Hệ thống phát hiện xâm nhập (IDS):
¥ Các hệ thống IDS tiên tiến sử dụng các mô hình nhận thức máy để nhận diện các
mẫu hành vi độc hại và cảnh báo về các nỗ lực xâm nhập không được phép.
b. Hệ thống quản lý sự kiện (SIEM):
¥ SIEM kết hợp giám sát an ninh và quản lý sự kiện để cung cấp cái nhìn tổng quan
về an ninh mạng và phản ứng nhanh chóng với các mối đe dọa.
c. Hệ thống phản ứng tự động:
¥ Hệ thống có khả năng tự động thực hiện các hành động khi phát hiện sự cố hoặc
mối đe dọa, như cách ly thiết bị nhiễm malware hoặc điều chỉnh cấu hình tường lửa. lOMoARcPSD| 37054152
3. Tự Động Hóa và Tối Ưu Hóa
a. Quản lý cấu hình mạng:
¥ Sử dụng AI để tự động hóa các nhiệm vụ cấu hình mạng, giảm sai sót do con người
và tăng tốc độ triển khai các thay đổi.
b. Cân bằng tải và phân bổ tài nguyên:
¥ Học máy giúp dự đoán và phân phối tài nguyên mạng một cách tối ưu dựa trên các
yêu cầu thực tế và dự đoán về lưu lượng sắp tới.
4. Bảo Dưỡng và Quản Lý Sự Cố a. Dự đoán sự cố:
¥ Sử dụng dữ liệu thu thập được để dự đoán và ngăn chặn các sự cố trước khi chúng
xảy ra, giảm downtime và tăng độ tin cậy của mạng.
b. Phân tích nguyên nhân gốc:
¥ Khi một sự cố xảy ra, nhận thức máy có thể phân tích một lượng lớn dữ liệu để xác
định nguyên nhân gốc rễ, giúp giải quyết nhanh chóng và ngăn ngừa lặp lại.
Trong mỗi trường hợp, việc tích hợp nhận thức máy vào quản lý mạng đòi hỏi dữ
liệu chất lượng cao, mô hình được đào tạo kỹ lưỡng và khả năng tích hợp sâu với hệ
thống mạng hiện hữu. Điều này không chỉ cải thiện đáng kể khả năng nhìn nhận và phản
ứng của hệ thống mạng, mà còn giảm thiểu sự can thiệp của con người và các chi phí liên quan.
4.3. Các trường hợp nghiên cứu thực tế
Hình 16. Trường Hợp Nghiên Cứu 1: AT&T's Network AI
AT&T đã phát triển Network AI, một hệ thống quản lý mạng sử dụng AI để giám
sát và phân tích lưu lượng mạng. Giảm đáng kể thời gian gián đoạn và tự động xử lý các
vấn đề mạng và nâng cao khả năng phục vụ khách hàng, giảm tải công việc cho nhân
viên kỹ thuật, cho phép họ tập trung vào các công việc có giá trị cao hơn. lOMoARcPSD| 37054152
Hình 17. Trường Hợp Nghiên Cứu 2: DeepMind's AI for Data Center Cooling
DeepMind đã triển khai hệ thống AI của mình để quản lý hiệu quả năng lượng
trong các trung tâm dữ liệu của Google. Giảm tiêu thụ năng lượng dành cho làm mát lên
đến 40%. Đánh giá ảnh hưởng: Không chỉ tiết kiệm chi phí mà còn giảm ảnh hưởng đến
môi trường, hướng tới việc vận hành trung tâm dữ liệu một cách bền vững hơn.
Hình 18. Trường Hợp Nghiên Cứu 3: Juniper Networks' Mist AI
Juniper Networks đã sử dụng Mist AI để tự động hóa và tối ưu hóa các hoạt động
quản lý mạng không dây giúp cải thiện đáng kể trải nghiệm người dùng thông qua việc
tối ưu hóa liên tục và dự đoán vấn đề trước khi chúng xảy ra. Các doanh nghiệp có thể
cung cấp một dịch vụ không dây ổn định hơn với chi phí vận hành thấp hơn và ít sự gián đoạn hơn.
4.4. Thách thức và giải pháp
Thách thức Kỹ thuật:
1. Thu thập và Làm sạch Dữ liệu:
¥ Thu thập dữ liệu đủ lớn và chất lượng cao để đào tạo các mô hình AI là một thách thức. lOMoARcPSD| 37054152
¥ Giải pháp: Sử dụng công cụ tự động để làm sạch và tiền xử lý dữ liệu, và
triển khai các kỹ thuật tăng cường dữ liệu để mở rộng bộ dữ liệu đào tạo. 2. Tích hợp Hệ thống:
¥ Việc tích hợp Nhận thức máy vào hệ thống quản lý mạng hiện tại đòi hỏi
giao diện lập trình ứng dụng (API) và các chuẩn mở.
¥ Giải pháp: Sử dụng các API tiêu chuẩn và mô hình dịch vụ dựa trên
microservices để tích hợp linh hoạt. 3. Hiệu suất và Quy mô:
¥ Các mô hình học sâu đặc biệt đòi hỏi nguồn lực tính toán lớn, đặc biệt là khi quy mô mạng lớn.
¥ Giải pháp: Sử dụng các giải pháp điện toán đám mây, điện toán biên, và tối
ưu hóa mô hình để cải thiện hiệu suất.
4. Bảo mật và Quyền riêng tư:
¥ Bảo vệ dữ liệu khi đào tạo và sử dụng các mô hình Nhận thức máy là rất quan trọng.
¥ Giải pháp: Áp dụng các kỹ thuật như mã hóa dữ liệu và học máy liên quan đến quyền riêng tư.
5. Độ tin cậy và Độ chính xác:
¥ Đảm bảo các mô hình đưa ra quyết định chính xác và đáng tin cậy là không
dễ dàng, nhất là trong các tình huống không dự đoán trước được.
¥ Giải pháp: Sử dụng kỹ thuật học tăng cường và phát triển các hệ thống giám
sát để kiểm soát quyết định tự động.
Thách thức Quản lý:
1. Lao động và Kỹ năng:
¥ Thiếu nhân sự có kỹ năng cần thiết trong AI để phát triển và quản lý các hệ thống Nhận thức máy.
¥ Giải pháp: Đào tạo nội bộ, tuyển dụng các chuyên gia và hợp tác với các tổ
chức giáo dục để phát triển kỹ năng cần thiết.
2. Thay đổi Quản lý và Văn hóa Tổ chức:
¥ Các tổ chức cần thích ứng với việc sử dụng AI và Nhận thức máy, điều này
đôi khi đối đầu với văn hóa công ty hiện tại.
¥ Giải pháp: Tập trung vào việc xây dựng văn hóa dữ liệu và thúc đẩy sự đổi
mới thông qua việc giáo dục và tham gia từ cấp cao nhất của tổ chức.
3. Đạo đức và Trách nhiệm:
¥ Việc áp dụng AI nêu ra các vấn đề đạo đức và trách nhiệm về quyết định tự động.
¥ Giải pháp: Phát triển các khung đạo đức AI và đảm bảo rằng các quyết định
của AI có thể giải thích được và có trách nhiệm.
4.5. Tương lai của quản lý mạng
¥ Hướng Phát Triển Công Nghệ 1. Hợp Nhất AI và IoT
Với sự phát triển của IoT, việc hợp nhất AI để tự động phân tích và quản lý dữ liệu
từ hàng tỉ thiết bị sẽ là một lĩnh vực quan trọng. Điều này bao gồm cả việc phát triển các
mô hình AI tiết kiệm năng lượng có thể chạy trực tiếp trên các thiết bị IoT. lOMoARcPSD| 37054152
2. Tự Động Hóa Dựa Trên AI
Nghiên cứu về việc mở rộng khả năng tự động hóa để không chỉ giám sát và phản
hứng với các sự kiện mạng mà còn dự đoán và ngăn chặn các vấn đề trước khi chúng xảy ra.
3. Phát Triển Mô hình Phân Tán
Tạo ra các mô hình ML có thể học hỏi và cập nhật liên tục dựa trên dữ liệu từ nhiều
nguồn, giảm thiểu thời gian và chi phí cho việc truyền dữ liệu về trung tâm.
¥ Hướng Nghiên Cứu
1. Bảo Mật và Quyền Riêng Tư
Nghiên cứu về cách thức bảo vệ dữ liệu và quyền riêng tư trong một mạng lưới
đầy đủ các thiết bị thông minh, đặc biệt là khi áp dụng các thuật toán học sâu yêu cầu
truy cập vào lượng lớn dữ liệu nhạy cảm.
2. Tích hợp AI và Blockchain
Khám phá việc kết hợp AI với công nghệ blockchain để tăng cường bảo mật và
minh bạch trong việc quản lý mạng.
3. Tự Động Hóa Quyết Định
Nghiên cứu về việc đưa ra quyết định tự động dựa trên dữ liệu thời gian thực và
dự đoán xu hướng để cải thiện hiệu suất và độ tin cậy của mạng. 4. Adaptive Networks
Phát triển các mạng có khả năng thích nghi với sự thay đổi về môi trường và nhu
cầu sử dụng, sử dụng công nghệ nhận thức để điều chỉnh mạng một cách tự động.
5. Xử Lý Ngôn Ngữ Tự Nhiên (NLP) Trong Quản Lý Mạng
Ứng dụng NLP để giúp các chuyên gia quản lý mạng tương tác với hệ thống thông
qua ngôn ngữ tự nhiên, đơn giản hóa quá trình quản lý mạng.
6. Đánh Giá và Tối Ưu Hóa Liên Tục
Tạo ra các hệ thống có khả năng tự đánh giá hiệu suất và tự động tối ưu hóa mà
không cần sự can thiệp của con người.
Tất cả những hướng nghiên cứu và phát triển này không chỉ đòi hỏi sự tiến bộ trong công
nghệ mà còn cần sự thay đổi trong chính sách, chuẩn mực quản lý, và chiến lược đào
tạo nhân lực. Đồng thời, sự hợp tác giữa các nhà cung cấp dịch vụ, nhà sản xuất thiết bị,
và cộng đồng nghiên cứu sẽ rất quan trọng để đạt được tiến bộ toàn diện trong quản lý
mạng dựa trên nhận thức máy. lOMoARcPSD| 37054152 KẾT LUẬN
Trong thế giới kỹ thuật số ngày nay, việc quản lý mạng không chỉ là một
hoạt động kỹ thuật thông thường mà đã trở thành một trong những phần quan
trọng nhất của cơ sở hạ tầng công nghệ thông tin. Sự phức tạp ngày càng tăng của
mạng máy tính đòi hỏi các giải pháp tiên tiến, và đó là nơi mà nhận thức máy
(machine cognition) đã và đang đóng một vai trò không thể thiếu.
Nhận thức máy, với sức mạnh của AI, đã cung cấp những tiềm năng to lớn
cho việc tự động hóa, tối ưu hóa và bảo vệ hệ thống mạng. Từ giám sát tự động
đến phát hiện sự cố, từ dự đoán tình trạng mạng đến việc triển khai các phản ứng
an ninh thông minh, nhận thức máy đã chứng tỏ giá trị to lớn trong việc nâng cao
hiệu suất và độ tin cậy của hệ thống mạng.
Tuy nhiên, sự tích hợp của nhận thức máy vào quản lý mạng không phải
không gặp phải thách thức. Vấn đề về quyền riêng tư dữ liệu, an ninh mạng, và sự
thiếu hụt kỹ năng là những vấn đề đáng kể mà ngành công nghiệp cần phải giải
quyết khi tiến về phía trước. Ngoài ra, việc đảm bảo rằng các hệ thống nhận thức
máy hoạt động một cách minh bạch và có thể giải thích là rất quan trọng, để người
dùng có thể tin tưởng và hiểu rõ các quyết định được thực hiện bởi máy móc.
Nhìn về tương lai, sự hợp nhất giữa nhận thức và các công nghệ như IoT,
điện toán biên, và điện toán đám mây sẽ mở ra những khả năng mới trong việc
quản lý mạng. Mạng sẽ không chỉ thông minh và tự động hơn mà còn trở nên linh
hoạt, có khả năng thích ứng với các nhu cầu thay đổi nhanh chóng và đa dạng của
người dùng và doanh nghiệp.
Cuối cùng, việc nắm bắt và phát huy toàn bộ tiềm năng của nhận thức máy
trong quản lý mạng không chỉ phụ thuộc vào những bước tiến trong công nghệ
mà còn đòi hỏi sự chấp nhận và thích nghi từ phía con người. Chúng ta cần một
lực lượng lao động có kỹ năng cao, cùng với những chính sách thông thoáng và
hợp tác đa ngành, để tạo ra một tương lai mà trong đó nhận thức máy có thể đạt
được tiềm năng đầy đủ của mình, cải thiện quản lý mạng và, cuối cùng, đem lại
lợi ích cho toàn xã hội.
TÀI LIỆU THAM KHẢO
1. J. Strassner, How policy empowers business-driven device management. Third
International.Workshop on Policies for Distributed Systems and Networks (2002)
2. S. van der Meer, A. Davy, S. Davy, R. Carroll, B. Jennings, J. Strassner,
Autonomic Networking:Prototype Implementation of the Policy Continuum
(Broadband Convergence Networks,Vancouver, 2006) 3.
J. Strassner, Management of autonomic systems-theory and practice.
Network Operationsand Management Symposium (NOMS) 2010 Tutorial, Osaka, Japan (2010) 4.
J. Strassner, Policy-Based Network Management (Morgan-Kaufman, Burlington, 2003) 5.
S. Davy, B. Jennings, J. Strassner, The policy continuum—policy authoring
and confict analy-sis. Comput. Commun. J. 31(13), 2981–2995 (2008) 6.
E. Gamma, R. Helm, R. Johnson, J. Vlissides, Design Patterns: Elements
of Reusable Object-Oriented Software (Addison-Wesley, Boston, 1994) lOMoAR cPSD| 37054152 7.
A. Khalil, J. Dingel, Optimizing the symbolic execution of evolving
rhapsody statecharts. Adv.Comput. 108, 145–281 (2018) 8.
Strassner, J., Agoulmine, N., Lehtihet, E.: "FOCALE - A novel autonomic
networking archi-tecture", ITSSA J. 3(1), pgs 64-79, 2007. 9.
J. Famaey, S. Latré, J. Strassner, F. De Turck, An ontology-driven semantic
bus for auto-nomic communication elements, in IEEE International Workshop on Modelling Autonomic
Tài liệu liên quan:
-

Wireshark Network Analysis: The Official Wireshark Certified Network Analyst Study Guide (Second Edition) | Học viện Công Nghệ Bưu Chính Viễn Thông
22 11 -

Bài tập lớn môn An toàn mạng truyền thông | Học viện Công nghệ Bưu chính Viễn thông
561 281 -

Đề cương ôn tập An ninh mạng nội dung chương 1 | Học viện Công nghệ Bưu chính Viễn thông
397 199 -

Bài tiểu luận môn An toàn mạng đề tài "Giải pháp an ninh mạng với Honeypot thông minh"
741 371 -

Bài báo cáo thực hành số 02 môn An toàn mạng | Học viện Công nghệ Bưu chính Viễn thông
316 158